第 1 章 - 基础 #
修复世界 #
如何解释 ZeroMQ?我们中的一些人会先说它所做的所有美妙的事情。它是打了兴奋剂的套接字。它就像带路由的邮箱。它速度飞快!其他人试图分享他们的顿悟时刻,那种突然领悟、豁然开朗的范式转变时刻。事情变得更简单了。复杂性消失了。它能打开你的思维。还有人试图通过比较来解释。它更小巧、更简单,但看起来仍然很熟悉。就我个人而言,我喜欢回顾我们为何要创建 ZeroMQ,因为这很可能就是你,读者,今天所处的位置。
编程是伪装成艺术的科学,因为我们大多数人不理解软件的物理学,即使教也很少教。软件的物理学不是算法、数据结构、语言和抽象。这些只是我们制造、使用、丢弃的工具。软件真正的物理学是人的物理学——具体来说,是我们在复杂性方面的局限性,以及我们渴望通过合作来分块解决大型问题。这就是编程的科学:制造人们可以理解和轻松使用的构建块,这样人们就会一起努力解决那些最大的问题。
我们生活在一个互联世界,现代软件必须在这个世界中航行。所以未来大型解决方案的构建块是相互连接且大规模并行的。代码不再仅仅是“强壮而沉默”的。代码必须与代码对话。代码必须是健谈的、善于交际的、连接良好的。代码必须像人类大脑一样运行,数万亿个独立的神经元相互发送消息,这是一个没有中心控制、没有单点故障的大规模并行网络,却能解决极其困难的问题。未来的代码看起来像人类大脑绝非偶然,因为每个网络的终端,在某种程度上,都是人类大脑。
如果你做过任何线程、协议或网络相关的工作,你会意识到这几乎是不可能的。这只是一个梦想。当你开始处理现实生活中的情况时,即使是连接几台程序通过几个套接字也是相当糟糕的。数万亿?成本将无法想象。连接计算机如此困难,以至于提供这类软件和服务的行业价值达数十亿美元。
所以我们生活在一个布线远超我们使用能力的时代。我们在 20 世纪 80 年代经历了一场软件危机,当时 Fred Brooks 等顶尖软件工程师认为不存在“银弹”能够“承诺在生产力、可靠性或简单性方面带来哪怕一个数量级的提升”。
Brooks 错过了自由和开源软件,这解决了那场危机,使我们能够高效地共享知识。今天我们面临另一场软件危机,但这危机我们很少谈论。只有最大、最富有的公司才能负担得起创建互联应用。确实有云,但它是专有的。我们的数据和知识正在从我们的个人电脑中消失,进入我们无法访问、无法与之竞争的云端。谁拥有我们的社交网络?这就像大型机-PC 革命的反向进行。
我们可以把政治哲学留给另一本书。重点是,虽然互联网提供了大规模互联代码的潜力,但现实是这对我们大多数人来说遥不可及,因此许多有趣的大问题(在健康、教育、经济、交通等方面)仍未解决,因为没有办法连接代码,也就没有办法连接那些可以共同解决这些问题的大脑。
已经有许多尝试来解决互联代码的挑战。有成千上万的 IETF 规范,每种都解决了部分难题。对于应用开发者来说,HTTP 也许是足够简单且行之有效的唯一解决方案,但它无疑通过鼓励开发者和架构师以大型服务器和瘦弱、愚蠢的客户端来思考问题,从而让问题变得更糟。
因此,今天人们仍然使用原始的 UDP 和 TCP、专有协议、HTTP 和 Websockets 来连接应用程序。这仍然是痛苦的、缓慢的、难以扩展的,并且本质上是中心化的。分布式 P2P 架构大多用于娱乐,而非工作。有多少应用程序使用 Skype 或 Bittorrent 来交换数据?
这又把我们带回了编程的科学。要修复世界,我们需要做两件事。第一,解决“如何将任何代码连接到任何代码,无论在哪里”这个普遍问题。第二,将其封装成人们可以理解和轻松使用的最简单的构建块。
这听起来简单得可笑。也许它就是这样。这就是整个重点所在。
初始假设 #
我们假设你至少使用 ZeroMQ 3.2 版本。我们假设你使用 Linux 或类似的系统。我们假设你大致能读懂 C 代码,因为这是示例的默认语言。我们假设当我们写像 PUSH 或 SUBSCRIBE 这样的常量时,你可以想象它们实际上叫做ZMQ_PUSH或ZMQ_SUBSCRIBE如果编程语言需要的话。
获取示例 #
示例代码存放在公共的GitHub 仓库中。获取所有示例最简单的方法是克隆这个仓库
git clone --depth=1 https://github.com/imatix/zguide.git
接下来,浏览 examples 子目录。你会按语言找到示例。如果你使用的语言缺少示例,我们鼓励你提交翻译。感谢许多人的辛勤工作,这使得本书内容如此实用。所有示例均遵循 MIT/X11 许可。
有求必应 #
那么,让我们从代码开始。当然,我们从一个 Hello World 示例开始。我们将创建一个客户端和一个服务器。客户端发送“Hello”给服务器,服务器回复“World”。以下是用 C 语言编写的服务器代码,它在端口 5555 上打开一个 ZeroMQ 套接字,读取请求,并对每个请求回复“World”。
hwserver: Ada 语言实现的 Hello World 服务器
hwserver: Basic 语言实现的 Hello World 服务器
hwserver: C 语言实现的 Hello World 服务器
// Hello World server
#include <zmq.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <assert.h>
int main (void)
{
// Socket to talk to clients
void *context = zmq_ctx_new ();
void *responder = zmq_socket (context, ZMQ_REP);
int rc = zmq_bind (responder, "tcp://*:5555");
assert (rc == 0);
while (1) {
char buffer [10];
zmq_recv (responder, buffer, 10, 0);
printf ("Received Hello\n");
sleep (1); // Do some 'work'
zmq_send (responder, "World", 5, 0);
}
return 0;
}

hwserver: C++ 语言实现的 Hello World 服务器
//
// Hello World server in C++
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
//
#include <zmq.hpp>
#include <string>
#include <iostream>
#ifndef _WIN32
#include <unistd.h>
#else
#include <windows.h>
#define sleep(n) Sleep(n)
#endif
int main () {
// Prepare our context and socket
zmq::context_t context (2);
zmq::socket_t socket (context, zmq::socket_type::rep);
socket.bind ("tcp://*:5555");
while (true) {
zmq::message_t request;
// Wait for next request from client
socket.recv (request, zmq::recv_flags::none);
std::cout << "Received Hello" << std::endl;
// Do some 'work'
sleep(1);
// Send reply back to client
zmq::message_t reply (5);
memcpy (reply.data (), "World", 5);
socket.send (reply, zmq::send_flags::none);
}
return 0;
}
hwserver: C# 语言实现的 Hello World 服务器
hwserver: CL 语言实现的 Hello World 服务器
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-
;;;
;;; Hello World server in Common Lisp
;;; Binds REP socket to tcp://*:5555
;;; Expects "Hello" from client, replies with "World"
;;;
;;; Kamil Shakirov <kamils80@gmail.com>
;;;
(defpackage #:zguide.hwserver
(:nicknames #:hwserver)
(:use #:cl #:zhelpers)
(:export #:main))
(in-package :zguide.hwserver)
(defun main ()
;; Prepare our context and socket
(zmq:with-context (context 1)
(zmq:with-socket (socket context zmq:rep)
(zmq:bind socket "tcp://*:5555")
(loop
(let ((request (make-instance 'zmq:msg)))
;; Wait for next request from client
(zmq:recv socket request)
(message "Received request: [~A]~%"
(zmq:msg-data-as-string request))
;; Do some 'work'
(sleep 1)
;; Send reply back to client
(let ((reply (make-instance 'zmq:msg :data "World")))
(zmq:send socket reply))))))
(cleanup))
hwserver: Delphi 语言实现的 Hello World 服务器
program hwserver;
//
// Hello World server
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
{$I zmq.inc}
uses
SysUtils
, zmq
;
var
context,
responder: Pointer;
request,
reply: zmq_msg_t;
begin
context := zmq_init(1);
// Socket to talk to clients
responder := zmq_socket( context, ZMQ_REP );
zmq_bind( responder, 'tcp://*:5555' );
while true do
begin
// Wait for next request from client
zmq_msg_init( request );
{$ifdef zmq3}
zmq_recvmsg( responder, request, 0 );
{$else}
zmq_recv( responder, request, 0 );
{$endif}
Writeln( 'Received Hello' );
zmq_msg_close( request );
// Do some 'work'
sleep( 1000 );
// Send reply back to client
zmq_msg_init( reply );
zmq_msg_init_size( reply, 5 );
Move( 'World', zmq_msg_data( reply )^, 5 );
{$ifdef zmq3}
zmq_sendmsg( responder, reply, 0 );
{$else}
zmq_send( responder, reply, 0 );
{$endif}
zmq_msg_close( reply );
end;
// We never get here but if we did, this would be how we end
zmq_close( responder );
zmq_term( context );
end.
hwserver: Erlang 语言实现的 Hello World 服务器
#! /usr/bin/env escript
%% Starts a local hello server.
%% Binds to tcp://:5555
main(_Args) ->
application:start(chumak),
{ok, Socket} = chumak:socket(rep, "my-rep"),
{ok, _Pid} = chumak:bind(Socket, tcp, "localhost", 5555),
loop(Socket).
loop(Socket) ->
{ok, RecvMessage} = chumak:recv(Socket),
io:format("Received request : ~p\n", [RecvMessage]),
timer:sleep(1000),
chumak:send(Socket, "World"),
loop(Socket).
hwserver: Elixir 语言实现的 Hello World 服务器
defmodule Hwserver do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:24
"""
def main(_) do
IO.puts("hwserver starting")
{:ok, context} = :erlzmq.context()
{:ok, responder} = :erlzmq.socket(context, :rep)
:ok = :erlzmq.bind(responder, 'tcp://*:5555')
loop(responder)
:ok = :erlzmq.close(responder)
:ok = :erlzmq.term(context)
end
def loop(responder) do
{:ok, msg} = :erlzmq.recv(responder)
:io.format('Received ~s~n', [msg])
:timer.sleep(1000)
:ok = :erlzmq.send(responder, "World")
loop(responder)
end
end
Hwserver.main(:ok)
hwserver: F# 语言实现的 Hello World 服务器
hwserver: Felix 语言实现的 Hello World 服务器
// Hello World server
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
open ZMQ;
println "hwserver, Felix version";
var context = zmq_init (1);
// Socket to talk to clients
var responder = context.mk_socket ZMQ_REP;
responder.bind "tcp://*:5555";
var request = #zmq_msg_t;
var reply = #zmq_msg_t;
while true do
// Wait for next request from client
request.init_string "Hello";
responder.recv_msg request;
println$ "Received Hello=" + string(request);
request.close;
// Do some 'work'
Faio::sleep (sys_clock,1.0);
// Send reply back to client
reply.init_size 5.size;
memcpy (zmq_msg_data reply, c"World".address, 5.size);
responder.send_msg reply;
reply.close;
done
hwserver: Go 语言实现的 Hello World 服务器
//
// Hello World Zeromq server
//
// Author: Aaron Raddon github.com/araddon
// Requires: http://github.com/alecthomas/gozmq
//
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"time"
)
func main() {
context, _ := zmq.NewContext()
socket, _ := context.NewSocket(zmq.REP)
defer context.Close()
defer socket.Close()
socket.Bind("tcp://*:5555")
// Wait for messages
for {
msg, _ := socket.Recv(0)
println("Received ", string(msg))
// do some fake "work"
time.Sleep(time.Second)
// send reply back to client
reply := fmt.Sprintf("World")
socket.Send([]byte(reply), 0)
}
}
hwserver: Haskell 语言实现的 Hello World 服务器
{-# LANGUAGE OverloadedStrings #-}
-- Hello World server
module Main where
import Control.Concurrent
import Control.Monad
import System.ZMQ4.Monadic
main :: IO ()
main = runZMQ $ do
-- Socket to talk to clients
responder <- socket Rep
bind responder "tcp://*:5555"
forever $ do
buffer <- receive responder
liftIO $ do
putStrLn "Received Hello"
threadDelay 1000000 -- Do some 'work'
send responder [] "World"
hwserver: Haxe 语言实现的 Hello World 服务器
package ;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZMQ;
import org.zeromq.ZMQContext;
import org.zeromq.ZMQException;
import org.zeromq.ZMQSocket;
/**
* Hello World server in Haxe
* Binds REP to tcp://*:5556
* Expects "Hello" from client, replies with "World"
* Use with HelloWorldClient.hx
*
*/
class HelloWorldServer
{
public static function main() {
var context:ZMQContext = ZMQContext.instance();
var responder:ZMQSocket = context.socket(ZMQ_REP);
Lib.println("** HelloWorldServer (see: https://zguide.zeromq.cn/page:all#Ask-and-Ye-Shall-Receive)");
responder.setsockopt(ZMQ_LINGER, 0);
responder.bind("tcp://*:5556");
try {
while (true) {
// Wait for next request from client
var request:Bytes = responder.recvMsg();
trace ("Received request:" + request.toString());
// Do some work
Sys.sleep(1);
// Send reply back to client
responder.sendMsg(Bytes.ofString("World"));
}
} catch (e:ZMQException) {
trace (e.toString());
}
responder.close();
context.term();
}
}hwserver: Java 语言实现的 Hello World 服务器
package guide;
//
// Hello World server in Java
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
//
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZContext;
public class hwserver
{
public static void main(String[] args) throws Exception
{
try (ZContext context = new ZContext()) {
// Socket to talk to clients
ZMQ.Socket socket = context.createSocket(SocketType.REP);
socket.bind("tcp://*:5555");
while (!Thread.currentThread().isInterrupted()) {
byte[] reply = socket.recv(0);
System.out.println(
"Received " + ": [" + new String(reply, ZMQ.CHARSET) + "]"
);
Thread.sleep(1000); // Do some 'work'
String response = "world";
socket.send(response.getBytes(ZMQ.CHARSET), 0);
}
}
}
}
hwserver: Julia 语言实现的 Hello World 服务器
#!/usr/bin/env julia
#
# Hello World server in Julia
# Binds REP socket to tcp://*:5555
# Expects "Hello" from client, replies "World"
#
using ZMQ
context = Context()
socket = Socket(context, REP)
ZMQ.bind(socket, "tcp://*:5555")
while true
# Wait for next request from client
message = String(ZMQ.recv(socket))
println("Received request: $message")
# Do some 'work'
sleep(1)
# Send reply back to client
ZMQ.send(socket, "World")
end
# classy hit men always clean up when finish the job.
ZMQ.close(socket)
ZMQ.close(context)
hwserver: Lua 语言实现的 Hello World 服务器
--
-- Hello World server
-- Binds REP socket to tcp://*:5555
-- Expects "Hello" from client, replies with "World"
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zhelpers"
local context = zmq.init(1)
-- Socket to talk to clients
local socket = context:socket(zmq.REP)
socket:bind("tcp://*:5555")
while true do
-- Wait for next request from client
local request = socket:recv()
print("Received Hello [" .. request .. "]")
-- Do some 'work'
s_sleep(1000)
-- Send reply back to client
socket:send("World")
end
-- We never get here but if we did, this would be how we end
socket:close()
context:term()
hwserver: Node.js 语言实现的 Hello World 服务器
// Hello World server
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "world"
var zmq = require('zeromq');
// socket to talk to clients
var responder = zmq.socket('rep');
responder.on('message', function(request) {
console.log("Received request: [", request.toString(), "]");
// do some 'work'
setTimeout(function() {
// send reply back to client.
responder.send("World");
}, 1000);
});
responder.bind('tcp://*:5555', function(err) {
if (err) {
console.log(err);
} else {
console.log("Listening on 5555...");
}
});
process.on('SIGINT', function() {
responder.close();
});
hwserver: Objective-C 语言实现的 Hello World 服务器
//
// Hello World server
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
//
#import <Foundation/Foundation.h>
#import "ZMQObjc.h"
int
main(void)
{
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init];
ZMQContext *ctx = [[[ZMQContext alloc] initWithIOThreads:1U] autorelease];
/* Get a socket to talk to clients. */
static NSString *const kEndpoint = @"tcp://*:5555";
ZMQSocket *responder = [ctx socketWithType:ZMQ_REP];
BOOL didBind = [responder bindToEndpoint:kEndpoint];
if (!didBind) {
NSLog(@"*** Failed to bind to endpoint [%@].", kEndpoint);
return EXIT_FAILURE;
}
for (;;) {
/* Create a local pool so that autoreleased objects can be disposed of
* at the end of each go through the loop.
* Otherwise, memory usage would continue to rise
* until the end of the process.
*/
NSAutoreleasePool *localPool = [[NSAutoreleasePool alloc] init];
/* Block waiting for next request from client. */
NSData *request = [responder receiveDataWithFlags:0];
NSString *text = [[[NSString alloc]
initWithData:request encoding:NSUTF8StringEncoding] autorelease];
NSLog(@"Received request: %@", text);
/* "Work" for a bit. */
sleep(1);
/* Send reply back to client. */
static NSString *const kWorld = @"World";
const char *replyCString = [kWorld UTF8String];
const NSUInteger replyLength = [kWorld
lengthOfBytesUsingEncoding:NSUTF8StringEncoding];
NSData *reply = [NSData dataWithBytes:replyCString length:replyLength];
[responder sendData:reply withFlags:0];
[localPool drain];
}
/* Close the socket to avoid blocking in -[ZMQContext terminate]. */
[responder close];
/* Dispose of the context and socket. */
[pool drain];
return EXIT_SUCCESS;
}
hwserver: ooc 语言实现的 Hello World 服务器
hwserver: Perl 语言实现的 Hello World 服务器
# Hello World server in Perl
use strict;
use warnings;
use v5.10;
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_REP);
# Socket to talk to clients
my $context = ZMQ::FFI->new();
my $responder = $context->socket(ZMQ_REP);
$responder->bind("tcp://*:5555");
while (1) {
$responder->recv();
say "Received Hello";
sleep 1;
$responder->send("World");
}
hwserver: PHP 语言实现的 Hello World 服务器
<?php
/*
* Hello World server
* Binds REP socket to tcp://*:5555
* Expects "Hello" from client, replies with "World"
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
$context = new ZMQContext(1);
// Socket to talk to clients
$responder = new ZMQSocket($context, ZMQ::SOCKET_REP);
$responder->bind("tcp://*:5555");
while (true) {
// Wait for next request from client
$request = $responder->recv();
printf ("Received request: [%s]\n", $request);
// Do some 'work'
sleep (1);
// Send reply back to client
$responder->send("World");
}
hwserver: Python 语言实现的 Hello World 服务器
#
# Hello World server in Python
# Binds REP socket to tcp://*:5555
# Expects b"Hello" from client, replies with b"World"
#
import time
import zmq
context = zmq.Context()
socket = context.socket(zmq.REP)
socket.bind("tcp://*:5555")
while True:
# Wait for next request from client
message = socket.recv()
print(f"Received request: {message}")
# Do some 'work'
time.sleep(1)
# Send reply back to client
socket.send_string("World")
hwserver: Q 语言实现的 Hello World 服务器
// Hello World server
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
\l qzmq.q
ctx:zctx.new[]
// Socket to talk to clients
responder:zsocket.new[ctx; zmq`REP]
port:zsocket.bind[responder; `$"tcp://*:5555"]
while[1b and not zctx.interrupted[];
// Wait for next request from client
s:zmsg.recv responder;
// Do some 'work'
zclock.sleep 1;
// Send reply back to client
m1:zmsg.new[];
zmsg.push[m1; zframe.new["World"]];
zmsg.send[m1; responder]]
// We never get here but if we did, this would how we end
zsocket.destroy[ctx; responder]
zctx.destroy[ctx]
hwserver: Racket 语言实现的 Hello World 服务器
#lang racket
#|
Hello World server in Racket
Binds REP socket to tcp://*:5555
Expects "Hello" from client, replies with "World"
|#
(require net/zmq)
(define ctxt (context 1))
(define sock (socket ctxt 'REP))
(socket-bind! sock "tcp://*:5555")
(let loop ()
(define message (socket-recv! sock))
(printf "Received request: ~a\n" message)
(sleep 1)
(socket-send! sock #"World")
(loop))
(context-close! ctxt)
hwserver: Ruby 语言实现的 Hello World 服务器
#!/usr/bin/env ruby
# author: Bill Desmarais bill@witsaid.com
# this code is licenced under the MIT/X11 licence.
require 'rubygems'
require 'ffi-rzmq'
context = ZMQ::Context.new(1)
puts "Starting Hello World server..."
# socket to listen for clients
socket = context.socket(ZMQ::REP)
socket.bind("tcp://*:5555")
while true do
# Wait for next request from client
request = ''
rc = socket.recv_string(request)
puts "Received request. Data: #{request.inspect}"
# Do some 'work'
sleep 1
# Send reply back to client
socket.send_string("world")
end
hwserver: Rust 语言实现的 Hello World 服务器
use std::{thread, time};
fn main() {
let context = zmq::Context::new();
let responder = context.socket(zmq::REP).unwrap();
assert!(responder.bind("tcp://*:5555").is_ok());
loop {
let buffer = &mut [0; 10];
responder.recv_into(buffer, 0).unwrap();
println!("Received Hello");
thread::sleep(time::Duration::from_secs(1));
responder.send("World", 0).unwrap();
}
}
hwserver: Scala 语言实现的 Hello World 服务器
//
// Hello World server in Scala
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
//
// author Giovanni Ruggiero
// email giovanni.ruggiero@gmail.com
//
//
import org.zeromq.ZMQ
import org.zeromq.ZMQ.{Context,Socket}
object HelloWorldServer {
def main(args : Array[String]) {
// Prepare our context and socket
val context = ZMQ.context(1)
val socket = context.socket(ZMQ.REP)
println ("starting")
socket.bind ("tcp://*:5555")
while (true) {
// Wait for next request from client
// We will wait for a 0-terminated string (C string) from the client,
// so that this server also works with The Guide's C and C++ "Hello World" clients
val request = socket.recv (0)
// In order to display the 0-terminated string as a String,
// we omit the last byte from request
println ("Received request: ["
+ new String(request,0,request.length-1) // Creates a String from request, minus the last byte
+ "]")
// Do some 'work'
try {
Thread.sleep (1000)
} catch {
case e: InterruptedException => e.printStackTrace()
}
// Send reply back to client
// We will send a 0-terminated string (C string) back to the client,
// so that this server also works with The Guide's C and C++ "Hello World" clients
val reply = "World ".getBytes
reply(reply.length-1)=0 //Sets the last byte of the reply to 0
socket.send(reply, 0)
}
}
}
hwserver: Tcl 语言实现的 Hello World 服务器
package require zmq
zmq context context
zmq socket responder context REP
responder bind "tcp://*:5555"
while {1} {
zmq message request
responder recv_msg request
puts "Received [request data]"
request close
zmq message reply -data "World @ [clock format [clock seconds]]"
responder send_msg reply
reply close
}
responder close
context term
hwserver: OCaml 语言实现的 Hello World 服务器
(** Hello World server *)
open Zmq
open Helpers
let () =
with_context @@ fun ctx ->
with_socket ctx Socket.rep @@ fun resp ->
Socket.bind resp "tcp://*:5555";
while not !should_exit do
let s = Socket.recv resp in
printfn "Received : %S" s;
sleep_ms 1000; (* Do some 'work' *)
Socket.send resp "World";
done
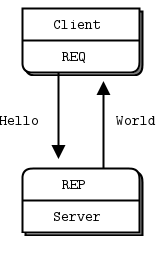
REQ-REP 套接字对是同步的。客户端执行 zmq_send()然后执行 zmq_recv(),循环进行(或者如果只需要一次就执行一次)。执行任何其他顺序(例如,连续发送两条消息)将导致从send或recv调用返回 -1。同样,服务方执行 zmq_recv()然后执行 zmq_send(),按此顺序,根据需要重复执行。
ZeroMQ 使用 C 作为其参考语言,这也是我们示例中主要使用的语言。如果你在线阅读本文,示例下方的链接会带你查看其他编程语言的翻译。我们来比较一下同样的服务器代码在 C++ 中是怎样的。
hwserver: C++ 语言实现的 Hello World 服务器
//
// Hello World server in C++
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
//
#include <zmq.hpp>
#include <string>
#include <iostream>
#ifndef _WIN32
#include <unistd.h>
#else
#include <windows.h>
#define sleep(n) Sleep(n)
#endif
int main () {
// Prepare our context and socket
zmq::context_t context (2);
zmq::socket_t socket (context, zmq::socket_type::rep);
socket.bind ("tcp://*:5555");
while (true) {
zmq::message_t request;
// Wait for next request from client
socket.recv (request, zmq::recv_flags::none);
std::cout << "Received Hello" << std::endl;
// Do some 'work'
sleep(1);
// Send reply back to client
zmq::message_t reply (5);
memcpy (reply.data (), "World", 5);
socket.send (reply, zmq::send_flags::none);
}
return 0;
}
你可以看到 ZeroMQ 的 API 在 C 和 C++ 中是相似的。在像 PHP 或 Java 这样的语言中,我们可以隐藏更多细节,代码变得更容易阅读。
hwserver: PHP 语言实现的 Hello World 服务器
<?php
/*
* Hello World server
* Binds REP socket to tcp://*:5555
* Expects "Hello" from client, replies with "World"
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
$context = new ZMQContext(1);
// Socket to talk to clients
$responder = new ZMQSocket($context, ZMQ::SOCKET_REP);
$responder->bind("tcp://*:5555");
while (true) {
// Wait for next request from client
$request = $responder->recv();
printf ("Received request: [%s]\n", $request);
// Do some 'work'
sleep (1);
// Send reply back to client
$responder->send("World");
}
hwserver: Java 语言实现的 Hello World 服务器
package guide;
//
// Hello World server in Java
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
//
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZContext;
public class hwserver
{
public static void main(String[] args) throws Exception
{
try (ZContext context = new ZContext()) {
// Socket to talk to clients
ZMQ.Socket socket = context.createSocket(SocketType.REP);
socket.bind("tcp://*:5555");
while (!Thread.currentThread().isInterrupted()) {
byte[] reply = socket.recv(0);
System.out.println(
"Received " + ": [" + new String(reply, ZMQ.CHARSET) + "]"
);
Thread.sleep(1000); // Do some 'work'
String response = "world";
socket.send(response.getBytes(ZMQ.CHARSET), 0);
}
}
}
}
其他语言实现的服务器
hwserver: Ada 语言实现的 Hello World 服务器
hwserver: Basic 语言实现的 Hello World 服务器
hwserver: C 语言实现的 Hello World 服务器
// Hello World server
#include <zmq.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <assert.h>
int main (void)
{
// Socket to talk to clients
void *context = zmq_ctx_new ();
void *responder = zmq_socket (context, ZMQ_REP);
int rc = zmq_bind (responder, "tcp://*:5555");
assert (rc == 0);
while (1) {
char buffer [10];
zmq_recv (responder, buffer, 10, 0);
printf ("Received Hello\n");
sleep (1); // Do some 'work'
zmq_send (responder, "World", 5, 0);
}
return 0;
}
hwserver: C++ 语言实现的 Hello World 服务器
//
// Hello World server in C++
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
//
#include <zmq.hpp>
#include <string>
#include <iostream>
#ifndef _WIN32
#include <unistd.h>
#else
#include <windows.h>
#define sleep(n) Sleep(n)
#endif
int main () {
// Prepare our context and socket
zmq::context_t context (2);
zmq::socket_t socket (context, zmq::socket_type::rep);
socket.bind ("tcp://*:5555");
while (true) {
zmq::message_t request;
// Wait for next request from client
socket.recv (request, zmq::recv_flags::none);
std::cout << "Received Hello" << std::endl;
// Do some 'work'
sleep(1);
// Send reply back to client
zmq::message_t reply (5);
memcpy (reply.data (), "World", 5);
socket.send (reply, zmq::send_flags::none);
}
return 0;
}
hwserver: C# 语言实现的 Hello World 服务器
hwserver: CL 语言实现的 Hello World 服务器
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-
;;;
;;; Hello World server in Common Lisp
;;; Binds REP socket to tcp://*:5555
;;; Expects "Hello" from client, replies with "World"
;;;
;;; Kamil Shakirov <kamils80@gmail.com>
;;;
(defpackage #:zguide.hwserver
(:nicknames #:hwserver)
(:use #:cl #:zhelpers)
(:export #:main))
(in-package :zguide.hwserver)
(defun main ()
;; Prepare our context and socket
(zmq:with-context (context 1)
(zmq:with-socket (socket context zmq:rep)
(zmq:bind socket "tcp://*:5555")
(loop
(let ((request (make-instance 'zmq:msg)))
;; Wait for next request from client
(zmq:recv socket request)
(message "Received request: [~A]~%"
(zmq:msg-data-as-string request))
;; Do some 'work'
(sleep 1)
;; Send reply back to client
(let ((reply (make-instance 'zmq:msg :data "World")))
(zmq:send socket reply))))))
(cleanup))
hwserver: Delphi 语言实现的 Hello World 服务器
program hwserver;
//
// Hello World server
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
{$I zmq.inc}
uses
SysUtils
, zmq
;
var
context,
responder: Pointer;
request,
reply: zmq_msg_t;
begin
context := zmq_init(1);
// Socket to talk to clients
responder := zmq_socket( context, ZMQ_REP );
zmq_bind( responder, 'tcp://*:5555' );
while true do
begin
// Wait for next request from client
zmq_msg_init( request );
{$ifdef zmq3}
zmq_recvmsg( responder, request, 0 );
{$else}
zmq_recv( responder, request, 0 );
{$endif}
Writeln( 'Received Hello' );
zmq_msg_close( request );
// Do some 'work'
sleep( 1000 );
// Send reply back to client
zmq_msg_init( reply );
zmq_msg_init_size( reply, 5 );
Move( 'World', zmq_msg_data( reply )^, 5 );
{$ifdef zmq3}
zmq_sendmsg( responder, reply, 0 );
{$else}
zmq_send( responder, reply, 0 );
{$endif}
zmq_msg_close( reply );
end;
// We never get here but if we did, this would be how we end
zmq_close( responder );
zmq_term( context );
end.
hwserver: Erlang 语言实现的 Hello World 服务器
#! /usr/bin/env escript
%% Starts a local hello server.
