第四章 - 可靠的请求-回复模式 #
第三章 - 高级请求-回复模式 涵盖了 ZeroMQ 请求-回复模式的高级用法,并提供了可运行的示例。本章着眼于可靠性这个普遍问题,并在 ZeroMQ 核心请求-回复模式的基础上构建了一系列可靠的消息模式。
在本章中,我们重点关注用户空间的请求-回复 模式,这些是可重用的模型,有助于你设计自己的 ZeroMQ 架构
- Lazy Pirate 模式:客户端的可靠请求-回复
- Simple Pirate 模式:使用负载均衡的可靠请求-回复
- Paranoid Pirate 模式:带心跳的可靠请求-回复
- Majordomo 模式:面向服务的可靠排队
- Titanic 模式:基于磁盘/断开连接的可靠排队
- Binary Star 模式:主备服务器故障转移
- Freelance 模式:无代理的可靠请求-回复
什么是“可靠性”? #
大多数谈论“可靠性”的人并不真正知道他们在说什么。我们只能根据失败来定义可靠性。也就是说,如果我们能够处理一组定义明确且易于理解的失败,那么相对于这些失败,我们就是可靠的。不多不少。所以让我们来看看分布式 ZeroMQ 应用中可能导致失败的原因,按概率大致降序排列:
-
应用程序代码是罪魁祸首。它可能崩溃退出,冻结并停止响应输入,运行太慢而无法处理输入,耗尽所有内存等等。
-
系统代码——例如我们使用 ZeroMQ 编写的代理——可能因与应用程序代码相同的原因而死亡。系统代码应该比应用程序代码更可靠,但它仍然可能崩溃和失败,特别是如果它试图为慢客户端排队消息时,可能会耗尽内存。
-
消息队列可能会溢出,这通常发生在学会残酷对待慢客户端的系统代码中。当队列溢出时,它会开始丢弃消息。因此,我们得到的是“丢失”的消息。
-
网络可能会发生故障(例如,WiFi 关闭或超出范围)。ZeroMQ 在这种情况下会自动重连,但在重连期间,消息可能会丢失。
-
硬件可能会发生故障,并导致该机器上运行的所有进程随之终止。
-
网络可能以奇特的方式发生故障,例如,交换机上的某些端口可能损坏,导致部分网络无法访问。
-
整个数据中心可能遭受雷击、地震、火灾,或更常见的电源或冷却故障。
要使一个软件系统能够完全可靠地应对所有这些可能的失败,这是一项极其困难和昂贵的工作,超出了本书的范围。
由于上述列表中的前五种情况涵盖了大型公司以外现实世界需求的 99.9%(根据我刚刚进行的一项高度科学的研究,该研究还告诉我 78% 的统计数据都是凭空捏造的,而且我们永远不应该相信未经我们自己证伪的统计数据),所以这就是我们将要探讨的内容。如果你是一家大型公司,有钱用于处理最后两种情况,请立即联系我的公司!我家海滨别墅后面有一个大洞,正等着改造成行政游泳池呢。
设计可靠性 #
因此,简单粗暴地说,可靠性就是“在代码冻结或崩溃时保持事物正常运行”,这种情况我们简称“死亡”。然而,我们希望保持正常运行的事物比简单的消息更复杂。我们需要研究每种核心 ZeroMQ 消息模式,看看即使代码“死亡”时,我们如何(如果可能的话)使其继续工作。
让我们逐一 살펴보
-
请求-回复:如果服务器“死亡”(正在处理请求时),客户端可以发现这一点,因为它收不到回复。然后它可以恼火地放弃,或者稍后等待并重试,或者寻找另一台服务器,等等。至于客户端“死亡”,我们现在可以将其视为“别人的问题”。
-
发布-订阅:如果客户端“死亡”(已经收到一些数据),服务器并不知道。发布-订阅不会从客户端向服务器发送任何信息。但客户端可以通过带外方式(例如,通过请求-回复)联系服务器,并询问“请重新发送我遗漏的所有内容”。至于服务器“死亡”,这超出了本文的范围。订阅者也可以自我验证它们是否运行得太慢,并在确实太慢时采取行动(例如,警告操作员并“死亡”)。
-
管道:如果一个 worker “死亡”(正在工作时),ventilator(鼓风机)并不知道。管道就像时间的齿轮一样,只在一个方向工作。但是下游的 collector(收集器)可以检测到某个任务没有完成,并向 ventilator 发送一条消息说:“嘿,重发任务 324!”如果 ventilator 或 collector 死亡,最初发送工作批次的任何上游客户端都可能因为等待太久而感到厌烦,然后重发全部任务。这并不优雅,但系统代码应该不会经常死亡到成为问题。
在本章中,我们将重点讨论请求-回复,这是可靠消息传递中容易实现的部分。
基本的请求-回复模式(一个 REQ 客户端套接字对 REP 服务器套接字进行阻塞发送/接收)在处理最常见的故障类型方面得分较低。如果服务器在处理请求时崩溃,客户端只会永远挂起。如果网络丢失了请求或回复,客户端也会永远挂起。
由于 ZeroMQ 能够静默重连对端、负载均衡消息等等,请求-回复仍然比 TCP 好得多。但它仍然不足以应对实际工作。唯一可以真正信任基本请求-回复模式的情况是在同一进程中的两个线程之间,因为没有网络或独立的服务器进程会“死亡”。
然而,只需做一些额外的工作,这种基础模式就能成为分布式网络中实际工作的良好基础,并且我们得到了一组可靠请求-回复 (RRR) 模式,我喜欢称之为 Pirate 模式(我希望你最终能明白这个笑话)。
根据我的经验,客户端连接服务器的方式大致有三种。每种都需要特定的可靠性处理方法
-
多个客户端直接与单个服务器通信。用例:客户端需要与之通信的单个知名服务器。我们旨在处理的故障类型:服务器崩溃和重启,以及网络断开连接。
-
多个客户端与一个代理通信,该代理将工作分发给多个 worker。用例:面向服务的事务处理。我们旨在处理的故障类型:worker 崩溃和重启,worker 忙循环,worker 过载,队列崩溃和重启,以及网络断开连接。
-
多个客户端与多个服务器通信,中间没有代理。用例:分布式服务,如名称解析。我们旨在处理的故障类型:服务崩溃和重启,服务忙循环,服务过载,以及网络断开连接。
这些方法各有优缺点,而且你经常会混合使用它们。我们将详细 بررسی 这三种方法。
客户端可靠性 (Lazy Pirate 模式) #
通过对客户端进行一些更改,我们可以实现非常简单的可靠请求-回复。我们称之为 Lazy Pirate 模式。我们不是进行阻塞接收,而是:
- 轮询 REQ 套接字,并仅在确定收到回复时才进行接收。
- 如果在超时时间内没有收到回复,则重新发送请求。
- 如果几次请求后仍未收到回复,则放弃该事务。
如果你尝试以非严格的发送/接收方式使用 REQ 套接字,你会收到错误(技术上,REQ 套接字实现了一个小型有限状态机来强制执行发送/接收的乒乓式交互,因此错误代码称为“EFSM”)。这在我们想要在 pirate 模式中使用 REQ 时稍微有点烦人,因为我们在收到回复之前可能会发送多次请求。
一个相当不错的暴力解决方案是在出错后关闭并重新打开 REQ 套接字
lpclient: Ada 中的 Lazy Pirate 客户端
lpclient: Basic 中的 Lazy Pirate 客户端
lpclient: C 中的 Lazy Pirate 客户端
#include <czmq.h>
#define REQUEST_TIMEOUT 2500 // msecs, (>1000!)
#define REQUEST_RETRIES 3 // Before we abandon
#define SERVER_ENDPOINT "tcp://:5555"
int main()
{
zsock_t *client = zsock_new_req(SERVER_ENDPOINT);
printf("I: Connecting to server...\n");
assert(client);
int sequence = 0;
int retries_left = REQUEST_RETRIES;
printf("Entering while loop...\n");
while(retries_left) // interrupt needs to be handled
{
// We send a request, then we get a reply
char request[10];
sprintf(request, "%d", ++sequence);
zstr_send(client, request);
int expect_reply = 1;
while(expect_reply)
{
printf("Expecting reply....\n");
zmq_pollitem_t items [] = {{zsock_resolve(client), 0, ZMQ_POLLIN, 0}};
printf("After polling\n");
int rc = zmq_poll(items, 1, REQUEST_TIMEOUT * ZMQ_POLL_MSEC);
printf("Polling Done.. \n");
if (rc == -1)
break; // Interrupted
// Here we process a server reply and exit our loop if the
// reply is valid. If we didn't get a reply we close the
// client socket, open it again and resend the request. We
// try a number times before finally abandoning:
if (items[0].revents & ZMQ_POLLIN)
{
// We got a reply from the server, must match sequence
char *reply = zstr_recv(client);
if(!reply)
break; // interrupted
if (atoi(reply) == sequence)
{
printf("I: server replied OK (%s)\n", reply);
retries_left=REQUEST_RETRIES;
expect_reply = 0;
}
else
{
printf("E: malformed reply from server: %s\n", reply);
}
free(reply);
}
else
{
if(--retries_left == 0)
{
printf("E: Server seems to be offline, abandoning\n");
break;
}
else
{
printf("W: no response from server, retrying...\n");
zsock_destroy(&client);
printf("I: reconnecting to server...\n");
client = zsock_new_req(SERVER_ENDPOINT);
zstr_send(client, request);
}
}
}
zsock_destroy(&client);
return 0;
}
}
lpclient: C++ 中的 Lazy Pirate 客户端
//
// Lazy Pirate client
// Use zmq_poll to do a safe request-reply
// To run, start piserver and then randomly kill/restart it
//
#include "zhelpers.hpp"
#include <sstream>
#define REQUEST_TIMEOUT 2500 // msecs, (> 1000!)
#define REQUEST_RETRIES 3 // Before we abandon
// Helper function that returns a new configured socket
// connected to the Hello World server
//
static zmq::socket_t * s_client_socket (zmq::context_t & context) {
std::cout << "I: connecting to server..." << std::endl;
zmq::socket_t * client = new zmq::socket_t (context, ZMQ_REQ);
client->connect ("tcp://:5555");
// Configure socket to not wait at close time
int linger = 0;
client->setsockopt (ZMQ_LINGER, &linger, sizeof (linger));
return client;
}
int main () {
zmq::context_t context (1);
zmq::socket_t * client = s_client_socket (context);
int sequence = 0;
int retries_left = REQUEST_RETRIES;
while (retries_left) {
std::stringstream request;
request << ++sequence;
s_send (*client, request.str());
sleep (1);
bool expect_reply = true;
while (expect_reply) {
// Poll socket for a reply, with timeout
zmq::pollitem_t items[] = {
{ *client, 0, ZMQ_POLLIN, 0 } };
zmq::poll (&items[0], 1, REQUEST_TIMEOUT);
// If we got a reply, process it
if (items[0].revents & ZMQ_POLLIN) {
// We got a reply from the server, must match sequence
std::string reply = s_recv (*client);
if (atoi (reply.c_str ()) == sequence) {
std::cout << "I: server replied OK (" << reply << ")" << std::endl;
retries_left = REQUEST_RETRIES;
expect_reply = false;
}
else {
std::cout << "E: malformed reply from server: " << reply << std::endl;
}
}
else
if (--retries_left == 0) {
std::cout << "E: server seems to be offline, abandoning" << std::endl;
expect_reply = false;
break;
}
else {
std::cout << "W: no response from server, retrying..." << std::endl;
// Old socket will be confused; close it and open a new one
delete client;
client = s_client_socket (context);
// Send request again, on new socket
s_send (*client, request.str());
}
}
}
delete client;
return 0;
}
lpclient: C# 中的 Lazy Pirate 客户端
lpclient: CL 中的 Lazy Pirate 客户端
lpclient: Delphi 中的 Lazy Pirate 客户端
program lpclient;
//
// Lazy Pirate client
// Use zmq_poll to do a safe request-reply
// To run, start lpserver and then randomly kill/restart it
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
const
REQUEST_TIMEOUT = 2500; // msecs, (> 1000!)
REQUEST_RETRIES = 3; // Before we abandon
SERVER_ENDPOINT = 'tcp://:5555';
var
ctx: TZMQContext;
client: TZMQSocket;
sequence,
retries_left,
expect_reply: Integer;
request,
reply: Utf8String;
poller: TZMQPoller;
begin
ctx := TZMQContext.create;
Writeln( 'I: connecting to server...' );
client := ctx.Socket( stReq );
client.Linger := 0;
client.connect( SERVER_ENDPOINT );
poller := TZMQPoller.Create( true );
poller.Register( client, [pePollIn] );
sequence := 0;
retries_left := REQUEST_RETRIES;
while ( retries_left > 0 ) and not ctx.Terminated do
try
// We send a request, then we work to get a reply
inc( sequence );
request := Format( '%d', [sequence] );
client.send( request );
expect_reply := 1;
while ( expect_reply > 0 ) do
begin
// Poll socket for a reply, with timeout
poller.poll( REQUEST_TIMEOUT );
// Here we process a server reply and exit our loop if the
// reply is valid. If we didn't a reply we close the client
// socket and resend the request. We try a number of times
// before finally abandoning:
if pePollIn in poller.PollItem[0].revents then
begin
// We got a reply from the server, must match sequence
client.recv( reply );
if StrToInt( reply ) = sequence then
begin
Writeln( Format( 'I: server replied OK (%s)', [reply] ) );
retries_left := REQUEST_RETRIES;
expect_reply := 0;
end else
Writeln( Format( 'E: malformed reply from server: %s', [ reply ] ) );
end else
begin
dec( retries_left );
if retries_left = 0 then
begin
Writeln( 'E: server seems to be offline, abandoning' );
break;
end else
begin
Writeln( 'W: no response from server, retrying...' );
// Old socket is confused; close it and open a new one
poller.Deregister( client, [pePollIn] );
client.Free;
Writeln( 'I: reconnecting to server...' );
client := ctx.Socket( stReq );
client.Linger := 0;
client.connect( SERVER_ENDPOINT );
poller.Register( client, [pePollIn] );
// Send request again, on new socket
client.send( request );
end;
end;
end;
except
end;
poller.Free;
ctx.Free;
end.
lpclient: Erlang 中的 Lazy Pirate 客户端
lpclient: Elixir 中的 Lazy Pirate 客户端
lpclient: F# 中的 Lazy Pirate 客户端
lpclient: Felix 中的 Lazy Pirate 客户端
lpclient: Go 中的 Lazy Pirate 客户端
// Lazy Pirate client
// Use zmq_poll to do a safe request-reply
// To run, start lpserver and then randomly kill/restart it
//
// Author: iano <scaly.iano@gmail.com>
// Based on C example
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"strconv"
"time"
)
const (
REQUEST_TIMEOUT = time.Duration(2500) * time.Millisecond
REQUEST_RETRIES = 3
SERVER_ENDPOINT = "tcp://:5555"
)
func main() {
context, _ := zmq.NewContext()
defer context.Close()
fmt.Println("I: Connecting to server...")
client, _ := context.NewSocket(zmq.REQ)
client.Connect(SERVER_ENDPOINT)
for sequence, retriesLeft := 1, REQUEST_RETRIES; retriesLeft > 0; sequence++ {
fmt.Printf("I: Sending (%d)\n", sequence)
client.Send([]byte(strconv.Itoa(sequence)), 0)
for expectReply := true; expectReply; {
// Poll socket for a reply, with timeout
items := zmq.PollItems{
zmq.PollItem{Socket: client, Events: zmq.POLLIN},
}
if _, err := zmq.Poll(items, REQUEST_TIMEOUT); err != nil {
panic(err) // Interrupted
}
// .split process server reply
// Here we process a server reply and exit our loop if the
// reply is valid. If we didn't a reply we close the client
// socket and resend the request. We try a number of times
// before finally abandoning:
if item := items[0]; item.REvents&zmq.POLLIN != 0 {
// We got a reply from the server, must match sequence
reply, err := item.Socket.Recv(0)
if err != nil {
panic(err) // Interrupted
}
if replyInt, err := strconv.Atoi(string(reply)); replyInt == sequence && err == nil {
fmt.Printf("I: Server replied OK (%s)\n", reply)
retriesLeft = REQUEST_RETRIES
expectReply = false
} else {
fmt.Printf("E: Malformed reply from server: %s", reply)
}
} else if retriesLeft--; retriesLeft == 0 {
fmt.Println("E: Server seems to be offline, abandoning")
client.SetLinger(0)
client.Close()
break
} else {
fmt.Println("W: No response from server, retrying...")
// Old socket is confused; close it and open a new one
client.SetLinger(0)
client.Close()
client, _ = context.NewSocket(zmq.REQ)
client.Connect(SERVER_ENDPOINT)
fmt.Printf("I: Resending (%d)\n", sequence)
// Send request again, on new socket
client.Send([]byte(strconv.Itoa(sequence)), 0)
}
}
}
}
lpclient: Haskell 中的 Lazy Pirate 客户端
{--
Lazy Pirate client in Haskell
--}
module Main where
import System.ZMQ4.Monadic
import System.Random (randomRIO)
import System.Exit (exitSuccess)
import Control.Monad (forever, when)
import Control.Concurrent (threadDelay)
import Data.ByteString.Char8 (pack, unpack)
requestRetries = 3
requestTimeout_ms = 2500
serverEndpoint = "tcp://:5555"
main :: IO ()
main =
runZMQ $ do
liftIO $ putStrLn "I: Connecting to server"
client <- socket Req
connect client serverEndpoint
sendServer 1 requestRetries client
sendServer :: Int -> Int -> Socket z Req -> ZMQ z ()
sendServer _ 0 _ = return ()
sendServer seq retries client = do
send client [] (pack $ show seq)
pollServer seq retries client
pollServer :: Int -> Int -> Socket z Req -> ZMQ z ()
pollServer seq retries client = do
[evts] <- poll requestTimeout_ms [Sock client [In] Nothing]
if In `elem` evts
then do
reply <- receive client
if (read . unpack $ reply) == seq
then do
liftIO $ putStrLn $ "I: Server replied OK " ++ (unpack reply)
sendServer (seq+1) requestRetries client
else do
liftIO $ putStrLn $ "E: malformed reply from server: " ++ (unpack reply)
pollServer seq retries client
else
if retries == 0
then liftIO $ putStrLn "E: Server seems to be offline, abandoning" >> exitSuccess
else do
liftIO $ putStrLn $ "W: No response from server, retrying..."
client' <- socket Req
connect client' serverEndpoint
send client' [] (pack $ show seq)
pollServer seq (retries-1) client'
lpclient: Haxe 中的 Lazy Pirate 客户端
package ;
import haxe.Stack;
import neko.Lib;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQException;
import org.zeromq.ZMQPoller;
import org.zeromq.ZSocket;
/**
* Lazy Pirate client
* Use zmq_poll to do a safe request-reply
* To run, start lpserver and then randomly kill / restart it.
*
* @see https://zguide.zeromq.cn/page:all#Client-side-Reliability-Lazy-Pirate-Pattern
*/
class LPClient
{
private static inline var REQUEST_TIMEOUT = 2500; // msecs, (> 1000!)
private static inline var REQUEST_RETRIES = 3; // Before we abandon
private static inline var SERVER_ENDPOINT = "tcp://:5555";
public static function main() {
Lib.println("** LPClient (see: https://zguide.zeromq.cn/page:all#Client-side-Reliability-Lazy-Pirate-Pattern)");
var ctx:ZContext = new ZContext();
Lib.println("I: connecting to server ...");
var client = ctx.createSocket(ZMQ_REQ);
if (client == null)
return;
client.connect(SERVER_ENDPOINT);
var sequence = 0;
var retries_left = REQUEST_RETRIES;
var poller = new ZMQPoller();
while (retries_left > 0 && !ZMQ.isInterrupted()) {
// We send a request, then we work to get a reply
var request = Std.string(++sequence);
ZFrame.newStringFrame(request).send(client);
var expect_reply = true;
while (expect_reply) {
poller.registerSocket(client, ZMQ.ZMQ_POLLIN());
// Poll socket for a reply, with timeout
try {
var res = poller.poll(REQUEST_TIMEOUT * 1000);
} catch (e:ZMQException) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
ctx.destroy();
return;
}
// If we got a reply, process it
if (poller.pollin(1)) {
// We got a reply from the server, must match sequence
var replyFrame = ZFrame.recvFrame(client);
if (replyFrame == null)
break; // Interrupted
if (Std.parseInt(replyFrame.toString()) == sequence) {
Lib.println("I: server replied OK (" + sequence + ")");
retries_left = REQUEST_RETRIES;
expect_reply = false;
} else
Lib.println("E: malformed reply from server: " + replyFrame.toString());
replyFrame.destroy();
} else if (--retries_left == 0) {
Lib.println("E: server seems to be offline, abandoning");
break;
} else {
Lib.println("W: no response from server, retrying...");
// Old socket is confused, close it and open a new one
ctx.destroySocket(client);
Lib.println("I: reconnecting to server...");
client = ctx.createSocket(ZMQ_REQ);
client.connect(SERVER_ENDPOINT);
// Send request again, on new socket
ZFrame.newStringFrame(request).send(client);
}
poller.unregisterAllSockets();
}
}
ctx.destroy();
}
}lpclient: Java 中的 Lazy Pirate 客户端
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
//
// Lazy Pirate client
// Use zmq_poll to do a safe request-reply
// To run, start lpserver and then randomly kill/restart it
//
public class lpclient
{
private final static int REQUEST_TIMEOUT = 2500; // msecs, (> 1000!)
private final static int REQUEST_RETRIES = 3; // Before we abandon
private final static String SERVER_ENDPOINT = "tcp://:5555";
public static void main(String[] argv)
{
try (ZContext ctx = new ZContext()) {
System.out.println("I: connecting to server");
Socket client = ctx.createSocket(SocketType.REQ);
assert (client != null);
client.connect(SERVER_ENDPOINT);
Poller poller = ctx.createPoller(1);
poller.register(client, Poller.POLLIN);
int sequence = 0;
int retriesLeft = REQUEST_RETRIES;
while (retriesLeft > 0 && !Thread.currentThread().isInterrupted()) {
// We send a request, then we work to get a reply
String request = String.format("%d", ++sequence);
client.send(request);
int expect_reply = 1;
while (expect_reply > 0) {
// Poll socket for a reply, with timeout
int rc = poller.poll(REQUEST_TIMEOUT);
if (rc == -1)
break; // Interrupted
// Here we process a server reply and exit our loop if the
// reply is valid. If we didn't a reply we close the client
// socket and resend the request. We try a number of times
// before finally abandoning:
if (poller.pollin(0)) {
// We got a reply from the server, must match
// getSequence
String reply = client.recvStr();
if (reply == null)
break; // Interrupted
if (Integer.parseInt(reply) == sequence) {
System.out.printf(
"I: server replied OK (%s)\n", reply
);
retriesLeft = REQUEST_RETRIES;
expect_reply = 0;
}
else System.out.printf(
"E: malformed reply from server: %s\n", reply
);
}
else if (--retriesLeft == 0) {
System.out.println(
"E: server seems to be offline, abandoning\n"
);
break;
}
else {
System.out.println(
"W: no response from server, retrying\n"
);
// Old socket is confused; close it and open a new one
poller.unregister(client);
ctx.destroySocket(client);
System.out.println("I: reconnecting to server\n");
client = ctx.createSocket(SocketType.REQ);
client.connect(SERVER_ENDPOINT);
poller.register(client, Poller.POLLIN);
// Send request again, on new socket
client.send(request);
}
}
}
}
}
}
lpclient: Julia 中的 Lazy Pirate 客户端
lpclient: Lua 中的 Lazy Pirate 客户端
--
-- Lazy Pirate client
-- Use zmq_poll to do a safe request-reply
-- To run, start lpserver and then randomly kill/restart it
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.poller"
require"zhelpers"
local REQUEST_TIMEOUT = 2500 -- msecs, (> 1000!)
local REQUEST_RETRIES = 3 -- Before we abandon
-- Helper function that returns a new configured socket
-- connected to the Hello World server
--
local function s_client_socket(context)
printf ("I: connecting to server...\n")
local client = context:socket(zmq.REQ)
client:connect("tcp://:5555")
-- Configure socket to not wait at close time
client:setopt(zmq.LINGER, 0)
return client
end
s_version_assert (2, 1)
local context = zmq.init(1)
local client = s_client_socket (context)
local sequence = 0
local retries_left = REQUEST_RETRIES
local expect_reply = true
local poller = zmq.poller(1)
local function client_cb()
-- We got a reply from the server, must match sequence
--local reply = assert(client:recv(zmq.NOBLOCK))
local reply = client:recv()
if (tonumber(reply) == sequence) then
printf ("I: server replied OK (%s)\n", reply)
retries_left = REQUEST_RETRIES
expect_reply = false
else
printf ("E: malformed reply from server: %s\n", reply)
end
end
poller:add(client, zmq.POLLIN, client_cb)
while (retries_left > 0) do
sequence = sequence + 1
-- We send a request, then we work to get a reply
local request = string.format("%d", sequence)
client:send(request)
expect_reply = true
while (expect_reply) do
-- Poll socket for a reply, with timeout
local cnt = assert(poller:poll(REQUEST_TIMEOUT * 1000))
-- Check if there was no reply
if (cnt == 0) then
retries_left = retries_left - 1
if (retries_left == 0) then
printf ("E: server seems to be offline, abandoning\n")
break
else
printf ("W: no response from server, retrying...\n")
-- Old socket is confused; close it and open a new one
poller:remove(client)
client:close()
client = s_client_socket (context)
poller:add(client, zmq.POLLIN, client_cb)
-- Send request again, on new socket
client:send(request)
end
end
end
end
client:close()
context:term()
lpclient: Node.js 中的 Lazy Pirate 客户端
lpclient: Objective-C 中的 Lazy Pirate 客户端
lpclient: ooc 中的 Lazy Pirate 客户端
lpclient: Perl 中的 Lazy Pirate 客户端
# Lazy Pirate client in Perl
# Use poll to do a safe request-reply
# To run, start lpserver.pl then randomly kill/restart it
use strict;
use warnings;
use v5.10;
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_REQ);
use EV;
my $REQUEST_TIMEOUT = 2500; # msecs
my $REQUEST_RETRIES = 3; # Before we abandon
my $SERVER_ENDPOINT = 'tcp://:5555';
my $ctx = ZMQ::FFI->new();
say 'I: connecting to server...';
my $client = $ctx->socket(ZMQ_REQ);
$client->connect($SERVER_ENDPOINT);
my $sequence = 0;
my $retries_left = $REQUEST_RETRIES;
REQUEST_LOOP:
while ($retries_left) {
# We send a request, then we work to get a reply
my $request = ++$sequence;
$client->send($request);
my $expect_reply = 1;
RETRY_LOOP:
while ($expect_reply) {
# Poll socket for a reply, with timeout
EV::once $client->get_fd, EV::READ, $REQUEST_TIMEOUT / 1000, sub {
my ($revents) = @_;
# Here we process a server reply and exit our loop if the
# reply is valid. If we didn't get a reply we close the client
# socket and resend the request. We try a number of times
# before finally abandoning:
if ($revents == EV::READ) {
while ($client->has_pollin) {
# We got a reply from the server, must match sequence
my $reply = $client->recv();
if ($reply == $sequence) {
say "I: server replied OK ($reply)";
$retries_left = $REQUEST_RETRIES;
$expect_reply = 0;
}
else {
say "E: malformed reply from server: $reply";
}
}
}
elsif (--$retries_left == 0) {
say 'E: server seems to be offline, abandoning';
}
else {
say "W: no response from server, retrying...";
# Old socket is confused; close it and open a new one
$client->close;
say "reconnecting to server...";
$client = $ctx->socket(ZMQ_REQ);
$client->connect($SERVER_ENDPOINT);
# Send request again, on new socket
$client->send($request);
}
};
last RETRY_LOOP if $retries_left == 0;
EV::run;
}
}
lpclient: PHP 中的 Lazy Pirate 客户端
<?php
/*
* Lazy Pirate client
* Use zmq_poll to do a safe request-reply
* To run, start lpserver and then randomly kill/restart it
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
define("REQUEST_TIMEOUT", 2500); // msecs, (> 1000!)
define("REQUEST_RETRIES", 3); // Before we abandon
/*
* Helper function that returns a new configured socket
* connected to the Hello World server
*/
function client_socket(ZMQContext $context)
{
echo "I: connecting to server...", PHP_EOL;
$client = new ZMQSocket($context,ZMQ::SOCKET_REQ);
$client->connect("tcp://:5555");
// Configure socket to not wait at close time
$client->setSockOpt(ZMQ::SOCKOPT_LINGER, 0);
return $client;
}
$context = new ZMQContext();
$client = client_socket($context);
$sequence = 0;
$retries_left = REQUEST_RETRIES;
$read = $write = array();
while ($retries_left) {
// We send a request, then we work to get a reply
$client->send(++$sequence);
$expect_reply = true;
while ($expect_reply) {
// Poll socket for a reply, with timeout
$poll = new ZMQPoll();
$poll->add($client, ZMQ::POLL_IN);
$events = $poll->poll($read, $write, REQUEST_TIMEOUT);
// If we got a reply, process it
if ($events > 0) {
// We got a reply from the server, must match sequence
$reply = $client->recv();
if (intval($reply) == $sequence) {
printf ("I: server replied OK (%s)%s", $reply, PHP_EOL);
$retries_left = REQUEST_RETRIES;
$expect_reply = false;
} else {
printf ("E: malformed reply from server: %s%s", $reply, PHP_EOL);
}
} elseif (--$retries_left == 0) {
echo "E: server seems to be offline, abandoning", PHP_EOL;
break;
} else {
echo "W: no response from server, retrying...", PHP_EOL;
// Old socket will be confused; close it and open a new one
$client = client_socket($context);
// Send request again, on new socket
$client->send($sequence);
}
}
}
lpclient: Python 中的 Lazy Pirate 客户端
#
# Lazy Pirate client
# Use zmq_poll to do a safe request-reply
# To run, start lpserver and then randomly kill/restart it
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
import itertools
import logging
import sys
import zmq
logging.basicConfig(format="%(levelname)s: %(message)s", level=logging.INFO)
REQUEST_TIMEOUT = 2500
REQUEST_RETRIES = 3
SERVER_ENDPOINT = "tcp://:5555"
context = zmq.Context()
logging.info("Connecting to server…")
client = context.socket(zmq.REQ)
client.connect(SERVER_ENDPOINT)
for sequence in itertools.count():
request = str(sequence).encode()
logging.info("Sending (%s)", request)
client.send(request)
retries_left = REQUEST_RETRIES
while True:
if (client.poll(REQUEST_TIMEOUT) & zmq.POLLIN) != 0:
reply = client.recv()
if int(reply) == sequence:
logging.info("Server replied OK (%s)", reply)
retries_left = REQUEST_RETRIES
break
else:
logging.error("Malformed reply from server: %s", reply)
continue
retries_left -= 1
logging.warning("No response from server")
# Socket is confused. Close and remove it.
client.setsockopt(zmq.LINGER, 0)
client.close()
if retries_left == 0:
logging.error("Server seems to be offline, abandoning")
sys.exit()
logging.info("Reconnecting to server…")
# Create new connection
client = context.socket(zmq.REQ)
client.connect(SERVER_ENDPOINT)
logging.info("Resending (%s)", request)
client.send(request)
lpclient: Q 中的 Lazy Pirate 客户端
lpclient: Racket 中的 Lazy Pirate 客户端
lpclient: Ruby 中的 Lazy Pirate 客户端
#!/usr/bin/env ruby
# Author: Han Holl <han.holl@pobox.com>
require 'rubygems'
require 'ffi-rzmq'
class LPClient
def initialize(connect, retries = nil, timeout = nil)
@connect = connect
@retries = (retries || 3).to_i
@timeout = (timeout || 10).to_i
@ctx = ZMQ::Context.new(1)
client_sock
at_exit do
@socket.close
end
end
def client_sock
@socket = @ctx.socket(ZMQ::REQ)
@socket.setsockopt(ZMQ::LINGER, 0)
@socket.connect(@connect)
end
def send(message)
@retries.times do |tries|
raise("Send: #{message} failed") unless @socket.send(message)
if ZMQ.select( [@socket], nil, nil, @timeout)
yield @socket.recv
return
else
@socket.close
client_sock
end
end
raise 'Server down'
end
end
if $0 == __FILE__
server = LPClient.new(ARGV[0] || "tcp://:5555", ARGV[1], ARGV[2])
count = 0
loop do
request = "#{count}"
count += 1
server.send(request) do |reply|
if reply == request
puts("I: server replied OK (#{reply})")
else
puts("E: malformed reply from server: #{reply}")
end
end
end
puts 'success'
end
lpclient: Rust 中的 Lazy Pirate 客户端
use std::convert::TryInto;
const REQUEST_TIMEOUT: i64 = 2500;
const REQUEST_RETRIES: usize = 3;
const SERVER_ENDPOINT: &'static str = "tcp://:5555";
fn connect(context: &zmq::Context) -> zmq::Socket {
let socket = context.socket(zmq::REQ).unwrap();
socket.set_linger(0).unwrap();
socket.connect(SERVER_ENDPOINT).unwrap();
socket
}
fn reconnect(context: &zmq::Context, socket: zmq::Socket) -> zmq::Socket {
drop(socket);
connect(context)
}
fn main() {
let mut retries_left = REQUEST_RETRIES;
let context = zmq::Context::new();
let mut socket = connect(&context);
let mut i = 0i64;
loop {
let value = i.to_le_bytes();
i += 1;
while retries_left > 0 {
retries_left -= 1;
let request = zmq::Message::from(&value.as_slice());
println!("Sending request {request:?}");
socket.send(request, 0).unwrap();
if socket.poll(zmq::POLLIN, REQUEST_TIMEOUT).unwrap() != 0 {
let reply = socket.recv_msg(0).unwrap();
let reply_content =
TryInto::<[u8; 8]>::try_into(&*reply).and_then(|x| Ok(i64::from_le_bytes(x)));
if let Ok(i) = reply_content {
println!("Server replied OK {i}");
retries_left = REQUEST_RETRIES;
break;
} else {
println!("Malformed message: {reply:?}");
continue;
}
}
println!("No response from Server");
println!("Reconnecting server...");
socket = reconnect(&context, socket);
println!("Resending Request");
}
if retries_left == 0 {
println!("Server is offline. Goodbye...");
return;
}
}
}
lpclient: Scala 中的 Lazy Pirate 客户端
lpclient: Tcl 中的 Lazy Pirate 客户端
#
# Lazy Pirate client
# Use zmq_poll to do a safe request-reply
# To run, start lpserver and then randomly kill/restart it
#
package require zmq
set REQUEST_TIMEOUT 2500 ;# msecs, (> 1000!)
set REQUEST_RETRIES 3 ;# Before we abandon
set SERVER_ENDPOINT "tcp://:5555"
zmq context context
puts "I: connecting to server..."
zmq socket client context REQ
client connect $SERVER_ENDPOINT
set sequence 0
set retries_left $REQUEST_RETRIES
while {$retries_left} {
# We send a request, then we work to get a reply
client send [incr sequence]
set expect_reply 1
while {$expect_reply} {
# Poll socket for a reply, with timeout
set rpoll_set [zmq poll {{client {POLLIN}}} $REQUEST_TIMEOUT]
# If we got a reply, process it
if {[llength $rpoll_set] && [lindex $rpoll_set 0 0] eq "client"} {
# We got a reply from the server, must match sequence
set reply [client recv]
if {$reply eq $sequence} {
puts "I: server replied OK ($reply)"
set retries_left $REQUEST_RETRIES
set expect_reply 0
} else {
puts "E: malformed reply from server: $reply"
}
} elseif {[incr retries_left -1] <= 0} {
puts "E: server seems to be offline, abandoning"
set retries_left 0
break
} else {
puts "W: no response from server, retrying..."
# Old socket is confused; close it and open a new one
client close
puts "I: connecting to server..."
zmq socket client context REQ
client connect $SERVER_ENDPOINT
# Send request again, on new socket
client send $sequence
}
}
}
client close
context term
lpclient: OCaml 中的 Lazy Pirate 客户端
将其与配套的服务器一起运行
lpserver: Ada 中的 Lazy Pirate 服务器
lpserver: Basic 中的 Lazy Pirate 服务器
lpserver: C 中的 Lazy Pirate 服务器
// Lazy Pirate server
// Binds REQ socket to tcp://*:5555
// Like hwserver except:
// - echoes request as-is
// - randomly runs slowly, or exits to simulate a crash.
#include "zhelpers.h"
#include <unistd.h>
int main (void)
{
srandom ((unsigned) time (NULL));
void *context = zmq_ctx_new ();
void *server = zmq_socket (context, ZMQ_REP);
zmq_bind (server, "tcp://*:5555");
int cycles = 0;
while (1) {
char *request = s_recv (server);
cycles++;
// Simulate various problems, after a few cycles
if (cycles > 3 && randof (3) == 0) {
printf ("I: simulating a crash\n");
break;
}
else
if (cycles > 3 && randof (3) == 0) {
printf ("I: simulating CPU overload\n");
sleep (2);
}
printf ("I: normal request (%s)\n", request);
sleep (1); // Do some heavy work
s_send (server, request);
free (request);
}
zmq_close (server);
zmq_ctx_destroy (context);
return 0;
}
lpserver: C++ 中的 Lazy Pirate 服务器
//
// Lazy Pirate server
// Binds REQ socket to tcp://*:5555
// Like hwserver except:
// - echoes request as-is
// - randomly runs slowly, or exits to simulate a crash.
//
#include "zhelpers.hpp"
int main ()
{
srandom ((unsigned) time (NULL));
zmq::context_t context(1);
zmq::socket_t server(context, ZMQ_REP);
server.bind("tcp://*:5555");
int cycles = 0;
while (1) {
std::string request = s_recv (server);
cycles++;
// Simulate various problems, after a few cycles
if (cycles > 3 && within (3) == 0) {
std::cout << "I: simulating a crash" << std::endl;
break;
}
else
if (cycles > 3 && within (3) == 0) {
std::cout << "I: simulating CPU overload" << std::endl;
sleep (2);
}
std::cout << "I: normal request (" << request << ")" << std::endl;
sleep (1); // Do some heavy work
s_send (server, request);
}
return 0;
}
lpserver: C# 中的 Lazy Pirate 服务器
lpserver: CL 中的 Lazy Pirate 服务器
lpserver: Delphi 中的 Lazy Pirate 服务器
program lpserver;
//
// Lazy Pirate server
// Binds REQ socket to tcp://*:5555
// Like hwserver except:
// - echoes request as-is
// - randomly runs slowly, or exits to simulate a crash.
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
var
context: TZMQContext;
server: TZMQSocket;
cycles: Integer;
request: Utf8String;
begin
Randomize;
context := TZMQContext.create;
server := context.socket( stRep );
server.bind( 'tcp://*:5555' );
cycles := 0;
while not context.Terminated do
try
server.recv( request );
inc( cycles );
// Simulate various problems, after a few cycles
if ( cycles > 3 ) and ( random(3) = 0) then
begin
Writeln( 'I: simulating a crash' );
break;
end else
if ( cycles > 3 ) and ( random(3) = 0 ) then
begin
Writeln( 'I: simulating CPU overload' );
sleep(2000);
end;
Writeln( Format( 'I: normal request (%s)', [request] ) );
sleep (1000); // Do some heavy work
server.send( request );
except
end;
context.Free;
end.
lpserver: Erlang 中的 Lazy Pirate 服务器
lpserver: Elixir 中的 Lazy Pirate 服务器
lpserver: F# 中的 Lazy Pirate 服务器
lpserver: Felix 中的 Lazy Pirate 服务器
lpserver: Go 中的 Lazy Pirate 服务器
// Lazy Pirate server
// Binds REQ socket to tcp://*:5555
// Like hwserver except:
// - echoes request as-is
// - randomly runs slowly, or exits to simulate a crash.
//
// Author: iano <scaly.iano@gmail.com>
// Based on C example
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"time"
)
const (
SERVER_ENDPOINT = "tcp://*:5555"
)
func main() {
src := rand.NewSource(time.Now().UnixNano())
random := rand.New(src)
context, _ := zmq.NewContext()
defer context.Close()
server, _ := context.NewSocket(zmq.REP)
defer server.Close()
server.Bind(SERVER_ENDPOINT)
for cycles := 1; ; cycles++ {
request, _ := server.Recv(0)
// Simulate various problems, after a few cycles
if cycles > 3 {
switch r := random.Intn(3); r {
case 0:
fmt.Println("I: Simulating a crash")
return
case 1:
fmt.Println("I: simulating CPU overload")
time.Sleep(2 * time.Second)
}
}
fmt.Printf("I: normal request (%s)\n", request)
time.Sleep(1 * time.Second) // Do some heavy work
server.Send(request, 0)
}
}
lpserver: Haskell 中的 Lazy Pirate 服务器
{--
Lazy Pirate server in Haskell
--}
module Main where
import System.ZMQ4.Monadic
import System.Random (randomRIO)
import System.Exit (exitSuccess)
import Control.Monad (forever, when)
import Control.Concurrent (threadDelay)
import Data.ByteString.Char8 (pack, unpack)
main :: IO ()
main =
runZMQ $ do
server <- socket Rep
bind server "tcp://*:5555"
sendClient 0 server
sendClient :: Int -> Socket z Rep -> ZMQ z ()
sendClient cycles server = do
req <- receive server
chance <- liftIO $ randomRIO (0::Int, 3)
when (cycles > 3 && chance == 0) $ do
liftIO crash
chance' <- liftIO $ randomRIO (0::Int, 3)
when (cycles > 3 && chance' == 0) $ do
liftIO overload
liftIO $ putStrLn $ "I: normal request " ++ (unpack req)
liftIO $ threadDelay $ 1 * 1000 * 1000
send server [] req
sendClient (cycles+1) server
crash = do
putStrLn "I: Simulating a crash"
exitSuccess
overload = do
putStrLn "I: Simulating CPU overload"
threadDelay $ 2 * 1000 * 1000
lpserver: Haxe 中的 Lazy Pirate 服务器
package ;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
/**
* Lazy Pirate server
* Binds REP socket to tcp://*:5555
* Like HWServer except:
* - echoes request as-is
* - randomly runs slowly, or exists to simulate a crash.
*
* @see https://zguide.zeromq.cn/page:all#Client-side-Reliability-Lazy-Pirate-Pattern
*
*/
class LPServer
{
public static function main() {
Lib.println("** LPServer (see: https://zguide.zeromq.cn/page:all#Client-side-Reliability-Lazy-Pirate-Pattern)");
var ctx = new ZContext();
var server = ctx.createSocket(ZMQ_REP);
server.bind("tcp://*:5555");
var cycles = 0;
while (true) {
var requestFrame = ZFrame.recvFrame(server);
cycles++;
// Simulate various problems, after a few cycles
if (cycles > 3 && ZHelpers.randof(3) == 0) {
Lib.println("I: simulating a crash");
break;
}
else if (cycles > 3 && ZHelpers.randof(3) == 0) {
Lib.println("I: simulating CPU overload");
Sys.sleep(2.0);
}
Lib.println("I: normal request (" + requestFrame.toString() + ")");
Sys.sleep(1.0); // Do some heavy work
requestFrame.send(server);
requestFrame.destroy();
}
server.close();
ctx.destroy();
}
}lpserver: Java 中的 Lazy Pirate 服务器
package guide;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZContext;
//
// Lazy Pirate server
// Binds REQ socket to tcp://*:5555
// Like hwserver except:
// - echoes request as-is
// - randomly runs slowly, or exits to simulate a crash.
//
public class lpserver
{
public static void main(String[] argv) throws Exception
{
Random rand = new Random(System.nanoTime());
try (ZContext context = new ZContext()) {
Socket server = context.createSocket(SocketType.REP);
server.bind("tcp://*:5555");
int cycles = 0;
while (true) {
String request = server.recvStr();
cycles++;
// Simulate various problems, after a few cycles
if (cycles > 3 && rand.nextInt(3) == 0) {
System.out.println("I: simulating a crash");
break;
}
else if (cycles > 3 && rand.nextInt(3) == 0) {
System.out.println("I: simulating CPU overload");
Thread.sleep(2000);
}
System.out.printf("I: normal request (%s)\n", request);
Thread.sleep(1000); // Do some heavy work
server.send(request);
}
}
}
}
lpserver: Julia 中的 Lazy Pirate 服务器
lpserver: Lua 中的 Lazy Pirate 服务器
--
-- Lazy Pirate server
-- Binds REQ socket to tcp://*:5555
-- Like hwserver except:
-- - echoes request as-is
-- - randomly runs slowly, or exits to simulate a crash.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zhelpers"
math.randomseed(os.time())
local context = zmq.init(1)
local server = context:socket(zmq.REP)
server:bind("tcp://*:5555")
local cycles = 0
while true do
local request = server:recv()
cycles = cycles + 1
-- Simulate various problems, after a few cycles
if (cycles > 3 and randof (3) == 0) then
printf("I: simulating a crash\n")
break
elseif (cycles > 3 and randof (3) == 0) then
printf("I: simulating CPU overload\n")
s_sleep(2000)
end
printf("I: normal request (%s)\n", request)
s_sleep(1000) -- Do some heavy work
server:send(request)
end
server:close()
context:term()
lpserver: Node.js 中的 Lazy Pirate 服务器
lpserver: Objective-C 中的 Lazy Pirate 服务器
lpserver: ooc 中的 Lazy Pirate 服务器
lpserver: Perl 中的 Lazy Pirate 服务器
# Lazy Pirate server in Perl
# Binds REQ socket to tcp://*:5555
# Like hwserver except:
# - echoes request as-is
# - randomly runs slowly, or exits to simulate a crash.
use strict;
use warnings;
use v5.10;
use ZMQ::FFI;
use ZMQ::FFI::Constants qw(ZMQ_REP);
my $context = ZMQ::FFI->new();
my $server = $context->socket(ZMQ_REP);
$server->bind('tcp://*:5555');
my $cycles = 0;
SERVER_LOOP:
while (1) {
my $request = $server->recv();
$cycles++;
# Simulate various problems, after a few cycles
if ($cycles > 3 && int(rand(3)) == 0) {
say "I: simulating a crash";
last SERVER_LOOP;
}
elsif ($cycles > 3 && int(rand(3)) == 0) {
say "I: simulating CPU overload";
sleep 2;
}
say "I: normal request ($request)";
sleep 1; # Do some heavy work
$server->send($request);
}
lpserver: PHP 中的 Lazy Pirate 服务器
<?php
/*
* Lazy Pirate server
* Binds REQ socket to tcp://*:5555
* Like hwserver except:
* - echoes request as-is
* - randomly runs slowly, or exits to simulate a crash.
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
$context = new ZMQContext();
$server = new ZMQSocket($context, ZMQ::SOCKET_REP);
$server->bind("tcp://*:5555");
$cycles = 0;
while (true) {
$request = $server->recv();
$cycles++;
// Simulate various problems, after a few cycles
if ($cycles > 3 && rand(0, 3) == 0) {
echo "I: simulating a crash", PHP_EOL;
break;
} elseif ($cycles > 3 && rand(0, 3) == 0) {
echo "I: simulating CPU overload", PHP_EOL;
sleep(5);
}
printf ("I: normal request (%s)%s", $request, PHP_EOL);
sleep(1); // Do some heavy work
$server->send($request);
}
lpserver: Python 中的 Lazy Pirate 服务器
#
# Lazy Pirate server
# Binds REQ socket to tcp://*:5555
# Like hwserver except:
# - echoes request as-is
# - randomly runs slowly, or exits to simulate a crash.
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
from random import randint
import itertools
import logging
import time
import zmq
logging.basicConfig(format="%(levelname)s: %(message)s", level=logging.INFO)
context = zmq.Context()
server = context.socket(zmq.REP)
server.bind("tcp://*:5555")
for cycles in itertools.count():
request = server.recv()
# Simulate various problems, after a few cycles
if cycles > 3 and randint(0, 3) == 0:
logging.info("Simulating a crash")
break
elif cycles > 3 and randint(0, 3) == 0:
logging.info("Simulating CPU overload")
time.sleep(2)
logging.info("Normal request (%s)", request)
time.sleep(1) # Do some heavy work
server.send(request)
lpserver: Q 中的 Lazy Pirate 服务器
lpserver: Racket 中的 Lazy Pirate 服务器
lpserver: Ruby 中的 Lazy Pirate 服务器
#!/usr/bin/env ruby
# Author: Han Holl <han.holl@pobox.com>
require 'rubygems'
require 'zmq'
class LPServer
def initialize(connect)
@ctx = ZMQ::Context.new(1)
@socket = @ctx.socket(ZMQ::REP)
@socket.bind(connect)
end
def run
begin
loop do
rsl = yield @socket.recv
@socket.send rsl
end
ensure
@socket.close
@ctx.close
end
end
end
if $0 == __FILE__
cycles = 0
srand
LPServer.new(ARGV[0] || "tcp://*:5555").run do |request|
cycles += 1
if cycles > 3
if rand(3) == 0
puts "I: simulating a crash"
break
elsif rand(3) == 0
puts "I: simulating CPU overload"
sleep(3)
end
end
puts "I: normal request (#{request})"
sleep(1)
request
end
end
lpserver: Rust 中的 Lazy Pirate 服务器
use rand::{thread_rng, Rng};
use std::time::Duration;
fn main() {
let context = zmq::Context::new();
let server = context.socket(zmq::REP).unwrap();
server.bind("tcp://*:5555").unwrap();
let mut i = 0;
loop {
i += 1;
let request = server.recv_msg(0).unwrap();
println!("Got Request: {request:?}");
server.send(request, 0).unwrap();
std::thread::sleep(Duration::from_secs(1));
if (i > 3) && (thread_rng().gen_range(0..3) == 0) {
// simulate a crash
println!("Oh no! Server crashed.");
break;
}
if (i > 3) && (thread_rng().gen_range(0..3) == 0) {
// simulate overload
println!("Server is busy.");
std::thread::sleep(Duration::from_secs(2));
}
}
}
lpserver: Scala 中的 Lazy Pirate 服务器
import org.zeromq.ZMQ;
import java.util.Random;
/*
* Lazy Pirate server
* @author Zac Li
* @email zac.li.cmu@gmail.com
*/
object lpserver{
def main (args : Array[String]) {
val rand = new Random(System.nanoTime())
val context = ZMQ.context(1)
val server = context.socket(ZMQ.REP)
server.bind("tcp://*:5555")
val cycles = 0;
while (true) {
val request = server.recvStr()
cycles++
// Simulate various problems, after a few cycles
if (cycles > 3 && rand.nextInt(3) == 0) {
println("I: simulating a crash")
break
} else if (cycles > 3 && rand.nextInt(3) == 0) {
println("I: simulating CPU overload")
Thread.sleep(2000)
}
println(f"I: normal request (%s)\n", request)
Thread.sleep(1000)
server.send(request)
}
server close()
context term()
}
}lpserver: Tcl 中的 Lazy Pirate 服务器
#
# Lazy Pirate server
# Binds REQ socket to tcp://*:5555
# Like hwserver except:
# - echoes request as-is
# - randomly runs slowly, or exits to simulate a crash.
#
package require zmq
expr {srand([pid])}
zmq context context
zmq socket server context REP
server bind "tcp://*:5555"
set cycles 0
while {1} {
set request [server recv]
incr cycles
# Simulate various problems, after a few cycles
if {$cycles > 3 && int(rand()*3) == 0} {
puts "I: simulating a crash"
break;
} elseif {$cycles > 3 && int(rand()*3) == 0} {
puts "I: simulating CPU overload"
after 2000
}
puts "I: normal request ($request)"
after 1000 ;# Do some heavy work
server send $request
}
server close
context term
lpserver: OCaml 中的 Lazy Pirate 服务器
要运行此测试用例,请在两个控制台窗口中分别启动客户端和服务器。服务器将在发送几条消息后随机出现异常行为。你可以检查客户端的响应。以下是服务器的典型输出:
I: normal request (1)
I: normal request (2)
I: normal request (3)
I: simulating CPU overload
I: normal request (4)
I: simulating a crash
以下是客户端的响应:
I: connecting to server...
I: server replied OK (1)
I: server replied OK (2)
I: server replied OK (3)
W: no response from server, retrying...
I: connecting to server...
W: no response from server, retrying...
I: connecting to server...
E: server seems to be offline, abandoning
客户端对每条消息进行编号,并检查回复是否完全按顺序返回:确保没有请求或回复丢失,也没有回复返回多次或乱序。多运行几次测试,直到你确信这个机制确实有效。在生产应用中不需要序号;它们只是帮助我们验证我们的设计。
客户端使用 REQ 套接字,并执行暴力关闭/重新打开操作,因为 REQ 套接字强制执行严格的发送/接收循环。你可能会想使用 DEALER 代替,但这并不是一个好主意。首先,这意味着你需要模拟 REQ 在 envelope(信封)方面做的特殊处理(如果你忘了那是什么,这说明你不想自己去实现它)。其次,这意味着你可能会收到意料之外的回复。
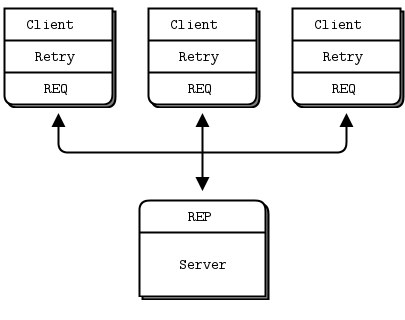
仅在客户端处理失败的情况适用于一组客户端与单个服务器通信的场景。它可以处理服务器崩溃,但仅限于恢复意味着重新启动同一台服务器的情况。如果存在永久性错误,例如服务器硬件电源故障,这种方法将不起作用。由于服务器中的应用程序代码通常是任何架构中最大的故障源,因此依赖于单个服务器并非明智之举。
所以,优缺点:
- 优点:易于理解和实现。
- 优点:易于与现有客户端和服务器应用程序代码一起工作。
- 优点:ZeroMQ 会自动重试实际的重连直到成功。
- 缺点:不会故障转移到备用或备选服务器。
基本可靠排队 (Simple Pirate 模式) #
我们的第二种方法是在 Lazy Pirate 模式的基础上扩展一个队列代理,该代理允许我们透明地与多个服务器通信,我们可以更准确地称这些服务器为“worker”。我们将分阶段开发这个模式,从一个最简工作模型 Simple Pirate 模式开始。
在所有这些 Pirate 模式中,worker 都是无状态的。如果应用程序需要一些共享状态,例如共享数据库,我们在设计消息框架时并不知道这些。拥有一个队列代理意味着 worker 可以随时加入和离开,而客户端对此一无所知。如果一个 worker 死了,另一个会接管。这是一个不错、简单的拓扑结构,只有一个真正的弱点,那就是中心队列本身,它可能变得难以管理,并成为单点故障。
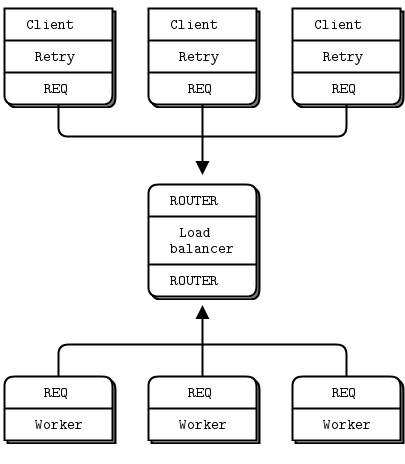
队列代理的基础是 第三章 - 高级请求-回复模式 中的负载均衡代理。为了处理死亡或阻塞的 worker,我们需要做最少的事情是什么?结果是,出乎意料地少。客户端已经有了重试机制。所以使用负载均衡模式会工作得很好。这符合 ZeroMQ 的哲学,即我们可以通过在中间插入简单的代理来扩展请求-回复这样的点对点模式。
我们不需要特殊的客户端;我们仍然使用 Lazy Pirate 客户端。以下是队列,它与负载均衡代理的主要任务完全相同:
spqueue: Ada 中的 Simple Pirate 队列
spqueue: Basic 中的 Simple Pirate 队列
spqueue: C 中的 Simple Pirate 队列
// Simple Pirate broker
// This is identical to load-balancing pattern, with no reliability
// mechanisms. It depends on the client for recovery. Runs forever.
#include "czmq.h"
#define WORKER_READY "\001" // Signals worker is ready
int main (void)
{
zctx_t *ctx = zctx_new ();
void *frontend = zsocket_new (ctx, ZMQ_ROUTER);
void *backend = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_bind (frontend, "tcp://*:5555"); // For clients
zsocket_bind (backend, "tcp://*:5556"); // For workers
// Queue of available workers
zlist_t *workers = zlist_new ();
// The body of this example is exactly the same as lbbroker2.
// .skip
while (true) {
zmq_pollitem_t items [] = {
{ backend, 0, ZMQ_POLLIN, 0 },
{ frontend, 0, ZMQ_POLLIN, 0 }
};
// Poll frontend only if we have available workers
int rc = zmq_poll (items, zlist_size (workers)? 2: 1, -1);
if (rc == -1)
break; // Interrupted
// Handle worker activity on backend
if (items [0].revents & ZMQ_POLLIN) {
// Use worker identity for load-balancing
zmsg_t *msg = zmsg_recv (backend);
if (!msg)
break; // Interrupted
zframe_t *identity = zmsg_unwrap (msg);
zlist_append (workers, identity);
// Forward message to client if it's not a READY
zframe_t *frame = zmsg_first (msg);
if (memcmp (zframe_data (frame), WORKER_READY, 1) == 0)
zmsg_destroy (&msg);
else
zmsg_send (&msg, frontend);
}
if (items [1].revents & ZMQ_POLLIN) {
// Get client request, route to first available worker
zmsg_t *msg = zmsg_recv (frontend);
if (msg) {
zmsg_wrap (msg, (zframe_t *) zlist_pop (workers));
zmsg_send (&msg, backend);
}
}
}
// When we're done, clean up properly
while (zlist_size (workers)) {
zframe_t *frame = (zframe_t *) zlist_pop (workers);
zframe_destroy (&frame);
}
zlist_destroy (&workers);
zctx_destroy (&ctx);
return 0;
// .until
}
spqueue: C++ 中的 Simple Pirate 队列
//
// Simple Pirate queue
// This is identical to the LRU pattern, with no reliability mechanisms
// at all. It depends on the client for recovery. Runs forever.
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at
#include "zmsg.hpp"
#include <queue>
#define MAX_WORKERS 100
int main (void)
{
s_version_assert (2, 1);
// Prepare our context and sockets
zmq::context_t context(1);
zmq::socket_t frontend (context, ZMQ_ROUTER);
zmq::socket_t backend (context, ZMQ_ROUTER);
frontend.bind("tcp://*:5555"); // For clients
backend.bind("tcp://*:5556"); // For workers
// Queue of available workers
std::queue<std::string> worker_queue;
while (1) {
zmq::pollitem_t items [] = {
{ backend, 0, ZMQ_POLLIN, 0 },
{ frontend, 0, ZMQ_POLLIN, 0 }
};
// Poll frontend only if we have available workers
if (worker_queue.size())
zmq::poll (items, 2, -1);
else
zmq::poll (items, 1, -1);
// Handle worker activity on backend
if (items [0].revents & ZMQ_POLLIN) {
zmsg zm(backend);
//zmsg_t *zmsg = zmsg_recv (backend);
// Use worker address for LRU routing
assert (worker_queue.size() < MAX_WORKERS);
worker_queue.push(zm.unwrap());
// Return reply to client if it's not a READY
if (strcmp (zm.address(), "READY") == 0)
zm.clear();
else
zm.send (frontend);
}
if (items [1].revents & ZMQ_POLLIN) {
// Now get next client request, route to next worker
zmsg zm(frontend);
// REQ socket in worker needs an envelope delimiter
zm.wrap(worker_queue.front().c_str(), "");
zm.send(backend);
// Dequeue and drop the next worker address
worker_queue.pop();
}
}
// We never exit the main loop
return 0;
}
spqueue: C# 中的 Simple Pirate 队列
spqueue: CL 中的 Simple Pirate 队列
spqueue: Delphi 中的 Simple Pirate 队列
program spqueue;
//
// Simple Pirate broker
// This is identical to load-balancing pattern, with no reliability
// mechanisms. It depends on the client for recovery. Runs forever.
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
;
const
WORKER_READY = '\001'; // Signals worker is ready
var
ctx: TZMQContext;
frontend,
backend: TZMQSocket;
workers: TZMQMsg;
poller: TZMQPoller;
pc: Integer;
msg: TZMQMsg;
identity,
frame: TZMQFrame;
begin
ctx := TZMQContext.create;
frontend := ctx.Socket( stRouter );
backend := ctx.Socket( stRouter );
frontend.bind( 'tcp://*:5555' ); // For clients
backend.bind( 'tcp://*:5556' ); // For workers
// Queue of available workers
workers := TZMQMsg.create;
poller := TZMQPoller.Create( true );
poller.Register( backend, [pePollIn] );
poller.Register( frontend, [pePollIn] );
// The body of this example is exactly the same as lbbroker2.
while not ctx.Terminated do
try
// Poll frontend only if we have available workers
if workers.size > 0 then
pc := 2
else
pc := 1;
poller.poll( 1000, pc );
// Handle worker activity on backend
if pePollIn in poller.PollItem[0].revents then
begin
// Use worker identity for load-balancing
backend.recv( msg );
identity := msg.unwrap;
workers.add( identity );
// Forward message to client if it's not a READY
frame := msg.first;
if frame.asUtf8String = WORKER_READY then
begin
msg.Free;
msg := nil;
end else
frontend.send( msg );
end;
if pePollIn in poller.PollItem[1].revents then
begin
// Get client request, route to first available worker
frontend.recv( msg );
msg.wrap( workers.pop );
backend.send( msg );
end;
except
end;
workers.Free;
ctx.Free;
end.
spqueue: Erlang 中的 Simple Pirate 队列
spqueue: Elixir 中的 Simple Pirate 队列
spqueue: F# 中的 Simple Pirate 队列
spqueue: Felix 中的 Simple Pirate 队列
spqueue: Go 中的 Simple Pirate 队列
// Simple Pirate broker
// This is identical to load-balancing pattern, with no reliability
// mechanisms. It depends on the client for recovery. Runs forever.
//
// Author: iano <scaly.iano@gmail.com>
// Based on C & Python example
package main
import (
zmq "github.com/alecthomas/gozmq"
)
const LRU_READY = "\001"
func main() {
context, _ := zmq.NewContext()
defer context.Close()
frontend, _ := context.NewSocket(zmq.ROUTER)
defer frontend.Close()
frontend.Bind("tcp://*:5555") // For clients
backend, _ := context.NewSocket(zmq.ROUTER)
defer backend.Close()
backend.Bind("tcp://*:5556") // For workers
// Queue of available workers
workers := make([][]byte, 0, 0)
for {
items := zmq.PollItems{
zmq.PollItem{Socket: backend, Events: zmq.POLLIN},
zmq.PollItem{Socket: frontend, Events: zmq.POLLIN},
}
// Poll frontend only if we have available workers
if len(workers) > 0 {
zmq.Poll(items, -1)
} else {
zmq.Poll(items[:1], -1)
}
// Handle worker activity on backend
if items[0].REvents&zmq.POLLIN != 0 {
// Use worker identity for load-balancing
msg, err := backend.RecvMultipart(0)
if err != nil {
panic(err) // Interrupted
}
address := msg[0]
workers = append(workers, address)
// Forward message to client if it's not a READY
if reply := msg[2:]; string(reply[0]) != LRU_READY {
frontend.SendMultipart(reply, 0)
}
}
if items[1].REvents&zmq.POLLIN != 0 {
// Get client request, route to first available worker
msg, err := frontend.RecvMultipart(0)
if err != nil {
panic(err) // Interrupted
}
last := workers[len(workers)-1]
workers = workers[:len(workers)-1]
request := append([][]byte{last, nil}, msg...)
backend.SendMultipart(request, 0)
}
}
}
spqueue: Haskell 中的 Simple Pirate 队列
{--
Simple Pirate queue in Haskell
--}
module Main where
import System.ZMQ4.Monadic
import Control.Concurrent (threadDelay)
import Control.Applicative ((<$>))
import Control.Monad (when)
import Data.ByteString.Char8 (pack, unpack, empty)
import Data.List (intercalate)
type SockID = String
workerReady = "\001"
main :: IO ()
main =
runZMQ $ do
frontend <- socket Router
bind frontend "tcp://*:5555"
backend <- socket Router
bind backend "tcp://*:5556"
pollPeers frontend backend []
pollPeers :: Socket z Router -> Socket z Router -> [SockID] -> ZMQ z ()
pollPeers frontend backend workers = do
let toPoll = getPollList workers
evts <- poll 0 toPoll
workers' <- getBackend backend frontend evts workers
workers'' <- getFrontend frontend backend evts workers'
pollPeers frontend backend workers''
where getPollList [] = [Sock backend [In] Nothing]
getPollList _ = [Sock backend [In] Nothing, Sock frontend [In] Nothing]
getBackend :: Socket z Router -> Socket z Router ->
[[Event]] -> [SockID] -> ZMQ z ([SockID])
getBackend backend frontend evts workers =
if (In `elem` (evts !! 0))
then do
wkrID <- receive backend
id <- (receive backend >> receive backend)
msg <- (receive backend >> receive backend)
when ((unpack msg) /= workerReady) $ do
liftIO $ putStrLn $ "I: sending backend - " ++ (unpack msg)
send frontend [SendMore] id
send frontend [SendMore] empty
send frontend [] msg
return $ (unpack wkrID):workers
else return workers
getFrontend :: Socket z Router -> Socket z Router ->
[[Event]] -> [SockID] -> ZMQ z [SockID]
getFrontend frontend backend evts workers =
if (length evts > 1 && In `elem` (evts !! 1))
then do
id <- receive frontend
msg <- (receive frontend >> receive frontend)
liftIO $ putStrLn $ "I: msg on frontend - " ++ (unpack msg)
let wkrID = head workers
send backend [SendMore] (pack wkrID)
send backend [SendMore] empty
send backend [SendMore] id
send backend [SendMore] empty
send backend [] msg
return $ tail workers
else return workers
spqueue: Haxe 中的 Simple Pirate 队列
package ;
import haxe.Stack;
import neko.Lib;
import org.zeromq.ZFrame;
import org.zeromq.ZContext;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQ;
import org.zeromq.ZMsg;
import org.zeromq.ZMQException;
/**
* Simple Pirate queue
* This is identical to the LRU pattern, with no reliability mechanisms
* at all. It depends on the client for recovery. Runs forever.
*
* @see https://zguide.zeromq.cn/page:all#Basic-Reliable-Queuing-Simple-Pirate-Pattern
*/
class SPQueue
{
// Signals workers are ready
private static inline var LRU_READY:String = String.fromCharCode(1);
public static function main() {
Lib.println("** SPQueue (see: https://zguide.zeromq.cn/page:all#Basic-Reliable-Queuing-Simple-Pirate-Pattern)");
// Prepare our context and sockets
var context:ZContext = new ZContext();
var frontend:ZMQSocket = context.createSocket(ZMQ_ROUTER);
var backend:ZMQSocket = context.createSocket(ZMQ_ROUTER);
frontend.bind("tcp://*:5555"); // For clients
backend.bind("tcp://*:5556"); // For workers
// Queue of available workers
var workerQueue:List<ZFrame> = new List<ZFrame>();
var poller:ZMQPoller = new ZMQPoller();
poller.registerSocket(backend, ZMQ.ZMQ_POLLIN());
while (true) {
poller.unregisterSocket(frontend);
if (workerQueue.length > 0) {
// Only poll frontend if there is at least 1 worker ready to do work
poller.registerSocket(frontend, ZMQ.ZMQ_POLLIN());
}
try {
poller.poll( -1 );
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
if (poller.pollin(1)) {
// Use worker address for LRU routing
var msg = ZMsg.recvMsg(backend);
if (msg == null)
break; // Interrupted
var address = msg.unwrap();
workerQueue.add(address);
// Forward message to client if it's not a READY
var frame = msg.first();
if (frame.streq(LRU_READY))
msg.destroy();
else
msg.send(frontend);
}
if (poller.pollin(2)) {
// Get client request, route to first available worker
var msg = ZMsg.recvMsg(frontend);
if (msg != null) {
msg.wrap(workerQueue.pop());
msg.send(backend);
}
}
}
// When we're done, clean up properly
for (f in workerQueue) {
f.destroy();
}
context.destroy();
}
}spqueue: Java 中的 Simple Pirate 队列
package guide;
import java.util.ArrayList;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
//
// Simple Pirate queue
// This is identical to load-balancing pattern, with no reliability mechanisms
// at all. It depends on the client for recovery. Runs forever.
//
public class spqueue
{
private final static String WORKER_READY = "\001"; // Signals worker is ready
public static void main(String[] args)
{
try (ZContext ctx = new ZContext()) {
Socket frontend = ctx.createSocket(SocketType.ROUTER);
Socket backend = ctx.createSocket(SocketType.ROUTER);
frontend.bind("tcp://*:5555"); // For clients
backend.bind("tcp://*:5556"); // For workers
// Queue of available workers
ArrayList<ZFrame> workers = new ArrayList<ZFrame>();
Poller poller = ctx.createPoller(2);
poller.register(backend, Poller.POLLIN);
poller.register(frontend, Poller.POLLIN);
// The body of this example is exactly the same as lruqueue2.
while (true) {
boolean workersAvailable = workers.size() > 0;
int rc = poller.poll(-1);
// Poll frontend only if we have available workers
if (rc == -1)
break; // Interrupted
// Handle worker activity on backend
if (poller.pollin(0)) {
// Use worker address for LRU routing
ZMsg msg = ZMsg.recvMsg(backend);
if (msg == null)
break; // Interrupted
ZFrame address = msg.unwrap();
workers.add(address);
// Forward message to client if it's not a READY
ZFrame frame = msg.getFirst();
if (new String(frame.getData(), ZMQ.CHARSET).equals(WORKER_READY))
msg.destroy();
else msg.send(frontend);
}
if (workersAvailable && poller.pollin(1)) {
// Get client request, route to first available worker
ZMsg msg = ZMsg.recvMsg(frontend);
if (msg != null) {
msg.wrap(workers.remove(0));
msg.send(backend);
}
}
}
// When we're done, clean up properly
while (workers.size() > 0) {
ZFrame frame = workers.remove(0);
frame.destroy();
}
workers.clear();
}
}
}
spqueue: Julia 中的 Simple Pirate 队列
spqueue: Lua 中的 Simple Pirate 队列
--
-- Simple Pirate queue
-- This is identical to the LRU pattern, with no reliability mechanisms
-- at all. It depends on the client for recovery. Runs forever.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.poller"
require"zhelpers"
require"zmsg"
local tremove = table.remove
local MAX_WORKERS = 100
s_version_assert (2, 1)
-- Prepare our context and sockets
local context = zmq.init(1)
local frontend = context:socket(zmq.ROUTER)
local backend = context:socket(zmq.ROUTER)
frontend:bind("tcp://*:5555"); -- For clients
backend:bind("tcp://*:5556"); -- For workers
-- Queue of available workers
local worker_queue = {}
local is_accepting = false
local poller = zmq.poller(2)
local function frontend_cb()
-- Now get next client request, route to next worker
local msg = zmsg.recv (frontend)
-- Dequeue a worker from the queue.
local worker = tremove(worker_queue, 1)
msg:wrap(worker, "")
msg:send(backend)
if (#worker_queue == 0) then
-- stop accepting work from clients, when no workers are available.
poller:remove(frontend)
is_accepting = false
end
end
-- Handle worker activity on backend
poller:add(backend, zmq.POLLIN, function()
local msg = zmsg.recv(backend)
-- Use worker address for LRU routing
worker_queue[#worker_queue + 1] = msg:unwrap()
-- start accepting client requests, if we are not already doing so.
if not is_accepting then
is_accepting = true
poller:add(frontend, zmq.POLLIN, frontend_cb)
end
-- Forward message to client if it's not a READY
if (msg:address() ~= "READY") then
msg:send(frontend)
end
end)
-- start poller's event loop
poller:start()
-- We never exit the main loop
spqueue: Node.js 中的 Simple Pirate 队列
spqueue: Objective-C 中的 Simple Pirate 队列
spqueue: ooc 中的 Simple Pirate 队列
spqueue: Perl 中的 Simple Pirate 队列
spqueue: PHP 中的 Simple Pirate 队列
<?php
/*
* Simple Pirate queue
* This is identical to the LRU pattern, with no reliability mechanisms
* at all. It depends on the client for recovery. Runs forever.
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
define("MAX_WORKERS", 100);
// Prepare our context and sockets
$context = new ZMQContext();
$frontend = $context->getSocket(ZMQ::SOCKET_ROUTER);
$backend = $context->getSocket(ZMQ::SOCKET_ROUTER);
$frontend->bind("tcp://*:5555"); // For clients
$backend->bind("tcp://*:5556"); // For workers
// Queue of available workers
$available_workers = 0;
$worker_queue = array();
$read = $write = array();
while (true) {
$poll = new ZMQPoll();
$poll->add($backend, ZMQ::POLL_IN);
// Poll frontend only if we have available workers
if ($available_workers) {
$poll->add($frontend, ZMQ::POLL_IN);
}
$events = $poll->poll($read, $write);
foreach ($read as $socket) {
$zmsg = new Zmsg($socket);
$zmsg->recv();
// Handle worker activity on backend
if ($socket === $backend) {
// Use worker address for LRU routing
assert($available_workers < MAX_WORKERS);
array_push($worker_queue, $zmsg->unwrap());
$available_workers++;
// Return reply to client if it's not a READY
if ($zmsg->address() != "READY") {
$zmsg->set_socket($frontend)->send();
}
} elseif ($socket === $frontend) {
// Now get next client request, route to next worker
// REQ socket in worker needs an envelope delimiter
// Dequeue and drop the next worker address
$zmsg->wrap(array_shift($worker_queue), "");
$zmsg->set_socket($backend)->send();
$available_workers--;
}
}
// We never exit the main loop
}
spqueue: Python 中的 Simple Pirate 队列
#
# Simple Pirate queue
# This is identical to the LRU pattern, with no reliability mechanisms
# at all. It depends on the client for recovery. Runs forever.
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
import zmq
LRU_READY = "\x01"
context = zmq.Context(1)
frontend = context.socket(zmq.ROUTER) # ROUTER
backend = context.socket(zmq.ROUTER) # ROUTER
frontend.bind("tcp://*:5555") # For clients
backend.bind("tcp://*:5556") # For workers
poll_workers = zmq.Poller()
poll_workers.register(backend, zmq.POLLIN)
poll_both = zmq.Poller()
poll_both.register(frontend, zmq.POLLIN)
poll_both.register(backend, zmq.POLLIN)
workers = []
while True:
if workers:
socks = dict(poll_both.poll())
else:
socks = dict(poll_workers.poll())
# Handle worker activity on backend
if socks.get(backend) == zmq.POLLIN:
# Use worker address for LRU routing
msg = backend.recv_multipart()
if not msg:
break
address = msg[0]
workers.append(address)
# Everything after the second (delimiter) frame is reply
reply = msg[2:]
# Forward message to client if it's not a READY
if reply[0] != LRU_READY:
frontend.send_multipart(reply)
if socks.get(frontend) == zmq.POLLIN:
# Get client request, route to first available worker
msg = frontend.recv_multipart()
request = [workers.pop(0), ''.encode()] + msg
backend.send_multipart(request)
spqueue: Q 中的 Simple Pirate 队列
spqueue: Racket 中的 Simple Pirate 队列
spqueue: Ruby 中的 Simple Pirate 队列
spqueue: Rust 中的 Simple Pirate 队列
spqueue: Scala 中的 Simple Pirate 队列
spqueue: Tcl 中的 Simple Pirate 队列
#
# Simple Pirate queue
# This is identical to the LRU pattern, with no reliability mechanisms
# at all. It depends on the client for recovery. Runs forever.
#
package require zmq
set LRU_READY "READY" ;# Signals worker is ready
# Prepare our context and sockets
zmq context context
zmq socket frontend context ROUTER
zmq socket backend context ROUTER
frontend bind "tcp://*:5555" ;# For clients
backend bind "tcp://*:5556" ;# For workers
# Queue of available workers
set workers {}
while {1} {
if {[llength $workers]} {
set poll_set [list [list backend [list POLLIN]] [list frontend [list POLLIN]]]
} else {
set poll_set [list [list backend [list POLLIN]]]
}
set rpoll_set [zmq poll $poll_set -1]
foreach rpoll $rpoll_set {
switch [lindex $rpoll 0] {
backend {
# Use worker address for LRU routing
set msg [zmsg recv backend]
set address [zmsg unwrap msg]
lappend workers $address
# Forward message to client if it's not a READY
if {[lindex $msg 0] ne $LRU_READY} {
zmsg send frontend $msg
}
}
frontend {
# Get client request, route to first available worker
set msg [zmsg recv frontend]
set workers [lassign $workers worker]
set msg [zmsg wrap $msg $worker]
zmsg send backend $msg
}
}
}
}
frontend close
backend close
context term
spqueue: OCaml 中的 Simple Pirate 队列
以下是 worker,它使用了 Lazy Pirate 服务器并将其适配到负载均衡模式(使用 REQ 的“ready”信号):
spworker: Ada 中的 Simple Pirate worker
spworker: Basic 中的 Simple Pirate worker
spworker: C 中的 Simple Pirate worker
// Simple Pirate worker
// Connects REQ socket to tcp://*:5556
// Implements worker part of load-balancing
#include "czmq.h"
#define WORKER_READY "\001" // Signals worker is ready
int main (void)
{
zctx_t *ctx = zctx_new ();
void *worker = zsocket_new (ctx, ZMQ_REQ);
// Set random identity to make tracing easier
srandom ((unsigned) time (NULL));
char identity [10];
sprintf (identity, "%04X-%04X", randof (0x10000), randof (0x10000));
zmq_setsockopt (worker, ZMQ_IDENTITY, identity, strlen (identity));
zsocket_connect (worker, "tcp://:5556");
// Tell broker we're ready for work
printf ("I: (%s) worker ready\n", identity);
zframe_t *frame = zframe_new (WORKER_READY, 1);
zframe_send (&frame, worker, 0);
int cycles = 0;
while (true) {
zmsg_t *msg = zmsg_recv (worker);
if (!msg)
break; // Interrupted
// Simulate various problems, after a few cycles
cycles++;
if (cycles > 3 && randof (5) == 0) {
printf ("I: (%s) simulating a crash\n", identity);
zmsg_destroy (&msg);
break;
}
else
if (cycles > 3 && randof (5) == 0) {
printf ("I: (%s) simulating CPU overload\n", identity);
sleep (3);
if (zctx_interrupted)
break;
}
printf ("I: (%s) normal reply\n", identity);
sleep (1); // Do some heavy work
zmsg_send (&msg, worker);
}
zctx_destroy (&ctx);
return 0;
}
spworker: C++ 中的 Simple Pirate worker
//
// Simple Pirate worker
// Connects REQ socket to tcp://*:5556
// Implements worker part of LRU queueing
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
#include "zmsg.hpp"
int main (void)
{
srandom ((unsigned) time (NULL));
zmq::context_t context(1);
zmq::socket_t worker(context, ZMQ_REQ);
// Set random identity to make tracing easier
std::string identity = s_set_id(worker);
worker.connect("tcp://:5556");
// Tell queue we're ready for work
std::cout << "I: (" << identity << ") worker ready" << std::endl;
s_send (worker, std::string("READY"));
int cycles = 0;
while (1) {
zmsg zm (worker);
// Simulate various problems, after a few cycles
cycles++;
if (cycles > 3 && within (5) == 0) {
std::cout << "I: (" << identity << ") simulating a crash" << std::endl;
zm.clear ();
break;
}
else
if (cycles > 3 && within (5) == 0) {
std::cout << "I: (" << identity << ") simulating CPU overload" << std::endl;
sleep (5);
}
std::cout << "I: (" << identity << ") normal reply - " << zm.body () << std::endl;
sleep (1); // Do some heavy work
zm.send(worker);
}
return 0;
}
spworker: C# 中的 Simple Pirate worker
spworker: CL 中的 Simple Pirate worker
spworker: Delphi 中的 Simple Pirate worker
program spworker;
//
// Simple Pirate worker
// Connects REQ socket to tcp://*:5556
// Implements worker part of load-balancing
// @author Varga Balazs <bb.varga@gmail.com>
//
{$APPTYPE CONSOLE}
uses
SysUtils
, zmqapi
, zhelpers
;
const
WORKER_READY = '\001'; // Signals worker is ready
var
ctx: TZMQContext;
worker: TZMQSocket;
identity: String;
frame: TZMQFrame;
cycles: Integer;
msg: TZMQMsg;
begin
ctx := TZMQContext.create;
worker := ctx.Socket( stReq );
// Set random identity to make tracing easier
identity := s_random( 8 );
worker.Identity := identity;
worker.connect( 'tcp://:5556' );
// Tell broker we're ready for work
Writeln( Format( 'I: (%s) worker ready', [identity] ) );
frame := TZMQFrame.create;
frame.asUtf8String := WORKER_READY;
worker.send( frame );
cycles := 0;
while not ctx.Terminated do
try
worker.recv( msg );
// Simulate various problems, after a few cycles
Inc( cycles );
if ((cycles > 3) and (random(5) = 0)) then
begin
Writeln( Format( 'I: (%s) simulating a crash', [identity] ) );
msg.Free;
msg := nil;
break;
end else
if ( (cycles > 3) and (random(5) = 0) ) then
begin
Writeln( Format( 'I: (%s) simulating CPU overload', [identity] ));
sleep (3000);
end;
Writeln( Format('I: (%s) normal reply', [identity]) );
sleep(1000); // Do some heavy work
worker.send( msg );
except
end;
ctx.Free;
end.
spworker: Erlang 中的 Simple Pirate worker
spworker: Elixir 中的 Simple Pirate worker
spworker: F# 中的 Simple Pirate worker
spworker: Felix 中的 Simple Pirate worker
spworker: Go 中的 Simple Pirate worker
// Simple Pirate worker
// Connects REQ socket to tcp://*:5556
// Implements worker part of load-balancing
//
// Author: iano <scaly.iano@gmail.com>
// Based on C & Python example
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"time"
)
const LRU_READY = "\001"
func main() {
context, _ := zmq.NewContext()
defer context.Close()
worker, _ := context.NewSocket(zmq.REQ)
defer worker.Close()
// Set random identity to make tracing easier
src := rand.NewSource(time.Now().UnixNano())
random := rand.New(src)
identity := fmt.Sprintf("%04X-%04X", random.Intn(0x10000), random.Intn(0x10000))
worker.SetIdentity(identity)
worker.Connect("tcp://:5556")
// Tell broker we're ready for work
fmt.Printf("I: (%s) worker ready\n", identity)
worker.Send([]byte(LRU_READY), 0)
for cycles := 1; ; cycles++ {
msg, err := worker.RecvMultipart(0)
if err != nil {
panic(err) // Interrupted
}
if cycles > 3 {
switch r := random.Intn(5); r {
case 0:
fmt.Printf("I: (%s) simulating a crash\n", identity)
return
case 1:
fmt.Printf("I: (%s) simulating CPU overload\n", identity)
time.Sleep(3 * time.Second)
}
}
fmt.Printf("I: (%s) normal reply\n", identity)
time.Sleep(1 * time.Second) // Do some heavy work
worker.SendMultipart(msg, 0)
}
}
spworker: Haskell 中的 Simple Pirate worker
{--
Simple Pirate worker in Haskell
--}
module Main where
import System.ZMQ4.Monadic
import ZHelpers
import System.Random (randomRIO)
import System.Exit (exitSuccess)
import Control.Monad (when)
import Control.Concurrent (threadDelay)
import Control.Applicative ((<$>))
import Data.ByteString.Char8 (pack, unpack, empty)
workerReady = "\001"
main :: IO ()
main =
runZMQ $ do
worker <- socket Req
setRandomIdentity worker
connect worker "tcp://:5556"
id <- identity worker
liftIO $ putStrLn $ "I: Worker ready " ++ unpack id
send worker [SendMore] empty
send worker [SendMore] empty
send worker [] (pack workerReady)
sendRequests worker 1
sendRequests :: Socket z Req -> Int -> ZMQ z ()
sendRequests worker cycles = do
clID <- receive worker
msg <- (receive worker >> receive worker)
chance <- liftIO $ randomRIO (0::Int, 5)
id <- identity worker
if cycles > 3 && chance == 0
then do
liftIO $ putStrLn $ "I: Simulating a crash " ++ unpack id
liftIO $ exitSuccess
else do
chance' <- liftIO $ randomRIO (0::Int, 5)
when (cycles > 3 && chance' == 0) $ do
liftIO $ putStrLn $ "I: Simulating overload " ++ unpack id
liftIO $ threadDelay $ 3 * 1000 * 1000
liftIO $ putStrLn $ "I: Normal reply " ++ unpack id
liftIO $ threadDelay $ 1 * 1000 * 1000
send worker [SendMore] clID
send worker [SendMore] (pack "")
send worker [] msg
sendRequests worker (cycles+1)
spworker: Haxe 中的 Simple Pirate worker
package ;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
/**
* Simple Pirate worker
* Connects REQ socket to tcp://*:5556
* Implements worker part of LRU queuing
* @see https://zguide.zeromq.cn/page:all#Basic-Reliable-Queuing-Simple-Pirate-Pattern
*/
class SPWorker
{
// Signals workers are ready
private static inline var LRU_READY:String = String.fromCharCode(1);
public static function main() {
Lib.println("** SPWorker (see: https://zguide.zeromq.cn/page:all#Basic-Reliable-Queuing-Simple-Pirate-Pattern)");
var ctx = new ZContext();
var worker = ctx.createSocket(ZMQ_REQ);
// Set random identity to make tracing easier
var identity = ZHelpers.setID(worker);
worker.connect("tcp://:5556");
// Tell broker we're ready for work
Lib.println("I: (" + identity + ") worker ready");
ZFrame.newStringFrame(LRU_READY).send(worker);
var cycles = 0;
while (true) {
var msg = ZMsg.recvMsg(worker);
if (msg == null)
break; // Interrupted
cycles++;
// Simulate various problems, after a few cycles
if (cycles > 3 && ZHelpers.randof(5) == 0) {
Lib.println("I: simulating a crash");
break;
}
else if (cycles > 3 && ZHelpers.randof(5) == 0) {
Lib.println("I: simulating CPU overload");
Sys.sleep(3.0);
if (ZMQ.isInterrupted())
break;
}
Lib.println("I: ("+identity+") normal reply");
Sys.sleep(1.0); // Do some heavy work
msg.send(worker);
}
ctx.destroy();
}
}spworker: Java 中的 Simple Pirate worker
package guide;
import java.util.Random;
import org.zeromq.*;
import org.zeromq.ZMQ.Socket;
//
// Simple Pirate worker
// Connects REQ socket to tcp://*:5556
// Implements worker part of load-balancing queueing
//
public class spworker
{
private final static String WORKER_READY = "\001"; // Signals worker is ready
public static void main(String[] args) throws Exception
{
try (ZContext ctx = new ZContext()) {
Socket worker = ctx.createSocket(SocketType.REQ);
// Set random identity to make tracing easier
Random rand = new Random(System.nanoTime());
String identity = String.format(
"%04X-%04X", rand.nextInt(0x10000), rand.nextInt(0x10000)
);
worker.setIdentity(identity.getBytes(ZMQ.CHARSET));
worker.connect("tcp://:5556");
// Tell broker we're ready for work
System.out.printf("I: (%s) worker ready\n", identity);
ZFrame frame = new ZFrame(WORKER_READY);
frame.send(worker, 0);
int cycles = 0;
while (true) {
ZMsg msg = ZMsg.recvMsg(worker);
if (msg == null)
break; // Interrupted
// Simulate various problems, after a few cycles
cycles++;
if (cycles > 3 && rand.nextInt(5) == 0) {
System.out.printf("I: (%s) simulating a crash\n", identity);
msg.destroy();
break;
}
else if (cycles > 3 && rand.nextInt(5) == 0) {
System.out.printf(
"I: (%s) simulating CPU overload\n", identity
);
Thread.sleep(3000);
}
System.out.printf("I: (%s) normal reply\n", identity);
Thread.sleep(1000); // Do some heavy work
msg.send(worker);
}
}
}
}
spworker: Julia 中的 Simple Pirate worker
spworker: Lua 中的 Simple Pirate worker
--
-- Simple Pirate worker
-- Connects REQ socket to tcp://*:5556
-- Implements worker part of LRU queueing
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmsg"
math.randomseed(os.time())
local context = zmq.init(1)
local worker = context:socket(zmq.REQ)
-- Set random identity to make tracing easier
local identity = string.format("%04X-%04X", randof (0x10000), randof (0x10000))
worker:setopt(zmq.IDENTITY, identity)
worker:connect("tcp://:5556")
-- Tell queue we're ready for work
printf ("I: (%s) worker ready\n", identity)
worker:send("READY")
local cycles = 0
while true do
local msg = zmsg.recv (worker)
-- Simulate various problems, after a few cycles
cycles = cycles + 1
if (cycles > 3 and randof (5) == 0) then
printf ("I: (%s) simulating a crash\n", identity)
break
elseif (cycles > 3 and randof (5) == 0) then
printf ("I: (%s) simulating CPU overload\n", identity)
s_sleep (5000)
end
printf ("I: (%s) normal reply - %s\n",
identity, msg:body())
s_sleep (1000) -- Do some heavy work
msg:send(worker)
end
worker:close()
context:term()
spworker: Node.js 中的 Simple Pirate worker
spworker: Objective-C 中的 Simple Pirate worker
spworker: ooc 中的 Simple Pirate worker
spworker: Perl 中的 Simple Pirate worker
spworker: PHP 中的 Simple Pirate worker
<?php
/*
* Simple Pirate worker
* Connects REQ socket to tcp://*:5556
* Implements worker part of LRU queueing
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
$context = new ZMQContext();
$worker = new ZMQSocket($context, ZMQ::SOCKET_REQ);
// Set random identity to make tracing easier
$identity = sprintf ("%04X-%04X", rand(0, 0x10000), rand(0, 0x10000));
$worker->setSockOpt(ZMQ::SOCKOPT_IDENTITY, $identity);
$worker->connect("tcp://:5556");
// Tell queue we're ready for work
printf ("I: (%s) worker ready%s", $identity, PHP_EOL);
$worker->send("READY");
$cycles = 0;
while (true) {
$zmsg = new Zmsg($worker);
$zmsg->recv();
$cycles++;
// Simulate various problems, after a few cycles
if ($cycles > 3 && rand(0, 3) == 0) {
printf ("I: (%s) simulating a crash%s", $identity, PHP_EOL);
break;
} elseif ($cycles > 3 && rand(0, 3) == 0) {
printf ("I: (%s) simulating CPU overload%s", $identity, PHP_EOL);
sleep(5);
}
printf ("I: (%s) normal reply - %s%s", $identity, $zmsg->body(), PHP_EOL);
sleep(1); // Do some heavy work
$zmsg->send();
}
spworker: Python 中的 Simple Pirate worker
#
# Simple Pirate worker
# Connects REQ socket to tcp://*:5556
# Implements worker part of LRU queueing
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
from random import randint
import time
import zmq
LRU_READY = "\x01"
context = zmq.Context(1)
worker = context.socket(zmq.REQ)
identity = "%04X-%04X" % (randint(0, 0x10000), randint(0,0x10000))
worker.setsockopt_string(zmq.IDENTITY, identity)
worker.connect("tcp://:5556")
print("I: (%s) worker ready" % identity)
worker.send_string(LRU_READY)
cycles = 0
while True:
msg = worker.recv_multipart()
if not msg:
break
cycles += 1
if cycles>0 and randint(0, 5) == 0:
print("I: (%s) simulating a crash" % identity)
break
elif cycles>3 and randint(0, 5) == 0:
print("I: (%s) simulating CPU overload" % identity)
time.sleep(3)
print("I: (%s) normal reply" % identity)
time.sleep(1) # Do some heavy work
worker.send_multipart(msg)spworker: Q 中的 Simple Pirate worker
spworker: Racket 中的 Simple Pirate worker
spworker: Ruby 中的 Simple Pirate worker
spworker: Rust 中的 Simple Pirate worker
spworker: Scala 中的 Simple Pirate worker
spworker: Tcl 中的 Simple Pirate worker
#
# Simple Pirate worker
# Connects REQ socket to tcp://*:5556
# Implements worker part of LRU queueing
#
package require zmq
set LRU_READY "READY" ;# Signals worker is ready
expr {srand([pid])}
zmq context context
zmq socket worker context REQ
# Set random identity to make tracing easier
set identity [format "%04X-%04X" [expr {int(rand()*0x10000)}] [expr {int(rand()*0x10000)}]]
worker setsockopt IDENTITY $identity
worker connect "tcp://:5556"
# Tell broker we're ready for work
puts "I: ($identity) worker ready"
worker send $LRU_READY
set cycles 0
while {1} {
set msg [zmsg recv worker]
# Simulate various problems, after a few cycles
incr cycles
if {$cycles > 3 && [expr {int(rand()*5)}] == 0} {
puts "I: ($identity) simulating a crash"
break
} elseif {$cycles > 3 && [expr {int(rand()*5)}] == 0} {
puts "I: ($identity) simulating CPU overload"
after 3000
}
puts "I: ($identity) normal reply"
after 1000 ;# Do some heavy work
zmsg send worker $msg
}
worker close
context term
spworker: OCaml 中的 Simple Pirate worker
为了测试这个模式,启动几个 worker、一个 Lazy Pirate 客户端和一个队列,顺序不限。你会看到 worker 最终都会崩溃,然后客户端会重试并最终放弃。队列永远不会停止,你可以反复重启 worker 和客户端。这个模型适用于任意数量的客户端和 worker。
健壮可靠排队 (Paranoid Pirate 模式) #
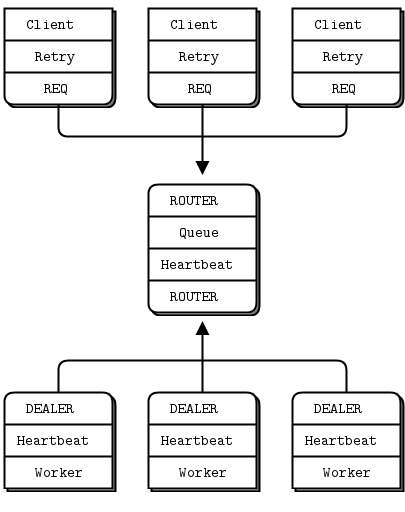
Simple Pirate 队列模式运行得相当不错,尤其因为它只是两个现有模式的组合。尽管如此,它确实有一些弱点:
-
它在队列崩溃并重启时不够健壮。客户端会恢复,但 worker 不会。虽然 ZeroMQ 会自动重连 worker 的套接字,但对于新启动的队列来说,worker 没有发送准备信号,所以它们似乎不存在。要解决这个问题,我们必须从队列向 worker 发送心跳,以便 worker 能检测到队列何时消失。
-
队列无法检测到工作器故障,因此如果工作器在空闲时死亡,队列无法将其从工作器队列中移除,直到队列向其发送请求。客户端白白等待和重试。这虽然不是一个关键问题,但也不好。为了使其正常工作,我们让工作器向队列发送心跳,以便队列可以在任何阶段检测到丢失的工作器。
我们将在一个恰当而严谨的偏执海盗模式(Paranoid Pirate Pattern)中修复这些问题。
之前我们为工作器使用了 REQ 套接字。对于偏执海盗工作器,我们将切换到 DEALER 套接字。这样做的好处是允许我们随时发送和接收消息,而不是像 REQ 那样强制同步的发送/接收。DEALER 的缺点是我们必须自己进行信封管理(请重新阅读 第 3 章 - 高级请求-回复模式 以了解此概念的背景)。
我们仍然使用懒惰海盗客户端。这是偏执海盗队列代理:
ppqueue:Ada 中的偏执海盗队列
ppqueue:Basic 中的偏执海盗队列
ppqueue:C 中的偏执海盗队列
// Paranoid Pirate queue
#include "czmq.h"
#define HEARTBEAT_LIVENESS 3 // 3-5 is reasonable
#define HEARTBEAT_INTERVAL 1000 // msecs
// Paranoid Pirate Protocol constants
#define PPP_READY "\001" // Signals worker is ready
#define PPP_HEARTBEAT "\002" // Signals worker heartbeat
// .split worker class structure
// Here we define the worker class; a structure and a set of functions that
// act as constructor, destructor, and methods on worker objects:
typedef struct {
zframe_t *identity; // Identity of worker
char *id_string; // Printable identity
int64_t expiry; // Expires at this time
} worker_t;
// Construct new worker
static worker_t *
s_worker_new (zframe_t *identity)
{
worker_t *self = (worker_t *) zmalloc (sizeof (worker_t));
self->identity = identity;
self->id_string = zframe_strhex (identity);
self->expiry = zclock_time ()
+ HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
return self;
}
// Destroy specified worker object, including identity frame.
static void
s_worker_destroy (worker_t **self_p)
{
assert (self_p);
if (*self_p) {
worker_t *self = *self_p;
zframe_destroy (&self->identity);
free (self->id_string);
free (self);
*self_p = NULL;
}
}
// .split worker ready method
// The ready method puts a worker to the end of the ready list:
static void
s_worker_ready (worker_t *self, zlist_t *workers)
{
worker_t *worker = (worker_t *) zlist_first (workers);
while (worker) {
if (streq (self->id_string, worker->id_string)) {
zlist_remove (workers, worker);
s_worker_destroy (&worker);
break;
}
worker = (worker_t *) zlist_next (workers);
}
zlist_append (workers, self);
}
// .split get next available worker
// The next method returns the next available worker identity:
static zframe_t *
s_workers_next (zlist_t *workers)
{
worker_t *worker = zlist_pop (workers);
assert (worker);
zframe_t *frame = worker->identity;
worker->identity = NULL;
s_worker_destroy (&worker);
return frame;
}
// .split purge expired workers
// The purge method looks for and kills expired workers. We hold workers
// from oldest to most recent, so we stop at the first alive worker:
static void
s_workers_purge (zlist_t *workers)
{
worker_t *worker = (worker_t *) zlist_first (workers);
while (worker) {
if (zclock_time () < worker->expiry)
break; // Worker is alive, we're done here
zlist_remove (workers, worker);
s_worker_destroy (&worker);
worker = (worker_t *) zlist_first (workers);
}
}
// .split main task
// The main task is a load-balancer with heartbeating on workers so we
// can detect crashed or blocked worker tasks:
int main (void)
{
zctx_t *ctx = zctx_new ();
void *frontend = zsocket_new (ctx, ZMQ_ROUTER);
void *backend = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_bind (frontend, "tcp://*:5555"); // For clients
zsocket_bind (backend, "tcp://*:5556"); // For workers
// List of available workers
zlist_t *workers = zlist_new ();
// Send out heartbeats at regular intervals
uint64_t heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
while (true) {
zmq_pollitem_t items [] = {
{ backend, 0, ZMQ_POLLIN, 0 },
{ frontend, 0, ZMQ_POLLIN, 0 }
};
// Poll frontend only if we have available workers
int rc = zmq_poll (items, zlist_size (workers)? 2: 1,
HEARTBEAT_INTERVAL * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
// Handle worker activity on backend
if (items [0].revents & ZMQ_POLLIN) {
// Use worker identity for load-balancing
zmsg_t *msg = zmsg_recv (backend);
if (!msg)
break; // Interrupted
// Any sign of life from worker means it's ready
zframe_t *identity = zmsg_unwrap (msg);
worker_t *worker = s_worker_new (identity);
s_worker_ready (worker, workers);
// Validate control message, or return reply to client
if (zmsg_size (msg) == 1) {
zframe_t *frame = zmsg_first (msg);
if (memcmp (zframe_data (frame), PPP_READY, 1)
&& memcmp (zframe_data (frame), PPP_HEARTBEAT, 1)) {
printf ("E: invalid message from worker");
zmsg_dump (msg);
}
zmsg_destroy (&msg);
}
else
zmsg_send (&msg, frontend);
}
if (items [1].revents & ZMQ_POLLIN) {
// Now get next client request, route to next worker
zmsg_t *msg = zmsg_recv (frontend);
if (!msg)
break; // Interrupted
zframe_t *identity = s_workers_next (workers);
zmsg_prepend (msg, &identity);
zmsg_send (&msg, backend);
}
// .split handle heartbeating
// We handle heartbeating after any socket activity. First, we send
// heartbeats to any idle workers if it's time. Then, we purge any
// dead workers:
if (zclock_time () >= heartbeat_at) {
worker_t *worker = (worker_t *) zlist_first (workers);
while (worker) {
zframe_send (&worker->identity, backend,
ZFRAME_REUSE + ZFRAME_MORE);
zframe_t *frame = zframe_new (PPP_HEARTBEAT, 1);
zframe_send (&frame, backend, 0);
worker = (worker_t *) zlist_next (workers);
}
heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
}
s_workers_purge (workers);
}
// When we're done, clean up properly
while (zlist_size (workers)) {
worker_t *worker = (worker_t *) zlist_pop (workers);
s_worker_destroy (&worker);
}
zlist_destroy (&workers);
zctx_destroy (&ctx);
return 0;
}
ppqueue:C++ 中的偏执海盗队列
//
// Paranoid Pirate queue
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
//
#include "zmsg.hpp"
#include <stdint.h>
#include <vector>
#define HEARTBEAT_LIVENESS 3 // 3-5 is reasonable
#define HEARTBEAT_INTERVAL 1000 // msecs
// This defines one active worker in our worker queue
typedef struct {
std::string identity; // Address of worker
int64_t expiry; // Expires at this time
} worker_t;
// Insert worker at end of queue, reset expiry
// Worker must not already be in queue
static void
s_worker_append (std::vector<worker_t> &queue, std::string &identity)
{
bool found = false;
for (std::vector<worker_t>::iterator it = queue.begin(); it < queue.end(); it++) {
if (it->identity.compare(identity) == 0) {
std::cout << "E: duplicate worker identity " << identity.c_str() << std::endl;
found = true;
break;
}
}
if (!found) {
worker_t worker;
worker.identity = identity;
worker.expiry = s_clock() + HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
queue.push_back(worker);
}
}
// Remove worker from queue, if present
static void
s_worker_delete (std::vector<worker_t> &queue, std::string &identity)
{
for (std::vector<worker_t>::iterator it = queue.begin(); it < queue.end(); it++) {
if (it->identity.compare(identity) == 0) {
it = queue.erase(it);
break;
}
}
}
// Reset worker expiry, worker must be present
static void
s_worker_refresh (std::vector<worker_t> &queue, std::string &identity)
{
bool found = false;
for (std::vector<worker_t>::iterator it = queue.begin(); it < queue.end(); it++) {
if (it->identity.compare(identity) == 0) {
it->expiry = s_clock ()
+ HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
found = true;
break;
}
}
if (!found) {
std::cout << "E: worker " << identity << " not ready" << std::endl;
}
}
// Pop next available worker off queue, return identity
static std::string
s_worker_dequeue (std::vector<worker_t> &queue)
{
assert (queue.size());
std::string identity = queue[0].identity;
queue.erase(queue.begin());
return identity;
}
// Look for & kill expired workers
static void
s_queue_purge (std::vector<worker_t> &queue)
{
int64_t clock = s_clock();
for (std::vector<worker_t>::iterator it = queue.begin(); it < queue.end(); it++) {
if (clock > it->expiry) {
it = queue.erase(it)-1;
}
}
}
int main (void)
{
s_version_assert (4, 0);
// Prepare our context and sockets
zmq::context_t context(1);
zmq::socket_t frontend(context, ZMQ_ROUTER);
zmq::socket_t backend (context, ZMQ_ROUTER);
frontend.bind("tcp://*:5555"); // For clients
backend.bind ("tcp://*:5556"); // For workers
// Queue of available workers
std::vector<worker_t> queue;
// Send out heartbeats at regular intervals
int64_t heartbeat_at = s_clock () + HEARTBEAT_INTERVAL;
while (1) {
zmq::pollitem_t items [] = {
{ backend, 0, ZMQ_POLLIN, 0 },
{ frontend, 0, ZMQ_POLLIN, 0 }
};
// Poll frontend only if we have available workers
if (queue.size()) {
zmq::poll (items, 2, HEARTBEAT_INTERVAL);
} else {
zmq::poll (items, 1, HEARTBEAT_INTERVAL);
}
// Handle worker activity on backend
if (items [0].revents & ZMQ_POLLIN) {
zmsg msg (backend);
std::string identity(msg.unwrap ());
// Return reply to client if it's not a control message
if (msg.parts () == 1) {
if (strcmp (msg.address (), "READY") == 0) {
s_worker_delete (queue, identity);
s_worker_append (queue, identity);
}
else {
if (strcmp (msg.address (), "HEARTBEAT") == 0) {
s_worker_refresh (queue, identity);
} else {
std::cout << "E: invalid message from " << identity << std::endl;
msg.dump ();
}
}
}
else {
msg.send (frontend);
s_worker_append (queue, identity);
}
}
if (items [1].revents & ZMQ_POLLIN) {
// Now get next client request, route to next worker
zmsg msg (frontend);
std::string identity = std::string(s_worker_dequeue (queue));
msg.push_front((char*)identity.c_str());
msg.send (backend);
}
// Send heartbeats to idle workers if it's time
if (s_clock () > heartbeat_at) {
for (std::vector<worker_t>::iterator it = queue.begin(); it < queue.end(); it++) {
zmsg msg ("HEARTBEAT");
msg.wrap (it->identity.c_str(), NULL);
msg.send (backend);
}
heartbeat_at = s_clock () + HEARTBEAT_INTERVAL;
}
s_queue_purge(queue);
}
// We never exit the main loop
// But pretend to do the right shutdown anyhow
queue.clear();
return 0;
}
ppqueue:C# 中的偏执海盗队列
ppqueue:CL 中的偏执海盗队列
ppqueue:Delphi 中的偏执海盗队列
ppqueue:Erlang 中的偏执海盗队列
ppqueue:Elixir 中的偏执海盗队列
ppqueue:F# 中的偏执海盗队列
ppqueue:Felix 中的偏执海盗队列
ppqueue:Go 中的偏执海盗队列
// Paranoid Pirate queue
//
// Author: iano <scaly.iano@gmail.com>
// Based on C & Python example
package main
import (
"container/list"
"fmt"
zmq "github.com/alecthomas/gozmq"
"time"
)
const (
HEARTBEAT_INTERVAL = time.Second // time.Duration
// Paranoid Pirate Protocol constants
PPP_READY = "\001" // Signals worker is ready
PPP_HEARTBEAT = "\002" // Signals worker heartbeat
)
type PPWorker struct {
address []byte // Address of worker
expiry time.Time // Expires at this time
}
func NewPPWorker(address []byte) *PPWorker {
return &PPWorker{
address: address,
expiry: time.Now().Add(HEARTBEAT_LIVENESS * HEARTBEAT_INTERVAL),
}
}
type WorkerQueue struct {
queue *list.List
}
func NewWorkerQueue() *WorkerQueue {
return &WorkerQueue{
queue: list.New(),
}
}
func (workers *WorkerQueue) Len() int {
return workers.queue.Len()
}
func (workers *WorkerQueue) Next() []byte {
elem := workers.queue.Back()
worker, _ := elem.Value.(*PPWorker)
workers.queue.Remove(elem)
return worker.address
}
func (workers *WorkerQueue) Ready(worker *PPWorker) {
for elem := workers.queue.Front(); elem != nil; elem = elem.Next() {
if w, _ := elem.Value.(*PPWorker); string(w.address) == string(worker.address) {
workers.queue.Remove(elem)
break
}
}
workers.queue.PushBack(worker)
}
func (workers *WorkerQueue) Purge() {
now := time.Now()
for elem := workers.queue.Front(); elem != nil; elem = workers.queue.Front() {
if w, _ := elem.Value.(*PPWorker); w.expiry.After(now) {
break
}
workers.queue.Remove(elem)
}
}
func main() {
context, _ := zmq.NewContext()
defer context.Close()
frontend, _ := context.NewSocket(zmq.ROUTER)
defer frontend.Close()
frontend.Bind("tcp://*:5555") // For clients
backend, _ := context.NewSocket(zmq.ROUTER)
defer backend.Close()
backend.Bind("tcp://*:5556") // For workers
workers := NewWorkerQueue()
heartbeatAt := time.Now().Add(HEARTBEAT_INTERVAL)
for {
items := zmq.PollItems{
zmq.PollItem{Socket: backend, Events: zmq.POLLIN},
zmq.PollItem{Socket: frontend, Events: zmq.POLLIN},
}
// Poll frontend only if we have available workers
if workers.Len() > 0 {
zmq.Poll(items, HEARTBEAT_INTERVAL)
} else {
zmq.Poll(items[:1], HEARTBEAT_INTERVAL)
}
// Handle worker activity on backend
if items[0].REvents&zmq.POLLIN != 0 {
frames, err := backend.RecvMultipart(0)
if err != nil {
panic(err) // Interrupted
}
address := frames[0]
workers.Ready(NewPPWorker(address))
// Validate control message, or return reply to client
if msg := frames[1:]; len(msg) == 1 {
switch status := string(msg[0]); status {
case PPP_READY:
fmt.Println("I: PPWorker ready")
case PPP_HEARTBEAT:
fmt.Println("I: PPWorker heartbeat")
default:
fmt.Println("E: Invalid message from worker: ", msg)
}
} else {
frontend.SendMultipart(msg, 0)
}
}
if items[1].REvents&zmq.POLLIN != 0 {
// Now get next client request, route to next worker
frames, err := frontend.RecvMultipart(0)
if err != nil {
panic(err)
}
frames = append([][]byte{workers.Next()}, frames...)
backend.SendMultipart(frames, 0)
}
// .split handle heartbeating
// We handle heartbeating after any socket activity. First we send
// heartbeats to any idle workers if it's time. Then we purge any
// dead workers:
if heartbeatAt.Before(time.Now()) {
for elem := workers.queue.Front(); elem != nil; elem = elem.Next() {
w, _ := elem.Value.(*PPWorker)
msg := [][]byte{w.address, []byte(PPP_HEARTBEAT)}
backend.SendMultipart(msg, 0)
}
heartbeatAt = time.Now().Add(HEARTBEAT_INTERVAL)
}
workers.Purge()
}
}
ppqueue:Haskell 中的偏执海盗队列
{-
Paranoid Pirate Pattern queue in Haskell.
