第三章 - 高级请求-应答模式 #
在第二章 - 套接字和模式中,我们通过开发一系列小型应用程序,每次探索 ZeroMQ 的新方面,来学习 ZeroMQ 的基础知识。本章我们将继续采用这种方法,探索基于 ZeroMQ 核心请求-应答模式构建的高级模式。
我们将涵盖:
- 请求-应答机制如何工作
- 如何组合使用 REQ、REP、DEALER 和 ROUTER 套接字
- ROUTER 套接字的工作原理详解
- 负载均衡模式
- 构建一个简单的负载均衡消息代理
- 设计 ZeroMQ 高级 API
- 构建异步请求-应答服务器
- 详细的代理间路由示例
请求-应答机制 #
我们已经简单了解了多部分消息。现在让我们看看一个主要的用例,即应答消息信封。信封是一种安全地将数据与地址打包在一起的方式,而无需触碰数据本身。通过将应答地址分离到信封中,我们可以编写通用的中介(如 API 和代理),它们无论消息载荷或结构如何,都能创建、读取和删除地址。
在请求-应答模式中,信封包含了应答的返回地址。这是无状态的 ZeroMQ 网络如何创建往返请求-应答对话的方式。
当你使用 REQ 和 REP 套接字时,你甚至看不到信封;这些套接字会自动处理它们。但对于大多数有趣的请求-应答模式,你会需要理解信封,特别是 ROUTER 套接字。我们将一步步进行。
简单应答信封 #
请求-应答交换包括一个请求消息和一个最终的应答消息。在简单请求-应答模式中,每个请求对应一个应答。在更高级的模式中,请求和应答可以异步流动。然而,应答信封的工作方式始终相同。
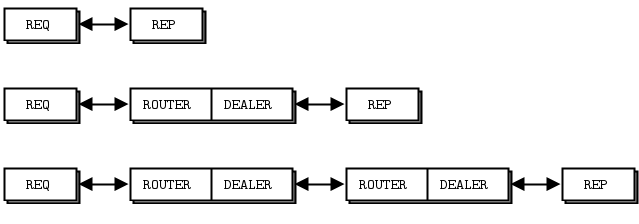
ZeroMQ 应答信封正式由零个或多个应答地址,后跟一个空帧(信封分隔符),再后跟消息体(零个或多个帧)组成。信封由链中协同工作的多个套接字创建。我们将详细分解这一点。
我们将从通过 REQ 套接字发送“Hello”开始。REQ 套接字创建了最简单的应答信封,它没有地址,只有一个空的分隔符帧和包含“Hello”字符串的消息帧。这是一个两帧消息。

REP 套接字完成匹配工作:它剥离信封,直到并包括分隔符帧,保存整个信封,并将“Hello”字符串传递给应用程序。因此,我们最初的 Hello World 示例在内部使用了请求-应答信封,但应用程序从未见过它们。
如果你窥探网络数据流,在hwclient和hwserver之间,你会看到:每个请求和每个应答实际上是两个帧,一个空帧,然后是消息体。对于简单的 REQ-REP 对话来说,这似乎没有多大意义。然而,当我们探索 ROUTER 和 DEALER 如何处理信封时,你就会明白其中的原因。
扩展应答信封 #
现在,让我们在 REQ-REP 对中间添加一个 ROUTER-DEALER 代理,看看这如何影响应答信封。这就是我们在第二章 - 套接字和模式中已经见过的扩展请求-应答模式。实际上,我们可以插入任意数量的代理步骤。其机制是相同的。
代理执行以下伪代码操作:
prepare context, frontend and backend sockets
while true:
poll on both sockets
if frontend had input:
read all frames from frontend
send to backend
if backend had input:
read all frames from backend
send to frontend
ROUTER 套接字与其他套接字不同,它会跟踪其所有连接,并将这些连接信息告知调用者。告知调用者的方式是将连接的身份放在接收到的每条消息前面。身份,有时也称为地址,只是一个二进制字符串,其含义仅为“这是连接的唯一句柄”。然后,当你通过 ROUTER 套接字发送消息时,你首先发送一个身份帧。
的 zmq_socket()手册页如此描述:
接收消息时,ZMQ_ROUTER 套接字应在将消息传递给应用程序之前,在消息前面加上包含发起对端身份的消息部分。接收到的消息会从所有连接的对端中公平地排队。发送消息时,ZMQ_ROUTER 套接字应移除消息的第一部分,并使用它来确定消息应路由到的对端的身份。
历史注:ZeroMQ v2.2 及更早版本使用 UUID 作为身份。ZeroMQ v3.0 及更高版本默认生成一个 5 字节的身份(0 + 一个随机 32 位整数)。这对网络性能有一些影响,但只在使用多个代理跳跃时才会发生,这种情况很少见。主要改动是为了通过移除对 UUID 库的依赖来简化构建libzmq。
身份是一个难以理解的概念,但如果你想成为 ZeroMQ 专家,这是必不可少的。ROUTER 套接字会为其与之工作的每个连接发明一个随机身份。如果有三个 REQ 套接字连接到 ROUTER 套接字,它将为每个 REQ 套接字发明三个随机身份。
因此,如果我们继续之前的示例,假设 REQ 套接字有一个 3 字节的身份:ABC。在内部,这意味着 ROUTER 套接字维护一个哈希表,它可以在其中搜索ABC并找到 REQ 套接字的 TCP 连接。
当我们从 ROUTER 套接字接收消息时,我们会得到三个帧。

代理循环的核心是“从一个套接字读取,写入另一个套接字”,所以我们实际上将这三个帧原封不动地通过 DEALER 套接字发送出去。如果你现在嗅探网络流量,你会看到这三个帧从 DEALER 套接字飞向 REP 套接字。REP 套接字像以前一样,剥离整个信封,包括新的应答地址,然后再次将“Hello”传递给调用者。
顺带一提,REP 套接字一次只能处理一个请求-应答交换,这就是为什么如果你试图读取多个请求或发送多个应答而不遵循严格的接收-发送循环时,它会报错。
现在你应该能够想象回程路径了。当hwserver发送“World”回来时,REP 套接字会用它保存的信封将消息包装起来,然后通过网络发送一个包含三个帧的应答消息到 DEALER 套接字。

现在 DEALER 读取这三个帧,并将全部三个通过 ROUTER 套接字发送出去。ROUTER 取消息的第一个帧,即ABC身份,并查找与之对应的连接。如果找到,它就会将接下来的两个帧发送到网络上。

REQ 套接字接收到这条消息,并检查第一个帧是否为空分隔符,确实如此。REQ 套接字丢弃该帧,并将“World”传递给调用应用程序,应用程序打印出来,让第一次接触 ZeroMQ 的我们感到惊奇。
有什么用? #
老实说,严格请求-应答或扩展请求-应答的用例有些受限。例如,当服务器由于有 bug 的应用程序代码而崩溃时,没有简单的方法恢复。我们将在第四章 - 可靠请求-应答模式中看到更多相关内容。然而,一旦你掌握了这四种套接字处理信封的方式以及它们之间如何交互,你就可以做很多有用的事情。我们看到了 ROUTER 如何使用应答信封来决定将应答路由回哪个客户端 REQ 套接字。现在让我们换一种方式来表达:
- 每次 ROUTER 给你一条消息时,它都会告诉你这条消息来自哪个对端,以身份的形式。
- 你可以将此信息与哈希表(以身份作为键)结合使用,以跟踪新连接的对端。
- 如果你将身份作为消息的第一个帧前缀,ROUTER 将异步地将消息路由到与其连接的任何对端。
ROUTER 套接字并不关心整个信封。它们不知道空分隔符的存在。它们只关心那个身份帧,以便确定将消息发送到哪个连接。
请求-应答套接字回顾 #
我们来回顾一下:
-
REQ 套接字在消息数据之前向网络发送一个空分隔符帧。REQ 套接字是同步的。REQ 套接字总是发送一个请求,然后等待一个应答。REQ 套接字一次与一个对端通信。如果将 REQ 套接字连接到多个对端,请求会轮流分配给每个对端,并轮流从每个对端接收应答。
-
REP 套接字读取并保存所有身份帧,直到并包括空分隔符,然后将随后的一个或多个帧传递给调用者。REP 套接字是同步的,一次与一个对端通信。如果将 REP 套接字连接到多个对端,请求会以公平的方式从对端读取,应答总是发送给发出上一个请求的那个对端。
-
DEALER 套接字对应答信封一无所知,并像处理任何多部分消息一样处理它。DEALER 套接字是异步的,并且像 PUSH 和 PULL 的组合。它们将发送的消息分发到所有连接,并从所有连接中公平地排队接收消息。
-
ROUTER 套接字对回复信封一无所知,就像 DEALER 一样。它为其连接创建身份,并将这些身份作为接收到的任何消息的第一个帧传递给调用者。反之,当调用者发送消息时,它使用消息的第一个帧作为身份来查找要发送到的连接。ROUTER 是异步的。
请求-应答组合 #
我们有四种请求-应答套接字,每种都有特定的行为。我们已经了解了它们在简单和扩展请求-应答模式中的连接方式。但这些套接字是你可以用来解决许多问题的构建块。
以下是合法的组合:
- REQ 到 REP
- DEALER 到 REP
- REQ 到 ROUTER
- DEALER 到 ROUTER
- DEALER 到 DEALER
- ROUTER 到 ROUTER
以下组合是无效的(我将解释原因):
- REQ 到 REQ
- REQ 到 DEALER
- REP 到 REP
- REP 到 ROUTER
这里有一些记住语义的技巧。DEALER 类似于异步 REQ 套接字,而 ROUTER 类似于异步 REP 套接字。在我们使用 REQ 套接字的地方,可以使用 DEALER;我们只需要自己读写信封。在我们使用 REP 套接字的地方,可以使用 ROUTER;我们只需要自己管理身份。
将 REQ 和 DEALER 套接字视为“客户端”,将 REP 和 ROUTER 套接字视为“服务器”。大多数情况下,你会希望绑定 REP 和 ROUTER 套接字,并将 REQ 和 DEALER 套接字连接到它们。这并非总是如此简单,但这是一个清晰且易于记忆的起点。
REQ 与 REP 组合 #
我们已经介绍了 REQ 客户端与 REP 服务器通信的情况,但我们来看看一个方面:REQ 客户端必须启动消息流。REP 服务器不能与尚未首先向其发送请求的 REQ 客户端通信。从技术上讲,这甚至是不可能的,如果你尝试这样做,API 也会返回一个EFSM错误。
DEALER 与 REP 组合 #
现在,让我们用 DEALER 替换 REQ 客户端。这为我们提供了一个可以与多个 REP 服务器通信的异步客户端。如果我们使用 DEALER 重写“Hello World”客户端,我们将能够发送任意数量的“Hello”请求,而无需等待应答。
当我们使用 DEALER 与 REP 套接字通信时,我们必须精确地模拟 REQ 套接字会发送的信封,否则 REP 套接字会将消息丢弃为无效。因此,要发送消息,我们:
- 发送一个设置了 MORE 标志的空消息帧;然后
- 发送消息体。
接收消息时,我们:
- 接收第一个帧,如果它不是空的,则丢弃整个消息;
- 接收下一个帧并将其传递给应用程序。
REQ 与 ROUTER 组合 #
就像我们可以用 DEALER 替换 REQ 一样,我们可以用 ROUTER 替换 REP。这为我们提供了一个可以同时与多个 REQ 客户端通信的异步服务器。如果我们使用 ROUTER 重写“Hello World”服务器,我们将能够并行处理任意数量的“Hello”请求。我们在第二章 - 套接字和模式中的mtserver示例中看到了这一点。
我们可以以两种不同的方式使用 ROUTER:
- 作为在前端和后端套接字之间切换消息的代理。
- 作为读取消息并对其进行操作的应用程序。
第一种情况下,ROUTER 只是简单地读取所有帧,包括人工身份帧,并盲目地将其传递下去。第二种情况下,ROUTER 必须知道发送给它的应答信封的格式。由于另一个对端是 REQ 套接字,ROUTER 将接收身份帧、一个空帧,然后是数据帧。
DEALER 与 ROUTER 组合 #
现在我们可以用 DEALER 和 ROUTER 替换 REQ 和 REP,从而获得最强大的套接字组合,即 DEALER 与 ROUTER 通信。它使异步客户端能够与异步服务器通信,并且双方都可以完全控制消息格式。
由于 DEALER 和 ROUTER 都可以处理任意消息格式,如果你希望安全地使用它们,你就必须稍微扮演一下协议设计者的角色。至少,你必须决定是否希望模仿 REQ/REP 应答信封。这取决于你是否确实需要发送应答。
DEALER 与 DEALER 组合 #
你可以用 ROUTER 替换 REP,但如果 DEALER 只与一个对端通信,你也可以用 DEALER 替换 REP。
当你用 DEALER 替换 REP 时,你的工作者可以突然完全异步,发送任意数量的应答。代价是你必须自己管理应答信封,并且要确保正确无误,否则一切都不会工作。我们稍后会看到一个实例。现在姑且说,DEALER 与 DEALER 组合是比较难以正确实现的模式之一,幸运的是我们很少需要它。
ROUTER 与 ROUTER 组合 #
这听起来很适合 N 对 N 连接,但它是最难使用的组合。在深入学习 ZeroMQ 之前,你应该避免使用它。我们将在第四章 - 可靠请求-应答模式的 Freelance 模式中看到一个例子,并在第八章 - 分布式计算框架中看到一种用于点对点工作的 DEALER 与 ROUTER 替代设计。
无效组合 #
通常来说,试图将客户端连接到客户端,或将服务器连接到服务器是一个糟糕的主意,并且不会奏效。然而,与其给出笼统含糊的警告,我将详细解释原因:
-
REQ 到 REQ:双方都想通过向对方发送消息来开始通信,这只有在你精确地安排时序,使得双方同时交换消息时才可能奏效。光是想想就让人头疼。
-
REQ 到 DEALER:理论上你可以这样做,但如果你添加第二个 REQ,它就会崩溃,因为 DEALER 没有办法将应答发送回原始对端。因此,REQ 套接字会混乱,并且/或者返回原本应发送给其他客户端的消息。
-
REP 到 REP:双方都会等待对方发送第一条消息。
-
REP 到 ROUTER:理论上,ROUTER 套接字可以在知道 REP 套接字已经连接并且知道该连接的身份的情况下发起对话并发送格式正确的请求。但这很混乱,并且相比 DEALER 到 ROUTER 没有任何额外的好处。
这些有效和无效组合分类的共同点是,ZeroMQ 套接字连接总是偏向于一个绑定到端点的对端,以及另一个连接到该端点的对端。此外,哪一方绑定,哪一方连接并非任意的,而是遵循自然模式。我们期望“始终存在”的一方进行绑定:它将是服务器、代理、发布者、收集者。“来来往往”的一方进行连接:它将是客户端和工作者。记住这一点将有助于你设计更好的 ZeroMQ 架构。
探索 ROUTER 套接字 #
让我们更仔细地看看 ROUTER 套接字。我们已经了解了它们通过将单独的消息路由到特定连接来工作的方式。我将更详细地解释我们如何识别这些连接,以及当 ROUTER 套接字无法发送消息时会发生什么。
身份和地址 #
ZeroMQ 中的身份概念特指 ROUTER 套接字及其如何识别与其他套接字的连接。更广泛地说,身份在应答信封中用作地址。在大多数情况下,身份是任意的,并且是 ROUTER 套接字的本地概念:它是哈希表中的查找键。独立于身份,对端可以拥有一个物理地址(如网络端点“tcp://192.168.55.117:5670”)或逻辑地址(如 UUID、电子邮件地址或其他唯一键)。
使用 ROUTER 套接字与特定对端通信的应用程序,如果构建了必要的哈希表,可以将逻辑地址转换为身份。因为 ROUTER 套接字只有在对端发送消息时才会公布该连接(到特定对端)的身份,所以你实际上只能回复消息,而不能自发地与对端通信。
即使你颠倒规则,让 ROUTER 连接对端而不是等待对端连接 ROUTER,这也是成立的。然而,你可以强制 ROUTER 套接字使用逻辑地址作为其身份。的zmq_setsockopt参考页将此称为设置套接字身份。其工作方式如下:
- 对端应用程序在绑定或连接之前,设置其对端套接字(DEALER 或 REQ)的ZMQ_IDENTITY选项。
- 通常情况下,对端会连接到已绑定的 ROUTER 套接字。但 ROUTER 也可以连接到对端。
- 在连接时,对端套接字会告诉路由器套接字:“请对该连接使用此身份”。
- 如果对端套接字没有指定,路由器会为其连接生成通常的任意随机身份。
- ROUTER 套接字现在将此逻辑地址作为前缀身份帧提供给应用程序,用于来自该对端的任何消息。
- ROUTER 也期望逻辑地址作为任何传出消息的前缀身份帧。
这是一个简单的例子,说明两个对端连接到 ROUTER 套接字,其中一个强加了一个逻辑地址“PEER2”:
identity: Ada 中的身份检查
identity: Basic 中的身份检查
identity: C 中的身份检查
// Demonstrate request-reply identities
#include "zhelpers.h"
int main (void)
{
void *context = zmq_ctx_new ();
void *sink = zmq_socket (context, ZMQ_ROUTER);
zmq_bind (sink, "inproc://example");
// First allow 0MQ to set the identity
void *anonymous = zmq_socket (context, ZMQ_REQ);
zmq_connect (anonymous, "inproc://example");
s_send (anonymous, "ROUTER uses a generated 5 byte identity");
s_dump (sink);
// Then set the identity ourselves
void *identified = zmq_socket (context, ZMQ_REQ);
zmq_setsockopt (identified, ZMQ_IDENTITY, "PEER2", 5);
zmq_connect (identified, "inproc://example");
s_send (identified, "ROUTER socket uses REQ's socket identity");
s_dump (sink);
zmq_close (sink);
zmq_close (anonymous);
zmq_close (identified);
zmq_ctx_destroy (context);
return 0;
}

identity: C++ 中的身份检查
//
// Demonstrate identities as used by the request-reply pattern. Run this
// program by itself.
//
#include <zmq.hpp>
#include "zhelpers.hpp"
int main () {
zmq::context_t context(1);
zmq::socket_t sink(context, ZMQ_ROUTER);
sink.bind( "inproc://example");
// First allow 0MQ to set the identity
zmq::socket_t anonymous(context, ZMQ_REQ);
anonymous.connect( "inproc://example");
s_send (anonymous, std::string("ROUTER uses a generated 5 byte identity"));
s_dump (sink);
// Then set the identity ourselves
zmq::socket_t identified (context, ZMQ_REQ);
identified.set( zmq::sockopt::routing_id, "PEER2");
identified.connect( "inproc://example");
s_send (identified, std::string("ROUTER socket uses REQ's socket identity"));
s_dump (sink);
return 0;
}
identity: C# 中的身份检查
identity: CL 中的身份检查
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-
;;;
;;; Demonstrate identities as used by the request-reply pattern in Common Lisp.
;;; Run this program by itself. Note that the utility functions are
;;; provided by zhelpers.lisp. It gets boring for everyone to keep repeating
;;; this code.
;;;
;;; Kamil Shakirov <kamils80@gmail.com>
;;;
(defpackage #:zguide.identity
(:nicknames #:identity)
(:use #:cl #:zhelpers)
(:export #:main))
(in-package :zguide.identity)
(defun main ()
(zmq:with-context (context 1)
(zmq:with-socket (sink context zmq:router)
(zmq:bind sink "inproc://example")
;; First allow 0MQ to set the identity
(zmq:with-socket (anonymous context zmq:req)
(zmq:connect anonymous "inproc://example")
(send-text anonymous "ROUTER uses a generated 5 byte identity")
(dump-socket sink)
;; Then set the identity ourselves
(zmq:with-socket (identified context zmq:req)
(zmq:setsockopt identified zmq:identity "PEER2")
(zmq:connect identified "inproc://example")
(send-text identified "ROUTER socket uses REQ's socket identity")
(dump-socket sink)))))
(cleanup))
identity: Delphi 中的身份检查
program identity;
//
// Demonstrate identities as used by the request-reply pattern. Run this
// program by itself.
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
, zhelpers
;
var
context: TZMQContext;
sink,
anonymous,
identified: TZMQSocket;
begin
context := TZMQContext.create;
sink := context.Socket( stRouter );
sink.bind( 'inproc://example' );
// First allow 0MQ to set the identity
anonymous := context.Socket( stReq );
anonymous.connect( 'inproc://example' );
anonymous.send( 'ROUTER uses a generated 5 byte identity' );
s_dump( sink );
// Then set the identity ourself
identified := context.Socket( stReq );
identified.Identity := 'PEER2';
identified.connect( 'inproc://example' );
identified.send( 'ROUTER socket uses REQ''s socket identity' );
s_dump( sink );
sink.Free;
anonymous.Free;
identified.Free;
context.Free;
end.
identity: Erlang 中的身份检查
#! /usr/bin/env escript
%%
%% Demonstrate identities as used by the request-reply pattern.
%%
main(_) ->
{ok, Context} = erlzmq:context(),
{ok, Sink} = erlzmq:socket(Context, router),
ok = erlzmq:bind(Sink, "inproc://example"),
%% First allow 0MQ to set the identity
{ok, Anonymous} = erlzmq:socket(Context, req),
ok = erlzmq:connect(Anonymous, "inproc://example"),
ok = erlzmq:send(Anonymous, <<"ROUTER uses a generated 5 byte identity">>),
erlzmq_util:dump(Sink),
%% Then set the identity ourselves
{ok, Identified} = erlzmq:socket(Context, req),
ok = erlzmq:setsockopt(Identified, identity, <<"PEER2">>),
ok = erlzmq:connect(Identified, "inproc://example"),
ok = erlzmq:send(Identified,
<<"ROUTER socket uses REQ's socket identity">>),
erlzmq_util:dump(Sink),
erlzmq:close(Sink),
erlzmq:close(Anonymous),
erlzmq:close(Identified),
erlzmq:term(Context).
identity: Elixir 中的身份检查
defmodule Identity do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:24
"""
def main() do
{:ok, context} = :erlzmq.context()
{:ok, sink} = :erlzmq.socket(context, :router)
:ok = :erlzmq.bind(sink, 'inproc://example')
{:ok, anonymous} = :erlzmq.socket(context, :req)
:ok = :erlzmq.connect(anonymous, 'inproc://example')
:ok = :erlzmq.send(anonymous, "ROUTER uses a generated 5 byte identity")
#:erlzmq_util.dump(sink)
IO.inspect(sink, label: "1. sink")
{:ok, identified} = :erlzmq.socket(context, :req)
:ok = :erlzmq.setsockopt(identified, :identity, "PEER2")
:ok = :erlzmq.connect(identified, 'inproc://example')
:ok = :erlzmq.send(identified, "ROUTER socket uses REQ's socket identity")
#:erlzmq_util.dump(sink)
IO.inspect(sink, label: "2. sink")
:erlzmq.close(sink)
:erlzmq.close(anonymous)
:erlzmq.close(identified)
:erlzmq.term(context)
end
end
Identity.main
identity: F# 中的身份检查
identity: Felix 中的身份检查
identity: Go 中的身份检查
//
// Demonstrate identities as used by the request-reply pattern. Run this
// program by itself.
//
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
)
func dump(sink *zmq.Socket) {
parts, err := sink.RecvMultipart(0)
if err != nil {
fmt.Println(err)
}
for _, msgdata := range parts {
is_text := true
fmt.Printf("[%03d] ", len(msgdata))
for _, char := range msgdata {
if char < 32 || char > 127 {
is_text = false
}
}
if is_text {
fmt.Printf("%s\n", msgdata)
} else {
fmt.Printf("%X\n", msgdata)
}
}
}
func main() {
context, _ := zmq.NewContext()
defer context.Close()
sink, err := context.NewSocket(zmq.ROUTER)
if err != nil {
print(err)
}
defer sink.Close()
sink.Bind("inproc://example")
// First allow 0MQ to set the identity
anonymous, err := context.NewSocket(zmq.REQ)
defer anonymous.Close()
if err != nil {
fmt.Println(err)
}
anonymous.Connect("inproc://example")
err = anonymous.Send([]byte("ROUTER uses a generated 5 byte identity"), 0)
if err != nil {
fmt.Println(err)
}
dump(sink)
// Then set the identity ourselves
identified, err := context.NewSocket(zmq.REQ)
if err != nil {
print(err)
}
defer identified.Close()
identified.SetIdentity("PEER2")
identified.Connect("inproc://example")
identified.Send([]byte("ROUTER socket uses REQ's socket identity"), zmq.NOBLOCK)
dump(sink)
}
identity: Haskell 中的身份检查
{-# LANGUAGE OverloadedStrings #-}
module Main where
import System.ZMQ4.Monadic
import ZHelpers (dumpSock)
main :: IO ()
main =
runZMQ $ do
sink <- socket Router
bind sink "inproc://example"
anonymous <- socket Req
connect anonymous "inproc://example"
send anonymous [] "ROUTER uses a generated 5 byte identity"
dumpSock sink
identified <- socket Req
setIdentity (restrict "PEER2") identified
connect identified "inproc://example"
send identified [] "ROUTER socket uses REQ's socket identity"
dumpSock sink
identity: Haxe 中的身份检查
package ;
import ZHelpers;
import neko.Lib;
import neko.Sys;
import haxe.io.Bytes;
import org.zeromq.ZMQ;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQSocket;
/**
* Demonstrate identities as used by the request-reply pattern. Run this
* program by itself.
*/
class Identity
{
public static function main() {
var context:ZContext = new ZContext();
Lib.println("** Identity (see: https://zguide.zeromq.cn/page:all#Request-Reply-Envelopes)");
// Socket facing clients
var sink:ZMQSocket = context.createSocket(ZMQ_ROUTER);
sink.bind("inproc://example");
// First allow 0MQ to set the identity
var anonymous:ZMQSocket = context.createSocket(ZMQ_REQ);
anonymous.connect("inproc://example");
anonymous.sendMsg(Bytes.ofString("ROUTER uses a generated 5 byte identity"));
ZHelpers.dump(sink);
// Then set the identity ourselves
var identified:ZMQSocket = context.createSocket(ZMQ_REQ);
identified.setsockopt(ZMQ_IDENTITY, Bytes.ofString("PEER2"));
identified.connect("inproc://example");
identified.sendMsg(Bytes.ofString("ROUTER socket uses REQ's socket identity"));
ZHelpers.dump(sink);
context.destroy();
}
}
identity: Java 中的身份检查
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZContext;
/**
* Demonstrate identities as used by the request-reply pattern.
*/
public class identity
{
public static void main(String[] args) throws InterruptedException
{
try (ZContext context = new ZContext()) {
Socket sink = context.createSocket(SocketType.ROUTER);
sink.bind("inproc://example");
// First allow 0MQ to set the identity, [00] + random 4byte
Socket anonymous = context.createSocket(SocketType.REQ);
anonymous.connect("inproc://example");
anonymous.send("ROUTER uses a generated UUID", 0);
ZHelper.dump(sink);
// Then set the identity ourself
Socket identified = context.createSocket(SocketType.REQ);
identified.setIdentity("PEER2".getBytes(ZMQ.CHARSET));
identified.connect("inproc://example");
identified.send("ROUTER socket uses REQ's socket identity", 0);
ZHelper.dump(sink);
}
}
}
identity: Julia 中的身份检查
identity: Lua 中的身份检查
--
-- Demonstrate identities as used by the request-reply pattern. Run this
-- program by itself. Note that the utility functions s_ are provided by
-- zhelpers.h. It gets boring for everyone to keep repeating this code.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zhelpers"
local context = zmq.init(1)
local sink = context:socket(zmq.ROUTER)
sink:bind("inproc://example")
-- First allow 0MQ to set the identity
local anonymous = context:socket(zmq.REQ)
anonymous:connect("inproc://example")
anonymous:send("ROUTER uses a generated 5 byte identity")
s_dump(sink)
-- Then set the identity ourselves
local identified = context:socket(zmq.REQ)
identified:setopt(zmq.IDENTITY, "PEER2")
identified:connect("inproc://example")
identified:send("ROUTER socket uses REQ's socket identity")
s_dump(sink)
sink:close()
anonymous:close()
identified:close()
context:term()
identity: Node.js 中的身份检查
// Demonstrate request-reply identities
var zmq = require('zeromq'),
zhelpers = require('./zhelpers');
var sink = zmq.socket("router");
sink.bind("inproc://example");
sink.on("message", zhelpers.dumpFrames);
// First allow 0MQ to set the identity
var anonymous = zmq.socket("req");
anonymous.connect("inproc://example");
anonymous.send("ROUTER uses generated 5 byte identity");
// Then set the identity ourselves
var identified = zmq.socket("req");
identified.identity = "PEER2";
identified.connect("inproc://example");
identified.send("ROUTER uses REQ's socket identity");
setTimeout(function() {
anonymous.close();
identified.close();
sink.close();
}, 250);
identity: Objective-C 中的身份检查
identity: ooc 中的身份检查
identity: Perl 中的身份检查
# Demonstrate request-reply identities in Perl
use strict;
use warnings;
use v5.10;
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_ROUTER ZMQ_REQ ZMQ_IDENTITY);
use zhelpers;
my $context = ZMQ::FFI->new();
my $sink = $context->socket(ZMQ_ROUTER);
$sink->bind('inproc://example');
# First allow 0MQ to set the identity
my $anonymous = $context->socket(ZMQ_REQ);
$anonymous->connect('inproc://example');
$anonymous->send('ROUTER uses a generated 5 byte identity');
zhelpers::dump($sink);
# Then set the identity ourselves
my $identified = $context->socket(ZMQ_REQ);
$identified->set_identity('PEER2');
$identified->connect('inproc://example');
$identified->send("ROUTER socket uses REQ's socket identity");
zhelpers::dump($sink);
identity: PHP 中的身份检查
<?php
/*
* Demonstrate identities as used by the request-reply pattern. Run this
* program by itself. Note that the utility functions s_ are provided by
* zhelpers.h. It gets boring for everyone to keep repeating this code.
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zhelpers.php';
$context = new ZMQContext();
$sink = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$sink->bind("inproc://example");
// First allow 0MQ to set the identity
$anonymous = new ZMQSocket($context, ZMQ::SOCKET_REQ);
$anonymous->connect("inproc://example");
$anonymous->send("ROUTER uses a generated 5 byte identity");
s_dump ($sink);
// Then set the identity ourselves
$identified = new ZMQSocket($context, ZMQ::SOCKET_REQ);
$identified->setSockOpt(ZMQ::SOCKOPT_IDENTITY, "PEER2");
$identified->connect("inproc://example");
$identified->send("ROUTER socket uses REQ's socket identity");
s_dump ($sink);
identity: Python 中的身份检查
# encoding: utf-8
#
# Demonstrate identities as used by the request-reply pattern. Run this
# program by itself.
#
# Author: Jeremy Avnet (brainsik) <spork(dash)zmq(at)theory(dot)org>
#
import zmq
import zhelpers
context = zmq.Context()
sink = context.socket(zmq.ROUTER)
sink.bind("inproc://example")
# First allow 0MQ to set the identity
anonymous = context.socket(zmq.REQ)
anonymous.connect("inproc://example")
anonymous.send(b"ROUTER uses a generated 5 byte identity")
zhelpers.dump(sink)
# Then set the identity ourselves
identified = context.socket(zmq.REQ)
identified.setsockopt(zmq.IDENTITY, b"PEER2")
identified.connect("inproc://example")
identified.send(b"ROUTER socket uses REQ's socket identity")
zhelpers.dump(sink)
identity: Q 中的身份检查
// Demonstrate identities as used by the request-reply pattern.
\l qzmq.q
ctx:zctx.new[]
sink:zsocket.new[ctx; zmq`ROUTER]
port:zsocket.bind[sink; `inproc://example]
// First allow 0MQ to set the identity
anonymous:zsocket.new[ctx; zmq`REQ]
zsocket.connect[anonymous; `inproc://example]
m0:zmsg.new[]
zmsg.push[m0; zframe.new["ROUTER uses a generated 5 byte identity"]]
zmsg.send[m0; anonymous]
zmsg.dump[zmsg.recv[sink]]
// Then set the identity ourselves
identified:zsocket.new[ctx; zmq`REQ]
zsockopt.set_identity[identified; "PEER2"]
zsocket.connect[identified; `inproc://example]
m1:zmsg.new[]
zmsg.push[m1; zframe.new["ROUTER socket users REQ's socket identity"]]
zmsg.send[m1; identified]
zmsg.dump[zmsg.recv[sink]]
zsocket.destroy[ctx; sink]
zsocket.destroy[ctx; anonymous]
zsocket.destroy[ctx; identified]
zctx.destroy[ctx]
\\
identity: Racket 中的身份检查
identity: Ruby 中的身份检查
#!/usr/bin/env ruby
#
#
# Identity check in Ruby
#
#
require 'ffi-rzmq'
require './zhelpers.rb'
context = ZMQ::Context.new
uri = "inproc://example"
sink = context.socket(ZMQ::ROUTER)
sink.bind(uri)
# 0MQ will set the identity here
anonymous = context.socket(ZMQ::DEALER)
anonymous.connect(uri)
anon_message = ZMQ::Message.new("ROUTER uses a generated 5 byte identity")
anonymous.sendmsg(anon_message)
s_dump(sink)
# Set the identity ourselves
identified = context.socket(ZMQ::DEALER)
identified.setsockopt(ZMQ::IDENTITY, "PEER2")
identified.connect(uri)
identified_message = ZMQ::Message.new("Router uses socket identity")
identified.sendmsg(identified_message)
s_dump(sink)
identity: Rust 中的身份检查
identity: Scala 中的身份检查
// Demonstrate identities as used by the request-reply pattern.
//
// @author Giovanni Ruggiero
// @email giovanni.ruggiero@gmail.com
import org.zeromq.ZMQ
import ZHelpers._
object identity {
def main(args : Array[String]) {
val context = ZMQ.context(1)
val sink = context.socket(ZMQ.DEALER)
sink.bind("inproc://example")
val anonymous = context.socket(ZMQ.REQ)
anonymous.connect("inproc://example")
anonymous.send("ROUTER uses a generated 5 byte identity".getBytes,0)
dump(sink)
val identified = context.socket(ZMQ.REQ)
identified.setIdentity("PEER2" getBytes)
identified.connect("inproc://example")
identified.send("ROUTER socket uses REQ's socket identity".getBytes,0)
dump(sink)
identified.close
}
}
identity: Tcl 中的身份检查
#
# Demonstrate identities as used by the request-reply pattern. Run this
# program by itself.
#
package require zmq
zmq context context
zmq socket sink context ROUTER
sink bind "inproc://example"
# First allow 0MQ to set the identity
zmq socket anonymous context REQ
anonymous connect "inproc://example"
anonymous send "ROUTER uses a generated 5 byte identity"
puts "--------------------------------------------------"
puts [join [sink dump] \n]
# Then set the identity ourselves
zmq socket identified context REQ
identified setsockopt IDENTITY "PEER2"
identified connect "inproc://example"
identified send "ROUTER socket uses REQ's socket identity"
puts "--------------------------------------------------"
puts [join [sink dump] \n]
sink close
anonymous close
identified close
context term
identity: OCaml 中的身份检查
以下是程序输出:
----------------------------------------
[005] 006B8B4567
[000]
[039] ROUTER uses a generated 5 byte identity
----------------------------------------
[005] PEER2
[000]
[038] ROUTER uses REQ's socket identity
ROUTER 错误处理 #
ROUTER 套接字处理无法发送的消息的方式有些简单粗暴:它们会静默丢弃这些消息。这种处理方式在正常工作的代码中是合理的,但会使调试变得困难。“将身份作为第一个帧发送”的方法本身就很微妙,我们在学习时经常会出错,而 ROUTER 在我们搞砸时的冰冷沉默并不具建设性。
自 ZeroMQ v3.2 起,你可以设置一个套接字选项来捕获此错误:ZMQ_ROUTER_MANDATORY。在 ROUTER 套接字上设置此选项后,当你发送消息时提供一个无法路由的身份,套接字将报告一个EHOSTUNREACH错误。
负载均衡模式 #
现在让我们看一些代码。我们将了解如何将 ROUTER 套接字连接到 REQ 套接字,然后再连接到 DEALER 套接字。这两个例子遵循相同的逻辑,即负载均衡模式。这种模式是我们第一次接触使用 ROUTER 套接字进行有意识的路由,而不仅仅是充当应答通道。
负载均衡模式非常常见,我们将在本书中多次看到它。它解决了简单的轮询路由(如 PUSH 和 DEALER 提供)的主要问题,即如果任务花费的时间差异很大,轮询就会变得效率低下。
这就像邮局的例子。如果你每个柜台都有一个队列,并且有些人购买邮票(一个快速、简单的交易),而有些人开设新账户(一个非常慢的交易),那么你会发现购买邮票的人会不公平地被困在队列中。就像在邮局一样,如果你的消息架构不公平,人们就会感到恼火。
邮局的解决方案是创建一个单一队列,这样即使一两个柜台被缓慢的工作卡住,其他柜台仍将继续以先到先得的方式为客户服务。
PUSH 和 DEALER 使用这种简单方法的其中一个原因是纯粹的性能。如果你抵达美国任何一个主要机场,你会看到排队等待过海关的长队。边境巡逻官员会提前将人们分配到每个柜台前排队,而不是使用单一队列。让人们提前走五十码可以为每位乘客节省一两分钟。而且由于每个护照检查所需的时间大致相同,所以或多或少是公平的。这就是 PUSH 和 DEALER 的策略:提前发送工作负载,以减少传输距离。
这是 ZeroMQ 反复出现的主题:世界上的问题是多样的,你可以通过以正确的方式解决不同的问题来受益。机场不是邮局,一刀切的方案对谁都不适用,真的。
让我们回到工作者(DEALER 或 REQ)连接到代理(ROUTER)的场景。代理必须知道工作者何时准备就绪,并维护一个工作者列表,以便每次都可以选择最近最少使用的工作者。
实际上,解决方案非常简单:工作者在启动时以及完成每个任务后发送一个“ready”消息。代理逐一读取这些消息。每次读取消息时,都是来自上一次使用的工作者。由于我们使用的是 ROUTER 套接字,我们得到了一个身份,然后可以使用这个身份将任务发送回工作者。
这可以看作是对请求-应答的一种变体,因为任务是随应答一起发送的,而任务的任何响应则作为一个新的请求发送。下面的代码示例应该会使其更清晰。
ROUTER 代理和 REQ 工作者 #
以下是一个使用 ROUTER 代理与一组 REQ 工作者通信的负载均衡模式示例:
rtreq: Ada 中的 ROUTER 到 REQ
rtreq: Basic 中的 ROUTER 到 REQ
rtreq: C 中的 ROUTER 到 REQ
// 2015-01-16T09:56+08:00
// ROUTER-to-REQ example
#include "zhelpers.h"
#include <pthread.h>
#define NBR_WORKERS 10
static void *
worker_task(void *args)
{
void *context = zmq_ctx_new();
void *worker = zmq_socket(context, ZMQ_REQ);
#if (defined (WIN32))
s_set_id(worker, (intptr_t)args);
#else
s_set_id(worker); // Set a printable identity.
#endif
zmq_connect(worker, "tcp://:5671");
int total = 0;
while (1) {
// Tell the broker we're ready for work
s_send(worker, "Hi Boss");
// Get workload from broker, until finished
char *workload = s_recv(worker);
int finished = (strcmp(workload, "Fired!") == 0);
free(workload);
if (finished) {
printf("Completed: %d tasks\n", total);
break;
}
total++;
// Do some random work
s_sleep(randof(500) + 1);
}
zmq_close(worker);
zmq_ctx_destroy(context);
return NULL;
}
// .split main task
// While this example runs in a single process, that is only to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
int main(void)
{
void *context = zmq_ctx_new();
void *broker = zmq_socket(context, ZMQ_ROUTER);
zmq_bind(broker, "tcp://*:5671");
srandom((unsigned)time(NULL));
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++) {
pthread_t worker;
pthread_create(&worker, NULL, worker_task, (void *)(intptr_t)worker_nbr);
}
// Run for five seconds and then tell workers to end
int64_t end_time = s_clock() + 5000;
int workers_fired = 0;
while (1) {
// Next message gives us least recently used worker
char *identity = s_recv(broker);
s_sendmore(broker, identity);
free(identity);
free(s_recv(broker)); // Envelope delimiter
free(s_recv(broker)); // Response from worker
s_sendmore(broker, "");
// Encourage workers until it's time to fire them
if (s_clock() < end_time)
s_send(broker, "Work harder");
else {
s_send(broker, "Fired!");
if (++workers_fired == NBR_WORKERS)
break;
}
}
zmq_close(broker);
zmq_ctx_destroy(context);
return 0;
}rtreq: C++ 中的 ROUTER 到 REQ
//
// Custom routing Router to Mama (ROUTER to REQ)
//
#include "zhelpers.hpp"
#include <thread>
#include <vector>
static void *
worker_thread(void *arg) {
zmq::context_t context(1);
zmq::socket_t worker(context, ZMQ_REQ);
// We use a string identity for ease here
#if (defined (WIN32))
s_set_id(worker, (intptr_t)arg);
worker.connect("tcp://:5671"); // "ipc" doesn't yet work on windows.
#else
s_set_id(worker);
worker.connect("ipc://routing.ipc");
#endif
int total = 0;
while (1) {
// Tell the broker we're ready for work
s_send(worker, std::string("Hi Boss"));
// Get workload from broker, until finished
std::string workload = s_recv(worker);
if ("Fired!" == workload) {
std::cout << "Processed: " << total << " tasks" << std::endl;
break;
}
total++;
// Do some random work
s_sleep(within(500) + 1);
}
return NULL;
}
int main() {
zmq::context_t context(1);
zmq::socket_t broker(context, ZMQ_ROUTER);
#if (defined(WIN32))
broker.bind("tcp://*:5671"); // "ipc" doesn't yet work on windows.
#else
broker.bind("ipc://routing.ipc");
#endif
const int NBR_WORKERS = 10;
std::vector<std::thread> workers;
for (int worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++) {
workers.push_back(std::move(std::thread(worker_thread, (void *)(intptr_t)worker_nbr)));
}
// Run for five seconds and then tell workers to end
int64_t end_time = s_clock() + 5000;
int workers_fired = 0;
while (1) {
// Next message gives us least recently used worker
std::string identity = s_recv(broker);
s_recv(broker); // Envelope delimiter
s_recv(broker); // Response from worker
s_sendmore(broker, identity);
s_sendmore(broker, std::string(""));
// Encourage workers until it's time to fire them
if (s_clock() < end_time)
s_send(broker, std::string("Work harder"));
else {
s_send(broker, std::string("Fired!"));
if (++workers_fired == NBR_WORKERS)
break;
}
}
for (int worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++) {
workers[worker_nbr].join();
}
return 0;
}
rtreq: C# 中的 ROUTER 到 REQ
rtreq: CL 中的 ROUTER 到 REQ
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-
;;;
;;; Custom routing Router to Mama (ROUTER to REQ) in Common Lisp
;;;
;;; Kamil Shakirov <kamils80@gmail.com>
;;;
(defpackage #:zguide.rtmama
(:nicknames #:rtmama)
(:use #:cl #:zhelpers)
(:export #:main))
(in-package :zguide.rtmama)
(defparameter *number-workers* 10)
(defun worker-thread (context)
(zmq:with-socket (worker context zmq:req)
;; We use a string identity for ease here
(set-socket-id worker)
(zmq:connect worker "ipc://routing.ipc")
(let ((total 0))
(loop
;; Tell the router we're ready for work
(send-text worker "ready")
;; Get workload from router, until finished
(let ((workload (recv-text worker)))
(when (string= workload "END")
(message "Processed: ~D tasks~%" total)
(return))
(incf total))
;; Do some random work
(isys:usleep (within 100000))))))
(defun main ()
(zmq:with-context (context 1)
(zmq:with-socket (client context zmq:router)
(zmq:bind client "ipc://routing.ipc")
(dotimes (i *number-workers*)
(bt:make-thread (lambda () (worker-thread context))
:name (format nil "worker-thread-~D" i)))
(loop :repeat (* 10 *number-workers*) :do
;; LRU worker is next waiting in queue
(let ((address (recv-text client)))
(recv-text client) ; empty
(recv-text client) ; ready
(send-more-text client address)
(send-more-text client "")
(send-text client "This is the workload")))
;; Now ask mamas to shut down and report their results
(loop :repeat *number-workers* :do
;; LRU worker is next waiting in queue
(let ((address (recv-text client)))
(recv-text client) ; empty
(recv-text client) ; ready
(send-more-text client address)
(send-more-text client "")
(send-text client "END")))
;; Give 0MQ/2.0.x time to flush output
(sleep 1)))
(cleanup))
rtreq: Delphi 中的 ROUTER 到 REQ
program rtreq;
//
// ROUTER-to-REQ example
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, Windows
, zmqapi
, zhelpers
;
const
NBR_WORKERS = 10;
procedure worker_task( args: Pointer );
var
context: TZMQContext;
worker: TZMQSocket;
total: Integer;
workload: Utf8String;
begin
context := TZMQContext.create;
worker := context.Socket( stReq );
s_set_id( worker ); // Set a printable identity
worker.connect( 'tcp://:5671' );
total := 0;
while true do
begin
// Tell the broker we're ready for work
worker.send( 'Hi Boss' );
// Get workload from broker, until finished
worker.recv( workload );
if workload = 'Fired!' then
begin
zNote( Format( 'Completed: %d tasks', [total] ) );
break;
end;
Inc( total );
// Do some random work
sleep( random( 500 ) + 1 );
end;
worker.Free;
context.Free;
end;
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
var
context: TZMQContext;
broker: TZMQSocket;
i,
workers_fired: Integer;
tid: Cardinal;
identity,
s: Utf8String;
fFrequency,
fstart,
fStop,
dt: Int64;
begin
context := TZMQContext.create;
broker := context.Socket( stRouter );
broker.bind( 'tcp://*:5671' );
Randomize;
for i := 0 to NBR_WORKERS - 1 do
BeginThread( nil, 0, @worker_task, nil, 0, tid );
// Start our clock now
QueryPerformanceFrequency( fFrequency );
QueryPerformanceCounter( fStart );
// Run for five seconds and then tell workers to end
workers_fired := 0;
while true do
begin
// Next message gives us least recently used worker
broker.recv( identity );
broker.send( identity, [sfSndMore] );
broker.recv( s ); // Envelope delimiter
broker.recv( s ); // Response from worker
broker.send( '', [sfSndMore] );
QueryPerformanceCounter( fStop );
dt := ( MSecsPerSec * ( fStop - fStart ) ) div fFrequency;
if dt < 5000 then
broker.send( 'Work harder' )
else begin
broker.send( 'Fired!' );
Inc( workers_fired );
if workers_fired = NBR_WORKERS then
break;
end;
end;
broker.Free;
context.Free;
end.
rtreq: Erlang 中的 ROUTER 到 REQ
#! /usr/bin/env escript
%%
%% Custom routing Router to Mama (ROUTER to REQ)
%%
%% While this example runs in a single process, that is just to make
%% it easier to start and stop the example. Each thread has its own
%% context and conceptually acts as a separate process.
%%
-define(NBR_WORKERS, 10).
worker_task() ->
random:seed(now()),
{ok, Context} = erlzmq:context(),
{ok, Worker} = erlzmq:socket(Context, req),
%% We use a string identity for ease here
ok = erlzmq:setsockopt(Worker, identity, pid_to_list(self())),
ok = erlzmq:connect(Worker, "ipc://routing.ipc"),
Total = handle_tasks(Worker, 0),
io:format("Processed ~b tasks~n", [Total]),
erlzmq:close(Worker),
erlzmq:term(Context).
handle_tasks(Worker, TaskCount) ->
%% Tell the router we're ready for work
ok = erlzmq:send(Worker, <<"ready">>),
%% Get workload from router, until finished
case erlzmq:recv(Worker) of
{ok, <<"END">>} -> TaskCount;
{ok, _} ->
%% Do some random work
timer:sleep(random:uniform(1000) + 1),
handle_tasks(Worker, TaskCount + 1)
end.
main(_) ->
{ok, Context} = erlzmq:context(),
{ok, Client} = erlzmq:socket(Context, router),
ok = erlzmq:bind(Client, "ipc://routing.ipc"),
start_workers(?NBR_WORKERS),
route_work(Client, ?NBR_WORKERS * 10),
stop_workers(Client, ?NBR_WORKERS),
ok = erlzmq:close(Client),
ok = erlzmq:term(Context).
start_workers(0) -> ok;
start_workers(N) when N > 0 ->
spawn(fun() -> worker_task() end),
start_workers(N - 1).
route_work(_Client, 0) -> ok;
route_work(Client, N) when N > 0 ->
%% LRU worker is next waiting in queue
{ok, Address} = erlzmq:recv(Client),
{ok, <<>>} = erlzmq:recv(Client),
{ok, <<"ready">>} = erlzmq:recv(Client),
ok = erlzmq:send(Client, Address, [sndmore]),
ok = erlzmq:send(Client, <<>>, [sndmore]),
ok = erlzmq:send(Client, <<"This is the workload">>),
route_work(Client, N - 1).
stop_workers(_Client, 0) -> ok;
stop_workers(Client, N) ->
%% Ask mama to shut down and report their results
{ok, Address} = erlzmq:recv(Client),
{ok, <<>>} = erlzmq:recv(Client),
{ok, _Ready} = erlzmq:recv(Client),
ok = erlzmq:send(Client, Address, [sndmore]),
ok = erlzmq:send(Client, <<>>, [sndmore]),
ok = erlzmq:send(Client, <<"END">>),
stop_workers(Client, N - 1).
rtreq: Elixir 中的 ROUTER 到 REQ
defmodule Rtreq do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:33
"""
defmacrop erlconst_NBR_WORKERS() do
quote do
10
end
end
def worker_task() do
:random.seed(:erlang.now())
{:ok, context} = :erlzmq.context()
{:ok, worker} = :erlzmq.socket(context, :req)
:ok = :erlzmq.setsockopt(worker, :identity, :erlang.pid_to_list(self()))
:ok = :erlzmq.connect(worker, 'ipc://routing.ipc')
total = handle_tasks(worker, 0)
:io.format('Processed ~b tasks~n', [total])
:erlzmq.close(worker)
:erlzmq.term(context)
end
def handle_tasks(worker, taskCount) do
:ok = :erlzmq.send(worker, "ready")
case(:erlzmq.recv(worker)) do
{:ok, "END"} ->
taskCount
{:ok, _} ->
:timer.sleep(:random.uniform(1000) + 1)
handle_tasks(worker, taskCount + 1)
end
end
def main() do
{:ok, context} = :erlzmq.context()
{:ok, client} = :erlzmq.socket(context, :router)
:ok = :erlzmq.bind(client, 'ipc://routing.ipc')
start_workers(erlconst_NBR_WORKERS())
route_work(client, erlconst_NBR_WORKERS() * 10)
stop_workers(client, erlconst_NBR_WORKERS())
:ok = :erlzmq.close(client)
:ok = :erlzmq.term(context)
end
def start_workers(0) do
:ok
end
def start_workers(n) when n > 0 do
:erlang.spawn(fn -> worker_task() end)
start_workers(n - 1)
end
def route_work(_client, 0) do
:ok
end
def route_work(client, n) when n > 0 do
{:ok, address} = :erlzmq.recv(client)
{:ok, <<>>} = :erlzmq.recv(client)
{:ok, "ready"} = :erlzmq.recv(client)
:ok = :erlzmq.send(client, address, [:sndmore])
:ok = :erlzmq.send(client, <<>>, [:sndmore])
:ok = :erlzmq.send(client, "This is the workload")
route_work(client, n - 1)
end
def stop_workers(_client, 0) do
:ok
end
def stop_workers(client, n) do
{:ok, address} = :erlzmq.recv(client)
{:ok, <<>>} = :erlzmq.recv(client)
{:ok, _ready} = :erlzmq.recv(client)
:ok = :erlzmq.send(client, address, [:sndmore])
:ok = :erlzmq.send(client, <<>>, [:sndmore])
:ok = :erlzmq.send(client, "END")
stop_workers(client, n - 1)
end
end
Rtreq.main
rtreq: F# 中的 ROUTER 到 REQ
rtreq: Felix 中的 ROUTER 到 REQ
rtreq: Go 中的 ROUTER 到 REQ
//
// ROUTER-to-REQ example
//
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"strings"
"time"
)
const NBR_WORKERS = 10
func randomString() string {
source := "abcdefghijklmnopqrstuvwxyz"
target := make([]string, 20)
for i := 0; i < 20; i++ {
target[i] = string(source[rand.Intn(len(source))])
}
return strings.Join(target, "")
}
func workerTask() {
context, _ := zmq.NewContext()
defer context.Close()
worker, _ := context.NewSocket(zmq.REQ)
worker.SetIdentity(randomString())
worker.Connect("tcp://:5671")
defer worker.Close()
total := 0
for {
err := worker.Send([]byte("Hi Boss"), 0)
if err != nil {
print(err)
}
workload, _ := worker.Recv(0)
if string(workload) == "Fired!" {
id, _ := worker.Identity()
fmt.Printf("Completed: %d tasks (%s)\n", total, id)
break
}
total += 1
msec := rand.Intn(1000)
time.Sleep(time.Duration(msec) * time.Millisecond)
}
}
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each goroutine has its own
// context and conceptually acts as a separate process.
func main() {
context, _ := zmq.NewContext()
defer context.Close()
broker, _ := context.NewSocket(zmq.ROUTER)
defer broker.Close()
broker.Bind("tcp://*:5671")
rand.Seed(time.Now().Unix())
for i := 0; i < NBR_WORKERS; i++ {
go workerTask()
}
end_time := time.Now().Unix() + 5
workers_fired := 0
for {
// Next message gives us least recently used worker
parts, err := broker.RecvMultipart(0)
if err != nil {
print(err)
}
identity := parts[0]
now := time.Now().Unix()
if now < end_time {
broker.SendMultipart([][]byte{identity, []byte(""), []byte("Work harder")}, 0)
} else {
broker.SendMultipart([][]byte{identity, []byte(""), []byte("Fired!")}, 0)
workers_fired++
if workers_fired == NBR_WORKERS {
break
}
}
}
}
rtreq: Haskell 中的 ROUTER 到 REQ
{-# LANGUAGE OverloadedStrings #-}
-- |
-- Router broker and REQ workers (p.92)
module Main where
import System.ZMQ4.Monadic
import Control.Concurrent (threadDelay, forkIO)
import Control.Concurrent.MVar (withMVar, newMVar, MVar)
import Data.ByteString.Char8 (unpack)
import Control.Monad (replicateM_, unless)
import ZHelpers (setRandomIdentity)
import Text.Printf
import Data.Time.Clock (diffUTCTime, getCurrentTime, UTCTime)
import System.Random
nbrWorkers :: Int
nbrWorkers = 10
-- In general, although locks are an antipattern in ZeroMQ, we need a lock
-- for the stdout handle, otherwise we will get jumbled text. We don't
-- use the lock for anything zeroMQ related, just output to screen.
workerThread :: MVar () -> IO ()
workerThread lock =
runZMQ $ do
worker <- socket Req
setRandomIdentity worker
connect worker "ipc://routing.ipc"
work worker
where
work = loop 0 where
loop val sock = do
send sock [] "ready"
workload <- receive sock
if unpack workload == "Fired!"
then liftIO $ withMVar lock $ \_ -> printf "Completed: %d tasks\n" (val::Int)
else do
rand <- liftIO $ getStdRandom (randomR (500::Int, 5000))
liftIO $ threadDelay rand
loop (val+1) sock
main :: IO ()
main =
runZMQ $ do
client <- socket Router
bind client "ipc://routing.ipc"
-- We only need MVar for printing the output (so output doesn't become interleaved)
-- The alternative is to Make an ipc channel, but that distracts from the example
-- or to 'NoBuffering' 'stdin'
lock <- liftIO $ newMVar ()
liftIO $ replicateM_ nbrWorkers (forkIO $ workerThread lock)
start <- liftIO getCurrentTime
clientTask client start
-- You need to give some time to the workers so they can exit properly
liftIO $ threadDelay $ 1 * 1000 * 1000
where
clientTask :: Socket z Router -> UTCTime -> ZMQ z ()
clientTask = loop nbrWorkers where
loop c sock start = unless (c <= 0) $ do
-- Next message is the leaset recently used worker
ident <- receive sock
send sock [SendMore] ident
-- Envelope delimiter
receive sock
-- Ready signal from worker
receive sock
-- Send delimiter
send sock [SendMore] ""
-- Send Work unless time is up
now <- liftIO getCurrentTime
if c /= nbrWorkers || diffUTCTime now start > 5
then do
send sock [] "Fired!"
loop (c-1) sock start
else do
send sock [] "Work harder"
loop c sock startrtreq: Haxe 中的 ROUTER 到 REQ
package ;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
#if (neko || cpp)
import neko.vm.Thread;
#end
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZContext;
import org.zeromq.ZMQSocket;
import ZHelpers;
/**
* Custom routing Router to Mama (ROUTER to REQ)
*
* While this example runs in a single process (for cpp & neko), that is just
* to make it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* See: https://zguide.zeromq.cn/page:all#Least-Recently-Used-Routing-LRU-Pattern
*/
class RTMama
{
private static inline var NBR_WORKERS = 10;
public static function workerTask() {
var context:ZContext = new ZContext();
var worker:ZMQSocket = context.createSocket(ZMQ_REQ);
// Use a random string identity for ease here
var id = ZHelpers.setID(worker);
worker.connect("ipc:///tmp/routing.ipc");
var total = 0;
while (true) {
// Tell the router we are ready
ZFrame.newStringFrame("ready").send(worker);
// Get workload from router, until finished
var workload:ZFrame = ZFrame.recvFrame(worker);
if (workload == null) break;
if (workload.streq("END")) {
Lib.println("Processed: " + total + " tasks");
break;
}
total++;
// Do some random work
Sys.sleep((ZHelpers.randof(1000) + 1) / 1000.0);
}
context.destroy();
}
public static function main() {
Lib.println("** RTMama (see: https://zguide.zeromq.cn/page:all#Least-Recently-Used-Routing-LRU-Pattern)");
// Implementation note: Had to move php forking before main thread ZMQ Context creation to
// get the main thread to receive messages from the child processes.
for (worker_nbr in 0 ... NBR_WORKERS) {
#if php
forkWorkerTask();
#else
Thread.create(workerTask);
#end
}
var context:ZContext = new ZContext();
var client:ZMQSocket = context.createSocket(ZMQ_ROUTER);
// Implementation note: Had to add the /tmp prefix to get this to work on Linux Ubuntu 10
client.bind("ipc:///tmp/routing.ipc");
Sys.sleep(1);
for (task_nbr in 0 ... NBR_WORKERS * 10) {
// LRU worker is next waiting in queue
var address:ZFrame = ZFrame.recvFrame(client);
var empty:ZFrame = ZFrame.recvFrame(client);
var ready:ZFrame = ZFrame.recvFrame(client);
address.send(client, ZFrame.ZFRAME_MORE);
ZFrame.newStringFrame("").send(client, ZFrame.ZFRAME_MORE);
ZFrame.newStringFrame("This is the workload").send(client);
}
// Now ask mamas to shut down and report their results
for (worker_nbr in 0 ... NBR_WORKERS) {
var address:ZFrame = ZFrame.recvFrame(client);
var empty:ZFrame = ZFrame.recvFrame(client);
var ready:ZFrame = ZFrame.recvFrame(client);
address.send(client, ZFrame.ZFRAME_MORE);
ZFrame.newStringFrame("").send(client, ZFrame.ZFRAME_MORE);
ZFrame.newStringFrame("END").send(client);
}
context.destroy();
}
#if php
private static inline function forkWorkerTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
RTMama::workerTask();
exit();
}');
return;
}
#end
}rtreq: Java 中的 ROUTER 到 REQ
package guide;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZContext;
/**
* ROUTER-TO-REQ example
*/
public class rtreq
{
private static Random rand = new Random();
private static final int NBR_WORKERS = 10;
private static class Worker extends Thread
{
@Override
public void run()
{
try (ZContext context = new ZContext()) {
Socket worker = context.createSocket(SocketType.REQ);
ZHelper.setId(worker); // Set a printable identity
worker.connect("tcp://:5671");
int total = 0;
while (true) {
// Tell the broker we're ready for work
worker.send("Hi Boss");
// Get workload from broker, until finished
String workload = worker.recvStr();
boolean finished = workload.equals("Fired!");
if (finished) {
System.out.printf("Completed: %d tasks\n", total);
break;
}
total++;
// Do some random work
try {
Thread.sleep(rand.nextInt(500) + 1);
}
catch (InterruptedException e) {
}
}
}
}
}
/**
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*/
public static void main(String[] args) throws Exception
{
try (ZContext context = new ZContext()) {
Socket broker = context.createSocket(SocketType.ROUTER);
broker.bind("tcp://*:5671");
for (int workerNbr = 0; workerNbr < NBR_WORKERS; workerNbr++) {
Thread worker = new Worker();
worker.start();
}
// Run for five seconds and then tell workers to end
long endTime = System.currentTimeMillis() + 5000;
int workersFired = 0;
while (true) {
// Next message gives us least recently used worker
String identity = broker.recvStr();
broker.sendMore(identity);
broker.recvStr(); // Envelope delimiter
broker.recvStr(); // Response from worker
broker.sendMore("");
// Encourage workers until it's time to fire them
if (System.currentTimeMillis() < endTime)
broker.send("Work harder");
else {
broker.send("Fired!");
if (++workersFired == NBR_WORKERS)
break;
}
}
}
}
}
rtreq: Julia 中的 ROUTER 到 REQ
rtreq: Lua 中的 ROUTER 到 REQ
--
-- Custom routing Router to Mama (ROUTER to REQ)
--
-- While this example runs in a single process, that is just to make
-- it easier to start and stop the example. Each thread has its own
-- context and conceptually acts as a separate process.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.threads"
require"zhelpers"
NBR_WORKERS = 10
local pre_code = [[
local identity, seed = ...
local zmq = require"zmq"
require"zhelpers"
math.randomseed(seed)
]]
local worker_task = pre_code .. [[
local context = zmq.init(1)
local worker = context:socket(zmq.REQ)
-- We use a string identity for ease here
worker:setopt(zmq.IDENTITY, identity)
worker:connect("ipc://routing.ipc")
local total = 0
while true do
-- Tell the router we're ready for work
worker:send("ready")
-- Get workload from router, until finished
local workload = worker:recv()
local finished = (workload == "END")
if (finished) then
printf ("Processed: %d tasks\n", total)
break
end
total = total + 1
-- Do some random work
s_sleep (randof (1000) + 1)
end
worker:close()
context:term()
]]
s_version_assert (2, 1)
local context = zmq.init(1)
local client = context:socket(zmq.ROUTER)
client:bind("ipc://routing.ipc")
math.randomseed(os.time())
local workers = {}
for n=1,NBR_WORKERS do
local identity = string.format("%04X-%04X", randof (0x10000), randof (0x10000))
local seed = os.time() + math.random()
workers[n] = zmq.threads.runstring(context, worker_task, identity, seed)
workers[n]:start()
end
for n=1,(NBR_WORKERS * 10) do
-- LRU worker is next waiting in queue
local address = client:recv()
local empty = client:recv()
local ready = client:recv()
client:send(address, zmq.SNDMORE)
client:send("", zmq.SNDMORE)
client:send("This is the workload")
end
-- Now ask mamas to shut down and report their results
for n=1,NBR_WORKERS do
local address = client:recv()
local empty = client:recv()
local ready = client:recv()
client:send(address, zmq.SNDMORE)
client:send("", zmq.SNDMORE)
client:send("END")
end
for n=1,NBR_WORKERS do
assert(workers[n]:join())
end
client:close()
context:term()
rtreq: Node.js 中的 ROUTER 到 REQ
var zmq = require('zeromq');
var WORKERS_NUM = 10;
var router = zmq.socket('router');
var d = new Date();
var endTime = d.getTime() + 5000;
router.bindSync('tcp://*:9000');
router.on('message', function () {
// get the identity of current worker
var identity = Array.prototype.slice.call(arguments)[0];
var d = new Date();
var time = d.getTime();
if (time < endTime) {
router.send([identity, '', 'Work harder!'])
