第 5 章 - 高级发布/订阅模式 #
在第 3 章 - 高级请求/回复模式和第 4 章 - 可靠请求/回复模式中,我们探讨了 ZeroMQ 请求/回复模式的高级用法。如果你能消化所有这些内容,恭喜你。在本章中,我们将重点关注发布/订阅,并用更高级的模式来扩展 ZeroMQ 的核心发布/订阅模式,以实现性能、可靠性、状态分发和监控。
我们将涵盖
- 何时使用发布/订阅
- 如何处理过慢的订阅者 (Suicidal Snail 模式)
- 如何设计高速订阅者 (Black Box 模式)
- 如何监控发布/订阅网络 (Espresso 模式)
- 如何构建共享键值存储 (Clone 模式)
- 如何使用 Reactor 简化复杂服务器
- 如何使用 Binary Star 模式为服务器添加故障转移功能
发布/订阅的优缺点 #
ZeroMQ 的底层模式各具特点。发布/订阅解决了 오래된 消息传递问题,即 多播 (multicast) 或 组播 (group messaging)。它具有 ZeroMQ 独特的细致的简洁性和残酷的漠视的结合。理解发布/订阅的权衡、它们如何使我们受益,以及如果需要如何绕过它们,是很有价值的。
首先,PUB 将每条消息发送给“许多中的所有”,而 PUSH 和 DEALER 将消息轮流发送给“许多中的一个”。你不能简单地用 PUB 替换 PUSH 或反过来,然后指望一切正常。这一点值得重申,因为人们似乎经常建议这样做。
更深层地说,发布/订阅旨在实现可伸缩性。这意味着大量数据快速发送给许多接收者。如果你需要每秒向数千个点发送数百万条消息,你将比只需每秒向少数接收者发送几条消息更能体会到发布/订阅的价值。
为了获得可伸缩性,发布/订阅使用了与 push-pull 相同的技巧,即去除回话。这意味着接收者不会回复发送者。有一些例外,例如 SUB 套接字会向 PUB 套接字发送订阅信息,但它是匿名的且不频繁的。
去除回话对于真正的可伸缩性至关重要。在发布/订阅中,这是该模式如何干净地映射到 PGM 多播协议的方式,该协议由网络交换机处理。换句话说,订阅者根本不连接到发布者,他们连接到交换机上的一个多播组,发布者将消息发送到该组。
当我们去除回话时,整体消息流会变得 훨씬 简单,这使得我们可以构建更简单的 API、更简单的协议,并且通常能够触达更多人。但我们也消除了协调发送者和接收者的任何可能性。这意味着
-
发布者无法知道订阅者何时成功连接,无论是在初始连接还是在网络故障后重新连接时。
-
订阅者无法告知发布者任何信息来让发布者控制他们发送消息的速度。发布者只有一个设置,即全速,订阅者必须跟上,否则就会丢失消息。
-
发布者无法知道订阅者何时因进程崩溃、网络中断等原因而消失。
缺点是,如果我们想实现可靠的多播,我们就确实需要所有这些功能。当订阅者正在连接时、网络故障发生时,或者仅仅是订阅者或网络无法跟上发布者时,ZeroMQ 发布/订阅模式会任意丢失消息。
好处是,在许多用例中,几乎 可靠的多播已经足够好。当我们需要这种回话时,我们可以切换到使用 ROUTER-DEALER (我在大多数正常流量情况下倾向于这样做),或者我们可以添加一个独立的通道用于同步 (在本章后面我们将看到一个例子)。
发布/订阅就像无线电广播;在你加入之前,你会错过所有内容,然后你收到多少信息取决于你的接收质量。令人惊讶的是,这种模式很有用并且广泛应用,因为它与现实世界的信息分发完美契合。想想 Facebook 和 Twitter、BBC 世界广播以及体育比赛结果。
就像我们在请求/回复模式中所做的那样,让我们根据可能出现的问题来定义可靠性。以下是发布/订阅的经典故障情况:
- 订阅者加入较晚,因此他们会错过服务器已经发送的消息。
- 订阅者获取消息速度过慢,导致队列积压并溢出。
- 订阅者可能断开连接并在断开期间丢失消息。
- 订阅者可能崩溃并重启,丢失他们已经收到的任何数据。
- 网络可能过载并丢弃数据 (特别是对于 PGM)。
- 网络可能变得过慢,导致发布者端的队列溢出,发布者崩溃。
可能出现的问题还有很多,但这些是我们在现实系统中看到的典型故障。自 v3.x 版本起,ZeroMQ 对其内部缓冲区(即所谓的高水位标记或 HWM)强制设置了默认限制,因此发布者崩溃的情况较少见,除非您故意将 HWM 设置为无限大。
所有这些故障情况都有解决方案,尽管并非总是简单的。可靠性需要我们大多数人大多数时候不需要的复杂性,这就是 ZeroMQ 不试图开箱即用提供它的原因(即使存在一种全局的可靠性设计,而实际上并不存在)。
发布/订阅跟踪 (Espresso 模式) #
让我们从查看一种跟踪发布/订阅网络的方法开始本章。在第 2 章 - 套接字与模式中,我们看到了一个使用这些套接字进行传输桥接的简单代理。该 zmq_proxy()方法有三个参数:它桥接在一起的 frontend 和 backend 套接字,以及一个 capture 套接字,它将所有消息发送到该套接字。
代码看起来很简单
espresso: Ada 中的 Espresso 模式
espresso: Basic 中的 Espresso 模式
espresso: C 中的 Espresso 模式
// Espresso Pattern
// This shows how to capture data using a pub-sub proxy
#include "czmq.h"
// The subscriber thread requests messages starting with
// A and B, then reads and counts incoming messages.