%% Binds to tcp://:5555
main(_Args) ->
application:start(chumak),
{ok, Socket} = chumak:socket(rep, "my-rep"),
{ok, _Pid} = chumak:bind(Socket, tcp, "localhost", 5555),
loop(Socket).
loop(Socket) ->
{ok, RecvMessage} = chumak:recv(Socket),
io:format("Received request : ~p\n", [RecvMessage]),
timer:sleep(1000),
chumak:send(Socket, "World"),
loop(Socket).
hwserver: Elixir 语言实现的 Hello World 服务器
defmodule Hwserver do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:24
"""
def main(_) do
IO.puts("hwserver starting")
{:ok, context} = :erlzmq.context()
{:ok, responder} = :erlzmq.socket(context, :rep)
:ok = :erlzmq.bind(responder, 'tcp://*:5555')
loop(responder)
:ok = :erlzmq.close(responder)
:ok = :erlzmq.term(context)
end
def loop(responder) do
{:ok, msg} = :erlzmq.recv(responder)
:io.format('Received ~s~n', [msg])
:timer.sleep(1000)
:ok = :erlzmq.send(responder, "World")
loop(responder)
end
end
Hwserver.main(:ok)
hwserver: F# 语言实现的 Hello World 服务器
hwserver: Felix 语言实现的 Hello World 服务器
// Hello World server
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
open ZMQ;
println "hwserver, Felix version";
var context = zmq_init (1);
// Socket to talk to clients
var responder = context.mk_socket ZMQ_REP;
responder.bind "tcp://*:5555";
var request = #zmq_msg_t;
var reply = #zmq_msg_t;
while true do
// Wait for next request from client
request.init_string "Hello";
responder.recv_msg request;
println$ "Received Hello=" + string(request);
request.close;
// Do some 'work'
Faio::sleep (sys_clock,1.0);
// Send reply back to client
reply.init_size 5.size;
memcpy (zmq_msg_data reply, c"World".address, 5.size);
responder.send_msg reply;
reply.close;
done
hwserver: Go 语言实现的 Hello World 服务器
//
// Hello World Zeromq server
//
// Author: Aaron Raddon github.com/araddon
// Requires: http://github.com/alecthomas/gozmq
//
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"time"
)
func main() {
context, _ := zmq.NewContext()
socket, _ := context.NewSocket(zmq.REP)
defer context.Close()
defer socket.Close()
socket.Bind("tcp://*:5555")
// Wait for messages
for {
msg, _ := socket.Recv(0)
println("Received ", string(msg))
// do some fake "work"
time.Sleep(time.Second)
// send reply back to client
reply := fmt.Sprintf("World")
socket.Send([]byte(reply), 0)
}
}
hwserver: Haskell 语言实现的 Hello World 服务器
{-# LANGUAGE OverloadedStrings #-}
-- Hello World server
module Main where
import Control.Concurrent
import Control.Monad
import System.ZMQ4.Monadic
main :: IO ()
main = runZMQ $ do
-- Socket to talk to clients
responder <- socket Rep
bind responder "tcp://*:5555"
forever $ do
buffer <- receive responder
liftIO $ do
putStrLn "Received Hello"
threadDelay 1000000 -- Do some 'work'
send responder [] "World"
hwserver: Haxe 语言实现的 Hello World 服务器
package ;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZMQ;
import org.zeromq.ZMQContext;
import org.zeromq.ZMQException;
import org.zeromq.ZMQSocket;
/**
* Hello World server in Haxe
* Binds REP to tcp://*:5556
* Expects "Hello" from client, replies with "World"
* Use with HelloWorldClient.hx
*
*/
class HelloWorldServer
{
public static function main() {
var context:ZMQContext = ZMQContext.instance();
var responder:ZMQSocket = context.socket(ZMQ_REP);
Lib.println("** HelloWorldServer (see: https://zguide.zeromq.cn/page:all#Ask-and-Ye-Shall-Receive)");
responder.setsockopt(ZMQ_LINGER, 0);
responder.bind("tcp://*:5556");
try {
while (true) {
// Wait for next request from client
var request:Bytes = responder.recvMsg();
trace ("Received request:" + request.toString());
// Do some work
Sys.sleep(1);
// Send reply back to client
responder.sendMsg(Bytes.ofString("World"));
}
} catch (e:ZMQException) {
trace (e.toString());
}
responder.close();
context.term();
}
}hwserver: Java 语言实现的 Hello World 服务器
package guide;
//
// Hello World server in Java
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
//
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZContext;
public class hwserver
{
public static void main(String[] args) throws Exception
{
try (ZContext context = new ZContext()) {
// Socket to talk to clients
ZMQ.Socket socket = context.createSocket(SocketType.REP);
socket.bind("tcp://*:5555");
while (!Thread.currentThread().isInterrupted()) {
byte[] reply = socket.recv(0);
System.out.println(
"Received " + ": [" + new String(reply, ZMQ.CHARSET) + "]"
);
Thread.sleep(1000); // Do some 'work'
String response = "world";
socket.send(response.getBytes(ZMQ.CHARSET), 0);
}
}
}
}
hwserver: Julia 语言实现的 Hello World 服务器
#!/usr/bin/env julia
#
# Hello World server in Julia
# Binds REP socket to tcp://*:5555
# Expects "Hello" from client, replies "World"
#
using ZMQ
context = Context()
socket = Socket(context, REP)
ZMQ.bind(socket, "tcp://*:5555")
while true
# Wait for next request from client
message = String(ZMQ.recv(socket))
println("Received request: $message")
# Do some 'work'
sleep(1)
# Send reply back to client
ZMQ.send(socket, "World")
end
# classy hit men always clean up when finish the job.
ZMQ.close(socket)
ZMQ.close(context)
hwserver: Lua 语言实现的 Hello World 服务器
--
-- Hello World server
-- Binds REP socket to tcp://*:5555
-- Expects "Hello" from client, replies with "World"
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zhelpers"
local context = zmq.init(1)
-- Socket to talk to clients
local socket = context:socket(zmq.REP)
socket:bind("tcp://*:5555")
while true do
-- Wait for next request from client
local request = socket:recv()
print("Received Hello [" .. request .. "]")
-- Do some 'work'
s_sleep(1000)
-- Send reply back to client
socket:send("World")
end
-- We never get here but if we did, this would be how we end
socket:close()
context:term()
hwserver: Node.js 语言实现的 Hello World 服务器
// Hello World server
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "world"
var zmq = require('zeromq');
// socket to talk to clients
var responder = zmq.socket('rep');
responder.on('message', function(request) {
console.log("Received request: [", request.toString(), "]");
// do some 'work'
setTimeout(function() {
// send reply back to client.
responder.send("World");
}, 1000);
});
responder.bind('tcp://*:5555', function(err) {
if (err) {
console.log(err);
} else {
console.log("Listening on 5555...");
}
});
process.on('SIGINT', function() {
responder.close();
});
hwserver: Objective-C 语言实现的 Hello World 服务器
//
// Hello World server
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
//
#import <Foundation/Foundation.h>
#import "ZMQObjc.h"
int
main(void)
{
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init];
ZMQContext *ctx = [[[ZMQContext alloc] initWithIOThreads:1U] autorelease];
/* Get a socket to talk to clients. */
static NSString *const kEndpoint = @"tcp://*:5555";
ZMQSocket *responder = [ctx socketWithType:ZMQ_REP];
BOOL didBind = [responder bindToEndpoint:kEndpoint];
if (!didBind) {
NSLog(@"*** Failed to bind to endpoint [%@].", kEndpoint);
return EXIT_FAILURE;
}
for (;;) {
/* Create a local pool so that autoreleased objects can be disposed of
* at the end of each go through the loop.
* Otherwise, memory usage would continue to rise
* until the end of the process.
*/
NSAutoreleasePool *localPool = [[NSAutoreleasePool alloc] init];
/* Block waiting for next request from client. */
NSData *request = [responder receiveDataWithFlags:0];
NSString *text = [[[NSString alloc]
initWithData:request encoding:NSUTF8StringEncoding] autorelease];
NSLog(@"Received request: %@", text);
/* "Work" for a bit. */
sleep(1);
/* Send reply back to client. */
static NSString *const kWorld = @"World";
const char *replyCString = [kWorld UTF8String];
const NSUInteger replyLength = [kWorld
lengthOfBytesUsingEncoding:NSUTF8StringEncoding];
NSData *reply = [NSData dataWithBytes:replyCString length:replyLength];
[responder sendData:reply withFlags:0];
[localPool drain];
}
/* Close the socket to avoid blocking in -[ZMQContext terminate]. */
[responder close];
/* Dispose of the context and socket. */
[pool drain];
return EXIT_SUCCESS;
}
hwserver: ooc 语言实现的 Hello World 服务器
hwserver: Perl 语言实现的 Hello World 服务器
# Hello World server in Perl
use strict;
use warnings;
use v5.10;
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_REP);
# Socket to talk to clients
my $context = ZMQ::FFI->new();
my $responder = $context->socket(ZMQ_REP);
$responder->bind("tcp://*:5555");
while (1) {
$responder->recv();
say "Received Hello";
sleep 1;
$responder->send("World");
}
hwserver: PHP 语言实现的 Hello World 服务器
<?php
/*
* Hello World server
* Binds REP socket to tcp://*:5555
* Expects "Hello" from client, replies with "World"
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
$context = new ZMQContext(1);
// Socket to talk to clients
$responder = new ZMQSocket($context, ZMQ::SOCKET_REP);
$responder->bind("tcp://*:5555");
while (true) {
// Wait for next request from client
$request = $responder->recv();
printf ("Received request: [%s]\n", $request);
// Do some 'work'
sleep (1);
// Send reply back to client
$responder->send("World");
}
hwserver: Python 语言实现的 Hello World 服务器
#
# Hello World server in Python
# Binds REP socket to tcp://*:5555
# Expects b"Hello" from client, replies with b"World"
#
import time
import zmq
context = zmq.Context()
socket = context.socket(zmq.REP)
socket.bind("tcp://*:5555")
while True:
# Wait for next request from client
message = socket.recv()
print(f"Received request: {message}")
# Do some 'work'
time.sleep(1)
# Send reply back to client
socket.send_string("World")
hwserver: Q 语言实现的 Hello World 服务器
// Hello World server
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
\l qzmq.q
ctx:zctx.new[]
// Socket to talk to clients
responder:zsocket.new[ctx; zmq`REP]
port:zsocket.bind[responder; `$"tcp://*:5555"]
while[1b and not zctx.interrupted[];
// Wait for next request from client
s:zmsg.recv responder;
// Do some 'work'
zclock.sleep 1;
// Send reply back to client
m1:zmsg.new[];
zmsg.push[m1; zframe.new["World"]];
zmsg.send[m1; responder]]
// We never get here but if we did, this would how we end
zsocket.destroy[ctx; responder]
zctx.destroy[ctx]
hwserver: Racket 语言实现的 Hello World 服务器
#lang racket
#|
Hello World server in Racket
Binds REP socket to tcp://*:5555
Expects "Hello" from client, replies with "World"
|#
(require net/zmq)
(define ctxt (context 1))
(define sock (socket ctxt 'REP))
(socket-bind! sock "tcp://*:5555")
(let loop ()
(define message (socket-recv! sock))
(printf "Received request: ~a\n" message)
(sleep 1)
(socket-send! sock #"World")
(loop))
(context-close! ctxt)
hwserver: Ruby 语言实现的 Hello World 服务器
#!/usr/bin/env ruby
# author: Bill Desmarais bill@witsaid.com
# this code is licenced under the MIT/X11 licence.
require 'rubygems'
require 'ffi-rzmq'
context = ZMQ::Context.new(1)
puts "Starting Hello World server..."
# socket to listen for clients
socket = context.socket(ZMQ::REP)
socket.bind("tcp://*:5555")
while true do
# Wait for next request from client
request = ''
rc = socket.recv_string(request)
puts "Received request. Data: #{request.inspect}"
# Do some 'work'
sleep 1
# Send reply back to client
socket.send_string("world")
end
hwserver: Rust 语言实现的 Hello World 服务器
use std::{thread, time};
fn main() {
let context = zmq::Context::new();
let responder = context.socket(zmq::REP).unwrap();
assert!(responder.bind("tcp://*:5555").is_ok());
loop {
let buffer = &mut [0; 10];
responder.recv_into(buffer, 0).unwrap();
println!("Received Hello");
thread::sleep(time::Duration::from_secs(1));
responder.send("World", 0).unwrap();
}
}
hwserver: Scala 语言实现的 Hello World 服务器
//
// Hello World server in Scala
// Binds REP socket to tcp://*:5555
// Expects "Hello" from client, replies with "World"
//
// author Giovanni Ruggiero
// email giovanni.ruggiero@gmail.com
//
//
import org.zeromq.ZMQ
import org.zeromq.ZMQ.{Context,Socket}
object HelloWorldServer {
def main(args : Array[String]) {
// Prepare our context and socket
val context = ZMQ.context(1)
val socket = context.socket(ZMQ.REP)
println ("starting")
socket.bind ("tcp://*:5555")
while (true) {
// Wait for next request from client
// We will wait for a 0-terminated string (C string) from the client,
// so that this server also works with The Guide's C and C++ "Hello World" clients
val request = socket.recv (0)
// In order to display the 0-terminated string as a String,
// we omit the last byte from request
println ("Received request: ["
+ new String(request,0,request.length-1) // Creates a String from request, minus the last byte
+ "]")
// Do some 'work'
try {
Thread.sleep (1000)
} catch {
case e: InterruptedException => e.printStackTrace()
}
// Send reply back to client
// We will send a 0-terminated string (C string) back to the client,
// so that this server also works with The Guide's C and C++ "Hello World" clients
val reply = "World ".getBytes
reply(reply.length-1)=0 //Sets the last byte of the reply to 0
socket.send(reply, 0)
}
}
}
hwserver: Tcl 语言实现的 Hello World 服务器
package require zmq
zmq context context
zmq socket responder context REP
responder bind "tcp://*:5555"
while {1} {
zmq message request
responder recv_msg request
puts "Received [request data]"
request close
zmq message reply -data "World @ [clock format [clock seconds]]"
responder send_msg reply
reply close
}
responder close
context term
hwserver: OCaml 语言实现的 Hello World 服务器
(** Hello World server *)
open Zmq
open Helpers
let () =
with_context @@ fun ctx ->
with_socket ctx Socket.rep @@ fun resp ->
Socket.bind resp "tcp://*:5555";
while not !should_exit do
let s = Socket.recv resp in
printfn "Received : %S" s;
sleep_ms 1000; (* Do some 'work' *)
Socket.send resp "World";
done
以下是客户端代码
hwclient: Ada 语言实现的 Hello World 客户端
hwclient: Basic 语言实现的 Hello World 客户端
hwclient: C 语言实现的 Hello World 客户端
// Hello World client
#include <zmq.h>
#include <string.h>
#include <stdio.h>
#include <unistd.h>
int main (void)
{
printf ("Connecting to hello world server...\n");
void *context = zmq_ctx_new ();
void *requester = zmq_socket (context, ZMQ_REQ);
zmq_connect (requester, "tcp://:5555");
int request_nbr;
for (request_nbr = 0; request_nbr != 10; request_nbr++) {
char buffer [10];
printf ("Sending Hello %d...\n", request_nbr);
zmq_send (requester, "Hello", 5, 0);
zmq_recv (requester, buffer, 10, 0);
printf ("Received World %d\n", request_nbr);
}
zmq_close (requester);
zmq_ctx_destroy (context);
return 0;
}
hwclient: C++ 语言实现的 Hello World 客户端
//
// Hello World client in C++
// Connects REQ socket to tcp://:5555
// Sends "Hello" to server, expects "World" back
//
#include <zmq.hpp>
#include <string>
#include <iostream>
int main ()
{
// Prepare our context and socket
zmq::context_t context (1);
zmq::socket_t socket (context, zmq::socket_type::req);
std::cout << "Connecting to hello world server..." << std::endl;
socket.connect ("tcp://:5555");
// Do 10 requests, waiting each time for a response
for (int request_nbr = 0; request_nbr != 10; request_nbr++) {
zmq::message_t request (5);
memcpy (request.data (), "Hello", 5);
std::cout << "Sending Hello " << request_nbr << "..." << std::endl;
socket.send (request, zmq::send_flags::none);
// Get the reply.
zmq::message_t reply;
socket.recv (reply, zmq::recv_flags::none);
std::cout << "Received World " << request_nbr << std::endl;
}
return 0;
}
hwclient: C# 语言实现的 Hello World 客户端
hwclient: CL 语言实现的 Hello World 客户端
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-
;;;
;;; Hello World client in Common Lisp
;;; Connects REQ socket to tcp://:5555
;;; Sends "Hello" to server, expects "World" back
;;;
;;; Kamil Shakirov <kamils80@gmail.com>
;;;
(defpackage #:zguide.hwclient
(:nicknames #:hwclient)
(:use #:cl #:zhelpers)
(:export #:main))
(in-package :zguide.hwclient)
(defun main ()
;; Prepare our context and socket
(zmq:with-context (context 1)
(zmq:with-socket (socket context zmq:req)
(message "Connecting to hello world server...~%")
(zmq:connect socket "tcp://:5555")
;; Do 10 requests, waiting each time for a response
(dotimes (request-nbr 10)
(let ((request (make-instance 'zmq:msg :data "Hello")))
(message "Sending request ~D...~%" request-nbr)
(zmq:send socket request))
;; Get the reply
(let ((response (make-instance 'zmq:msg)))
(zmq:recv socket response)
(message "Received reply ~D: [~A]~%"
request-nbr (zmq:msg-data-as-string response))))))
(cleanup))
hwclient: Delphi 语言实现的 Hello World 客户端
program hwclient;
//
// Hello World client
// Connects REQ socket to tcp://:5555
// Sends "Hello" to server, expects "World" back
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
context: TZMQContext;
requester: TZMQSocket;
i: Integer;
sMsg: Utf8String;
begin
context := TZMQContext.Create;
// Socket to talk to server
Writeln('Connecting to hello world server...');
requester := Context.Socket( stReq );
requester.connect( 'tcp://:5555' );
for i := 0 to 9 do
begin
sMsg := 'Hello';
Writeln( Format( 'Sending %s %d',[ sMsg, i ] ));
requester.send( sMsg );
requester.recv( sMsg );
Writeln( Format( 'Received %s %d', [ sMsg, i ] ) );
end;
sleep(2000);
requester.Free;
context.Free;
end.
hwclient: Erlang 语言实现的 Hello World 客户端
#! /usr/bin/env escript
%%
%% "Hello world" client example.
%% Connects to tcp://:5555
%% Sends <<"Hello">> to server and prints the response
%%
main(_Args) ->
application:start(chumak),
{ok, Socket} = chumak:socket(req, "my-req"),
{ok, _Pid} = chumak:connect(Socket, tcp, "localhost", 5555),
loop(Socket).
loop(Socket) ->
chumak:send(Socket, "Hello"),
{ok, RecvMessage} = chumak:recv(Socket),
io:format("Recv Reply: ~p\n", [RecvMessage]),
loop(Socket).
hwclient: Elixir 语言实现的 Hello World 客户端
defmodule Hwclient do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:23
"""
def main(_) do
{:ok, context} = :erlzmq.context()
:io.format('Connecting to hello world server...~n')
{:ok, requester} = :erlzmq.socket(context, :req)
:ok = :erlzmq.connect(requester, 'tcp://:5555')
:lists.foreach(fn n ->
:io.format('Sending Hello ~b...~n', [n])
:ok = :erlzmq.send(requester, "Hello")
{:ok, reply} = :erlzmq.recv(requester)
:io.format('Received ~s ~b~n', [reply, n])
end, :lists.seq(1, 10))
:ok = :erlzmq.close(requester)
:ok = :erlzmq.term(context)
end
end
Hwclient.main(:ok)
hwclient: F# 语言实现的 Hello World 客户端
hwclient: Felix 语言实现的 Hello World 客户端
// Hello World client
// Connects REQ socket to tcp://:5555
// Sends "Hello" to server, expects "World" back
open ZMQ;
println "hwclient, Felix version";
var context = zmq_init 1;
// Socket to talk to server
println "Connecting to hello world server";
var requester = context.mk_socket ZMQ_REQ;
requester.connect "tcp://:5555";
var request = #zmq_msg_t;
var reply = #zmq_msg_t;
for var request_nbr in 0 upto 9 do
request.init_size 5.size;
memcpy (zmq_msg_data request, c"Hello".address, 5.size);
print$ f"Sending Hello %d\n" request_nbr;
requester.send_msg request;
request.close;
reply.init_size 5.size;
requester.recv_msg reply;
println$ f"Received World %d=%S" (request_nbr, reply.string);
reply.close;
done
requester.close;
context.term;
hwclient: Go 语言实现的 Hello World 客户端
//
// Hello World Zeromq Client
//
// Author: Aaron Raddon github.com/araddon
// Requires: http://github.com/alecthomas/gozmq
//
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
)
func main() {
context, _ := zmq.NewContext()
socket, _ := context.NewSocket(zmq.REQ)
defer context.Close()
defer socket.Close()
fmt.Printf("Connecting to hello world server...")
socket.Connect("tcp://:5555")
for i := 0; i < 10; i++ {
// send hello
msg := fmt.Sprintf("Hello %d", i)
socket.Send([]byte(msg), 0)
println("Sending ", msg)
// Wait for reply:
reply, _ := socket.Recv(0)
println("Received ", string(reply))
}
}
hwclient: Haskell 语言实现的 Hello World 客户端
{-# LANGUAGE OverloadedStrings #-}
-- Hello World client
module Main where
import Control.Monad
import System.ZMQ4.Monadic
main :: IO ()
main = runZMQ $ do
liftIO $ putStrLn "Connecting to hello world server..."
requester <- socket Req
connect requester "tcp://:5555"
forM_ [1..10] $ \i -> do
liftIO . putStrLn $ "Sending Hello " ++ show i ++ "..."
send requester [] "Hello"
_ <- receive requester
liftIO . putStrLn $ "Received World " ++ show i
hwclient: Haxe 语言实现的 Hello World 客户端
package ;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZMQ;
import org.zeromq.ZMQContext;
import org.zeromq.ZMQSocket;
/**
* Hello World client in Haxe.
* Use with HelloWorldServer.hx and MTServer.hx
*/
class HelloWorldClient
{
public static function main() {
var context:ZMQContext = ZMQContext.instance();
var socket:ZMQSocket = context.socket(ZMQ_REQ);
Lib.println("** HelloWorldClient (see: https://zguide.zeromq.cn/page:all#Ask-and-Ye-Shall-Receive)");
trace ("Connecting to hello world server...");
socket.connect ("tcp://:5556");
// Do 10 requests, waiting each time for a response
for (i in 0...10) {
var requestString = "Hello ";
// Send the message
trace ("Sending request " + i + " ...");
socket.sendMsg(Bytes.ofString(requestString));
// Wait for the reply
var msg:Bytes = socket.recvMsg();
trace ("Received reply " + i + ": [" + msg.toString() + "]");
}
// Shut down socket and context
socket.close();
context.term();
}
}hwclient: Java 语言实现的 Hello World 客户端
package guide;
//
// Hello World client in Java
// Connects REQ socket to tcp://:5555
// Sends "Hello" to server, expects "World" back
//
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZContext;
public class hwclient
{
public static void main(String[] args)
{
try (ZContext context = new ZContext()) {
// Socket to talk to server
System.out.println("Connecting to hello world server");
ZMQ.Socket socket = context.createSocket(SocketType.REQ);
socket.connect("tcp://:5555");
for (int requestNbr = 0; requestNbr != 10; requestNbr++) {
String request = "Hello";
System.out.println("Sending Hello " + requestNbr);
socket.send(request.getBytes(ZMQ.CHARSET), 0);
byte[] reply = socket.recv(0);
System.out.println(
"Received " + new String(reply, ZMQ.CHARSET) + " " +
requestNbr
);
}
}
}
}
hwclient: Julia 语言实现的 Hello World 客户端
#!/usr/bin/env julia
#
# Hello World client in Julia
# Connects REQ socket to tcp://:5555
# Sends "Hello" to server, expects "World" back
#
using ZMQ
context = Context()
# Socket to talk to server
println("Connecting to hello world server...")
socket = Socket(context, REQ)
ZMQ.connect(socket, "tcp://:5555")
for request in 1:10
println("Sending request $request ...")