Uses heartbeating to detect crashed or blocked workers.
-}
module Main where
import System.ZMQ4.Monadic
import ZHelpers
import Control.Monad (when, forM_)
import Control.Applicative ((<$>))
import System.IO (hSetEncoding, stdout, utf8)
import Data.ByteString.Char8 (pack, unpack, empty)
import qualified Data.List.NonEmpty as N
type SockID = String
data Worker = Worker {
sockID :: SockID
, expiry :: Integer
} deriving (Show)
heartbeatLiveness = 3
heartbeatInterval_ms = 1000
pppReady = "\001"
pppHeartbeat = "\002"
main :: IO ()
main =
runZMQ $ do
frontend <- socket Router
bind frontend "tcp://*:5555"
backend <- socket Router
bind backend "tcp://*:5556"
liftIO $ hSetEncoding stdout utf8
heartbeat_at <- liftIO $ nextHeartbeatTime_ms heartbeatInterval_ms
pollPeers frontend backend [] heartbeat_at
createWorker :: SockID -> IO Worker
createWorker id = do
currTime <- currentTime_ms
let expiry = currTime + heartbeatInterval_ms * heartbeatLiveness
return (Worker id expiry)
pollPeers :: Socket z Router -> Socket z Router -> [Worker] -> Integer -> ZMQ z ()
pollPeers frontend backend workers heartbeat_at = do
let toPoll = getPollList workers
evts <- poll (fromInteger heartbeatInterval_ms) toPoll
workers' <- getBackend backend frontend evts workers
workers'' <- getFrontend frontend backend evts workers'
newHeartbeatAt <- heartbeat backend workers'' heartbeat_at
workersPurged <- purge workers''
pollPeers frontend backend workersPurged newHeartbeatAt
where getPollList [] = [Sock backend [In] Nothing]
getPollList _ = [Sock backend [In] Nothing, Sock frontend [In] Nothing]
getBackend :: Socket z Router -> Socket z Router ->
[[Event]] -> [Worker] -> ZMQ z ([Worker])
getBackend backend frontend evts workers =
if (In `elem` (evts !! 0))
then do
frame <- receiveMulti backend
let wkrID = frame !! 0
msg = frame !! 1
if ((length frame) == 2) -- PPP message
then when (unpack msg `notElem` [pppReady, pppHeartbeat]) $ do
liftIO $ putStrLn $ "E: Invalid message from worker " ++ (unpack msg)
else do -- Route the message to the client
liftIO $ putStrLn "I: Sending normal message to client"
let id = frame !! 1
msg = frame !! 3
send frontend [SendMore] id
send frontend [SendMore] empty
send frontend [] msg
newWorker <- liftIO $ createWorker $ unpack wkrID
return $ workers ++ [newWorker]
else return workers
getFrontend :: Socket z Router -> Socket z Router ->
[[Event]] -> [Worker] -> ZMQ z ([Worker])
getFrontend frontend backend evts workers =
if (length evts > 1 && In `elem` (evts !! 1))
then do -- Route message to workers
frame <- receiveMulti frontend
let wkrID = sockID . head $ workers
send backend [SendMore] (pack wkrID)
send backend [SendMore] empty
sendMulti backend (N.fromList frame)
return $ tail workers
else return workers
heartbeat :: Socket z Router -> [Worker] -> Integer -> ZMQ z Integer
heartbeat backend workers heartbeat_at = do
currTime <- liftIO currentTime_ms
if (currTime >= heartbeat_at)
then do
forM_ workers (\worker -> do
send backend [SendMore] (pack $ sockID worker)
send backend [SendMore] empty
send backend [] (pack pppHeartbeat)
liftIO $ putStrLn $ "I: sending heartbeat to '" ++ (sockID worker) ++ "'")
liftIO $ nextHeartbeatTime_ms heartbeatInterval_ms
else return heartbeat_at
purge :: [Worker] -> ZMQ z ([Worker])
purge workers = do
currTime <- liftIO currentTime_ms
return $ filter (\wkr -> expiry wkr > currTime) workers
ppqueue:Haxe 中的偏执海盗队列
package ;
import haxe.Stack;
import neko.Lib;
import org.zeromq.ZFrame;
import org.zeromq.ZContext;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQ;
import org.zeromq.ZMsg;
import org.zeromq.ZMQException;
/**
* Paranoid Pirate Queue
*
* @see https://zguide.zeromq.cn/page:all#Robust-Reliable-Queuing-Paranoid-Pirate-Pattern
*
* Author: rsmith (at) rsbatechnology (dot) co (dot) uk
*/
class PPQueue
{
private static inline var HEARTBEAT_LIVENESS = 3;
private static inline var HEARTBEAT_INTERVAL = 1000; // msecs
private static inline var PPP_READY = String.fromCharCode(1);
private static inline var PPP_HEARTBEAT = String.fromCharCode(2);
public static function main() {
Lib.println("** PPQueue (see: https://zguide.zeromq.cn/page:all#Robust-Reliable-Queuing-Paranoid-Pirate-Pattern)");
// Prepare our context and sockets
var context:ZContext = new ZContext();
var frontend:ZMQSocket = context.createSocket(ZMQ_ROUTER);
var backend:ZMQSocket = context.createSocket(ZMQ_ROUTER);
frontend.bind("tcp://*:5555"); // For clients
backend.bind("tcp://*:5556"); // For workerQueue
// Queue of available workerQueue
var workerQueue = new WorkerQueue(HEARTBEAT_LIVENESS, HEARTBEAT_INTERVAL);
// Send out heartbeats at regular intervals
var heartbeatAt = Date.now().getTime() + HEARTBEAT_INTERVAL;
var poller = new ZMQPoller();
while (true) {
poller.unregisterAllSockets();
poller.registerSocket(backend, ZMQ.ZMQ_POLLIN());
// Only poll frontend clients if we have at least one worker to do stuff
if (workerQueue.size() > 0) {
poller.registerSocket(frontend, ZMQ.ZMQ_POLLIN());
}
try {
poller.poll(HEARTBEAT_INTERVAL * 1000);
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
// Handle worker activity
if (poller.pollin(1)) {
// use worker addressFrame for LRU routing
var msg = ZMsg.recvMsg(backend);
if (msg == null)
break; // Interrupted
// Any sign of life from worker means it's ready
var addressFrame = msg.unwrap();
var identity = addressFrame.toString();
// Validate control message, or return reply to client
if (msg.size() == 1) {
var frame = msg.first();
if (frame.streq(PPP_READY)) {
workerQueue.delete(identity);
workerQueue.append(addressFrame,identity);
} else if (frame.streq(PPP_HEARTBEAT)) {
workerQueue.refresh(identity);
} else {
Lib.println("E: invalid message from worker");
Lib.println(msg.toString());
}
msg.destroy();
} else {
msg.send(frontend);
workerQueue.append(addressFrame, identity);
}
}
if (poller.pollin(2)) {
// Now get next client request, route to next worker
var msg = ZMsg.recvMsg(frontend);
if (msg == null)
break; // Interrupted
var worker = workerQueue.dequeue();
msg.push(worker.addressFrame.duplicate());
msg.send(backend);
}
// Send heartbeats to idle workerQueue if it's time
if (Date.now().getTime() >= heartbeatAt) {
for ( w in workerQueue) {
var msg = new ZMsg();
msg.add(w.addressFrame.duplicate()); // Add a duplicate of the stored worker addressFrame frame,
// to prevent w.addressFrame ZFrame object from being destroyed when msg is sent
msg.addString(PPP_HEARTBEAT);
msg.send(backend);
}
heartbeatAt = Date.now().getTime() + HEARTBEAT_INTERVAL;
}
workerQueue.purge();
}
// When we're done, clean up properly
context.destroy();
}
}
typedef WorkerT = {
addressFrame:ZFrame,
identity:String,
expiry:Float // in msecs since 1 Jan 1970
};
/**
* Internal class managing a queue of workerQueue
*/
private class WorkerQueue {
// Stores hash of worker heartbeat expiries, keyed by worker identity
private var queue:List<WorkerT>;
private var heartbeatLiveness:Int;
private var heartbeatInterval:Int;
/**
* Constructor
* @param liveness
* @param interval
*/
public function new(liveness:Int, interval:Int) {
queue = new List<WorkerT>();
heartbeatLiveness = liveness;
heartbeatInterval = interval;
}
// Implement Iterable typedef signature
public function iterator():Iterator<WorkerT> {
return queue.iterator();
}
/**
* Insert worker at end of queue, reset expiry
* Worker must not already be in queue
* @param identity
*/
public function append(addressFrame:ZFrame,identity:String) {
if (get(identity) != null)
Lib.println("E: duplicate worker identity " + identity);
else
queue.add({addressFrame:addressFrame, identity:identity, expiry:generateExpiry()});
}
/**
* Remove worker from queue, if present
* @param identity
*/
public function delete(identity:String) {
var w = get(identity);
if (w != null) {
queue.remove(w);
}
}
public function refresh(identity:String) {
var w = get(identity);
if (w == null)
Lib.println("E: worker " + identity + " not ready");
else
w.expiry = generateExpiry();
}
/**
* Pop next worker off queue, return WorkerT
* @param identity
*/
public function dequeue():WorkerT {
return queue.pop();
}
/**
* Look for & kill expired workerQueue
*/
public function purge() {
for (w in queue) {
if (Date.now().getTime() > w.expiry) {
queue.remove(w);
}
}
}
/**
* Return the size of this worker Queue
* @return
*/
public function size():Int {
return queue.length;
}
/**
* Returns a WorkerT anon object if exists in the queue, else null
* @param identity
* @return
*/
private function get(identity:String):WorkerT {
for (w in queue) {
if (w.identity == identity)
return w;
}
return null; // nothing found
}
private inline function generateExpiry():Float {
return Date.now().getTime() + heartbeatInterval * heartbeatLiveness;
}
}
ppqueue:Java 中的偏执海盗队列
package guide;
import java.util.ArrayList;
import java.util.Iterator;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
//
// Paranoid Pirate queue
//
public class ppqueue
{
private final static int HEARTBEAT_LIVENESS = 3; // 3-5 is reasonable
private final static int HEARTBEAT_INTERVAL = 1000; // msecs
// Paranoid Pirate Protocol constants
private final static String PPP_READY = "\001"; // Signals worker is ready
private final static String PPP_HEARTBEAT = "\002"; // Signals worker heartbeat
// Here we define the worker class; a structure and a set of functions that
// as constructor, destructor, and methods on worker objects:
private static class Worker
{
ZFrame address; // Address of worker
String identity; // Printable identity
long expiry; // Expires at this time
protected Worker(ZFrame address)
{
this.address = address;
identity = new String(address.getData(), ZMQ.CHARSET);
expiry = System.currentTimeMillis() + HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
}
// The ready method puts a worker to the end of the ready list:
protected void ready(ArrayList<Worker> workers)
{
Iterator<Worker> it = workers.iterator();
while (it.hasNext()) {
Worker worker = it.next();
if (identity.equals(worker.identity)) {
it.remove();
break;
}
}
workers.add(this);
}
// The next method returns the next available worker address:
protected static ZFrame next(ArrayList<Worker> workers)
{
Worker worker = workers.remove(0);
assert (worker != null);
ZFrame frame = worker.address;
return frame;
}
// The purge method looks for and kills expired workers. We hold workers
// from oldest to most recent, so we stop at the first alive worker:
protected static void purge(ArrayList<Worker> workers)
{
Iterator<Worker> it = workers.iterator();
while (it.hasNext()) {
Worker worker = it.next();
if (System.currentTimeMillis() < worker.expiry) {
break;
}
it.remove();
}
}
};
// The main task is an LRU queue with heartbeating on workers so we can
// detect crashed or blocked worker tasks:
public static void main(String[] args)
{
try (ZContext ctx = new ZContext()) {
Socket frontend = ctx.createSocket(SocketType.ROUTER);
Socket backend = ctx.createSocket(SocketType.ROUTER);
frontend.bind("tcp://*:5555"); // For clients
backend.bind("tcp://*:5556"); // For workers
// List of available workers
ArrayList<Worker> workers = new ArrayList<Worker>();
// Send out heartbeats at regular intervals
long heartbeat_at = System.currentTimeMillis() + HEARTBEAT_INTERVAL;
Poller poller = ctx.createPoller(2);
poller.register(backend, Poller.POLLIN);
poller.register(frontend, Poller.POLLIN);
while (true) {
boolean workersAvailable = workers.size() > 0;
int rc = poller.poll(HEARTBEAT_INTERVAL);
if (rc == -1)
break; // Interrupted
// Handle worker activity on backend
if (poller.pollin(0)) {
// Use worker address for LRU routing
ZMsg msg = ZMsg.recvMsg(backend);
if (msg == null)
break; // Interrupted
// Any sign of life from worker means it's ready
ZFrame address = msg.unwrap();
Worker worker = new Worker(address);
worker.ready(workers);
// Validate control message, or return reply to client
if (msg.size() == 1) {
ZFrame frame = msg.getFirst();
String data = new String(frame.getData(), ZMQ.CHARSET);
if (!data.equals(PPP_READY) &&
!data.equals(PPP_HEARTBEAT)) {
System.out.println(
"E: invalid message from worker"
);
msg.dump(System.out);
}
msg.destroy();
}
else msg.send(frontend);
}
if (workersAvailable && poller.pollin(1)) {
// Now get next client request, route to next worker
ZMsg msg = ZMsg.recvMsg(frontend);
if (msg == null)
break; // Interrupted
msg.push(Worker.next(workers));
msg.send(backend);
}
// We handle heartbeating after any socket activity. First we
// send heartbeats to any idle workers if it's time. Then we
// purge any dead workers:
if (System.currentTimeMillis() >= heartbeat_at) {
for (Worker worker : workers) {
worker.address.send(
backend, ZFrame.REUSE + ZFrame.MORE
);
ZFrame frame = new ZFrame(PPP_HEARTBEAT);
frame.send(backend, 0);
}
long now = System.currentTimeMillis();
heartbeat_at = now + HEARTBEAT_INTERVAL;
}
Worker.purge(workers);
}
// When we're done, clean up properly
workers.clear();
}
}
}
ppqueue:Julia 中的偏执海盗队列
ppqueue:Lua 中的偏执海盗队列
--
-- Paranoid Pirate queue
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.poller"
require"zmsg"
local MAX_WORKERS = 100
local HEARTBEAT_LIVENESS = 3 -- 3-5 is reasonable
local HEARTBEAT_INTERVAL = 1000 -- msecs
local tremove = table.remove
-- Insert worker at end of queue, reset expiry
-- Worker must not already be in queue
local function s_worker_append(queue, identity)
if queue[identity] then
printf ("E: duplicate worker identity %s", identity)
else
assert (#queue < MAX_WORKERS)
queue[identity] = s_clock() + HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS
queue[#queue + 1] = identity
end
end
-- Remove worker from queue, if present
local function s_worker_delete(queue, identity)
for i=1,#queue do
if queue[i] == identity then
tremove(queue, i)
break
end
end
queue[identity] = nil
end
-- Reset worker expiry, worker must be present
local function s_worker_refresh(queue, identity)
if queue[identity] then
queue[identity] = s_clock() + HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS
else
printf("E: worker %s not ready\n", identity)
end
end
-- Pop next available worker off queue, return identity
local function s_worker_dequeue(queue)
assert (#queue > 0)
local identity = tremove(queue, 1)
queue[identity] = nil
return identity
end
-- Look for & kill expired workers
local function s_queue_purge(queue)
local curr_clock = s_clock()
-- Work backwards from end to simplify removal
for i=#queue,1,-1 do
local id = queue[i]
if (curr_clock > queue[id]) then
tremove(queue, i)
queue[id] = nil
end
end
end
s_version_assert (2, 1)
-- Prepare our context and sockets
local context = zmq.init(1)
local frontend = context:socket(zmq.ROUTER)
local backend = context:socket(zmq.ROUTER)
frontend:bind("tcp://*:5555"); -- For clients
backend:bind("tcp://*:5556"); -- For workers
-- Queue of available workers
local queue = {}
local is_accepting = false
-- Send out heartbeats at regular intervals
local heartbeat_at = s_clock() + HEARTBEAT_INTERVAL
local poller = zmq.poller(2)
local function frontend_cb()
-- Now get next client request, route to next worker
local msg = zmsg.recv(frontend)
local identity = s_worker_dequeue (queue)
msg:push(identity)
msg:send(backend)
if (#queue == 0) then
-- stop accepting work from clients, when no workers are available.
poller:remove(frontend)
is_accepting = false
end
end
-- Handle worker activity on backend
poller:add(backend, zmq.POLLIN, function()
local msg = zmsg.recv(backend)
local identity = msg:unwrap()
-- Return reply to client if it's not a control message
if (msg:parts() == 1) then
if (msg:address() == "READY") then
s_worker_delete(queue, identity)
s_worker_append(queue, identity)
elseif (msg:address() == "HEARTBEAT") then
s_worker_refresh(queue, identity)
else
printf("E: invalid message from %s\n", identity)
msg:dump()
end
else
-- reply for client.
msg:send(frontend)
s_worker_append(queue, identity)
end
-- start accepting client requests, if we are not already doing so.
if not is_accepting and #queue > 0 then
is_accepting = true
poller:add(frontend, zmq.POLLIN, frontend_cb)
end
end)
-- start poller's event loop
while true do
local cnt = assert(poller:poll(HEARTBEAT_INTERVAL * 1000))
-- Send heartbeats to idle workers if it's time
if (s_clock() > heartbeat_at) then
for i=1,#queue do
local msg = zmsg.new("HEARTBEAT")
msg:wrap(queue[i], nil)
msg:send(backend)
end
heartbeat_at = s_clock() + HEARTBEAT_INTERVAL
end
s_queue_purge(queue)
end
-- We never exit the main loop
-- But pretend to do the right shutdown anyhow
while (#queue > 0) do
s_worker_dequeue(queue)
end
frontend:close()
backend:close()
ppqueue:Node.js 中的偏执海盗队列
ppqueue:Objective-C 中的偏执海盗队列
ppqueue:ooc 中的偏执海盗队列
ppqueue:Perl 中的偏执海盗队列
ppqueue:PHP 中的偏执海盗队列
<?php
/*
* Paranoid Pirate queue
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
define("MAX_WORKERS", 100);
define("HEARTBEAT_LIVENESS", 3); // 3-5 is reasonable
define("HEARTBEAT_INTERVAL", 1); // secs
class Queue_T implements Iterator
{
private $queue = array();
/* Iterator functions */
public function rewind() { return reset($this->queue); }
public function valid() { return current($this->queue); }
public function key() { return key($this->queue); }
public function next() { return next($this->queue); }
public function current() { return current($this->queue); }
/*
* Insert worker at end of queue, reset expiry
* Worker must not already be in queue
*/
public function s_worker_append($identity)
{
if (isset($this->queue[$identity])) {
printf ("E: duplicate worker identity %s", $identity);
} else {
$this->queue[$identity] = microtime(true) + HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
}
}
/*
* Remove worker from queue, if present
*/
public function s_worker_delete($identity)
{
unset($this->queue[$identity]);
}
/*
* Reset worker expiry, worker must be present
*/
public function s_worker_refresh($identity)
{
if (!isset($this->queue[$identity])) {
printf ("E: worker %s not ready\n", $identity);
} else {
$this->queue[$identity] = microtime(true) + HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
}
}
/*
* Pop next available worker off queue, return identity
*/
public function s_worker_dequeue()
{
reset($this->queue);
$identity = key($this->queue);
unset($this->queue[$identity]);
return $identity;
}
/*
* Look for & kill expired workers
*/
public function s_queue_purge()
{
foreach ($this->queue as $id => $expiry) {
if (microtime(true) > $expiry) {
unset($this->queue[$id]);
}
}
}
/*
* Return the size of the queue
*/
public function size()
{
return count($this->queue);
}
}
// Prepare our context and sockets
$context = new ZMQContext();
$frontend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$backend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$frontend->bind("tcp://*:5555"); // For clients
$backend->bind("tcp://*:5556"); // For workers
$read = $write = array();
// Queue of available workers
$queue = new Queue_T();
// Send out heartbeats at regular intervals
$heartbeat_at = microtime(true) + HEARTBEAT_INTERVAL;
while (true) {
$poll = new ZMQPoll();
$poll->add($backend, ZMQ::POLL_IN);
// Poll frontend only if we have available workers
if ($queue->size()) {
$poll->add($frontend, ZMQ::POLL_IN);
}
$events = $poll->poll($read, $write, HEARTBEAT_INTERVAL * 1000 ); // milliseconds
if ($events > 0) {
foreach ($read as $socket) {
$zmsg = new Zmsg($socket);
$zmsg->recv();
// Handle worker activity on backend
if ($socket === $backend) {
$identity = $zmsg->unwrap();
// Return reply to client if it's not a control message
if ($zmsg->parts() == 1) {
if ($zmsg->address() == "READY") {
$queue->s_worker_delete($identity);
$queue->s_worker_append($identity);
} elseif ($zmsg->address() == 'HEARTBEAT') {
$queue->s_worker_refresh($identity);
} else {
printf ("E: invalid message from %s%s%s", $identity, PHP_EOL, $zmsg->__toString());
}
} else {
$zmsg->set_socket($frontend)->send();
$queue->s_worker_append($identity);
}
} else {
// Now get next client request, route to next worker
$identity = $queue->s_worker_dequeue();
$zmsg->wrap($identity);
$zmsg->set_socket($backend)->send();
}
}
if (microtime(true) > $heartbeat_at) {
foreach ($queue as $id => $expiry) {
$zmsg = new Zmsg($backend);
$zmsg->body_set("HEARTBEAT");
$zmsg->wrap($identity, NULL);
$zmsg->send();
}
$heartbeat_at = microtime(true) + HEARTBEAT_INTERVAL;
}
$queue->s_queue_purge();
}
}
ppqueue:Python 中的偏执海盗队列
#
## Paranoid Pirate queue
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
from collections import OrderedDict
import time
import zmq
HEARTBEAT_LIVENESS = 3 # 3..5 is reasonable
HEARTBEAT_INTERVAL = 1.0 # Seconds
# Paranoid Pirate Protocol constants
PPP_READY = b"\x01" # Signals worker is ready
PPP_HEARTBEAT = b"\x02" # Signals worker heartbeat
class Worker(object):
def __init__(self, address):
self.address = address
self.expiry = time.time() + HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS
class WorkerQueue(object):
def __init__(self):
self.queue = OrderedDict()
def ready(self, worker):
self.queue.pop(worker.address, None)
self.queue[worker.address] = worker
def purge(self):
"""Look for & kill expired workers."""
t = time.time()
expired = []
for address, worker in self.queue.items():
if t > worker.expiry: # Worker expired
expired.append(address)
for address in expired:
print("W: Idle worker expired: %s" % address)
self.queue.pop(address, None)
def next(self):
address, worker = self.queue.popitem(False)
return address
context = zmq.Context(1)
frontend = context.socket(zmq.ROUTER) # ROUTER
backend = context.socket(zmq.ROUTER) # ROUTER
frontend.bind("tcp://*:5555") # For clients
backend.bind("tcp://*:5556") # For workers
poll_workers = zmq.Poller()
poll_workers.register(backend, zmq.POLLIN)
poll_both = zmq.Poller()
poll_both.register(frontend, zmq.POLLIN)
poll_both.register(backend, zmq.POLLIN)
workers = WorkerQueue()
heartbeat_at = time.time() + HEARTBEAT_INTERVAL
while True:
if len(workers.queue) > 0:
poller = poll_both
else:
poller = poll_workers
socks = dict(poller.poll(HEARTBEAT_INTERVAL * 1000))
# Handle worker activity on backend
if socks.get(backend) == zmq.POLLIN:
# Use worker address for LRU routing
frames = backend.recv_multipart()
if not frames:
break
address = frames[0]
workers.ready(Worker(address))
# Validate control message, or return reply to client
msg = frames[1:]
if len(msg) == 1:
if msg[0] not in (PPP_READY, PPP_HEARTBEAT):
print("E: Invalid message from worker: %s" % msg)
else:
frontend.send_multipart(msg)
# Send heartbeats to idle workers if it's time
if time.time() >= heartbeat_at:
for worker in workers.queue:
msg = [worker, PPP_HEARTBEAT]
backend.send_multipart(msg)
heartbeat_at = time.time() + HEARTBEAT_INTERVAL
if socks.get(frontend) == zmq.POLLIN:
frames = frontend.recv_multipart()
if not frames:
break
frames.insert(0, workers.next())
backend.send_multipart(frames)
workers.purge()
ppqueue:Q 中的偏执海盗队列
ppqueue:Racket 中的偏执海盗队列
ppqueue:Ruby 中的偏执海盗队列
ppqueue:Rust 中的偏执海盗队列
ppqueue:Scala 中的偏执海盗队列
ppqueue:Tcl 中的偏执海盗队列
#
# Paranoid Pirate queue
#
package require zmq
set HEARTBEAT_LIVENESS 3 ;# 3-5 is reasonable
set HEARTBEAT_INTERVAL 1 ;# secs
# Paranoid Pirate Protocol constants
set PPP_READY "READY" ;# Signals worker is ready
set PPP_HEARTBEAT "HEARTBEAT" ;# Signals worker heartbeat
# This defines one active worker in our worker list
# dict with keys address, identity and expiry
# Construct new worker
proc s_worker_new {address} {
global HEARTBEAT_LIVENESS HEARTBEAT_INTERVAL
return [dict create address $address identity $address expiry [expr {[clock seconds] + $HEARTBEAT_INTERVAL * $HEARTBEAT_LIVENESS}]]
}
# Worker is ready, remove if on list and move to end
proc s_worker_ready {self workersnm} {
upvar $workersnm workers
set nworkers {}
foreach worker $workers {
if {[dict get $self identity] ne [dict get $worker identity]} {
lappend nworkers $worker
}
}
lappend nworkers $self
set workers $nworkers
}
# Return next available worker address
proc s_workers_next {workersnm} {
upvar $workersnm workers
set workers [lassign $workers worker]
return [dict get $worker address]
}
# Look for & kill expired workers. Workers are oldest to most recent,
# so we stop at the first alive worker.
proc s_workers_purge {workersnm} {
upvar $workersnm workers
set nworkers {}
foreach worker $workers {
if {[clock seconds] < [dict get $worker expiry]} {
# Worker is alive
lappend nworkers $worker
}
}
set workers $nworkers
}
set ctx [zmq context context]
zmq socket frontend $ctx ROUTER
zmq socket backend $ctx ROUTER
frontend bind "tcp://*:5555" ;# For clients
backend bind "tcp://*:5556";# For workers
# List of available workers
set workers {}
# Send out heartbeats at regular intervals
set heartbeat_at [expr {[clock seconds] + $HEARTBEAT_INTERVAL}]
while {1} {
if {[llength $workers]} {
set poll_set [list [list backend [list POLLIN]] [list frontend [list POLLIN]]]
} else {
set poll_set [list [list backend [list POLLIN]]]
}
set rpoll_set [zmq poll $poll_set $HEARTBEAT_INTERVAL]
foreach rpoll $rpoll_set {
switch [lindex $rpoll 0] {
backend {
# Handle worker activity on backend
# Use worker address for LRU routing
set msg [zmsg recv backend]
# Any sign of life from worker means it's ready
set address [zmsg unwrap msg]
set worker [s_worker_new $address]
s_worker_ready $worker workers
# Validate control message, or return reply to client
if {[llength $msg] == 1} {
if {[lindex $msg 0] ne $PPP_READY && [lindex $msg 0] ne $PPP_HEARTBEAT} {
puts "E: invalid message from worker"
zmsg dump $msg
}
} else {
zmsg send frontend $msg
}
}
frontend {
# Now get next client request, route to next worker
set msg [zmsg recv frontend]
set msg [zmsg push $msg [s_workers_next workers]]
zmsg send backend $msg
}
}
}
# Send heartbeats to idle workers if it's time
if {[clock seconds] >= $heartbeat_at} {
puts "I: heartbeat ([llength $workers])"
foreach worker $workers {
backend sendmore [dict get $worker address]
backend send $PPP_HEARTBEAT
}
set heartbeat_at [expr {[clock seconds] + $HEARTBEAT_INTERVAL}]
}
s_workers_purge workers
}
frontend close
backend close
$ctx term
ppqueue:OCaml 中的偏执海盗队列
队列通过工作器的心跳机制扩展了负载均衡模式。心跳机制是那些看似“简单”但很难做对的事情之一。稍后我会对此进行更多解释。
这是偏执海盗工作器
ppworker:Ada 中的偏执海盗工作器
ppworker:Basic 中的偏执海盗工作器
ppworker:C 中的偏执海盗工作器
// Paranoid Pirate worker
#include "czmq.h"
#define HEARTBEAT_LIVENESS 3 // 3-5 is reasonable
#define HEARTBEAT_INTERVAL 1000 // msecs
#define INTERVAL_INIT 1000 // Initial reconnect
#define INTERVAL_MAX 32000 // After exponential backoff
// Paranoid Pirate Protocol constants
#define PPP_READY "\001" // Signals worker is ready
#define PPP_HEARTBEAT "\002" // Signals worker heartbeat
// Helper function that returns a new configured socket
// connected to the Paranoid Pirate queue
static void *
s_worker_socket (zctx_t *ctx) {
void *worker = zsocket_new (ctx, ZMQ_DEALER);
zsocket_connect (worker, "tcp://:5556");
// Tell queue we're ready for work
printf ("I: worker ready\n");
zframe_t *frame = zframe_new (PPP_READY, 1);
zframe_send (&frame, worker, 0);
return worker;
}
// .split main task
// We have a single task that implements the worker side of the
// Paranoid Pirate Protocol (PPP). The interesting parts here are
// the heartbeating, which lets the worker detect if the queue has
// died, and vice versa:
int main (void)
{
zctx_t *ctx = zctx_new ();
void *worker = s_worker_socket (ctx);
// If liveness hits zero, queue is considered disconnected
size_t liveness = HEARTBEAT_LIVENESS;
size_t interval = INTERVAL_INIT;
// Send out heartbeats at regular intervals
uint64_t heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
srandom ((unsigned) time (NULL));
int cycles = 0;
while (true) {
zmq_pollitem_t items [] = { { worker, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (items, 1, HEARTBEAT_INTERVAL * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
if (items [0].revents & ZMQ_POLLIN) {
// Get message
// - 3-part envelope + content -> request
// - 1-part HEARTBEAT -> heartbeat
zmsg_t *msg = zmsg_recv (worker);
if (!msg)
break; // Interrupted
// .split simulating problems
// To test the robustness of the queue implementation we
// simulate various typical problems, such as the worker
// crashing or running very slowly. We do this after a few
// cycles so that the architecture can get up and running
// first:
if (zmsg_size (msg) == 3) {
cycles++;
if (cycles > 3 && randof (5) == 0) {
printf ("I: simulating a crash\n");
zmsg_destroy (&msg);
break;
}
else
if (cycles > 3 && randof (5) == 0) {
printf ("I: simulating CPU overload\n");
sleep (3);
if (zctx_interrupted)
break;
}
printf ("I: normal reply\n");
zmsg_send (&msg, worker);
liveness = HEARTBEAT_LIVENESS;
sleep (1); // Do some heavy work
if (zctx_interrupted)
break;
}
else
// .split handle heartbeats
// When we get a heartbeat message from the queue, it means the
// queue was (recently) alive, so we must reset our liveness
// indicator:
if (zmsg_size (msg) == 1) {
zframe_t *frame = zmsg_first (msg);
if (memcmp (zframe_data (frame), PPP_HEARTBEAT, 1) == 0)
liveness = HEARTBEAT_LIVENESS;
else {
printf ("E: invalid message\n");
zmsg_dump (msg);
}
zmsg_destroy (&msg);
}
else {
printf ("E: invalid message\n");
zmsg_dump (msg);
}
interval = INTERVAL_INIT;
}
else
// .split detecting a dead queue
// If the queue hasn't sent us heartbeats in a while, destroy the
// socket and reconnect. This is the simplest most brutal way of
// discarding any messages we might have sent in the meantime:
if (--liveness == 0) {
printf ("W: heartbeat failure, can't reach queue\n");
printf ("W: reconnecting in %zd msec...\n", interval);
zclock_sleep (interval);
if (interval < INTERVAL_MAX)
interval *= 2;
zsocket_destroy (ctx, worker);
worker = s_worker_socket (ctx);
liveness = HEARTBEAT_LIVENESS;
}
// Send heartbeat to queue if it's time
if (zclock_time () > heartbeat_at) {
heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
printf ("I: worker heartbeat\n");
zframe_t *frame = zframe_new (PPP_HEARTBEAT, 1);
zframe_send (&frame, worker, 0);
}
}
zctx_destroy (&ctx);
return 0;
}
ppworker:C++ 中的偏执海盗工作器
//
// Paranoid Pirate worker
//
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
//
#include "zmsg.hpp"
#include <iomanip>
#define HEARTBEAT_LIVENESS 3 // 3-5 is reasonable
#define HEARTBEAT_INTERVAL 1000 // msecs
#define INTERVAL_INIT 1000 // Initial reconnect
#define INTERVAL_MAX 32000 // After exponential backoff
// Helper function that returns a new configured socket
// connected to the Hello World server
//
std::string identity;
static zmq::socket_t *
s_worker_socket (zmq::context_t &context) {
zmq::socket_t * worker = new zmq::socket_t(context, ZMQ_DEALER);
// Set random identity to make tracing easier
identity = s_set_id(*worker);
worker->connect ("tcp://:5556");
// Configure socket to not wait at close time
int linger = 0;
worker->setsockopt (ZMQ_LINGER, &linger, sizeof (linger));
// Tell queue we're ready for work
std::cout << "I: (" << identity << ") worker ready" << std::endl;
s_send (*worker, std::string("READY"));
return worker;
}
int main (void)
{
s_version_assert (4, 0);
srandom ((unsigned) time (NULL));
zmq::context_t context (1);
zmq::socket_t * worker = s_worker_socket (context);
// If liveness hits zero, queue is considered disconnected
size_t liveness = HEARTBEAT_LIVENESS;
size_t interval = INTERVAL_INIT;
// Send out heartbeats at regular intervals
int64_t heartbeat_at = s_clock () + HEARTBEAT_INTERVAL;
int cycles = 0;
while (1) {
zmq::pollitem_t items[] = {
{static_cast<void*>(*worker), 0, ZMQ_POLLIN, 0 } };
zmq::poll (items, 1, HEARTBEAT_INTERVAL);
if (items [0].revents & ZMQ_POLLIN) {
// Get message
// - 3-part envelope + content -> request
// - 1-part "HEARTBEAT" -> heartbeat
zmsg msg (*worker);
if (msg.parts () == 3) {
// Simulate various problems, after a few cycles
cycles++;
if (cycles > 3 && within (5) == 0) {
std::cout << "I: (" << identity << ") simulating a crash" << std::endl;
msg.clear ();
break;
}
else {
if (cycles > 3 && within (5) == 0) {
std::cout << "I: (" << identity << ") simulating CPU overload" << std::endl;
sleep (5);
}
}
std::cout << "I: (" << identity << ") normal reply - " << msg.body() << std::endl;
msg.send (*worker);
liveness = HEARTBEAT_LIVENESS;
sleep (1); // Do some heavy work
}
else {
if (msg.parts () == 1
&& strcmp (msg.body (), "HEARTBEAT") == 0) {
liveness = HEARTBEAT_LIVENESS;
}
else {
std::cout << "E: (" << identity << ") invalid message" << std::endl;
msg.dump ();
}
}
interval = INTERVAL_INIT;
}
else
if (--liveness == 0) {
std::cout << "W: (" << identity << ") heartbeat failure, can't reach queue" << std::endl;
std::cout << "W: (" << identity << ") reconnecting in " << interval << " msec..." << std::endl;
s_sleep (interval);
if (interval < INTERVAL_MAX) {
interval *= 2;
}
delete worker;
worker = s_worker_socket (context);
liveness = HEARTBEAT_LIVENESS;
}
// Send heartbeat to queue if it's time
if (s_clock () > heartbeat_at) {
heartbeat_at = s_clock () + HEARTBEAT_INTERVAL;
std::cout << "I: (" << identity << ") worker heartbeat" << std::endl;
s_send (*worker, std::string("HEARTBEAT"));
}
}
delete worker;
return 0;
}
ppworker:C# 中的偏执海盗工作器
ppworker:CL 中的偏执海盗工作器
ppworker:Delphi 中的偏执海盗工作器
ppworker:Erlang 中的偏执海盗工作器
ppworker:Elixir 中的偏执海盗工作器
ppworker:F# 中的偏执海盗工作器
ppworker:Felix 中的偏执海盗工作器
ppworker:Go 中的偏执海盗工作器
// Paranoid Pirate worker
//
// Author: iano <scaly.iano@gmail.com>
// Based on C & Python example
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"math/rand"
"time"
)
const (
HEARTBEAT_INTERVAL = time.Second // time.Duration
INTERVAL_INIT = time.Second // Initial reconnect
INTERVAL_MAX = 32 * time.Second // After exponential backoff
// Paranoid Pirate Protocol constants
PPP_READY = "\001" // Signals worker is ready
PPP_HEARTBEAT = "\002" // Signals worker heartbeat
)
// Helper function that returns a new configured socket
// connected to the Paranoid Pirate queue
func WorkerSocket(context *zmq.Context) *zmq.Socket {
worker, _ := context.NewSocket(zmq.DEALER)
worker.Connect("tcp://:5556")
// Tell queue we're ready for work
fmt.Println("I: worker ready")
worker.Send([]byte(PPP_READY), 0)
return worker
}
// .split main task
// We have a single task, which implements the worker side of the
// Paranoid Pirate Protocol (PPP). The interesting parts here are
// the heartbeating, which lets the worker detect if the queue has
// died, and vice-versa:
func main() {
src := rand.NewSource(time.Now().UnixNano())
random := rand.New(src)
context, _ := zmq.NewContext()
defer context.Close()
worker := WorkerSocket(context)
liveness := HEARTBEAT_LIVENESS
interval := INTERVAL_INIT
heartbeatAt := time.Now().Add(HEARTBEAT_INTERVAL)
cycles := 0
for {
items := zmq.PollItems{
zmq.PollItem{Socket: worker, Events: zmq.POLLIN},
}
zmq.Poll(items, HEARTBEAT_INTERVAL)
if items[0].REvents&zmq.POLLIN != 0 {
frames, err := worker.RecvMultipart(0)
if err != nil {
panic(err)
}
if len(frames) == 3 {
cycles++
if cycles > 3 {
switch r := random.Intn(5); r {
case 0:
fmt.Println("I: Simulating a crash")
worker.Close()
return
case 1:
fmt.Println("I: Simulating CPU overload")
time.Sleep(3 * time.Second)
}
}
fmt.Println("I: Normal reply")
worker.SendMultipart(frames, 0)
liveness = HEARTBEAT_LIVENESS
time.Sleep(1 * time.Second)
} else if len(frames) == 1 && string(frames[0]) == PPP_HEARTBEAT {
fmt.Println("I: Queue heartbeat")
liveness = HEARTBEAT_LIVENESS
} else {
fmt.Println("E: Invalid message")
}
interval = INTERVAL_INIT
} else if liveness--; liveness == 0 {
fmt.Println("W: Heartbeat failure, can't reach queue")
fmt.Printf("W: Reconnecting in %ds...\n", interval/time.Second)
time.Sleep(interval)
if interval < INTERVAL_MAX {
interval *= 2
}
worker.Close()
worker = WorkerSocket(context)
liveness = HEARTBEAT_LIVENESS
}
if heartbeatAt.Before(time.Now()) {
heartbeatAt = time.Now().Add(HEARTBEAT_INTERVAL)
worker.Send([]byte(PPP_HEARTBEAT), 0)
}
}
}
ppworker:Haskell 中的偏执海盗工作器
{-
Paranoid Pirate worker in Haskell.
Uses heartbeating to detect crashed queue.
-}
module Main where
import System.ZMQ4.Monadic
import ZHelpers
import System.Random (randomRIO)
import System.Exit (exitSuccess)
import System.IO (hSetEncoding, stdout, utf8)
import Control.Monad (when)
import Control.Concurrent (threadDelay)
import Data.ByteString.Char8 (pack, unpack, empty)
heartbeatLiveness = 3
heartbeatInterval_ms = 1000 :: Integer
reconnectIntervalInit = 1000
reconnectIntervalLimit = 32000
pppReady = pack "\001"
pppHeartbeat = pack "\002"
createWorkerSocket :: ZMQ z (Socket z Dealer)
createWorkerSocket = do
worker <- socket Dealer
connect worker "tcp://:5556"
liftIO $ putStrLn "I: worker ready"
send worker [] pppReady
return worker
main :: IO ()
main =
runZMQ $ do
worker <- createWorkerSocket
heartbeatAt <- liftIO $ nextHeartbeatTime_ms heartbeatInterval_ms
liftIO $ hSetEncoding stdout utf8
pollWorker worker heartbeatAt heartbeatLiveness reconnectIntervalInit 0
pollWorker :: Socket z Dealer -> Integer -> Integer -> Integer -> Int -> ZMQ z ()
pollWorker worker heartbeat liveness reconnectInterval cycles = do
[evts] <- poll (fromInteger heartbeatInterval_ms) [Sock worker [In] Nothing]
if In `elem` evts
then do
frame <- receiveMulti worker
if length frame == 4 -- Handle normal message
then do
chance <- liftIO $ randomRIO (0::Int, 5)
if cycles > 3 && chance == 0
then do
liftIO $ putStrLn "I: Simulating a crash"
liftIO $ exitSuccess
else do
chance' <- liftIO $ randomRIO (0::Int, 5)
when (cycles > 3 && chance' == 0) $ do
liftIO $ putStrLn "I: Simulating CPU overload"
liftIO $ threadDelay $ 3 * 1000 * 1000
let id = frame !! 1
info = frame !! 3
liftIO $ putStrLn "I: Normal reply"
send worker [SendMore] id
send worker [SendMore] empty
send worker [] info
liftIO $ threadDelay $ 1 * 1000 * 1000
pollWorker worker heartbeat heartbeatLiveness reconnectIntervalInit (cycles+1)
else if length frame == 2 -- Handle heartbeat or eventual invalid message
then do
let msg = frame !! 1
if msg == pppHeartbeat
then pollWorker worker heartbeat heartbeatLiveness reconnectIntervalInit cycles
else do
liftIO $ putStrLn "E: invalid message"
pollWorker worker heartbeat liveness reconnectIntervalInit cycles
else do
liftIO $ putStrLn "E: invalid message"
pollWorker worker heartbeat liveness reconnectIntervalInit cycles
else do
when (liveness == 0) $ do -- Try to reconnect
liftIO $ putStrLn "W: heartbeat failure, can't reach queue"
liftIO $ putStrLn $ "W: reconnecting in " ++ (show reconnectInterval) ++ " msec..."
liftIO $ threadDelay $ (fromInteger reconnectInterval) * 1000
worker' <- createWorkerSocket
if (reconnectInterval < reconnectIntervalLimit)
then pollWorker worker' heartbeat heartbeatLiveness (reconnectInterval * 2) cycles
else pollWorker worker' heartbeat heartbeatLiveness reconnectInterval cycles
currTime <- liftIO $ currentTime_ms -- Send heartbeat
when (currTime > heartbeat) $ do
liftIO $ putStrLn "I: worker heartbeat"
send worker [] pppHeartbeat
newHeartbeat <- liftIO $ nextHeartbeatTime_ms heartbeat
pollWorker worker newHeartbeat (liveness-1) reconnectInterval cycles
pollWorker worker heartbeat (liveness-1) reconnectInterval cycles
ppworker:Haxe 中的偏执海盗工作器
package ;
import haxe.Stack;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMQException;
import org.zeromq.ZMsg;
import org.zeromq.ZSocket;
/**
* Paranoid Pirate worker
*
* @see https://zguide.zeromq.cn/page:all#Robust-Reliable-Queuing-Paranoid-Pirate-Pattern
*
* Author: rsmith (at) rsbatechnology (dot) co (dot) uk
*/
class PPWorker
{
private static inline var HEARTBEAT_LIVENESS = 3;
private static inline var HEARTBEAT_INTERVAL = 1000; // msecs
private static inline var INTERVAL_INIT = 1000; // Initial reconnect
private static inline var INTERVAL_MAX = 32000; // After exponential backoff
private static inline var PPP_READY = String.fromCharCode(1);
private static inline var PPP_HEARTBEAT = String.fromCharCode(2);
/**
* Helper function that returns a new configured socket
* connected to the Paranid Pirate queue
* @param ctx
* @return
*/
private static function workerSocket(ctx:ZContext):ZMQSocket {
var worker = ctx.createSocket(ZMQ_DEALER);
worker.connect("tcp://:5556");
// Tell queue we're ready for work
Lib.println("I: worker ready");
ZFrame.newStringFrame(PPP_READY).send(worker);
return worker;
}
public static function main() {
Lib.println("** PPWorker (see: https://zguide.zeromq.cn/page:all#Robust-Reliable-Queuing-Paranoid-Pirate-Pattern)");
var ctx = new ZContext();
var worker = workerSocket(ctx);
// If liveness hits zero, queue is considered disconnected
var liveness = HEARTBEAT_LIVENESS;
var interval = INTERVAL_INIT;
// Send out heartbeats at regular intervals
var heartbeatAt = Date.now().getTime() + HEARTBEAT_INTERVAL;
var cycles = 0;
var poller = new ZMQPoller();
poller.registerSocket(worker, ZMQ.ZMQ_POLLIN());
while (true) {
try {
poller.poll(HEARTBEAT_INTERVAL * 1000);
} catch (e:ZMQException) {
if (ZMQ.isInterrupted())
break;
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
if (poller.pollin(1)) {
// Get message
// - 3-part envelope + content -> request
// - 1-part HEARTBEAT -> heartbeat
var msg = ZMsg.recvMsg(worker);
if (msg == null)
break; // Interrupted
if (msg.size() == 3) {
// Simulate various problems, after a few cycles
cycles++;
if (cycles > 3 && ZHelpers.randof(5) == 0) {
Lib.println("I: simulating a crash");
msg.destroy();
break;
} else if (cycles > 3 && ZHelpers.randof(5) == 0) {
Lib.println("I: simulating CPU overload");
Sys.sleep(3.0);
if (ZMQ.isInterrupted())
break;
}
Lib.println("I: normal reply");
msg.send(worker);
liveness = HEARTBEAT_LIVENESS;
Sys.sleep(1.0); // Do some heavy work
if (ZMQ.isInterrupted())
break;
} else if (msg.size() == 1) {
var frame = msg.first();
if (frame.streq(PPP_HEARTBEAT))
liveness = HEARTBEAT_LIVENESS;
else {
Lib.println("E: invalid message");
Lib.println(msg.toString());
}
msg.destroy();
} else {
Lib.println("E: invalid message");
Lib.println(msg.toString());
}
interval = INTERVAL_INIT;
} else if (--liveness == 0) {
Lib.println("W: heartbeat failure, can't reach queue");
Lib.println("W: reconnecting in " + interval + " msec...");
Sys.sleep(interval / 1000.0);
if (interval < INTERVAL_MAX)
interval *= 2;
ctx.destroySocket(worker);
worker = workerSocket(ctx);
poller.unregisterAllSockets();
poller.registerSocket(worker, ZMQ.ZMQ_POLLIN());
liveness = HEARTBEAT_LIVENESS;
}
// Send heartbeat to queue if it's time
if (Date.now().getTime() > heartbeatAt) {
heartbeatAt = Date.now().getTime() + HEARTBEAT_INTERVAL;
Lib.println("I: worker heartbeat");
ZFrame.newStringFrame(PPP_HEARTBEAT).send(worker);
}
}
ctx.destroy();
}
}ppworker:Java 中的偏执海盗工作器
package guide;
import java.util.Random;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
//
// Paranoid Pirate worker
//
public class ppworker
{
private final static int HEARTBEAT_LIVENESS = 3; // 3-5 is reasonable
private final static int HEARTBEAT_INTERVAL = 1000; // msecs
private final static int INTERVAL_INIT = 1000; // Initial reconnect
private final static int INTERVAL_MAX = 32000; // After exponential backoff
// Paranoid Pirate Protocol constants
private final static String PPP_READY = "\001"; // Signals worker is ready
private final static String PPP_HEARTBEAT = "\002"; // Signals worker heartbeat
// Helper function that returns a new configured socket
// connected to the Paranoid Pirate queue
private static Socket worker_socket(ZContext ctx)
{
Socket worker = ctx.createSocket(SocketType.DEALER);
worker.connect("tcp://:5556");
// Tell queue we're ready for work
System.out.println("I: worker ready\n");
ZFrame frame = new ZFrame(PPP_READY);
frame.send(worker, 0);
return worker;
}
// We have a single task, which implements the worker side of the
// Paranoid Pirate Protocol (PPP). The interesting parts here are
// the heartbeating, which lets the worker detect if the queue has
// died, and vice-versa:
public static void main(String[] args)
{
try (ZContext ctx = new ZContext()) {
Socket worker = worker_socket(ctx);
Poller poller = ctx.createPoller(1);
poller.register(worker, Poller.POLLIN);
// If liveness hits zero, queue is considered disconnected
int liveness = HEARTBEAT_LIVENESS;
int interval = INTERVAL_INIT;
// Send out heartbeats at regular intervals
long heartbeat_at = System.currentTimeMillis() + HEARTBEAT_INTERVAL;
Random rand = new Random(System.nanoTime());
int cycles = 0;
while (true) {
int rc = poller.poll(HEARTBEAT_INTERVAL);
if (rc == -1)
break; // Interrupted
if (poller.pollin(0)) {
// Get message
// - 3-part envelope + content -> request
// - 1-part HEARTBEAT -> heartbeat
ZMsg msg = ZMsg.recvMsg(worker);
if (msg == null)
break; // Interrupted
// To test the robustness of the queue implementation we
// simulate various typical problems, such as the worker
// crashing, or running very slowly. We do this after a few
// cycles so that the architecture can get up and running
// first:
if (msg.size() == 3) {
cycles++;
if (cycles > 3 && rand.nextInt(5) == 0) {
System.out.println("I: simulating a crash\n");
msg.destroy();
msg = null;
break;
}
else if (cycles > 3 && rand.nextInt(5) == 0) {
System.out.println("I: simulating CPU overload\n");
try {
Thread.sleep(3000);
}
catch (InterruptedException e) {
break;
}
}
System.out.println("I: normal reply\n");
msg.send(worker);
liveness = HEARTBEAT_LIVENESS;
try {
Thread.sleep(1000);
}
catch (InterruptedException e) {
break;
} // Do some heavy work
}
else
// When we get a heartbeat message from the queue, it
// means the queue was (recently) alive, so reset our
// liveness indicator:
if (msg.size() == 1) {
ZFrame frame = msg.getFirst();
String frameData = new String(
frame.getData(), ZMQ.CHARSET
);
if (PPP_HEARTBEAT.equals(frameData))
liveness = HEARTBEAT_LIVENESS;
else {
System.out.println("E: invalid message\n");
msg.dump(System.out);
}
msg.destroy();
}
else {
System.out.println("E: invalid message\n");
msg.dump(System.out);
}
interval = INTERVAL_INIT;
}
else
// If the queue hasn't sent us heartbeats in a while,
// destroy the socket and reconnect. This is the simplest
// most brutal way of discarding any messages we might have
// sent in the meantime.
if (--liveness == 0) {
System.out.println(
"W: heartbeat failure, can't reach queue\n"
);
System.out.printf(
"W: reconnecting in %sd msec\n", interval
);
try {
Thread.sleep(interval);
}
catch (InterruptedException e) {
e.printStackTrace();
}
if (interval < INTERVAL_MAX)
interval *= 2;
ctx.destroySocket(worker);
worker = worker_socket(ctx);
liveness = HEARTBEAT_LIVENESS;
}
// Send heartbeat to queue if it's time
if (System.currentTimeMillis() > heartbeat_at) {
long now = System.currentTimeMillis();
heartbeat_at = now + HEARTBEAT_INTERVAL;
System.out.println("I: worker heartbeat\n");
ZFrame frame = new ZFrame(PPP_HEARTBEAT);
frame.send(worker, 0);
}
}
}
}
}
ppworker:Julia 中的偏执海盗工作器
ppworker:Lua 中的偏执海盗工作器
--
-- Paranoid Pirate worker
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.poller"
require"zmsg"
local HEARTBEAT_LIVENESS = 3 -- 3-5 is reasonable
local HEARTBEAT_INTERVAL = 1000 -- msecs
local INTERVAL_INIT = 1000 -- Initial reconnect
local INTERVAL_MAX = 32000 -- After exponential backoff
-- Helper function that returns a new configured socket
-- connected to the Hello World server
--
local identity
local function s_worker_socket (context)
local worker = context:socket(zmq.DEALER)
-- Set random identity to make tracing easier
identity = string.format("%04X-%04X", randof (0x10000), randof (0x10000))
worker:setopt(zmq.IDENTITY, identity)
worker:connect("tcp://:5556")
-- Configure socket to not wait at close time
worker:setopt(zmq.LINGER, 0)
-- Tell queue we're ready for work
printf("I: (%s) worker ready\n", identity)
worker:send("READY")
return worker
end
s_version_assert (2, 1)
math.randomseed(os.time())
local context = zmq.init(1)
local worker = s_worker_socket (context)
-- If liveness hits zero, queue is considered disconnected
local liveness = HEARTBEAT_LIVENESS
local interval = INTERVAL_INIT
-- Send out heartbeats at regular intervals
local heartbeat_at = s_clock () + HEARTBEAT_INTERVAL
local poller = zmq.poller(1)
local is_running = true
local cycles = 0
local function worker_cb()
-- Get message
-- - 3-part envelope + content -> request
-- - 1-part "HEARTBEAT" -> heartbeat
local msg = zmsg.recv (worker)
if (msg:parts() == 3) then
-- Simulate various problems, after a few cycles
cycles = cycles + 1
if (cycles > 3 and randof (5) == 0) then
printf ("I: (%s) simulating a crash\n", identity)
is_running = false
return
elseif (cycles > 3 and randof (5) == 0) then
printf ("I: (%s) simulating CPU overload\n",
identity)
s_sleep (5000)
end
printf ("I: (%s) normal reply - %s\n",
identity, msg:body())
msg:send(worker)
liveness = HEARTBEAT_LIVENESS
s_sleep(1000); -- Do some heavy work
elseif (msg:parts() == 1 and msg:body() == "HEARTBEAT") then
liveness = HEARTBEAT_LIVENESS
else
printf ("E: (%s) invalid message\n", identity)
msg:dump()
end
interval = INTERVAL_INIT
end
poller:add(worker, zmq.POLLIN, worker_cb)
while is_running do
local cnt = assert(poller:poll(HEARTBEAT_INTERVAL * 1000))
if (cnt == 0) then
liveness = liveness - 1
if (liveness == 0) then
printf ("W: (%s) heartbeat failure, can't reach queue\n",
identity)
printf ("W: (%s) reconnecting in %d msec...\n",
identity, interval)
s_sleep (interval)
if (interval < INTERVAL_MAX) then
interval = interval * 2
end
poller:remove(worker)
worker:close()
worker = s_worker_socket (context)
poller:add(worker, zmq.POLLIN, worker_cb)
liveness = HEARTBEAT_LIVENESS
end
end
-- Send heartbeat to queue if it's time
if (s_clock () > heartbeat_at) then
heartbeat_at = s_clock () + HEARTBEAT_INTERVAL
printf("I: (%s) worker heartbeat\n", identity)
worker:send("HEARTBEAT")
end
end
worker:close()
context:term()
ppworker:Node.js 中的偏执海盗工作器
ppworker:Objective-C 中的偏执海盗工作器
ppworker:ooc 中的偏执海盗工作器
ppworker:Perl 中的偏执海盗工作器
ppworker:PHP 中的偏执海盗工作器
<?php
/*
* Paranoid Pirate worker
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
define("HEARTBEAT_LIVENESS", 3); // 3-5 is reasonable
define("HEARTBEAT_INTERVAL", 1); // secs
define("INTERVAL_INIT", 1000); // Initial reconnect
define("INTERVAL_MAX", 32000); // After exponential backoff
/*
* Helper function that returns a new configured socket
* connected to the Hello World server
*/
function s_worker_socket($context)
{
$worker = new ZMQSocket($context, ZMQ::SOCKET_DEALER);
// Set random identity to make tracing easier
$identity = sprintf ("%04X-%04X", rand(0, 0x10000), rand(0, 0x10000));
$worker->setSockOpt(ZMQ::SOCKOPT_IDENTITY, $identity);
$worker->connect("tcp://:5556");
// Configure socket to not wait at close time
$worker->setSockOpt(ZMQ::SOCKOPT_LINGER, 0);
// Tell queue we're ready for work
printf ("I: (%s) worker ready%s", $identity, PHP_EOL);
$worker->send("READY");
return array($worker, $identity);
}
$context = new ZMQContext();
list($worker, $identity) = s_worker_socket($context);
// If liveness hits zero, queue is considered disconnected
$liveness = HEARTBEAT_LIVENESS;
$interval = INTERVAL_INIT;
// Send out heartbeats at regular intervals
$heartbeat_at = microtime(true) + HEARTBEAT_INTERVAL;
$read = $write = array();
$cycles = 0;
while (true) {
$poll = new ZMQPoll();
$poll->add($worker, ZMQ::POLL_IN);
$events = $poll->poll($read, $write, HEARTBEAT_INTERVAL * 1000);
if ($events) {
// Get message
// - 3-part envelope + content -> request
// - 1-part "HEARTBEAT" -> heartbeat
$zmsg = new Zmsg($worker);
$zmsg->recv();
if ($zmsg->parts() == 3) {
// Simulate various problems, after a few cycles
$cycles++;
if ($cycles > 3 && rand(0, 5) == 0) {
printf ("I: (%s) simulating a crash%s", $identity, PHP_EOL);
break;
} elseif ($cycles > 3 && rand(0, 5) == 0) {
printf ("I: (%s) simulating CPU overload%s", $identity, PHP_EOL);
sleep(5);
}
printf ("I: (%s) normal reply - %s%s", $identity, $zmsg->body(), PHP_EOL);
$zmsg->send();
$liveness = HEARTBEAT_LIVENESS;
sleep(1); // Do some heavy work
} elseif ($zmsg->parts() == 1 && $zmsg->body() == 'HEARTBEAT') {
$liveness = HEARTBEAT_LIVENESS;
} else {
printf ("E: (%s) invalid message%s%s", $identity, PHP_EOL, $zmsg->__toString());
}
$interval = INTERVAL_INIT;
} elseif (--$liveness == 0) {
printf ("W: (%s) heartbeat failure, can't reach queue%s", $identity, PHP_EOL);
printf ("W: (%s) reconnecting in %d msec...%s", $identity, $interval, PHP_EOL);
usleep ($interval * 1000);
if ($interval < INTERVAL_MAX) {
$interval *= 2;
}
list($worker, $identity) = s_worker_socket ($context);
$liveness = HEARTBEAT_LIVENESS;
}
// Send heartbeat to queue if it's time
if (microtime(true) > $heartbeat_at) {
$heartbeat_at = microtime(true) + HEARTBEAT_INTERVAL;
printf ("I: (%s) worker heartbeat%s", $identity, PHP_EOL);
$worker->send("HEARTBEAT");
}
}
ppworker:Python 中的偏执海盗工作器
#
## Paranoid Pirate worker
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
from random import randint
import time
import zmq
HEARTBEAT_LIVENESS = 3
HEARTBEAT_INTERVAL = 1
INTERVAL_INIT = 1
INTERVAL_MAX = 32
# Paranoid Pirate Protocol constants
PPP_READY = b"\x01" # Signals worker is ready
PPP_HEARTBEAT = b"\x02" # Signals worker heartbeat
def worker_socket(context, poller):
"""Helper function that returns a new configured socket
connected to the Paranoid Pirate queue"""
worker = context.socket(zmq.DEALER) # DEALER
identity = b"%04X-%04X" % (randint(0, 0x10000), randint(0, 0x10000))
worker.setsockopt(zmq.IDENTITY, identity)
poller.register(worker, zmq.POLLIN)
worker.connect("tcp://:5556")
worker.send(PPP_READY)
return worker
context = zmq.Context(1)
poller = zmq.Poller()
liveness = HEARTBEAT_LIVENESS
interval = INTERVAL_INIT
heartbeat_at = time.time() + HEARTBEAT_INTERVAL
worker = worker_socket(context, poller)
cycles = 0
while True:
socks = dict(poller.poll(HEARTBEAT_INTERVAL * 1000))
# Handle worker activity on backend
if socks.get(worker) == zmq.POLLIN:
# Get message
# - 3-part envelope + content -> request
# - 1-part HEARTBEAT -> heartbeat
frames = worker.recv_multipart()
if not frames:
break # Interrupted
if len(frames) == 3:
# Simulate various problems, after a few cycles
cycles += 1
if cycles > 3 and randint(0, 5) == 0:
print("I: Simulating a crash")
break
if cycles > 3 and randint(0, 5) == 0:
print("I: Simulating CPU overload")
time.sleep(3)
print("I: Normal reply")
worker.send_multipart(frames)
liveness = HEARTBEAT_LIVENESS
time.sleep(1) # Do some heavy work
elif len(frames) == 1 and frames[0] == PPP_HEARTBEAT:
print("I: Queue heartbeat")
liveness = HEARTBEAT_LIVENESS
else:
print("E: Invalid message: %s" % frames)
interval = INTERVAL_INIT
else:
liveness -= 1
if liveness == 0:
print("W: Heartbeat failure, can't reach queue")
print("W: Reconnecting in %0.2fs..." % interval)
time.sleep(interval)
if interval < INTERVAL_MAX:
interval *= 2
poller.unregister(worker)
worker.setsockopt(zmq.LINGER, 0)
worker.close()
worker = worker_socket(context, poller)
liveness = HEARTBEAT_LIVENESS
if time.time() > heartbeat_at:
heartbeat_at = time.time() + HEARTBEAT_INTERVAL
print("I: Worker heartbeat")
worker.send(PPP_HEARTBEAT)
ppworker:Q 中的偏执海盗工作器
ppworker:Racket 中的偏执海盗工作器
ppworker:Ruby 中的偏执海盗工作器
ppworker:Rust 中的偏执海盗工作器
ppworker:Scala 中的偏执海盗工作器
ppworker:Tcl 中的偏执海盗工作器
#
# Paranoid Pirate worker
#
package require zmq
set HEARTBEAT_LIVENESS 3 ;# 3-5 is reasonable
set HEARTBEAT_INTERVAL 1000 ;# msecs
set INTERVAL_INIT 1000 ;# Initial reconnect
set INTERVAL_MAX 32000 ;# After exponential backoff
# Paranoid Pirate Protocol constants
set PPP_READY "READY" ;# Signals worker is ready
set PPP_HEARTBEAT "HEARTBEAT" ;# Signals worker heartbeat
expr {srand([pid])}
# Helper function that returns a new configured socket
# connected to the Paranoid Pirate queue
proc s_worker_socket {ctx} {
global PPP_READY
set worker [zmq socket worker $ctx DEALER]
$worker connect "tcp://:5556"
# Tell queue we're ready for work
puts "I: worker ready"
$worker send $PPP_READY
return $worker
}
set ctx [zmq context context]
set worker [s_worker_socket $ctx]
# If liveness hits zero, queue is considered disconnected
set liveness $HEARTBEAT_LIVENESS
set interval $INTERVAL_INIT
# Send out heartbeats at regular intervals
set heartbeat_at [expr {[clock seconds] + $HEARTBEAT_INTERVAL}]
set cycles 0
while {1} {
set poll_set [list [list $worker [list POLLIN]]]
set rpoll_set [zmq poll $poll_set $HEARTBEAT_INTERVAL]
if {[llength $rpoll_set] && "POLLIN" in [lindex $rpoll_set 0 1]} {
# Get message
# - 3-part envelope + content -> request
# - 1-part HEARTBEAT -> heartbeat
set msg [zmsg recv $worker]
if {[llength $msg] == 3} {
# Simulate various problems, after a few cycles
incr cycles
if {$cycles > 3 && [expr {int(rand()*5)}] == 0} {
puts "I: simulating a crash"
break
} elseif {$cycles > 3 && [expr {int(rand()*5)}] == 0} {
puts "I: simulating CPU overload"
after 3000
}
puts "I: normal reply"
zmsg send $worker $msg
set liveness $HEARTBEAT_LIVENESS
after 1000 ;# Do some heavy work
} elseif {[llength $msg] == 1} {
if {[lindex $msg 0] eq $PPP_HEARTBEAT} {
puts "I: heartbeat"
set liveness $HEARTBEAT_LIVENESS
} else {
puts "E: invalid message"
zmsg dump $msg
}
} else {
puts "E: invalid message"
zmsg dump $msg
}
set interval $INTERVAL_INIT
} elseif {[incr liveness -1] == 0} {
puts "W: heartbeat failure, can't reach queue"
puts "W: reconnecting in $interval msec..."
after $interval
if {$interval < $INTERVAL_MAX} {
set interval [expr {$interval * 2}]
}
$worker close
set worker [s_worker_socket $ctx]
set liveness $HEARTBEAT_LIVENESS
}
# Send heartbeat to queue if it's time
if {[clock seconds] > $heartbeat_at} {
set heartbeat_at [expr {[clock seconds] + $HEARTBEAT_INTERVAL}]
puts "I: worker heartbeat"
$worker send $PPP_HEARTBEAT
}
}
$worker close
$ctx term
ppworker:OCaml 中的偏执海盗工作器
关于此示例的一些注释
-
代码中包含故障模拟,如之前一样。这使得它 (a) 非常难以调试,以及 (b) 重用时很危险。当你想要调试它时,请禁用故障模拟。
-
工作器使用了一种与我们为懒惰海盗客户端设计的相似的重连策略,但有两个主要区别:(a) 它采用指数退避,以及 (b) 它无限重试(而客户端在报告失败前只重试几次)。
尝试运行客户端、队列和工作器,例如使用这样的脚本:
ppqueue &
for i in 1 2 3 4; do
ppworker &
sleep 1
done
lpclient &
你应该会看到工作器在模拟崩溃时一个接一个地死亡,客户端最终放弃。你可以停止并重新启动队列,客户端和工作器都会重新连接并继续运行。而且无论你对队列和工作器做什么,客户端永远不会收到乱序的回复:整个链要么正常工作,要么客户端放弃。
心跳 #
心跳解决了判断对端是活着还是死亡的问题。这并不是 ZeroMQ 特有的问题。TCP 有一个很长的超时时间(30 分钟左右),这意味着你可能无法知道对端是死了、断开连接了,还是带着一箱伏特加、一个红发女郎和一笔巨额报销款去布拉格度周末了。
做对心跳机制并不容易。在编写偏执海盗示例时,花了我大约五个小时才让心跳机制正常工作。其余的请求-回复链可能只花了十分钟。尤其容易产生“误报故障”,即对端因为心跳发送不正常而判定对方已断开连接。
我们将看看人们在使用 ZeroMQ 时处理心跳机制的三种主要方法。
不予理会 #
最常见的方法是完全不做心跳,寄希望于一切顺利。很多(如果不是大多数)ZeroMQ 应用程序都这样做。在许多情况下,ZeroMQ 通过隐藏对端来鼓励这种做法。这种方法会导致什么问题呢?
-
当我们在一个跟踪对端的应用程序中使用 ROUTER 套接字时,随着对端断开和重新连接,应用程序会泄漏内存(应用程序为每个对端持有的资源),并且变得越来越慢。
-
当我们使用基于 SUB 或 DEALER 的数据接收方时,我们无法区分“好的沉默”(没有数据)和“坏的沉默”(另一端已死亡)。当接收方知道对方死亡时,例如,它可以切换到备用路由。
-
如果我们使用长时间保持沉默的 TCP 连接,在某些网络中它会直接断开。发送一些东西(技术上讲,这更像是一种“保活”而不是心跳)会保持网络连接活跃。
单向心跳 #
第二个选项是每个节点大约每秒向其对端发送一个心跳消息。当一个节点在一定超时时间内(通常是几秒)没有收到另一端的消息时,它就会将该对端视为已死亡。听起来不错,对吧?遗憾的是,并非如此。这在某些情况下可行,但在其他情况下存在棘手的边缘情况。
对于 pub-sub 模式,这是可行的,而且是你能使用的唯一模式。SUB 套接字无法回复 PUB 套接字,但 PUB 套接字可以愉快地向其订阅者发送“我还活着”的消息。
作为一种优化,你只在没有实际数据要发送时才发送心跳。此外,如果网络活动是问题(例如,在活动会耗尽电池的移动网络上),你可以逐渐降低发送心跳的频率。只要接收方能够检测到故障(活动突然停止),那就可以了。
这是这种设计的典型问题
-
当我们发送大量数据时,它可能不准确,因为心跳会延迟在数据后面。如果心跳延迟,你可能会因为网络拥堵而遇到误报超时和断开连接。因此,无论发送方是否省略了心跳,始终将任何接收到的数据视为心跳。
-
尽管 pub-sub 模式会丢弃发往已消失接收方的消息,但 PUSH 和 DEALER 套接字会将其排队。因此,如果你向一个已死亡的对端发送心跳,并且它重新上线,它会收到你发送的所有心跳,数量可能高达数千个。天哪,天哪!
-
这种设计假定整个网络中的心跳超时时间是相同的。但这并不准确。一些对端会想要非常积极的心跳(以便快速检测故障),而另一些则会想要非常宽松的心跳(以便让休眠的网络保持休眠状态并节省电量)。
Ping-Pong 心跳 #
第三种选择是使用 ping-pong 对话。一个对端向另一个对端发送 ping 命令,后者回复 pong 命令。这两个命令都没有负载。Ping 和 pong 不相关。由于在某些网络中,“客户端”和“服务器”的角色是任意的,我们通常规定任何一个对端都可以发送 ping 并期望收到 pong 回复。然而,由于超时时间取决于动态客户端最了解的网络拓扑,通常是客户端 ping 服务器。
这适用于所有基于 ROUTER 的代理。我们在第二种模型中使用的相同优化使这种方法效果更好:将任何接收到的数据视为 pong,并且只在不发送其他数据时发送 ping。
偏执海盗模式的心跳 #
对于偏执海盗模式,我们选择了第二种方法。这可能不是最简单的方法:如果今天来设计,我可能会尝试 ping-pong 方法。然而,其原理是相似的。心跳消息在两个方向上异步流动,任何一端都可以判定另一端“已死亡”并停止与之通信。
在工作器中,我们是这样处理来自队列的心跳的:
- 我们计算一个活跃度(liveness),它是我们在判定队列死亡之前还可以错过的心跳次数。它开始时为三,每次错过一个心跳就递减一次。
- 我们在zmq_poll循环中,每次等待一秒,这是我们的心跳间隔。
- 如果在这段时间内收到来自队列的任何消息,我们就将活跃度重置为三。
- 如果在这段时间内没有消息,我们就递减活跃度。
- 如果活跃度达到零,我们就认为队列已死亡。
- 如果队列已死亡,我们就销毁套接字,创建一个新的并重新连接。
- 为了避免打开和关闭过多的套接字,我们在重新连接之前会等待一定的时间间隔,并且每次都将间隔加倍,直到达到 32 秒。
我们是这样处理发送给队列的心跳的:
- 我们计算何时发送下一个心跳;这是一个单独的变量,因为我们只与一个对端(队列)通信。
- 在zmq_poll循环中,每当超过这个时间,我们就向队列发送一个心跳。
这是工作器的核心心跳代码:
#define HEARTBEAT_LIVENESS 3 // 3-5 is reasonable
#define HEARTBEAT_INTERVAL 1000 // msecs
#define INTERVAL_INIT 1000 // Initial reconnect
#define INTERVAL_MAX 32000 // After exponential backoff
...
// If liveness hits zero, queue is considered disconnected
size_t liveness = HEARTBEAT_LIVENESS;
size_t interval = INTERVAL_INIT;
// Send out heartbeats at regular intervals
uint64_t heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
while (true) {
zmq_pollitem_t items [] = { { worker, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (items, 1, HEARTBEAT_INTERVAL * ZMQ_POLL_MSEC);
if (items [0].revents & ZMQ_POLLIN) {
// Receive any message from queue
liveness = HEARTBEAT_LIVENESS;
interval = INTERVAL_INIT;
}
else
if (--liveness == 0) {
zclock_sleep (interval);
if (interval < INTERVAL_MAX)
interval *= 2;
zsocket_destroy (ctx, worker);
...
liveness = HEARTBEAT_LIVENESS;
}
// Send heartbeat to queue if it's time
if (zclock_time () > heartbeat_at) {
heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
// Send heartbeat message to queue
}
}
队列也做同样的事情,但为每个工作器管理一个过期时间。
以下是关于你自己实现心跳的一些技巧:
-
使用zmq_poll或反应器作为应用程序主任务的核心。
-
首先构建对端之间的心跳机制,通过模拟故障进行测试,然后再构建其余的消息流。之后再添加心跳机制要棘手得多。
-
使用简单的跟踪(即打印到控制台)来使其工作。为了帮助你跟踪对端之间的消息流,使用 zmsg 提供的转储(dump)方法,并按顺序给你的消息编号,这样你就可以看到是否有遗漏。
-
在实际应用程序中,心跳必须是可配置的,并且通常需要与对端协商。一些对端可能需要非常积极的心跳,低至 10 毫秒。其他对端可能距离很远,希望心跳间隔高达 30 秒。
-
如果你对不同的对端有不同的心跳间隔,你的 poll 超时时间应该是这些间隔中最低的(最短的)。不要使用无限超时。
-
在你用于发送消息的同一套接字上进行心跳,这样你的心跳也充当了保活(keep-alive)机制,阻止网络连接变得陈旧(有些防火墙对静默连接不太友好)。
契约和协议 #
如果你仔细留意,你会发现偏执海盗模式与简单海盗模式不互通,原因在于心跳。但是,我们如何定义“互通性”呢?为了保证互通性,我们需要一种契约,一种约定,它允许不同时间、不同地点的不同团队编写能够保证协同工作的代码。我们称之为“协议”。
在没有规范的情况下进行实验很有趣,但这并不是实际应用程序的合理基础。如果我们想用另一种语言编写工作器怎么办?我们是否必须阅读代码才能了解其工作原理?如果出于某种原因我们想更改协议怎么办?即使是一个简单的协议,如果成功,也会演变并变得更复杂。
缺乏契约是“一次性应用程序”的明显标志。所以,让我们为这个协议编写一份契约。我们该怎么做呢?
在 rfc.zeromq.org 有一个 Wiki,我们专门将其作为公共 ZeroMQ 契约的存放地。要创建新的规范,如果需要,请在 Wiki 上注册并遵循说明。这相当直接,尽管编写技术文本并非人人所爱。
我花了大约十五分钟起草了新的 海盗模式协议(Pirate Pattern Protocol)。它不是一个庞大的规范,但足以作为论证的基础(“你的队列与 PPP 不兼容;请修复它!”)。
将 PPP 变成一个真正的协议需要更多工作
-
READY 命令中应该包含协议版本号,以便区分不同版本的 PPP。
-
目前,READY 和 HEARTBEAT 与请求和回复并不完全区分。为了区分它们,我们需要一种包含“消息类型”部分的报文结构。
面向服务的可靠队列 (Majordomo 模式) #

进步的美妙之处在于,当律师和委员会不参与时,进展是多么迅速。一页纸的 MDP 规范将 PPP 变成了一些更可靠的东西。这就是我们应该设计复杂架构的方式:先写下契约,然后再编写软件来实现它们。
Majordomo 协议(MDP)以一种有趣的方式扩展和改进了 PPP:它在客户端发送的请求中添加了“服务名称”,并要求工作器注册特定服务。添加服务名称将我们的偏执海盗队列变成了面向服务的代理。MDP 的好处在于它源自可工作的代码、一个更简单的先祖协议(PPP),以及一套精确的改进措施,每个改进都解决了一个明确的问题。这使得起草工作变得容易。
要实现 Majordomo,我们需要为客户端和工作器编写一个框架。要求每个应用程序开发人员阅读规范并使其工作,而他们本可以使用更简单的 API 来为他们完成工作,这真的不明智。
因此,我们的第一个契约(MDP 本身)定义了我们分布式架构的各个部分如何相互通信,而我们的第二个契约则定义了用户应用程序如何与我们将要设计的技术框架进行通信。
Majordomo 有两个部分:客户端和服务端。由于我们将编写客户端和工作器应用程序,因此需要两个 API。这是使用简单的面向对象方法构建的客户端 API 草图:
mdcli_t *mdcli_new (char *broker);
void mdcli_destroy (mdcli_t **self_p);
zmsg_t *mdcli_send (mdcli_t *self, char *service, zmsg_t **request_p);
就这样。我们向代理打开一个会话,发送一个请求消息,收到一个回复消息,最后关闭连接。这是工作器 API 的草图:
mdwrk_t *mdwrk_new (char *broker,char *service);
void mdwrk_destroy (mdwrk_t **self_p);
zmsg_t *mdwrk_recv (mdwrk_t *self, zmsg_t *reply);
它或多或少是对称的,但工作器对话稍微有点不同。工作器第一次执行 recv() 时,会传递一个空回复。之后,它会传递当前的回复,并获取一个新的请求。
客户端和工作器 API 构造起来相当简单,因为它们很大程度上基于我们已经开发的偏执海盗代码。这是客户端 API:
mdcliapi:Ada 中的 Majordomo 客户端 API
mdcliapi:Basic 中的 Majordomo 客户端 API
mdcliapi:C 中的 Majordomo 客户端 API
// mdcliapi class - Majordomo Protocol Client API
// Implements the MDP/Worker spec at https://rfc.zeromq.cn/spec:7.
#include "mdcliapi.h"
// Structure of our class
// We access these properties only via class methods
struct _mdcli_t {
zctx_t *ctx; // Our context
char *broker;
void *client; // Socket to broker
int verbose; // Print activity to stdout
int timeout; // Request timeout
int retries; // Request retries
};
// Connect or reconnect to broker
void s_mdcli_connect_to_broker (mdcli_t *self)
{
if (self->client)
zsocket_destroy (self->ctx, self->client);
self->client = zsocket_new (self->ctx, ZMQ_REQ);
zmq_connect (self->client, self->broker);
if (self->verbose)
zclock_log ("I: connecting to broker at %s...", self->broker);
}
// .split constructor and destructor
// Here we have the constructor and destructor for our class:
// Constructor
mdcli_t *
mdcli_new (char *broker, int verbose)
{
assert (broker);
mdcli_t *self = (mdcli_t *) zmalloc (sizeof (mdcli_t));
self->ctx = zctx_new ();
self->broker = strdup (broker);
self->verbose = verbose;
self->timeout = 2500; // msecs
self->retries = 3; // Before we abandon
s_mdcli_connect_to_broker (self);
return self;
}
// Destructor
void
mdcli_destroy (mdcli_t **self_p)
{
assert (self_p);
if (*self_p) {
mdcli_t *self = *self_p;
zctx_destroy (&self->ctx);
free (self->broker);
free (self);
*self_p = NULL;
}
}
// .split configure retry behavior
// These are the class methods. We can set the request timeout and number
// of retry attempts before sending requests:
// Set request timeout
void
mdcli_set_timeout (mdcli_t *self, int timeout)
{
assert (self);
self->timeout = timeout;
}
// Set request retries
void
mdcli_set_retries (mdcli_t *self, int retries)
{
assert (self);
self->retries = retries;
}
// .split send request and wait for reply
// Here is the {{send}} method. It sends a request to the broker and gets
// a reply even if it has to retry several times. It takes ownership of
// the request message, and destroys it when sent. It returns the reply
// message, or NULL if there was no reply after multiple attempts:
zmsg_t *
mdcli_send (mdcli_t *self, char *service, zmsg_t **request_p)
{
assert (self);
assert (request_p);
zmsg_t *request = *request_p;
// Prefix request with protocol frames
// Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
// Frame 2: Service name (printable string)
zmsg_pushstr (request, service);
zmsg_pushstr (request, MDPC_CLIENT);
if (self->verbose) {
zclock_log ("I: send request to '%s' service:", service);
zmsg_dump (request);
}
int retries_left = self->retries;
while (retries_left && !zctx_interrupted) {
zmsg_t *msg = zmsg_dup (request);
zmsg_send (&msg, self->client);
zmq_pollitem_t items [] = {
{ self->client, 0, ZMQ_POLLIN, 0 }
};
// .split body of send
// On any blocking call, {{libzmq}} will return -1 if there was
// an error; we could in theory check for different error codes,
// but in practice it's OK to assume it was {{EINTR}} (Ctrl-C):
int rc = zmq_poll (items, 1, self->timeout * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
// If we got a reply, process it
if (items [0].revents & ZMQ_POLLIN) {
zmsg_t *msg = zmsg_recv (self->client);
if (self->verbose) {
zclock_log ("I: received reply:");
zmsg_dump (msg);
}
// We would handle malformed replies better in real code
assert (zmsg_size (msg) >= 3);
zframe_t *header = zmsg_pop (msg);
assert (zframe_streq (header, MDPC_CLIENT));
zframe_destroy (&header);
zframe_t *reply_service = zmsg_pop (msg);
assert (zframe_streq (reply_service, service));
zframe_destroy (&reply_service);
zmsg_destroy (&request);
return msg; // Success
}
else
if (--retries_left) {
if (self->verbose)
zclock_log ("W: no reply, reconnecting...");
s_mdcli_connect_to_broker (self);
}
else {
if (self->verbose)
zclock_log ("W: permanent error, abandoning");
break; // Give up
}
}
if (zctx_interrupted)
printf ("W: interrupt received, killing client...\n");
zmsg_destroy (&request);
return NULL;
}
mdcliapi:C++ 中的 Majordomo 客户端 API
#ifndef __MDCLIAPI_HPP_INCLUDED__
#define __MDCLIAPI_HPP_INCLUDED__
//#include "mdcliapi.h"
#include "zmsg.hpp"
#include "mdp.h"
class mdcli {
public:
// ---------------------------------------------------------------------
// Constructor
mdcli (std::string broker, int verbose): m_broker(broker), m_verbose(verbose)
{
assert (broker.size()!=0);
s_version_assert (4, 0);
m_context = new zmq::context_t(1);
s_catch_signals ();
connect_to_broker ();
}
// Destructor
virtual
~mdcli ()
{
delete m_client;
delete m_context;
}
// ---------------------------------------------------------------------
// Connect or reconnect to broker
void connect_to_broker ()
{
if (m_client) {
delete m_client;
}
m_client = new zmq::socket_t (*m_context, ZMQ_REQ);
s_set_id(*m_client);
int linger = 0;
m_client->setsockopt(ZMQ_LINGER, &linger, sizeof (linger));
m_client->connect (m_broker.c_str());
if (m_verbose) {
s_console ("I: connecting to broker at %s...", m_broker.c_str());
}
}
// ---------------------------------------------------------------------
// Set request timeout
void
set_timeout (int timeout)
{
m_timeout = timeout;
}
// ---------------------------------------------------------------------
// Set request retries
void
set_retries (int retries)
{
m_retries = retries;
}
// ---------------------------------------------------------------------
// Send request to broker and get reply by hook or crook
// Takes ownership of request message and destroys it when sent.
// Returns the reply message or NULL if there was no reply.
zmsg *
send (std::string service, zmsg *&request_p)
{
assert (request_p);
zmsg *request = request_p;
// Prefix request with protocol frames
// Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
// Frame 2: Service name (printable string)
request->push_front(service.c_str());
request->push_front(k_mdp_client.data());
if (m_verbose) {
s_console ("I: send request to '%s' service:", service.c_str());
request->dump();
}
int retries_left = m_retries;
while (retries_left && !s_interrupted) {
zmsg * msg = new zmsg(*request);
msg->send(*m_client);
while (!s_interrupted) {
// Poll socket for a reply, with timeout
zmq::pollitem_t items [] = {
{ *m_client, 0, ZMQ_POLLIN, 0 } };
zmq::poll (items, 1, m_timeout);
// If we got a reply, process it
if (items [0].revents & ZMQ_POLLIN) {
zmsg * recv_msg = new zmsg(*m_client);
if (m_verbose) {
s_console ("I: received reply:");
recv_msg->dump ();
}
// Don't try to handle errors, just assert noisily
assert (recv_msg->parts () >= 3);
ustring header = recv_msg->pop_front();
assert (header.compare((unsigned char *)k_mdp_client.data()) == 0);
ustring reply_service = recv_msg->pop_front();
assert (reply_service.compare((unsigned char *)service.c_str()) == 0);
delete request;
return recv_msg; // Success
}
else {
if (--retries_left) {
if (m_verbose) {
s_console ("W: no reply, reconnecting...");
}
// Reconnect, and resend message
connect_to_broker ();
zmsg msg (*request);
msg.send (*m_client);
}
else {
if (m_verbose) {
s_console ("W: permanent error, abandoning request");
}
break; // Give up
}
}
}
}
if (s_interrupted) {
std::cout << "W: interrupt received, killing client..." << std::endl;
}
delete request;
return 0;
}
private:
const std::string m_broker;
zmq::context_t * m_context;
zmq::socket_t * m_client{nullptr}; // Socket to broker
const int m_verbose; // Print activity to stdout
int m_timeout{2500}; // Request timeout
int m_retries{3}; // Request retries
};
#endif
mdcliapi:C# 中的 Majordomo 客户端 API
mdcliapi:CL 中的 Majordomo 客户端 API
mdcliapi:Delphi 中的 Majordomo 客户端 API
mdcliapi:Erlang 中的 Majordomo 客户端 API
mdcliapi:Elixir 中的 Majordomo 客户端 API
mdcliapi:F# 中的 Majordomo 客户端 API
mdcliapi:Felix 中的 Majordomo 客户端 API
mdcliapi:Go 中的 Majordomo 客户端 API
// mdcliapi class - Majordomo Protocol Client API
// Implements the MDP/Worker spec at https://rfc.zeromq.cn/spec:7
//
// Author: iano <scaly.iano@gmail.com>
// Based on C & Python example
package main
import (
zmq "github.com/alecthomas/gozmq"
"log"
"time"
)
type Client interface {
Close()
Send([]byte, [][]byte) [][]byte
}
type mdClient struct {
broker string
client *zmq.Socket
context *zmq.Context
retries int
timeout time.Duration
verbose bool
}
func NewClient(broker string, verbose bool) Client {
context, _ := zmq.NewContext()
self := &mdClient{
broker: broker,
context: context,
retries: 3,
timeout: 2500 * time.Millisecond,
verbose: verbose,
}
self.reconnect()
return self
}
func (self *mdClient) reconnect() {
if self.client != nil {
self.client.Close()
}
self.client, _ = self.context.NewSocket(zmq.REQ)
self.client.SetLinger(0)
self.client.Connect(self.broker)
if self.verbose {
log.Printf("I: connecting to broker at %s...\n", self.broker)
}
}
func (self *mdClient) Close() {
if self.client != nil {
self.client.Close()
}
self.context.Close()
}
func (self *mdClient) Send(service []byte, request [][]byte) (reply [][]byte) {
// Prefix request with protocol frames
// Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
// Frame 2: Service name (printable string)
frame := append([][]byte{[]byte(MDPC_CLIENT), service}, request...)
if self.verbose {
log.Printf("I: send request to '%s' service:", service)
Dump(request)
}
for retries := self.retries; retries > 0; {
self.client.SendMultipart(frame, 0)
items := zmq.PollItems{
zmq.PollItem{Socket: self.client, Events: zmq.POLLIN},
}
_, err := zmq.Poll(items, self.timeout)
if err != nil {
panic(err) // Interrupted
}
if item := items[0]; item.REvents&zmq.POLLIN != 0 {
msg, _ := self.client.RecvMultipart(0)
if self.verbose {
log.Println("I: received reply: ")
Dump(msg)
}
// We would handle malformed replies better in real code
if len(msg) < 3 {
panic("Error msg len")
}
header := msg[0]
if string(header) != MDPC_CLIENT {
panic("Error header")
}
replyService := msg[1]
if string(service) != string(replyService) {
panic("Error reply service")
}
reply = msg[2:]
break
} else if retries--; retries > 0 {
if self.verbose {
log.Println("W: no reply, reconnecting...")
}
self.reconnect()
} else {
if self.verbose {
log.Println("W: permanent error, abandoning")
}
break
}
}
return
}
mdcliapi:Haskell 中的 Majordomo 客户端 API
mdcliapi:Haxe 中的 Majordomo 客户端 API
package ;
import haxe.Stack;
import neko.Lib;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQException;
import MDP;
/**
* Majordomo Protocol Client API
* Implements the MDP/Worker spec at https://rfc.zeromq.cn/spec:7
*/
class MDCliAPI
{
/** Request timeout (in msec) */
public var timeout:Int;
/** Request #retries */
public var retries:Int;
// Private instance fields
/** Our context */
private var ctx:ZContext;
/** Connection string to reach broker */
private var broker:String;
/** Socket to broker */
private var client:ZMQSocket;
/** Print activity to stdout */
private var verbose:Bool;
/** Logger function used in verbose mode */
private var log:Dynamic->Void;
/**
* Constructor
* @param broker
* @param verbose
*/
public function new(broker:String, ?verbose:Bool=false, ?logger:Dynamic->Void) {
ctx = new ZContext();
this.broker = broker;
this.verbose = verbose;
this.timeout = 2500; // msecs
this.retries = 3; // before we abandon
if (logger != null)
log = logger;
else
log = Lib.println;
connectToBroker();
}
/**
* Connect or reconnect to broker
*/
public function connectToBroker() {
if (client != null)
client.close();
client = ctx.createSocket(ZMQ_REQ);
client.setsockopt(ZMQ_LINGER, 0);
client.connect(broker);
if (verbose)
log("I: client connecting to broker at " + broker + "...");
}
/**
* Destructor
*/
public function destroy() {
ctx.destroy();
}
/**
* Send request to broker and get reply by hook or crook.