} else {
router.send([identity, '', 'Fired!']);
}
});
// To keep it simple we going to use
// workers in closures and tcp instead of
// node clusters and threads
for (var i = 0; i < WORKERS_NUM; i++) {
(function () {
var worker = zmq.socket('req');
worker.connect('tcp://127.0.0.1:9000');
var total = 0;
worker.on('message', function (msg) {
var message = msg.toString();
if (message === 'Fired!'){
console.log('Completed %d tasks', total);
worker.close();
}
total++;
setTimeout(function () {
worker.send('Hi boss!');
}, 1000)
});
worker.send('Hi boss!');
})();
}
rtreq: Objective-C 中的 ROUTER 到 REQ
rtreq: ooc 中的 ROUTER 到 REQ
rtreq: Perl 中的 ROUTER 到 REQ
# ROUTER-to-REQ in Perl
use strict;
use warnings;
use v5.10;
use threads;
use Time::HiRes qw(usleep);
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_REQ ZMQ_ROUTER);
my $NBR_WORKERS = 10;
sub worker_task {
my $context = ZMQ::FFI->new();
my $worker = $context->socket(ZMQ_REQ);
$worker->set_identity(Time::HiRes::time());
$worker->connect('tcp://:5671');
my $total = 0;
WORKER_LOOP:
while (1) {
# Tell the broker we're ready for work
$worker->send('Hi Boss');
# Get workload from broker, until finished
my $workload = $worker->recv();
my $finished = $workload eq "Fired!";
if ($finished) {
say "Completed $total tasks";
last WORKER_LOOP;
}
$total++;
# Do some random work
usleep int(rand(500_000)) + 1;
}
}
# While this example runs in a single process, that is only to make
# it easier to start and stop the example. Each thread has its own
# context and conceptually acts as a separate process.
my $context = ZMQ::FFI->new();
my $broker = $context->socket(ZMQ_ROUTER);
$broker->bind('tcp://*:5671');
for my $worker_nbr (1..$NBR_WORKERS) {
threads->create('worker_task')->detach();
}
# Run for five seconds and then tell workers to end
my $end_time = time() + 5;
my $workers_fired = 0;
BROKER_LOOP:
while (1) {
# Next message gives us least recently used worker
my ($identity, $delimiter, $response) = $broker->recv_multipart();
# Encourage workers until it's time to fire them
if ( time() < $end_time ) {
$broker->send_multipart([$identity, '', 'Work harder']);
}
else {
$broker->send_multipart([$identity, '', 'Fired!']);
if ( ++$workers_fired == $NBR_WORKERS) {
last BROKER_LOOP;
}
}
}
rtreq: PHP 中的 ROUTER 到 REQ
<?php
/*
* Custom routing Router to Mama (ROUTER to REQ)
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>a
*/
define("NBR_WORKERS", 10);
function worker_thread()
{
$context = new ZMQContext();
$worker = new ZMQSocket($context, ZMQ::SOCKET_REQ);
$worker->connect("ipc://routing.ipc");
$total = 0;
while (true) {
// Tell the router we're ready for work
$worker->send("ready");
// Get workload from router, until finished
$workload = $worker->recv();
if ($workload == 'END') {
printf ("Processed: %d tasks%s", $total, PHP_EOL);
break;
}
$total++;
// Do some random work
usleep(mt_rand(1, 1000000));
}
}
for ($worker_nbr = 0; $worker_nbr < NBR_WORKERS; $worker_nbr++) {
if (pcntl_fork() == 0) {
worker_thread();
exit();
}
}
$context = new ZMQContext();
$client = $context->getSocket(ZMQ::SOCKET_ROUTER);
$client->bind("ipc://routing.ipc");
for ($task_nbr = 0; $task_nbr < NBR_WORKERS * 10; $task_nbr++) {
// LRU worker is next waiting in queue
$address = $client->recv();
$empty = $client->recv();
$read = $client->recv();
$client->send($address, ZMQ::MODE_SNDMORE);
$client->send("", ZMQ::MODE_SNDMORE);
$client->send("This is the workload");
}
// Now ask mamas to shut down and report their results
for ($task_nbr = 0; $task_nbr < NBR_WORKERS; $task_nbr++) {
// LRU worker is next waiting in queue
$address = $client->recv();
$empty = $client->recv();
$read = $client->recv();
$client->send($address, ZMQ::MODE_SNDMORE);
$client->send("", ZMQ::MODE_SNDMORE);
$client->send("END");
}
sleep (1); // Give 0MQ/2.0.x time to flush output
rtreq: Python 中的 ROUTER 到 REQ
# encoding: utf-8
#
# Custom routing Router to Mama (ROUTER to REQ)
#
# Author: Jeremy Avnet (brainsik) <spork(dash)zmq(at)theory(dot)org>
#
import time
import random
from threading import Thread
import zmq
import zhelpers
NBR_WORKERS = 10
def worker_thread(context=None):
context = context or zmq.Context.instance()
worker = context.socket(zmq.REQ)
# We use a string identity for ease here
zhelpers.set_id(worker)
worker.connect("tcp://:5671")
total = 0
while True:
# Tell the router we're ready for work
worker.send(b"ready")
# Get workload from router, until finished
workload = worker.recv()
finished = workload == b"END"
if finished:
print("Processed: %d tasks" % total)
break
total += 1
# Do some random work
time.sleep(0.1 * random.random())
context = zmq.Context.instance()
client = context.socket(zmq.ROUTER)
client.bind("tcp://*:5671")
for _ in range(NBR_WORKERS):
Thread(target=worker_thread).start()
for _ in range(NBR_WORKERS * 10):
# LRU worker is next waiting in the queue
address, empty, ready = client.recv_multipart()
client.send_multipart([
address,
b'',
b'This is the workload',
])
# Now ask mama to shut down and report their results
for _ in range(NBR_WORKERS):
address, empty, ready = client.recv_multipart()
client.send_multipart([
address,
b'',
b'END',
])
rtreq: Q 中的 ROUTER 到 REQ
rtreq: Racket 中的 ROUTER 到 REQ
rtreq: Ruby 中的 ROUTER 到 REQ
#!/usr/bin/env ruby
# Custom routing Router to Mama (ROUTER to REQ)
# Ruby version, based on the C version.
#
# While this example runs in a single process, that is just to make
# it easier to start and stop the example. Each thread has its own
# context and conceptually acts as a separate process.
#
# libzmq: 2.1.10
# ruby: 1.9.2p180 (2011-02-18 revision 30909) [i686-linux]
# ffi-rzmq: 0.9.0
#
# @author Pavel Mitin
# @email mitin.pavel@gmail.com
require 'rubygems'
require 'ffi-rzmq'
WORKER_NUMBER = 10
def receive_string(socket)
result = ''
socket.recv_string result
result
end
def worker_task
context = ZMQ::Context.new 1
worker = context.socket ZMQ::REQ
# We use a string identity for ease here
worker.setsockopt ZMQ::IDENTITY, sprintf("%04X-%04X", rand(10000), rand(10000))
worker.connect 'ipc://routing.ipc'
total = 0
loop do
# Tell the router we're ready for work
worker.send_string 'ready'
# Get workload from router, until finished
workload = receive_string worker
p "Processed: #{total} tasks" and break if workload == 'END'
total += 1
# Do some random work
sleep((rand(10) + 1) / 10.0)
end
end
context = ZMQ::Context.new 1
client = context.socket ZMQ::ROUTER
client.bind 'ipc://routing.ipc'
workers = (1..WORKER_NUMBER).map do
Thread.new { worker_task }
end
(WORKER_NUMBER * 10).times do
# LRU worker is next waitin in queue
address = receive_string client
empty = receive_string client
ready = receive_string client
client.send_string address, ZMQ::SNDMORE
client.send_string '', ZMQ::SNDMORE
client.send_string 'This is the workload'
end
# Now ask mamas to shut down and report their results
WORKER_NUMBER.times do
address = receive_string client
empty = receive_string client
ready = receive_string client
client.send_string address, ZMQ::SNDMORE
client.send_string '', ZMQ::SNDMORE
client.send_string 'END'
end
workers.each &:join
rtreq: Rust 中的 ROUTER 到 REQ
rtreq: Scala 中的 ROUTER 到 REQ
/*
* Custom routing Router to Mama (ROUTER to REQ)
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
*
* @author Giovanni Ruggiero
* @email giovanni.ruggiero@gmail.com
*/
import org.zeromq.ZMQ
import ZHelpers._
object rtmama {
class WorkerTask() extends Runnable {
def run() {
val rand = new java.util.Random(System.currentTimeMillis)
val ctx = ZMQ.context(1)
val worker = ctx.socket(ZMQ.REQ)
// We use a string identity for ease here
setID(worker)
// println(new String(worker.getIdentity))
worker.connect("tcp://:5555")
var total = 0
var workload = ""
do {
// Tell the router we're ready for work
worker.send("Ready".getBytes,0)
workload = new String(worker.recv(0))
Thread.sleep (rand.nextInt(1) * 1000)
total += 1
// Get workload from router, until finished
} while (!workload.equalsIgnoreCase("END"))
printf("Processed: %d tasks\n", total)
}
}
def main(args : Array[String]) {
val NBR_WORKERS = 10
val ctx = ZMQ.context(1)
val client = ctx.socket(ZMQ.ROUTER)
// Workaround to ckeck version >= 2.1
assert(client.getType > -1)
client.bind("tcp://*:5555")
val workers = List.fill(NBR_WORKERS)(new Thread(new WorkerTask))
workers foreach (_.start)
for (i <- 1 to NBR_WORKERS * 10) {
// LRU worker is next waiting in queue
val address = client.recv(0)
val empty = client.recv(0)
val ready = client.recv(0)
client.send(address, ZMQ.SNDMORE)
client.send("".getBytes, ZMQ.SNDMORE)
client.send("This is the workload".getBytes,0)
}
// Now ask mamas to shut down and report their results
for (i <- 1 to NBR_WORKERS) {
val address = client.recv(0)
val empty = client.recv(0)
val ready = client.recv(0)
client.send(address, ZMQ.SNDMORE)
client.send("".getBytes, ZMQ.SNDMORE)
client.send("END".getBytes,0)
}
}
}
rtreq: Tcl 中的 ROUTER 到 REQ
#
# Custom routing Router to Mama (ROUTER to REQ)
#
package require zmq
if {[llength $argv] == 0} {
set argv [list driver 3]
} elseif {[llength $argv] != 2} {
puts "Usage: rtmama.tcl <driver|main|worker> <number_of_workers>"
exit 1
}
lassign $argv what NBR_WORKERS
set tclsh [info nameofexecutable]
set nbr_of_workers [lindex $argv 0]
expr {srand([pid])}
switch -exact -- $what {
worker {
zmq context context
zmq socket worker context REQ
# We use a string identity for ease here
set id [format "%04X-%04X" [expr {int(rand()*0x10000)}] [expr {int(rand()*0x10000)}]]
worker setsockopt IDENTITY $id
worker connect "ipc://routing.ipc"
set total 0
while {1} {
# Tell the router we're ready for work
worker send "ready"
# Get workload from router, until finished
set workload [worker recv]
if {$workload eq "END"} {
puts "Processed: $total tasks"
break
}
incr total
# Do some random work
after [expr {int(rand()*1000)}]
}
worker close
context term
}
main {
zmq context context
zmq socket client context ROUTER
client bind "ipc://routing.ipc"
for {set task_nbr 0} {$task_nbr < $NBR_WORKERS * 10} {incr task_nbr} {
# LRU worker is next waiting in queue
set address [client recv]
set empty [client recv]
set ready [client recv]
client sendmore $address
client sendmore ""
client send "This is the workload"
}
# Now ask mamas to shut down and report their results
for {set worker_nbr 0} {$worker_nbr < $NBR_WORKERS} {incr worker_nbr} {
set address [client recv]
set empty [client recv]
set ready [client recv]
client sendmore $address
client sendmore ""
client send "END"
}
client close
context term
}
driver {
puts "Start main, output redirected to main.log"
exec $tclsh rtmama.tcl main $NBR_WORKERS > main.log 2>@1 &
after 1000
for {set i 0} {$i < $NBR_WORKERS} {incr i} {
puts "Start worker $i, output redirected to worker$i.log"
exec $tclsh rtmama.tcl worker $NBR_WORKERS > worker$i.log 2>@1 &
}
}
}
rtreq: OCaml 中的 ROUTER 到 REQ
示例运行五秒钟,然后每个工作者打印他们处理了多少任务。如果路由工作正常,我们期望任务会被公平地分配。
Completed: 20 tasks
Completed: 18 tasks
Completed: 21 tasks
Completed: 23 tasks
Completed: 19 tasks
Completed: 21 tasks
Completed: 17 tasks
Completed: 17 tasks
Completed: 25 tasks
Completed: 19 tasks
在这个示例中与工作者对话,我们必须创建一个对 REQ 友好的信封,它由一个身份和一个空的信封分隔帧组成。

ROUTER 代理和 DEALER 工作者 #
任何可以使用 REQ 的地方,你都可以使用 DEALER。有两处具体的区别
- REQ 套接字在发送任何数据帧之前总是发送一个空的定界帧;DEALER 则不会。
- REQ 套接字在收到回复之前只会发送一条消息;DEALER 则是完全异步的。
同步与异步行为对我们的示例没有影响,因为我们执行的是严格的请求-回复模式。当我们在第 4 章 - 可靠请求-回复模式中讨论从故障中恢复时,它会更具相关性。
现在让我们看看完全相同的示例,但将 REQ 套接字替换为 DEALER 套接字
rtdealer:使用 Ada 的 ROUTER 到 DEALER 示例
rtdealer:使用 Basic 的 ROUTER 到 DEALER 示例
rtdealer:使用 C 的 ROUTER 到 DEALER 示例
// 2015-02-27T11:40+08:00
// ROUTER-to-DEALER example
#include "zhelpers.h"
#include <pthread.h>
#define NBR_WORKERS 10
static void *
worker_task(void *args)
{
void *context = zmq_ctx_new();
void *worker = zmq_socket(context, ZMQ_DEALER);
#if (defined (WIN32))
s_set_id(worker, (intptr_t)args);
#else
s_set_id(worker); // Set a printable identity
#endif
zmq_connect (worker, "tcp://:5671");
int total = 0;
while (1) {
// Tell the broker we're ready for work
s_sendmore(worker, "");
s_send(worker, "Hi Boss");
// Get workload from broker, until finished
free(s_recv(worker)); // Envelope delimiter
char *workload = s_recv(worker);
// .skip
int finished = (strcmp(workload, "Fired!") == 0);
free(workload);
if (finished) {
printf("Completed: %d tasks\n", total);
break;
}
total++;
// Do some random work
s_sleep(randof(500) + 1);
}
zmq_close(worker);
zmq_ctx_destroy(context);
return NULL;
}
// .split main task
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
int main(void)
{
void *context = zmq_ctx_new();
void *broker = zmq_socket(context, ZMQ_ROUTER);
zmq_bind(broker, "tcp://*:5671");
srandom((unsigned)time(NULL));
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++) {
pthread_t worker;
pthread_create(&worker, NULL, worker_task, (void *)(intptr_t)worker_nbr);
}
// Run for five seconds and then tell workers to end
int64_t end_time = s_clock() + 5000;
int workers_fired = 0;
while (1) {
// Next message gives us least recently used worker
char *identity = s_recv(broker);
s_sendmore(broker, identity);
free(identity);
free(s_recv(broker)); // Envelope delimiter
free(s_recv(broker)); // Response from worker
s_sendmore(broker, "");
// Encourage workers until it's time to fire them
if (s_clock() < end_time)
s_send(broker, "Work harder");
else {
s_send(broker, "Fired!");
if (++workers_fired == NBR_WORKERS)
break;
}
}
zmq_close(broker);
zmq_ctx_destroy(context);
return 0;
}
// .until
rtdealer:使用 C++ 的 ROUTER 到 DEALER 示例
//
// Custom routing Router to Dealer
//
#include "zhelpers.hpp"
#include <thread>
#include <vector>
static void *
worker_task(void *args)
{
zmq::context_t context(1);
zmq::socket_t worker(context, ZMQ_DEALER);
#if (defined (WIN32))
s_set_id(worker, (intptr_t)args);
#else
s_set_id(worker); // Set a printable identity
#endif
worker.connect("tcp://:5671");
int total = 0;
while (1) {
// Tell the broker we're ready for work
s_sendmore(worker, std::string(""));
s_send(worker, std::string("Hi Boss"));
// Get workload from broker, until finished
s_recv(worker); // Envelope delimiter
std::string workload = s_recv(worker);
// .skip
if ("Fired!" == workload) {
std::cout << "Completed: " << total << " tasks" << std::endl;
break;
}
total++;
// Do some random work
s_sleep(within(500) + 1);
}
return NULL;
}
// .split main task
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
int main() {
zmq::context_t context(1);
zmq::socket_t broker(context, ZMQ_ROUTER);
broker.bind("tcp://*:5671");
srandom((unsigned)time(NULL));
const int NBR_WORKERS = 10;
std::vector<std::thread> workers;
for (int worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++) {
workers.push_back(std::move(std::thread(worker_task, (void *)(intptr_t)worker_nbr)));
}
// Run for five seconds and then tell workers to end
int64_t end_time = s_clock() + 5000;
int workers_fired = 0;
while (1) {
// Next message gives us least recently used worker
std::string identity = s_recv(broker);
{
s_recv(broker); // Envelope delimiter
s_recv(broker); // Response from worker
}
s_sendmore(broker, identity);
s_sendmore(broker, std::string(""));
// Encourage workers until it's time to fire them
if (s_clock() < end_time)
s_send(broker, std::string("Work harder"));
else {
s_send(broker, std::string("Fired!"));
if (++workers_fired == NBR_WORKERS)
break;
}
}
for (int worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++) {
workers[worker_nbr].join();
}
return 0;
}
rtdealer:使用 C# 的 ROUTER 到 DEALER 示例
rtdealer:使用 CL 的 ROUTER 到 DEALER 示例
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-
;;;
;;; Custom routing Router to Dealer in Common Lisp
;;;
;;; Kamil Shakirov <kamils80@gmail.com>
;;;
;;; We have two workers, here we copy the code, normally these would run on
;;; different boxes...
(defpackage #:zguide.rtdealer
(:nicknames #:rtdealer)
(:use #:cl #:zhelpers)
(:export #:main))
(in-package :zguide.rtdealer)
(defun worker-a (context)
(zmq:with-socket (worker context zmq:dealer)
(zmq:setsockopt worker zmq:identity "A")
(zmq:connect worker "ipc://routing.ipc")
(let ((total 0))
(loop
;; We receive one part, with the workload
(let ((request (recv-text worker)))
(when (string= request "END")
(message "A received: ~D~%" total)
(return))
(incf total))))))
(defun worker-b (context)
(zmq:with-socket (worker context zmq:dealer)
(zmq:setsockopt worker zmq:identity "B")
(zmq:connect worker "ipc://routing.ipc")
(let ((total 0))
(loop
;; We receive one part, with the workload
(let ((request (recv-text worker)))
(when (string= request "END")
(message "B received: ~D~%" total)
(return))
(incf total))))))
(defun main ()
(zmq:with-context (context 1)
(zmq:with-socket (client context zmq:router)
(zmq:bind client "ipc://routing.ipc")
(bt:make-thread (lambda () (worker-a context))
:name "worker-a")
(bt:make-thread (lambda () (worker-b context))
:name "worker-b")
;; Wait for threads to stabilize
(sleep 1)
;; Send 10 tasks scattered to A twice as often as B
(loop :repeat 10 :do
;; Send two message parts, first the address...
(if (> (1- (within 3)) 0)
(send-more-text client "A")
(send-more-text client "B"))
;; And then the workload
(send-text client "This is the workload"))
(send-more-text client "A")
(send-text client "END")
;; we can get messy output when two threads concurrently print results
;; so Let worker-a to print results first
(sleep 0.1)
(send-more-text client "B")
(send-text client "END")
;; Give 0MQ/2.0.x time to flush output
(sleep 1)))
(cleanup))
rtdealer:使用 Delphi 的 ROUTER 到 DEALER 示例
program rtdealer;
//
// ROUTER-to-DEALER example
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, Windows
, zmqapi
, zhelpers
;
const
NBR_WORKERS = 10;
procedure worker_task( args: Pointer );
var
context: TZMQContext;
worker: TZMQSocket;
total: Integer;
workload,
s: Utf8String;
begin
context := TZMQContext.create;
worker := context.Socket( stDealer );
s_set_id( worker ); // Set a printable identity
worker.connect( 'tcp://:5671' );
total := 0;
while true do
begin
// Tell the broker we're ready for work
worker.send( ['','Hi Boss'] );
// Get workload from broker, until finished
worker.recv( s ); // Envelope delimiter
worker.recv( workload );
if workload = 'Fired!' then
begin
zNote( Format( 'Completed: %d tasks', [total] ) );
break;
end;
Inc( total );
// Do some random work
sleep( random( 500 ) + 1 );
end;
worker.Free;
context.Free;
end;
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
var
context: TZMQContext;
broker: TZMQSocket;
i,
workers_fired: Integer;
tid: Cardinal;
identity,
s: Utf8String;
fFrequency,
fstart,
fStop,
dt: Int64;
begin
context := TZMQContext.create;
broker := context.Socket( stRouter );
broker.bind( 'tcp://*:5671' );
Randomize;
for i := 0 to NBR_WORKERS - 1 do
BeginThread( nil, 0, @worker_task, nil, 0, tid );
// Start our clock now
QueryPerformanceFrequency( fFrequency );
QueryPerformanceCounter( fStart );
// Run for five seconds and then tell workers to end
workers_fired := 0;
while true do
begin
// Next message gives us least recently used worker
broker.recv( identity );
broker.send( identity, [sfSndMore] );
broker.recv( s ); // Envelope delimiter
broker.recv( s ); // Response from worker
broker.send( '', [sfSndMore] );
QueryPerformanceCounter( fStop );
dt := ( MSecsPerSec * ( fStop - fStart ) ) div fFrequency;
if dt < 5000 then
broker.send( 'Work harder' )
else begin
broker.send( 'Fired!' );
Inc( workers_fired );
if workers_fired = NBR_WORKERS then
break;
end;
end;
broker.Free;
context.Free;
end.
rtdealer:使用 Erlang 的 ROUTER 到 DEALER 示例
#! /usr/bin/env escript
%%
%% Custom routing Router to Dealer
%%
%% While this example runs in a single process, that is just to make
%% it easier to start and stop the example. Each thread has its own
%% context and conceptually acts as a separate process.
%%
%% We start multiple workers in this process - these would normally be on
%% different nodes...
worker_task(Id) ->
{ok, Context} = erlzmq:context(),
{ok, Worker} = erlzmq:socket(Context, dealer),
ok = erlzmq:setsockopt(Worker, identity, Id),
ok = erlzmq:connect(Worker, "ipc://routing.ipc"),
Count = count_messages(Worker, 0),
io:format("~s received: ~b~n", [Id, Count]),
ok = erlzmq:close(Worker),
ok = erlzmq:term(Context).
count_messages(Socket, Count) ->
case erlzmq:recv(Socket) of
{ok, <<"END">>} -> Count;
{ok, _} -> count_messages(Socket, Count + 1)
end.
main(_) ->
{ok, Context} = erlzmq:context(),
{ok, Client} = erlzmq:socket(Context, router),
ok = erlzmq:bind(Client, "ipc://routing.ipc"),
spawn(fun() -> worker_task(<<"A">>) end),
spawn(fun() -> worker_task(<<"B">>) end),
%% Wait for threads to connect, since otherwise the messages
%% we send won't be routable.
timer:sleep(1000),
%% Send 10 tasks scattered to A twice as often as B
lists:foreach(
fun(Num) ->
%% Send two message parts, first the address
case Num rem 3 of
0 ->
ok = erlzmq:send(Client, <<"B">>, [sndmore]);
_ ->
ok = erlzmq:send(Client, <<"A">>, [sndmore])
end,
%% And then the workload
ok = erlzmq:send(Client, <<"Workload">>)
end, lists:seq(1, 10)),
ok = erlzmq:send(Client, <<"A">>, [sndmore]),
ok = erlzmq:send(Client, <<"END">>),
ok = erlzmq:send(Client, <<"B">>, [sndmore]),
ok = erlzmq:send(Client, <<"END">>),
%% Workers use separate context, so we can't rely on Context term
%% below to wait for them to finish. Manually wait instead.
timer:sleep(100),
ok = erlzmq:close(Client),
ok = erlzmq:term(Context).
rtdealer:使用 Elixir 的 ROUTER 到 DEALER 示例
defmodule Rtdealer do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:32
"""
def worker_task(id) do
{:ok, context} = :erlzmq.context()
{:ok, worker} = :erlzmq.socket(context, :dealer)
:ok = :erlzmq.setsockopt(worker, :identity, id)
:ok = :erlzmq.connect(worker, 'ipc://routing.ipc')
count = count_messages(worker, 0)
:io.format('~s received: ~b~n', [id, count])
:ok = :erlzmq.close(worker)
:ok = :erlzmq.term(context)
end
def count_messages(socket, count) do
case(:erlzmq.recv(socket)) do
{:ok, "END"} ->
count
{:ok, _} ->
count_messages(socket, count + 1)
end
end
def main() do
{:ok, context} = :erlzmq.context()
{:ok, client} = :erlzmq.socket(context, :router)
:ok = :erlzmq.bind(client, 'ipc://routing.ipc')
:erlang.spawn(fn -> worker_task("A") end)
:erlang.spawn(fn -> worker_task("B") end)
:timer.sleep(1000)
:lists.foreach(fn num ->
case(rem(num, 3)) do
0 ->
:ok = :erlzmq.send(client, "B", [:sndmore])
_ ->
:ok = :erlzmq.send(client, "A", [:sndmore])
end
:ok = :erlzmq.send(client, "Workload")
end, :lists.seq(1, 10))
:ok = :erlzmq.send(client, "A", [:sndmore])
:ok = :erlzmq.send(client, "END")
:ok = :erlzmq.send(client, "B", [:sndmore])
:ok = :erlzmq.send(client, "END")
:timer.sleep(100)
:ok = :erlzmq.close(client)
:ok = :erlzmq.term(context)
end
end
Rtdealer.main
rtdealer:使用 F# 的 ROUTER 到 DEALER 示例
rtdealer:使用 Felix 的 ROUTER 到 DEALER 示例
rtdealer:使用 Go 的 ROUTER 到 DEALER 示例
//
// ROUTER-to-DEALER example
//
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"strings"
"time"
)
const NBR_WORKERS int = 10
func randomString() string {
source := "abcdefghijklmnopqrstuvwxyz"
target := make([]string, 20)
for i := 0; i < 20; i++ {
target[i] = string(source[rand.Intn(len(source))])
}
return strings.Join(target, "")
}
func worker_task() {
context, _ := zmq.NewContext()
defer context.Close()
worker, _ := context.NewSocket(zmq.DEALER)
defer worker.Close()
worker.SetIdentity(randomString())
worker.Connect("tcp://:5671")
total := 0
for {
// Tell the broker we're ready for work
worker.SendMultipart([][]byte{[]byte(""), []byte("Hi Boss")}, 0)
// Get workload from broker, until finished
parts, _ := worker.RecvMultipart(0)
workload := parts[1]
if string(workload) == "Fired!" {
id, _ := worker.Identity()
fmt.Printf("Completed: %d tasks (%s)\n", total, id)
break
}
total++
// Do some random work
time.Sleep(time.Duration(rand.Intn(500)) * time.Millisecond)
}
}
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
func main() {
context, _ := zmq.NewContext()
defer context.Close()
broker, _ := context.NewSocket(zmq.ROUTER)
defer broker.Close()
broker.Bind("tcp://*:5671")
rand.Seed(time.Now().Unix())
for i := 0; i < NBR_WORKERS; i++ {
go worker_task()
}
end_time := time.Now().Unix() + 5
workers_fired := 0
for {
// Next message gives us least recently used worker
parts, err := broker.RecvMultipart(0)
if err != nil {
print(err)
}
identity := parts[0]
now := time.Now().Unix()
if now < end_time {
broker.SendMultipart([][]byte{identity, []byte(""), []byte("Work harder")}, 0)
} else {
broker.SendMultipart([][]byte{identity, []byte(""), []byte("Fired!")}, 0)
workers_fired++
if workers_fired == NBR_WORKERS {
break
}
}
}
}
rtdealer:使用 Haskell 的 ROUTER 到 DEALER 示例
{-# LANGUAGE OverloadedStrings #-}
-- |
-- Router broker and DEALER workers (p.94)
module Main where
import System.ZMQ4.Monadic
import Control.Concurrent (threadDelay, forkIO)
import Control.Concurrent.MVar (withMVar, newMVar, MVar)
import Data.ByteString.Char8 (unpack)
import Control.Monad (replicateM_, unless)
import ZHelpers (setRandomIdentity)
import Text.Printf
import Data.Time.Clock
import System.Random
nbrWorkers :: Int
nbrWorkers = 10
-- In general, although locks are an antipattern in ZeroMQ, we need a lock
-- for the stdout handle, otherwise we will get jumbled text. We don't
-- use the lock for anything zeroMQ related, just output to screen.
workerThread :: MVar () -> IO ()
workerThread lock =
runZMQ $ do
worker <- socket Dealer
setRandomIdentity worker
connect worker "ipc://routing.ipc"
work worker
where
work = loop 0 where
loop val sock = do
-- Send an empty frame manually
-- Unlike the Request socket, the Dealer does not it automatically
send sock [SendMore] ""
send sock [] "Ready"
-- unlike the Request socket we need to read the empty frame
receive sock
workload <- receive sock
if unpack workload == "Fired!"
then liftIO $ withMVar lock $ \_ -> printf "Completed: %d tasks\n" (val::Int)
else do
rand <- liftIO $ getStdRandom (randomR (500 :: Int, 5000))
liftIO $ threadDelay rand
loop (val+1) sock
main :: IO ()
main =
runZMQ $ do
client <- socket Router
bind client "ipc://routing.ipc"
-- We only Need the MVar For Printing the Output (so output doesn't become interleaved)
-- The alternative is to Make an ipc channel, but that distracts from the example
-- Another alternative is to 'NoBuffering' 'stdin' and press Ctr-C manually
lock <- liftIO $ newMVar ()
liftIO $ replicateM_ nbrWorkers (forkIO $ workerThread lock)
start <- liftIO getCurrentTime
sendWork client start
-- You need to give some time to the workers so they can exit properly
liftIO $ threadDelay $ 1 * 1000 * 1000
where
sendWork :: Socket z Router -> UTCTime -> ZMQ z ()
sendWork = loop nbrWorkers where
loop c sock start = unless (c <= 0) $ do
-- Next message is the leaset recently used worker
ident <- receive sock
send sock [SendMore] ident
-- Envelope delimiter
receive sock
-- Ready signal from worker
receive sock
-- Send delimiter
send sock [SendMore] ""
-- Send Work unless time is up
now <- liftIO getCurrentTime
if c /= nbrWorkers || diffUTCTime now start > 5
then do
send sock [] "Fired!"
loop (c-1) sock start
else do
send sock [] "Work harder"
loop c sock startrtdealer:使用 Haxe 的 ROUTER 到 DEALER 示例
package ;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
#if (neko || cpp)
import neko.Random;
import neko.vm.Thread;
#end
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZContext;
import org.zeromq.ZMQSocket;
/**
* Custom routing Router to Dealer
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* See: https://zguide.zeromq.cn/page:all#Router-to-Dealer-Routing
*/
class RTDealer
{
public static function workerTask(id:String) {
var context:ZContext = new ZContext();
var worker:ZMQSocket = context.createSocket(ZMQ_DEALER);
worker.setsockopt(ZMQ_IDENTITY, Bytes.ofString(id));
worker.connect("ipc:///tmp/routing.ipc");
var total = 0;
while (true) {
// We receive one part, with the workload
var request:ZFrame = ZFrame.recvFrame(worker);
if (request == null) break;
if (request.streq("END")) {
Lib.println(id + " received: " + total);
break;
}
total++;
}
context.destroy();
}
public static function main() {
Lib.println("** RTDealer (see: https://zguide.zeromq.cn/page:all#Router-to-Dealer-Routing)");
// Implementation note: Had to move php forking before main thread ZMQ Context creation to
// get the main thread to receive messages from the child processes.
#if php
// For PHP, use processes, not threads
forkWorkerTasks();
#else
var workerA = Thread.create(callback(workerTask, "A"));
var workerB = Thread.create(callback(workerTask, "B"));
#end
var context:ZContext = new ZContext();
var client:ZMQSocket = context.createSocket(ZMQ_ROUTER);
// Implementation note: Had to add the /tmp prefix to get this to work on Linux Ubuntu 10
client.bind("ipc:///tmp/routing.ipc");
// Wait for threads to connect, since otherwise the messages
// we send won't be routable.
Sys.sleep(1);
// Send 10 tasks scattered to A twice as often as B
var workload = ZFrame.newStringFrame("This is the workload");
var address:ZFrame;
#if !php
var rnd = new Random();
rnd.setSeed(Date.now().getSeconds());
#end
for (task_nbr in 0 ... 10) {
// Send two message parts, first the address...
var randNumber:Int;
#if php
randNumber = untyped __php__('rand(0, 2)');
#else
randNumber = rnd.int(2);
#end
if (randNumber > 0)
address = ZFrame.newStringFrame("A");
else
address = ZFrame.newStringFrame("B");
address.send(client, ZFrame.ZFRAME_MORE);
// And then the workload
workload.send(client, ZFrame.ZFRAME_REUSE);
}
ZFrame.newStringFrame("A").send(client, ZFrame.ZFRAME_MORE);
ZFrame.newStringFrame("END").send(client);
ZFrame.newStringFrame("B").send(client, ZFrame.ZFRAME_MORE);
ZFrame.newStringFrame("END").send(client);
workload.destroy();
context.destroy();
}
#if php
private static inline function forkWorkerTasks() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
RTDealer::workerTask("A");
exit();
}');
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
RTDealer::workerTask("B");
exit();
}');
return;
}
#end
}rtdealer:使用 Java 的 ROUTER 到 DEALER 示例
package guide;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZContext;
/**
* ROUTER-TO-REQ example
*/
public class rtdealer
{
private static Random rand = new Random();
private static final int NBR_WORKERS = 10;
private static class Worker extends Thread
{
@Override
public void run()
{
try (ZContext context = new ZContext()) {
Socket worker = context.createSocket(SocketType.DEALER);
ZHelper.setId(worker); // Set a printable identity
worker.connect("tcp://:5671");
int total = 0;
while (true) {
// Tell the broker we're ready for work
worker.sendMore("");
worker.send("Hi Boss");
// Get workload from broker, until finished
worker.recvStr(); // Envelope delimiter
String workload = worker.recvStr();
boolean finished = workload.equals("Fired!");
if (finished) {
System.out.printf("Completed: %d tasks\n", total);
break;
}
total++;
// Do some random work
try {
Thread.sleep(rand.nextInt(500) + 1);
}
catch (InterruptedException e) {
}
}
}
}
}
/**
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*/
public static void main(String[] args) throws Exception
{
try (ZContext context = new ZContext()) {
Socket broker = context.createSocket(SocketType.ROUTER);
broker.bind("tcp://*:5671");
for (int workerNbr = 0; workerNbr < NBR_WORKERS; workerNbr++) {
Thread worker = new Worker();
worker.start();
}
// Run for five seconds and then tell workers to end
long endTime = System.currentTimeMillis() + 5000;
int workersFired = 0;
while (true) {
// Next message gives us least recently used worker
String identity = broker.recvStr();
broker.sendMore(identity);
broker.recv(0); // Envelope delimiter
broker.recv(0); // Response from worker
broker.sendMore("");
// Encourage workers until it's time to fire them
if (System.currentTimeMillis() < endTime)
broker.send("Work harder");
else {
broker.send("Fired!");
if (++workersFired == NBR_WORKERS)
break;
}
}
}
}
}
rtdealer:使用 Julia 的 ROUTER 到 DEALER 示例
rtdealer:使用 Lua 的 ROUTER 到 DEALER 示例
--
-- Custom routing Router to Dealer
--
-- While this example runs in a single process, that is just to make
-- it easier to start and stop the example. Each thread has its own
-- context and conceptually acts as a separate process.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.threads"
require"zhelpers"
local pre_code = [[
local zmq = require"zmq"
require"zhelpers"
--local threads = require"zmq.threads"
--local context = threads.get_parent_ctx()
]]
-- We have two workers, here we copy the code, normally these would
-- run on different boxes...
--
local worker_task_a = pre_code .. [[
local context = zmq.init(1)
local worker = context:socket(zmq.DEALER)
worker:setopt(zmq.IDENTITY, "A")
worker:connect("ipc://routing.ipc")
local total = 0
while true do
-- We receive one part, with the workload
local request = worker:recv()
local finished = (request == "END")
if (finished) then
printf ("A received: %d\n", total)
break
end
total = total + 1
end
worker:close()
context:term()
]]
local worker_task_b = pre_code .. [[
local context = zmq.init(1)
local worker = context:socket(zmq.DEALER)
worker:setopt(zmq.IDENTITY, "B")
worker:connect("ipc://routing.ipc")
local total = 0
while true do
-- We receive one part, with the workload
local request = worker:recv()
local finished = (request == "END")
if (finished) then
printf ("B received: %d\n", total)
break
end
total = total + 1
end
worker:close()
context:term()
]]
s_version_assert (2, 1)
local context = zmq.init(1)
local client = context:socket(zmq.ROUTER)
client:bind("ipc://routing.ipc")
local task_a = zmq.threads.runstring(context, worker_task_a)
task_a:start()
local task_b = zmq.threads.runstring(context, worker_task_b)
task_b:start()
-- Wait for threads to connect, since otherwise the messages
-- we send won't be routable.
s_sleep (1000)
-- Send 10 tasks scattered to A twice as often as B
math.randomseed(os.time())
for n=1,10 do
-- Send two message parts, first the address...
if (randof (3) > 0) then
client:send("A", zmq.SNDMORE)
else
client:send("B", zmq.SNDMORE)
end
-- And then the workload
client:send("This is the workload")
end
client:send("A", zmq.SNDMORE)
client:send("END")
client:send("B", zmq.SNDMORE)
client:send("END")
client:close()
context:term()
assert(task_a:join())
assert(task_b:join())
rtdealer:使用 Node.js 的 ROUTER 到 DEALER 示例
'use strict';
var cluster = require('cluster')
, zmq = require('zeromq');
var NBR_WORKERS = 3;
function randomBetween(min, max) {
return Math.floor(Math.random() * (max - min) + min);
}
function randomString() {
var source = 'abcdefghijklmnopqrstuvwxyz'
, target = [];
for (var i = 0; i < 20; i++) {
target.push(source[randomBetween(0, source.length)]);
}
return target.join('');
}
function workerTask() {
var dealer = zmq.socket('dealer');
dealer.identity = randomString();
dealer.connect('tcp://:5671');
var total = 0;
var sendMessage = function () {
dealer.send(['', 'Hi Boss']);
};
// Get workload from broker, until finished
dealer.on('message', function onMessage() {
var args = Array.apply(null, arguments);
var workload = args[1].toString('utf8');
if (workload === 'Fired!') {
console.log('Completed: '+total+' tasks ('+dealer.identity+')');
dealer.removeListener('message', onMessage);
dealer.close();
return;
}
total++;
setTimeout(sendMessage, randomBetween(0, 500));
});
// Tell the broker we're ready for work
sendMessage();
}
function main() {
var broker = zmq.socket('router');
broker.bindSync('tcp://*:5671');
var endTime = Date.now() + 5000
, workersFired = 0;
broker.on('message', function () {
var args = Array.apply(null, arguments)
, identity = args[0]
, now = Date.now();
if (now < endTime) {
broker.send([identity, '', 'Work harder']);
} else {
broker.send([identity, '', 'Fired!']);
workersFired++;
if (workersFired === NBR_WORKERS) {
setImmediate(function () {
broker.close();
cluster.disconnect();
});
}
}
});
for (var i=0;i<NBR_WORKERS;i++) {
cluster.fork();
}
}
if (cluster.isMaster) {
main();
} else {
workerTask();
}
rtdealer:使用 Objective-C 的 ROUTER 到 DEALER 示例
rtdealer:使用 ooc 的 ROUTER 到 DEALER 示例
rtdealer:使用 Perl 的 ROUTER 到 DEALER 示例
# ROUTER-to-DEALER in Perl
use strict;
use warnings;
use v5.10;
use threads;
use Time::HiRes qw(usleep);
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_DEALER ZMQ_ROUTER);
my $NBR_WORKERS = 10;
sub worker_task {
my $context = ZMQ::FFI->new();
my $worker = $context->socket(ZMQ_DEALER);
$worker->set_identity(Time::HiRes::time());
$worker->connect('tcp://:5671');
my $total = 0;
WORKER_LOOP:
while (1) {
# Tell the broker we're ready for work
$worker->send_multipart(['', 'Hi Boss']);
# Get workload from broker, until finished
my ($delimiter, $workload) = $worker->recv_multipart();
my $finished = $workload eq "Fired!";
if ($finished) {
say "Completed $total tasks";
last WORKER_LOOP;
}
$total++;
# Do some random work
usleep int(rand(500_000)) + 1;
}
}
# While this example runs in a single process, that is only to make
# it easier to start and stop the example. Each thread has its own
# context and conceptually acts as a separate process.
my $context = ZMQ::FFI->new();
my $broker = $context->socket(ZMQ_ROUTER);
$broker->bind('tcp://*:5671');
for my $worker_nbr (1..$NBR_WORKERS) {
threads->create('worker_task')->detach();
}
# Run for five seconds and then tell workers to end
my $end_time = time() + 5;
my $workers_fired = 0;
BROKER_LOOP:
while (1) {
# Next message gives us least recently used worker
my ($identity, $delimiter, $response) = $broker->recv_multipart();
# Encourage workers until it's time to fire them
if ( time() < $end_time ) {
$broker->send_multipart([$identity, '', 'Work harder']);
}
else {
$broker->send_multipart([$identity, '', 'Fired!']);
if ( ++$workers_fired == $NBR_WORKERS) {
last BROKER_LOOP;
}
}
}
rtdealer:使用 PHP 的 ROUTER 到 DEALER 示例
<?php
/*
* Custom routing Router to Dealer
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
// We have two workers, here we copy the code, normally these would
// run on different boxes...
function worker_a()
{
$context = new ZMQContext();
$worker = $context->getSocket(ZMQ::SOCKET_DEALER);
$worker->setSockOpt(ZMQ::SOCKOPT_IDENTITY, "A");
$worker->connect("ipc://routing.ipc");
$total = 0;
while (true) {
// We receive one part, with the workload
$request = $worker->recv();
if ($request == 'END') {
printf ("A received: %d%s", $total, PHP_EOL);
break;
}
$total++;
}
}
function worker_b()
{
$context = new ZMQContext();
$worker = $context->getSocket(ZMQ::SOCKET_DEALER);
$worker->setSockOpt(ZMQ::SOCKOPT_IDENTITY, "B");
$worker->connect("ipc://routing.ipc");
$total = 0;
while (true) {
// We receive one part, with the workload
$request = $worker->recv();
if ($request == 'END') {
printf ("B received: %d%s", $total, PHP_EOL);
break;
}
$total++;
}
}
$pid = pcntl_fork();
if ($pid == 0) { worker_a(); exit(); }
$pid = pcntl_fork();
if ($pid == 0) { worker_b(); exit(); }
$context = new ZMQContext();
$client = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$client->bind("ipc://routing.ipc");
// Wait for threads to stabilize
sleep(1);
// Send 10 tasks scattered to A twice as often as B
for ($task_nbr = 0; $task_nbr != 10; $task_nbr++) {
// Send two message parts, first the address...
if (mt_rand(0, 2) > 0) {
$client->send("A", ZMQ::MODE_SNDMORE);
} else {
$client->send("B", ZMQ::MODE_SNDMORE);
}
// And then the workload
$client->send("This is the workload");
}
$client->send("A", ZMQ::MODE_SNDMORE);
$client->send("END");
$client->send("B", ZMQ::MODE_SNDMORE);
$client->send("END");
sleep (1); // Give 0MQ/2.0.x time to flush output
rtdealer:使用 Python 的 ROUTER 到 DEALER 示例
# encoding: utf-8
#
# Custom routing Router to Dealer
#
# Author: Jeremy Avnet (brainsik) <spork(dash)zmq(at)theory(dot)org>
#
import time
import random
from threading import Thread
import zmq
# We have two workers, here we copy the code, normally these would
# run on different boxes...
#
def worker_a(context=None):
context = context or zmq.Context.instance()
worker = context.socket(zmq.DEALER)
worker.setsockopt(zmq.IDENTITY, b'A')
worker.connect("ipc://routing.ipc")
total = 0
while True:
# We receive one part, with the workload
request = worker.recv()
finished = request == b"END"
if finished:
print("A received: %s" % total)
break
total += 1
def worker_b(context=None):
context = context or zmq.Context.instance()
worker = context.socket(zmq.DEALER)
worker.setsockopt(zmq.IDENTITY, b'B')
worker.connect("ipc://routing.ipc")
total = 0
while True:
# We receive one part, with the workload
request = worker.recv()
finished = request == b"END"
if finished:
print("B received: %s" % total)
break
total += 1
context = zmq.Context.instance()
client = context.socket(zmq.ROUTER)
client.bind("ipc://routing.ipc")
Thread(target=worker_a).start()
Thread(target=worker_b).start()
# Wait for threads to stabilize
time.sleep(1)
# Send 10 tasks scattered to A twice as often as B
for _ in range(10):
# Send two message parts, first the address...
ident = random.choice([b'A', b'A', b'B'])
# And then the workload
work = b"This is the workload"
client.send_multipart([ident, work])
client.send_multipart([b'A', b'END'])
client.send_multipart([b'B', b'END'])
rtdealer:使用 Q 的 ROUTER 到 DEALER 示例
rtdealer:使用 Racket 的 ROUTER 到 DEALER 示例
rtdealer:使用 Ruby 的 ROUTER 到 DEALER 示例
#!/usr/bin/env ruby
# Custom routing Router to Dealer.
# Ruby version, based on the C version from
# https://zguide.zeromq.cn/chapter:all#toc45
#
# libzmq: 2.1.10
# ruby: 1.9.2p180 (2011-02-18 revision 30909) [i686-linux]
# ffi-rzmq: 0.9.0
#
# @author Pavel Mitin
# @email mitin.pavel@gmail.com
require 'rubygems'
require 'ffi-rzmq'
module RTDealer
ENDPOINT = 'ipc://routing.ipc'
WORKER_ADDRESSES = %w(A B)
END_MESSAGE = 'END'
class Worker
def run
do_run
ensure
@socket.close
end
private
def initialize(context, address)
@address = address
@socket = context.socket ZMQ::DEALER
@socket.setsockopt ZMQ::IDENTITY, address
@socket.connect ENDPOINT
@total = 0
@workload = ''
end
def do_run
catch(:end) do
loop do
receive_workload
handle_workload
end
end
print_results
end
def receive_workload
@socket.recv_string @workload
end
def handle_workload
if @workload == END_MESSAGE
throw :end
else
@total += 1
end
end
def print_results
p "#{@address} received: #{@total}"
end
end
class Client
def run
send_workload
stop_workers
ensure
@socket.close
end
private
def initialize(context)
@socket = context.socket ZMQ::ROUTER
@socket.bind ENDPOINT
end
def send_workload
10.times do
address = rand(3) % 3 == 0 ? WORKER_ADDRESSES.first : WORKER_ADDRESSES.last
@socket.send_string address, ZMQ::SNDMORE
@socket.send_string "This is the workload"
end
end
def stop_workers
WORKER_ADDRESSES.each do |address|
@socket.send_string address, ZMQ::SNDMORE
@socket.send_string END_MESSAGE
end
end
end
end
if $0 == __FILE__
context = ZMQ::Context.new 1
client = RTDealer::Client.new context
workers = RTDealer::WORKER_ADDRESSES.map do |address|
Thread.new { RTDealer::Worker.new(context, address).run }
end
sleep 1
client.run
workers.each &:join
context.terminate
end
rtdealer:使用 Rust 的 ROUTER 到 DEALER 示例
rtdealer:使用 Scala 的 ROUTER 到 DEALER 示例
/**
* Custom routing Router to Dealer.
* Scala version, based on the C version from
* https://zguide.zeromq.cn/chapter:all#toc45
*
* @author Giovanni Ruggiero
* @email giovanni.ruggiero@gmail.com
*/
import org.zeromq.ZMQ
import java.util.Arrays
import java.util.Random
/**
* Router-to-dealer custom routing demo.
*
* The router, in this case the main function, uses ROUTER. The
* dealers, in this case the two worker threads, use DEALER.
*/
object rtdealer {
val NOFLAGS = 0
/**
* Worker runnable consumes messages until it receives an END
* message.
*/
class Worker(name: String) extends Runnable {
def run() {
val context = ZMQ.context(1)
val socket = context.socket(ZMQ.DEALER)
socket.setIdentity(name.getBytes())
socket.connect("tcp://:5555")
var total = 0
var workload = ""
do {
workload = new String(socket.recv(NOFLAGS))
total += 1
} while (!workload.equalsIgnoreCase("END"))
printf( "Worker %s received %d messages.\n", name, total )
socket.close
context.term
}
}
/* Random number generator to determine message distribution. */
val rand = new Random
def main(args : Array[String]) {
val context = ZMQ.context(1)
val socket = context.socket(ZMQ.ROUTER)
socket.bind("tcp://*:5555")
val workerA = new Thread(new Worker("A"))
val workerB = new Thread(new Worker("B"))
workerA.start()
workerB.start()
// Wait a second for the workers to connect their sockets.
println("Workers started, sleeping 1 second for warmup.")
Thread.sleep(1000)
// Send 10 tasks, scattered to A twice as often as B.
var address = Array[Byte]()
for (i <- 1 to 10) {
if (rand.nextInt() % 3 == 0) { // 1/3 to B.
address = "B".getBytes()
} else { // 2/3 to A.
address = "A".getBytes()
}
socket.send(address, ZMQ.SNDMORE)
socket.send("This is the workload.".getBytes, NOFLAGS)
}
socket.send("A".getBytes, ZMQ.SNDMORE)
socket.send("END".getBytes, NOFLAGS)
socket.send("B".getBytes, ZMQ.SNDMORE)
socket.send("END".getBytes, NOFLAGS)
socket.close
context.term
}
}
rtdealer:使用 Tcl 的 ROUTER 到 DEALER 示例
# Custom routing Router to Dealer
package require zmq
if {[llength $argv] == 0} {
set argv [list main {}]
} elseif {[llength $argv] != 2} {
puts "Usage: rtdelaer.tcl <worker|main> <identity>"
exit 1
}
set tclsh [info nameofexecutable]
lassign $argv what identity
expr {srand([pid])}
switch -exact -- $what {
worker {
zmq context context
zmq socket worker context DEALER
worker setsockopt IDENTITY $identity
worker connect "ipc://routing.ipc"
set total 0
while {1} {
# We receive one part, with the workload
set request [worker recv]
if {$request eq "END"} {
puts "$identity received: $total"
break;
}
incr total
}
worker close
context term
}
main {
zmq context context
zmq socket client context ROUTER
client bind "ipc://routing.ipc"
foreach c {A B} {
puts "Start worker $c, output redirected to worker$c.log"
exec $tclsh rtdealer.tcl worker $c > worker$c.log 2>@1 &
}
# Wait for threads to connect, since otherwise the messages
# we send won't be routable.
after 1000
# Send 10 tasks scattered to A twice as often as B
for {set task_nbr 0} {$task_nbr < 10} {incr task_nbr} {
# Send two message parts, first the address…
set id [expr {int(rand() * 3) > 0?"A":"B"}]
client sendmore $id
# And then the workload
client send "This is the workload"
}
client sendmore "A"
client send "END"
client sendmore "B"
client send "END"
client close
context term
}
}
rtdealer:使用 OCaml 的 ROUTER 到 DEALER 示例
代码几乎完全相同,区别在于工作者使用 DEALER 套接字,并在数据帧之前读写那个空的帧。这是当我想保持与 REQ 工作者兼容时使用的方法。
然而,请记住那个空的定界帧的原因:它是为了允许多跳扩展请求在 REP 套接字处终止,REP 套接字使用该定界符来分割回复信封,以便将数据帧交给其应用程序。
如果我们从不需要将消息传递给 REP 套接字,我们可以简单地在两端都丢弃空的定界帧,这会使事情变得更简单。这通常是我用于纯 DEALER 到 ROUTER 协议的设计。
一个负载均衡消息代理 #
上面的示例只完成了一半。它可以管理一组带有模拟请求和回复的工作者,但无法与客户端通信。如果我们添加第二个接受客户端请求的前端 ROUTER 套接字,并将我们的示例变成一个可以将消息从前端切换到后端的代理,我们就能得到一个有用且可重用的小型负载均衡消息代理。
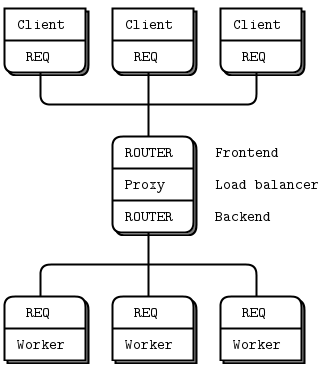
这个代理执行以下操作
- 接受来自一组客户端的连接。
- 接受来自一组工作者的连接。
- 接受来自客户端的请求,并将这些请求保存在一个队列中。
- 使用负载均衡模式将这些请求发送给工作者。
- 接收工作者返回的回复。
- 将这些回复发送回原始请求客户端。
代理的代码相当长,但值得理解
lbbroker:使用 Ada 的负载均衡代理示例
lbbroker:使用 Basic 的负载均衡代理示例
lbbroker:使用 C 的负载均衡代理示例
// Load-balancing broker
// Clients and workers are shown here in-process
#include "zhelpers.h"
#include <pthread.h>
#define NBR_CLIENTS 10
#define NBR_WORKERS 3
// Dequeue operation for queue implemented as array of anything
#define DEQUEUE(q) memmove (&(q)[0], &(q)[1], sizeof (q) - sizeof (q [0]))
// Basic request-reply client using REQ socket
// Because s_send and s_recv can't handle 0MQ binary identities, we
// set a printable text identity to allow routing.
//
static void *
client_task(void *args)
{
void *context = zmq_ctx_new();
void *client = zmq_socket(context, ZMQ_REQ);
#if (defined (WIN32))
s_set_id(client, (intptr_t)args);
zmq_connect(client, "tcp://:5672"); // frontend
#else
s_set_id(client); // Set a printable identity
zmq_connect(client, "ipc://frontend.ipc");
#endif
// Send request, get reply
s_send(client, "HELLO");
char *reply = s_recv(client);
printf("Client: %s\n", reply);
free(reply);
zmq_close(client);
zmq_ctx_destroy(context);
return NULL;
}
// .split worker task
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
// This is the worker task, using a REQ socket to do load-balancing.
// Because s_send and s_recv can't handle 0MQ binary identities, we
// set a printable text identity to allow routing.
static void *
worker_task(void *args)
{
void *context = zmq_ctx_new();
void *worker = zmq_socket(context, ZMQ_REQ);
#if (defined (WIN32))
s_set_id(worker, (intptr_t)args);
zmq_connect(worker, "tcp://:5673"); // backend
#else
s_set_id(worker);
zmq_connect(worker, "ipc://backend.ipc");
#endif
// Tell broker we're ready for work
s_send(worker, "READY");
while (1) {
// Read and save all frames until we get an empty frame
// In this example there is only 1, but there could be more
char *identity = s_recv(worker);
char *empty = s_recv(worker);
assert(*empty == 0);
free(empty);
// Get request, send reply
char *request = s_recv(worker);
printf("Worker: %s\n", request);
free(request);
s_sendmore(worker, identity);
s_sendmore(worker, "");
s_send(worker, "OK");
free(identity);
}
zmq_close(worker);
zmq_ctx_destroy(context);
return NULL;
}
// .split main task
// This is the main task. It starts the clients and workers, and then
// routes requests between the two layers. Workers signal READY when
// they start; after that we treat them as ready when they reply with
// a response back to a client. The load-balancing data structure is
// just a queue of next available workers.
int main(void)
{
// Prepare our context and sockets
void *context = zmq_ctx_new();
void *frontend = zmq_socket(context, ZMQ_ROUTER);
void *backend = zmq_socket(context, ZMQ_ROUTER);
#if (defined (WIN32))
zmq_bind(frontend, "tcp://*:5672"); // frontend
zmq_bind(backend, "tcp://*:5673"); // backend
#else
zmq_bind(frontend, "ipc://frontend.ipc");
zmq_bind(backend, "ipc://backend.ipc");
#endif
int client_nbr;
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++) {
pthread_t client;
pthread_create(&client, NULL, client_task, (void *)(intptr_t)client_nbr);
}
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++) {
pthread_t worker;
pthread_create(&worker, NULL, worker_task, (void *)(intptr_t)worker_nbr);
}
// .split main task body
// Here is the main loop for the least-recently-used queue. It has two
// sockets; a frontend for clients and a backend for workers. It polls
// the backend in all cases, and polls the frontend only when there are
// one or more workers ready. This is a neat way to use 0MQ's own queues
// to hold messages we're not ready to process yet. When we get a client
// request, we pop the next available worker and send the request to it,
// including the originating client identity. When a worker replies, we
// requeue that worker and forward the reply to the original client
// using the reply envelope.
// Queue of available workers
int available_workers = 0;
char *worker_queue[10];
while (1) {
zmq_pollitem_t items[] = {
{ backend, 0, ZMQ_POLLIN, 0 },
{ frontend, 0, ZMQ_POLLIN, 0 }
};
// Poll frontend only if we have available workers
int rc = zmq_poll(items, available_workers ? 2 : 1, -1);
if (rc == -1)
break; // Interrupted
// Handle worker activity on backend
if (items[0].revents & ZMQ_POLLIN) {
// Queue worker identity for load-balancing
char *worker_id = s_recv(backend);
assert(available_workers < NBR_WORKERS);
worker_queue[available_workers++] = worker_id;
// Second frame is empty
char *empty = s_recv(backend);
assert(empty[0] == 0);
free(empty);
// Third frame is READY or else a client reply identity
char *client_id = s_recv(backend);
// If client reply, send rest back to frontend
if (strcmp(client_id, "READY") != 0) {
empty = s_recv(backend);
assert(empty[0] == 0);
free(empty);
char *reply = s_recv(backend);
s_sendmore(frontend, client_id);
s_sendmore(frontend, "");
s_send(frontend, reply);
free(reply);
if (--client_nbr == 0)
break; // Exit after N messages
}
free(client_id);
}
// .split handling a client request
// Here is how we handle a client request:
if (items[1].revents & ZMQ_POLLIN) {
// Now get next client request, route to last-used worker
// Client request is [identity][empty][request]
char *client_id = s_recv(frontend);
char *empty = s_recv(frontend);
assert(empty[0] == 0);
free(empty);
char *request = s_recv(frontend);
s_sendmore(backend, worker_queue[0]);
s_sendmore(backend, "");
s_sendmore(backend, client_id);
s_sendmore(backend, "");
s_send(backend, request);
free(client_id);
free(request);
// Dequeue and drop the next worker identity
free(worker_queue[0]);
DEQUEUE(worker_queue);
available_workers--;
}
}
zmq_close(frontend);
zmq_close(backend);
zmq_ctx_destroy(context);
return 0;
}lbbroker:使用 C++ 的负载均衡代理示例
// Least-recently used (LRU) queue device
// Clients and workers are shown here in-process
//
#include "zhelpers.hpp"
#include <thread>
#include <queue>
// Basic request-reply client using REQ socket
//
void receive_empty_message(zmq::socket_t& sock)
{
std::string empty = s_recv(sock);
assert(empty.size() == 0);
}
void client_thread(int id) {
zmq::context_t context(1);
zmq::socket_t client(context, ZMQ_REQ);
#if (defined (WIN32))
s_set_id(client, id);
client.connect("tcp://:5672"); // frontend
#else
s_set_id(client); // Set a printable identity
client.connect("ipc://frontend.ipc");
#endif
// Send request, get reply
s_send(client, std::string("HELLO"));
std::string reply = s_recv(client);
std::cout << "Client: " << reply << std::endl;
return;
}
// Worker using REQ socket to do LRU routing
//
void worker_thread(int id) {
zmq::context_t context(1);
zmq::socket_t worker(context, ZMQ_REQ);
#if (defined (WIN32))
s_set_id(worker, id);
worker.connect("tcp://:5673"); // backend
#else
s_set_id(worker);
worker.connect("ipc://backend.ipc");
#endif
// Tell backend we're ready for work
s_send(worker, std::string("READY"));
while (1) {
// Read and save all frames until we get an empty frame
// In this example there is only 1 but it could be more
std::string address = s_recv(worker);
receive_empty_message(worker);
// Get request, send reply
std::string request = s_recv(worker);
std::cout << "Worker: " << request << std::endl;
s_sendmore(worker, address);
s_sendmore(worker, std::string(""));
s_send(worker, std::string("OK"));
}
return;
}
int main(int argc, char *argv[])
{
// Prepare our context and sockets
zmq::context_t context(1);
zmq::socket_t frontend(context, ZMQ_ROUTER);
zmq::socket_t backend(context, ZMQ_ROUTER);
#if (defined (WIN32))
frontend.bind("tcp://*:5672"); // frontend
backend.bind("tcp://*:5673"); // backend
#else
frontend.bind("ipc://frontend.ipc");
backend.bind("ipc://backend.ipc");
#endif
int client_nbr = 0;
for (; client_nbr < 10; client_nbr++) {
std::thread t(client_thread, client_nbr);
t.detach();
}
for (int worker_nbr = 0; worker_nbr < 3; worker_nbr++) {
std::thread t (worker_thread, worker_nbr);
t.detach();
}
// Logic of LRU loop
// - Poll backend always, frontend only if 1+ worker ready
// - If worker replies, queue worker as ready and forward reply
// to client if necessary
// - If client requests, pop next worker and send request to it
//
// A very simple queue structure with known max size
std::queue<std::string> worker_queue;
while (1) {
// Initialize poll set
zmq::pollitem_t items[] = {
// Always poll for worker activity on backend
{ backend, 0, ZMQ_POLLIN, 0 },
// Poll front-end only if we have available workers
{ frontend, 0, ZMQ_POLLIN, 0 }
};
if (worker_queue.size())
zmq::poll(&items[0], 2, -1);
else
zmq::poll(&items[0], 1, -1);
// Handle worker activity on backend
if (items[0].revents & ZMQ_POLLIN) {
// Queue worker address for LRU routing
worker_queue.push(s_recv(backend));
receive_empty_message(backend);
// Third frame is READY or else a client reply address
std::string client_addr = s_recv(backend);
// If client reply, send rest back to frontend
if (client_addr.compare("READY") != 0) {
receive_empty_message(backend);
std::string reply = s_recv(backend);
s_sendmore(frontend, client_addr);
s_sendmore(frontend, std::string(""));
s_send(frontend, reply);
if (--client_nbr == 0)
break;
}
}
if (items[1].revents & ZMQ_POLLIN) {
// Now get next client request, route to LRU worker
// Client request is [address][empty][request]
std::string client_addr = s_recv(frontend);
{
std::string empty = s_recv(frontend);
assert(empty.size() == 0);
}
std::string request = s_recv(frontend);
std::string worker_addr = worker_queue.front();//worker_queue [0];
worker_queue.pop();
s_sendmore(backend, worker_addr);
s_sendmore(backend, std::string(""));
s_sendmore(backend, client_addr);
s_sendmore(backend, std::string(""));
s_send(backend, request);
}
}
return 0;
}
lbbroker:使用 C# 的负载均衡代理示例
lbbroker:使用 CL 的负载均衡代理示例
;;; -*- Mode:Lisp; Syntax:ANSI-Common-Lisp; -*-
;;;
;;; Least-recently used (LRU) queue device in Common Lisp
;;; Clients and workers are shown here in-process
;;;
;;; Kamil Shakirov <kamils80@gmail.com>
;;;
(defpackage #:zguide.lruqueue
(:nicknames #:lruqueue)
(:use #:cl #:zhelpers)
(:shadow #:message)
(:export #:main))
(in-package :zguide.lruqueue)
(defun message (fmt &rest args)
(let ((new-fmt (format nil "[~A] ~A"
(bt:thread-name (bt:current-thread)) fmt)))
(apply #'zhelpers:message new-fmt args)))
(defparameter *number-clients* 10)
(defparameter *number-workers* 3)
;; Basic request-reply client using REQ socket
(defun client-thread (context)
(zmq:with-socket (client context zmq:req)
(set-socket-id client) ; Makes tracing easier
(zmq:connect client "ipc://frontend.ipc")
;; Send request, get reply
(send-text client "HELLO")
(let ((reply (recv-text client)))
(message "Client: ~A~%" reply))))
;; Worker using REQ socket to do LRU routing
(defun worker-thread (context)
(zmq:with-socket (worker context zmq:req)
(set-socket-id worker) ; Makes tracing easier
(zmq:connect worker "ipc://backend.ipc")
;; Tell broker we're ready for work
(send-text worker "READY")
;; Ignore errors and exit when the context gets terminated
(ignore-errors
(loop
;; Read and save all frames until we get an empty frame
;; In this example there is only 1 but it could be more
(let ((address (recv-text worker)))
(recv-text worker) ; empty
;; Get request, send reply
(let ((request (recv-text worker)))
(message "Worker: ~A~%" request)
(send-more-text worker address)
(send-more-text worker "")
(send-text worker "OK")))))))
(defun main ()
;; Prepare our context and sockets
(zmq:with-context (context 1)
(zmq:with-socket (frontend context zmq:router)
(zmq:with-socket (backend context zmq:router)
(zmq:bind frontend "ipc://frontend.ipc")
(zmq:bind backend "ipc://backend.ipc")
(dotimes (i *number-clients*)
(bt:make-thread (lambda () (client-thread context))
:name (format nil "client-thread-~D" i)))
(dotimes (i *number-workers*)
(bt:make-thread (lambda () (worker-thread context))
:name (format nil "worker-thread-~D" i)))
;; Logic of LRU loop
;; - Poll backend always, frontend only if 1+ worker ready
;; - If worker replies, queue worker as ready and forward reply
;; to client if necessary
;; - If client requests, pop next worker and send request to it
;; Queue of available workers
(let ((number-clients *number-clients*)
(available-workers 0)
(worker-queue (make-queue)))
(loop
;; Initialize poll set
(zmq:with-polls
((items2 .
;; Always poll for worker activity on backend
((backend . zmq:pollin)
(frontend . zmq:pollin)))
(items1 .
;; Poll front-end only if we have available workers
((backend . zmq:pollin))))
(let ((revents
(if (zerop available-workers)
(zmq:poll items1)
(zmq:poll items2))))
;; Handle worker activity on backend
(when (= (first revents) zmq:pollin)
;; Queue worker address for LRU routing
(let ((worker-addr (recv-text backend)))
(assert (< available-workers *number-workers*))
(enqueue worker-queue worker-addr)
(incf available-workers))
;; Second frame is empty
(recv-text backend) ; empty
;; Third frame is READY or else a client reply address
(let ((client-addr (recv-text backend)))
(when (string/= client-addr "READY")
(recv-text backend) ; empty
(let ((reply (recv-text backend)))
(send-more-text frontend client-addr)
(send-more-text frontend "")
(send-text frontend reply))
(when (zerop (decf number-clients))
(return)))))
(when (and (cdr revents)
(= (second revents) zmq:pollin))
;; Now get next client request, route to LRU worker
;; Client request is [address][empty][request]
(let ((client-addr (recv-text frontend)))
(recv-text frontend) ; empty
(let ((request (recv-text frontend)))
(send-more-text backend (dequeue worker-queue))
(send-more-text backend "")
(send-more-text backend client-addr)
(send-more-text backend "")
(send-text backend request))
(decf available-workers)))))))))
(sleep 2))
(cleanup))
lbbroker:使用 Delphi 的负载均衡代理示例
program lbbroker;
//
// Load-balancing broker
// Clients and workers are shown here in-process
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
Windows
, SysUtils
, zmqapi
, zhelpers
;
const
NBR_CLIENTS = 10;
NBR_WORKERS = 3;
// Basic request-reply client using REQ socket
procedure client_task( args: Pointer );
var
context: TZMQContext;
client: TZMQSocket;
reply: Utf8String;
begin
context := TZMQContext.create;
client := context.Socket( stReq );
s_set_id( client ); // Set a printable identity
{$ifdef unix}
client.connect( 'ipc://frontend.ipc' );
{$else}
client.connect( 'tcp://127.0.0.1:5555' );
{$endif}
// Send request, get reply
client.send( 'HELLO' );
client.recv( reply );
zNote( Format('Client: %s',[reply]) );
client.Free;
context.Free;
end;
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
// This is the worker task, using a REQ socket to do load-balancing.
procedure worker_task( args: Pointer );
var
context: TZMQContext;
worker: TZMQSocket;
identity,
empty,
request: Utf8String;
begin
context := TZMQContext.create;
worker := context.Socket( stReq );
s_set_id( worker ); // Set a printable identity
{$ifdef unix}
worker.connect( 'ipc://backend.ipc' );
{$else}
worker.connect( 'tcp://127.0.0.1:5556' );
{$endif}
// Tell broker we're ready for work
worker.send( 'READY' );
while true do
begin
// Read and save all frames until we get an empty frame
// In this example there is only 1 but it could be more
worker.recv( identity );
worker.recv( empty );
Assert( empty = '' );
// Get request, send reply
worker.recv( request );
zNote( Format('Worker: %s',[request]) );
worker.send([
identity,
'',
'OK'
]);
end;
worker.Free;
context.Free;
end;
// This is the main task. It starts the clients and workers, and then
// routes requests between the two layers. Workers signal READY when
// they start; after that we treat them as ready when they reply with
// a response back to a client. The load-balancing data structure is
// just a queue of next available workers.
var
context: TZMQContext;
frontend,
backend: TZMQSocket;
i,j,
client_nbr,
poll_c: Integer;
tid: Cardinal;
poller: TZMQPoller;
// Queue of available workers
available_workers: Integer = 0;
worker_queue: Array[0..9] of String;
worker_id,
empty,
client_id,
reply,
request: Utf8String;
begin
// Prepare our context and sockets
context := TZMQContext.create;
frontend := context.Socket( stRouter );
backend := context.Socket( stRouter );
{$ifdef unix}
frontend.bind( 'ipc://frontend.ipc' );
backend.bind( 'ipc://backend.ipc' );
{$else}
frontend.bind( 'tcp://127.0.0.1:5555' );
backend.bind( 'tcp://127.0.0.1:5556' );
{$endif}
for i := 0 to NBR_CLIENTS - 1 do
BeginThread( nil, 0, @client_task, nil, 0, tid );
client_nbr := NBR_CLIENTS;
for i := 0 to NBR_WORKERS - 1 do
BeginThread( nil, 0, @worker_task, nil, 0, tid );
// Here is the main loop for the least-recently-used queue. It has two
// sockets; a frontend for clients and a backend for workers. It polls
// the backend in all cases, and polls the frontend only when there are
// one or more workers ready. This is a neat way to use 0MQ's own queues
// to hold messages we're not ready to process yet. When we get a client
// reply, we pop the next available worker, and send the request to it,
// including the originating client identity. When a worker replies, we
// re-queue that worker, and we forward the reply to the original client,
// using the reply envelope.
poller := TZMQPoller.Create( true );
poller.register( backend, [pePollIn] );
poller.register( frontend, [pePollIn] );
while not context.Terminated and ( client_nbr > 0 ) do
begin
// Poll frontend only if we have available workers
if available_workers > 0 then
poll_c := -1
else
poll_c := 1;
poller.poll( -1, poll_c );
// Handle worker activity on backend
if pePollIn in poller.PollItem[0].revents then
begin
// Queue worker address for LRU routing
backend.recv( worker_id );
Assert( available_workers < NBR_WORKERS );
worker_queue[available_workers] := worker_id;
inc( available_workers );
// Second frame is empty
backend.recv( empty );
Assert( empty = '' );
// Third frame is READY or else a client reply address
backend.recv( client_id );
// If client reply, send rest back to frontend
if client_id <> 'READY' then
begin
backend.recv( empty );
Assert( empty = '' );
backend.recv( reply );
frontend.send([
client_id,
'',
reply
]);
dec( client_nbr );
end;
end;
// Here is how we handle a client request:
if ( poll_c = -1 ) and ( pePollIn in poller.PollItem[1].revents ) then
begin
// Now get next client request, route to last-used worker
// Client request is [address][empty][request]
frontend.recv( client_id );
frontend.recv( empty );
Assert( empty = '' );
frontend.recv( request );
backend.send([
worker_queue[0],
'',
client_id,
'',
request
]);
// Dequeue and drop the next worker address
dec( available_workers );
for j := 0 to available_workers - 1 do
worker_queue[j] := worker_queue[j+1];
end;
end;
poller.Free;
frontend.Free;
backend.Free;
context.Free;
end.
lbbroker:使用 Erlang 的负载均衡代理示例
#! /usr/bin/env escript
%%
%% Least-recently used (LRU) queue device
%% Clients and workers are shown here in-process
%%
%% While this example runs in a single process, that is just to make
%% it easier to start and stop the example. Each thread has its own
%% context and conceptually acts as a separate process.
%%
-define(NBR_CLIENTS, 10).
-define(NBR_WORKERS, 3).
%% Basic request-reply client using REQ socket
%% Since s_send and s_recv can't handle 0MQ binary identities we
%% set a printable text identity to allow routing.
%%
client_task() ->
{ok, Context} = erlzmq:context(),
{ok, Client} = erlzmq:socket(Context, req),
ok = erlzmq:setsockopt(Client, identity, pid_to_list(self())),
ok = erlzmq:connect(Client, "ipc://frontend.ipc"),
%% Send request, get reply
ok = erlzmq:send(Client, <<"HELLO">>),
{ok, Reply} = erlzmq:recv(Client),
io:format("Client: ~s~n", [Reply]),
ok = erlzmq:close(Client),
ok = erlzmq:term(Context).
%% Worker using REQ socket to do LRU routing
%% Since s_send and s_recv can't handle 0MQ binary identities we
%% set a printable text identity to allow routing.