ZMQ.send(socket, "Hello")
# Get the reply.
message = String(ZMQ.recv(socket))
println("Received reply $request [ $message ]")
end
# Making a clean exit.
ZMQ.close(socket)
ZMQ.close(context)
hwclient: Lua 语言实现的 Hello World 客户端
--
-- Hello World client
-- Connects REQ socket to tcp://:5555
-- Sends "Hello" to server, expects "World" back
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
local context = zmq.init(1)
-- Socket to talk to server
print("Connecting to hello world server...")
local socket = context:socket(zmq.REQ)
socket:connect("tcp://:5555")
for n=1,10 do
print("Sending Hello " .. n .. " ...")
socket:send("Hello")
local reply = socket:recv()
print("Received World " .. n .. " [" .. reply .. "]")
end
socket:close()
context:term()
hwclient: Node.js 语言实现的 Hello World 客户端
// Hello World client
// Connects REQ socket to tcp://:5555
// Sends "Hello" to server.
var zmq = require('zeromq');
// socket to talk to server
console.log("Connecting to hello world server...");
var requester = zmq.socket('req');
var x = 0;
requester.on("message", function(reply) {
console.log("Received reply", x, ": [", reply.toString(), ']');
x += 1;
if (x === 10) {
requester.close();
process.exit(0);
}
});
requester.connect("tcp://:5555");
for (var i = 0; i < 10; i++) {
console.log("Sending request", i, '...');
requester.send("Hello");
}
process.on('SIGINT', function() {
requester.close();
});
hwclient: Objective-C 语言实现的 Hello World 客户端
//
// Hello World client
// Connects REQ socket to tcp://:5555
// Sends "Hello" to server, expects "World" back
//
#import "ZMQObjC.h"
int
main (void)
{
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init];
ZMQContext *ctx = [[[ZMQContext alloc] initWithIOThreads:1U] autorelease];
/* Get a socket to talk to clients. */
NSLog(@"Connecting to hello world server...");
static NSString *const kEndpoint = @"tcp://:5555";
ZMQSocket *requester = [ctx socketWithType:ZMQ_REQ];
BOOL didBind = [requester connectToEndpoint:kEndpoint];
if (!didBind) {
NSLog(@"*** Failed to bind to endpoint [%@].", kEndpoint);
return EXIT_FAILURE;
}
static const int kMaxRequest = 10;
NSData *const request = [@"Hello" dataUsingEncoding:NSUTF8StringEncoding];
for (int request_nbr = 0; request_nbr < kMaxRequest; ++request_nbr) {
NSAutoreleasePool *localPool = [[NSAutoreleasePool alloc] init];
NSLog(@"Sending request %d.", request_nbr);
[requester sendData:request withFlags:0];
NSData *reply = [requester receiveDataWithFlags:0];
NSString *text = [[[NSString alloc]
initWithData:reply encoding:NSUTF8StringEncoding] autorelease];
NSLog(@"Received reply %d: %@", request_nbr, text);
[localPool drain];
}
[requester close];
[pool drain];
return EXIT_SUCCESS;
}
hwclient: ooc 语言实现的 Hello World 客户端
hwclient: Perl 语言实现的 Hello World 客户端
# Hello World client in Perl
use strict;
use warnings;
use v5.10;
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_REQ);
say "Connecting to hello world server...";
my $context = ZMQ::FFI->new();
my $requestor = $context->socket(ZMQ_REQ);
$requestor->connect("tcp://:5555");
for my $request_nbr (0..9) {
say "Sending Hello $request_nbr...";
$requestor->send("Hello");
$requestor->recv();
say "Received World $request_nbr";
}
hwclient: PHP 语言实现的 Hello World 客户端
<?php
/*
* Hello World client
* Connects REQ socket to tcp://:5555
* Sends "Hello" to server, expects "World" back
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
$context = new ZMQContext();
// Socket to talk to server
echo "Connecting to hello world server...\n";
$requester = new ZMQSocket($context, ZMQ::SOCKET_REQ);
$requester->connect("tcp://:5555");
for ($request_nbr = 0; $request_nbr != 10; $request_nbr++) {
printf ("Sending request %d...\n", $request_nbr);
$requester->send("Hello");
$reply = $requester->recv();
printf ("Received reply %d: [%s]\n", $request_nbr, $reply);
}
hwclient: Python 语言实现的 Hello World 客户端
#
# Hello World client in Python
# Connects REQ socket to tcp://:5555
# Sends "Hello" to server, expects "World" back
#
import zmq
context = zmq.Context()
# Socket to talk to server
print("Connecting to hello world server...")
socket = context.socket(zmq.REQ)
socket.connect("tcp://:5555")
# Do 10 requests, waiting each time for a response
for request in range(10):
print(f"Sending request {request} ...")
socket.send_string("Hello")
# Get the reply.
message = socket.recv()
print(f"Received reply {request} [ {message} ]")
hwclient: Q 语言实现的 Hello World 客户端
// Hello World client
// Connects REQ socket to tcp://:5555
// Sends "Hello" to server, expects "World" back
\l qzmq.q
zclock.log "Connecting to hello world server..."
ctx:zctx.new[]
// Socket to talk to server
requester:zsocket.new[ctx; zmq`REQ]
zsocket.connect[requester; `tcp://127.0.0.1:5555]
do[10; m:zmsg.new[]; zmsg.push[m; f:zframe.new["Hello"]];
zmsg.send[m; requester]; zmsg.dump[zmsg.recv[requester]]]
zsocket.destroy[ctx; requester]
zctx.destroy[ctx]
\\
hwclient: Racket 语言实现的 Hello World 客户端
#lang racket
#|
# Hello World client in Racket
# Connects REQ socket to tcp://:5555
# Sends "Hello" to server, expects "World" back
|#
(require net/zmq)
; Prepare our context and sockets
(define ctxt (context 1))
(define sock (socket ctxt 'REQ))
(printf "Connecting to hello world server...\n")
(socket-connect! sock "tcp://:5555")
; Do 10 requests, waiting each time for a response
(for ([request (in-range 10)])
(printf "Sending request ~a...\n" request)
(socket-send! sock #"Hello")
; Get the reply.
(define message (socket-recv! sock))
(printf "Received reply ~a [~a]\n" request message))
(context-close! ctxt)
hwclient: Ruby 语言实现的 Hello World 客户端
#!/usr/bin/env ruby
require 'rubygems'
require 'ffi-rzmq'
context = ZMQ::Context.new(1)
# Socket to talk to server
puts "Connecting to hello world server..."
requester = context.socket(ZMQ::REQ)
requester.connect("tcp://:5555")
0.upto(9) do |request_nbr|
puts "Sending request #{request_nbr}..."
requester.send_string "Hello"
reply = ''
rc = requester.recv_string(reply)
puts "Received reply #{request_nbr}: [#{reply}]"
end
hwclient: Rust 语言实现的 Hello World 客户端
fn main() {
println!("Connecting to hello world server...");
let context = zmq::Context::new();
let requester = context.socket(zmq::REQ).unwrap();
assert!(requester.connect("tcp://:5555").is_ok());
for request_nbr in 0..10 {
let buffer = &mut [0; 10];
println!("Sending Hello {:?}...", request_nbr);
requester.send("Hello", 0).unwrap();
requester.recv_into(buffer, 0).unwrap();
println!("Received World {:?}", request_nbr);
}
}
hwclient: Scala 语言实现的 Hello World 客户端
/*
*
* Hello World client in Scala
* Connects REQ socket to tcp://:5555
* Sends "Hello" to server, expects "World" back
*
* @author Giovanni Ruggiero
* @email giovanni.ruggiero@gmail.com
*/
import org.zeromq.ZMQ
import org.zeromq.ZMQ.{Context,Socket}
object HelloWorldClient{
def main(args : Array[String]) {
// Prepare our context and socket
val context = ZMQ.context(1)
val socket = context.socket(ZMQ.REQ)
println("Connecting to hello world server...")
socket.connect ("tcp://:5555")
// Do 10 requests, waiting each time for a response
for (request_nbr <- 1 to 10) {
// Create a "Hello" message.
// Ensure that the last byte of our "Hello" message is 0 because
// our "Hello World" server is expecting a 0-terminated string:
val request = "Hello ".getBytes()
request(request.length-1)=0 //Sets the last byte to 0
// Send the message
println("Sending request " + request_nbr + "...") + request.toString
socket.send(request, 0)
// Get the reply.
val reply = socket.recv(0)
// When displaying reply as a String, omit the last byte because
// our "Hello World" server has sent us a 0-terminated string:
println("Received reply " + request_nbr + ": [" + new String(reply,0,reply.length-1) + "]")
}
}
}
hwclient: Tcl 语言实现的 Hello World 客户端
package require zmq
zmq context context
zmq socket client context REQ
client connect "tcp://:5555"
for {set i 0} {$i < 10} {incr i} {
zmq message msg -data "Hello @ [clock format [clock seconds]]"
client send_msg msg
msg close
zmq message msg
client recv_msg msg
puts "Received [msg data]/[msg size]"
msg close
}
client close
context term
hwclient: OCaml 语言实现的 Hello World 客户端
(** Hello World client *)
open Zmq
open Helpers
let () =
printfn "Connecting to hello world server...";
with_context @@ fun ctx ->
with_socket ctx Socket.req @@ fun req ->
Socket.connect req "tcp://:5555";
for i = 0 to 9 do
printfn "Sending Hello %d..." i;
Socket.send req "Hello";
let answer = Socket.recv req in
printfn "Received %d : %S" i answer
done
现在看来这太简单了,不太现实,但正如我们之前了解到的,ZeroMQ 套接字拥有超能力。你可以同时向这个服务器发起数千个客户端连接,它仍然会愉快而快速地工作。为了好玩,尝试先启动客户端,然后启动服务器,看看一切如何仍然正常工作,然后思考一下这意味着什么。
让我们简要解释一下这两个程序实际上在做什么。它们创建一个 ZeroMQ 上下文进行工作,以及一个套接字。别担心这些词是什么意思。你会慢慢理解的。服务器将其 REP(回复)套接字绑定到端口 5555。服务器在循环中等待请求,并对每个请求回复。客户端发送一个请求并从服务器读取回复。
如果你终止服务器(Ctrl-C)并重新启动它,客户端将无法正常恢复。从崩溃的进程中恢复并非如此简单。构建一个可靠的请求-回复流程非常复杂,我们将在第 4 章 - 可靠请求-回复模式中才会介绍它。
幕后发生了很多事情,但对我们程序员来说,重要的是代码有多么简洁明了,以及即使在高负载下它也不常崩溃。这就是请求-回复模式,可能是使用 ZeroMQ 最简单的方式。它对应于 RPC 和经典的客户端/服务器模型。
关于字符串的一个小注 #
ZeroMQ 除了数据的字节大小之外,对你发送的数据一无所知。这意味着你有责任安全地格式化数据,以便应用程序能够读取回来。对于对象和复杂数据类型,这是 Protocol Buffers 等专门库的工作。但即使对于字符串,你也需要小心处理。
在 C 和一些其他语言中,字符串以 null 字节终止。我们可以发送一个像“HELLO”这样的字符串,带上那个额外的 null 字节
zmq_send (requester, "Hello", 6, 0);
然而,如果你从其他语言发送字符串,它可能不包含那个 null 字节。例如,当我们在 Python 中发送同样的字符串时,我们这样做
socket.send ("Hello")
然后在线路上发送的是一个长度(对于短字符串是一个字节)和字符串内容的单个字符。

如果你在 C 程序中读取这个,你会得到一个看起来像字符串的东西,如果幸运地那五个字节后面紧跟着一个无意中出现的 null,它可能偶然会表现得像一个字符串,但它不是一个真正的字符串。当你的客户端和服务器对字符串格式不一致时,你会得到奇怪的结果。
当你在 C 中从 ZeroMQ 接收字符串数据时,你不能相信它已被安全地终止。每一次接收字符串,你都应该分配一个新缓冲区,预留一个额外字节的空间,复制字符串,并用一个 null 字符正确终止它。
所以我们确立一个规则:ZeroMQ 字符串是由长度指定的,并且在线路上发送时不包含末尾的 null 字符。在最简单的情况下(我们将在示例中这样做),一个 ZeroMQ 字符串正好映射到一个 ZeroMQ 消息帧,它看起来就像上图所示——一个长度加上一些字节。
在 C 中,我们需要这样做来接收一个 ZeroMQ 字符串并将其作为有效的 C 字符串提供给应用程序:
// Receive ZeroMQ string from socket and convert into C string
// Chops string at 255 chars, if it's longer
static char *
s_recv (void *socket) {
char buffer [256];
int size = zmq_recv (socket, buffer, 255, 0);
if (size == -1)
return NULL;
if (size > 255)
size = 255;
buffer [size] = '\0';
/* use strndup(buffer, sizeof(buffer)-1) in *nix */
return strdup (buffer);
}
这形成了一个方便的辅助函数,本着创建可以有效重用的东西的精神,我们来写一个类似的s_send函数,该函数以正确的 ZeroMQ 格式发送字符串,并将其打包到一个我们可以重用的头文件中。
结果是zhelpers.h,它让我们可以用 C 编写更简洁、更短的 ZeroMQ 应用程序。这是一个相当长的源代码,只有 C 开发者会觉得有趣,所以你可以自行阅读。
关于命名约定 #
前缀s_在zhelpers.h和本指南接下来的示例中使用,表示静态方法或变量。
版本报告 #
ZeroMQ 确实有多个版本,而且通常情况下,如果你遇到问题,很可能是在更高版本中已修复的问题。所以知道你实际链接的 ZeroMQ 版本确切是什么是一个有用的技巧。
这里有一个小程序可以做到这一点
version: Ada 语言实现的 ZeroMQ 版本报告
version: Basic 语言实现的 ZeroMQ 版本报告
version: C 语言实现的 ZeroMQ 版本报告
// Report 0MQ version
#include <zmq.h>
int main (void)
{
int major, minor, patch;
zmq_version (&major, &minor, &patch);
printf ("Current 0MQ version is %d.%d.%d\n", major, minor, patch);
return 0;
}
version: C++ 语言实现的 ZeroMQ 版本报告
//
// Report 0MQ version
//
#include "zhelpers.hpp"
int main ()
{
s_version ();
return EXIT_SUCCESS;
}
version: C# 语言实现的 ZeroMQ 版本报告
version: CL 语言实现的 ZeroMQ 版本报告
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-
;;;
;;; Report 0MQ version
;;;
;;; Kamil Shakirov <kamils80@gmail.com>
;;;
(defpackage #:zguide.zversion
(:nicknames #:zversion)
(:use #:cl #:zhelpers)
(:export #:main))
(in-package :zguide.zversion)
(defun main ()
(version))
version: Delphi 语言实现的 ZeroMQ 版本报告
program version;
//
// Report 0MQ version
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
major,
minor,
patch: Integer;
begin
ZMQVersion( major, minor, patch );
Writeln( Format( 'Current 0MQ version is %d.%d.%d', [major, minor, patch]) );
end.
version: Erlang 语言实现的 ZeroMQ 版本报告
#! /usr/bin/env escript
%%
%% Report 0MQ version
%%
main(_) ->
{Maj, Min, Patch} = erlzmq:version(),
io:format("Current 0MQ version is ~b.~b.~b~n", [Maj, Min, Patch]).
version: Elixir 语言实现的 ZeroMQ 版本报告
defmodule Version do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:38
"""
def main() do
{maj, var_min, patch} = :erlzmq.version()
:io.format('Current 0MQ version is ~b.~b.~b~n', [maj, var_min, patch])
end
end
Version.main
version: F# 语言实现的 ZeroMQ 版本报告
version: Felix 语言实现的 ZeroMQ 版本报告
println$ f"Current 0MQ version is %d.%d.%d" #ZeroMQ::zmq_version;
version: Go 语言实现的 ZeroMQ 版本报告
//
// 0MQ version example.
//
// Author: Max Riveiro <kavu13@gmail.com>
// Requires: http://github.com/alecthomas/gozmq
//
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
)
func main() {
major, minor, patch := zmq.Version()
fmt.Printf("Current 0MQ version is %d.%d.%d\n", major, minor, patch)
}
version: Haskell 语言实现的 ZeroMQ 版本报告
module Main where
import System.ZMQ4 (version)
import Text.Printf (printf)
main :: IO ()
main = do
(major, minor, patch) <- version
printf "Current 0MQ version is %d.%d.%d" major minor patch
version: Haxe 语言实现的 ZeroMQ 版本报告
version: Java 语言实现的 ZeroMQ 版本报告
package guide;
import org.zeromq.ZMQ;
// Report 0MQ version
public class version
{
public static void main(String[] args)
{
String version = ZMQ.getVersionString();
int fullVersion = ZMQ.getFullVersion();
System.out.println(
String.format(
"Version string: %s, Version int: %d", version, fullVersion
)
);
}
}
version: Julia 语言实现的 ZeroMQ 版本报告
#!/usr/bin/env julia
using ZMQ
println("Current ZMQ version is $(ZMQ.version)")version: Lua 语言实现的 ZeroMQ 版本报告
--
-- Report 0MQ version
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
print("Current 0MQ version is " .. table.concat(zmq.version(), '.'))
version: Node.js 语言实现的 ZeroMQ 版本报告
// Report 0MQ version in Node.js
var zmq = require('zeromq');
console.log("Current 0MQ version is " + zmq.version);
version: Objective-C 语言实现的 ZeroMQ 版本报告
/* Reports the 0MQ version. */
#import "ZMQObjC.h"
int
main(void)
{
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init];
int major = 0;
int minor = 0;
int patch = 0;
[ZMQContext getZMQVersionMajor:&major minor:&minor patch:&patch];
NSLog(@"Current 0MQ version is %d.%d.%d.", major, minor, patch);
[pool drain];
return EXIT_SUCCESS;
}
version: ooc 语言实现的 ZeroMQ 版本报告
version: Perl 语言实现的 ZeroMQ 版本报告
# Report 0MQ version in Perl
use strict;
use warnings;
use v5.10;
use ZMQ::FFI;
my ($major, $minor, $patch) = ZMQ::FFI->new->version;
say "Current 0MQ version is $major.$minor.$patch";
version: PHP 语言实现的 ZeroMQ 版本报告
<?php
/* Report 0MQ version
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
if (class_exists("ZMQ") && defined("ZMQ::LIBZMQ_VER")) {
echo ZMQ::LIBZMQ_VER, PHP_EOL;
}
version: Python 语言实现的 ZeroMQ 版本报告
# Report 0MQ version
#
# Author: Lev Givon <lev(at)columbia(dot)edu>
import zmq
print(f"Current libzmq version is {zmq.zmq_version()}")
print(f"Current pyzmq version is {zmq.__version__}")
version: Q 语言实现的 ZeroMQ 版本报告
// Report 0MQ version
\l qzmq.q
mnp:libzmq.version[]
zclock.log "Current 0MQ version is ","." sv (string mnp)
\\
version: Racket 语言实现的 ZeroMQ 版本报告
version: Ruby 语言实现的 ZeroMQ 版本报告
#!/usr/bin/env ruby
#
# Report 0MQ version
#
require 'rubygems'
require 'ffi-rzmq'
version = LibZMQ.version
puts "Current 0MQ version is %d.%d.%d\n" \
% [version[:major], version[:minor], version[:patch]]
version: Rust 语言实现的 ZeroMQ 版本报告
fn main() {
let (major, minor, patch) = zmq::version();
println!("Current 0MQ version is {}.{}.{}", major, minor, patch);
}
version: Scala 语言实现的 ZeroMQ 版本报告
/*
*
* Version in Scala
*
* @author Vadim Shalts
* @email vshalts@gmail.com
*/
import org.zeromq.ZMQ
object version {
def main(args: Array[String]) {
printf("Version string: %s, Version int: %d\n", ZMQ.getVersionString, ZMQ.getFullVersion)
}
}
version: Tcl 语言实现的 ZeroMQ 版本报告
#
# Report 0MQ version
#
package require zmq
puts [zmq version]
version: OCaml 语言实现的 ZeroMQ 版本报告
(* Report 0MQ version *)
open Helpers
let () =
let (major, minor, patch) = Zmq.version () in
printfn "Current 0MQ version is %d.%d.%d" major minor patch
发出消息 #
第二个经典模式是单向数据分发,其中服务器将更新推送到一组客户端。我们来看一个推送包含邮政编码、温度和相对湿度天气更新的示例。我们将生成随机值,就像真实的气象站一样。
这是服务器代码。我们将使用端口 5556 用于此应用程序
wuserver: Ada 语言实现的天气更新服务器
wuserver: Basic 语言实现的天气更新服务器
wuserver: C 语言实现的天气更新服务器
// Weather update server
// Binds PUB socket to tcp://*:5556
// Publishes random weather updates
#include "zhelpers.h"
int main (void)
{
// Prepare our context and publisher
void *context = zmq_ctx_new ();
void *publisher = zmq_socket (context, ZMQ_PUB);
int rc = zmq_bind (publisher, "tcp://*:5556");
assert (rc == 0);
// Initialize random number generator
srandom ((unsigned) time (NULL));
while (1) {
// Get values that will fool the boss
int zipcode, temperature, relhumidity;
zipcode = randof (100000);
temperature = randof (215) - 80;
relhumidity = randof (50) + 10;
// Send message to all subscribers
char update [20];
sprintf (update, "%05d %d %d", zipcode, temperature, relhumidity);
s_send (publisher, update);
}
zmq_close (publisher);
zmq_ctx_destroy (context);
return 0;
}
wuserver: C++ 语言实现的天气更新服务器
//
// Weather update server in C++
// Binds PUB socket to tcp://*:5556
// Publishes random weather updates
//
#include <zmq.hpp>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#if (defined (WIN32))
#include <zhelpers.hpp>
#endif
#define within(num) (int) ((float) num * random () / (RAND_MAX + 1.0))
int main () {
// Prepare our context and publisher
zmq::context_t context (1);
zmq::socket_t publisher (context, zmq::socket_type::pub);
publisher.bind("tcp://*:5556");
publisher.bind("ipc://weather.ipc"); // Not usable on Windows.
// Initialize random number generator
srandom ((unsigned) time (NULL));
while (1) {
int zipcode, temperature, relhumidity;
// Get values that will fool the boss
zipcode = within (100000);
temperature = within (215) - 80;
relhumidity = within (50) + 10;
// Send message to all subscribers
zmq::message_t message(20);
snprintf ((char *) message.data(), 20 ,
"%05d %d %d", zipcode, temperature, relhumidity);
publisher.send(message, zmq::send_flags::none);
}
return 0;
}
wuserver: C# 语言实现的天气更新服务器
wuserver: CL 语言实现的天气更新服务器
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-
;;;
;;; Weather update server in Common Lisp
;;; Binds PUB socket to tcp://*:5556
;;; Publishes random weather updates
;;;
;;; Kamil Shakirov <kamils80@gmail.com>
;;;
(defpackage #:zguide.wuserver
(:nicknames #:wuserver)
(:use #:cl #:zhelpers)
(:export #:main))
(in-package :zguide.wuserver)
(defun main ()
;; Prepare our context and socket
(zmq:with-context (context 1)
(zmq:with-socket (publisher context zmq:pub)
(zmq:bind publisher "tcp://*:5556")
(zmq:bind publisher "ipc://weather.ipc")
(loop
;; Get values that will fool the boss
(let ((zipcode (within 100000))
(temperature (- (within 215) 80))
(relhumidity (+ (within 50) 10)))
;; Send message to all subscribers
(let ((message
(make-instance 'zmq:msg
:data (format nil "~5,'0D ~D ~D"
zipcode
temperature
relhumidity))))
;; Send message to all subscribers
(zmq:send publisher message))))))
(cleanup))
wuserver: Delphi 语言实现的天气更新服务器
program wuserver;
//
// Weather update server
// Binds PUB socket to tcp://*:5556
// Publishes random weather updates
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
context : TZMQContext;
publisher : TZMQSocket;
zipcode,
temperature,
relhumidity: Integer;
begin
// Prepare our context and publisher
context := TZMQContext.create;
publisher := Context.Socket( stPub );
publisher.bind( 'tcp://*:5556' );
{$ifdef unix}
publisher.bind( 'ipc://weather.ipc' );
{$endif}
Randomize;
while True do
begin
zipcode := Random( 100000 );
temperature := Random( 215 ) - 80;
relhumidity := Random( 50 ) + 10;
publisher.Send( Format( '%05d %d %d', [zipcode, temperature, relhumidity] ) );
end;
publisher.Free;
context.Free;
end.
wuserver: Erlang 语言实现的天气更新服务器
#! /usr/bin/env escript
%%
%% Weather update server
%% Binds PUB socket to tcp://*.5556
%% Publishes random weather updates
%%
main(_Args) ->
application:start(chumak),
{ok, Publisher} = chumak:socket(pub),
case chumak:bind(Publisher, tcp, "localhost", 5556) of
{ok, _BindPid} ->
io:format("Binding OK with Pid: ~p\n", [Publisher]);
{error, Reason} ->
io:format("Connection Failed for this reason: ~p\n", [Reason]);
X ->
io:format("Unhandled reply for bind ~p \n", [X])
end,
loop(Publisher).
loop(Publisher) ->
Zipcode = rand:uniform(100000),
Temperature = rand:uniform(135),
Relhumidity = rand:uniform(50) + 10,
BinZipCode = erlang:integer_to_binary(Zipcode),
BinTemperature = erlang:integer_to_binary(Temperature),
BinRelhumidity = erlang:integer_to_binary(Relhumidity),
ok = chumak:send(Publisher, [BinZipCode, " ", BinTemperature, " ", BinRelhumidity]),
loop(Publisher).
wuserver: Elixir 语言实现的天气更新服务器
defmodule Wuserver do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:40
"""
def main(_) do
{:ok, context} = :erlzmq.context()
{:ok, publisher} = :erlzmq.socket(context, :pub)
:ok = :erlzmq.bind(publisher, 'tcp://*:5556')
loop(publisher)
:ok = :erlzmq.close(publisher)
:ok = :erlzmq.term(context)
end
def loop(publisher) do
zipcode = :random.uniform(100000)
temperature = :random.uniform(215) - 80
relhumidity = :random.uniform(50) + 10
msg = :erlang.list_to_binary(:io_lib.format('~5..0b ~b ~b', [zipcode, temperature, relhumidity]))
:ok = :erlzmq.send(publisher, msg)
loop(publisher)
end
end
Wuserver.main(:ok)
wuserver: F# 语言实现的天气更新服务器
wuserver: Felix 语言实现的天气更新服务器
//
// Weather update server
// Binds PUB socket to tcp://*:5556
// Publishes random weather updates
//
open ZMQ;
// Prepare our context and publisher
var context = zmq_init 1;
var publisher = context.mk_socket ZMQ_PUB;
publisher.bind "tcp://*:5556";
publisher.bind "ipc://weather.ipc";
while true do
// Get values that will fool the boss
zipcode := #rand % 1000+1000;
temperature := #rand % 80 - 20; // Oztraila mate!