* Takes ownership of request message and destroys it when sent.
* Returns the reply message or NULL if there was no reply after #retries
* @param service
* @param request
* @return
*/
public function send(service:String, request:ZMsg):ZMsg {
// Prefix request with MDP protocol frames
// Frame 1: "MDPCxy" (six bytes, MDP/Client)
// Frame 2: Service name (printable string)
request.push(ZFrame.newStringFrame(service));
request.push(ZFrame.newStringFrame(MDP.MDPC_CLIENT));
if (verbose) {
log("I: send request to '" + service + "' service:");
log(request.toString());
}
var retries_left = retries;
var poller = new ZMQPoller();
while (retries_left > 0 && !ZMQ.isInterrupted()) {
// We send a request, then we work to get a reply
var msg = request.duplicate();
msg.send(client);
var expect_reply = true;
while (expect_reply) {
poller.registerSocket(client, ZMQ.ZMQ_POLLIN());
// Poll socket for a reply, with timeout
try {
var res = poller.poll(timeout * 1000);
} catch (e:ZMQException) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
ctx.destroy();
return null;
}
// If we got a reply, process it
if (poller.pollin(1)) {
// We got a reply from the server, must match sequence
var msg = ZMsg.recvMsg(client);
if (msg == null)
break; // Interrupted
if (verbose)
log("I: received reply:" + msg.toString());
if (msg.size() < 3)
break; // Don't try to handle errors
var header = msg.pop();
if (!header.streq(MDP.MDPC_CLIENT))
break; // Assert
header.destroy();
var reply_service = msg.pop();
if (!reply_service.streq(service))
break; // Assert
reply_service.destroy();
request.destroy();
return msg; // Success
} else if (--retries_left > 0) {
if (verbose)
log("W: no reply, reconnecting...");
// Reconnect , and resend message
connectToBroker();
msg = request.duplicate();
msg.send(client);
} else {
if (verbose)
log("E: permanent error, abandoning");
break;
}
poller.unregisterAllSockets();
}
}
return null;
}
}
mdcliapi:Java 中的 Majordomo 客户端 API
package guide;
import java.util.Formatter;
import org.zeromq.*;
/**
* Majordomo Protocol Client API, Java version Implements the MDP/Worker spec at
* https://rfc.zeromq.cn/spec:7.
*
*/
public class mdcliapi
{
private String broker;
private ZContext ctx;
private ZMQ.Socket client;
private long timeout = 2500;
private int retries = 3;
private boolean verbose;
private Formatter log = new Formatter(System.out);
public long getTimeout()
{
return timeout;
}
public void setTimeout(long timeout)
{
this.timeout = timeout;
}
public int getRetries()
{
return retries;
}
public void setRetries(int retries)
{
this.retries = retries;
}
public mdcliapi(String broker, boolean verbose)
{
this.broker = broker;
this.verbose = verbose;
ctx = new ZContext();
reconnectToBroker();
}
/**
* Connect or reconnect to broker
*/
void reconnectToBroker()
{
if (client != null) {
ctx.destroySocket(client);
}
client = ctx.createSocket(SocketType.REQ);
client.connect(broker);
if (verbose)
log.format("I: connecting to broker at %s\n", broker);
}
/**
* Send request to broker and get reply by hook or crook Takes ownership of
* request message and destroys it when sent. Returns the reply message or
* NULL if there was no reply.
*
* @param service
* @param request
* @return
*/
public ZMsg send(String service, ZMsg request)
{
request.push(new ZFrame(service));
request.push(MDP.C_CLIENT.newFrame());
if (verbose) {
log.format("I: send request to '%s' service: \n", service);
request.dump(log.out());
}
ZMsg reply = null;
int retriesLeft = retries;
while (retriesLeft > 0 && !Thread.currentThread().isInterrupted()) {
request.duplicate().send(client);
// Poll socket for a reply, with timeout
ZMQ.Poller items = ctx.createPoller(1);
items.register(client, ZMQ.Poller.POLLIN);
if (items.poll(timeout) == -1)
break; // Interrupted
if (items.pollin(0)) {
ZMsg msg = ZMsg.recvMsg(client);
if (verbose) {
log.format("I: received reply: \n");
msg.dump(log.out());
}
// Don't try to handle errors, just assert noisily
assert (msg.size() >= 3);
ZFrame header = msg.pop();
assert (MDP.C_CLIENT.equals(header.toString()));
header.destroy();
ZFrame replyService = msg.pop();
assert (service.equals(replyService.toString()));
replyService.destroy();
reply = msg;
break;
}
else {
items.unregister(client);
if (--retriesLeft == 0) {
log.format("W: permanent error, abandoning\n");
break;
}
log.format("W: no reply, reconnecting\n");
reconnectToBroker();
}
items.close();
}
request.destroy();
return reply;
}
public void destroy()
{
ctx.destroy();
}
}
mdcliapi:Julia 中的 Majordomo 客户端 API
mdcliapi:Lua 中的 Majordomo 客户端 API
--
-- mdcliapi.lua - Majordomo Protocol Client API
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
local setmetatable = setmetatable
local mdp = require"mdp"
local zmq = require"zmq"
local zpoller = require"zmq.poller"
local zmsg = require"zmsg"
require"zhelpers"
local s_version_assert = s_version_assert
local obj_mt = {}
obj_mt.__index = obj_mt
function obj_mt:set_timeout(timeout)
self.timeout = timeout
end
function obj_mt:set_retries(retries)
self.retries = retries
end
function obj_mt:destroy()
if self.client then self.client:close() end
self.context:term()
end
local function s_mdcli_connect_to_broker(self)
-- close old socket.
if self.client then
self.poller:remove(self.client)
self.client:close()
end
self.client = assert(self.context:socket(zmq.REQ))
assert(self.client:setopt(zmq.LINGER, 0))
assert(self.client:connect(self.broker))
if self.verbose then
s_console("I: connecting to broker at %s...", self.broker)
end
-- add socket to poller
self.poller:add(self.client, zmq.POLLIN, function()
self.got_reply = true
end)
end
--
-- Send request to broker and get reply by hook or crook
-- Returns the reply message or nil if there was no reply.
--
function obj_mt:send(service, request)
-- Prefix request with protocol frames
-- Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
-- Frame 2: Service name (printable string)
request:push(service)
request:push(mdp.MDPC_CLIENT)
if self.verbose then
s_console("I: send request to '%s' service:", service)
request:dump()
end
local retries = self.retries
while (retries > 0) do
local msg = request:dup()
msg:send(self.client)
self.got_reply = false
while true do
local cnt = assert(self.poller:poll(self.timeout * 1000))
if cnt ~= 0 and self.got_reply then
local msg = zmsg.recv(self.client)
if self.verbose then
s_console("I: received reply:")
msg:dump()
end
assert(msg:parts() >= 3)
local header = msg:pop()
assert(header == mdp.MDPC_CLIENT)
local reply_service = msg:pop()
assert(reply_service == service)
return msg
else
retries = retries - 1
if (retries > 0) then
if self.verbose then
s_console("W: no reply, reconnecting...")
end
-- Reconnect
s_mdcli_connect_to_broker(self)
break -- outer loop will resend request.
else
if self.verbose then
s_console("W: permanent error, abandoning request")
end
return nil -- Giving up
end
end
end
end
end
module(...)
function new(broker, verbose)
s_version_assert (2, 1);
local self = setmetatable({
context = zmq.init(1),
poller = zpoller.new(1),
broker = broker,
verbose = verbose,
timeout = 2500, -- msecs
retries = 3, -- before we abandon
}, obj_mt)
s_mdcli_connect_to_broker(self)
return self
end
setmetatable(_M, { __call = function(self, ...) return new(...) end })
mdcliapi:Node.js 中的 Majordomo 客户端 API
mdcliapi:Objective-C 中的 Majordomo 客户端 API
mdcliapi:ooc 中的 Majordomo 客户端 API
mdcliapi:Perl 中的 Majordomo 客户端 API
mdcliapi:PHP 中的 Majordomo 客户端 API
<?php
/* =====================================================================
* mdcliapi.h
*
* Majordomo Protocol Client API
* Implements the MDP/Worker spec at https://rfc.zeromq.cn/spec:7.
*/
include_once 'zmsg.php';
include_once 'mdp.php';
class MDCli
{
// Structure of our class
// We access these properties only via class methods
private $broker;
private $context;
private $client; // Socket to broker
private $verbose; // Print activity to stdout
private $timeout; // Request timeout
private $retries; // Request retries
/**
* Constructor
*
* @param string $broker
* @param boolean $verbose
*/
public function __construct($broker, $verbose = false)
{
$this->broker = $broker;
$this->context = new ZMQContext();
$this->verbose = $verbose;
$this->timeout = 2500; // msecs
$this->retries = 3; // Before we abandon
$this->connect_to_broker();
}
/**
* Connect or reconnect to broker
*/
protected function connect_to_broker()
{
if ($this->client) {
unset($this->client);
}
$this->client = new ZMQSocket($this->context, ZMQ::SOCKET_REQ);
$this->client->setSockOpt(ZMQ::SOCKOPT_LINGER, 0);
$this->client->connect($this->broker);
if ($this->verbose) {
printf("I: connecting to broker at %s...", $this->broker);
}
}
/**
* Set request timeout
*
* @param int $timeout (msecs)
*/
public function set_timeout($timeout)
{
$this->timeout = $timeout;
}
/**
* Set request retries
*
* @param int $retries
*/
public function set_retries($retries)
{
$this->retries = $retries;
}
/**
* Send request to broker and get reply by hook or crook
* Takes ownership of request message and destroys it when sent.
* Returns the reply message or NULL if there was no reply.
*
* @param string $service
* @param Zmsg $request
* @param string $client
* @return Zmsg
*/
public function send($service, Zmsg $request)
{
// Prefix request with protocol frames
// Frame 1: "MDPCxy" (six bytes, MDP/Client
// Frame 2: Service name (printable string)
$request->push($service);
$request->push(MDPC_CLIENT);
if ($this->verbose) {
printf ("I: send request to '%s' service:", $service);
echo $request->__toString();
}
$retries_left = $this->retries;
$read = $write = array();
while ($retries_left) {
$request->set_socket($this->client)->send();
// Poll socket for a reply, with timeout
$poll = new ZMQPoll();
$poll->add($this->client, ZMQ::POLL_IN);
$events = $poll->poll($read, $write, $this->timeout);
// If we got a reply, process it
if ($events) {
$request->recv();
if ($this->verbose) {
echo "I: received reply:", $request->__toString(), PHP_EOL;
}
// Don't try to handle errors, just assert noisily
assert ($request->parts() >= 3);
$header = $request->pop();
assert($header == MDPC_CLIENT);
$reply_service = $request->pop();
assert($reply_service == $service);
return $request; // Success
} elseif ($retries_left--) {
if ($this->verbose) {
echo "W: no reply, reconnecting...", PHP_EOL;
}
// Reconnect, and resend message
$this->connect_to_broker();
$request->send();
} else {
echo "W: permanent error, abandoning request", PHP_EOL;
break; // Give up
}
}
}
}
mdcliapi:Python 中的 Majordomo 客户端 API
"""Majordomo Protocol Client API, Python version.
Implements the MDP/Worker spec at http:#rfc.zeromq.org/spec:7.
Author: Min RK <benjaminrk@gmail.com>
Based on Java example by Arkadiusz Orzechowski
"""
import logging
import zmq
import MDP
from zhelpers import dump
class MajorDomoClient(object):
"""Majordomo Protocol Client API, Python version.
Implements the MDP/Worker spec at http:#rfc.zeromq.org/spec:7.
"""
broker = None
ctx = None
client = None
poller = None
timeout = 2500
retries = 3
verbose = False
def __init__(self, broker, verbose=False):
self.broker = broker
self.verbose = verbose
self.ctx = zmq.Context()
self.poller = zmq.Poller()
logging.basicConfig(format="%(asctime)s %(message)s", datefmt="%Y-%m-%d %H:%M:%S",
level=logging.INFO)
self.reconnect_to_broker()
def reconnect_to_broker(self):
"""Connect or reconnect to broker"""
if self.client:
self.poller.unregister(self.client)
self.client.close()
self.client = self.ctx.socket(zmq.REQ)
self.client.linger = 0
self.client.connect(self.broker)
self.poller.register(self.client, zmq.POLLIN)
if self.verbose:
logging.info("I: connecting to broker at %s...", self.broker)
def send(self, service, request):
"""Send request to broker and get reply by hook or crook.
Takes ownership of request message and destroys it when sent.
Returns the reply message or None if there was no reply.
"""
if not isinstance(request, list):
request = [request]
request = [MDP.C_CLIENT, service] + request
if self.verbose:
logging.warn("I: send request to '%s' service: ", service)
dump(request)
reply = None
retries = self.retries
while retries > 0:
self.client.send_multipart(request)
try:
items = self.poller.poll(self.timeout)
except KeyboardInterrupt:
break # interrupted
if items:
msg = self.client.recv_multipart()
if self.verbose:
logging.info("I: received reply:")
dump(msg)
# Don't try to handle errors, just assert noisily
assert len(msg) >= 3
header = msg.pop(0)
assert MDP.C_CLIENT == header
reply_service = msg.pop(0)
assert service == reply_service
reply = msg
break
else:
if retries:
logging.warn("W: no reply, reconnecting...")
self.reconnect_to_broker()
else:
logging.warn("W: permanent error, abandoning")
break
retries -= 1
return reply
def destroy(self):
self.context.destroy()
mdcliapi:Q 中的 Majordomo 客户端 API
mdcliapi:Racket 中的 Majordomo 客户端 API
mdcliapi:Ruby 中的 Majordomo 客户端 API
mdcliapi:Rust 中的 Majordomo 客户端 API
mdcliapi:Scala 中的 Majordomo 客户端 API
mdcliapi:Tcl 中的 Majordomo 客户端 API
# Majordomo Protocol Client API, Tcl version.
# Implements the MDP/Worker spec at http:#rfc.zeromq.org/spec:7.
package require TclOO
package require zmq
package require mdp
package provide MDClient 1.0
oo::class create MDClient {
variable context broker verbose timeout retries client
constructor {ibroker {iverbose 0}} {
set context [zmq context mdcli_context_[::mdp::contextid]]
set broker $ibroker
set verbose $iverbose
set timeout 2500
set retries 3
set client ""
my connect_to_broker
}
destructor {
$client close
$context term
}
method connect_to_broker {} {
if {[string length $client]} {
$client close
}
set client [zmq socket mdcli_socket_[::mdp::socketid] $context REQ]
$client connect $broker
if {$verbose} {
puts "I: connecting to broker at $broker..."
}
}
method set_timeout {itimeout} {
set timeout $itimeout
}
method set_retries {iretries} {
set retries $iretries
}
# Send request to broker and get reply by hook or crook
# Takes ownership of request message and destroys it when sent.
# Returns the reply message or NULL if there was no reply.
method send {service request} {
# Prefix request with protocol frames
# Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
# Frame 2: Service name (printable string)
set request [zmsg push $request $service]
set request [zmsg push $request $mdp::MDPC_CLIENT]
if {$verbose} {
puts "I: send request to '$service' service:"
puts [join [zmsg dump $request] \n]
}
set retries_left $retries
while {$retries_left} {
set msg $request
zmsg send $client $msg
# Poll socket for a reply, with timeout
set poll_set [list [list $client [list POLLIN]]]
set rpoll_set [zmq poll $poll_set $timeout]
# If we got a reply, process it
if {[llength $rpoll_set] && "POLLIN" in [lindex $rpoll_set 0 1]} {
set msg [zmsg recv $client]
if {$verbose} {
puts "I: received reply:"
puts [join [zmsg dump $msg] \n]
}
# Don't try to handle errors, just assert noisily
if {[llength $msg] < 3} {
error "message size < 3"
}
set header [zmsg pop msg]
if {$header ne $mdp::MDPC_CLIENT} {
error "unexpected header"
}
set reply_service [zmsg pop msg]
if {$reply_service ne $service} {
error "unexpected service"
}
return $msg
} elseif {[incr retries_left -1]} {
if {$verbose} {
puts "W: no reply, reconnecting..."
}
# Reconnect socket
my connect_to_broker
} else {
if {$verbose} {
puts "W: permanent error, abandoning"
}
break ;# Give up
}
}
return {}
}
}
mdcliapi:OCaml 中的 Majordomo 客户端 API
让我们通过一个执行 10 万次请求-回复循环的示例测试程序来看看客户端 API 的实际应用:
mdclient:Ada 中的 Majordomo 客户端应用程序
mdclient:Basic 中的 Majordomo 客户端应用程序
mdclient:C 中的 Majordomo 客户端应用程序
// Majordomo Protocol client example
// Uses the mdcli API to hide all MDP aspects
// Lets us build this source without creating a library
#include "mdcliapi.c"
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && streq (argv [1], "-v"));
mdcli_t *session = mdcli_new ("tcp://:5555", verbose);
int count;
for (count = 0; count < 100000; count++) {
zmsg_t *request = zmsg_new ();
zmsg_pushstr (request, "Hello world");
zmsg_t *reply = mdcli_send (session, "echo", &request);
if (reply)
zmsg_destroy (&reply);
else
break; // Interrupt or failure
}
printf ("%d requests/replies processed\n", count);
mdcli_destroy (&session);
return 0;
}
mdclient:C++ 中的 Majordomo 客户端应用程序
//
// Majordomo Protocol client example
// Uses the mdcli API to hide all MDP aspects
//
// Lets us 'build mdclient' and 'build all'
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
//
#include "mdcliapi.hpp"
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && strcmp (argv [1], "-v") == 0);
mdcli session ("tcp://:5555", verbose);
int count;
for (count = 0; count < 100000; count++) {
zmsg * request = new zmsg("Hello world");
zmsg * reply = session.send ("echo", request);
if (reply) {
delete reply;
} else {
break; // Interrupt or failure
}
}
std::cout << count << " requests/replies processed" << std::endl;
return 0;
}
mdclient:C# 中的 Majordomo 客户端应用程序
mdclient:CL 中的 Majordomo 客户端应用程序
mdclient:Delphi 中的 Majordomo 客户端应用程序
mdclient:Erlang 中的 Majordomo 客户端应用程序
mdclient:Elixir 中的 Majordomo 客户端应用程序
mdclient:F# 中的 Majordomo 客户端应用程序
mdclient:Felix 中的 Majordomo 客户端应用程序
mdclient:Go 中的 Majordomo 客户端应用程序
// Majordomo Protocol client example
// Uses the mdcli API to hide all MDP aspects
//
// To run this example, you may need to run multiple *.go files as below
// go run mdp.go zhelpers.go mdcliapi.go mdclient.go [-v]
//
// Author: iano <scaly.iano@gmail.com>
package main
import (
"fmt"
"os"
)
func main() {
verbose := len(os.Args) >= 2 && os.Args[1] == "-v"
client := NewClient("tcp://:5555", verbose)
defer client.Close()
count := 0
for ; count < 1e5; count++ {
request := [][]byte{[]byte("Hello world")}
reply := client.Send([]byte("echo"), request)
if len(reply) == 0 {
break
}
}
fmt.Printf("%d requests/replies processed\n", count)
}
mdclient:Haskell 中的 Majordomo 客户端应用程序
import MDClientAPI
import ZHelpers
import System.Environment
import Control.Monad (forM_, when)
import Data.ByteString.Char8 (unpack, pack)
main :: IO ()
main = do
args <- getArgs
when (length args /= 1) $
error "usage: mdclient <is_verbose(True|False)>"
let isVerbose = read (args !! 0) :: Bool
withMDCli "tcp://:5555" isVerbose $ \api ->
forM_ [0..10000] $ \i -> do
mdSend api "echo" [pack "Hello world"]
mdclient:Haxe 中的 Majordomo 客户端应用程序
package ;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZMsg;
/**
* Majordomo Protocol client example
* Uses the MDPCli API to hide all MDP aspects
*
* @author Richard J Smith
*/
class MDClient
{
public static function main() {
var argArr = Sys.args();
var verbose = (argArr.length > 1 && argArr[argArr.length - 1] == "-v");
var session = new MDCliAPI("tcp://:5555", verbose);
var count = 0;
for (i in 0 ... 100000) {
var request = new ZMsg();
request.pushString("Hello world: "+i);
var reply = session.send("echo", request);
if (reply != null)
reply.destroy();
else
break; // Interrupt or failure
count++;
}
Lib.println(count + " requests/replies processed");
session.destroy();
}
}mdclient:Java 中的 Majordomo 客户端应用程序
package guide;
import org.zeromq.ZMsg;
/**
* Majordomo Protocol client example. Uses the mdcli API to hide all MDP aspects
*/
public class mdclient
{
public static void main(String[] args)
{
boolean verbose = (args.length > 0 && "-v".equals(args[0]));
mdcliapi clientSession = new mdcliapi("tcp://:5555", verbose);
int count;
for (count = 0; count < 100000; count++) {
ZMsg request = new ZMsg();
request.addString("Hello world");
ZMsg reply = clientSession.send("echo", request);
if (reply != null)
reply.destroy();
else break; // Interrupt or failure
}
System.out.printf("%d requests/replies processed\n", count);
clientSession.destroy();
}
}
mdclient:Julia 中的 Majordomo 客户端应用程序
mdclient:Lua 中的 Majordomo 客户端应用程序
--
-- Majordomo Protocol client example
-- Uses the mdcli API to hide all MDP aspects
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"mdcliapi"
require"zmsg"
require"zhelpers"
local verbose = (arg[1] == "-v")
local session = mdcliapi.new("tcp://:5555", verbose)
local count=1
repeat
local request = zmsg.new("Hello world")
local reply = session:send("echo", request)
if not reply then
break -- Interrupt or failure
end
count = count + 1
until (count == 100000)
printf("%d requests/replies processed\n", count)
session:destroy()
mdclient:Node.js 中的 Majordomo 客户端应用程序
mdclient:Objective-C 中的 Majordomo 客户端应用程序
mdclient:ooc 中的 Majordomo 客户端应用程序
mdclient:Perl 中的 Majordomo 客户端应用程序
mdclient:PHP 中的 Majordomo 客户端应用程序
<?php
/*
* Majordomo Protocol client example
* Uses the mdcli API to hide all MDP aspects
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include_once 'mdcliapi.php';
$verbose = $_SERVER['argc'] > 1 && $_SERVER['argv'][1] == '-v';
$session = new MDCli("tcp://:5555", $verbose);
for ($count = 0; $count < 100000; $count++) {
$request = new Zmsg();
$request->body_set("Hello world");
$reply = $session->send("echo", $request);
if (!$reply) {
break; // Interrupt or failure
}
}
printf ("%d requests/replies processed", $count);
echo PHP_EOL;
mdclient:Python 中的 Majordomo 客户端应用程序
"""
Majordomo Protocol client example. Uses the mdcli API to hide all MDP aspects
Author : Min RK <benjaminrk@gmail.com>
"""
import sys
from mdcliapi import MajorDomoClient
def main():
verbose = '-v' in sys.argv
client = MajorDomoClient("tcp://:5555", verbose)
count = 0
while count < 100000:
request = b"Hello world"
try:
reply = client.send(b"echo", request)
except KeyboardInterrupt:
break
else:
# also break on failure to reply:
if reply is None:
break
count += 1
print ("%i requests/replies processed" % count)
if __name__ == '__main__':
main()
mdclient:Q 中的 Majordomo 客户端应用程序
mdclient:Racket 中的 Majordomo 客户端应用程序
mdclient:Ruby 中的 Majordomo 客户端应用程序
mdclient:Rust 中的 Majordomo 客户端应用程序
mdclient:Scala 中的 Majordomo 客户端应用程序
mdclient:Tcl 中的 Majordomo 客户端应用程序
#
# Majordomo Protocol client example
# Uses the mdcli API to hide all MDP aspects
#
lappend auto_path .
package require MDClient 1.0
set verbose 0
foreach {k v} $argv {
if {$k eq "-v"} { set verbose 1 }
}
set session [MDClient new "tcp://:5555" $verbose]
for {set count 0} {$count < 10000} {incr count} {
set request [list "Hello world"]
set reply [$session send "echo" $request]
if {[llength $reply] == 0} {
break ;# Interrupt or failure
}
}
puts "$count requests/replies processed"
$session destroy
mdclient:OCaml 中的 Majordomo 客户端应用程序
这是工作器 API:
mdwrkapi:Ada 中的 Majordomo 工作器 API
mdwrkapi:Basic 中的 Majordomo 工作器 API
mdwrkapi:C 中的 Majordomo 工作器 API
// mdwrkapi class - Majordomo Protocol Worker API
// Implements the MDP/Worker spec at https://rfc.zeromq.cn/spec:7.
#include "mdwrkapi.h"
// Reliability parameters
#define HEARTBEAT_LIVENESS 3 // 3-5 is reasonable
// .split worker class structure
// This is the structure of a worker API instance. We use a pseudo-OO
// approach in a lot of the C examples, as well as the CZMQ binding:
// Structure of our class
// We access these properties only via class methods
struct _mdwrk_t {
zctx_t *ctx; // Our context
char *broker;
char *service;
void *worker; // Socket to broker
int verbose; // Print activity to stdout
// Heartbeat management
uint64_t heartbeat_at; // When to send HEARTBEAT
size_t liveness; // How many attempts left
int heartbeat; // Heartbeat delay, msecs
int reconnect; // Reconnect delay, msecs
int expect_reply; // Zero only at start
zframe_t *reply_to; // Return identity, if any
};
// .split utility functions
// We have two utility functions; to send a message to the broker and
// to (re)connect to the broker:
// Send message to broker
// If no msg is provided, creates one internally
static void
s_mdwrk_send_to_broker (mdwrk_t *self, char *command, char *option,
zmsg_t *msg)
{
msg = msg? zmsg_dup (msg): zmsg_new ();
// Stack protocol envelope to start of message
if (option)
zmsg_pushstr (msg, option);
zmsg_pushstr (msg, command);
zmsg_pushstr (msg, MDPW_WORKER);
zmsg_pushstr (msg, "");
if (self->verbose) {
zclock_log ("I: sending %s to broker",
mdps_commands [(int) *command]);
zmsg_dump (msg);
}
zmsg_send (&msg, self->worker);
}
// Connect or reconnect to broker
void s_mdwrk_connect_to_broker (mdwrk_t *self)
{
if (self->worker)
zsocket_destroy (self->ctx, self->worker);
self->worker = zsocket_new (self->ctx, ZMQ_DEALER);
zmq_connect (self->worker, self->broker);
if (self->verbose)
zclock_log ("I: connecting to broker at %s...", self->broker);
// Register service with broker
s_mdwrk_send_to_broker (self, MDPW_READY, self->service, NULL);
// If liveness hits zero, queue is considered disconnected
self->liveness = HEARTBEAT_LIVENESS;
self->heartbeat_at = zclock_time () + self->heartbeat;
}
// .split constructor and destructor
// Here we have the constructor and destructor for our mdwrk class:
// Constructor
mdwrk_t *
mdwrk_new (char *broker,char *service, int verbose)
{
assert (broker);
assert (service);
mdwrk_t *self = (mdwrk_t *) zmalloc (sizeof (mdwrk_t));
self->ctx = zctx_new ();
self->broker = strdup (broker);
self->service = strdup (service);
self->verbose = verbose;
self->heartbeat = 2500; // msecs
self->reconnect = 2500; // msecs
s_mdwrk_connect_to_broker (self);
return self;
}
// Destructor
void
mdwrk_destroy (mdwrk_t **self_p)
{
assert (self_p);
if (*self_p) {
mdwrk_t *self = *self_p;
zctx_destroy (&self->ctx);
free (self->broker);
free (self->service);
free (self);
*self_p = NULL;
}
}
// .split configure worker
// We provide two methods to configure the worker API. You can set the
// heartbeat interval and retries to match the expected network performance.
// Set heartbeat delay
void
mdwrk_set_heartbeat (mdwrk_t *self, int heartbeat)
{
self->heartbeat = heartbeat;
}
// Set reconnect delay
void
mdwrk_set_reconnect (mdwrk_t *self, int reconnect)
{
self->reconnect = reconnect;
}
// .split recv method
// This is the {{recv}} method; it's a little misnamed because it first sends
// any reply and then waits for a new request. If you have a better name
// for this, let me know.
// Send reply, if any, to broker and wait for next request.
zmsg_t *
mdwrk_recv (mdwrk_t *self, zmsg_t **reply_p)
{
// Format and send the reply if we were provided one
assert (reply_p);
zmsg_t *reply = *reply_p;
assert (reply || !self->expect_reply);
if (reply) {
assert (self->reply_to);
zmsg_wrap (reply, self->reply_to);
s_mdwrk_send_to_broker (self, MDPW_REPLY, NULL, reply);
zmsg_destroy (reply_p);
}
self->expect_reply = 1;
while (true) {
zmq_pollitem_t items [] = {
{ self->worker, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (items, 1, self->heartbeat * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
if (items [0].revents & ZMQ_POLLIN) {
zmsg_t *msg = zmsg_recv (self->worker);
if (!msg)
break; // Interrupted
if (self->verbose) {
zclock_log ("I: received message from broker:");
zmsg_dump (msg);
}
self->liveness = HEARTBEAT_LIVENESS;
// Don't try to handle errors, just assert noisily
assert (zmsg_size (msg) >= 3);
zframe_t *empty = zmsg_pop (msg);
assert (zframe_streq (empty, ""));
zframe_destroy (&empty);
zframe_t *header = zmsg_pop (msg);
assert (zframe_streq (header, MDPW_WORKER));
zframe_destroy (&header);
zframe_t *command = zmsg_pop (msg);
if (zframe_streq (command, MDPW_REQUEST)) {
// We should pop and save as many addresses as there are
// up to a null part, but for now, just save one...
self->reply_to = zmsg_unwrap (msg);
zframe_destroy (&command);
// .split process message
// Here is where we actually have a message to process; we
// return it to the caller application:
return msg; // We have a request to process
}
else
if (zframe_streq (command, MDPW_HEARTBEAT))
; // Do nothing for heartbeats
else
if (zframe_streq (command, MDPW_DISCONNECT))
s_mdwrk_connect_to_broker (self);
else {
zclock_log ("E: invalid input message");
zmsg_dump (msg);
}
zframe_destroy (&command);
zmsg_destroy (&msg);
}
else
if (--self->liveness == 0) {
if (self->verbose)
zclock_log ("W: disconnected from broker - retrying...");
zclock_sleep (self->reconnect);
s_mdwrk_connect_to_broker (self);
}
// Send HEARTBEAT if it's time
if (zclock_time () > self->heartbeat_at) {
s_mdwrk_send_to_broker (self, MDPW_HEARTBEAT, NULL, NULL);
self->heartbeat_at = zclock_time () + self->heartbeat;
}
}
if (zctx_interrupted)
printf ("W: interrupt received, killing worker...\n");
return NULL;
}
mdwrkapi:C++ 中的 Majordomo 工作器 API
#ifndef __MDWRKAPI_HPP_INCLUDED__
#define __MDWRKAPI_HPP_INCLUDED__
#include "zmsg.hpp"
#include "mdp.h"
// Reliability parameters
// Structure of our class
// We access these properties only via class methods
class mdwrk {
public:
// ---------------------------------------------------------------------
// Constructor
mdwrk (std::string broker, std::string service, int verbose): m_broker(broker), m_service(service),m_verbose(verbose)
{
s_version_assert (4, 0);
m_context = new zmq::context_t (1);
s_catch_signals ();
connect_to_broker ();
}
// ---------------------------------------------------------------------
// Destructor
virtual
~mdwrk ()
{
delete m_worker;
delete m_context;
}
// ---------------------------------------------------------------------
// Send message to broker
// If no _msg is provided, creates one internally
void send_to_broker(const char *command, std::string option, zmsg *_msg)
{
zmsg *msg = _msg? new zmsg(*_msg): new zmsg ();
// Stack protocol envelope to start of message
if (!option.empty()) {
msg->push_front (option.c_str());
}
msg->push_front (command);
msg->push_front (k_mdpw_worker.data());
msg->push_front ("");
if (m_verbose) {
s_console ("I: sending %s to broker",
mdps_commands [(int) *command].data());
msg->dump ();
}
msg->send (*m_worker);
delete msg;
}
// ---------------------------------------------------------------------
// Connect or reconnect to broker
void connect_to_broker ()
{
if (m_worker) {
delete m_worker;
}
m_worker = new zmq::socket_t (*m_context, ZMQ_DEALER);
int linger = 0;
m_worker->setsockopt (ZMQ_LINGER, &linger, sizeof (linger));
s_set_id(*m_worker);
m_worker->connect (m_broker.c_str());
if (m_verbose)
s_console ("I: connecting to broker at %s...", m_broker.c_str());
// Register service with broker
send_to_broker (k_mdpw_ready.data(), m_service, NULL);
// If liveness hits zero, queue is considered disconnected
m_liveness = n_heartbeat_liveness;
m_heartbeat_at = s_clock () + m_heartbeat;
}
// ---------------------------------------------------------------------
// Set heartbeat delay
void
set_heartbeat (int heartbeat)
{
m_heartbeat = heartbeat;
}
// ---------------------------------------------------------------------
// Set reconnect delay
void
set_reconnect (int reconnect)
{
m_reconnect = reconnect;
}
// ---------------------------------------------------------------------
// Send reply, if any, to broker and wait for next request.
zmsg *
recv (zmsg *&reply_p)
{
// Format and send the reply if we were provided one
zmsg *reply = reply_p;
assert (reply || !m_expect_reply);
if (reply) {
assert (m_reply_to.size()!=0);
reply->wrap (m_reply_to.c_str(), "");
m_reply_to = "";
send_to_broker (k_mdpw_reply.data(), "", reply);
delete reply_p;
reply_p = 0;
}
m_expect_reply = true;
while (!s_interrupted) {
zmq::pollitem_t items[] = {
{ *m_worker, 0, ZMQ_POLLIN, 0 } };
zmq::poll (items, 1, m_heartbeat);
if (items[0].revents & ZMQ_POLLIN) {
zmsg *msg = new zmsg(*m_worker);
if (m_verbose) {
s_console ("I: received message from broker:");
msg->dump ();
}
m_liveness = n_heartbeat_liveness;
// Don't try to handle errors, just assert noisily
assert (msg->parts () >= 3);
ustring empty = msg->pop_front ();
assert (empty.compare((unsigned char *)"") == 0);
//assert (strcmp (empty, "") == 0);
//free (empty);
ustring header = msg->pop_front ();
assert (header.compare((unsigned char *)k_mdpw_worker.data()) == 0);
//free (header);
std::string command =(char*) msg->pop_front ().c_str();
if (command.compare (k_mdpw_request.data()) == 0) {
// We should pop and save as many addresses as there are
// up to a null part, but for now, just save one...
m_reply_to = msg->unwrap ();
return msg; // We have a request to process
}
else if (command.compare (k_mdpw_heartbeat.data()) == 0) {
// Do nothing for heartbeats
}
else if (command.compare (k_mdpw_disconnect.data()) == 0) {
connect_to_broker ();
}
else {
s_console ("E: invalid input message (%d)",
(int) *(command.c_str()));
msg->dump ();
}
delete msg;
}
else
if (--m_liveness == 0) {
if (m_verbose) {
s_console ("W: disconnected from broker - retrying...");
}
s_sleep (m_reconnect);
connect_to_broker ();
}
// Send HEARTBEAT if it's time
if (s_clock () >= m_heartbeat_at) {
send_to_broker (k_mdpw_heartbeat.data(), "", NULL);
m_heartbeat_at += m_heartbeat;
}
}
if (s_interrupted)
printf ("W: interrupt received, killing worker...\n");
return NULL;
}
private:
static constexpr uint32_t n_heartbeat_liveness = 3;// 3-5 is reasonable
const std::string m_broker;
const std::string m_service;
zmq::context_t *m_context;
zmq::socket_t *m_worker{}; // Socket to broker
const int m_verbose; // Print activity to stdout
// Heartbeat management
int64_t m_heartbeat_at; // When to send HEARTBEAT
size_t m_liveness; // How many attempts left
int m_heartbeat{2500}; // Heartbeat delay, msecs
int m_reconnect{2500}; // Reconnect delay, msecs
// Internal state
bool m_expect_reply{false}; // Zero only at start
// Return address, if any
std::string m_reply_to;
};
#endif
mdwrkapi:C# 中的 Majordomo 工作器 API
mdwrkapi:CL 中的 Majordomo 工作器 API
mdwrkapi:Delphi 中的 Majordomo 工作器 API
mdwrkapi: Erlang 中的 Majordomo worker API
mdwrkapi: Elixir 中的 Majordomo worker API
mdwrkapi: F# 中的 Majordomo worker API
mdwrkapi: Felix 中的 Majordomo worker API
mdwrkapi: Go 中的 Majordomo worker API
// mdwrkapi class - Majordomo Protocol Worker API
// Implements the MDP/Worker spec at https://rfc.zeromq.cn/spec:7.
//
// Author: iano <scaly.iano@gmail.com>
// Based on C & Python example
package main
import (
zmq "github.com/alecthomas/gozmq"
"log"
"time"
)
type Worker interface {
Close()
Recv([][]byte) [][]byte
}
type mdWorker struct {
broker string
context *zmq.Context
service string
verbose bool
worker *zmq.Socket
heartbeat time.Duration
heartbeatAt time.Time
liveness int
reconnect time.Duration
expectReply bool
replyTo []byte
}
func NewWorker(broker, service string, verbose bool) Worker {
context, _ := zmq.NewContext()
self := &mdWorker{
broker: broker,
context: context,
service: service,
verbose: verbose,
heartbeat: 2500 * time.Millisecond,
liveness: 0,
reconnect: 2500 * time.Millisecond,
}
self.reconnectToBroker()
return self
}
func (self *mdWorker) reconnectToBroker() {
if self.worker != nil {
self.worker.Close()
}
self.worker, _ = self.context.NewSocket(zmq.DEALER)
self.worker.SetLinger(0)
self.worker.Connect(self.broker)
if self.verbose {
log.Printf("I: connecting to broker at %s...\n", self.broker)
}
self.sendToBroker(MDPW_READY, []byte(self.service), nil)
self.liveness = HEARTBEAT_LIVENESS
self.heartbeatAt = time.Now().Add(self.heartbeat)
}
func (self *mdWorker) sendToBroker(command string, option []byte, msg [][]byte) {
if len(option) > 0 {
msg = append([][]byte{option}, msg...)
}
msg = append([][]byte{nil, []byte(MDPW_WORKER), []byte(command)}, msg...)
if self.verbose {
log.Printf("I: sending %X to broker\n", command)
Dump(msg)
}
self.worker.SendMultipart(msg, 0)
}
func (self *mdWorker) Close() {
if self.worker != nil {
self.worker.Close()
}
self.context.Close()
}
func (self *mdWorker) Recv(reply [][]byte) (msg [][]byte) {
// Format and send the reply if we were provided one
if len(reply) == 0 && self.expectReply {
panic("Error reply")
}
if len(reply) > 0 {
if len(self.replyTo) == 0 {
panic("Error replyTo")
}
reply = append([][]byte{self.replyTo, nil}, reply...)
self.sendToBroker(MDPW_REPLY, nil, reply)
}
self.expectReply = true
for {
items := zmq.PollItems{
zmq.PollItem{Socket: self.worker, Events: zmq.POLLIN},
}
_, err := zmq.Poll(items, self.heartbeat)
if err != nil {
panic(err) // Interrupted
}
if item := items[0]; item.REvents&zmq.POLLIN != 0 {
msg, _ = self.worker.RecvMultipart(0)
if self.verbose {
log.Println("I: received message from broker: ")
Dump(msg)
}
self.liveness = HEARTBEAT_LIVENESS
if len(msg) < 3 {
panic("Invalid msg") // Interrupted
}
header := msg[1]
if string(header) != MDPW_WORKER {
panic("Invalid header") // Interrupted
}
switch command := string(msg[2]); command {
case MDPW_REQUEST:
// We should pop and save as many addresses as there are
// up to a null part, but for now, just save one...
self.replyTo = msg[3]
msg = msg[5:]
return
case MDPW_HEARTBEAT:
// do nothin
case MDPW_DISCONNECT:
self.reconnectToBroker()
default:
log.Println("E: invalid input message:")
Dump(msg)
}
} else if self.liveness--; self.liveness <= 0 {
if self.verbose {
log.Println("W: disconnected from broker - retrying...")
}
time.Sleep(self.reconnect)
self.reconnectToBroker()
}
// Send HEARTBEAT if it's time
if self.heartbeatAt.Before(time.Now()) {
self.sendToBroker(MDPW_HEARTBEAT, nil, nil)
self.heartbeatAt = time.Now().Add(self.heartbeat)
}
}
return
}
mdwrkapi: Haskell 中的 Majordomo worker API
mdwrkapi: Haxe 中的 Majordomo worker API
package ;
import MDP;
import haxe.Stack;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQException;
/**
* Majordomo Protocol Worker API
* Implements the MDP/Worker spec at https://rfc.zeromq.cn/spec:7
*/
class MDWrkAPI
{
/** When to send HEARTBEAT */
public var heartbeatAt:Float;
/** Reconnect delay, in msecs */
public var reconnect:Int;
// Private instance fields
/** Our context */
private var ctx:ZContext;
/** Connection string to broker */
private var broker:String;
/** Socket to broker */
private var worker:ZMQSocket;
/** Defines service string provided by this worker */
private var service:String;
/** Print activity to stdout */
private var verbose:Bool;
/** Logger function used in verbose mode */
private var log:Dynamic->Void;
/** How many attempts left */
private var liveness:Int;
/** Heartbeat delay, in msecs */
private var heartbeat:Int;
/** Internal state */
private var expect_reply:Bool;
/** Return address frame, if any */
private var replyTo:ZFrame;
/** Reliability parameters */
private static inline var HEARTBEAT_LIVENESS = 3;
/**
* Constructor
* @param broker
* @param service
* @param ?verbose
* @param ?logger
*/
public function new(broker:String, service:String, ?verbose:Bool = false, ?logger:Dynamic->Void) {
ctx = new ZContext();
this.broker = broker;
this.service = service;
this.verbose = verbose;
this.heartbeat = 2500; // msecs
this.reconnect = 2500; // msecs
if (logger != null)
log = logger;
else
log = neko.Lib.println;
expect_reply = false;
connectToBroker();
}
/**
* Connect or reconnect to broker
*/
public function connectToBroker() {
if (worker != null)
worker.close();
worker = ctx.createSocket(ZMQ_DEALER);
worker.setsockopt(ZMQ_LINGER, 0);
worker.connect(broker);
if (verbose)
log("I: worker connecting to broker at " + broker + "...");
sendToBroker(MDP.MDPW_READY, service);
// If liveness hits zero, queue is considered disconnected
liveness = HEARTBEAT_LIVENESS;
heartbeatAt = Date.now().getTime() + heartbeat;
}
/**
* Destructor
*/
public function destroy() {
ctx.destroy();
}
/**
* Send message to broker
* If no msg is provided, creates one internally
*
* @param command
* @param option
* @param ?msg
*/
public function sendToBroker(command:String, option:String, ?msg:ZMsg) {
var _msg:ZMsg = { if (msg != null) msg.duplicate(); else new ZMsg(); }
// Stack protocol envelope to start of message
if (option != null) {
_msg.pushString(option);
}
_msg.pushString(command);
_msg.pushString(MDP.MDPW_WORKER);
_msg.pushString("");
if (verbose)
log("I: sending " + MDP.MDPS_COMMANDS[command.charCodeAt(0)] + " to broker " + _msg.toString());
_msg.send(worker);
}
/**
* Send reply, if any, to broker and wait for next request
*
* @param reply Message to send back. Destroyed if send if successful
* @return ZMsg Returns if there is a request to process
*/
public function recv(?reply:ZMsg):ZMsg {
if (reply == null && expect_reply)
return null;
if (reply != null) {
if (replyTo == null)
return null; // Cannot send if we dont know which client to reply to
reply.wrap(replyTo);
sendToBroker(MDP.MDPW_REPLY, null, reply);
reply.destroy();
}
expect_reply = true;
var poller = new ZMQPoller();
poller.registerSocket(worker, ZMQ.ZMQ_POLLIN());
while (true) {
// Poll socket for a reply, with timeout
try {
var res = poller.poll(heartbeat * 1000);
} catch (e:ZMQException) {
if (!ZMQ.isInterrupted()) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
} else {
Lib.println("W: interrupt received, killing worker...");
}
ctx.destroy();
return null;
}
if (poller.pollin(1)) {
var msg = ZMsg.recvMsg(worker);
if (msg == null)
break; // Interrupted
if (verbose)
log("I: received message from broker:" + msg.toString());
liveness = HEARTBEAT_LIVENESS;
if (msg.size() < 2)
return null; // Don't handle errors, just quit quietly
msg.pop();
var header = msg.pop();
if (!header.streq(MDP.MDPW_WORKER))
return null; // Don't handle errors, just quit quietly
header.destroy();
var command = msg.pop();
if (command.streq(MDP.MDPW_REQUEST)) {
// We should pop and save as many addresses as there are
// up to a null part, but for now, just save one...
replyTo = msg.unwrap();
command.destroy();
return msg; // We have a request to process
} else if (command.streq(MDP.MDPW_HEARTBEAT)) {
// Do nothing for heartbeats
} else if (command.streq(MDP.MDPW_DISCONNECT)) {
connectToBroker();
poller.unregisterAllSockets();
poller.registerSocket(worker, ZMQ.ZMQ_POLLIN());
} else {
log("E: invalid input message:" + msg.toString());
}
command.destroy();
msg.destroy();
} else if (--liveness == 0) {
if (verbose)
log("W: disconnected from broker - retrying...");
Sys.sleep(reconnect / 1000);
connectToBroker();
poller.unregisterAllSockets();
poller.registerSocket(worker, ZMQ.ZMQ_POLLIN());
}
// Send HEARTBEAT if it's time
if (Date.now().getTime() > heartbeatAt) {
sendToBroker(MDP.MDPW_HEARTBEAT, null, null);
heartbeatAt = Date.now().getTime() + heartbeat;
}
}
return null;
}
}
mdwrkapi: Java 中的 Majordomo worker API
package guide;
import java.util.Formatter;
import org.zeromq.*;
/**
* Majordomo Protocol Client API, Java version Implements the MDP/Worker spec at
* https://rfc.zeromq.cn/spec:7.
*/
public class mdwrkapi
{
private static final int HEARTBEAT_LIVENESS = 3; // 3-5 is reasonable
private String broker;
private ZContext ctx;
private String service;
private ZMQ.Socket worker; // Socket to broker
private long heartbeatAt; // When to send HEARTBEAT
private int liveness; // How many attempts left
private int heartbeat = 2500; // Heartbeat delay, msecs
private int reconnect = 2500; // Reconnect delay, msecs
// Internal state
private boolean expectReply = false; // false only at start
private long timeout = 2500;
private boolean verbose; // Print activity to stdout
private Formatter log = new Formatter(System.out);
// Return address, if any
private ZFrame replyTo;
public mdwrkapi(String broker, String service, boolean verbose)
{
assert (broker != null);
assert (service != null);
this.broker = broker;
this.service = service;
this.verbose = verbose;
ctx = new ZContext();
reconnectToBroker();
}
/**
* Send message to broker If no msg is provided, creates one internally
*
* @param command
* @param option
* @param msg
*/
void sendToBroker(MDP command, String option, ZMsg msg)
{
msg = msg != null ? msg.duplicate() : new ZMsg();
// Stack protocol envelope to start of message
if (option != null)
msg.addFirst(new ZFrame(option));
msg.addFirst(command.newFrame());
msg.addFirst(MDP.W_WORKER.newFrame());
msg.addFirst(new ZFrame(ZMQ.MESSAGE_SEPARATOR));
if (verbose) {
log.format("I: sending %s to broker\n", command);
msg.dump(log.out());
}
msg.send(worker);
}
/**
* Connect or reconnect to broker
*/
void reconnectToBroker()
{
if (worker != null) {
ctx.destroySocket(worker);
}
worker = ctx.createSocket(SocketType.DEALER);
worker.connect(broker);
if (verbose)
log.format("I: connecting to broker at %s\n", broker);
// Register service with broker
sendToBroker(MDP.W_READY, service, null);
// If liveness hits zero, queue is considered disconnected
liveness = HEARTBEAT_LIVENESS;
heartbeatAt = System.currentTimeMillis() + heartbeat;
}
/**
* Send reply, if any, to broker and wait for next request.
*/
public ZMsg receive(ZMsg reply)
{
// Format and send the reply if we were provided one
assert (reply != null || !expectReply);
if (reply != null) {
assert (replyTo != null);
reply.wrap(replyTo);
sendToBroker(MDP.W_REPLY, null, reply);
reply.destroy();
}
expectReply = true;
while (!Thread.currentThread().isInterrupted()) {
// Poll socket for a reply, with timeout
ZMQ.Poller items = ctx.createPoller(1);
items.register(worker, ZMQ.Poller.POLLIN);
if (items.poll(timeout) == -1)
break; // Interrupted
if (items.pollin(0)) {
ZMsg msg = ZMsg.recvMsg(worker);
if (msg == null)
break; // Interrupted
if (verbose) {
log.format("I: received message from broker: \n");
msg.dump(log.out());
}
liveness = HEARTBEAT_LIVENESS;
// Don't try to handle errors, just assert noisily
assert (msg != null && msg.size() >= 3);
ZFrame empty = msg.pop();
assert (empty.getData().length == 0);
empty.destroy();
ZFrame header = msg.pop();
assert (MDP.W_WORKER.frameEquals(header));
header.destroy();
ZFrame command = msg.pop();
if (MDP.W_REQUEST.frameEquals(command)) {
// We should pop and save as many addresses as there are
// up to a null part, but for now, just save one
replyTo = msg.unwrap();
command.destroy();
return msg; // We have a request to process
}
else if (MDP.W_HEARTBEAT.frameEquals(command)) {
// Do nothing for heartbeats
}
else if (MDP.W_DISCONNECT.frameEquals(command)) {
reconnectToBroker();
}
else {
log.format("E: invalid input message: \n");
msg.dump(log.out());
}
command.destroy();
msg.destroy();
}
else if (--liveness == 0) {
if (verbose)
log.format("W: disconnected from broker - retrying\n");
try {
Thread.sleep(reconnect);
}
catch (InterruptedException e) {
Thread.currentThread().interrupt(); // Restore the
// interrupted status
break;
}
reconnectToBroker();
}
// Send HEARTBEAT if it's time
if (System.currentTimeMillis() > heartbeatAt) {
sendToBroker(MDP.W_HEARTBEAT, null, null);
heartbeatAt = System.currentTimeMillis() + heartbeat;
}
items.close();
}
if (Thread.currentThread().isInterrupted())
log.format("W: interrupt received, killing worker\n");
return null;
}
public void destroy()
{
ctx.destroy();
}
// ============== getters and setters =================
public int getHeartbeat()
{
return heartbeat;
}
public void setHeartbeat(int heartbeat)
{
this.heartbeat = heartbeat;
}
public int getReconnect()
{
return reconnect;
}
public void setReconnect(int reconnect)
{
this.reconnect = reconnect;
}
}
mdwrkapi: Julia 中的 Majordomo worker API
mdwrkapi: Lua 中的 Majordomo worker API
--
-- mdwrkapi.lua - Majordomo Protocol Worker API
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
local HEARTBEAT_LIVENESS = 3 -- 3-5 is reasonable
local setmetatable = setmetatable
local mdp = require"mdp"
local zmq = require"zmq"
local zpoller = require"zmq.poller"
local zmsg = require"zmsg"
require"zhelpers"
local s_version_assert = s_version_assert
local obj_mt = {}
obj_mt.__index = obj_mt
function obj_mt:set_heartbeat(heartbeat)
self.heartbeat = heartbeat
end
function obj_mt:set_reconnect(reconnect)
self.reconnect = reconnect
end
function obj_mt:destroy()
if self.worker then self.worker:close() end
self.context:term()
end
-- Send message to broker
-- If no msg is provided, create one internally
local function s_mdwrk_send_to_broker(self, command, option, msg)
msg = msg or zmsg.new()
-- Stack protocol envelope to start of message
if option then
msg:push(option)
end
msg:push(command)
msg:push(mdp.MDPW_WORKER)
msg:push("")
if self.verbose then
s_console("I: sending %s to broker", mdp.mdps_commands[command])
msg:dump()
end
msg:send(self.worker)
end
local function s_mdwrk_connect_to_broker(self)
-- close old socket.
if self.worker then
self.poller:remove(self.worker)
self.worker:close()
end
self.worker = assert(self.context:socket(zmq.DEALER))
assert(self.worker:setopt(zmq.LINGER, 0))
assert(self.worker:connect(self.broker))
if self.verbose then
s_console("I: connecting to broker at %s...", self.broker)
end
-- Register service with broker
s_mdwrk_send_to_broker(self, mdp.MDPW_READY, self.service)
-- If liveness hits zero, queue is considered disconnected
self.liveness = HEARTBEAT_LIVENESS
self.heartbeat_at = s_clock() + self.heartbeat
-- add socket to poller
self.poller:add(self.worker, zmq.POLLIN, function()
self.got_msg = true
end)
end
--
-- Send reply, if any, to broker and wait for next request.
--
function obj_mt:recv(reply)
-- Format and send the reply if we are provided one
if reply then
assert(self.reply_to)
reply:wrap(self.reply_to, "")
self.reply_to = nil
s_mdwrk_send_to_broker(self, mdp.MDPW_REPLY, nil, reply)
end
self.expect_reply = true
self.got_msg = false
while true do
local cnt = assert(self.poller:poll(self.heartbeat * 1000))
if cnt ~= 0 and self.got_msg then
self.got_msg = false
local msg = zmsg.recv(self.worker)
if self.verbose then
s_console("I: received message from broker:")
msg:dump()
end
self.liveness = HEARTBEAT_LIVENESS
-- Don't try to handle errors, just assert noisily
assert(msg:parts() >= 3)
local empty = msg:pop()
assert(empty == "")
local header = msg:pop()
assert(header == mdp.MDPW_WORKER)
local command = msg:pop()
if command == mdp.MDPW_REQUEST then
-- We should pop and save as many addresses as there are
-- up to a null part, but for now, just save one...
self.reply_to = msg:unwrap()
return msg -- We have a request to process
elseif command == mdp.MDPW_HEARTBEAT then
-- Do nothing for heartbeats
elseif command == mdp.MDPW_DISCONNECT then
-- dis-connect and re-connect to broker.
s_mdwrk_connect_to_broker(self)
else
s_console("E: invalid input message (%d)", command:byte(1,1))
msg:dump()
end
else
self.liveness = self.liveness - 1
if (self.liveness == 0) then
if self.verbose then
s_console("W: disconnected from broker - retrying...")
end
-- sleep then Reconnect
s_sleep(self.reconnect)
s_mdwrk_connect_to_broker(self)
end
-- Send HEARTBEAT if it's time
if (s_clock() > self.heartbeat_at) then
s_mdwrk_send_to_broker(self, mdp.MDPW_HEARTBEAT)
self.heartbeat_at = s_clock() + self.heartbeat
end
end
end
end
module(...)
function new(broker, service, verbose)
s_version_assert(2, 1);
local self = setmetatable({
context = zmq.init(1),
poller = zpoller.new(1),
broker = broker,
service = service,
verbose = verbose,
heartbeat = 2500, -- msecs
reconnect = 2500, -- msecs
}, obj_mt)
s_mdwrk_connect_to_broker(self)
return self
end
setmetatable(_M, { __call = function(self, ...) return new(...) end })
mdwrkapi: Node.js 中的 Majordomo worker API
mdwrkapi: Objective-C 中的 Majordomo worker API
mdwrkapi: ooc 中的 Majordomo worker API
mdwrkapi: Perl 中的 Majordomo worker API
mdwrkapi: PHP 中的 Majordomo worker API
<?php
/* =====================================================================
* mdwrkapi.php
*
* Majordomo Protocol Worker API
* Implements the MDP/Worker spec at https://rfc.zeromq.cn/spec:7.
*/
include_once 'zmsg.php';
include_once 'mdp.php';
// Reliability parameters
define("HEARTBEAT_LIVENESS", 3); // 3-5 is reasonable
// Structure of our class
// We access these properties only via class methods
class MDWrk
{
private $ctx; // Our context
private $broker;
private $service;
private $worker; // Socket to broker
private $verbose = false; // Print activity to stdout
// Heartbeat management
private $heartbeat_at; // When to send HEARTBEAT
private $liveness; // How many attempts left
private $heartbeat; // Heartbeat delay, msecs
private $reconnect; // Reconnect delay, msecs
// Internal state
private $expect_reply = 0;
// Return address, if any
private $reply_to;
/**
* Constructor
*
* @param string $broker
* @param string $service
* @param boolean $verbose
*/
public function __construct($broker, $service, $verbose = false)
{
$this->ctx = new ZMQContext();
$this->broker = $broker;
$this->service = $service;
$this->verbose = $verbose;
$this->heartbeat = 2500; // msecs
$this->reconnect = 2500; // msecs
$this->connect_to_broker();
}
/**
* Send message to broker
* If no msg is provided, creates one internally
*
* @param string $command
* @param string $option
* @param Zmsg $msg
*/
public function send_to_broker($command, $option, $msg = null)
{
$msg = $msg ? $msg : new Zmsg();
if ($option) {
$msg->push($option);
}
$msg->push($command);
$msg->push(MDPW_WORKER);
$msg->push("");
if ($this->verbose) {
printf("I: sending %s to broker %s", $command, PHP_EOL);
echo $msg->__toString();
}
$msg->set_socket($this->worker)->send();
}
/**
* Connect or reconnect to broker
*/
public function connect_to_broker()
{
$this->worker = new ZMQSocket($this->ctx, ZMQ::SOCKET_DEALER);
$this->worker->connect($this->broker);
if ($this->verbose) {
printf("I: connecting to broker at %s... %s", $this->broker, PHP_EOL);
}
// Register service with broker
$this->send_to_broker(MDPW_READY, $this->service, NULL);
// If liveness hits zero, queue is considered disconnected
$this->liveness = HEARTBEAT_LIVENESS;
$this->heartbeat_at = microtime(true) + ($this->heartbeat / 1000);
}
/**
* Set heartbeat delay
*
* @param int $heartbeat
*/
public function set_heartbeat($heartbeat)
{
$this->heartbeat = $heartbeat;
}
/**
* Set reconnect delay
*
* @param int $reconnect
*/
public function set_reconnect($reconnect)
{
$this->reconnect = $reconnect;
}
/**
* Send reply, if any, to broker and wait for next request.
*
* @param Zmsg $reply
* @return Zmsg Returns if there is a request to process
*/
public function recv($reply = null)
{
// Format and send the reply if we were provided one
assert ($reply || !$this->expect_reply);
if ($reply) {
$reply->wrap($this->reply_to);
$this->send_to_broker(MDPW_REPLY, NULL, $reply);
}
$this->expect_reply = true;
$read = $write = array();
while (true) {
$poll = new ZMQPoll();
$poll->add($this->worker, ZMQ::POLL_IN);
$events = $poll->poll($read, $write, $this->heartbeat);
if ($events) {
$zmsg = new Zmsg($this->worker);
$zmsg->recv();
if ($this->verbose) {
echo "I: received message from broker:", PHP_EOL;
echo $zmsg->__toString();
}
$this->liveness = HEARTBEAT_LIVENESS;
// Don't try to handle errors, just assert noisily
assert ($zmsg->parts() >= 3);
$zmsg->pop();
$header = $zmsg->pop();
assert($header == MDPW_WORKER);
$command = $zmsg->pop();
if ($command == MDPW_REQUEST) {
// We should pop and save as many addresses as there are
// up to a null part, but for now, just save one...
$this->reply_to = $zmsg->unwrap();
return $zmsg;// We have a request to process
} elseif ($command == MDPW_HEARTBEAT) {
// Do nothing for heartbeats
} elseif ($command == MDPW_DISCONNECT) {
$this->connect_to_broker();
} else {
echo "E: invalid input message", PHP_EOL;
echo $zmsg->__toString();
}
} elseif (--$this->liveness == 0) { // poll ended on timeout, $event being false
if ($this->verbose) {
echo "W: disconnected from broker - retrying...", PHP_EOL;
}
usleep($this->reconnect*1000);
$this->connect_to_broker();
}
// Send HEARTBEAT if it's time
if (microtime(true) > $this->heartbeat_at) {
$this->send_to_broker(MDPW_HEARTBEAT, NULL, NULL);
$this->heartbeat_at = microtime(true) + ($this->heartbeat/1000);
}
}
}
}
mdwrkapi: Python 中的 Majordomo worker API
"""Majordomo Protocol Worker API, Python version
Implements the MDP/Worker spec at http:#rfc.zeromq.org/spec:7.
Author: Min RK <benjaminrk@gmail.com>
Based on Java example by Arkadiusz Orzechowski
"""
import logging
import time
import zmq
from zhelpers import dump
# MajorDomo protocol constants:
import MDP
class MajorDomoWorker(object):
"""Majordomo Protocol Worker API, Python version
Implements the MDP/Worker spec at http:#rfc.zeromq.org/spec:7.
"""
HEARTBEAT_LIVENESS = 3 # 3-5 is reasonable
broker = None
ctx = None
service = None
worker = None # Socket to broker
heartbeat_at = 0 # When to send HEARTBEAT (relative to time.time(), so in seconds)
liveness = 0 # How many attempts left
heartbeat = 2500 # Heartbeat delay, msecs
reconnect = 2500 # Reconnect delay, msecs
# Internal state
expect_reply = False # False only at start
timeout = 2500 # poller timeout
verbose = False # Print activity to stdout
# Return address, if any
reply_to = None
def __init__(self, broker, service, verbose=False):
self.broker = broker
self.service = service
self.verbose = verbose
self.ctx = zmq.Context()
self.poller = zmq.Poller()
logging.basicConfig(format="%(asctime)s %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
level=logging.INFO)
self.reconnect_to_broker()
def reconnect_to_broker(self):
"""Connect or reconnect to broker"""
if self.worker:
self.poller.unregister(self.worker)
self.worker.close()
self.worker = self.ctx.socket(zmq.DEALER)
self.worker.linger = 0
self.worker.connect(self.broker)
self.poller.register(self.worker, zmq.POLLIN)
if self.verbose:
logging.info("I: connecting to broker at %s...", self.broker)
# Register service with broker
self.send_to_broker(MDP.W_READY, self.service, [])
# If liveness hits zero, queue is considered disconnected
self.liveness = self.HEARTBEAT_LIVENESS
self.heartbeat_at = time.time() + 1e-3 * self.heartbeat
def send_to_broker(self, command, option=None, msg=None):
"""Send message to broker.
If no msg is provided, creates one internally
"""
if msg is None:
msg = []
elif not isinstance(msg, list):
msg = [msg]
if option:
msg = [option] + msg
msg = [b'', MDP.W_WORKER, command] + msg
if self.verbose:
logging.info("I: sending %s to broker", command)
dump(msg)
self.worker.send_multipart(msg)
def recv(self, reply=None):
"""Send reply, if any, to broker and wait for next request."""
# Format and send the reply if we were provided one
assert reply is not None or not self.expect_reply
if reply is not None:
assert self.reply_to is not None
reply = [self.reply_to, b''] + reply
self.send_to_broker(MDP.W_REPLY, msg=reply)
self.expect_reply = True
while True:
# Poll socket for a reply, with timeout
try:
items = self.poller.poll(self.timeout)
except KeyboardInterrupt:
break # Interrupted
if items:
msg = self.worker.recv_multipart()
if self.verbose:
logging.info("I: received message from broker: ")
dump(msg)
self.liveness = self.HEARTBEAT_LIVENESS
# Don't try to handle errors, just assert noisily
assert len(msg) >= 3
empty = msg.pop(0)
assert empty == b''
header = msg.pop(0)
assert header == MDP.W_WORKER
command = msg.pop(0)
if command == MDP.W_REQUEST:
# We should pop and save as many addresses as there are
# up to a null part, but for now, just save one...
self.reply_to = msg.pop(0)
# pop empty
empty = msg.pop(0)
assert empty == b''
return msg # We have a request to process
elif command == MDP.W_HEARTBEAT:
# Do nothing for heartbeats
pass
elif command == MDP.W_DISCONNECT:
self.reconnect_to_broker()
else :
logging.error("E: invalid input message: ")
dump(msg)
else:
self.liveness -= 1
if self.liveness == 0:
if self.verbose:
logging.warn("W: disconnected from broker - retrying...")
try:
time.sleep(1e-3*self.reconnect)
except KeyboardInterrupt:
break
self.reconnect_to_broker()
# Send HEARTBEAT if it's time
if time.time() > self.heartbeat_at:
self.send_to_broker(MDP.W_HEARTBEAT)
self.heartbeat_at = time.time() + 1e-3*self.heartbeat
logging.warn("W: interrupt received, killing worker...")
return None
def destroy(self):
# context.destroy depends on pyzmq >= 2.1.10
self.ctx.destroy(0)
mdwrkapi: Q 中的 Majordomo worker API
mdwrkapi: Racket 中的 Majordomo worker API
mdwrkapi: Ruby 中的 Majordomo worker API
#!/usr/bin/env ruby
# Majordomo Protocol Worker API, Ruby version
#
# Implements the MDP/Worker spec at http:#rfc.zeromq.org/spec:7.
#
# Author: Tom van Leeuwen <tom@vleeuwen.eu>
# Based on Python example by Min RK
require 'ffi-rzmq'
require './mdp.rb'
class MajorDomoWorker
HEARTBEAT_LIVENESS = 3 # 3-5 is reasonable
def initialize broker, service
@broker = broker
@service = service
@context = ZMQ::Context.new(1)
@poller = ZMQ::Poller.new
@worker = nil # Socket to broker
@heartbeat_at = 0 # When to send HEARTBEAT (relative to time.time(), so in seconds)
@liveness = 0 # How many attempts left
@timeout = 2500
@heartbeat = 2500 # Heartbeat delay, msecs
@reconnect = 2500 # Reconnect delay, msecs
@expect_reply = false # false only at start
@reply_to = nil
reconnect_to_broker
end
def recv reply
if reply and @reply_to
reply = reply.is_a?(Array) ? [@reply_to, ''].concat(reply) : [@reply_to, '', reply]
send_to_broker MDP::W_REPLY, nil, reply
end
@expect_reply = true
loop do
items = @poller.poll(@timeout)
if items
messages = []
@worker.recv_strings messages
@liveness = HEARTBEAT_LIVENESS
messages.shift # empty
if messages.shift != MDP::W_WORKER
puts "E: Header is not MDP::WORKER"
end
command = messages.shift
case command
when MDP::W_REQUEST
# We should pop and save as many addresses as there are
# up to a null part, but for now, just save one...
@reply_to = messages.shift
messages.shift # empty
return messages # We have a request to process
when MDP::W_HEARTBEAT
# do nothing
when MDP::W_DISCONNECT
reconnect_to_broker
else
end
else
@liveness -= 1
if @liveness == 0
sleep 0.001*@reconnect
reconnect_to_broker
end
end
if Time.now > @heartbeat_at
send_to_broker MDP::W_HEARTBEAT
@heartbeat_at = Time.now + 0.001 * @heartbeat
end
end
end
def reconnect_to_broker
if @worker
@poller.deregister @worker, ZMQ::DEALER
@worker.close
end
@worker = @context.socket ZMQ::DEALER
@worker.setsockopt ZMQ::LINGER, 0
@worker.connect @broker
@poller.register @worker, ZMQ::POLLIN
send_to_broker(MDP::W_READY, @service, [])
@liveness = HEARTBEAT_LIVENESS
@heartbeat_at = Time.now + 0.001 * @heartbeat
end
def send_to_broker command, option=nil, message=nil
# if no message is provided, create on internally
if message.nil?
message = []
elsif not message.is_a?(Array)
message = [message]
end
message = [option].concat message if option
message = ['', MDP::W_WORKER, command].concat message
@worker.send_strings message
end
end
mdwrkapi: Rust 中的 Majordomo worker API
mdwrkapi: Scala 中的 Majordomo worker API
mdwrkapi: Tcl 中的 Majordomo worker API
# Majordomo Protocol Worker API, Tcl version.
# Implements the MDP/Worker spec at https://rfc.zeromq.cn/spec:7.
package require TclOO
package require zmq
package require mdp
package provide MDWorker 1.0
oo::class create MDWorker {
variable context broker service worker verbose heartbeat_at liveness heartbeat reconnect expect_reply reply_to
constructor {ibroker iservice {iverbose}} {
set context [zmq context mdwrk_context_[::mdp::contextid]]
set broker $ibroker
set service $iservice
set verbose $iverbose
set heartbeat 2500
set reconnect 2500
set expect_reply 0
set reply_to ""
set worker ""
my connect_to_broker
}
destructor {
$worker close
$context term
}
# Send message to broker
method send_to_broker {command option msg} {
# Stack protocol envelope to start of message
if {[string length $option]} {
set msg [zmsg push $msg $option]
}
set msg [zmsg push $msg $::mdp::MDPW_COMMAND($command)]
set msg [zmsg push $msg $::mdp::MDPW_WORKER]
set msg [zmsg push $msg ""]
if {$verbose} {
puts "I: sending $command to broker"
puts [join [zmsg dump $msg] \n]
}
zmsg send $worker $msg
}
# Connect or reconnect to broker
method connect_to_broker {} {
if {[string length $worker]} {
$worker close
}
set worker [zmq socket mdwrk_socket_[::mdp::socketid] $context DEALER]
$worker connect $broker
if {$verbose} {
puts "I: connecting to broker at $broker..."
}
# Register service with broker
my send_to_broker READY $service {}
# If liveness hits zero, queue is considered disconnected
set liveness $::mdp::HEARTBEAT_LIVENESS
set heartbeat_at [expr {[clock milliseconds] + $heartbeat}]
}
# Set heartbeat delay
method set_heartbeat {iheartbeat} {
set heartbeat $iheartbeat
}
# Set reconnect delay
method set_reconnect {ireconnect} {
set reconnect $ireconnect
}
# Send reply, if any, to broker and wait for next request.
method recv {reply} {
# Format and send the reply if we were provided one
if {!([string length $reply] || !$expect_reply)} {
error "reply expected"
}
if {[string length $reply]} {
if {![string length $reply_to]} {
error "no reply_to found"
}
set reply [zmsg wrap $reply $reply_to]
my send_to_broker REPLY {} $reply
}
set expect_reply 1
while {1} {
set poll_set [list [list $worker [list POLLIN]]]
set rpoll_set [zmq poll $poll_set $heartbeat]
if {[llength $rpoll_set] && "POLLIN" in [lindex $rpoll_set 0 1]} {
set msg [zmsg recv $worker]
if {$verbose} {
puts "I: received message from broker:"
puts [join [zmsg dump $msg] \n]
}
set liveness $::mdp::HEARTBEAT_LIVENESS
# Don't try to handle errors, just assert noisily
if {[llength $msg] < 3} {
error "invalid message size"
}
set empty [zmsg pop msg]
if {[string length $empty]} {
error "expected empty frame"
}
set header [zmsg pop msg]
if {$header ne $mdp::MDPW_WORKER} {
error "unexpected header"
}
set command [zmsg pop msg]
if {$command eq $::mdp::MDPW_COMMAND(REQUEST)} {
# We should pop and save as many addresses as there are
# up to a null part, but for now, just save one…
set reply_to [zmsg unwrap msg]
return $msg ;# We have a request to process
} elseif {$command eq $mdp::MDPW_COMMAND(HEARTBEAT)} {
;# Do nothing for heartbeats
} elseif {$command eq $mdp::MDPW_COMMAND(DISCONNECT)} {
my connect_to_broker
} else {
puts "E: invalid input message"
puts [join [zmsg dump $msg] \n]
}
} elseif {[incr liveness -1] == 0} {
if {$verbose} {
puts "W: disconnected from broker - retrying..."
}
after $reconnect
my connect_to_broker
}
# Send HEARTBEAT if it's time
if {[clock milliseconds] > $heartbeat_at} {
my send_to_broker HEARTBEAT {} {}
set heartbeat_at [expr {[clock milliseconds] + $heartbeat}]
}
}
}
}
mdwrkapi: OCaml 中的 Majordomo worker API
让我们看看 worker API 实际运行起来是什么样子,这里有一个实现回显服务的示例测试程序
mdworker: Ada 中的 Majordomo worker 应用
mdworker: Basic 中的 Majordomo worker 应用
mdworker: C 中的 Majordomo worker 应用
// Majordomo Protocol worker example
// Uses the mdwrk API to hide all MDP aspects
// Lets us build this source without creating a library
#include "mdwrkapi.c"
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && streq (argv [1], "-v"));
mdwrk_t *session = mdwrk_new (
"tcp://:5555", "echo", verbose);
zmsg_t *reply = NULL;
while (true) {
zmsg_t *request = mdwrk_recv (session, &reply);
if (request == NULL)
break; // Worker was interrupted
reply = request; // Echo is complex... :-)
}
mdwrk_destroy (&session);
return 0;
}
mdworker: C++ 中的 Majordomo worker 应用
//
// Majordomo Protocol worker example
// Uses the mdwrk API to hide all MDP aspects
//
// Lets us 'build mdworker' and 'build all'
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
//
#include "mdwrkapi.hpp"
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && strcmp (argv [1], "-v") == 0);
mdwrk session ("tcp://:5555", "echo", verbose);
zmsg *reply = 0;
while (1) {
zmsg *request = session.recv (reply);
if (request == 0) {
break; // Worker was interrupted
}
reply = request; // Echo is complex... :-)
}
return 0;
}
mdworker: C# 中的 Majordomo worker 应用
mdworker: CL 中的 Majordomo worker 应用
mdworker: Delphi 中的 Majordomo worker 应用
mdworker: Erlang 中的 Majordomo worker 应用
mdworker: Elixir 中的 Majordomo worker 应用
mdworker: F# 中的 Majordomo worker 应用
mdworker: Felix 中的 Majordomo worker 应用
mdworker: Go 中的 Majordomo worker 应用
// Majordomo Protocol worker example
// Uses the mdwrk API to hide all MDP aspects
//
// To run this example, you may need to run multiple *.go files as below
// go run mdp.go zhelpers.go mdwrkapi.go mdworker.go [-v]
//
// Author: iano <scaly.iano@gmail.com>
package main
import (
"os"
)
func main() {
verbose := len(os.Args) >= 2 && os.Args[1] == "-v"
worker := NewWorker("tcp://:5555", "echo", verbose)
for reply := [][]byte{}; ; {
request := worker.Recv(reply)
if len(request) == 0 {
break
}
reply = request
}
}
mdworker: Haskell 中的 Majordomo worker 应用
import MDWorkerAPI
import ZHelpers
import System.Environment (getArgs)
import System.IO (hSetBuffering, stdout, BufferMode(NoBuffering))
import Control.Monad (forever, mapM_, when)
import Data.ByteString.Char8 (unpack, empty, ByteString(..))
main :: IO ()
main = do
args <- getArgs
when (length args /= 1) $
error "usage: mdworker <isVerbose(True|False)>"
let isVerbose = read (args !! 0) :: Bool
hSetBuffering stdout NoBuffering
withMDWorker "tcp://:5555" "echo" isVerbose $ \session ->
doEcho session [empty]
where doEcho session reply = do
request <- mdwkrExchange session reply
doEcho (fst request) (snd request)
mdworker: Haxe 中的 Majordomo worker 应用
package ;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZMsg;
/**
* Majordomo Protocol worker example
* Uses the MDWrk API to hde all MDP aspects
* @author Richard J Smith
*/
class MDWorker
{
public static function main() {
Lib.println("** MDWorker (see: https://zguide.zeromq.cn/page:all#Service-Oriented-Reliable-Queuing-Majordomo-Pattern)");
var argArr = Sys.args();
var verbose = (argArr.length > 1 && argArr[argArr.length - 1] == "-v");
var session = new MDWrkAPI("tcp://:5555", "echo", verbose);
var reply:ZMsg = null;
while (true) {
var request = session.recv(reply);
if (request == null)
break; // Interrupted
reply = request;
}
session.destroy();
}
}mdworker: Java 中的 Majordomo worker 应用
package guide;
import org.zeromq.ZMsg;
/**
* Majordomo Protocol worker example. Uses the mdwrk API to hide all MDP aspects
*
*/
public class mdworker
{
/**
* @param args
*/
public static void main(String[] args)
{
boolean verbose = (args.length > 0 && "-v".equals(args[0]));
mdwrkapi workerSession = new mdwrkapi("tcp://:5555", "echo", verbose);
ZMsg reply = null;
while (!Thread.currentThread().isInterrupted()) {
ZMsg request = workerSession.receive(reply);
if (request == null)
break; //Interrupted
reply = request; // Echo is complex :-)
}
workerSession.destroy();
}
}
mdworker: Julia 中的 Majordomo worker 应用
mdworker: Lua 中的 Majordomo worker 应用
--
-- Majordomo Protocol worker example
-- Uses the mdwrk API to hide all MDP aspects
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"mdwrkapi"
require"zmsg"
local verbose = (arg[1] == "-v")
local session = mdwrkapi.new("tcp://:5555", "echo", verbose)
local reply
while true do
local request = session:recv(reply)
if not request then
break -- Worker was interrupted
end
reply = request -- Echo is complex... :-)
end
session:destroy()
mdworker: Node.js 中的 Majordomo worker 应用
mdworker: Objective-C 中的 Majordomo worker 应用
mdworker: ooc 中的 Majordomo worker 应用
mdworker: Perl 中的 Majordomo worker 应用
mdworker: PHP 中的 Majordomo worker 应用
<?php
/*
* Majordomo Protocol worker example
* Uses the mdwrk API to hide all MDP aspects
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include_once 'mdwrkapi.php';
$verbose = $_SERVER['argc'] > 1 && $_SERVER['argv'][1] == "-v";
$mdwrk = new Mdwrk("tcp://:5555", "echo", $verbose);
$reply = null;
while (true) {
$request = $mdwrk->recv($reply);
$reply = $request; // Echo is complex... :-)
}
mdworker: Python 中的 Majordomo worker 应用
"""Majordomo Protocol worker example.
Uses the mdwrk API to hide all MDP aspects
Author: Min RK <benjaminrk@gmail.com>
"""
import sys
from mdwrkapi import MajorDomoWorker
def main():
verbose = '-v' in sys.argv
worker = MajorDomoWorker("tcp://:5555", b"echo", verbose)
reply = None
while True:
request = worker.recv(reply)
if request is None:
break # Worker was interrupted
reply = request # Echo is complex... :-)
if __name__ == '__main__':
main()
mdworker: Q 中的 Majordomo worker 应用
mdworker: Racket 中的 Majordomo worker 应用
mdworker: Ruby 中的 Majordomo worker 应用
#!/usr/bin/env ruby
# Majordomo Protocol worker example.
#
# Author: Tom van Leeuwen <tom@vleeuwen.eu>
require './mdwrkapi.rb'
worker = MajorDomoWorker.new('tcp://:5555', 'echo')
reply = nil
loop do
request = worker.recv reply
reply = request # Echo is complex... :-)
end
mdworker: Rust 中的 Majordomo worker 应用
mdworker: Scala 中的 Majordomo worker 应用
mdworker: Tcl 中的 Majordomo worker 应用
#
# Majordomo Protocol worker example
# Uses the mdwrk API to hide all MDP aspects
#
lappend auto_path .
package require MDWorker 1.0
set verbose 0
foreach {k v} $argv {
if {$k eq "-v"} { set verbose 1 }
}
set session [MDWorker new "tcp://:5555" "echo" $verbose]
set reply {}
while {1} {
set request [$session recv $reply]
if {[llength $request] == 0} {
break ;# Worker was interrupted
}
set reply [list "$request @ [clock format [clock seconds]] from $session"] ;# Echo is complex… :-)
}
$session destroy
mdworker: OCaml 中的 Majordomo worker 应用
关于 worker API 代码的一些注意事项
-
这些 API 是单线程的。这意味着,例如,worker 不会在后台发送心跳。令人高兴的是,这正是我们想要的:如果 worker 应用卡住了,心跳就会停止,broker 也将停止向该 worker 发送请求。
-
worker API 不会进行指数退避;这样做不值得增加额外的复杂性。
-
这些 API 不会进行任何错误报告。如果出现意外情况,它们会引发断言(或异常,取决于语言)。这对于参考实现来说是理想的,这样任何协议错误都会立即显示出来。对于实际应用,API 应该能够健壮地处理无效消息。
您可能想知道为什么 worker API 会手动关闭并重新打开其套接字,而 ZeroMQ 在对端消失并重新出现时会自动重新连接套接字。回顾 Simple Pirate 和 Paranoid Pirate worker 即可理解。尽管 ZeroMQ 会在 broker 死亡并重新启动时自动重新连接 worker,但这不足以让 worker 向 broker 重新注册。我知道至少有两种解决方案。这里使用的最简单方法是 worker 使用心跳来监控连接,如果确定 broker 已死,就关闭其套接字并使用新套接字重新开始。另一种方法是当 broker 收到来自 worker 的心跳时,对其进行质询并要求它们重新注册。这需要协议支持。
现在让我们设计 Majordomo broker。其核心结构是一组队列,每个服务一个。我们会在 worker 出现时创建这些队列(我们也可以在 worker 消失时删除它们,但现在先忽略这一点,因为它会变得复杂)。此外,我们为每个服务维护一个 worker 队列。
以下是 broker
mdbroker: Ada 中的 Majordomo broker
mdbroker: Basic 中的 Majordomo broker
mdbroker: C 中的 Majordomo broker
// Majordomo Protocol broker
// A minimal C implementation of the Majordomo Protocol as defined in
// https://rfc.zeromq.cn/spec:7 and https://rfc.zeromq.cn/spec:8.
#include "czmq.h"
#include "mdp.h"
// We'd normally pull these from config data
#define HEARTBEAT_LIVENESS 3 // 3-5 is reasonable
#define HEARTBEAT_INTERVAL 2500 // msecs
#define HEARTBEAT_EXPIRY HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS
// .split broker class structure
// The broker class defines a single broker instance:
typedef struct {
zctx_t *ctx; // Our context
void *socket; // Socket for clients & workers
int verbose; // Print activity to stdout
char *endpoint; // Broker binds to this endpoint
zhash_t *services; // Hash of known services
zhash_t *workers; // Hash of known workers
zlist_t *waiting; // List of waiting workers
uint64_t heartbeat_at; // When to send HEARTBEAT
} broker_t;
static broker_t *
s_broker_new (int verbose);
static void
s_broker_destroy (broker_t **self_p);
static void
s_broker_bind (broker_t *self, char *endpoint);
static void
s_broker_worker_msg (broker_t *self, zframe_t *sender, zmsg_t *msg);
static void
s_broker_client_msg (broker_t *self, zframe_t *sender, zmsg_t *msg);
static void
s_broker_purge (broker_t *self);
// .split service class structure
// The service class defines a single service instance:
typedef struct {
broker_t *broker; // Broker instance
char *name; // Service name
zlist_t *requests; // List of client requests
zlist_t *waiting; // List of waiting workers
size_t workers; // How many workers we have
} service_t;
static service_t *
s_service_require (broker_t *self, zframe_t *service_frame);
static void
s_service_destroy (void *argument);
static void
s_service_dispatch (service_t *service, zmsg_t *msg);
// .split worker class structure
// The worker class defines a single worker, idle or active:
typedef struct {
broker_t *broker; // Broker instance
char *id_string; // Identity of worker as string
zframe_t *identity; // Identity frame for routing
service_t *service; // Owning service, if known
int64_t expiry; // When worker expires, if no heartbeat
} worker_t;
static worker_t *
s_worker_require (broker_t *self, zframe_t *identity);
static void
s_worker_delete (worker_t *self, int disconnect);
static void
s_worker_destroy (void *argument);
static void
s_worker_send (worker_t *self, char *command, char *option,
zmsg_t *msg);
static void
s_worker_waiting (worker_t *self);
// .split broker constructor and destructor
// Here are the constructor and destructor for the broker:
static broker_t *
s_broker_new (int verbose)
{
broker_t *self = (broker_t *) zmalloc (sizeof (broker_t));
// Initialize broker state
self->ctx = zctx_new ();
self->socket = zsocket_new (self->ctx, ZMQ_ROUTER);
self->verbose = verbose;
self->services = zhash_new ();
self->workers = zhash_new ();
self->waiting = zlist_new ();
self->heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
return self;
}
static void
s_broker_destroy (broker_t **self_p)
{
assert (self_p);
if (*self_p) {
broker_t *self = *self_p;
zctx_destroy (&self->ctx);
zhash_destroy (&self->services);
zhash_destroy (&self->workers);
zlist_destroy (&self->waiting);
free (self);
*self_p = NULL;
}
}
// .split broker bind method
// This method binds the broker instance to an endpoint. We can call
// this multiple times. Note that MDP uses a single socket for both clients
// and workers:
void
s_broker_bind (broker_t *self, char *endpoint)
{
zsocket_bind (self->socket, endpoint);
zclock_log ("I: MDP broker/0.2.0 is active at %s", endpoint);
}
// .split broker worker_msg method
// This method processes one READY, REPLY, HEARTBEAT, or
// DISCONNECT message sent to the broker by a worker:
static void
s_broker_worker_msg (broker_t *self, zframe_t *sender, zmsg_t *msg)
{
assert (zmsg_size (msg) >= 1); // At least, command
zframe_t *command = zmsg_pop (msg);
char *id_string = zframe_strhex (sender);
int worker_ready = (zhash_lookup (self->workers, id_string) != NULL);
free (id_string);
worker_t *worker = s_worker_require (self, sender);
if (zframe_streq (command, MDPW_READY)) {
if (worker_ready) // Not first command in session
s_worker_delete (worker, 1);
else
if (zframe_size (sender) >= 4 // Reserved service name
&& memcmp (zframe_data (sender), "mmi.", 4) == 0)
s_worker_delete (worker, 1);
else {
// Attach worker to service and mark as idle
zframe_t *service_frame = zmsg_pop (msg);
worker->service = s_service_require (self, service_frame);
worker->service->workers++;
s_worker_waiting (worker);
zframe_destroy (&service_frame);
}
}
else
if (zframe_streq (command, MDPW_REPLY)) {
if (worker_ready) {
// Remove and save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
zframe_t *client = zmsg_unwrap (msg);
zmsg_pushstr (msg, worker->service->name);
zmsg_pushstr (msg, MDPC_CLIENT);
zmsg_wrap (msg, client);
zmsg_send (&msg, self->socket);
s_worker_waiting (worker);
}
else
s_worker_delete (worker, 1);
}
else
if (zframe_streq (command, MDPW_HEARTBEAT)) {
if (worker_ready)
worker->expiry = zclock_time () + HEARTBEAT_EXPIRY;
else
s_worker_delete (worker, 1);
}
else
if (zframe_streq (command, MDPW_DISCONNECT))
s_worker_delete (worker, 0);
else {
zclock_log ("E: invalid input message");
zmsg_dump (msg);
}
free (command);
zmsg_destroy (&msg);
}
// .split broker client_msg method
// Process a request coming from a client. We implement MMI requests
// directly here (at present, we implement only the mmi.service request):
static void
s_broker_client_msg (broker_t *self, zframe_t *sender, zmsg_t *msg)
{
assert (zmsg_size (msg) >= 2); // Service name + body
zframe_t *service_frame = zmsg_pop (msg);
service_t *service = s_service_require (self, service_frame);
// Set reply return identity to client sender
zmsg_wrap (msg, zframe_dup (sender));
// If we got a MMI service request, process that internally
if (zframe_size (service_frame) >= 4
&& memcmp (zframe_data (service_frame), "mmi.", 4) == 0) {
char *return_code;
if (zframe_streq (service_frame, "mmi.service")) {
char *name = zframe_strdup (zmsg_last (msg));
service_t *service =
(service_t *) zhash_lookup (self->services, name);
return_code = service && service->workers? "200": "404";
free (name);
}
else
return_code = "501";
zframe_reset (zmsg_last (msg), return_code, strlen (return_code));
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
zframe_t *client = zmsg_unwrap (msg);
zmsg_prepend (msg, &service_frame);
zmsg_pushstr (msg, MDPC_CLIENT);
zmsg_wrap (msg, client);
zmsg_send (&msg, self->socket);
}
else
// Else dispatch the message to the requested service
s_service_dispatch (service, msg);
zframe_destroy (&service_frame);
}
// .split broker purge method
// This method deletes any idle workers that haven't pinged us in a
// while. We hold workers from oldest to most recent so we can stop
// scanning whenever we find a live worker. This means we'll mainly stop
// at the first worker, which is essential when we have large numbers of
// workers (we call this method in our critical path):
static void
s_broker_purge (broker_t *self)
{
worker_t *worker = (worker_t *) zlist_first (self->waiting);
while (worker) {
if (zclock_time () < worker->expiry)
break; // Worker is alive, we're done here
if (self->verbose)
zclock_log ("I: deleting expired worker: %s",
worker->id_string);
s_worker_delete (worker, 0);
worker = (worker_t *) zlist_first (self->waiting);
}
}
// .split service methods
// Here is the implementation of the methods that work on a service:
// Lazy constructor that locates a service by name or creates a new
// service if there is no service already with that name.
static service_t *
s_service_require (broker_t *self, zframe_t *service_frame)
{
assert (service_frame);
char *name = zframe_strdup (service_frame);
service_t *service =
(service_t *) zhash_lookup (self->services, name);
if (service == NULL) {
service = (service_t *) zmalloc (sizeof (service_t));
service->broker = self;
service->name = name;
service->requests = zlist_new ();
service->waiting = zlist_new ();
zhash_insert (self->services, name, service);
zhash_freefn (self->services, name, s_service_destroy);
if (self->verbose)
zclock_log ("I: added service: %s", name);
}
else
free (name);
return service;
}
// Service destructor is called automatically whenever the service is
// removed from broker->services.
static void
s_service_destroy (void *argument)
{
service_t *service = (service_t *) argument;
while (zlist_size (service->requests)) {
zmsg_t *msg = zlist_pop (service->requests);
zmsg_destroy (&msg);
}
zlist_destroy (&service->requests);
zlist_destroy (&service->waiting);
free (service->name);
free (service);
}
// .split service dispatch method
// This method sends requests to waiting workers:
static void
s_service_dispatch (service_t *self, zmsg_t *msg)
{
assert (self);
if (msg) // Queue message if any
zlist_append (self->requests, msg);
s_broker_purge (self->broker);
while (zlist_size (self->waiting) && zlist_size (self->requests)) {
worker_t *worker = zlist_pop (self->waiting);
zlist_remove (self->broker->waiting, worker);
zmsg_t *msg = zlist_pop (self->requests);
s_worker_send (worker, MDPW_REQUEST, NULL, msg);
zmsg_destroy (&msg);
}
}
// .split worker methods
// Here is the implementation of the methods that work on a worker:
// Lazy constructor that locates a worker by identity, or creates a new
// worker if there is no worker already with that identity.
static worker_t *
s_worker_require (broker_t *self, zframe_t *identity)
{
assert (identity);
// self->workers is keyed off worker identity
char *id_string = zframe_strhex (identity);
worker_t *worker =
(worker_t *) zhash_lookup (self->workers, id_string);
if (worker == NULL) {
worker = (worker_t *) zmalloc (sizeof (worker_t));
worker->broker = self;
worker->id_string = id_string;
worker->identity = zframe_dup (identity);
zhash_insert (self->workers, id_string, worker);
zhash_freefn (self->workers, id_string, s_worker_destroy);
if (self->verbose)
zclock_log ("I: registering new worker: %s", id_string);
}
else
free (id_string);
return worker;
}
// This method deletes the current worker.
static void
s_worker_delete (worker_t *self, int disconnect)
{
assert (self);
if (disconnect)
s_worker_send (self, MDPW_DISCONNECT, NULL, NULL);
if (self->service) {
zlist_remove (self->service->waiting, self);
self->service->workers--;
}
zlist_remove (self->broker->waiting, self);
// This implicitly calls s_worker_destroy
zhash_delete (self->broker->workers, self->id_string);
}
// Worker destructor is called automatically whenever the worker is
// removed from broker->workers.
static void
s_worker_destroy (void *argument)
{
worker_t *self = (worker_t *) argument;
zframe_destroy (&self->identity);
free (self->id_string);
free (self);
}
// .split worker send method
// This method formats and sends a command to a worker. The caller may
// also provide a command option, and a message payload:
static void
s_worker_send (worker_t *self, char *command, char *option, zmsg_t *msg)
{
msg = msg? zmsg_dup (msg): zmsg_new ();
// Stack protocol envelope to start of message
if (option)
zmsg_pushstr (msg, option);
zmsg_pushstr (msg, command);
zmsg_pushstr (msg, MDPW_WORKER);
// Stack routing envelope to start of message
zmsg_wrap (msg, zframe_dup (self->identity));
if (self->broker->verbose) {
zclock_log ("I: sending %s to worker",
mdps_commands [(int) *command]);
zmsg_dump (msg);
}
zmsg_send (&msg, self->broker->socket);
}
// This worker is now waiting for work
static void
s_worker_waiting (worker_t *self)
{
// Queue to broker and service waiting lists
assert (self->broker);
zlist_append (self->broker->waiting, self);
zlist_append (self->service->waiting, self);
self->expiry = zclock_time () + HEARTBEAT_EXPIRY;
s_service_dispatch (self->service, NULL);
}
// .split main task
// Finally, here is the main task. We create a new broker instance and
// then process messages on the broker socket:
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && streq (argv [1], "-v"));
broker_t *self = s_broker_new (verbose);
s_broker_bind (self, "tcp://*:5555");
// Get and process messages forever or until interrupted
while (true) {
zmq_pollitem_t items [] = {
{ self->socket, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (items, 1, HEARTBEAT_INTERVAL * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
// Process next input message, if any
if (items [0].revents & ZMQ_POLLIN) {
zmsg_t *msg = zmsg_recv (self->socket);
if (!msg)
break; // Interrupted
if (self->verbose) {
zclock_log ("I: received message:");
zmsg_dump (msg);
}
zframe_t *sender = zmsg_pop (msg);
zframe_t *empty = zmsg_pop (msg);
zframe_t *header = zmsg_pop (msg);
if (zframe_streq (header, MDPC_CLIENT))
s_broker_client_msg (self, sender, msg);
else
if (zframe_streq (header, MDPW_WORKER))
s_broker_worker_msg (self, sender, msg);
else {
zclock_log ("E: invalid message:");
zmsg_dump (msg);
zmsg_destroy (&msg);
}
zframe_destroy (&sender);
zframe_destroy (&empty);
zframe_destroy (&header);
}
// Disconnect and delete any expired workers
// Send heartbeats to idle workers if needed
if (zclock_time () > self->heartbeat_at) {
s_broker_purge (self);
worker_t *worker = (worker_t *) zlist_first (self->waiting);
while (worker) {
s_worker_send (worker, MDPW_HEARTBEAT, NULL, NULL);
worker = (worker_t *) zlist_next (self->waiting);
}
self->heartbeat_at = zclock_time () + HEARTBEAT_INTERVAL;
}
}
if (zctx_interrupted)
printf ("W: interrupt received, shutting down...\n");
s_broker_destroy (&self);
return 0;
}
mdbroker: C++ 中的 Majordomo broker
//
// Majordomo Protocol broker
// A minimal implementation of https://rfc.zeromq.cn/spec:7 and spec:8
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
//
#include "zmsg.hpp"
#include "mdp.h"
#include <map>
#include <set>
#include <deque>
#include <list>
// We'd normally pull these from config data
static constexpr uint32_t n_heartbeat_liveness = 3;
static constexpr uint32_t n_heartbeat_interval = 2500; // msecs
static constexpr uint32_t n_heartbeat_expiry = n_heartbeat_interval * n_heartbeat_liveness; // msecs
struct service;
// This defines one worker, idle or active
struct worker
{
std::string m_identity; // Address of worker
service * m_service; // Owning service, if known
int64_t m_expiry; // Expires at unless heartbeat
worker(std::string identity, service * service = nullptr, int64_t expiry = 0): m_identity(identity), m_service(service), m_expiry(expiry) {}
};
// This defines a single service
struct service
{
~service ()
{
for(size_t i = 0; i < m_requests.size(); i++) {
delete m_requests[i];
}
}
const std::string m_name; // Service name
std::deque<zmsg*> m_requests; // List of client requests
std::list<worker*> m_waiting; // List of waiting workers
size_t m_workers; // How many workers we have
service(std::string name): m_name(name) {}
};
// This defines a single broker
class broker {
public:
// ---------------------------------------------------------------------
// Constructor for broker object
broker (int verbose):m_verbose(verbose)
{
// Initialize broker state
m_context = new zmq::context_t(1);
m_socket = new zmq::socket_t(*m_context, ZMQ_ROUTER);
}
// ---------------------------------------------------------------------
// Destructor for broker object
virtual
~broker ()
{
while (! m_services.empty())
{
delete m_services.begin()->second;
m_services.erase(m_services.begin());
}
while (! m_workers.empty())
{
delete m_workers.begin()->second;
m_workers.erase(m_workers.begin());
}
}
// ---------------------------------------------------------------------
// Bind broker to endpoint, can call this multiple times
// We use a single socket for both clients and workers.
void
bind (std::string endpoint)
{
m_endpoint = endpoint;
m_socket->bind(m_endpoint.c_str());
s_console ("I: MDP broker/0.1.1 is active at %s", endpoint.c_str());
}
private:
// ---------------------------------------------------------------------
// Delete any idle workers that haven't pinged us in a while.
void
purge_workers ()
{
std::deque<worker*> toCull;
int64_t now = s_clock();
for (auto wrk = m_waiting.begin(); wrk != m_waiting.end(); ++wrk)
{
if ((*wrk)->m_expiry <= now)
toCull.push_back(*wrk);
}
for (auto wrk = toCull.begin(); wrk != toCull.end(); ++wrk)
{
if (m_verbose) {
s_console ("I: deleting expired worker: %s",
(*wrk)->m_identity.c_str());
}
worker_delete(*wrk, 0);
}
}
// ---------------------------------------------------------------------
// Locate or create new service entry
service *
service_require (std::string name)
{
assert (!name.empty());
if (m_services.count(name)) {
return m_services.at(name);
}
service * srv = new service(name);
m_services.insert(std::pair{name, srv});
if (m_verbose) {
s_console("I: added service: %s", name.c_str());
}
return srv;
}
// ---------------------------------------------------------------------
// Dispatch requests to waiting workers as possible
void
service_dispatch (service *srv, zmsg *msg)
{
assert (srv);
if (msg) { // Queue message if any
srv->m_requests.push_back(msg);
}
purge_workers ();
while (! srv->m_waiting.empty() && ! srv->m_requests.empty())
{
// Choose the most recently seen idle worker; others might be about to expire
auto wrk = srv->m_waiting.begin();
auto next = wrk;
for (++next; next != srv->m_waiting.end(); ++next)
{
if ((*next)->m_expiry > (*wrk)->m_expiry)
wrk = next;
}
zmsg *msg = srv->m_requests.front();
srv->m_requests.pop_front();
worker_send (*wrk, k_mdpw_request.data(), "", msg);
m_waiting.erase(*wrk);
srv->m_waiting.erase(wrk);
delete msg;
}
}
// ---------------------------------------------------------------------
// Handle internal service according to 8/MMI specification
void
service_internal (std::string service_name, zmsg *msg)
{
if (service_name.compare("mmi.service") == 0) {
// service *srv = m_services[msg->body()]; // Dangerous! Silently add key with default value
service *srv = m_services.count(msg->body()) ? m_services.at(msg->body()) : nullptr;
if (srv && srv->m_workers) {
msg->body_set("200");
} else {
msg->body_set("404");
}
} else {
msg->body_set("501");
}
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
std::string client = msg->unwrap();
msg->wrap(k_mdp_client.data(), service_name.c_str());
msg->wrap(client.c_str(), "");
msg->send (*m_socket);
delete msg;
}
// ---------------------------------------------------------------------
// Creates worker if necessary
worker *
worker_require (std::string identity)
{
assert (!identity.empty());
// self->workers is keyed off worker identity
if (m_workers.count(identity)) {
return m_workers.at(identity);
} else {
worker *wrk = new worker(identity);
m_workers.insert(std::make_pair(identity, wrk));
if (m_verbose) {
s_console ("I: registering new worker: %s", identity.c_str());
}
return wrk;
}
}
// ---------------------------------------------------------------------
// Deletes worker from all data structures, and destroys worker
void
worker_delete (worker *&wrk, int disconnect)
{
assert (wrk);
if (disconnect) {
worker_send (wrk, k_mdpw_disconnect.data(), "", NULL);
}
if (wrk->m_service) {
for(auto it = wrk->m_service->m_waiting.begin();
it != wrk->m_service->m_waiting.end();) {
if (*it == wrk) {
it = wrk->m_service->m_waiting.erase(it);
}
else {
++it;
}
}
wrk->m_service->m_workers--;
}
m_waiting.erase(wrk);
// This implicitly calls the worker destructor
m_workers.erase(wrk->m_identity);
delete wrk;
}
// ---------------------------------------------------------------------
// Process message sent to us by a worker
void
worker_process (std::string sender, zmsg *msg)
{
assert (msg && msg->parts() >= 1); // At least, command
std::string command = (char *)msg->pop_front().c_str();
bool worker_ready = m_workers.count(sender)>0;
worker *wrk = worker_require (sender);
if (command.compare (k_mdpw_ready.data()) == 0) {
if (worker_ready) { // Not first command in session
worker_delete (wrk, 1);
}
else {
if (sender.size() >= 4 // Reserved service name
&& sender.find_first_of("mmi.") == 0) {
worker_delete (wrk, 1);
} else {
// Attach worker to service and mark as idle
std::string service_name = (char *) msg->pop_front ().c_str();
wrk->m_service = service_require (service_name);
wrk->m_service->m_workers++;
worker_waiting (wrk);
}
}
} else {
if (command.compare (k_mdpw_reply.data()) == 0) {
if (worker_ready) {
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
std::string client = msg->unwrap ();
msg->wrap (k_mdp_client.data(), wrk->m_service->m_name.c_str());
msg->wrap (client.c_str(), "");
msg->send (*m_socket);
worker_waiting (wrk);
}
else {
worker_delete (wrk, 1);
}
} else {
if (command.compare (k_mdpw_heartbeat.data()) == 0) {
if (worker_ready) {
wrk->m_expiry = s_clock () + n_heartbeat_expiry;
} else {
worker_delete (wrk, 1);
}
} else {
if (command.compare (k_mdpw_disconnect.data()) == 0) {
worker_delete (wrk, 0);
} else {
s_console ("E: invalid input message (%d)", (int) *command.c_str());
msg->dump ();
}
}
}
}
delete msg;
}
// ---------------------------------------------------------------------
// Send message to worker
// If pointer to message is provided, sends that message
void
worker_send (worker *worker,
const char *command, std::string option, zmsg *msg)
{
msg = (msg ? new zmsg(*msg) : new zmsg ());
// Stack protocol envelope to start of message
if (option.size()>0) { // Optional frame after command
msg->push_front (option.c_str());
}
msg->push_front (command);
msg->push_front (k_mdpw_worker.data());
// Stack routing envelope to start of message
msg->wrap(worker->m_identity.c_str(), "");
if (m_verbose) {
s_console ("I: sending %s to worker",
mdps_commands [(int) *command].data());
msg->dump ();
}
msg->send (*m_socket);
delete msg;
}
// ---------------------------------------------------------------------
// This worker is now waiting for work
void
worker_waiting (worker *worker)
{
assert (worker);
// Queue to broker and service waiting lists
m_waiting.insert(worker);
worker->m_service->m_waiting.push_back(worker);
worker->m_expiry = s_clock () + n_heartbeat_expiry;
// Attempt to process outstanding requests
service_dispatch (worker->m_service, 0);
}
// ---------------------------------------------------------------------
// Process a request coming from a client
void
client_process (std::string sender, zmsg *msg)
{
assert (msg && msg->parts () >= 2); // Service name + body
std::string service_name =(char *) msg->pop_front().c_str();
service *srv = service_require (service_name);
// Set reply return address to client sender
msg->wrap (sender.c_str(), "");
if (service_name.length() >= 4
&& service_name.find_first_of("mmi.") == 0) {
service_internal (service_name, msg);
} else {
service_dispatch (srv, msg);
}
}
public:
// Get and process messages forever or until interrupted
void
start_brokering() {
int64_t now = s_clock();
int64_t heartbeat_at = now + n_heartbeat_interval;
while (!s_interrupted) {
zmq::pollitem_t items [] = {
{ *m_socket, 0, ZMQ_POLLIN, 0} };
int64_t timeout = heartbeat_at - now;
if (timeout < 0)
timeout = 0;
zmq::poll (items, 1, (long)timeout);
// Process next input message, if any
if (items [0].revents & ZMQ_POLLIN) {
zmsg *msg = new zmsg(*m_socket);
if (m_verbose) {
s_console ("I: received message:");
msg->dump ();
}
std::string sender = (char*)msg->pop_front ().c_str();
msg->pop_front (); //empty message
std::string header = (char*)msg->pop_front ().c_str();
if (header.compare(k_mdp_client.data()) == 0) {
client_process (sender, msg);
}
else if (header.compare(k_mdpw_worker.data()) == 0) {
worker_process (sender, msg);
}
else {
s_console ("E: invalid message:");
msg->dump ();
delete msg;
}
}
// Disconnect and delete any expired workers
// Send heartbeats to idle workers if needed
now = s_clock();
if (now >= heartbeat_at) {
purge_workers ();
for (auto it = m_waiting.begin();
it != m_waiting.end() && (*it)!=0; it++) {
worker_send (*it, k_mdpw_heartbeat.data(), "", NULL);
}
heartbeat_at += n_heartbeat_interval;
now = s_clock();
}
}
}
private:
zmq::context_t * m_context; // 0MQ context
zmq::socket_t * m_socket; // Socket for clients & workers
const int m_verbose; // Print activity to stdout
std::string m_endpoint; // Broker binds to this endpoint
std::map<std::string, service*> m_services; // Hash of known services
std::map<std::string, worker*> m_workers; // Hash of known workers
std::set<worker*> m_waiting; // List of waiting workers
};
// ---------------------------------------------------------------------
// Main broker work happens here
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && strcmp (argv [1], "-v") == 0);
s_version_assert (4, 0);
s_catch_signals ();
broker brk(verbose);
brk.bind ("tcp://*:5555");
brk.start_brokering();
if (s_interrupted)
printf ("W: interrupt received, shutting down...\n");
return 0;
}
mdbroker: C# 中的 Majordomo broker
mdbroker: CL 中的 Majordomo broker
mdbroker: Delphi 中的 Majordomo broker
mdbroker: Erlang 中的 Majordomo broker
mdbroker: Elixir 中的 Majordomo broker
mdbroker: F# 中的 Majordomo broker
mdbroker: Felix 中的 Majordomo broker
mdbroker: Go 中的 Majordomo broker
// Majordomo Protocol broker
// A minimal C implementation of the Majordomo Protocol as defined in
// https://rfc.zeromq.cn/spec:7 and https://rfc.zeromq.cn/spec:8.