%%
worker_task() ->
{ok, Context} = erlzmq:context(),
{ok, Worker} = erlzmq:socket(Context, req),
ok = erlzmq:setsockopt(Worker, identity, pid_to_list(self())),
ok = erlzmq:connect(Worker, "ipc://backend.ipc"),
%% Tell broker we're ready for work
ok = erlzmq:send(Worker, <<"READY">>),
worker_loop(Worker),
ok = erlzmq:close(Worker),
ok = erlzmq:term(Context).
worker_loop(Worker) ->
%% Read and save all frames until we get an empty frame
%% In this example there is only 1 but it could be more
{ok, Address} = erlzmq:recv(Worker),
{ok, <<>>} = erlzmq:recv(Worker),
%% Get request, send reply
{ok, Request} = erlzmq:recv(Worker),
io:format("Worker: ~s~n", [Request]),
ok = erlzmq:send(Worker, Address, [sndmore]),
ok = erlzmq:send(Worker, <<>>, [sndmore]),
ok = erlzmq:send(Worker, <<"OK">>),
worker_loop(Worker).
main(_) ->
%% Prepare our context and sockets
{ok, Context} = erlzmq:context(),
{ok, Frontend} = erlzmq:socket(Context, [router, {active, true}]),
{ok, Backend} = erlzmq:socket(Context, [router, {active, true}]),
ok = erlzmq:bind(Frontend, "ipc://frontend.ipc"),
ok = erlzmq:bind(Backend, "ipc://backend.ipc"),
start_clients(?NBR_CLIENTS),
start_workers(?NBR_WORKERS),
%% Logic of LRU loop
%% - Poll backend always, frontend only if 1+ worker ready
%% - If worker replies, queue worker as ready and forward reply
%% to client if necessary
%% - If client requests, pop next worker and send request to it
%% Queue of available workers
WorkerQueue = queue:new(),
lru_loop(?NBR_CLIENTS, WorkerQueue, Frontend, Backend),
ok = erlzmq:close(Frontend),
ok = erlzmq:close(Backend),
ok = erlzmq:term(Context).
start_clients(0) -> ok;
start_clients(N) when N > 0 ->
spawn(fun() -> client_task() end),
start_clients(N - 1).
start_workers(0) -> ok;
start_workers(N) when N > 0 ->
spawn(fun() -> worker_task() end),
start_workers(N - 1).
lru_loop(0, _, _, _) -> ok;
lru_loop(NumClients, WorkerQueue, Frontend, Backend) when NumClients > 0 ->
case queue:len(WorkerQueue) of
0 ->
receive
{zmq, Backend, Msg, _} ->
lru_loop_backend(
NumClients, WorkerQueue, Frontend, Backend, Msg)
end;
_ ->
receive
{zmq, Backend, Msg, _} ->
lru_loop_backend(
NumClients, WorkerQueue, Frontend, Backend, Msg);
{zmq, Frontend, Msg, _} ->
lru_loop_frontend(
NumClients, WorkerQueue, Frontend, Backend, Msg)
end
end.
lru_loop_backend(NumClients, WorkerQueue, Frontend, Backend, WorkerAddr) ->
%% Queue worker address for LRU routing
NewWorkerQueue = queue:in(WorkerAddr, WorkerQueue),
{ok, <<>>} = active_recv(Backend),
case active_recv(Backend) of
{ok, <<"READY">>} ->
lru_loop(NumClients, NewWorkerQueue, Frontend, Backend);
{ok, ClientAddr} ->
{ok, <<>>} = active_recv(Backend),
{ok, Reply} = active_recv(Backend),
erlzmq:send(Frontend, ClientAddr, [sndmore]),
erlzmq:send(Frontend, <<>>, [sndmore]),
erlzmq:send(Frontend, Reply),
lru_loop(NumClients - 1, NewWorkerQueue, Frontend, Backend)
end.
lru_loop_frontend(NumClients, WorkerQueue, Frontend, Backend, ClientAddr) ->
%% Get next client request, route to LRU worker
%% Client request is [address][empty][request]
{ok, <<>>} = active_recv(Frontend),
{ok, Request} = active_recv(Frontend),
{{value, WorkerAddr}, NewWorkerQueue} = queue:out(WorkerQueue),
ok = erlzmq:send(Backend, WorkerAddr, [sndmore]),
ok = erlzmq:send(Backend, <<>>, [sndmore]),
ok = erlzmq:send(Backend, ClientAddr, [sndmore]),
ok = erlzmq:send(Backend, <<>>, [sndmore]),
ok = erlzmq:send(Backend, Request),
lru_loop(NumClients, NewWorkerQueue, Frontend, Backend).
active_recv(Socket) ->
receive
{zmq, Socket, Msg, _Flags} -> {ok, Msg}
end.
lbbroker:使用 Elixir 的负载均衡代理示例
defmodule Lbbroker do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:26
"""
defmacrop erlconst_NBR_CLIENTS() do
quote do
10
end
end
defmacrop erlconst_NBR_WORKERS() do
quote do
3
end
end
def client_task() do
{:ok, context} = :erlzmq.context()
{:ok, client} = :erlzmq.socket(context, :req)
:ok = :erlzmq.setsockopt(client, :identity, :erlang.pid_to_list(self()))
:ok = :erlzmq.connect(client, 'ipc://frontend.ipc')
:ok = :erlzmq.send(client, "HELLO")
{:ok, reply} = :erlzmq.recv(client)
:io.format('Client: ~s~n', [reply])
:ok = :erlzmq.close(client)
:ok = :erlzmq.term(context)
end
def worker_task() do
{:ok, context} = :erlzmq.context()
{:ok, worker} = :erlzmq.socket(context, :req)
:ok = :erlzmq.setsockopt(worker, :identity, :erlang.pid_to_list(self()))
:ok = :erlzmq.connect(worker, 'ipc://backend.ipc')
:ok = :erlzmq.send(worker, "READY")
worker_loop(worker)
:ok = :erlzmq.close(worker)
:ok = :erlzmq.term(context)
end
def worker_loop(worker) do
{:ok, address} = :erlzmq.recv(worker)
{:ok, <<>>} = :erlzmq.recv(worker)
{:ok, request} = :erlzmq.recv(worker)
:io.format('Worker: ~s~n', [request])
:ok = :erlzmq.send(worker, address, [:sndmore])
:ok = :erlzmq.send(worker, <<>>, [:sndmore])
:ok = :erlzmq.send(worker, "OK")
worker_loop(worker)
end
def main() do
{:ok, context} = :erlzmq.context()
{:ok, frontend} = :erlzmq.socket(context, [:router, {:active, true}])
{:ok, backend} = :erlzmq.socket(context, [:router, {:active, true}])
:ok = :erlzmq.bind(frontend, 'ipc://frontend.ipc')
:ok = :erlzmq.bind(backend, 'ipc://backend.ipc')
start_clients(erlconst_NBR_CLIENTS())
start_workers(erlconst_NBR_WORKERS())
workerQueue = :queue.new()
lru_loop(erlconst_NBR_CLIENTS(), workerQueue, frontend, backend)
:ok = :erlzmq.close(frontend)
:ok = :erlzmq.close(backend)
:ok = :erlzmq.term(context)
end
def start_clients(0) do
:ok
end
def start_clients(n) when n > 0 do
:erlang.spawn(fn -> client_task() end)
start_clients(n - 1)
end
def start_workers(0) do
:ok
end
def start_workers(n) when n > 0 do
:erlang.spawn(fn -> worker_task() end)
start_workers(n - 1)
end
def lru_loop(0, _, _, _) do
:ok
end
def lru_loop(numClients, workerQueue, frontend, backend) when numClients > 0 do
case(:queue.len(workerQueue)) do
0 ->
receive do
{:zmq, ^backend, msg, _} ->
lru_loop_backend(numClients, workerQueue, frontend, backend, msg)
end
_ ->
receive do
{:zmq, ^backend, msg, _} ->
lru_loop_backend(numClients, workerQueue, frontend, backend, msg)
{:zmq, ^frontend, msg, _} ->
lru_loop_frontend(numClients, workerQueue, frontend, backend, msg)
end
end
end
def lru_loop_backend(numClients, workerQueue, frontend, backend, workerAddr) do
newWorkerQueue = :queue.in(workerAddr, workerQueue)
{:ok, <<>>} = active_recv(backend)
case(active_recv(backend)) do
{:ok, "READY"} ->
lru_loop(numClients, newWorkerQueue, frontend, backend)
{:ok, clientAddr} ->
{:ok, <<>>} = active_recv(backend)
{:ok, reply} = active_recv(backend)
:erlzmq.send(frontend, clientAddr, [:sndmore])
:erlzmq.send(frontend, <<>>, [:sndmore])
:erlzmq.send(frontend, reply)
lru_loop(numClients - 1, newWorkerQueue, frontend, backend)
end
end
def lru_loop_frontend(numClients, workerQueue, frontend, backend, clientAddr) do
{:ok, <<>>} = active_recv(frontend)
{:ok, request} = active_recv(frontend)
{{:value, workerAddr}, newWorkerQueue} = :queue.out(workerQueue)
:ok = :erlzmq.send(backend, workerAddr, [:sndmore])
:ok = :erlzmq.send(backend, <<>>, [:sndmore])
:ok = :erlzmq.send(backend, clientAddr, [:sndmore])
:ok = :erlzmq.send(backend, <<>>, [:sndmore])
:ok = :erlzmq.send(backend, request)
lru_loop(numClients, newWorkerQueue, frontend, backend)
end
def active_recv(socket) do
receive do
{:zmq, ^socket, msg, _flags} ->
{:ok, msg}
end
end
end
Lbbroker.main()
lbbroker:使用 F# 的负载均衡代理示例
lbbroker:使用 Felix 的负载均衡代理示例
lbbroker:使用 Go 的负载均衡代理示例
//
// Load balancing message broker
// Port of lbbroker.c
// Written by: Aleksandar Janicijevic
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"strings"
)
const (
NBR_CLIENTS int = 10
NBR_WORKERS int = 3
)
func randomString() string {
source := "abcdefghijklmnopqrstuvwxyz"
target := make([]string, 20)
for i := 0; i < 20; i++ {
target[i] = string(source[rand.Intn(len(source))])
}
return strings.Join(target, "")
}
func set_id(socket *zmq.Socket) {
socket.SetIdentity(randomString())
}
func client_task() {
context, _ := zmq.NewContext()
defer context.Close()
client, _ := context.NewSocket(zmq.REQ)
set_id(client)
client.Connect("ipc://frontend.ipc")
defer client.Close()
// Send request, get reply
client.Send([]byte("HELLO"), 0)
reply, _ := client.Recv(0)
fmt.Println("Client: ", string(reply))
}
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each goroutine has its own
// context and conceptually acts as a separate process.
// This is the worker task, using a REQ socket to do load-balancing.
// Since s_send and s_recv can't handle 0MQ binary identities we
// set a printable text identity to allow routing.
func worker_task() {
context, _ := zmq.NewContext()
defer context.Close()
worker, _ := context.NewSocket(zmq.REQ)
defer worker.Close()
set_id(worker)
worker.Connect("ipc://backend.ipc")
// Tell broker we're ready for work
worker.Send([]byte("READY"), 0)
for {
// Read and save all frames until we get an empty frame
// In this example there is only 1 but it could be more
messageParts, _ := worker.RecvMultipart(0)
identity := messageParts[0]
empty := messageParts[1]
request := messageParts[2]
fmt.Println("Worker: ", string(request))
worker.SendMultipart([][]byte{identity, empty, []byte("OK")}, 0)
}
}
// This is the main task. It starts the clients and workers, and then
// routes requests between the two layers. Workers signal READY when
// they start; after that we treat them as ready when they reply with
// a response back to a client. The load-balancing data structure is
// just a queue of next available workers.
func main() {
context, _ := zmq.NewContext()
defer context.Close()
frontend, _ := context.NewSocket(zmq.ROUTER)
defer frontend.Close()
frontend.Bind("ipc://frontend.ipc")
backend, _ := context.NewSocket(zmq.ROUTER)
defer backend.Close()
backend.Bind("ipc://backend.ipc")
var client_nbr int
var worker_nbr int
for client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++ {
go client_task()
}
for worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++ {
go worker_task()
}
// Here is the main loop for the least-recently-used queue. It has two
// sockets; a frontend for clients and a backend for workers. It polls
// the backend in all cases, and polls the frontend only when there are
// one or more workers ready. This is a neat way to use 0MQ's own queues
// to hold messages we're not ready to process yet. When we get a client
// reply, we pop the next available worker, and send the request to it,
// including the originating client identity. When a worker replies, we
// re-queue that worker, and we forward the reply to the original client,
// using the reply envelope.
// Queue of available workers
available_workers := 0
var worker_queue []string = make([]string, 0)
for {
items := zmq.PollItems{
zmq.PollItem{Socket: backend, Events: zmq.POLLIN},
zmq.PollItem{Socket: frontend, Events: zmq.POLLIN},
}
// Poll frontend only if we have available workers
var err error
if available_workers > 0 {
_, err = zmq.Poll(items, -1)
} else {
_, err = zmq.Poll(items[:1], -1)
}
if err != nil {
break // Interrupted
}
// Handle worker activity on backend
if items[0].REvents&zmq.POLLIN != 0 {
parts, _ := backend.RecvMultipart(0)
// Queue worker identity for load-balancing
worker_id := string(parts[0])
worker_queue = append(worker_queue, worker_id)
available_workers++
// Second frame is empty
empty := parts[1]
// Third frame is READY or else a client reply identity
client_id := parts[2]
// If client reply, send rest back to frontend
if string(client_id) != "READY" {
empty = parts[3]
reply := parts[4]
frontend.SendMultipart([][]byte{client_id, empty, reply}, 0)
client_nbr--
if client_nbr == 0 {
// Exit after N messages
break
}
}
}
// Here is how we handle a client request:
if items[1].REvents&zmq.POLLIN != 0 {
// Now get next client request, route to last-used worker
// Client request is [identity][empty][request]
parts, _ := frontend.RecvMultipart(0)
client_id := parts[0]
empty := parts[1]
request := parts[2]
backend.SendMultipart([][]byte{[]byte(worker_queue[0]), empty, client_id,
empty, request}, 0)
worker_queue = worker_queue[1:]
available_workers--
}
}
}
lbbroker:使用 Haskell 的负载均衡代理示例
{-# LANGUAGE OverloadedStrings #-}
-- |
-- Load balancing broker (p.96)
-- (Clients) [REQ] >-> (frontend) ROUTER (Proxy) ROUTER (backend) >-> [REQ] (Workers)
-- Clients and workers are shown here in-process
-- Compile with -threaded
module Main where
import System.ZMQ4.Monadic
import Control.Concurrent (threadDelay)
import Data.ByteString.Char8 (pack, unpack)
import Control.Monad (forM_, forever, when)
import Control.Applicative ((<$>))
import Text.Printf
nbrClients :: Int
nbrClients = 10
nbrWorkers :: Int
nbrWorkers = 3
workerThread :: Show a => a -> ZMQ z ()
workerThread i = do
sock <- socket Req
let ident = "Worker-" ++ show i
setIdentity (restrict $ pack ident) sock
connect sock "inproc://workers"
send sock [] "READY"
forever $ do
address <- receive sock
receive sock -- empty frame
receive sock >>= liftIO . printf "%s : %s\n" ident . unpack
send sock [SendMore] address
send sock [SendMore] ""
send sock [] "OK"
clientThread :: Show a => a -> ZMQ z ()
clientThread i = do
sock <- socket Req
let ident = "Client-" ++ show i
setIdentity (restrict $ pack ident) sock
connect sock "inproc://clients"
send sock [] "GO"
msg <- receive sock
liftIO $ printf "%s : %s\n" ident (unpack msg)
-- | Handle worker activity on backend
processBackend :: (Receiver r, Sender s) => [String] -> Int -> Socket z r -> Socket z s -> [Event] -> ZMQ z ([String], Int)
processBackend availableWorkers clientCount backend frontend evts
-- A msg can be received without bloking
| In `elem` evts = do
-- the msg comes from a worker: first frame is the worker id
workerId <- unpack <$> receive backend
empty <- unpack <$> receive backend
when (empty /= "") $ error "The second frame should be empty"
let workerQueue = availableWorkers ++ [workerId]
-- the third frame is the msg "READY" from a or a client reply id
msg <- unpack <$> receive backend
if msg == "READY"
then
return (workerQueue, clientCount)
else do
empty' <- unpack <$> receive backend
when (empty' /= "") $ error "The fourth frame should be an empty delimiter"
-- the fifth frame is the client message
reply <- receive backend
-- send back an acknowledge msg to the client (msg is the clientId)
send frontend [SendMore] (pack msg)
send frontend [SendMore] ""
send frontend [] reply
-- decrement clientCount to mark a job done
return (workerQueue, clientCount - 1)
| otherwise = return (availableWorkers, clientCount)
processFrontend :: (Receiver r, Sender s) => [String] -> Socket z r -> Socket z s -> [Event] -> ZMQ z [String]
processFrontend availableWorkers frontend backend evts
| In `elem` evts = do
clientId <- receive frontend
empty <- unpack <$> receive frontend
when (empty /= "") $ error "The second frame should be empty"
request <- receive frontend
send backend [SendMore] (pack $ head availableWorkers)
send backend [SendMore] ""
send backend [SendMore] clientId
send backend [SendMore] ""
send backend [] request
return (tail availableWorkers)
| otherwise = return availableWorkers
lruQueue :: Socket z Router -> Socket z Router -> ZMQ z ()
lruQueue backend frontend =
-- start with an empty list of available workers
loop [] nbrClients
where
loop availableWorkers clientCount = do
[evtsB, evtsF] <- poll (-1) [Sock backend [In] Nothing, Sock frontend [In] Nothing]
-- (always) poll for workers activity
(availableWorkers', clientCount') <- processBackend availableWorkers clientCount backend frontend evtsB
when (clientCount' > 0) $
-- Poll frontend only if we have available workers
if not (null availableWorkers')
then do
availableWorkers'' <- processFrontend availableWorkers' frontend backend evtsF
loop availableWorkers'' clientCount'
else loop availableWorkers' clientCount'
main :: IO ()
main =
runZMQ $ do
frontend <- socket Router
bind frontend "inproc://clients"
backend <- socket Router
bind backend "inproc://workers"
forM_ [1..nbrWorkers] $ \i -> async (workerThread i)
forM_ [1..nbrClients] $ \i -> async (clientThread i)
lruQueue backend frontend
liftIO $ threadDelay $ 1 * 1000 * 1000
lbbroker:使用 Haxe 的负载均衡代理示例
package ;
import haxe.io.Bytes;
import neko.Lib;
#if (neko || cpp)
import neko.vm.Thread;
#end
import haxe.Stack;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQContext;
import org.zeromq.ZMQException;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
/**
* Least - recently used (LRU) queue device
* Clients and workers are shown here in-process
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* NB: LRUQueue deliberately uses the lower-level ZMQxxx.hx classes.
* See LRUQueue2 for a cleaner implementation using the Zxxx.hx classes, modelled on czmq
*
* See: https://zguide.zeromq.cn/page:all#A-Request-Reply-Message-Broker
*/
class LRUQueue
{
private static inline var NBR_CLIENTS = 10;
private static inline var NBR_WORKERS = 3;
/**
* Basic request-reply client using REQ socket.
*/
public static function clientTask() {
var context:ZContext = new ZContext();
var client:ZMQSocket = context.createSocket(ZMQ_REQ);
var id = ZHelpers.setID(client);
client.connect("ipc:///tmp/frontend.ipc");
// Send request, receive reply
client.sendMsg(Bytes.ofString("HELLO"));
var reply = client.recvMsg();
Lib.println("Client "+id+": " + reply.toString());
context.destroy();
}
/**
* Worker using REQ socket to do LRU routing.
*/
public static function workerTask() {
var context:ZContext = new ZContext();
var worker:ZMQSocket = context.createSocket(ZMQ_REQ);
var id = ZHelpers.setID(worker);
worker.connect("ipc:///tmp/backend.ipc");
// Tell broker we're ready to do work
worker.sendMsg(Bytes.ofString("READY"));
while (true) {
// Read and save all frames until we get an empty frame
// In this example, there is only 1 but it could be more.
var address = worker.recvMsg();
var empty = worker.recvMsg();
// Get request, send reply
var request = worker.recvMsg();
Lib.println("Worker "+id+": " + request.toString());
worker.sendMsg(address, SNDMORE);
worker.sendMsg(empty, SNDMORE);
worker.sendMsg(Bytes.ofString("OK"));
}
context.destroy();
}
public static function main() {
Lib.println("** LRUQueue (see: https://zguide.zeromq.cn/page:all#A-Request-Reply-Message-Broker)");
var client_nbr:Int = 0, worker_nbr:Int;
#if php
// PHP appears to require tasks to be forked before main process creates ZMQ context
for (client_nbr in 0 ... NBR_CLIENTS) {
forkClientTask();
}
for (worker_nbr in 0 ... NBR_WORKERS) {
forkWorkerTask();
}
#end
// Prepare our context and sockets
var context:ZContext = new ZContext();
var frontend:ZMQSocket = context.createSocket(ZMQ_ROUTER);
var backend:ZMQSocket = context.createSocket(ZMQ_ROUTER);
frontend.bind("ipc:///tmp/frontend.ipc");
backend.bind("ipc:///tmp/backend.ipc");
#if !php
// Non-PHP targets require threads to be created after main thread has set up ZMQ Context
for (client_nbr in 0 ... NBR_CLIENTS) {
Thread.create(clientTask);
}
for (worker_nbr in 0 ... NBR_WORKERS) {
Thread.create(workerTask);
}
#end
// Logic of LRU loop:
// - Poll backend always, frontend only if 1 or more worker si ready
// - If worker replies, queue worker as ready and forward reply
// to client if necessary.
// - If client requests, pop next worker and send request to it.
// Queue of available workers
var workerQueue:List<String> = new List<String>();
var poller:ZMQPoller = new ZMQPoller();
poller.registerSocket(backend, ZMQ.ZMQ_POLLIN());
client_nbr = NBR_CLIENTS;
while (true) {
poller.unregisterSocket(frontend);
if (workerQueue.length > 0) {
// Only poll frontend if there is at least 1 worker ready to do work
poller.registerSocket(frontend, ZMQ.ZMQ_POLLIN());
}
try {
poller.poll( -1 );
} catch (e:ZMQException) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
// Handle worker activity on backend
if (poller.pollin(1)) {
// Queue worker address for LRU routing
var workerAddr = backend.recvMsg();
if (workerQueue.length < NBR_WORKERS)
workerQueue.add(workerAddr.toString());
// Second frame is empty
var empty = backend.recvMsg();
// Third frame is READY or else a client reply address
var clientAddr = backend.recvMsg();
// If client reply, send rest back to frontend
if (clientAddr.toString() != "READY") {
empty = backend.recvMsg();
var reply = backend.recvMsg();
frontend.sendMsg(clientAddr, SNDMORE);
frontend.sendMsg(Bytes.ofString(""), SNDMORE);
frontend.sendMsg(reply);
if (--client_nbr == 0)
break; // Exit after NBR_CLIENTS messages
}
}
if (poller.pollin(2)) {
// Now get next client request, route to LRU worker
// Client request is [address][empty][request]
var clientAddr = frontend.recvMsg();
var empty = frontend.recvMsg();
var request = frontend.recvMsg();
backend.sendMsg(Bytes.ofString(workerQueue.pop()), SNDMORE);
backend.sendMsg(Bytes.ofString(""), SNDMORE);
backend.sendMsg(clientAddr, SNDMORE);
backend.sendMsg(Bytes.ofString(""), SNDMORE);
backend.sendMsg(request);
}
}
context.destroy();
}
#if php
private static inline function forkWorkerTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
LRUQueue::workerTask();
exit();
}');
return;
}
private static inline function forkClientTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
LRUQueue::clientTask();
exit();
}');
return;
}
#end
}lbbroker:使用 Java 的负载均衡代理示例
package guide;
import java.util.LinkedList;
import java.util.Queue;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZContext;
public class lbbroker
{
private static final int NBR_CLIENTS = 10;
private static final int NBR_WORKERS = 3;
/**
* Basic request-reply client using REQ socket
*/
private static class ClientTask extends Thread
{
@Override
public void run()
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
Socket client = context.createSocket(SocketType.REQ);
ZHelper.setId(client); // Set a printable identity
client.connect("ipc://frontend.ipc");
// Send request, get reply
client.send("HELLO");
String reply = client.recvStr();
System.out.println("Client: " + reply);
}
}
}
/**
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
* This is the worker task, using a REQ socket to do load-balancing.
*/
private static class WorkerTask extends Thread
{
@Override
public void run()
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
Socket worker = context.createSocket(SocketType.REQ);
ZHelper.setId(worker); // Set a printable identity
worker.connect("ipc://backend.ipc");
// Tell backend we're ready for work
worker.send("READY");
while (!Thread.currentThread().isInterrupted()) {
String address = worker.recvStr();
String empty = worker.recvStr();
assert (empty.length() == 0);
// Get request, send reply
String request = worker.recvStr();
System.out.println("Worker: " + request);
worker.sendMore(address);
worker.sendMore("");
worker.send("OK");
}
}
}
}
/**
* This is the main task. It starts the clients and workers, and then
* routes requests between the two layers. Workers signal READY when
* they start; after that we treat them as ready when they reply with
* a response back to a client. The load-balancing data structure is
* just a queue of next available workers.
*/
public static void main(String[] args)
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
Socket frontend = context.createSocket(SocketType.ROUTER);
Socket backend = context.createSocket(SocketType.ROUTER);
frontend.bind("ipc://frontend.ipc");
backend.bind("ipc://backend.ipc");
int clientNbr;
for (clientNbr = 0; clientNbr < NBR_CLIENTS; clientNbr++)
new ClientTask().start();
for (int workerNbr = 0; workerNbr < NBR_WORKERS; workerNbr++)
new WorkerTask().start();
// Here is the main loop for the least-recently-used queue. It has
// two sockets; a frontend for clients and a backend for workers.
// It polls the backend in all cases, and polls the frontend only
// when there are one or more workers ready. This is a neat way to
// use 0MQ's own queues to hold messages we're not ready to process
// yet. When we get a client reply, we pop the next available
// worker, and send the request to it, including the originating
// client identity. When a worker replies, we re-queue that worker,
// and we forward the reply to the original client, using the reply
// envelope.
// Queue of available workers
Queue<String> workerQueue = new LinkedList<String>();
while (!Thread.currentThread().isInterrupted()) {
// Initialize poll set
Poller items = context.createPoller(2);
// Always poll for worker activity on backend
items.register(backend, Poller.POLLIN);
// Poll front-end only if we have available workers
if (workerQueue.size() > 0)
items.register(frontend, Poller.POLLIN);
if (items.poll() < 0)
break; // Interrupted
// Handle worker activity on backend
if (items.pollin(0)) {
// Queue worker address for LRU routing
workerQueue.add(backend.recvStr());
// Second frame is empty
String empty = backend.recvStr();
assert (empty.length() == 0);
// Third frame is READY or else a client reply address
String clientAddr = backend.recvStr();
// If client reply, send rest back to frontend
if (!clientAddr.equals("READY")) {
empty = backend.recvStr();
assert (empty.length() == 0);
String reply = backend.recvStr();
frontend.sendMore(clientAddr);
frontend.sendMore("");
frontend.send(reply);
if (--clientNbr == 0)
break;
}
}
if (items.pollin(1)) {
// Now get next client request, route to LRU worker
// Client request is [address][empty][request]
String clientAddr = frontend.recvStr();
String empty = frontend.recvStr();
assert (empty.length() == 0);
String request = frontend.recvStr();
String workerAddr = workerQueue.poll();
backend.sendMore(workerAddr);
backend.sendMore("");
backend.sendMore(clientAddr);
backend.sendMore("");
backend.send(request);
}
}
}
}
}
lbbroker:使用 Julia 的负载均衡代理示例
lbbroker:使用 Lua 的负载均衡代理示例
--
-- Least-recently used (LRU) queue device
-- Clients and workers are shown here in-process
--
-- While this example runs in a single process, that is just to make
-- it easier to start and stop the example. Each thread has its own
-- context and conceptually acts as a separate process.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.threads"
require"zmq.poller"
require"zhelpers"
local tremove = table.remove
local NBR_CLIENTS = 10
local NBR_WORKERS = 3
local pre_code = [[
local identity, seed = ...
local zmq = require"zmq"
require"zhelpers"
math.randomseed(seed)
]]
-- Basic request-reply client using REQ socket
-- Since s_send and s_recv can't handle 0MQ binary identities we
-- set a printable text identity to allow routing.
--
local client_task = pre_code .. [[
local context = zmq.init(1)
local client = context:socket(zmq.REQ)
client:setopt(zmq.IDENTITY, identity) -- Set a printable identity
client:connect("ipc://frontend.ipc")
-- Send request, get reply
client:send("HELLO")
local reply = client:recv()
printf ("Client: %s\n", reply)
client:close()
context:term()
]]
-- Worker using REQ socket to do LRU routing
-- Since s_send and s_recv can't handle 0MQ binary identities we
-- set a printable text identity to allow routing.
--
local worker_task = pre_code .. [[
local context = zmq.init(1)
local worker = context:socket(zmq.REQ)
worker:setopt(zmq.IDENTITY, identity) -- Set a printable identity
worker:connect("ipc://backend.ipc")
-- Tell broker we're ready for work
worker:send("READY")
while true do
-- Read and save all frames until we get an empty frame
-- In this example there is only 1 but it could be more
local address = worker:recv()
local empty = worker:recv()
assert (#empty == 0)
-- Get request, send reply
local request = worker:recv()
printf ("Worker: %s\n", request)
worker:send(address, zmq.SNDMORE)
worker:send("", zmq.SNDMORE)
worker:send("OK")
end
worker:close()
context:term()
]]
s_version_assert (2, 1)
-- Prepare our context and sockets
local context = zmq.init(1)
local frontend = context:socket(zmq.ROUTER)
local backend = context:socket(zmq.ROUTER)
frontend:bind("ipc://frontend.ipc")
backend:bind("ipc://backend.ipc")
local clients = {}
for n=1,NBR_CLIENTS do
local identity = string.format("%04X-%04X", randof (0x10000), randof (0x10000))
local seed = os.time() + math.random()
clients[n] = zmq.threads.runstring(context, client_task, identity, seed)
clients[n]:start()
end
local workers = {}
for n=1,NBR_WORKERS do
local identity = string.format("%04X-%04X", randof (0x10000), randof (0x10000))
local seed = os.time() + math.random()
workers[n] = zmq.threads.runstring(context, worker_task, identity, seed)
workers[n]:start(true)
end
-- Logic of LRU loop
-- - Poll backend always, frontend only if 1+ worker ready
-- - If worker replies, queue worker as ready and forward reply
-- to client if necessary
-- - If client requests, pop next worker and send request to it
-- Queue of available workers
local worker_queue = {}
local is_accepting = false
local max_requests = #clients
local poller = zmq.poller(2)
local function frontend_cb()
-- Now get next client request, route to LRU worker
-- Client request is [address][empty][request]
local client_addr = frontend:recv()
local empty = frontend:recv()
assert (#empty == 0)
local request = frontend:recv()
-- Dequeue a worker from the queue.
local worker = tremove(worker_queue, 1)
backend:send(worker, zmq.SNDMORE)
backend:send("", zmq.SNDMORE)
backend:send(client_addr, zmq.SNDMORE)
backend:send("", zmq.SNDMORE)
backend:send(request)
if (#worker_queue == 0) then
-- stop accepting work from clients, when no workers are available.
poller:remove(frontend)
is_accepting = false
end
end
poller:add(backend, zmq.POLLIN, function()
-- Queue worker address for LRU routing
local worker_addr = backend:recv()
worker_queue[#worker_queue + 1] = worker_addr
-- start accepting client requests, if we are not already doing so.
if not is_accepting then
is_accepting = true
poller:add(frontend, zmq.POLLIN, frontend_cb)
end
-- Second frame is empty
local empty = backend:recv()
assert (#empty == 0)
-- Third frame is READY or else a client reply address
local client_addr = backend:recv()
-- If client reply, send rest back to frontend
if (client_addr ~= "READY") then
empty = backend:recv()
assert (#empty == 0)
local reply = backend:recv()
frontend:send(client_addr, zmq.SNDMORE)
frontend:send("", zmq.SNDMORE)
frontend:send(reply)
max_requests = max_requests - 1
if (max_requests == 0) then
poller:stop() -- Exit after N messages
end
end
end)
-- start poller's event loop
poller:start()
frontend:close()
backend:close()
context:term()
for n=1,NBR_CLIENTS do
assert(clients[n]:join())
end
-- workers are detached, we don't need to join with them.
lbbroker:使用 Node.js 的负载均衡代理示例
cluster = require('cluster')
, zmq = require('zeromq')
, backAddr = 'tcp://127.0.0.1:12345'
, frontAddr = 'tcp://127.0.0.1:12346'
, clients = 10
, workers = 3;
function clientProcess() {
var sock = zmq.socket('req');
sock.identity = "client" + process.pid
sock.connect(frontAddr)
sock.send("HELLO")
sock.on('message', function(data) {
console.log(sock.identity + " <- '" + data + "'");
sock.close()
cluster.worker.kill()
})
}
function workerProcess() {
var sock = zmq.socket('req');
sock.identity = "worker" + process.pid
sock.connect(backAddr)
sock.send('READY')
sock.on('message', function() {
var args = Array.apply(null, arguments)
console.log("'" + args + "' -> " + sock.identity);
sock.send([arguments[0], '', 'OK'])
})
}
function loadBalancer() {
var workers = [] // list of available worker id's
var backSvr = zmq.socket('router')
backSvr.identity = 'backSvr' + process.pid
backSvr.bind(backAddr, function(err) {
if (err) throw err;
backSvr.on('message', function() {
// Any worker that messages us is ready for more work
workers.push(arguments[0])
if (arguments[2] != 'READY') {
frontSvr.send([arguments[2], arguments[3], arguments[4]])
}
})
})
var frontSvr = zmq.socket('router');
frontSvr.identity = 'frontSvr' + process.pid;
frontSvr.bind(frontAddr, function(err) {
if (err) throw err;
frontSvr.on('message', function() {
var args = Array.apply(null, arguments)
// What if no workers are available? Delay till one is ready.
// This is because I don't know the equivalent of zmq_poll
// in Node.js zeromq, which is basically an event loop itself.
// I start an interval so that the message is eventually sent. \
// Maybe there is a better way.
var interval = setInterval(function() {
if (workers.length > 0) {
backSvr.send([workers.shift(), '', args[0], '', args[2]])
clearInterval(interval)
}
}, 10)
});
});
}
// Example is finished.
// Node process management noise below
if (cluster.isMaster) {
// create the workers and clients.
// Use env variables to dictate client or worker
for (var i = 0; i < workers; i++) cluster.fork({
"TYPE": 'worker'
});
for (var i = 0; i < clients; i++) cluster.fork({
"TYPE": 'client'
});
cluster.on('death', function(worker) {
console.log('worker ' + worker.pid + ' died');
});
var deadClients = 0;
cluster.on('disconnect', function(worker) {
deadClients++
if (deadClients === clients) {
console.log('finished')
process.exit(0)
}
});
loadBalancer()
} else {
if (process.env.TYPE === 'client') {
clientProcess()
} else {
workerProcess()
}
}
lbbroker:使用 Objective-C 的负载均衡代理示例
lbbroker:使用 ooc 的负载均衡代理示例
lbbroker:使用 Perl 的负载均衡代理示例
# Load-balancing broker
# Clients and workers are shown here in-process
use strict;
use warnings;
use v5.10;
use threads;
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_REQ ZMQ_ROUTER);
use AnyEvent;
use EV;
my $NBR_CLIENTS = 10;
my $NBR_WORKERS = 3;
# Basic request-reply client using REQ socket
sub client_task {
my ($client_nbr) = @_;
my $context = ZMQ::FFI->new();
my $client = $context->socket(ZMQ_REQ);
$client->set_identity("client-$client_nbr");
$client->connect('ipc://frontend.ipc');
# Send request, get reply
$client->send("HELLO");
my $reply = $client->recv();
say "Client: $reply";
}
# While this example runs in a single process, that is just to make
# it easier to start and stop the example. Each client_thread has its own
# context and conceptually acts as a separate process.
# This is the worker task, using a REQ socket to do load-balancing.
sub worker_task {
my ($worker_nbr) = @_;
my $context = ZMQ::FFI->new();
my $worker = $context->socket(ZMQ_REQ);
$worker->set_identity("worker-$worker_nbr");
$worker->connect('ipc://backend.ipc');
# Tell broker we're ready for work
$worker->send('READY');
while (1) {
# Read and save all frames, including empty frame and request
# This example has only one frame before the empty one,
# but there could be more
my ($identity, $empty, $request) = $worker->recv_multipart();
say "Worker: $request";
# Send reply
$worker->send_multipart([$identity, '', 'OK']);
}
}
# This is the main task. It starts the clients and workers, and then
# routes requests between the two layers. Workers signal READY when
# they start; after that we treat them as ready when they reply with
# a response back to a client. The load-balancing data structure is
# just a queue of next available workers.
# Prepare our context and sockets
my $context = ZMQ::FFI->new();
my $frontend = $context->socket(ZMQ_ROUTER);
my $backend = $context->socket(ZMQ_ROUTER);
$frontend->bind('ipc://frontend.ipc');
$backend->bind('ipc://backend.ipc');
my @client_thr;
my $client_nbr;
for (1..$NBR_CLIENTS) {
push @client_thr, threads->create('client_task', ++$client_nbr);
}
for my $worker_nbr (1..$NBR_WORKERS) {
threads->create('worker_task', $worker_nbr)->detach();
}
# Here is the main loop for the least-recently-used queue. It has two
# sockets; a frontend for clients and a backend for workers. It polls
# the backend in all cases, and polls the frontend only when there are
# one or more workers ready. This is a neat way to use 0MQ's own queues
# to hold messages we're not ready to process yet. When we get a client
# reply, we pop the next available worker and send the request to it,
# including the originating client identity. When a worker replies, we
# requeue that worker and forward the reply to the original client
# using the reply envelope.
# Queue of available workers
my @workers;
# Only poll for requests from backend until workers are available
my $worker_poller = AE::io $backend->get_fd, 0, \&poll_backend;
my $client_poller;
# Start the loop
EV::run;
# Give client threads time to flush final output after main loop finishes
$_->join() for @client_thr;
sub poll_backend {
while ($backend->has_pollin) {
# Handle worker activity on backend
my $worker_id = $backend->recv();
if (!@workers) {
# Poll for clients now that a worker is available
$client_poller = AE::io $frontend->get_fd, 0, \&poll_frontend;
}
# Queue worker identity for load-balancing
push @workers, $worker_id;
# Second frame is empty
$backend->recv();
# Third frame is READY or else a client reply identity
my $client_id = $backend->recv();
# If client reply, send rest back to frontend
if ($client_id ne 'READY') {
my ($empty, $reply) = $backend->recv_multipart();
$frontend->send_multipart([$client_id, '', $reply]);
--$client_nbr;
}
if ($client_nbr == 0) {
# End the loop after N messages
EV::break;
}
}
}
sub poll_frontend {
while ($frontend->has_pollin) {
if (!@workers) {
# Stop polling clients until more workers becomes available
undef $client_poller;
return;
}
# Here is how we handle a client request:
# Get next client request, route to last-used worker
my ($client_id, $empty, $request) = $frontend->recv_multipart();
my $worker_id = shift @workers;
$backend->send_multipart(
[$worker_id, '', $client_id, '', $request]
);
}
}
lbbroker:使用 PHP 的负载均衡代理示例
<?php
/*
* Least-recently used (LRU) queue device
* Clients and workers are shown here as IPC as PHP
* does not have threads.
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
define("NBR_CLIENTS", 10);
define("NBR_WORKERS", 3);
// Basic request-reply client using REQ socket
function client_thread()
{
$context = new ZMQContext();
$client = new ZMQSocket($context, ZMQ::SOCKET_REQ);
$client->connect("ipc://frontend.ipc");
// Send request, get reply
$client->send("HELLO");
$reply = $client->recv();
printf("Client: %s%s", $reply, PHP_EOL);
}
// Worker using REQ socket to do LRU routing
function worker_thread ()
{
$context = new ZMQContext();
$worker = $context->getSocket(ZMQ::SOCKET_REQ);
$worker->connect("ipc://backend.ipc");
// Tell broker we're ready for work
$worker->send("READY");
while (true) {
// Read and save all frames until we get an empty frame
// In this example there is only 1 but it could be more
$address = $worker->recv();
// Additional logic to clean up workers.
if ($address == "END") {
exit();
}
$empty = $worker->recv();
assert(empty($empty));
// Get request, send reply
$request = $worker->recv();
printf ("Worker: %s%s", $request, PHP_EOL);
$worker->send($address, ZMQ::MODE_SNDMORE);
$worker->send("", ZMQ::MODE_SNDMORE);
$worker->send("OK");
}
}
function main()
{
for ($client_nbr = 0; $client_nbr < NBR_CLIENTS; $client_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
client_thread();
return;
}
}
for ($worker_nbr = 0; $worker_nbr < NBR_WORKERS; $worker_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
worker_thread();
return;
}
}
$context = new ZMQContext();
$frontend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$backend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$frontend->bind("ipc://frontend.ipc");
$backend->bind("ipc://backend.ipc");
// Logic of LRU loop
// - Poll backend always, frontend only if 1+ worker ready
// - If worker replies, queue worker as ready and forward reply
// to client if necessary
// - If client requests, pop next worker and send request to it
// Queue of available workers
$available_workers = 0;
$worker_queue = array();
$writeable = $readable = array();
while ($client_nbr > 0) {
$poll = new ZMQPoll();
// Poll front-end only if we have available workers
if ($available_workers > 0) {
$poll->add($frontend, ZMQ::POLL_IN);
}
// Always poll for worker activity on backend
$poll->add($backend, ZMQ::POLL_IN);
$events = $poll->poll($readable, $writeable);
if ($events > 0) {
foreach ($readable as $socket) {
// Handle worker activity on backend
if ($socket === $backend) {
// Queue worker address for LRU routing
$worker_addr = $socket->recv();
assert($available_workers < NBR_WORKERS);
$available_workers++;
array_push($worker_queue, $worker_addr);
// Second frame is empty
$empty = $socket->recv();
assert(empty($empty));
// Third frame is READY or else a client reply address
$client_addr = $socket->recv();
if ($client_addr != "READY") {
$empty = $socket->recv();
assert(empty($empty));
$reply = $socket->recv();
$frontend->send($client_addr, ZMQ::MODE_SNDMORE);
$frontend->send("", ZMQ::MODE_SNDMORE);
$frontend->send($reply);
// exit after all messages relayed
$client_nbr--;
}
} elseif ($socket === $frontend) {
// Now get next client request, route to LRU worker
// Client request is [address][empty][request]
$client_addr = $socket->recv();
$empty = $socket->recv();
assert(empty($empty));
$request = $socket->recv();
$backend->send(array_shift($worker_queue), ZMQ::MODE_SNDMORE);
$backend->send("", ZMQ::MODE_SNDMORE);
$backend->send($client_addr, ZMQ::MODE_SNDMORE);
$backend->send("", ZMQ::MODE_SNDMORE);
$backend->send($request);
$available_workers--;
}
}
}
}
// Clean up our worker processes
foreach ($worker_queue as $worker) {
$backend->send($worker, ZMQ::MODE_SNDMORE);
$backend->send("", ZMQ::MODE_SNDMORE);
$backend->send('END');
}
sleep(1);
}
main();
lbbroker:使用 Python 的负载均衡代理示例
"""
Load-balancing broker
Clients and workers are shown here in-process.
Author: Brandon Carpenter (hashstat) <brandon(dot)carpenter(at)pnnl(dot)gov>
"""
from __future__ import print_function
import multiprocessing
import zmq
NBR_CLIENTS = 10
NBR_WORKERS = 3
def client_task(ident):
"""Basic request-reply client using REQ socket."""
socket = zmq.Context().socket(zmq.REQ)
socket.identity = u"Client-{}".format(ident).encode("ascii")
socket.connect("ipc://frontend.ipc")
# Send request, get reply
socket.send(b"HELLO")
reply = socket.recv()
print("{}: {}".format(socket.identity.decode("ascii"),
reply.decode("ascii")))
def worker_task(ident):
"""Worker task, using a REQ socket to do load-balancing."""
socket = zmq.Context().socket(zmq.REQ)
socket.identity = u"Worker-{}".format(ident).encode("ascii")
socket.connect("ipc://backend.ipc")
# Tell broker we're ready for work
socket.send(b"READY")
while True:
address, empty, request = socket.recv_multipart()
print("{}: {}".format(socket.identity.decode("ascii"),
request.decode("ascii")))
socket.send_multipart([address, b"", b"OK"])
def main():
"""Load balancer main loop."""
# Prepare context and sockets
context = zmq.Context.instance()
frontend = context.socket(zmq.ROUTER)
frontend.bind("ipc://frontend.ipc")
backend = context.socket(zmq.ROUTER)
backend.bind("ipc://backend.ipc")
# Start background tasks
def start(task, *args):
process = multiprocessing.Process(target=task, args=args)
process.daemon = True
process.start()
for i in range(NBR_CLIENTS):
start(client_task, i)
for i in range(NBR_WORKERS):
start(worker_task, i)
# Initialize main loop state
count = NBR_CLIENTS
backend_ready = False
workers = []
poller = zmq.Poller()
# Only poll for requests from backend until workers are available
poller.register(backend, zmq.POLLIN)
while True:
sockets = dict(poller.poll())
if backend in sockets:
# Handle worker activity on the backend
request = backend.recv_multipart()
worker, empty, client = request[:3]
workers.append(worker)
if workers and not backend_ready:
# Poll for clients now that a worker is available and backend was not ready
poller.register(frontend, zmq.POLLIN)
backend_ready = True
if client != b"READY" and len(request) > 3:
# If client reply, send rest back to frontend
empty, reply = request[3:]
frontend.send_multipart([client, b"", reply])
count -= 1
if not count:
break
if frontend in sockets:
# Get next client request, route to last-used worker
client, empty, request = frontend.recv_multipart()
worker = workers.pop(0)
backend.send_multipart([worker, b"", client, b"", request])
if not workers:
# Don't poll clients if no workers are available and set backend_ready flag to false
poller.unregister(frontend)
backend_ready = False
# Clean up
backend.close()
frontend.close()
context.term()
if __name__ == "__main__":
main()
lbbroker:使用 Q 的负载均衡代理示例
lbbroker:使用 Racket 的负载均衡代理示例
lbbroker:使用 Ruby 的负载均衡代理示例
#!/usr/bin/env ruby
# Load-balancing broker
# Clients and workers are shown here in-process
require 'rubygems'
require 'ffi-rzmq'
CLIENT_SIZE = 10
WORKER_SIZE = 3
def client_task(identity)
context = ZMQ::Context.new
client = context.socket ZMQ::REQ
client.identity = identity
client.connect "ipc://frontend.ipc"
client.send_string "HELLO"
client.recv_string reply = ""
puts "#{identity}: #{reply}"
client.close
context.destroy
end
def worker_task(identity)
context = ZMQ::Context.new
worker = context.socket ZMQ::REQ
worker.identity = identity
worker.connect "ipc://backend.ipc"
worker.send_string "READY"
loop do
worker.recv_string client = ""
worker.recv_string empty = ""
worker.recv_string request = ""
puts "#{identity}: #{request} from #{client}"
worker.send_strings [client, empty, "OK from #{identity}"]
end
worker.close
context.destroy
end
def main_task
context = ZMQ::Context.new
frontend = context.socket ZMQ::ROUTER
backend = context.socket ZMQ::ROUTER
frontend.bind "ipc://frontend.ipc"
backend.bind "ipc://backend.ipc"
CLIENT_SIZE.times do |client_id|
Thread.new { client_task "CLIENT-#{client_id}" }
end
WORKER_SIZE.times do |worker_id|
Thread.new { worker_task "WORKER-#{worker_id}" }
end
available_workers = []
poller = ZMQ::Poller.new
poller.register_readable backend
poller.register_readable frontend
# The poller will continuously poll the backend and will poll the
# frontend when there is at least one worker available.
while poller.poll > 0
poller.readables.each do |readable|
if readable === backend
backend.recv_string worker = ""
backend.recv_string empty = ""
backend.recv_strings reply = []
frontend.send_strings reply unless reply[0] == "READY"
# Add this worker to the list of available workers
available_workers << worker
elsif readable === frontend && available_workers.any?
# Read the request from the client and forward it to the LRU worker
frontend.recv_strings request = []
backend.send_strings [available_workers.shift, ""] + request
end
end
end
frontend.close
backend.close
context.destroy
end
main_task
lbbroker:使用 Rust 的负载均衡代理示例
lbbroker:使用 Scala 的负载均衡代理示例
/*
* Least-recently used (LRU) queue device
* Clients and workers are shown here in-process
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
*
* Author: Giovanni Ruggiero
* Email: giovanni.ruggiero@gmail.com
*/
import org.zeromq.ZMQ
import ZHelpers._
// Basic request-reply client using REQ socket
//
class ClientTask() extends Runnable {
def run() {
val ctx = ZMQ.context(1)
val client = ctx.socket(ZMQ.REQ)
setID(client)
client.connect("tcp://:5555")
// Send request, get reply
client.send("HELLO".getBytes, 0)
val reply = client.recv(0)
printf("Client: %s\n", new String(reply))
}
}
// Worker using REQ socket to do LRU routing
//
class WorkerTask() extends Runnable {
def run() {
// println("worker started")
// Thread.sleep(1000)
val ctx = ZMQ.context(1)
val worker = ctx.socket(ZMQ.REQ)
setID(worker)
worker.connect("tcp://:5556")
// Tell broker we're ready for work
worker.send("READY".getBytes, 0)
while (true) {
// Read and save all frames until we get an empty frame
// In this example there is only 1 but it could be more
val address = worker.recv(0)
val empty = worker.recv(0)
// Get request, send reply
val request = worker.recv(0)
printf("Worker: %s\n", new String(request))
worker.send(address, ZMQ.SNDMORE)
worker.send("".getBytes, ZMQ.SNDMORE)
worker.send("OK".getBytes, 0)
}
}
}
object lruqueue {
def main(args : Array[String]) {
val NOFLAGS = 0
// Worker using REQ socket to do LRU routing
//
val NBR_CLIENTS = 10
val NBR_WORKERS = 3
// Prepare our context and sockets
val ctx = ZMQ.context(1)
val frontend = ctx.socket(ZMQ.ROUTER)
val backend = ctx.socket(ZMQ.ROUTER)
frontend.bind("tcp://*:5555")
backend.bind("tcp://*:5556")
val clients = List.fill(NBR_CLIENTS)(new Thread(new ClientTask))
clients foreach (_.start)
val workers = List.fill(NBR_WORKERS)(new Thread(new WorkerTask))
workers foreach (_.start)
// Logic of LRU loop
// - Poll backend always, frontend only if 1+ worker ready
// - If worker replies, queue worker as ready and forward reply
// to client if necessary
// - If client requests, pop next worker and send request to it
val workerQueue = scala.collection.mutable.Queue[Array[Byte]]()
var availableWorkers = 0
val poller = ctx.poller(2)
// Always poll for worker activity on backend
poller.register(backend,ZMQ.Poller.POLLIN)
// Poll front-end only if we have available workers
poller.register(frontend,ZMQ.Poller.POLLIN)
var clientNbr = NBR_CLIENTS
while (true) {
poller.poll
if(poller.pollin(0) && clientNbr > 0) {
val workerAddr = backend.recv(NOFLAGS)
assert (availableWorkers < NBR_WORKERS)
availableWorkers += 1
// Queue worker address for LRU routing
workerQueue.enqueue(workerAddr)
// Second frame is empty
var empty = backend.recv(NOFLAGS)
assert(new String(empty) == "")
// Third frame is READY or else a client reply address
val clientAddr = backend.recv(NOFLAGS)
if (!new String(clientAddr).equals("READY")) {
val reply = backend.recv(NOFLAGS)
frontend.send(clientAddr, ZMQ.SNDMORE)
frontend.send("".getBytes, ZMQ.SNDMORE)
frontend.send(reply, NOFLAGS)
clientNbr -=1 // Exit after N messages
}
}
if(availableWorkers > 0 && poller.pollin(1)) {
// Now get next client request, route to LRU worker
// Client request is [address][empty][request]
val clientAddr = frontend.recv(NOFLAGS)
val empty = frontend.recv(NOFLAGS)
val request = frontend.recv(NOFLAGS)
backend.send(workerQueue.dequeue, ZMQ.SNDMORE)
backend.send("".getBytes, ZMQ.SNDMORE)
backend.send(clientAddr, ZMQ.SNDMORE)
backend.send("".getBytes, ZMQ.SNDMORE)
backend.send(request, NOFLAGS)
availableWorkers -= 1
}
}
}
}
lbbroker:使用 Tcl 的负载均衡代理示例
#
# Least-recently used (LRU) queue device
#
package require zmq
if {[llength $argv] == 0} {
set argv [list driver 0 3 5]
} elseif {[llength $argv] != 4} {
puts "Usage: lruqueue.tcl <driver|client|worker|main_sync|main_async> <asynchronous> <number_of_clients> <number_of_workers>"
exit 1
}
set tclsh [info nameofexecutable]
lassign $argv what asynchronous NBR_CLIENTS NBR_WORKERS
expr {srand([pid])}
switch -exact -- $what {
client {
# Basic request-reply client using REQ socket
# Since send and recv can't handle 0MQ binary identities we
# set a printable text identity to allow routing.
package require zmq
zmq context context
zmq socket client context REQ
set id [format "%04X-%04X" [expr {int(rand()*0x10000)}] [expr {int(rand()*0x10000)}]]
client setsockopt IDENTITY $id
client connect "ipc://frontend.ipc"
# Send request, get reply
client send "HELLO"
set reply [client recv]
puts "Client $id: $reply"
client close
context term
}
worker {
# Worker using REQ socket to do LRU routing
# Since send and recv can't handle 0MQ binary identities we
# set a printable text identity to allow routing.
zmq context context
zmq socket worker context REQ
set id [format "%04X-%04X" [expr {int(rand()*0x10000)}] [expr {int(rand()*0x10000)}]]
worker setsockopt IDENTITY $id
worker connect "ipc://backend.ipc"
# Tell broker we're ready for work
worker send "READY"
while {1} {
# Read and save all frames until we get an empty frame
# In this example there is only 1 but it could be more
set address [worker recv]
set empty [worker recv]
# Get request, send reply
set request [worker recv]
puts "Worker $id: $request"
worker sendmore $address
worker sendmore ""
worker send "OK"
}
worker close
context term
}
main_sync {
zmq context context
zmq socket frontend context ROUTER
zmq socket backend context ROUTER
frontend bind "ipc://frontend.ipc"
backend bind "ipc://backend.ipc"
# Logic of LRU loop
# - Poll backend always, frontend only if 1+ worker ready
# - If worker replies, queue worker as ready and forward reply
# to client if necessary
# - If client requests, pop next worker and send request to it
# Queue of available workers
set client_nbr $NBR_CLIENTS
set worker_queue {}
set done 0
while {!$done} {
if {[llength $worker_queue]} {
set poll_set [list [list backend [list POLLIN]] [list frontend [list POLLIN]]]
} else {
set poll_set [list [list backend [list POLLIN]]]
}
set rpoll_set [zmq poll $poll_set -1]
foreach rpoll $rpoll_set {
switch [lindex $rpoll 0] {
backend {
# Queue worker address for LRU routing
set worker_addr [backend recv]
if {!([llength $worker_queue] < $NBR_WORKERS)} {
error "available_workers < NBR_WORKERS"
}
lappend worker_queue $worker_addr
# Second frame is empty
set empty [backend recv]
# Third frame is READY or else a client reply address
set client_addr [backend recv]
# If client reply, send rest back to frontend
if {$client_addr ne "READY"} {
set empty [backend recv]
set reply [backend recv]
frontend sendmore $client_addr
frontend sendmore ""
frontend send $reply
incr client_nbr -1
if {$client_nbr == 0} {
set done 1
break
}
}
}
frontend {
# Now get next client request, route to LRU worker
# Client request is [address][empty][request]
set client_addr [frontend recv]
set empty [frontend recv]
set request [frontend recv]
backend sendmore [lindex $worker_queue 0]
backend sendmore ""
backend sendmore $client_addr
backend sendmore ""
backend send $request
# Dequeue and drop the next worker address
set worker_queue [lrange $worker_queue 1 end]
}
}
}
}
frontend close
backend close
context term
}
main_async {
zmq context context
zmq socket frontend context ROUTER
zmq socket backend context ROUTER
frontend bind "ipc://frontend.ipc"
backend bind "ipc://backend.ipc"
# Logic of LRU loop
# - Poll backend always, frontend only if 1+ worker ready
# - If worker replies, queue worker as ready and forward reply
# to client if necessary
# - If client requests, pop next worker and send request to it
# Queue of available workers
set client_nbr $NBR_CLIENTS
set worker_queue {}
set done 0
proc process_backend {fe be} {
global done worker_queue client_nbr NBR_WORKERS
# Queue worker address for LRU routing
set worker_addr [$be recv]
if {!([llength $worker_queue] < $NBR_WORKERS)} {
error "available_workers < NBR_WORKERS"
}
lappend worker_queue $worker_addr
# Second frame is empty
set empty [$be recv]
# Third frame is READY or else a client reply address
set client_addr [$be recv]
# If client reply, send rest back to frontend
if {$client_addr ne "READY"} {
set empty [$be recv]
set reply [$be recv]
$fe sendmore $client_addr
$fe sendmore ""
$fe send $reply
incr client_nbr -1
if {$client_nbr == 0} {
set ::done 1
break
}
}
}
proc process_frontend {fe be} {
global done worker_queue client_nbr
if {[llength $worker_queue]} {
# Now get next client request, route to LRU worker
# Client request is [address][empty][request]
set client_addr [$fe recv]
set empty [$fe recv]
set request [$fe recv]
$be sendmore [lindex $worker_queue 0]
$be sendmore ""
$be sendmore $client_addr
$be sendmore ""
$be send $request
# Dequeue and drop the next worker address
set worker_queue [lrange $worker_queue 1 end]
}
}
frontend readable [list process_frontend ::frontend ::backend]
backend readable [list process_backend ::frontend ::backend]
vwait done
frontend close
backend close
context term
}
driver {
puts "Start main, output redirect to main.log"
exec $tclsh lruqueue.tcl [expr {$asynchronous?"main_async":"main_sync"}] $asynchronous $NBR_CLIENTS $NBR_WORKERS > main.log 2>@1 &
after 1000
for {set i 0} {$i < $NBR_WORKERS} {incr i} {
puts "Start worker $i, output redirect to worker$i.log"
exec $tclsh lruqueue.tcl worker $asynchronous $NBR_CLIENTS $NBR_WORKERS > worker$i.log 2>@1 &
}
after 1000
for {set i 0} {$i < $NBR_CLIENTS} {incr i} {
puts "Start client $i, output redirect to client$i.log"
exec $tclsh lruqueue.tcl client $asynchronous $NBR_CLIENTS $NBR_WORKERS > client$i.log 2>@1 &
}
}
}
lbbroker:使用 OCaml 的负载均衡代理示例
这个程序困难的部分在于 (a) 每个套接字读写的信封,以及 (b) 负载均衡算法。我们将依次讲解这些部分,从消息信封格式开始。
让我们逐步了解从客户端到工作者再返回的完整请求-回复链。在这段代码中,我们设置了客户端和工作者套接字的身份,以便更容易跟踪消息帧。实际上,我们会允许 ROUTER 套接字为连接创建身份。假设客户端的身份是“CLIENT”,工作者的身份是“WORKER”。客户端应用程序发送一个包含“Hello”的单帧。

由于 REQ 套接字添加了空的定界帧,并且 ROUTER 套接字添加了其连接身份,代理从前端 ROUTER 套接字读取客户端地址、空的定界帧和数据部分。

代理将此消息发送给工作者,并在消息前面加上选定工作者的地址,外加一个额外的空部分,以使另一端的 REQ 套接字工作正常。
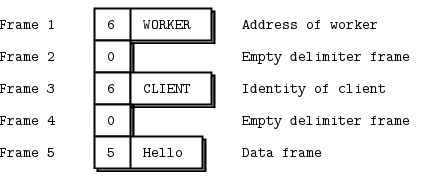
这个复杂的信封堆栈首先被后端 ROUTER 套接字处理,它会移除第一个帧。然后,工作者中的 REQ 套接字移除空的部分,并将剩余部分提供给工作者应用程序。

工作者必须保存信封(即直到并包括空消息帧的所有部分),然后才能对数据部分进行所需的操作。请注意,REP 套接字会自动完成此操作,但我们正在使用 REQ-ROUTER 模式,以便获得适当的负载均衡。
在返回路径上,消息与进来时相同,即后端套接字给代理一个包含五部分的消息,代理发送给前端套接字一个包含三部分的消息,而客户端收到一个包含一部分的消息。
现在让我们看一下负载均衡算法。它要求客户端和工作者都使用 REQ 套接字,并且工作者能够正确地存储并重播他们收到的消息的信封。算法如下:
-
创建一个 pollset,它始终轮询后端,并且仅当有一个或多个工作者可用时才轮询前端。
-
使用无限超时进行轮询活动。
-
如果后端有活动,我们要么收到“就绪”消息,要么收到给客户端的回复。在任何一种情况下,我们都将工作者地址(第一部分)存储在我们的工作者队列中;如果其余部分是客户端回复,我们就通过前端将其发送回给该客户端。
-
如果前端有活动,我们就接收客户端请求,取出下一个工作者(即上次使用的那个),并将请求发送到后端。这意味着发送工作者地址、空的部分,然后是客户端请求的三部分。
现在你应该明白,你可以根据工作者在初始“就绪”消息中提供的信息来重用和扩展负载均衡算法。例如,工作者启动后可以进行性能自检,然后告诉代理它们的速度。代理 then 可以选择最快可用的工作者,而不是最旧的。
ZeroMQ 的高层 API #
我们将把请求-回复模式放在一边,开启另一个领域,即 ZeroMQ API 本身。这次绕道是有原因的:随着我们编写更复杂的示例,低级的 ZeroMQ API 开始显得越来越笨拙。看看我们的负载均衡代理中工作者线程的核心代码:
while (true) {
// Get one address frame and empty delimiter
char *address = s_recv (worker);
char *empty = s_recv (worker);
assert (*empty == 0);
free (empty);
// Get request, send reply
char *request = s_recv (worker);
printf ("Worker: %s\n", request);
free (request);
s_sendmore (worker, address);
s_sendmore (worker, "");
s_send (worker, "OK");
free (address);
}
那段代码甚至不可重用,因为它在信封中只能处理一个回复地址,而且它已经对 ZeroMQ API 进行了一些封装。如果我们使用libzmq简单的消息 API,我们就不得不写出这样的代码:
while (true) {
// Get one address frame and empty delimiter
char address [255];
int address_size = zmq_recv (worker, address, 255, 0);
if (address_size == -1)
break;
char empty [1];
int empty_size = zmq_recv (worker, empty, 1, 0);
assert (empty_size <= 0);
if (empty_size == -1)
break;
// Get request, send reply
char request [256];
int request_size = zmq_recv (worker, request, 255, 0);
if (request_size == -1)
return NULL;
request [request_size] = 0;
printf ("Worker: %s\n", request);
zmq_send (worker, address, address_size, ZMQ_SNDMORE);
zmq_send (worker, empty, 0, ZMQ_SNDMORE);
zmq_send (worker, "OK", 2, 0);
}
当代码太长而无法快速编写时,它也太长而难以理解。到目前为止,我一直坚持使用原生 API,因为作为 ZeroMQ 用户,我们需要对它有深入的了解。但当它妨碍我们时,我们必须将其视为一个需要解决的问题。
当然,我们不能仅仅改变 ZeroMQ API,它是一个有文档记载的公共契约,成千上万的人同意并依赖它。相反,我们基于目前的经验,特别是从编写更复杂的请求-回复模式中获得的经验,在其之上构建一个更高层的 API。
我们想要一个 API,它能让我们一次性接收和发送整个消息,包括包含任意数量回复地址的回复信封。一个能让我们用最少的代码行实现我们想要的功能的 API。
构建一个好的消息 API 是相当困难的。我们存在术语上的问题:ZeroMQ 使用“消息”来描述多部分消息和单个消息帧。我们存在期望上的问题:有时将消息内容视为可打印的字符串数据是很自然的,有时则是二进制大块。而且我们还面临技术挑战,特别是如果想避免过多地复制数据。
构建一个好的 API 的挑战影响所有语言,尽管我的特定用例是 C 语言。无论你使用何种语言,都请思考如何为你的语言绑定做贡献,使其与我将要描述的 C 语言绑定一样好(或更好)。
高层 API 的特性 #
我的解决方案是使用三个相当自然且显而易见的概念:字符串(已经是我们现有s_send和s_recv)辅助函数、帧(一个消息帧)和消息(包含一个或多个帧的列表)。这是使用这些概念重写的工人代码 API:
while (true) {
zmsg_t *msg = zmsg_recv (worker);
zframe_reset (zmsg_last (msg), "OK", 2);
zmsg_send (&msg, worker);
}
减少读写复杂消息所需的代码量非常好:结果易于阅读和理解。让我们继续将这个过程应用于使用 ZeroMQ 的其他方面。以下是我根据目前使用 ZeroMQ 的经验,希望在高层 API 中包含的功能清单:
-
套接字的自动处理。我发现手动关闭套接字以及在某些(但非全部)情况下必须明确定义 linger 超时很麻烦。如果能在我关闭上下文时自动关闭套接字,那就太好了。
-
可移植的线程管理。每个非琐碎的 ZeroMQ 应用程序都使用线程,但 POSIX 线程不可移植。因此,一个体面的高层 API 应该在可移植层下隐藏这一点。
-
父线程到子线程的管道通信。这是一个反复出现的问题:如何在父子线程之间发送信号。我们的 API 应该提供一个 ZeroMQ 消息管道(使用 PAIR 套接字和inproc自动完成)。
-
可移植的时钟。即使获取毫秒级精度的时间,或休眠几毫秒,都不可移植。实际的 ZeroMQ 应用程序需要可移植的时钟,所以我们的 API 应该提供它们。
-
一个用于替换 zmq_poll() 的反应器。轮询循环很简单,但很笨拙。写很多这样的代码,我们最终会一遍又一遍地做同样的工作:计算定时器,并在套接字就绪时调用代码。一个带有套接字读取器和定时器的简单反应器可以节省大量重复工作。
-
Ctrl-C 的正确处理。我们已经看到了如何捕获中断。如果所有应用程序都能做到这一点,那就太好了。
CZMQ 高层 API #
将这个愿望清单变为现实,对于 C 语言来说就是 CZMQ,这是一个 ZeroMQ 的 C 语言绑定。这个高层绑定实际上是从早期版本的示例中发展出来的。它结合了更优雅的 ZeroMQ 使用语义以及一些可移植层,还有(对 C 语言很重要,但对其他语言次之)哈希和列表等容器。CZMQ 还使用了一种优雅的对象模型,可以写出非常漂亮的代码。
这是使用更高层 API (C 语言示例中使用 CZMQ) 重写的负载均衡代理
lbbroker2:使用高层 API 的负载均衡代理 (Ada)
lbbroker2:使用高层 API 的负载均衡代理 (Basic)
lbbroker2:使用高层 API 的负载均衡代理 (C)
// Load-balancing broker
// Demonstrates use of the CZMQ API
#include "czmq.h"
#define NBR_CLIENTS 10
#define NBR_WORKERS 3
#define WORKER_READY "READY" // Signals worker is ready
// Basic request-reply client using REQ socket
//
static void
client_task(zsock_t *pipe, void *args)
{
// Signal caller zactor has started
zsock_signal(pipe, 0);
zsock_t *client = zsock_new(ZMQ_REQ);
#if (defined (WIN32))
zsock_connect(client, "tcp://:5672"); // frontend
#else
zsock_connect(client, "ipc://frontend.ipc");
#endif
// Send request, get reply
zstr_send(client, "HELLO");
char *reply = zstr_recv(client);
if (reply) {
printf("Client: %s\n", reply);
free(reply);
}
zsock_destroy(&client);
}
// Worker using REQ socket to do load-balancing
//
static void
worker_task(zsock_t *pipe, void *args)
{
// Signal caller zactor has started
zsock_signal(pipe, 0);
zsock_t *worker = zsock_new(ZMQ_REQ);
#if (defined (WIN32))
zsock_connect(worker, "tcp://:5673"); // backend
#else
zsock_connect(worker, "ipc://backend.ipc");
#endif
// Tell broker we're ready for work
zframe_t *frame = zframe_new(WORKER_READY, strlen(WORKER_READY));
zframe_send(&frame, worker, 0);
// Process messages as they arrive
zpoller_t *poll = zpoller_new(pipe, worker, NULL);
while (true) {
zsock_t *ready = zpoller_wait(poll, -1);
if (ready == pipe)
break; // Done
assert(ready == worker);
zmsg_t *msg = zmsg_recv(worker);
if (!msg)
break; // Interrupted
zframe_print(zmsg_last(msg), "Worker: ");
zframe_reset(zmsg_last(msg), "OK", 2);
zmsg_send(&msg, worker);
}
if (frame)
zframe_destroy(&frame);
zsock_destroy(&worker);
zpoller_destroy(&poll);
// Signal done
zsock_signal(pipe, 0);
}
// .split main task
// Now we come to the main task. This has the identical functionality to
// the previous {{lbbroker}} broker example, but uses CZMQ to start child
// threads, to hold the list of workers, and to read and send messages:
int main(void)
{
zsock_t *frontend = zsock_new(ZMQ_ROUTER);
zsock_t *backend = zsock_new(ZMQ_ROUTER);
// IPC doesn't yet work on MS Windows.
#if (defined (WIN32))
zsock_bind(frontend, "tcp://*:5672");
zsock_bind(backend, "tcp://*:5673");
#else
zsock_bind(frontend, "ipc://frontend.ipc");
zsock_bind(backend, "ipc://backend.ipc");
#endif
int actor_nbr = 0;
zactor_t *actors[NBR_CLIENTS + NBR_WORKERS];
int client_nbr;
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++)
actors[actor_nbr++] = zactor_new(client_task, NULL);
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
actors[actor_nbr++] = zactor_new(worker_task, NULL);
// Queue of available workers
zlist_t *workers = zlist_new();
// .split main load-balancer loop
// Here is the main loop for the load balancer. It works the same way
// as the previous example, but is a lot shorter because CZMQ gives
// us an API that does more with fewer calls:
zpoller_t *poll1 = zpoller_new(backend, NULL);
zpoller_t *poll2 = zpoller_new(backend, frontend, NULL);
while (true) {
// Poll frontend only if we have available workers
zpoller_t *poll = zlist_size(workers) ? poll2 : poll1;
zsock_t *ready = zpoller_wait(poll, -1);
if (ready == NULL)
break; // Interrupted
// Handle worker activity on backend
if (ready == backend) {
// Use worker identity for load-balancing
zmsg_t *msg = zmsg_recv(backend);
if (!msg)
break; // Interrupted
#if 0
// zmsg_unwrap is DEPRECATED as over-engineered, poor style
zframe_t *identity = zmsg_unwrap(msg);
#else
zframe_t *identity = zmsg_pop(msg);
zframe_t *delimiter = zmsg_pop(msg);
zframe_destroy(&delimiter);
#endif
zlist_append(workers, identity);
// Forward message to client if it's not a READY
zframe_t *frame = zmsg_first(msg);
if (memcmp(zframe_data(frame), WORKER_READY, strlen(WORKER_READY)) == 0) {
zmsg_destroy(&msg);
} else {
zmsg_send(&msg, frontend);
if (--client_nbr == 0)
break; // Exit after N messages
}
}
else if (ready == frontend) {
// Get client request, route to first available worker
zmsg_t *msg = zmsg_recv(frontend);
if (msg) {
#if 0
// zmsg_wrap is DEPRECATED as unsafe
zmsg_wrap(msg, (zframe_t *)zlist_pop(workers));
#else
zmsg_pushmem(msg, NULL, 0); // delimiter
zmsg_push(msg, (zframe_t *)zlist_pop(workers));
#endif
zmsg_send(&msg, backend);
}
}
}
// When we're done, clean up properly
while (zlist_size(workers)) {
zframe_t *frame = (zframe_t *)zlist_pop(workers);
zframe_destroy(&frame);
}
zlist_destroy(&workers);
for (actor_nbr = 0; actor_nbr < NBR_CLIENTS + NBR_WORKERS; actor_nbr++) {
zactor_destroy(&actors[actor_nbr]);
}
zpoller_destroy(&poll1);
zpoller_destroy(&poll2);
zsock_destroy(&frontend);
zsock_destroy(&backend);
return 0;
}
lbbroker2:使用高层 API 的负载均衡代理 (C++)
// 2015-05-12T11:55+08:00
// Load-balancing broker
// Demonstrates use of the CZMQ API
#include "czmq.h"
#include <iostream>
#define NBR_CLIENTS 10
#define NBR_WORKERS 3
#define WORKER_READY "READY" // Signals worker is ready
// Basic request-reply client using REQ socket
//
static void *
client_task(void *args)
{
zctx_t *ctx = zctx_new();
void *client = zsocket_new(ctx, ZMQ_REQ);
#if (defined (WIN32))
zsocket_connect(client, "tcp://:5672"); // frontend
#else
zsocket_connect(client, "ipc://frontend.ipc");
#endif
// Send request, get reply
zstr_send(client, "HELLO");
char *reply = zstr_recv(client);
if (reply) {
std::cout << "Client: " << reply << std::endl;
free(reply);
}
zctx_destroy(&ctx);
return NULL;
}
// Worker using REQ socket to do load-balancing
//
static void *
worker_task(void *args)
{
zctx_t *ctx = zctx_new();
void *worker = zsocket_new(ctx, ZMQ_REQ);
#if (defined (WIN32))
zsocket_connect(worker, "tcp://:5673"); // backend
#else
zsocket_connect(worker, "ipc://backend.ipc");
#endif
// Tell broker we're ready for work
zframe_t *frame = zframe_new(WORKER_READY, strlen(WORKER_READY));
zframe_send(&frame, worker, 0);
// Process messages as they arrive
while (1) {
zmsg_t *msg = zmsg_recv(worker);
if (!msg)
break; // Interrupted
zframe_print(zmsg_last(msg), "Worker: ");
zframe_reset(zmsg_last(msg), "OK", 2);
zmsg_send(&msg, worker);
}
zctx_destroy(&ctx);
return NULL;
}
// .split main task
// Now we come to the main task. This has the identical functionality to
// the previous {{lbbroker}} broker example, but uses CZMQ to start child
// threads, to hold the list of workers, and to read and send messages:
int main(void)
{
zctx_t *ctx = zctx_new();
void *frontend = zsocket_new(ctx, ZMQ_ROUTER);
void *backend = zsocket_new(ctx, ZMQ_ROUTER);
// IPC doesn't yet work on MS Windows.