relhumidity := #rand % 50 + 10;
// Send message to all subscribers
update := f"%03d %d %d" (zipcode, temperature, relhumidity);
publisher.send_string update;
done
wuserver: Go 语言实现的天气更新服务器
//
// Weather update server
// Binds PUB socket to tcp://*:5556
// Publishes random weather updates
//
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"time"
)
func main() {
context, _ := zmq.NewContext()
socket, _ := context.NewSocket(zmq.PUB)
defer context.Close()
defer socket.Close()
socket.Bind("tcp://*:5556")
socket.Bind("ipc://weather.ipc")
// Seed the random number generator
rand.Seed(time.Now().UnixNano())
// loop for a while aparently
for {
// make values that will fool the boss
zipcode := rand.Intn(100000)
temperature := rand.Intn(215) - 80
relhumidity := rand.Intn(50) + 10
msg := fmt.Sprintf("%d %d %d", zipcode, temperature, relhumidity)
// Send message to all subscribers
socket.Send([]byte(msg), 0)
}
}
wuserver: Haskell 语言实现的天气更新服务器
{-# LANGUAGE ScopedTypeVariables #-}
-- Weather update server
-- Binds PUB socket to tcp://*:5556
-- Publishes random weather updates
module Main where
import Control.Monad
import qualified Data.ByteString.Char8 as BS
import System.Random
import System.ZMQ4.Monadic
import Text.Printf
main :: IO ()
main = runZMQ $ do
-- Prepare our publisher
publisher <- socket Pub
bind publisher "tcp://*:5556"
forever $ do
-- Get values that will fool the boss
zipcode :: Int <- liftIO $ randomRIO (0, 100000)
temperature :: Int <- liftIO $ randomRIO (-30, 135)
relhumidity :: Int <- liftIO $ randomRIO (10, 60)
-- Send message to all subscribers
let update = printf "%05d %d %d" zipcode temperature relhumidity
send publisher [] (BS.pack update)
wuserver: Haxe 语言实现的天气更新服务器
package ;
import haxe.io.Bytes;
import neko.Lib;
import org.zeromq.ZMQ;
import org.zeromq.ZMQContext;
import org.zeromq.ZMQSocket;
/**
* Weather update server in Haxe
* Binds PUB socket to tcp://*:5556
* Publishes random weather updates
*
* See: https://zguide.zeromq.cn/page:all#Getting-the-Message-Out
*
* Use with WUClient.hx
*/
class WUServer
{
public static function main() {
var context:ZMQContext = ZMQContext.instance();
Lib.println("** WUServer (see: https://zguide.zeromq.cn/page:all#Getting-the-Message-Out)");
var publisher:ZMQSocket = context.socket(ZMQ_PUB);
publisher.bind("tcp://127.0.0.1:5556");
while (true) {
// Get values that will fool the boss
var zipcode, temperature, relhumidity;
zipcode = Std.random(100000) + 1;
temperature = Std.random(215) - 80 + 1;
relhumidity = Std.random(50) + 10 + 1;
// Send message to all subscribers
var update:String = zipcode + " " + temperature + " " + relhumidity;
publisher.sendMsg(Bytes.ofString(update));
}
}
}wuserver: Java 语言实现的天气更新服务器
package guide;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZContext;
//
// Weather update server in Java
// Binds PUB socket to tcp://*:5556
// Publishes random weather updates
//
public class wuserver
{
public static void main(String[] args) throws Exception
{
// Prepare our context and publisher
try (ZContext context = new ZContext()) {
ZMQ.Socket publisher = context.createSocket(SocketType.PUB);
publisher.bind("tcp://*:5556");
publisher.bind("ipc://weather");
// Initialize random number generator
Random srandom = new Random(System.currentTimeMillis());
while (!Thread.currentThread().isInterrupted()) {
// Get values that will fool the boss
int zipcode, temperature, relhumidity;
zipcode = 10000 + srandom.nextInt(10000);
temperature = srandom.nextInt(215) - 80 + 1;
relhumidity = srandom.nextInt(50) + 10 + 1;
// Send message to all subscribers
String update = String.format(
"%05d %d %d", zipcode, temperature, relhumidity
);
publisher.send(update, 0);
}
}
}
}
wuserver: Julia 语言实现的天气更新服务器
#!/usr/bin/env julia
#
# Weather update server
# Binds PUB socket to tcp://*:5556
# Publishes random weather updates
#
using ZMQ
context = Context()
socket = Socket(context, PUB)
bind(socket, "tcp://*:5556")
while true
zipcode = rand(10000:99999)
temperature = rand(-80:135)
relhumidity = rand(10:60)
message = "$zipcode $temperature $relhumidity"
send(socket, message)
yield()
end
close(socket)
close(context)
wuserver: Lua 语言实现的天气更新服务器
--
-- Weather update server
-- Binds PUB socket to tcp://*:5556
-- Publishes random weather updates
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
-- Prepare our context and publisher
local context = zmq.init(1)
local publisher = context:socket(zmq.PUB)
publisher:bind("tcp://*:5556")
publisher:bind("ipc://weather.ipc")
-- Initialize random number generator
math.randomseed(os.time())
while (1) do
-- Get values that will fool the boss
local zipcode, temperature, relhumidity
zipcode = math.random(0, 99999)
temperature = math.random(-80, 135)
relhumidity = math.random(10, 60)
-- Send message to all subscribers
publisher:send(string.format("%05d %d %d", zipcode, temperature, relhumidity))
end
publisher:close()
context:term()
wuserver: Node.js 语言实现的天气更新服务器
// Weather update server in node.js
// Binds PUB socket to tcp://*:5556
// Publishes random weather updates
var zmq = require('zeromq')
, publisher = zmq.socket('pub');
publisher.bindSync("tcp://*:5556");
publisher.bindSync("ipc://weather.ipc");
function zeropad(num) {
return num.toString().padStart(5, "0");
};
function rand(upper, extra) {
var num = Math.abs(Math.round(Math.random() * upper));
return num + (extra || 0);
};
while (true) {
// Get values that will fool the boss
var zipcode = rand(100000)
, temperature = rand(215, -80)
, relhumidity = rand(50, 10)
, update = `${zeropad(zipcode)} ${temperature} ${relhumidity}`;
publisher.send(update);
}
wuserver: Objective-C 语言实现的天气更新服务器
//
// Weather update server
// Binds PUB socket to tcp://*:5556
// Publishes random weather updates
//
#import "ZMQObjC.h"
#import "ZMQHelper.h"
int
main(void)
{
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init];
// Prepare our context and publisher
ZMQContext *ctx = [[[ZMQContext alloc] initWithIOThreads:1U] autorelease];
ZMQSocket *publisher = [ctx socketWithType:ZMQ_PUB];
[publisher bindToEndpoint:@"tcp://*:5556"];
[publisher bindToEndpoint:@"ipc://weather.ipc"];
// Initialize random number generator
srandom ((unsigned) time (NULL));
for (;;) {
// Get values that will fool the boss
int zipcode, temperature, relhumidity;
zipcode = within (100000);
temperature = within (215) - 80;
relhumidity = within (50) + 10;
// Send message to all subscribers
NSString *update = [NSString stringWithFormat:@"%05d %d %d",
zipcode, temperature, relhumidity];
NSData *data = [update dataUsingEncoding:NSUTF8StringEncoding];
[publisher sendData:data withFlags:0];
}
[publisher close];
[pool drain];
return EXIT_SUCCESS;
}
wuserver: ooc 语言实现的天气更新服务器
wuserver: Perl 语言实现的天气更新服务器
# Weather update server in Perl
# Binds PUB socket to tcp://*:5556
# Publishes random weather updates
use strict;
use warnings;
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_PUB);
my $context = ZMQ::FFI->new();
my $publisher = $context->socket(ZMQ_PUB);
$publisher->bind("tcp://*:5556");
my ($update, $zipcode, $temperature, $relhumidity);
while (1) {
$zipcode = rand(100_000);
$temperature = rand(215) - 80;
$relhumidity = rand(50) + 10;
$update = sprintf('%d %d %d', $zipcode,$temperature,$relhumidity);
$publisher->send($update);
}
wuserver: PHP 语言实现的天气更新服务器
<?php
/*
* Weather update server
* Binds PUB socket to tcp://*:5556
* Publishes random weather updates
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
// Prepare our context and publisher
$context = new ZMQContext();
$publisher = $context->getSocket(ZMQ::SOCKET_PUB);
$publisher->bind("tcp://*:5556");
$publisher->bind("ipc://weather.ipc");
while (true) {
// Get values that will fool the boss
$zipcode = mt_rand(0, 100000);
$temperature = mt_rand(-80, 135);
$relhumidity = mt_rand(10, 60);
// Send message to all subscribers
$update = sprintf ("%05d %d %d", $zipcode, $temperature, $relhumidity);
$publisher->send($update);
}
wuserver: Python 语言实现的天气更新服务器
#
# Weather update server
# Binds PUB socket to tcp://*:5556
# Publishes random weather updates
#
import zmq
from random import randrange
context = zmq.Context()
socket = context.socket(zmq.PUB)
socket.bind("tcp://*:5556")
while True:
zipcode = randrange(1, 100000)
temperature = randrange(-80, 135)
relhumidity = randrange(10, 60)
socket.send_string(f"{zipcode} {temperature} {relhumidity}")
wuserver: Q 语言实现的天气更新服务器
wuserver: Racket 语言实现的天气更新服务器
#lang racket
#|
# Weather update server
# Binds PUB socket to tcp://*:5556
# Publishes random weather updates
|#
(require net/zmq)
(define ctxt (context 1))
(define sock (socket ctxt 'PUB))
(socket-bind! sock "tcp://*:5556")
(let loop ()
(define zipcode (random 100000))
(define temp (- (random 215) 80))
(define humidity (+ (random 50) 10))
(socket-send! sock (string->bytes/utf-8 (format "~a ~a ~a" zipcode temp humidity)))
(loop))
(context-close! ctxt)
wuserver: Ruby 语言实现的天气更新服务器
#!/usr/bin/env ruby
#
# Weather update server in Ruby
# Binds PUB socket to tcp://*:5556
# Publishes random weather updates
#
require 'rubygems'
require 'ffi-rzmq'
context = ZMQ::Context.new(1)
publisher = context.socket(ZMQ::PUB)
publisher.bind("tcp://*:5556")
publisher.bind("ipc://weather.ipc")
while true
# Get values that will fool the boss
zipcode = rand(100000)
temperature = rand(215) - 80
relhumidity = rand(50) + 10
update = "%05d %d %d" % [zipcode, temperature, relhumidity]
puts update
publisher.send_string(update)
end
wuserver: Rust 语言实现的天气更新服务器
use rand::Rng;
fn main() {
let context = zmq::Context::new();
let publisher = context.socket(zmq::PUB).unwrap();
assert!(publisher.bind("tcp://*:5556").is_ok());
let mut rng = rand::thread_rng();
loop {
let zipcode = rng.gen_range(0..100000);
let temperature = rng.gen_range(-80..135);
let relhumidity = rng.gen_range(10..60);
let update = format!("{:05} {} {}", zipcode, temperature, relhumidity);
publisher.send(&update, 0).unwrap();
}
}
wuserver: Scala 语言实现的天气更新服务器
//
// Weather update server in Scala
// Binds PUB socket to tcp://*:5556
// Publishes random weather updates
//
// author Giovanni Ruggiero
// email giovanni.ruggiero@gmail.com
import java.util.Random
import org.zeromq.ZMQ
object wuserver {
def main(args : Array[String]) {
// Prepare our context and publisher
val context = ZMQ.context(1)
val publisher = context.socket(ZMQ.PUB)
publisher.bind("tcp://*:5556")
// Initialize random number generator
val srandom = new Random(System.currentTimeMillis())
while (true) {
// Get values that will fool the boss
val zipcode: Integer = srandom.nextInt(100000) + 1
val temperature: Integer = srandom.nextInt(215) - 80 + 1
val relhumidity: Integer = srandom.nextInt(50) + 10 + 1
// Send message to all subscribers
val update = String.format("%05d %d %d\u0000", zipcode, temperature, relhumidity);
publisher.send(update.getBytes(), 0)
}
}
}
wuserver: Tcl 语言实现的天气更新服务器
#
# Weather update server
# Binds PUB socket to tcp:#*:5556
# Publishes random weather updates
#
package require zmq
# Prepare our context and publisher
zmq context context
zmq socket publisher context PUB
publisher bind "tcp://*:5556"
publisher bind "ipc://weather.ipc"
# Initialize random number generator
expr {srand([clock seconds])}
while {1} {
# Get values that will fool the boss
set zipcode [expr {int(rand()*100000)}]
set temperature [expr {int(rand()*215)-80}]
set relhumidity [expr {int(rand()*50)+50}]
# Send message to all subscribers
set data [format "%05d %d %d" $zipcode $temperature $relhumidity]
if {$zipcode eq "10001"} {
puts $data
}
zmq message msg -data $data
publisher send_msg msg
msg close
}
publisher close
context term
wuserver: OCaml 语言实现的天气更新服务器
(**
Weather update server
Binds PUB socket to tcp://*:5556
Publishes random weather updates
*)
open Zmq
open Helpers
let () =
with_context @@ fun ctx ->
with_socket ctx Socket.pub @@ fun pub ->
Socket.bind pub "tcp://*:5556";
Socket.bind pub "ipc://weather.ipc";
Random.self_init ();
while not !should_exit do
(* Get values that will fool the boss *)
let zipcode = Random.int 100_000 in
let temperature = Random.int 215 - 80 in
let relhumidity = Random.int 50 + 10 in
(* Send message to all subscribers *)
Socket.send pub (Printf.sprintf "%05d %d %d" zipcode temperature relhumidity);
done
这个更新流没有开始也没有结束,它就像一个永不停止的广播。
这是客户端应用程序,它监听更新流,并抓取与特定邮政编码相关的所有信息,默认为纽约市,因为那是开始任何冒险的好地方。
wuclient: Ada 语言实现的天气更新客户端
wuclient: Basic 语言实现的天气更新客户端
wuclient: C 语言实现的天气更新客户端
// Weather update client
// Connects SUB socket to tcp://:5556
// Collects weather updates and finds avg temp in zipcode
#include "zhelpers.h"
int main (int argc, char *argv [])
{
// Socket to talk to server
printf ("Collecting updates from weather server...\n");
void *context = zmq_ctx_new ();
void *subscriber = zmq_socket (context, ZMQ_SUB);
int rc = zmq_connect (subscriber, "tcp://:5556");
assert (rc == 0);
// Subscribe to zipcode, default is NYC, 10001
const char *filter = (argc > 1)? argv [1]: "10001 ";
rc = zmq_setsockopt (subscriber, ZMQ_SUBSCRIBE,
filter, strlen (filter));
assert (rc == 0);
// Process 100 updates
int update_nbr;
long total_temp = 0;
for (update_nbr = 0; update_nbr < 100; update_nbr++) {
char *string = s_recv (subscriber);
int zipcode, temperature, relhumidity;
sscanf (string, "%d %d %d",
&zipcode, &temperature, &relhumidity);
total_temp += temperature;
free (string);
}
printf ("Average temperature for zipcode '%s' was %dF\n",
filter, (int) (total_temp / update_nbr));
zmq_close (subscriber);
zmq_ctx_destroy (context);
return 0;
}
wuclient: C++ 语言实现的天气更新客户端
//
// Weather update client in C++
// Connects SUB socket to tcp://:5556
// Collects weather updates and finds avg temp in zipcode
//
#include <zmq.hpp>
#include <iostream>
#include <sstream>
int main (int argc, char *argv[])
{
zmq::context_t context (1);
// Socket to talk to server
std::cout << "Collecting updates from weather server...\n" << std::endl;
zmq::socket_t subscriber (context, zmq::socket_type::sub);
subscriber.connect("tcp://:5556");
// Subscribe to zipcode, default is NYC, 10001
const char *filter = (argc > 1)? argv [1]: "10001 ";
subscriber.set(zmq::sockopt::subscribe, filter);
// Process 100 updates
int update_nbr;
long total_temp = 0;
for (update_nbr = 0; update_nbr < 100; update_nbr++) {
zmq::message_t update;
int zipcode, temperature, relhumidity;
subscriber.recv(update, zmq::recv_flags::none);
std::istringstream iss(static_cast<char*>(update.data()));
iss >> zipcode >> temperature >> relhumidity ;
total_temp += temperature;
}
std::cout << "Average temperature for zipcode '"<< filter
<<"' was "<<(int) (total_temp / update_nbr) <<"F"
<< std::endl;
return 0;
}
wuclient: C# 语言实现的天气更新客户端
wuclient: CL 语言实现的天气更新客户端
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-
;;;
;;; Weather update client in Common Lisp
;;; Connects SUB socket to tcp://:5556
;;; Collects weather updates and finds avg temp in zipcode
;;;
;;; Kamil Shakirov <kamils80@gmail.com>
;;;
(defpackage #:zguide.wuclient
(:nicknames #:wuclient)
(:use #:cl #:zhelpers)
(:export #:main))
(in-package :zguide.wuclient)
(defun main ()
(zmq:with-context (context 1)
(message "Collecting updates from weather server...~%")
;; Socket to talk to server
(zmq:with-socket (subscriber context zmq:sub)
(zmq:connect subscriber "tcp://:5556")
;; Subscribe to zipcode, default is NYC, 10001
(let ((filter (or (first (cmd-args)) "10001 ")))
(zmq:setsockopt subscriber zmq:subscribe filter)
;; Process 100 updates
(let ((number-updates 100)
(total-temp 0.0))
(loop :repeat number-updates :do
(let ((update (make-instance 'zmq:msg)))
(zmq:recv subscriber update)
(destructuring-bind (zipcode_ temperature relhumidity_)
(split-sequence:split-sequence #\Space (zmq:msg-data-as-string update))
(declare (ignore zipcode_ relhumidity_))
(incf total-temp (parse-integer temperature)))))
(message "Average temperature for zipcode ~A was ~FF~%"
filter (/ total-temp number-updates))))))
(cleanup))
wuclient: Delphi 语言实现的天气更新客户端
program wuclient;
//
// Weather update client
// Connects SUB socket to tcp://:5556
// Collects weather updates and finds avg temp in zipcode
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, Classes
, zmqapi
;
const
update_count = 100;
var
context: TZMQContext;
subscriber: TZMQSocket;
filter: String;
i, total_temp: Integer;
s: Utf8String;
tsl: TStringList;
begin
context := TZMQContext.Create;
// Socket to talk to server
Writeln ( 'Collecting updates from weather server...' );
subscriber := Context.Socket( stSub );
subscriber.connect( 'tcp://:5556' );
// Subscribe to zipcode, default is NYC, 10001
if ParamCount > 0 then
filter := ParamStr( 1 )
else
filter := '10001';
subscriber.subscribe( filter );
tsl := TStringList.Create;
tsl.Delimiter := ' ';
total_temp := 0;
// Process 100 updates
for i := 0 to update_count - 1 do
begin
subscriber.recv( s );
tsl.Clear;
tsl.DelimitedText := s;
total_temp := total_temp + StrToInt( tsl[1] );
end;
Writeln( Format( 'Average temperature for zipcode "%s" was %fF',
[ filter, total_temp / update_count]));
tsl.Free;
subscriber.Free;
context.Free;
end.
wuclient: Erlang 语言实现的天气更新客户端
#! /usr/bin/env escript
%%
%% Weather update client
%% Connects SUB socket to tcp://:5556
%% Collects weather updates and fins avg temp in zipcode
%%
main(Args) ->
application:start(chumak),
{ok, Subscriber} = chumak:socket(sub),
%% select default topic or from the args
Topic = case Args of
[] -> <<"10001">>;
[Arg1 | _] -> list_to_binary(Arg1)
end,
io:format("Collecting updates from weather server...~n"),
io:format("For zipcode: ~p\n", [Topic]),
chumak:subscribe(Subscriber, Topic),
case chumak:connect(Subscriber, tcp, "localhost", 5556) of
{ok, _BindPid} ->
io:format("Binding OK with Pid: ~p\n", [Subscriber]);
{error, Reason} ->
io:foramt("Connection failed for this reason: ~p\n", [Reason]);
X ->
io:format("Unhandled reply for bind ~p \n", [X])
end,
N = 10, %% number of records to collect
TotalTemp = collect_temperature(Subscriber, N, 0),
io:format("Average Temperature is ~p\n", [TotalTemp/N]).
collect_temperature(_Subscriber, 0, Total) -> Total;
collect_temperature(Subscriber, N, Total) when N > 0 ->
{ok, Data} = chumak:recv(Subscriber),
io:format("RECEIVED : ~p\n", [Data]),
[_, Temp, _] = string:split(Data, " ", all),
IntTemp = erlang:binary_to_integer(Temp),
collect_temperature(Subscriber, N-1, Total + IntTemp).
wuclient: Elixir 语言实现的天气更新客户端
defmodule Wuclient do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:39
"""
def main(args) do
{:ok, context} = :erlzmq.context()
:io.format('Collecting updates from weather server...~n')
{:ok, subscriber} = :erlzmq.socket(context, :sub)
:ok = :erlzmq.connect(subscriber, 'tcp://:5556')
filter = case(args) do
[] ->
"10001"
[arg1 | _] ->
:erlang.list_to_binary(arg1)
end
:ok = :erlzmq.setsockopt(subscriber, :subscribe, filter)
updateNbr = 5
totalTemp = collect_temperature(subscriber, updateNbr, 0)
:io.format('Average temperature for zipcode \'~s\' was ~bF~n', [filter, trunc(totalTemp / updateNbr)])
:ok = :erlzmq.close(subscriber)
:ok = :erlzmq.term(context)
end
def collect_temperature(_subscriber, 0, total) do
total
end
def collect_temperature(subscriber, n, total) when n > 0 do
{:ok, msg} = :erlzmq.recv(subscriber)
collect_temperature(subscriber, n - 1, total + msg_temperature(msg))
end
def msg_temperature(msg) do
{:ok, [_, temp, _], _} = :io_lib.fread('~d ~d ~d', :erlang.binary_to_list(msg))
temp
end
end
Wuclient.main([])
wuclient: F# 语言实现的天气更新客户端
wuclient: Felix 语言实现的天气更新客户端
//
// Weather update client
// Connects SUB socket to tcp://:5556
// Collects weather updates and finds avg temp in zipcode
//
open ZMQ;
fun parse_int(s:string,var i:int) = {
var acc = 0;
while s.[i] \in "0123456789" do
acc = acc * 10 + s.[i].ord - "0".char.ord;
++i;
done
return i,acc;
}
fun parse_space(s:string, i:int)=> i+1;
fun parse_weather(s:string) = {
var i = 0;
def i, val zipcode = parse_int (s,i);
i = parse_space(s,i);
def i, val temperature = parse_int (s,i);
i = parse_space(s,i);
def i, val relhumidity= parse_int (s,i);
return zipcode, temperature, relhumidity;
}
var context = zmq_init 1;
// Socket to talk to server
println "Collecting updates from weather server...";
var subscriber = context.mk_socket ZMQ_SUB;
subscriber.connect "tcp://:5556";
// Subscribe to zipcode 100
filter := if System::argc > 1 then System::argv 1 else "1001" endif;
subscriber.set_opt$ zmq_subscribe filter;
// Process 100 updates
var total_temp = 0;
for var update_nbr in 0 upto 99 do
s := subscriber.recv_string;
zipcode, temperature, relhumidity := parse_weather s;
total_temp += temperature;
done
println$
f"Average temperature for zipcode '%S' was %d C\n"$
filter, total_temp / update_nbr
;
subscriber.close;
context.term;
wuclient: Go 语言实现的天气更新客户端
//
// Weather proxy listens to weather server which is constantly
// emitting weather data
// Binds SUB socket to tcp://*:5556
//
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"os"
"strconv"
"strings"
)
func main() {
context, _ := zmq.NewContext()
socket, _ := context.NewSocket(zmq.SUB)
defer context.Close()
defer socket.Close()
var temps []string
var err error
var temp int64
total_temp := 0
filter := "59937"
// find zipcode
if len(os.Args) > 1 { // ./wuclient 85678
filter = string(os.Args[1])
}
// Subscribe to just one zipcode (whitefish MT 59937)
fmt.Printf("Collecting updates from weather server for %s…\n", filter)
socket.SetSubscribe(filter)
socket.Connect("tcp://:5556")
for i := 0; i < 101; i++ {
// found temperature point
datapt, _ := socket.Recv(0)
temps = strings.Split(string(datapt), " ")
temp, err = strconv.ParseInt(temps[1], 10, 64)
if err == nil {
// Invalid string
total_temp += int(temp)
}
}
fmt.Printf("Average temperature for zipcode %s was %dF \n\n", filter, total_temp/100)
}
wuclient: Haskell 语言实现的天气更新客户端
{-# LANGUAGE LambdaCase #-}
{-# LANGUAGE OverloadedStrings #-}
{-# LANGUAGE ScopedTypeVariables #-}
-- Weather update client
-- Connects SUB socket to tcp://:5556
-- Collects weather updates and finds avg temp in zipcode
module Main where
import Control.Monad
import qualified Data.ByteString.Char8 as BS
import System.Environment
import System.ZMQ4.Monadic
import Text.Printf
main :: IO ()
main = runZMQ $ do
liftIO $ putStrLn "Collecting updates from weather server..."
-- Socket to talk to server
subscriber <- socket Sub
connect subscriber "tcp://:5556"
-- Subscribe to zipcode, default is NYC, 10001
filter <- liftIO getArgs >>= \case
[] -> return "10001 "
(zipcode:_) -> return (BS.pack zipcode)
subscribe subscriber filter
-- Process 100 updates
temperature <- fmap sum $
replicateM 100 $ do
string <- receive subscriber
let [_, temperature :: Int, _] = map read . words . BS.unpack $ string
return temperature
liftIO $
printf "Average temperature for zipcode '%s' was %dF"
(BS.unpack filter)
(temperature `div` 100)
wuclient: Haxe 语言实现的天气更新客户端
package ;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZMQ;
import org.zeromq.ZMQContext;
import org.zeromq.ZMQException;
import org.zeromq.ZMQSocket;
/**
* Weather update client in Haxe
* Connects SUB socket to tcp://:5556
* Collects weather updates and finds average temp in zipcode
*
* Use optional argument to specify zip code (in range 1 to 100000)
*
* See: https://zguide.zeromq.cn/page:all#Getting-the-Message-Out
*
* Use with WUServer.hx
*/
class WUClient
{
public static function main() {
var context:ZMQContext = ZMQContext.instance();
Lib.println("** WUClient (see: https://zguide.zeromq.cn/page:all#Getting-the-Message-Out)");
// Socket to talk to server
trace ("Collecting updates from weather server...");
var subscriber:ZMQSocket = context.socket(ZMQ_SUB);
subscriber.setsockopt(ZMQ_LINGER, 0); // Don't block when closing socket at end
subscriber.connect("tcp://:5556");
// Subscribe to zipcode, default in NYC, 10001
var filter:String =
if (Sys.args().length > 0) {
Sys.args()[0];
} else {
"10001";
};
try {
subscriber.setsockopt(ZMQ_SUBSCRIBE, Bytes.ofString(filter));
} catch (e:ZMQException) {
trace (e.str());
}
// Process 100 updates
var update_nbr = 0;
var total_temp:Int = 0;
for (update_nbr in 0...100) {
var msg:Bytes = subscriber.recvMsg();
trace (update_nbr+ ". Received: " + msg.toString());
var zipcode, temperature, relhumidity;
var sscanf:Array<String> = msg.toString().split(" ");
zipcode = sscanf[0];
temperature = sscanf[1];
relhumidity = sscanf[2];
total_temp += Std.parseInt(temperature);
}
trace ("Average temperature for zipcode " + filter + " was " + total_temp / 100);
// Close gracefully
subscriber.close();
context.term();
}
}wuclient: Java 语言实现的天气更新客户端
package guide;
import java.util.StringTokenizer;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZContext;
//
// Weather update client in Java
// Connects SUB socket to tcp://:5556
// Collects weather updates and finds avg temp in zipcode
//
public class wuclient
{
public static void main(String[] args)
{
try (ZContext context = new ZContext()) {
// Socket to talk to server
System.out.println("Collecting updates from weather server");
ZMQ.Socket subscriber = context.createSocket(SocketType.SUB);
subscriber.connect("tcp://:5556");
// Subscribe to zipcode, default is NYC, 10001
String filter = (args.length > 0) ? args[0] : "10001 ";
subscriber.subscribe(filter.getBytes(ZMQ.CHARSET));
// Process 100 updates
int update_nbr;
long total_temp = 0;
for (update_nbr = 0; update_nbr < 100; update_nbr++) {
// Use trim to remove the tailing '0' character
String string = subscriber.recvStr(0).trim();
StringTokenizer sscanf = new StringTokenizer(string, " ");
int zipcode = Integer.valueOf(sscanf.nextToken());
int temperature = Integer.valueOf(sscanf.nextToken());
int relhumidity = Integer.valueOf(sscanf.nextToken());
total_temp += temperature;
}
System.out.println(
String.format(
"Average temperature for zipcode '%s' was %d.",
filter,
(int)(total_temp / update_nbr)
)
);
}
}
}
wuclient: Julia 语言实现的天气更新客户端
#!/usr/bin/env julia
#
# Weather update client
# Connects SUB socket to tcp://:5556
# Collects weather updates and finds avg temp in zipcode
#
using ZMQ
context = Context()
socket = Socket(context, SUB)
println("Collecting updates from weather server...")
connect(socket, "tcp://:5556")
# Subscribe to zipcode, default is NYC, 10001
zip_filter = length(ARGS) > 0 ? int(ARGS[1]) : 10001
subscribe(socket, string(zip_filter))
# Process 5 updates
update_nbr = 5
total_temp = 0
for update in 1:update_nbr
global total_temp
message = unsafe_string(recv(socket))
zipcode, temperature, relhumidity = split(message)
total_temp += parse(Int, temperature)
end
avg_temp = total_temp / update_nbr
println("Average temperature for zipcode $zip_filter was $(avg_temp)F")
# Making a clean exit.
close(socket)
close(context)
wuclient: Lua 语言实现的天气更新客户端
--
-- Weather update client
-- Connects SUB socket to tcp://:5556
-- Collects weather updates and finds avg temp in zipcode
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
local context = zmq.init(1)
-- Socket to talk to server
print("Collecting updates from weather server...")
local subscriber = context:socket(zmq.SUB)
subscriber:connect(arg[2] or "tcp://:5556")
-- Subscribe to zipcode, default is NYC, 10001
local filter = arg[1] or "10001 "
subscriber:setopt(zmq.SUBSCRIBE, filter)
-- Process 100 updates
local update_nbr = 0
local total_temp = 0
for n=1,100 do
local message = subscriber:recv()
local zipcode, temperature, relhumidity = message:match("([%d-]*) ([%d-]*) ([%d-]*)")
total_temp = total_temp + temperature
update_nbr = update_nbr + 1
end
print(string.format("Average temperature for zipcode '%s' was %dF, total = %d",
filter, (total_temp / update_nbr), total_temp))
subscriber:close()
context:term()
wuclient: Node.js 语言实现的天气更新客户端
// weather update client in node.js
// connects SUB socket to tcp://:5556
// collects weather updates and finds avg temp in zipcode
var zmq = require('zeromq');
console.log("Collecting updates from weather server...");
// Socket to talk to server
var subscriber = zmq.socket('sub');
// Subscribe to zipcode, default is NYC, 10001
var filter = null;
if (process.argv.length > 2) {
filter = process.argv[2];
} else {
filter = "10001";
}
console.log(filter);
subscriber.subscribe(filter);
// process 100 updates
var total_temp = 0
, temps = 0;
subscriber.on('message', function(data) {
var pieces = data.toString().split(" ")
, zipcode = parseInt(pieces[0], 10)
, temperature = parseInt(pieces[1], 10)
, relhumidity = parseInt(pieces[2], 10);
temps += 1;
total_temp += temperature;
if (temps === 100) {
console.log([
"Average temperature for zipcode '",
filter,
"' was ",
(total_temp / temps).toFixed(2),
" F"].join(""));
total_temp = 0;
temps = 0;
}
});
subscriber.connect("tcp://:5556");
wuclient: Objective-C 语言实现的天气更新客户端
//
// Weather update client
// Connects SUB socket to tcp://:5556
// Collects weather updates and finds avg temp in zipcode
//
#import "ZMQObjC.h"
int
main(int argc, const char *argv[])
{
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init];
ZMQContext *ctx = [[[ZMQContext alloc] initWithIOThreads:1U] autorelease];
// Socket to talk to server
ZMQSocket *subscriber = [ctx socketWithType:ZMQ_SUB];
if (![subscriber connectToEndpoint:@"tcp://:5556"]) {
/* ZMQSocket will already have logged the error. */
return EXIT_FAILURE;
}
/* Subscribe to zipcode (defaults to NYC, 10001). */
const char *kNYCZipCode = "10001";
const char *filter = (argc > 1)? argv[1] : kNYCZipCode;
NSData *filterData = [NSData dataWithBytes:filter length:strlen(filter)];
[subscriber setData:filterData forOption:ZMQ_SUBSCRIBE];
/* Write to stdout immediately rather than at each newline.