//
// To run this example, you may need to run multiple *.go files as below
// go run mdp.go zhelpers.go mdbroker.go [-v]
//
// Author: iano <scaly.iano@gmail.com>
// Based on C & Python example
package main
import (
"encoding/hex"
zmq "github.com/alecthomas/gozmq"
"log"
"os"
"time"
)
const (
INTERNAL_SERVICE_PREFIX = "mmi."
HEARTBEAT_INTERVAL = 2500 * time.Millisecond
HEARTBEAT_EXPIRY = HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS
)
type Broker interface {
Close()
Run()
}
type mdbWorker struct {
identity string // Hex Identity of worker
address []byte // Address to route to
expiry time.Time // Expires at this point, unless heartbeat
service *mdService // Owning service, if known
}
type mdService struct {
broker Broker
name string
requests [][][]byte // List of client requests
waiting *ZList // List of waiting workers
}
type mdBroker struct {
context *zmq.Context // Context
heartbeatAt time.Time // When to send HEARTBEAT
services map[string]*mdService // Known services
socket *zmq.Socket // Socket for clients & workers
waiting *ZList // Idle workers
workers map[string]*mdbWorker // Known workers
verbose bool // Print activity to stdout
}
func NewBroker(endpoint string, verbose bool) Broker {
context, _ := zmq.NewContext()
socket, _ := context.NewSocket(zmq.ROUTER)
socket.SetLinger(0)
socket.Bind(endpoint)
log.Printf("I: MDP broker/0.1.1 is active at %s\n", endpoint)
return &mdBroker{
context: context,
heartbeatAt: time.Now().Add(HEARTBEAT_INTERVAL),
services: make(map[string]*mdService),
socket: socket,
waiting: NewList(),
workers: make(map[string]*mdbWorker),
verbose: verbose,
}
}
// Deletes worker from all data structures, and deletes worker.
func (self *mdBroker) deleteWorker(worker *mdbWorker, disconnect bool) {
if worker == nil {
panic("Nil worker")
}
if disconnect {
self.sendToWorker(worker, MDPW_DISCONNECT, nil, nil)
}
if worker.service != nil {
worker.service.waiting.Delete(worker)
}
self.waiting.Delete(worker)
delete(self.workers, worker.identity)
}
// Dispatch requests to waiting workers as possible
func (self *mdBroker) dispatch(service *mdService, msg [][]byte) {
if service == nil {
panic("Nil service")
}
// Queue message if any
if len(msg) != 0 {
service.requests = append(service.requests, msg)
}
self.purgeWorkers()
for service.waiting.Len() > 0 && len(service.requests) > 0 {
msg, service.requests = service.requests[0], service.requests[1:]
elem := service.waiting.Pop()
self.waiting.Remove(elem)
worker, _ := elem.Value.(*mdbWorker)
self.sendToWorker(worker, MDPW_REQUEST, nil, msg)
}
}
// Process a request coming from a client.
func (self *mdBroker) processClient(sender []byte, msg [][]byte) {
// Service name + body
if len(msg) < 2 {
panic("Invalid msg")
}
service := msg[0]
// Set reply return address to client sender
msg = append([][]byte{sender, nil}, msg[1:]...)
if string(service[:4]) == INTERNAL_SERVICE_PREFIX {
self.serviceInternal(service, msg)
} else {
self.dispatch(self.requireService(string(service)), msg)
}
}
// Process message sent to us by a worker.
func (self *mdBroker) processWorker(sender []byte, msg [][]byte) {
// At least, command
if len(msg) < 1 {
panic("Invalid msg")
}
command, msg := msg[0], msg[1:]
identity := hex.EncodeToString(sender)
worker, workerReady := self.workers[identity]
if !workerReady {
worker = &mdbWorker{
identity: identity,
address: sender,
expiry: time.Now().Add(HEARTBEAT_EXPIRY),
}
self.workers[identity] = worker
if self.verbose {
log.Printf("I: registering new worker: %s\n", identity)
}
}
switch string(command) {
case MDPW_READY:
// At least, a service name
if len(msg) < 1 {
panic("Invalid msg")
}
service := msg[0]
// Not first command in session or Reserved service name
if workerReady || string(service[:4]) == INTERNAL_SERVICE_PREFIX {
self.deleteWorker(worker, true)
} else {
// Attach worker to service and mark as idle
worker.service = self.requireService(string(service))
self.workerWaiting(worker)
}
case MDPW_REPLY:
if workerReady {
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
client := msg[0]
msg = append([][]byte{client, nil, []byte(MDPC_CLIENT), []byte(worker.service.name)}, msg[2:]...)
self.socket.SendMultipart(msg, 0)
self.workerWaiting(worker)
} else {
self.deleteWorker(worker, true)
}
case MDPW_HEARTBEAT:
if workerReady {
worker.expiry = time.Now().Add(HEARTBEAT_EXPIRY)
} else {
self.deleteWorker(worker, true)
}
case MDPW_DISCONNECT:
self.deleteWorker(worker, false)
default:
log.Println("E: invalid message:")
Dump(msg)
}
}
// Look for & kill expired workers.
// Workers are oldest to most recent, so we stop at the first alive worker.
func (self *mdBroker) purgeWorkers() {
now := time.Now()
for elem := self.waiting.Front(); elem != nil; elem = self.waiting.Front() {
worker, _ := elem.Value.(*mdbWorker)
if worker.expiry.After(now) {
break
}
self.deleteWorker(worker, false)
}
}
// Locates the service (creates if necessary).
func (self *mdBroker) requireService(name string) *mdService {
if len(name) == 0 {
panic("Invalid service name")
}
service, ok := self.services[name]
if !ok {
service = &mdService{
name: name,
waiting: NewList(),
}
self.services[name] = service
}
return service
}
// Send message to worker.
// If message is provided, sends that message.
func (self *mdBroker) sendToWorker(worker *mdbWorker, command string, option []byte, msg [][]byte) {
// Stack routing and protocol envelopes to start of message and routing envelope
if len(option) > 0 {
msg = append([][]byte{option}, msg...)
}
msg = append([][]byte{worker.address, nil, []byte(MDPW_WORKER), []byte(command)}, msg...)
if self.verbose {
log.Printf("I: sending %X to worker\n", command)
Dump(msg)
}
self.socket.SendMultipart(msg, 0)
}
// Handle internal service according to 8/MMI specification
func (self *mdBroker) serviceInternal(service []byte, msg [][]byte) {
returncode := "501"
if string(service) == "mmi.service" {
name := string(msg[len(msg)-1])
if _, ok := self.services[name]; ok {
returncode = "200"
} else {
returncode = "404"
}
}
msg[len(msg)-1] = []byte(returncode)
// insert the protocol header and service name after the routing envelope
msg = append([][]byte{msg[0], nil, []byte(MDPC_CLIENT), service}, msg[2:]...)
self.socket.SendMultipart(msg, 0)
}
// This worker is now waiting for work.
func (self *mdBroker) workerWaiting(worker *mdbWorker) {
// Queue to broker and service waiting lists
self.waiting.PushBack(worker)
worker.service.waiting.PushBack(worker)
worker.expiry = time.Now().Add(HEARTBEAT_EXPIRY)
self.dispatch(worker.service, nil)
}
func (self *mdBroker) Close() {
if self.socket != nil {
self.socket.Close()
}
self.context.Close()
}
// Main broker working loop
func (self *mdBroker) Run() {
for {
items := zmq.PollItems{
zmq.PollItem{Socket: self.socket, Events: zmq.POLLIN},
}
_, err := zmq.Poll(items, HEARTBEAT_INTERVAL)
if err != nil {
panic(err) // Interrupted
}
if item := items[0]; item.REvents&zmq.POLLIN != 0 {
msg, _ := self.socket.RecvMultipart(0)
if self.verbose {
log.Printf("I: received message:")
Dump(msg)
}
sender := msg[0]
header := msg[2]
msg = msg[3:]
if string(header) == MDPC_CLIENT {
self.processClient(sender, msg)
} else if string(header) == MDPW_WORKER {
self.processWorker(sender, msg)
} else {
log.Println("E: invalid message:")
Dump(msg)
}
}
if self.heartbeatAt.Before(time.Now()) {
self.purgeWorkers()
for elem := self.waiting.Front(); elem != nil; elem = elem.Next() {
worker, _ := elem.Value.(*mdbWorker)
self.sendToWorker(worker, MDPW_HEARTBEAT, nil, nil)
}
self.heartbeatAt = time.Now().Add(HEARTBEAT_INTERVAL)
}
}
}
func main() {
verbose := len(os.Args) >= 2 && os.Args[1] == "-v"
broker := NewBroker("tcp://*:5555", verbose)
defer broker.Close()
broker.Run()
}
mdbroker: Haskell 中的 Majordomo broker
{-
Majordomo Protocol Broker
-}
module Main where
import System.ZMQ4
import ZHelpers
import MDPDef
import System.Environment
import System.Exit
import Control.Exception (bracket)
import Control.Monad (forever, forM_, mapM_, foldM, when)
import Data.Maybe (catMaybes, maybeToList, fromJust, isJust)
import qualified Data.ByteString.Char8 as B
import qualified Data.Map as M
import qualified Data.List as L
import qualified Data.List.NonEmpty as N
heartbeatLiveness = 1
heartbeatInterval = 2500
heartbeatExpiry = heartbeatInterval * heartbeatLiveness
data Broker = Broker {
ctx :: Context
, bSocket :: Socket Router
, verbose :: Bool
, endpoint :: String
, services :: M.Map B.ByteString Service
, workers :: M.Map B.ByteString Worker
, bWaiting :: [Worker]
, heartbeatAt :: Integer
}
data Service = Service {
name :: B.ByteString
, requests :: [Message]
, sWaiting :: [Worker]
, workersCount :: Int
}
data Worker = Worker {
wId :: B.ByteString
, serviceName :: B.ByteString
, identityFrame :: Frame
, expiry :: Integer
} deriving (Eq)
withBroker :: Bool -> (Broker -> IO a) -> IO a
withBroker verbose action =
bracket (s_brokerNew verbose)
(s_brokerDestroy)
action
-- Broker functions
s_brokerNew :: Bool -> IO Broker
s_brokerNew verbose = do
ctx <- context
bSocket <- socket ctx Router
nextHeartbeat <- nextHeartbeatTime_ms heartbeatInterval
return Broker { ctx = ctx
, bSocket = bSocket
, verbose = verbose
, services = M.empty
, workers = M.empty
, bWaiting = []
, heartbeatAt = nextHeartbeat
, endpoint = []
}
s_brokerDestroy :: Broker -> IO ()
s_brokerDestroy broker = do
close $ bSocket broker
shutdown $ ctx broker
s_brokerBind :: Broker -> String -> IO ()
s_brokerBind broker endpoint = do
bind (bSocket broker) endpoint
putStrLn $ "I: MDP broker/0.2.0 is active at " ++ endpoint
-- Processes READY, REPLY, HEARTBEAT, or DISCONNECT worker message
s_brokerWorkerMsg :: Broker -> Frame -> Message -> IO Broker
s_brokerWorkerMsg broker senderFrame msg = do
when (L.length msg < 1) $ do
error "E: Too little frames in message for worker"
let (cmdFrame, msg') = z_pop msg
id_string = senderFrame
isWorkerReady = M.member id_string (workers broker)
(worker, newBroker) = s_workerRequire broker id_string
case cmdFrame of
cmd | cmd == mdpwReady ->
-- Not first cmd in session or reserved service frame.
if isWorkerReady || (B.pack "mmi.") `B.isPrefixOf` senderFrame
then do
s_workerSendDisconnect newBroker worker
return $ s_brokerDeleteWorker newBroker worker
else do
let (serviceFrame, _) = z_pop msg'
(service, newBroker') = s_serviceRequire newBroker serviceFrame
newService = service { workersCount = workersCount service + 1 }
s_workerWaiting newBroker' newService worker
| cmd == mdpwReply ->
if isWorkerReady
then do
let (client, msg'') = z_unwrap msg'
finalMsg = z_wrap (mdpcClient : serviceName worker : msg'') client
wkrService = (services broker) M.! (serviceName worker)
sendMulti (bSocket newBroker) (N.fromList finalMsg)
s_workerWaiting newBroker wkrService worker
else do
s_workerSendDisconnect newBroker worker
return $ s_brokerDeleteWorker newBroker worker
| cmd == mdpwHeartbeat ->
if isWorkerReady
then do
currTime <- currentTime_ms
let newWorker = worker { expiry = currTime + heartbeatExpiry }
return newBroker { workers = M.insert (wId newWorker) newWorker (workers newBroker) }
else do
s_workerSendDisconnect newBroker worker
return $ s_brokerDeleteWorker newBroker worker
| cmd == mdpwDisconnect ->
return $ s_brokerDeleteWorker newBroker worker
| otherwise -> do
putStrLn $ "E: Invalid input message " ++ (B.unpack cmd)
dumpMsg msg'
return newBroker
-- Process a request coming from a client.
s_brokerClientMsg :: Broker -> Frame -> Message -> IO Broker
s_brokerClientMsg broker senderFrame msg = do
when (L.length msg < 2) $ do
error "E: Too little frames in message for client"
let (serviceFrame, msg') = z_pop msg
(service, newBroker) = s_serviceRequire broker serviceFrame
msg'' = z_wrap msg' senderFrame
if (B.pack "mmi.") `B.isPrefixOf` serviceFrame
then do
let returnCode = B.pack $ checkService service serviceFrame msg''
returnMsg = L.init msg'' ++ [returnCode]
(client, msg''') = z_unwrap returnMsg
finalMsg = z_wrap (mdpcClient : serviceFrame : msg''') client
sendMulti (bSocket newBroker) (N.fromList finalMsg)
return newBroker
else do
s_serviceDispatch newBroker service (Just msg'')
where checkService service serviceFrame msg =
if serviceFrame == B.pack "mmi.service"
then let name = last msg
namedService = M.lookup name (services broker)
in if isJust namedService && workersCount (fromJust namedService) > 0
then "200"
else "404"
else "501"
s_brokerDeleteWorker :: Broker -> Worker -> Broker
s_brokerDeleteWorker broker worker =
let purgedServices = M.map purgeWorker (services broker)
in broker { bWaiting = L.delete worker (bWaiting broker)
, workers = M.delete (wId worker) (workers broker)
, services = purgedServices }
where purgeWorker service =
service { sWaiting = L.delete worker (sWaiting service)
, workersCount = workersCount service - 1 }
-- Removes expired workers from the broker and its services
s_brokerPurge :: Broker -> IO Broker
s_brokerPurge broker = do
currTime <- currentTime_ms
let (toPurge, rest) = L.span (\worker -> currTime >= expiry worker)
(bWaiting broker)
leftInMap = M.filterWithKey (isNotPurgedKey toPurge) (workers broker)
purgedServices = purgeWorkersFromServices toPurge (services broker)
return broker { bWaiting = rest
, workers = leftInMap
, services = purgedServices
}
where isNotPurgedKey toPurge key _ =
key `notElem` (map wId toPurge)
purgeWorkersFromServices workers = M.map (purge workers)
purge workers service =
let (toPurge, rest) = L.partition (\worker -> worker `elem` workers)
(sWaiting service)
in service { sWaiting = rest
, workersCount = (workersCount service) - (length toPurge)
}
-- Service functions
-- Inserts a new service in the broker's services if that service didn't exist.
s_serviceRequire :: Broker -> Frame -> (Service, Broker)
s_serviceRequire broker serviceFrame =
let foundService = M.lookup serviceFrame (services broker)
in case foundService of
Nothing -> createNewService
Just fs -> (fs, broker)
where createNewService =
let newService = Service { name = serviceFrame
, requests = []
, sWaiting = []
, workersCount = 0
}
in (newService
, broker { services = M.insert (name newService) newService (services broker) })
-- Dispatch queued messages from workers
s_serviceDispatch :: Broker -> Service -> Maybe Message -> IO Broker
s_serviceDispatch broker service msg = do
purgedBroker <- s_brokerPurge broker
let workersWithMessages = zip (sWaiting newService) (requests newService)
wkrsToRemain = filter (\wkr -> wkr `notElem` (map fst workersWithMessages)) (bWaiting purgedBroker)
rqsToRemain = filter (\rq -> rq `notElem` (map snd workersWithMessages)) (requests newService)
forM_ workersWithMessages $ \wkrMsg -> do
s_workerSend purgedBroker (fst wkrMsg) mdpwRequest Nothing (Just $ snd wkrMsg)
return ( purgedBroker { bWaiting = wkrsToRemain
, services = M.insert (name newService)
(newService { requests = rqsToRemain
, sWaiting = wkrsToRemain
, workersCount = length wkrsToRemain })
(services purgedBroker) }
)
where newService =
if isJust msg
then service { requests = requests service ++ [(fromJust msg)] }
else service
-- Worker functions
-- Inserts a new worker in the broker's workers if that worker didn't exist.
s_workerRequire :: Broker -> Frame -> (Worker, Broker)
s_workerRequire broker identity =
let foundWorker = M.lookup identity (workers broker)
in case foundWorker of
Nothing -> createNewWorker
Just fw -> (fw, broker)
where createNewWorker =
let newWorker = Worker { wId = identity
, serviceName = B.empty
, identityFrame = identity
, expiry = 0
}
in (newWorker
, broker { workers = M.insert (wId newWorker) newWorker (workers broker) })
s_workerSendDisconnect :: Broker -> Worker -> IO ()
s_workerSendDisconnect broker worker =
s_workerSend broker worker mdpwDisconnect Nothing Nothing
-- Sends a message to the client
s_workerSend :: Broker -> Worker -> Frame -> Maybe Frame -> Maybe Message -> IO ()
s_workerSend broker worker cmd option msg = do
let msgOpts = [Just mdpwWorker, Just cmd, option]
msgFinal = (catMaybes msgOpts) ++ (concat . maybeToList $ msg)
msgWithId = z_wrap msgFinal (wId worker)
when (verbose broker) $ do
putStrLn $ "I: sending '" ++ (B.unpack $ mdpsCommands !! mdpGetIdx (B.unpack cmd)) ++ "' to worker"
dumpMsg msgWithId
sendMulti (bSocket broker) (N.fromList msgWithId)
-- Adds a worker to the waiting lists
s_workerWaiting :: Broker -> Service -> Worker -> IO Broker
s_workerWaiting broker wService worker = do
currTime <- currentTime_ms
let newWorker = worker { expiry = currTime + heartbeatExpiry
, serviceName = name wService }
newService = wService { sWaiting = sWaiting wService ++ [newWorker] }
newBroker = broker { bWaiting = bWaiting broker ++ [newWorker]
, services = M.insert (name newService) newService (services broker)
, workers = M.insert (wId newWorker) newWorker (workers broker) }
s_serviceDispatch newBroker newService Nothing
-- Main. Create a new broker and process messages on its socket.
main :: IO ()
main = do
args <- getArgs
when (length args /= 1) $ do
putStrLn "usage: mdbroker <isVerbose(True|False)>"
exitFailure
let isVerbose = read (args !! 0) :: Bool
withBroker isVerbose $ \broker -> do
s_brokerBind broker "tcp://*:5555"
process broker
where process broker = do
[evts] <- poll (fromInteger $ heartbeatInterval)
[Sock (bSocket broker) [In] Nothing]
when (In `L.elem` evts) $ do
msg <- receiveMulti (bSocket broker)
when (verbose broker) $ do
putStrLn "I: Received message: "
dumpMsg msg
let (sender, msg') = z_pop msg
(empty, msg'') = z_pop msg'
(header, finalMsg) = z_pop msg''
case header of
head | head == mdpcClient -> do
newBroker <- s_brokerClientMsg broker sender finalMsg
process newBroker
| head == mdpwWorker -> do
newBroker <- s_brokerWorkerMsg broker sender finalMsg
process newBroker
| otherwise -> do
putStrLn $ "E: Invalid message: " ++ (B.unpack head)
dumpMsg finalMsg
process broker
currTime <- currentTime_ms
when (currTime > heartbeatAt broker) $ do
newBroker <- s_brokerPurge broker
mapM_ (\worker -> s_workerSend newBroker worker mdpwHeartbeat Nothing Nothing) (bWaiting broker)
currTime <- currentTime_ms
process newBroker { heartbeatAt = currTime + heartbeatInterval }
process broker
mdbroker: Haxe 中的 Majordomo broker
package ;
import haxe.io.Bytes;
import haxe.Stack;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQException;
import MDP;
/**
* Majordomo Protocol broker
* A minimal implementation of https://rfc.zeromq.cn/spec:7 and spec:8
*/
class MDBroker
{
public static function main() {
var argArr = Sys.args();
var verbose = (argArr.length > 1 && argArr[argArr.length - 1] == "-v");
var log = Lib.println;
var broker = new Broker(verbose, log);
broker.bind("tcp://*:5555");
var poller = new ZMQPoller();
poller.registerSocket(broker.socket, ZMQ.ZMQ_POLLIN());
// Get and process messages forever or until interrupted
while (true) {
try {
var res = poller.poll(Constants.HEARTBEAT_INTERVAL);
} catch (e:ZMQException) {
if (!ZMQ.isInterrupted()) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
} else {
Lib.println("W: interrupt received, killing broker...");
}
broker.destroy();
return;
}
// Process next input message, if any
if (poller.pollin(1)) {
var msg = ZMsg.recvMsg(broker.socket);
if (msg == null)
break; // Interrupted
if (verbose)
log("I: received message:" + msg.toString());
var sender = msg.pop();
var empty = msg.pop();
var header = msg.pop();
if (header.streq(MDP.MDPC_CLIENT))
broker.processClient(sender, msg);
else if (header.streq(MDP.MDPW_WORKER))
broker.processWorker(sender, msg);
else {
log("E: invalid message:" + msg.toString());
msg.destroy();
}
sender.destroy();
empty.destroy();
header.destroy();
}
// Disconnect and delete any expired workers
// Send heartbeats to idle workers if needed
if (Date.now().getTime() > broker.heartbeatAt) {
broker.purgeWorkers();
for (w in broker.waiting) {
broker.sendWorker(w, MDP.MDPW_HEARTBEAT, null, null);
}
broker.heartbeatAt = Date.now().getTime() + Constants.HEARTBEAT_INTERVAL;
}
}
if (ZMQ.isInterrupted())
log("W: interrupt received, shutting down...");
broker.destroy();
}
}
private class Constants {
// We'd normally pull these from config data
public static inline var HEARTBEAT_LIVENESS = 3; // 3-5 is reasonable
public static inline var HEARTBEAT_INTERVAL = 2500; // msecs
public static inline var HEARTBEAT_EXPIRY = HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
}
/**
* Internal class, managing a single service
*/
private class Service {
/** Service name */
public var name(default, null):String;
/** List of client requests */
public var requests:List<ZMsg>;
/** List of waiting service workers */
public var waiting:List<Worker>;
/** How many workers the service has */
public var numWorkers:Int;
/**
* Constructor
* @param name
*/
public function new(name:String) {
this.name = name;
this.requests = new List<ZMsg>();
this.waiting = new List<Worker>();
this.numWorkers = 0;
}
/**
* Destructor
*/
public function destroy() {
for (r in requests) {
r.destroy();
}
requests = null;
waiting = null;
}
public function removeWorker(worker:Worker) {
if (worker == null)
return;
waiting.remove(worker);
numWorkers--;
}
}
/**
* Internal class, managing a single worker
*/
private class Worker {
/** Identity of worker */
public var identity(default, null):String;
/** Address frame to route to */
public var address(default, null):ZFrame;
/** Owning service, if known */
public var service:Service;
/** Expires at unless heartbeat */
public var expiry:Float;
public function new(address:ZFrame, identity:String, ?service:Service, ?expiry:Float = 0.0) {
this.address = address;
this.identity = identity;
this.service = service;
this.expiry = expiry;
}
/**
* Deconstructor
*/
public function destroy() {
address.destroy();
}
/**
* Return true if worker has expired and must be deleted
* @return
*/
public function expired():Bool {
return expiry < Date.now().getTime();
}
}
/**
* Main class definining state and behaviour of a MDBroker
*/
private class Broker {
/** Socket for clients and workers */
public var socket(default, null):ZMQSocket;
/** When to send heartbeat */
public var heartbeatAt:Float;
/** Hash of waiting workers */
public var waiting(default, null):List<Worker>;
// Private fields
/** Our context */
private var ctx:ZContext;
/** Broker binds to this endpoint */
private var endpoint:String;
/** Hash of known services */
private var services:Hash<Service>;
/** Hash of known workers */
private var workers:Hash<Worker>;
/** Print activity to stdout */
private var verbose:Bool;
/** Logger function used in verbose mode */
private var log:Dynamic->Void;
/**
* Construct new broker
*/
public function new(?verbose:Bool = false, ?logger:Dynamic->Void)
{
ctx = new ZContext();
socket = ctx.createSocket(ZMQ_ROUTER);
services = new Hash<Service>();
workers = new Hash<Worker>();
waiting = new List<Worker>();
heartbeatAt = Date.now().getTime() + Constants.HEARTBEAT_INTERVAL;
this.verbose = verbose;
if (logger != null)
log = logger;
else
log = Lib.println;
}
/**
* Destructor
*/
public function destroy() {
ctx.destroy();
}
/**
* Bind broker to endpoint, can call this multiple times
* We use a single socket for both clients and workers.
* @param endpoint
*/
public function bind(endpoint:String) {
socket.bind(endpoint);
log("I: MDP broker/0.1.1 is active at " + endpoint);
}
/**
* Delete any idle workers that haven't pinged us in a while
*/
public function purgeWorkers() {
for (w in waiting) {
if (Date.now().getTime() < w.expiry)
continue; // Worker is alive, we're done here
if (verbose)
log("I: deleting expired worker: " + w.identity);
deleteWorker(w, false);
}
}
/**
* Locate or create a new service entry
* @param name
* @return
*/
private function requireService(name:String):Service {
if (name == null)
return null;
if (services.exists(name))
return services.get(name);
else {
var srv = new Service(name);
services.set(name, srv);
if (verbose)
log("I: Added service :" + name);
return srv;
}
return null;
}
/**
* Dispatch as many requests to waiting workers as possible
* @param service
* @param msg
*/
private function dispatchService(service:Service, ?msg:ZMsg) {
// Tidy up workers first
purgeWorkers();
if (msg != null)
service.requests.add(msg);
while (!service.waiting.isEmpty() && !service.requests.isEmpty()) {
var worker = service.waiting.pop();
waiting.remove(worker);
var _msg = service.requests.pop();
sendWorker(worker, MDP.MDPW_REQUEST, null, _msg);
}
}
/**
* Handle internal service according to 8/MMI specification
* @param serviceFrame
* @param msg
* @return
*/
private function internalService(serviceFrame:ZFrame, msg:ZMsg) {
var returnCode = "";
if (serviceFrame == null || msg == null)
return;
if (serviceFrame.streq("mmi.service")) {
var name = msg.last().toString();
var service = services.get(name);
returnCode = {
if ((service != null) && (service.numWorkers > 0))
"200";
else
"404";
};
} else
returnCode = "501";
msg.last().reset(Bytes.ofString(returnCode));
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
var client = msg.unwrap();
msg.push(serviceFrame.duplicate());
msg.pushString(MDP.MDPC_CLIENT);
msg.wrap(client);
msg.send(socket);
}
/**
* Creates worker if necessary
* @param address
* @return
*/
private function requireWorker(address:ZFrame):Worker {
if (address == null)
return null;
// workers Hash is keyed off worker identity
var identity = address.strhex();
var worker = workers.get(identity);
if (worker == null) {
worker = new Worker(address.duplicate(), identity);
workers.set(identity, worker);
if (verbose)
log("I: registering new worker: " + identity);
}
return worker;
}
/**
* Deletes worker from all data structures, and destroys worker object itself
* @param worker
* @param disconnect
*/
private function deleteWorker(worker:Worker, disconnect:Bool) {
if (worker == null)
return;
if (disconnect)
sendWorker(worker, MDP.MDPW_DISCONNECT, null, null);
if (worker.service != null)
worker.service.removeWorker(worker);
waiting.remove(worker);
workers.remove(worker.identity);
worker.destroy();
}
/**
* Process message sent to us by a worker
* @param sender
* @param msg
*/
public function processWorker(sender:ZFrame, msg:ZMsg) {
if (msg.size() < 1)
return; // At least, command
var command = msg.pop();
var identity = sender.strhex();
var workerReady = workers.exists(identity);
var worker = requireWorker(sender);
if (command.streq(MDP.MDPW_READY)) {
if (workerReady) // Not first command in session
deleteWorker(worker, true); // Disconnect worker
else if ( sender.size() >= 4 // Reserved for service name
&& sender.toString().indexOf("mmi.") == 0)
deleteWorker(worker, true);
else {
// Attach worker to service and mark as idle
var serviceFrame = msg.pop();
worker.service = requireService(serviceFrame.toString());
worker.service.numWorkers++;
waitingWorker(worker);
serviceFrame.destroy();
}
} else if (command.streq(MDP.MDPW_REPLY)) {
if (workerReady) {
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
var client = msg.unwrap();
msg.pushString(worker.service.name);
msg.pushString(MDP.MDPC_CLIENT);
msg.wrap(client);
msg.send(socket);
waitingWorker(worker);
} else
deleteWorker(worker, true);
} else if (command.streq(MDP.MDPW_HEARTBEAT)) {
if (workerReady)
worker.expiry = Date.now().getTime() + Constants.HEARTBEAT_EXPIRY;
else
deleteWorker(worker, true);
} else if (command.streq(MDP.MDPW_DISCONNECT))
deleteWorker(worker, false);
else
log("E: invalid input message:" + msg.toString());
if (msg != null)
msg.destroy();
}
/**
* Send message to worker
* If message is provided, sends that message. Does not
* destroy the message, this is the caller's job.
* @param worker
* @param command
* @param option
* @param msg
*/
public function sendWorker(worker:Worker, command:String, option:String, msg:ZMsg) {
var _msg = { if (msg != null) msg.duplicate(); else new ZMsg(); };
// Stack protocol envelope to start of message
if (option != null)
_msg.pushString(option);
_msg.pushString(command);
_msg.pushString(MDP.MDPW_WORKER);
// Stack routing envelope to start of message
_msg.wrap(worker.address.duplicate());
if (verbose)
log("I: sending " + MDP.MDPS_COMMANDS[command.charCodeAt(0)] + " to worker: " + _msg.toString());
_msg.send(socket);
}
/**
* This worker is now waiting for work
* @param worker
*/
private function waitingWorker(worker:Worker) {
waiting.add(worker);
worker.service.waiting.add(worker);
worker.expiry = Date.now().getTime() + Constants.HEARTBEAT_EXPIRY;
dispatchService(worker.service);
}
public function processClient(sender:ZFrame, msg:ZMsg) {
if (msg.size() < 2) // Service name and body
return;
var serviceFrame = msg.pop();
var service = requireService(serviceFrame.toString());
// Set reply return address to client sender
msg.wrap(sender.duplicate());
if ( serviceFrame.size() >= 4 // Reserved for service name
&& serviceFrame.toString().indexOf("mmi.") == 0)
internalService(serviceFrame, msg);
else
dispatchService(service, msg);
serviceFrame.destroy();
}
}
mdbroker: Java 中的 Majordomo broker
package guide;
import java.util.ArrayDeque;
import java.util.Deque;
import java.util.Formatter;
import java.util.HashMap;
import java.util.Map;
import org.zeromq.*;
/**
* Majordomo Protocol broker
* A minimal implementation of https://rfc.zeromq.cn/spec:7 and spec:8
*/
public class mdbroker
{
// We'd normally pull these from config data
private static final String INTERNAL_SERVICE_PREFIX = "mmi.";
private static final int HEARTBEAT_LIVENESS = 3; // 3-5 is reasonable
private static final int HEARTBEAT_INTERVAL = 2500; // msecs
private static final int HEARTBEAT_EXPIRY = HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
// ---------------------------------------------------------------------
/**
* This defines a single service.
*/
private static class Service
{
public final String name; // Service name
Deque<ZMsg> requests; // List of client requests
Deque<Worker> waiting; // List of waiting workers
public Service(String name)
{
this.name = name;
this.requests = new ArrayDeque<ZMsg>();
this.waiting = new ArrayDeque<Worker>();
}
}
/**
* This defines one worker, idle or active.
*/
private static class Worker
{
String identity;// Identity of worker
ZFrame address; // Address frame to route to
Service service; // Owning service, if known
long expiry; // Expires at unless heartbeat
public Worker(String identity, ZFrame address)
{
this.address = address;
this.identity = identity;
this.expiry = System.currentTimeMillis() + HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS;
}
}
// ---------------------------------------------------------------------
private ZContext ctx; // Our context
private ZMQ.Socket socket; // Socket for clients & workers
private long heartbeatAt;// When to send HEARTBEAT
private Map<String, Service> services; // known services
private Map<String, Worker> workers; // known workers
private Deque<Worker> waiting; // idle workers
private boolean verbose = false; // Print activity to stdout
private Formatter log = new Formatter(System.out);
// ---------------------------------------------------------------------
/**
* Main method - create and start new broker.
*/
public static void main(String[] args)
{
mdbroker broker = new mdbroker(args.length > 0 && "-v".equals(args[0]));
// Can be called multiple times with different endpoints
broker.bind("tcp://*:5555");
broker.mediate();
}
/**
* Initialize broker state.
*/
public mdbroker(boolean verbose)
{
this.verbose = verbose;
this.services = new HashMap<String, Service>();
this.workers = new HashMap<String, Worker>();
this.waiting = new ArrayDeque<Worker>();
this.heartbeatAt = System.currentTimeMillis() + HEARTBEAT_INTERVAL;
this.ctx = new ZContext();
this.socket = ctx.createSocket(SocketType.ROUTER);
}
// ---------------------------------------------------------------------
/**
* Main broker work happens here
*/
public void mediate()
{
while (!Thread.currentThread().isInterrupted()) {
ZMQ.Poller items = ctx.createPoller(1);
items.register(socket, ZMQ.Poller.POLLIN);
if (items.poll(HEARTBEAT_INTERVAL) == -1)
break; // Interrupted
if (items.pollin(0)) {
ZMsg msg = ZMsg.recvMsg(socket);
if (msg == null)
break; // Interrupted
if (verbose) {
log.format("I: received message:\n");
msg.dump(log.out());
}
ZFrame sender = msg.pop();
ZFrame empty = msg.pop();
ZFrame header = msg.pop();
if (MDP.C_CLIENT.frameEquals(header)) {
processClient(sender, msg);
}
else if (MDP.W_WORKER.frameEquals(header))
processWorker(sender, msg);
else {
log.format("E: invalid message:\n");
msg.dump(log.out());
msg.destroy();
}
sender.destroy();
empty.destroy();
header.destroy();
}
items.close();
purgeWorkers();
sendHeartbeats();
}
destroy(); // interrupted
}
/**
* Disconnect all workers, destroy context.
*/
private void destroy()
{
Worker[] deleteList = workers.entrySet().toArray(new Worker[0]);
for (Worker worker : deleteList) {
deleteWorker(worker, true);
}
ctx.destroy();
}
/**
* Process a request coming from a client.
*/
private void processClient(ZFrame sender, ZMsg msg)
{
assert (msg.size() >= 2); // Service name + body
ZFrame serviceFrame = msg.pop();
// Set reply return address to client sender
msg.wrap(sender.duplicate());
if (serviceFrame.toString().startsWith(INTERNAL_SERVICE_PREFIX))
serviceInternal(serviceFrame, msg);
else dispatch(requireService(serviceFrame), msg);
serviceFrame.destroy();
}
/**
* Process message sent to us by a worker.
*/
private void processWorker(ZFrame sender, ZMsg msg)
{
assert (msg.size() >= 1); // At least, command
ZFrame command = msg.pop();
boolean workerReady = workers.containsKey(sender.strhex());
Worker worker = requireWorker(sender);
if (MDP.W_READY.frameEquals(command)) {
// Not first command in session || Reserved service name
if (workerReady || sender.toString().startsWith(INTERNAL_SERVICE_PREFIX))
deleteWorker(worker, true);
else {
// Attach worker to service and mark as idle
ZFrame serviceFrame = msg.pop();
worker.service = requireService(serviceFrame);
workerWaiting(worker);
serviceFrame.destroy();
}
}
else if (MDP.W_REPLY.frameEquals(command)) {
if (workerReady) {
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
ZFrame client = msg.unwrap();
msg.addFirst(worker.service.name);
msg.addFirst(MDP.C_CLIENT.newFrame());
msg.wrap(client);
msg.send(socket);
workerWaiting(worker);
}
else {
deleteWorker(worker, true);
}
}
else if (MDP.W_HEARTBEAT.frameEquals(command)) {
if (workerReady) {
worker.expiry = System.currentTimeMillis() + HEARTBEAT_EXPIRY;
}
else {
deleteWorker(worker, true);
}
}
else if (MDP.W_DISCONNECT.frameEquals(command))
deleteWorker(worker, false);
else {
log.format("E: invalid message:\n");
msg.dump(log.out());
}
msg.destroy();
}
/**
* Deletes worker from all data structures, and destroys worker.
*/
private void deleteWorker(Worker worker, boolean disconnect)
{
assert (worker != null);
if (disconnect) {
sendToWorker(worker, MDP.W_DISCONNECT, null, null);
}
if (worker.service != null)
worker.service.waiting.remove(worker);
workers.remove(worker);
worker.address.destroy();
}
/**
* Finds the worker (creates if necessary).
*/
private Worker requireWorker(ZFrame address)
{
assert (address != null);
String identity = address.strhex();
Worker worker = workers.get(identity);
if (worker == null) {
worker = new Worker(identity, address.duplicate());
workers.put(identity, worker);
if (verbose)
log.format("I: registering new worker: %s\n", identity);
}
return worker;
}
/**
* Locates the service (creates if necessary).
*/
private Service requireService(ZFrame serviceFrame)
{
assert (serviceFrame != null);
String name = serviceFrame.toString();
Service service = services.get(name);
if (service == null) {
service = new Service(name);
services.put(name, service);
}
return service;
}
/**
* Bind broker to endpoint, can call this multiple times. We use a single
* socket for both clients and workers.
*/
private void bind(String endpoint)
{
socket.bind(endpoint);
log.format("I: MDP broker/0.1.1 is active at %s\n", endpoint);
}
/**
* Handle internal service according to 8/MMI specification
*/
private void serviceInternal(ZFrame serviceFrame, ZMsg msg)
{
String returnCode = "501";
if ("mmi.service".equals(serviceFrame.toString())) {
String name = msg.peekLast().toString();
returnCode = services.containsKey(name) ? "200" : "400";
}
msg.peekLast().reset(returnCode.getBytes(ZMQ.CHARSET));
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
ZFrame client = msg.unwrap();
msg.addFirst(serviceFrame.duplicate());
msg.addFirst(MDP.C_CLIENT.newFrame());
msg.wrap(client);
msg.send(socket);
}
/**
* Send heartbeats to idle workers if it's time
*/
public synchronized void sendHeartbeats()
{
// Send heartbeats to idle workers if it's time
if (System.currentTimeMillis() >= heartbeatAt) {
for (Worker worker : waiting) {
sendToWorker(worker, MDP.W_HEARTBEAT, null, null);
}
heartbeatAt = System.currentTimeMillis() + HEARTBEAT_INTERVAL;
}
}
/**
* Look for & kill expired workers. Workers are oldest to most recent, so we
* stop at the first alive worker.
*/
public synchronized void purgeWorkers()
{
for (Worker w = waiting.peekFirst(); w != null
&& w.expiry < System.currentTimeMillis(); w = waiting.peekFirst()) {
log.format("I: deleting expired worker: %s\n", w.identity);
deleteWorker(waiting.pollFirst(), false);
}
}
/**
* This worker is now waiting for work.
*/
public synchronized void workerWaiting(Worker worker)
{
// Queue to broker and service waiting lists
waiting.addLast(worker);
worker.service.waiting.addLast(worker);
worker.expiry = System.currentTimeMillis() + HEARTBEAT_EXPIRY;
dispatch(worker.service, null);
}
/**
* Dispatch requests to waiting workers as possible
*/
private void dispatch(Service service, ZMsg msg)
{
assert (service != null);
if (msg != null)// Queue message if any
service.requests.offerLast(msg);
purgeWorkers();
while (!service.waiting.isEmpty() && !service.requests.isEmpty()) {
msg = service.requests.pop();
Worker worker = service.waiting.pop();
waiting.remove(worker);
sendToWorker(worker, MDP.W_REQUEST, null, msg);
msg.destroy();
}
}
/**
* Send message to worker. If message is provided, sends that message. Does
* not destroy the message, this is the caller's job.
*/
public void sendToWorker(Worker worker, MDP command, String option, ZMsg msgp)
{
ZMsg msg = msgp == null ? new ZMsg() : msgp.duplicate();
// Stack protocol envelope to start of message
if (option != null)
msg.addFirst(new ZFrame(option));
msg.addFirst(command.newFrame());
msg.addFirst(MDP.W_WORKER.newFrame());
// Stack routing envelope to start of message
msg.wrap(worker.address.duplicate());
if (verbose) {
log.format("I: sending %s to worker\n", command);
msg.dump(log.out());
}
msg.send(socket);
}
}
mdbroker: Julia 中的 Majordomo broker
mdbroker: Lua 中的 Majordomo broker
--
-- Majordomo Protocol broker
-- A minimal implementation of https://rfc.zeromq.cn/spec:7 and spec:8
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.poller"
require"zmsg"
require"zhelpers"
require"mdp"
local tremove = table.remove
-- We'd normally pull these from config data
local HEARTBEAT_LIVENESS = 3 -- 3-5 is reasonable
local HEARTBEAT_INTERVAL = 2500 -- msecs
local HEARTBEAT_EXPIRY = HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS
-- ---------------------------------------------------------------------
-- Constructor for broker object
-- ---------------------------------------------------------------------
-- Broker object's metatable.
local broker_mt = {}
broker_mt.__index = broker_mt
function broker_new(verbose)
local context = zmq.init(1)
-- Initialize broker state
return setmetatable({
context = context,
socket = context:socket(zmq.ROUTER),
verbose = verbose,
services = {},
workers = {},
waiting = {},
heartbeat_at = s_clock() + HEARTBEAT_INTERVAL,
}, broker_mt)
end
-- ---------------------------------------------------------------------
-- Service object
local service_mt = {}
service_mt.__index = service_mt
-- Worker object
local worker_mt = {}
worker_mt.__index = worker_mt
-- helper list remove function
local function zlist_remove(list, item)
for n=#list,1,-1 do
if list[n] == item then
tremove(list, n)
end
end
end
-- ---------------------------------------------------------------------
-- Destructor for broker object
function broker_mt:destroy()
self.socket:close()
self.context:term()
for name, service in pairs(self.services) do
service:destroy()
end
for id, worker in pairs(self.workers) do
worker:destroy()
end
end
-- ---------------------------------------------------------------------
-- Bind broker to endpoint, can call this multiple times
-- We use a single socket for both clients and workers.
function broker_mt:bind(endpoint)
self.socket:bind(endpoint)
s_console("I: MDP broker/0.1.1 is active at %s", endpoint)
end
-- ---------------------------------------------------------------------
-- Delete any idle workers that haven't pinged us in a while.
function broker_mt:purge_workers()
local waiting = self.waiting
for n=1,#waiting do
local worker = waiting[n]
if (worker:expired()) then
if (self.verbose) then
s_console("I: deleting expired worker: %s", worker.identity)
end
self:worker_delete(worker, false)
end
end
end
-- ---------------------------------------------------------------------
-- Locate or create new service entry
function broker_mt:service_require(name)
assert (name)
local service = self.services[name]
if not service then
service = setmetatable({
name = name,
requests = {},
waiting = {},
workers = 0,
}, service_mt)
self.services[name] = service
if (self.verbose) then
s_console("I: received message:")
end
end
return service
end
-- ---------------------------------------------------------------------
-- Destroy service object, called when service is removed from
-- broker.services.
function service_mt:destroy()
end
-- ---------------------------------------------------------------------
-- Dispatch requests to waiting workers as possible
function broker_mt:service_dispatch(service, msg)
assert (service)
local requests = service.requests
if (msg) then -- Queue message if any
requests[#requests + 1] = msg
end
self:purge_workers()
local waiting = service.waiting
while (#waiting > 0 and #requests > 0) do
local worker = tremove(waiting, 1) -- pop worker from service's waiting queue.
zlist_remove(self.waiting, worker) -- also remove worker from broker's waiting queue.
local msg = tremove(requests, 1) -- pop request from service's request queue.
self:worker_send(worker, mdp.MDPW_REQUEST, nil, msg)
end
end
-- ---------------------------------------------------------------------
-- Handle internal service according to 8/MMI specification
function broker_mt:service_internal(service_name, msg)
if (service_name == "mmi.service") then
local name = msg:body()
local service = self.services[name]
if (service and service.workers) then
msg:body_set("200")
else
msg:body_set("404")
end
else
msg:body_set("501")
end
-- Remove & save client return envelope and insert the
-- protocol header and service name, then rewrap envelope.
local client = msg:unwrap()
msg:wrap(mdp.MDPC_CLIENT, service_name)
msg:wrap(client, "")
msg:send(self.socket)
end
-- ---------------------------------------------------------------------
-- Creates worker if necessary
function broker_mt:worker_require(identity)
assert (identity)
-- self.workers is keyed off worker identity
local worker = self.workers[identity]
if (not worker) then
worker = setmetatable({
identity = identity,
expiry = 0,
}, worker_mt)
self.workers[identity] = worker
if (self.verbose) then
s_console("I: registering new worker: %s", identity)
end
end
return worker
end
-- ---------------------------------------------------------------------
-- Deletes worker from all data structures, and destroys worker
function broker_mt:worker_delete(worker, disconnect)
assert (worker)
if (disconnect) then
self:worker_send(worker, mdp.MDPW_DISCONNECT)
end
local service = worker.service
if (service) then
zlist_remove (service.waiting, worker)
service.workers = service.workers - 1
end
zlist_remove (self.waiting, worker)
self.workers[worker.identity] = nil
worker:destroy()
end
-- ---------------------------------------------------------------------
-- Destroy worker object, called when worker is removed from
-- broker.workers.
function worker_mt:destroy(argument)
end
-- ---------------------------------------------------------------------
-- Process message sent to us by a worker
function broker_mt:worker_process(sender, msg)
assert (msg:parts() >= 1) -- At least, command
local command = msg:pop()
local worker_ready = (self.workers[sender] ~= nil)
local worker = self:worker_require(sender)
if (command == mdp.MDPW_READY) then
if (worker_ready) then -- Not first command in session then
self:worker_delete(worker, true)
elseif (sender:sub(1,4) == "mmi.") then -- Reserved service name
self:worker_delete(worker, true)
else
-- Attach worker to service and mark as idle
local service_name = msg:pop()
local service = self:service_require(service_name)
worker.service = service
service.workers = service.workers + 1
self:worker_waiting(worker)
end
elseif (command == mdp.MDPW_REPLY) then
if (worker_ready) then
-- Remove & save client return envelope and insert the
-- protocol header and service name, then rewrap envelope.
local client = msg:unwrap()
msg:wrap(mdp.MDPC_CLIENT, worker.service.name)
msg:wrap(client, "")
msg:send(self.socket)
self:worker_waiting(worker)
else
self:worker_delete(worker, true)
end
elseif (command == mdp.MDPW_HEARTBEAT) then
if (worker_ready) then
worker.expiry = s_clock() + HEARTBEAT_EXPIRY
else
self:worker_delete(worker, true)
end
elseif (command == mdp.MDPW_DISCONNECT) then
self:worker_delete(worker, false)
else
s_console("E: invalid input message (%d)", command:byte(1,1))
msg:dump()
end
end
-- ---------------------------------------------------------------------
-- Send message to worker
-- If pointer to message is provided, sends & destroys that message
function broker_mt:worker_send(worker, command, option, msg)
msg = msg and msg:dup() or zmsg.new()
-- Stack protocol envelope to start of message
if (option) then -- Optional frame after command
msg:push(option)
end
msg:push(command)
msg:push(mdp.MDPW_WORKER)
-- Stack routing envelope to start of message
msg:wrap(worker.identity, "")
if (self.verbose) then
s_console("I: sending %s to worker", mdp.mdps_commands[command])
msg:dump()
end
msg:send(self.socket)
end
-- ---------------------------------------------------------------------
-- This worker is now waiting for work
function broker_mt:worker_waiting(worker)
-- Queue to broker and service waiting lists
self.waiting[#self.waiting + 1] = worker
worker.service.waiting[#worker.service.waiting + 1] = worker
worker.expiry = s_clock() + HEARTBEAT_EXPIRY
self:service_dispatch(worker.service, nil)
end
-- ---------------------------------------------------------------------
-- Return 1 if worker has expired and must be deleted
function worker_mt:expired()
return (self.expiry < s_clock())
end
-- ---------------------------------------------------------------------
-- Process a request coming from a client
function broker_mt:client_process(sender, msg)
assert (msg:parts() >= 2) -- Service name + body
local service_name = msg:pop()
local service = self:service_require(service_name)
-- Set reply return address to client sender
msg:wrap(sender, "")
if (service_name:sub(1,4) == "mmi.") then
self:service_internal(service_name, msg)
else
self:service_dispatch(service, msg)
end
end
-- ---------------------------------------------------------------------
-- Main broker work happens here
local verbose = (arg[1] == "-v")
s_version_assert (2, 1)
s_catch_signals ()
local self = broker_new(verbose)
self:bind("tcp://*:5555")
local poller = zmq.poller.new(1)
-- Process next input message, if any
poller:add(self.socket, zmq.POLLIN, function()
local msg = zmsg.recv(self.socket)
if (self.verbose) then
s_console("I: received message:")
msg:dump()
end
local sender = msg:pop()
local empty = msg:pop()
local header = msg:pop()
if (header == mdp.MDPC_CLIENT) then
self:client_process(sender, msg)
elseif (header == mdp.MDPW_WORKER) then
self:worker_process(sender, msg)
else
s_console("E: invalid message:")
msg:dump()
end
end)
-- Get and process messages forever or until interrupted
while (not s_interrupted) do
local cnt = assert(poller:poll(HEARTBEAT_INTERVAL * 1000))
-- Disconnect and delete any expired workers
-- Send heartbeats to idle workers if needed
if (s_clock() > self.heartbeat_at) then
self:purge_workers()
local waiting = self.waiting
for n=1,#waiting do
local worker = waiting[n]
self:worker_send(worker, mdp.MDPW_HEARTBEAT)
end
self.heartbeat_at = s_clock() + HEARTBEAT_INTERVAL
end
end
if (s_interrupted) then
printf("W: interrupt received, shutting down...\n")
end
self:destroy()
mdbroker: Node.js 中的 Majordomo broker
mdbroker: Objective-C 中的 Majordomo broker
mdbroker: ooc 中的 Majordomo broker
mdbroker: Perl 中的 Majordomo broker
mdbroker: PHP 中的 Majordomo broker
<?php
/*
* Majordomo Protocol broker
* A minimal implementation of https://rfc.zeromq.cn/spec:7 and spec:8
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include_once 'zmsg.php';
include_once 'mdp.php';
// We'd normally pull these from config data
define("HEARTBEAT_LIVENESS", 3); // 3-5 is reasonable
define("HEARTBEAT_INTERVAL", 2500); // msecs
define("HEARTBEAT_EXPIRY", HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS);
/* Main broker work happens here */
$verbose = $_SERVER['argc'] > 1 && $_SERVER['argv'][1] == '-v';
$broker = new Mdbroker($verbose);
$broker->bind("tcp://*:5555");
$broker->listen();
class mdbroker
{
private $ctx; // Our context
private $socket; // Socket for clients & workers
private $endpoint; // Broker binds to this endpoint
private $services = array(); // Hash of known services
private $workers = array(); // Hash of known workers
private $waiting = array(); // List of waiting workers
private $verbose = false; // Print activity to stdout
// Heartbeat management
private $heartbeat_at; // When to send HEARTBEAT
/**
* Constructor
*
* @param boolean $verbose
*/
public function __construct($verbose = false)
{
$this->ctx = new ZMQContext();
$this->socket = new ZMQSocket($this->ctx, ZMQ::SOCKET_ROUTER);
$this->verbose = $verbose;
$this->heartbeat_at = microtime(true) + (HEARTBEAT_INTERVAL/1000);
}
/**
* Bind broker to endpoint, can call this multiple time
* We use a single socket for both clients and workers.
*
* @param string $endpoint
*/
public function bind($endpoint)
{
$this->socket->bind($endpoint);
if ($this->verbose) {
printf("I: MDP broker/0.1.1 is active at %s %s", $endpoint, PHP_EOL);
}
}
/**
* This is the main listen and process loop
*/
public function listen()
{
$read = $write = array();
// Get and process messages forever or until interrupted
while (true) {
$poll = new ZMQPoll();
$poll->add($this->socket, ZMQ::POLL_IN);
$events = $poll->poll($read, $write, HEARTBEAT_INTERVAL);
// Process next input message, if any
if ($events) {
$zmsg = new Zmsg($this->socket);
$zmsg->recv();
if ($this->verbose) {
echo "I: received message:", PHP_EOL, $zmsg->__toString();
}
$sender = $zmsg->pop();
$empty = $zmsg->pop();
$header = $zmsg->pop();
if ($header == MDPC_CLIENT) {
$this->client_process($sender, $zmsg);
} elseif ($header == MDPW_WORKER) {
$this->worker_process($sender, $zmsg);
} else {
echo "E: invalid message", PHP_EOL, $zmsg->__toString();
}
}
// Disconnect and delete any expired workers
// Send heartbeats to idle workers if needed
if (microtime(true) > $this->heartbeat_at) {
$this->purge_workers();
foreach ($this->workers as $worker) {
$this->worker_send($worker, MDPW_HEARTBEAT, NULL, NULL);
}
$this->heartbeat_at = microtime(true) + (HEARTBEAT_INTERVAL/1000);
}
}
}
/**
* Delete any idle workers that haven't pinged us in a while.
* We know that workers are ordered from oldest to most recent.
*/
public function purge_workers()
{
foreach ($this->waiting as $id => $worker) {
if (microtime(true) < $worker->expiry) {
break; // Worker is alive, we're done here
}
if ($this->verbose) {
printf("I: deleting expired worker: %s %s",
$worker->identity, PHP_EOL);
}
$this->worker_delete($worker);
}
}
/**
* Locate or create new service entry
*
* @param string $name
* @return stdClass
*/
public function service_require($name)
{
$service = isset($this->services[$name]) ? $this->services[$name] : NULL;
if ($service == NULL) {
$service = new stdClass();
$service->name = $name;
$service->requests = array();
$service->waiting = array();
$service->workers = 0;
$this->services[$name] = $service;
}
return $service;
}
/**
* Dispatch requests to waiting workers as possible
*
* @param type $service
* @param type $msg
*/
public function service_dispatch($service, $msg)
{
if ($msg) {
$service->requests[] = $msg;
}
$this->purge_workers();
while (count($service->waiting) && count($service->requests)) {
$worker = array_shift($service->waiting);
$msg = array_shift($service->requests);
$this->worker_remove_from_array($worker, $this->waiting);
$this->worker_send($worker, MDPW_REQUEST, NULL, $msg);
}
}
/**
* Handle internal service according to 8/MMI specification
*
* @param string $frame
* @param Zmsg $msg
*/
public function service_internal($frame, $msg)
{
if ($frame == "mmi.service") {
$name = $msg->last();
$service = $this->services[$name];
$return_code = $service && $service->workers ? "200" : "404";
} else {
$return_code = "501";
}
$msg->set_last($return_code);
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope
$client = $msg->unwrap();
$msg->push($frame);
$msg->push(MDPC_CLIENT);
$msg->wrap($client, "");
$msg->set_socket($this->socket)->send();
}
/**
* Creates worker if necessary
*
* @param string $address
* @return stdClass
*/
public function worker_require($address)
{
$worker = isset($this->workers[$address]) ? $this->workers[$address] : NULL;
if ($worker == NULL) {
$worker = new stdClass();
$worker->identity = $address;
$worker->address = $address;
if ($this->verbose) {
printf("I: registering new worker: %s %s", $address, PHP_EOL);
}
$this->workers[$address] = $worker;
}
return $worker;
}
/**
* Remove a worker
*
* @param stdClass $worker
* @param boolean $disconnect
*/
public function worker_delete($worker, $disconnect = false)
{
if ($disconnect) {
$this->worker_send($worker, MDPW_DISCONNECT, NULL, NULL);
}
if (isset($worker->service)) {
$sw = $this->worker_remove_from_array($worker, $worker->service->waiting);
} else {
$sw = null;
}
$w = $this->worker_remove_from_array($worker, $this->waiting);
if ($sw || $w && $sw === false) {
$worker->service->workers--;
}
unset($this->workers[$worker->identity]);
}
private function worker_remove_from_array($worker, &$array)
{
$index = array_search($worker, $array);
if ($index !== false) {
unset($array[$index]);
return true;
}
return false;
}
/**
* Process message sent to us by a worker
*
* @param string $sender
* @param Zmsg $msg
*/
public function worker_process($sender, $msg)
{
$command = $msg->pop();
$worker_ready = isset($this->workers[$sender]);
$worker = $this->worker_require($sender);
if ($command == MDPW_READY) {
if ($worker_ready) {
$this->worker_delete($worker, true); // Not first command in session
} else if(strlen($sender) >= 4 // Reserved service name
&& substr($sender, 0, 4) == 'mmi.') {
$this->worker_delete($worker, true);
} else {
// Attach worker to service and mark as idle
$service_frame = $msg->pop();
$worker->service = $this->service_require($service_frame);
$worker->service->workers++;
$this->worker_waiting($worker);
}
} elseif ($command == MDPW_REPLY) {
if ($worker_ready) {
// Remove & save client return envelope and insert the
// protocol header and service name, then rewrap envelope.
$client = $msg->unwrap();
$msg->push($worker->service->name);
$msg->push(MDPC_CLIENT);
$msg->wrap($client, "");
$msg->set_socket($this->socket)->send();
$this->worker_waiting($worker);
} else {
$this->worker_delete($worker, true);
}
} elseif ($command == MDPW_HEARTBEAT) {
if ($worker_ready) {
$worker->expiry = microtime(true) + (HEARTBEAT_EXPIRY/1000);
} else {
$this->worker_delete($worker, true);
}
} elseif ($command == MDPW_DISCONNECT) {
$this->worker_delete($worker, true);
} else {
echo "E: invalid input message", PHP_EOL, $msg->__toString();
}
}
/**
* Send message to worker
*
* @param stdClass $worker
* @param string $command
* @param mixed $option
* @param Zmsg $msg
*/
public function worker_send($worker, $command, $option, $msg)
{
$msg = $msg ? $msg : new Zmsg();
// Stack protocol envelope to start of message
if ($option) {
$msg->push($option);
}
$msg->push($command);
$msg->push(MDPW_WORKER);
// Stack routing envelope to start of message
$msg->wrap($worker->address, "");
if ($this->verbose) {
printf("I: sending %s to worker %s",
$command, PHP_EOL);
echo $msg->__toString();
}
$msg->set_socket($this->socket)->send();
}
/**
* This worker is now waiting for work
*
* @param stdClass $worker
*/
public function worker_waiting($worker)
{
// Queue to broker and service waiting lists
$this->waiting[] = $worker;
$worker->service->waiting[] = $worker;
$worker->expiry = microtime(true) + (HEARTBEAT_EXPIRY/1000);
$this->service_dispatch($worker->service, NULL);
}
/**
* Process a request coming from a client
*
* @param string $sender
* @param Zmsg $msg
*/
public function client_process($sender, $msg)
{
$service_frame = $msg->pop();
$service = $this->service_require($service_frame);
// Set reply return address to client sender
$msg->wrap($sender, "");
if (substr($service_frame, 0, 4) == 'mmi.') {
$this->service_internal($service_frame, $msg);
} else {
$this->service_dispatch($service, $msg);
}
}
}
mdbroker: Python 中的 Majordomo broker
"""
Majordomo Protocol broker
A minimal implementation of http:#rfc.zeromq.org/spec:7 and spec:8
Author: Min RK <benjaminrk@gmail.com>
Based on Java example by Arkadiusz Orzechowski
"""
import logging
import sys
import time
from binascii import hexlify
import zmq
# local
import MDP
from zhelpers import dump
class Service(object):
"""a single Service"""
name = None # Service name
requests = None # List of client requests
waiting = None # List of waiting workers
def __init__(self, name):
self.name = name
self.requests = []
self.waiting = []
class Worker(object):
"""a Worker, idle or active"""
identity = None # hex Identity of worker
address = None # Address to route to
service = None # Owning service, if known
expiry = None # expires at this point, unless heartbeat
def __init__(self, identity, address, lifetime):
self.identity = identity
self.address = address
self.expiry = time.time() + 1e-3*lifetime
class MajorDomoBroker(object):
"""
Majordomo Protocol broker
A minimal implementation of http:#rfc.zeromq.org/spec:7 and spec:8
"""
# We'd normally pull these from config data
INTERNAL_SERVICE_PREFIX = b"mmi."
HEARTBEAT_LIVENESS = 3 # 3-5 is reasonable
HEARTBEAT_INTERVAL = 2500 # msecs
HEARTBEAT_EXPIRY = HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS
# ---------------------------------------------------------------------
ctx = None # Our context
socket = None # Socket for clients & workers
poller = None # our Poller
heartbeat_at = None# When to send HEARTBEAT
services = None # known services
workers = None # known workers
waiting = None # idle workers
verbose = False # Print activity to stdout
# ---------------------------------------------------------------------
def __init__(self, verbose=False):
"""Initialize broker state."""
self.verbose = verbose
self.services = {}
self.workers = {}
self.waiting = []
self.heartbeat_at = time.time() + 1e-3*self.HEARTBEAT_INTERVAL
self.ctx = zmq.Context()
self.socket = self.ctx.socket(zmq.ROUTER)
self.socket.linger = 0
self.poller = zmq.Poller()
self.poller.register(self.socket, zmq.POLLIN)
logging.basicConfig(format="%(asctime)s %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
level=logging.INFO)
# ---------------------------------------------------------------------
def mediate(self):
"""Main broker work happens here"""
while True:
try:
items = self.poller.poll(self.HEARTBEAT_INTERVAL)
except KeyboardInterrupt:
break # Interrupted
if items:
msg = self.socket.recv_multipart()
if self.verbose:
logging.info("I: received message:")
dump(msg)
sender = msg.pop(0)
empty = msg.pop(0)
assert empty == b''
header = msg.pop(0)
if (MDP.C_CLIENT == header):
self.process_client(sender, msg)
elif (MDP.W_WORKER == header):
self.process_worker(sender, msg)
else:
logging.error("E: invalid message:")
dump(msg)
self.purge_workers()
self.send_heartbeats()
def destroy(self):
"""Disconnect all workers, destroy context."""
while self.workers:
self.delete_worker(self.workers.values()[0], True)
self.ctx.destroy(0)
def process_client(self, sender, msg):
"""Process a request coming from a client."""
assert len(msg) >= 2 # Service name + body
service = msg.pop(0)
# Set reply return address to client sender
msg = [sender, b''] + msg
if service.startswith(self.INTERNAL_SERVICE_PREFIX):
self.service_internal(service, msg)
else:
self.dispatch(self.require_service(service), msg)
def process_worker(self, sender, msg):
"""Process message sent to us by a worker."""
assert len(msg) >= 1 # At least, command
command = msg.pop(0)
worker_ready = hexlify(sender) in self.workers
worker = self.require_worker(sender)
if (MDP.W_READY == command):
assert len(msg) >= 1 # At least, a service name
service = msg.pop(0)
# Not first command in session or Reserved service name
if (worker_ready or service.startswith(self.INTERNAL_SERVICE_PREFIX)):
self.delete_worker(worker, True)
else:
# Attach worker to service and mark as idle
worker.service = self.require_service(service)
self.worker_waiting(worker)
elif (MDP.W_REPLY == command):
if (worker_ready):
# Remove & save client return envelope and insert the
# protocol header and service name, then rewrap envelope.
client = msg.pop(0)
empty = msg.pop(0) # ?
msg = [client, b'', MDP.C_CLIENT, worker.service.name] + msg
self.socket.send_multipart(msg)
self.worker_waiting(worker)
else:
self.delete_worker(worker, True)
elif (MDP.W_HEARTBEAT == command):
if (worker_ready):
worker.expiry = time.time() + 1e-3*self.HEARTBEAT_EXPIRY
else:
self.delete_worker(worker, True)
elif (MDP.W_DISCONNECT == command):
self.delete_worker(worker, False)
else:
logging.error("E: invalid message:")
dump(msg)
def delete_worker(self, worker, disconnect):
"""Deletes worker from all data structures, and deletes worker."""
assert worker is not None
if disconnect:
self.send_to_worker(worker, MDP.W_DISCONNECT, None, None)
if worker.service is not None:
worker.service.waiting.remove(worker)
self.workers.pop(worker.identity)
def require_worker(self, address):
"""Finds the worker (creates if necessary)."""
assert (address is not None)
identity = hexlify(address)
worker = self.workers.get(identity)
if (worker is None):
worker = Worker(identity, address, self.HEARTBEAT_EXPIRY)
self.workers[identity] = worker
if self.verbose:
logging.info("I: registering new worker: %s", identity)
return worker
def require_service(self, name):
"""Locates the service (creates if necessary)."""
assert (name is not None)
service = self.services.get(name)
if (service is None):
service = Service(name)
self.services[name] = service
return service
def bind(self, endpoint):
"""Bind broker to endpoint, can call this multiple times.
We use a single socket for both clients and workers.
"""
self.socket.bind(endpoint)
logging.info("I: MDP broker/0.1.1 is active at %s", endpoint)
def service_internal(self, service, msg):
"""Handle internal service according to 8/MMI specification"""
returncode = b"501"
if b"mmi.service" == service:
name = msg[-1]
returncode = b"200" if name in self.services else b"404"
msg[-1] = returncode
# insert the protocol header and service name after the routing envelope ([client, ''])
msg = msg[:2] + [MDP.C_CLIENT, service] + msg[2:]
self.socket.send_multipart(msg)
def send_heartbeats(self):
"""Send heartbeats to idle workers if it's time"""
if (time.time() > self.heartbeat_at):
for worker in self.waiting:
self.send_to_worker(worker, MDP.W_HEARTBEAT, None, None)
self.heartbeat_at = time.time() + 1e-3*self.HEARTBEAT_INTERVAL
def purge_workers(self):
"""Look for & kill expired workers.
Workers are oldest to most recent, so we stop at the first alive worker.
"""
while self.waiting:
w = self.waiting[0]
if w.expiry < time.time():
logging.info("I: deleting expired worker: %s", w.identity)
self.delete_worker(w,False)
self.waiting.pop(0)
else:
break
def worker_waiting(self, worker):
"""This worker is now waiting for work."""
# Queue to broker and service waiting lists
self.waiting.append(worker)
worker.service.waiting.append(worker)
worker.expiry = time.time() + 1e-3*self.HEARTBEAT_EXPIRY
self.dispatch(worker.service, None)
def dispatch(self, service, msg):
"""Dispatch requests to waiting workers as possible"""
assert (service is not None)
if msg is not None:# Queue message if any
service.requests.append(msg)
self.purge_workers()
while service.waiting and service.requests:
msg = service.requests.pop(0)
worker = service.waiting.pop(0)
self.waiting.remove(worker)
self.send_to_worker(worker, MDP.W_REQUEST, None, msg)
def send_to_worker(self, worker, command, option, msg=None):
"""Send message to worker.
If message is provided, sends that message.
"""
if msg is None:
msg = []
elif not isinstance(msg, list):
msg = [msg]
# Stack routing and protocol envelopes to start of message
# and routing envelope
if option is not None:
msg = [option] + msg
msg = [worker.address, b'', MDP.W_WORKER, command] + msg
if self.verbose:
logging.info("I: sending %r to worker", command)
dump(msg)
self.socket.send_multipart(msg)
def main():
"""create and start new broker"""
verbose = '-v' in sys.argv
broker = MajorDomoBroker(verbose)
broker.bind("tcp://*:5555")
broker.mediate()
if __name__ == '__main__':
main()
mdbroker: Q 中的 Majordomo broker
mdbroker: Racket 中的 Majordomo broker
mdbroker: Ruby 中的 Majordomo broker
#!/usr/bin/env ruby
# Majordomo Protocol broker
# A minimal implementation of http:#rfc.zeromq.org/spec:7 and spec:8
#
# Author: Tom van Leeuwen <tom@vleeuwen.eu>
# Based on Python example by Min RK
require 'ffi-rzmq'
require './mdp.rb'
class MajorDomoBroker
HEARTBEAT_INTERVAL = 2500
HEARTBEAT_LIVENESS = 3 # 3-5 is reasonable
HEARTBEAT_EXPIRY = HEARTBEAT_INTERVAL * HEARTBEAT_LIVENESS
INTERNAL_SERVICE_PREFIX = 'mmi.'
def initialize
@context = ZMQ::Context.new
@socket = @context.socket(ZMQ::ROUTER)
@socket.setsockopt ZMQ::LINGER, 0
@poller = ZMQ::Poller.new
@poller.register @socket, ZMQ::POLLIN
@workers = {}
@services = {}
@waiting = []
@heartbeat_at = Time.now + 0.001 * HEARTBEAT_INTERVAL
end
def bind endpoint
# Bind broker to endpoint, can call this multiple times.
# We use a single socket for both clients and workers.
@socket.bind endpoint
end
def mediate
#count = 0
loop do
#puts "mediate: count: #{count}"
#count += 1
items = @poller.poll HEARTBEAT_INTERVAL
if items > 0
message = []
@socket.recv_strings message
#puts "recv: #{message.inspect}"
address = message.shift
message.shift # empty
header = message.shift
case header
when MDP::C_CLIENT
process_client address, message
when MDP::W_WORKER
process_worker address, message
else
puts "E: invalid messages: #{message.inspect}"
end
else
#
end
if Time.now > @heartbeat_at
# purge waiting expired workers
# send heartbeats to the non expired workers
@waiting.each do |worker|
if Time.now > worker.expiry
delete_worker worker
else
send_to_worker worker, MDP::W_HEARTBEAT
end
end
puts "workers: #{@workers.count}"
@services.each do |service, object|
puts "service: #{service}: requests: #{object.requests.count} waiting: #{object.waiting.count}"
end
@heartbeat_at = Time.now + 0.001 * HEARTBEAT_INTERVAL
end
end
end
private
def delete_worker worker, disconnect=false
puts "delete_worker: #{worker.address.inspect} disconnect: #{disconnect}"
send_to_worker(worker, MDP::W_DISCONNECT) if disconnect
worker.service.waiting.delete(worker) if worker.service
@waiting.delete worker
@workers.delete worker.address
end
def send_to_worker worker, command, option=nil, message=[]
message = [message] unless message.is_a?(Array)
message.unshift option if option
message.unshift command
message.unshift MDP::W_WORKER
message.unshift ''
message.unshift worker.address
#puts "send: #{message.inspect}"
@socket.send_strings message
end
def process_client address, message
service = message.shift
message.unshift '' # empty
message.unshift address
if service.start_with?(INTERNAL_SERVICE_PREFIX)
service_internal service, message
else
dispatch require_service(service), message
end
end
def service_internal service, message
# Handle internal service according to 8/MMI specification
code = '501'
if service == 'mmi.service'
code = @services.key?(message.last) ? '200' : '404'
end
message.insert 2, [MDP::C_CLIENT, service]
message[-1] = code
message.flatten!
@socket.send_strings message
end
def process_worker address, message
command = message.shift
worker_exists = @workers[address]
worker = require_worker address
case command
when MDP::W_REPLY
if worker_exists
# Remove & save client return envelope and insert the
# protocol header and service name, then rewrap envelope.
client = message.shift
message.shift # empty
message = [client, '', MDP::C_CLIENT, worker.service.name].concat(message)
@socket.send_strings message
worker_waiting worker
else
delete_worker worker, true
end
when MDP::W_READY
service = message.shift
if worker_exists or service.start_with?(INTERNAL_SERVICE_PREFIX)
delete_worker worker, true # not first command in session
else
worker.service = require_service service
worker_waiting worker
end
when MDP::W_HEARTBEAT
if worker_exists
worker.expiry = Time.now + 0.001 * HEARTBEAT_EXPIRY
else
delete_worker worker, true
end
when MDP::W_DISCONNECT
delete_worker worker
else
puts "E: invalid message: #{message.inspect}"
end
end
def dispatch service, message
service.requests << message if message
while service.waiting.any? and service.requests.any?
message = service.requests.shift
worker = service.waiting.shift
@waiting.delete worker
send_to_worker worker, MDP::W_REQUEST, nil, message
end
end
def require_worker address
@workers[address] ||= Worker.new address, HEARTBEAT_EXPIRY
end
def require_service name
@services[name] ||= Service.new name
end
def worker_waiting worker
# This worker is waiting for work!
@waiting << worker
worker.service.waiting << worker
worker.expiry = Time.now + 0.001 * HEARTBEAT_EXPIRY
dispatch worker.service, nil
end
class Worker
#attr_reader :service
#attr_reader :identity
attr_accessor :service
attr_accessor :expiry
attr_accessor :address
#def initialize identity, address, lifetime
def initialize address, lifetime
#@identity = identity
@address = address
#@service = nil
@expiry = Time.now + 0.001 * lifetime
end
end
class Service
attr_accessor :requests
attr_accessor :waiting
attr_reader :name
def initialize name
@name = name
@requests = []
@waiting = []
end
end
end
broker = MajorDomoBroker.new
broker.bind('tcp://*:5555')
broker.mediate
mdbroker: Rust 中的 Majordomo broker
mdbroker: Scala 中的 Majordomo broker
mdbroker: Tcl 中的 Majordomo broker
#
# Majordomo Protocol broker
# A minimal implementation of https://rfc.zeromq.cn/spec:7 and spec:8
#
lappend auto_path .
package require TclOO
package require zmq
package require mdp
lappend auto_path .
set verbose 0
foreach {k v} $argv {
if {$k eq "-v"} { set verbose 1 }
}
oo::class create MDBroker {
variable ctx socket verbose services workers waiting heartbeat_at endpoint
constructor {{iverbose 0}} {
set ctx [zmq context mdbroker_context_[::mdp::contextid]]
set socket [zmq socket mdbroker_socket_[::mdp::socketid] $ctx ROUTER]
set verbose $iverbose
# services -> array
# workers -> array
set waiting [list]
set heartbeat_at [expr {[clock milliseconds] + $::mdp::HEARTBEAT_INTERVAL}]
set endpoint ""
}
destructor {
foreach {k v} [array get services] { $v destroy }
foreach {k v} [array get workers] { $v destroy }
$socket close
$ctx term
}
# Bind broker to endpoint, can call this multiple times
# We use a single socket for both clients and workers.
method bind {iendpoint} {
set endpoint $iendpoint
$socket bind $endpoint
if {$verbose} {
puts "I: MDP broker is active at $endpoint"
}
}
# Delete any idle workers that haven't pinged us in a while.
# We know that workers are ordered from oldest to most recent.
method purge_workers {} {
set i 0
foreach worker $waiting {
if {[clock milliseconds] < [$worker expiry]} {
break ;# Worker is alive, we're done here
}
my worker_delete $worker 0
incr i
}
set waiting [lrange $waiting $i end]
}
# Send heartbeat request to all workers
method heartbeat_workers {} {
foreach worker $waiting {
my worker_send $worker HEARTBEAT {} {}
}
set heartbeat_at [expr {[clock milliseconds] + $::mdp::HEARTBEAT_INTERVAL}]
}
# Locate or create new service entry
method service_require {name} {
if {![info exists services($name)]} {
set services($name) [MDBrokerService new $name]
if {$verbose} {
puts "I: added service: $name"
}
}
return $services($name)
}
# Dispatch requests to waiting workers as possible
method service_dispatch {service {msg {}}} {
if {[llength $msg]} {
$service add_request $msg
}
my purge_workers
while {[$service serviceable]} {
lassign [$service pop_worker_and_request] worker msg
set idx [lsearch $waiting $worker]
if {$idx >= 0} {
set waiting [lreplace $waiting $idx $idx]
}
my worker_send $worker REQUEST {} $msg
}
}
# Handle internal service according to 8/MMI specification
method service_internal {service_frame msg} {
if {$service_frame eq "mmi.service"} {
if {[info exists services([lindex $msg end])] && [$services([lindex $msg end]) has_workers]} {
set return_code 200
} else {
set return_code 404
}
} else {
set return_code 501
}
lset msg end $return_code
my rewrap_and_send $msg $service_frame
}
# Creates worker if necessary
method worker_require {address} {
set identity [zmq zframe_strhex $address]
if {![info exists workers($identity)]} {
set workers($identity) [MDBrokerWorker new $address $identity]
if {$verbose} {
puts "I: registering new worker: $identity"
}
}
return $workers($identity)
}
# Deletes worker from all data structures, and destroys worker
method worker_delete {worker disconnect} {
if {$disconnect} {
my worker_send $worker DISCONNECT {} {}
}
if {[$worker has_service]} {
$worker remove_from_service
}
set idx [lsearch $waiting $worker]
if {$idx >= 0} {
set waiting [lreplace $waiting $idx $idx]
}
unset workers([$worker identity])
$worker destroy
}
method rewrap_and_send {msg service_frame} {
# Remove & save client return envelope and insert the
# protocol header and service name, then rewrap envelope.
set client [zmsg unwrap msg]
set msg [zmsg push $msg $service_frame]
set msg [zmsg push $msg $::mdp::MDPC_CLIENT]
set msg [zmsg wrap $msg $client]
zmsg send $socket $msg
}
# Process message sent to us by a worker
method worker_process {sender msg} {
if {[llength $msg] < 1} {
error "Invalid message, need at least command"
}
set command [zmsg pop msg]
set identity [zmq zframe_strhex $sender]
set worker_ready [info exists workers($identity)]
set worker [my worker_require $sender]
if {$command eq $::mdp::MDPW_COMMAND(READY)} {
if {$worker_ready} {
# Not first command in session
my worker_delete $worker 1
} elseif {[string match "mmi.*" $sender]} {
# Reserved service name
my worker_delete $worker 1
} else {
# Attach worker to service and mark as idle
set service_frame [zmsg pop msg]
$worker set_service [my service_require $service_frame]
my worker_waiting $worker
}
} elseif {$command eq $::mdp::MDPW_COMMAND(REPLY)} {
if {$worker_ready} {
my rewrap_and_send $msg [[$worker service] name]
my worker_waiting $worker
} else {
my worker_delete $worker 1
}
} elseif {$command eq $::mdp::MDPW_COMMAND(HEARTBEAT)} {
if {$worker_ready} {
$worker update_expiry
} else {
my worker_delete $worker 1
}
} elseif {$command eq $::mdp::MDPW_COMMAND(DISCONNECT)} {
my worker_delete $worker 0
} else {
puts "E: invalid input message"
puts [join [zmsg dump $msg] \n]
}
}
# Send message to worker
# If pointer to message is provided, sends that message. Does not
# destroy the message, this is the caller's job.
method worker_send {worker command option msg} {
# Stack protocol envelope to start of message
if {[string length $option]} {
set msg [zmsg push $msg $option]
}
set msg [zmsg push $msg $::mdp::MDPW_COMMAND($command)]
set msg [zmsg push $msg $::mdp::MDPW_WORKER]
# Stack routing envelope to start of message
set msg [zmsg wrap $msg [$worker address]]
if {$verbose} {
puts "I: sending $command to worker"
puts [join [zmsg dump $msg] \n]
}
zmsg send $socket $msg
}
# This worker is now waiting for work
method worker_waiting {worker} {
lappend waiting $worker
$worker add_to_service
my service_dispatch [$worker service]
}
# Process a request coming from a client
method client_process {sender msg} {
if {[llength $msg] < 2} {
error "Invalud message, need name + body"
}
set service_frame [zmsg pop msg]
set service [my service_require $service_frame]
# Set reply return address to client sender
set msg [zmsg wrap $msg $sender]
if {[string match "mmi.*" $service_frame]} {
my service_internal $service_frame $msg
} else {
my service_dispatch $service $msg
}
}
method socket {} {
return $socket
}
method heartbeat_at {} {
return $heartbeat_at
}
method verbose {} {
return $verbose
}
}
oo::class create MDBrokerService {
variable name requests waiting
constructor {iname} {
set name $iname
set requests [list]
set waiting [list]
}
destructor {
}
method serviceable {} {
return [expr {[llength $waiting] && [llength $requests]}]
}
method add_request {msg} {
lappend requests $msg
}
method has_workers {} {
return [llength $waiting]
}
method pop_worker_and_request {} {
set waiting [lassign $waiting worker]
set requests [lassign $requests msg]
return [list $worker $msg]
}
method add_worker {worker} {
lappend waiting $worker
}
method remove_worker {worker} {
set idx [lsearch $waiting $worker]
if {$idx >= 0} {
set waiting [lreplace $waiting $idx $idx]
}
}
method name {} {
return $name
}
}
oo::class create MDBrokerWorker {
variable identity address service expiry
constructor {iaddress iidentity} {
set address $iaddress
set identity $iidentity
set service ""
set expiry 0
}
destructor {
}
method has_service {} {
return [string length $service]
}
method service {} {
return $service
}
method expiry {} {
return $expiry
}
method address {} {
return $address
}
method identity {} {
return $identity
}
method set_service {iservice} {
set service $iservice
}
method remove_from_service {} {
$service remove_worker [self]
set service ""
}
method add_to_service {} {
$service add_worker [self]
my update_expiry
}
method update_expiry {} {
set expiry [expr {[clock milliseconds] + $::mdp::HEARTBEAT_EXPIRY}]
}
}
set broker [MDBroker new $verbose]
$broker bind "tcp://*:5555"
# Get and process messages forever
while {1} {
set poll_set [list [list [$broker socket] [list POLLIN]]]
set rpoll_set [zmq poll $poll_set $::mdp::HEARTBEAT_INTERVAL]
# Process next input message, if any
if {[llength $rpoll_set] && "POLLIN" in [lindex $rpoll_set 0 1]} {
set msg [zmsg recv [$broker socket]]
if {[$broker verbose]} {
puts "I: received message:"
puts [join [zmsg dump $msg] \n]
}
set sender [zmsg pop msg]
set empty [zmsg pop msg]
set header [zmsg pop msg]
if {$header eq $::mdp::MDPC_CLIENT} {
$broker client_process $sender $msg
} elseif {$header eq $::mdp::MDPW_WORKER} {
$broker worker_process $sender $msg
} else {
puts "E: invalid message:"
puts [join [zmsg dump $msg] \n]
}
}
# Disconnect and delete any expired workers
# Send heartbeats to idle workers if needed
if {[clock milliseconds] > [$broker heartbeat_at]} {
$broker purge_workers
$broker heartbeat_workers
}
}
$broker destroy
mdbroker: OCaml 中的 Majordomo broker
这是目前为止我们见过最复杂的示例。它将近 500 行代码。编写并使其具有一定健壮性花费了两天时间。然而,对于一个完整的面向服务的 broker 来说,这仍然是一小段代码。
关于 broker 代码的一些注意事项
-
Majordomo 协议允许我们在单个套接字上处理客户端和 worker。这对于部署和管理 broker 的人来说更友好:它只需要一个 ZeroMQ 端点,而不是大多数代理所需的两个。
-
这个 broker 正确地实现了 MDP/0.1 的所有功能(据我所知),包括在 broker 发送无效命令时的断开连接、心跳机制等等。
-
它可以扩展为运行多个线程,每个线程管理一个套接字和一组客户端及 worker。这对于对大型架构进行分段可能很有用。C 代码已经围绕一个 broker 类组织,使得这一点变得简单。
-
实现主/备或活/活的 broker 可靠性模型很容易,因为 broker 除了服务存在状态外,基本上没有其他状态。客户端和 worker 需要在首选 broker 不在线时选择另一个。
-
示例使用五秒一次的心跳,主要是为了减少启用跟踪时的输出量。对于大多数局域网(LAN)应用,实际值会更低。然而,任何重试都必须足够慢,以便服务能够重新启动,例如至少 10 秒。
我们后来改进和扩展了协议以及 Majordomo 实现,该实现现在有自己的 Github 项目。如果您想要一个真正可用的 Majordomo 栈,请使用 GitHub 项目。
异步 Majordomo 模式 #
前面章节中的 Majordomo 实现是简单而笨拙的。客户端就是原始的 Simple Pirate,被包装在一个漂亮的 API 中。当我在一台测试机上启动一个客户端、broker 和 worker 时,它可以在大约 14 秒内处理 100,000 个请求。这部分归因于代码,它高兴地复制消息帧,好像 CPU 周期是免费的一样。但真正的问题在于我们正在进行网络往返。ZeroMQ 会禁用 Nagle 算法,但往返仍然很慢。
理论上,理论是很棒的,但在实践中,实践更重要。让我们用一个简单的测试程序来衡量往返的实际成本。这个程序发送一批消息,首先等待每条消息的回复,然后批量发送,并批量读取所有回复。这两种方法做的工作相同,但结果却大相径庭。我们模拟一个客户端、broker 和 worker
tripping: Ada 中的往返演示器
tripping: Basic 中的往返演示器
tripping: C 中的往返演示器
// Round-trip demonstrator
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. The client task signals to
// main when it's ready.
#include "czmq.h"
static void
client_task (void *args, zctx_t *ctx, void *pipe)
{
void *client = zsocket_new (ctx, ZMQ_DEALER);
zsocket_connect (client, "tcp://:5555");
printf ("Setting up test...\n");
zclock_sleep (100);
int requests;
int64_t start;
printf ("Synchronous round-trip test...\n");
start = zclock_time ();
for (requests = 0; requests < 10000; requests++) {
zstr_send (client, "hello");
char *reply = zstr_recv (client);
free (reply);
}
printf (" %d calls/second\n",
(1000 * 10000) / (int) (zclock_time () - start));
printf ("Asynchronous round-trip test...\n");
start = zclock_time ();
for (requests = 0; requests < 100000; requests++)
zstr_send (client, "hello");
for (requests = 0; requests < 100000; requests++) {
char *reply = zstr_recv (client);
free (reply);
}
printf (" %d calls/second\n",
(1000 * 100000) / (int) (zclock_time () - start));
zstr_send (pipe, "done");
}
// .split worker task
// Here is the worker task. All it does is receive a message, and
// bounce it back the way it came:
static void *
worker_task (void *args)
{
zctx_t *ctx = zctx_new ();
void *worker = zsocket_new (ctx, ZMQ_DEALER);
zsocket_connect (worker, "tcp://:5556");
while (true) {
zmsg_t *msg = zmsg_recv (worker);
zmsg_send (&msg, worker);
}
zctx_destroy (&ctx);
return NULL;
}
// .split broker task
// Here is the broker task. It uses the {{zmq_proxy}} function to switch
// messages between frontend and backend:
static void *
broker_task (void *args)
{
// Prepare our context and sockets
zctx_t *ctx = zctx_new ();
void *frontend = zsocket_new (ctx, ZMQ_DEALER);
zsocket_bind (frontend, "tcp://*:5555");
void *backend = zsocket_new (ctx, ZMQ_DEALER);
zsocket_bind (backend, "tcp://*:5556");
zmq_proxy (frontend, backend, NULL);
zctx_destroy (&ctx);
return NULL;
}
// .split main task
// Finally, here's the main task, which starts the client, worker, and
// broker, and then runs until the client signals it to stop:
int main (void)
{
// Create threads
zctx_t *ctx = zctx_new ();
void *client = zthread_fork (ctx, client_task, NULL);
zthread_new (worker_task, NULL);
zthread_new (broker_task, NULL);
// Wait for signal on client pipe
char *signal = zstr_recv (client);
free (signal);
zctx_destroy (&ctx);
return 0;
}
tripping: C++ 中的往返演示器
//
// Round-trip demonstrator
//
// While this example runs in a single process, that is just to make
// it easier to start and stop the example. Each thread has its own
// context and conceptually acts as a separate process.
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
//
#include "zmsg.hpp"
static void *
client_task (void *args)
{
zmq::context_t context (1);
zmq::socket_t client (context, ZMQ_DEALER);
client.set(zmq::sockopt::routing_id, "C");
client.connect ("tcp://:5555");
std::cout << "Setting up test..." << std::endl;
s_sleep (100);
int requests;
int64_t start;
std::cout << "Synchronous round-trip test..." << std::endl;
start = s_clock ();
for (requests = 0; requests < 10000; requests++) {
zmsg msg ("HELLO");
msg.send (client);
msg.recv (client);
}
std::cout << (1000 * 10000) / (int) (s_clock () - start) << " calls/second" << std::endl;
std::cout << "Asynchronous round-trip test..." << std::endl;
start = s_clock ();
for (requests = 0; requests < 100000; requests++) {
zmsg msg ("HELLO");
msg.send (client);
}
for (requests = 0; requests < 100000; requests++) {
zmsg msg (client);
}
std::cout << (1000 * 100000) / (int) (s_clock () - start) << " calls/second" << std::endl;
return 0;
}
static void *
worker_task (void *args)
{
zmq::context_t context (1);
zmq::socket_t worker (context, ZMQ_DEALER);
worker.set(zmq::sockopt::routing_id, "W");
worker.connect ("tcp://:5556");
while (1) {
zmsg msg (worker);
msg.send (worker);
}
return 0;
}
static void *
broker_task (void *args)
{
// Prepare our context and sockets
zmq::context_t context (1);
zmq::socket_t frontend (context, ZMQ_ROUTER);
zmq::socket_t backend (context, ZMQ_ROUTER);
frontend.bind ("tcp://*:5555");
backend.bind ("tcp://*:5556");
// Initialize poll set
zmq::pollitem_t items [] = {
{ frontend, 0, ZMQ_POLLIN, 0 },
{ backend, 0, ZMQ_POLLIN, 0 }
};
while (1) {
zmq::poll (items, 2, -1);
if (items [0].revents & ZMQ_POLLIN) {
zmsg msg (frontend);
msg.pop_front ();
msg.push_front ((char *)"W");
msg.send (backend);
}
if (items [1].revents & ZMQ_POLLIN) {
zmsg msg (backend);
msg.pop_front ();
msg.push_front ((char *)"C");
msg.send (frontend);
}
}
return 0;
}
int main ()
{
s_version_assert (2, 1);
pthread_t client;
pthread_create (&client, NULL, client_task, NULL);
pthread_t worker;
pthread_create (&worker, NULL, worker_task, NULL);
pthread_t broker;
pthread_create (&broker, NULL, broker_task, NULL);
pthread_join (client, NULL);
return 0;
}
tripping: C# 中的往返演示器
tripping: CL 中的往返演示器
tripping: Delphi 中的往返演示器
tripping: Erlang 中的往返演示器
tripping: Elixir 中的往返演示器
tripping: F# 中的往返演示器
tripping: Felix 中的往返演示器
tripping: Go 中的往返演示器
//
// Round-trip demonstrator
//
// Author: amyangfei <amyangfei@gmail.com>
// Requires: http://github.com/alecthomas/gozmq
package main
import (
"fmt"
zmq "github.com/alecthomas/gozmq"
"time"
)
func client_task(c chan string) {
context, _ := zmq.NewContext()
client, _ := context.NewSocket(zmq.DEALER)
defer context.Close()
defer client.Close()
client.SetIdentity("C")
client.Connect("tcp://:5555")
fmt.Println("Setting up test...")
time.Sleep(time.Duration(100) * time.Millisecond)
fmt.Println("Synchronous round-trip test...")
start := time.Now()
requests := 10000
for i := 0; i < requests; i++ {
client.Send([]byte("hello"), 0)
client.Recv(0)
}
fmt.Printf("%d calls/second\n", int64(float64(requests)/time.Since(start).Seconds()))
fmt.Println("Asynchronous round-trip test...")
start = time.Now()
for i := 0; i < requests; i++ {
client.Send([]byte("hello"), 0)
}
for i := 0; i < requests; i++ {
client.Recv(0)
}
fmt.Printf("%d calls/second\n", int64(float64(requests)/time.Since(start).Seconds()))
c <- "done"
}
func worker_task() {
context, _ := zmq.NewContext()
worker, _ := context.NewSocket(zmq.DEALER)
defer context.Close()
defer worker.Close()
worker.SetIdentity("W")
worker.Connect("tcp://:5556")
for {
msg, _ := worker.RecvMultipart(0)
worker.SendMultipart(msg, 0)
}
}
func broker_task() {
context, _ := zmq.NewContext()
frontend, _ := context.NewSocket(zmq.ROUTER)
backend, _ := context.NewSocket(zmq.ROUTER)
defer context.Close()
defer frontend.Close()
defer backend.Close()
frontend.Bind("tcp://*:5555")
backend.Bind("tcp://*:5556")
// Initialize poll set
items := zmq.PollItems{
zmq.PollItem{Socket: frontend, Events: zmq.POLLIN},
zmq.PollItem{Socket: backend, Events: zmq.POLLIN},
}
for {
zmq.Poll(items, -1)
switch {
case items[0].REvents&zmq.POLLIN != 0:
msg, _ := frontend.RecvMultipart(0)
msg[0][0] = 'W'
backend.SendMultipart(msg, 0)
case items[1].REvents&zmq.POLLIN != 0:
msg, _ := backend.RecvMultipart(0)
msg[0][0] = 'C'
frontend.SendMultipart(msg, 0)
}
}
}
func main() {
done := make(chan string)
go client_task(done)
go worker_task()
go broker_task()
<-done
}
tripping: Haskell 中的往返演示器
{-
Round-trip demonstrator.