#if (defined (WIN32))
zsocket_bind(frontend, "tcp://*:5672");
zsocket_bind(backend, "tcp://*:5673");
#else
zsocket_bind(frontend, "ipc://frontend.ipc");
zsocket_bind(backend, "ipc://backend.ipc");
#endif
int client_nbr;
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++)
zthread_new(client_task, NULL);
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
zthread_new(worker_task, NULL);
// Queue of available workers
zlist_t *workers = zlist_new();
// .split main load-balancer loop
// Here is the main loop for the load balancer. It works the same way
// as the previous example, but is a lot shorter because CZMQ gives
// us an API that does more with fewer calls:
while (1) {
zmq_pollitem_t items[] = {
{ backend, 0, ZMQ_POLLIN, 0 },
{ frontend, 0, ZMQ_POLLIN, 0 }
};
// Poll frontend only if we have available workers
int rc = zmq_poll(items, zlist_size(workers) ? 2 : 1, -1);
if (rc == -1)
break; // Interrupted
// Handle worker activity on backend
if (items[0].revents & ZMQ_POLLIN) {
// Use worker identity for load-balancing
zmsg_t *msg = zmsg_recv(backend);
if (!msg)
break; // Interrupted
#if 0
// zmsg_unwrap is DEPRECATED as over-engineered, poor style
zframe_t *identity = zmsg_unwrap(msg);
#else
zframe_t *identity = zmsg_pop(msg);
zframe_t *delimiter = zmsg_pop(msg);
zframe_destroy(&delimiter);
#endif
zlist_append(workers, identity);
// Forward message to client if it's not a READY
zframe_t *frame = zmsg_first(msg);
if (memcmp(zframe_data(frame), WORKER_READY, strlen(WORKER_READY)) == 0) {
zmsg_destroy(&msg);
} else {
zmsg_send(&msg, frontend);
if (--client_nbr == 0)
break; // Exit after N messages
}
}
if (items[1].revents & ZMQ_POLLIN) {
// Get client request, route to first available worker
zmsg_t *msg = zmsg_recv(frontend);
if (msg) {
#if 0
// zmsg_wrap is DEPRECATED as unsafe
zmsg_wrap(msg, (zframe_t *)zlist_pop(workers));
#else
zmsg_pushmem(msg, NULL, 0); // delimiter
zmsg_push(msg, (zframe_t *)zlist_pop(workers));
#endif
zmsg_send(&msg, backend);
}
}
}
// When we're done, clean up properly
while (zlist_size(workers)) {
zframe_t *frame = (zframe_t *)zlist_pop(workers);
zframe_destroy(&frame);
}
zlist_destroy(&workers);
zctx_destroy(&ctx);
return 0;
}
lbbroker2:使用高层 API 的负载均衡代理 (C#)
lbbroker2:使用高层 API 的负载均衡代理 (CL)
lbbroker2:使用高层 API 的负载均衡代理 (Delphi)
program lbbroker2;
//
// Load-balancing broker
// Clients and workers are shown here in-process
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
Windows
, SysUtils
, zmqapi
, zhelpers
;
const
NBR_CLIENTS = 10;
NBR_WORKERS = 3;
WORKER_READY = '\001'; // Signals worker is ready
// Basic request-reply client using REQ socket
procedure client_task( args: Pointer );
var
context: TZMQContext;
client: TZMQSocket;
reply: Utf8String;
begin
context := TZMQContext.create;
client := context.Socket( stReq );
{$ifdef unix}
client.connect( 'ipc://frontend.ipc' );
{$else}
client.connect( 'tcp://127.0.0.1:5555' );
{$endif}
// Send request, get reply
while not context.Terminated do
try
client.send( 'HELLO' );
client.recv( reply );
zNote( Format('Client: %s',[reply]) );
sleep( 1000 );
except
context.Terminate;
end;
context.Free;
end;
// Worker using REQ socket to do load-balancing
procedure worker_task( args: Pointer );
var
context: TZMQContext;
worker: TZMQSocket;
msg: TZMQMsg;
begin
context := TZMQContext.create;
worker := context.Socket( stReq );
{$ifdef unix}
worker.connect( 'ipc://backend.ipc' );
{$else}
worker.connect( 'tcp://127.0.0.1:5556' );
{$endif}
msg := nil;
// Tell broker we're ready for work
worker.send( WORKER_READY );
// Process messages as they arrive
while not context.Terminated do
try
worker.recv( msg );
msg.last.asUtf8String := 'OK';
worker.send( msg );
except
context.Terminate;
end;
context.Free;
end;
var
context: TZMQContext;
frontend,
backend: TZMQSocket;
i,
poll_c: Integer;
tid: Cardinal;
poller: TZMQPoller;
workers,
msg: TZMQMsg;
begin
context := TZMQContext.create;
frontend := context.Socket( stRouter );
backend := context.Socket( stRouter );
{$ifdef unix}
frontend.bind( 'ipc://frontend.ipc' );
backend.bind( 'ipc://backend.ipc' );
{$else}
frontend.bind( 'tcp://127.0.0.1:5555' );
backend.bind( 'tcp://127.0.0.1:5556' );
{$endif}
for i := 0 to NBR_CLIENTS - 1 do
BeginThread( nil, 0, @client_task, nil, 0, tid );
for i := 0 to NBR_WORKERS - 1 do
BeginThread( nil, 0, @worker_task, nil, 0, tid );
// Queue of available workers
workers := TZMQMsg.Create;
msg := nil;
poller := TZMQPoller.Create( true );
poller.register( backend, [pePollIn] );
poller.register( frontend, [pePollIn] );
while not context.Terminated do
try
// Poll frontend only if we have available workers
if workers.size > 0 then
poll_c := -1
else
poll_c := 1;
poller.poll( -1, poll_c );
// Handle worker activity on backend
if pePollIn in poller.PollItem[0].revents then
begin
// Use worker identity for load-balancing
backend.recv( msg );
workers.add( msg.unwrap );
// Forward message to client if it's not a READY
if msg.first.asUtf8String <> WORKER_READY then
frontend.send( msg )
else
FreeAndNil( msg );
end;
if ( poll_c = -1 ) and ( pePollIn in poller.PollItem[1].revents ) then
begin
// Get client request, route to first available worker
frontend.recv( msg );
msg.wrap( workers.pop );
backend.send( msg );
end;
except
context.Terminate;
end;
poller.Free;
frontend.Free;
backend.Free;
context.Free;
end.
lbbroker2:使用高层 API 的负载均衡代理 (Erlang)
lbbroker2:使用高层 API 的负载均衡代理 (Elixir)
lbbroker2:使用高层 API 的负载均衡代理 (F#)
lbbroker2:使用高层 API 的负载均衡代理 (Felix)
lbbroker2:使用高层 API 的负载均衡代理 (Go)
lbbroker2:使用高层 API 的负载均衡代理 (Haskell)
lbbroker2:使用高层 API 的负载均衡代理 (Haxe)
package ;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZFrame;
import org.zeromq.ZMsg;
#if (neko || cpp)
import neko.vm.Thread;
#end
import haxe.Stack;
import org.zeromq.ZContext;
import org.zeromq.ZSocket;
using org.zeromq.ZSocket;
import org.zeromq.ZMQ;
import org.zeromq.ZMQException;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
/**
* Least - recently used (LRU) queue device
* Clients and workers are shown here in-process
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* See: https://zguide.zeromq.cn/page:all#A-High-Level-API-for-MQ
*/
class LRUQueue2
{
private static inline var NBR_CLIENTS = 10;
private static inline var NBR_WORKERS = 3;
// Signals workers are ready
private static inline var LRU_READY:String = String.fromCharCode(1);
private static inline var WORKER_DONE:Bytes = Bytes.ofString("OK");
/**
* Basic request-reply client using REQ socket.
*/
public static function clientTask() {
var context:ZContext = new ZContext();
var client:ZMQSocket = context.createSocket(ZMQ_REQ);
var id = ZHelpers.setID(client);
client.connectEndpoint("ipc", "/tmp/frontend.ipc");
while (true) {
ZFrame.newStringFrame("HELLO").send(client);
var reply = ZFrame.recvFrame(client);
if (reply == null) {
break;
}
Lib.println("Client "+id+": " + reply.toString());
Sys.sleep(1);
}
context.destroy();
}
/**
* Worker using REQ socket to do LRU routing.
*/
public static function workerTask() {
var context:ZContext = new ZContext();
var worker:ZMQSocket = context.createSocket(ZMQ_REQ);
var id = ZHelpers.setID(worker);
worker.connectEndpoint("ipc", "/tmp/backend.ipc");
// Tell broker we're ready to do work
ZFrame.newStringFrame(LRU_READY).send(worker);
// Process messages as they arrive
while (true) {
var msg:ZMsg = ZMsg.recvMsg(worker);
if (msg == null) {
break;
}
// Lib.println("Worker " + id + " received " + msg.toString());
msg.last().reset(WORKER_DONE);
msg.send(worker);
}
context.destroy();
}
public static function main() {
Lib.println("** LRUQueue2 (see: https://zguide.zeromq.cn/page:all#A-High-Level-API-for-MQ)");
#if php
// PHP appears to require tasks to be forked before main process creates ZMQ context
for (client_nbr in 0 ... NBR_CLIENTS) {
forkClientTask();
}
for (worker_nbr in 0 ... NBR_WORKERS) {
forkWorkerTask();
}
#end
// Prepare our context and sockets
var context:ZContext = new ZContext();
var frontend:ZMQSocket = context.createSocket(ZMQ_ROUTER);
var backend:ZMQSocket = context.createSocket(ZMQ_ROUTER);
frontend.bindEndpoint("ipc", "/tmp/frontend.ipc");
backend.bindEndpoint("ipc", "/tmp/backend.ipc");
#if !php
// Non-PHP targets require threads to be created after main thread has set up ZMQ Context
for (client_nbr in 0 ... NBR_CLIENTS) {
Thread.create(clientTask);
}
for (worker_nbr in 0 ... NBR_WORKERS) {
Thread.create(workerTask);
}
#end
// Logic of LRU loop:
// - Poll backend always, frontend only if 1 or more worker si ready
// - If worker replies, queue worker as ready and forward reply
// to client if necessary.
// - If client requests, pop next worker and send request to it.
// Queue of available workers
var workerQueue:List<ZFrame> = new List<ZFrame>();
var poller:ZMQPoller = new ZMQPoller();
poller.registerSocket(backend, ZMQ.ZMQ_POLLIN());
while (true) {
poller.unregisterSocket(frontend);
if (workerQueue.length > 0) {
// Only poll frontend if there is at least 1 worker ready to do work
poller.registerSocket(frontend, ZMQ.ZMQ_POLLIN());
}
try {
poller.poll( -1 );
} catch (e:ZMQException) {
if (ZMQ.isInterrupted()) {
break; // Interrupted or terminated
}
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
// Handle worker activity on backend
if (poller.pollin(1)) {
// Use worker address for LRU routing
var msg:ZMsg = ZMsg.recvMsg(backend);
if (msg == null) {
break;
}
var workerAddr = msg.unwrap();
if (workerQueue.length < NBR_WORKERS)
workerQueue.add(workerAddr);
// Third frame is READY or else a client reply address
var frame = msg.first();
// If client reply, send rest back to frontend
if (frame.toString() == LRU_READY) {
msg.destroy();
} else {
msg.send(frontend);
}
}
if (poller.pollin(2)) {
// get client request, route to first available worker
var msg = ZMsg.recvMsg(frontend);
if (msg != null) {
msg.wrap(workerQueue.pop());
msg.send(backend);
}
}
}
// When we're done, clean up properly
for (f in workerQueue) {
f.destroy();
}
context.destroy();
}
#if php
private static inline function forkWorkerTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
LRUQueue2::workerTask();
exit();
}');
return;
}
private static inline function forkClientTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
LRUQueue2::clientTask();
exit();
}');
return;
}
#end
}lbbroker2:使用高层 API 的负载均衡代理 (Java)
package guide;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.Queue;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
/**
* Load-balancing broker
* Demonstrates use of the high level API
*/
public class lbbroker2
{
private static final int NBR_CLIENTS = 10;
private static final int NBR_WORKERS = 3;
private static byte[] WORKER_READY = { '\001' }; // Signals worker is ready
/**
* Basic request-reply client using REQ socket
*/
private static class ClientTask implements ZThread.IDetachedRunnable
{
@Override
public void run(Object[] args)
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
Socket client = context.createSocket(SocketType.REQ);
ZHelper.setId(client); // Set a printable identity
client.connect("ipc://frontend.ipc");
// Send request, get reply
client.send("HELLO");
String reply = client.recvStr();
System.out.println("Client: " + reply);
}
}
}
/**
* Worker using REQ socket to do load-balancing
*/
private static class WorkerTask implements ZThread.IDetachedRunnable
{
@Override
public void run(Object[] args)
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
Socket worker = context.createSocket(SocketType.REQ);
ZHelper.setId(worker); // Set a printable identity
worker.connect("ipc://backend.ipc");
// Tell backend we're ready for work
ZFrame frame = new ZFrame(WORKER_READY);
frame.send(worker, 0);
while (true) {
ZMsg msg = ZMsg.recvMsg(worker);
if (msg == null)
break;
msg.getLast().reset("OK");
msg.send(worker);
}
}
}
}
/**
* This is the main task. This has the identical functionality to
* the previous lbbroker example but uses higher level classes to start child threads
* to hold the list of workers, and to read and send messages:
*/
public static void main(String[] args)
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
Socket frontend = context.createSocket(SocketType.ROUTER);
Socket backend = context.createSocket(SocketType.ROUTER);
frontend.bind("ipc://frontend.ipc");
backend.bind("ipc://backend.ipc");
int clientNbr;
for (clientNbr = 0; clientNbr < NBR_CLIENTS; clientNbr++)
ZThread.start(new ClientTask());
for (int workerNbr = 0; workerNbr < NBR_WORKERS; workerNbr++)
ZThread.start(new WorkerTask());
// Queue of available workers
Queue<ZFrame> workerQueue = new LinkedList<ZFrame>();
// Here is the main loop for the load-balancer. It works the same
// way as the previous example, but is a lot shorter because ZMsg
// class gives us an API that does more with fewer calls:
while (!Thread.currentThread().isInterrupted()) {
// Initialize poll set
Poller items = context.createPoller(2);
// Always poll for worker activity on backend
items.register(backend, Poller.POLLIN);
// Poll front-end only if we have available workers
if (workerQueue.size() > 0)
items.register(frontend, Poller.POLLIN);
if (items.poll() < 0)
break; // Interrupted
// Handle worker activity on backend
if (items.pollin(0)) {
ZMsg msg = ZMsg.recvMsg(backend);
if (msg == null)
break; // Interrupted
ZFrame identity = msg.unwrap();
// Queue worker address for LRU routing
workerQueue.add(identity);
// Forward message to client if it's not a READY
ZFrame frame = msg.getFirst();
if (Arrays.equals(frame.getData(), WORKER_READY))
msg.destroy();
else msg.send(frontend);
}
if (items.pollin(1)) {
// Get client request, route to first available worker
ZMsg msg = ZMsg.recvMsg(frontend);
if (msg != null) {
msg.wrap(workerQueue.poll());
msg.send(backend);
}
}
}
}
}
}
lbbroker2:使用高层 API 的负载均衡代理 (Julia)
lbbroker2:使用高层 API 的负载均衡代理 (Lua)
--
-- Least-recently used (LRU) queue device
-- Demonstrates use of the msg class
--
-- While this example runs in a single process, that is just to make
-- it easier to start and stop the example. Each thread has its own
-- context and conceptually acts as a separate process.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.threads"
require"zmq.poller"
require"zmsg"
local tremove = table.remove
local NBR_CLIENTS = 10
local NBR_WORKERS = 3
local pre_code = [[
local identity, seed = ...
local zmq = require"zmq"
local zmsg = require"zmsg"
require"zhelpers"
math.randomseed(seed)
]]
-- Basic request-reply client using REQ socket
--
local client_task = pre_code .. [[
local context = zmq.init(1)
local client = context:socket(zmq.REQ)
client:setopt(zmq.IDENTITY, identity) -- Set a printable identity
client:connect("ipc://frontend.ipc")
-- Send request, get reply
client:send("HELLO")
local reply = client:recv()
printf ("Client: %s\n", reply)
client:close()
context:term()
]]
-- Worker using REQ socket to do LRU routing
--
local worker_task = pre_code .. [[
local context = zmq.init(1)
local worker = context:socket(zmq.REQ)
worker:setopt(zmq.IDENTITY, identity) -- Set a printable identity
worker:connect("ipc://backend.ipc")
-- Tell broker we're ready for work
worker:send("READY")
while true do
local msg = zmsg.recv (worker)
printf ("Worker: %s\n", msg:body())
msg:body_set("OK")
msg:send(worker)
end
worker:close()
context:term()
]]
s_version_assert (2, 1)
-- Prepare our context and sockets
local context = zmq.init(1)
local frontend = context:socket(zmq.ROUTER)
local backend = context:socket(zmq.ROUTER)
frontend:bind("ipc://frontend.ipc")
backend:bind("ipc://backend.ipc")
local clients = {}
for n=1,NBR_CLIENTS do
local identity = string.format("%04X-%04X", randof (0x10000), randof (0x10000))
local seed = os.time() + math.random()
clients[n] = zmq.threads.runstring(context, client_task, identity, seed)
clients[n]:start()
end
local workers = {}
for n=1,NBR_WORKERS do
local identity = string.format("%04X-%04X", randof (0x10000), randof (0x10000))
local seed = os.time() + math.random()
workers[n] = zmq.threads.runstring(context, worker_task, identity, seed)
workers[n]:start(true)
end
-- Logic of LRU loop
-- - Poll backend always, frontend only if 1+ worker ready
-- - If worker replies, queue worker as ready and forward reply
-- to client if necessary
-- - If client requests, pop next worker and send request to it
-- Queue of available workers
local worker_queue = {}
local is_accepting = false
local max_requests = #clients
local poller = zmq.poller(2)
local function frontend_cb()
-- Now get next client request, route to next worker
local msg = zmsg.recv (frontend)
-- Dequeue a worker from the queue.
local worker = tremove(worker_queue, 1)
msg:wrap(worker, "")
msg:send(backend)
if (#worker_queue == 0) then
-- stop accepting work from clients, when no workers are available.
poller:remove(frontend)
is_accepting = false
end
end
poller:add(backend, zmq.POLLIN, function()
local msg = zmsg.recv(backend)
-- Use worker address for LRU routing
worker_queue[#worker_queue + 1] = msg:unwrap()
-- start accepting client requests, if we are not already doing so.
if not is_accepting then
is_accepting = true
poller:add(frontend, zmq.POLLIN, frontend_cb)
end
-- Forward message to client if it's not a READY
if (msg:address() ~= "READY") then
msg:send(frontend)
max_requests = max_requests - 1
if (max_requests == 0) then
poller:stop() -- Exit after N messages
end
end
end)
-- start poller's event loop
poller:start()
frontend:close()
backend:close()
context:term()
for n=1,NBR_CLIENTS do
assert(clients[n]:join())
end
-- workers are detached, we don't need to join with them.
lbbroker2:使用高层 API 的负载均衡代理 (Node.js)
lbbroker2:使用高层 API 的负载均衡代理 (Objective-C)
lbbroker2:使用高层 API 的负载均衡代理 (ooc)
lbbroker2:使用高层 API 的负载均衡代理 (Perl)
lbbroker2:使用高层 API 的负载均衡代理 (PHP)
<?php
/*
* Least-recently used (LRU) queue device
* Demonstrates use of the zmsg class
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
define("NBR_CLIENTS", 10);
define("NBR_WORKERS", 3);
// Basic request-reply client using REQ socket
function client_thread()
{
$context = new ZMQContext();
$client = new ZMQSocket($context, ZMQ::SOCKET_REQ);
$client->connect("ipc://frontend.ipc");
// Send request, get reply
$client->send("HELLO");
$reply = $client->recv();
printf("Client: %s%s", $reply, PHP_EOL);
}
// Worker using REQ socket to do LRU routing
function worker_thread ()
{
$context = new ZMQContext();
$worker = $context->getSocket(ZMQ::SOCKET_REQ);
$worker->connect("ipc://backend.ipc");
// Tell broker we're ready for work
$worker->send("READY");
while (true) {
$zmsg = new Zmsg($worker);
$zmsg->recv();
// Additional logic to clean up workers.
if ($zmsg->address() == "END") {
exit();
}
printf ("Worker: %s\n", $zmsg->body());
$zmsg->body_set("OK");
$zmsg->send();
}
}
function main()
{
for ($client_nbr = 0; $client_nbr < NBR_CLIENTS; $client_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
client_thread();
return;
}
}
for ($worker_nbr = 0; $worker_nbr < NBR_WORKERS; $worker_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
worker_thread();
return;
}
}
$context = new ZMQContext();
$frontend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$backend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$frontend->bind("ipc://frontend.ipc");
$backend->bind("ipc://backend.ipc");
// Logic of LRU loop
// - Poll backend always, frontend only if 1+ worker ready
// - If worker replies, queue worker as ready and forward reply
// to client if necessary
// - If client requests, pop next worker and send request to it
// Queue of available workers
$available_workers = 0;
$worker_queue = array();
$writeable = $readable = array();
while ($client_nbr > 0) {
$poll = new ZMQPoll();
// Poll front-end only if we have available workers
if ($available_workers > 0) {
$poll->add($frontend, ZMQ::POLL_IN);
}
// Always poll for worker activity on backend
$poll->add($backend, ZMQ::POLL_IN);
$events = $poll->poll($readable, $writeable);
if ($events > 0) {
foreach ($readable as $socket) {
// Handle worker activity on backend
if ($socket === $backend) {
// Queue worker address for LRU routing
$zmsg = new Zmsg($socket);
$zmsg->recv();
assert($available_workers < NBR_WORKERS);
$available_workers++;
array_push($worker_queue, $zmsg->unwrap());
if ($zmsg->body() != "READY") {
$zmsg->set_socket($frontend)->send();
// exit after all messages relayed
$client_nbr--;
}
} elseif ($socket === $frontend) {
$zmsg = new Zmsg($socket);
$zmsg->recv();
$zmsg->wrap(array_shift($worker_queue), "");
$zmsg->set_socket($backend)->send();
$available_workers--;
}
}
}
}
// Clean up our worker processes
foreach ($worker_queue as $worker) {
$zmsg = new Zmsg($backend);
$zmsg->body_set('END')->wrap($worker, "")->send();
}
sleep(1);
}
main();
lbbroker2:使用高层 API 的负载均衡代理 (Python)
"""
Least-recently used (LRU) queue device
Clients and workers are shown here in-process
Author: Guillaume Aubert (gaubert) <guillaume(dot)aubert(at)gmail(dot)com>
"""
from __future__ import print_function
import threading
import time
import zmq
NBR_CLIENTS = 10
NBR_WORKERS = 3
def worker_thread(worker_url, context, i):
""" Worker using REQ socket to do LRU routing """
socket = context.socket(zmq.REQ)
# set worker identity
socket.identity = (u"Worker-%d" % (i)).encode('ascii')
socket.connect(worker_url)
# Tell the broker we are ready for work
socket.send(b"READY")
try:
while True:
address, empty, request = socket.recv_multipart()
print("%s: %s\n" % (socket.identity.decode('ascii'),
request.decode('ascii')), end='')
socket.send_multipart([address, b'', b'OK'])
except zmq.ContextTerminated:
# context terminated so quit silently
return
def client_thread(client_url, context, i):
""" Basic request-reply client using REQ socket """
socket = context.socket(zmq.REQ)
# Set client identity. Makes tracing easier
socket.identity = (u"Client-%d" % (i)).encode('ascii')
socket.connect(client_url)
# Send request, get reply
socket.send(b"HELLO")
reply = socket.recv()
print("%s: %s\n" % (socket.identity.decode('ascii'),
reply.decode('ascii')), end='')
def main():
""" main method """
url_worker = "inproc://workers"
url_client = "inproc://clients"
client_nbr = NBR_CLIENTS
# Prepare our context and sockets
context = zmq.Context()
frontend = context.socket(zmq.ROUTER)
frontend.bind(url_client)
backend = context.socket(zmq.ROUTER)
backend.bind(url_worker)
# create workers and clients threads
for i in range(NBR_WORKERS):
thread = threading.Thread(target=worker_thread,
args=(url_worker, context, i, ))
thread.start()
for i in range(NBR_CLIENTS):
thread_c = threading.Thread(target=client_thread,
args=(url_client, context, i, ))
thread_c.start()
# Logic of LRU loop
# - Poll backend always, frontend only if 1+ worker ready
# - If worker replies, queue worker as ready and forward reply
# to client if necessary
# - If client requests, pop next worker and send request to it
# Queue of available workers
available_workers = 0
workers_list = []
# init poller
poller = zmq.Poller()
# Always poll for worker activity on backend
poller.register(backend, zmq.POLLIN)
# Poll front-end only if we have available workers
poller.register(frontend, zmq.POLLIN)
while True:
socks = dict(poller.poll())
# Handle worker activity on backend
if (backend in socks and socks[backend] == zmq.POLLIN):
# Queue worker address for LRU routing
message = backend.recv_multipart()
assert available_workers < NBR_WORKERS
worker_addr = message[0]
# add worker back to the list of workers
available_workers += 1
workers_list.append(worker_addr)
# Second frame is empty
empty = message[1]
assert empty == b""
# Third frame is READY or else a client reply address
client_addr = message[2]
# If client reply, send rest back to frontend
if client_addr != b'READY':
# Following frame is empty
empty = message[3]
assert empty == b""
reply = message[4]
frontend.send_multipart([client_addr, b"", reply])
client_nbr -= 1
if client_nbr == 0:
break # Exit after N messages
# poll on frontend only if workers are available
if available_workers > 0:
if (frontend in socks and socks[frontend] == zmq.POLLIN):
# Now get next client request, route to LRU worker
# Client request is [address][empty][request]
[client_addr, empty, request] = frontend.recv_multipart()
assert empty == b""
# Dequeue and drop the next worker address
available_workers += -1
worker_id = workers_list.pop()
backend.send_multipart([worker_id, b"",
client_addr, b"", request])
#out of infinite loop: do some housekeeping
time.sleep(1)
frontend.close()
backend.close()
context.term()
if __name__ == "__main__":
main()
lbbroker2:使用高层 API 的负载均衡代理 (Q)
lbbroker2:使用高层 API 的负载均衡代理 (Racket)
lbbroker2:使用高层 API 的负载均衡代理 (Ruby)
lbbroker2:使用高层 API 的负载均衡代理 (Rust)
lbbroker2:使用高层 API 的负载均衡代理 (Scala)
/*
* Least-recently used (LRU) queue device
* Clients and workers are shown here in-process
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
*
* @Author: Giovanni Ruggiero
* @Email: giovanni.ruggiero@gmail.com
*/
import org.zeromq.ZMQ
import ZHelpers._
object lruqueue2OK {
// Basic request-reply client using REQ socket
//
class ClientTask() extends Runnable {
def run() {
val ctx = ZMQ.context(1)
val client = ctx.socket(ZMQ.REQ)
setID(client);
client.connect("tcp://:5555");
// Send request, get reply
client.send("HELLO".getBytes, 0);
val reply = client.recv(0);
printf("Client: %s\n", new String(reply));
}
}
// Worker using REQ socket to do LRU routing
//
class WorkerTask() extends Runnable {
def run() {
val ctx = ZMQ.context(1)
val worker = ctx.socket(ZMQ.REQ)
setID(worker);
worker.connect("tcp://:5556");
// Tell broker we're ready for work
worker.send("READY".getBytes, 0);
while (true) {
// Read and save all frames until we get an empty frame
// In this example there is only 1 but it could be more
val msg = new ZMsg(worker)
printf("Worker: %s\n", msg.bodyToString);
msg.stringToBody("OK")
msg.send(worker)
}
}
}
def main(args : Array[String]) {
val NOFLAGS = 0
// Worker using REQ socket to do LRU routing
//
val NBR_CLIENTS = 10;
val NBR_WORKERS = 3;
// Prepare our context and sockets
val ctx = ZMQ.context(1)
val frontend = ctx.socket(ZMQ.ROUTER)
val backend = ctx.socket(ZMQ.ROUTER)
frontend.bind("tcp://*:5555")
backend.bind("tcp://*:5556")
val clients = List.fill(NBR_CLIENTS)(new Thread(new ClientTask))
clients foreach (_.start)
val workers = List.fill(NBR_WORKERS)(new Thread(new WorkerTask))
workers foreach (_.start)
// Logic of LRU loop
// - Poll backend always, frontend only if 1+ worker ready
// - If worker replies, queue worker as ready and forward reply
// to client if necessary
// - If client requests, pop next worker and send request to it
val workerQueue = scala.collection.mutable.Queue[Array[Byte]]()
var availableWorkers = 0
val poller = ctx.poller(2)
// Always poll for worker activity on backend
poller.register(backend,ZMQ.Poller.POLLIN)
// Poll front-end only if we have available workers
poller.register(frontend,ZMQ.Poller.POLLIN)
var clientNbr = NBR_CLIENTS
while (true) {
poller.poll
if(poller.pollin(0) && clientNbr > 0) {
val msg = new ZMsg(backend)
val workerAddr = msg.unwrap
assert (availableWorkers < NBR_WORKERS)
availableWorkers += 1
// Queue worker address for LRU routing
workerQueue.enqueue(workerAddr)
// Address is READY or else a client reply address
val clientAddr = msg.address
if (!new String(clientAddr).equals("READY")) {
frontend.sendMsg(msg)
clientNbr -=1 // Exit after N messages
}
}
if(availableWorkers > 0 && poller.pollin(1)) {
// Now get next client request, route to LRU worker
// Client request is [address][empty][request]
val msg = new ZMsg(frontend)
msg.wrap(workerQueue.dequeue)
backend.sendMsg(msg)
availableWorkers -= 1
}
}
}
}
lbbroker2:使用高层 API 的负载均衡代理 (Tcl)
lbbroker2:使用高层 API 的负载均衡代理 (OCaml)
CZMQ 提供的一项功能是干净的中断处理。这意味着 Ctrl-C 将导致任何阻塞的 ZeroMQ 调用退出,返回代码为 -1,并将 errno 设置为EINTR。在这种情况下,高层接收方法将返回 NULL。因此,你可以像这样干净地退出循环:
while (true) {
zstr_send (client, "Hello");
char *reply = zstr_recv (client);
if (!reply)
break; // Interrupted
printf ("Client: %s\n", reply);
free (reply);
sleep (1);
}
或者,如果你正在调用 zmq_poll(),检查返回值
if (zmq_poll (items, 2, 1000 * 1000) == -1)
break; // Interrupted
上面的示例仍然使用 zmq_poll()。那么反应器怎么样呢?CZMQ 的zloop反应器很简单但功能强大。它允许你
- 在任何套接字上设置读取器,即当套接字有输入时调用的代码。
- 取消套接字上的读取器。
- 设置一个在特定时间间隔内触发一次或多次的定时器。
- 取消定时器。
zloop当然在内部使用 zmq_poll()。它每次添加或移除读取器时都会重建其 poll set,并计算轮询超时时间以匹配下一个定时器。然后,它会为每个需要关注的套接字和定时器调用相应的读取器和定时器处理函数。
当我们使用反应器模式时,我们的代码会发生颠倒。主要逻辑看起来像这样:
zloop_t *reactor = zloop_new ();
zloop_reader (reactor, self->backend, s_handle_backend, self);
zloop_start (reactor);
zloop_destroy (&reactor);
实际的消息处理位于专门的函数或方法内部。你可能不喜欢这种风格——这取决于个人喜好。它有助于混合处理定时器和套接字活动。在本文的其余部分,我们将在更简单的情况下使用 zmq_poll(),而在更复杂的示例中则使用zloop。
这是再次重写的负载均衡代理,这次使用zloop:
lbbroker3:使用 zloop 的负载均衡代理 (Ada)
lbbroker3:使用 zloop 的负载均衡代理 (Basic)
lbbroker3:使用 zloop 的负载均衡代理 (C)
// Load-balancing broker
// Demonstrates use of the CZMQ API and reactor style
//
// The client and worker tasks are similar to the previous example.
// .skip
#include "czmq.h"
#define NBR_CLIENTS 10
#define NBR_WORKERS 3
#define WORKER_READY "\001" // Signals worker is ready
// Basic request-reply client using REQ socket
//
static void
client_task (zsock_t *pipe, void *args)
{
// Signal ready
zsock_signal(pipe, 0);
zsock_t *client = zsock_new_req ("ipc://frontend.ipc");
zpoller_t *poller = zpoller_new (pipe, client, NULL);
zpoller_set_nonstop(poller,true);
// Send request, get reply
while (true) {
zstr_send (client, "HELLO");
zsock_t *ready = zpoller_wait (poller, -1);
if (ready == NULL) continue; // Interrupted
else if (ready == pipe) break; // Shutdown
else assert(ready == client); // Data Available
char *reply = zstr_recv (client);
if (!reply)
break;
printf ("Client: %s\n", reply);
free (reply);
sleep (1);
}
zpoller_destroy(&poller);
zsock_destroy(&client);
}
// Worker using REQ socket to do load-balancing
//
static void
worker_task (zsock_t *pipe, void *args)
{
// Signal ready
zsock_signal(pipe, 0);
zsock_t *worker = zsock_new_req ("ipc://backend.ipc");
zpoller_t *poller = zpoller_new (pipe, worker, NULL);
zpoller_set_nonstop(poller, true);
// Tell broker we're ready for work
zframe_t *frame = zframe_new (WORKER_READY, 1);
zframe_send (&frame, worker, 0);
// Process messages as they arrive
while (true) {
zsock_t *ready = zpoller_wait (poller, -1);
if (ready == NULL) continue; // Interrupted
else if (ready == pipe) break; // Shutdown
else assert(ready == worker); // Data Available
zmsg_t *msg = zmsg_recv (worker);
if (!msg)
break; // Interrupted
zframe_print (zmsg_last (msg), "Worker: ");
zframe_reset (zmsg_last (msg), "OK", 2);
zmsg_send (&msg, worker);
}
zpoller_destroy(&poller);
zsock_destroy(&worker);
}
// .until
// Our load-balancer structure, passed to reactor handlers
typedef struct {
zsock_t *frontend; // Listen to clients
zsock_t *backend; // Listen to workers
zlist_t *workers; // List of ready workers
} lbbroker_t;
// .split reactor design
// In the reactor design, each time a message arrives on a socket, the
// reactor passes it to a handler function. We have two handlers; one
// for the frontend, one for the backend:
// Handle input from client, on frontend
static int s_handle_frontend (zloop_t *loop, zsock_t *reader, void *arg)
{
lbbroker_t *self = (lbbroker_t *) arg;
zmsg_t *msg = zmsg_recv (self->frontend);
if (msg) {
zmsg_pushmem (msg, NULL, 0); // delimiter
zmsg_push (msg, (zframe_t *) zlist_pop (self->workers));
zmsg_send (&msg, self->backend);
// Cancel reader on frontend if we went from 1 to 0 workers
if (zlist_size (self->workers) == 0) {
zloop_reader_end (loop, self->frontend);
}
}
return 0;
}
// Handle input from worker, on backend
static int s_handle_backend (zloop_t *loop, zsock_t *reader, void *arg)
{
// Use worker identity for load-balancing
lbbroker_t *self = (lbbroker_t *) arg;
zmsg_t *msg = zmsg_recv (self->backend);
if (msg) {
zframe_t *identity = zmsg_pop (msg);
zframe_t *delimiter = zmsg_pop (msg);
zframe_destroy (&delimiter);
zlist_append (self->workers, identity);
// Enable reader on frontend if we went from 0 to 1 workers
if (zlist_size (self->workers) == 1) {
zloop_reader (loop, self->frontend, s_handle_frontend, self);
}
// Forward message to client if it's not a READY
zframe_t *frame = zmsg_first (msg);
if (memcmp (zframe_data (frame), WORKER_READY, 1) == 0)
zmsg_destroy (&msg);
else
zmsg_send (&msg, self->frontend);
}
return 0;
}
// .split main task
// And the main task now sets up child tasks, then starts its reactor.
// If you press Ctrl-C, the reactor exits and the main task shuts down.
// Because the reactor is a CZMQ class, this example may not translate
// into all languages equally well.
int main (void)
{
lbbroker_t *self = (lbbroker_t *) zmalloc (sizeof (lbbroker_t));
self->frontend = zsock_new_router ("ipc://frontend.ipc");
self->backend = zsock_new_router ("ipc://backend.ipc");
zactor_t *actors[NBR_CLIENTS + NBR_WORKERS];
int actor_nbr = 0;
int client_nbr;
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++)
actors[actor_nbr++] = zactor_new (client_task, NULL);
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
actors[actor_nbr++] = zactor_new (worker_task, NULL);
// Queue of available workers
self->workers = zlist_new ();
// Prepare reactor and fire it up
zloop_t *reactor = zloop_new ();
zloop_reader (reactor, self->backend, s_handle_backend, self);
zloop_start (reactor);
zloop_destroy (&reactor);
for (actor_nbr = 0; actor_nbr < NBR_CLIENTS + NBR_WORKERS; actor_nbr++)
zactor_destroy(&actors[actor_nbr]);
// When we're done, clean up properly
while (zlist_size (self->workers)) {
zframe_t *frame = (zframe_t *) zlist_pop (self->workers);
zframe_destroy (&frame);
}
zlist_destroy (&self->workers);
zsock_destroy (&self->frontend);
zsock_destroy (&self->backend);
free (self);
return 0;
}
lbbroker3:使用 zloop 的负载均衡代理 (C++)
lbbroker3:使用 zloop 的负载均衡代理 (C#)
lbbroker3:使用 zloop 的负载均衡代理 (CL)
lbbroker3:使用 zloop 的负载均衡代理 (Delphi)
lbbroker3:使用 zloop 的负载均衡代理 (Erlang)
lbbroker3:使用 zloop 的负载均衡代理 (Elixir)
lbbroker3:使用 zloop 的负载均衡代理 (F#)
lbbroker3:使用 zloop 的负载均衡代理 (Felix)
lbbroker3:使用 zloop 的负载均衡代理 (Go)
lbbroker3:使用 zloop 的负载均衡代理 (Haskell)
lbbroker3:使用 zloop 的负载均衡代理 (Haxe)
package ;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZFrame;
import org.zeromq.ZLoop;
import org.zeromq.ZMsg;
#if (neko || cpp)
import neko.vm.Thread;
#end
import haxe.Stack;
import org.zeromq.ZContext;
import org.zeromq.ZSocket;
using org.zeromq.ZSocket;
import org.zeromq.ZMQ;
import org.zeromq.ZMQException;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
/**
* Least - recently used (LRU) queue device 3
* Demonstrates use of Zxxxx.hx API and reactor style using the ZLoop class.
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* See: https://zguide.zeromq.cn/page:all#A-High-Level-API-for-MQ
*/
class LRUQueue3
{
private static inline var NBR_CLIENTS = 10;
private static inline var NBR_WORKERS = 3;
// Signals workers are ready
private static inline var LRU_READY:String = String.fromCharCode(1);
private static inline var WORKER_DONE:Bytes = Bytes.ofString("OK");
/**
* Basic request-reply client using REQ socket.
*/
public static function clientTask() {
var context:ZContext = new ZContext();
var client:ZMQSocket = context.createSocket(ZMQ_REQ);
var id = ZHelpers.setID(client);
client.connectEndpoint("ipc", "/tmp/frontend.ipc");
while (true) {
ZFrame.newStringFrame("HELLO").send(client);
var reply = ZFrame.recvFrame(client);
if (reply == null) {
break;
}
Lib.println("Client "+id+": " + reply.toString());
Sys.sleep(1);
}
context.destroy();
}
/**
* Worker using REQ socket to do LRU routing.
*/
public static function workerTask() {
var context:ZContext = new ZContext();
var worker:ZMQSocket = context.createSocket(ZMQ_REQ);
var id = ZHelpers.setID(worker);
worker.connectEndpoint("ipc", "/tmp/backend.ipc");
// Tell broker we're ready to do work
ZFrame.newStringFrame(LRU_READY).send(worker);
// Process messages as they arrive
while (true) {
var msg:ZMsg = ZMsg.recvMsg(worker);
if (msg == null) {
break;
}
// Lib.println("Worker " + id + " received " + msg.toString());
msg.last().reset(WORKER_DONE);
msg.send(worker);
}
context.destroy();
}
// Hold information baout our LRU Queue structure
private static var frontend:ZMQSocket;
private static var backend:ZMQSocket;
private static var workerQueue:List<ZFrame>;
/**
* Handle input from client, on frontend
* @param loop
* @param socket
* @return
*/
private static function handleFrontEnd(loop:ZLoop, socket:ZMQSocket):Int {
var msg = ZMsg.recvMsg(frontend);
if (msg != null) {
msg.wrap(workerQueue.pop());
msg.send(backend);
// Cancel reader on frontend if we went from 1 to 0 workers
if (workerQueue.length == 0)
loop.unregisterPoller({socket:frontend,event:ZMQ.ZMQ_POLLIN()});
}
return 0;
}
/**
* Hande input from worker on backend
* @param loop
* @param socket
* @return
*/
private static function handleBackEnd(loop:ZLoop, socket:ZMQSocket):Int {
var msg:ZMsg = ZMsg.recvMsg(backend);
if (msg != null) {
var address = msg.unwrap();
workerQueue.add(address);
if (workerQueue.length == 1)
loop.registerPoller( { socket:frontend, event:ZMQ.ZMQ_POLLIN() }, handleFrontEnd);
// Forward message to client if it is not a READY
var frame = msg.first();
if (frame.streq(LRU_READY))
msg.destroy();
else
msg.send(frontend);
}
return 0;
}
public static function main() {
Lib.println("** LRUQueue3 (see: https://zguide.zeromq.cn/page:all#A-High-Level-API-for-MQ)");
#if php
// PHP appears to require tasks to be forked before main process creates ZMQ context
for (client_nbr in 0 ... NBR_CLIENTS) {
forkClientTask();
}
for (worker_nbr in 0 ... NBR_WORKERS) {
forkWorkerTask();
}
#end
// Prepare our context and sockets
var context:ZContext = new ZContext();
frontend = context.createSocket(ZMQ_ROUTER);
backend = context.createSocket(ZMQ_ROUTER);
frontend.bindEndpoint("ipc", "/tmp/frontend.ipc");
backend.bindEndpoint("ipc", "/tmp/backend.ipc");
#if !php
// Non-PHP targets require threads to be created after main thread has set up ZMQ Context
for (client_nbr in 0 ... NBR_CLIENTS) {
Thread.create(clientTask);
}
for (worker_nbr in 0 ... NBR_WORKERS) {
Thread.create(workerTask);
}
#end
// Logic of LRU loop:
// - Poll backend always, frontend only if 1 or more worker si ready
// - If worker replies, queue worker as ready and forward reply
// to client if necessary.
// - If client requests, pop next worker and send request to it.
// Initialise queue of available workers
workerQueue = new List<ZFrame>();
// Prepare reactor and fire it up
var reactor:ZLoop = new ZLoop();
reactor.registerPoller( { socket:backend, event:ZMQ.ZMQ_POLLIN() }, handleBackEnd);
reactor.start();
reactor.destroy();
// When we're done, clean up properly
for (f in workerQueue) {
f.destroy();
}
context.destroy();
}
#if php
private static inline function forkWorkerTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
LRUQueue3::workerTask();
exit();
}');
return;
}
private static inline function forkClientTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
LRUQueue3::clientTask();
exit();
}');
return;
}
#end
}lbbroker3:使用 zloop 的负载均衡代理 (Java)
package guide;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.Queue;
import org.zeromq.*;
import org.zeromq.ZMQ.PollItem;
import org.zeromq.ZMQ.Socket;
/**
* Load-balancing broker
* Demonstrates use of the ZLoop API and reactor style
*
* The client and worker tasks are identical from the previous example.
*/
public class lbbroker3
{
private static final int NBR_CLIENTS = 10;
private static final int NBR_WORKERS = 3;
private static byte[] WORKER_READY = { '\001' };
/**
* Basic request-reply client using REQ socket
*/
private static class ClientTask implements ZThread.IDetachedRunnable
{
@Override
public void run(Object [] args)
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
Socket client = context.createSocket(SocketType.REQ);
ZHelper.setId(client); // Set a printable identity
client.connect("ipc://frontend.ipc");
// Send request, get reply
client.send("HELLO");
String reply = client.recvStr();
System.out.println("Client: " + reply);
}
}
}
/**
* Worker using REQ socket to do load-balancing
*/
private static class WorkerTask implements ZThread.IDetachedRunnable
{
@Override
public void run(Object [] args)
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
Socket worker = context.createSocket(SocketType.REQ);
ZHelper.setId(worker); // Set a printable identity
worker.connect("ipc://backend.ipc");
// Tell backend we're ready for work
ZFrame frame = new ZFrame(WORKER_READY);
frame.send(worker, 0);
while (true) {
ZMsg msg = ZMsg.recvMsg(worker);
if (msg == null)
break;
msg.getLast().reset("OK");
msg.send(worker);
}
}
}
}
//Our load-balancer structure, passed to reactor handlers
private static class LBBroker
{
Socket frontend; // Listen to clients
Socket backend; // Listen to workers
Queue<ZFrame> workers; // List of ready workers
};
/**
* In the reactor design, each time a message arrives on a socket, the
* reactor passes it to a handler function. We have two handlers; one
* for the frontend, one for the backend:
*/
private static class FrontendHandler implements ZLoop.IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg_)
{
LBBroker arg = (LBBroker) arg_;
ZMsg msg = ZMsg.recvMsg(arg.frontend);
if (msg != null) {
msg.wrap(arg.workers.poll());
msg.send(arg.backend);
// Cancel reader on frontend if we went from 1 to 0 workers
if (arg.workers.size() == 0) {
loop.removePoller(new PollItem(arg.frontend, 0));
}
}
return 0;
}
}
private static class BackendHandler implements ZLoop.IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg_)
{
LBBroker arg = (LBBroker) arg_;
ZMsg msg = ZMsg.recvMsg(arg.backend);
if (msg != null) {
ZFrame address = msg.unwrap();
// Queue worker address for load-balancing
arg.workers.add(address);
// Enable reader on frontend if we went from 0 to 1 workers
if (arg.workers.size() == 1) {
PollItem newItem = new PollItem(arg.frontend, ZMQ.Poller.POLLIN);
loop.addPoller(newItem, frontendHandler, arg);
}
// Forward message to client if it's not a READY
ZFrame frame = msg.getFirst();
if (Arrays.equals(frame.getData(), WORKER_READY))
msg.destroy();
else msg.send(arg.frontend);
}
return 0;
}
}
private final static FrontendHandler frontendHandler = new FrontendHandler();
private final static BackendHandler backendHandler = new BackendHandler();
/**
* And the main task now sets-up child tasks, then starts its reactor.
* If you press Ctrl-C, the reactor exits and the main task shuts down.
*/
public static void main(String[] args)
{
// Prepare our context and sockets
try (ZContext context = new ZContext()) {
LBBroker arg = new LBBroker();
arg.frontend = context.createSocket(SocketType.ROUTER);
arg.backend = context.createSocket(SocketType.ROUTER);
arg.frontend.bind("ipc://frontend.ipc");
arg.backend.bind("ipc://backend.ipc");
int clientNbr;
for (clientNbr = 0; clientNbr < NBR_CLIENTS; clientNbr++)
ZThread.start(new ClientTask());
for (int workerNbr = 0; workerNbr < NBR_WORKERS; workerNbr++)
ZThread.start(new WorkerTask());
// Queue of available workers
arg.workers = new LinkedList<ZFrame>();
// Prepare reactor and fire it up
ZLoop reactor = new ZLoop(context);
PollItem item = new PollItem(arg.backend, ZMQ.Poller.POLLIN);
reactor.addPoller(item, backendHandler, arg);
reactor.start();
}
}
}
lbbroker3:使用 zloop 的负载均衡代理 (Julia)
lbbroker3:使用 zloop 的负载均衡代理 (Lua)
lbbroker3:使用 zloop 的负载均衡代理 (Node.js)
lbbroker3:使用 zloop 的负载均衡代理 (Objective-C)
lbbroker3:使用 zloop 的负载均衡代理 (ooc)
lbbroker3:使用 zloop 的负载均衡代理 (Perl)
lbbroker3:使用 zloop 的负载均衡代理 (PHP)
lbbroker3:使用 zloop 的负载均衡代理 (Python)
"""
Least-recently used (LRU) queue device
Demonstrates use of pyzmq IOLoop reactor
While this example runs in a single process, that is just to make
it easier to start and stop the example. Each thread has its own
context and conceptually acts as a separate process.
Author: Min RK <benjaminrk(at)gmail(dot)com>
Adapted from lruqueue.py by
Guillaume Aubert (gaubert) <guillaume(dot)aubert(at)gmail(dot)com>
"""
from __future__ import print_function
import threading
import time
import zmq
from zmq.eventloop.ioloop import IOLoop
from zmq.eventloop.zmqstream import ZMQStream
NBR_CLIENTS = 10
NBR_WORKERS = 3
def worker_thread(worker_url, i):
""" Worker using REQ socket to do LRU routing """
context = zmq.Context.instance()
socket = context.socket(zmq.REQ)
# set worker identity
socket.identity = (u"Worker-%d" % (i)).encode('ascii')
socket.connect(worker_url)
# Tell the broker we are ready for work
socket.send(b"READY")
try:
while True:
address, empty, request = socket.recv_multipart()
print("%s: %s\n" % (socket.identity.decode('ascii'),
request.decode('ascii')), end='')
socket.send_multipart([address, b'', b'OK'])
except zmq.ContextTerminated:
# context terminated so quit silently
return
def client_thread(client_url, i):
""" Basic request-reply client using REQ socket """
context = zmq.Context.instance()
socket = context.socket(zmq.REQ)
# Set client identity. Makes tracing easier
socket.identity = (u"Client-%d" % (i)).encode('ascii')
socket.connect(client_url)
# Send request, get reply
socket.send(b"HELLO")
reply = socket.recv()
print("%s: %s\n" % (socket.identity.decode('ascii'),
reply.decode('ascii')), end='')
class LRUQueue(object):
"""LRUQueue class using ZMQStream/IOLoop for event dispatching"""
def __init__(self, backend_socket, frontend_socket):
self.available_workers = 0
self.is_workers_ready = False
self.workers = []
self.client_nbr = NBR_CLIENTS
self.backend = ZMQStream(backend_socket)
self.frontend = ZMQStream(frontend_socket)
self.backend.on_recv(self.handle_backend)
self.loop = IOLoop.instance()
def handle_backend(self, msg):
# Queue worker address for LRU routing
worker_addr, empty, client_addr = msg[:3]
assert self.available_workers < NBR_WORKERS
# add worker back to the list of workers
self.available_workers += 1
self.is_workers_ready = True
self.workers.append(worker_addr)
# Second frame is empty
assert empty == b""
# Third frame is READY or else a client reply address
# If client reply, send rest back to frontend
if client_addr != b"READY":
empty, reply = msg[3:]
# Following frame is empty
assert empty == b""
self.frontend.send_multipart([client_addr, b'', reply])
self.client_nbr -= 1
if self.client_nbr == 0:
# Exit after N messages
self.loop.add_timeout(time.time() + 1, self.loop.stop)
if self.is_workers_ready:
# when atleast 1 worker is ready, start accepting frontend messages
self.frontend.on_recv(self.handle_frontend)
def handle_frontend(self, msg):
# Now get next client request, route to LRU worker
# Client request is [address][empty][request]
client_addr, empty, request = msg
assert empty == b""
# Dequeue and drop the next worker address
self.available_workers -= 1
worker_id = self.workers.pop()
self.backend.send_multipart([worker_id, b'', client_addr, b'', request])
if self.available_workers == 0:
# stop receiving until workers become available again
self.is_workers_ready = False
self.frontend.stop_on_recv()
def main():
"""main method"""
url_worker = "ipc://backend.ipc"
url_client = "ipc://frontend.ipc"
# Prepare our context and sockets
context = zmq.Context()
frontend = context.socket(zmq.ROUTER)
frontend.bind(url_client)
backend = context.socket(zmq.ROUTER)
backend.bind(url_worker)
# create workers and clients threads
for i in range(NBR_WORKERS):
thread = threading.Thread(target=worker_thread, args=(url_worker, i, ))
thread.daemon = True
thread.start()
for i in range(NBR_CLIENTS):
thread_c = threading.Thread(target=client_thread,
args=(url_client, i, ))
thread_c.daemon = True
thread_c.start()
# create queue with the sockets
queue = LRUQueue(backend, frontend)
# start reactor
IOLoop.instance().start()
if __name__ == "__main__":
main()
lbbroker3:使用 zloop 的负载均衡代理 (Q)
lbbroker3:使用 zloop 的负载均衡代理 (Racket)
lbbroker3:使用 zloop 的负载均衡代理 (Ruby)
lbbroker3:使用 zloop 的负载均衡代理 (Rust)
lbbroker3:使用 zloop 的负载均衡代理 (Scala)
lbbroker3:使用 zloop 的负载均衡代理 (Tcl)
lbbroker3:使用 zloop 的负载均衡代理 (OCaml)
当你发送 Ctrl-C 时,让应用程序正确关闭可能会很棘手。如果你使用zctx类,它会自动设置信号处理,但你的代码仍然需要配合。如果zmq_poll返回 -1,或者如果任何zstr_recv, zframe_recv,或zmsg_recv方法返回 NULL,你必须中断任何循环。如果你有嵌套循环,将外部循环设置为依赖于!zctx_interrupted.
可能会很有用。如果你使用子线程,它们不会接收到中断信号。要告知它们关闭,你可以选择
- 如果它们共享同一个上下文,销毁该上下文,在这种情况下,它们正在等待的任何阻塞调用将以 ETERM 结束。
- 如果它们使用自己的上下文,发送关闭消息给它们。为此你需要一些套接字管道。
异步客户端/服务器模式 #
在 ROUTER 到 DEALER 的示例中,我们看到了一个 1 对 N 的用例,其中一个服务器异步地与多个工作者通信。我们可以将这种情况颠倒过来,得到一个非常有用的 N 对 1 架构,其中各种客户端与单个服务器通信,并且是异步进行的。
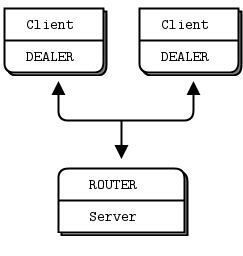
工作原理如下:
- 客户端连接到服务器并发送请求。
- 对于每个请求,服务器发送 0 个或多个回复。
- 客户端可以发送多个请求,而无需等待回复。
- 服务器可以发送多个回复,而无需等待新的请求。
以下是展示其工作原理的代码
asyncsrv: Ada 中的异步客户端/服务器
asyncsrv: Basic 中的异步客户端/服务器
asyncsrv: C 中的异步客户端/服务器
// Asynchronous client-to-server (DEALER to ROUTER)
//
// While this example runs in a single process, that is to make
// it easier to start and stop the example. Each task conceptually
// acts as a separate process.
#include "czmq.h"
// This is our client task
// It connects to the server, and then sends a request once per second
// It collects responses as they arrive, and it prints them out. We will
// run several client tasks in parallel, each with a different random ID.
static void
client_task (zsock_t *pipe, void *args)
{
zsock_signal(pipe, 0);
zsock_t *client = zsock_new (ZMQ_DEALER);
// Set random identity to make tracing easier (must be done before zsock_connect)
char identity [10];
sprintf (identity, "%04X-%04X", randof (0x10000), randof (0x10000));
zsock_set_identity (client, identity);
zsock_connect (client, "tcp://:5570");
zpoller_t *poller = zpoller_new (pipe, client, NULL);
zpoller_set_nonstop(poller, true);
bool signaled = false;
int request_nbr = 0;
while (!signaled) {
// Tick once per second, pulling in arriving messages
int centitick;
for (centitick = 0; centitick < 100; centitick++) {
zsock_t *ready = zpoller_wait(poller, 10 * ZMQ_POLL_MSEC);
if (ready == NULL) continue;
else if (ready == pipe) {
signaled = true;
break;
} else assert (ready == client);
zmsg_t *msg = zmsg_recv (client);
zframe_print (zmsg_last (msg), identity);
zmsg_destroy (&msg);
}
zstr_sendf (client, "request #%d", ++request_nbr);
}
zpoller_destroy(&poller);
zsock_destroy(&client);
}
// .split server task
// This is our server task.
// It uses the multithreaded server model to deal requests out to a pool
// of workers and route replies back to clients. One worker can handle
// one request at a time but one client can talk to multiple workers at
// once.
static void server_worker (zsock_t *pipe, void *args);
static void server_task (zsock_t *pipe, void *args)
{
zsock_signal(pipe, 0);
// Launch pool of worker threads, precise number is not critical
enum { NBR_THREADS = 5 };
zactor_t *threads[NBR_THREADS];
int thread_nbr;
for (thread_nbr = 0; thread_nbr < NBR_THREADS; thread_nbr++)
threads[thread_nbr] = zactor_new (server_worker, NULL);
// Connect backend to frontend via a zproxy
zactor_t *proxy = zactor_new (zproxy, NULL);
zstr_sendx (proxy, "FRONTEND", "ROUTER", "tcp://*:5570", NULL);
zsock_wait (proxy);
zstr_sendx (proxy, "BACKEND", "DEALER", "inproc://backend", NULL);
zsock_wait (proxy);
// Wait for shutdown signal
zsock_wait(pipe);
zactor_destroy(&proxy);
for (thread_nbr = 0; thread_nbr < NBR_THREADS; thread_nbr++)
zactor_destroy(&threads[thread_nbr]);
}
// .split worker task
// Each worker task works on one request at a time and sends a random number
// of replies back, with random delays between replies:
static void
server_worker (zsock_t *pipe, void *args)
{
zsock_signal(pipe, 0);
zsock_t *worker = zsock_new_dealer ("inproc://backend");
zpoller_t *poller = zpoller_new (pipe, worker, NULL);
zpoller_set_nonstop (poller, true);
while (true) {
zsock_t *ready = zpoller_wait (poller, -1);
if (ready == NULL) continue;
else if (ready == pipe) break;
else assert (ready == worker);
// The DEALER socket gives us the reply envelope and message
zmsg_t *msg = zmsg_recv (worker);
zframe_t *identity = zmsg_pop (msg);
zframe_t *content = zmsg_pop (msg);
assert (content);
zmsg_destroy (&msg);
// Send 0..4 replies back
int reply, replies = randof (5);
for (reply = 0; reply < replies; reply++) {
// Sleep for some fraction of a second
zclock_sleep (randof (1000) + 1);
zframe_send (&identity, worker, ZFRAME_REUSE | ZFRAME_MORE | ZFRAME_DONTWAIT );
zframe_send (&content, worker, ZFRAME_REUSE | ZFRAME_DONTWAIT );
}
zframe_destroy (&identity);
zframe_destroy (&content);
}
zpoller_destroy (&poller);
zsock_destroy (&worker);
}
// The main thread simply starts several clients and a server, and then
// waits for the server to finish.
int main (void)
{
zactor_t *client1 = zactor_new (client_task, NULL);
zactor_t *client2 = zactor_new (client_task, NULL);
zactor_t *client3 = zactor_new (client_task, NULL);
zactor_t *server = zactor_new (server_task, NULL);
zclock_sleep (5 * 1000); // Run for 5 seconds then quit
zsock_signal (server, 0);
zactor_destroy (&server);
zactor_destroy (&client1);
zactor_destroy (&client2);
zactor_destroy (&client3);
return 0;
}
asyncsrv: C++ 中的异步客户端/服务器
// Asynchronous client-to-server (DEALER to ROUTER)
//
// While this example runs in a single process, that is to make
// it easier to start and stop the example. Each task has its own
// context and conceptually acts as a separate process.
#include <vector>
#include <thread>
#include <memory>
#include <functional>
#include <zmq.hpp>
#include "zhelpers.hpp"
// This is our client task class.
// It connects to the server, and then sends a request once per second
// It collects responses as they arrive, and it prints them out. We will
// run several client tasks in parallel, each with a different random ID.
// Attention! -- this random work well only on linux.
class client_task {
public:
client_task()
: ctx_(1),
client_socket_(ctx_, ZMQ_DEALER)
{}
void start() {
// generate random identity
char identity[10] = {};
sprintf(identity, "%04X-%04X", within(0x10000), within(0x10000));
printf("%s\n", identity);
client_socket_.set(zmq::sockopt::routing_id, identity);
client_socket_.connect("tcp://:5570");
zmq::pollitem_t items[] = {
{ client_socket_, 0, ZMQ_POLLIN, 0 } };
int request_nbr = 0;
try {
while (true) {
for (int i = 0; i < 100; ++i) {
// 10 milliseconds
zmq::poll(items, 1, 10);
if (items[0].revents & ZMQ_POLLIN) {
printf("\n%s ", identity);
s_dump(client_socket_);
}
}
char request_string[16] = {};
sprintf(request_string, "request #%d", ++request_nbr);
client_socket_.send(request_string, strlen(request_string));
}
}
catch (std::exception &e) {}
}
private:
zmq::context_t ctx_;
zmq::socket_t client_socket_;
};
// .split worker task
// Each worker task works on one request at a time and sends a random number
// of replies back, with random delays between replies:
class server_worker {
public:
server_worker(zmq::context_t &ctx, int sock_type)
: ctx_(ctx),
worker_(ctx_, sock_type)
{}
void work() {
worker_.connect("inproc://backend");
try {
while (true) {
zmq::message_t identity;
zmq::message_t msg;
zmq::message_t copied_id;
zmq::message_t copied_msg;
worker_.recv(&identity);
worker_.recv(&msg);
int replies = within(5);
for (int reply = 0; reply < replies; ++reply) {
s_sleep(within(1000) + 1);
copied_id.copy(&identity);
copied_msg.copy(&msg);
worker_.send(copied_id, ZMQ_SNDMORE);
worker_.send(copied_msg);
}
}
}
catch (std::exception &e) {}
}
private:
zmq::context_t &ctx_;
zmq::socket_t worker_;
};
// .split server task
// This is our server task.
// It uses the multithreaded server model to deal requests out to a pool
// of workers and route replies back to clients. One worker can handle
// one request at a time but one client can talk to multiple workers at
// once.
class server_task {
public:
server_task()
: ctx_(1),
frontend_(ctx_, ZMQ_ROUTER),
backend_(ctx_, ZMQ_DEALER)
{}
enum { kMaxThread = 5 };
void run() {
frontend_.bind("tcp://*:5570");
backend_.bind("inproc://backend");
std::vector<server_worker *> worker;
std::vector<std::thread *> worker_thread;
for (int i = 0; i < kMaxThread; ++i) {
worker.push_back(new server_worker(ctx_, ZMQ_DEALER));
worker_thread.push_back(new std::thread(std::bind(&server_worker::work, worker[i])));
worker_thread[i]->detach();
}
try {
zmq::proxy(static_cast<void*>(frontend_),
static_cast<void*>(backend_),
nullptr);
}
catch (std::exception &e) {}
for (int i = 0; i < kMaxThread; ++i) {
delete worker[i];
delete worker_thread[i];
}
}
private:
zmq::context_t ctx_;
zmq::socket_t frontend_;
zmq::socket_t backend_;
};
// The main thread simply starts several clients and a server, and then
// waits for the server to finish.
int main (void)
{
client_task ct1;
client_task ct2;
client_task ct3;
server_task st;
std::thread t1(std::bind(&client_task::start, &ct1));
std::thread t2(std::bind(&client_task::start, &ct2));
std::thread t3(std::bind(&client_task::start, &ct3));
std::thread t4(std::bind(&server_task::run, &st));
t1.detach();
t2.detach();
t3.detach();
t4.detach();
getchar();
return 0;
}
asyncsrv: C# 中的异步客户端/服务器
asyncsrv: CL 中的异步客户端/服务器
asyncsrv: Delphi 中的异步客户端/服务器
program asyncsrv;
//
// Asynchronous client-to-server (DEALER to ROUTER)
//
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each task has its own
// context and conceptually acts as a separate process.
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, Classes
, zmqapi
, zhelpers
;
// ---------------------------------------------------------------------
// This is our client task.
// It connects to the server, and then sends a request once per second
// It collects responses as they arrive, and it prints them out. We will
// run several client tasks in parallel, each with a different random ID.
procedure client_task( args: Pointer );
var
ctx: TZMQContext;
client: TZMQSocket;
poller: TZMQPoller;
i, request_nbr: Integer;
msg: TZMQMsg;
begin
ctx := TZMQContext.create;
client := ctx.Socket( stDealer );
// Set random identity to make tracing easier
s_set_id( client );
client.connect( 'tcp://:5570' );
poller := TZMQPoller.Create( true );
poller.register( client, [pePollIn] );
msg := nil;
request_nbr := 0;
while true do
begin
// Tick once per second, pulling in arriving messages
for i := 0 to 100 - 1 do
begin
poller.poll( 10 );
if ( pePollIn in poller.PollItem[0].revents ) then
begin
client.recv( msg );
zNote( client.Identity + ': ' + msg.last.dump );
msg.Free;
msg := nil;
end;
end;
request_nbr := request_nbr + 1;
client.send( Format('request #%d',[request_nbr]) )
end;
poller.Free;
ctx.Free;
end;
// This is our server task.
// It uses the multithreaded server model to deal requests out to a pool
// of workers and route replies back to clients. One worker can handle
// one request at a time but one client can talk to multiple workers at
// once.
procedure server_worker( args: Pointer ); forward;
procedure server_task( args: Pointer );
var
ctx: TZMQContext;
frontend,
backend: TZMQSocket;
i: Integer;
tid: Cardinal;
begin
ctx := TZMQContext.create;
// Frontend socket talks to clients over TCP
frontend := ctx.Socket( stRouter );
frontend.bind( 'tcp://*:5570' );
// Backend socket talks to workers over inproc
backend := ctx.Socket( stDealer );
backend.bind( 'inproc://backend' );
// Launch pool of worker threads, precise number is not critical
for i := 0 to 4 do
BeginThread( nil, 0, @server_worker, ctx, 0, tid );
// Connect backend to frontend via a proxy
ZMQProxy( frontend, backend, nil );
ctx.Free;
end;
// Each worker task works on one request at a time and sends a random number
// of replies back, with random delays between replies:
procedure server_worker( args: Pointer );
var
ctx: TZMQContext;
worker: TZMQSocket;
msg: TZMQMsg;
identity,
content: TZMQFrame;
i,replies: Integer;
begin
ctx := args;
worker := ctx.Socket( stDealer );
worker.connect( 'inproc://backend' );
msg := nil;
while not ctx.Terminated do
begin
// The DEALER socket gives us the reply envelope and message
worker.recv( msg );
identity := msg.pop;
content := msg.pop;
assert(content <> nil);
msg.Free;
msg := nil;
// Send 0..4 replies back
replies := Random( 5 );
for i := 0 to replies - 1 do
begin
// Sleep for some fraction of a second
sleep( Random(1000) + 1 );
msg := TZMQMsg.Create;
msg.add( identity.dup );
msg.add( content.dup );
worker.send( msg );
end;
identity.Free;
content.Free;
end;
end;
var
tid: Cardinal;
begin
// The main thread simply starts several clients, and a server, and then
// waits for the server to finish.
Randomize;
BeginThread( nil, 0, @client_task, nil, 0, tid );
BeginThread( nil, 0, @client_task, nil, 0, tid );
BeginThread( nil, 0, @client_task, nil, 0, tid );
BeginThread( nil, 0, @server_task, nil, 0, tid );
// Run for 5 seconds then quit
sleep( 5 * 1000 );
end.
asyncsrv: Erlang 中的异步客户端/服务器
#!/usr/bin/env escript
%%
%% Asynchronous client-to-server (DEALER to ROUTER)
%%
%% While this example runs in a single process, that is just to make
%% it easier to start and stop the example. Each task has its own
%% context and conceptually acts as a separate process.
%% ---------------------------------------------------------------------
%% This is our client task
%% It connects to the server, and then sends a request once per second
%% It collects responses as they arrive, and it prints them out. We will
%% run several client tasks in parallel, each with a different random ID.
client_task() ->
{ok, Ctx} = erlzmq:context(),
{ok, Client} = erlzmq:socket(Ctx, dealer),
%% Set identity to make tracing easier
ok = erlzmq:setsockopt(Client, identity, pid_to_list(self())),
ok = erlzmq:connect(Client, "tcp://:5570"),
client_loop(Client, 0),
ok = erlzmq:term(Ctx).
client_loop(Client, RequestNbr) ->
%% Tick once per second, pulling in arriving messages (check 100 times
%% using 10 poll delay for each call)
client_check_messages(Client, 100, 10),
Msg = list_to_binary(io_lib:format("request #~b", [RequestNbr])),
erlzmq:send(Client, Msg),
client_loop(Client, RequestNbr + 1).
client_check_messages(_Client, 0, _PollDelay) -> ok;
client_check_messages(Client, N, PollDelay) when N > 0 ->
case erlzmq:recv(Client, [noblock]) of
{ok, Msg} -> io:format("~s [~p]~n", [Msg, self()]);
{error, eagain} -> timer:sleep(PollDelay)
end,
client_check_messages(Client, N - 1, PollDelay).
%% ---------------------------------------------------------------------
%% This is our server task
%% It uses the multithreaded server model to deal requests out to a pool
%% of workers and route replies back to clients. One worker can handle
%% one request at a time but one client can talk to multiple workers at
%% once.
server_task() ->
{ok, Ctx} = erlzmq:context(),
random:seed(now()),
%% Frontend socket talks to clients over TCP
{ok, Frontend} = erlzmq:socket(Ctx, [router, {active, true}]),
ok = erlzmq:bind(Frontend, "tcp://*:5570"),
%% Backend socket talks to workers over inproc
{ok, Backend} = erlzmq:socket(Ctx, [dealer, {active, true}]),
ok = erlzmq:bind(Backend, "inproc://backend"),
start_server_workers(Ctx, 5),
%% Connect backend to frontend via a queue device
erlzmq_device:queue(Frontend, Backend),
ok = erlzmq:term(Ctx).
start_server_workers(_Ctx, 0) -> ok;
start_server_workers(Ctx, N) when N > 0 ->
spawn(fun() -> server_worker(Ctx) end),
start_server_workers(Ctx, N - 1).
%% Accept a request and reply with the same text a random number of
%% times, with random delays between replies.
%%
server_worker(Ctx) ->
random:seed(now()),
{ok, Worker} = erlzmq:socket(Ctx, dealer),
ok = erlzmq:connect(Worker, "inproc://backend"),
server_worker_loop(Worker).
server_worker_loop(Worker) ->
{ok, Address} = erlzmq:recv(Worker),
{ok, Content} = erlzmq:recv(Worker),
send_replies(Worker, Address, Content, random:uniform(4) - 1),
server_worker_loop(Worker).
send_replies(_, _, _, 0) -> ok;
send_replies(Worker, Address, Content, N) when N > 0 ->
%% Sleep for some fraction of a second
timer:sleep(random:uniform(1000)),
ok = erlzmq:send(Worker, Address, [sndmore]),
ok = erlzmq:send(Worker, Content),
send_replies(Worker, Address, Content, N - 1).