* This makes the incremental temperatures appear incrementally.
*/
(void)setvbuf(stdout, NULL, _IONBF, BUFSIZ);
/* Process updates. */
NSLog(@"Collecting temperatures for zipcode %s from weather server...", filter);
const int kMaxUpdate = 100;
long total_temp = 0;
for (int update_nbr = 0; update_nbr < kMaxUpdate; ++update_nbr) {
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init];
NSData *msg = [subscriber receiveDataWithFlags:0];
const char *string = [msg bytes];
int zipcode = 0, temperature = 0, relhumidity = 0;
(void)sscanf(string, "%d %d %d", &zipcode, &temperature, &relhumidity);
printf("%d ", temperature);
total_temp += temperature;
[pool drain];
}
/* End line of temperatures. */
putchar('\n');
NSLog(@"Average temperature for zipcode '%s' was %ld degF.",
filter, total_temp / kMaxUpdate);
/* [ZMQContext sockets] makes it easy to close all associated sockets. */
[[ctx sockets] makeObjectsPerformSelector:@selector(close)];
[pool drain];
return EXIT_SUCCESS;
}
wuclient: ooc 语言实现的天气更新客户端
wuclient: Perl 语言实现的天气更新客户端
# Weather update client in Perl
# Connects SUB socket to tcp://:5556
# Collects weather updates and finds avg temp in zipcode
use strict;
use warnings;
use v5.10;
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_SUB);
# Socket to talk to server
say "Collecting updates from weather station...";
my $context = ZMQ::FFI->new();
my $subscriber = $context->socket(ZMQ_SUB);
$subscriber->connect("tcp://:5556");
# Subscribe to zipcode, default is NYC, 10001
my $filter = $ARGV[0] // "10001";
$subscriber->subscribe($filter);
# Process 100 updates
my $update_nbr = 100;
my $total_temp = 0;
my ($update, $zipcode, $temperature, $relhumidity);
for (1..$update_nbr) {
$update = $subscriber->recv();
($zipcode, $temperature, $relhumidity) = split ' ', $update;
$total_temp += $temperature;
}
printf "Average temperature for zipcode '%s' was %dF\n",
$filter, $total_temp / $update_nbr;
wuclient: PHP 语言实现的天气更新客户端
<?php
/*
* Weather update client
* Connects SUB socket to tcp://:5556
* Collects weather updates and finds avg temp in zipcode
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
$context = new ZMQContext();
// Socket to talk to server
echo "Collecting updates from weather server...", PHP_EOL;
$subscriber = new ZMQSocket($context, ZMQ::SOCKET_SUB);
$subscriber->connect("tcp://:5556");
// Subscribe to zipcode, default is NYC, 10001
$filter = $_SERVER['argc'] > 1 ? $_SERVER['argv'][1] : "10001";
$subscriber->setSockOpt(ZMQ::SOCKOPT_SUBSCRIBE, $filter);
// Process 100 updates
$total_temp = 0;
for ($update_nbr = 0; $update_nbr < 100; $update_nbr++) {
$string = $subscriber->recv();
sscanf ($string, "%d %d %d", $zipcode, $temperature, $relhumidity);
$total_temp += $temperature;
}
printf ("Average temperature for zipcode '%s' was %dF\n",
$filter, (int) ($total_temp / $update_nbr));
wuclient: Python 语言实现的天气更新客户端
#
# Weather update client
# Connects SUB socket to tcp://:5556
# Collects weather updates and finds avg temp in zipcode
#
import sys
import zmq
# Socket to talk to server
context = zmq.Context()
socket = context.socket(zmq.SUB)
print("Collecting updates from weather server...")
socket.connect("tcp://:5556")
# Subscribe to zipcode, default is NYC, 10001
zip_filter = sys.argv[1] if len(sys.argv) > 1 else "10001"
socket.setsockopt_string(zmq.SUBSCRIBE, zip_filter)
# Process 5 updates
total_temp = 0
for update_nbr in range(100):
string = socket.recv_string()
zipcode, temperature, relhumidity = string.split()
total_temp += int(temperature)
print((f"Average temperature for zipcode "
f"'{zip_filter}' was {total_temp / (update_nbr+1)} F"))
wuclient: Q 语言实现的天气更新客户端
wuclient: Racket 语言实现的天气更新客户端
#lang racket
#|
# Weather update client
# Connects SUB socket to tcp://:5556
# Collects weather updates and finds avg temp in zipcode
|#
(require net/zmq)
; Socket to talk to server
(define ctxt (context 1))
(define sock (socket ctxt 'SUB))
(printf "Collecting updates from weather server...\n")
(socket-connect! sock "tcp://:5556")
; Subscribe to zipcode, default is NYC, 10001
(define filter
(command-line #:program "wuclient" #:args maybe-zip
(match maybe-zip
[(list zipcode) zipcode]
[(list) "10001"]
[else (error 'wuclient "Incorrect argument list")])))
(set-socket-option! sock 'SUBSCRIBE (string->bytes/utf-8 filter))
; Process 5 updates
(define how-many 5)
(define total-temp
(for/fold ([tot 0])
([i (in-range how-many)])
(match-define (regexp #rx"([0-9]+) (-?[0-9]+) ([0-9]+)" (list _ zipcode temp humid))
(socket-recv! sock))
(+ tot (string->number (bytes->string/utf-8 temp)))))
(printf "Average temperature for zipcode '~a' was ~a\n"
filter (/ total-temp how-many))
(context-close! ctxt)
wuclient: Ruby 语言实现的天气更新客户端
#!/usr/bin/env ruby
#
# Weather update client in Ruby
# Connects SUB socket to tcp://:5556
# Collects weather updates and finds avg temp in zipcode
#
require 'rubygems'
require 'ffi-rzmq'
COUNT = 100
context = ZMQ::Context.new(1)
# Socket to talk to server
puts "Collecting updates from weather server..."
subscriber = context.socket(ZMQ::SUB)
subscriber.connect("tcp://:5556")
# Subscribe to zipcode, default is NYC, 10001
filter = ARGV.size > 0 ? ARGV[0] : "10001 "
subscriber.setsockopt(ZMQ::SUBSCRIBE, filter)
# Process 100 updates
total_temp = 0
1.upto(COUNT) do |update_nbr|
s = ''
subscriber.recv_string(s)#.split.map(&:to_i)
zipcode, temperature, relhumidity = s.split.map(&:to_i)
total_temp += temperature
end
puts "Average temperature for zipcode '#{filter}' was #{total_temp / COUNT}F"
wuclient: Rust 语言实现的天气更新客户端
use std::env;
fn atoi(s: &str) -> i64 {
s.parse().unwrap()
}
fn main() {
println!("Collecting updates from weather server...");
let context = zmq::Context::new();
let subscriber = context.socket(zmq::SUB).unwrap();
assert!(subscriber.connect("tcp://:5556").is_ok());
let args: Vec<String> = env::args().collect();
let filter = if args.len() > 1 { &args[1] } else { "10001" };
assert!(subscriber.set_subscribe(filter.as_bytes()).is_ok());
let mut total_temp = 0;
for _ in 0..100 {
let string = subscriber.recv_string(0).unwrap().unwrap();
let chks: Vec<i64> = string.split(' ').map(atoi).collect();
let (_zipcode, temperature, _relhumidity) = (chks[0], chks[1], chks[2]);
total_temp += temperature;
}
println!(
"Average temperature for zipcode {} was {}F",
filter,
total_temp / 100
);
}
wuclient: Scala 语言实现的天气更新客户端
/*
* Weather update client in Scala
* Connects SUB socket to tcp://:5556
* Collects weather updates and finds avg temp in zipcode
*
* @author Giovanni Ruggiero
* @email giovanni.ruggiero@gmail.com
*/
import java.util.StringTokenizer
import org.zeromq.ZMQ
object wuclient {
def main(args : Array[String]) {
val context = ZMQ.context(1)
// Socket to talk to server
println("Collecting updates from weather server...")
val subscriber = context.socket(ZMQ.SUB)
subscriber.connect("tcp://:5556")
// Subscribe to zipcode, default is NYC, 10001
val filter = {if (args.length > 0) args(0) else "10001 "}
subscriber.subscribe(filter.getBytes())
// Process 100 updates
val update_nbr = 100
var total_temp = 0
for (i <- 1 to update_nbr ) {
// Use trim to remove the tailing '0' character
val sscanf = new String(subscriber.recv(0)).trim.split(' ').map(_.toInt)
val zipcode = sscanf(0)
val temperature = sscanf(1)
val relhumidity = sscanf(2)
total_temp += temperature
}
println("Average temperature for zipcode '" + filter + "' was " + (total_temp / update_nbr))
}
}
wuclient: Tcl 语言实现的天气更新客户端
#
# Weather update client
# Connects SUB socket to tcp:#localhost:5556
# Collects weather updates and finds avg temp in zipcode
#
package require zmq
# Socket to talk to server
zmq context context
zmq socket subscriber context SUB
subscriber connect "tcp://:5556"
# Subscribe to zipcode, default is NYC, 10001
if {[llength $argv]} {
set filter [lindex $argv 0]
} else {
set filter "10001"
}
subscriber setsockopt SUBSCRIBE $filter
# Process 100 updates
set total_temp 0
for {set update_nbr 0} {$update_nbr < 100} {incr update_nbr} {
zmq message msg
subscriber recv_msg msg
lassign [msg data] zipcode temperature relhumidity
puts [msg data]
msg close
incr total_temp $temperature
}
puts "Averate temperatur for zipcode $filter was [expr {$total_temp/$update_nbr}]F"
subscriber close
context term
wuclient: OCaml 语言实现的天气更新客户端
(**
Weather update client
Connects SUB socket to tcp://:5556
Collects weather updates and finds avg temp in zipcode
*)
open Zmq
open Helpers
let () =
with_context @@ fun ctx ->
with_socket ctx Socket.sub @@ fun sub ->
printfn "Collecting updates from weather server...";
Socket.connect sub "tcp://:5556";
(* Subscribe to zipcode, default is NYC, 10001 *)
let filter = match Array.to_list Sys.argv with _::zip::_ -> zip | _ -> "10001 " in
Socket.subscribe sub filter;
(* Process 100 updates *)
let total_temp = ref 0 in
for i = 0 to pred 100 do
Scanf.sscanf (Socket.recv sub) "%d %d %d" begin fun _zipcode temperature _relhumidity ->
total_temp := !total_temp + temperature
end
done;
printfn "Average temperature for zipcode '%s' was %dF" filter (!total_temp / 100)
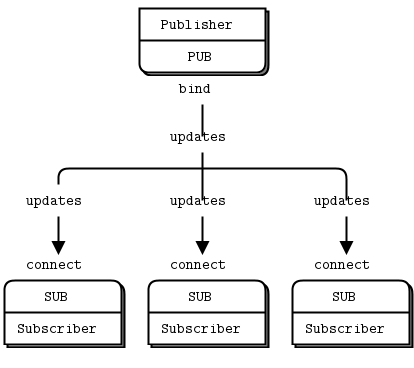
请注意,当你使用 SUB 套接字时,你必须使用以下方法设置订阅 zmq_setsockopt()和 SUBSCRIBE,就像这段代码中所示。如果你没有设置任何订阅,你就不会收到任何消息。这是初学者常犯的错误。订阅者可以设置多个订阅,它们会累加。也就是说,如果一个更新匹配了任意一个订阅,订阅者就会收到它。订阅者也可以取消特定的订阅。订阅通常是一个可打印的字符串,但并非总是如此。参见 zmq_setsockopt()了解其工作原理。
PUB-SUB 套接字对是异步的。客户端执行 zmq_recv(),循环进行(或者如果只需要一次就执行一次)。试图向 SUB 套接字发送消息会导致错误。同样,服务方执行 zmq_send(),根据需要重复执行,但绝不能执行 zmq_recv()在 PUB 套接字上。
理论上,对于 ZeroMQ 套接字,哪一端连接哪一端绑定并不重要。然而,实际上存在未记录的差异,我稍后会讲到。目前,请将 PUB 绑定并将 SUB 连接,除非你的网络设计使得这不可能。
关于 PUB-SUB 套接字,还有一件重要的事情需要知道:你无法精确知道订阅者何时开始接收消息。即使你启动一个订阅者,等待一段时间,然后启动发布者,订阅者总是会错过发布者发送的最初几条消息。这是因为当订阅者连接发布者时(这个过程需要很短但非零的时间),发布者可能已经开始发送消息了。
这个“慢加入者”问题困扰了足够多的人,而且经常发生,所以我们将详细解释它。请记住 ZeroMQ 是异步 I/O,即在后台进行。假设你有两个节点按以下顺序操作:
- 订阅者连接到一个端点并接收和计数消息。
- 发布者绑定到一个端点并立即发送 1,000 条消息。
那么订阅者很可能什么也收不到。你会眨眨眼,检查是否设置了正确的过滤器并再次尝试,但订阅者仍然收不到任何东西。
建立 TCP 连接涉及来回握手,根据你的网络和对等节点之间的跳数,这需要几毫秒。在这段时间里,ZeroMQ 可以发送许多消息。假设建立连接需要 5 毫秒,而同一条链路每秒可以处理 100 万条消息。在订阅者连接发布者的这 5 毫秒内,发布者只需要 1 毫秒就可以发送出那 1 千条消息。
在第 2 章 - 套接字与模式中,我们将解释如何同步发布者和订阅者,这样在你确定订阅者真正连接并准备好之前,你不会开始发布数据。有一种简单而愚蠢的方法可以延迟发布者,那就是睡眠。但在真实的应用程序中不要这样做,因为它极其脆弱、不优雅且缓慢。你可以使用睡眠来证明自己正在发生的事情,然后等待第 2 章 - 套接字与模式来了解如何正确地做这件事。
同步的替代方法是简单地假设发布的 数据流是无限的,没有开始也没有结束。还假设订阅者不关心它启动之前发生了什么。这就是我们构建天气客户端示例的方式。
因此,客户端订阅其选择的邮政编码,并为该邮政编码收集 100 条更新。如果邮政编码是随机分布的,这意味着服务器发送了大约一千万条更新。你可以先启动客户端,然后启动服务器,客户端将继续工作。你可以随意停止和重新启动服务器,客户端也会继续工作。当客户端收集了 100 条更新后,它会计算平均值,打印出来,然后退出。
关于发布-订阅(pub-sub)模式的几点说明
-
订阅者可以通过多次调用 connect 来连接多个发布者。然后数据会到达并交错排列(“公平队列”),这样任何单个发布者都不会压垮其他发布者。
-
如果发布者没有连接的订阅者,那么它会简单地丢弃所有消息。
-
如果你使用 TCP,并且订阅者速度较慢,消息将在发布者端排队。我们稍后将介绍如何使用“高水位标记”来保护发布者免受此影响。
-
从 ZeroMQ v3.x 开始,当使用连接协议(tcp:@<*>@*或ipc:@<>@)时,过滤发生在发布者端。使用epgm:@@协议,过滤发生在订阅者端。在 ZeroMQ v2.x 中,所有过滤都发生在订阅者端。
这是我的笔记本电脑(一台 2011 年的 Intel i5,不错但没什么特别的)接收和过滤 1000 万条消息所需的时间
$ time wuclient
Collecting updates from weather server...
Average temperature for zipcode '10001 ' was 28F
real 0m4.470s
user 0m0.000s
sys 0m0.008s
分而治之 #
作为最后一个例子(你肯定已经厌倦了那些有趣的代码,想要深入探讨关于比较抽象规范的语文学讨论了),让我们来做一点点超级计算。然后再喝咖啡。我们的超级计算应用程序是一个相当典型的并行处理模型。我们有
- 一个产生可以并行执行任务的通风器(ventilator)
- 一组处理任务的工作者(workers)
- 一个汇集(sink)从工作进程返回结果的收集器
实际上,工作者运行在超高速的机器上,也许使用 GPU(图形处理单元)来完成繁重的计算。这里是通风器。它生成 100 个任务,每个任务是一条消息,告诉工作者睡眠若干毫秒
taskvent: Ada 中的并行任务通风器
taskvent: Basic 中的并行任务通风器
taskvent: C 中的并行任务通风器
// Task ventilator
// Binds PUSH socket to tcp://:5557
// Sends batch of tasks to workers via that socket
#include "zhelpers.h"
int main (void)
{
void *context = zmq_ctx_new ();
// Socket to send messages on
void *sender = zmq_socket (context, ZMQ_PUSH);
zmq_bind (sender, "tcp://*:5557");
// Socket to send start of batch message on
void *sink = zmq_socket (context, ZMQ_PUSH);
zmq_connect (sink, "tcp://:5558");
printf ("Press Enter when the workers are ready: ");
getchar ();
printf ("Sending tasks to workers...\n");
// The first message is "0" and signals start of batch
s_send (sink, "0");
// Initialize random number generator
srandom ((unsigned) time (NULL));
// Send 100 tasks
int task_nbr;
int total_msec = 0; // Total expected cost in msecs
for (task_nbr = 0; task_nbr < 100; task_nbr++) {
int workload;
// Random workload from 1 to 100msecs
workload = randof (100) + 1;
total_msec += workload;
char string [10];
sprintf (string, "%d", workload);
s_send (sender, string);
}
printf ("Total expected cost: %d msec\n", total_msec);
zmq_close (sink);
zmq_close (sender);
zmq_ctx_destroy (context);
return 0;
}
taskvent: C++ 中的并行任务通风器
//
// Task ventilator in C++
// Binds PUSH socket to tcp://:5557
// Sends batch of tasks to workers via that socket
//
#include <zmq.hpp>
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <iostream>
#define within(num) (int) ((float) num * random () / (RAND_MAX + 1.0))
int main (int argc, char *argv[])
{
zmq::context_t context (1);
// Socket to send messages on
zmq::socket_t sender(context, ZMQ_PUSH);
sender.bind("tcp://*:5557");
std::cout << "Press Enter when the workers are ready: " << std::endl;
getchar ();
std::cout << "Sending tasks to workers...\n" << std::endl;
// The first message is "0" and signals start of batch
zmq::socket_t sink(context, ZMQ_PUSH);
sink.connect("tcp://:5558");
zmq::message_t message(2);
memcpy(message.data(), "0", 1);
sink.send(message);
// Initialize random number generator
srandom ((unsigned) time (NULL));
// Send 100 tasks
int task_nbr;
int total_msec = 0; // Total expected cost in msecs
for (task_nbr = 0; task_nbr < 100; task_nbr++) {
int workload;
// Random workload from 1 to 100msecs
workload = within (100) + 1;
total_msec += workload;
message.rebuild(10);
memset(message.data(), '\0', 10);
sprintf ((char *) message.data(), "%d", workload);
sender.send(message);
}
std::cout << "Total expected cost: " << total_msec << " msec" << std::endl;
sleep (1); // Give 0MQ time to deliver
return 0;
}
taskvent: C# 中的并行任务通风器
taskvent: CL 中的并行任务通风器
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-
;;;
;;; Task ventilator in Common Lisp
;;; Binds PUSH socket to tcp://:5557
;;; Sends batch of tasks to workers via that socket
;;;
;;; Kamil Shakirov <kamils80@gmail.com>
;;;
(defpackage #:zguide.taskvent
(:nicknames #:taskvent)
(:use #:cl #:zhelpers)
(:export #:main))
(in-package :zguide.taskvent)
(defun main ()
(zmq:with-context (context 1)
;; Socket to send messages on
(zmq:with-socket (sender context zmq:push)
(zmq:bind sender "tcp://*:5557")
(message "Press Enter when the workers are ready: ")
(read-char)
(message "Sending tasks to workers...~%")
;; The first message is "0" and signals start of batch
(let ((msg (make-instance 'zmq:msg :data "0")))
(zmq:send sender msg))
;; Send 100 tasks
(let ((total-msec 0))
(loop :repeat 100 :do
;; Random workload from 1 to 100 msecs
(let ((workload (within 100)))
(incf total-msec workload)
(let ((msg (make-instance 'zmq:msg
:data (format nil "~D" workload))))
(zmq:send sender msg))))
(message "Total expected cost: ~D msec~%" total-msec)
;; Give 0MQ time to deliver
(sleep 1))))
(cleanup))
taskvent: Delphi 中的并行任务通风器
program taskvent;
//
// Task ventilator
// Binds PUSH socket to tcp://:5557
// Sends batch of tasks to workers via that socket
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
const
task_count = 100;
var
context: TZMQContext;
sender,
sink: TZMQSocket;
s: String;
i,
total_msec,
workload: Integer;
begin
context := TZMQContext.Create;
// Socket to send messages on
sender := Context.Socket( stPush );
sender.bind( 'tcp://*:5557' );
// Socket to send start of batch message on
sink := Context.Socket( stPush );
sink.connect( 'tcp://:5558' );
Write( 'Press Enter when the workers are ready: ' );
Readln( s );
Writeln( 'Sending tasks to workers...' );
// The first message is "0" and signals start of batch
sink.send( '0' );
// Initialize random number generator
randomize;
// Send 100 tasks
total_msec := 0; // Total expected cost in msecs
for i := 0 to task_count - 1 do
begin
// Random workload from 1 to 100msecs
workload := Random( 100 ) + 1;
total_msec := total_msec + workload;
s := IntToStr( workload );
sender.send( s );
end;
Writeln( Format( 'Total expected cost: %d msec', [total_msec] ) );
sleep(1000); // Give 0MQ time to deliver
sink.Free;
sender.Free;
Context.Free;
end.
taskvent: Erlang 中的并行任务通风器
#! /usr/bin/env escript
%%
%% Task ventilator
%% Binds PUSH socket to tcp://:5557
%% Sends batch of tasks to workers via that socket
%%
main(_Args) ->
application:start(chumak),
{ok, Sender} = chumak:socket(push),
case chumak:bind(Sender, tcp, "*", 5557) of
{ok, _BindPid} ->
io:format("Binding OK with Pid: ~p\n", [Sender]);
{error, Reason} ->
io:format("Connection Failed for this reason: ~p\n", [Reason]);
X ->
io:format("Unhandled reply for bind ~p\n", [X])
end,
{ok, Sink} = chumak:socket(push),
case chumak:connect(Sink, tcp, "localhost", 5558) of
{ok, _ConnectPid} ->
io:format("Connection OK with Pid: ~p\n", [Sink]);
{error, Reason2} ->
io:format("Connection Failed for this reason: ~p\n", [Reason2]);
X2 ->
io:format("Unhandled reply for connect ~p\n", [X2])
end,
{ok, _} = io:fread("Press Enter when workers are ready: ", ""),
io:format("Sending task to workers~n", []),
ok = chumak:send(Sink, <<"0">>),
%% Send 100 tasks
TotalCost = send_tasks(Sender, 100, 0),
io:format("Total expected cost: ~b msec~n", [TotalCost]).
send_tasks(_Sender, 0, TotalCost) -> TotalCost;
send_tasks(Sender, N, TotalCost) when N>0 ->
Workload = rand:uniform(100) + 1,
ok = chumak:send(Sender, list_to_binary(integer_to_list(Workload))),
send_tasks(Sender, N-1, TotalCost + Workload).
taskvent: Elixir 中的并行任务通风器
defmodule Taskvent do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:36
"""
def main() do
{:ok, context} = :erlzmq.context()
{:ok, sender} = :erlzmq.socket(context, :push)
:ok = :erlzmq.bind(sender, 'tcp://*:5557')
{:ok, sink} = :erlzmq.socket(context, :push)
:ok = :erlzmq.connect(sink, 'tcp://:5558')
{:ok, _} = :io.fread('Press Enter when workers are ready: ', [])
:io.format('Sending task to workers~n', [])
:ok = :erlzmq.send(sink, "0")
totalCost = send_tasks(sender, 100, 0)
:io.format('Total expected cost: ~b msec~n', [totalCost])
:ok = :erlzmq.close(sink)
:ok = :erlzmq.close(sender)
:erlzmq.term(context, 1000)
end
def send_tasks(_sender, 0, totalCost) do
totalCost
end
def send_tasks(sender, n, totalCost) when n > 0 do
workload = :random.uniform(100) + 1
:ok = :erlzmq.send(sender, :erlang.list_to_binary(:erlang.integer_to_list(workload)))
send_tasks(sender, n - 1, totalCost + workload)
end
end
Taskvent.main
taskvent: F# 中的并行任务通风器
taskvent: Felix 中的并行任务通风器
//
// Task ventilator
// Binds PUSH socket to tcp://:5557
// Sends batch of tasks to workers via that socket
open ZMQ;
var context = zmq_init 1;
// Socket to send messages on
var sender = context.mk_socket ZMQ_PUSH;
sender.bind "tcp://*:5557";
// Socket to send start of batch message on
var sink = context.mk_socket ZMQ_PUSH;
sink.connect "tcp://:5558";
print ("Press Enter when the workers are ready: "); fflush;
C_hack::ignore (readln stdin);
println "Sending tasks to workers...";
// The first message is "0" and signals start of batch
sink.send_string "0";
// Send 100 tasks
var total_msec = 0; // Total expected cost in msecs
for var task_nbr in 0 upto 99 do
// Random workload from 1 to 100msecs
var workload = #rand % 100 + 1;
total_msec += workload;
var s = f"%d" workload;
sender.send_string s;
done
println$ f"Total expected cost: %d msec" total_msec;
Faio::sleep (sys_clock, 1.0); // Give 0MQ time to deliver
sink.close;
sender.close;
context.term;
taskvent: Go 中的并行任务通风器
//
// Task ventilator
// Binds PUSH socket to tcp://:5557
// Sends batch of tasks to workers via that socket
//
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"time"
)
func main() {
context, _ := zmq.NewContext()
defer context.Close()
// Socket to send messages On
sender, _ := context.NewSocket(zmq.PUSH)
defer sender.Close()
sender.Bind("tcp://*:5557")
// Socket to send start of batch message on
sink, _ := context.NewSocket(zmq.PUSH)
defer sink.Close()
sink.Connect("tcp://:5558")
fmt.Print("Press Enter when the workers are ready: ")
var line string
fmt.Scanln(&line)
fmt.Println("Sending tasks to workers…")
sink.Send([]byte("0"), 0)
// Seed the random number generator
rand.Seed(time.Now().UnixNano())
total_msec := 0
for i := 0; i < 100; i++ {
workload := rand.Intn(100)
total_msec += workload
msg := fmt.Sprintf("%d", workload)
sender.Send([]byte(msg), 0)
}
fmt.Printf("Total expected cost: %d msec\n", total_msec)
time.Sleep(1e9) // Give 0MQ time to deliver: one second == 1e9 ns
}
taskvent: Haskell 中的并行任务通风器
{-# LANGUAGE OverloadedStrings #-}
{-# LANGUAGE ScopedTypeVariables #-}
-- Task ventilator
-- Binds PUSH socket to tcp://:5557
-- Sends batch of tasks to workers via that socket
module Main where
import Control.Monad
import qualified Data.ByteString.Char8 as BS
import System.ZMQ4.Monadic
import System.Random
main :: IO ()
main = runZMQ $ do
-- Socket to send messages on
sender <- socket Push
bind sender "tcp://*:5557"
-- Socket to send start of batch message on
sink <- socket Push
connect sink "tcp://:5558"
liftIO $ do
putStrLn "Press Enter when the workers are ready: "
_ <- getLine
putStrLn "Sending tasks to workers..."