Runs as a single process for easier testing.
The client task signals to main when it's ready.
-}
import System.ZMQ4
import Control.Concurrent
import Control.Monad (forM_, forever)
import Data.ByteString.Char8 (pack, unpack)
import Data.Time.Clock (getCurrentTime, diffUTCTime)
client_task :: Context -> Socket Pair -> IO ()
client_task ctx pipe =
withSocket ctx Dealer $ \client -> do
connect client "tcp://:5555"
putStrLn "Setting up test..."
threadDelay $ 100 * 1000
putStrLn "Synchronous round-trip test..."
start <- getCurrentTime
forM_ [0..10000] $ \_ -> do
send client [] (pack "hello")
receive client
end <- getCurrentTime
let elapsed_ms = (diffUTCTime end start) * 1000
putStrLn $ " " ++ (show $ (1000 * 10000) `quot` (round elapsed_ms)) ++ " calls/second"
putStrLn "Asynchronous round-trip test..."
start <- getCurrentTime
forM_ [0..10000] $ \_ -> do
send client [] (pack "hello")
forM_ [0..10000] $ \_ -> do
receive client
end <- getCurrentTime
let elapsed_ms = (diffUTCTime end start) * 1000
putStrLn $ " " ++ (show $ (1000 * 10000) `quot` (round elapsed_ms)) ++ " calls/second"
send pipe [] (pack "done")
worker_task :: IO ()
worker_task =
withContext $ \ctx ->
withSocket ctx Dealer $ \worker -> do
connect worker "tcp://:5556"
forever $ do
msg <- receive worker
send worker [] msg
broker_task :: IO ()
broker_task =
withContext $ \ctx ->
withSocket ctx Dealer $ \frontend ->
withSocket ctx Dealer $ \backend -> do
bind frontend "tcp://*:5555"
bind backend "tcp://*:5556"
proxy frontend backend Nothing
main :: IO ()
main =
withContext $ \ctx ->
withSocket ctx Pair $ \pipeServer ->
withSocket ctx Pair $ \pipeClient -> do
bind pipeServer "inproc://my-pipe"
connect pipeClient "inproc://my-pipe"
forkIO (client_task ctx pipeClient)
forkIO worker_task
forkIO broker_task
signal <- receive pipeServer
putStrLn $ unpack signal
tripping: Haxe 中的往返演示器
package ;
import haxe.Stack;
import haxe.io.Bytes;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZMQException;
import org.zeromq.ZThread;
/**
* Round-trip demonstrator
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Client thread signals to
* main when it's ready.
*
* @author Richard J Smith
*/
class Tripping
{
private static function clientTask(ctx:ZContext, pipe:ZMQSocket, ?args:Dynamic) {
var hello = Bytes.ofString("hello");
var client = ctx.createSocket(ZMQ_DEALER);
client.setsockopt(ZMQ_IDENTITY, Bytes.ofString("C"));
client.connect("tcp://:5555");
Lib.println("Setting up test...");
Sys.sleep(0.1); // 100 msecs
var start:Float = 0.0;
Lib.println("Synchronous round-trip test...");
start = Date.now().getTime();
for (requests in 0 ... 10000) {
client.sendMsg(hello);
var reply = client.recvMsg();
}
Lib.println(" " + Std.int((1000.0 * 10000.0) / (Date.now().getTime() - start)) + " calls/second");
Lib.println("Asynchronous round-trip test...");
start = Date.now().getTime();
for (requests in 0 ... 10000)
client.sendMsg(hello);
for (requests in 0 ... 10000) {
var reply = client.recvMsg();
}
Lib.println(" " + Std.int((1000.0 * 10000.0) / (Date.now().getTime() - start)) + " calls/second");
pipe.sendMsg(Bytes.ofString("done"));
}
private static function workerTask(?args:Dynamic) {
var ctx = new ZContext();
var worker = ctx.createSocket(ZMQ_DEALER);
worker.setsockopt(ZMQ_IDENTITY, Bytes.ofString("W"));
worker.connect("tcp://:5556");
while (true) {
var msg = ZMsg.recvMsg(worker);
msg.send(worker);
}
ctx.destroy();
}
private static function brokerTask(?args:Dynamic) {
// Prepare our contexts and sockets
var ctx = new ZContext();
var frontend = ctx.createSocket(ZMQ_ROUTER);
var backend = ctx.createSocket(ZMQ_ROUTER);
frontend.bind("tcp://*:5555");
backend.bind("tcp://*:5556");
// Initialise pollset
var poller = new ZMQPoller();
poller.registerSocket(frontend, ZMQ.ZMQ_POLLIN());
poller.registerSocket(backend, ZMQ.ZMQ_POLLIN());
while (true) {
try {
poller.poll(-1);
} catch (e:ZMQException) {
if (ZMQ.isInterrupted()) {
ctx.destroy();
return;
}
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
}
if (poller.pollin(1)) {
var msg = ZMsg.recvMsg(frontend);
var address = msg.pop();
msg.pushString("W");
msg.send(backend);
}
if (poller.pollin(2)) {
var msg = ZMsg.recvMsg(backend);
var address = msg.pop();
msg.pushString("C");
msg.send(frontend);
}
}
}
public static function main() {
Lib.println("** Tripping (see: https://zguide.zeromq.cn/page:all#Asynchronous-Majordomo-Pattern)");
// Create threads
var ctx = new ZContext();
var client = ZThread.attach(ctx, clientTask, null);
ZThread.detach(workerTask, null);
ZThread.detach(brokerTask, null);
// Wait for signal on client pipe
var signal = client.recvMsg();
ctx.destroy();
}
}tripping: Java 中的往返演示器
package guide;
import org.zeromq.*;
import org.zeromq.ZMQ.Socket;
/**
* Round-trip demonstrator. Broker, Worker and Client are mocked as separate
* threads.
*/
public class tripping
{
static class Broker implements Runnable
{
@Override
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket frontend = ctx.createSocket(SocketType.ROUTER);
Socket backend = ctx.createSocket(SocketType.ROUTER);
frontend.setHWM(0);
backend.setHWM(0);
frontend.bind("tcp://*:5555");
backend.bind("tcp://*:5556");
while (!Thread.currentThread().isInterrupted()) {
ZMQ.Poller items = ctx.createPoller(2);
items.register(frontend, ZMQ.Poller.POLLIN);
items.register(backend, ZMQ.Poller.POLLIN);
if (items.poll() == -1)
break; // Interrupted
if (items.pollin(0)) {
ZMsg msg = ZMsg.recvMsg(frontend);
if (msg == null)
break; // Interrupted
ZFrame address = msg.pop();
address.destroy();
msg.addFirst(new ZFrame("W"));
msg.send(backend);
}
if (items.pollin(1)) {
ZMsg msg = ZMsg.recvMsg(backend);
if (msg == null)
break; // Interrupted
ZFrame address = msg.pop();
address.destroy();
msg.addFirst(new ZFrame("C"));
msg.send(frontend);
}
items.close();
}
}
}
}
static class Worker implements Runnable
{
@Override
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket worker = ctx.createSocket(SocketType.DEALER);
worker.setHWM(0);
worker.setIdentity("W".getBytes(ZMQ.CHARSET));
worker.connect("tcp://:5556");
while (!Thread.currentThread().isInterrupted()) {
ZMsg msg = ZMsg.recvMsg(worker);
msg.send(worker);
}
}
}
}
static class Client implements Runnable
{
private static int SAMPLE_SIZE = 10000;
@Override
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket client = ctx.createSocket(SocketType.DEALER);
client.setHWM(0);
client.setIdentity("C".getBytes(ZMQ.CHARSET));
client.connect("tcp://:5555");
System.out.println("Setting up test");
try {
Thread.sleep(100);
}
catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
int requests;
long start;
System.out.println("Synchronous round-trip test");
start = System.currentTimeMillis();
for (requests = 0; requests < SAMPLE_SIZE; requests++) {
ZMsg req = new ZMsg();
req.addString("hello");
req.send(client);
ZMsg.recvMsg(client).destroy();
}
long now = System.currentTimeMillis();
System.out.printf(
" %d calls/second\n", (1000 * SAMPLE_SIZE) / (now - start)
);
System.out.println("Asynchronous round-trip test");
start = System.currentTimeMillis();
for (requests = 0; requests < SAMPLE_SIZE; requests++) {
ZMsg req = new ZMsg();
req.addString("hello");
req.send(client);
}
for (requests = 0;
requests < SAMPLE_SIZE && !Thread.currentThread()
.isInterrupted();
requests++) {
ZMsg.recvMsg(client).destroy();
}
long now2 = System.currentTimeMillis();
System.out.printf(
" %d calls/second\n", (1000 * SAMPLE_SIZE) / (now2 - start)
);
}
}
}
public static void main(String[] args)
{
if (args.length == 1)
Client.SAMPLE_SIZE = Integer.parseInt(args[0]);
Thread brokerThread = new Thread(new Broker());
Thread workerThread = new Thread(new Worker());
Thread clientThread = new Thread(new Client());
brokerThread.setDaemon(true);
workerThread.setDaemon(true);
brokerThread.start();
workerThread.start();
clientThread.start();
try {
clientThread.join();
workerThread.interrupt();
brokerThread.interrupt();
Thread.sleep(200);// give them some time
}
catch (InterruptedException e) {
}
}
}
tripping: Julia 中的往返演示器
tripping: Lua 中的往返演示器
--
-- Round-trip demonstrator
--
-- While this example runs in a single process, that is just to make
-- it easier to start and stop the example. Each thread has its own
-- context and conceptually acts as a separate process.
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.threads"
require"zmsg"
local common_code = [[
require"zmq"
require"zmsg"
require"zhelpers"
]]
local client_task = common_code .. [[
local context = zmq.init(1)
local client = context:socket(zmq.DEALER)
client:setopt(zmq.IDENTITY, "C", 1)
client:connect("tcp://:5555")
printf("Setting up test...\n")
s_sleep(100)
local requests
local start
printf("Synchronous round-trip test...\n")
requests = 10000
start = s_clock()
for n=1,requests do
local msg = zmsg.new("HELLO")
msg:send(client)
msg = zmsg.recv(client)
end
printf(" %d calls/second\n",
(1000 * requests) / (s_clock() - start))
printf("Asynchronous round-trip test...\n")
requests = 100000
start = s_clock()
for n=1,requests do
local msg = zmsg.new("HELLO")
msg:send(client)
end
for n=1,requests do
local msg = zmsg.recv(client)
end
printf(" %d calls/second\n",
(1000 * requests) / (s_clock() - start))
client:close()
context:term()
]]
local worker_task = common_code .. [[
local context = zmq.init(1)
local worker = context:socket(zmq.DEALER)
worker:setopt(zmq.IDENTITY, "W", 1)
worker:connect("tcp://:5556")
while true do
local msg = zmsg.recv(worker)
msg:send(worker)
end
worker:close()
context:term()
]]
local broker_task = common_code .. [[
-- Prepare our context and sockets
local context = zmq.init(1)
local frontend = context:socket(zmq.ROUTER)
local backend = context:socket(zmq.ROUTER)
frontend:bind("tcp://*:5555")
backend:bind("tcp://*:5556")
require"zmq.poller"
local poller = zmq.poller(2)
poller:add(frontend, zmq.POLLIN, function()
local msg = zmsg.recv(frontend)
--msg[1] = "W"
msg:pop()
msg:push("W")
msg:send(backend)
end)
poller:add(backend, zmq.POLLIN, function()
local msg = zmsg.recv(backend)
--msg[1] = "C"
msg:pop()
msg:push("C")
msg:send(frontend)
end)
poller:start()
frontend:close()
backend:close()
context:term()
]]
s_version_assert(2, 1)
local client = zmq.threads.runstring(nil, client_task)
assert(client:start())
local worker = zmq.threads.runstring(nil, worker_task)
assert(worker:start(true))
local broker = zmq.threads.runstring(nil, broker_task)
assert(broker:start(true))
assert(client:join())
tripping: Node.js 中的往返演示器
tripping: Objective-C 中的往返演示器
tripping: ooc 中的往返演示器
tripping: Perl 中的往返演示器
tripping: PHP 中的往返演示器
<?php
/*
* Round-trip demonstrator
*
* While this example runs in a single process, that is just to make
* it easier to start and stop the example. Each thread has its own
* context and conceptually acts as a separate process.
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'zmsg.php';
function client_task()
{
$context = new ZMQContext();
$client = new ZMQSocket($context, ZMQ::SOCKET_DEALER);
$client->setSockOpt(ZMQ::SOCKOPT_IDENTITY, "C");
$client->connect("tcp://:5555");
echo "Setting up test...", PHP_EOL;
usleep(10000);
echo "Synchronous round-trip test...", PHP_EOL;
$start = microtime(true);
$text = "HELLO";
for ($requests = 0; $requests < 10000; $requests++) {
$client->send($text);
$msg = $client->recv();
}
printf (" %d calls/second%s",
(1000 * 10000) / (int) ((microtime(true) - $start) * 1000),
PHP_EOL);
echo "Asynchronous round-trip test...", PHP_EOL;
$start = microtime(true);
for ($requests = 0; $requests < 100000; $requests++) {
$client->send($text);
}
for ($requests = 0; $requests < 100000; $requests++) {
$client->recv();
}
printf (" %d calls/second%s",
(1000 * 100000) / (int) ((microtime(true) - $start) * 1000),
PHP_EOL);
}
function worker_task()
{
$context = new ZMQContext();
$worker = new ZMQSocket($context, ZMQ::SOCKET_DEALER);
$worker->setSockOpt(ZMQ::SOCKOPT_IDENTITY, "W");
$worker->connect("tcp://:5556");
while (true) {
$zmsg = new Zmsg($worker);
$zmsg->recv();
$zmsg->send();
}
}
function broker_task()
{
// Prepare our context and sockets
$context = new ZMQContext();
$frontend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$backend = new ZMQSocket($context, ZMQ::SOCKET_ROUTER);
$frontend->bind("tcp://*:5555");
$backend->bind("tcp://*:5556");
// Initialize poll set
$poll = new ZMQPoll();
$poll->add($frontend, ZMQ::POLL_IN);
$poll->add($backend, ZMQ::POLL_IN);
$read = $write = array();
while (true) {
$events = $poll->poll($read, $write);
foreach ($read as $socket) {
$zmsg = new Zmsg($socket);
$zmsg->recv();
if ($socket === $frontend) {
$zmsg->push("W");
$zmsg->set_socket($backend)->send();
} elseif ($socket === $backend) {
$zmsg->pop();
$zmsg->push("C");
$zmsg->set_socket($frontend)->send();
}
}
}
}
$wpid = pcntl_fork();
if ($wpid == 0) {
worker_task();
exit;
}
$bpid = pcntl_fork();
if ($bpid == 0) {
broker_task();
exit;
}
sleep(1);
client_task();
posix_kill($wpid, SIGKILL);
posix_kill($bpid, SIGKILL);
tripping: Python 中的往返演示器
"""Round-trip demonstrator
While this example runs in a single process, that is just to make
it easier to start and stop the example. Client thread signals to
main when it's ready.
"""
import sys
import threading
import time
import zmq
from zhelpers import zpipe
def client_task (ctx, pipe):
client = ctx.socket(zmq.DEALER)
client.identity = b'C'
client.connect("tcp://:5555")
print ("Setting up test...")
time.sleep(0.1)
print ("Synchronous round-trip test...")
start = time.time()
requests = 10000
for r in range(requests):
client.send(b"hello")
client.recv()
print (" %d calls/second" % (requests / (time.time()-start)))
print ("Asynchronous round-trip test...")
start = time.time()
for r in range(requests):
client.send(b"hello")
for r in range(requests):
client.recv()
print (" %d calls/second" % (requests / (time.time()-start)))
# signal done:
pipe.send(b"done")
def worker_task():
ctx = zmq.Context()
worker = ctx.socket(zmq.DEALER)
worker.identity = b'W'
worker.connect("tcp://:5556")
while True:
msg = worker.recv_multipart()
worker.send_multipart(msg)
ctx.destroy(0)
def broker_task():
# Prepare our context and sockets
ctx = zmq.Context()
frontend = ctx.socket(zmq.ROUTER)
backend = ctx.socket(zmq.ROUTER)
frontend.bind("tcp://*:5555")
backend.bind("tcp://*:5556")
# Initialize poll set
poller = zmq.Poller()
poller.register(backend, zmq.POLLIN)
poller.register(frontend, zmq.POLLIN)
while True:
try:
items = dict(poller.poll())
except:
break # Interrupted
if frontend in items:
msg = frontend.recv_multipart()
msg[0] = b'W'
backend.send_multipart(msg)
if backend in items:
msg = backend.recv_multipart()
msg[0] = b'C'
frontend.send_multipart(msg)
def main():
# Create threads
ctx = zmq.Context()
client,pipe = zpipe(ctx)
client_thread = threading.Thread(target=client_task, args=(ctx, pipe))
worker_thread = threading.Thread(target=worker_task)
worker_thread.daemon=True
broker_thread = threading.Thread(target=broker_task)
broker_thread.daemon=True
worker_thread.start()
broker_thread.start()
client_thread.start()
# Wait for signal on client pipe
client.recv()
if __name__ == '__main__':
main()
tripping: Q 中的往返演示器
tripping: Racket 中的往返演示器
tripping: Ruby 中的往返演示器
tripping: Rust 中的往返演示器
tripping: Scala 中的往返演示器
tripping: Tcl 中的往返演示器
#
# Round-trip demonstrator
#
package require zmq
if {[llength $argv] == 0} {
set argv [list driver]
} elseif {[llength $argv] != 1} {
puts "Usage: tripping.tcl <driver|worker|client|broker>"
exit 1
}
set tclsh [info nameofexecutable]
expr {srand([pid])}
lassign $argv what
switch -exact -- $what {
client {
zmq context context
zmq socket client context DEALER
client setsockopt IDENTITY "C"
client connect "tcp://:5555"
puts "Setting up test..."
after 1000
puts "Synchronous round-trip test..."
set start [clock milliseconds]
for {set requests 0} {$requests < 10000} {incr requests} {
client send "hello"
client recv
}
puts "[expr {1000.0*10000/([clock milliseconds] - $start)}] calls/second"
puts "Asynchronous round-trip test..."
set start [clock milliseconds]
for {set requests 0} {$requests < 10000} {incr requests} {
client send "hello"
}
for {set requests 0} {$requests < 10000} {incr requests} {
client recv
}
puts "[expr {1000.0*10000/([clock milliseconds] - $start)}] calls/second"
puts "Callback round-trip test..."
proc recv_client {} {
client recv
incr ::cnt
if {$::cnt == 10000} {
set ::done 1
}
}
set start [clock milliseconds]
client readable recv_client
for {set requests 0} {$requests < 10000} {incr requests} {
client send "hello"
}
vwait done
puts "[expr {1000.0*10000/([clock milliseconds] - $start)}] calls/second"
}
worker {
zmq context context
zmq socket worker context DEALER
worker setsockopt IDENTITY "W"
worker connect "tcp://:5556"
while {1} {
zmsg send worker [zmsg recv worker]
}
worker close
context term
}
broker {
zmq context context
zmq socket frontend context ROUTER
zmq socket backend context ROUTER
frontend bind "tcp://*:5555"
backend bind "tcp://*:5556"
while {1} {
set poll_set [list [list backend [list POLLIN]] [list frontend [list POLLIN]]]
set rpoll_set [zmq poll $poll_set -1]
foreach rpoll $rpoll_set {
switch [lindex $rpoll 0] {
backend {
set msg [zmsg recv backend]
set address [zmsg pop msg]
set msg [zmsg push $msg "C"]
zmsg send frontend $msg
}
frontend {
set msg [zmsg recv frontend]
set address [zmsg pop msg]
set msg [zmsg push $msg "W"]
zmsg send backend $msg
}
}
}
}
frontend close
backend close
context term
}
driver {
exec $tclsh tripping.tcl client > client.log 2>@1 &
exec $tclsh tripping.tcl worker > worker.log 2>@1 &
exec $tclsh tripping.tcl broker > broker.log 2>@1 &
}
}
tripping: OCaml 中的往返演示器
在我的开发机上,这个程序输出:
Setting up test...
Synchronous round-trip test...
9057 calls/second
Asynchronous round-trip test...
173010 calls/second
注意,客户端线程在开始前会有一个小的暂停。这是为了绕过 router 套接字的一个“特性”:如果您向一个尚未连接的对端地址发送消息,该消息会被丢弃。在这个示例中,我们没有使用负载均衡机制,所以如果没有睡眠,如果 worker 线程连接太慢,它会丢失消息,导致我们的测试出现问题。
正如我们所见,在最简单的情况下,往返比异步的“尽可能快地推入管道”方法慢 20 倍。让我们看看是否可以将此应用于 Majordomo 以使其更快。
首先,我们将客户端 API 修改为使用两个独立的方法进行发送和接收
mdcli_t *mdcli_new (char *broker);
void mdcli_destroy (mdcli_t **self_p);
int mdcli_send (mdcli_t *self, char *service, zmsg_t **request_p);
zmsg_t *mdcli_recv (mdcli_t *self);
将同步客户端 API 重构为异步版本,字面上只需要几分钟的工作量
mdcliapi2: Ada 中的 Majordomo 异步客户端 API
mdcliapi2: Basic 中的 Majordomo 异步客户端 API
mdcliapi2: C 中的 Majordomo 异步客户端 API
// mdcliapi2 class - Majordomo Protocol Client API
// Implements the MDP/Worker spec at https://rfc.zeromq.cn/spec:7.
#include "mdcliapi2.h"
// Structure of our class
// We access these properties only via class methods
struct _mdcli_t {
zctx_t *ctx; // Our context
char *broker;
void *client; // Socket to broker
int verbose; // Print activity to stdout
int timeout; // Request timeout
};
// Connect or reconnect to broker. In this asynchronous class we use a
// DEALER socket instead of a REQ socket; this lets us send any number
// of requests without waiting for a reply.
void s_mdcli_connect_to_broker (mdcli_t *self)
{
if (self->client)
zsocket_destroy (self->ctx, self->client);
self->client = zsocket_new (self->ctx, ZMQ_DEALER);
zmq_connect (self->client, self->broker);
if (self->verbose)
zclock_log ("I: connecting to broker at %s...", self->broker);
}
// The constructor and destructor are the same as in mdcliapi, except
// we don't do retries, so there's no retries property.
// .skip
// ---------------------------------------------------------------------
// Constructor
mdcli_t *
mdcli_new (char *broker, int verbose)
{
assert (broker);
mdcli_t *self = (mdcli_t *) zmalloc (sizeof (mdcli_t));
self->ctx = zctx_new ();
self->broker = strdup (broker);
self->verbose = verbose;
self->timeout = 2500; // msecs
s_mdcli_connect_to_broker (self);
return self;
}
// Destructor
void
mdcli_destroy (mdcli_t **self_p)
{
assert (self_p);
if (*self_p) {
mdcli_t *self = *self_p;
zctx_destroy (&self->ctx);
free (self->broker);
free (self);
*self_p = NULL;
}
}
// Set request timeout
void
mdcli_set_timeout (mdcli_t *self, int timeout)
{
assert (self);
self->timeout = timeout;
}
// .until
// .skip
// The send method now just sends one message, without waiting for a
// reply. Since we're using a DEALER socket we have to send an empty
// frame at the start, to create the same envelope that the REQ socket
// would normally make for us:
int
mdcli_send (mdcli_t *self, char *service, zmsg_t **request_p)
{
assert (self);
assert (request_p);
zmsg_t *request = *request_p;
// Prefix request with protocol frames
// Frame 0: empty (REQ emulation)
// Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
// Frame 2: Service name (printable string)
zmsg_pushstr (request, service);
zmsg_pushstr (request, MDPC_CLIENT);
zmsg_pushstr (request, "");
if (self->verbose) {
zclock_log ("I: send request to '%s' service:", service);
zmsg_dump (request);
}
zmsg_send (&request, self->client);
return 0;
}
// .skip
// The recv method waits for a reply message and returns that to the
// caller.
// ---------------------------------------------------------------------
// Returns the reply message or NULL if there was no reply. Does not
// attempt to recover from a broker failure, this is not possible
// without storing all unanswered requests and resending them all...
zmsg_t *
mdcli_recv (mdcli_t *self)
{
assert (self);
// Poll socket for a reply, with timeout
zmq_pollitem_t items [] = { { self->client, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (items, 1, self->timeout * ZMQ_POLL_MSEC);
if (rc == -1)
return NULL; // Interrupted
// If we got a reply, process it
if (items [0].revents & ZMQ_POLLIN) {
zmsg_t *msg = zmsg_recv (self->client);
if (self->verbose) {
zclock_log ("I: received reply:");
zmsg_dump (msg);
}
// Don't try to handle errors, just assert noisily
assert (zmsg_size (msg) >= 4);
zframe_t *empty = zmsg_pop (msg);
assert (zframe_streq (empty, ""));
zframe_destroy (&empty);
zframe_t *header = zmsg_pop (msg);
assert (zframe_streq (header, MDPC_CLIENT));
zframe_destroy (&header);
zframe_t *service = zmsg_pop (msg);
zframe_destroy (&service);
return msg; // Success
}
if (zctx_interrupted)
printf ("W: interrupt received, killing client...\n");
else
if (self->verbose)
zclock_log ("W: permanent error, abandoning request");
return NULL;
}
mdcliapi2: C++ 中的 Majordomo 异步客户端 API
#ifndef __MDCLIAPI_HPP_INCLUDED__
#define __MDCLIAPI_HPP_INCLUDED__
#include "zmsg.hpp"
#include "mdp.h"
// Structure of our class
// We access these properties only via class methods
class mdcli {
public:
// ---------------------------------------------------------------------
// Constructor
mdcli (std::string broker, int verbose): m_broker(broker), m_verbose(verbose)
{
s_version_assert (4, 0);
m_context = new zmq::context_t (1);
s_catch_signals ();
connect_to_broker ();
}
// ---------------------------------------------------------------------
// Destructor
virtual
~mdcli ()
{
delete m_client;
delete m_context;
}
// ---------------------------------------------------------------------
// Connect or reconnect to broker
void connect_to_broker ()
{
if (m_client) {
delete m_client;
}
m_client = new zmq::socket_t (*m_context, ZMQ_DEALER);
int linger = 0;
m_client->setsockopt (ZMQ_LINGER, &linger, sizeof (linger));
s_set_id(*m_client);
m_client->connect (m_broker.c_str());
if (m_verbose)
s_console ("I: connecting to broker at %s...", m_broker.c_str());
}
// ---------------------------------------------------------------------
// Set request timeout
void
set_timeout (int timeout)
{
m_timeout = timeout;
}
// ---------------------------------------------------------------------
// Send request to broker
// Takes ownership of request message and destroys it when sent.
int
send (std::string service, zmsg *&request_p)
{
assert (request_p);
zmsg *request = request_p;
// Prefix request with protocol frames
// Frame 0: empty (REQ emulation)
// Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
// Frame 2: Service name (printable string)
request->push_front (service.c_str());
request->push_front (k_mdp_client.data());
request->push_front ("");
if (m_verbose) {
s_console ("I: send request to '%s' service:", service.c_str());
request->dump ();
}
request->send (*m_client);
return 0;
}
// ---------------------------------------------------------------------
// Returns the reply message or NULL if there was no reply. Does not
// attempt to recover from a broker failure, this is not possible
// without storing all unanswered requests and resending them all...
zmsg *
recv ()
{
// Poll socket for a reply, with timeout
zmq::pollitem_t items[] = {
{ *m_client, 0, ZMQ_POLLIN, 0 } };
zmq::poll (items, 1, m_timeout);
// If we got a reply, process it
if (items[0].revents & ZMQ_POLLIN) {
zmsg *msg = new zmsg (*m_client);
if (m_verbose) {
s_console ("I: received reply:");
msg->dump ();
}
// Don't try to handle errors, just assert noisily
assert (msg->parts () >= 4);
assert (msg->pop_front ().length() == 0); // empty message
ustring header = msg->pop_front();
assert (header.compare((unsigned char *)k_mdp_client.data()) == 0);
ustring service = msg->pop_front();
assert (service.compare((unsigned char *)service.c_str()) == 0);
return msg; // Success
}
if (s_interrupted)
std::cout << "W: interrupt received, killing client..." << std::endl;
else
if (m_verbose)
s_console ("W: permanent error, abandoning request");
return 0;
}
private:
const std::string m_broker;
zmq::context_t * m_context;
zmq::socket_t * m_client{}; // Socket to broker
const int m_verbose; // Print activity to stdout
int m_timeout{2500}; // Request timeout
};
#endif
mdcliapi2: C# 中的 Majordomo 异步客户端 API
mdcliapi2: CL 中的 Majordomo 异步客户端 API
mdcliapi2: Delphi 中的 Majordomo 异步客户端 API
mdcliapi2: Erlang 中的 Majordomo 异步客户端 API
mdcliapi2: Elixir 中的 Majordomo 异步客户端 API
mdcliapi2: F# 中的 Majordomo 异步客户端 API
mdcliapi2: Felix 中的 Majordomo 异步客户端 API
mdcliapi2: Go 中的 Majordomo 异步客户端 API
mdcliapi2: Haskell 中的 Majordomo 异步客户端 API
mdcliapi2: Haxe 中的 Majordomo 异步客户端 API
package ;
import haxe.Stack;
import neko.Lib;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQException;
import MDP;
/**
* Majordomo Protocol Client API (async version)
* Implements the MDP/Worker spec at https://rfc.zeromq.cn/spec:7
*/
class MDCliAPI2
{
/** Request timeout (in msec) */
public var timeout:Int;
// Private instance fields
/** Our context */
private var ctx:ZContext;
/** Connection string to reach broker */
private var broker:String;
/** Socket to broker */
private var client:ZMQSocket;
/** Print activity to stdout */
private var verbose:Bool;
/** Logger function used in verbose mode */
private var log:Dynamic->Void;
/**
* Constructor
* @param broker
* @param verbose
*/
public function new(broker:String, ?verbose:Bool=false, ?logger:Dynamic->Void) {
ctx = new ZContext();
this.broker = broker;
this.verbose = verbose;
this.timeout = 2500; // msecs
if (logger != null)
log = logger;
else
log = Lib.println;
connectToBroker();
}
/**
* Connect or reconnect to broker
*/
public function connectToBroker() {
if (client != null)
client.close();
client = ctx.createSocket(ZMQ_DEALER);
client.setsockopt(ZMQ_LINGER, 0);
client.connect(broker);
if (verbose)
log("I: connecting to broker at " + broker + "...");
}
/**
* Destructor
*/
public function destroy() {
ctx.destroy();
}
/**
* Send request to broker
* Takes ownership of request message and destroys it when sent.
* @param service
* @param request
* @return
*/
public function send(service:String, request:ZMsg) {
// Prefix request with MDP protocol frames
// Frame 0: empty (REQ socket emulation)
// Frame 1: "MDPCxy" (six bytes, MDP/Client)
// Frame 2: Service name (printable string)
request.push(ZFrame.newStringFrame(service));
request.push(ZFrame.newStringFrame(MDP.MDPC_CLIENT));
request.push(ZFrame.newStringFrame(""));
if (verbose) {
log("I: send request to '" + service + "' service:");
log(request.toString());
}
request.send(client);
}
/**
* Returns the reply message or NULL if there was no reply. Does not
* attempt to recover from a broker failure, this is not possible
* without storing all answered requests and re-sending them all...
* @return
*/
public function recv():ZMsg {
var poller = new ZMQPoller();
poller.registerSocket(client, ZMQ.ZMQ_POLLIN());
// Poll socket for a reply, with timeout
try {
var res = poller.poll(timeout * 1000);
} catch (e:ZMQException) {
if (!ZMQ.isInterrupted()) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
} else
log("W: interrupt received, killing client...");
ctx.destroy();
return null;
}
// If we got a reply, process it
if (poller.pollin(1)) {
// We got a reply from the server, must match sequence
var msg = ZMsg.recvMsg(client);
if (msg == null)
return null; // Interrupted
if (verbose)
log("I: received reply:" + msg.toString());
if (msg.size() < 3)
return null; // Don't try to handle errors
var empty = msg.pop(); // Empty frame
if (empty.size() != 0) {
return null; // Assert
}
empty.destroy();
var header = msg.pop();
if (!header.streq(MDP.MDPC_CLIENT)) {
return null; // Assert
}
header.destroy();
var reply_service = msg.pop();
reply_service.destroy();
return msg; // Success
} else {
if (verbose)
log("E: permanent error, abandoning");
}
return null;
}
}
mdcliapi2: Java 中的 Majordomo 异步客户端 API
package guide;
import java.util.Formatter;
import org.zeromq.*;
/**
* Majordomo Protocol Client API, asynchronous Java version. Implements the
* MDP/Worker spec at https://rfc.zeromq.cn/spec:7.
*/
public class mdcliapi2
{
private String broker;
private ZContext ctx;
private ZMQ.Socket client;
private long timeout = 2500;
private boolean verbose;
private Formatter log = new Formatter(System.out);
public long getTimeout()
{
return timeout;
}
public void setTimeout(long timeout)
{
this.timeout = timeout;
}
public mdcliapi2(String broker, boolean verbose)
{
this.broker = broker;
this.verbose = verbose;
ctx = new ZContext();
reconnectToBroker();
}
/**
* Connect or reconnect to broker
*/
void reconnectToBroker()
{
if (client != null) {
ctx.destroySocket(client);
}
client = ctx.createSocket(SocketType.DEALER);
client.connect(broker);
if (verbose)
log.format("I: connecting to broker at %s...\n", broker);
}
/**
* Returns the reply message or NULL if there was no reply. Does not attempt
* to recover from a broker failure, this is not possible without storing
* all unanswered requests and resending them all…
*/
public ZMsg recv()
{
ZMsg reply = null;
// Poll socket for a reply, with timeout
ZMQ.Poller items = ctx.createPoller(1);
items.register(client, ZMQ.Poller.POLLIN);
if (items.poll(timeout * 1000) == -1)
return null; // Interrupted
if (items.pollin(0)) {
ZMsg msg = ZMsg.recvMsg(client);
if (verbose) {
log.format("I: received reply: \n");
msg.dump(log.out());
}
// Don't try to handle errors, just assert noisily
assert (msg.size() >= 4);
ZFrame empty = msg.pop();
assert (empty.getData().length == 0);
empty.destroy();
ZFrame header = msg.pop();
assert (MDP.C_CLIENT.equals(header.toString()));
header.destroy();
ZFrame replyService = msg.pop();
replyService.destroy();
reply = msg;
}
items.close();
return reply;
}
/**
* Send request to broker and get reply by hook or crook Takes ownership of
* request message and destroys it when sent.
*/
public boolean send(String service, ZMsg request)
{
assert (request != null);
// Prefix request with protocol frames
// Frame 0: empty (REQ emulation)
// Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
// Frame 2: Service name (printable string)
request.addFirst(service);
request.addFirst(MDP.C_CLIENT.newFrame());
request.addFirst("");
if (verbose) {
log.format("I: send request to '%s' service: \n", service);
request.dump(log.out());
}
return request.send(client);
}
public void destroy()
{
ctx.destroy();
}
}
mdcliapi2: Julia 中的 Majordomo 异步客户端 API
mdcliapi2: Lua 中的 Majordomo 异步客户端 API
--
-- mdcliapi2.lua - Majordomo Protocol Client API (async version)
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
local setmetatable = setmetatable
local mdp = require"mdp"
local zmq = require"zmq"
local zpoller = require"zmq.poller"
local zmsg = require"zmsg"
require"zhelpers"
local s_version_assert = s_version_assert
local obj_mt = {}
obj_mt.__index = obj_mt
function obj_mt:set_timeout(timeout)
self.timeout = timeout
end
function obj_mt:destroy()
if self.client then self.client:close() end
self.context:term()
end
local function s_mdcli_connect_to_broker(self)
-- close old socket.
if self.client then
self.poller:remove(self.client)
self.client:close()
end
self.client = assert(self.context:socket(zmq.DEALER))
assert(self.client:setopt(zmq.LINGER, 0))
assert(self.client:connect(self.broker))
if self.verbose then
s_console("I: connecting to broker at %s...", self.broker)
end
-- add socket to poller
self.poller:add(self.client, zmq.POLLIN, function()
self.got_reply = true
end)
end
--
-- Send request to broker and get reply by hook or crook
--
function obj_mt:send(service, request)
-- Prefix request with protocol frames
-- Frame 0: empty (REQ emulation)
-- Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
-- Frame 2: Service name (printable string)
request:push(service)
request:push(mdp.MDPC_CLIENT)
request:push("")
if self.verbose then
s_console("I: send request to '%s' service:", service)
request:dump()
end
request:send(self.client)
return 0
end
-- Returns the reply message or NULL if there was no reply. Does not
-- attempt to recover from a broker failure, this is not possible
-- without storing all unanswered requests and resending them all...
function obj_mt:recv()
self.got_reply = false
local cnt = assert(self.poller:poll(self.timeout * 1000))
if cnt ~= 0 and self.got_reply then
local msg = zmsg.recv(self.client)
if self.verbose then
s_console("I: received reply:")
msg:dump()
end
assert(msg:parts() >= 3)
local empty = msg:pop()
assert(empty == "")
local header = msg:pop()
assert(header == mdp.MDPC_CLIENT)
return msg
end
if self.verbose then
s_console("W: permanent error, abandoning request")
end
return nil -- Giving up
end
module(...)
function new(broker, verbose)
s_version_assert (2, 1);
local self = setmetatable({
context = zmq.init(1),
poller = zpoller.new(1),
broker = broker,
verbose = verbose,
timeout = 2500, -- msecs
}, obj_mt)
s_mdcli_connect_to_broker(self)
return self
end
setmetatable(_M, { __call = function(self, ...) return new(...) end })
mdcliapi2: Node.js 中的 Majordomo 异步客户端 API
mdcliapi2: Objective-C 中的 Majordomo 异步客户端 API
mdcliapi2: ooc 中的 Majordomo 异步客户端 API
mdcliapi2: Perl 中的 Majordomo 异步客户端 API
mdcliapi2: PHP 中的 Majordomo 异步客户端 API
<?php
/* =====================================================================
* mdcliapi2.c
*
* Majordomo Protocol Client API (async version)
* Implements the MDP/Worker spec at https://rfc.zeromq.cn/spec:7.
*/
include_once 'zmsg.php';
include_once 'mdp.php';
class MDCli
{
// Structure of our class
// We access these properties only via class methods
private $broker;
private $context;
private $client; // Socket to broker
private $verbose; // Print activity to stdout
private $timeout; // Request timeout
private $retries; // Request retries
/**
* Constructor
*
* @param string $broker
* @param boolean $verbose
*/
public function __construct($broker, $verbose = false)
{
$this->broker = $broker;
$this->context = new ZMQContext();
$this->verbose = $verbose;
$this->timeout = 2500; // msecs
$this->connect_to_broker();
}
/**
* Connect or reconnect to broker
*/
protected function connect_to_broker()
{
if ($this->client) {
unset($this->client);
}
$this->client = new ZMQSocket($this->context, ZMQ::SOCKET_DEALER);
$this->client->setSockOpt(ZMQ::SOCKOPT_LINGER, 0);
$this->client->connect($this->broker);
if ($this->verbose) {
printf("I: connecting to broker at %s...", $this->broker);
}
}
/**
* Set request timeout
*
* @param int $timeout (msecs)
*/
public function set_timeout($timeout)
{
$this->timeout = $timeout;
}
/**
* Send request to broker
* Takes ownership of request message and destroys it when sent.
*
* @param string $service
* @param Zmsg $request
*/
public function send($service, Zmsg $request)
{
// Prefix request with protocol frames
// Frame 0: empty (REQ emulation)
// Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
// Frame 2: Service name (printable string)
$request->push($service);
$request->push(MDPC_CLIENT);
$request->push("");
if ($this->verbose) {
printf ("I: send request to '%s' service: %s", $service, PHP_EOL);
echo $request->__toString();
}
$request->set_socket($this->client)->send();
}
/**
* Returns the reply message or NULL if there was no reply. Does not
* attempt to recover from a broker failure, this is not possible
* without storing all unanswered requests and resending them all...
*
*/
public function recv()
{
$read = $write = array();
// Poll socket for a reply, with timeout
$poll = new ZMQPoll();
$poll->add($this->client, ZMQ::POLL_IN);
$events = $poll->poll($read, $write, $this->timeout);
// If we got a reply, process it
if ($events) {
$msg = new Zmsg($this->client);
$msg->recv();
if ($this->verbose) {
echo "I: received reply:", $msg->__toString(), PHP_EOL;
}
// Don't try to handle errors, just assert noisily
assert ($msg->parts() >= 4);
$msg->pop(); // empty
$header = $msg->pop();
assert($header == MDPC_CLIENT);
$reply_service = $msg->pop();
return $msg; // Success
} else {
echo "W: permanent error, abandoning request", PHP_EOL;
return; // Give up
}
}
}
mdcliapi2: Python 中的 Majordomo 异步客户端 API
"""Majordomo Protocol Client API, Python version.
Implements the MDP/Worker spec at http:#rfc.zeromq.org/spec:7.
Author: Min RK <benjaminrk@gmail.com>
Based on Java example by Arkadiusz Orzechowski
"""
import logging
import zmq
import MDP
from zhelpers import dump
class MajorDomoClient(object):
"""Majordomo Protocol Client API, Python version.
Implements the MDP/Worker spec at http:#rfc.zeromq.org/spec:7.
"""
broker = None
ctx = None
client = None
poller = None
timeout = 2500
verbose = False
def __init__(self, broker, verbose=False):
self.broker = broker
self.verbose = verbose
self.ctx = zmq.Context()
self.poller = zmq.Poller()
logging.basicConfig(format="%(asctime)s %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
level=logging.INFO)
self.reconnect_to_broker()
def reconnect_to_broker(self):
"""Connect or reconnect to broker"""
if self.client:
self.poller.unregister(self.client)
self.client.close()
self.client = self.ctx.socket(zmq.DEALER)
self.client.linger = 0
self.client.connect(self.broker)
self.poller.register(self.client, zmq.POLLIN)
if self.verbose:
logging.info("I: connecting to broker at %s...", self.broker)
def send(self, service, request):
"""Send request to broker
"""
if not isinstance(request, list):
request = [request]
# Prefix request with protocol frames
# Frame 0: empty (REQ emulation)
# Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
# Frame 2: Service name (printable string)
request = [b'', MDP.C_CLIENT, service] + request
if self.verbose:
logging.warn("I: send request to '%s' service: ", service)
dump(request)
self.client.send_multipart(request)
def recv(self):
"""Returns the reply message or None if there was no reply."""
try:
items = self.poller.poll(self.timeout)
except KeyboardInterrupt:
return # interrupted
if items:
# if we got a reply, process it
msg = self.client.recv_multipart()
if self.verbose:
logging.info("I: received reply:")
dump(msg)
# Don't try to handle errors, just assert noisily
assert len(msg) >= 4
empty = msg.pop(0)
header = msg.pop(0)
assert MDP.C_CLIENT == header
service = msg.pop(0)
return msg
else:
logging.warn("W: permanent error, abandoning request")
mdcliapi2: Q 中的 Majordomo 异步客户端 API
mdcliapi2: Racket 中的 Majordomo 异步客户端 API
mdcliapi2: Ruby 中的 Majordomo 异步客户端 API
#!/usr/bin/env ruby
# Majordomo Protocol Client API, Python version.
#
# Implements the MDP/Worker spec at http:#rfc.zeromq.org/spec:7.
#
# Author: Tom van Leeuwen <tom@vleeuwen.eu>
# Based on Python example by Min RK
require 'ffi-rzmq'
require './mdp.rb'
class MajorDomoClient
include MDP
attr_accessor :timeout
def initialize broker
@broker = broker
@context = ZMQ::Context.new(1)
@client = nil
@poller = ZMQ::Poller.new
@timeout = 2500
reconnect_to_broker
end
def send service, request
request = [request] unless request.is_a?(Array)
# Prefix request with protocol frames
# Frame 0: empty (REQ emulation)
# Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
# Frame 2: Service name (printable string)
request = ['', MDP::C_CLIENT, service].concat(request)
@client.send_strings request
nil
end
def recv
items = @poller.poll(@timeout)
if items
messages = []
@client.recv_strings messages
messages.shift # empty
# header
if messages.shift != MDP::C_CLIENT
raise RuntimeError, "Not a valid MDP message"
end
messages.shift # service
return messages
end
nil
end
def reconnect_to_broker
if @client
@poller.deregister @client, ZMQ::DEALER
end
@client = @context.socket ZMQ::DEALER
@client.setsockopt ZMQ::LINGER, 0
@client.connect @broker
@poller.register @client, ZMQ::POLLIN
end
end
mdcliapi2: Rust 中的 Majordomo 异步客户端 API
mdcliapi2: Scala 中的 Majordomo 异步客户端 API
mdcliapi2: Tcl 中的 Majordomo 异步客户端 API
# Majordomo Protocol Client API, Tcl version.
# Implements the MDP/Worker spec at http:#rfc.zeromq.org/spec:7.
package require TclOO
package require zmq
package require mdp
package provide MDClient 2.0
oo::class create MDClient {
variable context broker verbose timeout retries client
constructor {ibroker {iverbose 0}} {
set context [zmq context mdcli_context_[::mdp::contextid]]
set broker $ibroker
set verbose $iverbose
set timeout 2500
set client ""
my connect_to_broker
}
destructor {
$client close
$context term
}
method connect_to_broker {} {
if {[string length $client]} {
$client close
}
set client [zmq socket mdcli_socket_[::mdp::socketid] $context DEALER]
$client connect $broker
if {$verbose} {
puts "I: connecting to broker at $broker..."
}
}
method set_timeout {itimeout} {
set timeout $itimeout
}
# Send request to broker
# Takes ownership of request message and destroys it when sent.
method send {service request} {
# Prefix request with protocol frames
# Frame 0: empty (REQ emulation)
# Frame 1: "MDPCxy" (six bytes, MDP/Client x.y)
# Frame 2: Service name (printable string)
set request [zmsg push $request $service]
set request [zmsg push $request $mdp::MDPC_CLIENT]
set request [zmsg push $request ""]
if {$verbose} {
puts "I: send request to '$service' service:"
puts [join [zmsg dump $request] \n]
}
zmsg send $client $request
}
# Returns the reply message or NULL if there was no reply. Does not
# attempt to recover from a broker failure, this is not possible
# without storing all unanswered requests and resending them all...
method recv {} {
# Poll socket for a reply, with timeout
set poll_set [list [list $client [list POLLIN]]]
set rpoll_set [zmq poll $poll_set $timeout]
# If we got a reply, process it
if {[llength $rpoll_set] && "POLLIN" in [lindex $rpoll_set 0 1]} {
set msg [zmsg recv $client]
if {$verbose} {
puts "I: received reply:"
puts [join [zmsg dump $msg] \n]
}
# Don't try to handle errors, just assert noisily
if {[llength $msg] < 4} {
error "message size < 4"
}
set empty [zmsg pop msg]
if {[string length $empty]} {
error "expected empty frame"
}
set header [zmsg pop msg]
if {$header ne $mdp::MDPC_CLIENT} {
error "unexpected header"
}
set service [zmsg pop msg]
return $msg ;# Success
}
if {$verbose} {
puts "W: permanent error, abandoning"
}
return {}
}
}
mdcliapi2: OCaml 中的 Majordomo 异步客户端 API
区别在于
- 我们使用 DEALER 套接字而不是 REQ,因此我们在每个请求和每个响应之前使用一个空分隔符帧来模拟 REQ。
- 我们不重试请求;如果应用程序需要重试,它可以自行处理。
- 我们将同步的send方法分解为独立的send和recv方法。
- 其中,sendsend 方法是异步的,发送后立即返回。调用者因此可以在收到回复之前发送多个消息。
- 其中,recvrecv 方法等待一个回复(带超时)并将其返回给调用者。
以下是相应的客户端测试程序,它发送 100,000 条消息,然后接收 100,000 条回复
mdclient2: Ada 中的 Majordomo 客户端应用
mdclient2: Basic 中的 Majordomo 客户端应用
mdclient2: C 中的 Majordomo 客户端应用
// Majordomo Protocol client example - asynchronous
// Uses the mdcli API to hide all MDP aspects
// Lets us build this source without creating a library
#include "mdcliapi2.c"
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && streq (argv [1], "-v"));
mdcli_t *session = mdcli_new ("tcp://:5555", verbose);
int count;
for (count = 0; count < 100000; count++) {
zmsg_t *request = zmsg_new ();
zmsg_pushstr (request, "Hello world");
mdcli_send (session, "echo", &request);
}
for (count = 0; count < 100000; count++) {
zmsg_t *reply = mdcli_recv (session);
if (reply)
zmsg_destroy (&reply);
else
break; // Interrupted by Ctrl-C
}
printf ("%d replies received\n", count);
mdcli_destroy (&session);
return 0;
}
mdclient2: C++ 中的 Majordomo 客户端应用
//
// Majordomo Protocol client example - asynchronous
// Uses the mdcli API to hide all MDP aspects
//
// Lets us 'build mdclient' and 'build all'
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
//
#include "mdcliapi2.hpp"
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && strcmp (argv [1], "-v") == 0);
mdcli session ("tcp://:5555", verbose);
int count;
for (count = 0; count < 100000; count++) {
zmsg * request = new zmsg("Hello world");
session.send ("echo", request);
}
for (count = 0; count < 100000; count++) {
zmsg *reply = session.recv ();
if (reply) {
delete reply;
} else {
break; // Interrupted by Ctrl-C
}
}
std::cout << count << " replies received" << std::endl;
return 0;
}
mdclient2: C# 中的 Majordomo 客户端应用
mdclient2: CL 中的 Majordomo 客户端应用
mdclient2: Delphi 中的 Majordomo 客户端应用
mdclient2: Erlang 中的 Majordomo 客户端应用
mdclient2: Elixir 中的 Majordomo 客户端应用
mdclient2: F# 中的 Majordomo 客户端应用
mdclient2: Felix 中的 Majordomo 客户端应用
mdclient2: Go 中的 Majordomo 客户端应用
mdclient2: Haskell 中的 Majordomo 客户端应用
mdclient2: Haxe 中的 Majordomo 客户端应用
package ;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZMsg;
/**
* Majordomo Protocol client example (asynchronous)
* Uses the MDPCli API to hide all MDP aspects
*
* @author Richard J Smith
*/
class MDClient2
{
public static function main() {
Lib.println("** MDClient2 (see: https://zguide.zeromq.cn/page:all#Asynchronous-Majordomo-Pattern)");
var argArr = Sys.args();
var verbose = (argArr.length > 1 && argArr[argArr.length - 1] == "-v");
var session = new MDCliAPI2("tcp://:5555", verbose);
for (i in 0 ... 100000) {
var request = new ZMsg();
request.pushString("Hello world: "+i);
session.send("echo", request);
}
var count = 0;
for (i in 0 ... 100000) {
var reply = session.recv();
if (reply != null)
reply.destroy();
else
break; // Interrupt or failure
count++;
}
Lib.println(count + " requests/replies processed");
session.destroy();
}
}mdclient2: Java 中的 Majordomo 客户端应用
package guide;
import org.zeromq.ZMsg;
/**
* Majordomo Protocol client example, asynchronous. Uses the mdcli API to hide
* all MDP aspects
*/
public class mdclient2
{
public static void main(String[] args)
{
boolean verbose = (args.length > 0 && "-v".equals(args[0]));
mdcliapi2 clientSession = new mdcliapi2("tcp://:5555", verbose);
int count;
for (count = 0; count < 100000; count++) {
ZMsg request = new ZMsg();
request.addString("Hello world");
clientSession.send("echo", request);
}
for (count = 0; count < 100000; count++) {
ZMsg reply = clientSession.recv();
if (reply != null)
reply.destroy();
else break; // Interrupt or failure
}
System.out.printf("%d requests/replies processed\n", count);
clientSession.destroy();
}
}
mdclient2: Julia 中的 Majordomo 客户端应用
mdclient2: Lua 中的 Majordomo 客户端应用
--
-- Majordomo Protocol client example - asynchronous
-- Uses the mdcli API to hide all MDP aspects
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"mdcliapi2"
require"zmsg"
require"zhelpers"
local verbose = (arg[1] == "-v")
local session = mdcliapi2.new("tcp://:5555", verbose)
local count=100000
for n=1,count do
local request = zmsg.new("Hello world")
session:send("echo", request)
end
for n=1,count do
local reply = session:recv()
if not reply then
break -- Interrupted by Ctrl-C
end
end
printf("%d replies received\n", count)
session:destroy()
mdclient2: Node.js 中的 Majordomo 客户端应用
mdclient2: Objective-C 中的 Majordomo 客户端应用
mdclient2: ooc 中的 Majordomo 客户端应用
mdclient2: Perl 中的 Majordomo 客户端应用
mdclient2: PHP 中的 Majordomo 客户端应用
<?php
/*
* Majordomo Protocol client example - asynchronous
* Uses the mdcli API to hide all MDP aspects
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include_once 'mdcliapi2.php';
$verbose = $_SERVER['argc'] > 1 && $_SERVER['argv'][1] == '-v';
$session = new MDCli("tcp://:5555", $verbose);
for ($count = 0; $count < 10000; $count++) {
$request = new Zmsg();
$request->body_set("Hello world");
$session->send("echo", $request);
}
for ($count = 0; $count < 10000; $count++) {
$reply = $session->recv();
if (!$reply) {
break; // Interrupt or failure
}
}
printf ("%d replies received", $count);
echo PHP_EOL;
mdclient2: Python 中的 Majordomo 客户端应用
"""
Majordomo Protocol client example. Uses the mdcli API to hide all MDP aspects
Author : Min RK <benjaminrk@gmail.com>
"""
import sys
from mdcliapi2 import MajorDomoClient
def main():
verbose = '-v' in sys.argv
client = MajorDomoClient("tcp://:5555", verbose)
requests = 100000
for i in range(requests):
request = b"Hello world"
try:
client.send(b"echo", request)
except KeyboardInterrupt:
print ("send interrupted, aborting")
return
count = 0
while count < requests:
try:
reply = client.recv()
except KeyboardInterrupt:
break
else:
# also break on failure to reply:
if reply is None:
break
count += 1
print ("%i requests/replies processed" % count)
if __name__ == '__main__':
main()
mdclient2: Q 中的 Majordomo 客户端应用
mdclient2: Racket 中的 Majordomo 客户端应用
mdclient2: Ruby 中的 Majordomo 客户端应用
#!/usr/bin/env ruby
# Majordomo Protocol client example. Uses the mdcliapi2 API to hide all MDP aspects
#
# Author : Tom van Leeuwen <tom@vleeuwen.eu>
# Based on Python example by Min RK
require './mdcliapi2.rb'
client = MajorDomoClient.new('tcp://:5555')
requests = 100000
requests.times do |i|
request = 'Hello world'
begin
client.send('echo', request)
end
end
count = 0
while count < requests do
begin
reply = client.recv
end
count += 1
end
puts "#{count} requests/replies processed"
mdclient2: Rust 中的 Majordomo 客户端应用
mdclient2: Scala 中的 Majordomo 客户端应用
mdclient2: Tcl 中的 Majordomo 客户端应用
#
# Majordomo Protocol client example
# Uses the mdcli API to hide all MDP aspects
#
lappend auto_path .
package require MDClient 2.0
set verbose 0
foreach {k v} $argv {
if {$k eq "-v"} { set verbose 1 }
}
set session [MDClient new "tcp://:5555" $verbose]
for {set count 0} {$count < 10000} {incr count} {
set request [list "Hello world"]
set reply [$session send "echo" $request]
}
for {set count 0} {$count < 10000} {incr count} {
set reply [$session recv]
if {[llength $reply] == 0} {
break ;# Interrupt or failure
}
}
puts "$count requests received"
$session destroy
mdclient2: OCaml 中的 Majordomo 客户端应用
代理和工作节点没有改变,因为我们完全没有修改协议。我们立即看到了性能提升。这是同步客户端处理 10 万次请求-应答循环的情况
$ time mdclient
100000 requests/replies processed
real 0m14.088s
user 0m1.310s
sys 0m2.670s
这是异步客户端,使用单个工作节点的情况
$ time mdclient2
100000 replies received
real 0m8.730s
user 0m0.920s
sys 0m1.550s
快了一倍。不错,但让我们启动 10 个工作节点,看看它如何处理流量
$ time mdclient2
100000 replies received
real 0m3.863s
user 0m0.730s
sys 0m0.470s
它不是完全异步的,因为工作节点严格按照上次使用的时间获取消息。但使用更多工作节点时,它的伸缩性会更好。在我的 PC 上,达到八个左右的工作节点后,速度就不会再提升了。四个核心的性能也就到此为止了。但只需几分钟的工作,我们就获得了 4 倍的吞吐量提升。代理仍然没有优化。它大部分时间都花在复制消息帧上,而不是使用零拷贝,尽管它可以做到。不过,我们以相当低的代价实现了每秒 2.5 万次可靠的请求/应答调用。
然而,异步 Majordomo 模式并非完美无缺。它有一个根本性弱点,即如果代理崩溃,它无法在不进行额外工作的情况下恢复。如果你看一下mdcliapi2代码,你会发现它在失败后没有尝试重新连接。一个适当的重新连接将需要以下几点
- 每个请求上有一个编号,每个应答上有一个匹配的编号,这最好通过修改协议来实现强制执行。
- 在客户端 API 中跟踪并保存所有未完成的请求,即那些尚未收到应答的请求。
- 在故障转移的情况下,客户端 API 需要将所有未完成的请求 重新发送 给代理。
这并非决定性问题,但这确实表明性能往往意味着复杂性。这对 Majordomo 来说值得做吗?这取决于你的使用场景。对于每个会话只调用一次的名称查找服务,不值得。对于服务数千个客户端的 Web 前端,可能值得。
服务发现 #
好的,我们有了一个很好的面向服务的代理,但我们无法知道某个特定的服务是否可用。我们知道请求是否失败了,但不知道原因。能够询问代理“echo 服务正在运行吗?”是很有用的。最明显的方法是修改我们的 MDP/客户端协议,添加命令来询问这一点。但 MDP/客户端最大的魅力在于其简单性。向其中添加服务发现会使其像 MDP/工作节点协议一样复杂。
另一个选项是像电子邮件那样,要求返回无法投递的请求。这在异步世界中可能运作良好,但它也增加了复杂性。我们需要区分被返回的请求和正常的应答,并正确处理它们的方法。
让我们尝试利用我们已有的构建,在 MDP 之上构建,而不是修改它。服务发现本身就是一个服务。它实际上可能是多个管理服务之一,例如“禁用服务 X”、“提供统计数据”等等。我们想要的是一个通用、可扩展的解决方案,它不影响协议或现有应用程序。
于是,这里有一个小型 RFC,它将此功能叠加在 MDP 之上:Majordomo 管理接口 (MMI)。我们已经在代理中实现了它,但除非你通读全文,否则你可能错过了这一点。我将解释它在代理中是如何工作的
-
当客户端请求一个以mmi.开头的服务时,我们会在内部处理它,而不是将其路由到工作节点。
-
在这个代理中,我们只处理一个服务,那就是mmi.service,即服务发现服务。
-
请求的载荷是一个外部服务(由工作节点提供的实际服务)的名称。
-
代理根据是否有为该服务注册的工作节点,返回“200”(OK)或“404”(未找到)。
以下是如何在应用程序中使用服务发现
mmiecho:Ada 中的 Majordomo 服务发现示例
mmiecho:Basic 中的 Majordomo 服务发现示例
mmiecho:C 中的 Majordomo 服务发现示例
// MMI echo query example
// Lets us build this source without creating a library
#include "mdcliapi.c"
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && streq (argv [1], "-v"));
mdcli_t *session = mdcli_new ("tcp://:5555", verbose);
// This is the service we want to look up
zmsg_t *request = zmsg_new ();
zmsg_addstr (request, "echo");
// This is the service we send our request to
zmsg_t *reply = mdcli_send (session, "mmi.service", &request);
if (reply) {
char *reply_code = zframe_strdup (zmsg_first (reply));
printf ("Lookup echo service: %s\n", reply_code);
free (reply_code);
zmsg_destroy (&reply);
}
else
printf ("E: no response from broker, make sure it's running\n");
mdcli_destroy (&session);
return 0;
}
mmiecho:C++ 中的 Majordomo 服务发现示例
#include "mdcliapi.hpp"
int main(int argc, char **argv) {
int verbose = (argc > 1 && strcmp(argv[1], "-v")== 0);
mdcli session("tcp://:5555", verbose);
zmsg* request = new zmsg("echo");
zmsg *reply = session.send("mmi.service", request);
if (reply) {
ustring status = reply->pop_front();
std::cout << "Lookup echo service: " <<(char *) status.c_str() << std::endl;
delete reply;
}
return 0;
}
mmiecho:C# 中的 Majordomo 服务发现示例
mmiecho:CL 中的 Majordomo 服务发现示例
mmiecho:Delphi 中的 Majordomo 服务发现示例
mmiecho:Erlang 中的 Majordomo 服务发现示例
mmiecho:Elixir 中的 Majordomo 服务发现示例
mmiecho:F# 中的 Majordomo 服务发现示例
mmiecho:Felix 中的 Majordomo 服务发现示例
mmiecho:Go 中的 Majordomo 服务发现示例
//
// MMI echo query example
//
// Author: amyangfei <amyangfei@gmail.com>
// Requires: http://github.com/alecthomas/gozmq
package main
import (
"fmt"
"os"
)
func main() {
verbose := len(os.Args) > 1 && os.Args[1] == "-v"
client := NewClient("tcp://:5555", verbose)
defer client.Close()
// This is the service we send our request to
reply := client.Send([]byte("mmi.service"), [][]byte{[]byte("echo")})
fmt.Println("here")
if len(reply) > 0 {
reply_code := reply[0]
fmt.Printf("Lookup echo service: %s\n", reply_code)
} else {
fmt.Printf("E: no response from broker, make sure it's running\n")
}
}
mmiecho:Haskell 中的 Majordomo 服务发现示例
mmiecho:Haxe 中的 Majordomo 服务发现示例
package ;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZMsg;
/**
* MMI echo query example
*/
class MMIEcho
{
public static function main() {
Lib.println("** MMIEcho (see: https://zguide.zeromq.cn/page:all#Service-Discovery)");
var argArr = Sys.args();
var verbose = (argArr.length > 1 && argArr[argArr.length - 1] == "-v");
var session = new MDCliAPI("tcp://:5555", verbose);
// This is the service we want to look up
var request = new ZMsg();
request.addString("echo");
// This is the service we send our request to
var reply = session.send("mmi.service", request);
if (reply != null) {
var replyCode = reply.first().toString();
Lib.println("Lookup echo service: " + replyCode);
} else
Lib.println("E: no response from broker, make sure it's running");
session.destroy();
}
}mmiecho:Java 中的 Majordomo 服务发现示例
package guide;
import org.zeromq.ZMsg;
/**
* MMI echo query example
*/
public class mmiecho
{
public static void main(String[] args)
{
boolean verbose = (args.length > 0 && "-v".equals(args[0]));
mdcliapi clientSession = new mdcliapi("tcp://:5555", verbose);
ZMsg request = new ZMsg();
// This is the service we want to look up
request.addString("echo");
// This is the service we send our request to
ZMsg reply = clientSession.send("mmi.service", request);
if (reply != null) {
String replyCode = reply.getFirst().toString();
System.out.printf("Lookup echo service: %s\n", replyCode);
}
else {
System.out.println("E: no response from broker, make sure it's running");
}
clientSession.destroy();
}
}
mmiecho:Julia 中的 Majordomo 服务发现示例
mmiecho:Lua 中的 Majordomo 服务发现示例
--
-- MMI echo query example
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"mdcliapi"
require"zmsg"
require"zhelpers"
local verbose = (arg[1] == "-v")
local session = mdcliapi.new("tcp://:5555", verbose)
-- This is the service we want to look up
local request = zmsg.new("echo")
-- This is the service we send our request to
local reply = session:send("mmi.service", request)
if (reply) then
printf ("Lookup echo service: %s\n", reply:body())
else
printf ("E: no response from broker, make sure it's running\n")
end
session:destroy()
mmiecho:Node.js 中的 Majordomo 服务发现示例
mmiecho:Objective-C 中的 Majordomo 服务发现示例
mmiecho:ooc 中的 Majordomo 服务发现示例
mmiecho:Perl 中的 Majordomo 服务发现示例
mmiecho:PHP 中的 Majordomo 服务发现示例
<?php
/*
* MMI echo query example
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include 'mdcliapi.php';
$verbose = $_SERVER['argc'] > 1 && $_SERVER['argv'][1] == '-v';
$session = new MDCli("tcp://:5555", $verbose);
// This is the service we want to look up
$request = new Zmsg();
$request->body_set("echo");
// This is the service we send our request to
$reply = $session->send("mmi.service", $request);
if ($reply) {
$reply_code = $reply->pop();
printf ("Lookup echo service: %s %s", $reply_code, PHP_EOL);
}
mmiecho:Python 中的 Majordomo 服务发现示例
"""
MMI echo query example
Author : Min RK <benjaminrk@gmail.com>
"""
import sys
from mdcliapi import MajorDomoClient
def main():
verbose = '-v' in sys.argv
client = MajorDomoClient("tcp://:5555", verbose)
request = b"echo"
reply = client.send(b"mmi.service", request)
if reply:
replycode = reply[0]
print ("Lookup echo service:", replycode)
else:
print ("E: no response from broker, make sure it's running")
if __name__ == '__main__':
main()
mmiecho:Q 中的 Majordomo 服务发现示例
mmiecho:Racket 中的 Majordomo 服务发现示例
mmiecho:Ruby 中的 Majordomo 服务发现示例
#!/usr/bin/env ruby
# MMI echo query example. Uses the mdcliapi2 API to hide all MDP aspects
#
# Author : Tom van Leeuwen <tom@vleeuwen.eu>
require './mdcliapi2.rb'
client = MajorDomoClient.new('tcp://:5555')
client.send('mmi.service', 'echo')
reply = client.recv
puts "Lookup echo service: #{reply}"
mmiecho:Rust 中的 Majordomo 服务发现示例
mmiecho:Scala 中的 Majordomo 服务发现示例
mmiecho:Tcl 中的 Majordomo 服务发现示例
#
# MMI echo query example
#
lappend auto_path .
package require MDClient 1.0
set verbose 0
foreach {k v} $argv {
if {$k eq "-v"} { set verbose 1 }
}
set session [MDClient new "tcp://:5555" $verbose]
foreach service {echo nonexisting} {
set reply [$session send "mmi.service" $service]
if {[llength $reply]} {
puts "Lookup '$service' service: [lindex $reply 0]"
} else {
puts "E: no response from broker, make sure it's running"
break
}
}
$session destroy
mmiecho:OCaml 中的 Majordomo 服务发现示例
在工作节点运行和不运行的情况下尝试这个程序,你应该会看到这个小程序相应地报告“200”或“404”。我们示例代理中 MMI 的实现很简陋。例如,如果一个工作节点消失了,服务仍然显示为“存在”。实际上,代理应该在某个可配置的超时后移除没有工作节点的服务。
幂等服务 #
幂等性不是吃药就能有的东西。它意味着重复操作是安全的。检查时钟是幂等的。把信用卡借给孩子则不是。虽然许多客户端到服务器的使用场景是幂等的,但有些不是。幂等使用场景的例子包括
-
无状态任务分发,即服务器是无状态工作节点的流水线,它们完全基于请求提供的状态计算应答。在这种情况下,多次执行同一请求是安全的(尽管效率不高)。
-
将逻辑地址转换为绑定或连接端点的名称服务。在这种情况下,多次进行相同的查找请求是安全的。
以下是非幂等使用场景的例子
-
日志服务。人们不希望同一条日志信息被记录多次。
-
任何对下游节点有影响的服务,例如,向其他节点发送信息。如果该服务多次收到同一请求,下游节点将收到重复的信息。
-
以某种非幂等方式修改共享数据的任何服务;例如,一个扣除银行账户金额的服务,如果没有额外处理,就不是幂等的。
当我们的服务器应用程序不是幂等时,我们必须更仔细地考虑它们究竟会在何时崩溃。如果应用程序在空闲时或处理请求时崩溃,通常没问题。我们可以使用数据库事务来确保借记和贷记(如果发生的话)总是同时完成。如果服务器在发送应答时崩溃,那是个问题,因为就它而言,它已经完成了工作。
如果网络在应答返回客户端的途中中断,同样的问题也会发生。客户端会认为服务器崩溃了并重新发送请求,服务器会重复同样的工作,这不是我们想要的。
为了处理非幂等操作,可以使用相当标准的解决方案:检测并拒绝重复请求。这意味着
-
客户端必须为每个请求加上一个唯一的客户端标识符和一个唯一的消息编号。
-
服务器在发送应答之前,使用客户端 ID 和消息编号的组合作为键来存储应答。
-
服务器在收到来自某个客户端的请求时,首先检查是否有针对该客户端 ID 和消息编号的应答。如果有,它不会处理该请求,而只是重新发送应答。
断开连接可靠性 (Titanic 模式) #
一旦你意识到 Majordomo 是一个“可靠的”消息代理,你可能会想添加一些旋转的铁锈(即基于铁的硬盘盘片)。毕竟,这对所有企业消息系统都有效。这个想法如此诱人,以至于不得不对其持否定态度有点令人伤心。但冷酷的犬儒主义是我的专长之一。所以,你不希望基于“铁锈”的代理位于你架构中心的一些原因有
-
正如你所见,Lazy Pirate 客户端表现得非常出色。它适用于各种架构,从直接客户端到服务器到分布式队列代理。它确实倾向于假设工作节点是无状态和幂等的。但我们可以在不依赖“铁锈”的情况下绕过这个限制。
-
“铁锈”带来了一系列问题,从性能低下到需要管理、修复和处理清晨 6 点的崩溃,因为它们不可避免地会在日常运营开始时出现问题。Pirate 模式的总体美妙之处在于它们的简单性。它们不会崩溃。如果你仍然担心硬件问题,你可以转向完全没有代理的对等模式。我将在本章后面解释。
然而,话虽如此,基于“铁锈”的可靠性有一个合理的用例,那就是异步断开连接的网络。它解决了 Pirate 的一个主要问题,即客户端必须实时等待应答。如果客户端和工作节点只是间歇性地连接(可以类比电子邮件),我们就不能在客户端和工作节点之间使用无状态网络。我们必须在中间层维护状态。
于是,这里是 Titanic 模式,在这种模式下,我们将消息写入磁盘以确保它们永不丢失,无论客户端和工作节点的连接多么间歇性。正如我们在服务发现中所做的那样,我们将 Titanic 叠加在 MDP 之上,而不是对其进行扩展。这样做非常省力,因为这意味着我们可以在一个专门的工作节点中实现我们的即发即忘可靠性,而不是在代理中。这对于以下几个原因来说非常出色
- 它 容易得多,因为我们分而治之:代理处理消息路由,工作节点处理可靠性。
- 它允许我们将用一种语言编写的代理与用另一种语言编写的工作节点混合使用。
- 它允许我们独立地发展即发即忘技术。
唯一的缺点是代理和硬盘之间多了一次网络跳跃。但这些好处绝对值得。
有许多方法可以构建持久化的请求-应答架构。我们将尝试一种简单且无痛的方法。在研究了几个小时后,我能想到的最简单的设计是“代理服务”。也就是说,Titanic 完全不影响工作节点。如果客户端希望立即获得应答,它就直接与服务对话,并希望服务可用。如果客户端乐意等待一段时间,它就会转而与 Titanic 对话,并问:“嘿,伙计,在我去买菜的时候,你能帮我处理这件事吗?”
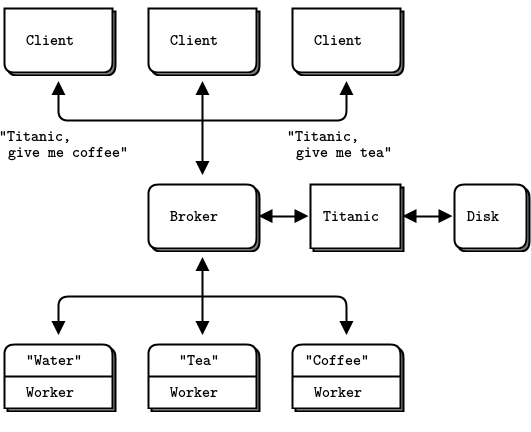
因此,Titanic 既是工作节点又是客户端。客户端和 Titanic 之间的对话大致如下
- 客户端:请帮我接受这个请求。Titanic:好的,完成了。
- 客户端:你有我的应答吗?Titanic:是的,在这里。或者,不,还没有。
- 客户端:好的,你现在可以清除那个请求了,我很满意。Titanic:好的,完成了。
而 Titanic 与代理和工作节点之间的对话是这样的
- Titanic:嘿,代理,有 coffee 服务吗?代理:嗯,好像有。
- Titanic:嘿,coffee 服务,请帮我处理这件事。
- Coffee:当然,给你。
- Titanic:太好了!
你可以仔细研究这种情况以及可能的失败场景。如果工作节点在处理请求时崩溃,Titanic 会无限次重试。如果应答在某个地方丢失,Titanic 会重试。如果请求被处理了但客户端没有收到应答,它会再次请求。如果 Titanic 在处理请求或应答时崩溃,客户端会再次尝试。只要请求被完全提交到安全存储中,工作就不会丢失。
握手过程有些冗长,但可以进行管道化,即客户端可以使用异步 Majordomo 模式处理大量工作,然后在稍后获取应答。
我们需要某种方法让客户端请求 它的 应答。我们将有很多客户端请求相同的服务,并且客户端会以不同的身份消失和重新出现。这里有一个简单、合理安全的解决方案
- 每个请求生成一个通用唯一标识符 (UUID),Titanic 在将请求排队后将其返回给客户端。
- 当客户端请求应答时,它必须指定原始请求的 UUID。
在实际情况中,客户端可能希望安全地存储其请求 UUID,例如,在本地数据库中。
在我们急着去写另一个正式规范(真有趣!)之前,让我们考虑一下客户端如何与 Titanic 对话。一种方法是使用单个服务并向其发送三种不同的请求类型。另一种看起来更简单的方法是使用三种服务
- titanic.request:存储请求消息,并返回该请求的 UUID。
- titanic.reply:根据给定的请求 UUID 获取应答(如果可用)。
- titanic.close:确认应答已存储并处理。
我们只需创建一个多线程工作节点,正如我们从 ZeroMQ 的多线程经验中看到的那样,这是非常简单的。然而,让我们首先勾勒出 Titanic 在 ZeroMQ 消息和帧方面的样子。这为我们提供了 Titanic 服务协议 (TSP)。
使用 TSP 对客户端应用程序来说显然比直接通过 MDP 访问服务工作量更大。以下是最短的健壮“echo”客户端示例
ticlient:Ada 中的 Titanic 客户端示例
ticlient:Basic 中的 Titanic 客户端示例
ticlient:C 中的 Titanic 客户端示例
// Titanic client example
// Implements client side of https://rfc.zeromq.cn/spec:9
// Lets build this source without creating a library
#include "mdcliapi.c"
// Calls a TSP service
// Returns response if successful (status code 200 OK), else NULL
//
static zmsg_t *
s_service_call (mdcli_t *session, char *service, zmsg_t **request_p)
{
zmsg_t *reply = mdcli_send (session, service, request_p);
if (reply) {
zframe_t *status = zmsg_pop (reply);
if (zframe_streq (status, "200")) {
zframe_destroy (&status);
return reply;
}
else
if (zframe_streq (status, "400")) {
printf ("E: client fatal error, aborting\n");
exit (EXIT_FAILURE);
}
else
if (zframe_streq (status, "500")) {
printf ("E: server fatal error, aborting\n");
exit (EXIT_FAILURE);
}
}
else
exit (EXIT_SUCCESS); // Interrupted or failed
zmsg_destroy (&reply);
return NULL; // Didn't succeed; don't care why not
}
// .split main task
// The main task tests our service call by sending an echo request:
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && streq (argv [1], "-v"));
mdcli_t *session = mdcli_new ("tcp://:5555", verbose);
// 1. Send 'echo' request to Titanic
zmsg_t *request = zmsg_new ();
zmsg_addstr (request, "echo");
zmsg_addstr (request, "Hello world");
zmsg_t *reply = s_service_call (
session, "titanic.request", &request);
zframe_t *uuid = NULL;
if (reply) {
uuid = zmsg_pop (reply);
zmsg_destroy (&reply);
zframe_print (uuid, "I: request UUID ");
}
// 2. Wait until we get a reply
while (!zctx_interrupted) {
zclock_sleep (100);
request = zmsg_new ();
zmsg_add (request, zframe_dup (uuid));
zmsg_t *reply = s_service_call (
session, "titanic.reply", &request);
if (reply) {
char *reply_string = zframe_strdup (zmsg_last (reply));
printf ("Reply: %s\n", reply_string);
free (reply_string);
zmsg_destroy (&reply);
// 3. Close request
request = zmsg_new ();
zmsg_add (request, zframe_dup (uuid));
reply = s_service_call (session, "titanic.close", &request);
zmsg_destroy (&reply);
break;
}
else {
printf ("I: no reply yet, trying again...\n");
zclock_sleep (5000); // Try again in 5 seconds
}
}
zframe_destroy (&uuid);
mdcli_destroy (&session);
return 0;
}
ticlient:C++ 中的 Titanic 客户端示例
//
// created by Jinyang Shao on 9/3/2024
//
#include "mdcliapi.hpp"
static zmsg*
s_service_call(mdcli* session, std::string service, zmsg *&request) {
zmsg* reply = session->send(service, request);
if (reply) {
std::string status = (char *)reply->pop_front().c_str();
if (status.compare("200") == 0) {
return reply;
} else if (status.compare("400") == 0) {
std::cout << "E: client fatal error, aborting\n" << std::endl;
exit(EXIT_FAILURE);
} else if (status.compare("500") == 0) {
std::cout << "E: server fatal error, aborting\n" << std::endl;
exit(EXIT_FAILURE);
}
} else {
exit(EXIT_SUCCESS); // interrupted or failed
}
delete reply;
return nullptr; // Didn't succeed; don't care why not
}
// .split main task
// The main task tests our service call by sending an echo request:
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && strcmp (argv [1], "-v") == 0);
mdcli session("tcp://:5555", verbose);
session.set_timeout(3000);
session.set_retries(10);
// 1. Send 'echo' request to Titanic
zmsg *request = new zmsg("Hello world");
request->push_front("echo");
zmsg *reply = s_service_call(&session, "titanic.request", request);
ustring uuid;
if (reply) {
uuid = reply->pop_front();
delete reply;
std::cout << "I: request UUID: " << uuid.c_str() << std::endl;
}
// 2. Wait until we get a reply
while (!s_interrupted) {
s_sleep(100); // 100 ms
request = new zmsg((char *)uuid.c_str());
zmsg *reply = s_service_call(&session, "titanic.reply", request);
if (reply) {
std::cout << "Reply: " << reply->body() << std::endl;
delete reply;
// 3. Close request
request = new zmsg((char *)uuid.c_str());
reply = s_service_call(&session, "titanic.close", request);
delete reply;
break;
} else {
std::cout << "I: no reply yet, trying again...\n" << std::endl;
s_sleep(5000); // 5 sec
}
}
return 0;
}
ticlient:C# 中的 Titanic 客户端示例
ticlient:CL 中的 Titanic 客户端示例
ticlient:Delphi 中的 Titanic 客户端示例
ticlient:Erlang 中的 Titanic 客户端示例
ticlient:Elixir 中的 Titanic 客户端示例
ticlient:F# 中的 Titanic 客户端示例
ticlient:Felix 中的 Titanic 客户端示例
ticlient:Go 中的 Titanic 客户端示例
ticlient:Haskell 中的 Titanic 客户端示例
ticlient:Haxe 中的 Titanic 客户端示例
package ;
import haxe.Stack;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQException;
import MDP;
import MDCliAPI;
/**
* Titanic client example
* Implements client side of https://rfc.zeromq.cn/spec:9
*
* Wraps MDCltAPI
*
* @author Richard J Smith
*/
class TIClient
{
public static function main()
{
Lib.println("** TIClient (see: https://zguide.zeromq.cn/page:all#Disconnected-Reliability-Titanic-Pattern)");
var argArr = Sys.args();
var verbose = (argArr.length > 1 && argArr[argArr.length - 1] == "-v");
var session = new TICltAPI("tcp://:5555", verbose);
// 1. Send 'echo' request to Titanic
var request = ZMsg.newStringMsg("Hello World");
var reply = session.request("echo", request);
var uuid:ZFrame = null;
if (reply != null) {
uuid = reply.pop();
Lib.println("I: request UUID:" + uuid.toString());
// 2. Wait until we get a reply
while (!ZMQ.isInterrupted()) {
Sys.sleep(0.1);
reply = session.reply(uuid);
if (reply != null) {
var replyString = reply.last().toString();
Lib.println("I: Reply: " + replyString);
// 3. Close request
reply = session.close(uuid);
break;
} else {
Lib.println("I: no reply yet, trying again...");
Sys.sleep(5.0); // Try again in 5 seconds
}
}
}
session.destroy();
}
}
/**
* Titanic Protocol Client API class (synchronous)
*/
private class TICltAPI {
// Private instance fields
/** Synchronous Majordomo Client API object */
private var clientAPI:MDCliAPI;
/** Connection string to reach broker */
private var broker:String;
/** Print activity to stdout */
private var verbose:Bool;
/** Logger function used in verbose mode */
private var log:Dynamic->Void;
/**
* Constructor
* @param broker
* @param verbose
*/
public function new(broker:String, ?verbose:Bool=false, ?logger:Dynamic->Void) {
this.broker = broker;
this.verbose = verbose;
this.clientAPI = new MDCliAPI(broker, verbose, logger);
if (logger != null)
log = logger;
else
log = Lib.println;
clientAPI.connectToBroker();
}
/**
* Destructor
*/
public function destroy() {
clientAPI.destroy();
}
/**
* Sends a TI request message to a designated MD service, via a TI proxy
* Takes ownership of request message and destroys it when sent.
* @param service
* @param request
* @return
*/
public function request(service:String, request:ZMsg):ZMsg {
request.pushString(service);
var ret = callService("titanic.request", request);
return {
if (ret.OK)
ret.msg;
else
null;
};
}
/**
* Sends a TI Reply message to a TI server
* @param uuid UUID of original TI Request message, as returned from previous sendRequest method call
* @return
*/
public function reply(uuid:ZFrame):ZMsg {
var request = new ZMsg();
request.add(uuid.duplicate());
var ret = callService("titanic.reply", request);
return {
if (ret.OK)
ret.msg;
else
null;
};
}
/**
* Sends a TI Close message to a TI server
* @param uuid UUID of original TI Request message, as returned from previous sendRequest method call
* @return
*/
public function close(uuid:ZFrame):ZMsg {
var request = new ZMsg();
request.add(uuid.duplicate());
var ret = callService("titanic.close", request);
return {
if (ret.OK)
ret.msg;
else
null;
};
}
/**
* Calls TSP service
* Returns response if successful (status code 200 OK), else null
* @param service
* @param request
* @return
*/
private function callService(service:String, request:ZMsg): { msg:ZMsg, OK:Bool} {
var reply = clientAPI.send(service, request);
if (reply != null) {
var status = reply.pop();
if (status.streq("200")) {
return {msg:reply, OK:true};
}
else
if (status.streq("400")) {
log("E: client fatal error");
return {msg:null, OK: false};
}
else
if (status.streq("500")) {
log("E: server fatal error");
return {msg:null, OK:false};
}
}
return {msg:null, OK:true}; // Interrupted or failed
}
}ticlient:Java 中的 Titanic 客户端示例
package guide;
// Titanic client example
// Implements client side of https://rfc.zeromq.cn/spec:9
// Calls a TSP service
// Returns response if successful (status code 200 OK), else NULL
//
import org.zeromq.ZFrame;
import org.zeromq.ZMsg;
public class ticlient
{
static ZMsg serviceCall(mdcliapi session, String service, ZMsg request)
{
ZMsg reply = session.send(service, request);
if (reply != null) {
ZFrame status = reply.pop();
if (status.streq("200")) {
status.destroy();
return reply;
}
else if (status.streq("400")) {
System.out.println("E: client fatal error, aborting");
}
else if (status.streq("500")) {
System.out.println("E: server fatal error, aborting");
}
reply.destroy();
}
return null; // Didn't succeed; don't care why not
}
public static void main(String[] args) throws Exception
{
boolean verbose = (args.length > 0 && args[0].equals("-v"));
mdcliapi session = new mdcliapi("tcp://:5555", verbose);
// 1. Send 'echo' request to Titanic
ZMsg request = new ZMsg();
request.add("echo");
request.add("Hello world");
ZMsg reply = serviceCall(session, "titanic.request", request);
ZFrame uuid = null;
if (reply != null) {
uuid = reply.pop();
reply.destroy();
uuid.print("I: request UUID ");
}
// 2. Wait until we get a reply
while (!Thread.currentThread().isInterrupted()) {
Thread.sleep(100);
request = new ZMsg();
request.add(uuid.duplicate());
reply = serviceCall(session, "titanic.reply", request);
if (reply != null) {
String replyString = reply.getLast().toString();
System.out.printf("Reply: %s\n", replyString);
reply.destroy();
// 3. Close request
request = new ZMsg();
request.add(uuid.duplicate());
reply = serviceCall(session, "titanic.close", request);
reply.destroy();
break;
}
else {
System.out.println("I: no reply yet, trying again...");
Thread.sleep(5000); // Try again in 5 seconds
}
}
uuid.destroy();
session.destroy();
}
}
ticlient:Julia 中的 Titanic 客户端示例
ticlient:Lua 中的 Titanic 客户端示例
ticlient:Node.js 中的 Titanic 客户端示例
ticlient:Objective-C 中的 Titanic 客户端示例
ticlient:ooc 中的 Titanic 客户端示例
ticlient:Perl 中的 Titanic 客户端示例
ticlient:PHP 中的 Titanic 客户端示例
<?php
/* Titanic client example
* Implements client side of https://rfc.zeromq.cn/spec:9
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include_once 'mdcliapi.php';
/**
* Calls a TSP service
* Returns response if successful (status code 200 OK), else NULL
*
* @param string $session
* @param string $service
* @param Zmsg $request
*/
function s_service_call($session, $service, $request)
{
$reply = $session->send($service, $request);
if ($reply) {
$status = $reply->pop();
if ($status == "200") {
return $reply;
} elseif ($status == "404") {
echo "E: client fatal error, aborting", PHP_EOL;
exit(1);
} elseif ($status == "500") {
echo "E: server fatal error, aborting", PHP_EOL;
exit(1);
}
} else {
exit(0);
}
return NULL; // Didn't succeed, don't care why not
}
$verbose = $_SERVER['argc'] > 1 && $_SERVER['argv'][1] == '-v';
$session = new Mdcli("tcp://:5555", $verbose);
// 1. Send 'echo' request to Titanic
$request = new Zmsg();
$request->push("Hello world");
$request->push("echo");
$reply = s_service_call($session, "titanic.request", $request);
$uuid = null;
if ($reply) {
$uuid = $reply->pop();
printf("I: request UUID %s %s", $uuid, PHP_EOL);
}
// 2. Wait until we get a reply
while (true) {
usleep(100000);
$request = new Zmsg();
$request->push($uuid);
$reply = s_service_call ($session, "titanic.reply", $request);
if ($reply) {
$reply_string = $reply->last();
printf ("Reply: %s %s", $reply_string, PHP_EOL);
// 3. Close request
$request = new Zmsg();
$request->push($uuid);
$reply = s_service_call ($session, "titanic.close", $request);
break;
} else {
echo "I: no reply yet, trying again...", PHP_EOL;
usleep (5000000); // Try again in 5 seconds
}
}
ticlient:Python 中的 Titanic 客户端示例
"""
Titanic client example
Implements client side of http:rfc.zeromq.org/spec:9
Author : Min RK <benjaminrk@gmail.com>
"""
import sys
import time
from mdcliapi import MajorDomoClient
def service_call (session, service, request):
"""Calls a TSP service
Returns reponse if successful (status code 200 OK), else None
"""
reply = session.send(service, request)
if reply:
status = reply.pop(0)
if status == b"200":
return reply
elif status == b"400":
print ("E: client fatal error 400, aborting")
sys.exit (1)
elif status == b"500":
print ("E: server fatal error 500, aborting")
sys.exit (1)
else:
sys.exit (0); # Interrupted or failed
def main():
verbose = '-v' in sys.argv
session = MajorDomoClient("tcp://:5555", verbose)
# 1. Send 'echo' request to Titanic
request = [b"echo", b"Hello world"]
reply = service_call(session, b"titanic.request", request)
uuid = None
if reply:
uuid = reply.pop(0)
print ("I: request UUID ", uuid)
# 2. Wait until we get a reply
while True:
time.sleep (.1)
request = [uuid]
reply = service_call (session, b"titanic.reply", request)
if reply:
reply_string = reply[-1]
print ("I: reply:", reply_string)
# 3. Close request
request = [uuid]
reply = service_call (session, b"titanic.close", request)
break
else:
print ("I: no reply yet, trying again...")
time.sleep(5) # Try again in 5 seconds
return 0
if __name__ == '__main__':
main()
ticlient:Q 中的 Titanic 客户端示例
ticlient:Racket 中的 Titanic 客户端示例
ticlient:Ruby 中的 Titanic 客户端示例
#!/usr/bin/env ruby
# Titanic client example
# Implements client side of http:rfc.zeromq.org/spec:9
#
# Author: Tom van Leeuwen <tom@vleeuwen.eu>
# Based on Python example by Min RK
require './mdcliapi2.rb'
def service_call session, service, request
# Returns reponse if successful (status code 200 OK), else nil
session.send service, request
reply = session.recv
if reply
status = reply.shift
case status
when '200'
return reply
when /^[45]00$/
puts "E: client fatal error, aborting"
exit 1
end
exit 0
end
end
session = MajorDomoClient.new('tcp://:5555')
# 1. Send 'echo' request to Titanic
request = ['echo', 'Hello world']
reply = service_call session, 'titanic.request', request
uuid = nil
if reply
uuid = reply.shift
puts "I: request UUID #{uuid}"
end
# 2. Wait until we get a reply
loop do
sleep 10.1
reply = service_call session, 'titanic.reply', uuid
if reply
puts "Reply: #{reply.last}"
# 3. Close request
reply = service_call session, 'titanic.close', uuid
break
else
puts "I: no reply yet, trying again..."
sleep 2
end
end
ticlient:Rust 中的 Titanic 客户端示例
ticlient:Scala 中的 Titanic 客户端示例
ticlient:Tcl 中的 Titanic 客户端示例
#
# Titanic client example
# Implements client side of https://rfc.zeromq.cn/spec:9
lappend auto_path .
package require MDClient 1.0
set verbose 0
foreach {k v} $argv {
if {$k eq "-v"} { set verbose 1 }
}
# Calls a TSP service
# Returns reponse if successful (status code 200 OK), else NULL
#
proc s_service_call {session service request} {
set reply [$session send $service $request]
if {[llength $reply]} {
set status [zmsg pop reply]
switch -exact -- $status {
200 {
return $reply
}
400 {
puts "E: client fatal error, aborting"
exit 1
}
500 {
puts "E: server fatal error, aborting"
exit 1
}
}
} else {
puts "I: Interrupted or failed"
exit 0 ;# Interrupted or failed
}
return {} ;# Didn't succeed, don't care why not
}
set session [MDClient new "tcp://:5555" $verbose]
# 1. Send 'echo' request to Titanic
set request [list "echo" "Hello world"]
set reply [s_service_call $session "titanic.request" $request]
set uuid ""
if {[llength $reply]} {
set uuid [zmsg pop reply]
puts "I: request UUID [zmsg dump [list $uuid]]"
}
# 2. Wait until we get a reply
while {1} {
after 100
set request [list $uuid]
set reply [s_service_call $session "titanic.reply" $request]
if {[llength $reply]} {
set reply_string [lindex $reply end]
puts "Reply: $reply_string"
# 3. Close request
s_service_call $session "titanic.close" $request
break
} else {
puts "I: no reply yet, trying again..."
after 5000
}
}
$session destroy
ticlient:OCaml 中的 Titanic 客户端示例
当然,这可以也应该被封装在某种框架或 API 中。让普通应用程序开发者学习消息传递的全部细节是不健康的:这会让他们伤脑筋,耗费时间,并且提供了太多制造复杂 bug 的方式。此外,这也使得添加智能变得困难。
例如,这个客户端在每个请求上都会阻塞,而在实际应用程序中,我们希望在任务执行期间能够做其他有用的工作。这需要一些不简单的管道来构建后台线程并与之干净地通信。这是那种你想封装在一个简单易用的 API 中的东西,这样普通开发者就不会误用。这与我们用于 Majordomo 的方法相同。
以下是 Titanic 的实现。这个服务器按照提议,使用三个线程处理这三个服务。它使用最简单粗暴的方法实现了完全的磁盘持久化:每个消息一个文件。它简单得令人害怕。唯一复杂的部分是它维护了一个单独的所有请求队列,以避免反复读取目录。
titanic:Ada 中的 Titanic 代理示例
titanic:Basic 中的 Titanic 代理示例
titanic:C 中的 Titanic 代理示例
// Titanic service
// Implements server side of https://rfc.zeromq.cn/spec:9
// Lets us build this source without creating a library
#include "mdwrkapi.c"
#include "mdcliapi.c"
#include "zfile.h"
#include <uuid/uuid.h>
// Return a new UUID as a printable character string
// Caller must free returned string when finished with it
static char *
s_generate_uuid (void)
{
char hex_char [] = "0123456789ABCDEF";
char *uuidstr = zmalloc (sizeof (uuid_t) * 2 + 1);
uuid_t uuid;
uuid_generate (uuid);
int byte_nbr;
for (byte_nbr = 0; byte_nbr < sizeof (uuid_t); byte_nbr++) {
uuidstr [byte_nbr * 2 + 0] = hex_char [uuid [byte_nbr] >> 4];
uuidstr [byte_nbr * 2 + 1] = hex_char [uuid [byte_nbr] & 15];
}
return uuidstr;
}
// Returns freshly allocated request filename for given UUID
#define TITANIC_DIR ".titanic"
static char *
s_request_filename (char *uuid) {
char *filename = malloc (256);
snprintf (filename, 256, TITANIC_DIR "/%s.req", uuid);
return filename;
}
// Returns freshly allocated reply filename for given UUID
static char *
s_reply_filename (char *uuid) {
char *filename = malloc (256);
snprintf (filename, 256, TITANIC_DIR "/%s.rep", uuid);
return filename;
}
// .split Titanic request service
// The {{titanic.request}} task waits for requests to this service. It writes
// each request to disk and returns a UUID to the client. The client picks
// up the reply asynchronously using the {{titanic.reply}} service:
static void
titanic_request (void *args, zctx_t *ctx, void *pipe)
{
mdwrk_t *worker = mdwrk_new (
"tcp://:5555", "titanic.request", 0);
zmsg_t *reply = NULL;
while (true) {
// Send reply if it's not null
// And then get next request from broker
zmsg_t *request = mdwrk_recv (worker, &reply);
if (!request)
break; // Interrupted, exit
// Ensure message directory exists
zfile_mkdir (TITANIC_DIR);
// Generate UUID and save message to disk
char *uuid = s_generate_uuid ();
char *filename = s_request_filename (uuid);
FILE *file = fopen (filename, "w");
assert (file);
zmsg_save (request, file);
fclose (file);
free (filename);
zmsg_destroy (&request);
// Send UUID through to message queue
reply = zmsg_new ();
zmsg_addstr (reply, uuid);
zmsg_send (&reply, pipe);
// Now send UUID back to client
// Done by the mdwrk_recv() at the top of the loop
reply = zmsg_new ();
zmsg_addstr (reply, "200");
zmsg_addstr (reply, uuid);
free (uuid);
}
mdwrk_destroy (&worker);
}
// .split Titanic reply service
// The {{titanic.reply}} task checks if there's a reply for the specified
// request (by UUID), and returns a 200 (OK), 300 (Pending), or 400
// (Unknown) accordingly:
static void *
titanic_reply (void *context)
{
mdwrk_t *worker = mdwrk_new (
"tcp://:5555", "titanic.reply", 0);
zmsg_t *reply = NULL;
while (true) {
zmsg_t *request = mdwrk_recv (worker, &reply);
if (!request)
break; // Interrupted, exit
char *uuid = zmsg_popstr (request);
char *req_filename = s_request_filename (uuid);
char *rep_filename = s_reply_filename (uuid);
if (zfile_exists (rep_filename)) {
FILE *file = fopen (rep_filename, "r");
assert (file);
reply = zmsg_load (NULL, file);
zmsg_pushstr (reply, "200");
fclose (file);
}
else {
reply = zmsg_new ();
if (zfile_exists (req_filename))
zmsg_pushstr (reply, "300"); //Pending
else
zmsg_pushstr (reply, "400"); //Unknown
}
zmsg_destroy (&request);
free (uuid);
free (req_filename);
free (rep_filename);
}
mdwrk_destroy (&worker);
return 0;
}
// .split Titanic close task
// The {{titanic.close}} task removes any waiting replies for the request
// (specified by UUID). It's idempotent, so it is safe to call more than
// once in a row:
static void *
titanic_close (void *context)
{
mdwrk_t *worker = mdwrk_new (
"tcp://:5555", "titanic.close", 0);
zmsg_t *reply = NULL;
while (true) {
zmsg_t *request = mdwrk_recv (worker, &reply);
if (!request)
break; // Interrupted, exit
char *uuid = zmsg_popstr (request);
char *req_filename = s_request_filename (uuid);
char *rep_filename = s_reply_filename (uuid);
zfile_delete (req_filename);
zfile_delete (rep_filename);
free (uuid);
free (req_filename);
free (rep_filename);
zmsg_destroy (&request);
reply = zmsg_new ();
zmsg_addstr (reply, "200");
}
mdwrk_destroy (&worker);
return 0;
}
// .split worker task
// This is the main thread for the Titanic worker. It starts three child
// threads; for the request, reply, and close services. It then dispatches
// requests to workers using a simple brute force disk queue. It receives
// request UUIDs from the {{titanic.request}} service, saves these to a disk
// file, and then throws each request at MDP workers until it gets a
// response.