%% This main thread simply starts several clients, and a server, and then
%% waits for the server to finish.
%%
main(_) ->
spawn(fun() -> client_task() end),
spawn(fun() -> client_task() end),
spawn(fun() -> client_task() end),
spawn(fun() -> server_task() end),
timer:sleep(5000).
asyncsrv: Elixir 中的异步客户端/服务器
defmodule asyncsrv do
@moduledoc """
Generated by erl2ex (http://github.com/dazuma/erl2ex)
From Erlang source: (Unknown source file)
At: 2019-12-20 13:57:22
"""
def client_task() do
{:ok, ctx} = :erlzmq.context()
{:ok, client} = :erlzmq.socket(ctx, :dealer)
:ok = :erlzmq.setsockopt(client, :identity, :erlang.pid_to_list(self()))
:ok = :erlzmq.connect(client, 'tcp://:5570')
client_loop(client, 0)
:ok = :erlzmq.term(ctx)
end
def client_loop(client, requestNbr) do
client_check_messages(client, 100, 10)
msg = :erlang.list_to_binary(:io_lib.format('request #~b', [requestNbr]))
:erlzmq.send(client, msg)
client_loop(client, requestNbr + 1)
end
def client_check_messages(_client, 0, _pollDelay) do
:ok
end
def client_check_messages(client, n, pollDelay) when n > 0 do
case(:erlzmq.recv(client, [:noblock])) do
{:ok, msg} ->
:io.format('~s [~p]~n', [msg, self()])
{:error, :eagain} ->
:timer.sleep(pollDelay)
end
client_check_messages(client, n - 1, pollDelay)
end
def server_task() do
{:ok, ctx} = :erlzmq.context()
:random.seed(:erlang.now())
{:ok, frontend} = :erlzmq.socket(ctx, [:router, {:active, true}])
:ok = :erlzmq.bind(frontend, 'tcp://*:5570')
{:ok, backend} = :erlzmq.socket(ctx, [:dealer, {:active, true}])
:ok = :erlzmq.bind(backend, 'inproc://backend')
start_server_workers(ctx, 5)
:erlzmq_device.queue(frontend, backend)
:ok = :erlzmq.term(ctx)
end
def start_server_workers(_ctx, 0) do
:ok
end
def start_server_workers(ctx, n) when n > 0 do
:erlang.spawn(fn -> server_worker(ctx) end)
start_server_workers(ctx, n - 1)
end
def server_worker(ctx) do
:random.seed(:erlang.now())
{:ok, worker} = :erlzmq.socket(ctx, :dealer)
:ok = :erlzmq.connect(worker, 'inproc://backend')
server_worker_loop(worker)
end
def server_worker_loop(worker) do
{:ok, address} = :erlzmq.recv(worker)
{:ok, content} = :erlzmq.recv(worker)
send_replies(worker, address, content, :random.uniform(4) - 1)
server_worker_loop(worker)
end
def send_replies(_, _, _, 0) do
:ok
end
def send_replies(worker, address, content, n) when n > 0 do
:timer.sleep(:random.uniform(1000))
:ok = :erlzmq.send(worker, address, [:sndmore])
:ok = :erlzmq.send(worker, content)
send_replies(worker, address, content, n - 1)
end
def main(_) do
:erlang.spawn(fn -> client_task() end)
:erlang.spawn(fn -> client_task() end)
:erlang.spawn(fn -> client_task() end)
:erlang.spawn(fn -> server_task() end)
:timer.sleep(5000)
end
end
asyncsrv: F# 中的异步客户端/服务器
asyncsrv: Felix 中的异步客户端/服务器
asyncsrv: Go 中的异步客户端/服务器
//
// Asynchronous client-server
// While this example runs in a single process, that is to make
// it easier to start and stop the example. Each task has its own
// context and conceptually acts as a separate process.
//
// Port of asyncsrv.c
// Written by: Aaron Clawson
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
//"strings"
"strconv"
"time"
)
var finished = make(chan int)
func randomString() string {
source := "abcdefghijklmnopqrstuvwxyz1234567890ABCDEFGHIJKLMNOPQRSTUVWXYZ"
target := make([]byte, 20)
for i := 0; i < 20; i++ {
target[i] = source[rand.Intn(len(source))]
}
return string(target)
}
// This is our client task
// It connects to the server, and then sends a request once per second
// It collects responses as they arrive, and it prints them out. We will
// run several client tasks in parallel, each with a different random ID.
func client_task() {
context, _ := zmq.NewContext()
defer context.Close()
// Set random identity to make tracing easier
identity := "Client-" + randomString()
client, _ := context.NewSocket(zmq.DEALER)
client.SetIdentity(identity)
client.Connect("ipc://frontend.ipc")
defer client.Close()
items := zmq.PollItems{
zmq.PollItem{Socket: client, Events: zmq.POLLIN},
}
reqs := 0
for {
//Read for a response 100 times for every message we send out
for i := 0; i < 100; i++ {
_, err := zmq.Poll(items, time.Millisecond*10)
if err != nil {
break // Interrupted
}
if items[0].REvents&zmq.POLLIN != 0 {
reply, _ := client.Recv(0)
fmt.Println(identity, "received", string(reply))
}
}
reqs += 1
req_str := "Request #" + strconv.Itoa(reqs)
client.Send([]byte(req_str), 0)
}
}
// This is our server task.
// It uses the multithreaded server model to deal requests out to a pool
// of workers and route replies back to clients. One worker can handle
// one request at a time but one client can talk to multiple workers at
// once.
func server_task() {
context, _ := zmq.NewContext()
defer context.Close()
// Frontend socket talks to clients over TCP
frontend, _ := context.NewSocket(zmq.ROUTER)
frontend.Bind("ipc://frontend.ipc")
defer frontend.Close()
// Backend socket talks to workers over inproc
backend, _ := context.NewSocket(zmq.DEALER)
backend.Bind("ipc://backend.ipc")
defer backend.Close()
// Launch pool of worker threads, precise number is not critical
for i := 0; i < 5; i++ {
go server_worker()
}
// Connect backend to frontend via a proxy
items := zmq.PollItems{
zmq.PollItem{Socket: frontend, Events: zmq.POLLIN},
zmq.PollItem{Socket: backend, Events: zmq.POLLIN},
}
for {
_, err := zmq.Poll(items, -1)
if err != nil {
fmt.Println("Server exited with error:", err)
break
}
if items[0].REvents&zmq.POLLIN != 0 {
parts, _ := frontend.RecvMultipart(0)
backend.SendMultipart(parts, 0)
}
if items[1].REvents&zmq.POLLIN != 0 {
parts, _ := backend.RecvMultipart(0)
frontend.SendMultipart(parts, 0)
}
}
}
// Each worker task works on one request at a time and sends a random number
// of replies back, with random delays between replies:
func server_worker() {
context, _ := zmq.NewContext()
defer context.Close()
// The DEALER socket gives us the reply envelope and message
worker, _ := context.NewSocket(zmq.DEALER)
worker.Connect("ipc://backend.ipc")
defer worker.Close()
for {
parts, _ := worker.RecvMultipart(0)
//Reply with 0..4 responses
replies := rand.Intn(5)
for i := 0; i < replies; i++ {
time.Sleep(time.Duration(rand.Intn(100)) * time.Millisecond)
worker.SendMultipart(parts, 0)
}
}
}
// The main thread simply starts several clients and a server, and then
// waits for the server to finish.
func main() {
rand.Seed(time.Now().UTC().UnixNano())
go client_task()
go client_task()
go client_task()
go server_task()
time.Sleep(time.Second * 5) // Run for 5 seconds then quit
}
asyncsrv: Haskell 中的异步客户端/服务器
-- |
-- Asynchronous client-to-server (DEALER to ROUTER) p.111
-- Compile with -threaded
module Main where
import System.ZMQ4.Monadic
import ZHelpers (setRandomIdentity)
import Control.Concurrent (threadDelay)
import Data.ByteString.Char8 (pack, unpack)
import Control.Monad (forever, forM_, replicateM_)
import System.Random (randomRIO)
import Text.Printf
clientTask :: String -> ZMQ z ()
clientTask ident = do
client <- socket Dealer
setRandomIdentity client
connect client "tcp://:5570"
forM_ [1..] $ \i -> do -- (long enough) forever
-- tick one per second, pulling in arriving messages
forM_ [0..100] $ \_ ->
poll 10 -- timeout of 10 ms
[Sock client [In] -- wait for incoming event
$ Just $ -- if it happens do
\_ -> receive client >>= liftIO . printf "Client %s has received back from worker its msg \"%s\"\n" ident . unpack ]
send client [] (pack $ unwords ["Client", ident, "sends request", show i])
serverTask :: ZMQ z ()
serverTask = do
frontend <- socket Router
bind frontend "tcp://*:5570"
backend <- socket Dealer
bind backend "inproc://backend"
replicateM_ 5 $ async serverWorker
proxy frontend backend Nothing
serverWorker :: ZMQ z ()
serverWorker = do
worker <- socket Dealer
connect worker "inproc://backend"
liftIO $ putStrLn "Worker Started"
forever $ -- receive both ident and msg and send back the msg to the ident client.
receive worker >>= \ident -> receive worker >>= \msg -> sendback worker msg ident
where
-- send back to client 0 to 4 times max
sendback worker msg ident = do
resentNb <- liftIO $ randomRIO (0, 4)
timeoutMsec <- liftIO $ randomRIO (1, 1000)
forM_ [0::Int ..resentNb] $ \_ -> do
liftIO $ threadDelay $ timeoutMsec * 1000
send worker [SendMore] ident
send worker [] msg
main :: IO ()
main =
runZMQ $ do
async $ clientTask "A"
async $ clientTask "B"
async $ clientTask "C"
async serverTask
liftIO $ threadDelay $ 5 * 1000 * 1000asyncsrv: Haxe 中的异步客户端/服务器
package ;
import neko.Lib;
import org.zeromq.ZMQException;
#if !php
import neko.Random;
import neko.vm.Thread;
#end
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMQ;
import org.zeromq.ZMsg;
/**
* Asynchronous client-server (DEALER to ROUTER)
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* See: https://zguide.zeromq.cn/page:all#Asynchronous-Client-Server
*/
class ASyncSrv
{
#if php
private static inline var internalServerEndpoint:String = "ipc:///tmp/backend";
#else
private static inline var internalServerEndpoint:String = "inproc://backend";
#end
/**
* This is our client task
* It connects to the server, and then sends a request once per second
* It collects responses as they arrive, and it prints them out. We will
* run several client tasks in parallel, each with a different random ID.
*/
public static function clientTask(context:ZContext) {
var client:ZMQSocket = context.createSocket(ZMQ_DEALER);
// Set random identity to make tracing easier
var id = ZHelpers.setID(client);
client.connect("tcp://:5570");
//trace ("Started client " + id);
var poller = new ZMQPoller();
poller.registerSocket(client, ZMQ.ZMQ_POLLIN());
var request_nbr = 0;
while (true) {
for (centitick in 0 ... 100) {
try {
poller.poll(10000); // Poll for 10ms
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace (e.toString());
break;
}
if (poller.pollin(1)) {
var msg:ZMsg = ZMsg.recvMsg(client);
Lib.println("Client: " + id + " received:" + msg.last().toString());
msg.destroy();
}
}
if (poller == null)
break; // Interrupted
ZMsg.newStringMsg("request #" + ++request_nbr).send(client);
}
context.destroy();
}
/**
* Accept a request and reply with the same text a random number of
* times, with random delays between replies.
*/
public static function serverWorker(context:ZContext) {
var worker:ZMQSocket = context.createSocket(ZMQ_DEALER);
worker.connect(internalServerEndpoint);
while (true) {
// The DEALER socket gives us the address envelope and message
var msg = ZMsg.recvMsg(worker);
var address:ZFrame = msg.pop();
var content:ZFrame = msg.pop();
//trace ("Got request from " + address.toString());
if (content == null)
break;
msg.destroy();
// Send 0...4 replies back
#if php
var replies = untyped __php__('rand(0, 4)');
#else
var replies = new Random().int(4);
#end
for (reply in 0...replies) {
// Sleep for some fraction of a second
#if php
Sys.sleep((untyped __php__('rand(0, 1000)') + 1) / 1000);
#else
Sys.sleep(new Random().float() + 0.001);
#end
address.send(worker, ZFrame.ZFRAME_MORE + ZFrame.ZFRAME_REUSE);
content.send(worker, ZFrame.ZFRAME_REUSE);
}
address.destroy();
content.destroy();
}
}
/**
* This is our server task
* It uses the multithreaded server model to deal requests out to a pool
* of workers and route replies back to clients. One worker can handle
* one request at a time but one client can talk to multiple workers at
* once.
*/
public static function serverTask(context:ZContext) {
#if php
for (thread_nbr in 0 ... 5) {
forkServerWorker(context);
}
#end
// Frontend socket talks to clients over TCP
var frontend = context.createSocket(ZMQ_ROUTER);
frontend.bind("tcp://*:5570");
// Backend socket talks to workers over inproc
var backend = context.createSocket(ZMQ_DEALER);
backend.bind(internalServerEndpoint);
// Launch pool of worker threads, precise number is not critical
#if !php
for (thread_nbr in 0 ... 5) {
Thread.create(callback(serverWorker,context));
}
#end
// Connect backend to frontend via queue device
// We could do this via
// new ZMQDevice(ZMQ_QUEUE, frontend, backend);
// but doing it ourselves means we can debug this more easily
// Switch messages between frontend and backend
var poller:ZMQPoller = new ZMQPoller();
poller.registerSocket(frontend, ZMQ.ZMQ_POLLIN());
poller.registerSocket(backend, ZMQ.ZMQ_POLLIN());
while (true) {
try {
poller.poll( -1);
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace (e.toString());
break;
}
if (poller.pollin(1)) {
var msg = ZMsg.recvMsg(frontend);
//trace("Request from client:"+msg.toString());
msg.send(backend);
}
if (poller.pollin(2)) {
var msg = ZMsg.recvMsg(backend);
//trace ("Reply from worker:" + msg.toString());
msg.send(frontend);
}
}
context.destroy();
}
public static function main() {
Lib.println("** ASyncSrv (see: https://zguide.zeromq.cn/page:all#Asynchronous-Client-Server)");
var context = new ZContext();
#if php
forkClientTask(context);
forkClientTask(context);
forkClientTask(context);
forkServerTask(context);
#else
Thread.create(callback(clientTask, context));
Thread.create(callback(clientTask, context));
Thread.create(callback(clientTask, context));
Thread.create(callback(serverTask, context));
#end
// Run for 5 seconds then quit
Sys.sleep(5);
context.destroy();
}
#if php
private static inline function forkServerWorker(context:ZContext) {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
ASyncSrv::serverWorker($context);
exit();
}');
return;
}
private static inline function forkClientTask(context:ZContext) {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
ASyncSrv::clientTask($context);
exit();
}');
return;
}
private static inline function forkServerTask(context:ZContext) {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
ASyncSrv::serverTask($context);
exit();
}');
return;
}
#end
}asyncsrv: Java 中的异步客户端/服务器
package guide;
import java.util.Random;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
//
//Asynchronous client-to-server (DEALER to ROUTER)
//
//While this example runs in a single process, that is just to make
//it easier to start and stop the example. Each task has its own
//context and conceptually acts as a separate process.
public class asyncsrv
{
//---------------------------------------------------------------------
//This is our client task
//It connects to the server, and then sends a request once per second
//It collects responses as they arrive, and it prints them out. We will
//run several client tasks in parallel, each with a different random ID.
private static Random rand = new Random(System.nanoTime());
private static class client_task implements Runnable
{
@Override
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket client = ctx.createSocket(SocketType.DEALER);
// Set random identity to make tracing easier
String identity = String.format(
"%04X-%04X", rand.nextInt(), rand.nextInt()
);
client.setIdentity(identity.getBytes(ZMQ.CHARSET));
client.connect("tcp://:5570");
Poller poller = ctx.createPoller(1);
poller.register(client, Poller.POLLIN);
int requestNbr = 0;
while (!Thread.currentThread().isInterrupted()) {
// Tick once per second, pulling in arriving messages
for (int centitick = 0; centitick < 100; centitick++) {
poller.poll(10);
if (poller.pollin(0)) {
ZMsg msg = ZMsg.recvMsg(client);
msg.getLast().print(identity);
msg.destroy();
}
}
client.send(String.format("request #%d", ++requestNbr), 0);
}
}
}
}
//This is our server task.
//It uses the multithreaded server model to deal requests out to a pool
//of workers and route replies back to clients. One worker can handle
//one request at a time but one client can talk to multiple workers at
//once.
private static class server_task implements Runnable
{
@Override
public void run()
{
try (ZContext ctx = new ZContext()) {
// Frontend socket talks to clients over TCP
Socket frontend = ctx.createSocket(SocketType.ROUTER);
frontend.bind("tcp://*:5570");
// Backend socket talks to workers over inproc
Socket backend = ctx.createSocket(SocketType.DEALER);
backend.bind("inproc://backend");
// Launch pool of worker threads, precise number is not critical
for (int threadNbr = 0; threadNbr < 5; threadNbr++)
new Thread(new server_worker(ctx)).start();
// Connect backend to frontend via a proxy
ZMQ.proxy(frontend, backend, null);
}
}
}
//Each worker task works on one request at a time and sends a random number
//of replies back, with random delays between replies:
private static class server_worker implements Runnable
{
private ZContext ctx;
public server_worker(ZContext ctx)
{
this.ctx = ctx;
}
@Override
public void run()
{
Socket worker = ctx.createSocket(SocketType.DEALER);
worker.connect("inproc://backend");
while (!Thread.currentThread().isInterrupted()) {
// The DEALER socket gives us the address envelope and message
ZMsg msg = ZMsg.recvMsg(worker);
ZFrame address = msg.pop();
ZFrame content = msg.pop();
assert (content != null);
msg.destroy();
// Send 0..4 replies back
int replies = rand.nextInt(5);
for (int reply = 0; reply < replies; reply++) {
// Sleep for some fraction of a second
try {
Thread.sleep(rand.nextInt(1000) + 1);
}
catch (InterruptedException e) {
}
address.send(worker, ZFrame.REUSE + ZFrame.MORE);
content.send(worker, ZFrame.REUSE);
}
address.destroy();
content.destroy();
}
ctx.destroy();
}
}
//The main thread simply starts several clients, and a server, and then
//waits for the server to finish.
public static void main(String[] args) throws Exception
{
new Thread(new client_task()).start();
new Thread(new client_task()).start();
new Thread(new client_task()).start();
new Thread(new server_task()).start();
// Run for 5 seconds then quit
Thread.sleep(5 * 1000);
}
}
asyncsrv: Julia 中的异步客户端/服务器
asyncsrv: Lua 中的异步客户端/服务器
--
-- Asynchronous client-to-server (DEALER to ROUTER)
--
-- While this example runs in a single process, that is just to make
-- it easier to start and stop the example. Each task has its own
-- context and conceptually acts as a separate process.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.threads"
require"zmsg"
require"zhelpers"
local NBR_CLIENTS = 3
-- ---------------------------------------------------------------------
-- This is our client task
-- It connects to the server, and then sends a request once per second
-- It collects responses as they arrive, and it prints them out. We will
-- run several client tasks in parallel, each with a different random ID.
local client_task = [[
local identity, seed = ...
local zmq = require"zmq"
require"zmq.poller"
require"zmq.threads"
local zmsg = require"zmsg"
require"zhelpers"
math.randomseed(seed)
local context = zmq.init(1)
local client = context:socket(zmq.DEALER)
-- Generate printable identity for the client
client:setopt(zmq.IDENTITY, identity)
client:connect("tcp://:5570")
local poller = zmq.poller(2)
poller:add(client, zmq.POLLIN, function()
local msg = zmsg.recv (client)
printf ("%s: %s\n", identity, msg:body())
end)
local request_nbr = 0
while true do
-- Tick once per second, pulling in arriving messages
local centitick
for centitick=1,100 do
poller:poll(10000)
end
local msg = zmsg.new()
request_nbr = request_nbr + 1
msg:body_fmt("request #%d", request_nbr)
msg:send(client)
end
-- Clean up and end task properly
client:close()
context:term()
]]
-- ---------------------------------------------------------------------
-- This is our server task
-- It uses the multithreaded server model to deal requests out to a pool
-- of workers and route replies back to clients. One worker can handle
-- one request at a time but one client can talk to multiple workers at
-- once.
local server_task = [[
local server_worker = ...
local zmq = require"zmq"
require"zmq.poller"
require"zmq.threads"
local zmsg = require"zmsg"
require"zhelpers"
math.randomseed(os.time())
local context = zmq.init(1)
-- Frontend socket talks to clients over TCP
local frontend = context:socket(zmq.ROUTER)
frontend:bind("tcp://*:5570")
-- Backend socket talks to workers over inproc
local backend = context:socket(zmq.DEALER)
backend:bind("inproc://backend")
-- Launch pool of worker threads, precise number is not critical
local workers = {}
for n=1,5 do
local seed = os.time() + math.random()
workers[n] = zmq.threads.runstring(context, server_worker, seed)
workers[n]:start()
end
-- Connect backend to frontend via a queue device
-- We could do this:
-- zmq:device(.QUEUE, frontend, backend)
-- But doing it ourselves means we can debug this more easily
local poller = zmq.poller(2)
poller:add(frontend, zmq.POLLIN, function()
local msg = zmsg.recv (frontend)
--print ("Request from client:")
--msg:dump()
msg:send(backend)
end)
poller:add(backend, zmq.POLLIN, function()
local msg = zmsg.recv (backend)
--print ("Reply from worker:")
--msg:dump()
msg:send(frontend)
end)
-- Switch messages between frontend and backend
poller:start()
for n=1,5 do
assert(workers[n]:join())
end
frontend:close()
backend:close()
context:term()
]]
-- Accept a request and reply with the same text a random number of
-- times, with random delays between replies.
--
local server_worker = [[
local seed = ...
local zmq = require"zmq"
require"zmq.threads"
local zmsg = require"zmsg"
require"zhelpers"
math.randomseed(seed)
local threads = require"zmq.threads"
local context = threads.get_parent_ctx()
local worker = context:socket(zmq.DEALER)
worker:connect("inproc://backend")
while true do
-- The DEALER socket gives us the address envelope and message
local msg = zmsg.recv (worker)
assert (msg:parts() == 2)
-- Send 0..4 replies back
local reply
local replies = randof (5)
for reply=1,replies do
-- Sleep for some fraction of a second
s_sleep (randof (1000) + 1)
local dup = msg:dup()
dup:send(worker)
end
end
worker:close()
]]
-- This main thread simply starts several clients, and a server, and then
-- waits for the server to finish.
--
s_version_assert (2, 1)
local clients = {}
for n=1,NBR_CLIENTS do
local identity = string.format("%04X", randof (0x10000))
local seed = os.time() + math.random()
clients[n] = zmq.threads.runstring(nil, client_task, identity, seed)
clients[n]:start()
end
local server = zmq.threads.runstring(nil, server_task, server_worker)
assert(server:start())
assert(server:join())
asyncsrv: Node.js 中的异步客户端/服务器
cluster = require('cluster')
, zmq = require('zeromq')
, backAddr = 'tcp://127.0.0.1:12345'
, frontAddr = 'tcp://127.0.0.1:12346'
, clients = 5
, workers = 2;
// We do this bit repeatedly. Should use with connect or bindSync.
function makeASocket(sockType, idPrefix, addr, bindSyncOrConnect) {
var sock = zmq.socket(sockType)
sock.identity = idPrefix + process.pid
// call the function name in bindSyncOrConnect
sock[bindSyncOrConnect](addr)
return sock
}
function clientTask(){
var sock = makeASocket('dealer', 'client', frontAddr, 'connect')
var count = 0;
var interval = setInterval(function() {
sock.send('request ' + count++)
if (count >= 10){
sock.close()
cluster.worker.kill() // Done after 10 messages
}
}, Math.ceil(Math.random() * 500))
sock.on('message', function(data) {
var args = Array.apply(null, arguments)
console.log(sock.identity + " <- '" + args + "'");
})
}
function serverTask(){
var backSvr = makeASocket('dealer', 'back', backAddr, 'bindSync')
backSvr.on('message', function(){
var args = Array.apply(null, arguments)
frontSvr.send(args)
})
var frontSvr = makeASocket('router', 'front', frontAddr, 'bindSync')
frontSvr.on('message', function(){
var args = Array.apply(null, arguments)
backSvr.send(args)
})
}
function workerTask(){
var sock = makeASocket('dealer', 'wkr', backAddr , 'connect')
sock.on('message', function() {
var args = Array.apply(null, arguments)
var replies = Math.ceil(Math.random() * 4);
var count = 0;
var interval = setInterval(function(){
sock.send([args[0], '', 'response ' + count++])
if (count == replies){
clearInterval(interval)
}
}, Math.floor(Math.random() * 10)) // sleep a small random time
})
}
// Node process management noise below
if (cluster.isMaster) {
// create the workers and clients.
// Use env variables to dictate client or worker
for (var i = 0; i < workers; i++) {
cluster.fork({ "TYPE": 'worker'})
}
for (var i = 0; i < clients; i++) {
cluster.fork({ "TYPE": 'client' })
}
cluster.on('death', function(worker) {
console.log('worker ' + worker.pid + ' died');
});
var deadClients = 0;
cluster.on('disconnect', function(worker) {
deadClients++
if (deadClients === clients) {
console.log('finished')
process.exit(0)
}
});
serverTask()
} else {
if (process.env.TYPE === 'client') {
clientTask()
} else {
workerTask()
}
}
asyncsrv: Objective-C 中的异步客户端/服务器
asyncsrv: ooc 中的异步客户端/服务器
asyncsrv: Perl 中的异步客户端/服务器
asyncsrv: PHP 中的异步客户端/服务器
<?php
/*
* Asynchronous client-to-server (DEALER to ROUTER)
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each task has its own
* context and conceptually acts as a separate process.
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
/* ---------------------------------------------------------------------
* This is our client task
* It connects to the server, and then sends a request once per second
* It collects responses as they arrive, and it prints them out. We will
* run several client tasks in parallel, each with a different random ID.
*/
function client_task()
{
$context = new ZMQContext();
$client = new ZMQSocket($context, ZMQ::SOCKET_DEALER);
// Generate printable identity for the client
$identity = sprintf ("%04X", rand(0, 0x10000));
$client->setSockOpt(ZMQ::SOCKOPT_IDENTITY, $identity);
$client->connect("tcp://:5570");
$read = $write = array();
$poll = new ZMQPoll();
$poll->add($client, ZMQ::POLL_IN);
$request_nbr = 0;
while (true) {
// Tick once per second, pulling in arriving messages
for ($centitick = 0; $centitick < 100; $centitick++) {
$events = $poll->poll($read, $write, 1000);
$zmsg = new Zmsg($client);
if ($events) {
$zmsg->recv();
printf ("%s: %s%s", $identity, $zmsg->body(), PHP_EOL);
}
}
$zmsg = new Zmsg($client);
$zmsg->body_fmt("request #%d", ++$request_nbr)->send();
}
}
/* ---------------------------------------------------------------------
* This is our server task
* It uses the multithreaded server model to deal requests out to a pool
* of workers and route replies back to clients. One worker can handle
* one request at a time but one client can talk to multiple workers at
* once.
*/
function server_task()
{
// Launch pool of worker threads, precise number is not critical
for ($thread_nbr = 0; $thread_nbr < 5; $thread_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
server_worker();
exit();
}
}
$context = new ZMQContext();
// Frontend socket talks to clients over TCP
$frontend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$frontend->bind("tcp://*:5570");
// Backend socket talks to workers over ipc
$backend = new ZMQSocket($context, ZMQ::SOCKET_DEALER);
$backend->bind("ipc://backend");
// Connect backend to frontend via a queue device
// We could do this:
// $device = new ZMQDevice($frontend, $backend);
// But doing it ourselves means we can debug this more easily
$read = $write = array();
// Switch messages between frontend and backend
while (true) {
$poll = new ZMQPoll();
$poll->add($frontend, ZMQ::POLL_IN);
$poll->add($backend, ZMQ::POLL_IN);
$poll->poll($read, $write);
foreach ($read as $socket) {
$zmsg = new Zmsg($socket);
$zmsg->recv();
if ($socket === $frontend) {
//echo "Request from client:";
//echo $zmsg->__toString();
$zmsg->set_socket($backend)->send();
} elseif ($socket === $backend) {
//echo "Request from worker:";
//echo $zmsg->__toString();
$zmsg->set_socket($frontend)->send();
}
}
}
}
function server_worker()
{
$context = new ZMQContext();
$worker = new ZMQSocket($context, ZMQ::SOCKET_DEALER);
$worker->connect("ipc://backend");
$zmsg = new Zmsg($worker);
while (true) {
// The DEALER socket gives us the address envelope and message
$zmsg->recv();
assert($zmsg->parts() == 2);
// Send 0..4 replies back
$replies = rand(0,4);
for ($reply = 0; $reply < $replies; $reply++) {
// Sleep for some fraction of a second
usleep(rand(0,1000) + 1);
$zmsg->send(false);
}
}
}
/* This main thread simply starts several clients, and a server, and then
* waits for the server to finish.
*/
function main()
{
for ($num_clients = 0; $num_clients < 3; $num_clients++) {
$pid = pcntl_fork();
if ($pid == 0) {
client_task();
exit();
}
}
$pid = pcntl_fork();
if ($pid == 0) {
server_task();
exit();
}
}
main();
asyncsrv: Python 中的异步客户端/服务器
import zmq
import sys
import threading
import time
from random import randint, random
__author__ = "Felipe Cruz <felipecruz@loogica.net>"
__license__ = "MIT/X11"
def tprint(msg):
"""like print, but won't get newlines confused with multiple threads"""
sys.stdout.write(msg + '\n')
sys.stdout.flush()
class ClientTask(threading.Thread):
"""ClientTask"""
def __init__(self, id):
self.id = id
threading.Thread.__init__ (self)
def run(self):
context = zmq.Context()
socket = context.socket(zmq.DEALER)
identity = u'worker-%d' % self.id
socket.identity = identity.encode('ascii')
socket.connect('tcp://:5570')
print('Client %s started' % (identity))
poll = zmq.Poller()
poll.register(socket, zmq.POLLIN)
reqs = 0
while True:
reqs = reqs + 1
print('Req #%d sent..' % (reqs))
socket.send_string(u'request #%d' % (reqs))
for i in range(5):
sockets = dict(poll.poll(1000))
if socket in sockets:
msg = socket.recv()
tprint('Client %s received: %s' % (identity, msg))
socket.close()
context.term()
class ServerTask(threading.Thread):
"""ServerTask"""
def __init__(self):
threading.Thread.__init__ (self)
def run(self):
context = zmq.Context()
frontend = context.socket(zmq.ROUTER)
frontend.bind('tcp://*:5570')
backend = context.socket(zmq.DEALER)
backend.bind('inproc://backend')
workers = []
for i in range(5):
worker = ServerWorker(context)
worker.start()
workers.append(worker)
zmq.proxy(frontend, backend)
frontend.close()
backend.close()
context.term()
class ServerWorker(threading.Thread):
"""ServerWorker"""
def __init__(self, context):
threading.Thread.__init__ (self)
self.context = context
def run(self):
worker = self.context.socket(zmq.DEALER)
worker.connect('inproc://backend')
tprint('Worker started')
while True:
ident, msg = worker.recv_multipart()
tprint('Worker received %s from %s' % (msg, ident))
replies = randint(0,4)
for i in range(replies):
time.sleep(1. / (randint(1,10)))
worker.send_multipart([ident, msg])
worker.close()
def main():
"""main function"""
server = ServerTask()
server.start()
for i in range(3):
client = ClientTask(i)
client.start()
server.join()
if __name__ == "__main__":
main()
asyncsrv: Q 中的异步客户端/服务器
asyncsrv: Racket 中的异步客户端/服务器
asyncsrv: Ruby 中的异步客户端/服务器
#!/usr/bin/env ruby
# Asynchronous client-to-server (DEALER to ROUTER)
require 'rubygems'
require 'ffi-rzmq'
def client
context = ZMQ::Context.new
client = context.socket ZMQ::DEALER
client.identity = "%04X-%04X" % [rand(0x10000), rand(0x10000)]
client.connect "ipc://frontend.ipc"
poller = ZMQ::Poller.new
poller.register_readable(client)
request_number = 0
loop do
100.times do |tick|
if poller.poll(10) == 1
client.recv_strings message = []
puts "#{client.identity}: #{message.last}"
end
end
client.send_string "Req ##{request_number += 1}"
end
client.close
context.destroy
end
def worker(context)
worker = context.socket ZMQ::DEALER
worker.connect "inproc://backend"
loop do
worker.recv_strings message = []
rand(0..4).times do
sleep rand
worker.send_strings message
end
end
worker.close
end
def server
context = ZMQ::Context.new
frontend = context.socket ZMQ::ROUTER
backend = context.socket ZMQ::DEALER
frontend.bind "ipc://frontend.ipc"
backend.bind "inproc://backend"
poller = ZMQ::Poller.new
poller.register_readable frontend
poller.register_readable backend
5.times { Thread.new { worker context } }
ZMQ::Device.create ZMQ::QUEUE, frontend, backend
end
3.times { Thread.new { client } }
server
asyncsrv: Rust 中的异步客户端/服务器
asyncsrv: Scala 中的异步客户端/服务器
/*
* Asynchronous client-to-server (DEALER to BROKER)
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each task has its own
* context and conceptually acts as a separate process.
*
* @Author: Giovanni Ruggiero
* @Email: giovanni.ruggiero@gmail.com
*/
import org.zeromq.ZMQ
import ZHelpers._
object asyncsrv {
// ---------------------------------------------------------------------
// This is our client task
// It connects to the server, and then sends a request once per second
// It collects responses as they arrive, and it prints them out. We will
// run several client tasks in parallel, each with a different random ID.
class ClientTask() extends Runnable {
def run() {
val ctx = ZMQ.context(1)
val client = ctx.socket(ZMQ.DEALER)
// Generate printable identity for the client
setID(client);
val identity = new String(client getIdentity)
// println(identity)
client.connect("tcp://:5570")
val poller = ctx.poller(1)
poller.register(client,ZMQ.Poller.POLLIN)
var requestNbr = 0
while (true) {
// Tick once per second, pulling in arriving messages
for (centitick <- 1 to 100) {
poller.poll(10000)
if(poller.pollin(0)) {
val msg = new ZMsg(client)
printf("%s : %s\n", identity, msg.bodyToString)
}
}
requestNbr += 1
val msg = new ZMsg("request: %d" format requestNbr)
client.sendMsg(msg)
}
}
}
// ---------------------------------------------------------------------
// This is our server task
// It uses the multithreaded server model to deal requests out to a pool
// of workers and route replies back to clients. One worker can handle
// one request at a time but one client can talk to multiple workers at
// once.
class ServerTask() extends Runnable {
def run() {
val Nworkers = 5
val ctx = ZMQ.context(1)
val frontend = ctx.socket(ZMQ.ROUTER)
val backend = ctx.socket(ZMQ.DEALER)
// Frontend socket talks to clients over TCP
frontend.bind("tcp://*:5570");
// Backend socket talks to workers over inproc
backend.bind("inproc://backend");
// Launch pool of worker threads, precise number is not critical
val workers = List.fill(Nworkers)(new Thread(new ServerWorker(ctx)))
workers foreach (_.start)
// Connect backend to frontend via a queue device
// We could do this:
// zmq_device (ZMQ_QUEUE, frontend, backend);
// But doing it ourselves means we can debug this more easily
// Switch messages between frontend and backend
val sockets = List(frontend,backend)
val poller = ctx.poller(2)
poller.register(frontend,ZMQ.Poller.POLLIN)
poller.register(backend,ZMQ.Poller.POLLIN)
while (true) {
poller.poll
if (poller.pollin(0)) {
val msg = new ZMsg(frontend)
println("Request from client: " + msg)
backend.sendMsg(msg)
}
if (poller.pollin(1)) {
val msg = new ZMsg(backend)
println("Reply from worker: " + msg)
frontend.sendMsg(msg)
}
}
}
}
// Accept a request and reply with the same text a random number of
// times, with random delays between replies.
//
class ServerWorker(ctx: ZMQ.Context) extends Runnable {
def run() {
val rand = new java.util.Random(System.currentTimeMillis)
val worker = ctx.socket(ZMQ.DEALER)
worker.connect("inproc://backend")
while (true) {
// The DEALER socket gives us the address envelope and message
val zmsg = new ZMsg(worker);
// Send 0..4 replies back
val replies = rand.nextInt(5);
for (reply <- 1 to replies) {
Thread.sleep (rand.nextInt(1) * 1000)
worker.sendMsg(zmsg)
}
}
}
}
// This main thread simply starts several clients, and a server, and then
// waits for the server to finish.
//
def main(args : Array[String]) {
val Nclients = 3
val clients = List.fill(Nclients)(new Thread(new ClientTask()))
clients foreach (_.start)
new Thread(new ServerTask()).start
}
}
asyncsrv: Tcl 中的异步客户端/服务器
#
# Asynchronous client-to-server (DEALER to ROUTER)
#
if {[llength $argv] == 0} {
set argv [list driver 3 5]
} elseif {[llength $argv] != 3} {
puts "Usage: asyncsrv.tcl ?<driver|client|server|worker> <number_of_clients> <number_of_workers>?"
exit 1
}
set tclsh [info nameofexecutable]
lassign $argv what NBR_CLIENTS NBR_WORKERS
expr {srand([pid])}
switch -exact -- $what {
client {
# This is our client task
# It connects to the server, and then sends a request once per second
# It collects responses as they arrive, and it prints them out. We will
# run several client tasks in parallel, each with a different random ID.
package require zmq
zmq context context
zmq socket client context DEALER
# Set random identity to make tracing easier
set identity [format "%04X-%04X" [expr {int(rand()*0x10000)}] [expr {int(rand()*0x10000)}]]
client setsockopt IDENTITY $identity
client connect "tcp://:5570"
proc receive {} {
global identity
puts "Client $identity received [client recv]"
}
proc request {} {
global request_nbr identity
incr request_nbr
puts "Client $identity sent request \#$request_nbr"
client send "request \#$request_nbr"
after 1000 "request"
}
# Process responses
client readable receive
# Send a request every second
set request_nbr 0
after 1000 request
vwait forever
client close
context term
}
worker {
# This is our worker task
# Accept a request and reply with the same text a random number of
# times, with random delays between replies.
package require zmq
zmq context context
zmq socket worker context DEALER
worker connect "ipc://backend"
while {1} {
# The DEALER socket gives us the address envelope and message
set address [worker recv]
set content [worker recv]
puts "worker received $content from $address"
# Send 0..4 replies back
set replies [expr {int(rand()*5)}]
for {set reply 0} {$reply < $replies} {incr reply} {
# Sleep for some fraction of a second
after [expr {int(rand()*1000) + 1}]
puts "worker send $content to $address"
worker sendmore $address
worker send $content
}
}
}
server {
# This is our server task It uses the multithreaded server model to deal
# requests out to a pool of workers and route replies back to clients. One
# worker can handle one request at a time but one client can talk to multiple
# workers at once.
package require zmq
zmq context context
# Frontend socket talks to clients over TCP
zmq socket frontend context ROUTER
frontend bind "tcp://*:5570"
# Backend socket talks to workers over inproc
zmq socket backend context DEALER
backend bind "ipc://backend"
# Launch pool of worker threads, precise number is not critical
for {set thread_nbr 0} {$thread_nbr < $NBR_WORKERS} {incr thread_nbr} {
exec $tclsh asyncsrv.tcl worker $NBR_CLIENTS $NBR_WORKERS > worker$thread_nbr.log 2>@1 &
}
# Connect backend to frontend via a queue device
# We could do this:
# zmq_device (ZMQ_QUEUE, frontend, backend);
# But doing it ourselves means we can debug this more easily
proc do_frontend {} {
set address [frontend recv]
set data [frontend recv]
backend sendmore $address
backend send $data
}
proc do_backend {} {
set address [backend recv]
set data [backend recv]
frontend sendmore $address
frontend send $data
}
backend readable do_backend
frontend readable do_frontend
vwait forever
frontend close
backend close
context term
}
driver {
puts "Start server, output redirected to server.log"
exec $tclsh asyncsrv.tcl server $NBR_CLIENTS $NBR_WORKERS > server.log 2>@1 &
after 1000
for {set i 0} {$i < $NBR_CLIENTS} {incr i} {
puts "Start client $i, output redirect to client$i.log"
exec $tclsh asyncsrv.tcl client $NBR_CLIENTS $NBR_WORKERS > client$i.log 2>@1 &
}
}
}
asyncsrv: OCaml 中的异步客户端/服务器
该示例在一个进程中运行,通过多个线程模拟真实的多进程架构。运行示例时,您会看到三个客户端(每个客户端都有一个随机 ID),打印出它们从服务器获得的回复。仔细观察,您会发现每个客户端任务在每个请求中获得 0 个或更多回复。
关于此代码的一些评论
-
客户端每秒发送一个请求,并收到零个或多个回复。为了使用以下方法实现这一点 zmq_poll(),我们不能简单地使用 1 秒的超时时间进行轮询,否则我们将只在收到最后一个回复一秒后才发送新的请求。因此,我们以高频率(每秒轮询 100 次,每次间隔 1/100 秒)进行轮询,这大致是准确的。
-
服务器使用一个工作线程池,每个线程同步处理一个请求。它使用内部队列将这些线程连接到其前端套接字。它使用一个 zmq_proxy()调用。
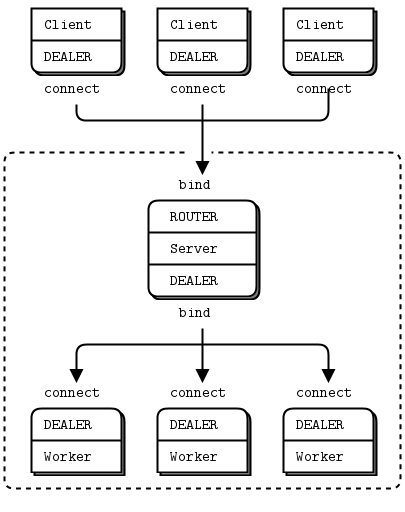
请注意,我们在客户端和服务器之间执行 DEALER 到 ROUTER 对话,但在服务器主线程和工作线程之间,我们执行 DEALER 到 DEALER。如果工作线程是严格同步的,我们将使用 REP。然而,因为我们想发送多个回复,我们需要一个异步套接字。我们不想路由回复,它们总是发送到向我们发送请求的单个服务器线程。
让我们考虑一下路由信封。客户端发送一个包含单个帧的消息。服务器线程接收一个双帧消息(原始消息前缀为客户端身份)。我们将这两个帧发送给工作线程,工作线程将其视为正常的回复信封,并以双帧消息的形式返回给我们。然后,我们使用第一个帧作为身份,将第二个帧路由回客户端作为回复。
它看起来像这样
client server frontend worker
[ DEALER ]<---->[ ROUTER <----> DEALER <----> DEALER ]
1 part 2 parts 2 parts
现在来说套接字:我们可以使用负载均衡的 ROUTER 到 DEALER 模式与工作线程通信,但这会增加额外的工作。在这种情况下,DEALER 到 DEALER 模式可能没问题:权衡是每个请求的延迟较低,但工作分布不平衡的风险较高。在这种情况下,简单性更重要。
当你构建维护与客户端有状态对话的服务器时,你会遇到一个经典问题。如果服务器为每个客户端保留一些状态,并且客户端不断地连接和断开,最终服务器将耗尽资源。即使是同一个客户端不断连接,如果你使用默认身份,每个连接都看起来像一个新的连接。
在上面的示例中,我们通过仅保留非常短时间(工作线程处理请求所需的时间)的状态,然后丢弃该状态来作弊。但这在许多情况下并不实用。为了在有状态的异步服务器中正确管理客户端状态,你必须
-
从客户端到服务器进行心跳。在我们的示例中,我们每秒发送一个请求,这可以可靠地用作心跳。
-
使用客户端身份(无论是生成的还是显式的)作为键来存储状态。
-
检测到停止的心跳。如果在例如两秒内没有来自客户端的请求,服务器可以检测到这一点并销毁其为该客户端保留的任何状态。
工作示例:中介间路由 #
让我们回顾一下到目前为止所看到的一切,并将其扩展到一个真实的应用程序。我们将分几个迭代步骤逐步构建。我们最好的客户紧急来电,请求设计一个大型云计算设施。他设想的云跨越多个数据中心,每个数据中心都是客户端和工作线程的集群,并且作为一个整体协同工作。因为我们足够聪明,知道实践总是胜过理论,所以我们建议使用 ZeroMQ 进行一个工作模拟。我们的客户,急于在他自己的老板改变主意之前确定预算,并且在 Twitter 上读到关于 ZeroMQ 的好评,欣然同意。
确定细节 #
喝了几杯意式浓缩咖啡后,我们想立即开始编写代码,但一个细微的声音告诉我们,在为一个完全错误的问题提供耸人听闻的解决方案之前,先了解更多细节。我们问:“云在做什么样的工作?”
客户解释道
-
工作线程运行在各种硬件上,但它们都能处理任何任务。每个集群有数百个工作线程,总共有多达十几个集群。
-
客户端为工作线程创建任务。每个任务都是一个独立的工作单元,客户端只希望尽快找到一个可用的工作线程并将其发送给它。将会有很多客户端,它们会任意地出现和消失。
-
真正的难点在于能够随时添加和移除集群。一个集群可以立即离开或加入云,并带走其所有工作线程和客户端。
-
如果客户端自己的集群中没有工作线程,它们的任务将发送给云中其他可用的工作线程。
-
客户端一次发送一个任务,等待回复。如果它们在 X 秒内没有收到回复,它们会再次发送该任务。这不是我们需要关注的问题;客户端 API 已经处理了。
-
工作线程一次处理一个任务;它们非常简单。如果它们崩溃,会由启动它们的脚本重新启动。
所以我们再次确认以确保我们正确理解了这一点
-
我们问:“集群之间会有某种超赞的网络互连,对吧?” 客户说:“是的,当然,我们又不是傻瓜。”
-
我们问:“我们谈论的规模是怎样的?” 客户回答说:“每个集群最多有一千个客户端,每个客户端每秒最多进行十次请求。请求很小,回复也很小,每个不超过 1K 字节。”
所以我们做了一个简单的计算,发现这在普通 TCP 上工作得很好。2,500 个客户端 x 10 次/秒 x 1,000 字节 x 2 方向 = 50MB/秒 或 400Mb/秒,对于 1Gb 网络来说不是问题。
这是一个直接的问题,不需要特殊的硬件或协议,只需要一些巧妙的路由算法和仔细的设计。我们首先设计一个集群(一个数据中心),然后弄清楚如何将集群连接在一起。
单个集群的架构 #
工作线程和客户端是同步的。我们想使用负载均衡模式将任务路由给工作线程。工作线程都是相同的;我们的设施没有不同服务的概念。工作线程是匿名的;客户端从不直接寻址它们。我们在此不尝试提供保证交付、重试等功能。
出于我们已经探讨过的原因,客户端和工作线程不会直接相互通信。这使得动态添加或移除节点变得不可能。因此,我们的基本模型由我们之前看到的请求-回复消息中介构成。
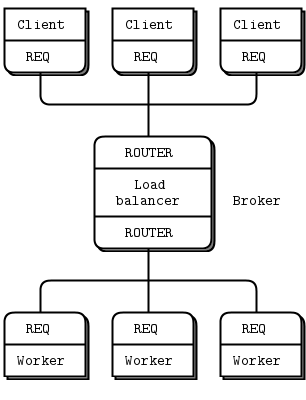
扩展到多个集群 #
现在我们将其扩展到多个集群。每个集群都有一组客户端和工作线程,以及一个将它们连接在一起的中介。
问题是:我们如何让每个集群的客户端与另一个集群的工作线程通信?有几种可能性,每种都有优缺点
-
客户端可以直接连接到两个中介。优点是我们无需修改中介或工作线程。但客户端会变得更复杂,并了解整体拓扑结构。例如,如果我们要添加第三个或第四个集群,所有客户端都会受到影响。实际上,我们必须将路由和故障转移逻辑移到客户端中,这并不好。
-
工作线程可以直接连接到两个中介。但是 REQ 工作线程做不到,它们只能回复一个中介。我们可以使用 REP,但 REP 不提供像负载均衡那样的可定制的中介到工作线程的路由,只有内置的负载均衡。这是一个失败;如果我们要将工作分配给空闲的工作线程,我们恰恰需要负载均衡。一个解决方案是为工作节点使用 ROUTER 套接字。我们将此标记为“想法 #1”。
-
中介可以相互连接。这看起来最简洁,因为它创建的额外连接最少。我们无法动态添加集群,但这可能超出了范围。现在客户端和工作线程仍然不了解真实的网络拓扑,并且中介在有空闲容量时相互告知。我们将此标记为“想法 #2”。
让我们探讨想法 #1。在这种模型中,工作线程连接到两个中介,并接受来自其中任何一个的任务。
这看起来可行。然而,它没有提供我们想要的东西,即客户端尽可能获得本地工作线程,只有在比等待更好的情况下才获得远程工作线程。此外,工作线程会向两个中介发送“就绪”信号,并可能同时获得两个任务,而其他工作线程仍然空闲。看起来这个设计失败了,因为我们再次将路由逻辑放在了边缘。
那么,就是想法 #2 了。我们连接中介,而不触碰客户端或工作线程,它们仍然是我们习惯的 REQ。
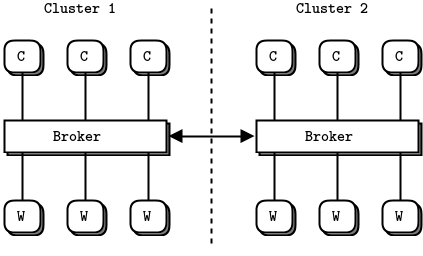
这种设计很有吸引力,因为问题在一个地方解决,对外界不可见。基本上,中介会相互开启秘密通道,像骆驼商人一样低语:“嘿,我有一些空闲容量。如果你客户端太多,叫我一声,我们就成交。”
实际上,这只是一种更复杂的路由算法:中介彼此成为分包商。即使在我们编写实际代码之前,这种设计还有其他值得喜欢的地方
-
它将常见情况(客户端和工作线程在同一集群)视为默认情况,并为异常情况(在集群之间分派任务)做额外工作。
-
它允许我们对不同类型的工作使用不同的消息流。这意味着我们可以以不同方式处理它们,例如使用不同类型的网络连接。
-
感觉它可以平滑地扩展。连接三个或更多中介并不会变得过于复杂。如果发现这是个问题,可以通过添加一个超级中介轻松解决。
现在我们将创建一个工作示例。我们将把整个集群打包到一个进程中。这显然不现实,但这使得模拟变得简单,并且该模拟可以精确地扩展到真实的进程。这就是 ZeroMQ 的魅力所在——你可以在微观层面进行设计,然后将其扩展到宏观层面。线程变成进程,然后变成盒子,模式和逻辑保持不变。我们的每个“集群”进程都包含客户端线程、工作线程和一个中介线程。
我们现在已经很清楚基本模型了
- REQ 客户端 (REQ) 线程创建工作负载并将其传递给中介 (ROUTER)。
- REQ 工作线程 (REQ) 线程处理工作负载并将结果返回给中介 (ROUTER)。
- 中介使用负载均衡模式对工作负载进行排队和分发。
联邦式 vs 对等式 #
有几种可能的方式可以连接中介。我们希望能够告诉其他中介“我们有容量”,然后接收多个任务。我们还需要能够告诉其他中介“停止,我们满了”。这不需要是完美的;有时我们可能会接受不能立即处理的任务,然后我们会尽快处理它们。
最简单的互连方式是联邦式 (federation),其中中介彼此模拟客户端和工作线程。我们会通过将我们的前端连接到另一个中介的后端套接字来实现这一点。请注意,将套接字绑定到一个端点并将其连接到其他端点是合法的。
这将使两个中介都拥有简单的逻辑和相对不错的机制:当没有工作线程时,告诉另一个中介“就绪”,并接受来自它的一个任务。问题在于,它对于这个问题来说也太简单了。一个联邦式中介一次只能处理一个任务。如果中介模拟的是一个锁步客户端和工作线程,那么它按定义也将是锁步的,而且如果它有很多可用工作线程,它们也不会被使用。我们的中介需要以完全异步的方式连接。
联邦式模型非常适合其他类型的路由,尤其是面向服务的架构 (SOA),它通过服务名称和邻近性进行路由,而不是负载均衡或轮询。所以不要认为它没用,它只是不适合所有用例。
除了联邦式,让我们看看对等式 (peering) 方法,其中中介明确地知道彼此,并通过特权通道通信。让我们分解一下,假设我们要连接 N 个中介。每个中介都有 (N - 1) 个对等体,并且所有中介都使用完全相同的代码和逻辑。中介之间有两种不同的信息流
-
每个中介需要随时告诉其对等体有多少可用工作线程。这可以是相当简单的信息——仅仅是一个定期更新的数量。为此,显而易见的(也是正确的)套接字模式是 pub-sub。因此,每个中介都会打开一个 PUB 套接字并发布状态信息,并且每个中介也会打开一个 SUB 套接字并将其连接到其他所有中介的 PUB 套接字,以从其对等体获取状态信息。
-
每个中介需要一种方式将任务委托给对等体并异步获取回复。我们将使用 ROUTER 套接字来实现这一点;没有其他组合可行。每个中介都有两个这样的套接字:一个用于接收任务,一个用于委托任务。如果我们不使用两个套接字,每次读取时要判断是请求还是回复会更麻烦。这意味着需要在消息信封中添加更多信息。
中介与其本地客户端和工作线程之间也存在信息流。
命名仪式 #
三个流 x 每个流两个套接字 = 我们必须在中介中管理的六个套接字。选择好名字对于在我们的头脑中保持多套接字操作的合理一致性至关重要。套接字会做某事,它们所做的事情应该构成其名称的基础。这是为了能够在几周后的寒冷星期一早上喝咖啡之前阅读代码,并且不会感到任何痛苦。
让我们为这些套接字举行一个萨满教的命名仪式。这三个流是
- 中介与其客户端和工作线程之间的本地请求-回复流。
- 中介与其对等中介之间的云端请求-回复流。
- 中介与其对等中介之间的状态流。
找到长度相同且有意义的名称意味着我们的代码将很好地对齐。这不是一件大事,但注意细节会有帮助。对于每个流,中介有两个套接字,我们可以正交地称之为前端 (frontend) 和后端 (backend)。我们经常使用这些名称。前端接收信息或任务。后端将这些信息或任务发送给其他对等体。概念上的流向是从前到后(回复的方向则从后到前)。
因此,在本教程编写的所有代码中,我们将使用这些套接字名称
- 本地流使用 localfe 和 localbe。
- 云端流使用 cloudfe 和 cloudbe。
- 状态流使用 statefe 和 statebe。
对于我们的传输方式,并且因为我们在一个盒子中模拟整个过程,我们将使用ipc用于所有通信。这具有像tcp一样工作的优点(即,它是一种非连接传输,与inproc不同),而且我们不需要 IP 地址或 DNS 名称,这在这里会很麻烦。相反,我们将使用ipc名为 something-local,something-cloud,以及 something-state的端点,其中 something 是我们模拟集群的名称。
您可能认为这只是为一些名字做了很多工作。为什么不称它们为 s1, s2, s3, s4 等等?答案是,如果你的大脑不是一个完美的机器,你在阅读代码时需要很多帮助,我们会看到这些名字确实有帮助。记住“三个流,两个方向”比记住“六个不同的套接字”更容易。
请注意,我们将每个中介中的 cloudbe 连接到其他所有中介中的 cloudfe,同样,我们将每个中介中的 statebe 连接到其他所有中介中的 statefe。
状态流原型实现 #
因为每个套接字流都有其自己针对粗心者的陷阱,我们将逐个在实际代码中测试它们,而不是试图一次性将所有内容放入代码中。当我们对每个流都满意后,就可以将它们组合成一个完整的程序。我们将从状态流开始。
以下是此代码的工作原理
peering1: Ada 中的状态流原型
peering1: Basic 中的状态流原型
peering1: C 中的状态流原型
// Broker peering simulation (part 1)
// Prototypes the state flow
#include "czmq.h"
int main (int argc, char *argv [])
{
// First argument is this broker's name
// Other arguments are our peers' names
//
if (argc < 2) {
printf ("syntax: peering1 me {you}...\n");
return 0;
}
char *self = argv [1];
printf ("I: preparing broker at %s...\n", self);
srandom ((unsigned) time (NULL));
zctx_t *ctx = zctx_new ();
// Bind state backend to endpoint
void *statebe = zsocket_new (ctx, ZMQ_PUB);
zsocket_bind (statebe, "ipc://%s-state.ipc", self);
// Connect statefe to all peers
void *statefe = zsocket_new (ctx, ZMQ_SUB);
zsocket_set_subscribe (statefe, "");
int argn;
for (argn = 2; argn < argc; argn++) {
char *peer = argv [argn];
printf ("I: connecting to state backend at '%s'\n", peer);
zsocket_connect (statefe, "ipc://%s-state.ipc", peer);
}
// .split main loop
// The main loop sends out status messages to peers, and collects
// status messages back from peers. The zmq_poll timeout defines
// our own heartbeat:
while (true) {
// Poll for activity, or 1 second timeout
zmq_pollitem_t items [] = { { statefe, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (items, 1, 1000 * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
// Handle incoming status messages
if (items [0].revents & ZMQ_POLLIN) {
char *peer_name = zstr_recv (statefe);
char *available = zstr_recv (statefe);
printf ("%s - %s workers free\n", peer_name, available);
free (peer_name);
free (available);
}
else {
// Send random values for worker availability
zstr_sendm (statebe, self);
zstr_sendf (statebe, "%d", randof (10));
}
}
zctx_destroy (&ctx);
return EXIT_SUCCESS;
}
peering1: C++ 中的状态流原型
//
// Created by ninehs on 4/29/22.
//
//
// Broker peering simulation (part 1)
// Prototypes the state flow
//
#include "zhelpers.hpp"
#define ZMQ_POLL_MSEC 1
int main(int argc, char *argv[]) {
// First argument is this broker's name
// Other arguments are our peers' names
if (argc < 2) {
std::cout << "syntax: peering1 me {you} ..." << std::endl;
return 0;
}
std::string self(argv[1]);
std::cout << "I: preparing broker at " << self << " ..." << std::endl;
srandom(static_cast<unsigned int>(time(nullptr)));
zmq::context_t context(1);
// Bind state backend to endpoint
zmq::socket_t statebe(context, zmq::socket_type::pub);
std::string bindURL = std::string("ipc://").append(self).append("-state.ipc");
statebe.bind(bindURL);
// Connect statefe to all peers
zmq::socket_t statefe(context, zmq::socket_type::sub);
statefe.set(zmq::sockopt::subscribe, "");
for(int argn = 2 ; argn < argc ; ++argn) {
std::string peer(argv[argn]);
std::string peerURL = std::string("ipc://").append(peer).append("-state.ipc");
statefe.connect(peerURL);
}
// The main loop sends out status messages to peers, and collects
// status messages back from peers. The zmq_poll timeout defines
// our own heartbeat
while(true) {
//
zmq::pollitem_t items[] = {
{statefe, 0, ZMQ_POLLIN, 0}
};
try {
zmq::poll(items, 1, 1000 * ZMQ_POLL_MSEC);
} catch(...) {
break;
}
if (items[0].revents & ZMQ_POLLIN) {
std::string peer_name(s_recv(statefe));
std::string available(s_recv(statefe));
std::cout << "\"" << self << "\" received subscribed message: \"" << peer_name << "\" has "
<< available << " workers available" << std::endl;
} else {
s_sendmore(statebe, self);
std::ostringstream intStream;
intStream << within(10);
s_send(statebe, intStream.str());
std::cout << "\"" << self << "\" broadcast: " << intStream.str() << " workers available." << std::endl;
}
}
return 0;
}
peering1: C# 中的状态流原型
peering1: CL 中的状态流原型
peering1: Delphi 中的状态流原型
program peering1;
//
// Broker peering simulation (part 1)
// Prototypes the state flow
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
self,
peer: Utf8String;
ctx: TZMQContext;
statebe,
statefe: TZMQSocket;
i, rc: Integer;
poller: TZMQPoller;
peer_name,
available: Utf8String;
begin
// First argument is this broker's name
// Other arguments are our peers' names
//
if ParamCount < 2 then
begin
Writeln( 'syntax: peering1 me {you}...' );
Halt( 1 );
end;
self := ParamStr( 1 );
Writeln( Format( 'I: preparing broker at %s...', [self]) );
Randomize;
ctx := TZMQContext.create;
// Bind state backend to endpoint
statebe := ctx.Socket( stPub );
{$ifdef unix}
statebe.bind( Format( 'ipc://%s-state.ipc', [self] ) );
{$else}
statebe.bind( Format( 'tcp://127.0.0.1:%s', [self] ) );
{$endif}
// Connect statefe to all peers
statefe := ctx.Socket( stSub );
statefe.Subscribe('');
for i := 2 to ParamCount do
begin
peer := ParamStr( i );
Writeln( Format( 'I: connecting to state backend at "%s"', [peer] ) );
{$ifdef unix}
statefe.connect( Format( 'ipc://%s-state.ipc', [peer] ) );
{$else}
statefe.connect( Format( 'tcp://127.0.0.1:%s', [peer] ) );
{$endif}
end;
// The main loop sends out status messages to peers, and collects
// status messages back from peers. The zmq_poll timeout defines
// our own heartbeat:
while not ctx.Terminated do
begin
// Poll for activity, or 1 second timeout
poller := TZMQPoller.Create( true );
poller.Register( statefe, [pePollIn] );
rc := poller.poll( 1000 );
// Handle incoming status messages
if pePollIn in poller.PollItem[0].revents then
//if pePollIn in poller.PollItem[0].events then
begin
statefe.recv( peer_name );
statefe.recv( available );
Writeln( Format( '%s - %s workers free', [ peer_name, available] ) );
end else
statebe.send( [self, IntToStr( Random( 10 ) ) ] );
end;
ctx.Free;
end.
peering1: Erlang 中的状态流原型
peering1: Elixir 中的状态流原型
peering1: F# 中的状态流原型
peering1: Felix 中的状态流原型
peering1: Go 中的状态流原型
// Broker peering simulation (part 1) in Python
//
// Author: amyangfei <amyangfei@gmail.com>
// Requires: http://github.com/alecthomas/gozmq
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"os"
"time"
)
func main() {
if len(os.Args) < 2 {
fmt.Println("syntax: peering1 me {you}...")
return
}
myself := os.Args[1]
fmt.Printf("I: preparing broker at %s...\n", myself)
rand.Seed(time.Now().UnixNano())
context, _ := zmq.NewContext()
statebe, _ := context.NewSocket(zmq.PUB)
defer context.Close()
defer statebe.Close()
// Bind state backend to endpoint
bindAddress := fmt.Sprintf("ipc://%s-state.ipc", myself)
statebe.Bind(bindAddress)
// Connect statefe to all peers
statefe, _ := context.NewSocket(zmq.SUB)
defer statefe.Close()
statefe.SetSubscribe("")
for i := 2; i < len(os.Args); i++ {
peer := os.Args[i]
fmt.Printf("I: connecting to state backend at '%s'\n", peer)
statefe.Connect(fmt.Sprintf("ipc://%s-state.ipc", peer))
}
items := zmq.PollItems{
zmq.PollItem{Socket: statefe, Events: zmq.POLLIN},
}
for {
zmq.Poll(items, time.Second)
// Handle incomming status messages
if items[0].REvents&zmq.POLLIN != 0 {
msg, _ := statefe.RecvMultipart(0)
fmt.Printf("%s - %s workers free\n", string(msg[0]), string(msg[1]))
} else {
// Send random values for worker availability
statebe.SendMultipart([][]byte{[]byte(myself), []byte(fmt.Sprintf("%d", rand.Intn(10)))}, 0)
}
}
}
peering1: Haskell 中的状态流原型
{-# LANGUAGE OverloadedLists #-}
{-# LANGUAGE OverloadedStrings #-}
module Main where
import Control.Monad (forever, when)
import qualified Data.ByteString.Char8 as C
import Data.Semigroup ((<>))
import System.Environment
import System.Exit
import System.Random
import System.ZMQ4.Monadic
connectPeer :: Socket z t -> String -> String -> ZMQ z ()
connectPeer sock name peer = do
connect sock (connectString peer name)
liftIO . putStrLn $ "Connecting to peer: " ++ connectString peer name
connectString :: String -> String -> String
connectString peer name = "ipc://" ++ peer ++ "-" ++ name ++ ".ipc"
main :: IO ()
main = do
args <- getArgs
when (length args < 2) $ do
putStrLn "Usage: peering1 <me> <you> [<you> ...]"
exitFailure
let self:peers = args
putStrLn $ "Preparing broker at " ++ self
runZMQ $ do
-- Bind state backend to endpoint
stateBack <- socket Pub
bind stateBack (connectString self "state")
-- Connect state frontend to peers
stateFront <- socket Sub
subscribe stateFront ""
mapM_ (connectPeer stateFront "state") peers
-- Send status, collect status
forever $ do
let pollItem = Sock stateFront [In] (Just pollEvent)
pollEvent _ = do
peerName:available:_ <- receiveMulti stateFront
liftIO . C.putStrLn $
peerName <> " " <> available <> " workers free"
pollEvents <- poll oneSec [pollItem]
when (pollEvents == [[]]) $ do
r <- liftIO $ randomRIO (0, 9)
sendMulti stateBack [C.pack self, C.pack (show (r :: Int))]
where
oneSec = 1000
peering1: Haxe 中的状态流原型
package ;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQException;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMsg;
import org.zeromq.ZSocket;
/**
* Broker peering simulation (part 1)
* Prototypes the state flow.
*
* NB: If running from Run.hx, set ARG_OFFSET to 1
* If running directly, set ARG_OFFSET to 0
*/
class Peering1
{
private static inline var ARG_OFFSET = 1;
public static function main() {
Lib.println("** Peering1 (see: https://zguide.zeromq.cn/page:all#Prototyping-the-State-Flow)");
// First argument is this broker's name
// Other arguments are our peers' names
if (Sys.args().length < 2+ARG_OFFSET) {
Lib.println("syntax: ./Peering1 me {you} ...");
return;
}
var self = Sys.args()[0+ARG_OFFSET];
Lib.println("I: preparing broker at " + self + " ...");
// Prepare our context and sockets
var ctx = new ZContext();
var statebe = ctx.createSocket(ZMQ_PUB);
statebe.bind("ipc:///tmp/" + self + "-state.ipc");
// Connect statefe to all peers
var statefe = ctx.createSocket(ZMQ_SUB);
statefe.setsockopt(ZMQ_SUBSCRIBE, Bytes.ofString(""));
for (argn in 1+ARG_OFFSET ... Sys.args().length) {
var peer = Sys.args()[argn];
Lib.println("I: connecting to state backend at '" + peer + "'");
statefe.connect("ipc:///tmp/" + peer + "-state.ipc");
}
// Send out status messages to peers, and collect from peers
// The ZMQPoller timeout defines our own heartbeating
//
var poller = new ZMQPoller();
while (true) {
// Initialise poll set
poller.registerSocket(statefe, ZMQ.ZMQ_POLLIN());
try {
// Poll for activity, or 1 second timeout
var res = poller.poll(1000 * 1000);
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace (e.toString());
return;
}
// Handle incoming status messages
if (poller.pollin(1)) {
var msg = ZMsg.recvMsg(statefe);
var peerNameFrame = msg.first();
var availableFrame = msg.last();
Lib.println(peerNameFrame.toString() + " - " + availableFrame.toString() + " workers free");
} else {
// Send random value for worker availability
// We stick our own address onto the envelope
var msg:ZMsg = new ZMsg();
msg.addString(self);
msg.addString(Std.string(ZHelpers.randof(10)));
msg.send(statebe);
}
}
ctx.destroy();
}
}peering1: Java 中的状态流原型
package guide;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
// Broker peering simulation (part 1)
// Prototypes the state flow
public class peering1
{
public static void main(String[] argv)
{
// First argument is this broker's name
// Other arguments are our peers' names
//
if (argv.length < 1) {
System.out.println("syntax: peering1 me {you}\n");
System.exit(-1);
}
String self = argv[0];
System.out.println(String.format("I: preparing broker at %s\n", self));
Random rand = new Random(System.nanoTime());
try (ZContext ctx = new ZContext()) {
// Bind state backend to endpoint
Socket statebe = ctx.createSocket(SocketType.PUB);
statebe.bind(String.format("ipc://%s-state.ipc", self));
// Connect statefe to all peers
Socket statefe = ctx.createSocket(SocketType.SUB);
statefe.subscribe(ZMQ.SUBSCRIPTION_ALL);
int argn;
for (argn = 1; argn < argv.length; argn++) {
String peer = argv[argn];
System.out.printf(
"I: connecting to state backend at '%s'\n", peer
);
statefe.connect(String.format("ipc://%s-state.ipc", peer));
}
// The main loop sends out status messages to peers, and collects
// status messages back from peers. The zmq_poll timeout defines
// our own heartbeat.