-- The first message is "0" and signals start of batch
send sink [] "0"
-- Send 100 tasks
total_msec <- fmap sum $
replicateM 100 $ do
-- Random workload from 1 to 100msecs
workload :: Int <- liftIO $ randomRIO (1, 100)
send sender [] $ BS.pack (show workload)
return workload
liftIO . putStrLn $ "Total expected cost: " ++ show total_msec ++ " msec"
taskvent: Haxe 中的并行任务通风器
package ;
import haxe.io.Bytes;
import haxe.Stack;
import neko.Lib;
import neko.io.File;
import neko.io.FileInput;
import neko.Sys;
import org.zeromq.ZMQ;
import org.zeromq.ZMQContext;
import org.zeromq.ZMQException;
import org.zeromq.ZMQSocket;
/**
* Task ventilator in Haxe
* Binds PUSH socket to tcp://:5557
* Sends batch of tasks to workers via that socket.
*
* Based on code from: https://zguide.zeromq.cn/java:taskvent
*
* Use with TaskWork.hx and TaskSink.hx
*/
class TaskVent
{
public static function main() {
try {
var context:ZMQContext = ZMQContext.instance();
var sender:ZMQSocket = context.socket(ZMQ_PUSH);
Lib.println("** TaskVent (see: https://zguide.zeromq.cn/page:all#Divide-and-Conquer)");
sender.bind("tcp://127.0.0.1:5557");
Lib.println("Press Enter when the workers are ready: ");
var f:FileInput = File.stdin();
var str:String = f.readLine();
Lib.println("Sending tasks to workers ...\n");
// The first message is "0" and signals starts of batch
sender.sendMsg(Bytes.ofString("0"));
// Send 100 tasks
var totalMsec:Int = 0; // Total expected cost in msec
for (task_nbr in 0 ... 100) {
var workload = Std.random(100) + 1; // Generates 1 to 100 msecs
totalMsec += workload;
Lib.print(workload + ".");
sender.sendMsg(Bytes.ofString(Std.string(workload)));
}
Lib.println("Total expected cost: " + totalMsec + " msec");
// Give 0MQ time to deliver
Sys.sleep(1);
sender.close();
context.term();
} catch (e:ZMQException) {
trace("ZMQException #:" + ZMQ.errNoToErrorType(e.errNo) + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
}
}taskvent: Java 中的并行任务通风器
package guide;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZContext;
//
// Task ventilator in Java
// Binds PUSH socket to tcp://:5557
// Sends batch of tasks to workers via that socket
//
public class taskvent
{
public static void main(String[] args) throws Exception
{
try (ZContext context = new ZContext()) {
// Socket to send messages on
ZMQ.Socket sender = context.createSocket(SocketType.PUSH);
sender.bind("tcp://*:5557");
// Socket to send messages on
ZMQ.Socket sink = context.createSocket(SocketType.PUSH);
sink.connect("tcp://:5558");
System.out.println("Press Enter when the workers are ready: ");
System.in.read();
System.out.println("Sending tasks to workers\n");
// The first message is "0" and signals start of batch
sink.send("0", 0);
// Initialize random number generator
Random srandom = new Random(System.currentTimeMillis());
// Send 100 tasks
int task_nbr;
int total_msec = 0; // Total expected cost in msecs
for (task_nbr = 0; task_nbr < 100; task_nbr++) {
int workload;
// Random workload from 1 to 100msecs
workload = srandom.nextInt(100) + 1;
total_msec += workload;
System.out.print(workload + ".");
String string = String.format("%d", workload);
sender.send(string, 0);
}
System.out.println("Total expected cost: " + total_msec + " msec");
Thread.sleep(1000); // Give 0MQ time to deliver
}
}
}
taskvent: Julia 中的并行任务通风器
#!/usr/bin/env julia
#
# Task ventilator
# Binds PUSH socket to tcp://:5557
# Sends batch of tasks to workers via that socket
#
using ZMQ
using Random: seed!
context = Context()
sender = Socket(context, PUSH)
bind(sender, "tcp://*:5557")
# Socket with direct access to the sink: used to synchronize start of batch
sink = Socket(context, PUSH)
connect(sink, "tcp://:5558")
println("Press Enter when the workers are ready: ")
_ = readline(stdin)
println("Sending tasks to workers...")
# The first message is "0" and signals start of batch
send(sink, 0x30)
# Initialize random number generator
seed!(1)
# Send 100 tasks
total_msec = 0
for task_nbr in 1:100
global total_msec
# Random workload from 1 to 100 msecs
workload = rand(1:100)
total_msec += workload
send(sender, "$workload")
end
println("Total expected cost: $total_msec msec")
# Give 0MQ time to deliver
sleep(1)
# Making a clean exit.
close(sender)
close(sink)
close(context)
taskvent: Lua 中的并行任务通风器
--
-- Task ventilator
-- Binds PUSH socket to tcp://:5557
-- Sends batch of tasks to workers via that socket
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zhelpers"
local context = zmq.init(1)
-- Socket to send messages on
local sender = context:socket(zmq.PUSH)
sender:bind("tcp://*:5557")
printf ("Press Enter when the workers are ready: ")
io.read('*l')
printf ("Sending tasks to workers...\n")
-- The first message is "0" and signals start of batch
sender:send("0")
-- Initialize random number generator
math.randomseed(os.time())
-- Send 100 tasks
local task_nbr
local total_msec = 0 -- Total expected cost in msecs
for task_nbr=0,99 do
local workload
-- Random workload from 1 to 100msecs
workload = randof (100) + 1
total_msec = total_msec + workload
local msg = string.format("%d", workload)
sender:send(msg)
end
printf ("Total expected cost: %d msec\n", total_msec)
s_sleep (1000) -- Give 0MQ time to deliver
sender:close()
context:term()
taskvent: Node.js 中的并行任务通风器
// Task ventilator in node.js
// Binds PUSH socket to tcp://:5557
// Sends batch of tasks to workers via that socket.
var zmq = require('zeromq');
process.stdin.resume();
process.stdin.setRawMode(true);
// Socket to send messages on
var sender = zmq.socket('push');
sender.bindSync("tcp://*:5557");
var sink = zmq.socket('push');
sink.connect('tcp://:5558');
var i = 0
, total_msec = 0;
function work() {
console.log("Sending tasks to workers...");
// The first message is "0" and signals start of batch
sink.send("0");
// send 100 tasks
while (i < 100) {
var workload = Math.abs(Math.round(Math.random() * 100)) + 1;
total_msec += workload;
process.stdout.write(workload.toString() + ".");
sender.send(workload.toString());
i++;
}
console.log("Total expected cost:", total_msec, "msec");
sink.close();
sender.close();
process.exit();
};
console.log("Press enter when the workers are ready...");
process.stdin.on("data", function() {
if (i === 0) {
work();
}
process.stdin.pause();
});
taskvent: Objective-C 中的并行任务通风器
/* Task ventilator - sends task batch to workers via PUSH socket. */
#import <Foundation/Foundation.h>
#import "ZMQObjC.h"
#import "ZMQHelper.h"
int
main(void)
{
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init];
ZMQContext *ctx = [[[ZMQContext alloc] initWithIOThreads:1U] autorelease];
ZMQSocket *sender = [ctx socketWithType:ZMQ_PUSH];
[sender bindToEndpoint:@"tcp://*:5557"];
NSLog(@"Press Enter when the workers are ready: ");
(void)getchar();
NSLog(@"Sending tasks to workers...");
/* Signal batch start with message of "0". */
NSData *signalData = [@"0" dataUsingEncoding:NSUTF8StringEncoding];
[sender sendData:signalData withFlags:0];
/* Initialize random number generator. */
(void)srandom((unsigned)time(NULL));
/* Send kTaskCount tasks. */
unsigned long totalMsec = 0UL;
static const int kTaskCount = 100;
for (int task = 0; task < kTaskCount; ++task) {
/* Random workload from 1 to 100 msec. */
int workload = within(100) + 1;
totalMsec += workload;
NSString *text = [NSString stringWithFormat:@"%d", workload];
NSData *textData = [text dataUsingEncoding:NSUTF8StringEncoding];
[sender sendData:textData withFlags:0];
}
NSLog(@"Total expected cost: %lu ms", totalMsec);
/* Let IOThreads finish sending. */
sleep(1);
[sender close];
[pool drain];
return EXIT_SUCCESS;
}
taskvent: ooc 中的并行任务通风器
taskvent: Perl 中的并行任务通风器
# Task ventilator
# Binds PUSH socket to tcp://:5557
# Sends batch of tasks to workers via that socket
use strict;
use warnings;
use v5.10;
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_PUSH);
my $ctx = ZMQ::FFI->new();
# Socket to send messages on
my $sender = $ctx->socket(ZMQ_PUSH);
$sender->bind('tcp://*:5557');
# Socket to send start of batch message on
my $sink = $ctx->socket(ZMQ_PUSH);
$sink->connect('tcp://:5558');
say "Press Enter when the workers are ready: ";
<STDIN>;
say "Sending tasks to workers...";
# The first message is "0" and signals start of batch
$sink->send('0');
# Send 100 tasks
my $total_msec = 0;
my $workload;
for (1..100) {
$workload = int(rand(100) + 1);
$total_msec += $workload;
$sender->send($workload);
}
say "Total expected cost: $total_msec msec";
taskvent: PHP 中的并行任务通风器
<?php
/*
* Task ventilator
* Binds PUSH socket to tcp://:5557
* Sends batch of tasks to workers via that socket
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
$context = new ZMQContext();
// Socket to send messages on
$sender = new ZMQSocket($context, ZMQ::SOCKET_PUSH);
$sender->bind("tcp://*:5557");
echo "Press Enter when the workers are ready: ";
$fp = fopen('php://stdin', 'r');
$line = fgets($fp, 512);
fclose($fp);
echo "Sending tasks to workers...", PHP_EOL;
// The first message is "0" and signals start of batch
$sender->send(0);
// Send 100 tasks
$total_msec = 0; // Total expected cost in msecs
for ($task_nbr = 0; $task_nbr < 100; $task_nbr++) {
// Random workload from 1 to 100msecs
$workload = mt_rand(1, 100);
$total_msec += $workload;
$sender->send($workload);
}
printf ("Total expected cost: %d msec\n", $total_msec);
sleep (1); // Give 0MQ time to deliver
taskvent: Python 中的并行任务通风器
# Task ventilator
# Binds PUSH socket to tcp://:5557
# Sends batch of tasks to workers via that socket
#
# Author: Lev Givon <lev(at)columbia(dot)edu>
import zmq
import random
import time
context = zmq.Context()
# Socket to send messages on
sender = context.socket(zmq.PUSH)
sender.bind("tcp://*:5557")
# Socket with direct access to the sink: used to synchronize start of batch
sink = context.socket(zmq.PUSH)
sink.connect("tcp://:5558")
print("Press Enter when the workers are ready: ")
_ = input()
print("Sending tasks to workers...")
# The first message is "0" and signals start of batch
sink.send(b'0')
# Initialize random number generator
random.seed()
# Send 100 tasks
total_msec = 0
for task_nbr in range(100):
# Random workload from 1 to 100 msecs
workload = random.randint(1, 100)
total_msec += workload
sender.send_string(f"{workload}")
print(f"Total expected cost: {total_msec} msec")
# Give 0MQ time to deliver
time.sleep(1)
taskvent: Q 中的并行任务通风器
taskvent: Racket 中的并行任务通风器
taskvent: Ruby 中的并行任务通风器
#!/usr/bin/env ruby
#
# Task ventilator in Ruby
# Binds PUSH socket to tcp://:5557
# Sends batch of tasks to workers via that socket
#
require 'rubygems'
require 'ffi-rzmq'
context = ZMQ::Context.new(1)
# Socket to send messages on
sender = context.socket(ZMQ::PUSH)
sender.bind("tcp://*:5557")
# Socket to start of batch message on
sink = context.socket(ZMQ::PUSH)
sink.connect("tcp://:5558")
puts "Press enter when the workers are ready..."
$stdin.read(1)
puts "Sending tasks to workers..."
# The first message is "0" and signals start of batch
sink.send_string('0')
# Send 100 tasks
total_msec = 0 # Total expected cost in msecs
100.times do
workload = rand(100) + 1
total_msec += workload
$stdout << "#{workload}."
sender.send_string(workload.to_s)
end
puts "Total expected cost: #{total_msec} msec"
Kernel.sleep(1) # Give 0MQ time to deliver
taskvent: Rust 中的并行任务通风器
use rand::Rng;
use std::io::{self, BufRead};
use std::{thread, time};
fn main() {
let context = zmq::Context::new();
let sender = context.socket(zmq::PUSH).unwrap();
assert!(sender.bind("tcp://*:5557").is_ok());
let sink = context.socket(zmq::PUSH).unwrap();
assert!(sink.connect("tcp://:5558").is_ok());
println!("Press Enter when the workers are ready: ");
let stdin = io::stdin();
stdin.lock().lines().next();
println!("Sending tasks to workers...");
sink.send("0", 0).unwrap();
let mut rng = rand::thread_rng();
let mut total_msec = 0;
for _ in 0..100 {
let workload = rng.gen_range(1..101);
total_msec += workload;
let string = format!("{}", workload);
sender.send(&string, 0).unwrap();
}
println!("Total expected cost: {} msec", total_msec);
thread::sleep(time::Duration::from_secs(1));
}
taskvent: Scala 中的并行任务通风器
/*
*
* Task ventilator in Scala
* Binds PUSH socket to tcp://:5557
* Sends batch of tasks to workers via that socket
*
* @author Giovanni Ruggiero
* @email giovanni.ruggiero@gmail.com
*/
import java.util.Random
import org.zeromq.ZMQ
object taskvent {
def main(args : Array[String]) {
val context = ZMQ.context(1)
// Socket to send messages on
val sender = context.socket(ZMQ.PUSH)
sender.bind("tcp://*:5557")
println("Press Enter when the workers are ready: ")
System.in.read()
println("Sending tasks to workers...\n")
// The first message is "0" and signals start of batch
sender.send("0\u0000".getBytes(), 0)
// Initialize random number generator
val srandom = new Random(System.currentTimeMillis())
// Send 100 tasks
var total_msec = 0 // Total expected cost in msecs
for (i <- 1 to 100 ) {
// Random workload from 1 to 100msecs
val workload = srandom.nextInt(100) + 1
total_msec += workload
print(workload + ".")
val string = String.format("%d\u0000", workload.asInstanceOf[Integer] )
sender.send(string.getBytes(), 0)
}
println("Total expected cost: " + total_msec + " msec")
Thread.sleep(1000) // Give 0MQ time to deliver
}
}
taskvent: Tcl 中的并行任务通风器
#
# Task ventilator
# Binds PUSH socket to tcp://:5557
# Sends batch of tasks to workers via that socket
#
package require zmq
zmq context context
zmq socket sender context PUSH
sender bind "tcp://*:5557"
zmq socket sink context PUSH
sink connect "tcp://:5558"
puts -nonewline "Press Enter when the workers are ready: "
flush stdout
gets stdin c
puts "Sending tasks to workers..."
# The first message is "0" and signals start of batch
sink send "0"
# Initialize random number generator
expr {srand([clock seconds])}
# Send 100 tasks
set total_msec 0
for {set task_nbr 0} {$task_nbr < 100} {incr task_nbr} {
set workload [expr {int(rand()*100)+1}]
puts -nonewline "$workload."
incr total_msec $workload
sender send $workload
}
puts "Total expected cost: $total_msec msec"
after 1000
sink close
sender close
context term
taskvent: OCaml 中的并行任务通风器
(**
Task ventilator
Binds PUSH socket to tcp://:5557
Sends batch of tasks to workers via that socket
*)
open Zmq
open Helpers
let () =
with_context @@ fun ctx ->
(* Socket to send messages on *)
with_socket ctx Socket.push @@ fun sender ->
Socket.bind sender "tcp://*:5557";
(* Socket to send start of batch message on *)
with_socket ctx Socket.push @@ fun sink ->
Socket.connect sink "tcp://:5558";
print_string "Press Enter when the workers are ready: ";
flush stdout;
let _ = input_line stdin in
printfn "Sending tasks to workers...";
(* The first message is "0" and signals start of batch *)
Socket.send sink "0";
(* Initialize random number generator *)
Random.self_init ();
(* Send 100 tasks *)
let total_msec = ref 0 in (* Total expected cost in msecs *)
for i = 0 to pred 100 do
(* Random workload from 1 to 100msecs *)
let workload = Random.int 100 + 1 in
total_msec := !total_msec + workload;
Socket.send sender (string_of_int workload)
done;
printfn "Total expected cost: %d msec" !total_msec
这里是工作者应用程序。它接收一条消息,然后睡眠若干秒,接着发出信号表示完成
taskwork: Ada 中的并行任务工作者
taskwork: Basic 中的并行任务工作者
taskwork: C 中的并行任务工作者
// Task worker
// Connects PULL socket to tcp://:5557
// Collects workloads from ventilator via that socket
// Connects PUSH socket to tcp://:5558
// Sends results to sink via that socket
#include "zhelpers.h"
int main (void)
{
// Socket to receive messages on
void *context = zmq_ctx_new ();
void *receiver = zmq_socket (context, ZMQ_PULL);
zmq_connect (receiver, "tcp://:5557");
// Socket to send messages to
void *sender = zmq_socket (context, ZMQ_PUSH);
zmq_connect (sender, "tcp://:5558");
// Process tasks forever
while (1) {
char *string = s_recv (receiver);
printf ("%s.", string); // Show progress
fflush (stdout);
s_sleep (atoi (string)); // Do the work
free (string);
s_send (sender, ""); // Send results to sink
}
zmq_close (receiver);
zmq_close (sender);
zmq_ctx_destroy (context);
return 0;
}
taskwork: C++ 中的并行任务工作者
//
// Task worker in C++
// Connects PULL socket to tcp://:5557
// Collects workloads from ventilator via that socket
// Connects PUSH socket to tcp://:5558
// Sends results to sink via that socket
//
#include "zhelpers.hpp"
#include <string>
int main (int argc, char *argv[])
{
zmq::context_t context(1);
// Socket to receive messages on
zmq::socket_t receiver(context, ZMQ_PULL);
receiver.connect("tcp://:5557");
// Socket to send messages to
zmq::socket_t sender(context, ZMQ_PUSH);
sender.connect("tcp://:5558");
// Process tasks forever
while (1) {
zmq::message_t message;
int workload; // Workload in msecs
receiver.recv(&message);
std::string smessage(static_cast<char*>(message.data()), message.size());
std::istringstream iss(smessage);
iss >> workload;
// Do the work
s_sleep(workload);
// Send results to sink
message.rebuild();
sender.send(message);
// Simple progress indicator for the viewer
std::cout << "." << std::flush;
}
return 0;
}
taskwork: C# 中的并行任务工作者
taskwork: CL 中的并行任务工作者
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-
;;;
;;; Task worker in Common Lisp
;;; Connects PULL socket to tcp://:5557
;;; Collects workloads from ventilator via that socket
;;; Connects PUSH socket to tcp://:5558
;;; Sends results to sink via that socket
;;;
;;; Kamil Shakirov <kamils80@gmail.com>
;;;
(defpackage #:zguide.taskwork
(:nicknames #:taskwork)
(:use #:cl #:zhelpers)
(:export #:main))
(in-package :zguide.taskwork)
(defun main ()
(zmq:with-context (context 1)
;; Socket to receive messages on
(zmq:with-socket (receiver context zmq:pull)
(zmq:connect receiver "tcp://:5557")
;; Socket to send messages to
(zmq:with-socket (sender context zmq:push)
(zmq:connect sender "tcp://:5558")
;; Process tasks forever
(loop
(let ((pull-msg (make-instance 'zmq:msg)))
(zmq:recv receiver pull-msg)
(let* ((string (zmq:msg-data-as-string pull-msg))
(delay (* (parse-integer string) 1000)))
;; Simple progress indicator for the viewer
(message "~A." string)
;; Do the work
(isys:usleep delay)
;; Send results to sink
(let ((push-msg (make-instance 'zmq:msg :data "")))
(zmq:send sender push-msg))))))))
(cleanup))
taskwork: Delphi 中的并行任务工作者
program taskwork;
//
// Task worker
// Connects PULL socket to tcp://:5557
// Collects workloads from ventilator via that socket
// Connects PUSH socket to tcp://:5558
// Sends results to sink via that socket
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
context: TZMQContext;
receiver,
sender: TZMQSocket;
s: Utf8String;
begin
context := TZMQContext.Create;
// Socket to receive messages on
receiver := Context.Socket( stPull );
receiver.connect( 'tcp://:5557' );
// Socket to send messages to
sender := Context.Socket( stPush );
sender.connect( 'tcp://:5558' );
// Process tasks forever
while True do
begin
receiver.recv( s );
// Simple progress indicator for the viewer
Writeln( s );
// Do the work
sleep( StrToInt( s ) );
// Send results to sink
sender.send('');
end;
receiver.Free;
sender.Free;
context.Free;
end.
taskwork: Erlang 中的并行任务工作者
#! /usr/bin/env escript
%%
%% Task worker
%% Connects PULL socket to tcp://:5557
%% Collects workloads from ventillator via that socket
%% Connects PUSH socket to tcp://:5558
%% Sends results to sink via that socket
%%
main(_) ->
application:start(chumak),
{ok, Receiver} = chumak:socket(pull),
case chumak:connect(Receiver, tcp, "localhost", 5557) of
{ok, _ConnectPid} ->
io:format("Connection OK with Pid: ~p\n", [Receiver]);
{error, Reason} ->
io:format("Connection failed for this reason: ~p\n", [Reason])
end,
{ok, Sender} = chumak:socket(push),
case chumak:connect(Sender, tcp, "localhost", 5558) of
{ok, _ConnectPid1} ->
io:format("Connection OK with Pid: ~p\n", [Sender])
end,
loop(Receiver, Sender).
loop(Receiver, Sender) ->
{ok, Work} = chumak:recv(Receiver),
io:format(" . "),
timer:sleep(list_to_integer(binary_to_list(Work))),
ok = chumak:send(Sender, <<" ">>),
loop(Receiver, Sender).
taskwork: Elixir 中的并行任务工作者
defmodule Taskwork do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:37
"""
def main() do
{:ok, context} = :erlzmq.context()
{:ok, receiver} = :erlzmq.socket(context, :pull)
:ok = :erlzmq.connect(receiver, 'tcp://:5557')
{:ok, sender} = :erlzmq.socket(context, :push)
:ok = :erlzmq.connect(sender, 'tcp://:5558')
loop(receiver, sender)
:ok = :erlzmq.close(receiver)
:ok = :erlzmq.close(sender)
:ok = :erlzmq.term(context)
end
def loop(receiver, sender) do
{:ok, work} = :erlzmq.recv(receiver)
:io.format('.')
:timer.sleep(:erlang.list_to_integer(:erlang.binary_to_list(work)))
:ok = :erlzmq.send(sender, "")
loop(receiver, sender)
end
end
Taskwork.main
taskwork: F# 中的并行任务工作者
taskwork: Felix 中的并行任务工作者
//
// Task worker
// Connects PULL socket to tcp://:5557
// Collects workloads from ventilator via that socket
// Connects PUSH socket to tcp://:5558
// Sends results to sink via that socket
open ZMQ;
var context = zmq_init (1);
// Socket to receive messages on
var receiver = context.mk_socket ZMQ_PULL;
receiver.connect "tcp://:5557";
// Socket to send messages to
var sender = context.mk_socket ZMQ_PUSH;
sender.connect "tcp://:5558";
// Process tasks forever
while true do
var s = receiver.recv_string;
// Simple progress indicator for the viewer
println s; fflush stdout;
// Do the work
Faio::sleep (sys_clock, atof s/1000.0);
// Send results to sink
sender.send_string "";
done
taskwork: Go 中的并行任务工作者
//
// Task Wroker
// Connects PULL socket to tcp://:5557
// Collects workloads from ventilator via that socket
// Connects PUSH socket to tcp://:5558
// Sends results to sink via that socket
//
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"strconv"
"time"
)
func main() {
context, _ := zmq.NewContext()
defer context.Close()
// Socket to receive messages on
receiver, _ := context.NewSocket(zmq.PULL)
defer receiver.Close()
receiver.Connect("tcp://:5557")
// Socket to send messages to task sink
sender, _ := context.NewSocket(zmq.PUSH)
defer sender.Close()
sender.Connect("tcp://:5558")
// Process tasks forever
for {
msgbytes, _ := receiver.Recv(0)
fmt.Printf("%s.\n", string(msgbytes))
// Do the work
msec, _ := strconv.ParseInt(string(msgbytes), 10, 64)
time.Sleep(time.Duration(msec) * 1e6)
// Send results to sink
sender.Send([]byte(""), 0)
}
}
taskwork: Haskell 中的并行任务工作者
{-# LANGUAGE OverloadedStrings #-}
-- Task worker
-- Connects PULL socket to tcp://:5557
-- Collects workloads from ventilator via that socket
-- Connects PUSH socket to tcp://:5558
-- Sends results to sink via that socket
module Main where
import Control.Concurrent
import Control.Monad
import Data.Monoid
import qualified Data.ByteString.Char8 as BS
import System.IO
import System.ZMQ4.Monadic
main :: IO ()
main = runZMQ $ do
-- Socket to receive messages on
receiver <- socket Pull
connect receiver "tcp://:5557"
-- Socket to send messages to
sender <- socket Push
connect sender "tcp://:5558"
-- Process tasks forever
forever $ do
string <- receive receiver
liftIO $ do
BS.putStr (string <> ".")
hFlush stdout
threadDelay $ read (BS.unpack string) * 1000
send sender [] ""
taskwork: Haxe 中的并行任务工作者
package ;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZMQ;
import org.zeromq.ZMQContext;
import org.zeromq.ZMQSocket;
/**
* Task worker in Haxe
* Connects PULL socket to tcp://:5557
* Collects workloads from ventilator via that socket
* Connects PUSH socket to tcp://:5558
* Sends results to sink via that socket
*
* See: https://zguide.zeromq.cn/page:all#Divide-and-Conquer
*
* Based on code from: https://zguide.zeromq.cn/java:taskwork
*
* Use with TaskVent.hx and TaskSink.hx
*/
class TaskWork
{
public static function main() {
var context:ZMQContext = ZMQContext.instance();
Lib.println("** TaskWork (see: https://zguide.zeromq.cn/page:all#Divide-and-Conquer)");
// Socket to receive messages on
var receiver:ZMQSocket = context.socket(ZMQ_PULL);
receiver.connect("tcp://127.0.0.1:5557");
// Socket to send messages to
var sender:ZMQSocket = context.socket(ZMQ_PUSH);
sender.connect("tcp://127.0.0.1:5558");
// Process tasks forever
while (true) {
var msgString = StringTools.trim(receiver.recvMsg().toString());
var sec:Float = Std.parseFloat(msgString) / 1000.0;
Lib.print(msgString + ".");
// Do the work
Sys.sleep(sec);
// Send results to sink
sender.sendMsg(Bytes.ofString(""));
}
}
}taskwork: Java 中的并行任务工作者
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZContext;
//
// Task worker in Java
// Connects PULL socket to tcp://:5557
// Collects workloads from ventilator via that socket
// Connects PUSH socket to tcp://:5558
// Sends results to sink via that socket
//
public class taskwork
{
public static void main(String[] args) throws Exception
{
try (ZContext context = new ZContext()) {
// Socket to receive messages on
ZMQ.Socket receiver = context.createSocket(SocketType.PULL);
receiver.connect("tcp://:5557");
// Socket to send messages to
ZMQ.Socket sender = context.createSocket(SocketType.PUSH);
sender.connect("tcp://:5558");
// Process tasks forever
while (!Thread.currentThread().isInterrupted()) {
String string = new String(receiver.recv(0), ZMQ.CHARSET).trim();
long msec = Long.parseLong(string);
// Simple progress indicator for the viewer
System.out.flush();
System.out.print(string + '.');
// Do the work
Thread.sleep(msec);
// Send results to sink
sender.send(ZMQ.MESSAGE_SEPARATOR, 0);
}
}
}
}
taskwork: Julia 中的并行任务工作者
#!/usr/bin/env julia
#
# Task worker
# Connects PULL socket to tcp://:5557
# Collects workloads from ventilator via that socket
# Connects PUSH socket to tcp://:5558
# Sends results to sink via that socket
#
using ZMQ
context = Context()
# Socket to receive messages on
receiver = Socket(context, PULL)
connect(receiver, "tcp://:5557")
# Socket to send messages to
sender = Socket(context, PUSH)
connect(sender, "tcp://:5558")
# Process tasks forever
while true
s = recv(receiver, String)
# Simple progress indicator for the viewer
write(stdout, ".")
flush(stdout)
# Do the work
sleep(parse(Int, s) * 0.001)
# Send results to sink
send(sender, 0x00)
end
close(sender)
close(receiver)
taskwork: Lua 中的并行任务工作者
--
-- Task worker
-- Connects PULL socket to tcp://:5557
-- Collects workloads from ventilator via that socket
-- Connects PUSH socket to tcp://:5558
-- Sends results to sink via that socket
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zhelpers"
local context = zmq.init(1)
-- Socket to receive messages on
local receiver = context:socket(zmq.PULL)
receiver:connect("tcp://:5557")
-- Socket to send messages to
local sender = context:socket(zmq.PUSH)
sender:connect("tcp://:5558")
-- Process tasks forever
while true do
local msg = receiver:recv()
-- Simple progress indicator for the viewer
io.stdout:flush()
printf("%s.", msg)
-- Do the work
s_sleep(tonumber(msg))
-- Send results to sink
sender:send("")
end
receiver:close()
sender:close()
context:term()
taskwork: Node.js 中的并行任务工作者
// Task worker in node.js
// Connects PULL socket to tcp://:5557
// Collects workloads from ventilator via that socket
// Connects PUSH socket to tcp://:5558
// Sends results to sink via that socket
var zmq = require('zeromq')
, receiver = zmq.socket('pull')
, sender = zmq.socket('push');
receiver.on('message', function(buf) {
var msec = parseInt(buf.toString(), 10);
// simple progress indicator for the viewer
process.stdout.write(buf.toString() + ".");
// do the work
// not a great node sample for zeromq,
// node receives messages while timers run.
setTimeout(function() {
sender.send("");
}, msec);
});
receiver.connect('tcp://:5557');
sender.connect('tcp://:5558');
process.on('SIGINT', function() {
receiver.close();
sender.close();
process.exit();
});
taskwork: Objective-C 中的并行任务工作者
/* taskwork.m: PULLs workload from tcp://:5557
* PUSHes results to tcp://:5558
*/
#import <Foundation/Foundation.h>
#import "ZMQObjC.h"
#define NSEC_PER_MSEC (1000000)
int
main(void)
{
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init];
ZMQContext *ctx = [[[ZMQContext alloc] initWithIOThreads:1U] autorelease];
/* (jws/2011-02-05)!!!: Do NOT terminate the endpoint with a final slash.