static int s_service_success (char *uuid);
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && streq (argv [1], "-v"));
zctx_t *ctx = zctx_new ();
void *request_pipe = zthread_fork (ctx, titanic_request, NULL);
zthread_new (titanic_reply, NULL);
zthread_new (titanic_close, NULL);
// Main dispatcher loop
while (true) {
// We'll dispatch once per second, if there's no activity
zmq_pollitem_t items [] = { { request_pipe, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (items, 1, 1000 * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
if (items [0].revents & ZMQ_POLLIN) {
// Ensure message directory exists
zfile_mkdir (TITANIC_DIR);
// Append UUID to queue, prefixed with '-' for pending
zmsg_t *msg = zmsg_recv (request_pipe);
if (!msg)
break; // Interrupted
FILE *file = fopen (TITANIC_DIR "/queue", "a");
char *uuid = zmsg_popstr (msg);
fprintf (file, "-%s\n", uuid);
fclose (file);
free (uuid);
zmsg_destroy (&msg);
}
// Brute force dispatcher
char entry [] = "?.......:.......:.......:.......:";
FILE *file = fopen (TITANIC_DIR "/queue", "r+");
while (file && fread (entry, 33, 1, file) == 1) {
// UUID is prefixed with '-' if still waiting
if (entry [0] == '-') {
if (verbose)
printf ("I: processing request %s\n", entry + 1);
if (s_service_success (entry + 1)) {
// Mark queue entry as processed
fseek (file, -33, SEEK_CUR);
fwrite ("+", 1, 1, file);
fseek (file, 32, SEEK_CUR);
}
}
// Skip end of line, LF or CRLF
if (fgetc (file) == '\r')
fgetc (file);
if (zctx_interrupted)
break;
}
if (file)
fclose (file);
}
return 0;
}
// .split try to call a service
// Here, we first check if the requested MDP service is defined or not,
// using a MMI lookup to the Majordomo broker. If the service exists,
// we send a request and wait for a reply using the conventional MDP
// client API. This is not meant to be fast, just very simple:
static int
s_service_success (char *uuid)
{
// Load request message, service will be first frame
char *filename = s_request_filename (uuid);
FILE *file = fopen (filename, "r");
free (filename);
// If the client already closed request, treat as successful
if (!file)
return 1;
zmsg_t *request = zmsg_load (NULL, file);
fclose (file);
zframe_t *service = zmsg_pop (request);
char *service_name = zframe_strdup (service);
// Create MDP client session with short timeout
mdcli_t *client = mdcli_new ("tcp://:5555", false);
mdcli_set_timeout (client, 1000); // 1 sec
mdcli_set_retries (client, 1); // only 1 retry
// Use MMI protocol to check if service is available
zmsg_t *mmi_request = zmsg_new ();
zmsg_add (mmi_request, service);
zmsg_t *mmi_reply = mdcli_send (client, "mmi.service", &mmi_request);
int service_ok = (mmi_reply
&& zframe_streq (zmsg_first (mmi_reply), "200"));
zmsg_destroy (&mmi_reply);
int result = 0;
if (service_ok) {
zmsg_t *reply = mdcli_send (client, service_name, &request);
if (reply) {
filename = s_reply_filename (uuid);
FILE *file = fopen (filename, "w");
assert (file);
zmsg_save (reply, file);
fclose (file);
free (filename);
result = 1;
}
zmsg_destroy (&reply);
}
else
zmsg_destroy (&request);
mdcli_destroy (&client);
free (service_name);
return result;
}
titanic:C++ 中的 Titanic 代理示例
#include <iostream>
#include <random>
#include <sstream>
#include <iomanip>
#include <thread>
#include <filesystem>
#include <fstream>
#include "mdcliapi.hpp"
#include "mdwrkapi.hpp"
#define ZMQ_POLL_MSEC 1
#define BROKER_ENDPOINT "tcp://:5555"
std::string generateUUID() {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(0, 15);
std::uniform_int_distribution<> dis2(8, 11);
std::stringstream ss;
ss << std::hex;
for (int i = 0; i < 8; ++i) ss << dis(gen);
// ss << "-";
for (int i = 0; i < 4; ++i) ss << dis(gen);
ss << "4"; // UUID version 4
for (int i = 0; i < 3; ++i) ss << dis(gen);
// ss << "-";
ss << dis2(gen); // UUID variant
for (int i = 0; i < 3; ++i) ss << dis(gen);
// ss << "-";
for (int i = 0; i < 12; ++i) ss << dis(gen);
return ss.str();
}
// Returns freshly allocated request filename for given UUID
#define TITANIC_DIR ".titanic"
static std::string s_request_filename(std::string uuid) {
return std::string(TITANIC_DIR) + "/" + uuid + ".req";
}
// Returns freshly allocated reply filename for given UUID
static std::string s_reply_filename(std::string uuid) {
return std::string(TITANIC_DIR) + "/" + uuid + ".rep";
}
static bool s_zmsg_save(zmsg *msg, const std::filesystem::path &filepath) {
std::ofstream ofs(filepath);
if (ofs) {
while (msg->parts() > 0)
{
ofs << msg->pop_front().c_str() << std::endl;
}
std::cout << "File created and data written: " << filepath << std::endl;
return true;
}
else {
std::cerr << "Failed to create or write to file: " << filepath << std::endl;
return false;
}
}
static zmsg* s_zmsg_load(const std::filesystem::path &filepath) {
zmsg *msg = new zmsg();
std::ifstream ifs(filepath);
if (ifs) {
std::string line;
while (std::getline(ifs, line)) {
msg->push_back(line.c_str());
}
ifs.close();
return msg;
}
else {
std::cerr << "Failed to read file: " << filepath << std::endl;
return nullptr;
}
}
// .split Titanic request service
// The {{titanic.request}} task waits for requests to this service. It writes
// each request to disk and returns a UUID to the client. The client picks
// up the reply asynchronously using the {{titanic.reply}} service:
static void titanic_request(zmq::context_t *ctx) {
mdwrk *worker = new mdwrk(BROKER_ENDPOINT, "titanic.request", 0);
worker->set_heartbeat(3000);
zmsg *reply = nullptr;
// communicate with parent thread
zmq::socket_t pipe(*ctx, ZMQ_PAIR);
pipe.bind("inproc://titanic_request");
while (true) {
// Send reply if it's not null
// And then get next request from broker
zmsg *request = worker->recv(reply);
std::cout << "titanic_request: received request" << std::endl;
request->dump();
if (!request) {
break; // Interrupted, exit
}
// Ensure message directory exists
std::filesystem::path titanic_dir(TITANIC_DIR);
std::filesystem::create_directory(titanic_dir);
// std::cout << "I: creating " << TITANIC_DIR << " directory" << std::endl;
// Generate UUID and save message to disk
std::string uuid = generateUUID();
std::filesystem::path request_file(s_request_filename(uuid));
if (!s_zmsg_save(request, request_file)) {
break; // dump file failed, exit
}
delete request;
// Send UUID through to message queue
reply = new zmsg(uuid.c_str());
reply->send(pipe);
std::cout << "titanic_request: sent reply to parent" << std::endl;
// Now send UUID back to client
// Done by the mdwrk_recv() at the top of the loop
reply = new zmsg("200");
reply->push_back(uuid.c_str());
}
delete worker;
return;
}
// .split Titanic reply service
// The {{titanic.reply}} task checks if there's a reply for the specified
// request (by UUID), and returns a 200 (OK), 300 (Pending), or 400
// (Unknown) accordingly:
static void titanic_reply(zmq::context_t *ctx) {
mdwrk *worker = new mdwrk(BROKER_ENDPOINT, "titanic.reply", 0);
worker->set_heartbeat(3000);
zmsg *reply = nullptr;
while(true) {
zmsg *request = worker->recv(reply);
if (!request) {
break; // Interrupted, exit
}
std::string uuid = std::string((char *)request->pop_front().c_str());
std::filesystem::path request_filename(s_request_filename(uuid));
std::filesystem::path reply_filename(s_reply_filename(uuid));
// Try to read the reply file
if (std::filesystem::exists(reply_filename)) {
reply = s_zmsg_load(reply_filename);
assert(reply);
reply->push_front("200");
}
else {
reply = new zmsg();
if (std::filesystem::exists(request_filename)) {
reply->push_front("300"); //Pending
}
else {
reply->push_front("400"); //Unknown
}
}
delete request;
}
delete worker;
}
// .split Titanic close task
// The {{titanic.close}} task removes any waiting replies for the request
// (specified by UUID). It's idempotent, so it is safe to call more than
// once in a row:
static void titanic_close(zmq::context_t *ctx) {
mdwrk *worker = new mdwrk(BROKER_ENDPOINT, "titanic.close", 0);
worker->set_heartbeat(3000);
zmsg *reply = nullptr;
while (true) {
zmsg *request = worker->recv(reply);
if (!request) {
break; // Interrupted, exit
}
std::string uuid = std::string((char *)request->pop_front().c_str());
std::filesystem::path request_filename(s_request_filename(uuid));
std::filesystem::path reply_filename(s_reply_filename(uuid));
std::filesystem::remove(request_filename);
std::filesystem::remove(reply_filename);
delete request;
reply = new zmsg("200");
}
delete worker;
return;
}
// .split worker task
// This is the main thread for the Titanic worker. It starts three child
// threads; for the request, reply, and close services. It then dispatches
// requests to workers using a simple brute force disk queue. It receives
// request UUIDs from the {{titanic.request}} service, saves these to a disk
// file, and then throws each request at MDP workers until it gets a
// response.
static bool s_service_success(std::string uuid);
// simulate zthread_fork, create attached thread and return the pipe socket
std::pair<std::thread, zmq::socket_t> zthread_fork(zmq::context_t& ctx, void (*thread_func)(zmq::context_t*)) {
// create the pipe socket for the main thread to communicate with its child thread
zmq::socket_t pipe(ctx, ZMQ_PAIR);
pipe.connect("inproc://titanic_request");
// start child thread
std::thread t(thread_func, &ctx);
return std::make_pair(std::move(t), std::move(pipe));
}
int main(int argc, char *argv[]) {
// std::string uuid = generateUUID();
// std::cout << "Generated UUID: " << uuid << std::endl;
// return 0;
int verbose = (argc > 1 && strcmp(argv[1], "-v") == 0);
zmq::context_t ctx(1);
// start the child threads
auto [titanic_request_thread, request_pipe] = zthread_fork(ctx, titanic_request);
std::thread titanic_reply_thread(titanic_reply, &ctx);
titanic_reply_thread.detach();
std::thread titanic_close_thread(titanic_close, &ctx);
titanic_close_thread.detach();
if (verbose) {
std::cout << "I: all service threads started(request, reply, close)" << std::endl;
}
// Main dispatcher loop
while (true) {
// We'll dispatch once per second, if there's no activity
zmq::pollitem_t items[] = {
{request_pipe, 0, ZMQ_POLLIN, 0}
};
try {
zmq::poll(items, 1, 1000 * ZMQ_POLL_MSEC);
} catch(...) {
break; // Interrupted
}
std::filesystem::path titanic_dir(TITANIC_DIR);
if (items[0].revents & ZMQ_POLLIN) {
// Ensure message directory exists
std::cout << "I: creating " << TITANIC_DIR << " directory" << std::endl;
std::filesystem::create_directory(titanic_dir);
// Append UUID to queue, prefixed with '-' for pending
zmsg *msg = new zmsg(request_pipe);
if (!msg) {
break; // Interrupted
}
std::ofstream ofs(titanic_dir / "queue", std::ios::app); // create if not exist, append
std::string uuid = std::string((char *)msg->pop_front().c_str());
ofs << "-" << uuid << std::endl;
delete msg;
}
// Brute force dispatcher
// std::array<char, 33> entry; // "?.......:.......:.......:.......:"
std::string line;
bool need_commit = false;
std::vector<std::string> new_lines;
std::ifstream file(titanic_dir / "queue");
if (!file.is_open()) {
if (verbose) {
std::cout << "I: queue file not open" << std::endl;
}
continue;
}
if (verbose) {
std::cout << "I: read from queue file" << std::endl;
}
while (std::getline(file, line)) {
if (line[0] == '-') {
std::string uuid = line.substr(1, 32);
if (verbose) {
std::cout << "I: processing request " << uuid << std::endl;
}
if (s_service_success(uuid)) {
line[0] = '+'; // Mark completed
need_commit = true;
}
}
new_lines.push_back(line);
}
file.close();
// Commit update
if (need_commit) {
std::ofstream outfile(titanic_dir / "queue");
if (!outfile.is_open()) {
std::cerr << "I: unable to open queue file" << std::endl;
return 1;
}
for (const auto &line : new_lines) {
outfile << line << std::endl;
}
outfile.close();
}
}
return 0;
}
// .split try to call a service
// Here, we first check if the requested MDP service is defined or not,
// using a MMI lookup to the Majordomo broker. If the service exists,
// we send a request and wait for a reply using the conventional MDP
// client API. This is not meant to be fast, just very simple:
static bool s_service_success(std::string uuid) {
// Load request message, service will be first frame
std::filesystem::path request_filepath(s_request_filename(uuid));
std::ifstream ifs(request_filepath);
// If the client already closed request, treat as successful
if (!ifs) {
return 1;
}
zmsg *request = s_zmsg_load(request_filepath);
char* service_name = (char *)request->pop_front().c_str();
// Create MDP client session with short timeout
mdcli client(BROKER_ENDPOINT, 1);
client.set_timeout(1000); // 1 sec
client.set_retries(1);
// Use MMI protocol to check if service is available
zmsg *mmi_request = new zmsg();
mmi_request->push_back(service_name);
zmsg *mmi_reply = client.send("mmi.service", mmi_request);
bool service_ok = (mmi_reply && strcmp(mmi_reply->address(), "200")==0);
delete mmi_reply;
bool result = false;
if (service_ok) {
zmsg *reply = client.send(service_name, request);
if (reply) {
std::filesystem::path reply_filepath(s_reply_filename(uuid));
s_zmsg_save(reply, reply_filepath);
result = true;
}
delete reply;
} else {
std::cout << "service not available: " << service_name << std::endl;
delete request;
}
return result;
}
titanic:C# 中的 Titanic 代理示例
titanic:CL 中的 Titanic 代理示例
titanic:Delphi 中的 Titanic 代理示例
titanic:Erlang 中的 Titanic 代理示例
titanic:Elixir 中的 Titanic 代理示例
titanic:F# 中的 Titanic 代理示例
titanic:Felix 中的 Titanic 代理示例
titanic:Go 中的 Titanic 代理示例
titanic:Haskell 中的 Titanic 代理示例
titanic:Haxe 中的 Titanic 代理示例
package ;
import haxe.Stack;
import neko.Lib;
import neko.Sys;
import haxe.io.Input;
import neko.FileSystem;
import neko.io.File;
import neko.io.FileInput;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZThread;
import org.zeromq.ZMQException;
/**
* Titanic service
* Implements server side of https://rfc.zeromq.cn/spec:9
* @author Richard Smith
*/
class Titanic
{
/** Connection string to broker */
private var broker:String;
/** Print activity to stdout */
private var verbose:Bool;
/** Logger function used in verbose mode */
private var log:Dynamic->Void;
private static inline var UID = "0123456789ABCDEF";
private static inline var TITANIC_DIR = ".titanic";
/**
* Main method
*/
public static function main() {
Lib.println("** Titanic (see: https://zguide.zeromq.cn/page:all#Disconnected-Reliability-Titanic-Pattern)");
var argArr = Sys.args();
var verbose = (argArr.length > 1 && argArr[argArr.length - 1] == "-v");
var log = Lib.println;
var ctx = new ZContext();
// Create Titanic worker class
var titanic = new Titanic("tcp://:5555", verbose);
// Create MDP client session with short timeout
var client = new MDCliAPI("tcp://:5555", verbose);
client.timeout = 1000; // 1 sec
client.retries = 1; // Only 1 retry
var requestPipe = ZThread.attach(ctx, titanic.titanicRequest,"tcp://:5555");
ZThread.detach(titanic.titanicReply, "tcp://:5555");
ZThread.detach(titanic.titanicClose, "tcp://:5555");
var poller = new ZMQPoller();
poller.registerSocket(requestPipe, ZMQ.ZMQ_POLLIN());
// Main dispatcher loop
while (true) {
// We'll dispatch once per second, if there's no activity
try {
var res = poller.poll(1000 * 1000); // 1 sec
} catch (e:ZMQException) {
if (!ZMQ.isInterrupted()) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
} else
log("W: interrupt received, sinking the titanic...");
ctx.destroy();
client.destroy();
return;
}
if (poller.pollin(1)) {
// Ensure message directory exists
if (!FileSystem.exists(TITANIC_DIR))
FileSystem.createDirectory(TITANIC_DIR);
// Append UUID to queue, prefixed with "-" for pending
var msg = ZMsg.recvMsg(requestPipe);
if (msg == null)
break; // Interrupted
var file = File.append(TITANIC_DIR + "/queue", false);
var uuid = msg.pop().toString();
file.writeString("-" + uuid);
file.flush();
file.close();
}
// Brute-force dispatcher
if (FileSystem.exists(TITANIC_DIR + "/queue")) {
try {
var filec = File.getContent(TITANIC_DIR + "/queue");
FileSystem.deleteFile(TITANIC_DIR + "/queue");
var fileh = File.write(TITANIC_DIR + "/queue", false);
var index = 0;
while (index+33 <= filec.length) {
var str = filec.substr(index, 33);
var prefix = "-";
// UUID is prefixed with '-' if still waiting
if (str.charAt(0) == "-") {
if (verbose)
log("I: processing request " + str.substr(1));
if (titanic.serviceSuccess(client, str.substr(1))) {
// Mark queue entry as processed
prefix = "+";
}
}
fileh.writeString(prefix + str.substr(1));
index += 33;
}
fileh.flush();
fileh.close();
} catch (e:Dynamic) {
log("E: error reading queue file " +e);
}
}
}
client.destroy();
ctx.destroy();
}
/**
* Constructor
* @param broker
* @param ?verbose
* @param ?logger
*/
public function new(broker:String, ?verbose:Bool, ?logger:Dynamic->Void) {
this.broker = broker;
this.verbose = verbose;
if (logger != null)
log = logger;
else
log = neko.Lib.println;
}
/**
* Returns a new UUID as a printable String
* @param ?size
* @return
*/
private function generateUUID(?size:Int):String {
if (size == null) size = 32;
var nchars = UID.length;
var uid = new StringBuf();
for (i in 0 ... size) {
uid.add(UID.charAt(ZHelpers.randof(nchars-1)));
}
return uid.toString();
}
/**
* Returns request filename for given UUID
* @param uuid
* @return
*/
private function requestFilename(uuid:String):String {
return TITANIC_DIR + "/" + uuid + ".req";
}
/**
* Returns reply filename for given UUID
* @param uuid
* @return
*/
private function replyFilename(uuid:String):String {
return TITANIC_DIR + "/" + uuid + ".rep";
}
/**
* Implements Titanic request service "titanic.request"
* @param ctx
* @param pipe
*/
public function titanicRequest(ctx:ZContext, pipe:ZMQSocket, broker:String) {
var worker = new MDWrkAPI(broker, "titanic.request", verbose);
var reply:ZMsg = null;
while (true) {
if (reply != null) trace("reply object:" + reply.toString());
// Send reply if it's not null
// and then get next request from broker
var request = worker.recv(reply);
if (request == null)
break; // Interrupted, exit
// Ensure message directory exists
if (!FileSystem.exists(TITANIC_DIR))
FileSystem.createDirectory(TITANIC_DIR);
// Generate UUID and save message to disk
var uuid = generateUUID();
var filename = requestFilename(uuid);
var file = File.write(filename, false);
ZMsg.save(request, file);
file.close();
request.destroy();
// Send UUID through to message queue
reply = new ZMsg();
reply.addString(uuid);
reply.send(pipe);
// Now send UUID back to client
// Done by the worker.recv() call at the top of the loop
reply = new ZMsg();
reply.addString("200");
reply.addString(uuid);
}
worker.destroy();
}
/**
* Implements titanic reply service "titanic.reply"
*/
public function titanicReply(broker:String) {
var worker = new MDWrkAPI(broker, "titanic.reply", verbose);
var reply:ZMsg = null;
while (true) {
// Send reply if it's not null
// and then get next request from broker
var request = worker.recv(reply);
if (request == null)
break; // Interrupted, exit
// Ensure message directory exists
if (!FileSystem.exists(TITANIC_DIR))
FileSystem.createDirectory(TITANIC_DIR);
// Generate UUID and save message to disk
var uuid = request.popString();
var reqfilename = requestFilename(uuid);
var repfilename = replyFilename(uuid);
if (FileSystem.exists(repfilename)) {
var file = File.read(repfilename, false);
reply = ZMsg.load(file);
reply.pushString("200");
file.close();
} else {
reply = new ZMsg();
if (FileSystem.exists(reqfilename))
reply.pushString("300"); // Pending
else
reply.pushString("400");
request.destroy();
}
}
worker.destroy();
}
/**
* Implements titanic close service "titanic.close"
* @param broker
*/
public function titanicClose(broker:String) {
var worker = new MDWrkAPI(broker, "titanic.close", verbose);
var reply:ZMsg = null;
while (true) {
// Send reply if it's not null
// and then get next request from broker
var request = worker.recv(reply);
if (request == null)
break; // Interrupted, exit
// Ensure message directory exists
if (!FileSystem.exists(TITANIC_DIR))
FileSystem.createDirectory(TITANIC_DIR);
// Generate UUID and save message to disk
var uuid = request.popString();
var reqfilename = requestFilename(uuid);
var repfilename = replyFilename(uuid);
FileSystem.deleteFile(reqfilename);
FileSystem.deleteFile(repfilename);
request.destroy();
reply = new ZMsg();
reply.addString("200");
}
worker.destroy();
}
/**
* Attempt to process a single service request message, return true if successful
* @param client
* @param uuid
* @return
*/
public function serviceSuccess(client:MDCliAPI, uuid:String):Bool {
// Load request message, service will be first frame
var filename = requestFilename(uuid);
var file = File.read(filename, false);
var request:ZMsg = null;
try {
request = ZMsg.load(file);
file.close();
} catch (e:Dynamic) {
log("E: Error loading file:" + filename + ", details:" + e);
return false;
}
var service = request.pop();
var serviceName = service.toString();
// Use MMI protocol to check if service is available
var mmiRequest = new ZMsg();
mmiRequest.add(service);
var mmiReply = client.send("mmi.service", mmiRequest);
var serviceOK = (mmiReply != null && mmiReply.first().streq("200"));
if (serviceOK) {
// Now call requested service and store reply from service
var reply = client.send(serviceName, request);
if (reply != null) {
filename = replyFilename(uuid);
try {
var file = File.write(filename, false);
ZMsg.save(reply, file);
file.close();
return true;
} catch (e:Dynamic) {
log("E: Error writing file:" + filename + ", details:" + e);
return false;
}
}
reply.destroy();
} else
request.destroy();
return false;
}
}titanic:Java 中的 Titanic 代理示例
package guide;
import java.io.BufferedWriter;
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.util.UUID;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZMsg;
import org.zeromq.ZThread;
import org.zeromq.ZThread.IAttachedRunnable;
import org.zeromq.ZThread.IDetachedRunnable;
public class titanic
{
// Return a new UUID as a printable character string
// Caller must free returned string when finished with it
static String generateUUID()
{
return UUID.randomUUID().toString();
}
private static final String TITANIC_DIR = ".titanic";
// Returns freshly allocated request filename for given UUID
private static String requestFilename(String uuid)
{
String filename = String.format("%s/%s.req", TITANIC_DIR, uuid);
return filename;
}
// Returns freshly allocated reply filename for given UUID
private static String replyFilename(String uuid)
{
String filename = String.format("%s/%s.rep", TITANIC_DIR, uuid);
return filename;
}
// .split Titanic request service
// The {{titanic.request}} task waits for requests to this service. It
// writes each request to disk and returns a UUID to the client. The client
// picks up the reply asynchronously using the {{titanic.reply}} service:
static class TitanicRequest implements IAttachedRunnable
{
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
mdwrkapi worker = new mdwrkapi(
"tcp://:5555", "titanic.request", false
);
ZMsg reply = null;
while (true) {
// Send reply if it's not null
// And then get next request from broker
ZMsg request = worker.receive(reply);
if (request == null)
break; // Interrupted, exit
// Ensure message directory exists
new File(TITANIC_DIR).mkdirs();
// Generate UUID and save message to disk
String uuid = generateUUID();
String filename = requestFilename(uuid);
DataOutputStream file = null;
try {
file = new DataOutputStream(new FileOutputStream(filename));
ZMsg.save(request, file);
}
catch (IOException e) {
e.printStackTrace();
}
finally {
try {
if (file != null)
file.close();
}
catch (IOException e) {
}
}
request.destroy();
// Send UUID through to message queue
reply = new ZMsg();
reply.add(uuid);
reply.send(pipe);
// Now send UUID back to client
// Done by the mdwrk_recv() at the top of the loop
reply = new ZMsg();
reply.add("200");
reply.add(uuid);
}
worker.destroy();
}
}
// .split Titanic reply service
// The {{titanic.reply}} task checks if there's a reply for the specified
// request (by UUID), and returns a 200 (OK), 300 (Pending), or 400
// (Unknown) accordingly:
static class TitanicReply implements IDetachedRunnable
{
@Override
public void run(Object[] args)
{
mdwrkapi worker = new mdwrkapi(
"tcp://:5555", "titanic.reply", false
);
ZMsg reply = null;
while (true) {
ZMsg request = worker.receive(reply);
if (request == null)
break; // Interrupted, exit
String uuid = request.popString();
String reqFilename = requestFilename(uuid);
String repFilename = replyFilename(uuid);
if (new File(repFilename).exists()) {
DataInputStream file = null;
try {
file = new DataInputStream(
new FileInputStream(repFilename)
);
reply = ZMsg.load(file);
reply.push("200");
}
catch (IOException e) {
e.printStackTrace();
}
finally {
try {
if (file != null)
file.close();
}
catch (IOException e) {
}
}
}
else {
reply = new ZMsg();
if (new File(reqFilename).exists())
reply.push("300"); //Pending
else reply.push("400"); //Unknown
}
request.destroy();
}
worker.destroy();
}
}
// .split Titanic close task
// The {{titanic.close}} task removes any waiting replies for the request
// (specified by UUID). It's idempotent, so it is safe to call more than
// once in a row:
static class TitanicClose implements IDetachedRunnable
{
@Override
public void run(Object[] args)
{
mdwrkapi worker = new mdwrkapi(
"tcp://:5555", "titanic.close", false
);
ZMsg reply = null;
while (true) {
ZMsg request = worker.receive(reply);
if (request == null)
break; // Interrupted, exit
String uuid = request.popString();
String req_filename = requestFilename(uuid);
String rep_filename = replyFilename(uuid);
new File(rep_filename).delete();
new File(req_filename).delete();
request.destroy();
reply = new ZMsg();
reply.add("200");
}
worker.destroy();
}
}
// .split worker task
// This is the main thread for the Titanic worker. It starts three child
// threads; for the request, reply, and close services. It then dispatches
// requests to workers using a simple brute force disk queue. It receives
// request UUIDs from the {{titanic.request}} service, saves these to a
// disk file, and then throws each request at MDP workers until it gets a
// response.
public static void main(String[] args)
{
boolean verbose = (args.length > 0 && "-v".equals(args[0]));
try (ZContext ctx = new ZContext()) {
Socket requestPipe = ZThread.fork(ctx, new TitanicRequest());
ZThread.start(new TitanicReply());
ZThread.start(new TitanicClose());
Poller poller = ctx.createPoller(1);
poller.register(requestPipe, ZMQ.Poller.POLLIN);
// Main dispatcher loop
while (true) {
// We'll dispatch once per second, if there's no activity
int rc = poller.poll(1000);
if (rc == -1)
break; // Interrupted
if (poller.pollin(0)) {
// Ensure message directory exists
new File(TITANIC_DIR).mkdirs();
// Append UUID to queue, prefixed with '-' for pending
ZMsg msg = ZMsg.recvMsg(requestPipe);
if (msg == null)
break; // Interrupted
String uuid = msg.popString();
BufferedWriter wfile = null;
try {
wfile = new BufferedWriter(
new FileWriter(TITANIC_DIR + "/queue", true)
);
wfile.write("-" + uuid + "\n");
}
catch (IOException e) {
e.printStackTrace();
break;
}
finally {
try {
if (wfile != null)
wfile.close();
}
catch (IOException e) {
}
}
msg.destroy();
}
// Brute force dispatcher
// "?........:....:....:....:............:";
byte[] entry = new byte[37];
RandomAccessFile file = null;
try {
file = new RandomAccessFile(TITANIC_DIR + "/queue", "rw");
while (file.read(entry) > 0) {
// UUID is prefixed with '-' if still waiting
if (entry[0] == '-') {
if (verbose)
System.out.printf(
"I: processing request %s\n",
new String(
entry, 1, entry.length - 1, ZMQ.CHARSET
)
);
if (serviceSuccess(
new String(
entry, 1, entry.length - 1, ZMQ.CHARSET
)
)) {
// Mark queue entry as processed
file.seek(file.getFilePointer() - 37);
file.writeBytes("+");
file.seek(file.getFilePointer() + 36);
}
}
// Skip end of line, LF or CRLF
if (file.readByte() == '\r')
file.readByte();
if (Thread.currentThread().isInterrupted())
break;
}
}
catch (FileNotFoundException e) {
}
catch (IOException e) {
e.printStackTrace();
}
finally {
if (file != null) {
try {
file.close();
}
catch (IOException e) {
}
}
}
}
}
}
// .split try to call a service
// Here, we first check if the requested MDP service is defined or not,
// using a MMI lookup to the Majordomo broker. If the service exists, we
// send a request and wait for a reply using the conventional MDP client
// API. This is not meant to be fast, just very simple:
static boolean serviceSuccess(String uuid)
{
// Load request message, service will be first frame
String filename = requestFilename(uuid);
// If the client already closed request, treat as successful
if (!new File(filename).exists())
return true;
DataInputStream file = null;
ZMsg request;
try {
file = new DataInputStream(new FileInputStream(filename));
request = ZMsg.load(file);
}
catch (IOException e) {
e.printStackTrace();
return true;
}
finally {
try {
if (file != null)
file.close();
}
catch (IOException e) {
}
}
ZFrame service = request.pop();
String serviceName = service.toString();
// Create MDP client session with short timeout
mdcliapi client = new mdcliapi("tcp://:5555", false);
client.setTimeout(1000); // 1 sec
client.setRetries(1); // only 1 retry
// Use MMI protocol to check if service is available
ZMsg mmiRequest = new ZMsg();
mmiRequest.add(service);
ZMsg mmiReply = client.send("mmi.service", mmiRequest);
boolean serviceOK = (mmiReply != null &&
mmiReply.getFirst().toString().equals("200"));
mmiReply.destroy();
boolean result = false;
if (serviceOK) {
ZMsg reply = client.send(serviceName, request);
if (reply != null) {
filename = replyFilename(uuid);
DataOutputStream ofile = null;
try {
ofile = new DataOutputStream(new FileOutputStream(filename));
ZMsg.save(reply, ofile);
}
catch (IOException e) {
e.printStackTrace();
return true;
}
finally {
try {
if (file != null)
file.close();
}
catch (IOException e) {
}
}
result = true;
}
reply.destroy();
}
else request.destroy();
client.destroy();
return result;
}
}
titanic:Julia 中的 Titanic 代理示例
titanic:Lua 中的 Titanic 代理示例
titanic:Node.js 中的 Titanic 代理示例
titanic:Objective-C 中的 Titanic 代理示例
titanic:ooc 中的 Titanic 代理示例
titanic:Perl 中的 Titanic 代理示例
titanic:PHP 中的 Titanic 代理示例
<?php
/*
* Titanic service
*
* Implements server side of https://rfc.zeromq.cn/spec:9
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
include_once 'mdwrkapi.php';
include_once 'mdcliapi.php';
/* Return a new UUID as a printable character string */
function s_generate_uuid()
{
$uuid = sprintf('%04x%04x%04x%03x4%04x%04x%04x%04x',
mt_rand(0, 65535), mt_rand(0, 65535), // 32 bits for "time_low"
mt_rand(0, 65535), // 16 bits for "time_mid"
mt_rand(0, 4095), // 12 bits before the 0100 of (version) 4 for "time_hi_and_version"
bindec(substr_replace(sprintf('%016b', mt_rand(0, 65535)), '01', 6, 2)),
// 8 bits, the last two of which (positions 6 and 7) are 01, for "clk_seq_hi_res"
// (hence, the 2nd hex digit after the 3rd hyphen can only be 1, 5, 9 or d)
// 8 bits for "clk_seq_low"
mt_rand(0, 65535), mt_rand(0, 65535), mt_rand(0, 65535) // 48 bits for "node"
);
return $uuid;
}
define("TITANIC_DIR", ".titanic");
/**
* Returns freshly allocated request filename for given UUID
*/
function s_request_filename($uuid)
{
return TITANIC_DIR . "/" . $uuid . ".req";
}
/**
* Returns freshly allocated reply filename for given UUID
*/
function s_reply_filename($uuid)
{
return TITANIC_DIR . "/" . $uuid . ".rep";
}
/**
* Titanic request service
*/
function titanic_request($pipe)
{
$worker = new Mdwrk("tcp://:5555", "titanic.request");
$reply = null;
while (true) {
// Get next request from broker
$request = $worker->recv($reply);
// Ensure message directory exists
if (!is_dir(TITANIC_DIR)) {
mkdir(TITANIC_DIR);
}
// Generate UUID and save message to disk
$uuid = s_generate_uuid();
$filename = s_request_filename($uuid);
$fh = fopen($filename, "w");
$request->save($fh);
fclose($fh);
// Send UUID through to message queue
$reply = new Zmsg($pipe);
$reply->push($uuid);
$reply->send();
// Now send UUID back to client
// - sent in the next loop iteration
$reply = new Zmsg();
$reply->push($uuid);
$reply->push("200");
}
}
/**
* Titanic reply service
*/
function titanic_reply()
{
$worker = new Mdwrk( "tcp://:5555", "titanic.reply", false);
$reply = null;
while (true) {
$request = $worker->recv($reply);
$uuid = $request->pop();
$req_filename = s_request_filename($uuid);
$rep_filename = s_reply_filename($uuid);
if (file_exists($rep_filename)) {
$fh = fopen($rep_filename, "r");
assert($fh);
$reply = new Zmsg();
$reply->load($fh);
$reply->push("200");
fclose($fh);
} else {
$reply = new Zmsg();
if (file_exists($req_filename)) {
$reply->push("300"); // Pending
} else {
$reply->push("400"); // Unknown
}
}
}
}
/**
* Titanic close service
*/
function titanic_close()
{
$worker = new Mdwrk("tcp://:5555", "titanic.close", false);
$reply = null;
while (true) {
$request = $worker->recv($reply);
$uuid = $request->pop();
$req_filename = s_request_filename($uuid);
$rep_filename = s_reply_filename($uuid);
unlink($req_filename);
unlink($rep_filename);
$reply = new Zmsg();
$reply->push("200");
}
}
/**
* Attempt to process a single request, return 1 if successful
*
* @param Mdcli $client
* @param string $uuid
*/
function s_service_success($client, $uuid)
{
// Load request message, service will be first frame
$filename = s_request_filename($uuid);
$fh = fopen($filename, "r");
// If the client already closed request, treat as successful
if (!$fh) {
return true;
}
$request = new Zmsg();
$request->load($fh);
fclose($fh);
$service = $request->pop();
// Use MMI protocol to check if service is available
$mmi_request = new Zmsg();
$mmi_request->push($service);
$mmi_reply = $client->send("mmi.service", $mmi_request);
$service_ok = $mmi_reply && $mmi_reply->pop() == "200";
if ($service_ok) {
$reply = $client->send($service, $request);
$filename = s_reply_filename($uuid);
$fh = fopen($filename, "w");
assert($fh);
$reply->save($fh);
fclose($fh);
return true;
}
return false;
}
$verbose = $_SERVER['argc'] > 1 && $_SERVER['argv'][1] == '-v';
$pid = pcntl_fork();
if ($pid == 0) {
titanic_reply();
exit();
}
$pid = pcntl_fork();
if ($pid == 0) {
titanic_close();
exit();
}
$pid = pcntl_fork();
if ($pid == 0) {
$pipe = new ZMQSocket(new ZMQContext(), ZMQ::SOCKET_PAIR);
$pipe->connect("ipc://" . sys_get_temp_dir() . "/titanicpipe");
titanic_request($pipe);
exit();
}
// Create MDP client session with short timeout
$client = new Mdcli("tcp://:5555", $verbose);
$client->set_timeout(1000); // 1 sec
$client->set_retries(1); // only 1 retry
$request_pipe = new ZMQSocket(new ZMQContext(), ZMQ::SOCKET_PAIR);
$request_pipe->bind("ipc://" . sys_get_temp_dir() . "/titanicpipe");
$read = $write = array();
// Main dispatcher loop
while (true) {
// We'll dispatch once per second, if there's no activity
$poll = new ZMQPoll();
$poll->add($request_pipe, ZMQ::POLL_IN);
$events = $poll->poll($read, $write, 1000);
if ($events) {
// Ensure message directory exists
if (!is_dir(TITANIC_DIR)) {
mkdir(TITANIC_DIR);
}
// Append UUID to queue, prefixed with '-' for pending
$msg = new Zmsg($request_pipe);
$msg->recv();
$fh = fopen(TITANIC_DIR . "/queue", "a");
$uuid = $msg->pop();
fprintf($fh, "-%s\n", $uuid);
fclose($fh);
}
// Brute-force dispatcher
if (file_exists(TITANIC_DIR . "/queue")) {
$fh = fopen(TITANIC_DIR . "/queue", "r+");
while ($fh && $entry = fread($fh, 33)) {
// UUID is prefixed with '-' if still waiting
if ($entry[0] == "-") {
if ($verbose) {
printf ("I: processing request %s%s", substr($entry, 1), PHP_EOL);
}
if (s_service_success($client, substr($entry, 1))) {
// Mark queue entry as processed
fseek($fh, -33, SEEK_CUR);
fwrite ($fh, "+");
fseek($fh, 32, SEEK_CUR);
}
}
// Skip end of line, LF or CRLF
if (fgetc($fh) == "\r") {
fgetc($fh);
}
}
if ($fh) {
fclose($fh);
}
}
}
titanic:Python 中的 Titanic 代理示例
"""
Titanic service
Implements server side of http:#rfc.zeromq.org/spec:9
Author: Min RK <benjaminrk@gmail.com>
"""
import pickle
import os
import sys
import threading
import time
from uuid import uuid4
import zmq
from mdwrkapi import MajorDomoWorker
from mdcliapi import MajorDomoClient
from zhelpers import zpipe
TITANIC_DIR = ".titanic"
def request_filename (suuid):
"""Returns freshly allocated request filename for given UUID str"""
return os.path.join(TITANIC_DIR, "%s.req" % suuid)
#
def reply_filename (suuid):
"""Returns freshly allocated reply filename for given UUID str"""
return os.path.join(TITANIC_DIR, "%s.rep" % suuid)
# ---------------------------------------------------------------------
# Titanic request service
def titanic_request (pipe):
worker = MajorDomoWorker("tcp://:5555", b"titanic.request")
reply = None
while True:
# Send reply if it's not null
# And then get next request from broker
request = worker.recv(reply)
if not request:
break # Interrupted, exit
# Ensure message directory exists
if not os.path.exists(TITANIC_DIR):
os.mkdir(TITANIC_DIR)
# Generate UUID and save message to disk
suuid = uuid4().hex
filename = request_filename (suuid)
with open(filename, 'wb') as f:
pickle.dump(request, f)
# Send UUID through to message queue
pipe.send_string(suuid)
# Now send UUID back to client
# Done by the worker.recv() at the top of the loop
reply = [b"200", suuid.encode('utf-8')]
# ---------------------------------------------------------------------
# Titanic reply service
def titanic_reply ():
worker = MajorDomoWorker("tcp://:5555", b"titanic.reply")
reply = None
while True:
request = worker.recv(reply)
if not request:
break # Interrupted, exit
suuid = request.pop(0).decode('utf-8')
req_filename = request_filename(suuid)
rep_filename = reply_filename(suuid)
if os.path.exists(rep_filename):
with open(rep_filename, 'rb') as f:
reply = pickle.load(f)
reply = [b"200"] + reply
else:
if os.path.exists(req_filename):
reply = [b"300"] # pending
else:
reply = [b"400"] # unknown
# ---------------------------------------------------------------------
# Titanic close service
def titanic_close():
worker = MajorDomoWorker("tcp://:5555", b"titanic.close")
reply = None
while True:
request = worker.recv(reply)
if not request:
break # Interrupted, exit
suuid = request.pop(0).decode('utf-8')
req_filename = request_filename(suuid)
rep_filename = reply_filename(suuid)
# should these be protected? Does zfile_delete ignore files
# that have already been removed? That's what we are doing here.
if os.path.exists(req_filename):
os.remove(req_filename)
if os.path.exists(rep_filename):
os.remove(rep_filename)
reply = [b"200"]
def service_success(client, suuid):
"""Attempt to process a single request, return True if successful"""
# Load request message, service will be first frame
filename = request_filename (suuid)
# If the client already closed request, treat as successful
if not os.path.exists(filename):
return True
with open(filename, 'rb') as f:
request = pickle.load(f)
service = request.pop(0)
# Use MMI protocol to check if service is available
mmi_request = [service]
mmi_reply = client.send(b"mmi.service", mmi_request)
service_ok = mmi_reply and mmi_reply[0] == b"200"
if service_ok:
reply = client.send(service, request)
if reply:
filename = reply_filename (suuid)
with open(filename, "wb") as f:
pickle.dump(reply, f)
return True
return False
def main():
verbose = '-v' in sys.argv
ctx = zmq.Context()
# Create MDP client session with short timeout
client = MajorDomoClient("tcp://:5555", verbose)
client.timeout = 1000 # 1 sec
client.retries = 1 # only 1 retry
request_pipe, peer = zpipe(ctx)
request_thread = threading.Thread(target=titanic_request, args=(peer,))
request_thread.daemon = True
request_thread.start()
reply_thread = threading.Thread(target=titanic_reply)
reply_thread.daemon = True
reply_thread.start()
close_thread = threading.Thread(target=titanic_close)
close_thread.daemon = True
close_thread.start()
poller = zmq.Poller()
poller.register(request_pipe, zmq.POLLIN)
queue_filename = os.path.join(TITANIC_DIR, 'queue')
# Main dispatcher loop
while True:
# Ensure message directory exists
if not os.path.exists(TITANIC_DIR):
os.mkdir(TITANIC_DIR)
f = open(queue_filename,'wb')
f.close()
# We'll dispatch once per second, if there's no activity
try:
items = poller.poll(1000)
except KeyboardInterrupt:
break; # Interrupted
if items:
# Append UUID to queue, prefixed with '-' for pending
suuid = request_pipe.recv().decode('utf-8')
with open(queue_filename, 'ab') as f:
line = "-%s\n" % suuid
f.write(line.encode('utf-8'))
# Brute-force dispatcher
with open(queue_filename, 'rb+') as f:
for entry in f.readlines():
entry = entry.decode('utf-8')
# UUID is prefixed with '-' if still waiting
if entry[0] == '-':
suuid = entry[1:].rstrip() # rstrip '\n' etc.
print ("I: processing request %s" % suuid)
if service_success(client, suuid):
# mark queue entry as processed
here = f.tell()
f.seek(-1*len(entry), os.SEEK_CUR)
f.write('+'.encode('utf-8'))
f.seek(here, os.SEEK_SET)
if __name__ == '__main__':
main()
titanic:Q 中的 Titanic 代理示例
titanic:Racket 中的 Titanic 代理示例
titanic:Ruby 中的 Titanic 代理示例
#!/usr/bin/env ruby
# Titanic service
#
# Implements server side of http:#rfc.zeromq.org/spec:9
#
# Author: Tom van Leeuwen <tom@vleeuwen.eu>
# Based on Python example by Min RK
require './mdcliapi2.rb'
require './mdwrkapi.rb'
require 'pathname'
require 'securerandom'
require 'json'
require 'thread'
require 'awesome_print'
TITANIC_DIR = Pathname(Dir.pwd).join('.titanic')
def request_filename uuid
TITANIC_DIR.join("#{uuid}.req")
end
def reply_filename uuid
TITANIC_DIR.join("#{uuid}.rep")
end
def titanic_request pipe
worker = MajorDomoWorker.new('tcp://:5555', 'titanic.request')
# Ensure message directory exists
Dir.mkdir(TITANIC_DIR) unless Dir.exist?(TITANIC_DIR)
reply = nil
loop do
request = worker.recv reply
# Generate UUID and save message to disk
uuid = SecureRandom.uuid
filename = request_filename uuid
File.open(filename, 'w') { |fh| fh.write request.to_json }
# Send UUID through to message queue
pipe.send_string uuid
# Now send UUID back to client
# Done by the worker.recv at the top of the loop
reply = ["200", uuid]
end
end
def titanic_reply
worker = MajorDomoWorker.new('tcp://:5555', 'titanic.reply')
reply = nil
loop do
request = worker.recv reply
uuid = request.shift
if File.exist?(reply_filename(uuid))
reply = %w[200]
reply.concat JSON.parse(File.read(reply_filename(uuid)))
elsif File.exist?(request_filename(uuid))
reply = %w[300] # pending
else
reply = %w[400] # unknown
end
end
end
def titanic_close
worker = MajorDomoWorker.new('tcp://:5555', 'titanic.close')
reply = nil
loop do
request = worker.recv reply
uuid = request.shift
File.unlink(request_filename(uuid)) if File.exist?(request_filename(uuid))
File.unlink(reply_filename(uuid)) if File.exist?(reply_filename(uuid))
reply = %w[200]
end
end
def service_success client, uuid
# Attempt to process a single request, return True if successful
return true unless File.exist?(request_filename(uuid))
request = JSON.parse(File.read(request_filename(uuid)))
service = request.shift
# Use MMI protocol to check if service is available
mmi_request = [service]
client.send('mmi.service', mmi_request)
mmi_reply = client.recv
if mmi_reply and mmi_reply.first == "200"
client.send service, request
reply = client.recv
if reply
File.open(reply_filename(uuid), 'w') { |fh| fh.write reply.to_json }
return true
end
end
false
end
context = ZMQ::Context.new
# Create MDP client session with short timeout
client = MajorDomoClient.new("tcp://:5555")
client.timeout = 1000 # 1 sec
# client.retries = 1 # only 1 retry
pipe = context.socket(ZMQ::PAIR)
pipe.setsockopt ZMQ::LINGER, 0
pipe.bind("inproc://titanic")
peer = context.socket(ZMQ::PAIR)
peer.setsockopt ZMQ::LINGER, 0
peer.connect("inproc://titanic")
Thread.start do
begin
titanic_request peer
rescue Exception => e
puts e ; puts e.backtrace.join("\n")
end
end
Thread.start do
begin
titanic_reply
rescue Exception => e
puts e ; puts e.backtrace.join("\n")
end
end
Thread.start do
begin
titanic_close
rescue Exception => e
puts e ; puts e.backtrace.join("\n")
end
end
poller = ZMQ::Poller.new
poller.register(pipe, ZMQ::POLLIN)
# Ensure message directory exists
Dir.mkdir(TITANIC_DIR) unless Dir.exist?(TITANIC_DIR)
# Main dispatcher loop
queue = TITANIC_DIR.join('queue')
# Ensure queue file exists and is empty
File.open(queue, 'w') { |fh| fh.write '' }
loop do
items = poller.poll(1000)
if items > 0
uuid = ""
pipe.recv_string uuid
File.open(queue, 'a') { |fh| fh.write "-#{uuid}\n" }
end
# Brute-force dispatcher
# yeah yeah... ugly
new = []
lines = File.read(queue).split("\n")
lines.each do |line|
if line =~ /^-(.*)$/
uuid = $1
puts "I: processing request #{uuid}"
if service_success client, uuid
# mark queue entry as processed
new << uuid
else
new << line
end
else
new << line
end
end
File.open(queue, 'w') { |fh| fh.write new.join("\n") + "\n" }
end
titanic:Rust 中的 Titanic 代理示例
titanic:Scala 中的 Titanic 代理示例
titanic:Tcl 中的 Titanic 代理示例
#
# Titanic service
#
# Implements server side of https://rfc.zeromq.cn/spec:9
lappend auto_path .
package require MDClient 1.0
package require MDWorker 1.0
package require uuid
if {[llength $argv] == 0} {
set argv [list driver]
} elseif {[llength $argv] != 1} {
puts "Usage: titanic.tcl <driver|request|reply|close>"
exit 1
}
set tclsh [info nameofexecutable]
expr {srand([pid])}
set verbose 0
lassign $argv what
set TITANIC_DIR ".titanic"
# Return a new UUID as a printable character string
proc s_generate_uuid {} {
return [uuid::uuid generate]
}
# Returns freshly allocated request filename for given UUID
proc s_request_filename {uuid} {
return [file join $::TITANIC_DIR $uuid.req]
}
# Returns freshly allocated reply filename for given UUID
proc s_reply_filename {uuid} {
return [file join $::TITANIC_DIR $uuid.rep]
}
# Titanic request service
proc titanic_request {} {
zmq context context
set pipe [zmq socket pipe context PAIR]
pipe connect "ipc://titanicpipe.ipc"
set worker [MDWorker new "tcp://:5555" "titanic.request" $::verbose]
set reply {}
while {1} {
# Send reply if it's not null
# And then get next request from broker
set request [$worker recv $reply]
if {[llength $request] == 0} {
break ;# Interrupted, exit
}
# Ensure message directory exists
file mkdir $::TITANIC_DIR
# Generate UUID and save message to disk
set uuid [s_generate_uuid]
set filename [s_request_filename $uuid]
set file [open $filename "w"]
puts -nonewline $file [join $request \n]
close $file
# Send UUID through to message queue
set reply [list]
set reply [zmsg add $reply $uuid]
zmsg send $pipe $reply
# Now send UUID back to client
# Done by the mdwrk_recv() at the top of the loop
set reply [list]
puts "I: titanic.request to $uuid / $reply"
set reply [zmsg add $reply "200"]
puts "I: titanic.request to $uuid / $reply"
set reply [zmsg add $reply $uuid]
puts "I: titanic.request to $uuid / $reply"
puts [join [zmsg dump $reply] \n]
}
$worker destroy
}
# Titanic reply service
proc titanic_reply {} {
set worker [MDWorker new "tcp://:5555" "titanic.reply" $::verbose]
set reply {}
while {1} {
set request [$worker recv $reply]
if {[llength $request] == 0} {
break
}
set uuid [zmsg pop request]
set req_filename [s_request_filename $uuid]
set rep_filename [s_reply_filename $uuid]
if {[file exists $rep_filename]} {
set file [open $rep_filename r]
set reply [split [read $file] \n]
set reply [zmsg push $reply "200"]
puts "I: titanic.reply to $uuid"
puts [join [zmsg dump $reply] \n]
close $file
} else {
if {[file exists $req_filename]} {
set reply "300"
} else {
set reply "400"
}
}
}
$worker destroy
return 0
}
# Titanic close service
proc titanic_close {} {
set worker [MDWorker new "tcp://:5555" "titanic.close" $::verbose]
set reply ""
while {1} {
set request [$worker recv $reply]
if {[llength $request] == 0} {
break
}
set uuid [zmsg pop request]
set req_filename [s_request_filename $uuid]
set rep_filename [s_reply_filename $uuid]
file delete -force $req_filename
file delete -force $rep_filename
set reply "200"
}
$worker destroy
return 0
}
# Attempt to process a single request, return 1 if successful
proc s_service_success {uuid} {
# Load request message, service will be first frame
set filename [s_request_filename $uuid]
# If the client already closed request, treat as successful
if {![file exists $filename]} {
return 1
}
set file [open $filename "r"]
set request [split [read $file] \n]
set service [zmsg pop request]
# Create MDP client session with short timeout
set client [MDClient new "tcp://:5555" $::verbose]
$client set_timeout 1000
$client set_retries 1
# Use MMI protocol to check if service is available
set mmi_request {}
set mmi_request [zmsg add $mmi_request $service]
set mmi_reply [$client send "mmi.service" $mmi_request]
if {[lindex $mmi_reply 0] eq "200"} {
set reply [$client send $service $request]
if {[llength $reply]} {
set filename [s_reply_filename $uuid]
set file [open $filename "w"]
puts -nonewline $file [join $reply \n]
close $file
return 1
}
}
$client destroy
return 0
}
switch -exact -- $what {
request { titanic_request }
reply { titanic_reply }
close { titanic_close }
driver {
exec $tclsh titanic.tcl request > request.log 2>@1 &
exec $tclsh titanic.tcl reply > reply.log 2>@1 &
exec $tclsh titanic.tcl close > close.log 2>@1 &
after 1000 ;# Wait for other parts to start
zmq context context
zmq socket request_pipe context PAIR
request_pipe bind "ipc://titanicpipe.ipc"
set queuefnm [file join $::TITANIC_DIR queue]
# Main dispatcher loop
while {1} {
# We'll dispatch once per second, if there's no activity
set poll_set [list [list request_pipe [list POLLIN]]]
set rpoll_set [zmq poll $poll_set 1000]
if {[llength $rpoll_set] && "POLLIN" in [lindex $rpoll_set 0 1]} {
# Ensure message directory exists
file mkdir $::TITANIC_DIR
# Append UUID to queue, prefixed with '-' for pending
set msg [zmsg recv request_pipe]
if {[llength $msg] == 0} {
break
}
set file [open $queuefnm "a"]
set uuid [zmsg pop msg]
puts $file "-$uuid"
close $file
}
# Brute-force dispatcher
if {[file exists $queuefnm]} {
set file [open $queuefnm "r"]
set queue_list [split [read $file] \n]
close $file
for {set i 0} {$i < [llength $queue_list]} {incr i} {
set entry [lindex $queue_list $i]
if {[string match "-*" $entry]} {
set entry [string range $entry 1 end]
puts "I: processing request $entry"
if {[s_service_success $entry]} {
lset queue_list $i "+$entry"
}
}
}
set file [open $queuefnm "w"]
puts -nonewline $file [join $queue_list \n]
close $file
}
}
return 0
}
}
titanic:OCaml 中的 Titanic 代理示例
要测试这一点,启动mdbroker和titanic,然后运行ticlient。现在启动mdworker任意次数,你应该会看到客户端收到应答并愉快地退出。
关于这段代码的一些注意事项
- 注意,有些循环以发送消息开始,有些则以接收消息开始。这是因为 Titanic 在不同的角色中既充当客户端又充当工作节点。
- Titanic 代理使用 MMI 服务发现协议,仅向看起来正在运行的服务发送请求。由于我们的小型 Majordomo 代理中的 MMI 实现相当简陋,这并非总是有效。
- 我们使用进程内连接将新的请求数据从titanic.request服务端发送到主分发器。这避免了分发器必须扫描磁盘目录、加载所有请求文件并按日期/时间排序的麻烦。
这个示例的重要之处不在于性能(尽管我没有测试,但肯定很糟糕),而在于它如何很好地实现了可靠性契约。要尝试它,启动 mdbroker 和 titanic 程序。然后启动 ticlient,再启动 mdworker echo 服务。你可以使用-v选项来执行详细活动跟踪。你可以停止和重新启动任何部分,除了客户端,并且不会丢失任何东西。
如果你想在实际案例中使用 Titanic,你会很快问:“如何让它更快?”
以下是我会做的事情,从示例实现开始
- 对所有数据使用单个磁盘文件,而不是多个文件。操作系统通常更擅长处理几个大文件,而不是许多小文件。
- 将该磁盘文件组织成一个循环缓冲区,以便新的请求可以连续写入(只有极少量的回绕)。一个线程全速写入磁盘文件,可以快速工作。
- 将索引保存在内存中,并在启动时从磁盘缓冲区重建索引。这避免了为了将索引完全安全地保存在磁盘上所需的额外磁盘头抖动。你可能希望在每条消息后执行一次 fsync,或者每隔 N 毫秒执行一次,如果你愿意在系统故障时丢失最后的 M 条消息的话。
- 使用固态硬盘,而不是旋转的氧化铁盘片(机械硬盘)。
- 预分配整个文件,或大块分配,这使得循环缓冲区可以根据需要增长和缩小。这避免了碎片化,并确保大多数读写是连续的。
等等。我不建议将消息存储在数据库中,即使是“快速”的键/值存储也不建议,除非你真的喜欢某个特定的数据库并且不担心性能问题。你将为这种抽象付出高昂的代价,比直接操作原始磁盘文件要慢十到一千倍。
如果你想让 Titanic 更加可靠,可以将请求复制到第二个服务器上,这个服务器应放置在第二个位置,距离你的主要位置足够远以抵御核攻击,但又不能太远以免引入过高的延迟。
如果你想让 Titanic 快得多且可靠性降低,则完全将请求和应答存储在内存中。这将为你提供断开连接网络的功能,但请求不会在 Titanic 服务器自身崩溃时幸存。
高可用对 (Binary Star 模式) #
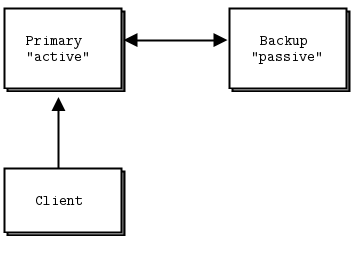
Binary Star 模式将两台服务器配置成一个主备高可用对。在任何给定时间,其中一台(活动的)接受客户端应用程序的连接。另一台(被动的)不执行任何操作,但这两台服务器相互监控。如果活动的服务器从网络中消失,被动的服务器会在一定时间后接管成为活动的服务器。
我们在 iMatix 为我们的 OpenAMQ 服务器 开发了 Binary Star 模式。我们设计它的目的是
- 提供一个简单易懂的高可用解决方案。
- 足够简单以便实际理解和使用。
- 在需要时可靠地进行故障转移,且仅在需要时进行。
假设我们有一个 Binary Star 对正在运行,以下是导致故障转移的不同场景
- 运行主服务器的硬件出现致命问题(电源爆炸、机器着火,或者有人不小心拔掉了电源),并从网络中消失。应用程序发现这一点后,会重新连接到备用服务器。
- 主服务器所在的网络段崩溃——也许是路由器受到电涌冲击——应用程序开始重新连接到备用服务器。
- 主服务器崩溃或被操作员终止,且未自动重启。
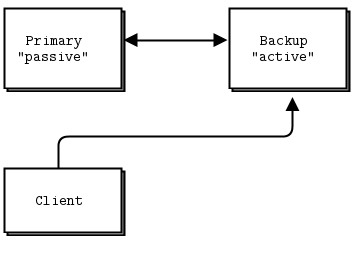
从故障转移中恢复的工作流程如下
- 操作员重启主服务器,并修复导致其从网络中消失的任何问题。
- 操作员在对应用程序造成最小中断的时刻停止备用服务器。
- 当应用程序重新连接到主服务器后,操作员重启备用服务器。
恢复(切换回使用主服务器作为活动的)是一个手动操作。痛苦的经验告诉我们,自动恢复是不可取的。原因有几个
-
故障转移会导致应用程序的服务中断,可能持续 10-30 秒。如果发生真正的紧急情况,这比完全中断要好得多。但如果恢复过程又导致额外的 10-30 秒中断,最好在非高峰时段进行,也就是用户不在网络上的时间。
-
当出现紧急情况时,首要任务是让修复人员拥有确定性。自动恢复给系统管理员带来了不确定性,他们无法再不经二次检查就确定哪台服务器是主导的。
-
自动恢复可能导致网络先故障转移然后又恢复的情况,这使得操作员难以分析发生了什么。服务中断了,但原因却不清楚。
话虽如此,如果主服务器(再次)运行且备用服务器发生故障,Binary Star 模式将切换回主服务器。事实上,这就是我们引发恢复的方式。
Binary Star 对的关闭过程可以按以下方式进行:
- 先停止被动服务器,然后在稍后的任何时间停止活动服务器;或者
- 以任何顺序停止两台服务器,但要在彼此关闭的几秒钟之内完成。
如果先停止活动服务器,然后停止被动服务器,并且两者之间的延迟超过了故障转移超时时间,则会导致应用程序先断开连接,然后重新连接,然后再次断开连接,这可能会干扰用户。
详细要求 #
Binary Star 模式尽可能简单,同时仍能准确工作。事实上,当前设计是第三次彻底重新设计。我们发现之前的每个设计都过于复杂,试图做太多事情,于是我们不断删减功能,直到得到一个易于理解、易于使用且足够可靠值得使用的设计。
以下是我们对高可用性架构的要求:
-
故障转移旨在为硬件故障、火灾、事故等灾难性系统故障提供保障。对于普通服务器崩溃,有更简单的恢复方法,我们已经介绍过了。
-
故障转移时间应在 60 秒以内,最好在 10 秒以内。
-
故障转移必须自动发生,而恢复必须手动进行。我们希望应用程序能够自动切换到备用服务器,但不希望它们切换回主服务器,除非操作员已经修复了问题,并决定此时适合再次中断应用程序。
-
客户端应用程序的语义应该简单易懂,方便开发者理解。理想情况下,它们应该隐藏在客户端 API 中。
-
应该有清晰的网络架构师指导,说明如何避免可能导致出现 split brain syndrome(脑裂综合症)的设计,在这种情况下,Binary Star 对中的两台服务器都认为自己是活动服务器。
-
不应对两台服务器的启动顺序存在任何依赖关系。
-
必须能够在不停止客户端应用程序的情况下对任一服务器进行计划性停止和重启(尽管它们可能被迫重新连接)。
-
操作员必须能够随时监控两台服务器。
-
必须能够使用高速专用网络连接来连接两台服务器。也就是说,故障转移同步必须能够使用特定的 IP 路由。
我们做出以下假设:
-
单个备用服务器提供了足够的保障;我们不需要多层备份。
-
主服务器和备用服务器都能够承受相同的应用程序负载。我们不尝试在服务器之间平衡负载。
-
有足够的预算来覆盖一个完全冗余的备用服务器,它几乎一直在空闲。
我们不尝试涵盖以下内容:
-
使用活动备用服务器或负载均衡。在 Binary Star 对中,备用服务器处于非活动状态,直到主服务器离线之前,它不做任何有用的工作。
-
以任何方式处理持久消息或事务。我们假设存在一个由不可靠(且可能不受信任)的服务器或 Binary Star 对组成的网络。
-
任何自动的网络探索。Binary Star 对是在网络中手动明确定义的,并且应用程序知道它(至少在其配置数据中)。
-
服务器之间的状态或消息复制。所有服务器端状态必须在应用程序发生故障转移时由应用程序重新创建。
以下是我们在 Binary Star 中使用的关键术语:
-
主服务器 (Primary):通常或最初是活动状态的服务器。
-
备用服务器 (Backup):通常处于被动状态的服务器。如果主服务器从网络中消失,并且当客户端应用程序请求连接备用服务器时,它将变为活动状态。
-
活动状态 (Active):接受客户端连接的服务器。最多只有一台活动服务器。
-
被动状态 (Passive):如果活动服务器消失,则接管的服务器。请注意,当 Binary Star 对正常运行时,主服务器处于活动状态,备用服务器处于被动状态。当发生故障转移时,角色会互换。
要配置 Binary Star 对,你需要:
- 告诉主服务器备用服务器的位置。
- 告诉备用服务器主服务器的位置。
- 可选地,调整故障转移响应时间,这两台服务器必须相同。
主要的调优考虑是你希望服务器检查其对等状态的频率,以及你希望多快激活故障转移。在我们的示例中,故障转移超时值默认为 2000 毫秒。如果你减少这个值,备用服务器将更快地接管成为活动状态,但可能会在主服务器可以恢复的情况下接管。例如,你可能使用一个 shell 脚本包装了主服务器,如果它崩溃就重启它。在这种情况下,超时时间应该高于重启主服务器所需的时间。
为了让客户端应用程序与 Binary Star 对正常工作,它们必须:
- 知道两台服务器的地址。
- 尝试连接主服务器,如果失败,则连接备用服务器。
- 检测连接失败,通常使用心跳机制。
- 尝试按顺序重新连接主服务器,然后是备用服务器,重试之间的延迟至少应等于服务器故障转移超时时间。
- 在服务器上重新创建它们所需的所有状态。
- 如果消息需要可靠,则重新发送在故障转移期间丢失的消息。
这不是一项简单的工作,我们通常会将其封装在一个 API 中,以将其从实际的最终用户应用程序中隐藏起来。
以下是 Binary Star 模式的主要限制:
- 一个服务器进程不能属于多个 Binary Star 对。
- 一个主服务器只能有一个备用服务器,不能更多。
- 被动服务器不做任何有用的工作,因此是被浪费的资源。
- 备用服务器必须能够处理完整的应用程序负载。
- 故障转移配置不能在运行时修改。
- 客户端应用程序必须做一些工作才能从故障转移中受益。
防止脑裂综合症 #
脑裂综合症 (Split-brain syndrome) 发生时,集群的不同部分同时认为自己处于活动状态。这会导致应用程序停止相互可见。Binary Star 有一种检测和消除脑裂的算法,它基于一种三方决策机制(一个服务器在收到应用程序连接请求且无法看到其对等服务器之前,不会决定成为活动状态)。
然而,仍然可能(错误地)设计网络来欺骗这种算法。一个典型的场景是,Binary Star 对分布在两栋建筑之间,每栋建筑都有一组应用程序,并且两栋建筑之间只有一条网络链接。断开此链接将创建两组客户端应用程序,每组都连接到 Binary Star 对中的一半,并且每个故障转移服务器都会变为活动状态。
为了防止脑裂情况,我们必须使用专用网络链接连接 Binary Star 对,这可以像将它们都插入同一个交换机一样简单,或者,更好的是,直接使用交叉线连接两台机器。
我们不能将 Binary Star 架构分成两个孤岛,每个孤岛都有一组应用程序。虽然这可能是一种常见的网络架构类型,但在这种情况下,你应该使用联邦(federation)模式,而不是高可用性故障转移。
一个足够偏执的网络配置会使用两条私有集群互联线路,而不是一条。此外,用于集群的网络卡将与用于消息流量的网络卡不同,甚至可能位于服务器硬件上不同的路径。目标是将网络中可能的故障与集群中可能的故障分离开来。网络端口可能具有相对较高的故障率。
Binary Star 实现 #
事不迟疑,以下是 Binary Star 服务器的概念验证实现。主服务器和备用服务器运行相同的代码,你在运行代码时选择它们的角色:
bstarsrv: Ada 语言的 Binary Star 服务器
bstarsrv: Basic 语言的 Binary Star 服务器
bstarsrv: C 语言的 Binary Star 服务器
// Binary Star server proof-of-concept implementation. This server does no
// real work; it just demonstrates the Binary Star failover model.
#include "czmq.h"
// States we can be in at any point in time
typedef enum {
STATE_PRIMARY = 1, // Primary, waiting for peer to connect
STATE_BACKUP = 2, // Backup, waiting for peer to connect
STATE_ACTIVE = 3, // Active - accepting connections
STATE_PASSIVE = 4 // Passive - not accepting connections
} state_t;
// Events, which start with the states our peer can be in
typedef enum {
PEER_PRIMARY = 1, // HA peer is pending primary
PEER_BACKUP = 2, // HA peer is pending backup
PEER_ACTIVE = 3, // HA peer is active
PEER_PASSIVE = 4, // HA peer is passive
CLIENT_REQUEST = 5 // Client makes request
} event_t;
// Our finite state machine
typedef struct {
state_t state; // Current state
event_t event; // Current event
int64_t peer_expiry; // When peer is considered 'dead'
} bstar_t;
// We send state information this often
// If peer doesn't respond in two heartbeats, it is 'dead'
#define HEARTBEAT 1000 // In msecs
// .split Binary Star state machine
// The heart of the Binary Star design is its finite-state machine (FSM).
// The FSM runs one event at a time. We apply an event to the current state,
// which checks if the event is accepted, and if so, sets a new state:
static bool
s_state_machine (bstar_t *fsm)
{
bool exception = false;
// These are the PRIMARY and BACKUP states; we're waiting to become
// ACTIVE or PASSIVE depending on events we get from our peer:
if (fsm->state == STATE_PRIMARY) {
if (fsm->event == PEER_BACKUP) {
printf ("I: connected to backup (passive), ready active\n");
fsm->state = STATE_ACTIVE;
}
else
if (fsm->event == PEER_ACTIVE) {
printf ("I: connected to backup (active), ready passive\n");
fsm->state = STATE_PASSIVE;
}
// Accept client connections
}
else
if (fsm->state == STATE_BACKUP) {
if (fsm->event == PEER_ACTIVE) {
printf ("I: connected to primary (active), ready passive\n");
fsm->state = STATE_PASSIVE;
}
else
// Reject client connections when acting as backup
if (fsm->event == CLIENT_REQUEST)
exception = true;
}
else
// .split active and passive states
// These are the ACTIVE and PASSIVE states:
if (fsm->state == STATE_ACTIVE) {
if (fsm->event == PEER_ACTIVE) {
// Two actives would mean split-brain
printf ("E: fatal error - dual actives, aborting\n");
exception = true;
}
}
else
// Server is passive
// CLIENT_REQUEST events can trigger failover if peer looks dead
if (fsm->state == STATE_PASSIVE) {
if (fsm->event == PEER_PRIMARY) {
// Peer is restarting - become active, peer will go passive
printf ("I: primary (passive) is restarting, ready active\n");
fsm->state = STATE_ACTIVE;
}
else
if (fsm->event == PEER_BACKUP) {
// Peer is restarting - become active, peer will go passive
printf ("I: backup (passive) is restarting, ready active\n");
fsm->state = STATE_ACTIVE;
}
else
if (fsm->event == PEER_PASSIVE) {
// Two passives would mean cluster would be non-responsive
printf ("E: fatal error - dual passives, aborting\n");
exception = true;
}
else
if (fsm->event == CLIENT_REQUEST) {
// Peer becomes active if timeout has passed
// It's the client request that triggers the failover
assert (fsm->peer_expiry > 0);
if (zclock_time () >= fsm->peer_expiry) {
// If peer is dead, switch to the active state
printf ("I: failover successful, ready active\n");
fsm->state = STATE_ACTIVE;
}
else
// If peer is alive, reject connections
exception = true;
}
}
return exception;
}
// .split main task
// This is our main task. First we bind/connect our sockets with our
// peer and make sure we will get state messages correctly. We use
// three sockets; one to publish state, one to subscribe to state, and
// one for client requests/replies:
int main (int argc, char *argv [])
{
// Arguments can be either of:
// -p primary server, at tcp://:5001
// -b backup server, at tcp://:5002
zctx_t *ctx = zctx_new ();
void *statepub = zsocket_new (ctx, ZMQ_PUB);
void *statesub = zsocket_new (ctx, ZMQ_SUB);
zsocket_set_subscribe (statesub, "");
void *frontend = zsocket_new (ctx, ZMQ_ROUTER);
bstar_t fsm = { 0 };
if (argc == 2 && streq (argv [1], "-p")) {
printf ("I: Primary active, waiting for backup (passive)\n");
zsocket_bind (frontend, "tcp://*:5001");
zsocket_bind (statepub, "tcp://*:5003");
zsocket_connect (statesub, "tcp://:5004");
fsm.state = STATE_PRIMARY;
}
else
if (argc == 2 && streq (argv [1], "-b")) {
printf ("I: Backup passive, waiting for primary (active)\n");
zsocket_bind (frontend, "tcp://*:5002");
zsocket_bind (statepub, "tcp://*:5004");
zsocket_connect (statesub, "tcp://:5003");
fsm.state = STATE_BACKUP;
}
else {
printf ("Usage: bstarsrv { -p | -b }\n");
zctx_destroy (&ctx);
exit (0);
}
// .split handling socket input
// We now process events on our two input sockets, and process these
// events one at a time via our finite-state machine. Our "work" for
// a client request is simply to echo it back:
// Set timer for next outgoing state message
int64_t send_state_at = zclock_time () + HEARTBEAT;
while (!zctx_interrupted) {
zmq_pollitem_t items [] = {
{ frontend, 0, ZMQ_POLLIN, 0 },
{ statesub, 0, ZMQ_POLLIN, 0 }
};
int time_left = (int) ((send_state_at - zclock_time ()));
if (time_left < 0)
time_left = 0;
int rc = zmq_poll (items, 2, time_left * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Context has been shut down
if (items [0].revents & ZMQ_POLLIN) {
// Have a client request
zmsg_t *msg = zmsg_recv (frontend);
fsm.event = CLIENT_REQUEST;
if (s_state_machine (&fsm) == false)
// Answer client by echoing request back
zmsg_send (&msg, frontend);
else
zmsg_destroy (&msg);
}
if (items [1].revents & ZMQ_POLLIN) {
// Have state from our peer, execute as event
char *message = zstr_recv (statesub);
fsm.event = atoi (message);
free (message);
if (s_state_machine (&fsm))
break; // Error, so exit
fsm.peer_expiry = zclock_time () + 2 * HEARTBEAT;
}
// If we timed out, send state to peer
if (zclock_time () >= send_state_at) {
char message [2];
sprintf (message, "%d", fsm.state);
zstr_send (statepub, message);
send_state_at = zclock_time () + HEARTBEAT;
}
}
if (zctx_interrupted)
printf ("W: interrupted\n");
// Shutdown sockets and context
zctx_destroy (&ctx);
return 0;
}
bstarsrv: C++ 语言的 Binary Star 服务器
// Binary Star server proof-of-concept implementation. This server does no
// real work; it just demonstrates the Binary Star failover model.
#include "zmsg.hpp"
#define ZMQ_POLL_MSEC 1 // One second
// States we can be in at any point in time
typedef enum {
STATE_NOTSET = 0, // Before we start, or if the state is invalid
STATE_PRIMARY = 1, // Primary, waiting for peer to connect
STATE_BACKUP = 2, // Backup, waiting for peer to connect
STATE_ACTIVE = 3, // Active - accepting connections
STATE_PASSIVE = 4 // Passive - not accepting connections
} state_t;
// Events, which start with the states our peer can be in
typedef enum {
EVENT_NOTSET = 0, // Before we start, or if the event is invalid
PEER_PRIMARY = 1, // HA peer is pending primary
PEER_BACKUP = 2, // HA peer is pending backup
PEER_ACTIVE = 3, // HA peer is active
PEER_PASSIVE = 4, // HA peer is passive
CLIENT_REQUEST = 5 // Client makes request
} event_t;
// We send state information this often
// If peer doesn't respond in two heartbeats, it is 'dead'
#define HEARTBEAT 1000 // In msecs
// .split Binary Star state machine
// The heart of the Binary Star design is its finite-state machine (FSM).
// The FSM runs one event at a time. We apply an event to the current state,
// which checks if the event is accepted, and if so, sets a new state:
// Our finite state machine
class bstar {
public:
bstar() : m_state(STATE_NOTSET), m_event(EVENT_NOTSET), m_peer_expiry(0) {}
bool state_machine(event_t event) {
m_event = event;
bool exception = false;
// These are the PRIMARY and BACKUP states; we're waiting to become
// ACTIVE or PASSIVE depending on events we get from our peer:
if (m_state == STATE_PRIMARY) {
if (m_event == PEER_BACKUP) {
std::cout << "I: connected to backup (passive), ready active" << std::endl;
m_state = STATE_ACTIVE;
} else if (m_event == PEER_ACTIVE) {
std::cout << "I: connected to backup (active), ready passive" << std::endl;
m_state = STATE_PASSIVE;
}
// Accept client connections
} else if (m_state == STATE_BACKUP) {
if (m_event == PEER_ACTIVE) {
std::cout << "I: connected to primary (active), ready passive" << std::endl;
m_state = STATE_PASSIVE;
} else if (m_event == CLIENT_REQUEST) {
// Reject client connections when acting as backup
exception = true;
}
// .split active and passive states
// These are the ACTIVE and PASSIVE states:
} else if (m_state == STATE_ACTIVE) {
if (m_event == PEER_ACTIVE) {
std::cout << "E: fatal error - dual actives, aborting" << std::endl;
exception = true;
}
// Server is passive
// CLIENT_REQUEST events can trigger failover if peer looks dead
} else if (m_state == STATE_PASSIVE) {
if (m_event == PEER_PRIMARY) {
// Peer is restarting - become active, peer will go passive
std::cout << "I: primary (passive) is restarting, ready active" << std::endl;
m_state = STATE_ACTIVE;
} else if (m_event == PEER_BACKUP) {
// Peer is restarting - become active, peer will go passive
std::cout << "I: backup (passive) is restarting, ready active" << std::endl;
m_state = STATE_ACTIVE;
} else if (m_event == PEER_PASSIVE) {
// Two passives would mean cluster would be non-responsive
std::cout << "E: fatal error - dual passives, aborting" << std::endl;
exception = true;
} else if (m_event == CLIENT_REQUEST) {
// Peer becomes active if timeout has passed
// It's the client request that triggers the failover
assert(m_peer_expiry > 0);
if (s_clock() >= m_peer_expiry) {
std::cout << "I: failover successful, ready active" << std::endl;
m_state = STATE_ACTIVE;
} else {
// If peer is alive, reject connections
exception = true;
}
}
}
return exception;
}
void set_state(state_t state) {
m_state = state;
}
state_t get_state() {
return m_state;
}
void set_peer_expiry(int64_t expiry) {
m_peer_expiry = expiry;
}
private:
state_t m_state; // Current state
event_t m_event; // Current event
int64_t m_peer_expiry; // When peer is considered 'dead', milliseconds
};
int main(int argc, char *argv []) {
// Arguments can be either of:
// -p primary server, at tcp://:5001
// -b backup server, at tcp://:5002
zmq::context_t context(1);
zmq::socket_t statepub(context, ZMQ_PUB);
zmq::socket_t statesub(context, ZMQ_SUB);
statesub.set(zmq::sockopt::subscribe, "");
zmq::socket_t frontend(context, ZMQ_ROUTER);
bstar fsm;
if (argc == 2 && strcmp(argv[1], "-p") == 0) {
std::cout << "I: Primary active, waiting for backup (passive)" << std::endl;
frontend.bind("tcp://*:5001");
statepub.bind("tcp://*:5003");
statesub.connect("tcp://:5004");
fsm.set_state(STATE_PRIMARY);
} else if (argc == 2 && strcmp(argv[1], "-b") == 0) {
std::cout << "I: Backup passive, waiting for primary (active)" << std::endl;
frontend.bind("tcp://*:5002");
statepub.bind("tcp://*:5004");
statesub.connect("tcp://:5003");
fsm.set_state(STATE_BACKUP);
} else {
std::cout << "Usage: bstarsrv { -p | -b }" << std::endl;
return 0;
}
// .split handling socket input
// We now process events on our two input sockets, and process these
// events one at a time via our finite-state machine. Our "work" for
// a client request is simply to echo it back:
// Set timer for next outgoing state message
int64_t send_state_at = s_clock() + HEARTBEAT;
s_catch_signals(); // catch SIGINT and SIGTERM
while(!s_interrupted) {
zmq::pollitem_t items [] = {
{ frontend, 0, ZMQ_POLLIN, 0 },
{ statesub, 0, ZMQ_POLLIN, 0 }
};
int time_left = (int) (send_state_at - s_clock());
if (time_left < 0)
time_left = 0;
try {
zmq::poll(items, 2, time_left * ZMQ_POLL_MSEC);
} catch (zmq::error_t &e) {
break; // Interrupted
}
if (items[0].revents & ZMQ_POLLIN) {
// Have client request, process it
zmsg msg;
msg.recv(frontend);
if (msg.parts() == 0)
break; // Ctrl-C
if (fsm.state_machine(CLIENT_REQUEST) == false) {
// Answer client by echoing request back
msg.send(frontend);
}
}
if (items[1].revents & ZMQ_POLLIN) {
// Have state from our peer, execute as event
std::string message = s_recv(statesub);
std::cout << "I: received state msg:" << message << std::endl;
event_t event = (event_t)std::stoi(message); // peer's state is our event
if (fsm.state_machine(event) == true) {
break; // Error, exit
}
fsm.set_peer_expiry(s_clock() + 2 * HEARTBEAT);
}
// If we timed out, send state to peer
if (s_clock() >= send_state_at) {
std::string state = std::to_string(fsm.get_state());
std::cout << "sending state:" << state << std::endl;
s_send(statepub, state);
// std::cout << "error: " << zmq_strerror(zmq_errno()) << std::endl;
send_state_at = s_clock() + HEARTBEAT;
}
}
if (s_interrupted) {
std::cout << "W: interrupt received, shutting down..." << std::endl;
}
return 0;
}
bstarsrv: C# 语言的 Binary Star 服务器
bstarsrv: CL 语言的 Binary Star 服务器
bstarsrv: Delphi 语言的 Binary Star 服务器
bstarsrv: Erlang 语言的 Binary Star 服务器
bstarsrv: Elixir 语言的 Binary Star 服务器
bstarsrv: F# 语言的 Binary Star 服务器
bstarsrv: Felix 语言的 Binary Star 服务器
bstarsrv: Go 语言的 Binary Star 服务器
bstarsrv: Haskell 语言的 Binary Star 服务器
bstarsrv: Haxe 语言的 Binary Star 服务器
package ;
import haxe.io.Bytes;
import haxe.Stack;
import neko.Sys;
import neko.Lib;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQException;
import org.zeromq.ZMsg;
import org.zeromq.ZSocket;
/**
* Binary Star Server
* @author Richard J Smith
*
* @see https://zguide.zeromq.cn/page:all#Binary-Star-Implementation
*/
class BStarSrv
{
private static inline var HEARTBEAT = 100;
/** Current state */
public var state:StateT;
/** Current event */
public var event:EventT;
/** When peer is considered 'dead' */
public var peerExpiry:Float;
/**
* BStarSrv constructor
* @param state Initial state
*/
public function new(state:StateT) {
this.state = state;
}
/**
* Main binary star server loop
*/
public function run() {
var ctx = new ZContext();
var statePub = ctx.createSocket(ZMQ_PUB);
var stateSub = ctx.createSocket(ZMQ_SUB);
var frontend = ctx.createSocket(ZMQ_ROUTER);
switch (state) {
case STATE_PRIMARY:
Lib.println("I: primary master, waiting for backup (slave)");
frontend.bind("tcp://*:5001");
statePub.bind("tcp://*:5003");
stateSub.setsockopt(ZMQ_SUBSCRIBE, Bytes.ofString(""));
stateSub.connect("tcp://:5004");
case STATE_BACKUP:
Lib.println("I: backup slave, waiting for primary (master)");
frontend.bind("tcp://*:5002");
statePub.bind("tcp://*:5004");
stateSub.setsockopt(ZMQ_SUBSCRIBE, Bytes.ofString(""));
stateSub.connect("tcp://:5003");
default:
ctx.destroy();
return;
}
// Set timer for next outgoing state message
var sendStateAt = Date.now().getTime() + HEARTBEAT;
var poller = new ZMQPoller();
poller.registerSocket(frontend, ZMQ.ZMQ_POLLIN());
poller.registerSocket(stateSub, ZMQ.ZMQ_POLLIN());
while (!ZMQ.isInterrupted()) {
var timeLeft = Std.int(sendStateAt - Date.now().getTime());
if (timeLeft < 0)
timeLeft = 0;
try {
var res = poller.poll(timeLeft * 1000); // Convert timeout to microseconds
} catch (e:ZMQException) {
if (!ZMQ.isInterrupted()) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
} else {
Lib.println("W: interrupt received, killing server...");
}
ctx.destroy();
return;
}
if (poller.pollin(1)) {
// Have a client request
var msg = ZMsg.recvMsg(frontend);
event = CLIENT_REQUEST;
if (!stateMachine())
// Answer client by echoing request back
msg.send(frontend); // Pretend do some work and then reply
else
msg.destroy();
}
if (poller.pollin(2)) {
// Have state from our peer, execute as event
var message = stateSub.recvMsg().toString();
event = Type.createEnumIndex(EventT, Std.parseInt(message));
if (stateMachine())
break; // Error, so exit
peerExpiry = Date.now().getTime() + (2 * HEARTBEAT);
}
// If we timed-out, send state to peer
if (Date.now().getTime() >= sendStateAt) {
statePub.sendMsg(Bytes.ofString(Std.string(Type.enumIndex(state))));
sendStateAt = Date.now().getTime() + HEARTBEAT;
}
}
ctx.destroy();
}
/**
* Executes finite state machine (apply event to this state)
* Returns true if there was an exception
* @return
*/
public function stateMachine():Bool
{
var exception = false;
switch (state) {
case STATE_PRIMARY:
// Primary server is waiting for peer to connect
// Accepts CLIENT_REQUEST events in this state
switch (event) {
case PEER_BACKUP:
Lib.println("I: connected to backup (slave), ready as master");
state = STATE_ACTIVE;
case PEER_ACTIVE:
Lib.println("I: connected to backup (master), ready as slave");
state = STATE_PASSIVE;
default:
}
case STATE_BACKUP:
// Backup server is waiting for peer to connect
// Rejects CLIENT_REQUEST events in this state
switch (event) {
case PEER_ACTIVE:
Lib.println("I: connected to primary (master), ready as slave");
state = STATE_PASSIVE;
case CLIENT_REQUEST:
exception = true;
default:
}
case STATE_ACTIVE:
// Server is active
// Accepts CLIENT_REQUEST events in this state
switch (event) {
case PEER_ACTIVE:
// Two masters would mean split-brain
Lib.println("E: fatal error - dual masters, aborting");
exception = true;
default:
}
case STATE_PASSIVE:
// Server is passive
// CLIENT_REQUEST events can trigger failover if peer looks dead
switch (event) {
case PEER_PRIMARY:
// Peer is restarting - become active, peer will go passive
Lib.println("I: primary (slave) is restarting, ready as master");
state = STATE_ACTIVE;
case PEER_BACKUP:
// Peer is restarting - become active, peer will go passive
Lib.println("I: backup (slave) is restarting, ready as master");
state = STATE_ACTIVE;
case PEER_PASSIVE:
// Two passives would mean cluster would be non-responsive
Lib.println("E: fatal error - dual slaves, aborting");
exception = true;
case CLIENT_REQUEST:
// Peer becomes master if timeout as passed
// It's the client request that triggers the failover
if (Date.now().getTime() >= peerExpiry) {
// If peer is dead, switch to the active state
Lib.println("I: failover successful, ready as master");
state = STATE_ACTIVE;
} else {
Lib.println("I: peer is active, so ignore connection");
exception = true;
}
default:
}
}
return exception;
}
public static function main() {
Lib.println("** BStarSrv (see: https://zguide.zeromq.cn/page:all#Binary-Star-Implementation)");
var state:StateT = null;
var argArr = Sys.args();
if (argArr.length > 1 && argArr[argArr.length - 1] == "-p") {
state = STATE_PRIMARY;
} else if (argArr.length > 1 && argArr[argArr.length - 1] == "-b") {
state = STATE_BACKUP;
} else {
Lib.println("Usage: bstartsrv { -p | -b }");
return;
}
var bstarServer = new BStarSrv(state);
bstarServer.run();
}
}
// States we can be in at any time
private enum StateT {
STATE_PRIMARY; // Primary, waiting for peer to connect
STATE_BACKUP; // Backup, waiting for peer to connect
STATE_ACTIVE; // Active - accepting connections
STATE_PASSIVE; // Passive - not accepting connections
}
private enum EventT {
PEER_PRIMARY; // HA peer is pending primary
PEER_BACKUP; // HA peer is pending backup
PEER_ACTIVE; // HA peer is active
PEER_PASSIVE; // HA peer is passive
CLIENT_REQUEST; // Client makes request
}
bstarsrv: Java 语言的 Binary Star 服务器
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZMsg;
// Binary Star server proof-of-concept implementation. This server does no
// real work; it just demonstrates the Binary Star failover model.
public class bstarsrv
{
// States we can be in at any point in time
enum State
{
STATE_PRIMARY, // Primary, waiting for peer to connect
STATE_BACKUP, // Backup, waiting for peer to connect
STATE_ACTIVE, // Active - accepting connections
STATE_PASSIVE // Passive - not accepting connections
}
// Events, which start with the states our peer can be in
enum Event
{
PEER_PRIMARY, // HA peer is pending primary
PEER_BACKUP, // HA peer is pending backup
PEER_ACTIVE, // HA peer is active
PEER_PASSIVE, // HA peer is passive
CLIENT_REQUEST // Client makes request
}
// Our finite state machine
private State state; // Current state
private Event event; // Current event
private long peerExpiry; // When peer is considered 'dead'
// We send state information this often
// If peer doesn't respond in two heartbeats, it is 'dead'
private final static long HEARTBEAT = 1000; // In msecs
// .split Binary Star state machine
// The heart of the Binary Star design is its finite-state machine (FSM).
// The FSM runs one event at a time. We apply an event to the current state,
// which checks if the event is accepted, and if so, sets a new state:
private boolean stateMachine()
{
boolean exception = false;
// These are the PRIMARY and BACKUP states; we're waiting to become
// ACTIVE or PASSIVE depending on events we get from our peer:
if (state == State.STATE_PRIMARY) {
if (event == Event.PEER_BACKUP) {
System.out.printf("I: connected to backup (passive), ready active\n");
state = State.STATE_ACTIVE;
}
else if (event == Event.PEER_ACTIVE) {
System.out.printf("I: connected to backup (active), ready passive\n");
state = State.STATE_PASSIVE;
}
// Accept client connections
}
else if (state == State.STATE_BACKUP) {
if (event == Event.PEER_ACTIVE) {
System.out.printf("I: connected to primary (active), ready passive\n");
state = State.STATE_PASSIVE;
}
else
// Reject client connections when acting as backup
if (event == Event.CLIENT_REQUEST)
exception = true;
}
else
// .split active and passive states
// These are the ACTIVE and PASSIVE states:
if (state == State.STATE_ACTIVE) {
if (event == Event.PEER_ACTIVE) {
// Two actives would mean split-brain
System.out.printf("E: fatal error - dual actives, aborting\n");
exception = true;
}
}
else
// Server is passive
// CLIENT_REQUEST events can trigger failover if peer looks dead
if (state == State.STATE_PASSIVE) {
if (event == Event.PEER_PRIMARY) {
// Peer is restarting - become active, peer will go passive
System.out.printf("I: primary (passive) is restarting, ready active\n");
state = State.STATE_ACTIVE;
}
else if (event == Event.PEER_BACKUP) {
// Peer is restarting - become active, peer will go passive
System.out.printf("I: backup (passive) is restarting, ready active\n");
state = State.STATE_ACTIVE;
}
else if (event == Event.PEER_PASSIVE) {
// Two passives would mean cluster would be non-responsive
System.out.printf("E: fatal error - dual passives, aborting\n");
exception = true;
}
else if (event == Event.CLIENT_REQUEST) {
// Peer becomes active if timeout has passed
// It's the client request that triggers the failover
assert (peerExpiry > 0);
if (System.currentTimeMillis() >= peerExpiry) {
// If peer is dead, switch to the active state
System.out.printf("I: failover successful, ready active\n");
state = State.STATE_ACTIVE;
}
else
// If peer is alive, reject connections
exception = true;
}
}
return exception;
}
// .split main task
// This is our main task. First we bind/connect our sockets with our
// peer and make sure we will get state messages correctly. We use
// three sockets; one to publish state, one to subscribe to state, and
// one for client requests/replies:
public static void main(String[] argv)
{
// Arguments can be either of:
// -p primary server, at tcp://:5001
// -b backup server, at tcp://:5002
try (ZContext ctx = new ZContext()) {
Socket statepub = ctx.createSocket(SocketType.PUB);
Socket statesub = ctx.createSocket(SocketType.SUB);
statesub.subscribe(ZMQ.SUBSCRIPTION_ALL);
Socket frontend = ctx.createSocket(SocketType.ROUTER);
bstarsrv fsm = new bstarsrv();
if (argv.length == 1 && argv[0].equals("-p")) {
System.out.printf("I: Primary active, waiting for backup (passive)\n");
frontend.bind("tcp://*:5001");
statepub.bind("tcp://*:5003");
statesub.connect("tcp://:5004");
fsm.state = State.STATE_PRIMARY;
}
else if (argv.length == 1 && argv[0].equals("-b")) {
System.out.printf("I: Backup passive, waiting for primary (active)\n");
frontend.bind("tcp://*:5002");
statepub.bind("tcp://*:5004");
statesub.connect("tcp://:5003");
fsm.state = State.STATE_BACKUP;
}
else {
System.out.printf("Usage: bstarsrv { -p | -b }\n");
ctx.destroy();
System.exit(0);
}
// .split handling socket input
// We now process events on our two input sockets, and process
// these events one at a time via our finite-state machine. Our
// "work" for a client request is simply to echo it back.