Poller poller = ctx.createPoller(1);
poller.register(statefe, Poller.POLLIN);
while (true) {
// Poll for activity, or 1 second timeout
int rc = poller.poll(1000);
if (rc == -1)
break; // Interrupted
// Handle incoming status messages
if (poller.pollin(0)) {
String peer_name = new String(statefe.recv(0), ZMQ.CHARSET);
String available = new String(statefe.recv(0), ZMQ.CHARSET);
System.out.printf(
"%s - %s workers free\n", peer_name, available
);
}
else {
// Send random values for worker availability
statebe.send(self, ZMQ.SNDMORE);
statebe.send(String.format("%d", rand.nextInt(10)), 0);
}
}
}
}
}
peering1: Julia 中的状态流原型
peering1: Lua 中的状态流原型
--
-- Broker peering simulation (part 1)
-- Prototypes the state flow
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.poller"
require"zmsg"
-- First argument is this broker's name
-- Other arguments are our peers' names
--
if (#arg < 1) then
printf ("syntax: peering1 me doyouend...\n")
os.exit(-1)
end
local self = arg[1]
printf ("I: preparing broker at %s...\n", self)
math.randomseed(os.time())
-- Prepare our context and sockets
local context = zmq.init(1)
-- Bind statebe to endpoint
local statebe = context:socket(zmq.PUB)
local endpoint = string.format("ipc://%s-state.ipc", self)
assert(statebe:bind(endpoint))
-- Connect statefe to all peers
local statefe = context:socket(zmq.SUB)
statefe:setopt(zmq.SUBSCRIBE, "", 0)
for n=2,#arg do
local peer = arg[n]
printf ("I: connecting to state backend at '%s'\n", peer)
local endpoint = string.format("ipc://%s-state.ipc", peer)
assert(statefe:connect(endpoint))
end
local poller = zmq.poller(1)
-- Send out status messages to peers, and collect from peers
-- The zmq_poll timeout defines our own heartbeating
--
poller:add(statefe, zmq.POLLIN, function()
local msg = zmsg.recv (statefe)
printf ("%s - %s workers free\n",
msg:address(), msg:body())
end)
while true do
-- Poll for activity, or 1 second timeout
local count = assert(poller:poll(1000000))
-- if no other activity.
if count == 0 then
-- Send random value for worker availability
local msg = zmsg.new()
msg:body_fmt("%d", randof (10))
-- We stick our own address onto the envelope
msg:wrap(self, nil)
msg:send(statebe)
end
end
-- We never get here but clean up anyhow
statebe:close()
statefe:close()
context:term()
peering1: Node.js 中的状态流原型
// Broker peering simulation (part 1)
// Prototypes the state flow
var zmq = require('zeromq')
, util = require('util');
if (process.argv.length < 3) {
console.log('usage: node peering1.js me [you ...]');
process.exit(0);
}
var self = process.argv[2];
console.log("I: preparing broker at %s…", self);
// flag for stopping timer
var done = false;
//
// Backend
//
var statebe = zmq.socket('pub');
statebe.bindSync(util.format("ipc://%s-state.ipc", self));
//
// Frontend
//
var statefe = zmq.socket('sub');
statefe.subscribe('');
for (var i = 3; i < process.argv.length; i++) {
var peer = process.argv[i];
console.log("I: connecting to state backend at '%s'", peer);
statefe.connect(util.format("ipc://%s-state.ipc", peer));
}
process.on('SIGINT', function() {
done = true;
statebe.close();
statefe.close();
});
// The main loop sends out status messages to peers, and collects
// status messages back from peers.
statefe.on('message', function(peer_name, available) {
console.log("%s - %s workers free", peer_name, available);
});
function sendWorkerAvailability() {
if (done) {
return;
}
var num_workers = util.format("%d", Math.floor(10 * Math.random()));
console.log("sending update: %s has %s", self, num_workers);
statebe.send([ self, num_workers ]);
var next_send_delay = Math.floor(3000 * Math.random());
setTimeout(sendWorkerAvailability, next_send_delay);
}
// Start worker update timer loop
sendWorkerAvailability();
peering1: Objective-C 中的状态流原型
peering1: ooc 中的状态流原型
peering1: Perl 中的状态流原型
peering1: PHP 中的状态流原型
<?php
/*
* Broker peering simulation (part 1)
* Prototypes the state flow
*/
// First argument is this broker's name
// Other arguments are our peers' names
if ($_SERVER['argc'] < 2) {
echo "syntax: peering1 me {you}...", PHP_EOL;
exit();
}
$self = $_SERVER['argv'][1];
printf ("I: preparing broker at %s... %s", $self, PHP_EOL);
// Prepare our context and sockets
$context = new ZMQContext();
// Bind statebe to endpoint
$statebe = $context->getSocket(ZMQ::SOCKET_PUB);
$endpoint = sprintf("ipc://%s-state.ipc", $self);
$statebe->bind($endpoint);
// Connect statefe to all peers
$statefe = $context->getSocket(ZMQ::SOCKET_SUB);
$statefe->setSockOpt(ZMQ::SOCKOPT_SUBSCRIBE, "");
for ($argn = 2; $argn < $_SERVER['argc']; $argn++) {
$peer = $_SERVER['argv'][$argn];
printf ("I: connecting to state backend at '%s'%s", $peer, PHP_EOL);
$endpoint = sprintf("ipc://%s-state.ipc", $peer);
$statefe->connect($endpoint);
}
$readable = $writeable = array();
// Send out status messages to peers, and collect from peers
// The zmq_poll timeout defines our own heartbeating
while (true) {
// Initialize poll set
$poll = new ZMQPoll();
$poll->add($statefe, ZMQ::POLL_IN);
// Poll for activity, or 1 second timeout
$events = $poll->poll($readable, $writeable, 1000);
if ($events > 0) {
// Handle incoming status message
foreach ($readable as $socket) {
$address = $socket->recv();
$body = $socket->recv();
printf ("%s - %s workers free%s", $address, $body, PHP_EOL);
}
} else {
// We stick our own address onto the envelope
$statebe->send($self, ZMQ::MODE_SNDMORE);
// Send random value for worker availability
$statebe->send(mt_rand(1, 10));
}
}
// We never get here
peering1: Python 中的状态流原型
#
# Broker peering simulation (part 1) in Python
# Prototypes the state flow
#
# Author : Piero Cornice
# Contact: root(at)pieroland(dot)net
#
import sys
import time
import random
import zmq
def main(myself, others):
print("Hello, I am %s" % myself)
context = zmq.Context()
# State Back-End
statebe = context.socket(zmq.PUB)
# State Front-End
statefe = context.socket(zmq.SUB)
statefe.setsockopt(zmq.SUBSCRIBE, b'')
bind_address = u"ipc://%s-state.ipc" % myself
statebe.bind(bind_address)
for other in others:
statefe.connect(u"ipc://%s-state.ipc" % other)
time.sleep(1.0)
poller = zmq.Poller()
poller.register(statefe, zmq.POLLIN)
while True:
########## Solution with poll() ##########
socks = dict(poller.poll(1000))
# Handle incoming status message
if socks.get(statefe) == zmq.POLLIN:
msg = statefe.recv_multipart()
print('%s Received: %s' % (myself, msg))
else:
# Send our address and a random value
# for worker availability
msg = [bind_address, (u'%i' % random.randrange(1, 10))]
msg = [ m.encode('ascii') for m in msg]
statebe.send_multipart(msg)
##################################
######### Solution with select() #########
# pollin, pollout, pollerr = zmq.select([statefe], [], [], 1)
#
# if pollin and pollin[0] == statefe:
# # Handle incoming status message
# msg = statefe.recv_multipart()
# print 'Received:', msg
#
# else:
# # Send our address and a random value
# # for worker availability
# msg = [bind_address, str(random.randrange(1, 10))]
# statebe.send_multipart(msg)
##################################
if __name__ == '__main__':
if len(sys.argv) >= 2:
main(myself=sys.argv[1], others=sys.argv[2:])
else:
print("Usage: peering.py <myself> <peer_1> ... <peer_N>")
sys.exit(1)
peering1: Q 中的状态流原型
peering1: Racket 中的状态流原型
#lang racket
#|
# Broker peering simulation (part 1) in Racket
# Prototypes the state flow
|#
(require net/zmq)
(define (main myself peers)
(printf "Hello, I am ~a\n" myself)
(define ctxt (context 1))
; State Back-End
(define statebe (socket ctxt 'PUB))
; State Front-End
(define statefe (socket ctxt 'SUB))
(set-socket-option! statefe 'SUBSCRIBE #"")
(define bind-address (format "ipc://~a-state.ipc" myself))
(socket-bind! statebe bind-address)
(for ([p (in-list peers)])
(socket-connect! statefe (format "ipc://~a-state.ipc" p)))
(define poller
(vector (make-poll-item statefe 0 'POLLIN empty)))
(let loop ()
(poll! poller 1000000)
(define revents (poll-item-revents (vector-ref poller 0)))
(if (equal? revents '(POLLIN))
(printf "Received: ~a" (socket-recv! statefe))
(socket-send! statebe
(string->bytes/utf-8
(format "~a ~a" bind-address (random 10)))))
(loop))
(context-close! ctxt))
(command-line #:program "peering1"
#:args (myself . peers)
(main myself peers))
peering1: Ruby 中的状态流原型
#!/usr/bin/env ruby
# Broker peering simulation (part 1)
# Prototypes the state flow
#
# Translated from C by Devin Christensen: http://github.com/devin-c
require "rubygems"
require "ffi-rzmq"
class Broker
def initialize(name, peers)
raise ArgumentError, "A broker require's a name" unless name
raise ArgumentError, "A broker require's peers" unless peers.any?
@name = name
@peers = peers
@context = ZMQ::Context.new
setup_state_backend
setup_state_frontend
end
def run
poller = ZMQ::Poller.new
poller.register_readable @state_frontend
until poller.poll(1000) == -1 do
if poller.readables.any?
@state_frontend.recv_string peer_name = ""
@state_frontend.recv_string available = ""
puts "#{peer_name} - #{available} workers free"
else
@state_backend.send_strings [@name, rand(10).to_s]
end
end
@state_frontend.close
@state_backend.close
@context.terminate
end
private
def setup_state_backend
@state_backend = @context.socket ZMQ::PUB
@state_backend.bind "ipc://#{@name}-state.ipc"
end
def setup_state_frontend
@state_frontend = @context.socket ZMQ::SUB
@peers.each do |peer|
puts "I: connecting to state backend at #{peer}"
@state_frontend.connect "ipc://#{peer}-state.ipc"
@state_frontend.setsockopt ZMQ::SUBSCRIBE, peer
end
end
end
begin
broker = Broker.new(ARGV.shift, ARGV)
broker.run
rescue ArgumentError
puts "usage: ruby peering1.rb broker_name [peer_name ...]"
end
peering1: Rust 中的状态流原型
peering1: Scala 中的状态流原型
/*
* Broker peering simulation (part 1)
* Prototypes the state flow
*
*
* @Author: Giovanni Ruggiero
* @Email: giovanni.ruggiero@gmail.com
*/
import org.zeromq.ZMQ
import ZHelpers._
import ClusterDns._
object peering1 {
val Statefe = "statefe"
val Statebe = "statebe"
def main(args : Array[String]) {
// First argument is this broker's name
// Other arguments are our peers' names
//
if (args.length < 2) {
println ("syntax: peering1 me {you}...")
exit()
}
val self = args(0)
implicit val dns = clusterDns
implicit val host = self
printf ("I: preparing broker at %s...\n", self);
val rand = new java.util.Random(System.currentTimeMillis)
val ctx = ZMQ.context(1)
val statebe = ctx.socket(ZMQ.PUB)
statebe.dnsBind(Statebe)
val statefe = ctx.socket(ZMQ.SUB)
statefe.subscribe("".getBytes)
for (cluster <- (1 until args.length)) {
printf ("I: connecting to state backend at '%s'\n", args(cluster))
statefe.dnsConnect(args(cluster),Statefe)
}
// Send out status messages to peers, and collect from peers
// The zmq_poll timeout defines our own heartbeating
while (true) {
val poller = ctx.poller(1)
poller.register(statefe,ZMQ.Poller.POLLIN)
poller.poll(1000000)
if(poller.pollin(0)) {
val msg = new ZMsg(statefe)
printf ("%s - %s workers free\n", msg.addressToString, msg.bodyToString)
} else {
// Send random value for worker availability
val msg = new ZMsg(rand.nextInt(10).toString)
msg.wrap(self getBytes)
statebe.sendMsg(msg)
}
}
}
}
peering1: Tcl 中的状态流原型
#
# Broker peering simulation (part 1)
# Prototypes the state flow
#
package require zmq
# First argument is this broker's name
# Other arguments are our peers' names
#
if {[llength $argv] < 1} {
puts "Usage: peering1.tcl me ?you ...?\n"
exit 1
}
set self [lindex $argv 0]
puts "I: preparing broker at $self"
expr {srand([pid])}
# Prepare our context and sockets
zmq context context
zmq socket statebe context PUB
statebe bind "ipc://$self-state.ipc"
# Connect statefe to all peers
zmq socket statefe context SUB
statefe setsockopt SUBSCRIBE ""
foreach peer [lrange $argv 1 end] {
puts "I: connecting to state backend at '$peer'"
statefe connect "ipc://$peer-state.ipc"
}
# Send out status messages to peers, and collect from peers
#
proc handle_incoming {} {
set peer_name [statefe recv]
set available [statefe recv]
puts "$peer_name - $available workers free"
}
proc send_random {} {
global self
set data [expr {int(rand()*10)}]
statebe sendmore $self
statebe send $data
after 1000 send_random
}
statefe readable handle_incoming
send_random
vwait forever
statebe close
statefe close
context term
peering1: OCaml 中的状态流原型
关于此代码的注意事项
-
每个中介都有一个身份,我们用来构建ipc端点名称。一个真正的中介需要使用 TCP 和更复杂的配置方案。我们将在本书后面讨论这些方案,但目前,使用生成的ipc名称使我们可以忽略获取 TCP/IP 地址或名称的问题。
-
我们使用一个 zmq_poll()循环作为程序的核心。它处理传入消息并发送状态消息。我们只有在没有收到任何传入消息并且等待了一秒钟后才发送状态消息。如果我们每次收到消息时都发送状态消息,就会造成消息风暴。
-
我们使用由发送者地址和数据组成的两部分 pub-sub 消息。请注意,为了向发布者发送任务,我们需要知道发布者的地址,唯一的方法是将此地址显式作为消息的一部分发送。
-
我们不在订阅者上设置身份,因为如果设置了,连接到正在运行的中介时会获取到过时的状态信息。
-
我们不在发布者上设置 HWM (High Water Mark),但如果使用 ZeroMQ v2.x,那会是一个明智的主意。
我们可以构建这个小程序并运行三次来模拟三个集群。我们将它们称为 DC1、DC2 和 DC3(名称是任意的)。我们在三个独立的窗口中运行这三个命令
peering1 DC1 DC2 DC3 # Start DC1 and connect to DC2 and DC3
peering1 DC2 DC1 DC3 # Start DC2 and connect to DC1 and DC3
peering1 DC3 DC1 DC2 # Start DC3 and connect to DC1 and DC2
您会看到每个集群报告其对等体的状态,几秒钟后,它们都会愉快地每秒打印一个随机数。尝试一下,并确认这三个中介都能匹配并同步到每秒的状态更新。
在实际生活中,我们不会定期发送状态消息,而是在状态发生变化时发送,例如,当工作线程变得可用或不可用时。这看起来流量很大,但状态消息很小,而且我们已经确定集群间的连接速度非常快。
如果我们要以精确的间隔发送状态消息,我们会创建一个子线程并在该线程中打开statebe套接字。然后我们会从主线程向该子线程发送不规则的状态更新,并允许子线程将它们合并成规则的传出消息。这比我们在这里需要的更多工作。
本地流和云端流原型实现 #
现在让我们通过本地和云端套接字原型实现任务流。这段代码从客户端拉取请求,然后随机分发给本地工作线程和云端对等体。
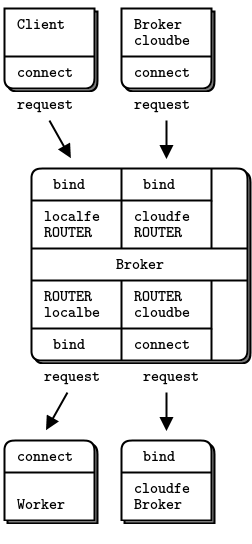
在我们深入代码之前(代码正变得有点复杂),让我们先勾勒出核心路由逻辑,并将其分解成一个简单但健壮的设计。
我们需要两个队列,一个用于接收来自本地客户端的请求,一个用于接收来自云端客户端的请求。一个选择是从本地和云端前端拉取消息,然后将它们推送到各自的队列中。但这有点没意义,因为 ZeroMQ 套接字本身就是队列。所以让我们使用 ZeroMQ 套接字缓冲区作为队列。
这是我们在负载均衡中介中使用的技术,效果很好。我们只在有地方发送请求时才从两个前端读取。我们可以随时从后端读取,因为它们提供要路由回去的回复。只要后端不与我们通信,就没有必要查看前端。
所以我们的主循环变成了
-
轮询后端以检查活动。当我们收到消息时,可能是来自工作者的“ready”消息,也可能是回复。如果是回复,则通过本地或云前端路由回去。
-
如果一个工作者回复了,它就变得可用,因此我们将其排队并计数。
-
当有可用工作者时,从任一前端获取请求(如果有的话),并路由到本地工作者,或者随机路由到云对等体。
随机将任务发送给对等broker而不是工作者,这模拟了集群中的工作分布。这很笨,但对于这个阶段来说没关系。
我们使用broker身份来路由broker之间的消息。在这个简单原型中,每个broker都有一个我们在命令行上提供的名称。只要这些名称不与用于客户端节点的 ZeroMQ 生成的 UUID 重叠,我们就能判断是应该将回复路由回客户端还是路由到broker。
这是代码中实现的方式。有趣的部分从注释“Interesting part”附近开始。
peering2:Ada 中的本地和云流程原型
peering2:Basic 中的本地和云流程原型
peering2:C 中的本地和云流程原型
// Broker peering simulation (part 2)
// Prototypes the request-reply flow
#include "czmq.h"
#define NBR_CLIENTS 10
#define NBR_WORKERS 3
#define WORKER_READY "\001" // Signals worker is ready
// Our own name; in practice this would be configured per node
static char *self;
// .split client task
// The client task does a request-reply dialog using a standard
// synchronous REQ socket:
static void client_task(zsock_t *pipe, void *args) {
// Signal caller zactor has started
zsock_signal(pipe, 0);
zsock_t *client = zsock_new(ZMQ_REQ);
zsock_connect(client, "ipc://%s-localfe.ipc", self);
zpoller_t *poll = zpoller_new(pipe, client, NULL);
while (true) {
// Send request, get reply
zstr_send (client, "HELLO");
zsock_t *ready = zpoller_wait(poll, -1);
if (ready == pipe || ready == NULL)
break; // Done
assert(ready == client);
char *reply = zstr_recv(client);
if (!reply)
break; // Interrupted
printf ("Client: %s\n", reply);
free (reply);
sleep (1);
}
zsock_destroy(&client);
zpoller_destroy(&poll);
// Signal done
zsock_signal(pipe, 0);
}
// .split worker task
// The worker task plugs into the load-balancer using a REQ
// socket:
static void worker_task(zsock_t *pipe, void *args) {
// Signal caller zactor has started
zsock_signal(pipe, 0);
zsock_t *worker = zsock_new(ZMQ_REQ);
zsock_connect(worker, "ipc://%s-localbe.ipc", self);
// Tell broker we're ready for work
zframe_t *frame = zframe_new(WORKER_READY, 1);
zframe_send(&frame, worker, 0);
// Process messages as they arrive
zpoller_t *poll = zpoller_new(pipe, worker, NULL);
while (true) {
zsock_t *ready = zpoller_wait(poll, -1);
if (ready == pipe || ready == NULL)
break; // Done
assert(ready == worker);
zmsg_t *msg = zmsg_recv(worker);
if (!msg)
break; // Interrupted
zframe_print(zmsg_last(msg), "Worker: ");
zframe_reset(zmsg_last(msg), "OK", 2);
zmsg_send(&msg, worker);
}
if (frame) zframe_destroy(&frame);
zsock_destroy(&worker);
zpoller_destroy(&poll);
// Signal done
zsock_signal(pipe, 0);
}
// .split main task
// The main task begins by setting-up its frontend and backend sockets
// and then starting its client and worker tasks:
int main(int argc, char *argv[]) {
// First argument is this broker's name
// Other arguments are our peers' names
//
if (argc < 2) {
printf("syntax: peering2 me {you}...\n");
return 0;
}
self = argv[1];
printf("I: preparing broker at %s...\n", self);
srandom((unsigned)time(NULL));
// Bind cloud frontend to endpoint
zsock_t *cloudfe = zsock_new(ZMQ_ROUTER);
zsock_set_identity(cloudfe, self);
zsock_bind(cloudfe, "ipc://%s-cloud.ipc", self);
// Connect cloud backend to all peers
zsock_t *cloudbe = zsock_new(ZMQ_ROUTER);
zsock_set_identity(cloudbe, self);
int argn;
for (argn = 2; argn < argc; argn++) {
char *peer = argv[argn];
printf("I: connecting to cloud frontend at '%s'\n", peer);
zsock_connect(cloudbe, "ipc://%s-cloud.ipc", peer);
}
// Prepare local frontend and backend
zsock_t *localfe = zsock_new(ZMQ_ROUTER);
zsock_bind(localfe, "ipc://%s-localfe.ipc", self);
zsock_t *localbe = zsock_new(ZMQ_ROUTER);
zsock_bind(localbe, "ipc://%s-localbe.ipc", self);
// Get user to tell us when we can start...
printf("Press Enter when all brokers are started: ");
getchar();
// Start local workers
int worker_nbr;
zactor_t *worker_actors[NBR_WORKERS];
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
worker_actors[worker_nbr] = zactor_new(worker_task, NULL);
// Start local clients
int client_nbr;
zactor_t *client_actors[NBR_CLIENTS];
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++)
client_actors[client_nbr] = zactor_new(client_task, NULL);
// Interesting part
// .split request-reply handling
// Here, we handle the request-reply flow. We're using load-balancing
// to poll workers at all times, and clients only when there are one
// or more workers available.
// Least recently used queue of available workers
int capacity = 0;
zlist_t *workers = zlist_new();
zpoller_t *poll_backends = zpoller_new(localbe, cloudbe, NULL);
zpoller_t *poll_frontends = zpoller_new(cloudfe, localfe, NULL);
while (true) {
// First, route any waiting replies from workers
// If we have no workers, wait indefinitely
zsock_t *ready = zpoller_wait(poll_backends, capacity ? 1000 * ZMQ_POLL_MSEC : -1);
zmsg_t *msg = NULL;
if (NULL == ready) {
if (zpoller_terminated(poll_backends))
break; // Interrupted
} else {
// Handle reply from local worker
if (ready == localbe) {
msg = zmsg_recv(localbe);
if (!msg) break; // Interrupted
zframe_t *identity = zmsg_unwrap(msg);
zlist_append(workers, identity);
capacity++;
// If it's READY, don't route the message any further
zframe_t *frame = zmsg_first(msg);
if (memcmp(zframe_data(frame), WORKER_READY, 1) == 0) zmsg_destroy(&msg);
}
// Or handle reply from peer broker
else if (ready == cloudbe) {
msg = zmsg_recv(cloudbe);
if (!msg) break; // Interrupted
// We don't use peer broker identity for anything
zframe_t *identity = zmsg_unwrap(msg);
zframe_destroy(&identity);
}
// Route reply to cloud if it's addressed to a broker
for (argn = 2; msg && argn < argc; argn++) {
char *data = (char *)zframe_data(zmsg_first(msg));
size_t size = zframe_size(zmsg_first(msg));
if (size == strlen(argv[argn]) && memcmp(data, argv[argn], size) == 0)
zmsg_send(&msg, cloudfe);
}
// Route reply to client if we still need to
if (msg) zmsg_send(&msg, localfe);
}
// .split route client requests
// Now we route as many client requests as we have worker capacity
// for. We may reroute requests from our local frontend, but not from
// the cloud frontend. We reroute randomly now, just to test things
// out. In the next version, we'll do this properly by calculating
// cloud capacity:
while (capacity) {
zsock_t *ready = zpoller_wait(poll_frontends, 0);
int reroutable = 0;
// We'll do peer brokers first, to prevent starvation
if (ready == cloudfe) {
msg = zmsg_recv(cloudfe);
reroutable = 0;
} else if (ready == localfe) {
msg = zmsg_recv(localfe);
reroutable = 1;
} else
break; // No work, go back to backends
// If reroutable, send to cloud 20% of the time
// Here we'd normally use cloud status information
if (reroutable && argc > 2 && randof(5) == 0) {
// Route to random broker peer
int peer = randof(argc - 2) + 2;
zmsg_pushmem(msg, argv[peer], strlen(argv[peer]));
zmsg_send(&msg, cloudbe);
} else {
zframe_t *frame = (zframe_t *)zlist_pop(workers);
zmsg_wrap(msg, frame);
zmsg_send(&msg, localbe);
capacity--;
}
}
}
// When we're done, clean up properly
while (zlist_size(workers)) {
zframe_t *frame = (zframe_t *)zlist_pop(workers);
zframe_destroy(&frame);
}
zlist_destroy(&workers);
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
zactor_destroy(&worker_actors[worker_nbr]);
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++)
zactor_destroy(&client_actors[client_nbr]);
zpoller_destroy(&poll_backends);
zpoller_destroy(&poll_frontends);
zsock_destroy(&cloudfe);
zsock_destroy(&cloudbe);
zsock_destroy(&localfe);
zsock_destroy(&localbe);
return EXIT_SUCCESS;
}
peering2:C++ 中的本地和云流程原型
//
// created by Jinyang Shao on 8/22/2024
//
// Broker peering simulation (part 2)
// Prototypes the request-reply flow
#include "zhelpers.hpp"
#include <thread>
#include <queue>
#include <vector>
#define NBR_CLIENTS 10
#define NBR_WORKERS 3
#define WORKER_READY "\001" // Signals worker is ready
#define ZMQ_POLL_MSEC 1
void receive_all_frames(zmq::socket_t& sock, std::vector<std::string>& frames) {
frames.clear();
while (1) {
// Process all parts of the message
std::string frame = s_recv(sock);
frames.emplace_back(frame);
int more = 0; // Multipart detection
size_t more_size = sizeof (more);
sock.getsockopt(ZMQ_RCVMORE, &more, &more_size);
if (!more)
break; // Last message part
}
return;
}
void send_all_frames(zmq::socket_t& sock, std::vector<std::string>& frames) {
for (int i = 0; i < frames.size(); i++) {
if (i == frames.size() - 1) {
s_send(sock, frames[i]);
} else {
s_sendmore(sock, frames[i]);
}
}
return;
}
void receive_empty_message(zmq::socket_t& sock)
{
std::string empty = s_recv(sock);
assert(empty.size() == 0);
}
void print_all_frames(std::vector<std::string>& frames) {
std::cout << "------------received------------" << std::endl;
for (std::string &frame : frames)
{
std::cout << frame << std::endl;
std::cout << "----------------------------------------" << std::endl;
}
}
// Broker's identity
static std::string self;
void client_thread(int id) {
zmq::context_t context(1);
zmq::socket_t client(context, ZMQ_REQ);
std::string connURL = std::string("ipc://").append(self).append("-localfe.ipc");
#if (defined (WIN32))
s_set_id(client, id);
client.connect(connURL); // localfe
#else
s_set_id(client); // Set a printable identity
client.connect(connURL);
#endif
while(true) {
// Send request, get reply
s_send(client, std::string("HELLO"));
std::string reply = s_recv(client);
std::cout << "Client" << reply << std::endl;
sleep(1);
}
return;
}
// Worker using REQ socket to do LRU routing
//
void worker_thread(int id) {
zmq::context_t context(1);
zmq::socket_t worker(context, ZMQ_REQ);
std::string connURL = std::string("ipc://").append(self).append("-localbe.ipc");
#if (defined (WIN32))
s_set_id(worker, id);
worker.connect(connURL); // backend
#else
s_set_id(worker);
worker.connect(connURL);
#endif
// Tell broker we're ready for work
s_send(worker, std::string(WORKER_READY));
while (true) {
// Read and save all frames until we get an empty frame
// In this example there is only 1 but it could be more
std::vector<std::string> frames;
receive_all_frames(worker, frames);
std::cout << "Worker: " << frames[frames.size()-1] << std::endl;
// Send reply
frames[frames.size()-1] = std::string("OK");
send_all_frames(worker, frames);
}
return;
}
int main(int argc, char *argv[]) {
// First argument is this broker's name
// Other arguments are our peers' names
if (argc < 2) {
std::cout << "syntax: peering2 me {you} ..." << std::endl;
return 0;
}
self = std::string(argv[1]);
std::cout << "I: preparing broker at " << self << " ..." << std::endl;
srandom(static_cast<unsigned int>(time(nullptr)));
zmq::context_t context(1);
// Bind cloud frontend to endpoint
zmq::socket_t cloudfe(context, ZMQ_ROUTER);
cloudfe.set(zmq::sockopt::routing_id, self); // remember to set identity
std::string bindURL = std::string("ipc://").append(self).append("-cloud.ipc");
cloudfe.bind(bindURL);
// Connect cloud backend to all peers
zmq::socket_t cloudbe(context, ZMQ_ROUTER);
cloudbe.set(zmq::sockopt::routing_id, self); // remember to set identity
for(int argn = 2 ; argn < argc ; ++argn) {
std::string peer(argv[argn]);
std::cout << "I: connecting to cloud frontend at " << peer << std::endl;
std::string peerURL = std::string("ipc://").append(peer).append("-cloud.ipc");
cloudbe.connect(peerURL);
}
// Prepare local frontend and backend
zmq::socket_t localfe(context, ZMQ_ROUTER);
{
std::string bindURL = std::string("ipc://").append(self).append("-localfe.ipc");
localfe.bind(bindURL);
}
zmq::socket_t localbe(context, ZMQ_ROUTER);
{
std::string bindURL = std::string("ipc://").append(self).append("-localbe.ipc");
localbe.bind(bindURL);
}
// Get user to tell us when we can start...
std::cout << "Press Enter when all brokers are started: " << std::endl;
getchar();
// Start local clients
int client_nbr = 0;
for (; client_nbr < NBR_CLIENTS; client_nbr++)
{
std::thread t(client_thread, client_nbr);
t.detach();
}
// Start local workers
for (int worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
{
std::thread t(worker_thread, worker_nbr);
t.detach();
}
// Interesting part
// .split request-reply handling
// Here, we handle the request-reply flow. We're using load-balancing
// to poll workers at all times, and clients only when there are one
// or more workers available.
// Least recently used queue of available workers
int capacity = 0;
std::queue<std::string> worker_queue;
zmq::pollitem_t frontend_items[] = {
{localfe, 0, ZMQ_POLLIN, 0},
{cloudfe, 0, ZMQ_POLLIN, 0}
};
zmq::pollitem_t backend_items[] = {
{localbe, 0, ZMQ_POLLIN, 0},
{cloudbe, 0, ZMQ_POLLIN, 0}
};
while(true) {
// First, route any waiting replies from workers
try {
// If we have no workers, wait indefinitely
std::chrono::milliseconds timeout{(capacity ? 1000 : -1)};
zmq::poll(backend_items, 2, timeout);
} catch(...) {
break;
}
if (backend_items[0].revents & ZMQ_POLLIN) {
// From localbe,Handle reply from local worker
std::string worker_identity = s_recv(localbe);
worker_queue.push(worker_identity);
capacity++;
receive_empty_message(localbe);
// Remain_frames may be:
// 1. [client_addr][0][OK]
// 2. [origin_broker][0][client_addr][0][OK]
// 3. [READY]
std::vector<std::string> remain_frames;
receive_all_frames(localbe, remain_frames);
assert(remain_frames.size() == 1 || remain_frames.size() == 3 || remain_frames.size() == 5);
// Third frame is READY or else a client reply address
std::string third_frame = remain_frames[0];
// If the third_frame is client_addr
if (third_frame.compare(WORKER_READY) != 0 && remain_frames.size() == 3) {
// Send to client
send_all_frames(localfe, remain_frames);
} else if (remain_frames.size() == 5) {
// The third_frame is origin_broker address
// Route the reply to the origin broker
for (int argn = 2; argn < argc; argn++) {
if (third_frame.compare(argv[argn]) == 0) {
send_all_frames(cloudfe, remain_frames);
}
}
}
} else if (backend_items[1].revents & ZMQ_POLLIN) {
// From cloudbe,handle reply from peer broker
std::string peer_broker_identity = s_recv(cloudbe); // useless
receive_empty_message(cloudbe);
std::string client_addr = s_recv(cloudbe);
receive_empty_message(cloudbe);
std::string reply = s_recv(cloudbe);
// Send to the client
s_sendmore(localfe, client_addr);
s_sendmore(localfe, std::string(""));
s_send(localfe, reply);
}
// .split route client requests
// Now we route as many client requests as we have worker capacity
// for. We may reroute requests from our local frontend, but not from
// the cloud frontend. We reroute randomly now, just to test things
// out. In the next version, we'll do this properly by calculating
// cloud capacity:
while (capacity){
try{
// No wait
zmq::poll(frontend_items, 2, 0);
}
catch (...) {
break;
}
bool reroutable = false; // not used in C++
if (frontend_items[0].revents & ZMQ_POLLIN) {
// From localfe, client's request
std::string client_addr = s_recv(localfe);
receive_empty_message(localfe);
std::string request = s_recv(localfe);
reroutable = true;
// Route in 20% of cases
if (argc > 2 && within(5) < 1) {
// Peers exist and routable
int peer = within(argc-2) + 2;
std::string peer_addr = argv[peer];
// Send to cloudbe, routing
s_sendmore(cloudbe, peer_addr);
s_sendmore(cloudbe, std::string(""));
s_sendmore(cloudbe, client_addr);
s_sendmore(cloudbe, std::string(""));
s_send(cloudbe, request);
} else {
// Use local workers
std::string worker_addr = worker_queue.front();
worker_queue.pop();
capacity--;
// Send to local worker
s_sendmore(localbe, worker_addr);
s_sendmore(localbe, std::string(""));
s_sendmore(localbe, client_addr);
s_sendmore(localbe, std::string(""));
s_send(localbe, request);
}
} else if (frontend_items[1].revents & ZMQ_POLLIN) {
// From cloudfe, other broker's request
std::string origin_peer_addr = s_recv(cloudfe);
receive_empty_message(cloudfe);
std::string client_addr = s_recv(cloudfe);
receive_empty_message(cloudfe);
std::string request = s_recv(cloudfe);
reroutable = false;
// Use local workers
std::string worker_addr = worker_queue.front();
worker_queue.pop();
capacity--;
// Send to local worker
s_sendmore(localbe, worker_addr);
s_sendmore(localbe, std::string(""));
s_sendmore(localbe, origin_peer_addr);
s_sendmore(localbe, std::string(""));
s_sendmore(localbe, client_addr);
s_sendmore(localbe, std::string(""));
s_send(localbe, request);
} else {
break; // No work, go back to backends
}
}
}
return 0;
}
peering2:C# 中的本地和云流程原型
peering2:CL 中的本地和云流程原型
peering2:Delphi 中的本地和云流程原型
program peering2;
//
// Broker peering simulation (part 2)
// Prototypes the request-reply flow
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
, zhelpers
;
const
NBR_CLIENTS = 10;
NBR_WORKERS = 3;
WORKER_READY = '\001'; // Signals worker is ready
var
// Our own name; in practice this would be configured per node
self: Utf8String;
// The client task does a request-reply dialog using a standard
// synchronous REQ socket:
procedure client_task( args: Pointer; ctx: TZMQContext );
var
client: TZMQSocket;
reply: Utf8String;
begin
client := ctx.Socket( stReq );
{$ifdef unix}
client.connect( Format( 'ipc://%s-localfe.ipc', [self] ) );
{$else}
client.connect( Format( 'tcp://127.0.0.1:%s', [self] ) );
{$endif}
while not ctx.Terminated do
try
client.send( 'HELLO' );
client.recv( reply );
zNote( Format( 'Client: %s', [reply] ) );
sleep( 1000 );
except
end;
end;
// The worker task plugs into the load-balancer using a REQ
// socket:
procedure worker_task( args: Pointer; ctx: TZMQContext );
var
worker: TZMQSocket;
msg: TZMQMsg;
begin
worker := ctx.Socket( stReq );
{$ifdef unix}
worker.connect( Format( 'ipc://%s-localbe.ipc', [self] ) );
{$else}
worker.connect( Format( 'tcp://127.0.0.1:1%s', [self] ) );
{$endif}
// Tell broker we're ready for work
worker.send( WORKER_READY );
// Process messages as they arrive
while not ctx.Terminated do
try
msg := TZMQMsg.create;
worker.recv( msg );
zNote( Format( 'Worker: %s', [msg.last.dump] ) );
msg.last.asUtf8String := 'OK';
worker.send( msg );
except
end;
end;
var
ctx: TZMQContext;
cloudfe,
cloudbe,
localfe,
localbe: TZMQSocket;
i: Integer;
peer,
s: Utf8String;
workers: TZMQMsg;
pollerbe,
pollerfe: TZMQPoller;
rc,timeout: Integer;
msg: TZMQMsg;
identity,
frame: TZMQFrame;
data: Utf8String;
reroutable,
random_peer: Integer;
thr: TZMQThread;
// The main task begins by setting-up its frontend and backend sockets
// and then starting its client and worker tasks:
begin
// First argument is this broker's name
// Other arguments are our peers' names
//
if ParamCount < 2 then
begin
Writeln( 'syntax: peering2 me {you}...' );
halt( 1 );
end;
// on windows it should be a 1024 <= number <= 9999
self := ParamStr( 1 );
writeln( Format( 'I: preparing broker at %s', [self] ) );
randomize;
ctx := TZMQContext.create;
// Bind cloud frontend to endpoint
cloudfe := ctx.Socket( stRouter );
cloudfe.Identity := self;
{$ifdef unix}
cloudfe.bind( Format( 'ipc://%s-cloud.ipc', [self] ) );
{$else}
cloudfe.bind( Format( 'tcp://127.0.0.1:2%s', [self] ) );
{$endif}
// Connect cloud backend to all peers
cloudbe := ctx.Socket( stRouter );
cloudbe.Identity := self;
for i := 2 to ParamCount do
begin
peer := ParamStr( i );
Writeln( Format( 'I: connecting to cloud frontend at "%s"', [peer] ) );
{$ifdef unix}
cloudbe.connect( Format( 'ipc://%s-cloud.ipc', [peer] ) );
{$else}
cloudbe.connect( Format( 'tcp://127.0.0.1:2%s', [peer] ) );
{$endif}
end;
// Prepare local frontend and backend
localfe := ctx.Socket( stRouter );
{$ifdef unix}
localfe.bind( Format( 'ipc://%s-localfe.ipc', [self] ) );
{$else}
localfe.bind( Format( 'tcp://127.0.0.1:%s', [self] ) );
{$endif}
localbe := ctx.Socket( stRouter );
{$ifdef unix}
localbe.bind( Format( 'ipc://%s-localbe.ipc', [self] ) );
{$else}
localbe.bind( Format( 'tcp://127.0.0.1:1%s', [self] ) );
{$endif}
// Get user to tell us when we can start
Writeln( 'Press Enter when all brokers are started: ');
Readln( s );
// Start local workers
for i := 0 to NBR_WORKERS - 1 do
begin
thr := TZMQThread.CreateDetachedProc( worker_task, nil );
thr.FreeOnTerminate := true;
thr.Resume;
end;
// Start local clients
for i := 0 to NBR_CLIENTS - 1 do
begin
thr := TZMQThread.CreateDetachedProc( client_task, nil );
thr.FreeOnTerminate := true;
thr.Resume;
end;
// Here we handle the request-reply flow. We're using load-balancing
// to poll workers at all times, and clients only when there are one or
// more workers available.
// Least recently used queue of available workers
workers := TZMQMsg.Create;
pollerbe := TZMQPoller.Create( true );
pollerbe.Register( localbe, [pePollIn] );
pollerbe.Register( cloudbe, [pePollIn] );
// I could do it with one poller too.
pollerfe := TZMQPoller.Create( true );
pollerfe.Register( localfe, [pePollIn] );
pollerfe.Register( cloudfe, [pePollIn] );
while not ctx.Terminated do
try
// First, route any waiting replies from workers
// If we have no workers anyhow, wait indefinitely
if workers.size = 0 then
timeout := -1
else
timeout := 1000;
pollerbe.poll( timeout );
msg := nil;
// Handle reply from local worker
if pePollIn in pollerbe.PollItem[0].revents then
begin
msg := TZMQMsg.Create;
localbe.recv( msg );
identity := msg.unwrap;
workers.Add( identity );
// If it's READY, don't route the message any further
frame := msg.first;
if frame.asUtf8String = WORKER_READY then
begin
msg.Free;
msg := nil;
end;
// Or handle reply from peer broker
end else
if pePollIn in pollerbe.PollItem[1].revents then
begin
msg := TZMQMsg.create;
cloudbe.recv( msg );
// We don't use peer broker identity for anything
identity := msg.unwrap;
identity.Free;
end;
// Route reply to cloud if it's addressed to a broker
if msg <> nil then
for i := 2 to ParamCount do
begin
data := msg.first.asUtf8String;
if data = ParamStr( i ) then
cloudfe.send( msg );
end;
// Route reply to client if we still need to
if msg <> nil then
localfe.send( msg );
// Now we route as many client requests as we have worker capacity
// for. We may reroute requests from our local frontend, but not from //
// the cloud frontend. We reroute randomly now, just to test things
// out. In the next version we'll do this properly by calculating
// cloud capacity://
while workers.size > 0 do
begin
rc := pollerfe.poll( 0 );
Assert( rc >= 0 );
// We'll do peer brokers first, to prevent starvation
if pePollIn in pollerfe.PollItem[1].revents then
begin
msg := TZMQMsg.create;
cloudfe.recv( msg );
reroutable := 0;
end else
if pePollIn in pollerfe.PollItem[0].revents then
begin
msg := TZMQMsg.create;
localfe.recv( msg );
reroutable := 1;
end else
break; // No work, go back to backends
// If reroutable, send to cloud 20% of the time
// Here we'd normally use cloud status information
//
if ( reroutable > 0 ) and ( ParamCount >= 2 ) and ( Random( 5 ) = 1 ) then
begin
// Route to random broker peer
random_peer := random( ParamCount - 2 ) + 2;
identity := TZMQFrame.create;
identity.asUtf8String := ParamStr( random_peer );
msg.push( identity );
cloudbe.send( msg );
end else
begin
frame := workers.pop;
msg.wrap( frame );
localbe.send( msg );
end;
end;
except
end;
// When we're done, clean up properly
while workers.size > 0 do
begin
frame := workers.pop;
frame.Free;
end;
workers.Free;
ctx.Free;
end.
peering2:Erlang 中的本地和云流程原型
peering2:Elixir 中的本地和云流程原型
peering2:F# 中的本地和云流程原型
peering2:Felix 中的本地和云流程原型
peering2:Go 中的本地和云流程原型
// Broker peering simulation (part 2)
// Prototypes the request-reply flow
//
// Author: amyangfei <amyangfei@gmail.com>
// Requires: http://github.com/alecthomas/gozmq
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"os"
"time"
)
const NBR_WORKERS = 3
const NBR_CLIENTS = 10
const WORKER_READY = "\001"
func client_task(name string, i int) {
context, _ := zmq.NewContext()
client, _ := context.NewSocket(zmq.REQ)
defer context.Close()
defer client.Close()
client.SetIdentity(fmt.Sprintf("Client-%s-%d", name, i))
client.Connect(fmt.Sprintf("ipc://%s-localfe.ipc", name))
for {
// Send request, get reply
client.Send([]byte("HELLO"), 0)
reply, _ := client.Recv(0)
fmt.Printf("Client-%d: %s\n", i, reply)
time.Sleep(time.Second)
}
}
func worker_task(name string, i int) {
context, _ := zmq.NewContext()
worker, _ := context.NewSocket(zmq.REQ)
defer context.Close()
defer worker.Close()
worker.SetIdentity(fmt.Sprintf("Worker-%s-%d", name, i))
worker.Connect(fmt.Sprintf("ipc://%s-localbe.ipc", name))
// Tell broker we're ready for work
worker.Send([]byte(WORKER_READY), 0)
// Process messages as they arrive
for {
msg, _ := worker.RecvMultipart(0)
fmt.Printf("Worker-%d: %s\n", i, msg)
msg[len(msg)-1] = []byte("OK")
worker.SendMultipart(msg, 0)
}
}
func main() {
if len(os.Args) < 2 {
fmt.Println("syntax: peering2 me {you}...")
return
}
myself := os.Args[1]
fmt.Printf("I: preparing broker at %s...\n", myself)
rand.Seed(time.Now().UnixNano())
context, _ := zmq.NewContext()
defer context.Close()
// Bind cloud fronted to endpoint
cloudfe, _ := context.NewSocket(zmq.ROUTER)
defer cloudfe.Close()
cloudfe.SetIdentity(myself)
cloudfe.Bind(fmt.Sprintf("ipc://%s-cloud.ipc", myself))
// Connect cloud backend to all peers
cloudbe, _ := context.NewSocket(zmq.ROUTER)
defer cloudbe.Close()
cloudbe.SetIdentity(myself)
for i := 2; i < len(os.Args); i++ {
peer := os.Args[i]
fmt.Printf("I: connecting to cloud frontend at '%s'\n", peer)
cloudbe.Connect(fmt.Sprintf("ipc://%s-cloud.ipc", peer))
}
// Prepare local frontend and backend
localfe, _ := context.NewSocket(zmq.ROUTER)
localbe, _ := context.NewSocket(zmq.ROUTER)
defer localfe.Close()
defer localbe.Close()
localfe.Bind(fmt.Sprintf("ipc://%s-localfe.ipc", myself))
localbe.Bind(fmt.Sprintf("ipc://%s-localbe.ipc", myself))
// Get user to tell us when we can start...
var input string
fmt.Printf("Press Enter when all brokers are started: \n")
fmt.Scanln(&input)
// Start local workers
for i := 0; i < NBR_WORKERS; i++ {
go worker_task(myself, i)
}
// Start local clients
for i := 0; i < NBR_CLIENTS; i++ {
go client_task(myself, i)
}
// Interesting part
// Here, we handle the request-reply flow. We're using load-balancing
// to poll workers at all times, and clients only when there are one
// or more workers available.
// Least recently used queue of available workers
workers := make([]string, 0)
pollerbe := zmq.PollItems{
zmq.PollItem{Socket: localbe, Events: zmq.POLLIN},
zmq.PollItem{Socket: cloudbe, Events: zmq.POLLIN},
}
pollerfe := zmq.PollItems{
zmq.PollItem{Socket: localfe, Events: zmq.POLLIN},
zmq.PollItem{Socket: cloudfe, Events: zmq.POLLIN},
}
for {
// If we have no workers, wait indefinitely
timeout := time.Second
if len(workers) == 0 {
timeout = -1
}
zmq.Poll(pollerbe, timeout)
// Handle reply from local workder
var msg [][]byte = nil
var err error = nil
if pollerbe[0].REvents&zmq.POLLIN != 0 {
msg, err = localbe.RecvMultipart(0)
if err != nil {
break
}
address, _ := msg[0], msg[1]
msg = msg[2:]
workers = append(workers, string(address))
// If it's READY, don't route the message any further
if string(msg[len(msg)-1]) == WORKER_READY {
msg = nil
}
} else if pollerbe[1].REvents&zmq.POLLIN != 0 {
msg, err = cloudbe.RecvMultipart(0)
if err != nil {
break
}
// We don't use peer broker identity for anything
msg = msg[2:]
}
if msg != nil {
address := string(msg[0])
for i := 2; i < len(os.Args); i++ {
// Route reply to cloud if it's addressed to a broker
if address == os.Args[i] {
cloudfe.SendMultipart(msg, 0)
msg = nil
break
}
}
// Route reply to client if we still need to
if msg != nil {
localfe.SendMultipart(msg, 0)
}
}
for len(workers) > 0 {
zmq.Poll(pollerfe, 0)
reroutable := false
// We'll do peer brokers first, to prevent starvation
if pollerfe[1].REvents&zmq.POLLIN != 0 {
msg, _ = cloudfe.RecvMultipart(0)
reroutable = false
} else if pollerfe[0].REvents&zmq.POLLIN != 0 {
msg, _ = localfe.RecvMultipart(0)
reroutable = true
} else {
break // No work, go back to backends
}
// If reroutable, send to cloud 20% of the time
// Here we'd normally use cloud status information
if reroutable && len(os.Args) > 0 && rand.Intn(5) == 0 {
// Route to random broker peer
randPeer := rand.Intn(len(os.Args)-2) + 2
msg = append(msg[:0], append([][]byte{[]byte(os.Args[randPeer]), []byte("")}, msg[0:]...)...)
cloudbe.SendMultipart(msg, 0)
} else {
var worker string
worker, workers = workers[0], workers[1:]
msg = append(msg[:0], append([][]byte{[]byte(worker), []byte("")}, msg[0:]...)...)
localbe.SendMultipart(msg, 0)
}
}
}
}
peering2:Haskell 中的本地和云流程原型
{-# LANGUAGE OverloadedStrings #-}
module Main where
import Control.Concurrent (threadDelay)
import Control.Monad (forM_, forever, void, when)
import Control.Monad.IO.Class
import qualified Data.ByteString.Char8 as C
import Data.List (find)
import Data.List.NonEmpty (NonEmpty (..), (<|))
import qualified Data.List.NonEmpty as N
import Data.Semigroup ((<>))
import Data.Sequence (Seq, ViewL (..), viewl, (|>))
import qualified Data.Sequence as S
import System.Environment
import System.Exit
import System.Random
import System.ZMQ4.Monadic
workerNum :: Int
workerNum = 3
clientNum :: Int
clientNum = 10
-- | The client task does a request-reply dialog using a standard
-- synchronous REQ socket.
clientTask :: Show a => String -> a -> ZMQ z ()
clientTask self i = do
client <- socket Req
connect client (connectString self "localfe")
let ident = "Client-" <> C.pack self <> C.pack (show i)
setIdentity (restrict ident) client
forever $ do
send client [] "HELLO"
reply <- receiveMulti client
liftIO $ do
C.putStrLn $ "Client: " <> C.pack (show reply)
threadDelay 10000
-- | The worker task plugs into the load-balancer using a REQ socket
workerTask :: Show a => String -> a -> ZMQ z ()
workerTask self i = do
worker <- socket Req
connect worker (connectString self "localbe")
let ident = "Worker-" <> C.pack self <> C.pack (show i)
setIdentity (restrict ident) worker
send worker [] "READY"
forever $ do
msg <- receiveMulti worker
liftIO $ print (ident, "Sending"::String, msg)
sendMulti worker (replaceLast "OK" msg)
-- | This is similar to zframe_reset(zmsg_last (msg), ..) in czmq.
replaceLast :: a -> [a] -> NonEmpty a
replaceLast y (_:[]) = y :| []
replaceLast y (x:xs) = x <| replaceLast y xs
replaceLast y [] = y :| []
-- | Connect a peer using the connectString function
connectPeer :: Socket z t -> String -> String -> ZMQ z ()
connectPeer sock name p = connect sock (connectString p name)
-- | An ipc connection string
connectString :: String -> String -> String
connectString peer name = "ipc://" ++ peer ++ "-" ++ name ++ ".ipc"
type Workers = Seq C.ByteString
-- | Interesting part
-- Here, we handle the request-reply flow. We're using load-balancing
-- to poll workers at all times, and clients only when there are one
-- or more workers available.
clientWorkerPoll
:: (Receiver t1, Receiver t2, Receiver t3, Receiver t4, Sender t1, Sender t2, Sender t3, Sender t4)
=> Socket z t1
-> Socket z t2
-> Socket z t3
-> Socket z t4
-> [String]
-> ZMQ z ()
clientWorkerPoll
localBack
cloudBack
localFront
cloudFront
peers = loop S.empty -- Queue of workers starts empty
where
loop workers = do
-- Poll backends, if we have no workers, wait indefinitely
[localEvents, cloudEvents] <- poll (if S.length workers > 0 then oneSec else -1) backends
availableWorkers <- reqRep workers localEvents cloudEvents
availableWorkers' <- workerLoop availableWorkers
loop availableWorkers'
reqRep workers local cloud
-- Handle reply from local worker
| In `elem` local = do
msg <- receiveMulti localBack
case msg of
-- Worker is READY, don't route the message further
ident:_:"READY":_ -> return (workers |> ident)
-- Worker replied
ident:_:restOfMsg -> do
route restOfMsg
return (workers |> ident)
-- Something strange happened
m -> do
liftIO $ print m
return workers
-- Handle reply from peer broker
| In `elem` cloud = do
msg <- receiveMulti cloudBack
case msg of
-- We don't use the peer broker identity for anything
_:restOfMsg -> route restOfMsg
-- Something strange happened
m -> liftIO $ print m
return workers
| otherwise = return workers
route msg@(ident:_) = do
let msg' = N.fromList msg
peer = find (== ident) bPeers
case peer of
-- Route reply to cloud if it's addressed to a broker
Just _ -> sendMulti cloudFront msg'
-- Route reply to local client
Nothing -> sendMulti localFront msg'
route m = liftIO $ print m -- Something strange happened
-- Now, we route as many client requests as we have worker capacity
-- for. We may reroute requests from our local frontend, but not from
-- the cloud frontend. We reroute randomly now, just to test things
-- out. In the next version, we'll do this properly by calculating
-- cloud capacity.
workerLoop workers = if S.null workers
then return workers
else do
[localEvents, cloudEvents] <- poll 0 frontends
routeRequests workers localEvents cloudEvents
routeRequests workers local cloud
-- We'll do peer brokers first, to prevent starvation
| In `elem` cloud = do
msg <- receiveMulti cloudFront
rerouteReqs workers (Left msg)
| In `elem` local = do
msg <- receiveMulti localFront
rerouteReqs workers (Right msg)
-- No work, go back to backends
| otherwise = return workers
-- If rerouteable, send to cloud 20% of the time
-- Here we'd normally use cloud status information
--
-- Right denotes rerouteable. Left denotes not-rerouteable.
rerouteReqs workers (Right msg) = do
cont <- liftIO $ randomRIO (0::Int,4)
if cont == 0
then do
-- Route to random broker peer
p <- liftIO $ randomRIO (0, length peers - 1)
let randomPeer = bPeers !! p
liftIO $ print ("Sending to random peer"::String, randomPeer)
sendMulti cloudBack (randomPeer :| msg)
return workers
else rerouteReqs workers (Left msg)
rerouteReqs workers (Left msg) = do
let (worker, newWorkers) = popWorker (viewl workers)
case worker of
Nothing -> workerLoop newWorkers
Just w -> do
sendMulti localBack $ w :| [""] ++ msg
return newWorkers
oneSec = 1000
bPeers = map C.pack peers
backends =
[ Sock localBack [In] Nothing
, Sock cloudBack [In] Nothing ]
frontends =
[ Sock localFront [In] Nothing
, Sock cloudFront [In] Nothing ]
popWorker EmptyL = (Nothing, S.empty)
popWorker (l :< s) = (Just l, s)
main :: IO ()
main = do
args <- getArgs
when (length args < 2) $ do
putStrLn "Usage: broker <me> <you> [<you> ...]"
exitFailure
-- First argument is this broker's name
-- Other arguments are our peers' names
let self:peers = args
putStrLn $ "Preparing broker at " ++ self
runZMQ $ do
-- Bind cloud frontend to endpoint
cloudFront <- socket Router
setIdentity (restrict (C.pack self)) cloudFront
bind cloudFront (connectString self "cloud")
-- Connect cloud backend to all peers
cloudBack <- socket Router
setIdentity (restrict (C.pack self)) cloudBack
mapM_ (connectPeer cloudBack "cloud") peers
-- Prepare local frontend and backend
localFront <- socket Router
bind localFront (connectString self "localfe")
localBack <- socket Router
bind localBack (connectString self "localbe")
-- Get user to tell us when we can start...
liftIO $ do
putStrLn "Press Enter when all brokers are started."
void getLine
-- Start workers and clients
forM_ [1..workerNum] $ async . workerTask self
forM_ [1..clientNum] $ async . clientTask self
-- Request reply flow
clientWorkerPoll
localBack
cloudBack
localFront
cloudFront
peers
peering2:Haxe 中的本地和云流程原型
package ;
import org.zeromq.ZMQException;
import ZHelpers;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
import neko.io.File;
import neko.io.FileInput;
#if (neko || cpp)
import neko.vm.Thread;
#end
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZFrame;
/**
* Broker peering simulation (part 2)
* Prototypes the request-reply flow
*
* While this example runs in a single process (for cpp & neko) and forked processes (for php), that is just
* to make it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* See: https://zguide.zeromq.cn/page:all#Prototyping-the-Local-and-Cloud-Flows
*
* NB: If running from Run.hx, set ARG_OFFSET to 1
* If running directly, set ARG_OFFSET to 0
*/
class Peering2
{
private static inline var NBR_CLIENTS = 10;
private static inline var NBR_WORKERS = 3;
private static inline var LRU_READY:String = String.fromCharCode(1); // Signals workers are ready
private static inline var WORKER_DONE = "OK";
// Our own name; in practise this would be configured per node
private static var self:String;
private static inline var ARG_OFFSET = 1;
/**
* Request - reply client using REQ socket
*/
private static function clientTask() {
var ctx = new ZContext();
var client = ctx.createSocket(ZMQ_REQ);
client.connect("ipc:///tmp/" + self + "-localfe.ipc");
while (true) {
ZFrame.newStringFrame("HELLO").send(client);
var reply = ZFrame.recvFrame(client);
if (reply == null) {
break;
}
Lib.println("Client: " + reply.toString());
Sys.sleep(1);
}
ctx.destroy();
}
/**
* Worker using REQ socket to do LRU routing
*/
public static function workerTask() {
var context:ZContext = new ZContext();
var worker:ZMQSocket = context.createSocket(ZMQ_REQ);
worker.connect("ipc:///tmp/"+self+"-localbe.ipc");
// Tell broker we're ready to do work
ZFrame.newStringFrame(LRU_READY).send(worker);
// Process messages as they arrive
while (true) {
var msg:ZMsg = ZMsg.recvMsg(worker);
if (msg == null) {
break;
}
Lib.println("Worker received " + msg.last().toString());
msg.last().reset(Bytes.ofString(WORKER_DONE));
msg.send(worker);
}
context.destroy();
}
public static function main() {
Lib.println("** Peering2 (see: https://zguide.zeromq.cn/page:all#Prototyping-the-Local-and-Cloud-Flows)");
// First argument is this broker's name
// Other arguments are our peers' names
if (Sys.args().length < 2+ARG_OFFSET) {
Lib.println("syntax: ./Peering2 me {you} ...");
return;
}
self = Sys.args()[0 + ARG_OFFSET];
#if php
// Start local workers
for (worker_nbr in 0 ... NBR_WORKERS) {
forkWorkerTask();
}
// Start local clients
for (client_nbr in 0 ... NBR_CLIENTS) {
forkClientTask();
}
#end
Lib.println("I: preparing broker at " + self + " ...");
// Prepare our context and sockets
var ctx = new ZContext();
var endpoint:String;
// Bind cloud frontend to endpoint
var cloudfe = ctx.createSocket(ZMQ_ROUTER);
cloudfe.setsockopt(ZMQ_IDENTITY, Bytes.ofString(self));
cloudfe.bind("ipc:///tmp/" + self + "-cloud.ipc");
// Connect cloud backend to all peers
var cloudbe = ctx.createSocket(ZMQ_ROUTER);
cloudbe.setsockopt(ZMQ_IDENTITY, Bytes.ofString(self));
for (argn in 1 + ARG_OFFSET ... Sys.args().length) {
var peer = Sys.args()[argn];
Lib.println("I: connecting to cloud frontend at '" + peer + "'");
cloudbe.connect("ipc:///tmp/" + peer + "-cloud.ipc");
}
// Prepare local frontend and backend
var localfe = ctx.createSocket(ZMQ_ROUTER);
localfe.bind("ipc:///tmp/" + self + "-localfe.ipc");
var localbe = ctx.createSocket(ZMQ_ROUTER);
localbe.bind("ipc:///tmp/" + self + "-localbe.ipc");
// Get user to tell us when we can start...
Lib.println("Press Enter when all brokers are started: ");
var f:FileInput = File.stdin();
var str:String = f.readLine();
#if !php
// Start local workers
for (worker_nbr in 0 ... NBR_WORKERS) {
Thread.create(workerTask);
}
// Start local clients
for (client_nbr in 0 ... NBR_CLIENTS) {
Thread.create(clientTask);
}
#end
// Interesting part
// -------------------------------------------------------------
// Request-reply flow
// - Poll backends and process local/cloud replies
// - While worker available, route localfe to local or cloud
// Queue of available workers
var capacity = 0;
var workerQueue:List<ZFrame> = new List<ZFrame>();
var backend = new ZMQPoller();
backend.registerSocket(localbe, ZMQ.ZMQ_POLLIN());
backend.registerSocket(cloudbe, ZMQ.ZMQ_POLLIN());
var frontend = new ZMQPoller();
frontend.registerSocket(localfe, ZMQ.ZMQ_POLLIN());
frontend.registerSocket(cloudfe, ZMQ.ZMQ_POLLIN());
while (true) {
var ret = 0;
try {
// If we have no workers anyhow, wait indefinitely
ret = backend.poll( {
if (capacity > 0) 1000 * 1000 else -1; } );
} catch (e:ZMQException) {
if (ZMQ.isInterrupted()) {
break;
}
trace (e.toString());
return;
}
var msg:ZMsg = null;
// Handle reply from local worker
if (backend.pollin(1)) {
msg = ZMsg.recvMsg(localbe);
if (msg == null)
break; // Interrupted
var address = msg.unwrap();
workerQueue.add(address);
capacity++;
// If it's READY, don't route the message any further
var frame = msg.first();
if (frame.streq(LRU_READY))
msg.destroy();
}
// Or handle reply from peer broker
else if (backend.pollin(2)) {
msg = ZMsg.recvMsg(cloudbe);
if (msg == null)
break;
// We don't use peer broker address for anything
var address = msg.unwrap();
}
// Route reply to cloud if it's addressed to a broker
if (msg != null && !msg.isEmpty()) {
for (argv in 1 + ARG_OFFSET ... Sys.args().length) {
if (!msg.isEmpty() && msg.first().streq(Sys.args()[argv])) {
msg.send(cloudfe);
}
}
}
// Route reply to client if we still need to
if (msg != null && !msg.isEmpty()) {
msg.send(localfe);
}
// Now route as many client requests as we can handle
while (capacity > 0) {
try {
ret = frontend.poll(0);
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace (e.toString());
return;
}
var reroutable = 0;
// We'll do peer brokers first, to prevent starvation
if (frontend.pollin(2)) {
msg = ZMsg.recvMsg(cloudfe);
reroutable = 0;
} else if (frontend.pollin(1)){
msg = ZMsg.recvMsg(localfe);
reroutable = 1;
} else
break; // No work, go back to the backends
// If reroutable, send to cloud 20% of the time
// Here we'd normally use cloud status information
//
if (reroutable > 0 && Sys.args().length > 1 + ARG_OFFSET && ZHelpers.randof(5) == 0) {
// Route to random broker peer
var randomPeer = ZHelpers.randof(Sys.args().length - (2 + ARG_OFFSET)) + (1 + ARG_OFFSET);
trace ("Routing to peer#"+randomPeer+":" + Sys.args()[randomPeer]);
msg.wrap(ZFrame.newStringFrame(Sys.args()[randomPeer]));
msg.send(cloudbe);
} else {
msg.wrap(workerQueue.pop());
msg.send(localbe);
capacity--;
}
}
}
// When we're done, clean up properly
ctx.destroy();
}
#if php
private static inline function forkClientTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
Peering2::clientTask();
exit();
}');
return;
}
private static inline function forkWorkerTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
Peering2::workerTask();
exit();
}');
return;
}
#end
}peering2:Java 中的本地和云流程原型
package guide;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Random;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
// Broker peering simulation (part 2)
// Prototypes the request-reply flow
public class peering2
{
private static final int NBR_CLIENTS = 10;
private static final int NBR_WORKERS = 3;
private static final String WORKER_READY = "\001"; // Signals worker is ready
// Our own name; in practice this would be configured per node
private static String self;
// The client task does a request-reply dialog using a standard
// synchronous REQ socket:
private static class client_task extends Thread
{
@Override
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket client = ctx.createSocket(SocketType.REQ);
client.connect(String.format("ipc://%s-localfe.ipc", self));
while (true) {
// Send request, get reply
client.send("HELLO", 0);
String reply = client.recvStr(0);
if (reply == null)
break; // Interrupted
System.out.printf("Client: %s\n", reply);
try {
Thread.sleep(1000);
}
catch (InterruptedException e) {
}
}
}
}
}
// The worker task plugs into the LRU routing dialog using a REQ
// socket:
private static class worker_task extends Thread
{
@Override
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket worker = ctx.createSocket(SocketType.REQ);
worker.connect(String.format("ipc://%s-localbe.ipc", self));
// Tell broker we're ready for work
ZFrame frame = new ZFrame(WORKER_READY);
frame.send(worker, 0);
while (true) {
// Send request, get reply
ZMsg msg = ZMsg.recvMsg(worker, 0);
if (msg == null)
break; // Interrupted
msg.getLast().print("Worker: ");
msg.getLast().reset("OK");
msg.send(worker);
}
}
}
}
// The main task begins by setting-up its frontend and backend sockets
// and then starting its client and worker tasks:
public static void main(String[] argv)
{
// First argument is this broker's name
// Other arguments are our peers' names
//
if (argv.length < 1) {
System.out.println("syntax: peering2 me {you}");
System.exit(-1);
}
self = argv[0];
System.out.printf("I: preparing broker at %s\n", self);
Random rand = new Random(System.nanoTime());
try (ZContext ctx = new ZContext()) {
// Bind cloud frontend to endpoint
Socket cloudfe = ctx.createSocket(SocketType.ROUTER);
cloudfe.setIdentity(self.getBytes(ZMQ.CHARSET));
cloudfe.bind(String.format("ipc://%s-cloud.ipc", self));
// Connect cloud backend to all peers
Socket cloudbe = ctx.createSocket(SocketType.ROUTER);
cloudbe.setIdentity(self.getBytes(ZMQ.CHARSET));
int argn;
for (argn = 1; argn < argv.length; argn++) {
String peer = argv[argn];
System.out.printf(
"I: connecting to cloud forintend at '%s'\n", peer
);
cloudbe.connect(String.format("ipc://%s-cloud.ipc", peer));
}
// Prepare local frontend and backend
Socket localfe = ctx.createSocket(SocketType.ROUTER);
localfe.bind(String.format("ipc://%s-localfe.ipc", self));
Socket localbe = ctx.createSocket(SocketType.ROUTER);
localbe.bind(String.format("ipc://%s-localbe.ipc", self));
// Get user to tell us when we can start
System.out.println("Press Enter when all brokers are started: ");
try {
System.in.read();
}
catch (IOException e) {
e.printStackTrace();
}
// Start local workers
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
new worker_task().start();
// Start local clients
int client_nbr;
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++)
new client_task().start();
// Here we handle the request-reply flow. We're using the LRU
// approach to poll workers at all times, and clients only when
// there are one or more workers available.