* If you connect to @"tcp://:5557/", you will get
* Assertion failed: rc == 0 (zmq_connecter.cpp:46)
* instead of a connected socket. Binding works fine, though. */
ZMQSocket *pull = [ctx socketWithType:ZMQ_PULL];
[pull connectToEndpoint:@"tcp://:5557"];
ZMQSocket *push = [ctx socketWithType:ZMQ_PUSH];
[push connectToEndpoint:@"tcp://:5558"];
/* Process tasks forever. */
struct timespec t;
NSData *emptyData = [NSData data];
for (;;) {
NSAutoreleasePool *p = [[NSAutoreleasePool alloc] init];
NSData *d = [pull receiveDataWithFlags:0];
NSString *s = [NSString stringWithUTF8String:[d bytes]];
t.tv_sec = 0;
t.tv_nsec = [s integerValue] * NSEC_PER_MSEC;
printf("%d.", [s intValue]);
fflush(stdout);
/* Do work, then report finished. */
(void)nanosleep(&t, NULL);
[push sendData:emptyData withFlags:0];
[p drain];
}
[ctx closeSockets];
[pool drain];
return EXIT_SUCCESS;
}
taskwork: ooc 中的并行任务工作者
taskwork: Perl 中的并行任务工作者
# Task worker in Perl
# Connects PULL socket to tcp://:5557
# Collects workloads from ventilator via that socket
# Connects PUSH socket to tcp://:5558
# Sends results to sink via that socket
use strict;
use warnings;
$| = 1; # autoflush stdout after each print
use Time::HiRes qw(usleep);
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_PUSH ZMQ_PULL);
my $context = ZMQ::FFI->new();
# Socket to receive messages on
my $receiver = $context->socket(ZMQ_PULL);
$receiver->connect('tcp://:5557');
# Socket to send messages on
my $sender = $context->socket(ZMQ_PUSH);
$sender->connect('tcp://:5558');
# Process tasks forever
my $string;
while (1) {
$string = $receiver->recv();
print "$string."; # Show progress
usleep $string*1000; # Do the work
$sender->send(""); # Send results to sink
}
taskwork: PHP 中的并行任务工作者
<?php
/*
* Task worker
* Connects PULL socket to tcp://:5557
* Collects workloads from ventilator via that socket
* Connects PUSH socket to tcp://:5558
* Sends results to sink via that socket
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
$context = new ZMQContext();
// Socket to receive messages on
$receiver = new ZMQSocket($context, ZMQ::SOCKET_PULL);
$receiver->connect("tcp://:5557");
// Socket to send messages to
$sender = new ZMQSocket($context, ZMQ::SOCKET_PUSH);
$sender->connect("tcp://:5558");
// Process tasks forever
while (true) {
$string = $receiver->recv();
// Simple progress indicator for the viewer
echo $string, PHP_EOL;
// Do the work
usleep($string * 1000);
// Send results to sink
$sender->send("");
}
taskwork: Python 中的并行任务工作者
# Task worker
# Connects PULL socket to tcp://:5557
# Collects workloads from ventilator via that socket
# Connects PUSH socket to tcp://:5558
# Sends results to sink via that socket
#
# Author: Lev Givon <lev(at)columbia(dot)edu>
import sys
import time
import zmq
context = zmq.Context()
# Socket to receive messages on
receiver = context.socket(zmq.PULL)
receiver.connect("tcp://:5557")
# Socket to send messages to
sender = context.socket(zmq.PUSH)
sender.connect("tcp://:5558")
# Process tasks forever
while True:
s = receiver.recv()
# Simple progress indicator for the viewer
sys.stdout.write('.')
sys.stdout.flush()
# Do the work
time.sleep(int(s)*0.001)
# Send results to sink
sender.send(b'')
taskwork: Q 中的并行任务工作者
taskwork: Racket 中的并行任务工作者
taskwork: Ruby 中的并行任务工作者
#!/usr/bin/env ruby
#
# Task worker in Ruby
# Connects PULL socket to tcp://:5557
# Collects workloads from ventilator via that socket
# Connects PUSH socket to tcp://:5558
# Sends results to sink via that socket
#
require 'rubygems'
require 'ffi-rzmq'
context = ZMQ::Context.new(1)
# Socket to receive messages on
receiver = context.socket(ZMQ::PULL)
receiver.connect("tcp://:5557")
# Socket to send messages to
sender = context.socket(ZMQ::PUSH)
sender.connect("tcp://:5558")
# Process tasks forever
while true
receiver.recv_string(msec = '')
# Simple progress indicator for the viewer
$stdout << "#{msec}."
$stdout.flush
# Do the work
sleep(msec.to_f / 1000)
# Send results to sink
sender.send_string("")
end
taskwork: Rust 中的并行任务工作者
use std::io::{self, Write};
use std::{thread, time};
fn atoi(s: &str) -> i64 {
s.parse().unwrap()
}
fn main() {
let context = zmq::Context::new();
let receiver = context.socket(zmq::PULL).unwrap();
assert!(receiver.connect("tcp://:5557").is_ok());
let sender = context.socket(zmq::PUSH).unwrap();
assert!(sender.connect("tcp://:5558").is_ok());
loop {
let string = receiver.recv_string(0).unwrap().unwrap();
println!("{}.", string);
let _ = io::stdout().flush();
thread::sleep(time::Duration::from_millis(atoi(&string) as u64));
sender.send("", 0).unwrap();
}
}
taskwork: Scala 中的并行任务工作者
/*
* Task worker in Scala
* Connects PULL socket to tcp://:5557
* Collects workloads from ventilator via that socket
* Connects PUSH socket to tcp://:5558
* Sends results to sink via that socket
*
* @author Giovanni Ruggiero
* @email giovanni.ruggiero@gmail.com
*/
import org.zeromq.ZMQ
object taskwork {
def main(args : Array[String]) {
val context = ZMQ.context(1)
// Socket to receive messages on
val receiver = context.socket(ZMQ.PULL)
receiver.connect("tcp://:5557")
// Socket to send messages to
val sender = context.socket(ZMQ.PUSH)
sender.connect("tcp://:5558")
// Process tasks forever
while (true) {
val string = new String(receiver.recv(0)).trim()
val nsec = string.toLong * 1000
// Simple progress indicator for the viewer
System.out.flush()
print(string + '.')
// Do the work
Thread.sleep(nsec)
// Send results to sink
sender.send("".getBytes(), 0)
}
}
}
taskwork: Tcl 中的并行任务工作者
#
# Task worker
# Connects PULL socket to tcp://:5557
# Collects workloads from ventilator via that socket
# Connects PUSH socket to tcp://:5558
# Sends results to sink via that socket
#
package require zmq
zmq context context
# Socket to receive messages on
zmq socket receiver context PULL
receiver connect "tcp://:5557"
# Socket to send messages to
zmq socket sender context PUSH
sender connect "tcp://:5558"
# Process tasks forever
while {1} {
set string [receiver recv]
# Simple progress indicator for the viewer
puts -nonewline "$string."
flush stdout
# Do the work
after $string
# Send result to sink
sender send "$string"
}
receiver close
sender close
context term
taskwork: OCaml 中的并行任务工作者
(**
Task worker
Connects PULL socket to tcp://:5557
Collects workloads from ventilator via that socket
Connects PUSH socket to tcp://:5558
Sends results to sink via that socket
*)
open Zmq
open Helpers
let () =
with_context @@ fun ctx ->
(* Socket to receive messages on *)
with_socket ctx Socket.pull @@ fun receiver ->
Socket.connect receiver "tcp://:5557";
(* Socket to send messages to *)
with_socket ctx Socket.push @@ fun sender ->
Socket.connect sender "tcp://:5558";
(* Process tasks forever *)
while true do
let s = Socket.recv receiver in
printfn "%s." s;
sleep_ms @@ int_of_string s; (* Do the work *)
Socket.send sender ""; (* Send results to sink *)
done
这里是汇集(sink)应用程序。它收集 100 个任务,然后计算整体处理花费了多长时间,这样我们就可以确认如果有一个以上的工作者,它们确实是在并行运行的
tasksink: Ada 中的并行任务汇集
tasksink: Basic 中的并行任务汇集
tasksink: C 中的并行任务汇集
// Task sink
// Binds PULL socket to tcp://:5558
// Collects results from workers via that socket
#include "zhelpers.h"
int main (void)
{
// Prepare our context and socket
void *context = zmq_ctx_new ();
void *receiver = zmq_socket (context, ZMQ_PULL);
zmq_bind (receiver, "tcp://*:5558");
// Wait for start of batch
char *string = s_recv (receiver);
free (string);
// Start our clock now
int64_t start_time = s_clock ();
// Process 100 confirmations
int task_nbr;
for (task_nbr = 0; task_nbr < 100; task_nbr++) {
char *string = s_recv (receiver);
free (string);
if (task_nbr % 10 == 0)
printf (":");
else
printf (".");
fflush (stdout);
}
// Calculate and report duration of batch
printf ("Total elapsed time: %d msec\n",
(int) (s_clock () - start_time));
zmq_close (receiver);
zmq_ctx_destroy (context);
return 0;
}
tasksink: C++ 中的并行任务汇集
//
// Task sink in C++
// Binds PULL socket to tcp://:5558
// Collects results from workers via that socket
//
#include <zmq.hpp>
#include <time.h>
#include <sys/time.h>
#include <iostream>
int main (int argc, char *argv[])
{
// Prepare our context and socket
zmq::context_t context(1);
zmq::socket_t receiver(context,ZMQ_PULL);
receiver.bind("tcp://*:5558");
// Wait for start of batch
zmq::message_t message;
receiver.recv(&message);
// Start our clock now
struct timeval tstart;
gettimeofday (&tstart, NULL);
// Process 100 confirmations
int task_nbr;
int total_msec = 0; // Total calculated cost in msecs
for (task_nbr = 0; task_nbr < 100; task_nbr++) {
receiver.recv(&message);
if (task_nbr % 10 == 0)
std::cout << ":" << std::flush;
else
std::cout << "." << std::flush;
}
// Calculate and report duration of batch
struct timeval tend, tdiff;
gettimeofday (&tend, NULL);
if (tend.tv_usec < tstart.tv_usec) {
tdiff.tv_sec = tend.tv_sec - tstart.tv_sec - 1;
tdiff.tv_usec = 1000000 + tend.tv_usec - tstart.tv_usec;
}
else {
tdiff.tv_sec = tend.tv_sec - tstart.tv_sec;
tdiff.tv_usec = tend.tv_usec - tstart.tv_usec;
}
total_msec = tdiff.tv_sec * 1000 + tdiff.tv_usec / 1000;
std::cout << "\nTotal elapsed time: " << total_msec << " msec\n" << std::endl;
return 0;
}
tasksink: C# 中的并行任务汇集
tasksink: CL 中的并行任务汇集
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-
;;;
;;; Task sink in Common Lisp
;;; Binds PULL socket to tcp://:5558
;;; Collects results from workers via that socket
;;;
;;; Kamil Shakirov <kamils80@gmail.com>
;;;
(defpackage #:zguide.tasksink
(:nicknames #:tasksink)
(:use #:cl #:zhelpers)
(:export #:main))
(in-package :zguide.tasksink)
(defun main ()
;; Prepare our context and socket
(zmq:with-context (context 1)
(zmq:with-socket (receiver context zmq:pull)
(zmq:bind receiver "tcp://*:5558")
;; Wait for start of batch
(let ((msg (make-instance 'zmq:msg)))
(zmq:recv receiver msg))
;; Start our clock now
(let ((elapsed-time
(with-stopwatch
(dotimes (task-nbr 100)
(let ((msg (make-instance 'zmq:msg)))
(zmq:recv receiver msg)
(let ((string (zmq:msg-data-as-string msg)))
(declare (ignore string))
(if (= 1 (denominator (/ task-nbr 10)))
(message ":")
(message "."))))))))
;; Calculate and report duration of batch
(message "Total elapsed time: ~F msec~%" (/ elapsed-time 1000.0)))))
(cleanup))
tasksink: Delphi 中的并行任务汇集
program tasksink;
//
// Task sink
// Binds PULL socket to tcp://:5558
// Collects results from workers via that socket
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, Windows
, zmqapi
;
const
task_count = 100;
var
context: TZMQContext;
receiver: TZMQSocket;
s: Utf8String;
i: Integer;
fFrequency,
fstart,
fStop : Int64;
begin
// Prepare our context and socket
context := TZMQContext.Create;
receiver := Context.Socket( stPull );
receiver.bind( 'tcp://*:5558' );
// Wait for start of batch
receiver.recv( s );
// Start our clock now
QueryPerformanceFrequency( fFrequency );
QueryPerformanceCounter( fStart );
// Process 100 confirmations
for i := 0 to task_count - 1 do
begin
receiver.recv( s );
if ((i / 10) * 10 = i) then
Write( ':' )
else
Write( '.' );
end;
// Calculate and report duration of batch
QueryPerformanceCounter( fStop );
Writeln( Format( 'Total elapsed time: %d msec', [
((MSecsPerSec * (fStop - fStart)) div fFrequency) ]) );
receiver.Free;
context.Free;
end.
tasksink: Erlang 中的并行任务汇集
#! /usr/bin/env escript
%%
%% Task sink
%% Binds PULL socket to tcp://:5558
%% Collects results from workers via that socket
%%
main(_) ->
application:start(chumak),
{ok, Receiver} = chumak:socket(pull),
case chumak:connect(Receiver, tcp, "localhost", 5557) of
{ok, _ConnectPid} ->
io:format("Connection OK with Pid: ~p\n", [Receiver]);
{error, Reason} ->
io:format("Connection failed for this reason: ~p\n", [Reason])
end,
{ok, Sender} = chumak:socket(push),
case chumak:connect(Sender, tcp, "localhost", 5558) of
{ok, _ConnectPid1} ->
io:format("Connection OK with Pid: ~p\n", [Sender])
end,
loop(Receiver, Sender).
loop(Receiver, Sender) ->
{ok, Work} = chumak:recv(Receiver),
io:format(" . "),
timer:sleep(list_to_integer(binary_to_list(Work))),
ok = chumak:send(Sender, <<" ">>),
loop(Receiver, Sender).
tasksink: Elixir 中的并行任务汇集
defmodule Tasksink do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:36
"""
def main() do
{:ok, context} = :erlzmq.context()
{:ok, receiver} = :erlzmq.socket(context, :pull)
:ok = :erlzmq.bind(receiver, 'tcp://*:5558')
{:ok, _} = :erlzmq.recv(receiver)
start = :erlang.now()
process_confirmations(receiver, 100)
:io.format('Total elapsed time: ~b msec~n', [div(:timer.now_diff(:erlang.now(), start), 1000)])
:ok = :erlzmq.close(receiver)
:ok = :erlzmq.term(context)
end
def process_confirmations(_receiver, 0) do
:ok
end
def process_confirmations(receiver, n) when n > 0 do
{:ok, _} = :erlzmq.recv(receiver)
case(n - rem(1, 10)) do
0 ->
:io.format(':')
_ ->
:io.format('.')
end
process_confirmations(receiver, n - 1)
end
end
Tasksink.main
tasksink: F# 中的并行任务汇集
tasksink: Felix 中的并行任务汇集
//
// Task sink
// Binds PULL socket to tcp://:5558
// Collects results from workers via that socket
//
include "std/posix/time";
open ZMQ;
// Prepare our context and socket
var context = zmq_init 1;
var receiver = context.mk_socket ZMQ_PULL;
receiver.bind "tcp://*:5558";
// Wait for start of batch
C_hack::ignore receiver.recv_string;
// Start our clock now
var start_time = #Time::time;
// Process 100 confirmations
for var task_nbr in 0 upto 99 do
C_hack::ignore receiver.recv_string;
if (task_nbr / 10) * 10 == task_nbr do
print ":";
else
print ".";
fflush (stdout);
done
done
// Calculate and report duration of batch
var now = #Time::time;
println$ f"Total elapsed time: %d ms"
((now - start_time)*1000.0).int
;
receiver.close;
context.term;
tasksink: Go 中的并行任务汇集
//
// Task sink
// Binds PULL socket to tcp://:5558
// Collects results from workers via that socket
//
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"time"
)
func main() {
context, _ := zmq.NewContext()
defer context.Close()
// Socket to receive messages on
receiver, _ := context.NewSocket(zmq.PULL)
defer receiver.Close()
receiver.Bind("tcp://*:5558")
// Wait for start of batch
msgbytes, _ := receiver.Recv(0)
fmt.Println("Received Start Msg ", string(msgbytes))
// Start our clock now
start_time := time.Now().UnixNano()
// Process 100 confirmations
for i := 0; i < 100; i++ {
msgbytes, _ = receiver.Recv(0)
fmt.Print(".")
}
// Calculate and report duration of batch
te := time.Now().UnixNano()
fmt.Printf("Total elapsed time: %d msec\n", (te-start_time)/1e6)
}
tasksink: Haskell 中的并行任务汇集
-- Task sink
-- Binds PULL socket to tcp://:5558
-- Collects results from workers via that socket
module Main where
import Control.Monad
import Data.Time.Clock
import System.IO
import System.ZMQ4.Monadic
main :: IO ()
main = runZMQ $ do
-- Prepare our socket
receiver <- socket Pull
bind receiver "tcp://*:5558"
-- Wait for start of batch
_ <- receive receiver
-- Start our clock now
start_time <- liftIO getCurrentTime
-- Process 100 confirmations
liftIO $ hSetBuffering stdout NoBuffering
forM_ [1..100] $ \i -> do
_ <- receive receiver
if i `mod` 10 == 0
then liftIO $ putStr ":"
else liftIO $ putStr "."
-- Calculate and report duration of batch
end_time <- liftIO getCurrentTime
liftIO . putStrLn $ "Total elapsed time: " ++ show (diffUTCTime end_time start_time * 1000) ++ " msec"
tasksink: Haxe 中的并行任务汇集
package ;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZMQ;
import org.zeromq.ZMQContext;
import org.zeromq.ZMQSocket;
/**
* Task sink in Haxe
* Binds PULL request socket to tcp://:5558
* Collects results from workers via this socket
*
* See: https://zguide.zeromq.cn/page:all#Divide-and-Conquer
*
* Based on https://zguide.zeromq.cn/java:tasksink
*
* Use with TaskVent.hx and TaskWork.hx
*/
class TaskSink
{
public static function main() {
var context:ZMQContext = ZMQContext.instance();
Lib.println("** TaskSink (see: https://zguide.zeromq.cn/page:all#Divide-and-Conquer)");
// Socket to receive messages on
var receiver:ZMQSocket = context.socket(ZMQ_PULL);
receiver.bind("tcp://127.0.0.1:5558");
// Wait for start of batch
var msgString = StringTools.trim(receiver.recvMsg().toString());
// Start our clock now
var tStart = Sys.time();
// Process 100 messages
var task_nbr:Int;
for (task_nbr in 0 ... 100) {
msgString = StringTools.trim(receiver.recvMsg().toString());
if (task_nbr % 10 == 0) {
Lib.println(":"); // Print a ":" every 10 messages
} else {
Lib.print(".");
}
}
// Calculate and report duation of batch
var tEnd = Sys.time();
Lib.println("Total elapsed time: " + Math.ceil((tEnd - tStart) * 1000) + " msec");
receiver.close();
context.term();
}
}tasksink: Java 中的并行任务汇集
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZContext;
//
// Task sink in Java
// Binds PULL socket to tcp://:5558
// Collects results from workers via that socket
//
public class tasksink
{
public static void main(String[] args) throws Exception
{
// Prepare our context and socket
try (ZContext context = new ZContext()) {
ZMQ.Socket receiver = context.createSocket(SocketType.PULL);
receiver.bind("tcp://*:5558");
// Wait for start of batch
String string = new String(receiver.recv(0), ZMQ.CHARSET);
// Start our clock now
long tstart = System.currentTimeMillis();
// Process 100 confirmations
int task_nbr;
int total_msec = 0; // Total calculated cost in msecs
for (task_nbr = 0; task_nbr < 100; task_nbr++) {
string = new String(receiver.recv(0), ZMQ.CHARSET).trim();
if ((task_nbr / 10) * 10 == task_nbr) {
System.out.print(":");
}
else {
System.out.print(".");
}
}
// Calculate and report duration of batch
long tend = System.currentTimeMillis();
System.out.println(
"\nTotal elapsed time: " + (tend - tstart) + " msec"
);
}
}
}
tasksink: Julia 中的并行任务汇集
#!/usr/bin/env julia
#
# Task sink
# Binds PULL socket to tcp://:5558
# Collects results from workers via that socket
#
using ZMQ
using Dates
context = Context()
# Socket to receive messages on
receiver = Socket(context, PULL)
bind(receiver, "tcp://*:5558")
# Wait for start of batch
s = recv(receiver)
# Start our tic toc clock
tstart = now()
# Process 100 confirmations
for task_nbr in 1:100
s = recv(receiver)
if task_nbr % 10 == 0
write(stdout, ":")
else
write(stdout, ".")
end
flush(stdout)
end
# Calculate and report duration of batch
tend = now()
elapsed = tend - tstart
println("\nTotal elapsed time: $(elapsed * 1000) msec")
# Making a clean exit.
close(receiver)
close(context)tasksink: Lua 中的并行任务汇集
--
-- Task sink
-- Binds PULL socket to tcp://:5558
-- Collects results from workers via that socket
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zhelpers"
local fmod = math.fmod
-- Prepare our context and socket
local context = zmq.init(1)
local receiver = context:socket(zmq.PULL)
receiver:bind("tcp://*:5558")
-- Wait for start of batch
local msg = receiver:recv()
-- Start our clock now
local start_time = s_clock ()
-- Process 100 confirmations
local task_nbr
for task_nbr=0,99 do
local msg = receiver:recv()
if (fmod(task_nbr, 10) == 0) then
printf (":")
else
printf (".")
end
io.stdout:flush()
end
-- Calculate and report duration of batch
printf("Total elapsed time: %d msec\n", (s_clock () - start_time))
receiver:close()
context:term()
tasksink: Node.js 中的并行任务汇集
// Task sink in node.js
// Binds PULL socket to tcp://:5558
// Collects results from workers via that socket.
var zmq = require('zeromq')
, receiver = zmq.socket('pull');
var started = false
, i = 0
, label = "Total elapsed time";
receiver.on('message', function() {
// wait for start of batch
if (!started) {
console.time(label);
started = true;
// process 100 confirmations
} else {
i += 1;
process.stdout.write(i % 10 === 0 ? ':' : '.');
if (i === 100) {
console.timeEnd(label);
receiver.close();
process.exit();
}
}
});
receiver.bindSync("tcp://*:5558");
tasksink: Objective-C 中的并行任务汇集
/* tasksink.m: PULLs workers' results from tcp://:5558/. */
/* You can wire up the vent, workers, and sink like so:
* $ ./tasksink &
* $ ./taskwork & # Repeat this as many times as you want workers.
* $ ./taskvent &
*/
#import <Foundation/Foundation.h>
#import "ZMQObjC.h"
#import <sys/time.h>
#define NSEC_PER_MSEC (1000000)
#define MSEC_PER_SEC (1000)
int
main(void)
{
NSAutoreleasePool *pool = [[NSAutoreleasePool alloc] init];
/* Prepare context and socket. */
ZMQContext *ctx = [[[ZMQContext alloc] initWithIOThreads:1U] autorelease];
ZMQSocket *pull = [ctx socketWithType:ZMQ_PULL];
[pull bindToEndpoint:@"tcp://*:5558"];
/* Wait for batch start. */
/* Cast result to void because we don't actually care about the value.