Poller poller = ctx.createPoller(2);
poller.register(frontend, ZMQ.Poller.POLLIN);
poller.register(statesub, ZMQ.Poller.POLLIN);
// Set timer for next outgoing state message
long sendStateAt = System.currentTimeMillis() + HEARTBEAT;
while (!Thread.currentThread().isInterrupted()) {
int timeLeft = (int) ((sendStateAt - System.currentTimeMillis()));
if (timeLeft < 0)
timeLeft = 0;
int rc = poller.poll(timeLeft);
if (rc == -1)
break; // Context has been shut down
if (poller.pollin(0)) {
// Have a client request
ZMsg msg = ZMsg.recvMsg(frontend);
fsm.event = Event.CLIENT_REQUEST;
if (fsm.stateMachine() == false)
// Answer client by echoing request back
msg.send(frontend);
else msg.destroy();
}
if (poller.pollin(1)) {
// Have state from our peer, execute as event
String message = statesub.recvStr();
fsm.event = Event.values()[Integer.parseInt(message)];
if (fsm.stateMachine())
break; // Error, so exit
fsm.peerExpiry = System.currentTimeMillis() + 2 * HEARTBEAT;
}
// If we timed out, send state to peer
if (System.currentTimeMillis() >= sendStateAt) {
statepub.send(String.valueOf(fsm.state.ordinal()));
sendStateAt = System.currentTimeMillis() + HEARTBEAT;
}
}
if (Thread.currentThread().isInterrupted())
System.out.printf("W: interrupted\n");
}
}
}
bstarsrv: Julia 语言的 Binary Star 服务器
bstarsrv: Lua 语言的 Binary Star 服务器
bstarsrv: Node.js 语言的 Binary Star 服务器
bstarsrv: Objective-C 语言的 Binary Star 服务器
bstarsrv: ooc 语言的 Binary Star 服务器
bstarsrv: Perl 语言的 Binary Star 服务器
bstarsrv: PHP 语言的 Binary Star 服务器
bstarsrv: Python 语言的 Binary Star 服务器
# Binary Star Server
#
# Author: Dan Colish <dcolish@gmail.com>
from argparse import ArgumentParser
import time
from zhelpers import zmq
STATE_PRIMARY = 1
STATE_BACKUP = 2
STATE_ACTIVE = 3
STATE_PASSIVE = 4
PEER_PRIMARY = 1
PEER_BACKUP = 2
PEER_ACTIVE = 3
PEER_PASSIVE = 4
CLIENT_REQUEST = 5
HEARTBEAT = 1000
class BStarState(object):
def __init__(self, state, event, peer_expiry):
self.state = state
self.event = event
self.peer_expiry = peer_expiry
class BStarException(Exception):
pass
fsm_states = {
STATE_PRIMARY: {
PEER_BACKUP: ("I: connected to backup (slave), ready as master",
STATE_ACTIVE),
PEER_ACTIVE: ("I: connected to backup (master), ready as slave",
STATE_PASSIVE)
},
STATE_BACKUP: {
PEER_ACTIVE: ("I: connected to primary (master), ready as slave",
STATE_PASSIVE),
CLIENT_REQUEST: ("", False)
},
STATE_ACTIVE: {
PEER_ACTIVE: ("E: fatal error - dual masters, aborting", False)
},
STATE_PASSIVE: {
PEER_PRIMARY: ("I: primary (slave) is restarting, ready as master",
STATE_ACTIVE),
PEER_BACKUP: ("I: backup (slave) is restarting, ready as master",
STATE_ACTIVE),
PEER_PASSIVE: ("E: fatal error - dual slaves, aborting", False),
CLIENT_REQUEST: (CLIENT_REQUEST, True) # Say true, check peer later
}
}
def run_fsm(fsm):
# There are some transitional states we do not want to handle
state_dict = fsm_states.get(fsm.state, {})
res = state_dict.get(fsm.event)
if res:
msg, state = res
else:
return
if state is False:
raise BStarException(msg)
elif msg == CLIENT_REQUEST:
assert fsm.peer_expiry > 0
if int(time.time() * 1000) > fsm.peer_expiry:
fsm.state = STATE_ACTIVE
else:
raise BStarException()
else:
print(msg)
fsm.state = state
def main():
parser = ArgumentParser()
group = parser.add_mutually_exclusive_group()
group.add_argument("-p", "--primary", action="store_true", default=False)
group.add_argument("-b", "--backup", action="store_true", default=False)
args = parser.parse_args()
ctx = zmq.Context()
statepub = ctx.socket(zmq.PUB)
statesub = ctx.socket(zmq.SUB)
statesub.setsockopt_string(zmq.SUBSCRIBE, u"")
frontend = ctx.socket(zmq.ROUTER)
fsm = BStarState(0, 0, 0)
if args.primary:
print("I: Primary master, waiting for backup (slave)")
frontend.bind("tcp://*:5001")
statepub.bind("tcp://*:5003")
statesub.connect("tcp://:5004")
fsm.state = STATE_PRIMARY
elif args.backup:
print("I: Backup slave, waiting for primary (master)")
frontend.bind("tcp://*:5002")
statepub.bind("tcp://*:5004")
statesub.connect("tcp://:5003")
statesub.setsockopt_string(zmq.SUBSCRIBE, u"")
fsm.state = STATE_BACKUP
send_state_at = int(time.time() * 1000 + HEARTBEAT)
poller = zmq.Poller()
poller.register(frontend, zmq.POLLIN)
poller.register(statesub, zmq.POLLIN)
while True:
time_left = send_state_at - int(time.time() * 1000)
if time_left < 0:
time_left = 0
socks = dict(poller.poll(time_left))
if socks.get(frontend) == zmq.POLLIN:
msg = frontend.recv_multipart()
fsm.event = CLIENT_REQUEST
try:
run_fsm(fsm)
frontend.send_multipart(msg)
except BStarException:
del msg
if socks.get(statesub) == zmq.POLLIN:
msg = statesub.recv()
fsm.event = int(msg)
del msg
try:
run_fsm(fsm)
fsm.peer_expiry = int(time.time() * 1000) + (2 * HEARTBEAT)
except BStarException:
break
if int(time.time() * 1000) >= send_state_at:
statepub.send("%d" % fsm.state)
send_state_at = int(time.time() * 1000) + HEARTBEAT
if __name__ == '__main__':
main()
bstarsrv: Q 语言的 Binary Star 服务器
bstarsrv: Racket 语言的 Binary Star 服务器
bstarsrv: Ruby 语言的 Binary Star 服务器
#!/usr/bin/env ruby
# vim: ft=ruby
# Binary Star server proof-of-concept implementation. This server does no
# real work; it just demonstrates the Binary Star failover model.
require 'optparse'
require 'cztop'
# We send state information this often
# If peer doesn't respond in two heartbeats, it is 'dead'
HEARTBEAT = 1000 # in msecs
# Binary Star finite-state machine.
class BStarState
Exception = Class.new(StandardError)
attr_accessor :state
attr_writer :peer_expiry
def initialize(state, peer_expiry = nil)
unless [:primary, :backup].include? state
abort "invalid initial state #{state.inspect}"
end
@state = state
@peer_expiry = peer_expiry
end
def <<(event)
puts "processing event #{event.inspect} ..."
case @state
when :primary
case event
when :peer_backup
puts "I: connected to backup (passive), ready active"
@state = :active
when :peer_active
puts "I: connected to backup (active), ready passive"
@state = :passive
end
# Accept client connections
when :backup
case event
when :peer_active
puts "I: connected to primary (active), ready passive"
@state = :passive
when :client_request
# Reject client connections when acting as backup
raise Exception, "not active"
end
when :active
case event
when :peer_active
# Two actives would mean split-brain
puts "E: fatal error - dual actives, aborting"
abort "split brain"
end
when :passive
case event
when :peer_primary
# Peer is restarting - become active, peer will go passive
puts "I: primary (passive) is restarting, ready active"
@state = :active
when :peer_backup
# Peer is restarting - become active, peer will go passive
puts "I: backup (passive) is restarting, ready active"
@state = :active;
when :peer_passive
# Two passives would mean cluster would be non-responsive
puts "E: fatal error - dual passives, aborting"
abort "dual passives"
when :client_request
# Peer becomes active if timeout has passed
# It's the client request that triggers the failover
abort "bad peer expiry" unless @peer_expiry
if Time.now >= @peer_expiry
# If peer is dead, switch to the active state
puts "I: failover successful, ready active"
@state = :active
else
# If peer is alive, reject connections
raise Exception, "peer is alive"
end
end
end
end
end
if __FILE__ == $0
options = {}
OptionParser.new do |opts|
opts.banner = "Usage: #$0 [options]"
opts.on("-p", "--primary", "run as primary server") do |v|
options[:role] = :primary
end
opts.on("-b", "--backup", "run as backup server") do |v|
options[:role] = :backup
end
end.parse!
unless options[:role]
abort "Usage: #$0 { -p | -b }"
end
# We use three sockets; one to publish state, one to subscribe to state, and
# one for client requests/replies.
statepub = CZTop::Socket::PUB.new
statesub = CZTop::Socket::SUB.new
statesub.subscribe
frontend = CZTop::Socket::ROUTER.new
# We bind/connect our sockets with our peer and make sure we will get state
# messages correctly.
case options[:role]
when :primary
puts "I: Primary master, waiting for backup (slave)"
statepub.bind("tcp://*:5003")
statesub.connect("tcp://:5004")
frontend.bind("tcp://*:5001")
bstar = BStarState.new(:primary)
when :backup
puts "I: Backup slave, waiting for primary (master)"
statepub.bind("tcp://*:5004")
statesub.connect("tcp://:5003")
statesub.subscribe
frontend.bind("tcp://*:5002")
bstar = BStarState.new(:backup)
end
# We now process events on our two input sockets, and process these events
# one at a time via our finite-state machine. Our "work" for a client
# request is simply to echo it back:
poller = CZTop::Poller.new(statesub, frontend)
send_state_at = Time.now + (HEARTBEAT/1000.0)
while true
# round to msec resolution to avoid polling bursts
time_left = (send_state_at - Time.now).round(3)
time_left = 0 if time_left < 0
time_left = (time_left * 1000).to_i # convert to msec
case poller.simple_wait(time_left)
when statesub
# state from peer
msg = statesub.receive
puts "received message from statesub: #{msg.to_a.inspect}"
bstar << :"peer_#{msg[0]}" # this could exit the process
bstar.peer_expiry = Time.now + 2 * (HEARTBEAT/1000.0)
when frontend
# client request
msg = frontend.receive
puts "received message from frontend: #{msg.to_a.inspect}"
begin
bstar << :client_request
frontend << msg
rescue BStarState::Exception
# We got a client request even though we're passive AND peer is alive.
# We'll just ignore it.
end
end
# If we timed out, send state to peer.
if Time.now >= send_state_at
statepub << bstar.state.to_s
send_state_at = Time.now + (HEARTBEAT/1000.0)
end
end
end
bstarsrv: Rust 语言的 Binary Star 服务器
bstarsrv: Scala 语言的 Binary Star 服务器
bstarsrv: Tcl 语言的 Binary Star 服务器
#
# Binary Star server
#
package require TclOO
package require zmq
# Arguments can be either of:
# -p primary server, at tcp://:5001
# -b backup server, at tcp://:5002
if {[llength $argv] != 1 || [lindex $argv 0] ni {-p -b}} {
puts "Usage: bstarsrv.tcl <-p|-b>"
exit 1
}
# We send state information every this often
# If peer doesn't respond in two heartbeats, it is 'dead'
set HEARTBEAT 1000 ;# In msecs
# States we can be in at any point in time
set STATE(NONE) 0
set STATE(PRIMARY) 1 ;# Primary, waiting for peer to connect
set STATE(BACKUP) 2 ;# Backup, waiting for peer to connect
set STATE(ACTIVE) 3 ;# Active - accepting connections
set STATE(PASSIVE) 4 ;# Passive - not accepting connections
# Events, which start with the states our peer can be in
set EVENT(NONE) 0
set EVENT(PRIMARY) 1 ;# HA peer is pending primary
set EVENT(BACKUP) 2 ;# HA peer is pending backup
set EVENT(ACTIVE) 3 ;# HA peer is active
set EVENT(PASSIVE) 4 ;# HA peer is passive
set EVENT(REQUEST) 5 ;# Client makes request
# Our finite state machine
oo::class create BStar {
variable state event peer_expiry
constructor {} {
set state NONE
set event NONE
set peer_expiry 0
}
destructor {
}
method state_machine {} {
set exception 0
if {$state eq "PRIMARY"} {
# Primary server is waiting for peer to connect
# Accepts CLIENT_REQUEST events in this state
if {$event eq "BACKUP"} {
puts "I: connected to backup (slave), ready as master"
set state ACTIVE
} elseif {$event eq "ACTIVE"} {
puts "I: connected to backup (master), ready as slave"
set state PASSIVE
}
} elseif {$state eq "BACKUP"} {
# Backup server is waiting for peer to connect
# Rejects CLIENT_REQUEST events in this state
if {$event eq "ACTIVE"} {
puts "I: connected to primary (master), ready as slave"
set state PASSIVE
} elseif {$event eq "REQUEST"} {
set exception 1
}
} elseif {$state eq "ACTIVE"} {
# Server is active
# Accepts CLIENT_REQUEST events in this state
if {$event eq "ACTIVE"} {
# Two masters would mean split-brain
puts "E: fatal error - dual masters, aborting"
set exception 1
}
} elseif {$state eq "PASSIVE"} {
# Server is passive
# CLIENT_REQUEST events can trigger failover if peer looks dead
if {$event eq "PRIMARY"} {
# Peer is restarting - become active, peer will go passive
puts "I: primary (slave) is restarting, ready as master"
set state ACTIVE
} elseif {$event eq "BACKUP"} {
# Peer is restarting - become active, peer will go passive
puts "I: backup (slave) is restarting, ready as master"
set state ACTIVE
} elseif {$event eq "PASSIVE"} {
# Two passives would mean cluster would be non-responsive
puts "E: fatal error - dual slaves, aborting"
set exception 1
} elseif {$event eq "REQUEST"} {
# Peer becomes master if timeout has passed
# It's the client request that triggers the failover
if {$peer_expiry <= 0} {
error "peer_expiry must be > 0"
}
if {[clock milliseconds] >= $peer_expiry} {
# If peer is dead, switch to the active state
puts "I: failover successful, ready as master"
set state ACTIVE
} else {
# If peer is alive, reject connections
set exception 1
}
}
}
return $exception
}
method set_state {istate} {
set state $istate
}
method set_event {ievent} {
set event $ievent
}
method state {} {
return $state
}
method update_peer_expiry {} {
set peer_expiry [expr {[clock milliseconds] + 2 * $::HEARTBEAT}]
}
}
zmq context context
zmq socket statepub context PUB
zmq socket statesub context SUB
statesub setsockopt SUBSCRIBE ""
zmq socket frontend context ROUTER
set fsm [BStar new]
if {[lindex $argv 0] eq "-p"} {
puts "I: Primary master, waiting for backup (slave)"
frontend bind "tcp://*:5001"
statepub bind "tcp://*:5003"
statesub connect "tcp://:5004"
$fsm set_state PRIMARY
} elseif {[lindex $argv 0] eq "-b"} {
puts "I: Backup slave, waiting for primary (master)"
frontend bind "tcp://*:5002"
statepub bind "tcp://*:5004"
statesub connect "tcp://:5003"
$fsm set_state BACKUP
}
# Set timer for next outgoing state message
set send_state_at [expr {[clock milliseconds] + $HEARTBEAT}]
while {1} {
set timeleft [expr {$send_state_at - [clock milliseconds]}]
if {$timeleft < 0} {
set timeleft 0
}
foreach rpoll [zmq poll {{frontend {POLLIN}} {statesub {POLLIN}}} $timeleft] {
switch -exact -- [lindex $rpoll 0] {
frontend {
# Have a client request
set msg [zmsg recv frontend]
$fsm set_event REQUEST
if {[$fsm state_machine] == 0} {
zmsg send frontend $msg
}
}
statesub {
# Have state from our peer, execute as event
set state [statesub recv]
$fsm set_event $state
if {[$fsm state_machine]} {
break ;# Error, so exit
}
$fsm update_peer_expiry
}
}
}
# If we timed-out, send state to peer
if {[clock milliseconds] >= $send_state_at} {
statepub send [$fsm state]
set send_state_at [expr {[clock milliseconds] + $HEARTBEAT}]
}
}
statepub close
statesub close
frontend close
context term
bstarsrv: OCaml 语言的 Binary Star 服务器
以下是客户端实现:
bstarcli: Ada 语言的 Binary Star 客户端
bstarcli: Basic 语言的 Binary Star 客户端
bstarcli: C 语言的 Binary Star 客户端
// Binary Star client proof-of-concept implementation. This client does no
// real work; it just demonstrates the Binary Star failover model.
#include "czmq.h"
#define REQUEST_TIMEOUT 1000 // msecs
#define SETTLE_DELAY 2000 // Before failing over
int main (void)
{
zctx_t *ctx = zctx_new ();
char *server [] = { "tcp://:5001", "tcp://:5002" };
uint server_nbr = 0;
printf ("I: connecting to server at %s...\n", server [server_nbr]);
void *client = zsocket_new (ctx, ZMQ_REQ);
zsocket_connect (client, server [server_nbr]);
int sequence = 0;
while (!zctx_interrupted) {
// We send a request, then we work to get a reply
char request [10];
sprintf (request, "%d", ++sequence);
zstr_send (client, request);
int expect_reply = 1;
while (expect_reply) {
// Poll socket for a reply, with timeout
zmq_pollitem_t items [] = { { client, 0, ZMQ_POLLIN, 0 } };
int rc = zmq_poll (items, 1, REQUEST_TIMEOUT * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Interrupted
// .split main body of client
// We use a Lazy Pirate strategy in the client. If there's no
// reply within our timeout, we close the socket and try again.
// In Binary Star, it's the client vote that decides which
// server is primary; the client must therefore try to connect
// to each server in turn:
if (items [0].revents & ZMQ_POLLIN) {
// We got a reply from the server, must match sequence
char *reply = zstr_recv (client);
if (atoi (reply) == sequence) {
printf ("I: server replied OK (%s)\n", reply);
expect_reply = 0;
sleep (1); // One request per second
}
else
printf ("E: bad reply from server: %s\n", reply);
free (reply);
}
else {
printf ("W: no response from server, failing over\n");
// Old socket is confused; close it and open a new one
zsocket_destroy (ctx, client);
server_nbr = (server_nbr + 1) % 2;
zclock_sleep (SETTLE_DELAY);
printf ("I: connecting to server at %s...\n",
server [server_nbr]);
client = zsocket_new (ctx, ZMQ_REQ);
zsocket_connect (client, server [server_nbr]);
// Send request again, on new socket
zstr_send (client, request);
}
}
}
zctx_destroy (&ctx);
return 0;
}
bstarcli: C++ 语言的 Binary Star 客户端
// Binary Star client proof-of-concept implementation. This client does no
// real work; it just demonstrates the Binary Star failover model.
#include "zmsg.hpp"
#define REQUEST_TIMEOUT 1000 // msecs
#define SETTLE_DELAY 2000 // Before failing over
#define ZMQ_POLL_MSEC 1 // zmq_poll delay
int main(void) {
zmq::context_t context(1);
char *server [] = {"tcp://:5001", "tcp://:5002"};
uint server_nbr = 0;
std::cout << "I: connecting to " << server[server_nbr] << "..." << std::endl;
zmq::socket_t *client = new zmq::socket_t(context, ZMQ_REQ);
// Configure socket to not wait at close time
int linger = 0;
client->setsockopt (ZMQ_LINGER, &linger, sizeof (linger));
client->connect(server[server_nbr]);
int sequence = 0;
while(true) {
// We send a request, then we work to get a reply
std::string request_string = std::to_string(++sequence);
s_send(*client, request_string);
int expect_reply = 1;
while(expect_reply) {
zmq::pollitem_t items[] = {{*client, 0, ZMQ_POLLIN, 0}};
try {
zmq::poll(items, 1, REQUEST_TIMEOUT * ZMQ_POLL_MSEC);
} catch (std::exception &e) {
break; // Interrupted
}
// .split main body of client
// We use a Lazy Pirate strategy in the client. If there's no
// reply within our timeout, we close the socket and try again.
// In Binary Star, it's the client vote that decides which
// server is primary; the client must therefore try to connect
// to each server in turn:
if (items[0].revents & ZMQ_POLLIN) {
// We got a reply from the server, must match sequence
std::string reply = s_recv(*client);
if (std::stoi(reply) == sequence) {
std::cout << "I: server replied OK (" << reply << ")" << std::endl;
expect_reply = 0;
s_sleep(1000); // One request per second
} else {
std::cout << "E: bad reply from server: " << reply << std::endl;
}
} else {
std::cout << "W: no response from server, failing over" << std::endl;
// Old socket is confused; close it and open a new one
delete client;
server_nbr = (server_nbr + 1) % 2;
s_sleep(SETTLE_DELAY);
std::cout << "I: connecting to " << server[server_nbr] << "..." << std::endl;
client = new zmq::socket_t(context, ZMQ_REQ);
linger = 0;
client->setsockopt(ZMQ_LINGER, &linger, sizeof(linger));
client->connect(server[server_nbr]);
// Send request again, on new socket
s_send(*client, request_string);
}
}
}
return 0;
}
bstarcli: C# 语言的 Binary Star 客户端
bstarcli: CL 语言的 Binary Star 客户端
bstarcli: Delphi 语言的 Binary Star 客户端
bstarcli: Erlang 语言的 Binary Star 客户端
bstarcli: Elixir 语言的 Binary Star 客户端
bstarcli: F# 语言的 Binary Star 客户端
bstarcli: Felix 语言的 Binary Star 客户端
bstarcli: Go 语言的 Binary Star 客户端
bstarcli: Haskell 语言的 Binary Star 客户端
bstarcli: Haxe 语言的 Binary Star 客户端
package ;
import haxe.Stack;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMsg;
import org.zeromq.ZMQException;
/**
* Binary Star Client
* @author Richard J Smith
*
* @see https://zguide.zeromq.cn/page:all#Binary-Star-Implementation
*/
class BStarCli
{
private static inline var REQUEST_TIMEOUT = 1000; // msecs
private static inline var SETTLE_DELAY = 2000; // Before failing over
public static function main()
{
Lib.println("** BStarCli (see: https://zguide.zeromq.cn/page:all#Binary-Star-Implementation)");
var ctx = new ZContext();
var server = ["tcp://:5001", "tcp://:5002"];
var server_nbr = 0;
Lib.println("I: connecting to server at " + server[server_nbr]);
var client = ctx.createSocket(ZMQ_REQ);
client.connect(server[server_nbr]);
var sequence = 0;
var poller = new ZMQPoller();
poller.registerSocket(client, ZMQ.ZMQ_POLLIN());
while (!ZMQ.isInterrupted()) {
// We send a request, then we work to get a reply
var request = Std.string(++sequence);
ZMsg.newStringMsg(request).send(client);
var expectReply = true;
while (expectReply) {
// Poll socket for a reply, with timeout
try {
var res = poller.poll(REQUEST_TIMEOUT * 1000); // Convert timeout to microseconds
} catch (e:ZMQException) {
if (!ZMQ.isInterrupted()) {
trace("ZMQException #:" + e.errNo + ", str:" + e.str());
trace (Stack.toString(Stack.exceptionStack()));
} else {
Lib.println("W: interrupt received, killing client...");
}
ctx.destroy();
return;
}
if (poller.pollin(1)) {
// We got a reply from the server, must match sequence
var reply = client.recvMsg().toString();
if (reply != null && Std.parseInt(reply) == sequence) {
Lib.println("I: server replied OK (" + reply + ")");
expectReply = false;
Sys.sleep(1.0); // One request per second
} else
Lib.println("E: malformed reply from server: " + reply);
} else {
Lib.println("W: no response from server, failing over");
// Old socket is confused; close it and open a new one
ctx.destroySocket(client);
server_nbr = (server_nbr + 1) % 2;
Sys.sleep(SETTLE_DELAY / 1000);
Lib.println("I: connecting to server at " + server[server_nbr]);
client = ctx.createSocket(ZMQ_REQ);
client.connect(server[server_nbr]);
poller.unregisterAllSockets();
poller.registerSocket(client, ZMQ.ZMQ_POLLIN());
ZMsg.newStringMsg(request).send(client);
}
}
}
ctx.destroy();
}
}bstarcli: Java 语言的 Binary Star 客户端
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
// Binary Star client proof-of-concept implementation. This client does no
// real work; it just demonstrates the Binary Star failover model.
public class bstarcli
{
private static final long REQUEST_TIMEOUT = 1000; // msecs
private static final long SETTLE_DELAY = 2000; // Before failing over
public static void main(String[] argv) throws Exception
{
try (ZContext ctx = new ZContext()) {
String[] server = { "tcp://:5001",
"tcp://:5002" };
int serverNbr = 0;
System.out.printf("I: connecting to server at %s...\n",
server[serverNbr]);
Socket client = ctx.createSocket(SocketType.REQ);
client.connect(server[serverNbr]);
Poller poller = ctx.createPoller(1);
poller.register(client, ZMQ.Poller.POLLIN);
int sequence = 0;
while (!Thread.currentThread().isInterrupted()) {
// We send a request, then we work to get a reply
String request = String.format("%d", ++sequence);
client.send(request);
boolean expectReply = true;
while (expectReply) {
// Poll socket for a reply, with timeout
int rc = poller.poll(REQUEST_TIMEOUT);
if (rc == -1)
break; // Interrupted
// .split main body of client
// We use a Lazy Pirate strategy in the client. If there's
// no reply within our timeout, we close the socket and try
// again. In Binary Star, it's the client vote that
// decides which server is primary; the client must
// therefore try to connect to each server in turn:
if (poller.pollin(0)) {
// We got a reply from the server, must match getSequence
String reply = client.recvStr();
if (Integer.parseInt(reply) == sequence) {
System.out.printf("I: server replied OK (%s)\n", reply);
expectReply = false;
Thread.sleep(1000); // One request per second
}
else System.out.printf("E: bad reply from server: %s\n", reply);
}
else {
System.out.printf("W: no response from server, failing over\n");
// Old socket is confused; close it and open a new one
poller.unregister(client);
ctx.destroySocket(client);
serverNbr = (serverNbr + 1) % 2;
Thread.sleep(SETTLE_DELAY);
System.out.printf("I: connecting to server at %s...\n", server[serverNbr]);
client = ctx.createSocket(SocketType.REQ);
client.connect(server[serverNbr]);
poller.register(client, ZMQ.Poller.POLLIN);
// Send request again, on new socket
client.send(request);
}
}
}
}
}
}
bstarcli: Julia 语言的 Binary Star 客户端
bstarcli: Lua 语言的 Binary Star 客户端
bstarcli: Node.js 语言的 Binary Star 客户端
bstarcli: Objective-C 语言的 Binary Star 客户端
bstarcli: ooc 语言的 Binary Star 客户端
bstarcli: Perl 语言的 Binary Star 客户端
bstarcli: PHP 语言的 Binary Star 客户端
bstarcli: Python 语言的 Binary Star 客户端
from time import sleep
import zmq
REQUEST_TIMEOUT = 1000 # msecs
SETTLE_DELAY = 2000 # before failing over
def main():
server = ['tcp://:5001', 'tcp://:5002']
server_nbr = 0
ctx = zmq.Context()
client = ctx.socket(zmq.REQ)
client.connect(server[server_nbr])
poller = zmq.Poller()
poller.register(client, zmq.POLLIN)
sequence = 0
while True:
client.send_string("%s" % sequence)
expect_reply = True
while expect_reply:
socks = dict(poller.poll(REQUEST_TIMEOUT))
if socks.get(client) == zmq.POLLIN:
reply = client.recv_string()
if int(reply) == sequence:
print("I: server replied OK (%s)" % reply)
expect_reply = False
sequence += 1
sleep(1)
else:
print("E: malformed reply from server: %s" % reply)
else:
print("W: no response from server, failing over")
sleep(SETTLE_DELAY / 1000)
poller.unregister(client)
client.close()
server_nbr = (server_nbr + 1) % 2
print("I: connecting to server at %s.." % server[server_nbr])
client = ctx.socket(zmq.REQ)
poller.register(client, zmq.POLLIN)
# reconnect and resend request
client.connect(server[server_nbr])
client.send_string("%s" % sequence)
if __name__ == '__main__':
main()
bstarcli: Q 语言的 Binary Star 客户端
bstarcli: Racket 语言的 Binary Star 客户端
bstarcli: Ruby 语言的 Binary Star 客户端
#!/usr/bin/env ruby
# vim: ft=ruby
# Binary Star client proof-of-concept implementation. This client does no
# real work; it just demonstrates the Binary Star failover model.
require 'optparse'
require 'cztop'
REQUEST_TIMEOUT = 1000 # msecs
SETTLE_DELAY = 2000 # before failing over
SERVERS = %w[tcp://:5001 tcp://:5002]
server_nbr = 0
puts "I: connecting to server at %s…" % SERVERS[server_nbr]
client = CZTop::Socket::REQ.new(SERVERS[server_nbr])
sequence = 0
poller = CZTop::Poller.new(client)
while true
sequence += 1
puts sequence
client << "#{sequence}"
expect_reply = true
while expect_reply
# We use a Lazy Pirate strategy in the client. If there's no
# reply within our timeout, we close the socket and try again.
# In Binary Star, it's the client vote that decides which
# server is primary; the client must therefore try to connect
# to each server in turn:
if poller.simple_wait(REQUEST_TIMEOUT)
reply = client.receive
# We got a reply from the server, must match sequence
if reply[0].to_i == sequence
puts "I: server replied OK (%p)" % reply[0]
expect_reply = false
sleep(1) # one request per second
else
puts "E: bad reply from server: %p" % reply
end
else
puts "W: no response from server, failing over"
# Old socket is confused; close it and open a new one
poller.remove_reader(client)
client.close
server_nbr = (server_nbr + 1) % 2
sleep(SETTLE_DELAY/1000.0)
puts "I: connecting to server at %s…\n" % SERVERS[server_nbr]
client = CZTop::Socket::REQ.new(SERVERS[server_nbr])
poller.add_reader(client)
client << "#{sequence}"
end
end
end
bstarcli: Rust 语言的 Binary Star 客户端
bstarcli: Scala 语言的 Binary Star 客户端
bstarcli: Tcl 语言的 Binary Star 客户端
#
# Binary Star client
#
package require zmq
set REQUEST_TIMEOUT 1000 ;# msecs
set SETTLE_DELAY 2000 ;# Before failing over, msecs
zmq context context
set server [list "tcp://:5001" "tcp://:5002"]
set server_nbr 0
puts "I: connecting to server at [lindex $server $server_nbr]..."
zmq socket client context REQ
client connect [lindex $server $server_nbr]
set sequence 0
while {1} {
# We send a request, then we work to get a reply
set request [incr sequence]
client send $request
set expect_reply 1
while {$expect_reply} {
# Poll socket for a reply, with timeout
set rpoll_set [zmq poll {{client {POLLIN}}} $REQUEST_TIMEOUT]
# If we got a reply, process it
if {[llength $rpoll_set] && "POLLIN" in [lindex $rpoll_set 0 1]} {
set reply [client recv]
if {$reply eq $request} {
puts "I: server replied OK ($reply)"
set expect_reply 0
after 1000 ;# One request per second
} else {
puts "E: malformed reply from server: $reply"
}
} else {
puts "W: no response from server, failing over"
# Old socket is confused; close it and open a new one
client close
set server_nbr [expr {($server_nbr + 1) % 2}]
after $SETTLE_DELAY
puts "I: connecting to server at [lindex $server $server_nbr]..."
zmq socket client context REQ
client connect [lindex $server $server_nbr]
# Send request again, on new socket
client send $request
}
}
}
client close
context term
bstarcli: OCaml 语言的 Binary Star 客户端
要测试 Binary Star,请以任何顺序启动服务器和客户端:
bstarsrv -p # Start primary
bstarsrv -b # Start backup
bstarcli
然后你可以通过杀死主服务器来引发故障转移,以及通过重启主服务器并杀死备用服务器来引发恢复。注意,是客户端投票触发了故障转移和恢复。
Binary Star 由一个有限状态机驱动。事件是节点的对等状态,因此“Peer Active”(对等活动)意味着另一台服务器告诉我们它是活动状态。“Client Request”(客户端请求)意味着我们收到了一个客户端请求。“Client Vote”(客户端投票)意味着我们收到了一个客户端请求,并且我们的对等节点在两个心跳周期内处于非活动状态。
请注意,服务器使用 PUB-SUB 套接字进行状态交换。没有其他套接字组合在这里能工作。如果没有准备好接收消息的对等节点,PUSH 和 DEALER 会阻塞。如果对等节点消失后又回来,PAIR 不会重新连接。ROUTER 在发送消息之前需要对等节点的地址。

Binary Star Reactor #
Binary Star 足够有用和通用,可以打包成一个可重用的 reactor 类。然后 reactor 运行,每当有需要处理的消息时就调用我们的代码。这比将 Binary Star 代码复制/粘贴到每个需要此功能的服务器中要好得多。
在 C 语言中,我们包装了 CZMQ 的zloop类,我们在前面看到过。zloop它让你注册处理程序,以响应套接字和定时器事件。在 Binary Star reactor 中,我们提供了投票者处理程序以及状态变化(从活动到被动,反之亦然)的处理程序。以下是bstarAPI。
// Create a new Binary Star instance, using local (bind) and
// remote (connect) endpoints to set up the server peering.
bstar_t *bstar_new (int primary, char *local, char *remote);
// Destroy a Binary Star instance
void bstar_destroy (bstar_t **self_p);
// Return underlying zloop reactor, for timer and reader
// registration and cancelation.
zloop_t *bstar_zloop (bstar_t *self);
// Register voting reader
int bstar_voter (bstar_t *self, char *endpoint, int type,
zloop_fn handler, void *arg);
// Register main state change handlers
void bstar_new_active (bstar_t *self, zloop_fn handler, void *arg);
void bstar_new_passive (bstar_t *self, zloop_fn handler, void *arg);
// Start the reactor, which ends if a callback function returns -1,
// or the process received SIGINT or SIGTERM.
int bstar_start (bstar_t *self);
以下是类实现:
bstar: Ada 语言的 Binary Star 核心类
bstar: Basic 语言的 Binary Star 核心类
bstar: C 语言的 Binary Star 核心类
// bstar class - Binary Star reactor
#include "bstar.h"
// States we can be in at any point in time
typedef enum {
STATE_PRIMARY = 1, // Primary, waiting for peer to connect
STATE_BACKUP = 2, // Backup, waiting for peer to connect
STATE_ACTIVE = 3, // Active - accepting connections
STATE_PASSIVE = 4 // Passive - not accepting connections
} state_t;
// Events, which start with the states our peer can be in
typedef enum {
PEER_PRIMARY = 1, // HA peer is pending primary
PEER_BACKUP = 2, // HA peer is pending backup
PEER_ACTIVE = 3, // HA peer is active
PEER_PASSIVE = 4, // HA peer is passive
CLIENT_REQUEST = 5 // Client makes request
} event_t;
// Structure of our class
struct _bstar_t {
zctx_t *ctx; // Our private context
zloop_t *loop; // Reactor loop
void *statepub; // State publisher
void *statesub; // State subscriber
state_t state; // Current state
event_t event; // Current event
int64_t peer_expiry; // When peer is considered 'dead'
zloop_fn *voter_fn; // Voting socket handler
void *voter_arg; // Arguments for voting handler
zloop_fn *active_fn; // Call when become active
void *active_arg; // Arguments for handler
zloop_fn *passive_fn; // Call when become passive
void *passive_arg; // Arguments for handler
};
// The finite-state machine is the same as in the proof-of-concept server.
// To understand this reactor in detail, first read the CZMQ zloop class.
// .skip
// We send state information every this often
// If peer doesn't respond in two heartbeats, it is 'dead'
#define BSTAR_HEARTBEAT 1000 // In msecs
// Binary Star finite state machine (applies event to state)
// Returns -1 if there was an exception, 0 if event was valid.
static int
s_execute_fsm (bstar_t *self)
{
int rc = 0;
// Primary server is waiting for peer to connect
// Accepts CLIENT_REQUEST events in this state
if (self->state == STATE_PRIMARY) {
if (self->event == PEER_BACKUP) {
zclock_log ("I: connected to backup (passive), ready as active");
self->state = STATE_ACTIVE;
if (self->active_fn)
(self->active_fn) (self->loop, NULL, self->active_arg);
}
else
if (self->event == PEER_ACTIVE) {
zclock_log ("I: connected to backup (active), ready as passive");
self->state = STATE_PASSIVE;
if (self->passive_fn)
(self->passive_fn) (self->loop, NULL, self->passive_arg);
}
else
if (self->event == CLIENT_REQUEST) {
// Allow client requests to turn us into the active if we've
// waited sufficiently long to believe the backup is not
// currently acting as active (i.e., after a failover)
assert (self->peer_expiry > 0);
if (zclock_time () >= self->peer_expiry) {
zclock_log ("I: request from client, ready as active");
self->state = STATE_ACTIVE;
if (self->active_fn)
(self->active_fn) (self->loop, NULL, self->active_arg);
} else
// Don't respond to clients yet - it's possible we're
// performing a failback and the backup is currently active
rc = -1;
}
}
else
// Backup server is waiting for peer to connect
// Rejects CLIENT_REQUEST events in this state
if (self->state == STATE_BACKUP) {
if (self->event == PEER_ACTIVE) {
zclock_log ("I: connected to primary (active), ready as passive");
self->state = STATE_PASSIVE;
if (self->passive_fn)
(self->passive_fn) (self->loop, NULL, self->passive_arg);
}
else
if (self->event == CLIENT_REQUEST)
rc = -1;
}
else
// Server is active
// Accepts CLIENT_REQUEST events in this state
// The only way out of ACTIVE is death
if (self->state == STATE_ACTIVE) {
if (self->event == PEER_ACTIVE) {
// Two actives would mean split-brain
zclock_log ("E: fatal error - dual actives, aborting");
rc = -1;
}
}
else
// Server is passive
// CLIENT_REQUEST events can trigger failover if peer looks dead
if (self->state == STATE_PASSIVE) {
if (self->event == PEER_PRIMARY) {
// Peer is restarting - become active, peer will go passive
zclock_log ("I: primary (passive) is restarting, ready as active");
self->state = STATE_ACTIVE;
}
else
if (self->event == PEER_BACKUP) {
// Peer is restarting - become active, peer will go passive
zclock_log ("I: backup (passive) is restarting, ready as active");
self->state = STATE_ACTIVE;
}
else
if (self->event == PEER_PASSIVE) {
// Two passives would mean cluster would be non-responsive
zclock_log ("E: fatal error - dual passives, aborting");
rc = -1;
}
else
if (self->event == CLIENT_REQUEST) {
// Peer becomes active if timeout has passed
// It's the client request that triggers the failover
assert (self->peer_expiry > 0);
if (zclock_time () >= self->peer_expiry) {
// If peer is dead, switch to the active state
zclock_log ("I: failover successful, ready as active");
self->state = STATE_ACTIVE;
}
else
// If peer is alive, reject connections
rc = -1;
}
// Call state change handler if necessary
if (self->state == STATE_ACTIVE && self->active_fn)
(self->active_fn) (self->loop, NULL, self->active_arg);
}
return rc;
}
static void
s_update_peer_expiry (bstar_t *self)
{
self->peer_expiry = zclock_time () + 2 * BSTAR_HEARTBEAT;
}
// Reactor event handlers...
// Publish our state to peer
int s_send_state (zloop_t *loop, int timer_id, void *arg)
{
bstar_t *self = (bstar_t *) arg;
zstr_sendf (self->statepub, "%d", self->state);
return 0;
}
// Receive state from peer, execute finite state machine
int s_recv_state (zloop_t *loop, zmq_pollitem_t *poller, void *arg)
{
bstar_t *self = (bstar_t *) arg;
char *state = zstr_recv (poller->socket);
if (state) {
self->event = atoi (state);
s_update_peer_expiry (self);
free (state);
}
return s_execute_fsm (self);
}
// Application wants to speak to us, see if it's possible
int s_voter_ready (zloop_t *loop, zmq_pollitem_t *poller, void *arg)
{
bstar_t *self = (bstar_t *) arg;
// If server can accept input now, call appl handler
self->event = CLIENT_REQUEST;
if (s_execute_fsm (self) == 0)
(self->voter_fn) (self->loop, poller, self->voter_arg);
else {
// Destroy waiting message, no-one to read it
zmsg_t *msg = zmsg_recv (poller->socket);
zmsg_destroy (&msg);
}
return 0;
}
// .until
// .split constructor
// This is the constructor for our {{bstar}} class. We have to tell it
// whether we're primary or backup server, as well as our local and
// remote endpoints to bind and connect to:
bstar_t *
bstar_new (int primary, char *local, char *remote)
{
bstar_t
*self;
self = (bstar_t *) zmalloc (sizeof (bstar_t));
// Initialize the Binary Star
self->ctx = zctx_new ();
self->loop = zloop_new ();
self->state = primary? STATE_PRIMARY: STATE_BACKUP;
// Create publisher for state going to peer
self->statepub = zsocket_new (self->ctx, ZMQ_PUB);
zsocket_bind (self->statepub, local);
// Create subscriber for state coming from peer
self->statesub = zsocket_new (self->ctx, ZMQ_SUB);
zsocket_set_subscribe (self->statesub, "");
zsocket_connect (self->statesub, remote);
// Set-up basic reactor events
zloop_timer (self->loop, BSTAR_HEARTBEAT, 0, s_send_state, self);
zmq_pollitem_t poller = { self->statesub, 0, ZMQ_POLLIN };
zloop_poller (self->loop, &poller, s_recv_state, self);
return self;
}
// .split destructor
// The destructor shuts down the bstar reactor:
void
bstar_destroy (bstar_t **self_p)
{
assert (self_p);
if (*self_p) {
bstar_t *self = *self_p;
zloop_destroy (&self->loop);
zctx_destroy (&self->ctx);
free (self);
*self_p = NULL;
}
}
// .split zloop method
// This method returns the underlying zloop reactor, so we can add
// additional timers and readers:
zloop_t *
bstar_zloop (bstar_t *self)
{
return self->loop;
}
// .split voter method
// This method registers a client voter socket. Messages received
// on this socket provide the CLIENT_REQUEST events for the Binary Star
// FSM and are passed to the provided application handler. We require
// exactly one voter per {{bstar}} instance:
int
bstar_voter (bstar_t *self, char *endpoint, int type, zloop_fn handler,
void *arg)
{
// Hold actual handler+arg so we can call this later
void *socket = zsocket_new (self->ctx, type);
zsocket_bind (socket, endpoint);
assert (!self->voter_fn);
self->voter_fn = handler;
self->voter_arg = arg;
zmq_pollitem_t poller = { socket, 0, ZMQ_POLLIN };
return zloop_poller (self->loop, &poller, s_voter_ready, self);
}
// .split register state-change handlers
// Register handlers to be called each time there's a state change:
void
bstar_new_active (bstar_t *self, zloop_fn handler, void *arg)
{
assert (!self->active_fn);
self->active_fn = handler;
self->active_arg = arg;
}
void
bstar_new_passive (bstar_t *self, zloop_fn handler, void *arg)
{
assert (!self->passive_fn);
self->passive_fn = handler;
self->passive_arg = arg;
}
// .split enable/disable tracing
// Enable/disable verbose tracing, for debugging:
void bstar_set_verbose (bstar_t *self, bool verbose)
{
zloop_set_verbose (self->loop, verbose);
}
// .split start the reactor
// Finally, start the configured reactor. It will end if any handler
// returns -1 to the reactor, or if the process receives SIGINT or SIGTERM:
int
bstar_start (bstar_t *self)
{
assert (self->voter_fn);
s_update_peer_expiry (self);
return zloop_start (self->loop);
}
bstar: C++ 语言的 Binary Star 核心类
#include <zmqpp/zmqpp.hpp>
// We send state information every this often
// If peer doesn't respond in two heartbeats, it is 'dead'
#define BSTAR_HEARTBEAT 1000 // In msecs
// States we can be in at any point in time
typedef enum {
STATE_NOTSET = 0, // Before we start, or if the state is invalid
STATE_PRIMARY = 1, // Primary, waiting for peer to connect
STATE_BACKUP = 2, // Backup, waiting for peer to connect
STATE_ACTIVE = 3, // Active - accepting connections
STATE_PASSIVE = 4 // Passive - not accepting connections
} state_t;
// Events, which start with the states our peer can be in
typedef enum {
EVENT_NOTSET = 0, // Before we start, or if the event is invalid
PEER_PRIMARY = 1, // HA peer is pending primary
PEER_BACKUP = 2, // HA peer is pending backup
PEER_ACTIVE = 3, // HA peer is active
PEER_PASSIVE = 4, // HA peer is passive
CLIENT_REQUEST = 5 // Client makes request
} event_t;
class bstar_t {
public:
bstar_t() = delete;
bstar_t(bool primary, std::string local, std::string remote) {
this->ctx = new zmqpp::context_t();
this->loop = new zmqpp::loop();
this->m_state = primary ? STATE_PRIMARY : STATE_BACKUP;
// Create publisher for state going to peer
this->statepub = new zmqpp::socket_t(*this->ctx, zmqpp::socket_type::pub);
this->statepub->bind(local);
// Create subscriber for state coming from peer
this->statesub = new zmqpp::socket_t(*this->ctx, zmqpp::socket_type::sub);
this->statesub->subscribe("");
this->statesub->connect(remote);
// Set-up basic reactor events
this->loop->add(*this->statesub, std::bind(&bstar_t::s_recv_state, this));
this->loop->add(std::chrono::milliseconds(BSTAR_HEARTBEAT), 0, std::bind(&bstar_t::s_send_state, this));
}
~bstar_t() {
if (statepub) delete statepub;
if (statesub) delete statesub;
if (loop) delete loop;
if (ctx) delete ctx;
}
bstar_t(const bstar_t &) = delete;
bstar_t &operator=(const bstar_t &) = delete;
bstar_t(bstar_t &&src) = default;
bstar_t &operator=(bstar_t &&src) = default;
void set_state(state_t state) {
m_state = state;
}
state_t get_state() {
return m_state;
}
void set_peer_expiry(int64_t expiry) {
m_peer_expiry = expiry;
}
void set_voter(std::function<void(zmqpp::loop*, zmqpp::socket_t *socket, void* args)> fn, void *arg) {
voter_fn = fn;
voter_arg = arg;
}
void set_new_active(std::function<void(zmqpp::loop*, zmqpp::socket_t *socket, void* args)> fn, void *arg) {
active_fn = fn;
active_arg = arg;
}
void set_new_passive(std::function<void(zmqpp::loop*, zmqpp::socket_t *socket, void* args)> fn, void *arg) {
passive_fn = fn;
passive_arg = arg;
}
zmqpp::loop *get_loop() {
return loop;
}
// Binary Star finite state machine (applies event to state)
// Returns true if there was an exception, false if event was valid.
bool execute_fsm(event_t event) {
m_event = event;
bool exception = false;
// These are the PRIMARY and BACKUP states; we're waiting to become
// ACTIVE or PASSIVE depending on events we get from our peer:
if (m_state == STATE_PRIMARY) {
if (m_event == PEER_BACKUP) {
std::cout << "I: connected to backup (passive), ready active" << std::endl;
m_state = STATE_ACTIVE;
if (active_fn) {
active_fn(loop, nullptr, active_arg);
}
} else if (m_event == PEER_ACTIVE) {
std::cout << "I: connected to backup (active), ready passive" << std::endl;
m_state = STATE_PASSIVE;
if (passive_fn) {
passive_fn(loop, nullptr, passive_arg);
}
}
// Accept client connections
} else if (m_state == STATE_BACKUP) {
if (m_event == PEER_ACTIVE) {
std::cout << "I: connected to primary (active), ready passive" << std::endl;
m_state = STATE_PASSIVE;
if (passive_fn) {
passive_fn(loop, nullptr, passive_arg);
}
} else if (m_event == CLIENT_REQUEST) {
// Reject client connections when acting as backup
exception = true;
}
// .split active and passive states
// These are the ACTIVE and PASSIVE states:
} else if (m_state == STATE_ACTIVE) {
if (m_event == PEER_ACTIVE) {
std::cout << "E: fatal error - dual actives, aborting" << std::endl;
exception = true;
}
// Server is passive
// CLIENT_REQUEST events can trigger failover if peer looks dead
} else if (m_state == STATE_PASSIVE) {
if (m_event == PEER_PRIMARY) {
// Peer is restarting - become active, peer will go passive
std::cout << "I: primary (passive) is restarting, ready active" << std::endl;
m_state = STATE_ACTIVE;
} else if (m_event == PEER_BACKUP) {
// Peer is restarting - become active, peer will go passive
std::cout << "I: backup (passive) is restarting, ready active" << std::endl;
m_state = STATE_ACTIVE;
} else if (m_event == PEER_PASSIVE) {
// Two passives would mean cluster would be non-responsive
std::cout << "E: fatal error - dual passives, aborting" << std::endl;
exception = true;
} else if (m_event == CLIENT_REQUEST) {
// Peer becomes active if timeout has passed
// It's the client request that triggers the failover
assert(m_peer_expiry > 0);
auto now = std::chrono::system_clock::now();
if (std::chrono::duration_cast<std::chrono::milliseconds>(now.time_since_epoch()).count() >= m_peer_expiry) {
std::cout << "I: failover successful, ready active" << std::endl;
m_state = STATE_ACTIVE;
} else {
// If peer is alive, reject connections
exception = true;
}
}
// Call state change handler if necessary
if (m_state == STATE_ACTIVE && active_fn) {
active_fn(loop, nullptr, active_arg);
}
}
return exception;
}
void update_peer_expiry() {
m_peer_expiry = std::chrono::duration_cast<std::chrono::milliseconds>(std::chrono::system_clock::now().time_since_epoch()).count() + 2 * BSTAR_HEARTBEAT;
}
static bool s_send_state(bstar_t *self) {
zmqpp::message_t msg;
msg << static_cast<int>(self->m_state);
std::cout << "I: publishing state " << self->m_state << std::endl;
self->statepub->send(msg);
return true;
}
static bool s_recv_state(bstar_t *self) {
zmqpp::message_t msg;
bool rc = self->statesub->receive(msg);
if (rc) {
int state;
msg >> state;
self->m_event = static_cast<event_t>(state);
self->update_peer_expiry();
}
bool exception = self->execute_fsm(self->m_event);
return !exception;
}
static bool s_voter_ready(bstar_t *self, zmqpp::socket_t *socket) {
self->m_event = CLIENT_REQUEST;
if (self->execute_fsm(self->m_event) == false) {
if (self->voter_fn) {
self->voter_fn(self->loop, socket, self->voter_arg);
}
} else {
// Destroy waiting message, no-one to read it
zmqpp::message_t msg;
socket->receive(msg);
}
return true;
}
// .split voter method
// This method registers a client voter socket. Messages received
// on this socket provide the CLIENT_REQUEST events for the Binary Star
// FSM and are passed to the provided application handler. We require
// exactly one voter per {{bstar}} instance:
int register_voter(std::string endpoint, zmqpp::socket_type type, std::function<void(zmqpp::loop*, zmqpp::socket_t *socket, void* args)> fn, void *arg) {
zmqpp::socket_t *socket = new zmqpp::socket_t(*ctx, type);
socket->bind(endpoint);
assert(!voter_fn);
voter_fn = fn;
voter_arg = arg;
loop->add(*socket, std::bind(&bstar_t::s_voter_ready, this, socket));
return 0;
}
int start() {
assert(voter_fn);
update_peer_expiry();
loop->start();
return 0;
}
private:
zmqpp::context_t *ctx; // Our context
zmqpp::loop *loop; // Reactor loop
zmqpp::socket_t *statepub; // State publisher
zmqpp::socket_t *statesub; // State subscriber
state_t m_state; // Current state
event_t m_event; // Current event
int64_t m_peer_expiry; // When peer is considered 'dead', milliseconds
std::function<void(zmqpp::loop*, zmqpp::socket_t *socket, void* args)> voter_fn; // Voting socket handler
void *voter_arg; // Arguments for voting handler
std::function<void(zmqpp::loop*, zmqpp::socket_t *socket, void* args)> active_fn; // Call when become active
void *active_arg; // Arguments for handler
std::function<void(zmqpp::loop*, zmqpp::socket_t *socket, void* args)> passive_fn; // Call when become passive
void *passive_arg; // Arguments for handler
};
bstar: C# 语言的 Binary Star 核心类
bstar: CL 语言的 Binary Star 核心类
bstar: Delphi 语言的 Binary Star 核心类
bstar: Erlang 语言的 Binary Star 核心类
bstar: Elixir 语言的 Binary Star 核心类
bstar: F# 语言的 Binary Star 核心类
bstar: Felix 语言的 Binary Star 核心类
bstar: Go 语言的 Binary Star 核心类
bstar: Haskell 语言的 Binary Star 核心类
bstar: Haxe 语言的 Binary Star 核心类
package ;
import haxe.io.Bytes;
import haxe.Stack;
import neko.Sys;
import neko.Lib;
import org.zeromq.ZContext;
import org.zeromq.ZLoop;
import org.zeromq.ZMQ;
import org.zeromq.ZMQPoller;
import org.zeromq.ZMQException;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
import org.zeromq.ZSocket;
// States we can be in at any time
private enum StateT {
STATE_PRIMARY; // Primary, waiting for peer to connect
STATE_BACKUP; // Backup, waiting for peer to connect
STATE_ACTIVE; // Active - accepting connections
STATE_PASSIVE; // Passive - not accepting connections
}
private enum EventT {
PEER_PRIMARY; // HA peer is pending primary
PEER_BACKUP; // HA peer is pending backup
PEER_ACTIVE; // HA peer is active
PEER_PASSIVE; // HA peer is passive
CLIENT_REQUEST; // Client makes request
}
/**
* Shortcut typedef for method signature of BStar reactor handler functions
*/
typedef HandlerFunctionType = ZLoop->ZMQSocket->Dynamic->Int;
/**
* Binary Star Reactor
*/
class BStar
{
/** We send state information every this often
* If peer doesn't respond in two heartbeats, it is 'dead'
*/
private static inline var BSTAR_HEARTBEAT = 100;
/** Our context */
private var ctx:ZContext;
/** Reactor loop */
public var loop(default, null):ZLoop;
/** State publisher socket */
private var statePub:ZMQSocket;
/** State subscriber socket */
private var stateSub:ZMQSocket;
/** Current state */
public var state(default, null):StateT;
/** Current event */
public var event(default, null):EventT;
/** When peer is considered 'dead' */
public var peerExpiry:Float;
/** Voting socket handler */
private var voterFn:HandlerFunctionType;
/** Arguments for voting handler */
private var voterArgs:Dynamic;
/** Master socket handler, called when become Master */
private var masterFn:HandlerFunctionType;
/** Arguments for Master handler */
private var masterArgs:Dynamic;
/** Slave socket handler, called when become Slave */
private var slaveFn:HandlerFunctionType;
/** Arguments for slave handler */
private var slaveArgs:Dynamic;
/** Print activity to stdout */
public var verbose:Bool;
/** Logger function used in verbose mode */
private var log:Dynamic->Void;
/**
* BStar Constructor
* @param isPrimary True if this instance is the primary instance, else false if slave
* @param local Network address to bind the statePub socket of this instance to
* @param remote Network address to connect the stateSub socket of this instance to
* @param ?verbose True to generate logging info
* @param ?logger Logger function
*/
public function new(isPrimary:Bool, local:String, remote:String, ?verbose:Bool = false, ?logger:Dynamic->Void)
{
// Initialise the binary star server
ctx = new ZContext();
loop = new ZLoop(logger);
loop.verbose = verbose;
state = { if (isPrimary) STATE_PRIMARY; else STATE_BACKUP; };
// Create publisher for state going to peer
statePub = ctx.createSocket(ZMQ_PUB);
statePub.bind(local);
// Create subscriber for state coming from peer
stateSub = ctx.createSocket(ZMQ_SUB);
stateSub.setsockopt(ZMQ_SUBSCRIBE, Bytes.ofString(""));
stateSub.connect(remote);
// Set up basic reactor events
loop.registerTimer(BSTAR_HEARTBEAT, 0, sendState);
var item = { socket: stateSub, event: ZMQ.ZMQ_POLLIN() };
loop.registerPoller(item, recvState);
this.verbose = verbose;
if (logger != null)
log = logger;
else
log = Lib.println;
}
/**
* Destructor
* Cleans up internal ZLoop reactor object and ZContext objects.
*/
public function destroy() {
if (loop != null)
loop.destroy();
if (ctx != null)
ctx.destroy();
}
/**
* Create socket, bind to local endpoint, and register as reader for
* voting. The socket will only be available if the Binary Star state
* machine allows it. Input on the socket will act as a "vote" in the
* Binary Star scheme. We require exactly one voter per bstar instance.
*
* @param endpoint Endpoint address
* @param type Socket Type to bind to endpoint
* @param handler Voter Handler method
* @param args Optional args to pass to Voter Handfler method when called.
* @return
*/
public function setVoter(endpoint:String, type:SocketType, handler:HandlerFunctionType, ?args:Dynamic):Bool {
// Hold actual handler + arg so we can call this later
var socket = ctx.createSocket(type);
socket.bind(endpoint);
voterFn = handler;
voterArgs = args;
return loop.registerPoller( { socket:socket, event:ZMQ.ZMQ_POLLIN() }, voterReady);
}
/**
* Sets handler method called when instance becomes Master
* @param handler
* @param ?args
*/
public function setMaster(handler:HandlerFunctionType, ?args:Dynamic) {
if (masterFn == null) {
masterFn = handler;
masterArgs = args;
}
}
/**
* Sets handler method called when instance becomes Slave
* @param handler
* @param ?args
*/
public function setSlave(handler:HandlerFunctionType, ?args:Dynamic) {
if (slaveFn == null) {
slaveFn = handler;
slaveArgs = args;
}
}
/**
* Executes finite state machine (apply event to this state)
* Returns true if there was an exception
* @return
*/
public function stateMachine():Bool
{
var exception = false;
switch (state) {
case STATE_PRIMARY:
// Primary server is waiting for peer to connect
// Accepts CLIENT_REQUEST events in this state
switch (event) {
case PEER_BACKUP:
if (verbose)
log("I: connected to backup (slave), ready as master");
state = STATE_ACTIVE;
if (masterFn != null)
masterFn(loop, null, masterArgs);
case PEER_ACTIVE:
if (verbose)
log("I: connected to backup (master), ready as slave");
state = STATE_PASSIVE;
if (slaveFn != null)
slaveFn(loop, null, slaveArgs);
case CLIENT_REQUEST:
if (verbose)
log("I: request from client, ready as master");
state = STATE_ACTIVE;
if (masterFn != null)
masterFn(loop, null, masterArgs);
default:
}
case STATE_BACKUP:
// Backup server is waiting for peer to connect
// Rejects CLIENT_REQUEST events in this state
switch (event) {
case PEER_ACTIVE:
if (verbose)
log("I: connected to primary (master), ready as slave");
state = STATE_PASSIVE;
if (slaveFn != null)
slaveFn(loop, null, slaveArgs);
case CLIENT_REQUEST:
exception = true;
default:
}
case STATE_ACTIVE:
// Server is active
// Accepts CLIENT_REQUEST events in this state
switch (event) {
case PEER_ACTIVE:
// Two masters would mean split-brain
log("E: fatal error - dual masters, aborting");
exception = true;
default:
}
case STATE_PASSIVE:
// Server is passive
// CLIENT_REQUEST events can trigger failover if peer looks dead
switch (event) {
case PEER_PRIMARY:
// Peer is restarting - I become active, peer will go passive
if (verbose)
log("I: primary (slave) is restarting, ready as master");
state = STATE_ACTIVE;
case PEER_BACKUP:
// Peer is restarting - become active, peer will go passive
if (verbose)
log("I: backup (slave) is restarting, ready as master");
state = STATE_ACTIVE;
case PEER_PASSIVE:
// Two passives would mean cluster would be non-responsive
log("E: fatal error - dual slaves, aborting");
exception = true;
case CLIENT_REQUEST:
// Peer becomes master if timeout as passed
// It's the client request that triggers the failover
if (Date.now().getTime() >= peerExpiry) {
// If peer is dead, switch to the active state
if (verbose)
log("I: failover successful, ready as master");
state = STATE_ACTIVE;
} else {
if (verbose)
log("I: peer is active, so ignore connection");
exception = true;
}
default:
}
}
return exception;
}
/**
* Reactor event handler
* Publish our state to peer
* @param loop
* @param socket
* @param arg
* @return
*/
public function sendState(loop:ZLoop, socket:ZMQSocket):Int {
statePub.sendMsg(Bytes.ofString(Std.string(Type.enumIndex(state))));
return 0;
}
/**
* Reactor event handler
* Receive state from peer, execute finite state machine.
* @param loop
* @param socket
* @return
*/
public function recvState(loop:ZLoop, socket:ZMQSocket):Int {
var message = stateSub.recvMsg().toString();
event = Type.createEnumIndex(EventT, Std.parseInt(message));
peerExpiry = Date.now().getTime() + (2 * BSTAR_HEARTBEAT);
return {
if (stateMachine())
-1; // Error, so exit
else
0;
};
}
/**
* Application wants to speak to us, see if it's possible
* @param loop
* @param socket
* @return
*/
public function voterReady(loop:ZLoop, socket:ZMQSocket):Int {
// If server can accept input now, call application handler
event = CLIENT_REQUEST;
if (stateMachine()) {
// Destroy waiting message, no-one to read it
var msg = socket.recvMsg();
} else {
if (verbose)
log("I: CLIENT REQUEST");
voterFn(loop, socket, voterArgs);
}
return 0;
}
/**
* Start the reactor, ends if a callback function returns -1, or the
* process receives SIGINT or SIGTERM
* @return 0 if interrupted or invalid, -1 if cancelled by handler
*/
public function start():Int {
if (voterFn != null && loop != null)
return loop.start();
else
return 0;
}
}
bstar: Java 语言的 Binary Star 核心类
package guide;
import org.zeromq.*;
import org.zeromq.ZLoop.IZLoopHandler;
import org.zeromq.ZMQ.PollItem;
import org.zeromq.ZMQ.Socket;
// bstar class - Binary Star reactor
public class bstar
{
// States we can be in at any point in time
enum State
{
STATE_PRIMARY, // Primary, waiting for peer to connect
STATE_BACKUP, // Backup, waiting for peer to connect
STATE_ACTIVE, // Active - accepting connections
STATE_PASSIVE // Passive - not accepting connections
}
// Events, which start with the states our peer can be in
enum Event
{
PEER_PRIMARY, // HA peer is pending primary
PEER_BACKUP, // HA peer is pending backup
PEER_ACTIVE, // HA peer is active
PEER_PASSIVE, // HA peer is passive
CLIENT_REQUEST // Client makes request
}
private ZContext ctx; // Our private context
private ZLoop loop; // Reactor loop
private Socket statepub; // State publisher
private Socket statesub; // State subscriber
private State state; // Current state
private Event event; // Current event
private long peerExpiry; // When peer is considered 'dead'
private ZLoop.IZLoopHandler voterFn; // Voting socket handler
private Object voterArg; // Arguments for voting handler
private ZLoop.IZLoopHandler activeFn; // Call when become active
private Object activeArg; // Arguments for handler
private ZLoop.IZLoopHandler passiveFn; // Call when become passive
private Object passiveArg; // Arguments for handler
// The finite-state machine is the same as in the proof-of-concept server.
// To understand this reactor in detail, first read the ZLoop class.
// .skip
// We send state information this often
// If peer doesn't respond in two heartbeats, it is 'dead'
private final static int BSTAR_HEARTBEAT = 1000; // In msecs
// Binary Star finite state machine (applies event to state)
// Returns false if there was an exception, true if event was valid.
private boolean execute()
{
boolean rc = true;
// Primary server is waiting for peer to connect
// Accepts CLIENT_REQUEST events in this state
if (state == State.STATE_PRIMARY) {
if (event == Event.PEER_BACKUP) {
System.out.printf("I: connected to backup (passive), ready active\n");
state = State.STATE_ACTIVE;
if (activeFn != null)
activeFn.handle(loop, null, activeArg);
}
else if (event == Event.PEER_ACTIVE) {
System.out.printf("I: connected to backup (active), ready passive\n");
state = State.STATE_PASSIVE;
if (passiveFn != null)
passiveFn.handle(loop, null, passiveArg);
}
else if (event == Event.CLIENT_REQUEST) {
// Allow client requests to turn us into the active if we've
// waited sufficiently long to believe the backup is not
// currently acting as active (i.e., after a failover)
assert (peerExpiry > 0);
if (System.currentTimeMillis() >= peerExpiry) {
System.out.printf("I: request from client, ready as active\n");
state = State.STATE_ACTIVE;
if (activeFn != null)
activeFn.handle(loop, null, activeArg);
}
else
// Don't respond to clients yet - it's possible we're
// performing a failback and the backup is currently active
rc = false;
}
}
else if (state == State.STATE_BACKUP) {
if (event == Event.PEER_ACTIVE) {
System.out.printf("I: connected to primary (active), ready passive\n");
state = State.STATE_PASSIVE;
if (passiveFn != null)
passiveFn.handle(loop, null, passiveArg);
}
else
// Reject client connections when acting as backup
if (event == Event.CLIENT_REQUEST)
rc = false;
}
else
// .split active and passive states
// These are the ACTIVE and PASSIVE states:
if (state == State.STATE_ACTIVE) {
if (event == Event.PEER_ACTIVE) {
// Two actives would mean split-brain
System.out.printf("E: fatal error - dual actives, aborting\n");
rc = false;
}
}
else
// Server is passive
// CLIENT_REQUEST events can trigger failover if peer looks dead
if (state == State.STATE_PASSIVE) {
if (event == Event.PEER_PRIMARY) {
// Peer is restarting - become active, peer will go passive
System.out.printf("I: primary (passive) is restarting, ready active\n");
state = State.STATE_ACTIVE;
}
else if (event == Event.PEER_BACKUP) {
// Peer is restarting - become active, peer will go passive
System.out.printf("I: backup (passive) is restarting, ready active\n");
state = State.STATE_ACTIVE;
}
else if (event == Event.PEER_PASSIVE) {
// Two passives would mean cluster would be non-responsive
System.out.printf("E: fatal error - dual passives, aborting\n");
rc = false;
}
else if (event == Event.CLIENT_REQUEST) {
// Peer becomes active if timeout has passed
// It's the client request that triggers the failover
assert (peerExpiry > 0);
if (System.currentTimeMillis() >= peerExpiry) {
// If peer is dead, switch to the active state
System.out.printf("I: failover successful, ready active\n");
state = State.STATE_ACTIVE;
}
else
// If peer is alive, reject connections
rc = false;
// Call state change handler if necessary
if (state == State.STATE_ACTIVE && activeFn != null)
activeFn.handle(loop, null, activeArg);
}
}
return rc;
}
private void updatePeerExpiry()
{
peerExpiry = System.currentTimeMillis() + 2 * BSTAR_HEARTBEAT;
}
// Reactor event handlers...
// Publish our state to peer
private static IZLoopHandler SendState = new IZLoopHandler()
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
bstar self = (bstar) arg;
self.statepub.send(String.format("%d", self.state.ordinal()));
return 0;
}
};
// Receive state from peer, execute finite state machine
private static IZLoopHandler RecvState = new IZLoopHandler()
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
bstar self = (bstar) arg;
String state = item.getSocket().recvStr();
if (state != null) {
self.event = Event.values()[Integer.parseInt(state)];
self.updatePeerExpiry();
}
return self.execute() ? 0 : -1;
}
};
// Application wants to speak to us, see if it's possible
private static IZLoopHandler VoterReady = new IZLoopHandler()
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
bstar self = (bstar) arg;
// If server can accept input now, call appl handler
self.event = Event.CLIENT_REQUEST;
if (self.execute())
self.voterFn.handle(loop, item, self.voterArg);
else {
// Destroy waiting message, no-one to read it
ZMsg msg = ZMsg.recvMsg(item.getSocket());
msg.destroy();
}
return 0;
}
};
// .until
// .split constructor
// This is the constructor for our {{bstar}} class. We have to tell it
// whether we're primary or backup server, as well as our local and
// remote endpoints to bind and connect to:
public bstar(boolean primary, String local, String remote)
{
// Initialize the Binary Star
ctx = new ZContext();
loop = new ZLoop(ctx);
state = primary ? State.STATE_PRIMARY : State.STATE_BACKUP;
// Create publisher for state going to peer
statepub = ctx.createSocket(SocketType.PUB);
statepub.bind(local);
// Create subscriber for state coming from peer
statesub = ctx.createSocket(SocketType.SUB);
statesub.subscribe(ZMQ.SUBSCRIPTION_ALL);
statesub.connect(remote);
// Set-up basic reactor events
loop.addTimer(BSTAR_HEARTBEAT, 0, SendState, this);
PollItem poller = new PollItem(statesub, ZMQ.Poller.POLLIN);
loop.addPoller(poller, RecvState, this);
}
// .split destructor
// The destructor shuts down the bstar reactor:
public void destroy()
{
loop.destroy();
ctx.destroy();
}
// .split zloop method
// This method returns the underlying zloop reactor, so we can add
// additional timers and readers:
public ZLoop zloop()
{
return loop;
}
// .split voter method
// This method registers a client voter socket. Messages received
// on this socket provide the CLIENT_REQUEST events for the Binary Star
// FSM and are passed to the provided application handler. We require
// exactly one voter per {{bstar}} instance:
public int voter(String endpoint, SocketType type, IZLoopHandler handler, Object arg)
{
// Hold actual handler+arg so we can call this later
Socket socket = ctx.createSocket(type);
socket.bind(endpoint);
voterFn = handler;
voterArg = arg;
PollItem poller = new PollItem(socket, ZMQ.Poller.POLLIN);
return loop.addPoller(poller, VoterReady, this);
}
// .split register state-change handlers
// Register handlers to be called each time there's a state change:
public void newActive(IZLoopHandler handler, Object arg)
{
activeFn = handler;
activeArg = arg;
}
public void newPassive(IZLoopHandler handler, Object arg)
{
passiveFn = handler;
passiveArg = arg;
}
// .split enable/disable tracing
// Enable/disable verbose tracing, for debugging:
public void setVerbose(boolean verbose)
{
loop.verbose(verbose);
}
// .split start the reactor
// Finally, start the configured reactor. It will end if any handler
// returns -1 to the reactor, or if the process receives Interrupt
public int start()
{
assert (voterFn != null);
updatePeerExpiry();
return loop.start();
}
}
bstar: Julia 语言的 Binary Star 核心类
bstar: Lua 语言的 Binary Star 核心类
bstar: Node.js 语言的 Binary Star 核心类
bstar: Objective-C 语言的 Binary Star 核心类
bstar: ooc 语言的 Binary Star 核心类
bstar: Perl 语言的 Binary Star 核心类
bstar: PHP 语言的 Binary Star 核心类
bstar: Python 语言的 Binary Star 核心类
"""
Binary Star server
Author: Min RK <benjaminrk@gmail.com>
"""
import time
import zmq
from zmq.eventloop.ioloop import IOLoop, PeriodicCallback
from zmq.eventloop.zmqstream import ZMQStream
# States we can be in at any point in time
STATE_PRIMARY = 1 # Primary, waiting for peer to connect
STATE_BACKUP = 2 # Backup, waiting for peer to connect
STATE_ACTIVE = 3 # Active - accepting connections
STATE_PASSIVE = 4 # Passive - not accepting connections
# Events, which start with the states our peer can be in
PEER_PRIMARY = 1 # HA peer is pending primary
PEER_BACKUP = 2 # HA peer is pending backup
PEER_ACTIVE = 3 # HA peer is active
PEER_PASSIVE = 4 # HA peer is passive
CLIENT_REQUEST = 5 # Client makes request
# We send state information every this often
# If peer doesn't respond in two heartbeats, it is 'dead'
HEARTBEAT = 1000 # In msecs
class FSMError(Exception):
"""Exception class for invalid state"""
pass
class BinaryStar(object):
def __init__(self, primary, local, remote):
# initialize the Binary Star
self.ctx = zmq.Context() # Our private context
self.loop = IOLoop.instance() # Reactor loop
self.state = STATE_PRIMARY if primary else STATE_BACKUP
self.event = None # Current event
self.peer_expiry = 0 # When peer is considered 'dead'
self.voter_callback = None # Voting socket handler
self.master_callback = None # Call when become master
self.slave_callback = None # Call when become slave
# Create publisher for state going to peer
self.statepub = self.ctx.socket(zmq.PUB)
self.statepub.bind(local)
# Create subscriber for state coming from peer
self.statesub = self.ctx.socket(zmq.SUB)
self.statesub.setsockopt_string(zmq.SUBSCRIBE, u'')
self.statesub.connect(remote)
# wrap statesub in ZMQStream for event triggers
self.statesub = ZMQStream(self.statesub, self.loop)
# setup basic reactor events
self.heartbeat = PeriodicCallback(self.send_state,
HEARTBEAT, self.loop)
self.statesub.on_recv(self.recv_state)
def update_peer_expiry(self):
"""Update peer expiry time to be 2 heartbeats from now."""
self.peer_expiry = time.time() + 2e-3 * HEARTBEAT
def start(self):
self.update_peer_expiry()
self.heartbeat.start()
return self.loop.start()
def execute_fsm(self):
"""Binary Star finite state machine (applies event to state)
returns True if connections should be accepted, False otherwise.
"""
accept = True
if self.state == STATE_PRIMARY:
# Primary server is waiting for peer to connect
# Accepts CLIENT_REQUEST events in this state
if self.event == PEER_BACKUP:
print("I: connected to backup (slave), ready as master")
self.state = STATE_ACTIVE
if self.master_callback:
self.loop.add_callback(self.master_callback)
elif self.event == PEER_ACTIVE:
print("I: connected to backup (master), ready as slave")
self.state = STATE_PASSIVE
if self.slave_callback:
self.loop.add_callback(self.slave_callback)
elif self.event == CLIENT_REQUEST:
if time.time() >= self.peer_expiry:
print("I: request from client, ready as master")
self.state = STATE_ACTIVE
if self.master_callback:
self.loop.add_callback(self.master_callback)
else:
# don't respond to clients yet - we don't know if
# the backup is currently Active as a result of
# a successful failover
accept = False
elif self.state == STATE_BACKUP:
# Backup server is waiting for peer to connect
# Rejects CLIENT_REQUEST events in this state
if self.event == PEER_ACTIVE:
print("I: connected to primary (master), ready as slave")
self.state = STATE_PASSIVE
if self.slave_callback:
self.loop.add_callback(self.slave_callback)
elif self.event == CLIENT_REQUEST:
accept = False
elif self.state == STATE_ACTIVE:
# Server is active
# Accepts CLIENT_REQUEST events in this state
# The only way out of ACTIVE is death
if self.event == PEER_ACTIVE:
# Two masters would mean split-brain
print("E: fatal error - dual masters, aborting")
raise FSMError("Dual Masters")
elif self.state == STATE_PASSIVE:
# Server is passive
# CLIENT_REQUEST events can trigger failover if peer looks dead
if self.event == PEER_PRIMARY:
# Peer is restarting - become active, peer will go passive
print("I: primary (slave) is restarting, ready as master")
self.state = STATE_ACTIVE
elif self.event == PEER_BACKUP:
# Peer is restarting - become active, peer will go passive
print("I: backup (slave) is restarting, ready as master")
self.state = STATE_ACTIVE
elif self.event == PEER_PASSIVE:
# Two passives would mean cluster would be non-responsive
print("E: fatal error - dual slaves, aborting")
raise FSMError("Dual slaves")
elif self.event == CLIENT_REQUEST:
# Peer becomes master if timeout has passed
# It's the client request that triggers the failover
assert self.peer_expiry > 0
if time.time() >= self.peer_expiry:
# If peer is dead, switch to the active state
print("I: failover successful, ready as master")
self.state = STATE_ACTIVE
else:
# If peer is alive, reject connections
accept = False
# Call state change handler if necessary
if self.state == STATE_ACTIVE and self.master_callback:
self.loop.add_callback(self.master_callback)
return accept
# ---------------------------------------------------------------------
# Reactor event handlers...
def send_state(self):
"""Publish our state to peer"""
self.statepub.send_string("%d" % self.state)
def recv_state(self, msg):
"""Receive state from peer, execute finite state machine"""
state = msg[0]
if state:
self.event = int(state)
self.update_peer_expiry()
self.execute_fsm()
def voter_ready(self, msg):
"""Application wants to speak to us, see if it's possible"""
# If server can accept input now, call appl handler
self.event = CLIENT_REQUEST
if self.execute_fsm():
print("CLIENT REQUEST")
self.voter_callback(self.voter_socket, msg)
else:
# Message will be ignored
pass
# -------------------------------------------------------------------------
#
def register_voter(self, endpoint, type, handler):
"""Create socket, bind to local endpoint, and register as reader for
voting. The socket will only be available if the Binary Star state
machine allows it. Input on the socket will act as a "vote" in the
Binary Star scheme. We require exactly one voter per bstar instance.
handler will always be called with two arguments: (socket,msg)
where socket is the one we are creating here, and msg is the message
that triggered the POLLIN event.
"""
assert self.voter_callback is None
socket = self.ctx.socket(type)
socket.bind(endpoint)
self.voter_socket = socket
self.voter_callback = handler
stream = ZMQStream(socket, self.loop)
stream.on_recv(self.voter_ready)
bstar: Q 语言的 Binary Star 核心类
bstar: Racket 语言的 Binary Star 核心类
bstar: Ruby 语言的 Binary Star 核心类
bstar: Rust 语言的 Binary Star 核心类
bstar: Scala 语言的 Binary Star 核心类
bstar: Tcl 语言的 Binary Star 核心类
# =====================================================================
# bstar - Binary Star reactor
# =====================================================================
package require TclOO
package require mdp
package require zmq
package provide BStar 1.0
# We send state information every this often
# If peer doesn't respond in two heartbeats, it is 'dead'
set BSTAR_HEARTBEAT 1000 ;# In msecs
# States we can be in at any point in time
# STATE(NONE) 0
# STATE(PRIMARY) 1 ;# Primary, waiting for peer to connect
# STATE(BACKUP) 2 ;# Backup, waiting for peer to connect
# STATE(ACTIVE) 3 ;# Active - accepting connections
# STATE(PASSIVE) 4 ;# Passive - not accepting connections
# Events, which start with the states our peer can be in
# EVENT(NONE) 0
# EVENT(PRIMARY) 1 ;# HA peer is pending primary
# EVENT(BACKUP) 2 ;# HA peer is pending backup
# EVENT(ACTIVE) 3 ;# HA peer is active
# EVENT(PASSIVE) 4 ;# HA peer is passive
# EVENT(REQUEST) 5 ;# Client makes request
oo::class create BStar {
variable verbose ctx statepub statesub voter state event peer_expiry voterfn masterfn slavefn
constructor {istate local remote iverbose} {
# Initialize the Binary Star
set verbose $iverbose
set ctx [zmq context bstar_context_[::mdp::contextid]]
set state $istate
set event NONE
set peer_expiry 0
set voterfn {}
set masterfn {}
set slavefn {}
# Create publisher for state going to peer
set statepub [zmq socket bstar_socket_[::mdp::socketid] $ctx PUB]
$statepub bind $local
# Create subscriber for state coming from peer
set statesub [zmq socket bstar_socket_[::mdp::socketid] $ctx SUB]
$statesub setsockopt SUBSCRIBE ""
$statesub connect $remote
}
destructor {
$statesub close
$statepub close
$ctx term
}
method voter_callback {} {
if {[llength $voterfn]} {
{*}$voterfn $voter
}
}
method master_callback {} {
if {[llength $masterfn]} {
{*}$masterfn
}
}
method slave_callback {} {
if {[llength $slavefn]} {
{*}$slavefn
}
}
method log {msg} {
if {$verbose} {
puts "[clock format [clock seconds]] $msg"
}
}
method execute_fsm {} {
set rc 0
if {$state eq "PRIMARY"} {
# Primary server is waiting for peer to connect
# Accepts CLIENT_REQUEST events in this state
if {$event eq "BACKUP"} {
my log "I: connected to backup (slave), ready as master"
set state ACTIVE
my master_callback
} elseif {$event eq "ACTIVE"} {
my log "I: connected to backup (master), ready as slave"
set state PASSIVE
my slave_callback
} elseif {$event eq "REQUEST"} {
# Allow client requests to turn us into the master if we've
# waited sufficiently long to believe the backup is not
# currently acting as master (i.e., after a failover)
if {$peer_expiry <= 0} {
error "expecte peer_expiry > 0"
}
if {[clock milliseconds] >= $peer_expiry} {
my log "I: request from client, ready as master"
set state ACTIVE
my master_callback
} else {
# Don't respond to clients yet - it's possible we're
# performing a failback and the backup is currently master
set rc -1
}
}
} elseif {$state eq "BACKUP"} {
# Backup server is waiting for peer to connect
# Rejects CLIENT_REQUEST events in this state
if {$event eq "ACTIVE"} {
my log "I: connected to primary (master), ready as slave"
set state PASSIVE
my slave_callback
} elseif {$event eq "REQUEST"} {
set rc -1
}
} elseif {$state eq "ACTIVE"} {
# Server is active
# Accepts CLIENT_REQUEST events in this state
# The only way out of ACTIVE is death
if {$event eq "ACTIVE"} {
my log "E: fatal error - dual masters, aborting"
set rc -1
}
} elseif {$state eq "PASSIVE"} {
# Server is passive
# CLIENT_REQUEST events can trigger failover if peer looks dead
if {$event eq "PRIMARY"} {
# Peer is restarting - become active, peer will go passive
my log "I: primary (slave) is restarting, ready as master"
set state ACTIVE
} elseif {$event eq "BACKUP"} {
# Peer is restarting - become active, peer will go passive
my log "I: backup (slave) is restarting, ready as master"
set state ACTIVE
} elseif {$event eq "PASSIVE"} {
# Two passives would mean cluster would be non-responsive
my log "E: fatal error - dual slaves, aborting"
set rc -1
} elseif {$event eq "REQUEST"} {
# Peer becomes master if timeout has passed
# It's the client request that triggers the failover
if {$peer_expiry < 0} {
error "expecte peer_expiry >= 0"
}
if {[clock milliseconds] >= $peer_expiry} {
# If peer is dead, switch to the active state
my log "I: failover successful, ready as master"
set state ACTIVE
} else {
# If peer is alive, reject connections
set rc -1
}
}
if {$state eq "ACTIVE"} {
my master_callback
}
}
return $rc
}
method update_peer_expiry {} {
set peer_expiry [expr {[clock milliseconds] + 2 * $::BSTAR_HEARTBEAT}]
}
# Reactor event handlers...
# Publish our state to peer
method send_state {} {
my log "I: send state $state to peer"
$statepub send $state
after $::BSTAR_HEARTBEAT [list [self] send_state]
}
# Receive state from peer, execute finite state machine
method recv_state {} {
set nstate [$statesub recv]
my log "I: got state $nstate from peer"
set event $nstate
my update_peer_expiry
my execute_fsm
}
# Application wants to speak to us, see if it's possible
method voter_ready {} {
# If server can accept input now, call appl handler
set event REQUEST
if {[my execute_fsm] == 0} {
puts "CLIENT REQUEST"
my voter_callback
} else {
# Destroy waiting message, no-one to read it
zmsg recv $voter
}
}
# Create socket, bind to local endpoint, and register as reader for
# voting. The socket will only be available if the Binary Star state
# machine allows it. Input on the socket will act as a "vote" in the
# Binary Star scheme. We require exactly one voter per bstar instance.
method voter {endpoint type handler} {
# Hold actual handler+arg so we can call this later
set voter [zmq socket bstar_socket_[::mdp::socketid] $ctx $type]
$voter bind $endpoint
set voterfn $handler
}
# Register state change handlers
method new_master {handler} {
set masterfn $handler
}
method new_slave {handler} {
set slavefn $handler
}
# Enable/disable verbose tracing
method set_verbose {iverbose} {
set verbose $iverbose
}
# Start the reactor, ends if a callback function returns -1
method start {} {
my update_peer_expiry
# Set-up reactor events
$statesub readable [list [self] recv_state]
$voter readable [list [self] voter_ready]
after $::BSTAR_HEARTBEAT [list [self] send_state]
}
}
bstar: OCaml 语言的 Binary Star 核心类
这为我们提供了以下使用核心类实现的简短服务器主程序:
bstarsrv2: Ada 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Basic 语言的使用核心类的 Binary Star 服务器
bstarsrv2: C 语言的使用核心类的 Binary Star 服务器
// Binary Star server, using bstar reactor
// Lets us build this source without creating a library
#include "bstar.c"
// Echo service
int s_echo (zloop_t *loop, zmq_pollitem_t *poller, void *arg)
{
zmsg_t *msg = zmsg_recv (poller->socket);
zmsg_send (&msg, poller->socket);
return 0;
}
int main (int argc, char *argv [])
{
// Arguments can be either of:
// -p primary server, at tcp://:5001
// -b backup server, at tcp://:5002
bstar_t *bstar;
if (argc == 2 && streq (argv [1], "-p")) {
printf ("I: Primary active, waiting for backup (passive)\n");
bstar = bstar_new (BSTAR_PRIMARY,
"tcp://*:5003", "tcp://:5004");
bstar_voter (bstar, "tcp://*:5001", ZMQ_ROUTER, s_echo, NULL);
}
else
if (argc == 2 && streq (argv [1], "-b")) {
printf ("I: Backup passive, waiting for primary (active)\n");
bstar = bstar_new (BSTAR_BACKUP,
"tcp://*:5004", "tcp://:5003");
bstar_voter (bstar, "tcp://*:5002", ZMQ_ROUTER, s_echo, NULL);
}
else {
printf ("Usage: bstarsrvs { -p | -b }\n");
exit (0);
}
bstar_start (bstar);
bstar_destroy (&bstar);
return 0;
}
bstarsrv2: C++ 语言的使用核心类的 Binary Star 服务器
// Binary Star server, using bstar reactor
#include "bstar.hpp"
// Echo service
void s_echo(zmqpp::loop *loop, zmqpp::socket_t *socket, void *arg) {
zmqpp::message_t msg;
socket->receive(msg);
socket->send(msg);
}
int main(int argc, char *argv []) {
// Arguments can be either of:
// -p primary server, at tcp://:5001
// -b backup server, at tcp://:5002
bstar_t *bstar = nullptr;
if (argc == 2 && strcmp(argv[1], "-p") == 0) {
std::cout << "I: Primary active, waiting for backup (passive)" << std::endl;
bstar = new bstar_t(true, "tcp://*:5003", "tcp://:5004");
bstar->register_voter("tcp://*:5001", zmqpp::socket_type::router, s_echo, NULL);
} else if (argc == 2 && strcmp(argv[1], "-b") == 0) {
std::cout << "I: Backup passive, waiting for primary (active)" << std::endl;
bstar = new bstar_t(false, "tcp://*:5004", "tcp://:5003");
bstar->register_voter("tcp://*:5002", zmqpp::socket_type::router, s_echo, NULL);
} else {
std::cout << "Usage: bstarsrv2 { -p | -b }" << std::endl;
return 0;
}
try {
std::cout << "starting bstar...\n";
bstar->start();
} catch (const std::exception &e) {
std::cerr << "Exception: " << e.what() << std::endl;
}
delete bstar;
return 0;
}
bstarsrv2: C# 语言的使用核心类的 Binary Star 服务器
bstarsrv2: CL 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Delphi 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Erlang 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Elixir 语言的使用核心类的 Binary Star 服务器
bstarsrv2: F# 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Felix 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Go 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Haskell 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Haxe 语言的使用核心类的 Binary Star 服务器
package ;
/**
* Binary Star server, using BStar reactor class
* @author Richard J Smith
*
* See: https://zguide.zeromq.cn/page:all#Binary-Star-Reactor
*/
import BStar;
import neko.Lib;
import neko.Sys;
import org.zeromq.ZLoop;
import org.zeromq.ZMQ;
import org.zeromq.ZMQSocket;
import org.zeromq.ZMsg;
class BStarSrv2
{
/**
* Echo service
* @param loop
* @param socket
* @return
*/
private static function echo(loop:ZLoop, socket:ZMQSocket, args:Dynamic):Int {
var msg = ZMsg.recvMsg(socket);
msg.send(socket);
return 0;
}
public static function main() {
Lib.println("** BStarSrv2 (see: https://zguide.zeromq.cn/page:all#Binary-Star-Reactor)");
var bstar:BStar = null;
// Arguments can be either of:
// -p primary server, at tcp://:5001
// -b backup server, at tcp://:5002
var argArr = Sys.args();
if (argArr.length > 1 && argArr[argArr.length - 1] == "-p") {
Lib.println("I: primary master, waiting for backup (slave)");
bstar = new BStar(true, "tcp://*:5003", "tcp://:5004", true, null);
bstar.setVoter("tcp://*:5001", ZMQ_ROUTER, echo);
} else if (argArr.length > 1 && argArr[argArr.length - 1] == "-b") {
Lib.println("I: backup slave, waiting for primary (master)");
bstar = new BStar(false, "tcp://*:5004", "tcp://:5003", true, null);
bstar.setVoter("tcp://*:5002", ZMQ_ROUTER, echo);
} else {
Lib.println("Usage: bstartsrv2 { -p | -b }");
return;
}
bstar.start();
bstar.destroy();
}
}bstarsrv2: Java 语言的使用核心类的 Binary Star 服务器
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZLoop;
import org.zeromq.ZLoop.IZLoopHandler;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.PollItem;
import org.zeromq.ZMsg;
// Binary Star server, using bstar reactor
public class bstarsrv2
{
private static IZLoopHandler Echo = new IZLoopHandler()
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
ZMsg msg = ZMsg.recvMsg(item.getSocket());
msg.send(item.getSocket());
return 0;
}
};
public static void main(String[] argv)
{
// Arguments can be either of:
// -p primary server, at tcp://:5001
// -b backup server, at tcp://:5002
bstar bs = null;
if (argv.length == 1 && argv[0].equals("-p")) {
System.out.printf("I: Primary active, waiting for backup (passive)\n");
bs = new bstar(true, "tcp://*:5003", "tcp://:5004");
bs.voter("tcp://*:5001", SocketType.ROUTER, Echo, null);
}
else if (argv.length == 1 && argv[0].equals("-b")) {
System.out.printf("I: Backup passive, waiting for primary (active)\n");
bs = new bstar(false, "tcp://*:5004", "tcp://:5003");
bs.voter("tcp://*:5002", SocketType.ROUTER, Echo, null);
}
else {
System.out.printf("Usage: bstarsrv { -p | -b }\n");
System.exit(0);
}
bs.start();
bs.destroy();
}
}
bstarsrv2: Julia 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Lua 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Node.js 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Objective-C 语言的使用核心类的 Binary Star 服务器
bstarsrv2: ooc 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Perl 语言的使用核心类的 Binary Star 服务器
bstarsrv2: PHP 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Python 语言的使用核心类的 Binary Star 服务器
"""
Binary Star server, using bstar reactor
Author: Min RK <benjaminrk@gmail.com>
"""
import sys
import zmq
from bstar import BinaryStar
def echo(socket, msg):
"""Echo service"""
socket.send_multipart(msg)
def main():
# Arguments can be either of:
# -p primary server, at tcp://:5001
# -b backup server, at tcp://:5002
if '-p' in sys.argv:
star = BinaryStar(True, "tcp://*:5003", "tcp://:5004")
star.register_voter("tcp://*:5001", zmq.ROUTER, echo)
elif '-b' in sys.argv:
star = BinaryStar(False, "tcp://*:5004", "tcp://:5003")
star.register_voter("tcp://*:5002", zmq.ROUTER, echo)
else:
print("Usage: bstarsrv2.py { -p | -b }\n")
return
star.start()
if __name__ == '__main__':
main()
bstarsrv2: Q 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Racket 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Ruby 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Rust 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Scala 语言的使用核心类的 Binary Star 服务器
bstarsrv2: Tcl 语言的使用核心类的 Binary Star 服务器
#
# Binary Star server, using bstar reactor
#
lappend auto_path .
package require BStar
# Echo service
proc echo {s} {
set msg [zmsg recv $s]
zmsg send $s $msg
return 0
}
# Arguments can be either of:
# -p primary server, at tcp://:5001
# -b backup server, at tcp://:5002
if {[lindex $argv 0] eq "-p"} {
set bstar [BStar new PRIMARY "tcp://*:5003" "tcp://:5004" [expr {[lindex $argv 1] eq "-v"}]]
$bstar voter "tcp://*:5001" ROUTER echo
} elseif {[lindex $argv 0] eq "-b"} {
set bstar [BStar new BACKUP "tcp://*:5004" "tcp://:5003" [expr {[lindex $argv 1] eq "-v"}]]
$bstar voter "tcp://*:5002" ROUTER echo
} else {
puts "Usage: bstarsrv2.tcl <-p|-b> ?-v?"
exit 1
}
$bstar start
vwait forever
$bstar destroy
bstarsrv2: OCaml 语言的使用核心类的 Binary Star 服务器
无 Broker 可靠性 (Freelance 模式) #
当我们经常将 ZeroMQ 解释为“无 broker 消息传递”时,花如此多精力关注基于 broker 的可靠性可能看起来有点讽刺。然而,在消息传递中,就像在现实生活中一样,中间人既是负担也是益处。实践中,大多数消息传递架构都受益于分布式和基于 broker 的消息传递的混合。当你能够自由决定想要做出哪些权衡时,你会得到最好的结果。这就是为什么我可以开车二十分钟去批发商那里为聚会买五箱葡萄酒,但我也可以步行十分钟到街角商店为晚餐买一瓶。我们高度依赖情境的时间、精力、成本的相对价值评估对现实世界的经济至关重要,它们对于最优的消息传递架构也至关重要。
这就是为什么 ZeroMQ 不强制要求基于 broker 的架构,尽管它确实提供了构建 broker 的工具,也称为代理 (proxies),到目前为止,我们已经构建了十几种不同的(broker),只是为了练习。
因此,我们将通过解构我们目前构建的基于 broker 的可靠性来结束本章,并将其转换回我称之为 Freelance 模式的分布式点对点架构。我们的用例将是一个名称解析服务。这是 ZeroMQ 架构中一个常见的问题:我们如何知道要连接的端点?在代码中硬编码 TCP/IP 地址非常脆弱。使用配置文件会造成管理噩梦。想象一下,你必须在你使用的每台 PC 或手机上手动配置你的网络浏览器,才能知道“google.com”是“74.125.230.82”。
一个 ZeroMQ 名称服务(我们将实现一个简单的版本)必须做到以下几点:
-
将逻辑名称解析为至少一个绑定端点和一个连接端点。一个实际的名称服务会提供多个绑定端点,也可能提供多个连接端点。
-
允许我们管理多个并行环境,例如“测试”与“生产”,而无需修改代码。
-
必须可靠,因为如果它不可用,应用程序将无法连接到网络。
将名称服务置于面向服务的 Majordomo broker 之后从某些角度看是聪明的。然而,更简单、也更少意外的是,只需将名称服务暴露为一个客户端可以直接连接的服务器。如果我们这样做得当,名称服务就成为我们在代码或配置文件中需要硬编码的唯一全局网络端点。

我们旨在处理的故障类型包括服务器崩溃和重启、服务器忙循环、服务器过载和网络问题。为了获得可靠性,我们将创建一个名称服务器池,这样如果一个崩溃或消失,客户端可以连接到另一个,依此类推。实践中,两台就足够了。但为了示例,我们假设服务器池可以是任何大小。
在这种架构中,大量客户端直接连接到少量服务器。服务器绑定到各自的地址。这与像 Majordomo 这样的基于 broker 的方法根本不同,在 Majordomo 中,工作者连接到 broker。客户端有几种选择:
-
使用 REQ 套接字和 Lazy Pirate 模式。这种方法简单,但需要一些额外的智能,以免客户端反复愚蠢地尝试重新连接到已死的服务器。
-
使用 DEALER 套接字并广播请求(这些请求会被负载均衡到所有连接的服务器),直到收到回复。这种方法有效,但不够优雅。
-
使用 ROUTER 套接字,以便客户端可以寻址特定的服务器。但客户端如何知道服务器套接字的身份?要么服务器必须先 ping 客户端(复杂),要么服务器必须使用客户端已知的一个硬编码的固定身份(糟糕)。
我们将在下面的小节中分别介绍这些方法。
模型一:简单重试和故障转移 #
看来我们的选择有:简单、粗暴、复杂或糟糕。让我们从简单开始,然后解决其中的问题。我们借鉴 Lazy Pirate 模式,并将其重写以支持多个服务器端点。
首先启动一个或多个服务器,将绑定端点指定为参数
flserver1:自由职业者服务器,Ada 语言实现,模型一
flserver1:自由职业者服务器,Basic 语言实现,模型一
flserver1:自由职业者服务器,C 语言实现,模型一
// Freelance server - Model 1
// Trivial echo service
#include "czmq.h"
int main (int argc, char *argv [])
{
if (argc < 2) {
printf ("I: syntax: %s <endpoint>\n", argv [0]);
return 0;
}
zctx_t *ctx = zctx_new ();
void *server = zsocket_new (ctx, ZMQ_REP);
zsocket_bind (server, argv [1]);
printf ("I: echo service is ready at %s\n", argv [1]);
while (true) {
zmsg_t *msg = zmsg_recv (server);
if (!msg)
break; // Interrupted
zmsg_send (&msg, server);
}
if (zctx_interrupted)
printf ("W: interrupted\n");
zctx_destroy (&ctx);
return 0;
}
flserver1:自由职业者服务器,C++ 语言实现,模型一
// Freelance server - Model 1
// Trivial echo service
#include <iostream>
#include <zmq.hpp>
int main(int argc, char* argv[]) {
if (argc < 2) {
std::cout << "I: syntax: " << argv[0] << " <endpoint>" << std::endl;
return 0;
}
zmq::context_t context{1};
zmq::socket_t server(context, zmq::socket_type::rep);
server.bind(argv[1]);
std::cout << "I: echo service is ready at " << argv[1] << std::endl;
while (true) {
zmq::message_t message;
try {
server.recv(message, zmq::recv_flags::none);
} catch (zmq::error_t& e) {
if (e.num() == EINTR)
std::cout << "W: interrupted" << std::endl;
else
std::cout << "E: error, errnum = " << e.num() << ", what = " << e.what()
<< std::endl;
break; // Interrupted
}
server.send(message, zmq::send_flags::none);
}
return 0;
}
flserver1:自由职业者服务器,C# 语言实现,模型一
flserver1:自由职业者服务器,CL 语言实现,模型一
flserver1:自由职业者服务器,Delphi 语言实现,模型一
flserver1:自由职业者服务器,Erlang 语言实现,模型一
flserver1:自由职业者服务器,Elixir 语言实现,模型一
flserver1:自由职业者服务器,F# 语言实现,模型一
flserver1:自由职业者服务器,Felix 语言实现,模型一
flserver1:自由职业者服务器,Go 语言实现,模型一
flserver1:自由职业者服务器,Haskell 语言实现,模型一
flserver1:自由职业者服务器,Haxe 语言实现,模型一
flserver1:自由职业者服务器,Java 语言实现,模型一
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZMsg;
// Freelance server - Model 1
// Trivial echo service
public class flserver1
{
public static void main(String[] args)
{
if (args.length < 1) {
System.out.printf("I: syntax: flserver1 <endpoint>\n");
System.exit(0);
}
try (ZContext ctx = new ZContext()) {
Socket server = ctx.createSocket(SocketType.REP);
server.bind(args[0]);
System.out.printf("I: echo service is ready at %s\n", args[0]);
while (true) {
ZMsg msg = ZMsg.recvMsg(server);
if (msg == null)
break; // Interrupted
msg.send(server);
}
if (Thread.currentThread().isInterrupted())
System.out.printf("W: interrupted\n");
}
}
}
flserver1:自由职业者服务器,Julia 语言实现,模型一
flserver1:自由职业者服务器,Lua 语言实现,模型一
--
-- Freelance server - Model 1
-- Trivial echo service
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmsg"
require"zmq"
if (#arg < 1) then
printf("I: syntax: %s <endpoint>\n", arg[0])
os.exit(0)
end
local context = zmq.init(1)
s_catch_signals()
-- Implement basic echo service
local server = context:socket(zmq.REP)
server:bind(arg[1])
printf("I: echo service is ready at %s\n", arg[1])
while (not s_interrupted) do
local msg, err = zmsg.recv(server)
if err then
print('recv error:', err)
break -- Interrupted
end
msg:send(server)
end
if (s_interrupted) then
printf("W: interrupted\n")
end
server:close()
context:term()
flserver1:自由职业者服务器,Node.js 语言实现,模型一
flserver1:自由职业者服务器,Objective-C 语言实现,模型一
flserver1:自由职业者服务器,ooc 语言实现,模型一
flserver1:自由职业者服务器,Perl 语言实现,模型一
flserver1:自由职业者服务器,PHP 语言实现,模型一
<?php
/*
* Freelance server - Model 1
* Trivial echo service
*
* Author: Rob Gagnon <rgagnon24(at)gmail(dot)com>
*/
if (count($argv) < 2) {
printf("I: Syntax: %s <endpoint>\n", $argv[0]);
exit;
}
$endpoint = $argv[1];
$context = new ZMQContext();
$server = $context->getSocket(ZMQ::SOCKET_REP);
$server->bind($endpoint);
printf("I: Echo service is ready at %s\n", $endpoint);
while (true) {
$msg = $server->recvMulti();
$server->sendMulti($msg);
}
flserver1:自由职业者服务器,Python 语言实现,模型一
#
# Freelance server - Model 1
# Trivial echo service
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
import sys
import zmq
if len(sys.argv) < 2:
print "I: Syntax: %s <endpoint>" % sys.argv[0]
sys.exit(0)
endpoint = sys.argv[1]
context = zmq.Context()
server = context.socket(zmq.REP)
server.bind(endpoint)
print "I: Echo service is ready at %s" % endpoint
while True:
msg = server.recv_multipart()
if not msg:
break # Interrupted
server.send_multipart(msg)
server.setsockopt(zmq.LINGER, 0) # Terminate immediately
flserver1:自由职业者服务器,Q 语言实现,模型一
flserver1:自由职业者服务器,Racket 语言实现,模型一
flserver1:自由职业者服务器,Ruby 语言实现,模型一
flserver1:自由职业者服务器,Rust 语言实现,模型一
flserver1:自由职业者服务器,Scala 语言实现,模型一
flserver1:自由职业者服务器,Tcl 语言实现,模型一
#
# Freelance server - Model 1
# Trivial echo service
#
package require zmq
if {[llength $argv] != 1} {
puts "Usage: flserver1.tcl <endpoint>"
exit 1
}
zmq context context
zmq socket server context REP
server bind [lindex $argv 0]
puts "I: echo service is ready at [lindex $argv 0]"
while {1} {
set msg [zmsg recv server]
if {[llength $msg] == 0} {
break
}
zmsg send server $msg
}
server close
context term
flserver1:自由职业者服务器,OCaml 语言实现,模型一
然后启动客户端,将一个或多个连接端点指定为参数
flclient1:自由职业者客户端,Ada 语言实现,模型一
flclient1:自由职业者客户端,Basic 语言实现,模型一
flclient1:自由职业者客户端,C 语言实现,模型一
// Freelance client - Model 1
// Uses REQ socket to query one or more services
#include "czmq.h"
#define REQUEST_TIMEOUT 1000
#define MAX_RETRIES 3 // Before we abandon
static zmsg_t *
s_try_request (zctx_t *ctx, char *endpoint, zmsg_t *request)
{
printf ("I: trying echo service at %s...\n", endpoint);
void *client = zsocket_new (ctx, ZMQ_REQ);
zsocket_connect (client, endpoint);
// Send request, wait safely for reply
zmsg_t *msg = zmsg_dup (request);
zmsg_send (&msg, client);
zmq_pollitem_t items [] = { { client, 0, ZMQ_POLLIN, 0 } };
zmq_poll (items, 1, REQUEST_TIMEOUT * ZMQ_POLL_MSEC);
zmsg_t *reply = NULL;
if (items [0].revents & ZMQ_POLLIN)
reply = zmsg_recv (client);
// Close socket in any case, we're done with it now
zsocket_destroy (ctx, client);
return reply;
}
// .split client task
// The client uses a Lazy Pirate strategy if it only has one server to talk
// to. If it has two or more servers to talk to, it will try each server just
// once:
int main (int argc, char *argv [])
{
zctx_t *ctx = zctx_new ();
zmsg_t *request = zmsg_new ();
zmsg_addstr (request, "Hello world");
zmsg_t *reply = NULL;
int endpoints = argc - 1;
if (endpoints == 0)
printf ("I: syntax: %s <endpoint> ...\n", argv [0]);
else
if (endpoints == 1) {
// For one endpoint, we retry N times
int retries;
for (retries = 0; retries < MAX_RETRIES; retries++) {
char *endpoint = argv [1];
reply = s_try_request (ctx, endpoint, request);
if (reply)
break; // Successful
printf ("W: no response from %s, retrying...\n", endpoint);
}
}
else {
// For multiple endpoints, try each at most once
int endpoint_nbr;
for (endpoint_nbr = 0; endpoint_nbr < endpoints; endpoint_nbr++) {
char *endpoint = argv [endpoint_nbr + 1];
reply = s_try_request (ctx, endpoint, request);
if (reply)
break; // Successful
printf ("W: no response from %s\n", endpoint);
}
}
if (reply)
printf ("Service is running OK\n");
zmsg_destroy (&request);
zmsg_destroy (&reply);
zctx_destroy (&ctx);
return 0;
}
flclient1:自由职业者客户端,C++ 语言实现,模型一
// Freelance client - Model 1
// Uses REQ socket to query one or more services
#include <iostream>
#include <zmq.hpp>
#include <zmq_addon.hpp>
const int REQUEST_TIMEOUT = 1000;
const int MAX_RETRIES = 3; // Before we abandon
static std::unique_ptr<zmq::message_t> s_try_request(zmq::context_t &context,
const std::string &endpoint,
const zmq::const_buffer &request) {
std::cout << "I: trying echo service at " << endpoint << std::endl;
zmq::socket_t client(context, zmq::socket_type::req);
// Set ZMQ_LINGER to REQUEST_TIMEOUT milliseconds, otherwise if we send a message to a server
// that is not working properly or even not exist, we may never be able to exit the program
client.setsockopt(ZMQ_LINGER, REQUEST_TIMEOUT);
client.connect(endpoint);
// Send request, wait safely for reply
zmq::message_t message(request.data(), request.size());
client.send(message, zmq::send_flags::none);
zmq_pollitem_t items[] = {{client, 0, ZMQ_POLLIN, 0}};
zmq::poll(items, 1, REQUEST_TIMEOUT);
std::unique_ptr<zmq::message_t> reply = std::make_unique<zmq::message_t>();
zmq::recv_result_t recv_result;
if (items[0].revents & ZMQ_POLLIN) recv_result = client.recv(*reply, zmq::recv_flags::none);
if (!recv_result) {
reply.release();
}
return reply;
}
// .split client task
// The client uses a Lazy Pirate strategy if it only has one server to talk
// to. If it has two or more servers to talk to, it will try each server just
// once:
int main(int argc, char *argv[]) {
zmq::context_t context{1};
zmq::const_buffer request = zmq::str_buffer("Hello World!");
std::unique_ptr<zmq::message_t> reply;
int endpoints = argc - 1;
if (endpoints == 0)
std::cout << "I: syntax: " << argv[0] << "<endpoint> ..." << std::endl;
else if (endpoints == 1) {
// For one endpoint, we retry N times
int retries;
for (retries = 0; retries < MAX_RETRIES; retries++) {
std::string endpoint = std::string(argv[1]);
reply = s_try_request(context, endpoint, request);
if (reply) break; // Successful
std::cout << "W: no response from " << endpoint << " retrying...\n" << std::endl;
}
} else {
// For multiple endpoints, try each at most once
int endpoint_nbr;
for (endpoint_nbr = 0; endpoint_nbr < endpoints; endpoint_nbr++) {
std::string endpoint = std::string(argv[endpoint_nbr + 1]);
reply = s_try_request(context, endpoint, request);
if (reply) break; // Successful
std::cout << "W: no response from " << endpoint << std::endl;
}
}
if (reply)
std::cout << "Service is running OK. Received message: " << reply->to_string() << std::endl;
return 0;
}
flclient1:自由职业者客户端,C# 语言实现,模型一
flclient1:自由职业者客户端,CL 语言实现,模型一
flclient1:自由职业者客户端,Delphi 语言实现,模型一
flclient1:自由职业者客户端,Erlang 语言实现,模型一
flclient1:自由职业者客户端,Elixir 语言实现,模型一
flclient1:自由职业者客户端,F# 语言实现,模型一
flclient1:自由职业者客户端,Felix 语言实现,模型一
flclient1:自由职业者客户端,Go 语言实现,模型一
flclient1:自由职业者客户端,Haskell 语言实现,模型一
flclient1:自由职业者客户端,Haxe 语言实现,模型一
flclient1:自由职业者客户端,Java 语言实现,模型一
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZMsg;
// Freelance client - Model 1
// Uses REQ socket to query one or more services
public class flclient1
{
private static final int REQUEST_TIMEOUT = 1000;
private static final int MAX_RETRIES = 3; // Before we abandon
private static ZMsg tryRequest(ZContext ctx, String endpoint, ZMsg request)
{
System.out.printf("I: trying echo service at %s...\n", endpoint);
Socket client = ctx.createSocket(SocketType.REQ);
client.connect(endpoint);
// Send request, wait safely for reply
ZMsg msg = request.duplicate();
msg.send(client);
Poller poller = ctx.createPoller(1);
poller.register(client, Poller.POLLIN);
poller.poll(REQUEST_TIMEOUT);
ZMsg reply = null;
if (poller.pollin(0))
reply = ZMsg.recvMsg(client);
// Close socket in any case, we're done with it now
ctx.destroySocket(client);
poller.close();
return reply;
}
// .split client task
// The client uses a Lazy Pirate strategy if it only has one server to talk
// to. If it has two or more servers to talk to, it will try each server just
// once:
public static void main(String[] argv)
{
try (ZContext ctx = new ZContext()) {
ZMsg request = new ZMsg();
request.add("Hello world");
ZMsg reply = null;
int endpoints = argv.length;
if (endpoints == 0)
System.out.printf("I: syntax: flclient1 <endpoint> ...\n");
else if (endpoints == 1) {
// For one endpoint, we retry N times
int retries;
for (retries = 0; retries < MAX_RETRIES; retries++) {
String endpoint = argv[0];
reply = tryRequest(ctx, endpoint, request);
if (reply != null)
break; // Successful
System.out.printf(
"W: no response from %s, retrying...\n", endpoint
);
}
}
else {
// For multiple endpoints, try each at most once
int endpointNbr;
for (endpointNbr = 0; endpointNbr < endpoints; endpointNbr++) {
String endpoint = argv[endpointNbr];
reply = tryRequest(ctx, endpoint, request);
if (reply != null)
break; // Successful
System.out.printf("W: no response from %s\n", endpoint);
}
}
if (reply != null) {
System.out.printf("Service is running OK\n");
reply.destroy();
}
request.destroy();
}
}
}
flclient1:自由职业者客户端,Julia 语言实现,模型一
flclient1:自由职业者客户端,Lua 语言实现,模型一
flclient1:自由职业者客户端,Node.js 语言实现,模型一
flclient1:自由职业者客户端,Objective-C 语言实现,模型一
flclient1:自由职业者客户端,ooc 语言实现,模型一
flclient1:自由职业者客户端,Perl 语言实现,模型一
flclient1:自由职业者客户端,PHP 语言实现,模型一
<?php
/*
* Freelance Client - Model 1
* Uses REQ socket to query one or more services
*
* Author: Rob Gagnon <rgagnon24(at)gmail(dot)com>
*/
$request_timeout = 1000; // ms
$max_retries = 3; # Before we abandon
/**
* @param ZMQContext $ctx
* @param string $endpoint
* @param string $request
*/
function try_request($ctx, $endpoint, $request)
{
global $request_timeout;
printf("I: Trying echo service at %s...\n", $endpoint);
$client = $ctx->getSocket(ZMQ::SOCKET_REQ);
$client->connect($endpoint);
$client->send($request);
$poll = new ZMQPoll();
$poll->add($client, ZMQ::POLL_IN);
$readable = $writable = array();
$events = $poll->poll($readable, $writable, $request_timeout);
$reply = null;
foreach ($readable as $sock) {
if ($sock == $client) {
$reply = $client->recvMulti();
} else {
$reply = null;
}
}
$poll->remove($client);
$poll = null;
$client = null;
return $reply;
}
$context = new ZMQContext();
$request = 'Hello world';
$reply = null;
$cmd = array_shift($argv);
$endpoints = count($argv);
if ($endpoints == 0) {
printf("I: syntax: %s <endpoint> ...\n", $cmd);
exit;
}
if ($endpoints == 1) {
// For one endpoint, we retry N times
$endpoint = $argv[0];
for ($retries = 0; $retries < $max_retries; $retries++) {
$reply = try_request($context, $endpoint, $request);
if (isset($reply)) {
break; // Success
}
printf("W: No response from %s, retrying\n", $endpoint);
}
} else {
// For multiple endpoints, try each at most once
foreach ($argv as $endpoint) {
$reply = try_request($context, $endpoint, $request);
if (isset($reply)) {
break; // Success
}
printf("W: No response from %s\n", $endpoint);
}
}
if (isset($reply)) {
print "Service is running OK\n";
}
flclient1:自由职业者客户端,Python 语言实现,模型一
#
# Freelance Client - Model 1
# Uses REQ socket to query one or more services
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
import sys
import time
import zmq
REQUEST_TIMEOUT = 1000 # ms
MAX_RETRIES = 3 # Before we abandon
def try_request(ctx, endpoint, request):
print "I: Trying echo service at %s..." % endpoint
client = ctx.socket(zmq.REQ)
client.setsockopt(zmq.LINGER, 0) # Terminate early
client.connect(endpoint)
client.send(request)
poll = zmq.Poller()
poll.register(client, zmq.POLLIN)
socks = dict(poll.poll(REQUEST_TIMEOUT))
if socks.get(client) == zmq.POLLIN:
reply = client.recv_multipart()
else:
reply = ''
poll.unregister(client)
client.close()
return reply
context = zmq.Context()
request = "Hello world"
reply = None
endpoints = len(sys.argv) - 1
if endpoints == 0:
print "I: syntax: %s <endpoint> ..." % sys.argv[0]
elif endpoints == 1:
# For one endpoint, we retry N times
endpoint = sys.argv[1]
for retries in xrange(MAX_RETRIES):
reply = try_request(context, endpoint, request)
if reply:
break # Success
print "W: No response from %s, retrying" % endpoint
else:
# For multiple endpoints, try each at most once
for endpoint in sys.argv[1:]:
reply = try_request(context, endpoint, request)
if reply:
break # Success
print "W: No response from %s" % endpoint
if reply:
print "Service is running OK"
flclient1:自由职业者客户端,Q 语言实现,模型一
flclient1:自由职业者客户端,Racket 语言实现,模型一
flclient1:自由职业者客户端,Ruby 语言实现,模型一
flclient1:自由职业者客户端,Rust 语言实现,模型一
flclient1:自由职业者客户端,Scala 语言实现,模型一
flclient1:自由职业者客户端,Tcl 语言实现,模型一
#
# Freelance client - Model 1
# Uses REQ socket to query one or more services
#
package require zmq
set REQUEST_TIMEOUT 1000
set MAX_RETRIES 3 ;# Before we abandon
if {[llength $argv] == 0} {
puts "Usage: flclient1.tcl <endpoint> ..."
exit 1
}
proc s_try_request {ctx endpoint request} {
puts "I: trying echo service at $endpoint..."
zmq socket client $ctx REQ
client connect $endpoint
# Send request, wait safely for reply
zmsg send client $request
set reply {}
set rpoll_set [zmq poll {{client {POLLIN}}} $::REQUEST_TIMEOUT]
if {[llength $rpoll_set] && "POLLIN" in [lindex $rpoll_set 0 1]} {
set reply [zmsg recv client]
}
# Close socket in any case, we're done with it now
client setsockopt LINGER 0
client close
return $reply
}
zmq context context
set request {}
set request [zmsg add $request "Hello World"]
set reply {}
if {[llength $argv] == 1} {
# For one endpoint, we retry N times
set endpoint [lindex $argv 0]
for {set retries 0} {$retries < $MAX_RETRIES} {incr retries} {
set reply [s_try_request context $endpoint $request]
if {[llength $reply]} {
break ;# Successful
}
puts "W: no response from $endpoint, retrying..."