// Least recently used queue of available workers
int capacity = 0;
ArrayList<ZFrame> workers = new ArrayList<ZFrame>();
Poller backends = ctx.createPoller(2);
backends.register(localbe, Poller.POLLIN);
backends.register(cloudbe, Poller.POLLIN);
Poller frontends = ctx.createPoller(2);
frontends.register(localfe, Poller.POLLIN);
frontends.register(cloudfe, Poller.POLLIN);
while (true) {
// First, route any waiting replies from workers
// If we have no workers anyhow, wait indefinitely
int rc = backends.poll(capacity > 0 ? 1000 : -1);
if (rc == -1)
break; // Interrupted
// Handle reply from local worker
ZMsg msg = null;
if (backends.pollin(0)) {
msg = ZMsg.recvMsg(localbe);
if (msg == null)
break; // Interrupted
ZFrame address = msg.unwrap();
workers.add(address);
capacity++;
// If it's READY, don't route the message any further
ZFrame frame = msg.getFirst();
String frameData = new String(frame.getData(), ZMQ.CHARSET);
if (frameData.equals(WORKER_READY)) {
msg.destroy();
msg = null;
}
}
// Or handle reply from peer broker
else if (backends.pollin(1)) {
msg = ZMsg.recvMsg(cloudbe);
if (msg == null)
break; // Interrupted
// We don't use peer broker address for anything
ZFrame address = msg.unwrap();
address.destroy();
}
// Route reply to cloud if it's addressed to a broker
for (argn = 1; msg != null && argn < argv.length; argn++) {
byte[] data = msg.getFirst().getData();
if (argv[argn].equals(new String(data, ZMQ.CHARSET))) {
msg.send(cloudfe);
msg = null;
}
}
// Route reply to client if we still need to
if (msg != null)
msg.send(localfe);
// Now we route as many client requests as we have worker
// capacity for. We may reroute requests from our local
// frontend, but not from // the cloud frontend. We reroute
// randomly now, just to test things out. In the next version
// we'll do this properly by calculating cloud capacity://
while (capacity > 0) {
rc = frontends.poll(0);
assert (rc >= 0);
int reroutable = 0;
// We'll do peer brokers first, to prevent starvation
if (frontends.pollin(1)) {
msg = ZMsg.recvMsg(cloudfe);
reroutable = 0;
}
else if (frontends.pollin(0)) {
msg = ZMsg.recvMsg(localfe);
reroutable = 1;
}
else break; // No work, go back to backends
// If reroutable, send to cloud 20% of the time
// Here we'd normally use cloud status information
if (reroutable != 0 &&
argv.length > 1 &&
rand.nextInt(5) == 0) {
// Route to random broker peer
int random_peer = rand.nextInt(argv.length - 1) + 1;
msg.push(argv[random_peer]);
msg.send(cloudbe);
}
else {
ZFrame frame = workers.remove(0);
msg.wrap(frame);
msg.send(localbe);
capacity--;
}
}
}
// When we're done, clean up properly
while (workers.size() > 0) {
ZFrame frame = workers.remove(0);
frame.destroy();
}
}
}
}
peering2:Julia 中的本地和云流程原型
peering2:Lua 中的本地和云流程原型
--
-- Broker peering simulation (part 2)
-- Prototypes the request-reply flow
--
-- While this example runs in a single process, that is just to make
-- it easier to start and stop the example. Each thread has its own
-- context and conceptually acts as a separate process.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.poller"
require"zmq.threads"
require"zmsg"
local tremove = table.remove
local NBR_CLIENTS = 10
local NBR_WORKERS = 3
local pre_code = [[
local self, seed = ...
local zmq = require"zmq"
local zmsg = require"zmsg"
require"zhelpers"
math.randomseed(seed)
local context = zmq.init(1)
]]
-- Request-reply client using REQ socket
--
local client_task = pre_code .. [[
local client = context:socket(zmq.REQ)
local endpoint = string.format("ipc://%s-localfe.ipc", self)
assert(client:connect(endpoint))
while true do
-- Send request, get reply
local msg = zmsg.new ("HELLO")
msg:send(client)
msg = zmsg.recv (client)
printf ("I: client status: %s\n", msg:body())
end
-- We never get here but if we did, this is how we'd exit cleanly
client:close()
context:term()
]]
-- Worker using REQ socket to do LRU routing
--
local worker_task = pre_code .. [[
local worker = context:socket(zmq.REQ)
local endpoint = string.format("ipc://%s-localbe.ipc", self)
assert(worker:connect(endpoint))
-- Tell broker we're ready for work
local msg = zmsg.new ("READY")
msg:send(worker)
while true do
msg = zmsg.recv (worker)
-- Do some 'work'
s_sleep (1000)
msg:body_fmt("OK - %04x", randof (0x10000))
msg:send(worker)
end
-- We never get here but if we did, this is how we'd exit cleanly
worker:close()
context:term()
]]
-- First argument is this broker's name
-- Other arguments are our peers' names
--
s_version_assert (2, 1)
if (#arg < 1) then
printf ("syntax: peering2 me doyouend...\n")
os.exit(-1)
end
-- Our own name; in practice this'd be configured per node
local self = arg[1]
printf ("I: preparing broker at %s...\n", self)
math.randomseed(os.time())
-- Prepare our context and sockets
local context = zmq.init(1)
-- Bind cloud frontend to endpoint
local cloudfe = context:socket(zmq.ROUTER)
local endpoint = string.format("ipc://%s-cloud.ipc", self)
cloudfe:setopt(zmq.IDENTITY, self)
assert(cloudfe:bind(endpoint))
-- Connect cloud backend to all peers
local cloudbe = context:socket(zmq.ROUTER)
cloudbe:setopt(zmq.IDENTITY, self)
local peers = {}
for n=2,#arg do
local peer = arg[n]
-- add peer name to peers list.
peers[#peers + 1] = peer
peers[peer] = true -- map peer's name to 'true' for fast lookup
printf ("I: connecting to cloud frontend at '%s'\n", peer)
local endpoint = string.format("ipc://%s-cloud.ipc", peer)
assert(cloudbe:connect(endpoint))
end
-- Prepare local frontend and backend
local localfe = context:socket(zmq.ROUTER)
local endpoint = string.format("ipc://%s-localfe.ipc", self)
assert(localfe:bind(endpoint))
local localbe = context:socket(zmq.ROUTER)
local endpoint = string.format("ipc://%s-localbe.ipc", self)
assert(localbe:bind(endpoint))
-- Get user to tell us when we can start...
printf ("Press Enter when all brokers are started: ")
io.read('*l')
-- Start local workers
local workers = {}
for n=1,NBR_WORKERS do
local seed = os.time() + math.random()
workers[n] = zmq.threads.runstring(nil, worker_task, self, seed)
workers[n]:start(true)
end
-- Start local clients
local clients = {}
for n=1,NBR_CLIENTS do
local seed = os.time() + math.random()
clients[n] = zmq.threads.runstring(nil, client_task, self, seed)
clients[n]:start(true)
end
-- Interesting part
-- -------------------------------------------------------------
-- Request-reply flow
-- - Poll backends and process local/cloud replies
-- - While worker available, route localfe to local or cloud
-- Queue of available workers
local worker_queue = {}
local backends = zmq.poller(2)
local function send_reply(msg)
local address = msg:address()
-- Route reply to cloud if it's addressed to a broker
if peers[address] then
msg:send(cloudfe) -- reply is for a peer.
else
msg:send(localfe) -- reply is for a local client.
end
end
backends:add(localbe, zmq.POLLIN, function()
local msg = zmsg.recv(localbe)
-- Use worker address for LRU routing
worker_queue[#worker_queue + 1] = msg:unwrap()
-- if reply is not "READY" then route reply back to client.
if (msg:address() ~= "READY") then
send_reply(msg)
end
end)
backends:add(cloudbe, zmq.POLLIN, function()
local msg = zmsg.recv(cloudbe)
-- We don't use peer broker address for anything
msg:unwrap()
-- send reply back to client.
send_reply(msg)
end)
local frontends = zmq.poller(2)
local localfe_ready = false
local cloudfe_ready = false
frontends:add(localfe, zmq.POLLIN, function() localfe_ready = true end)
frontends:add(cloudfe, zmq.POLLIN, function() cloudfe_ready = true end)
while true do
local timeout = (#worker_queue > 0) and 1000000 or -1
-- If we have no workers anyhow, wait indefinitely
rc = backends:poll(timeout)
assert (rc >= 0)
-- Now route as many clients requests as we can handle
--
while (#worker_queue > 0) do
rc = frontends:poll(0)
assert (rc >= 0)
local reroutable = false
local msg
-- We'll do peer brokers first, to prevent starvation
if (cloudfe_ready) then
cloudfe_ready = false -- reset flag
msg = zmsg.recv (cloudfe)
reroutable = false
elseif (localfe_ready) then
localfe_ready = false -- reset flag
msg = zmsg.recv (localfe)
reroutable = true
else
break; -- No work, go back to backends
end
-- If reroutable, send to cloud 20% of the time
-- Here we'd normally use cloud status information
--
local percent = randof (5)
if (reroutable and #peers > 0 and percent == 0) then
-- Route to random broker peer
local random_peer = randof (#peers) + 1
msg:wrap(peers[random_peer], nil)
msg:send(cloudbe)
else
-- Dequeue and drop the next worker address
local worker = tremove(worker_queue, 1)
msg:wrap(worker, "")
msg:send(localbe)
end
end
end
-- We never get here but clean up anyhow
localbe:close()
cloudbe:close()
localfe:close()
cloudfe:close()
context:term()
peering2:Node.js 中的本地和云流程原型
peering2:Objective-C 中的本地和云流程原型
peering2:ooc 中的本地和云流程原型
peering2:Perl 中的本地和云流程原型
peering2:PHP 中的本地和云流程原型
<?php
/*
* Broker peering simulation (part 2)
* Prototypes the request-reply flow
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
define("NBR_CLIENTS", 10);
define("NBR_WORKERS", 3);
// Request-reply client using REQ socket
function client_thread($self)
{
$context = new ZMQContext();
$client = new ZMQSocket($context, ZMQ::SOCKET_REQ);
$endpoint = sprintf("ipc://%s-localfe.ipc", $self);
$client->connect($endpoint);
while (true) {
// Send request, get reply
$client->send("HELLO");
$reply = $client->recv();
printf("I: client status: %s%s", $reply, PHP_EOL);
}
}
// Worker using REQ socket to do LRU routing
function worker_thread ($self)
{
$context = new ZMQContext();
$worker = $context->getSocket(ZMQ::SOCKET_REQ);
$endpoint = sprintf("ipc://%s-localbe.ipc", $self);
$worker->connect($endpoint);
// Tell broker we're ready for work
$worker->send("READY");
while (true) {
$zmsg = new Zmsg($worker);
$zmsg->recv();
sleep(1);
$zmsg->body_fmt("OK - %04x", mt_rand(0, 0x10000));
$zmsg->send();
}
}
// First argument is this broker's name
// Other arguments are our peers' names
if ($_SERVER['argc'] < 2) {
echo "syntax: peering2 me {you}...", PHP_EOL;
exit();
}
$self = $_SERVER['argv'][1];
for ($client_nbr = 0; $client_nbr < NBR_CLIENTS; $client_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
client_thread($self);
return;
}
}
for ($worker_nbr = 0; $worker_nbr < NBR_WORKERS; $worker_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
worker_thread($self);
return;
}
}
printf ("I: preparing broker at %s... %s", $self, PHP_EOL);
// Prepare our context and sockets
$context = new ZMQContext();
// Bind cloud frontend to endpoint
$cloudfe = $context->getSocket(ZMQ::SOCKET_ROUTER);
$endpoint = sprintf("ipc://%s-cloud.ipc", $self);
$cloudfe->setSockOpt(ZMQ::SOCKOPT_IDENTITY, $self);
$cloudfe->bind($endpoint);
// Connect cloud backend to all peers
$cloudbe = $context->getSocket(ZMQ::SOCKET_ROUTER);
$cloudbe->setSockOpt(ZMQ::SOCKOPT_IDENTITY, $self);
for ($argn = 2; $argn < $_SERVER['argc']; $argn++) {
$peer = $_SERVER['argv'][$argn];
printf ("I: connecting to cloud backend at '%s'%s", $peer, PHP_EOL);
$endpoint = sprintf("ipc://%s-cloud.ipc", $peer);
$cloudbe->connect($endpoint);
}
// Prepare local frontend and backend
$localfe = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$endpoint = sprintf("ipc://%s-localfe.ipc", $self);
$localfe->bind($endpoint);
$localbe = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$endpoint = sprintf("ipc://%s-localbe.ipc", $self);
$localbe->bind($endpoint);
// Get user to tell us when we can start...
printf ("Press Enter when all brokers are started: ");
$fp = fopen('php://stdin', 'r');
$line = fgets($fp, 512);
fclose($fp);
// Interesting part
// -------------------------------------------------------------
// Request-reply flow
// - Poll backends and process local/cloud replies
// - While worker available, route localfe to local or cloud
// Queue of available workers
$capacity = 0;
$worker_queue = array();
$readable = $writeable = array();
while (true) {
$poll = new ZMQPoll();
$poll->add($localbe, ZMQ::POLL_IN);
$poll->add($cloudbe, ZMQ::POLL_IN);
$events = 0;
// If we have no workers anyhow, wait indefinitely
try {
$events = $poll->poll($readable, $writeable, $capacity ? 1000000 : -1);
} catch (ZMQPollException $e) {
break;
}
if ($events > 0) {
foreach ($readable as $socket) {
$zmsg = new Zmsg($socket);
// Handle reply from local worker
if ($socket === $localbe) {
$zmsg->recv();
// Use worker address for LRU routing
$worker_queue[] = $zmsg->unwrap();
$capacity++;
if ($zmsg->address() == "READY") {
continue;
}
}
// Or handle reply from peer broker
else if ($socket === $cloudbe) {
// We don't use peer broker address for anything
$zmsg->recv()->unwrap();
}
// Route reply to cloud if it's addressed to a broker
for ($argn = 2; $argn < $_SERVER['argc']; $argn++) {
if ($zmsg->address() == $_SERVER['argv'][$argn]) {
$zmsg->set_socket($cloudfe)->send();
$zmsg = null;
}
}
// Route reply to client if we still need to
if ($zmsg) {
$zmsg->set_socket($localfe)->send();
}
}
}
// Now route as many clients requests as we can handle
while ($capacity) {
$poll = new ZMQPoll();
$poll->add($localfe, ZMQ::POLL_IN);
$poll->add($cloudfe, ZMQ::POLL_IN);
$reroutable = false;
$events = $poll->poll($readable, $writeable, 0);
if ($events > 0) {
foreach ($readable as $socket) {
$zmsg = new Zmsg($socket);
$zmsg->recv();
// We'll do peer brokers first, to prevent starvation
if ($socket === $cloudfe) {
$reroutable = false;
} elseif ($socket === $localfe) {
$reroutable = true;
}
// If reroutable, send to cloud 20% of the time
// Here we'd normally use cloud status information
if ($reroutable && $_SERVER['argc'] > 2 && mt_rand(0, 4) == 0) {
$zmsg->wrap($_SERVER['argv'][mt_rand(2, ($_SERVER['argc']-1))]);
$zmsg->set_socket($cloudbe)->send();
} else {
$zmsg->wrap(array_shift($worker_queue), "");
$zmsg->set_socket($localbe)->send();
$capacity--;
}
}
} else {
break; // No work, go back to backends
}
}
}
peering2:Python 中的本地和云流程原型
#
# Broker peering simulation (part 2) in Python
# Prototypes the request-reply flow
#
# While this example runs in a single process, that is just to make
# it easier to start and stop the example. Each thread has its own
# context and conceptually acts as a separate process.
#
# Author : Min RK
# Contact: benjaminrk(at)gmail(dot)com
#
import random
import sys
import threading
import time
import zmq
try:
raw_input
except NameError:
# Python 3
raw_input = input
NBR_CLIENTS = 10
NBR_WORKERS = 3
def tprint(msg):
sys.stdout.write(msg + '\n')
sys.stdout.flush()
def client_task(name, i):
"""Request-reply client using REQ socket"""
ctx = zmq.Context()
client = ctx.socket(zmq.REQ)
client.identity = (u"Client-%s-%s" % (name, i)).encode('ascii')
client.connect("ipc://%s-localfe.ipc" % name)
while True:
client.send(b"HELLO")
try:
reply = client.recv()
except zmq.ZMQError:
# interrupted
return
tprint("Client-%s: %s" % (i, reply))
time.sleep(1)
def worker_task(name, i):
"""Worker using REQ socket to do LRU routing"""
ctx = zmq.Context()
worker = ctx.socket(zmq.REQ)
worker.identity = (u"Worker-%s-%s" % (name, i)).encode('ascii')
worker.connect("ipc://%s-localbe.ipc" % name)
# Tell broker we're ready for work
worker.send(b"READY")
# Process messages as they arrive
while True:
try:
msg = worker.recv_multipart()
except zmq.ZMQError:
# interrupted
return
tprint("Worker-%s: %s\n" % (i, msg))
msg[-1] = b"OK"
worker.send_multipart(msg)
def main(myself, peers):
print("I: preparing broker at %s..." % myself)
# Prepare our context and sockets
ctx = zmq.Context()
# Bind cloud frontend to endpoint
cloudfe = ctx.socket(zmq.ROUTER)
if not isinstance(myself, bytes):
ident = myself.encode('ascii')
else:
ident = myself
cloudfe.identity = ident
cloudfe.bind("ipc://%s-cloud.ipc" % myself)
# Connect cloud backend to all peers
cloudbe = ctx.socket(zmq.ROUTER)
cloudbe.identity = ident
for peer in peers:
tprint("I: connecting to cloud frontend at %s" % peer)
cloudbe.connect("ipc://%s-cloud.ipc" % peer)
if not isinstance(peers[0], bytes):
peers = [peer.encode('ascii') for peer in peers]
# Prepare local frontend and backend
localfe = ctx.socket(zmq.ROUTER)
localfe.bind("ipc://%s-localfe.ipc" % myself)
localbe = ctx.socket(zmq.ROUTER)
localbe.bind("ipc://%s-localbe.ipc" % myself)
# Get user to tell us when we can start...
raw_input("Press Enter when all brokers are started: ")
# create workers and clients threads
for i in range(NBR_WORKERS):
thread = threading.Thread(target=worker_task, args=(myself, i))
thread.daemon = True
thread.start()
for i in range(NBR_CLIENTS):
thread_c = threading.Thread(target=client_task, args=(myself, i))
thread_c.daemon = True
thread_c.start()
# Interesting part
# -------------------------------------------------------------
# Request-reply flow
# - Poll backends and process local/cloud replies
# - While worker available, route localfe to local or cloud
workers = []
# setup pollers
pollerbe = zmq.Poller()
pollerbe.register(localbe, zmq.POLLIN)
pollerbe.register(cloudbe, zmq.POLLIN)
pollerfe = zmq.Poller()
pollerfe.register(localfe, zmq.POLLIN)
pollerfe.register(cloudfe, zmq.POLLIN)
while True:
# If we have no workers anyhow, wait indefinitely
try:
events = dict(pollerbe.poll(1000 if workers else None))
except zmq.ZMQError:
break # interrupted
# Handle reply from local worker
msg = None
if localbe in events:
msg = localbe.recv_multipart()
(address, empty), msg = msg[:2], msg[2:]
workers.append(address)
# If it's READY, don't route the message any further
if msg[-1] == b'READY':
msg = None
elif cloudbe in events:
msg = cloudbe.recv_multipart()
(address, empty), msg = msg[:2], msg[2:]
# We don't use peer broker address for anything
if msg is not None:
address = msg[0]
if address in peers:
# Route reply to cloud if it's addressed to a broker
cloudfe.send_multipart(msg)
else:
# Route reply to client if we still need to
localfe.send_multipart(msg)
# Now route as many clients requests as we can handle
while workers:
events = dict(pollerfe.poll(0))
reroutable = False
# We'll do peer brokers first, to prevent starvation
if cloudfe in events:
msg = cloudfe.recv_multipart()
reroutable = False
elif localfe in events:
msg = localfe.recv_multipart()
reroutable = True
else:
break # No work, go back to backends
# If reroutable, send to cloud 20% of the time
# Here we'd normally use cloud status information
if reroutable and peers and random.randint(0, 4) == 0:
# Route to random broker peer
msg = [random.choice(peers), b''] + msg
cloudbe.send_multipart(msg)
else:
msg = [workers.pop(0), b''] + msg
localbe.send_multipart(msg)
if __name__ == '__main__':
if len(sys.argv) >= 2:
main(myself=sys.argv[1], peers=sys.argv[2:])
else:
print("Usage: peering2.py <me> [<peer_1> [... <peer_N>]]")
sys.exit(1)
peering2:Q 中的本地和云流程原型
peering2:Racket 中的本地和云流程原型
peering2:Ruby 中的本地和云流程原型
#!/usr/bin/env ruby
# Broker peering simulation (part 2)
# Prototypes the request-reply flow
#
# Translated from C by Devin Christensen: http://github.com/devin-c
require "rubygems"
require "ffi-rzmq"
NUMBER_OF_CIENTS = 10
NUMBER_OF_WORKERS = 3
WORKER_READY = "\x01"
class Client
def initialize(broker_name)
@context = ZMQ::Context.new
@socket = @context.socket ZMQ::REQ
@socket.connect "ipc://#{broker_name}-localfe.ipc"
end
def run
loop do
break if @socket.send_string("HELLO") == -1
break if @socket.recv_string(reply = "") == -1
puts "Client: #{reply}"
sleep 1
end
@socket.close
@context.terminate
end
end
class Worker
def initialize(broker_name)
@context = ZMQ::Context.new
@socket = @context.socket ZMQ::REQ
@socket.connect "ipc://#{broker_name}-localbe.ipc"
end
def run
@socket.send_string WORKER_READY
loop do
break if @socket.recv_strings(frames = []) == -1
puts "Worker: #{frames.last}"
break if @socket.send_strings(frames[0..-2] + ["OK"]) == -1
end
@socket.close
@context.terminate
end
end
class Broker
attr_reader :name
def initialize(name, peers)
raise ArgumentError, "A broker require's a name" unless name
raise ArgumentError, "A broker require's peers" unless peers.any?
puts "I: preparing broker at #{name}..."
@name = name
@peers = peers
@context = ZMQ::Context.new
@available_workers = []
setup_cloud_backend
setup_cloud_frontend
setup_local_backend
setup_local_frontend
end
def run
poller = ZMQ::Poller.new
poller.register_readable @cloud_backend
poller.register_readable @local_backend
poller.register_readable @cloud_frontend
poller.register_readable @local_frontend
while poller.poll > 0
poller.readables.each do |readable|
if @available_workers.any?
if readable === @local_frontend
@local_frontend.recv_strings frames = []
route_to_backend frames, true
elsif readable === @cloud_frontend
@cloud_frontend.recv_strings frames = []
route_to_backend frames, false
end
else
if readable === @local_backend
@local_backend.recv_strings frames = []
@available_workers << frames.shift(2)[0]
route_to_frontend(frames) unless frames == [WORKER_READY]
elsif readable === @cloud_backend
@cloud_backend.recv_strings frames = []
route_to_frontend frames[2..-1]
end
end
end
end
@cloud_backend.close
@local_backend.close
@cloud_frontend.close
@local_frontend.close
@context.terminate
end
private
def route_to_frontend(frames)
if @peers.include? frames[0]
@cloud_frontend.send_strings frames
else
@local_frontend.send_strings frames
end
end
def route_to_backend(frames, reroutable = false)
if reroutable && rand(5) == 0
@cloud_backend.send_strings [@peers.sample, ""] + frames
else
@local_backend.send_strings [@available_workers.shift, ""] + frames
end
end
def setup_cloud_backend
@cloud_backend = @context.socket ZMQ::ROUTER
@cloud_backend.identity = @name
@peers.each do |peer|
puts "I: connecting to cloud frontend at #{peer}"
@cloud_backend.connect "ipc://#{peer}-cloud.ipc"
end
end
def setup_cloud_frontend
@cloud_frontend = @context.socket ZMQ::ROUTER
@cloud_frontend.identity = @name
@cloud_frontend.bind "ipc://#{@name}-cloud.ipc"
end
def setup_local_backend
@local_backend = @context.socket ZMQ::ROUTER
@local_backend.bind "ipc://#{@name}-localbe.ipc"
end
def setup_local_frontend
@local_frontend = @context.socket ZMQ::ROUTER
@local_frontend.bind "ipc://#{@name}-localfe.ipc"
end
end
begin
broker = Broker.new(ARGV.shift, ARGV)
puts "Press Enter when all the brokers are started: "
STDIN.getc
NUMBER_OF_WORKERS.times do
Thread.new { Worker.new(broker.name).run }
end
NUMBER_OF_CIENTS.times do
Thread.new { Client.new(broker.name).run }
end
broker.run
rescue ArgumentError
puts "usage: ruby peering2.rb broker_name [peer_name ...]"
end
peering2:Rust 中的本地和云流程原型
peering2:Scala 中的本地和云流程原型
/**
*
* Broker peering simulation (part 2)
* Prototypes the request-reply flow
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
*
* @Author: Giovanni Ruggiero
* @Email: giovanni.ruggiero@gmail.com
*/
import org.zeromq.ZMQ
import ZHelpers._
import ClusterDns._
object peering2 {
val Localfe = "localfe"
val Localbe = "localbe"
val Cloudfe = "cloudfe"
val Cloudbe = "cloudbe"
implicit val dns = clusterDns
// Basic request-reply client using REQ socket
//
class ClientTask(host: String) extends Runnable {
def run() {
val ctx = ZMQ.context(1)
val client = ctx.socket(ZMQ.REQ)
setID(client);
client.dnsConnect(host, Localfe)
// Send request, get reply
client.send("HELLO".getBytes, 0)
val reply = client.recv(0)
printf("Client: %s\n", new String(reply))
}
}
// Worker using REQ socket to do LRU routing
//
class WorkerTask(host: String) extends Runnable {
def run() {
val ctx = ZMQ.context(1)
val worker = ctx.socket(ZMQ.REQ)
setID(worker);
worker.dnsConnect(host, Localbe);
// Tell broker we're ready for work
worker.send("READY".getBytes, 0);
while (true) {
// Read and save all frames until we get an empty frame
// In this example there is only 1 but it could be more
val msg = new ZMsg(worker)
printf("Worker: %s\n", msg.bodyToString)
msg.stringToBody("OK")
msg.send(worker)
}
}
}
def main(args : Array[String]) {
val NOFLAGS = 0
// Worker using REQ socket to do LRU routing
//
val NbrClients = 10;
val NbrWorkers = 3;
// First argument is this broker's name
// Other arguments are our peers' names
//
if (args.length < 2) {
println ("syntax: peering2 me {you}...")
exit()
}
val self = args(0)
implicit val host = self
printf ("I: preparing broker at %s...\n", self);
val rand = new java.util.Random(System.currentTimeMillis)
val ctx = ZMQ.context(1)
// Bind cloud frontend to endpoint
val cloudfe = ctx.socket(ZMQ.ROUTER)
cloudfe.setIdentity(self getBytes)
cloudfe.dnsBind(Cloudfe)
val cloudbe = ctx.socket(ZMQ.ROUTER)
cloudbe.setIdentity(self getBytes)
for (cluster <- (1 until args.length)) {
printf ("I: connecting to cloud frontend at '%s'\n", args(cluster))
cloudbe.dnsConnect(args(cluster),Cloudbe)
}
// Prepare local frontend and backend
val localfe = ctx.socket(ZMQ.ROUTER)
val localbe = ctx.socket(ZMQ.ROUTER)
localfe.dnsBind(Localfe)
localbe.dnsBind(Localbe)
println ("Press Enter when all brokers are started: ");
readChar
// Start local clients
val clients = List.fill(NbrClients)(new Thread(new ClientTask(self)))
clients foreach (_.start)
// Start local workers
val workers = List.fill(NbrWorkers)(new Thread(new WorkerTask(self)))
workers foreach (_.start)
// Interesting part
// -------------------------------------------------------------
// Request-reply flow
// - Poll backends and process local/cloud replies
// - While worker available, route localfe to local or cloud
// Queue of available workers
val workerQueue = scala.collection.mutable.Queue[Array[Byte]]()
val backends = ctx.poller(2)
backends.register(localbe,ZMQ.Poller.POLLIN)
backends.register(cloudbe,ZMQ.Poller.POLLIN)
var capacity = 0
while (true) {
// If we have no workers anyhow, wait indefinitely
val timeout = if (capacity > 0) {1000000} else {-1}
val ret = backends.poll(timeout)
// Handle reply from local worker
var msg = new ZMsg()
if (backends.pollin(0)) {
msg = new ZMsg(localbe)
val workerAddr = msg.unwrap
assert(capacity < NbrWorkers)
// Use worker address for LRU routing
workerQueue.enqueue(workerAddr)
capacity += 1
// Address is READY or else a client reply address
} else {
// Or handle reply from peer broker
if (backends.pollin(1)) {
msg = new ZMsg(cloudbe)
}
}
// Route reply to cloud if it's addressed to a broker
if (msg != null) {
for (cluster <- (1 until args.length)) {
if (new String(msg.address) == cluster) {
cloudfe.sendMsg(msg)
}
}
}
// Route reply to client if we still need to
if (msg != null) {
localfe.sendMsg(msg)
}
// Now route as many clients requests as we can handle
while (capacity > 0) {
val frontends = ctx.poller(2)
frontends.register(localfe,ZMQ.Poller.POLLIN)
frontends.register(cloudfe,ZMQ.Poller.POLLIN)
frontends.poll
var reroutable = 0
// We'll do peer brokers first, to prevent starvation
if (frontends.pollin(1)) {
msg = new ZMsg(cloudfe)
reroutable = 0
} else if (frontends.pollin(0)) {
msg = new ZMsg(localfe)
reroutable = 1
}
// If reroutable, send to cloud 20% of the time
// Here we'd normally use cloud status information
val rand = new java.util.Random
if (reroutable > 0 && args.length > 1 && rand.nextInt() % 5 == 0) {
// Route to random broker peer
val randomPeer = rand.nextInt(args.length - 1) + 1
msg.wrap(args(randomPeer) getBytes)
cloudbe.sendMsg(msg)
} else {
msg.wrap(workerQueue(0))
localbe.sendMsg(msg)
workerQueue.dequeue
capacity -= 1
}
}
}
}
}
peering2:Tcl 中的本地和云流程原型
#
# Broker peering simulation (part 2)
# Prototypes the request-reply flow
#
package require zmq
if {[llength $argv] < 2} {
puts "Usage: peering2.tcl <main|client|worker> <self> <peer ...>"
exit 1
}
set NBR_CLIENTS 10
set NBR_WORKERS 3
set LRU_READY "READY" ; # Signals worker is ready
set peers [lassign $argv what self]
set tclsh [info nameofexecutable]
expr {srand([pid])}
switch -exact -- $what {
client {
# Request-reply client using REQ socket
#
zmq context context
zmq socket client context REQ
client connect "ipc://$self-localfe.ipc"
while {1} {
# Send request, get reply
puts "Client: HELLO"
client send "HELLO"
set reply [client recv]
puts "Client: $reply"
after 1000
}
client close
context term
}
worker {
# Worker using REQ socket to do LRU routing
#
zmq context context
zmq socket worker context REQ
worker connect "ipc://$self-localbe.ipc"
# Tell broker we're ready for work
worker send $LRU_READY
# Process messages as they arrive
while {1} {
set msg [zmsg recv worker]
puts "Worker: [lindex $msg end]"
lset msg end "OK"
zmsg send worker $msg
}
worker close
context term
}
main {
puts "I: preparing broker at $self..."
# Prepare our context and sockets
zmq context context
# Bind cloud frontend to endpoint
zmq socket cloudfe context ROUTER
cloudfe setsockopt IDENTITY $self
cloudfe bind "ipc://$self-cloud.ipc"
# Connect cloud backend to all peers
zmq socket cloudbe context ROUTER
cloudbe setsockopt IDENTITY $self
foreach peer $peers {
puts "I: connecting to cloud frontend at '$peer'"
cloudbe connect "ipc://$peer-cloud.ipc"
}
# Prepare local frontend and backend
zmq socket localfe context ROUTER
localfe bind "ipc://$self-localfe.ipc"
zmq socket localbe context ROUTER
localbe bind "ipc://$self-localbe.ipc"
# Get user to tell us when we can start…
puts -nonewline "Press Enter when all brokers are started: "
flush stdout
gets stdin c
# Start local workers
for {set worker_nbr 0} {$worker_nbr < $NBR_WORKERS} {incr worker_nbr} {
puts "Starting worker $worker_nbr, output redirected to worker-$self-$worker_nbr.log"
exec $tclsh peering2.tcl worker $self {*}$peers > worker-$self-$worker_nbr.log 2>@1 &
}
# Start local clients
for {set client_nbr 0} {$client_nbr < $NBR_CLIENTS} {incr client_nbr} {
puts "Starting client $client_nbr, output redirected to client-$self-$client_nbr.log"
exec $tclsh peering2.tcl client $self {*}$peers > client-$self-$client_nbr.log 2>@1 &
}
# Interesting part
# -------------------------------------------------------------
# Request-reply flow
# - Poll backends and process local/cloud replies
# - While worker available, route localfe to local or cloud
# Queue of available workers
set workers {}
proc route_to_cloud_or_local {msg} {
global peers
# Route reply to cloud if it's addressed to a broker
foreach peer $peers {
if {$peer eq [lindex $msg 0]} {
zmsg send cloudfe $msg
return
}
}
# Route reply to client if we still need to
zmsg send localfe $msg
}
proc handle_localbe {} {
global workers
# Handle reply from local worker
set msg [zmsg recv localbe]
set address [zmsg unwrap msg]
lappend workers $address
# If it's READY, don't route the message any further
if {[lindex $msg 0] ne "READY"} {
route_to_cloud_or_local $msg
}
}
proc handle_cloudbe {} {
# Or handle reply from peer broker
set msg [zmsg recv cloudbe]
# We don't use peer broker address for anything
zmsg unwrap msg
route_to_cloud_or_local $msg
}
proc handle_client {s reroutable} {
global peers workers
if {[llength $workers]} {
set msg [zmsg recv $s]
# If reroutable, send to cloud 20% of the time
# Here we'd normally use cloud status information
#
if {$reroutable && [llength $peers] && [expr {int(rand()*5)}] == 0} {
set peer [lindex $peers [expr {int(rand()*[llength $peers])}]]
set msg [zmsg push $msg $peer]
zmsg send cloudbe $msg
} else {
set frame [lindex $workers 0]
set workers [lrange $workers 1 end]
set msg [zmsg wrap $msg $frame]
zmsg send localbe $msg
}
}
}
proc handle_clients {} {
# We'll do peer brokers first, to prevent starvation
if {"POLLIN" in [cloudfe getsockopt EVENTS]} {
handle_client cloudfe 0
}
if {"POLLIN" in [localfe getsockopt EVENTS]} {
handle_client localfe 1
}
}
localbe readable handle_localbe
cloudbe readable handle_cloudbe
localfe readable handle_clients
cloudfe readable handle_clients
vwait forever
# When we're done, clean up properly
localbe close
localfe close
cloudbe close
cloudfe close
context term
}
}
peering2:OCaml 中的本地和云流程原型
例如,通过在两个窗口中启动两个broker实例来运行此程序。
peering2 me you
peering2 you me
关于此代码的一些评论
-
至少在 C 代码中,使用 zmsg 类会使开发变得容易得多,并且代码更短。显然这是一个有效的抽象。如果你在 C 中构建 ZeroMQ 应用程序,应该使用 CZMQ。
-
由于我们没有从对等体获取任何状态信息,我们天真地认为它们正在运行。代码会在你启动所有broker后提示你确认。在实际情况中,我们不会向没有告知我们其存在的broker发送任何消息。
你可以通过观察代码永远运行来证明它是有效的。如果有任何错误路由的消息,客户端最终会阻塞,并且broker会停止打印跟踪信息。你可以通过杀死其中任何一个broker来证明这一点。另一个broker会尝试将请求发送到云端,其客户端会逐个阻塞,等待回复。
整合起来 #
让我们将这一切整合到一个包中。和之前一样,我们将整个集群作为单个进程运行。我们将把前面的两个示例合并成一个正常工作的设计,让你能够模拟任意数量的集群。
这段代码的大小与前两个原型加起来差不多,共 270 行代码。对于一个包含客户端、工作者和云工作负载分布的集群模拟来说,这相当不错。代码如下
peering3:Ada 中的完整集群模拟
peering3:Basic 中的完整集群模拟
peering3:C 中的完整集群模拟
// Broker peering simulation (part 3)
// Prototypes the full flow of status and tasks
#include "czmq.h"
#define NBR_CLIENTS 10
#define NBR_WORKERS 5
#define WORKER_READY "\001" // Signals worker is ready
// Our own name; in practice, this would be configured per node
static char *self;
// .split client task
// This is the client task. It issues a burst of requests and then
// sleeps for a few seconds. This simulates sporadic activity; when
// a number of clients are active at once, the local workers should
// be overloaded. The client uses a REQ socket for requests and also
// pushes statistics to the monitor socket:
static void *
client_task (void *args)
{
zctx_t *ctx = zctx_new ();
void *client = zsocket_new (ctx, ZMQ_REQ);
zsocket_connect (client, "ipc://%s-localfe.ipc", self);
void *monitor = zsocket_new (ctx, ZMQ_PUSH);
zsocket_connect (monitor, "ipc://%s-monitor.ipc", self);
while (true) {
sleep (randof (5));
int burst = randof (15);
while (burst--) {
char task_id [5];
sprintf (task_id, "%04X", randof (0x10000));
// Send request with random hex ID
zstr_send (client, task_id);
// Wait max ten seconds for a reply, then complain
zmq_pollitem_t pollset [1] = { { client, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (pollset, 1, 10 * 1000 * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
if (pollset [0].revents & ZMQ_POLLIN) {
char *reply = zstr_recv (client);
if (!reply)
break; // Interrupted
// Worker is supposed to answer us with our task id
assert (streq (reply, task_id));
zstr_sendf (monitor, "%s", reply);
free (reply);
}
else {
zstr_sendf (monitor,
"E: CLIENT EXIT - lost task %s", task_id);
return NULL;
}
}
}
zctx_destroy (&ctx);
return NULL;
}
// .split worker task
// This is the worker task, which uses a REQ socket to plug into the
// load-balancer. It's the same stub worker task that you've seen in
// other examples:
static void *
worker_task (void *args)
{
zctx_t *ctx = zctx_new ();
void *worker = zsocket_new (ctx, ZMQ_REQ);
zsocket_connect (worker, "ipc://%s-localbe.ipc", self);
// Tell broker we're ready for work
zframe_t *frame = zframe_new (WORKER_READY, 1);
zframe_send (&frame, worker, 0);
// Process messages as they arrive
while (true) {
zmsg_t *msg = zmsg_recv (worker);
if (!msg)
break; // Interrupted
// Workers are busy for 0/1 seconds
sleep (randof (2));
zmsg_send (&msg, worker);
}
zctx_destroy (&ctx);
return NULL;
}
// .split main task
// The main task begins by setting up all its sockets. The local frontend
// talks to clients, and our local backend talks to workers. The cloud
// frontend talks to peer brokers as if they were clients, and the cloud
// backend talks to peer brokers as if they were workers. The state
// backend publishes regular state messages, and the state frontend
// subscribes to all state backends to collect these messages. Finally,
// we use a PULL monitor socket to collect printable messages from tasks:
int main (int argc, char *argv [])
{
// First argument is this broker's name
// Other arguments are our peers' names
if (argc < 2) {
printf ("syntax: peering3 me {you}...\n");
return 0;
}
self = argv [1];
printf ("I: preparing broker at %s...\n", self);
srandom ((unsigned) time (NULL));
// Prepare local frontend and backend
zctx_t *ctx = zctx_new ();
void *localfe = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_bind (localfe, "ipc://%s-localfe.ipc", self);
void *localbe = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_bind (localbe, "ipc://%s-localbe.ipc", self);
// Bind cloud frontend to endpoint
void *cloudfe = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_set_identity (cloudfe, self);
zsocket_bind (cloudfe, "ipc://%s-cloud.ipc", self);
// Connect cloud backend to all peers
void *cloudbe = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_set_identity (cloudbe, self);
int argn;
for (argn = 2; argn < argc; argn++) {
char *peer = argv [argn];
printf ("I: connecting to cloud frontend at '%s'\n", peer);
zsocket_connect (cloudbe, "ipc://%s-cloud.ipc", peer);
}
// Bind state backend to endpoint
void *statebe = zsocket_new (ctx, ZMQ_PUB);
zsocket_bind (statebe, "ipc://%s-state.ipc", self);
// Connect state frontend to all peers
void *statefe = zsocket_new (ctx, ZMQ_SUB);
zsocket_set_subscribe (statefe, "");
for (argn = 2; argn < argc; argn++) {
char *peer = argv [argn];
printf ("I: connecting to state backend at '%s'\n", peer);
zsocket_connect (statefe, "ipc://%s-state.ipc", peer);
}
// Prepare monitor socket
void *monitor = zsocket_new (ctx, ZMQ_PULL);
zsocket_bind (monitor, "ipc://%s-monitor.ipc", self);
// .split start child tasks
// After binding and connecting all our sockets, we start our child
// tasks - workers and clients:
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
zthread_new (worker_task, NULL);
// Start local clients
int client_nbr;
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++)
zthread_new (client_task, NULL);
// Queue of available workers
int local_capacity = 0;
int cloud_capacity = 0;
zlist_t *workers = zlist_new ();
// .split main loop
// The main loop has two parts. First, we poll workers and our two service
// sockets (statefe and monitor), in any case. If we have no ready workers,
// then there's no point in looking at incoming requests. These can remain
// on their internal 0MQ queues:
while (true) {
zmq_pollitem_t primary [] = {
{ localbe, 0, ZMQ_POLLIN, 0 },
{ cloudbe, 0, ZMQ_POLLIN, 0 },
{ statefe, 0, ZMQ_POLLIN, 0 },
{ monitor, 0, ZMQ_POLLIN, 0 }
};
// If we have no workers ready, wait indefinitely
int rc = zmq_poll (primary, 4,
local_capacity? 1000 * ZMQ_POLL_MSEC: -1);
if (rc == -1)
break; // Interrupted
// Track if capacity changes during this iteration
int previous = local_capacity;
zmsg_t *msg = NULL; // Reply from local worker
if (primary [0].revents & ZMQ_POLLIN) {
msg = zmsg_recv (localbe);
if (!msg)
break; // Interrupted
zframe_t *identity = zmsg_unwrap (msg);
zlist_append (workers, identity);
local_capacity++;
// If it's READY, don't route the message any further
zframe_t *frame = zmsg_first (msg);
if (memcmp (zframe_data (frame), WORKER_READY, 1) == 0)
zmsg_destroy (&msg);
}
// Or handle reply from peer broker
else
if (primary [1].revents & ZMQ_POLLIN) {
msg = zmsg_recv (cloudbe);
if (!msg)
break; // Interrupted
// We don't use peer broker identity for anything
zframe_t *identity = zmsg_unwrap (msg);
zframe_destroy (&identity);
}
// Route reply to cloud if it's addressed to a broker
for (argn = 2; msg && argn < argc; argn++) {
char *data = (char *) zframe_data (zmsg_first (msg));
size_t size = zframe_size (zmsg_first (msg));
if (size == strlen (argv [argn])
&& memcmp (data, argv [argn], size) == 0)
zmsg_send (&msg, cloudfe);
}
// Route reply to client if we still need to
if (msg)
zmsg_send (&msg, localfe);
// .split handle state messages
// If we have input messages on our statefe or monitor sockets, we
// can process these immediately:
if (primary [2].revents & ZMQ_POLLIN) {
char *peer = zstr_recv (statefe);
char *status = zstr_recv (statefe);
cloud_capacity = atoi (status);
free (peer);
free (status);
}
if (primary [3].revents & ZMQ_POLLIN) {
char *status = zstr_recv (monitor);
printf ("%s\n", status);
free (status);
}
// .split route client requests
// Now route as many clients requests as we can handle. If we have
// local capacity, we poll both localfe and cloudfe. If we have cloud
// capacity only, we poll just localfe. We route any request locally
// if we can, else we route to the cloud.
while (local_capacity + cloud_capacity) {
zmq_pollitem_t secondary [] = {
{ localfe, 0, ZMQ_POLLIN, 0 },
{ cloudfe, 0, ZMQ_POLLIN, 0 }
};
if (local_capacity)
rc = zmq_poll (secondary, 2, 0);
else
rc = zmq_poll (secondary, 1, 0);
assert (rc >= 0);
if (secondary [0].revents & ZMQ_POLLIN)
msg = zmsg_recv (localfe);
else
if (secondary [1].revents & ZMQ_POLLIN)
msg = zmsg_recv (cloudfe);
else
break; // No work, go back to primary
if (local_capacity) {
zframe_t *frame = (zframe_t *) zlist_pop (workers);
zmsg_wrap (msg, frame);
zmsg_send (&msg, localbe);
local_capacity--;
}
else {
// Route to random broker peer
int peer = randof (argc - 2) + 2;
zmsg_pushmem (msg, argv [peer], strlen (argv [peer]));
zmsg_send (&msg, cloudbe);
}
}
// .split broadcast capacity
// We broadcast capacity messages to other peers; to reduce chatter,
// we do this only if our capacity changed.
if (local_capacity != previous) {
// We stick our own identity onto the envelope
zstr_sendm (statebe, self);
// Broadcast new capacity
zstr_sendf (statebe, "%d", local_capacity);
}
}
// When we're done, clean up properly
while (zlist_size (workers)) {
zframe_t *frame = (zframe_t *) zlist_pop (workers);
zframe_destroy (&frame);
}
zlist_destroy (&workers);
zctx_destroy (&ctx);
return EXIT_SUCCESS;
}
peering3:C++ 中的完整集群模拟
#include "zhelpers.hpp"
#include <thread>
#include <queue>
#include <vector>
#define NBR_CLIENTS 6
#define NBR_WORKERS 3
#define WORKER_READY "\001" // Signals worker is ready
#define ZMQ_POLL_MSEC 1
void receive_all_frames(zmq::socket_t& sock, std::vector<std::string>& frames) {
frames.clear();
while (1) {
// Process all parts of the message
std::string frame = s_recv(sock);
frames.emplace_back(frame);
int more = 0; // Multipart detection
size_t more_size = sizeof (more);
sock.getsockopt(ZMQ_RCVMORE, &more, &more_size);
if (!more)
break; // Last message part
}
return;
}
void send_all_frames(zmq::socket_t& sock, std::vector<std::string>& frames) {
for (int i = 0; i < frames.size(); i++) {
if (i == frames.size() - 1) {
s_send(sock, frames[i]);
} else {
s_sendmore(sock, frames[i]);
}
}
return;
}
void receive_empty_message(zmq::socket_t& sock)
{
std::string empty = s_recv(sock);
assert(empty.size() == 0);
}
void print_all_frames(std::vector<std::string>& frames) {
std::cout << "------------received------------" << std::endl;
for (std::string &frame : frames)
{
std::cout << frame << std::endl;
std::cout << "----------------------------------------" << std::endl;
}
}
// Broker name
static std::string self;
// .split client task
// This is the client task. It issues a burst of requests and then
// sleeps for a few seconds. This simulates sporadic activity; when
// a number of clients are active at once, the local workers should
// be overloaded. The client uses a REQ socket for requests and also
// pushes statistics to the monitor socket:
void client_thread(int id) {
zmq::context_t context(1);
zmq::socket_t client(context, ZMQ_REQ);
std::string connURL = std::string("ipc://").append(self).append("-localfe.ipc");
#if (defined(WIN32))
s_set_id(client, id);
client.connect(connURL); // localfe
#else
s_set_id(client); // Set a printable identity
client.connect(connURL);
#endif
zmq::socket_t monitor(context, ZMQ_PUSH);
std::string moniURL = std::string("ipc://").append(self).append("-monitor.ipc");
monitor.connect(moniURL);
while (true) {
sleep(within(5));
int burst = within(15);
while (burst--) {
char task_id[5];
sprintf(task_id, "%04X", within(0x10000));
// Send request with random hex ID
s_send(client, std::string(task_id));
zmq_pollitem_t items[] = { { client, 0, ZMQ_POLLIN, 0 } };
try{
zmq::poll(items, 1, 10 * 1000 * ZMQ_POLL_MSEC); // 10 seconds timeout
} catch (zmq::error_t& e) {
std::cout << "client_thread: " << e.what() << std::endl;
break;
}
if (items[0].revents & ZMQ_POLLIN) {
std::string reply = s_recv(client);
assert(reply == std::string(task_id));
// Do not print directly, send to monitor
s_send(monitor, reply);
} else {
std::string reply = "E: CLIENT EXIT - lost task " + std::string(task_id);
s_send(monitor, reply);
return;
}
}
}
}
// .split worker task
// This is the worker task, which uses a REQ socket to plug into the
// load-balancer. It's the same stub worker task that you've seen in
// other examples:
void worker_thread(int id) {
zmq::context_t context(1);
zmq::socket_t worker(context, ZMQ_REQ);
std::string connURL = std::string("ipc://").append(self).append("-localbe.ipc");
#if (defined (WIN32))
s_set_id(worker, id);
worker.connect(connURL); // backend
#else
s_set_id(worker);
worker.connect(connURL);
#endif
// Tell broker we're ready for work
s_send(worker, std::string(WORKER_READY));
while (true) {
// Read and save all frames until we get an empty frame
// In this example there is only 1 but it could be more
std::vector<std::string> frames;
receive_all_frames(worker, frames);
// Workers are busy for 0/1 seconds
sleep(within(2));
send_all_frames(worker, frames);
}
return;
}
// .split main task
// The main task begins by setting up all its sockets. The local frontend
// talks to clients, and our local backend talks to workers. The cloud
// frontend talks to peer brokers as if they were clients, and the cloud
// backend talks to peer brokers as if they were workers. The state
// backend publishes regular state messages, and the state frontend
// subscribes to all state backends to collect these messages. Finally,
// we use a PULL monitor socket to collect printable messages from tasks:
int main(int argc, char *argv []) {
// First argument is this broker's name
// Other arguments are our peers' names
if (argc < 2) {
std::cout << "syntax: peering3 me {you} ..." << std::endl;
return 0;
}
self = std::string(argv[1]);
std::cout << "I: preparing broker at " << self << " ..." << std::endl;
srandom(static_cast<unsigned int>(time(nullptr)));
zmq::context_t context(1);
zmq::socket_t localfe(context, ZMQ_ROUTER);
{
std::string bindURL = std::string("ipc://").append(self).append("-localfe.ipc");
localfe.bind(bindURL);
}
zmq::socket_t localbe(context, ZMQ_ROUTER);
{
std::string bindURL = std::string("ipc://").append(self).append("-localbe.ipc");
localbe.bind(bindURL);
}
// Bind cloud frontend to endpoint
zmq::socket_t cloudfe(context, ZMQ_ROUTER);
cloudfe.set(zmq::sockopt::routing_id, self);
std::string bindURL = std::string("ipc://").append(self).append("-cloud.ipc");
cloudfe.bind(bindURL);
// Connect cloud backend to all peers
zmq::socket_t cloudbe(context, ZMQ_ROUTER);
cloudbe.set(zmq::sockopt::routing_id, self);
for(int argn = 2 ; argn < argc ; ++argn) {
std::string peer(argv[argn]);
std::cout << "I: connecting to cloud frontend at " << peer << std::endl;
std::string peerURL = std::string("ipc://").append(peer).append("-cloud.ipc");
cloudbe.connect(peerURL); // 将自己的cloudbe连接到其他broker的cloudfe
}
// Bind state backend to endpoint
zmq::socket_t statebe(context, ZMQ_PUB);
{
std::string bindURL = std::string("ipc://").append(self).append("-state.ipc");
statebe.bind(bindURL);
}
// Connect statefe to all peers
zmq::socket_t statefe(context, ZMQ_SUB);
statefe.set(zmq::sockopt::subscribe, "");
for(int argn = 2 ; argn < argc ; ++argn) {
std::string peer(argv[argn]);
std::string peerURL = std::string("ipc://").append(peer).append("-state.ipc");
statefe.connect(peerURL);
}
// Prepare monitor socket
zmq::socket_t monitor(context, ZMQ_PULL);
std::string moniURL = std::string("ipc://").append(self).append("-monitor.ipc");
monitor.bind(moniURL);
// .split start child tasks
// After binding and connecting all our sockets, we start our child
// tasks - workers and clients:
// Start local clients
int client_nbr = 0;
for (; client_nbr < NBR_CLIENTS; client_nbr++)
{
std::thread t(client_thread, client_nbr);
t.detach();
}
// Start local workers
for (int worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
{
std::thread t(worker_thread, worker_nbr);
t.detach();
}
// Queue of available workers
int local_capacity = 0;
int cloud_capacity = 0;
std::queue<std::string> workers;
// .split main loop
// The main loop has two parts. First, we poll workers and our two service
// sockets (statefe and monitor), in any case. If we have no ready workers,
// then there's no point in looking at incoming requests. These can remain
// on their internal 0MQ queues:
while (true) {
zmq_pollitem_t primary [] = {
{localbe, 0, ZMQ_POLLIN, 0},
{cloudbe, 0, ZMQ_POLLIN, 0},
{statefe, 0, ZMQ_POLLIN, 0},
{monitor, 0, ZMQ_POLLIN, 0}
};
try {
// If we have no workers ready, wait indefinitely
std::chrono::milliseconds timeout{(local_capacity ? 1000 * ZMQ_POLL_MSEC : -1)};
zmq::poll(primary, 4, timeout);
} catch(...) {
break;
}
// Track if capacity changes during this iteration
int previous = local_capacity;
if (primary[0].revents & ZMQ_POLLIN) {
// From localbe, reply from local worker
std::string worker_identity = s_recv(localbe);
workers.push(worker_identity);
local_capacity++;
receive_empty_message(localbe);
std::vector<std::string> remain_frames;
receive_all_frames(localbe, remain_frames);
assert(remain_frames.size() == 1 || remain_frames.size() == 3 || remain_frames.size() == 5);
// Third frame is READY or else a client reply address
std::string third_frame = remain_frames[0];
// If the third_frame is client_addr
if (third_frame.compare(WORKER_READY) != 0 && remain_frames.size() == 3) {
// Send to client
send_all_frames(localfe, remain_frames);
} else if (remain_frames.size() == 5) {
// The third_frame is origin_broker address
// Route the reply to the origin broker
for (int argn = 2; argn < argc; argn++) {
if (third_frame.compare(argv[argn]) == 0) {
send_all_frames(cloudfe, remain_frames);
}
}
}
} else if (primary[1].revents & ZMQ_POLLIN) {
// From cloudbe,handle reply from peer broker
std::string peer_broker_identity = s_recv(cloudbe); // useless
receive_empty_message(cloudbe);
std::string client_addr = s_recv(cloudbe);
receive_empty_message(cloudbe);
std::string reply = s_recv(cloudbe);
// send to the client
s_sendmore(localfe, client_addr);
s_sendmore(localfe, std::string(""));
s_send(localfe, reply);
}
// .split handle state messages
// If we have input messages on our statefe or monitor sockets, we
// can process these immediately:
if (primary[2].revents & ZMQ_POLLIN) {
// From statefe, receive other brokers state
std::string peer(s_recv(statefe));
std::string status(s_recv(statefe));
cloud_capacity = atoi(status.c_str());
}
if (primary[3].revents & ZMQ_POLLIN) {
// From monitor, receive printable message
std::string message(s_recv(monitor));
std::cout << "monitor: " << message << std::endl;
}
// .split route client requests
// Now route as many clients requests as we can handle. If we have
// local capacity, we poll both localfe and cloudfe. If we have cloud
// capacity only, we poll just localfe. We route any request locally
// if we can, else we route to the cloud.
while (local_capacity + cloud_capacity) {
zmq_pollitem_t secondary [] = {
{localfe, 0, ZMQ_POLLIN, 0},
{cloudfe, 0, ZMQ_POLLIN, 0}
};
if (local_capacity) {
try {
zmq::poll(secondary, 2, 0);
} catch(...) {
break;
}
} else {
try {
zmq::poll(secondary, 1, 0);
} catch(...) {
break;
}
}
std::vector<std::string> msg;
if (secondary[0].revents & ZMQ_POLLIN) {
// From localfe, receive client request
receive_all_frames(localfe, msg);
} else if (secondary[1].revents & ZMQ_POLLIN) {
// From cloudfe, receive other broker's request
receive_all_frames(cloudfe, msg);
} else {
break;
}
if (local_capacity) {
// Route to local worker
std::string worker_addr = workers.front();
workers.pop();
local_capacity--;
s_sendmore(localbe, worker_addr);
s_sendmore(localbe, std::string(""));
send_all_frames(localbe, msg);
} else {
// Route to cloud
int peer = within(argc - 2) + 2;
s_sendmore(cloudbe, std::string(argv[peer]));
s_sendmore(cloudbe, std::string(""));
send_all_frames(cloudbe, msg);
}
}
// .split broadcast capacity
// We broadcast capacity messages to other peers; to reduce chatter,
// we do this only if our capacity changed.
if (local_capacity != previous) {
std::ostringstream intStream;
intStream << local_capacity;
s_sendmore(statebe, self);
s_send(statebe, intStream.str());
}
}
return 0;
}
peering3:C# 中的完整集群模拟
peering3:CL 中的完整集群模拟
peering3:Delphi 中的完整集群模拟
program peering3;
//
// Broker peering simulation (part 3)
// Prototypes the full flow of status and tasks
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
, zhelpers
;
const
NBR_CLIENTS = 10;
NBR_WORKERS = 5;
WORKER_READY = '\001'; // Signals worker is ready
var
// Our own name; in practice this would be configured per node
self: Utf8String;
// This is the client task. It issues a burst of requests and then
// sleeps for a few seconds. This simulates sporadic activity; when
// a number of clients are active at once, the local workers should
// be overloaded. The client uses a REQ socket for requests and also
// pushes statistics to the monitor socket:
procedure client_task( args: Pointer; ctx: TZMQContext );
var
client,
monitor: TZMQSocket;
burst,
i: Integer;
task_id,
reply: Utf8String;
poller: TZMQPoller;
begin
client := ctx.Socket( stReq );
{$ifdef unix}
client.connect( Format( 'ipc://%s-localfe.ipc', [self] ) );
{$else}
client.connect( Format( 'tcp://127.0.0.1:%s', [self] ) );
{$endif}
monitor := ctx.Socket( stPush );
{$ifdef unix}
monitor.connect( Format( 'ipc://%s-monitor.ipc', [self] ) );
{$else}
monitor.connect( Format( 'tcp://127.0.0.1:4%s', [self] ) );
{$endif}
poller := TZMQPoller.Create( true );
poller.Register( client, [pePollIn] );
while not ctx.Terminated do
try
sleep( random( 5000 ) );
burst := random( 15 );
for i := 0 to burst - 1 do
begin
task_id := s_random( 5 );
// Send request with random hex ID
client.send( task_id );
// Wait max ten seconds for a reply, then complain
poller.poll( 10000 );
if pePollIn in poller.PollItem[0].revents then
begin
client.recv( reply );
// Worker is supposed to answer us with our task id
assert ( reply = task_id );
monitor.send( reply );
end else
begin
monitor.send( 'E: CLIENT EXIT - lost task ' + task_id );
ctx.Terminate;
end;
end;
except
end;
end;
// This is the worker task, which uses a REQ socket to plug into the
// load-balancer. It's the same stub worker task you've seen in other
// examples:
procedure worker_task( args: Pointer; ctx: TZMQContext );
var
worker: TZMQSocket;
msg: TZMQMsg;
begin
worker := ctx.Socket( stReq );
{$ifdef unix}
worker.connect( Format( 'ipc://%s-localbe.ipc', [self] ) );
{$else}
worker.connect( Format( 'tcp://127.0.0.1:1%s', [self] ) );
{$endif}
// Tell broker we're ready for work
worker.send( WORKER_READY );
// Process messages as they arrive
while not ctx.Terminated do
try
msg := TZMQMsg.Create;
worker.recv( msg );
// Workers are busy for 0/1 seconds
sleep(random (2000));
worker.send( msg );
except
end;
end;
// The main task begins by setting-up all its sockets. The local frontend
// talks to clients, and our local backend talks to workers. The cloud
// frontend talks to peer brokers as if they were clients, and the cloud
// backend talks to peer brokers as if they were workers. The state
// backend publishes regular state messages, and the state frontend
// subscribes to all state backends to collect these messages. Finally,
// we use a PULL monitor socket to collect printable messages from tasks:
var
ctx: TZMQContext;
cloudfe,
cloudbe,
localfe,
localbe,
statefe,
statebe,
monitor: TZMQSocket;
i,
timeout,
previous,
random_peer: Integer;
peer: Utf8String;
thr: TZMQThread;
cloud_capacity: Integer;
workers: TZMQMsg;
primary,
secondary: TZMQPoller;
msg: TZMQMsg;
identity,
frame: TZMQFrame;
data,
status: Utf8String;
begin
// First argument is this broker's name
// Other arguments are our peers' names
//
if ParamCount < 2 then
begin
Writeln( 'syntax: peering2 me {you}...' );
halt( 1 );
end;
// on windows it should be a 1024 <= number <= 9999
self := ParamStr( 1 );
writeln( Format( 'I: preparing broker at %s', [self] ) );
randomize;
ctx := TZMQContext.create;
// Prepare local frontend and backend
localfe := ctx.Socket( stRouter );
{$ifdef unix}
localfe.bind( Format( 'ipc://%s-localfe.ipc', [self] ) );
{$else}
localfe.bind( Format( 'tcp://127.0.0.1:%s', [self] ) );
{$endif}
localbe := ctx.Socket( stRouter );
{$ifdef unix}
localbe.bind( Format( 'ipc://%s-localbe.ipc', [self] ) );
{$else}
localbe.bind( Format( 'tcp://127.0.0.1:1%s', [self] ) );
{$endif}
// Bind cloud frontend to endpoint
cloudfe := ctx.Socket( stRouter );
cloudfe.Identity := self;
{$ifdef unix}
cloudfe.bind( Format( 'ipc://%s-cloud.ipc', [self] ) );
{$else}
cloudfe.bind( Format( 'tcp://127.0.0.1:2%s', [self] ) );
{$endif}
// Connect cloud backend to all peers
cloudbe := ctx.Socket( stRouter );
cloudbe.Identity := self;
for i := 2 to ParamCount do
begin
peer := ParamStr( i );
Writeln( Format( 'I: connecting to cloud frontend at "%s"', [peer] ) );
{$ifdef unix}
cloudbe.connect( Format( 'ipc://%s-cloud.ipc', [peer] ) );
{$else}
cloudbe.connect( Format( 'tcp://127.0.0.1:2%s', [peer] ) );
{$endif}
end;
// Bind state backend to endpoint
statebe := ctx.Socket( stPub );
{$ifdef unix}
statebe.bind( Format( 'ipc://%s-state.ipc', [self] ) );
{$else}
statebe.bind( Format( 'tcp://127.0.0.1:3%s', [self] ) );
{$endif}
// Connect statefe to all peers
statefe := ctx.Socket( stSub );
statefe.Subscribe('');
for i := 2 to ParamCount do
begin
peer := ParamStr( i );
Writeln( Format( 'I: connecting to state backend at "%s"', [peer] ) );
{$ifdef unix}
statefe.connect( Format( 'ipc://%s-state.ipc', [peer] ) );
{$else}
statefe.connect( Format( 'tcp://127.0.0.1:3%s', [peer] ) );
{$endif}
end;
// Prepare monitor socket
monitor := ctx.Socket( stPull );
{$ifdef unix}
monitor.bind( Format( 'ipc://%s-monitor.ipc', [self] ) );
{$else}
monitor.bind( Format( 'tcp://127.0.0.1:4%s', [self] ) );
{$endif}
// After binding and connecting all our sockets, we start our child
// tasks - workers and clients:
for i := 0 to NBR_WORKERS - 1 do
begin
thr := TZMQThread.CreateDetachedProc( worker_task, nil );
thr.FreeOnTerminate := true;
thr.Resume;
end;
// Start local clients
for i := 0 to NBR_CLIENTS - 1 do
begin
thr := TZMQThread.CreateDetachedProc( client_task, nil );
thr.FreeOnTerminate := true;
thr.Resume;
end;
// Queue of available workers
cloud_capacity := 0;
workers := TZMQMsg.Create;
primary := TZMQPoller.Create( true );
primary.Register( localbe, [pePollIn] );
primary.Register( cloudbe, [pePollIn] );
primary.Register( statefe, [pePollIn] );
primary.Register( monitor, [pePollIn] );
secondary := TZMQPoller.Create( true );
secondary.Register( localfe, [pePollIn] );
secondary.Register( cloudfe, [pePollIn] );
// The main loop has two parts. First we poll workers and our two service
// sockets (statefe and monitor), in any case. If we have no ready workers,
// there's no point in looking at incoming requests. These can remain on
// their internal 0MQ queues:
while not ctx.Terminated do
try
// If we have no workers ready, wait indefinitely
if workers.size = 0 then
timeout := -1
else
timeout := 1000;
primary.poll( timeout );
// Track if capacity changes during this iteration
previous := workers.size;
// Handle reply from local worker
msg := nil;
if pePollIn in primary.PollItem[0].revents then
begin
localbe.recv( msg );
identity := msg.unwrap;
workers.add( identity );
// If it's READY, don't route the message any further
if msg.first.asUtf8String = WORKER_READY then
FreeAndNil( msg );
end else
// Or handle reply from peer broker
if pePollIn in primary.PollItem[1].revents then
begin
cloudbe.recv( msg );
// We don't use peer broker identity for anything
msg.unwrap.Free;
end;
// Route reply to cloud if it's addressed to a broker
if msg <> nil then
for i := 2 to ParamCount do
begin
data := msg.first.asUtf8String;
if data = ParamStr( i ) then
cloudfe.send( msg );
end;
// Route reply to client if we still need to
if msg <> nil then
localfe.send( msg );
// If we have input messages on our statefe or monitor sockets we
// can process these immediately:
if pePollIn in primary.PollItem[2].revents then
begin
statefe.recv( peer );
statefe.recv( status );
cloud_capacity := StrToInt( status );
end;
if pePollIn in primary.PollItem[3].revents then
begin
monitor.recv( status );
zNote( status );
end;
// Now route as many clients requests as we can handle. If we have
// local capacity we poll both localfe and cloudfe. If we have cloud
// capacity only, we poll just localfe. We route any request locally
// if we can, else we route to the cloud.
while ( workers.size + cloud_capacity ) > 0 do
begin
if workers.size > 0 then
secondary.poll( 0, 2 )
else
secondary.poll( 0, 1 );
//msg := TZMQMsg.Create;
if pePollIn in secondary.PollItem[0].revents then
localfe.recv( msg ) else
if pePollIn in secondary.PollItem[1].revents then
cloudfe.recv( msg ) else
break; // No work, go back to primary
if workers.size > 0 then
begin
frame := workers.pop;
msg.wrap( frame );
localbe.send( msg );
end else
begin
random_peer := random( ParamCount - 2 ) + 2;
identity := TZMQFrame.create;
identity.asUtf8String := ParamStr( random_peer );
msg.push( identity );
cloudbe.send( msg );
end;
end;
// We broadcast capacity messages to other peers; to reduce chatter
// we do this only if our capacity changed.
if workers.size <> previous then
begin
// We stick our own identity onto the envelope
// Broadcast new capacity
statebe.send( [self, IntToStr( workers.size ) ] );
end;
except
end;
// When we're done, clean up properly
while workers.size > 0 do
begin
frame := workers.pop;
frame.Free;
end;
workers.Free;
ctx.Free;
end.
peering3:Erlang 中的完整集群模拟
peering3:Elixir 中的完整集群模拟
peering3:F# 中的完整集群模拟
peering3:Felix 中的完整集群模拟
peering3:Go 中的完整集群模拟
// Broker peering simulation (part 3)
// Prototypes the full flow of status and tasks
//
// Author: amyangfei <amyangfei@gmail.com>
// Requires: http://github.com/alecthomas/gozmq
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"os"
"strconv"
"time"
)
const NBR_CLIENTS = 10
const NBR_WORKERS = 5
const WORKER_READY = "\001"
func client_task(name string, i int) {
context, _ := zmq.NewContext()
client, _ := context.NewSocket(zmq.REQ)
monitor, _ := context.NewSocket(zmq.PUSH)
defer context.Close()
defer client.Close()
defer monitor.Close()
client.SetIdentity(fmt.Sprintf("Client-%s-%d", name, i))
client.Connect(fmt.Sprintf("ipc://%s-localfe.ipc", name))
monitor.Connect(fmt.Sprintf("ipc://%s-monitor.ipc", name))
for {
time.Sleep(time.Duration(rand.Intn(5)) * time.Second)
burst := rand.Intn(15)
for burst > 0 {
burst--
task_id := fmt.Sprintf("%04X", rand.Intn(0x10000))
// Send request with random hex ID
client.Send([]byte(task_id), 0)
// Wait max ten seconds for a reply, then complain
pollset := zmq.PollItems{
zmq.PollItem{Socket: client, Events: zmq.POLLIN},
}
zmq.Poll(pollset, 10*time.Second)
if pollset[0].REvents&zmq.POLLIN != 0 {
reply, err := client.Recv(0)
if err != nil {
break
}
if string(reply) != task_id {
panic("Worker is supposed to answer us with our task id")
}
monitor.Send(reply, 0)
} else {
monitor.Send([]byte(fmt.Sprintf("E: CLIENT EXIT - lost task %s", task_id)), 0)
}
}
}
}
func worker_task(name string, i int) {
context, _ := zmq.NewContext()
worker, _ := context.NewSocket(zmq.REQ)
defer context.Close()
defer worker.Close()
worker.SetIdentity(fmt.Sprintf("Worker-%s-%d", name, i))
worker.Connect(fmt.Sprintf("ipc://%s-localbe.ipc", name))
// Tell broker we're ready for work
worker.Send([]byte(WORKER_READY), 0)
// Process messages as they arrive
for {
msg, err := worker.RecvMultipart(0)
if err != nil {
break
}
// Workers are busy for 0/1 seconds
time.Sleep(time.Duration(rand.Intn(2)) * time.Second)
fmt.Printf("Worker-%s-%d done: %s\n", name, i, msg)
worker.SendMultipart(msg, 0)
}
}
func main() {
// First argument is this broker's name
// Other arguments are our peers' names
if len(os.Args) < 2 {
fmt.Println("syntax: peering3 me {you}...")
return
}
myself := os.Args[1]
fmt.Printf("I: preparing broker at %s...\n", myself)
rand.Seed(time.Now().UnixNano())
context, _ := zmq.NewContext()
defer context.Close()
// Prepare local frontend and backend
localfe, _ := context.NewSocket(zmq.ROUTER)
localbe, _ := context.NewSocket(zmq.ROUTER)
defer localfe.Close()
defer localbe.Close()
localfe.Bind(fmt.Sprintf("ipc://%s-localfe.ipc", myself))
localbe.Bind(fmt.Sprintf("ipc://%s-localbe.ipc", myself))
// Bind cloud fronted to endpoint
cloudfe, _ := context.NewSocket(zmq.ROUTER)
defer cloudfe.Close()
cloudfe.SetIdentity(myself)
cloudfe.Bind(fmt.Sprintf("ipc://%s-cloud.ipc", myself))
// Connect cloud backend to all peers
cloudbe, _ := context.NewSocket(zmq.ROUTER)
defer cloudbe.Close()
cloudbe.SetIdentity(myself)
for i := 2; i < len(os.Args); i++ {
peer := os.Args[i]
fmt.Printf("I: connecting to cloud frontend at '%s'\n", peer)
cloudbe.Connect(fmt.Sprintf("ipc://%s-cloud.ipc", peer))
}
// Bind state backend to endpoint
statebe, _ := context.NewSocket(zmq.PUB)
defer statebe.Close()
bindAddress := fmt.Sprintf("ipc://%s-state.ipc", myself)
statebe.Bind(bindAddress)
// Connect state frontend to all peers
statefe, _ := context.NewSocket(zmq.SUB)
defer statefe.Close()
statefe.SetSubscribe("")
for i := 2; i < len(os.Args); i++ {
peer := os.Args[i]
fmt.Printf("I: connecting to state backend at '%s'\n", peer)
statefe.Connect(fmt.Sprintf("ipc://%s-state.ipc", peer))
}
// Prepare monitor socket
monitor, _ := context.NewSocket(zmq.PULL)
defer monitor.Close()
monitor.Bind(fmt.Sprintf("ipc://%s-monitor.ipc", myself))
// Start local workers
for i := 0; i < NBR_WORKERS; i++ {
go worker_task(myself, i)
}
// Start local clients
for i := 0; i < NBR_CLIENTS; i++ {
go client_task(myself, i)
}
// Queue of available workers
local_capacity := 0
cloud_capacity := 0
workers := make([]string, 0)
pollerbe := zmq.PollItems{
zmq.PollItem{Socket: localbe, Events: zmq.POLLIN},
zmq.PollItem{Socket: cloudbe, Events: zmq.POLLIN},
zmq.PollItem{Socket: statefe, Events: zmq.POLLIN},
zmq.PollItem{Socket: monitor, Events: zmq.POLLIN},
}
for {
timeout := time.Second
if len(workers) == 0 {
timeout = -1
}
// If we have no workers anyhow, wait indefinitely
zmq.Poll(pollerbe, timeout)
// Track if capacity changes during this iteration
previous := local_capacity
var msg [][]byte = nil
var err error = nil
if pollerbe[0].REvents&zmq.POLLIN != 0 {
msg, err = localbe.RecvMultipart(0)
if err != nil {
break
}
identity, _ := msg[0], msg[1]
msg = msg[2:]
workers = append(workers, string(identity))
local_capacity++
// If it's READY, don't route the message any further
if string(msg[len(msg)-1]) == WORKER_READY {
msg = nil
}
} else if pollerbe[1].REvents&zmq.POLLIN != 0 {
msg, err = cloudbe.RecvMultipart(0)
if err != nil {
break
}
// We don't use peer broker identity for anything
msg = msg[2:]
}
if msg != nil {
identity := string(msg[0])
for i := 2; i < len(os.Args); i++ {
// Route reply to cloud if it's addressed to a broker
if identity == os.Args[i] {
cloudfe.SendMultipart(msg, 0)
msg = nil
break
}
}
// Route reply to client if we still need to
if msg != nil {
localfe.SendMultipart(msg, 0)
}
}
// Handle capacity updates
if pollerbe[2].REvents&zmq.POLLIN != 0 {
msg, _ := statefe.RecvMultipart(0)
status := msg[1]
cloud_capacity, _ = strconv.Atoi(string(status))
}
// handle monitor message
if pollerbe[3].REvents&zmq.POLLIN != 0 {
msg, _ := monitor.Recv(0)
fmt.Println(string(msg))
}
for (local_capacity + cloud_capacity) > 0 {
secondary := zmq.PollItems{
zmq.PollItem{Socket: localfe, Events: zmq.POLLIN},
}
if local_capacity > 0 {
secondary = append(secondary, zmq.PollItem{Socket: cloudfe, Events: zmq.POLLIN})
}
zmq.Poll(secondary, 0)
if secondary[0].REvents&zmq.POLLIN != 0 {
msg, _ = localfe.RecvMultipart(0)
} else if len(secondary) > 1 && secondary[1].REvents&zmq.POLLIN != 0 {
msg, _ = cloudfe.RecvMultipart(0)
} else {
break
}
if local_capacity > 0 {
var worker string
worker, workers = workers[0], workers[1:]
msg = append(msg[:0], append([][]byte{[]byte(worker), []byte("")}, msg[0:]...)...)
localbe.SendMultipart(msg, 0)
local_capacity--
} else {
// Route to random broker peer
randPeer := rand.Intn(len(os.Args)-2) + 2
msg = append(msg[:0], append([][]byte{[]byte(os.Args[randPeer]), []byte("")}, msg[0:]...)...)