* The return value has been autoreleased, so no memory is leaked. */
(void)[pull receiveDataWithFlags:0];
/* Start clock. */
struct timeval tstart, tdiff, tend;
(void)gettimeofday(&tstart, NULL);
/* Process |kTaskCount| confirmations. */
static const int kTaskCount = 100;
for (int task = 0; task < kTaskCount; ++task) {
NSAutoreleasePool *p = [[NSAutoreleasePool alloc] init];
(void)[pull receiveDataWithFlags:0];
BOOL isMultipleOfTen = (0 == (task % 10));
if (isMultipleOfTen) {
fputs(":", stdout);
} else {
fputs(".", stdout);
}
fflush(stdout);
[p drain];
}
fputc('\n', stdout);
/* Stop clock. */
(void)gettimeofday(&tend, NULL);
/* Calculate the difference. */
tdiff.tv_sec = tend.tv_sec - tstart.tv_sec;
tdiff.tv_usec = tend.tv_usec - tstart.tv_usec;
if (tdiff.tv_usec < 0) {
tdiff.tv_sec -= 1;
tdiff.tv_usec += NSEC_PER_SEC;
}
/* Convert it to milliseconds. */
unsigned long totalMsec = tdiff.tv_sec * MSEC_PER_SEC
+ tdiff.tv_usec / NSEC_PER_MSEC;
NSLog(@"Total elapsed time: %lu ms", totalMsec);
[ctx closeSockets];
[pool drain];
return EXIT_SUCCESS;
}
tasksink: ooc 中的并行任务汇集
tasksink: Perl 中的并行任务汇集
# Task sink in Perl
# Binds PULL socket to tcp://:5558
# Collects results from workers via that socket
use strict;
use warnings;
use v5.10;
use Time::HiRes qw(time);
$| = 1; # autoflush stdout after each print
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_PULL);
# Prepare our context and socket
my $ctx = ZMQ::FFI->new();
my $receiver = $ctx->socket(ZMQ_PULL);
$receiver->bind('tcp://*:5558');
# Wait for start of batch
my $string = $receiver->recv();
# Start our clock now;
my $start_time = time();
# Process 100 confirmations
for my $task_nbr (0..99) {
$receiver->recv();
if ($task_nbr % 10 == 0) {
print ":";
}
else {
print ".";
}
}
# Calculate and report duration of batch
printf "Total elapsed time: %d msec\n",
(time() - $start_time) * 1000;
tasksink: PHP 中的并行任务汇集
<?php
/*
* Task sink
* Binds PULL socket to tcp://:5558
* Collects results from workers via that socket
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
// Prepare our context and socket
$context = new ZMQContext();
$receiver = new ZMQSocket($context, ZMQ::SOCKET_PULL);
$receiver->bind("tcp://*:5558");
// Wait for start of batch
$string = $receiver->recv();
// Start our clock now
$tstart = microtime(true);
// Process 100 confirmations
$total_msec = 0; // Total calculated cost in msecs
for ($task_nbr = 0; $task_nbr < 100; $task_nbr++) {
$string = $receiver->recv();
if ($task_nbr % 10 == 0) {
echo ":";
} else {
echo ".";
}
}
$tend = microtime(true);
$total_msec = ($tend - $tstart) * 1000;
echo PHP_EOL;
printf ("Total elapsed time: %d msec", $total_msec);
echo PHP_EOL;
tasksink: Python 中的并行任务汇集
# Task sink
# Binds PULL socket to tcp://:5558
# Collects results from workers via that socket
#
# Author: Lev Givon <lev(at)columbia(dot)edu>
import sys
import time
import zmq
context = zmq.Context()
# Socket to receive messages on
receiver = context.socket(zmq.PULL)
receiver.bind("tcp://*:5558")
# Wait for start of batch
s = receiver.recv()
# Start our clock now
tstart = time.time()
# Process 100 confirmations
for task_nbr in range(100):
s = receiver.recv()
if task_nbr % 10 == 0:
sys.stdout.write(':')
else:
sys.stdout.write('.')
sys.stdout.flush()
# Calculate and report duration of batch
tend = time.time()
print(f"Total elapsed time: {(tend-tstart)*1000} msec")
tasksink: Q 中的并行任务汇集
tasksink: Racket 中的并行任务汇集
tasksink: Ruby 中的并行任务汇集
#!/usr/bin/env ruby
#
# Task sink in C
# Binds PULL socket to tcp://:5558
# Collects results from workers via that socket
#
require 'rubygems'
require 'ffi-rzmq'
# Prepare our context and socket
context = ZMQ::Context.new(1)
receiver = context.socket(ZMQ::PULL)
receiver.bind("tcp://*:5558")
# Wait for start of batch
receiver.recv_string('')
tstart = Time.now
# Process 100 confirmations
100.times do |task_nbr|
receiver.recv_string('')
$stdout << ((task_nbr % 10 == 0) ? ':' : '.')
$stdout.flush
end
# Calculate and report duration of batch
tend = Time.now
total_msec = (tend-tstart) * 1000
puts "Total elapsed time: #{total_msec} msec"
tasksink: Rust 中的并行任务汇集
use std::io::{self, Write};
use std::time::Instant;
fn main() {
let context = zmq::Context::new();
let receiver = context.socket(zmq::PULL).unwrap();
assert!(receiver.bind("tcp://*:5558").is_ok());
let _ = receiver.recv_string(0).unwrap();
let start_time = Instant::now();
for task_nbr in 0..100 {
let _ = receiver.recv_string(0).unwrap();
if task_nbr % 10 == 0 {
println!(":");
} else {
println!(".");
}
let _ = io::stdout().flush();
}
println!("Total elapsed time: {:?} msec", start_time.elapsed());
let control = context.socket(zmq::PUB).unwrap();
assert!(control.bind("tcp://*:5559").is_ok());
control.send("kill", 0).unwrap();
}
tasksink: Scala 中的并行任务汇集
/*
*
* Task sink in Scala
* Binds PULL socket to tcp://:5558
* Collects results from workers via that socket
*
* @author Giovanni Ruggiero
* @email giovanni.ruggiero@gmail.com
*/
import org.zeromq.ZMQ
object tasksink {
def main(args : Array[String]) {
// Prepare our context and socket
val context = ZMQ.context(1)
val receiver = context.socket(ZMQ.PULL)
receiver.bind("tcp://*:5558")
// Wait for start of batch
val string = new String(receiver.recv(0))
// Start our clock now
val tstart = System.currentTimeMillis()
// Process 100 confirmations
val total_msec = 0 // Total calculated cost in msecs
for (task_nbr <- 1 to 100 ) {
val string = new String(receiver.recv(0)).trim()
if ((task_nbr / 10) * 10 == task_nbr) {
System.out.print(":")
} else {
System.out.print(".")
}
System.out.flush()
}
// Calculate and report duration of batch
val tend = System.currentTimeMillis()
println("Total elapsed time: " + (tend - tstart) + " msec")
}
}
tasksink: Tcl 中的并行任务汇集
#
# Task sink
# Binds PULL socket to tcp://:5558
# Collects results from workers via that socket
#
package require zmq
# Prepare our context and socket
zmq context context
zmq socket receiver context PULL
receiver bind "tcp://*:5558"
# Wait for start of batch
set string [receiver recv]
# Start our clock now
set start_time [clock milliseconds]
# Process 100 confirmations
for {set task_nbr 0} {$task_nbr < 100} {incr task_nbr} {
set string [receiver recv]
if {($task_nbr/10)*10 == $task_nbr} {
puts -nonewline ":"
} else {
puts -nonewline "."
}
flush stdout
}
# Calculate and report duration of batch
puts "Total elapsed time: [expr {[clock milliseconds]-$start_time}]msec"
receiver close
context term
tasksink: OCaml 中的并行任务汇集
(**
Task sink
Binds PULL socket to tcp://:5558
Collects results from workers via that socket
*)
open Zmq
open Helpers
let () =
with_context @@ fun ctx ->
with_socket ctx Socket.pull @@ fun receiver ->
Socket.bind receiver "tcp://*:5558";
(* Wait for start of batch *)
let (_:string) = Socket.recv receiver in
(* Start our clock now *)
let start_time = clock_ms () in
(* Process 100 confirmations *)
for i = 0 to pred 100 do
let (_:string) = Socket.recv receiver in
print_char (if i mod 10 = 0 then ':' else '.');
flush stdout;
done;
(* Calculate and report duration of batch *)
printfn "Total elapsed time: %d msec" (clock_ms () - start_time)
一个批次的平均成本是 5 秒。当我们启动 1、2 或 4 个工作者时,我们从汇集器得到如下结果:
- 1 个工作者:总耗时:5034 毫秒。
- 2 个工作者:总耗时:2421 毫秒。
- 4 个工作者:总耗时:1018 毫秒。
让我们更详细地看看这段代码的一些方面
-
工作者向上游连接到通风器,向下游连接到汇集器。这意味着你可以随意添加工作者。如果工作者绑定到它们的端点,你将需要 (a) 更多的端点,并且 (b) 每次添加工作者时都要修改通风器和/或汇集器。我们说通风器和汇集器是我们架构中稳定的部分,而工作者是其中动态的部分。
-
我们必须同步批次的开始,确保所有工作者都已启动并运行。这是 ZeroMQ 中一个相当常见的陷阱,并且没有简单的解决方案。
zmq_connectzmq_connect方法需要一定的时间。因此,当一组工作者连接到通风器时,第一个成功连接的工作者会在其他工作者连接的这段短时间内获得大量的消息。如果你没有以某种方式同步批次的开始,系统根本不会并行运行。尝试移除通风器中的等待,看看会发生什么。 -
通风器的 PUSH 套接字(假设所有工作者都在批次开始发送之前连接好)将任务均匀地分发给工作者。这被称为负载均衡,我们将在后面更详细地讨论它。
-
汇集器的 PULL 套接字均匀地收集来自工作者的结果。这被称为公平排队。
管道模式也表现出“慢加入者”综合征,这导致了 PUSH 套接字不能正确进行负载均衡的指责。如果你正在使用 PUSH 和 PULL,并且你的某个工作者接收到的消息远远多于其他工作者,那是因为那个 PULL 套接字比其他套接字连接得更快,并在其他套接字设法连接之前抓取了大量消息。如果你想要适当的负载均衡,你可能需要查看第三章 - 高级请求-回复模式 中的负载均衡模式。
ZeroMQ 编程 #
看过一些示例后,你一定迫不及待地想在某些应用程序中使用 ZeroMQ 了。在你开始之前,深呼吸,放松一下,并思考一些基本的建议,这将为你省去很多压力和困惑。
-
一步一步学习 ZeroMQ。它只有一个简单的 API,但却隐藏着无限的可能性。慢慢来,掌握每一个可能性。
-
编写优雅的代码。丑陋的代码隐藏问题,让别人难以帮助你。你可能习惯了没有意义的变量名,但阅读你代码的人不会。使用实际的单词作为名称,它们能说明变量的用途,而不是说“我太粗心了,没告诉你这个变量是干什么的”。使用一致的缩进和清晰的布局。编写优雅的代码,你的世界会更舒适。
-
边写边测试。当你的程序无法工作时,你应该知道是哪五行代码出了问题。当你使用 ZeroMQ 神奇功能时尤其如此,它在第一次尝试时就是不会工作的。
-
当你发现事情没有按预期进行时,将你的代码分解成小块,分别测试每个部分,看看哪个有问题。ZeroMQ 让你能够编写本质上是模块化的代码;利用这一点来发挥你的优势。
-
根据需要创建抽象(类、方法等等)。如果你复制代码太多,你也会复制代码中的错误。
正确使用 Context #
ZeroMQ 应用程序总是先创建context,然后使用它来创建套接字。在 C 语言中,它是zmq_ctx_new()
zmq_ctx_new()调用。你应该在你的进程中只创建和使用一个 context。从技术上讲,context 是单个进程中所有套接字的容器,并充当inproc进程内套接字的传输层,这是连接同一进程中线程的最快方式。如果在运行时一个进程有两个 contexts,它们就像是独立的 ZeroMQ 实例。如果你明确想要这样,那没问题,否则请记住:在进程启动时调用一次zmq_ctx_new()
调用
zmq_ctx_new()在进程启动时调用一次,并且
zmq_ctx_destroy()在进程结束时调用一次。
如果你正在使用fork()fork()系统调用,请在zmq_ctx_new() 在 fork() 之后,并在子进程代码的开头调用。一般来说,你希望在子进程中做有趣的事情(ZeroMQ),而在父进程中做无聊的进程管理。
zmq_ctx_new() 在 fork 之后以及子进程代码的开头调用。通常,你会在子进程中做一些有趣(ZeroMQ相关)的事情,而在父进程中处理无聊的进程管理。
优雅地退出 #
优秀的程序员和优秀的杀手有同样的座右铭:完成工作后总是要清理现场。当你在像 Python 这样的语言中使用 ZeroMQ 时,内存会自动为你释放。但当使用 C 语言时,你必须在使用完对象后小心地释放它们,否则会导致内存泄漏、应用程序不稳定以及通常不好的结果。
内存泄漏是一回事,但 ZeroMQ 对如何退出应用程序非常挑剔。原因很技术也很令人头疼,但结果是如果你留下任何套接字没有关闭,zmq_ctx_destroy()
zmq_ctx_destroy()函数将永远挂起。即使你关闭了所有套接字,zmq_ctx_destroy()
zmq_ctx_destroy()默认情况下也会永远等待,如果存在未决的连接或发送,除非你在关闭这些套接字之前将它们的 LINGER 选项设置为零。
我们需要关心的 ZeroMQ 对象是消息、套接字和 context。幸运的是,这非常简单,至少在简单的程序中是这样:
-
使用
zmq_send()zmq_send()和zmq_recv()zmq_recv()当可以时,因为这可以避免使用zmq_msg_t对象。 -
如果你确实使用了
zmq_msg_recv()zmq_msg_recv(),请在使用完收到的消息后立即释放它,通过调用zmq_msg_close()zmq_msg_close(). -
如果你频繁地打开和关闭大量套接字,这很可能表明你需要重新设计你的应用程序。在某些情况下,套接字句柄直到你销毁 context 时才会被释放。
-
当你退出程序时,关闭你的套接字,然后调用
zmq_ctx_destroy()zmq_ctx_destroy()。这会销毁 context。
至少在 C 语言开发中是这样。在具有自动对象销毁的语言中,当你离开作用域时,套接字和 context 会被销毁。如果你使用异常,你必须在类似于“finally”的代码块中进行清理,这与其他任何资源一样。
如果你正在进行多线程工作,事情会变得更加复杂。我们将在下一章讨论多线程,但是由于你们中有些人尽管收到了警告,仍会尝试在安全掌握之前就去实践,下面是关于如何在多线程 ZeroMQ 应用程序中优雅退出的快速简要指南。
首先,不要尝试从多个线程使用同一个套接字。请不要解释你为什么认为这样做会很有趣,只是请不要这样做。其次,你需要关闭每个有正在进行请求的套接字。正确的方法是设置一个较低的 LINGER 值(1 秒),然后关闭套接字。如果你的语言绑定在销毁 context 时没有自动为你这样做,我建议你提交一个补丁。
最后,销毁 context。这会导致附属线程(即,共享同一个 context 的线程)中任何阻塞的接收、轮询或发送操作返回错误。捕获该错误,然后设置 linger,并关闭该线程中的套接字,然后退出。不要销毁同一个 context 两次。zmq_ctx_destroyzmq_ctx_destroy在主线程中将会阻塞,直到它知道的所有套接字都安全关闭为止。
瞧!这足够复杂和令人头疼,任何称职的语言绑定作者都会自动处理这些,让套接字关闭的“舞蹈”变得不必要。
为什么我们需要 ZeroMQ #
现在你已经看到了 ZeroMQ 的实际应用,让我们回到“为什么”的问题。
如今许多应用程序由跨越某种网络(局域网或互联网)的组件组成。因此,许多应用程序开发人员最终都会做一些消息传递的工作。有些开发人员使用消息队列产品,但大多数时候他们会自己使用 TCP 或 UDP 来实现。这些协议本身不难使用,但是从 A 发送几个字节到 B 与以任何可靠方式进行消息传递之间存在巨大的差异。
让我们看看当我们开始使用原始 TCP 连接各个部分时所面临的典型问题。任何可复用的消息层都需要解决所有或大部分这些问题:
-
我们如何处理 I/O?我们的应用程序是阻塞的,还是在后台处理 I/O?这是一个关键的设计决策。阻塞 I/O 创建的架构扩展性不好。但后台 I/O 可能非常难以正确处理。
-
我们如何处理动态组件,例如,暂时消失的部分?我们是否正式将组件分为“客户端”和“服务器”,并强制规定服务器不能消失?那么,如果我们要连接服务器到服务器呢?我们是否每隔几秒尝试重新连接?
-
我们如何在网络上传输消息?我们如何封装数据,使其易于写入和读取,避免缓冲区溢出,对小消息高效,同时又能满足传输戴派对帽跳舞猫的超大视频的需求?
-
我们如何处理无法立即发送的消息?特别是,如果我们正在等待某个组件重新上线?我们是丢弃消息,将其放入数据库,还是放入内存队列?
-
我们将消息队列存储在哪里?如果从队列中读取的组件非常慢,导致队列积压,会发生什么?那我们的策略是什么?
-
我们如何处理丢失的消息?我们是等待新的数据,请求重发,还是构建某种可靠性层来确保消息不会丢失?如果那个层本身崩溃了怎么办?
-
如果我们需要使用不同的网络传输方式怎么办?比如,使用多播而不是 TCP 单播?或者使用 IPv6?我们需要重写应用程序吗,还是传输方式在某个层中被抽象化了?
-
我们如何路由消息?我们可以将同一条消息发送给多个对等方吗?我们可以将回复发送回原始请求者吗?
-
我们如何为另一种语言编写 API?我们是重新实现一个网络协议,还是封装一个库?如果是前者,我们如何保证高效稳定的协议栈?如果是后者,我们如何保证互操作性?
-
我们如何表示数据,使其可以在不同架构之间读取?我们是否强制对数据类型使用特定的编码?这在多大程度上是消息系统的责任,而不是更高层的责任?
-
我们如何处理网络错误?我们是等待并重试,默默忽略它们,还是中止?
以一个典型的开源项目,如 Hadoop Zookeeper 为例,阅读其中的 C API 代码src/c/src/zookeeper.c
src/c/src/zookeeper.c。当我阅读这段代码时(2013 年 1 月),它是 4200 行的谜团,其中包含一个未文档化的客户端/服务器网络通信协议。我认为它很高效,因为它使用了pollpoll而不是selectselect。但实际上,Zookeeper 应该使用通用的消息层和一个明确文档化的网络协议。团队一遍又一遍地重复制造这个特定的轮子是令人难以置信的浪费。
但是如何创建一个可复用的消息层呢?为什么当这么多项目需要这项技术时,人们仍然通过在代码中操作 TCP 套接字来做这件事,一遍又一遍地解决那长串列表中的问题?
事实证明,构建可复用的消息系统非常困难,这就是为什么很少有 FOSS 项目尝试这样做,也是为什么商业消息产品复杂、昂贵、不够灵活且脆弱的原因。2006 年,iMatix 设计了 AMQP,这或许是首次为 FOSS 开发者提供了可复用的消息系统方案。AMQP 比许多其他设计表现得更好,但仍然相对复杂、昂贵且脆弱。学习使用它需要数周时间,创建在复杂情况下不会崩溃的稳定架构需要数月时间。

大多数消息项目,比如 AMQP,试图以可复用的方式解决这一长串问题,它们通过发明一个新概念——“消息代理(broker)”——来实现,消息代理负责寻址、路由和排队。这会产生一个客户端/服务器协议,或者在某个未文档化协议之上构建一套 API,让应用程序能够与这个消息代理通信。消息代理在降低大型网络复杂性方面非常出色。但是将基于消息代理的消息传递添加到像 Zookeeper 这样的产品中只会使其更糟,而不是更好。这意味着添加一个额外的庞大组件,并引入新的单点故障。消息代理很快就会成为瓶颈和一个需要管理的新风险。如果软件支持,我们可以添加第二个、第三个和第四个消息代理,并建立一些故障转移方案。人们确实这样做。但这会产生更多的活动部件、更多的复杂性以及更多可能发生故障的地方。
而且以消息代理为中心的设置需要自己的运维团队。你确实需要日夜监控消息代理,并在它们行为异常时“用棍子敲打它们”(比喻)。你需要机器,需要备份机器,还需要有人来管理这些机器。这只适用于由多个团队耗费数年时间构建的、具有许多活动部件的大型应用程序。

因此,中小型应用程序开发人员陷入了困境。要么他们避免网络编程,构建无法扩展的单体应用程序。要么他们投入网络编程,构建脆弱、复杂、难以维护的应用程序。要么他们选择某个消息产品,最终得到依赖于昂贵、易于损坏的技术的可扩展应用程序。一直以来都没有真正好的选择,这也许就是为什么消息传递在很大程度上停留在上个世纪,并激起强烈情感的原因:用户感到负面,而销售支持和许可证的人则感到欢欣鼓舞。
我们需要的是能够完成消息传递工作的东西,但其方式要如此简单和廉价,以至于几乎零成本地在任何应用程序中运行。它应该是一个你只需链接的库,没有任何其他依赖。没有额外的活动部件,因此没有额外的风险。它应该能在任何操作系统上运行,并与任何编程语言协同工作。
这就是 ZeroMQ:一个高效、可嵌入的库,它解决了应用程序在网络上实现良好弹性所需的大部分问题,而且成本不高。
具体来说
-
它在后台线程中异步处理 I/O。这些后台线程使用无锁数据结构与应用程序线程通信,因此并发的 ZeroMQ 应用程序不需要锁、信号量或其他等待状态。
-
组件可以动态加入和离开,ZeroMQ 会自动重新连接。这意味着你可以按任何顺序启动组件。你可以创建“面向服务的架构”(SOA),其中服务可以随时加入和离开网络。
-
它在需要时自动对消息进行排队。它会智能地执行此操作,在将消息排队之前,尽可能地将消息推送到接近接收方的位置。
-
它有处理队列过满的方法(称为“高水位标记”)。当队列满时,ZeroMQ 会根据你正在进行的消息类型(所谓的“模式”)自动阻塞发送者,或丢弃消息。
-
它允许你的应用程序通过任意传输方式相互通信:TCP、多播、进程内、进程间。你无需修改代码即可使用不同的传输方式。
-
它使用取决于消息模式的不同策略,安全地处理慢速/阻塞的读者。
-
它允许你使用各种模式(例如请求-回复和发布-订阅)来路由消息。这些模式是你创建网络拓扑结构的方式。
-
它允许你通过一次调用创建代理,来对消息进行排队、转发或捕获。代理可以降低网络的互连复杂性。
-
它使用简单的网络帧将完整的消息按发送时的样子交付。如果你发送一个 10k 的消息,你将收到一个 10k 的消息。
-
它不对消息强制要求任何格式。消息可以是零到数千兆字节大小的二进制数据块。当你想要表示数据时,你可以选择在其之上使用其他产品,例如 msgpack、Google 的 Protocol Buffers 等等。
-
它会智能地处理网络错误,在合理的场景下自动重试。
-
它减少了你的碳足迹。用更少的 CPU 完成更多工作意味着你的机器功耗更低,并且你可以更长时间地使用旧机器。阿尔·戈尔会喜欢 ZeroMQ 的。
实际上,ZeroMQ 的作用远不止于此。它对你开发网络应用程序的方式产生了颠覆性的影响。表面上看,它是一个受套接字启发的 API,你可以在其上进行zmq_send
zmq_recv()和zmq_recv()
zmq_send()和 zmq_recv。但是消息处理很快就成为中心循环,你的应用程序很快就会分解成一系列消息处理任务。这既优雅又自然。而且它可以扩展:这些任务中的每一个都映射到一个节点,并且这些节点可以通过任意传输方式相互通信。同一进程中的两个节点(节点是一个线程),同一台机器上的两个节点(节点是一个进程),或者同一网络上的两个节点(节点是一台机器)——都是一样的,无需更改应用程序代码。
套接字的可扩展性 #
让我们看看 ZeroMQ 的可扩展性实际表现。这是一个 shell 脚本,它启动天气服务器,然后并行启动一堆客户端
wuserver &
wuclient 12345 &
wuclient 23456 &
wuclient 34567 &
wuclient 45678 &
wuclient 56789 &
当客户端运行时,我们使用top顶部命令查看活跃进程,我们会看到类似这样的输出(在一台 4 核机器上):
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
7136 ph 20 0 1040m 959m 1156 R 157 12.0 16:25.47 wuserver
7966 ph 20 0 98608 1804 1372 S 33 0.0 0:03.94 wuclient
7963 ph 20 0 33116 1748 1372 S 14 0.0 0:00.76 wuclient
7965 ph 20 0 33116 1784 1372 S 6 0.0 0:00.47 wuclient
7964 ph 20 0 33116 1788 1372 S 5 0.0 0:00.25 wuclient
7967 ph 20 0 33072 1740 1372 S 5 0.0 0:00.35 wuclient
让我们稍微思考一下这里发生了什么。天气服务器只有一个套接字,但它却同时向五个客户端并行发送数据。我们可以拥有成千上万个并发客户端。服务器应用程序看不到它们,也不会直接与它们通信。因此,ZeroMQ 套接字就像一个小型服务器,默默地接受客户端请求,并以网络能处理的最快速度将数据推送给它们。而且它是一个多线程服务器,榨取了你 CPU 更大的性能。
从 ZeroMQ v2.2 升级到 ZeroMQ v3.2 #
兼容性变更 #
这些变更不会直接影响现有的应用程序代码
-
发布-订阅过滤现在发生在发布者端,而不是订阅者端。这显著提高了许多发布-订阅用例的性能。你可以安全地混合使用 v3.2 和 v2.1/v2.2 的发布者和订阅者。
-
ZeroMQ v3.2 有许多新的 API 方法(
zmq_disconnect()zmq_disconnect(),zmq_unbind(),zmq_monitor(),zmq_ctx_set()等)
不兼容变更 #
这些是对应用程序和语言绑定的主要影响领域
-
更改的发送/接收方法
zmq_send()zmq_send()和zmq_recv()zmq_recv()和zmq_recv()有了不同、更简单的接口,旧的功能现在由zmq_msg_send()提供。症状:编译错误。解决方案:修改你的代码。和zmq_recv()zmq_msg_recv(). 症状:编译错误。解决方案:修复你的代码。 -
zmq_send()和zmq_recv()在成功时返回正值,错误时返回 -1。在 v2.x 中,它们成功时总是返回零。症状:实际工作正常时却出现错误。解决方案:严格测试返回码是否等于 -1,而不是非零。 -
zmq_poll()现在等待的是毫秒,而不是微秒。症状:应用程序停止响应(实际上响应速度慢了 1000 倍)。解决方案:在所有ZMQ_POLL_MSEC宏定义(如下),在所有zmq_poll下面定义的宏,在所有zmq_poll调用中使用。 -
ZMQ_NOBLOCK现在称为ZMQ_DONTWAIT。症状:在ZMQ_NOBLOCK宏上出现编译失败。解决方案:使用ZMQ_DONTWAIT。ZMQ_NOBLOCK宏。 -
此
ZMQ_HWM套接字选项现在被拆分为ZMQ_SNDHWM和ZMQ_RCVHWM和zmq_recv()ZMQ_RCVHWM宏上出现编译失败。解决方案:使用ZMQ_DONTWAIT。ZMQ_HWM宏。 -
大多数但不是所有
zmq_getsockopt()选项现在是整数值。症状:在zmq_setsockopt选项现在是整数值。症状:在运行时返回错误和zmq_getsockopt和zmq_recv()调用时返回运行时错误。. -
此
ZMQ_SWAP选项已被移除。症状:在ZMQ_SWAPZMQ_SWAP上出现编译失败。解决方案:重新设计任何使用此功能的代码。
建议的 Shim 宏 #
对于希望在 v2.x 和 v3.2 上都能运行的应用程序,例如语言绑定,我们的建议是尽可能地模拟 v3.2。以下是 C 宏定义,它们有助于你的 C/C++ 代码兼容这两个版本(取自 CZMQ)
#ifndef ZMQ_DONTWAIT
# define ZMQ_DONTWAIT ZMQ_NOBLOCK
#endif
#if ZMQ_VERSION_MAJOR == 2
# define zmq_msg_send(msg,sock,opt) zmq_send (sock, msg, opt)
# define zmq_msg_recv(msg,sock,opt) zmq_recv (sock, msg, opt)
# define zmq_ctx_destroy(context) zmq_term(context)
# define ZMQ_POLL_MSEC 1000 // zmq_poll is usec
# define ZMQ_SNDHWM ZMQ_HWM
# define ZMQ_RCVHWM ZMQ_HWM
#elif ZMQ_VERSION_MAJOR == 3
# define ZMQ_POLL_MSEC 1 // zmq_poll is msec
#endif
警告:不稳定的范例! #
传统的网络编程建立在一般的假设之上:一个套接字与一个连接、一个对等方通信。存在多播协议,但这属于特殊情况。当我们假设“一个套接字 = 一个连接”时,我们就会以特定的方式扩展我们的架构。我们创建逻辑线程,每个线程处理一个套接字、一个对等方。我们将智能和状态置于这些线程中。
在 ZeroMQ 的世界里,套接字是通往快速后台通信引擎的门户,这些引擎会自动为你管理整套连接。你无法看到、操作、打开、关闭这些连接,也无法将状态附加到它们。无论你使用阻塞发送或接收,还是轮询,你所能与之通信的只有套接字,而不是它为你管理的连接。这些连接是私有的、不可见的,这是 ZeroMQ 可扩展性的关键所在。
这是因为你的代码通过与套接字通信,就可以处理跨越各种网络协议的任意数量的连接,而无需修改代码。ZeroMQ 中的消息模式比应用程序代码中的消息模式扩展成本更低。
因此,一般的假设不再适用。当你阅读代码示例时,你的大脑会尝试将其映射到你已知的事物上。你会读到“套接字”,然后想“啊,这代表了与另一个节点的连接”。这是错误的。你会读到“线程”,你的大脑会再次想“啊,一个线程代表了与另一个节点的连接”,你的大脑又错了。
如果你是第一次阅读本指南,请意识到,在你真正编写 ZeroMQ 代码一两天(也许三四天)之前,你可能会感到困惑,特别是 ZeroMQ 让事情变得如此简单,你可能会试图将那个普遍假设强加给 ZeroMQ,而它不会奏效。然后你就会体验到顿悟和信任的时刻,那个 zap-pow-kaboom 般令人茅塞顿开的范式转变时刻。