}
} else {
# For multiple endpoints, try each at most once
foreach endpoint $argv {
set reply [s_try_request context $endpoint $request]
if {[llength $reply]} {
break ;# Successful
}
puts "W: no response from $endpoint"
}
}
if {[llength $reply]} {
puts "Service is running OK"
}
context term
flclient1:自由职业者客户端,OCaml 语言实现,模型一
示例如下:
flserver1 tcp://*:5555 &
flserver1 tcp://*:5556 &
flclient1 tcp://:5555 tcp://:5556
尽管基本方法是 Lazy Pirate,但客户端旨在只获得一个成功的回复。它有两种技术,取决于你运行的是单个服务器还是多个服务器
- 使用单个服务器时,客户端将重试多次,与 Lazy Pirate 完全相同。
- 使用多个服务器时,客户端将尝试每个服务器最多一次,直到收到回复或已尝试所有服务器。
这解决了 Lazy Pirate 的主要弱点,即它无法故障转移到备份或备用服务器。
然而,这个设计在实际应用中效果不佳。如果我们连接许多套接字,并且我们的主要名称服务器宕机,每次都会经历这种痛苦的超时。
模型二:粗暴散弹枪扫射 #
让我们将客户端切换到使用 DEALER 套接字。我们的目标是确保在最短的时间内获得回复,无论特定服务器是运行还是宕机。我们的客户端采用这种方法:
- 我们进行设置,连接到所有服务器。
- 当我们有请求时,会向所有服务器发送请求。
- 我们等待第一个回复,并采用它。
- 我们忽略任何其他回复。
实际情况是,当所有服务器都在运行时,ZeroMQ 会分配请求,使每个服务器收到一个请求并发送一个回复。当有服务器离线或断开连接时,ZeroMQ 会将请求分发给剩余的服务器。因此,在某些情况下,服务器可能会多次收到同一个请求。
更让客户端烦恼的是,我们会收到多个回复,但不能保证收到准确数量的回复。请求和回复可能会丢失(例如,如果服务器在处理请求时崩溃)。
因此,我们必须为请求编号,并忽略任何与请求编号不匹配的回复。我们的模型一服务器之所以能工作,是因为它是一个回显服务器,但巧合并不是理解事物的良好基础。所以我们将构建一个模型二服务器,它会处理消息并返回带有正确编号且内容为“OK”的回复。我们将使用由两部分组成的消息:一个序列号和一个消息体。
启动一个或多个服务器,每次指定一个绑定端点
flserver2:自由职业者服务器,Ada 语言实现,模型二
flserver2:自由职业者服务器,Basic 语言实现,模型二
flserver2:自由职业者服务器,C 语言实现,模型二
// Freelance server - Model 2
// Does some work, replies OK, with message sequencing
#include "czmq.h"
int main (int argc, char *argv [])
{
if (argc < 2) {
printf ("I: syntax: %s <endpoint>\n", argv [0]);
return 0;
}
zctx_t *ctx = zctx_new ();
void *server = zsocket_new (ctx, ZMQ_REP);
zsocket_bind (server, argv [1]);
printf ("I: service is ready at %s\n", argv [1]);
while (true) {
zmsg_t *request = zmsg_recv (server);
if (!request)
break; // Interrupted
// Fail nastily if run against wrong client
assert (zmsg_size (request) == 2);
zframe_t *identity = zmsg_pop (request);
zmsg_destroy (&request);
zmsg_t *reply = zmsg_new ();
zmsg_add (reply, identity);
zmsg_addstr (reply, "OK");
zmsg_send (&reply, server);
}
if (zctx_interrupted)
printf ("W: interrupted\n");
zctx_destroy (&ctx);
return 0;
}
flserver2:自由职业者服务器,C++ 语言实现,模型二
// Freelance server - Model 2
// Does some work, replies OK, with message sequencing
#include <iostream>
#include <zmqpp/zmqpp.hpp>
int main(int argc, char *argv[]) {
if (argc < 2) {
std::cout << "I: syntax: " << argv[0] << " <endpoint>" << std::endl;
return 0;
}
zmqpp::context context;
zmqpp::socket server(context, zmqpp::socket_type::reply);
server.bind(argv[1]);
std::cout << "I: echo service is ready at " << argv[1] << std::endl;
while (true) {
zmqpp::message request;
try {
server.receive(request);
} catch (zmqpp::zmq_internal_exception &e) {
if (e.zmq_error() == EINTR)
std::cout << "W: interrupted" << std::endl;
else
std::cout << "E: error, errnum = " << e.zmq_error() << ", what = " << e.what()
<< std::endl;
break; // Interrupted
}
// Fail nastily if run against wrong client
assert(request.parts() == 2);
uint identity;
request.get(identity, 0);
// std::cout << "Received sequence: " << identity << std::endl;
zmqpp::message reply;
reply.push_back(identity);
reply.push_back("OK");
server.send(reply);
}
return 0;
}
flserver2:自由职业者服务器,C# 语言实现,模型二
flserver2:自由职业者服务器,CL 语言实现,模型二
flserver2:自由职业者服务器,Delphi 语言实现,模型二
flserver2:自由职业者服务器,Erlang 语言实现,模型二
flserver2:自由职业者服务器,Elixir 语言实现,模型二
flserver2:自由职业者服务器,F# 语言实现,模型二
flserver2:自由职业者服务器,Felix 语言实现,模型二
flserver2:自由职业者服务器,Go 语言实现,模型二
flserver2:自由职业者服务器,Haskell 语言实现,模型二
flserver2:自由职业者服务器,Haxe 语言实现,模型二
flserver2:自由职业者服务器,Java 语言实现,模型二
package guide;
import org.zeromq.*;
import org.zeromq.ZMQ.Socket;
// Freelance server - Model 2
// Does some work, replies OK, with message sequencing
public class flserver2
{
public static void main(String[] args)
{
if (args.length < 1) {
System.out.printf("I: syntax: flserver2 <endpoint>\n");
System.exit(0);
}
try (ZContext ctx = new ZContext()) {
Socket server = ctx.createSocket(SocketType.REP);
server.bind(args[0]);
System.out.printf("I: echo service is ready at %s\n", args[0]);
while (true) {
ZMsg request = ZMsg.recvMsg(server);
if (request == null)
break; // Interrupted
// Fail nastily if run against wrong client
assert (request.size() == 2);
ZFrame identity = request.pop();
request.destroy();
ZMsg reply = new ZMsg();
reply.add(identity);
reply.add("OK");
reply.send(server);
}
if (Thread.currentThread().isInterrupted())
System.out.printf("W: interrupted\n");
}
}
}
flserver2:自由职业者服务器,Julia 语言实现,模型二
flserver2:自由职业者服务器,Lua 语言实现,模型二
--
-- Freelance server - Model 2
-- Does some work, replies OK, with message sequencing
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmsg"
if (#arg < 1) then
printf ("I: syntax: %s <endpoint>\n", arg[0])
os.exit (0)
end
local context = zmq.init(1)
s_catch_signals()
local server = context:socket(zmq.REP)
server:bind(arg[1])
printf ("I: service is ready at %s\n", arg[1])
while (not s_interrupted) do
local msg, err = zmsg.recv(server)
if err then
print('recv error:', err)
break -- Interrupted
end
-- Fail nastily if run against wrong client
assert (msg:parts() == 2)
msg:body_set("OK")
msg:send(server)
end
if (s_interrupted) then
printf("W: interrupted\n")
end
server:close()
context:term()
flserver2:自由职业者服务器,Node.js 语言实现,模型二
flserver2:自由职业者服务器,Objective-C 语言实现,模型二
flserver2:自由职业者服务器,ooc 语言实现,模型二
flserver2:自由职业者服务器,Perl 语言实现,模型二
flserver2:自由职业者服务器,PHP 语言实现,模型二
<?php
/*
* Freelance server - Model 2
* Does some work, replies OK, with message sequencing
*
* Author: Rob Gagnon <rgagnon24(at)gmail(dot)com>
*/
if (count($argv) < 2) {
printf("I: Syntax: %s <endpoint>\n", $argv[0]);
exit;
}
$endpoint = $argv[1];
$context = new ZMQContext();
$server = $context->getSocket(ZMQ::SOCKET_REP);
$server->bind($endpoint);
printf("I: Echo service is ready at %s\n", $endpoint);
while (true) {
$request = $server->recvMulti();
if (count($request) != 2) {
// Fail nastily if run against wrong client
exit(-1);
}
$address = $request[0];
$reply = array($address, 'OK');
$server->sendMulti($reply);
}
flserver2:自由职业者服务器,Python 语言实现,模型二
#
# Freelance server - Model 2
# Does some work, replies OK, with message sequencing
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
import sys
import zmq
if len(sys.argv) < 2:
print "I: Syntax: %s <endpoint>" % sys.argv[0]
sys.exit(0)
endpoint = sys.argv[1]
context = zmq.Context()
server = context.socket(zmq.REP)
server.bind(endpoint)
print "I: Service is ready at %s" % endpoint
while True:
request = server.recv_multipart()
if not request:
break # Interrupted
# Fail nastily if run against wrong client
assert len(request) == 2
address = request[0]
reply = [address, "OK"]
server.send_multipart(reply)
server.setsockopt(zmq.LINGER, 0) # Terminate early
flserver2:自由职业者服务器,Q 语言实现,模型二
flserver2:自由职业者服务器,Racket 语言实现,模型二
flserver2:自由职业者服务器,Ruby 语言实现,模型二
flserver2:自由职业者服务器,Rust 语言实现,模型二
flserver2:自由职业者服务器,Scala 语言实现,模型二
flserver2:自由职业者服务器,Tcl 语言实现,模型二
#
# Freelance server - Model 2
# Does some work, replies OK, with message sequencing
#
package require zmq
if {[llength $argv] != 1} {
puts "Usage: flserver2.tcl <endpoint>"
exit 1
}
zmq context context
zmq socket server context REP
server bind [lindex $argv 0]
puts "I: echo service is ready at [lindex $argv 0]"
while {1} {
set request [zmsg recv server]
if {[llength $request] == 0} {
break
}
# Fail nastily if run against wrong client
if {[llength $request] != 2} {
error "request with length 2 expected"
}
set address [zmsg pop request]
set reply {}
set reply [zmsg add $reply $address]
set reply [zmsg add $reply "OK"]
zmsg send server $reply
}
server close
context term
flserver2:自由职业者服务器,OCaml 语言实现,模型二
然后启动客户端,将连接端点指定为参数
flclient2:自由职业者客户端,Ada 语言实现,模型二
flclient2:自由职业者客户端,Basic 语言实现,模型二
flclient2:自由职业者客户端,C 语言实现,模型二
// Freelance client - Model 2
// Uses DEALER socket to blast one or more services
#include "czmq.h"
// We design our client API as a class, using the CZMQ style
#ifdef __cplusplus
extern "C" {
#endif
typedef struct _flclient_t flclient_t;
flclient_t *flclient_new (void);
void flclient_destroy (flclient_t **self_p);
void flclient_connect (flclient_t *self, char *endpoint);
zmsg_t *flclient_request (flclient_t *self, zmsg_t **request_p);
#ifdef __cplusplus
}
#endif
// If not a single service replies within this time, give up
#define GLOBAL_TIMEOUT 2500
int main (int argc, char *argv [])
{
if (argc == 1) {
printf ("I: syntax: %s <endpoint> ...\n", argv [0]);
return 0;
}
// Create new freelance client object
flclient_t *client = flclient_new ();
// Connect to each endpoint
int argn;
for (argn = 1; argn < argc; argn++)
flclient_connect (client, argv [argn]);
// Send a bunch of name resolution 'requests', measure time
int requests = 10000;
uint64_t start = zclock_time ();
while (requests--) {
zmsg_t *request = zmsg_new ();
zmsg_addstr (request, "random name");
zmsg_t *reply = flclient_request (client, &request);
if (!reply) {
printf ("E: name service not available, aborting\n");
break;
}
zmsg_destroy (&reply);
}
printf ("Average round trip cost: %d usec\n",
(int) (zclock_time () - start) / 10);
flclient_destroy (&client);
return 0;
}
// .split class implementation
// Here is the {{flclient}} class implementation. Each instance has a
// context, a DEALER socket it uses to talk to the servers, a counter
// of how many servers it's connected to, and a request sequence number:
struct _flclient_t {
zctx_t *ctx; // Our context wrapper
void *socket; // DEALER socket talking to servers
size_t servers; // How many servers we have connected to
uint sequence; // Number of requests ever sent
};
// Constructor
flclient_t *
flclient_new (void)
{
flclient_t
*self;
self = (flclient_t *) zmalloc (sizeof (flclient_t));
self->ctx = zctx_new ();
self->socket = zsocket_new (self->ctx, ZMQ_DEALER);
return self;
}
// Destructor
void
flclient_destroy (flclient_t **self_p)
{
assert (self_p);
if (*self_p) {
flclient_t *self = *self_p;
zctx_destroy (&self->ctx);
free (self);
*self_p = NULL;
}
}
// Connect to new server endpoint
void
flclient_connect (flclient_t *self, char *endpoint)
{
assert (self);
zsocket_connect (self->socket, endpoint);
self->servers++;
}
// .split request method
// This method does the hard work. It sends a request to all
// connected servers in parallel (for this to work, all connections
// must be successful and completed by this time). It then waits
// for a single successful reply, and returns that to the caller.
// Any other replies are just dropped:
zmsg_t *
flclient_request (flclient_t *self, zmsg_t **request_p)
{
assert (self);
assert (*request_p);
zmsg_t *request = *request_p;
// Prefix request with sequence number and empty envelope
char sequence_text [10];
sprintf (sequence_text, "%u", ++self->sequence);
zmsg_pushstr (request, sequence_text);
zmsg_pushstr (request, "");
// Blast the request to all connected servers
int server;
for (server = 0; server < self->servers; server++) {
zmsg_t *msg = zmsg_dup (request);
zmsg_send (&msg, self->socket);
}
// Wait for a matching reply to arrive from anywhere
// Since we can poll several times, calculate each one
zmsg_t *reply = NULL;
uint64_t endtime = zclock_time () + GLOBAL_TIMEOUT;
while (zclock_time () < endtime) {
zmq_pollitem_t items [] = { { self->socket, 0, ZMQ_POLLIN, 0 } };
zmq_poll (items, 1, (endtime - zclock_time ()) * ZMQ_POLL_MSEC);
if (items [0].revents & ZMQ_POLLIN) {
// Reply is [empty][sequence][OK]
reply = zmsg_recv (self->socket);
assert (zmsg_size (reply) == 3);
free (zmsg_popstr (reply));
char *sequence = zmsg_popstr (reply);
int sequence_nbr = atoi (sequence);
free (sequence);
if (sequence_nbr == self->sequence)
break;
zmsg_destroy (&reply);
}
}
zmsg_destroy (request_p);
return reply;
}
flclient2:自由职业者客户端,C++ 语言实现,模型二
// Freelance client - Model 2
// Uses DEALER socket to blast one or more services
#include <chrono>
#include <iostream>
#include <memory>
#include <zmqpp/zmqpp.hpp>
// If not a single service replies within this time, give up
const int GLOBAL_TIMEOUT = 2500;
// Total requests times
const int TOTAL_REQUESTS = 10000;
// .split class implementation
// Here is the {{flclient}} class implementation. Each instance has a
// context, a DEALER socket it uses to talk to the servers, a counter
// of how many servers it's connected to, and a request sequence number:
class flclient {
public:
flclient();
~flclient() {}
void connect(const std::string &endpoint);
std::unique_ptr<zmqpp::message> request(zmqpp::message &request);
private:
zmqpp::context context_; // Our context
zmqpp::socket socket_; // DEALER socket talking to servers
size_t servers_; // How many servers we have connected to
uint sequence_; // Number of requests ever sent
};
// Constructor
flclient::flclient() : socket_(context_, zmqpp::socket_type::dealer) {
socket_.set(zmqpp::socket_option::linger, GLOBAL_TIMEOUT);
servers_ = 0;
sequence_ = 0;
}
// Connect to new server endpoint
void flclient::connect(const std::string &endpoint) {
socket_.connect(endpoint);
servers_++;
}
// .split request method
// This method does the hard work. It sends a request to all
// connected servers in parallel (for this to work, all connections
// must be successful and completed by this time). It then waits
// for a single successful reply, and returns that to the caller.
// Any other replies are just dropped:
std::unique_ptr<zmqpp::message> flclient::request(zmqpp::message &request) {
// Prefix request with sequence number and empty envelope
request.push_front(++sequence_);
request.push_front("");
// Blast the request to all connected servers
size_t server;
for (server = 0; server < servers_; server++) {
zmqpp::message msg;
msg.copy(request);
socket_.send(msg);
}
// Wait for a matching reply to arrive from anywhere
// Since we can poll several times, calculate each one
std::unique_ptr<zmqpp::message> reply;
zmqpp::poller poller;
poller.add(socket_, zmqpp::poller::poll_in);
auto endTime = std::chrono::system_clock::now() + std::chrono::milliseconds(GLOBAL_TIMEOUT);
while (std::chrono::system_clock::now() < endTime) {
int milliSecondsToWait = std::chrono::duration_cast<std::chrono::milliseconds>(
endTime - std::chrono::system_clock::now())
.count();
if (poller.poll(milliSecondsToWait)) {
if (poller.has_input(socket_)) {
reply = std::make_unique<zmqpp::message>();
// Reply is [empty][sequence][OK]
socket_.receive(*reply);
assert(reply->parts() == 3);
reply->pop_front();
uint sequence;
reply->get(sequence, 0);
reply->pop_front();
// std::cout << "Current sequence: " << sequence_ << ", Server reply: " << sequence
// << std::endl;
if (sequence == sequence_)
break;
else
reply.release();
}
}
}
return reply;
}
int main(int argc, char *argv[]) {
if (argc == 1) {
std::cout << "I: syntax: " << argv[0] << " <endpoint> ..." << std::endl;
return 0;
}
// Create new freelance client object
flclient client;
// Connect to each endpoint
int argn;
for (argn = 1; argn < argc; argn++) client.connect(argv[argn]);
// Send a bunch of name resolution 'requests', measure time
int requests = TOTAL_REQUESTS;
auto startTime = std::chrono::steady_clock::now();
while (requests--) {
zmqpp::message request;
request.push_back("random name");
std::unique_ptr<zmqpp::message> reply;
reply = client.request(request);
if (!reply) {
std::cout << "E: name service not available, aborting" << std::endl;
break;
}
}
auto endTime = std::chrono::steady_clock::now();
std::cout
<< "Average round trip cost: "
<< std::chrono::duration_cast<std::chrono::microseconds>(endTime - startTime).count() /
TOTAL_REQUESTS
<< " µs" << std::endl;
return 0;
}
flclient2:自由职业者客户端,C# 语言实现,模型二
flclient2:自由职业者客户端,CL 语言实现,模型二
flclient2:自由职业者客户端,Delphi 语言实现,模型二
flclient2:自由职业者客户端,Erlang 语言实现,模型二
flclient2:自由职业者客户端,Elixir 语言实现,模型二
flclient2:自由职业者客户端,F# 语言实现,模型二
flclient2:自由职业者客户端,Felix 语言实现,模型二
flclient2:自由职业者客户端,Go 语言实现,模型二
flclient2:自由职业者客户端,Haskell 语言实现,模型二
flclient2:自由职业者客户端,Haxe 语言实现,模型二
flclient2:自由职业者客户端,Java 语言实现,模型二
package guide;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZMsg;
// Freelance client - Model 2
// Uses DEALER socket to blast one or more services
public class flclient2
{
// If not a single service replies within this time, give up
private static final int GLOBAL_TIMEOUT = 2500;
// .split class implementation
// Here is the {{flclient}} class implementation. Each instance has a
// context, a DEALER socket it uses to talk to the servers, a counter
// of how many servers it's connected to, and a request getSequence number:
private ZContext ctx; // Our context wrapper
private Socket socket; // DEALER socket talking to servers
private int servers; // How many servers we have connected to
private int sequence; // Number of requests ever sent
public flclient2()
{
ctx = new ZContext();
socket = ctx.createSocket(SocketType.DEALER);
}
public void destroy()
{
ctx.destroy();
}
private void connect(String endpoint)
{
socket.connect(endpoint);
servers++;
}
private ZMsg request(ZMsg request)
{
// Prefix request with getSequence number and empty envelope
String sequenceText = String.format("%d", ++sequence);
request.push(sequenceText);
request.push("");
// Blast the request to all connected servers
int server;
for (server = 0; server < servers; server++) {
ZMsg msg = request.duplicate();
msg.send(socket);
}
// Wait for a matching reply to arrive from anywhere
// Since we can poll several times, calculate each one
ZMsg reply = null;
long endtime = System.currentTimeMillis() + GLOBAL_TIMEOUT;
Poller poller = ctx.createPoller(1);
poller.register(socket, Poller.POLLIN);
while (System.currentTimeMillis() < endtime) {
poller.poll(endtime - System.currentTimeMillis());
if (poller.pollin(0)) {
// Reply is [empty][getSequence][OK]
reply = ZMsg.recvMsg(socket);
assert (reply.size() == 3);
reply.pop();
String sequenceStr = reply.popString();
int sequenceNbr = Integer.parseInt(sequenceStr);
if (sequenceNbr == sequence)
break;
reply.destroy();
}
}
poller.close();
request.destroy();
return reply;
}
public static void main(String[] argv)
{
if (argv.length == 0) {
System.out.printf("I: syntax: flclient2 <endpoint> ...\n");
System.exit(0);
}
// Create new freelance client object
flclient2 client = new flclient2();
// Connect to each endpoint
int argn;
for (argn = 0; argn < argv.length; argn++)
client.connect(argv[argn]);
// Send a bunch of name resolution 'requests', measure time
int requests = 10000;
long start = System.currentTimeMillis();
while (requests-- > 0) {
ZMsg request = new ZMsg();
request.add("random name");
ZMsg reply = client.request(request);
if (reply == null) {
System.out.printf("E: name service not available, aborting\n");
break;
}
reply.destroy();
}
System.out.printf("Average round trip cost: %d usec\n", (int) (System.currentTimeMillis() - start) / 10);
client.destroy();
}
}
flclient2:自由职业者客户端,Julia 语言实现,模型二
flclient2:自由职业者客户端,Lua 语言实现,模型二
flclient2:自由职业者客户端,Node.js 语言实现,模型二
flclient2:自由职业者客户端,Objective-C 语言实现,模型二
flclient2:自由职业者客户端,ooc 语言实现,模型二
flclient2:自由职业者客户端,Perl 语言实现,模型二
flclient2:自由职业者客户端,PHP 语言实现,模型二
<?php
/*
* Freelance Client - Model 2
* Uses DEALER socket to blast one or more services
*
* Author: Rob Gagnon <rgagnon24(at)gmail(dot)com>
*/
class FLClient
{
const GLOBAL_TIMEOUT = 2500; // ms
private $servers = 0;
private $sequence = 0;
/** @var ZMQContext */
private $context = null;
/** @var ZMQSocket */
private $socket = null;
public function __construct()
{
$this->servers = 0;
$this->sequence = 0;
$this->context = new ZMQContext();
$this->socket = $this->context->getSocket(ZMQ::SOCKET_DEALER);
}
public function __destruct()
{
$this->socket->setSockOpt(ZMQ::SOCKOPT_LINGER, 0);
$this->socket = null;
$this->context = null;
}
/**
* @param string $endpoint
*/
public function connect($endpoint)
{
$this->socket->connect($endpoint);
$this->servers++;
printf("I: Connected to %s\n", $endpoint);
}
/**
* @param string $request
*/
public function request($request)
{
// Prefix request with sequence number and empty envelope
$this->sequence++;
$msg = array('', $this->sequence, $request);
// Blast the request to all connected servers
for ($server = 1; $server <= $this->servers; $server++) {
$this->socket->sendMulti($msg);
}
// Wait for a matching reply to arrive from anywhere
// Since we can poll several times, calculate each one
$poll = new ZMQPoll();
$poll->add($this->socket, ZMQ::POLL_IN);
$reply = null;
$endtime = time() + self::GLOBAL_TIMEOUT / 1000;
while (time() < $endtime) {
$readable = $writable = array();
$events = $poll->poll($readable, $writable, ($endtime - time()) * 1000);
foreach ($readable as $sock) {
if ($sock == $this->socket) {
$reply = $this->socket->recvMulti();
if (count($reply) != 3) {
exit;
}
$sequence = $reply[1];
if ($sequence == $this->sequence) {
break;
}
}
}
}
return $reply;
}
}
$cmd = array_shift($argv);
if (count($argv) == 0) {
printf("I: syntax: %s <endpoint> ...\n", $cmd);
exit;
}
// Create new freelance client object
$client = new FLClient();
foreach ($argv as $endpoint) {
$client->connect($endpoint);
}
$start = time();
for ($requests = 0; $requests < 10000; $requests++) {
$request = "random name";
$reply = $client->request($request);
if (!isset($reply)) {
print "E: name service not available, aborting\n";
break;
}
}
printf("Average round trip cost: %i ms\n", ((time() - $start) / 100));
$client = null;
flclient2:自由职业者客户端,Python 语言实现,模型二
#
# Freelance Client - Model 2
# Uses DEALER socket to blast one or more services
#
# Author: Daniel Lundin <dln(at)eintr(dot)org>
#
import sys
import time
import zmq
GLOBAL_TIMEOUT = 2500 # ms
class FLClient(object):
def __init__(self):
self.servers = 0
self.sequence = 0
self.context = zmq.Context()
self.socket = self.context.socket(zmq.DEALER) # DEALER
def destroy(self):
self.socket.setsockopt(zmq.LINGER, 0) # Terminate early
self.socket.close()
self.context.term()
def connect(self, endpoint):
self.socket.connect(endpoint)
self.servers += 1
print "I: Connected to %s" % endpoint
def request(self, *request):
# Prefix request with sequence number and empty envelope
self.sequence += 1
msg = ['', str(self.sequence)] + list(request)
# Blast the request to all connected servers
for server in xrange(self.servers):
self.socket.send_multipart(msg)
# Wait for a matching reply to arrive from anywhere
# Since we can poll several times, calculate each one
poll = zmq.Poller()
poll.register(self.socket, zmq.POLLIN)
reply = None
endtime = time.time() + GLOBAL_TIMEOUT / 1000
while time.time() < endtime:
socks = dict(poll.poll((endtime - time.time()) * 1000))
if socks.get(self.socket) == zmq.POLLIN:
reply = self.socket.recv_multipart()
assert len(reply) == 3
sequence = int(reply[1])
if sequence == self.sequence:
break
return reply
if len(sys.argv) == 1:
print "I: Usage: %s <endpoint> ..." % sys.argv[0]
sys.exit(0)
# Create new freelance client object
client = FLClient()
for endpoint in sys.argv[1:]:
client.connect(endpoint)
start = time.time()
for requests in xrange(10000):
request = "random name"
reply = client.request(request)
if not reply:
print "E: Name service not available, aborting"
break
print "Average round trip cost: %i usec" % ((time.time() - start) / 100)
client.destroy()
flclient2:自由职业者客户端,Q 语言实现,模型二
flclient2:自由职业者客户端,Racket 语言实现,模型二
flclient2:自由职业者客户端,Ruby 语言实现,模型二
flclient2:自由职业者客户端,Rust 语言实现,模型二
flclient2:自由职业者客户端,Scala 语言实现,模型二
flclient2:自由职业者客户端,Tcl 语言实现,模型二
#
# Freelance client - Model 2
# Uses DEALER socket to blast one or more services
#
lappend auto_path .
package require TclOO
package require zmq
package require mdp
if {[llength $argv] == 0} {
puts "Usage: flclient2.tcl <endpoint> ..."
exit 1
}
# If not a single service replies within this time, give up
set GLOBAL_TIMEOUT 2500
oo::class create FLClient {
variable ctx socket servers sequence
constructor {} {
set ctx [zmq context mdcli_context_[::mdp::contextid]]
set socket [zmq socket mdcli_socket_[::mdp::socketid] $ctx DEALER]
set servers 0
set sequence 0
}
destructor {
$socket setsockopt LINGER 0
$socket close
$ctx term
}
method connect {endpoint} {
$socket connect $endpoint
incr servers
}
# Send request, get reply
method request {request} {
# Prefix request with sequence number and empty envelope
set request [zmsg push $request [incr sequence]]
set request [zmsg push $request ""]
# Blast the request to all connected servers
for {set server 0} {$server < $servers} {incr server} {
zmsg send $socket $request
}
# Wait for a matching reply to arrive from anywhere
# Since we can poll several times, calculate each one
set reply {}
set endtime [expr {[clock milliseconds] + $::GLOBAL_TIMEOUT}]
while {[clock milliseconds] < $endtime} {
set rpoll_set [zmq poll [list [list $socket {POLLIN}]] [expr {($endtime - [clock milliseconds])}]]
if {[llength $rpoll_set] && "POLLIN" in [lindex $rpoll_set 0 1]} {
# Reply is [empty][sequence][OK]
set reply [zmsg recv $socket]
if {[llength $reply] != 3} {
error "expected reply with length 3"
}
zmsg pop reply
set rsequence [zmsg pop reply]
if {$rsequence == $sequence} {
break
}
}
}
return $reply
}
}
# Create new freelance client object
set client [FLClient new]
# Connect to each endpoint
foreach endpoint $argv {
$client connect $endpoint
}
# Send a bunch of name resolution 'requests', measure time
set requests 100
set start [clock microseconds]
for {set i 0} {$i < $requests} {incr i} {
set request {}
set request [zmsg add $request "random name"]
set reply [$client request $request]
if {[llength $reply] == 0} {
puts "E: name service not available, aborting"
break
}
}
puts "Average round trip cost: [expr {([clock microseconds] - $start) / $requests}] usec"
$client destroy
flclient2:自由职业者客户端,OCaml 语言实现,模型二
以下是关于客户端实现的一些注意事项:
-
客户端被构建成一个精致的基于类的 API,它隐藏了创建 ZeroMQ 上下文和套接字以及与服务器通信的脏活累活。也就是说,如果对腹部进行散弹枪扫射可以被称为“通信”的话。
-
如果在几秒钟内找不到任何响应的服务器,客户端将放弃尝试。
-
客户端必须创建一个有效的 REP 包络,即在消息前面添加一个空消息帧。
客户端执行 10,000 个名称解析请求(假的,因为我们的服务器基本上什么都不做)并测量平均开销。在我的测试机上,与一个服务器通信需要大约 60 微秒。与三个服务器通信需要大约 80 微秒。
我们的散弹枪方法的优缺点如下:
- 优点:简单,易于构建和理解。
- 优点:实现故障转移,并且工作迅速,只要至少有一个服务器正在运行。
- 缺点:产生冗余的网络流量。
- 缺点:无法优先处理服务器,例如:主服务器,然后是备用服务器。
- 缺点:服务器一次最多只能处理一个请求,仅此而已。
模型三:复杂且糟糕 #
散弹枪方法似乎好得令人难以置信。让我们科学地分析所有备选方案。我们将探索复杂/糟糕的选项,即使最终只是为了意识到我们更喜欢粗暴的方法。啊,这就是我的人生故事。
我们可以通过切换到 ROUTER 套接字来解决客户端的主要问题。这使我们可以向特定服务器发送请求,避免已知宕机的服务器,并且总的来说可以随心所欲地智能。我们也可以通过切换到 ROUTER 套接字来解决服务器的主要问题(单线程)。
但在两个匿名套接字(未设置身份)之间进行 ROUTER 到 ROUTER 的通信是不可能的。双方只有在收到第一条消息时才会为对方生成一个身份,因此任何一方都无法与对方通信,直到先收到消息。解决这个难题的唯一方法是“作弊”,即在一个方向上使用硬编码的身份。在客户端/服务器场景中,正确的“作弊”方式是让客户端“知道”服务器的身份。反过来做会是疯狂的,而且是复杂和糟糕的,因为任意数量的客户端都应该能够独立启动。疯狂、复杂和糟糕是种族灭绝独裁者的绝佳属性,但对于软件来说却是糟糕透顶的。
我们不发明另一个需要管理的概念,而是将连接端点用作身份。这是一个独特的字符串,双方无需比散弹枪模型已有的先验知识更多就能达成一致。这是连接两个 ROUTER 套接字的一种巧妙且有效的方式。
回顾一下 ZeroMQ 身份的工作原理。服务器 ROUTER 套接字在绑定其套接字之前设置一个身份。当客户端连接时,双方会进行一个小的握手来交换身份,然后任何一方才发送真正的消息。客户端 ROUTER 套接字由于未设置身份,会向服务器发送一个空身份。服务器生成一个随机 UUID 来标识客户端供自己使用。服务器将其身份(我们约定它将是一个端点字符串)发送给客户端。
这意味着我们的客户端一旦连接建立,就可以将消息路由到服务器(即在其 ROUTER 套接字上发送,将服务器端点指定为身份)。但这并非是执行立即之后 zmq_connect(),而是在某个随机时间之后。这里存在一个问题:我们不知道服务器何时真正可用并完成连接握手。如果服务器在线,可能在几毫秒之后。如果服务器宕机并且系统管理员外出吃午饭,那可能要等一个小时。
这里有一个小小的悖论。我们需要知道服务器何时连接并准备好工作。在自由职业者模式中,不像本章前面看到的基于代理的模式,服务器在被告知之前是沉默的。因此,我们无法与服务器通信,直到它告诉我们它在线,而它只有在我们问过它之后才能这样做。
我的解决方案是混合使用模型 2 的散弹枪方法,这意味着我们会向任何能射击到的东西发射(无害的)“子弹”,如果有什么东西动了,我们就知道它还活着。我们不会发送真正的请求,而是一种乒乓心跳信号。
这再次将我们带到了协议领域,这里是一个 定义自由职业者客户端和服务器如何交换乒乓命令和请求-回复命令的简短规范。
作为服务器实现,它简洁又易懂。这是我们的回显服务器,模型三,现在使用 FLP 协议:
flserver3:自由职业者服务器,Ada 语言实现,模型三
flserver3:自由职业者服务器,Basic 语言实现,模型三
flserver3:自由职业者服务器,C 语言实现,模型三
// Freelance server - Model 3
// Uses an ROUTER/ROUTER socket but just one thread
#include "czmq.h"
int main (int argc, char *argv [])
{
int verbose = (argc > 1 && streq (argv [1], "-v"));
zctx_t *ctx = zctx_new ();
// Prepare server socket with predictable identity
char *bind_endpoint = "tcp://*:5555";
char *connect_endpoint = "tcp://:5555";
void *server = zsocket_new (ctx, ZMQ_ROUTER);
zmq_setsockopt (server,
ZMQ_IDENTITY, connect_endpoint, strlen (connect_endpoint));
zsocket_bind (server, bind_endpoint);
printf ("I: service is ready at %s\n", bind_endpoint);
while (!zctx_interrupted) {
zmsg_t *request = zmsg_recv (server);
if (verbose && request)
zmsg_dump (request);
if (!request)
break; // Interrupted
// Frame 0: identity of client
// Frame 1: PING, or client control frame
// Frame 2: request body
zframe_t *identity = zmsg_pop (request);
zframe_t *control = zmsg_pop (request);
zmsg_t *reply = zmsg_new ();
if (zframe_streq (control, "PING"))
zmsg_addstr (reply, "PONG");
else {
zmsg_add (reply, control);
zmsg_addstr (reply, "OK");
}
zmsg_destroy (&request);
zmsg_prepend (reply, &identity);
if (verbose && reply)
zmsg_dump (reply);
zmsg_send (&reply, server);
}
if (zctx_interrupted)
printf ("W: interrupted\n");
zctx_destroy (&ctx);
return 0;
}
flserver3:自由职业者服务器,C++ 语言实现,模型三
// Freelance server - Model 3
// Uses an ROUTER/ROUTER socket but just one thread
#include <iostream>
#include <zmqpp/zmqpp.hpp>
void dump_binary(const zmqpp::message &msg);
int main(int argc, char *argv[]) {
int verbose = (argc > 1 && (std::string(argv[1]) == "-v"));
if (verbose) std::cout << "verbose active" << std::endl;
zmqpp::context context;
// Prepare server socket with predictable identity
std::string bind_endpoint = "tcp://*:5555";
std::string connect_endpoint = "tcp://:5555";
zmqpp::socket server(context, zmqpp::socket_type::router);
server.set(zmqpp::socket_option::identity, connect_endpoint);
server.bind(bind_endpoint);
std::cout << "I: service is ready at " << bind_endpoint << std::endl;
while (true) {
zmqpp::message request;
try {
server.receive(request);
} catch (zmqpp::zmq_internal_exception &e) {
if (e.zmq_error() == EINTR)
std::cout << "W: interrupted" << std::endl;
else
std::cout << "E: error, errnum = " << e.zmq_error() << ", what = " << e.what()
<< std::endl;
break; // Interrupted
}
if (verbose) {
std::cout << "Message received from client, all data will dump. " << std::endl;
dump_binary(request);
}
// Frame 0: identity of client
// Frame 1: PING, or client control frame
// Frame 2: request body
std::string identity;
std::string control;
request >> identity >> control;
zmqpp::message reply;
if (control == "PING")
reply.push_back("PONG");
else {
reply.push_back(control);
reply.push_back("OK");
}
reply.push_front(identity);
if (verbose) {
std::cout << "Message reply to client dump." << std::endl;
dump_binary(reply);
}
server.send(reply);
}
return 0;
}
void dump_binary(const zmqpp::message &msg) {
std::cout << "Dump message ..." << std::endl;
for (size_t part = 0; part < msg.parts(); ++part) {
std::cout << "Part: " << part << std::endl;
const unsigned char *bin = static_cast<const unsigned char *>(msg.raw_data(part));
for (size_t i = 0; i < msg.size(part); ++i) {
std::cout << std::hex << static_cast<uint16_t>(*(bin++)) << " ";
}
std::cout << std::endl;
}
std::cout << "Dump finish ..." << std::endl;
}
flserver3:自由职业者服务器,C# 语言实现,模型三
flserver3:自由职业者服务器,CL 语言实现,模型三
flserver3:自由职业者服务器,Delphi 语言实现,模型三
flserver3:自由职业者服务器,Erlang 语言实现,模型三
flserver3:自由职业者服务器,Elixir 语言实现,模型三
flserver3:自由职业者服务器,F# 语言实现,模型三
flserver3:自由职业者服务器,Felix 语言实现,模型三
flserver3:自由职业者服务器,Go 语言实现,模型三
flserver3:自由职业者服务器,Haskell 语言实现,模型三
flserver3:自由职业者服务器,Haxe 语言实现,模型三
flserver3:自由职业者服务器,Java 语言实现,模型三
package guide;
import org.zeromq.*;
import org.zeromq.ZMQ.Socket;
// Freelance server - Model 3
// Uses an ROUTER/ROUTER socket but just one thread
public class flserver3
{
public static void main(String[] args)
{
boolean verbose = (args.length > 0 && args[0].equals("-v"));
try (ZContext ctx = new ZContext()) {
// Prepare server socket with predictable identity
String bindEndpoint = "tcp://*:5555";
String connectEndpoint = "tcp://:5555";
Socket server = ctx.createSocket(SocketType.ROUTER);
server.setIdentity(connectEndpoint.getBytes(ZMQ.CHARSET));
server.bind(bindEndpoint);
System.out.printf("I: service is ready at %s\n", bindEndpoint);
while (!Thread.currentThread().isInterrupted()) {
ZMsg request = ZMsg.recvMsg(server);
if (verbose && request != null)
request.dump(System.out);
if (request == null)
break; // Interrupted
// Frame 0: identity of client
// Frame 1: PING, or client control frame
// Frame 2: request body
ZFrame identity = request.pop();
ZFrame control = request.pop();
ZMsg reply = new ZMsg();
if (control.equals(new ZFrame("PING")))
reply.add("PONG");
else {
reply.add(control);
reply.add("OK");
}
request.destroy();
reply.push(identity);
if (verbose && reply != null)
reply.dump(System.out);
reply.send(server);
}
if (Thread.currentThread().isInterrupted())
System.out.printf("W: interrupted\n");
}
}
}
flserver3:自由职业者服务器,Julia 语言实现,模型三
flserver3:自由职业者服务器,Lua 语言实现,模型三
--
-- Freelance server - Model 3
-- Uses an ROUTER/ROUTER socket but just one thread
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmsg"
local verbose = (arg[1] == "-v")
local context = zmq.init(1)
s_catch_signals ()
-- Prepare server socket with predictable identity
local bind_endpoint = "tcp://*:5555"
local connect_endpoint = "tcp://:5555"
local server = context:socket(zmq.ROUTER)
server:setopt(zmq.IDENTITY, connect_endpoint)
server:bind(bind_endpoint)
printf ("I: service is ready at %s\n", bind_endpoint)
while (not s_interrupted) do
local request = zmsg.recv (server)
local reply = nil
if (not request) then
break -- Interrupted
end
if (verbose) then
request:dump()
end
-- Frame 0: identity of client
-- Frame 1: PING, or client control frame
-- Frame 2: request body
local address = request:pop()
if (request:parts() == 1 and request:body() == "PING") then
reply = zmsg.new ("PONG")
elseif (request:parts() > 1) then
reply = request
request = nil
reply:body_set("OK")
end
reply:push(address)
if (verbose and reply) then
reply:dump()
end
reply:send(server)
end
if (s_interrupted) then
printf ("W: interrupted\n")
end
server:close()
context:term()
flserver3:自由职业者服务器,Node.js 语言实现,模型三
flserver3:自由职业者服务器,Objective-C 语言实现,模型三
flserver3:自由职业者服务器,ooc 语言实现,模型三
flserver3:自由职业者服务器,Perl 语言实现,模型三
flserver3:自由职业者服务器,PHP 语言实现,模型三
flserver3: Freelance server, Model Three in Python
"""Freelance server - Model 3
Uses an ROUTER/ROUTER socket but just one thread
Author: Min RK <benjaminrk@gmail.com>
"""
import sys
import zmq
from zhelpers import dump
def main():
verbose = '-v' in sys.argv
ctx = zmq.Context()
# Prepare server socket with predictable identity
bind_endpoint = "tcp://*:5555"
connect_endpoint = "tcp://:5555"
server = ctx.socket(zmq.ROUTER)
server.identity = connect_endpoint
server.bind(bind_endpoint)
print "I: service is ready at", bind_endpoint
while True:
try:
request = server.recv_multipart()
except:
break # Interrupted
# Frame 0: identity of client
# Frame 1: PING, or client control frame
# Frame 2: request body
address, control = request[:2]
reply = [address, control]
if control == "PING":
reply[1] = "PONG"
else:
reply.append("OK")
if verbose:
dump(reply)
server.send_multipart(reply)
print "W: interrupted"
if __name__ == '__main__':
main()
flserver3: Freelance server, Model Three in Q
flserver3: Freelance server, Model Three in Racket
flserver3: Freelance server, Model Three in Ruby
flserver3: Freelance server, Model Three in Rust
flserver3: Freelance server, Model Three in Scala
flserver3: Freelance server, Model Three in Tcl
#
# Freelance server - Model 2
# Does some work, replies OK, with message sequencing
#
package require zmq
if {[llength $argv] != 1} {
puts "Usage: flserver3.tcl <endpoint> ?-v?"
exit 1
}
set connect_endpoint [lindex $argv 0]
set bind_endpoint [regsub {tcp\://[^\:]+} $connect_endpoint "tcp://*"]
set verbose 0
zmq context context
zmq socket server context ROUTER
server setsockopt IDENTITY $connect_endpoint
server bind $bind_endpoint
puts "I: service is ready at $bind_endpoint"
while {1} {
set request [zmsg recv server]
if {$verbose} {
puts "Request:"
puts [join [zmsg dump $request] \n]
}
if {[llength $request] == 0} {
break
}
set address [zmsg pop request]
set control [zmsg pop request]
set reply {}
if {$control eq "PING"} {
puts "PING"
set reply [zmsg add $reply "PONG"]
} else {
puts "REQUEST $control"
set reply [zmsg add $reply $control]
set reply [zmsg add $reply "OK"]
set reply [zmsg add $reply "payload"]
}
set reply [zmsg push $reply $address]
if {$verbose} {
puts "Reply:"
puts [join [zmsg dump $reply] \n]
}
zmsg send server $reply
}
server close
context term
flserver3: Freelance server, Model Three in OCaml
然而,自由职业客户端已经变得很大。为了清晰起见,它被拆分成一个示例应用程序和一个负责核心工作的类。以下是顶层应用程序:
flclient3: 自由职业客户端,第三版,使用 Ada
flclient3: 自由职业客户端,第三版,使用 Basic
flclient3: 自由职业客户端,第三版,使用 C
// Freelance client - Model 3
// Uses flcliapi class to encapsulate Freelance pattern
// Lets us build this source without creating a library
#include "flcliapi.c"
int main (void)
{
// Create new freelance client object
flcliapi_t *client = flcliapi_new ();
// Connect to several endpoints
flcliapi_connect (client, "tcp://:5555");
flcliapi_connect (client, "tcp://:5556");
flcliapi_connect (client, "tcp://:5557");
// Send a bunch of name resolution 'requests', measure time
int requests = 1000;
uint64_t start = zclock_time ();
while (requests--) {
zmsg_t *request = zmsg_new ();
zmsg_addstr (request, "random name");
zmsg_t *reply = flcliapi_request (client, &request);
if (!reply) {
printf ("E: name service not available, aborting\n");
break;
}
zmsg_destroy (&reply);
}
printf ("Average round trip cost: %d usec\n",
(int) (zclock_time () - start) / 10);
flcliapi_destroy (&client);
return 0;
}
flclient3: 自由职业客户端,第三版,使用 C++
// Freelance client - Model 3
// Uses flcliapi class to encapsulate Freelance pattern
#include <chrono>
#include "flcliapi.hpp"
const int TOTAL_REQUESTS = 10000;
int main(void) {
// Create new freelance client object
Flcliapi client;
// Connect to several endpoints
client.connect("tcp://:5555");
client.connect("tcp://:5556");
client.connect("tcp://:5557");
// Send a bunch of name resolution 'requests', measure time
int requests = TOTAL_REQUESTS;
auto startTime = std::chrono::steady_clock::now();
while (requests--) {
zmqpp::message request;
request.push_back("random name");
std::unique_ptr<zmqpp::message> reply;
reply = client.request(request);
if (!reply) {
std::cout << "E: name service not available, aborting" << std::endl;
break;
}
}
auto endTime = std::chrono::steady_clock::now();
std::cout
<< "Average round trip cost: "
<< std::chrono::duration_cast<std::chrono::microseconds>(endTime - startTime).count() /
TOTAL_REQUESTS
<< " µs" << std::endl;
return 0;
}
flclient3: 自由职业客户端,第三版,使用 C#
flclient3: 自由职业客户端,第三版,使用 CL
flclient3: 自由职业客户端,第三版,使用 Delphi
flclient3: 自由职业客户端,第三版,使用 Erlang
flclient3: 自由职业客户端,第三版,使用 Elixir
flclient3: 自由职业客户端,第三版,使用 F#
flclient3: 自由职业客户端,第三版,使用 Felix
flclient3: 自由职业客户端,第三版,使用 Go
flclient3: 自由职业客户端,第三版,使用 Haskell
flclient3: 自由职业客户端,第三版,使用 Haxe
flclient3: 自由职业客户端,第三版,使用 Java
package guide;
import org.zeromq.ZMsg;
// Freelance client - Model 3
// Uses flcliapi class to encapsulate Freelance pattern
public class flclient3
{
public static void main(String[] argv)
{
// Create new freelance client object
flcliapi client = new flcliapi();
// Connect to several endpoints
client.connect("tcp://:5555");
client.connect("tcp://:5556");
client.connect("tcp://:5557");
// Send a bunch of name resolution 'requests', measure time
int requests = 10000;
long start = System.currentTimeMillis();
while (requests-- > 0) {
ZMsg request = new ZMsg();
request.add("random name");
ZMsg reply = client.request(request);
if (reply == null) {
System.out.printf("E: name service not available, aborting\n");
break;
}
reply.destroy();
}
System.out.printf("Average round trip cost: %d usec\n", (int) (System.currentTimeMillis() - start) / 10);
client.destroy();
}
}
flclient3: 自由职业客户端,第三版,使用 Julia
flclient3: 自由职业客户端,第三版,使用 Lua
flclient3: 自由职业客户端,第三版,使用 Node.js
flclient3: 自由职业客户端,第三版,使用 Objective-C
flclient3: 自由职业客户端,第三版,使用 ooc
flclient3: 自由职业客户端,第三版,使用 Perl
flclient3: 自由职业客户端,第三版,使用 PHP
flclient3: 自由职业客户端,第三版,使用 Python
"""
Freelance client - Model 3
Uses flcliapi class to encapsulate Freelance pattern
Author : Min RK <benjaminrk@gmail.com>
"""
import time
from flcliapi import FreelanceClient
def main():
# Create new freelance client object
client = FreelanceClient()
# Connect to several endpoints
client.connect ("tcp://:5555")
client.connect ("tcp://:5556")
client.connect ("tcp://:5557")
# Send a bunch of name resolution 'requests', measure time
requests = 10000
start = time.time()
for i in range(requests):
request = ["random name"]
reply = client.request(request)
if not reply:
print "E: name service not available, aborting"
return
print "Average round trip cost: %d usec" % (1e6*(time.time() - start) / requests)
if __name__ == '__main__':
main()
flclient3: 自由职业客户端,第三版,使用 Q
flclient3: 自由职业客户端,第三版,使用 Racket
flclient3: 自由职业客户端,第三版,使用 Ruby
flclient3: 自由职业客户端,第三版,使用 Rust
flclient3: 自由职业客户端,第三版,使用 Scala
flclient3: 自由职业客户端,第三版,使用 Tcl
#
# Freelance client - Model 3
# Uses flcliapi class to encapsulate Freelance pattern
#
lappend auto_path .
package require FLClient
# Create new freelance client object
set client [FLClient new]
# Connect to several endpoints
puts connect
$client connect "tcp://:5555"
$client connect "tcp://:5556"
$client connect "tcp://:5557"
set requests 100
set start [clock microseconds]
for {set i 0} {$i < $requests} {incr i} {
puts "request $i --------------------------------------------------"
set request {}
set request [zmsg add $request "random name"]
set reply [$client request $request]
puts "reply $i --------------------------------------------------"
if {[llength $reply] == 0} {
puts "E: name service not available, aborting"
break
} else {
puts [join [zmsg dump $reply] \n]
}
}
puts "Average round trip cost: [expr {([clock microseconds] - $start) / $requests}] usec"
$client destroy
flclient3: 自由职业客户端,第三版,使用 OCaml
同样,这里是客户端 API 类,其复杂度和规模几乎与 Majordomo 代理(broker)相当
flcliapi: 自由职业客户端 API,使用 Ada
flcliapi: 自由职业客户端 API,使用 Basic
flcliapi: 自由职业客户端 API,使用 C
// flcliapi class - Freelance Pattern agent class
// Implements the Freelance Protocol at https://rfc.zeromq.cn/spec:10
#include "flcliapi.h"
// If no server replies within this time, abandon request
#define GLOBAL_TIMEOUT 3000 // msecs
// PING interval for servers we think are alive
#define PING_INTERVAL 2000 // msecs
// Server considered dead if silent for this long
#define SERVER_TTL 6000 // msecs
// .split API structure
// This API works in two halves, a common pattern for APIs that need to
// run in the background. One half is an frontend object our application
// creates and works with; the other half is a backend "agent" that runs
// in a background thread. The frontend talks to the backend over an
// inproc pipe socket:
// Structure of our frontend class
struct _flcliapi_t {
zctx_t *ctx; // Our context wrapper
void *pipe; // Pipe through to flcliapi agent
};
// This is the thread that handles our real flcliapi class
static void flcliapi_agent (void *args, zctx_t *ctx, void *pipe);
// Constructor
flcliapi_t *
flcliapi_new (void)
{
flcliapi_t
*self;
self = (flcliapi_t *) zmalloc (sizeof (flcliapi_t));
self->ctx = zctx_new ();
self->pipe = zthread_fork (self->ctx, flcliapi_agent, NULL);
return self;
}
// Destructor
void
flcliapi_destroy (flcliapi_t **self_p)
{
assert (self_p);
if (*self_p) {
flcliapi_t *self = *self_p;
zctx_destroy (&self->ctx);
free (self);
*self_p = NULL;
}
}
// .split connect method
// To implement the connect method, the frontend object sends a multipart
// message to the backend agent. The first part is a string "CONNECT", and
// the second part is the endpoint. It waits 100msec for the connection to
// come up, which isn't pretty, but saves us from sending all requests to a
// single server, at startup time:
void
flcliapi_connect (flcliapi_t *self, char *endpoint)
{
assert (self);
assert (endpoint);
zmsg_t *msg = zmsg_new ();
zmsg_addstr (msg, "CONNECT");
zmsg_addstr (msg, endpoint);
zmsg_send (&msg, self->pipe);
zclock_sleep (100); // Allow connection to come up
}
// .split request method
// To implement the request method, the frontend object sends a message
// to the backend, specifying a command "REQUEST" and the request message:
zmsg_t *
flcliapi_request (flcliapi_t *self, zmsg_t **request_p)
{
assert (self);
assert (*request_p);
zmsg_pushstr (*request_p, "REQUEST");
zmsg_send (request_p, self->pipe);
zmsg_t *reply = zmsg_recv (self->pipe);
if (reply) {
char *status = zmsg_popstr (reply);
if (streq (status, "FAILED"))
zmsg_destroy (&reply);
free (status);
}
return reply;
}
// .split backend agent
// Here we see the backend agent. It runs as an attached thread, talking
// to its parent over a pipe socket. It is a fairly complex piece of work
// so we'll break it down into pieces. First, the agent manages a set of
// servers, using our familiar class approach:
// Simple class for one server we talk to
typedef struct {
char *endpoint; // Server identity/endpoint
uint alive; // 1 if known to be alive
int64_t ping_at; // Next ping at this time
int64_t expires; // Expires at this time
} server_t;
server_t *
server_new (char *endpoint)
{
server_t *self = (server_t *) zmalloc (sizeof (server_t));
self->endpoint = strdup (endpoint);
self->alive = 0;
self->ping_at = zclock_time () + PING_INTERVAL;
self->expires = zclock_time () + SERVER_TTL;
return self;
}
void
server_destroy (server_t **self_p)
{
assert (self_p);
if (*self_p) {
server_t *self = *self_p;
free (self->endpoint);
free (self);
*self_p = NULL;
}
}
int
server_ping (const char *key, void *server, void *socket)
{
server_t *self = (server_t *) server;
if (zclock_time () >= self->ping_at) {
zmsg_t *ping = zmsg_new ();
zmsg_addstr (ping, self->endpoint);
zmsg_addstr (ping, "PING");
zmsg_send (&ping, socket);
self->ping_at = zclock_time () + PING_INTERVAL;
}
return 0;
}
int
server_tickless (const char *key, void *server, void *arg)
{
server_t *self = (server_t *) server;
uint64_t *tickless = (uint64_t *) arg;
if (*tickless > self->ping_at)
*tickless = self->ping_at;
return 0;
}
// .split backend agent class
// We build the agent as a class that's capable of processing messages
// coming in from its various sockets:
// Simple class for one background agent
typedef struct {
zctx_t *ctx; // Own context
void *pipe; // Socket to talk back to application
void *router; // Socket to talk to servers
zhash_t *servers; // Servers we've connected to
zlist_t *actives; // Servers we know are alive
uint sequence; // Number of requests ever sent
zmsg_t *request; // Current request if any
zmsg_t *reply; // Current reply if any
int64_t expires; // Timeout for request/reply
} agent_t;
agent_t *
agent_new (zctx_t *ctx, void *pipe)
{
agent_t *self = (agent_t *) zmalloc (sizeof (agent_t));
self->ctx = ctx;
self->pipe = pipe;
self->router = zsocket_new (self->ctx, ZMQ_ROUTER);
self->servers = zhash_new ();
self->actives = zlist_new ();
return self;
}
void
agent_destroy (agent_t **self_p)
{
assert (self_p);
if (*self_p) {
agent_t *self = *self_p;
zhash_destroy (&self->servers);
zlist_destroy (&self->actives);
zmsg_destroy (&self->request);
zmsg_destroy (&self->reply);
free (self);
*self_p = NULL;
}
}
// .split control messages
// This method processes one message from our frontend class
// (it's going to be CONNECT or REQUEST):
// Callback when we remove server from agent 'servers' hash table
static void
s_server_free (void *argument)
{
server_t *server = (server_t *) argument;
server_destroy (&server);
}
void
agent_control_message (agent_t *self)
{
zmsg_t *msg = zmsg_recv (self->pipe);
char *command = zmsg_popstr (msg);
if (streq (command, "CONNECT")) {
char *endpoint = zmsg_popstr (msg);
printf ("I: connecting to %s...\n", endpoint);
int rc = zmq_connect (self->router, endpoint);
assert (rc == 0);
server_t *server = server_new (endpoint);
zhash_insert (self->servers, endpoint, server);
zhash_freefn (self->servers, endpoint, s_server_free);
zlist_append (self->actives, server);
server->ping_at = zclock_time () + PING_INTERVAL;
server->expires = zclock_time () + SERVER_TTL;
free (endpoint);
}
else
if (streq (command, "REQUEST")) {
assert (!self->request); // Strict request-reply cycle
// Prefix request with sequence number and empty envelope
char sequence_text [10];
sprintf (sequence_text, "%u", ++self->sequence);
zmsg_pushstr (msg, sequence_text);
// Take ownership of request message
self->request = msg;
msg = NULL;
// Request expires after global timeout
self->expires = zclock_time () + GLOBAL_TIMEOUT;
}
free (command);
zmsg_destroy (&msg);
}
// .split router messages
// This method processes one message from a connected
// server:
void
agent_router_message (agent_t *self)
{
zmsg_t *reply = zmsg_recv (self->router);
// Frame 0 is server that replied
char *endpoint = zmsg_popstr (reply);
server_t *server =
(server_t *) zhash_lookup (self->servers, endpoint);
assert (server);
free (endpoint);
if (!server->alive) {
zlist_append (self->actives, server);
server->alive = 1;
}
server->ping_at = zclock_time () + PING_INTERVAL;
server->expires = zclock_time () + SERVER_TTL;
// Frame 1 may be sequence number for reply
char *sequence = zmsg_popstr (reply);
if (atoi (sequence) == self->sequence) {
zmsg_pushstr (reply, "OK");
zmsg_send (&reply, self->pipe);
zmsg_destroy (&self->request);
}
else
zmsg_destroy (&reply);
}
// .split backend agent implementation
// Finally, here's the agent task itself, which polls its two sockets
// and processes incoming messages:
static void
flcliapi_agent (void *args, zctx_t *ctx, void *pipe)
{
agent_t *self = agent_new (ctx, pipe);
zmq_pollitem_t items [] = {
{ self->pipe, 0, ZMQ_POLLIN, 0 },
{ self->router, 0, ZMQ_POLLIN, 0 }
};
while (!zctx_interrupted) {
// Calculate tickless timer, up to 1 hour
uint64_t tickless = zclock_time () + 1000 * 3600;
if (self->request
&& tickless > self->expires)
tickless = self->expires;
zhash_foreach (self->servers, server_tickless, &tickless);
int rc = zmq_poll (items, 2,
(tickless - zclock_time ()) * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Context has been shut down
if (items [0].revents & ZMQ_POLLIN)
agent_control_message (self);
if (items [1].revents & ZMQ_POLLIN)
agent_router_message (self);
// If we're processing a request, dispatch to next server
if (self->request) {
if (zclock_time () >= self->expires) {
// Request expired, kill it
zstr_send (self->pipe, "FAILED");
zmsg_destroy (&self->request);
}
else {
// Find server to talk to, remove any expired ones
while (zlist_size (self->actives)) {
server_t *server =
(server_t *) zlist_first (self->actives);
if (zclock_time () >= server->expires) {
zlist_pop (self->actives);
server->alive = 0;
}
else {
zmsg_t *request = zmsg_dup (self->request);
zmsg_pushstr (request, server->endpoint);
zmsg_send (&request, self->router);
break;
}
}
}
}
// Disconnect and delete any expired servers
// Send heartbeats to idle servers if needed
zhash_foreach (self->servers, server_ping, self->router);
}
agent_destroy (&self);
}
flcliapi: 自由职业客户端 API,使用 C++
// flcliapi class - Freelance Pattern agent class
// Implements the Freelance Protocol at https://rfc.zeromq.cn/spec:10
#include "flcliapi.hpp"
// If no server replies within this time, abandon request
const int GLOBAL_TIMEOUT = 3000; // msecs
// PING interval for servers we think are alive
const int PING_INTERVAL = 500; // msecs
// Server considered dead if silent for this long
const int SERVER_TTL = 1000; // msecs
// This API works in two halves, a common pattern for APIs that need to
// run in the background. One half is an frontend object our application
// creates and works with; the other half is a backend "agent" that runs
// in a background thread. The frontend talks to the backend over an
// inproc pipe socket created by actor object:
// Constructor
Flcliapi::Flcliapi()
: actor_(std::bind(&Flcliapi::agent, this, std::placeholders::_1, std::ref(context_))) {}
Flcliapi::~Flcliapi() {}
// connect interface
// To implement the connect method, the frontend object sends a multipart
// message to the backend agent. The first part is a string "CONNECT", and
// the second part is the endpoint. It waits 100msec for the connection to
// come up, which isn't pretty, but saves us from sending all requests to a
// single server, at startup time:
void Flcliapi::connect(const std::string& endpoint) {
zmqpp::message msg;
msg.push_back("CONNECT");
msg.push_back(endpoint);
actor_.pipe()->send(msg);
std::this_thread::sleep_for(std::chrono::milliseconds(100)); // Allow connection to come up
}
// request interface
// To implement the request method, the frontend object sends a message
// to the backend, specifying a command "REQUEST" and the request message:
std::unique_ptr<zmqpp::message> Flcliapi::request(zmqpp::message& request) {
assert(request.parts() > 0);
request.push_front("REQUEST");
actor_.pipe()->send(request);
std::unique_ptr<zmqpp::message> reply = std::make_unique<zmqpp::message>();
actor_.pipe()->receive(*reply);
if (0 != reply->parts()) {
if (reply->get(0) == "FAILED") reply.release();
} else {
reply.release();
}
return reply;
}
Server::Server(const std::string& endpoint) {
endpoint_ = endpoint;
alive_ = false;
ping_at_ = std::chrono::steady_clock::now() + std::chrono::milliseconds(PING_INTERVAL);
expires_ = std::chrono::steady_clock::now() + std::chrono::milliseconds(SERVER_TTL);
}
Server::~Server() {}
int Server::ping(zmqpp::socket& socket) {
if (std::chrono::steady_clock::now() >= ping_at_) {
zmqpp::message ping;
ping.push_back(endpoint_);
ping.push_back("PING");
socket.send(ping);
ping_at_ = std::chrono::steady_clock::now() + std::chrono::milliseconds(PING_INTERVAL);
}
return 0;
}
int Server::tickless(std::chrono::time_point<std::chrono::steady_clock>& tickless_at) {
if (tickless_at > ping_at_) tickless_at = ping_at_;
return 0;
}
Agent::Agent(zmqpp::context& context, zmqpp::socket* pipe)
: context_(context), pipe_(pipe), router_(context, zmqpp::socket_type::router) {
router_.set(zmqpp::socket_option::linger, GLOBAL_TIMEOUT);
sequence_ = 0;
}
Agent::~Agent() {}
// control messages
// This method processes one message from our frontend class
// (it's going to be CONNECT or REQUEST):
void Agent::control_message(std::unique_ptr<zmqpp::message> msg) {
std::string command = msg->get(0);
msg->pop_front();
if (command == "CONNECT") {
std::string endpoint = msg->get(0);
msg->pop_front();
std::cout << "I: connecting to " << endpoint << "..." << std::endl;
try {
router_.connect(endpoint);
} catch (zmqpp::zmq_internal_exception& e) {
std::cerr << "failed to bind to endpoint " << endpoint << ": " << e.what() << std::endl;
return;
}
std::shared_ptr<Server> server = std::make_shared<Server>(endpoint);
servers_.insert(std::pair<std::string, std::shared_ptr<Server>>(endpoint, server));
// actives_.push_back(server);
server->setPingAt(std::chrono::steady_clock::now() +
std::chrono::milliseconds(PING_INTERVAL));
server->setExpires(std::chrono::steady_clock::now() +
std::chrono::milliseconds(SERVER_TTL));
} else if (command == "REQUEST") {
assert(!request_); // Strict request-reply cycle
// Prefix request with sequence number and empty envelope
msg->push_front(++sequence_);
// Take ownership of request message
request_ = std::move(msg);
// Request expires after global timeout
expires_ = std::chrono::steady_clock::now() + std::chrono::milliseconds(GLOBAL_TIMEOUT);
}
}
// .split router messages
// This method processes one message from a connected
// server:
void Agent::router_message() {
zmqpp::message reply;
router_.receive(reply);
// Frame 0 is server that replied
std::string endpoint = reply.get(0);
reply.pop_front();
assert(servers_.count(endpoint));
std::shared_ptr<Server> server = servers_.at(endpoint);
if (!server->isAlive()) {
actives_.push_back(server);
server->setAlive(true);
}
server->setPingAt(std::chrono::steady_clock::now() + std::chrono::milliseconds(PING_INTERVAL));
server->setExpires(std::chrono::steady_clock::now() + std::chrono::milliseconds(SERVER_TTL));
// Frame 1 may be sequence number for reply
uint sequence;
reply.get(sequence, 0);
reply.pop_front();
if (request_) {
if (sequence == sequence_) {
request_.release();
reply.push_front("OK");
pipe_->send(reply);
}
}
}
// .split backend agent implementation
// Finally, here's the agent task itself, which polls its two sockets
// and processes incoming messages:
bool Flcliapi::agent(zmqpp::socket* pipe, zmqpp::context& context) {
Agent self(context, pipe);
zmqpp::poller poller;
poller.add(*self.getPipe());
poller.add(self.getRouter());
pipe->send(zmqpp::signal::ok); // signal we successfully started
while (true) {
// Calculate tickless timer, up to 1 hour
std::chrono::time_point<std::chrono::steady_clock> tickless =
std::chrono::steady_clock::now() + std::chrono::hours(1);
if (self.request_ && tickless > self.expires_) tickless = self.expires_;
for (auto& kv : self.servers_) {
kv.second->tickless(tickless);
}
if (poller.poll(std::chrono::duration_cast<std::chrono::milliseconds>(
tickless - std::chrono::steady_clock::now())
.count())) {
if (poller.has_input(*self.getPipe())) {
std::unique_ptr<zmqpp::message> msg = std::make_unique<zmqpp::message>();
pipe->receive(*msg);
if (msg->is_signal()) {
zmqpp::signal sig;
msg->get(sig, 0);
if (sig == zmqpp::signal::stop) break; // actor receive stop signal, exit
} else
self.control_message(std::move(msg));
}
if (poller.has_input(self.getRouter())) self.router_message();
}
// If we're processing a request, dispatch to next server
if (self.request_) {
if (std::chrono::steady_clock::now() >= self.expires_) {
// Request expired, kill it
self.request_.release();
self.getPipe()->send("FAILED");
} else {
// Find server to talk to, remove any expired ones
while (self.actives_.size() > 0) {
auto& server = self.actives_.front();
if (std::chrono::steady_clock::now() >= server->getExpires()) {
server->setAlive(false);
self.actives_.pop_front();
} else {
zmqpp::message request;
request.copy(*self.request_);
request.push_front(server->getEndpoint());
self.getRouter().send(request);
break;
}
}
}
}
for (auto& kv : self.servers_) {
kv.second->ping(self.getRouter());
}
}
return true; // will send signal::ok to signal successful shutdown
}
flcliapi: 自由职业客户端 API,使用 C#
flcliapi: 自由职业客户端 API,使用 CL
flcliapi: 自由职业客户端 API,使用 Delphi
flcliapi: 自由职业客户端 API,使用 Erlang
flcliapi: 自由职业客户端 API,使用 Elixir
flcliapi: 自由职业客户端 API,使用 F#
flcliapi: 自由职业客户端 API,使用 Felix
flcliapi: 自由职业客户端 API,使用 Go
flcliapi: 自由职业客户端 API,使用 Haskell
flcliapi: 自由职业客户端 API,使用 Haxe
flcliapi: 自由职业客户端 API,使用 Java
package guide;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZThread.IAttachedRunnable;
// flcliapi class - Freelance Pattern agent class
// Implements the Freelance Protocol at https://rfc.zeromq.cn/spec:10
public class flcliapi
{
// If not a single service replies within this time, give up
private static final int GLOBAL_TIMEOUT = 2500;
// PING interval for servers we think are alive
private static final int PING_INTERVAL = 2000; // msecs
// Server considered dead if silent for this long
private static final int SERVER_TTL = 6000; // msecs
// .split API structure
// This API works in two halves, a common pattern for APIs that need to
// run in the background. One half is an frontend object our application
// creates and works with; the other half is a backend "agent" that runs
// in a background thread. The frontend talks to the backend over an
// inproc pipe socket:
// Structure of our frontend class
private ZContext ctx; // Our context wrapper
private Socket pipe; // Pipe through to flcliapi agent
public flcliapi()
{
ctx = new ZContext();
FreelanceAgent agent = new FreelanceAgent();
pipe = ZThread.fork(ctx, agent);
}
public void destroy()
{
ctx.destroy();
}
// .split connect method
// To implement the connect method, the frontend object sends a multipart
// message to the backend agent. The first part is a string "CONNECT", and
// the second part is the endpoint. It waits 100msec for the connection to
// come up, which isn't pretty, but saves us from sending all requests to a
// single server, at startup time:
public void connect(String endpoint)
{
ZMsg msg = new ZMsg();
msg.add("CONNECT");
msg.add(endpoint);
msg.send(pipe);
try {
Thread.sleep(100); // Allow connection to come up
}
catch (InterruptedException e) {
}
}
// .split request method
// To implement the request method, the frontend object sends a message
// to the backend, specifying a command "REQUEST" and the request message:
public ZMsg request(ZMsg request)
{
request.push("REQUEST");
request.send(pipe);
ZMsg reply = ZMsg.recvMsg(pipe);
if (reply != null) {
String status = reply.popString();
if (status.equals("FAILED"))
reply.destroy();
}
return reply;
}
// .split backend agent
// Here we see the backend agent. It runs as an attached thread, talking
// to its parent over a pipe socket. It is a fairly complex piece of work
// so we'll break it down into pieces. First, the agent manages a set of
// servers, using our familiar class approach:
// Simple class for one server we talk to
private static class Server
{
private String endpoint; // Server identity/endpoint
private boolean alive; // 1 if known to be alive
private long pingAt; // Next ping at this time
private long expires; // Expires at this time
protected Server(String endpoint)
{
this.endpoint = endpoint;
alive = false;
pingAt = System.currentTimeMillis() + PING_INTERVAL;
expires = System.currentTimeMillis() + SERVER_TTL;
}
protected void destroy()
{
}
private void ping(Socket socket)
{
if (System.currentTimeMillis() >= pingAt) {
ZMsg ping = new ZMsg();
ping.add(endpoint);
ping.add("PING");
ping.send(socket);
pingAt = System.currentTimeMillis() + PING_INTERVAL;
}
}
private long tickless(long tickless)
{
if (tickless > pingAt)
return pingAt;
return -1;
}
}
// .split backend agent class
// We build the agent as a class that's capable of processing messages
// coming in from its various sockets:
// Simple class for one background agent
private static class Agent
{
private ZContext ctx; // Own context
private Socket pipe; // Socket to talk back to application
private Socket router; // Socket to talk to servers
private Map<String, Server> servers; // Servers we've connected to
private List<Server> actives; // Servers we know are alive
private int sequence; // Number of requests ever sent
private ZMsg request; // Current request if any
private ZMsg reply; // Current reply if any
private long expires; // Timeout for request/reply
protected Agent(ZContext ctx, Socket pipe)
{
this.ctx = ctx;
this.pipe = pipe;
router = ctx.createSocket(SocketType.ROUTER);
servers = new HashMap<String, Server>();
actives = new ArrayList<Server>();
}
protected void destroy()
{
for (Server server : servers.values())
server.destroy();
}
// .split control messages
// This method processes one message from our frontend class
// (it's going to be CONNECT or REQUEST):
// Callback when we remove server from agent 'servers' hash table
private void controlMessage()
{
ZMsg msg = ZMsg.recvMsg(pipe);
String command = msg.popString();
if (command.equals("CONNECT")) {
String endpoint = msg.popString();
System.out.printf("I: connecting to %s...\n", endpoint);
router.connect(endpoint);
Server server = new Server(endpoint);
servers.put(endpoint, server);
actives.add(server);
server.pingAt = System.currentTimeMillis() + PING_INTERVAL;
server.expires = System.currentTimeMillis() + SERVER_TTL;
}
else if (command.equals("REQUEST")) {
assert (request == null); // Strict request-reply cycle
// Prefix request with getSequence number and empty envelope
String sequenceText = String.format("%d", ++sequence);
msg.push(sequenceText);
// Take ownership of request message
request = msg;
msg = null;
// Request expires after global timeout
expires = System.currentTimeMillis() + GLOBAL_TIMEOUT;
}
if (msg != null)
msg.destroy();
}
// .split router messages
// This method processes one message from a connected
// server:
private void routerMessage()
{
ZMsg reply = ZMsg.recvMsg(router);
// Frame 0 is server that replied
String endpoint = reply.popString();
Server server = servers.get(endpoint);
assert (server != null);
if (!server.alive) {
actives.add(server);
server.alive = true;
}
server.pingAt = System.currentTimeMillis() + PING_INTERVAL;
server.expires = System.currentTimeMillis() + SERVER_TTL;
// Frame 1 may be getSequence number for reply
String sequenceStr = reply.popString();
if (Integer.parseInt(sequenceStr) == sequence) {
reply.push("OK");
reply.send(pipe);
request.destroy();
request = null;
}
else reply.destroy();
}
}
// .split backend agent implementation
// Finally, here's the agent task itself, which polls its two sockets
// and processes incoming messages:
static private class FreelanceAgent implements IAttachedRunnable
{
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
Agent agent = new Agent(ctx, pipe);
Poller poller = ctx.createPoller(2);
poller.register(agent.pipe, Poller.POLLIN);
poller.register(agent.router, Poller.POLLIN);
while (!Thread.currentThread().isInterrupted()) {
// Calculate tickless timer, up to 1 hour
long tickless = System.currentTimeMillis() + 1000 * 3600;
if (agent.request != null && tickless > agent.expires)
tickless = agent.expires;
for (Server server : agent.servers.values()) {
long newTickless = server.tickless(tickless);
if (newTickless > 0)
tickless = newTickless;
}
int rc = poller.poll(tickless - System.currentTimeMillis());
if (rc == -1)
break; // Context has been shut down
if (poller.pollin(0))
agent.controlMessage();
if (poller.pollin(1))
agent.routerMessage();
// If we're processing a request, dispatch to next server
if (agent.request != null) {
if (System.currentTimeMillis() >= agent.expires) {
// Request expired, kill it
agent.pipe.send("FAILED");
agent.request.destroy();
agent.request = null;
}
else {
// Find server to talk to, remove any expired ones
while (!agent.actives.isEmpty()) {
Server server = agent.actives.get(0);
if (System.currentTimeMillis() >= server.expires) {
agent.actives.remove(0);
server.alive = false;
}
else {
ZMsg request = agent.request.duplicate();
request.push(server.endpoint);
request.send(agent.router);
break;
}
}
}
}
// Disconnect and delete any expired servers
// Send heartbeats to idle servers if needed
for (Server server : agent.servers.values())
server.ping(agent.router);
}
agent.destroy();
}
}
}
flcliapi: 自由职业客户端 API,使用 Julia
flcliapi: 自由职业客户端 API,使用 Lua
flcliapi: 自由职业客户端 API,使用 Node.js
flcliapi: 自由职业客户端 API,使用 Objective-C
flcliapi: 自由职业客户端 API,使用 ooc
flcliapi: 自由职业客户端 API,使用 Perl
flcliapi: 自由职业客户端 API,使用 PHP
flcliapi: 自由职业客户端 API,使用 Python
"""
flcliapi - Freelance Pattern agent class
Model 3: uses ROUTER socket to address specific services
Author: Min RK <benjaminrk@gmail.com>
"""
import threading
import time
import zmq
from zhelpers import zpipe
# If no server replies within this time, abandon request
GLOBAL_TIMEOUT = 3000 # msecs
# PING interval for servers we think are alivecp
PING_INTERVAL = 2000 # msecs
# Server considered dead if silent for this long
SERVER_TTL = 6000 # msecs
def flciapi_agent(peer):
"""This is the thread that handles our real flcliapi class
"""
pass
# =====================================================================
# Synchronous part, works in our application thread
class FreelanceClient(object):
ctx = None # Our Context
pipe = None # Pipe through to flciapi agent
agent = None # agent in a thread
def __init__(self):
self.ctx = zmq.Context()
self.pipe, peer = zpipe(self.ctx)
self.agent = threading.Thread(target=agent_task, args=(self.ctx,peer))
self.agent.daemon = True
self.agent.start()
def connect(self, endpoint):
"""Connect to new server endpoint
Sends [CONNECT][endpoint] to the agent
"""
self.pipe.send_multipart(["CONNECT", endpoint])
time.sleep(0.1) # Allow connection to come up
def request(self, msg):
"Send request, get reply"
request = ["REQUEST"] + msg
self.pipe.send_multipart(request)
reply = self.pipe.recv_multipart()
status = reply.pop(0)
if status != "FAILED":
return reply
# =====================================================================
# Asynchronous part, works in the background
# ---------------------------------------------------------------------
# Simple class for one server we talk to
class FreelanceServer(object):
endpoint = None # Server identity/endpoint
alive = True # 1 if known to be alive
ping_at = 0 # Next ping at this time
expires = 0 # Expires at this time
def __init__(self, endpoint):
self.endpoint = endpoint
self.alive = True
self.ping_at = time.time() + 1e-3*PING_INTERVAL
self.expires = time.time() + 1e-3*SERVER_TTL
def ping(self, socket):
if time.time() > self.ping_at:
socket.send_multipart([self.endpoint, 'PING'])
self.ping_at = time.time() + 1e-3*PING_INTERVAL
def tickless(self, tickless):
if tickless > self.ping_at:
tickless = self.ping_at
return tickless
# ---------------------------------------------------------------------
# Simple class for one background agent
class FreelanceAgent(object):
ctx = None # Own context
pipe = None # Socket to talk back to application
router = None # Socket to talk to servers
servers = None # Servers we've connected to
actives = None # Servers we know are alive
sequence = 0 # Number of requests ever sent
request = None # Current request if any
reply = None # Current reply if any
expires = 0 # Timeout for request/reply
def __init__(self, ctx, pipe):
self.ctx = ctx
self.pipe = pipe
self.router = ctx.socket(zmq.ROUTER)
self.servers = {}
self.actives = []
def control_message (self):
msg = self.pipe.recv_multipart()
command = msg.pop(0)
if command == "CONNECT":
endpoint = msg.pop(0)
print "I: connecting to %s...\n" % endpoint,
self.router.connect(endpoint)
server = FreelanceServer(endpoint)
self.servers[endpoint] = server
self.actives.append(server)
# these are in the C case, but seem redundant:
server.ping_at = time.time() + 1e-3*PING_INTERVAL
server.expires = time.time() + 1e-3*SERVER_TTL
elif command == "REQUEST":
assert not self.request # Strict request-reply cycle
# Prefix request with sequence number and empty envelope
self.request = [str(self.sequence), ''] + msg
# Request expires after global timeout
self.expires = time.time() + 1e-3*GLOBAL_TIMEOUT
def router_message (self):
reply = self.router.recv_multipart()
# Frame 0 is server that replied
endpoint = reply.pop(0)
server = self.servers[endpoint]
if not server.alive:
self.actives.append(server)
server.alive = 1
server.ping_at = time.time() + 1e-3*PING_INTERVAL
server.expires = time.time() + 1e-3*SERVER_TTL;
# Frame 1 may be sequence number for reply
sequence = reply.pop(0)
if int(sequence) == self.sequence:
self.sequence += 1
reply = ["OK"] + reply
self.pipe.send_multipart(reply)
self.request = None
# ---------------------------------------------------------------------
# Asynchronous agent manages server pool and handles request/reply
# dialog when the application asks for it.
def agent_task(ctx, pipe):
agent = FreelanceAgent(ctx, pipe)
poller = zmq.Poller()
poller.register(agent.pipe, zmq.POLLIN)
poller.register(agent.router, zmq.POLLIN)
while True:
# Calculate tickless timer, up to 1 hour
tickless = time.time() + 3600
if (agent.request and tickless > agent.expires):
tickless = agent.expires
for server in agent.servers.values():
tickless = server.tickless(tickless)
try:
items = dict(poller.poll(1000 * (tickless - time.time())))
except:
break # Context has been shut down
if agent.pipe in items:
agent.control_message()
if agent.router in items:
agent.router_message()
# If we're processing a request, dispatch to next server
if (agent.request):
if (time.time() >= agent.expires):
# Request expired, kill it
agent.pipe.send("FAILED")
agent.request = None
else:
# Find server to talk to, remove any expired ones
while agent.actives:
server = agent.actives[0]
if time.time() >= server.expires:
server.alive = 0
agent.actives.pop(0)
else:
request = [server.endpoint] + agent.request
agent.router.send_multipart(request)
break
# Disconnect and delete any expired servers
# Send heartbeats to idle servers if needed
for server in agent.servers.values():
server.ping(agent.router)
flcliapi: 自由职业客户端 API,使用 Q
flcliapi: 自由职业客户端 API,使用 Racket
flcliapi: 自由职业客户端 API,使用 Ruby
flcliapi: 自由职业客户端 API,使用 Rust
flcliapi: 自由职业客户端 API,使用 Scala
flcliapi: 自由职业客户端 API,使用 Tcl
# =====================================================================
# flcliapi - Freelance Pattern agent class
# Model 3: uses ROUTER socket to address specific services
package require TclOO
package require zmq
package require mdp
package provide FLClient 1.0
# If no server replies within this time, abandon request
set GLOBAL_TIMEOUT 3000 ;# msecs
# PING interval for servers we think are alive
set PING_INTERVAL 2000 ;# msecs
# Server considered dead if silent for this long
set SERVER_TTL 6000 ;# msecs
oo::class create FLClient {
variable ctx pipe pipe_address readable agent
constructor {} {
set ctx [zmq context flcli_context_[::mdp::contextid]]
set pipe [zmq socket flcli_pipe_[::mdp::socketid] $ctx PAIR]
set pipe_address "ipc://flclientpipe_[::mdp::socketid].ipc"
$pipe connect $pipe_address
set agent [FLClient_agent new $ctx $pipe_address]
$agent process
set readable 0
}
destructor {
$agent destroy
$pipe setsockopt LINGER 0
$pipe close
$ctx term
}
# Sends [CONNECT][endpoint] to the agent
method connect {endpoint} {
set msg {}
set msg [zmsg add $msg "CONNECT"]
set msg [zmsg add $msg $endpoint]
zmsg send $pipe $msg
after 100 ;# Allow connection to come up
}
# Send & destroy request, get reply
method is_readable {} {
set readable 1
}
method request {request} {
set request [zmsg push $request "REQUEST"]
zmsg send $pipe $request
$pipe readable [list [self] is_readable]
vwait [my varname readable]
$pipe readable {}
set reply [zmsg recv $pipe]
if {[llength $reply]} {
set status [zmsg pop reply]
if {$status eq "FAILED"} {
set reply {}
}
}
return $reply
}
}
oo::class create FLClient_server {
variable endpoint alive ping_at expires
constructor {iendpoint} {
set endpoint $iendpoint
set alive 0
set ping_at [expr {[clock milliseconds] + $::PING_INTERVAL}]
set expires [expr {[clock milliseconds] + $::SERVER_TTL}]
}
destructor {
}
method ping {socket} {
if {[clock milliseconds] >= $ping_at} {
puts "ping [self]"
set ping {}
set ping [zmsg add $ping $endpoint]
set ping [zmsg add $ping "PING"]
zmsg send $socket $ping
set ping_at [expr {[clock milliseconds] + $::PING_INTERVAL}]
}
}
method ping_at {} {
return $ping_at
}
method activate {} {
set oalive $alive
set alive 1
set ping_at [expr {[clock milliseconds] + $::PING_INTERVAL}]
set expires [expr {[clock milliseconds] + $::SERVER_TTL}]
return $oalive
}
method expires {} {
return $expires
}
method endpoint {} {
return $endpoint
}
method no_longer_alive {} {
set alive 0
}
}
oo::class create FLClient_agent {
variable ctx pipe router servers actives sequence request reply expires afterid
constructor {context pipe_address} {
set ctx $context
set pipe [zmq socket flcli_agent_pipe_[::mdp::socketid] $ctx PAIR]
$pipe bind $pipe_address
set router [zmq socket flcli_router_[::mdp::socketid] $ctx ROUTER]
# set servers ;# array
set actives [list]
set sequence 0
set request {}
set reply {}
set expires 0
after 100 ;# Allow connection to come up
}
destructor {
$pipe setsockopt LINGER 0
$pipe close
$router setsockopt LINGER 0
$router close
}
method control_message {} {
puts "control message"
catch {
$pipe readable {}
$router readable {}
if {[info exists $afterid]} {
catch {after cancel $afterid}
}
set msg [zmsg recv $pipe]
puts [join [zmsg dump $msg] \n]
set command [zmsg pop msg]
if {$command eq "CONNECT"} {
set endpoint [zmsg pop msg]
puts "I: connecting to $endpoint..."
$router connect $endpoint
set server [FLClient_server new $endpoint]
set servers($endpoint) $server
lappend actives $server
} elseif {$command eq "REQUEST"} {
# Prefix request with sequence number and empty envelope
set request [zmsg push $msg [incr sequence]]
set expires [expr {[clock milliseconds] + $::GLOBAL_TIMEOUT}]
}
my process_request
} emsg
}
method router_message {} {
puts "router message"
catch {
$pipe readable {}
$router readable {}
if {[info exists $afterid]} {
catch {after cancel $afterid}
}
set reply [zmsg recv $router]
puts "Reply"
puts [join [zmsg dump $reply] \n]
# Frame 0 is server that replied
set endpoint [zmsg pop reply]
if {![info exists servers($endpoint)]} {
error "server for endpoint '$endpoint' not found"
}
if {[$servers($endpoint) activate] == 0} {
lappend actives $servers($endpoint)
}
# Frame 1 may be sequence number for reply
set nsequence [zmsg pop reply]
puts "$sequence == $nsequence"
if {$sequence == $nsequence} {
set reply [zmsg push $reply "OK"]
zmsg send $pipe $reply
set request {}
}
my process_request
} emsg
}
method process_request {} {
puts "process request"
catch {
if {[llength $request]} {
puts [join [zmsg dump $request] \n]
if {[clock milliseconds] >= $expires} {
# Request expired, kill it
$pipe send "FAILED"
set request {}
} else {
# Find server to talk to, remove any expired ones
while {[llength $actives]} {
set server [lindex $actives 0]
if {[clock milliseconds] >= [$server expires]} {
$server no_longer_alive
set actives [lassign $actives server]
} else {
set nrequest $request
set nrequest [zmsg push $nrequest [$server endpoint]]
zmsg send $router $nrequest
break
}
}
}
}
foreach server [array names servers] {
$servers($server) ping $router
}
set t [my get_timeout]
$pipe readable [list [self] control_message]
$router readable [list [self] router_message]
puts "after $t"
set afterid [after $t [list [self] poll]]
} emsg
}
method poll {} {
puts "poll"
$pipe readable {}
$router readable {}
if {[info exists $afterid]} {
catch {after cancel $afterid}
}
my process_request
}
method get_timeout {} {
# Calculate tickless timer, up to 1 hour
set tickless [expr {[clock milliseconds] + 1000 * 3600}]
if {[llength $request] && $tickless > $expires} {
set tickless $expires
}
foreach {endpoint server} [array get servers] {
set ping_at [$server ping_at]
if {$tickless > $ping_at} {
set tickless $ping_at
}
}
set timeout [expr {$tickless - [clock milliseconds]}]
if {$timeout < 0} {
set timeout 0
}
return $timeout
}
# Asynchronous agent manages server pool and handles request/reply
# dialog when the application asks for it.
method process {} {
$pipe readable [list [self] control_message]
$router readable [list [self] router_message]
set t [my get_timeout]
set afterid [after $t [list [self] poll]]
}
}
flcliapi: 自由职业客户端 API,使用 OCaml
这个 API 实现相当复杂,并使用了我们之前没有见过的一些技术。
-
多线程 API:客户端 API 包含两部分,一个同步的flcliapi类在应用程序线程中运行,以及一个作为后台线程运行的异步代理类。记住 ZeroMQ 如何轻松创建多线程应用程序。flcliapi 和代理类通过一个inproc套接字使用消息相互通信。所有 ZeroMQ 相关操作(例如创建和销毁上下文)都隐藏在 API 中。代理实际上就像一个迷你代理,在后台与服务器通信,这样当我们发出请求时,它就可以尽力连接到它认为可用的服务器。
-
无时钟滴答的轮询计时器:在之前的轮询循环中,我们总是使用固定的时钟滴答间隔,例如 1 秒,这足够简单,但在对功耗敏感的客户端(例如笔记本电脑或手机)上效果不佳,因为唤醒 CPU 会消耗电力。为了有趣并帮助节约能源,代理使用了无时钟滴答计时器,它根据我们预期的下一个超时时间来计算轮询延迟。一个合适的实现会维护一个有序的超时列表。我们只是检查所有超时,并计算直到下一个超时为止的轮询延迟。
总结 #
在本章中,我们看到了各种可靠的请求-应答机制,每种机制都有特定的成本和收益。示例代码大体上已可用于实际应用,尽管尚未进行优化。在所有不同的模式中,用于生产环境的两种突出模式是:用于基于代理可靠性的 Majordomo 模式,以及用于无代理可靠性的 Freelance 模式。