cloudbe.SendMultipart(msg, 0)
}
}
if local_capacity != previous {
statebe.SendMultipart([][]byte{[]byte(myself), []byte(strconv.Itoa(local_capacity))}, 0)
}
}
}
peering3:Haskell 中的完整集群模拟
{-# LANGUAGE OverloadedStrings #-}
module Main where
import Control.Concurrent (threadDelay)
import Control.Monad (forM_, forever, when)
import Control.Monad.IO.Class
import Data.Attoparsec.ByteString.Char8 hiding (take)
import qualified Data.ByteString.Char8 as C
import Data.List (find, unfoldr)
import Data.List.NonEmpty (NonEmpty (..))
import qualified Data.List.NonEmpty as N
import Data.Semigroup ((<>))
import Data.Sequence (Seq, ViewL (..), viewl, (|>))
import qualified Data.Sequence as S
import System.Environment
import System.Exit
import System.Random
import System.ZMQ4.Monadic
workerNum :: Int
workerNum = 5
clientNum :: Int
clientNum = 10
-- | This is the client task. It issues a burst of requests and then
-- sleeps for a few seconds. This simulates sporadic activity; when
-- a number of clients are active at once, the local workers should
-- be overloaded. The client uses a REQ socket for requests and also
-- pushes statistics over the monitor socket.
clientTask :: Show a => String -> a -> ZMQ z ()
clientTask self i = do
client <- socket Req
connect client (connectString self "localfe")
mon <- socket Push
connect mon (connectString self "monitor")
let ident = "Client-" <> C.pack self <> C.pack (show i)
setIdentity (restrict ident) client
forever $ do
-- Sleep random amount. 0 to 4 seconds.
liftIO $ randomRIO (0,4000000) >>= threadDelay
numTasks <- liftIO $ randomRIO (0,14)
g <- liftIO newStdGen
let taskIds :: [Int]
taskIds = take numTasks $ unfoldr (Just . randomR (0,0x10000)) g
pollset taskId = [ Sock client [In] (Just $ const $ receivedReply taskId) ]
receivedReply taskId = do
reply <- receive client
-- Worker is supposed to answer us with our task ID
when (taskId /= reply) $
liftIO $ print (reply, taskId)
send mon [] reply
forM_ taskIds $ \taskId -> do
-- Send request with random ID
let bTaskId = C.pack (show taskId)
send client [] bTaskId
-- Wait max ten seconds for a reply, then complain
[pollEvt] <- poll 10000 (pollset bTaskId)
when (null pollEvt) $
send mon [] $ "Client exit - lost task " <> bTaskId
-- | This is the worker task, which uses a REQ socket to plug into the
-- load-balancer. It's the same stub worker task that you've seen in
-- other examples.
workerTask :: Show a => String -> a -> ZMQ z ()
workerTask self i = do
worker <- socket Req
connect worker (connectString self "localbe")
let ident = "Worker-" <> C.pack self <> C.pack (show i)
setIdentity (restrict ident) worker
-- Tell broker we're ready for work
send worker [] "READY"
-- Process messages as they arrive
forever $ do
msg <- receiveMulti worker
-- Workers are busy for 0-1 seconds
liftIO $ randomRIO (0,1000000) >>= threadDelay
sendMulti worker (N.fromList msg)
-- | Connect a peer using the connectString function
connectPeer :: Socket z t -> String -> String -> ZMQ z ()
connectPeer sock name p = connect sock (connectString p name)
-- | An ipc connection string
connectString :: String -> String -> String
connectString peer name = "ipc://" ++ peer ++ "-" ++ name ++ ".ipc"
type Workers = Seq C.ByteString
-- | The main loop has two parts. First, we poll workers and our two service
-- sockets (stateFront and mon), in any case. If we have no ready workers,
-- then there's no point in looking at incoming requests. These can remain
-- on their internal 0MQ queues.
clientWorkerPoll
:: ( Receiver t1
, Receiver t2
, Receiver t4
, Receiver t5
, Receiver t6
, Receiver t7
, Sender t1
, Sender t2
, Sender t3
, Sender t4
, Sender t5 )
=> String
-> Socket z t1
-> Socket z t2
-> Socket z t3
-> Socket z t4
-> Socket z t5
-> Socket z t6
-> Socket z t7
-> [String]
-> ZMQ z ()
clientWorkerPoll
self
localBack
cloudBack
stateBack
localFront
cloudFront
stateFront
mon
peers = loop S.empty 0 -- Queue of workers starts empty
where
loop workers cloudCapacity = do
-- Poll primary, if we have no workers, wait indefinitely
[localEvents, cloudEvents, stateEvents, _] <- poll (if S.length workers > 0 then oneSec else -1) primary
availableWorkers <- reqRep workers localEvents cloudEvents
-- If we have input messages on the stateFront socket,
-- process it immediately.
cloudCapacity' <- if In `elem` stateEvents
then stateChange cloudCapacity
else return cloudCapacity
availableWorkers' <- workerLoop workers availableWorkers cloudCapacity'
loop availableWorkers' cloudCapacity'
reqRep workers local cloud
-- Handle reply from local worker
| In `elem` local = do
msg <- receiveMulti localBack
case msg of
-- Worker is READY, don't route the message further
ident:_:"READY":_ -> return (workers |> ident)
-- Worker replied
ident:_:restOfMsg -> do
route restOfMsg
return (workers |> ident)
-- Something strange happened
_ -> return workers
-- Handle reply from peer broker
| In `elem` cloud = do
msg <- receiveMulti cloudBack
case msg of
-- We don't use the peer broker identity for anything
_:restOfMsg -> route restOfMsg
-- Something strange happened
_ -> return ()
return workers
| otherwise = return workers
route msg@(ident:_) = do
let msg' = N.fromList msg
peer = find (== ident) bPeers
case peer of
-- Route reply to cloud if it's addressed to a broker
Just _ -> sendMulti cloudFront msg'
-- Route reply to local client
Nothing -> sendMulti localFront msg'
route _ = return () -- Something strange happened
-- Now, we route as many client requests as we can handle. If we have
-- local capacity, we poll both localFront and cloudFront. If we have
-- cloud capacity only, we poll just localFront. We route any request
-- locally if we can, else we route to the cloud.
workerLoop oldWorkers workers cloudCapacity = if areWorkers || areCloud
then do
evts <- poll 0 ((if areWorkers then id else take 1) secondary)
case evts of
[localEvents] ->
routeRequests oldWorkers workers cloudCapacity localEvents []
[localEvents, cloudEvents] ->
routeRequests oldWorkers workers cloudCapacity localEvents cloudEvents
_ -> return workers
else return workers
where
areWorkers = not (S.null workers)
areCloud = cloudCapacity > 0
routeRequests oldWorkers workers cloudCapacity local cloud
| In `elem` local =
receiveMulti localFront >>= rerouteReqs oldWorkers workers cloudCapacity
| In `elem` cloud =
receiveMulti cloudFront >>= rerouteReqs oldWorkers workers cloudCapacity
-- No work, go back to primary
| otherwise = return workers
rerouteReqs oldWorkers workers cloudCapacity msg = do
newWorkers <- if S.null workers
then do
-- Route to random broker peer
p <- liftIO $ randomRIO (0, length peers - 1)
let randomPeer = bPeers !! p
sendMulti cloudBack (randomPeer :| msg)
return workers
else do
let (worker, newWorkers) = popWorker (viewl workers)
case worker of
Nothing -> return ()
Just w -> sendMulti localBack $ w :| [""] <> msg
return newWorkers
-- We broadcast capacity messages to other peers; to reduce chatter,
-- we do this only if our capacity changed.
when (S.length oldWorkers /= S.length newWorkers) $
sendMulti stateBack $ C.pack self :| [C.pack . show . S.length $ newWorkers]
workerLoop oldWorkers newWorkers cloudCapacity
oneSec = 1000
bPeers = map C.pack peers
-- If the state changed, update the cloud capacity.
stateChange cloudCapacity = do
msg <- receiveMulti stateFront
case msg of
_:status:_ -> do
-- If we can't parse, assume 0...
let statusNum = either (const 0) id (parseOnly decimal status)
return (statusNum :: Int)
_ -> return cloudCapacity -- Could not parse message
primary =
[ Sock localBack [In] Nothing
, Sock cloudBack [In] Nothing
, Sock stateFront [In] Nothing
-- If we have messages on the monitor socket, process it immediately
, Sock mon [In] (Just $ const $ receive mon >>= liftIO . C.putStrLn) ]
secondary =
[ Sock localFront [In] Nothing
, Sock cloudFront [In] Nothing ]
popWorker EmptyL = (Nothing, S.empty)
popWorker (l :< s) = (Just l, s)
-- | The main task begins by setting up all its sockets. The local frontend
-- talks to clients, and our local backend talks to workers. The cloud
-- frontend talks to peer brokers as if they were clients, and the cloud
-- backend talks to peer brokers as if they were workers. The state
-- backend publishes regular state messages, and the state frontend
-- subscribes to all state backends to collect these messages. Finally,
-- we use a PULL monitor socket to sollect printable messages from tasks.
main :: IO ()
main = do
args <- getArgs
when (length args < 2) $ do
putStrLn "Usage: broker <me> <you> [<you> ...]"
exitFailure
-- First argument is this broker's name
-- Other arguments are our peers' names
let self:peers = args
putStrLn $ "Preparing broker at " ++ self
runZMQ $ do
-- Prepare local frontend and backend
localFront <- socket Router
bind localFront (connectString self "localfe")
localBack <- socket Router
bind localBack (connectString self "localbe")
-- Bind cloud frontend to endpoint
cloudFront <- socket Router
setIdentity (restrict (C.pack self)) cloudFront
bind cloudFront (connectString self "cloud")
-- Connect cloud backend to all peers
cloudBack <- socket Router
setIdentity (restrict (C.pack self)) cloudBack
mapM_ (connectPeer cloudBack "cloud") peers
-- Bind state backend to endpoint
stateBack <- socket Pub
bind stateBack (connectString self "state")
-- Connect state frontend to all peers
stateFront <- socket Sub
subscribe stateFront ""
mapM_ (connectPeer stateFront "state") peers
-- Prepare monitor socket
mon <- socket Pull
bind mon (connectString self "monitor")
-- Start workers and clients
forM_ [1..workerNum] $ async . workerTask self
forM_ [1..clientNum] $ async . clientTask self
-- Request reply flow
clientWorkerPoll
self
localBack
cloudBack
stateBack
localFront
cloudFront
stateFront
mon
peers
peering3:Haxe 中的完整集群模拟
package ;
import org.zeromq.ZMQException;
import ZHelpers;
import haxe.io.Bytes;
import haxe.Stack;
import neko.Lib;
import neko.Sys;
#if (neko || cpp)
import neko.vm.Thread;
#end
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZFrame;
/**
* Broker peering simulation (part 3)
* Prototypes the full flow of status and tasks
*
* While this example runs in a single process (for cpp & neko) and forked processes (for php), that is just
* to make it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* See: https://zguide.zeromq.cn/page:all#Putting-it-All-Together
*
* NB: If running from Run.hx, set ARG_OFFSET to 1
* If running directly, set ARG_OFFSET to 0
*/
class Peering3
{
private static inline var NBR_CLIENTS = 10;
private static inline var NBR_WORKERS = 3;
private static inline var LRU_READY:String = String.fromCharCode(1); // Signals workers are ready
// Our own name; in practise this would be configured per node
private static var self:String;
private static inline var ARG_OFFSET = 1;
/**
* Request - reply client using REQ socket
* To simulate load, clients issue a burst of requests and then
* sleep for a random period.
*/
private static function clientTask() {
var ctx = new ZContext();
var client = ctx.createSocket(ZMQ_REQ);
client.connect("ipc:///tmp/" + self + "-localfe.ipc");
var monitor = ctx.createSocket(ZMQ_PUSH);
monitor.connect("ipc:///tmp/" + self + "-monitor.ipc");
var poller = new ZMQPoller();
poller.registerSocket(client, ZMQ.ZMQ_POLLIN());
while (true) {
Sys.sleep(ZHelpers.randof(5));
var burst = ZHelpers.randof(14);
for (i in 0 ... burst) {
var taskID = StringTools.hex(ZHelpers.randof(0x10000), 4);
// Send request with random hex ID
Lib.println("Client send task " + taskID);
try {
ZFrame.newStringFrame(taskID).send(client);
} catch (e:ZMQException) {
trace("ZMQException #:" + ZMQ.errNoToErrorType(e.errNo) + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
return; // quit
} catch (e:Dynamic) {
trace (e);
}
// Wait max ten seconds for a reply, then complain
try {
poller.poll(10 * 1000 * 1000);
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace("ZMQException #:" + ZMQ.errNoToErrorType(e.errNo) + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
return; // quit
}
if (poller.pollin(1)) {
var reply = ZFrame.recvFrame(client);
if (reply == null)
break;
// Worker is supposed to answer us with our task id
if (!reply.streq(taskID)) {
Lib.println("E: Returned task ID:" + reply.toString() + " does not match requested taskID:" + taskID);
break;
}
} else {
ZMsg.newStringMsg("E: CLIENT EXIT - lost task " + taskID).send(monitor);
}
}
}
ctx.destroy();
}
/**
* Worker using REQ socket to do LRU routing
*/
public static function workerTask() {
var context:ZContext = new ZContext();
var worker:ZMQSocket = context.createSocket(ZMQ_REQ);
worker.connect("ipc:///tmp/"+self+"-localbe.ipc");
// Tell broker we're ready to do work
ZFrame.newStringFrame(LRU_READY).send(worker);
// Process messages as they arrive
while (true) {
try {
var msg:ZMsg = ZMsg.recvMsg(worker);
if (msg == null) {
context.destroy();
return;
}
Lib.println("Worker received " + msg.last().toString());
// Workers are busy for 0 / 1/ 2 seconds
Sys.sleep(ZHelpers.randof(2));
msg.send(worker);
} catch (e:ZMQException) {
trace("ZMQException #:" + ZMQ.errNoToErrorType(e.errNo) + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
}
context.destroy();
}
public static function main() {
Lib.println("** Peering3 (see: https://zguide.zeromq.cn/page:all#Putting-it-All-Together)");
// First argument is this broker's name
// Other arguments are our peers' names
if (Sys.args().length < 2+ARG_OFFSET) {
Lib.println("syntax: ./Peering3 me {you} ...");
return;
}
self = Sys.args()[0 + ARG_OFFSET];
#if php
// Start local workers
for (worker_nbr in 0 ... NBR_WORKERS) {
forkWorkerTask();
}
// Start local clients
for (client_nbr in 0 ... NBR_CLIENTS) {
forkClientTask();
}
#end
Lib.println("I: preparing broker at " + self + " ...");
// Prepare our context and sockets
var ctx = new ZContext();
var endpoint:String;
// Bind cloud frontend to endpoint
var cloudfe = ctx.createSocket(ZMQ_ROUTER);
cloudfe.setsockopt(ZMQ_IDENTITY, Bytes.ofString(self));
cloudfe.bind("ipc:///tmp/" + self + "-cloud.ipc");
// Bind state backend / publisher to endpoint
var statebe = ctx.createSocket(ZMQ_PUB);
statebe.bind("ipc:///tmp/" + self + "-state.ipc");
// Connect cloud backend to all peers
var cloudbe = ctx.createSocket(ZMQ_ROUTER);
cloudbe.setsockopt(ZMQ_IDENTITY, Bytes.ofString(self));
for (argn in 1 + ARG_OFFSET ... Sys.args().length) {
var peer = Sys.args()[argn];
Lib.println("I: connecting to cloud frontend at '" + peer + "'");
cloudbe.connect("ipc:///tmp/" + peer + "-cloud.ipc");
}
// Connect statefe to all peers
var statefe = ctx.createSocket(ZMQ_SUB);
statefe.setsockopt(ZMQ_SUBSCRIBE, Bytes.ofString(""));
for (argn in 1+ARG_OFFSET ... Sys.args().length) {
var peer = Sys.args()[argn];
Lib.println("I: connecting to state backend at '" + peer + "'");
statefe.connect("ipc:///tmp/" + peer + "-state.ipc");
}
// Prepare local frontend and backend
var localfe = ctx.createSocket(ZMQ_ROUTER);
localfe.bind("ipc:///tmp/" + self + "-localfe.ipc");
var localbe = ctx.createSocket(ZMQ_ROUTER);
localbe.bind("ipc:///tmp/" + self + "-localbe.ipc");
// Prepare monitor socket
var monitor = ctx.createSocket(ZMQ_PULL);
monitor.bind("ipc:///tmp/" + self + "-monitor.ipc");
#if !php
// Start local workers
for (worker_nbr in 0 ... NBR_WORKERS) {
Thread.create(workerTask);
}
// Start local clients
for (client_nbr in 0 ... NBR_CLIENTS) {
Thread.create(clientTask);
}
#end
// Interesting part
// -------------------------------------------------------------
// Publish-subscribe flow
// - Poll statefe and process capacity updates
// - Each time capacity changes, broadcast new value
// Request-reply flow
// - Poll primary and process local/cloud replies
// - While worker available, route localfe to local or cloud
// Queue of available workers
var localCapacity = 0;
var cloudCapacity = 0;
var workerQueue:List<ZFrame> = new List<ZFrame>();
var primary = new ZMQPoller();
primary.registerSocket(localbe, ZMQ.ZMQ_POLLIN());
primary.registerSocket(cloudbe, ZMQ.ZMQ_POLLIN());
primary.registerSocket(statefe, ZMQ.ZMQ_POLLIN());
primary.registerSocket(monitor, ZMQ.ZMQ_POLLIN());
while (true) {
trace ("**Start main loop iteration");
var ret = 0;
try {
// If we have no workers anyhow, wait indefinitely
ret = primary.poll( {
if (localCapacity > 0) 1000 * 1000 else -1; } );
} catch (e:ZMQException) {
if (ZMQ.isInterrupted()) {
break;
}
trace("ZMQException #:" + ZMQ.errNoToErrorType(e.errNo) + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
return;
}
// Track if capacity changes in this iteration
var previous = localCapacity;
var msg:ZMsg = null;
// Handle reply from local worker
if (primary.pollin(1)) {
msg = ZMsg.recvMsg(localbe);
if (msg == null)
break; // Interrupted
var address = msg.unwrap();
workerQueue.add(address);
localCapacity++;
// If it's READY, don't route the message any further
var frame = msg.first();
if (frame.streq(LRU_READY))
msg.destroy();
}
// Or handle reply from peer broker
else if (primary.pollin(2)) {
msg = ZMsg.recvMsg(cloudbe);
if (msg == null)
break;
// We don't use peer broker address for anything
var address = msg.unwrap();
}
// Route reply to cloud if it's addressed to a broker
if (msg != null && !msg.isEmpty()) {
for (argv in 1 + ARG_OFFSET ... Sys.args().length) {
if (!msg.isEmpty() && msg.first().streq(Sys.args()[argv])) {
trace ("Route reply to peer:" + Sys.args()[argv]);
msg.send(cloudfe);
}
}
}
// Route reply to client if we still need to
if (msg != null && !msg.isEmpty()) {
msg.send(localfe);
}
// Handle capacity updates
if (primary.pollin(3)) {
try {
var msg = ZMsg.recvMsg(statefe);
trace ("State msg received:" + msg.toString());
var availableFrame = msg.last();
cloudCapacity = Std.parseInt(availableFrame.data.toString());
} catch (e:ZMQException) {
trace("ZMQException #:" + ZMQ.errNoToErrorType(e.errNo) + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
} catch (e:Dynamic) {
trace (e);
}
}
// Handle monitor message
if (primary.pollin(4)) {
try {
var status = ZMsg.recvMsg(monitor);
Lib.println(status.first().data.toString());
return;
} catch (e:ZMQException) {
trace("ZMQException #:" + ZMQ.errNoToErrorType(e.errNo) + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
} catch (e:Dynamic) {
trace (e);
}
}
trace ("** Polling secondary sockets");
// Now route as many clients requests as we can handle
// - If we have local capacity we poll both localfe and cloudfe
// - If we have cloud capacity only, we poll just localfe
// - Route any request locally if we can, else to cloud
//
while (localCapacity + cloudCapacity > 0) {
trace (" ** polling secondary, with total capacity:" + Std.string(localCapacity + cloudCapacity));
var secondary = new ZMQPoller();
secondary.registerSocket(localfe, ZMQ.ZMQ_POLLIN());
if (localCapacity > 0) {
secondary.registerSocket(cloudfe, ZMQ.ZMQ_POLLIN());
}
try {
ret = secondary.poll(0);
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace("ZMQException #:" + ZMQ.errNoToErrorType(e.errNo) + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
return;
}
// We'll do peer brokers first, to prevent starvation
trace (" ** Secondary poll completed");
if (secondary.pollin(1)) {
trace (" ** About to receive from localfe");
msg = ZMsg.recvMsg(localfe);
trace (msg.toString());
} else if (secondary.pollin(2)) {
trace (" ** About to receive from cloudfe");
msg = ZMsg.recvMsg(cloudfe);
trace (msg.toString());
} else {
trace (" ** No requests, go back to primary");
break; // No work, go back to the primary
}
if (localCapacity > 0) {
var frame = workerQueue.pop();
msg.wrap(frame);
msg.send(localbe);
localCapacity--;
} else {
// Route to random broker peer
var randomPeer = ZHelpers.randof(Sys.args().length - (2 + ARG_OFFSET)) + (1 + ARG_OFFSET);
trace ("Routing to peer#"+randomPeer+":" + Sys.args()[randomPeer]);
msg.wrap(ZFrame.newStringFrame(Sys.args()[randomPeer]));
msg.send(cloudbe);
}
}
trace ("Updating status :"+ Std.string(localCapacity != previous));
if (localCapacity != previous) {
// We stick our own address onto the envelope
msg = new ZMsg();
msg.add(ZFrame.newStringFrame(Std.string(localCapacity)));
msg.wrap(ZFrame.newStringFrame(self));
trace ("Updating status:" + msg.toString());
msg.send(statebe);
}
}
// When we're done, clean up properly
ctx.destroy();
}
#if php
private static inline function forkClientTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
Peering2::clientTask();
exit();
}');
return;
}
private static inline function forkWorkerTask() {
untyped __php__('
$pid = pcntl_fork();
if ($pid == 0) {
Peering2::workerTask();
exit();
}');
return;
}
#end
}peering3:Java 中的完整集群模拟
package guide;
import java.util.ArrayList;
import java.util.Random;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
// Broker peering simulation (part 3)
// Prototypes the full flow of status and tasks
public class peering3
{
private static final int NBR_CLIENTS = 10;
private static final int NBR_WORKERS = 5;
// Signals worker is ready
private static final String WORKER_READY = "\001";
// Our own name; in practice this would be configured per node
private static String self;
// This is the client task. It issues a burst of requests and then sleeps
// for a few seconds. This simulates sporadic activity; when a number of
// clients are active at once, the local workers should be overloaded. The
// client uses a REQ socket for requests and also pushes statistics to the
// monitor socket:
private static class client_task extends Thread
{
@Override
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket client = ctx.createSocket(SocketType.REQ);
client.connect(String.format("ipc://%s-localfe.ipc", self));
Socket monitor = ctx.createSocket(SocketType.PUSH);
monitor.connect(String.format("ipc://%s-monitor.ipc", self));
Random rand = new Random(System.nanoTime());
Poller poller = ctx.createPoller(1);
poller.register(client, Poller.POLLIN);
boolean done = false;
while (!done) {
try {
Thread.sleep(rand.nextInt(5) * 1000);
}
catch (InterruptedException e1) {
}
int burst = rand.nextInt(15);
while (burst > 0) {
String taskId = String.format(
"%04X", rand.nextInt(10000)
);
// Send request, get reply
client.send(taskId, 0);
// Wait max ten seconds for a reply, then complain
int rc = poller.poll(10 * 1000);
if (rc == -1)
break; // Interrupted
if (poller.pollin(0)) {
String reply = client.recvStr(0);
if (reply == null)
break; // Interrupted
// Worker is supposed to answer us with our task id
assert (reply.equals(taskId));
monitor.send(String.format("%s", reply), 0);
}
else {
monitor.send(
String.format(
"E: CLIENT EXIT - lost task %s", taskId
),
0);
done = true;
break;
}
burst--;
}
}
}
}
}
// This is the worker task, which uses a REQ socket to plug into the LRU
// router. It's the same stub worker task you've seen in other examples:
private static class worker_task extends Thread
{
@Override
public void run()
{
Random rand = new Random(System.nanoTime());
try (ZContext ctx = new ZContext()) {
Socket worker = ctx.createSocket(SocketType.REQ);
worker.connect(String.format("ipc://%s-localbe.ipc", self));
// Tell broker we're ready for work
ZFrame frame = new ZFrame(WORKER_READY);
frame.send(worker, 0);
while (true) {
// Send request, get reply
ZMsg msg = ZMsg.recvMsg(worker, 0);
if (msg == null)
break; // Interrupted
// Workers are busy for 0/1 seconds
try {
Thread.sleep(rand.nextInt(2) * 1000);
}
catch (InterruptedException e) {
}
msg.send(worker);
}
}
}
}
// The main task begins by setting-up all its sockets. The local frontend
// talks to clients, and our local backend talks to workers. The cloud
// frontend talks to peer brokers as if they were clients, and the cloud
// backend talks to peer brokers as if they were workers. The state
// backend publishes regular state messages, and the state frontend
// subscribes to all state backends to collect these messages. Finally,
// we use a PULL monitor socket to collect printable messages from tasks:
public static void main(String[] argv)
{
// First argument is this broker's name
// Other arguments are our peers' names
//
if (argv.length < 1) {
System.out.println("syntax: peering3 me {you}");
System.exit(-1);
}
self = argv[0];
System.out.printf("I: preparing broker at %s\n", self);
Random rand = new Random(System.nanoTime());
try (ZContext ctx = new ZContext()) {
// Prepare local frontend and backend
Socket localfe = ctx.createSocket(SocketType.ROUTER);
localfe.bind(String.format("ipc://%s-localfe.ipc", self));
Socket localbe = ctx.createSocket(SocketType.ROUTER);
localbe.bind(String.format("ipc://%s-localbe.ipc", self));
// Bind cloud frontend to endpoint
Socket cloudfe = ctx.createSocket(SocketType.ROUTER);
cloudfe.setIdentity(self.getBytes(ZMQ.CHARSET));
cloudfe.bind(String.format("ipc://%s-cloud.ipc", self));
// Connect cloud backend to all peers
Socket cloudbe = ctx.createSocket(SocketType.ROUTER);
cloudbe.setIdentity(self.getBytes(ZMQ.CHARSET));
int argn;
for (argn = 1; argn < argv.length; argn++) {
String peer = argv[argn];
System.out.printf(
"I: connecting to cloud forintend at '%s'\n", peer
);
cloudbe.connect(String.format("ipc://%s-cloud.ipc", peer));
}
// Bind state backend to endpoint
Socket statebe = ctx.createSocket(SocketType.PUB);
statebe.bind(String.format("ipc://%s-state.ipc", self));
// Connect statefe to all peers
Socket statefe = ctx.createSocket(SocketType.SUB);
statefe.subscribe(ZMQ.SUBSCRIPTION_ALL);
for (argn = 1; argn < argv.length; argn++) {
String peer = argv[argn];
System.out.printf(
"I: connecting to state backend at '%s'\n", peer
);
statefe.connect(String.format("ipc://%s-state.ipc", peer));
}
// Prepare monitor socket
Socket monitor = ctx.createSocket(SocketType.PULL);
monitor.bind(String.format("ipc://%s-monitor.ipc", self));
// Start local workers
int worker_nbr;
for (worker_nbr = 0; worker_nbr < NBR_WORKERS; worker_nbr++)
new worker_task().start();
// Start local clients
int client_nbr;
for (client_nbr = 0; client_nbr < NBR_CLIENTS; client_nbr++)
new client_task().start();
// Queue of available workers
int localCapacity = 0;
int cloudCapacity = 0;
ArrayList<ZFrame> workers = new ArrayList<ZFrame>();
// The main loop has two parts. First we poll workers and our two
// service sockets (statefe and monitor), in any case. If we have
// no ready workers, there's no point in looking at incoming
// requests. These can remain on their internal 0MQ queues:
Poller primary = ctx.createPoller(4);
primary.register(localbe, Poller.POLLIN);
primary.register(cloudbe, Poller.POLLIN);
primary.register(statefe, Poller.POLLIN);
primary.register(monitor, Poller.POLLIN);
Poller secondary = ctx.createPoller(2);
secondary.register(localfe, Poller.POLLIN);
secondary.register(cloudfe, Poller.POLLIN);
while (true) {
// First, route any waiting replies from workers
// If we have no workers anyhow, wait indefinitely
int rc = primary.poll(localCapacity > 0 ? 1000 : -1);
if (rc == -1)
break; // Interrupted
// Track if capacity changes during this iteration
int previous = localCapacity;
// Handle reply from local worker
ZMsg msg = null;
if (primary.pollin(0)) {
msg = ZMsg.recvMsg(localbe);
if (msg == null)
break; // Interrupted
ZFrame address = msg.unwrap();
workers.add(address);
localCapacity++;
// If it's READY, don't route the message any further
ZFrame frame = msg.getFirst();
String frameData = new String(frame.getData(), ZMQ.CHARSET);
if (frameData.equals(WORKER_READY)) {
msg.destroy();
msg = null;
}
}
// Or handle reply from peer broker
else if (primary.pollin(1)) {
msg = ZMsg.recvMsg(cloudbe);
if (msg == null)
break; // Interrupted
// We don't use peer broker address for anything
ZFrame address = msg.unwrap();
address.destroy();
}
// Route reply to cloud if it's addressed to a broker
for (argn = 1; msg != null && argn < argv.length; argn++) {
byte[] data = msg.getFirst().getData();
if (argv[argn].equals(new String(data, ZMQ.CHARSET))) {
msg.send(cloudfe);
msg = null;
}
}
// Route reply to client if we still need to
if (msg != null)
msg.send(localfe);
// If we have input messages on our statefe or monitor sockets
// we can process these immediately:
if (primary.pollin(2)) {
String peer = statefe.recvStr();
String status = statefe.recvStr();
cloudCapacity = Integer.parseInt(status);
}
if (primary.pollin(3)) {
String status = monitor.recvStr();
System.out.println(status);
}
// Now we route as many client requests as we have worker
// capacity for. We may reroute requests from our local
// frontend, but not from the cloud frontend. We reroute
// randomly now, just to test things out. In the next version
// we'll do this properly by calculating cloud capacity.
while (localCapacity + cloudCapacity > 0) {
rc = secondary.poll(0);
assert (rc >= 0);
if (secondary.pollin(0)) {
msg = ZMsg.recvMsg(localfe);
}
else if (localCapacity > 0 && secondary.pollin(1)) {
msg = ZMsg.recvMsg(cloudfe);
}
else break; // No work, go back to backends
if (localCapacity > 0) {
ZFrame frame = workers.remove(0);
msg.wrap(frame);
msg.send(localbe);
localCapacity--;
}
else {
// Route to random broker peer
int random_peer = rand.nextInt(argv.length - 1) + 1;
msg.push(argv[random_peer]);
msg.send(cloudbe);
}
}
// We broadcast capacity messages to other peers; to reduce
// chatter we do this only if our capacity changed.
if (localCapacity != previous) {
// We stick our own address onto the envelope
statebe.sendMore(self);
// Broadcast new capacity
statebe.send(String.format("%d", localCapacity), 0);
}
}
// When we're done, clean up properly
while (workers.size() > 0) {
ZFrame frame = workers.remove(0);
frame.destroy();
}
}
}
}
peering3:Julia 中的完整集群模拟
peering3:Lua 中的完整集群模拟
--
-- Broker peering simulation (part 3)
-- Prototypes the full flow of status and tasks
--
-- While this example runs in a single process, that is just to make
-- it easier to start and stop the example. Each thread has its own
-- context and conceptually acts as a separate process.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.poller"
require"zmq.threads"
require"zmsg"
local tremove = table.remove
local NBR_CLIENTS = 10
local NBR_WORKERS = 5
local pre_code = [[
local self, seed = ...
local zmq = require"zmq"
local zmsg = require"zmsg"
require"zhelpers"
math.randomseed(seed)
local context = zmq.init(1)
]]
-- Request-reply client using REQ socket
-- To simulate load, clients issue a burst of requests and then
-- sleep for a random period.
--
local client_task = pre_code .. [[
require"zmq.poller"
local client = context:socket(zmq.REQ)
local endpoint = string.format("ipc://%s-localfe.ipc", self)
assert(client:connect(endpoint))
local monitor = context:socket(zmq.PUSH)
local endpoint = string.format("ipc://%s-monitor.ipc", self)
assert(monitor:connect(endpoint))
local poller = zmq.poller(1)
local task_id = nil
poller:add(client, zmq.POLLIN, function()
local msg = zmsg.recv (client)
-- Worker is supposed to answer us with our task id
assert (msg:body() == task_id)
-- mark task as processed.
task_id = nil
end)
local is_running = true
while is_running do
s_sleep (randof (5) * 1000)
local burst = randof (15)
while (burst > 0) do
burst = burst - 1
-- Send request with random hex ID
task_id = string.format("%04X", randof (0x10000))
local msg = zmsg.new(task_id)
msg:send(client)
-- Wait max ten seconds for a reply, then complain
rc = poller:poll(10 * 1000000)
assert (rc >= 0)
if task_id then
local msg = zmsg.new()
msg:body_fmt(
"E: CLIENT EXIT - lost task %s", task_id)
msg:send(monitor)
-- exit event loop
is_running = false
break
end
end
end
-- We never get here but if we did, this is how we'd exit cleanly
client:close()
monitor:close()
context:term()
]]
-- Worker using REQ socket to do LRU routing
--
local worker_task = pre_code .. [[
local worker = context:socket(zmq.REQ)
local endpoint = string.format("ipc://%s-localbe.ipc", self)
assert(worker:connect(endpoint))
-- Tell broker we're ready for work
local msg = zmsg.new ("READY")
msg:send(worker)
while true do
-- Workers are busy for 0/1/2 seconds
msg = zmsg.recv (worker)
s_sleep (randof (2) * 1000)
msg:send(worker)
end
-- We never get here but if we did, this is how we'd exit cleanly
worker:close()
context:term()
]]
-- First argument is this broker's name
-- Other arguments are our peers' names
--
s_version_assert (2, 1)
if (#arg < 1) then
printf ("syntax: peering3 me doyouend...\n")
os.exit(-1)
end
-- Our own name; in practice this'd be configured per node
local self = arg[1]
printf ("I: preparing broker at %s...\n", self)
math.randomseed(os.time())
-- Prepare our context and sockets
local context = zmq.init(1)
-- Bind cloud frontend to endpoint
local cloudfe = context:socket(zmq.ROUTER)
local endpoint = string.format("ipc://%s-cloud.ipc", self)
cloudfe:setopt(zmq.IDENTITY, self)
assert(cloudfe:bind(endpoint))
-- Bind state backend / publisher to endpoint
local statebe = context:socket(zmq.PUB)
local endpoint = string.format("ipc://%s-state.ipc", self)
assert(statebe:bind(endpoint))
-- Connect cloud backend to all peers
local cloudbe = context:socket(zmq.ROUTER)
cloudbe:setopt(zmq.IDENTITY, self)
for n=2,#arg do
local peer = arg[n]
printf ("I: connecting to cloud frontend at '%s'\n", peer)
local endpoint = string.format("ipc://%s-cloud.ipc", peer)
assert(cloudbe:connect(endpoint))
end
-- Connect statefe to all peers
local statefe = context:socket(zmq.SUB)
statefe:setopt(zmq.SUBSCRIBE, "", 0)
local peers = {}
for n=2,#arg do
local peer = arg[n]
-- add peer name to peers list.
peers[#peers + 1] = peer
peers[peer] = 0 -- set peer's initial capacity to zero.
printf ("I: connecting to state backend at '%s'\n", peer)
local endpoint = string.format("ipc://%s-state.ipc", peer)
assert(statefe:connect(endpoint))
end
-- Prepare local frontend and backend
local localfe = context:socket(zmq.ROUTER)
local endpoint = string.format("ipc://%s-localfe.ipc", self)
assert(localfe:bind(endpoint))
local localbe = context:socket(zmq.ROUTER)
local endpoint = string.format("ipc://%s-localbe.ipc", self)
assert(localbe:bind(endpoint))
-- Prepare monitor socket
local monitor = context:socket(zmq.PULL)
local endpoint = string.format("ipc://%s-monitor.ipc", self)
assert(monitor:bind(endpoint))
-- Start local workers
local workers = {}
for n=1,NBR_WORKERS do
local seed = os.time() + math.random()
workers[n] = zmq.threads.runstring(nil, worker_task, self, seed)
workers[n]:start(true)
end
-- Start local clients
local clients = {}
for n=1,NBR_CLIENTS do
local seed = os.time() + math.random()
clients[n] = zmq.threads.runstring(nil, client_task, self, seed)
clients[n]:start(true)
end
-- Interesting part
-- -------------------------------------------------------------
-- Publish-subscribe flow
-- - Poll statefe and process capacity updates
-- - Each time capacity changes, broadcast new value
-- Request-reply flow
-- - Poll primary and process local/cloud replies
-- - While worker available, route localfe to local or cloud
-- Queue of available workers
local local_capacity = 0
local cloud_capacity = 0
local worker_queue = {}
local backends = zmq.poller(2)
local function send_reply(msg)
local address = msg:address()
-- Route reply to cloud if it's addressed to a broker
if peers[address] then
msg:send(cloudfe) -- reply is for a peer.
else
msg:send(localfe) -- reply is for a local client.
end
end
backends:add(localbe, zmq.POLLIN, function()
local msg = zmsg.recv(localbe)
-- Use worker address for LRU routing
local_capacity = local_capacity + 1
worker_queue[local_capacity] = msg:unwrap()
-- if reply is not "READY" then route reply back to client.
if (msg:address() ~= "READY") then
send_reply(msg)
end
end)
backends:add(cloudbe, zmq.POLLIN, function()
local msg = zmsg.recv(cloudbe)
-- We don't use peer broker address for anything
msg:unwrap()
-- send reply back to client.
send_reply(msg)
end)
backends:add(statefe, zmq.POLLIN, function()
local msg = zmsg.recv (statefe)
-- TODO: track capacity for each peer
cloud_capacity = tonumber(msg:body())
end)
backends:add(monitor, zmq.POLLIN, function()
local msg = zmsg.recv (monitor)
printf("%s\n", msg:body())
end)
local frontends = zmq.poller(2)
local localfe_ready = false
local cloudfe_ready = false
frontends:add(localfe, zmq.POLLIN, function() localfe_ready = true end)
frontends:add(cloudfe, zmq.POLLIN, function() cloudfe_ready = true end)
local MAX_BACKEND_REPLIES = 20
while true do
-- If we have no workers anyhow, wait indefinitely
local timeout = (local_capacity > 0) and 1000000 or -1
local rc, err = backends:poll(timeout)
assert (rc >= 0, err)
-- Track if capacity changes during this iteration
local previous = local_capacity
-- Now route as many clients requests as we can handle
-- - If we have local capacity we poll both localfe and cloudfe
-- - If we have cloud capacity only, we poll just localfe
-- - Route any request locally if we can, else to cloud
--
while ((local_capacity + cloud_capacity) > 0) do
local rc, err = frontends:poll(0)
assert (rc >= 0, err)
if (localfe_ready) then
localfe_ready = false
msg = zmsg.recv (localfe)
elseif (cloudfe_ready and local_capacity > 0) then
cloudfe_ready = false
-- we have local capacity poll cloud frontend for work.
msg = zmsg.recv (cloudfe)
else
break; -- No work, go back to primary
end
if (local_capacity > 0) then
-- Dequeue and drop the next worker address
local worker = tremove(worker_queue, 1)
local_capacity = local_capacity - 1
msg:wrap(worker, "")
msg:send(localbe)
else
-- Route to random broker peer
printf ("I: route request %s to cloud...\n",
msg:body())
local random_peer = randof (#peers) + 1
msg:wrap(peers[random_peer], nil)
msg:send(cloudbe)
end
end
if (local_capacity ~= previous) then
-- Broadcast new capacity
local msg = zmsg.new()
-- TODO: send our name with capacity.
msg:body_fmt("%d", local_capacity)
-- We stick our own address onto the envelope
msg:wrap(self, nil)
msg:send(statebe)
end
end
-- We never get here but clean up anyhow
localbe:close()
cloudbe:close()
localfe:close()
cloudfe:close()
statefe:close()
monitor:close()
context:term()
peering3:Node.js 中的完整集群模拟
peering3:Objective-C 中的完整集群模拟
peering3:ooc 中的完整集群模拟
peering3:Perl 中的完整集群模拟
peering3:PHP 中的完整集群模拟
<?php
/*
* Broker peering simulation (part 3)
* Prototypes the full flow of status and tasks
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
define("NBR_CLIENTS", 10);
define("NBR_WORKERS", 3);
/*
* Request-reply client using REQ socket
* To simulate load, clients issue a burst of requests and then
* sleep for a random period.
*/
function client_thread($self)
{
$context = new ZMQContext();
$client = new ZMQSocket($context, ZMQ::SOCKET_REQ);
$endpoint = sprintf("ipc://%s-localfe.ipc", $self);
$client->connect($endpoint);
$monitor = new ZMQSocket($context, ZMQ::SOCKET_PUSH);
$endpoint = sprintf("ipc://%s-monitor.ipc", $self);
$monitor->connect($endpoint);
$readable = $writeable = array();
while (true) {
sleep(mt_rand(0, 4));
$burst = mt_rand(1, 14);
while ($burst--) {
// Send request with random hex ID
$task_id = sprintf("%04X", mt_rand(0, 10000));
$client->send($task_id);
// Wait max ten seconds for a reply, then complain
$poll = new ZMQPoll();
$poll->add($client, ZMQ::POLL_IN);
$events = $poll->poll($readable, $writeable, 10 * 1000000);
if ($events > 0) {
foreach ($readable as $socket) {
$zmsg = new Zmsg($socket);
$zmsg->recv();
// Worker is supposed to answer us with our task id
assert($zmsg->body() == $task_id);
}
} else {
$monitor->send(sprintf("E: CLIENT EXIT - lost task %s", $task_id));
exit();
}
}
}
}
// Worker using REQ socket to do LRU routing
function worker_thread ($self)
{
$context = new ZMQContext();
$worker = $context->getSocket(ZMQ::SOCKET_REQ);
$endpoint = sprintf("ipc://%s-localbe.ipc", $self);
$worker->connect($endpoint);
// Tell broker we're ready for work
$worker->send("READY");
while (true) {
$zmsg = new Zmsg($worker);
$zmsg->recv();
sleep(mt_rand(0,2));
$zmsg->send();
}
}
// First argument is this broker's name
// Other arguments are our peers' names
if ($_SERVER['argc'] < 2) {
echo "syntax: peering2 me {you}...", PHP_EOL;
exit();
}
$self = $_SERVER['argv'][1];
for ($client_nbr = 0; $client_nbr < NBR_CLIENTS; $client_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
client_thread($self);
return;
}
}
for ($worker_nbr = 0; $worker_nbr < NBR_WORKERS; $worker_nbr++) {
$pid = pcntl_fork();
if ($pid == 0) {
worker_thread($self);
return;
}
}
printf ("I: preparing broker at %s... %s", $self, PHP_EOL);
// Prepare our context and sockets
$context = new ZMQContext();
// Bind cloud frontend to endpoint
$cloudfe = $context->getSocket(ZMQ::SOCKET_ROUTER);
$endpoint = sprintf("ipc://%s-cloud.ipc", $self);
$cloudfe->setSockOpt(ZMQ::SOCKOPT_IDENTITY, $self);
$cloudfe->bind($endpoint);
// Connect cloud backend to all peers
$cloudbe = $context->getSocket(ZMQ::SOCKET_ROUTER);
$cloudbe->setSockOpt(ZMQ::SOCKOPT_IDENTITY, $self);
for ($argn = 2; $argn < $_SERVER['argc']; $argn++) {
$peer = $_SERVER['argv'][$argn];
printf ("I: connecting to cloud backend at '%s'%s", $peer, PHP_EOL);
$endpoint = sprintf("ipc://%s-cloud.ipc", $peer);
$cloudbe->connect($endpoint);
}
// Bind state backend / publisher to endpoint
$statebe = new ZMQSocket($context, ZMQ::SOCKET_PUB);
$endpoint = sprintf("ipc://%s-state.ipc", $self);
$statebe->bind($endpoint);
// Connect statefe to all peers
$statefe = $context->getSocket(ZMQ::SOCKET_SUB);
$statefe->setSockOpt(ZMQ::SOCKOPT_SUBSCRIBE, "");
for ($argn = 2; $argn < $_SERVER['argc']; $argn++) {
$peer = $_SERVER['argv'][$argn];
printf ("I: connecting to state backend at '%s'%s", $peer, PHP_EOL);
$endpoint = sprintf("ipc://%s-state.ipc", $peer);
$statefe->connect($endpoint);
}
// Prepare monitor socket
$monitor = new ZMQSocket($context, ZMQ::SOCKET_PULL);
$endpoint = sprintf("ipc://%s-monitor.ipc", $self);
$monitor->bind($endpoint);
// Prepare local frontend and backend
$localfe = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$endpoint = sprintf("ipc://%s-localfe.ipc", $self);
$localfe->bind($endpoint);
$localbe = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$endpoint = sprintf("ipc://%s-localbe.ipc", $self);
$localbe->bind($endpoint);
// Interesting part
// -------------------------------------------------------------
// Publish-subscribe flow
// - Poll statefe and process capacity updates
// - Each time capacity changes, broadcast new value
// Request-reply flow
// - Poll primary and process local/cloud replies
// - While worker available, route localfe to local or cloud
// Queue of available workers
$local_capacity = 0;
$cloud_capacity = 0;
$worker_queue = array();
$readable = $writeable = array();
while (true) {
$poll = new ZMQPoll();
$poll->add($localbe, ZMQ::POLL_IN);
$poll->add($cloudbe, ZMQ::POLL_IN);
$poll->add($statefe, ZMQ::POLL_IN);
$poll->add($monitor, ZMQ::POLL_IN);
$events = 0;
// If we have no workers anyhow, wait indefinitely
try {
$events = $poll->poll($readable, $writeable, $local_capacity ? 1000000 : -1);
} catch (ZMQPollException $e) {
break;
}
// Track if capacity changes during this iteration
$previous = $local_capacity;
foreach ($readable as $socket) {
$zmsg = new Zmsg($socket);
// Handle reply from local worker
if ($socket === $localbe) {
// Use worker address for LRU routing
$zmsg->recv();
$worker_queue[] = $zmsg->unwrap();
$local_capacity++;
if ($zmsg->body() == "READY") {
$zmsg = null; // Don't route it
}
}
// Or handle reply from peer broker
else if ($socket === $cloudbe) {
// We don't use peer broker address for anything
$zmsg->recv()->unwrap();
}
// Handle capacity updates
else if ($socket === $statefe) {
$zmsg->recv();
$cloud_capacity = $zmsg->body();
$zmsg = null;
}
// Handle monitor message
else if ($socket === $monitor) {
$zmsg->recv();
echo $zmsg->body(), PHP_EOL;
$zmsg = null;
}
if ($zmsg) {
// Route reply to cloud if it's addressed to a broker
for ($argn = 2; $argn < $_SERVER['argc']; $argn++) {
if ($zmsg->address() == $_SERVER['argv'][$argn]) {
$zmsg->set_socket($cloudfe)->send();
$zmsg = null;
}
}
}
// Route reply to client if we still need to
if ($zmsg) {
$zmsg->set_socket($localfe)->send();
}
}
// Now route as many clients requests as we can handle
// - If we have local capacity we poll both localfe and cloudfe
// - If we have cloud capacity only, we poll just localfe
// - Route any request locally if we can, else to cloud
while ($local_capacity + $cloud_capacity) {
$poll = new ZMQPoll();
$poll->add($localfe, ZMQ::POLL_IN);
if ($local_capacity) {
$poll->add($cloudfe, ZMQ::POLL_IN);
}
$reroutable = false;
$events = $poll->poll($readable, $writeable, 0);
if ($events > 0) {
foreach ($readable as $socket) {
$zmsg = new Zmsg($socket);
$zmsg->recv();
if ($local_capacity) {
$zmsg->wrap(array_shift($worker_queue), "");
$zmsg->set_socket($localbe)->send();
$local_capacity--;
} else {
// Route to random broker peer
printf ("I: route request %s to cloud...%s", $zmsg->body(), PHP_EOL);
$zmsg->wrap($_SERVER['argv'][mt_rand(2, ($_SERVER['argc']-1))]);
$zmsg->set_socket($cloudbe)->send();
}
}
} else {
break; // No work, go back to backends
}
}
if ($local_capacity != $previous) {
// Broadcast new capacity
$zmsg = new Zmsg($statebe);
$zmsg->body_set($local_capacity);
// We stick our own address onto the envelope
$zmsg->wrap($self)->send();
}
}
peering3:Python 中的完整集群模拟
#
# Broker peering simulation (part 3) in Python
# Prototypes the full flow of status and tasks
#
# While this example runs in a single process, that is just to make
# it easier to start and stop the example. Each thread has its own
# context and conceptually acts as a separate process.
#
# Author : Min RK
# Contact: benjaminrk(at)gmail(dot)com
#
import random
import sys
import threading
import time
import zmq
NBR_CLIENTS = 10
NBR_WORKERS = 5
def asbytes(obj):
s = str(obj)
if str is not bytes:
# Python 3
s = s.encode('ascii')
return s
def client_task(name, i):
"""Request-reply client using REQ socket"""
ctx = zmq.Context()
client = ctx.socket(zmq.REQ)
client.identity = (u"Client-%s-%s" % (name, i)).encode('ascii')
client.connect("ipc://%s-localfe.ipc" % name)
monitor = ctx.socket(zmq.PUSH)
monitor.connect("ipc://%s-monitor.ipc" % name)
poller = zmq.Poller()
poller.register(client, zmq.POLLIN)
while True:
time.sleep(random.randint(0, 5))
for _ in range(random.randint(0, 15)):
# send request with random hex ID
task_id = u"%04X" % random.randint(0, 10000)
client.send_string(task_id)
# wait max 10 seconds for a reply, then complain
try:
events = dict(poller.poll(10000))
except zmq.ZMQError:
return # interrupted
if events:
reply = client.recv_string()
assert reply == task_id, "expected %s, got %s" % (task_id, reply)
monitor.send_string(reply)
else:
monitor.send_string(u"E: CLIENT EXIT - lost task %s" % task_id)
return
def worker_task(name, i):
"""Worker using REQ socket to do LRU routing"""
ctx = zmq.Context()
worker = ctx.socket(zmq.REQ)
worker.identity = ("Worker-%s-%s" % (name, i)).encode('ascii')
worker.connect("ipc://%s-localbe.ipc" % name)
# Tell broker we're ready for work
worker.send(b"READY")
# Process messages as they arrive
while True:
try:
msg = worker.recv_multipart()
except zmq.ZMQError:
# interrupted
return
# Workers are busy for 0/1 seconds
time.sleep(random.randint(0, 1))
worker.send_multipart(msg)
def main(myself, peers):
print("I: preparing broker at %s..." % myself)
# Prepare our context and sockets
ctx = zmq.Context()
# Bind cloud frontend to endpoint
cloudfe = ctx.socket(zmq.ROUTER)
cloudfe.setsockopt(zmq.IDENTITY, myself)
cloudfe.bind("ipc://%s-cloud.ipc" % myself)
# Bind state backend / publisher to endpoint
statebe = ctx.socket(zmq.PUB)
statebe.bind("ipc://%s-state.ipc" % myself)
# Connect cloud and state backends to all peers
cloudbe = ctx.socket(zmq.ROUTER)
statefe = ctx.socket(zmq.SUB)
statefe.setsockopt(zmq.SUBSCRIBE, b"")
cloudbe.setsockopt(zmq.IDENTITY, myself)
for peer in peers:
print("I: connecting to cloud frontend at %s" % peer)
cloudbe.connect("ipc://%s-cloud.ipc" % peer)
print("I: connecting to state backend at %s" % peer)
statefe.connect("ipc://%s-state.ipc" % peer)
# Prepare local frontend and backend
localfe = ctx.socket(zmq.ROUTER)
localfe.bind("ipc://%s-localfe.ipc" % myself)
localbe = ctx.socket(zmq.ROUTER)
localbe.bind("ipc://%s-localbe.ipc" % myself)
# Prepare monitor socket
monitor = ctx.socket(zmq.PULL)
monitor.bind("ipc://%s-monitor.ipc" % myself)
# Get user to tell us when we can start...
# raw_input("Press Enter when all brokers are started: ")
# create workers and clients threads
for i in range(NBR_WORKERS):
thread = threading.Thread(target=worker_task, args=(myself, i))
thread.daemon = True
thread.start()
for i in range(NBR_CLIENTS):
thread_c = threading.Thread(target=client_task, args=(myself, i))
thread_c.daemon = True
thread_c.start()
# Interesting part
# -------------------------------------------------------------
# Publish-subscribe flow
# - Poll statefe and process capacity updates
# - Each time capacity changes, broadcast new value
# Request-reply flow
# - Poll primary and process local/cloud replies
# - While worker available, route localfe to local or cloud
local_capacity = 0
cloud_capacity = 0
workers = []
# setup backend poller
pollerbe = zmq.Poller()
pollerbe.register(localbe, zmq.POLLIN)
pollerbe.register(cloudbe, zmq.POLLIN)
pollerbe.register(statefe, zmq.POLLIN)
pollerbe.register(monitor, zmq.POLLIN)
while True:
# If we have no workers anyhow, wait indefinitely
try:
events = dict(pollerbe.poll(1000 if local_capacity else None))
except zmq.ZMQError:
break # interrupted
previous = local_capacity
# Handle reply from local worker
msg = None
if localbe in events:
msg = localbe.recv_multipart()
(address, empty), msg = msg[:2], msg[2:]
workers.append(address)
local_capacity += 1
# If it's READY, don't route the message any further
if msg[-1] == b'READY':
msg = None
elif cloudbe in events:
msg = cloudbe.recv_multipart()
(address, empty), msg = msg[:2], msg[2:]
# We don't use peer broker address for anything
if msg is not None:
address = msg[0]
if address in peers:
# Route reply to cloud if it's addressed to a broker
cloudfe.send_multipart(msg)
else:
# Route reply to client if we still need to
localfe.send_multipart(msg)
# Handle capacity updates
if statefe in events:
peer, s = statefe.recv_multipart()
cloud_capacity = int(s)
# handle monitor message
if monitor in events:
print(monitor.recv_string())
# Now route as many clients requests as we can handle
# - If we have local capacity we poll both localfe and cloudfe
# - If we have cloud capacity only, we poll just localfe
# - Route any request locally if we can, else to cloud
while local_capacity + cloud_capacity:
secondary = zmq.Poller()
secondary.register(localfe, zmq.POLLIN)
if local_capacity:
secondary.register(cloudfe, zmq.POLLIN)
events = dict(secondary.poll(0))
# We'll do peer brokers first, to prevent starvation
if cloudfe in events:
msg = cloudfe.recv_multipart()
elif localfe in events:
msg = localfe.recv_multipart()
else:
break # No work, go back to backends
if local_capacity:
msg = [workers.pop(0), b''] + msg
localbe.send_multipart(msg)
local_capacity -= 1
else:
# Route to random broker peer
msg = [random.choice(peers), b''] + msg
cloudbe.send_multipart(msg)
if local_capacity != previous:
statebe.send_multipart([myself, asbytes(local_capacity)])
if __name__ == '__main__':
if len(sys.argv) >= 2:
myself = asbytes(sys.argv[1])
main(myself, peers=[ asbytes(a) for a in sys.argv[2:] ])
else:
print("Usage: peering3.py <me> [<peer_1> [... <peer_N>]]")
sys.exit(1)
peering3:Q 中的完整集群模拟
peering3:Racket 中的完整集群模拟
peering3:Ruby 中的完整集群模拟
#!/usr/bin/env ruby
# Broker peering simulation (part 3)
# Prototypes the full flow of status and tasks
#
# Translated from C by Devin Christensen: http://github.com/devin-c
require "rubygems"
require "ffi-rzmq"
NUMBER_OF_CIENTS = 10
NUMBER_OF_WORKERS = 3
WORKER_READY = "\x01"
class Client
def initialize(broker_name)
@context = ZMQ::Context.new
@frontend = @context.socket ZMQ::REQ
@monitor = @context.socket ZMQ::PUSH
@frontend.connect "ipc://#{broker_name}-localfe.ipc"
@monitor.connect "ipc://#{broker_name}-monitor.ipc"
end
def run
poller = ZMQ::Poller.new
poller.register_readable @frontend
catch(:exit) do
loop do
sleep rand 5
rand(15).times do
task_id = "%04X" % rand(0x10000)
@frontend.send_string task_id
if poller.poll(10_000) == 1
@frontend.recv_string reply = ""
throw :exit unless reply == task_id
@monitor.send_string "#{reply}"
else
@monitor.send_string "E:CLIENT EXIT - lost task #{task_id}"
throw :exit
end
end
end
end
@frontend.close
@monitor.close
@context.terminate
end
end
class Worker
def initialize(broker_name)
@context = ZMQ::Context.new
@backend = @context.socket ZMQ::REQ
@backend.connect "ipc://#{broker_name}-localbe.ipc"
end
def run
@backend.send_string WORKER_READY
loop do
@backend.recv_strings frames = []
sleep rand 2 # Sleep either 0 or 1 second
@backend.send_strings frames
end
@backend.close
@context.terminate
end
end
class Broker
attr_reader :name
def initialize(name, peers)
raise ArgumentError, "A broker require's a name" unless name
raise ArgumentError, "A broker require's peers" unless peers.any?
puts "I: preparing broker at #{name}..."
@name = name
@peers = peers
@context = ZMQ::Context.new
@available_workers = []
@peers_capacity = {}
setup_cloud_backend
setup_cloud_frontend
setup_local_backend
setup_local_frontend
setup_state_frontend
setup_state_backend
setup_monitor
end
def run
poller = ZMQ::Poller.new
poller.register_readable @cloud_backend
poller.register_readable @cloud_frontend
poller.register_readable @local_backend
poller.register_readable @local_frontend
poller.register_readable @state_frontend
poller.register_readable @monitor
while poller.poll > 0
cached_local_capacity = @available_workers.size
poller.readables.each do |readable|
case readable
when @local_frontend
# Route local tasks to local or cloud workers
if total_capacity > 0
@local_frontend.recv_strings frames = []
route_to_backend frames
end
when @cloud_frontend
# Route tasks from the cloud to local workers only
if @available_workers.any?
@cloud_frontend.recv_strings frames = []
route_to_backend frames
end
when @local_backend
@local_backend.recv_strings frames = []
@available_workers << frames.shift(2)[0]
route_to_frontend(frames) unless frames == [WORKER_READY]
when @cloud_backend
@cloud_backend.recv_strings frames = []
route_to_frontend frames[2..-1]
when @state_frontend
@state_frontend.recv_string peer = ""
@state_frontend.recv_string capacity = ""
@peers_capacity[peer] = capacity.to_i
when @monitor
@monitor.recv_string message = ""
puts message
end
end
unless cached_local_capacity == @available_workers.size
@state_backend.send_strings [@name, @available_workers.size.to_s]
end
end
@cloud_backend.close
@local_backend.close
@cloud_frontend.close
@local_frontend.close
@context.terminate
end
private
def total_capacity
cloud_capacity = @peers_capacity.reduce(0) do |sum, (peer, capacity)|
sum + capacity
end
cloud_capacity + @available_workers.size
end
def route_to_backend(frames)
# Route to local workers whenever they're available
if @available_workers.any?
@local_backend.send_strings [@available_workers.shift, ""] + frames
# When there are no local workers available, route to the peer with
# the greatest capacity
else
peer = @peers_capacity.max_by { |x| x[1] }[0]
@cloud_backend.send_strings [peer, ""] + frames
end
def route_to_frontend(frames)
if @peers.include? frames[0]
@cloud_frontend.send_strings frames
else
@local_frontend.send_strings frames
end
end
end
def setup_cloud_backend
@cloud_backend = @context.socket ZMQ::ROUTER
@cloud_backend.identity = @name
@peers.each do |peer|
puts "I: connecting to cloud frontend at #{peer}"
@cloud_backend.connect "ipc://#{peer}-cloud.ipc"
end
end
def setup_cloud_frontend
@cloud_frontend = @context.socket ZMQ::ROUTER
@cloud_frontend.identity = @name
@cloud_frontend.bind "ipc://#{@name}-cloud.ipc"
end
def setup_local_backend
@local_backend = @context.socket ZMQ::ROUTER
@local_backend.bind "ipc://#{@name}-localbe.ipc"
end
def setup_local_frontend
@local_frontend = @context.socket ZMQ::ROUTER
@local_frontend.bind "ipc://#{@name}-localfe.ipc"
end
def setup_monitor
@monitor = @context.socket ZMQ::PULL
@monitor.bind "ipc://#{@name}-monitor.ipc"
end
def setup_state_backend
@state_backend = @context.socket ZMQ::PUB
@state_backend.bind "ipc://#{@name}-state.ipc"
end
def setup_state_frontend
@state_frontend = @context.socket ZMQ::SUB
@peers.each do |peer|
puts "I: connecting to state backend at #{peer}"
@state_frontend.connect "ipc://#{peer}-state.ipc"
@state_frontend.setsockopt ZMQ::SUBSCRIBE, peer
end
end
end
begin
broker = Broker.new(ARGV.shift, ARGV)
NUMBER_OF_WORKERS.times do
Thread.new { Worker.new(broker.name).run }
end
NUMBER_OF_CIENTS.times do
Thread.new { Client.new(broker.name).run }
end
broker.run
rescue ArgumentError
puts "usage: ruby peering3.rb broker_name [peer_name ...]"
end
peering3:Rust 中的完整集群模拟
peering3:Scala 中的完整集群模拟
peering3:Tcl 中的完整集群模拟
#
# Broker peering simulation (part 3)
# Prototypes the full flow of status and tasks
#
package require zmq
if {[llength $argv] < 2} {
puts "Usage: peering2.tcl <main|client|worker> <self> <peer ...>"
exit 1
}
set NBR_CLIENTS 10
set NBR_WORKERS 3
set LRU_READY "READY" ; # Signals worker is ready
set peers [lassign $argv what self]
set tclsh [info nameofexecutable]
expr {srand([pid])}
switch -exact -- $what {
client {
# Request-reply client using REQ socket
# To simulate load, clients issue a burst of requests and then
# sleep for a random period.
#
zmq context context
zmq socket client context REQ
client connect "ipc://$self-localfe.ipc"
zmq socket monitor context PUSH
monitor connect "ipc://$self-monitor.ipc"
proc process_client {} {
global task_id done self
client readable {}
set reply [client recv]
if {$task_id ne [lindex $reply 0]} {
monitor send "E [clock seconds]: CLIENT EXIT - reply '$reply' not equal to task-id '$task_id'"
exit 1
}
monitor send "OK [clock seconds]: CLIENT REPLY - $reply"
set_done 1
}
proc set_done {v} {
global done
if {$done < 0} {
set done $v
}
}
while {1} {
after [expr {int(rand()*5)*1000}]
set burst [expr {int(rand()*15)}]
while {$burst} {
set task_id [format "%04X" [expr {int(rand()*0x10000)}]]
# Send request with random hex ID
client send $task_id
# Wait max ten seconds for a reply, then complain
set done -1
client readable process_client
set aid [after 10000 [list set_done 0]]
vwait done
catch {after cancel $aid}
if {$done == 0} {
monitor send "E [clock seconds]: CLIENT EXIT - lost task '$task_id'"
exit 1
}
incr burst -1
}
}
client close
control close
context term
}
worker {
# Worker using REQ socket to do LRU routing
#
zmq context context
zmq socket worker context REQ
worker connect "ipc://$self-localbe.ipc"
# Tell broker we're ready for work
worker send $LRU_READY
# Process messages as they arrive
while {1} {
# Workers are busy for 0/1 seconds
set msg [zmsg recv worker]
set payload [list [lindex $msg end] $self]
lset msg end $payload
after [expr {int(rand()*2)*1000}]
zmsg send worker $msg
}
worker close
context term
}
main {
puts "I: preparing broker at $self..."
# Prepare our context and sockets
zmq context context
# Bind cloud frontend to endpoint
zmq socket cloudfe context ROUTER
cloudfe setsockopt IDENTITY $self
cloudfe bind "ipc://$self-cloud.ipc"
# Bind state backend / publisher to endpoint
zmq socket statebe context PUB
statebe bind "ipc://$self-state.ipc"
# Connect cloud backend to all peers
zmq socket cloudbe context ROUTER
cloudbe setsockopt IDENTITY $self
foreach peer $peers {
puts "I: connecting to cloud frontend at '$peer'"
cloudbe connect "ipc://$peer-cloud.ipc"
}
# Connect statefe to all peers
zmq socket statefe context SUB
statefe setsockopt SUBSCRIBE ""
foreach peer $peers {
puts "I: connecting to state backend at '$peer'"
statefe connect "ipc://$peer-state.ipc"
}
# Prepare local frontend and backend
zmq socket localfe context ROUTER
localfe bind "ipc://$self-localfe.ipc"
zmq socket localbe context ROUTER
localbe bind "ipc://$self-localbe.ipc"
# Prepare monitor socket
zmq socket monitor context PULL
monitor bind "ipc://$self-monitor.ipc"
# Start local workers
for {set worker_nbr 0} {$worker_nbr < $NBR_WORKERS} {incr worker_nbr} {
puts "Starting worker $worker_nbr, output redirected to worker-$self-$worker_nbr.log"
exec $tclsh peering3.tcl worker $self {*}$peers > worker-$self-$worker_nbr.log 2>@1 &
}
# Start local clients
for {set client_nbr 0} {$client_nbr < $NBR_CLIENTS} {incr client_nbr} {
puts "Starting client $client_nbr, output redirected to client-$self-$client_nbr.log"
exec $tclsh peering3.tcl client $self {*}$peers > client-$self-$client_nbr.log 2>@1 &
}
# Interesting part
# -------------------------------------------------------------
# Publish-subscribe flow
# - Poll statefe and process capacity updates
# - Each time capacity changes, broadcast new value
# Request-reply flow
# - Poll primary and process local/cloud replies
# - While worker available, route localfe to local or cloud
# Queue of available workers
set local_capacity 0
set cloud_capacity 0
set old_cloud_capacity -1
set workers {}
proc route_to_cloud_or_local {msg} {
global peers
# Route reply to cloud if it's addressed to a broker
foreach peer $peers {
if {$peer eq [lindex $msg 0]} {
zmsg send cloudfe $msg
return
}
}
# Route reply to client if we still need to
zmsg send localfe $msg
}
proc handle_localbe {} {
global workers
# Handle reply from local worker
set msg [zmsg recv localbe]
set address [zmsg unwrap msg]
lappend workers $address
# If it's READY, don't route the message any further
if {[lindex $msg 0] ne "READY"} {
route_to_cloud_or_local $msg
}
}
proc handle_cloudbe {} {
# Or handle reply from peer broker
set msg [zmsg recv cloudbe]
# We don't use peer broker address for anything
zmsg unwrap msg
route_to_cloud_or_local $msg
}
proc handle_statefe {} {
global cloud_capacity
# Handle capacity updates
set peer [statefe recv]
set cloud_capacity [statefe recv]
}
proc handle_monitor {} {
# Handle monitor message
puts [monitor recv]
}
# Now route as many clients requests as we can handle
# - If we have local capacity we poll both localfe and cloudfe
# - If we have cloud capacity only, we poll just localfe
# - Route any request locally if we can, else to cloud
#
proc handle_client {s} {
global peers workers workers cloud_capacity self
set msg [zmsg recv $s]
if {[llength $workers]} {
set workers [lassign $workers frame]
set msg [zmsg wrap $msg $frame]
zmsg send localbe $msg
} else {
set peer [lindex $peers [expr {int(rand()*[llength $peers])}]]
set msg [zmsg push $msg $peer]
zmsg send cloudbe $msg
}
}
proc handle_clients {} {
if {[catch {
global workers cloud_capacity
if {[llength $workers] && ("POLLIN" in [cloudfe getsockopt EVENTS])} {
handle_client cloudfe
}
if {([llength $workers] || $cloud_capacity) && ("POLLIN" in [localfe getsockopt EVENTS])} {
handle_client localfe
}
} msg]} {
puts $msg
}
}
proc publish_capacity {} {
global self workers old_cloud_capacity
if {[llength $workers] != $old_cloud_capacity} {
puts "OK [clock seconds] : PUBLISH CAPACITY [llength $workers]"
# We stick our own address onto the envelope
statebe sendmore $self
# Broadcast new capacity
statebe send [llength $workers]
set old_cloud_capacity [llength $workers]
}
# Repeat
after 1000 publish_capacity
}
localbe readable handle_localbe
cloudbe readable handle_cloudbe
statefe readable handle_statefe
monitor readable handle_monitor
localfe readable handle_clients
cloudfe readable handle_clients
publish_capacity
vwait forever
# When we're done, clean up properly
localbe close
localfe close
cloudbe close
cloudfe close
monitor close
statefe close
context term
}
}
peering3:OCaml 中的完整集群模拟
这是一个非简单的程序,花费了大约一天时间才使其工作。主要内容如下
-
客户端线程检测并报告失败的请求。它们通过轮询等待响应来实现这一点,如果一段时间(10秒)后没有收到响应,则打印错误消息。
-
客户端线程不直接打印,而是将消息发送到一个监控 socket (PUSH),主循环收集 (PULL) 并打印出来。这是我们第一次看到使用 ZeroMQ socket 进行监控和日志记录的案例;这是一个重要的用例,我们稍后会再讨论。
-
客户端模拟不同的负载,以便在随机时刻使集群达到 100% 利用率,从而将任务转移到云端。客户端和工作者的数量,以及客户端和工作者线程中的延迟控制着这一点。欢迎调整这些参数,看看是否能创建一个更真实的模拟。
-
主循环使用两个 pollset。实际上,它可以使用三个:信息、后端和前端。如同早期的原型一样,如果后端没有容量,接收前端消息就没有意义。
这些是开发此程序期间出现的一些问题
-
客户端会冻结,因为请求或回复在某个地方丢失了。回想一下,ROUTER socket 会丢弃无法路由的消息。这里的第一个策略是修改客户端线程以检测和报告此类问题。其次,我放了zmsg_dump()在主循环中的每次接收后和每次发送前调用,直到问题的根源清晰为止。
-
主循环错误地从多个就绪 socket 中读取。这导致第一条消息丢失。我通过仅从第一个就绪 socket 读取来修复了这个问题。
-
的zmsg类未能正确地将 UUID 编码为 C 字符串。这导致包含零字节的 UUID 被损坏。我通过修改zmsg将 UUID 编码为可打印的十六进制字符串来修复了这个问题。
这个模拟没有检测到云对等体的消失。如果你启动了几个对等体并停止了其中一个,并且它正在向其他对等体广播容量信息,即使它已消失,其他对等体仍会继续向其发送工作。你可以尝试一下,你会发现客户端会抱怨请求丢失。解决方案有两个方面:首先,只保留短时间的容量信息,这样如果一个对等体消失了,其容量会很快设置为零。其次,为请求-回复链增加可靠性。我们将在下一章探讨可靠性。