static void
subscriber_thread (void *args, zctx_t *ctx, void *pipe)
{
// Subscribe to "A" and "B"
void *subscriber = zsocket_new (ctx, ZMQ_SUB);
zsocket_connect (subscriber, "tcp://:6001");
zsocket_set_subscribe (subscriber, "A");
zsocket_set_subscribe (subscriber, "B");
int count = 0;
while (count < 5) {
char *string = zstr_recv (subscriber);
if (!string)
break; // Interrupted
free (string);
count++;
}
zsocket_destroy (ctx, subscriber);
}
// .split publisher thread
// The publisher sends random messages starting with A-J:
static void
publisher_thread (void *args, zctx_t *ctx, void *pipe)
{
void *publisher = zsocket_new (ctx, ZMQ_PUB);
zsocket_bind (publisher, "tcp://*:6000");
while (!zctx_interrupted) {
char string [10];
sprintf (string, "%c-%05d", randof (10) + 'A', randof (100000));
if (zstr_send (publisher, string) == -1)
break; // Interrupted
zclock_sleep (100); // Wait for 1/10th second
}
}
// .split listener thread
// The listener receives all messages flowing through the proxy, on its
// pipe. In CZMQ, the pipe is a pair of ZMQ_PAIR sockets that connect
// attached child threads. In other languages your mileage may vary:
static void
listener_thread (void *args, zctx_t *ctx, void *pipe)
{
// Print everything that arrives on pipe
while (true) {
zframe_t *frame = zframe_recv (pipe);
if (!frame)
break; // Interrupted
zframe_print (frame, NULL);
zframe_destroy (&frame);
}
}
// .split main thread
// The main task starts the subscriber and publisher, and then sets
// itself up as a listening proxy. The listener runs as a child thread:
int main (void)
{
// Start child threads
zctx_t *ctx = zctx_new ();
zthread_fork (ctx, publisher_thread, NULL);
zthread_fork (ctx, subscriber_thread, NULL);
void *subscriber = zsocket_new (ctx, ZMQ_XSUB);
zsocket_connect (subscriber, "tcp://:6000");
void *publisher = zsocket_new (ctx, ZMQ_XPUB);
zsocket_bind (publisher, "tcp://*:6001");
void *listener = zthread_fork (ctx, listener_thread, NULL);
zmq_proxy (subscriber, publisher, listener);
puts (" interrupted");
// Tell attached threads to exit
zctx_destroy (&ctx);
return 0;
}

espresso: C++ 中的 Espresso 模式
#include <iostream>
#include <thread>
#include <zmq.hpp>
#include <string>
#include <chrono>
#include <unistd.h>
// Subscriber thread function
void subscriber_thread(zmq::context_t& ctx) {
zmq::socket_t subscriber(ctx, ZMQ_SUB);
subscriber.connect("tcp://:6001");
subscriber.set(zmq::sockopt::subscribe, "A");
subscriber.set(zmq::sockopt::subscribe, "B");
int count = 0;
while (count < 5) {
zmq::message_t message;
if (subscriber.recv(message)) {
std::string msg = std::string((char*)(message.data()), message.size());
std::cout << "Received: " << msg << std::endl;
count++;
}
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
}
// Publisher thread function
void publisher_thread(zmq::context_t& ctx) {
zmq::socket_t publisher(ctx, ZMQ_PUB);
publisher.bind("tcp://*:6000");
while (true) {
char string[10];
sprintf(string, "%c-%05d", rand() % 10 + 'A', rand() % 100000);
zmq::message_t message(string, strlen(string));
publisher.send(message, zmq::send_flags::none);
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
}
// Listener thread function
void listener_thread(zmq::context_t& ctx) {
zmq::socket_t listener(ctx, ZMQ_PAIR);
listener.connect("inproc://listener");
while (true) {
zmq::message_t message;
if (listener.recv(message)) {
std::string msg = std::string((char*)(message.data()), message.size());
std::cout << "Listener Received: ";
if (msg[0] == 0 || msg[0] == 1){
std::cout << int(msg[0]);
std::cout << msg[1]<< std::endl;
} else {
std::cout << msg << std::endl;
}
}
}
}
int main() {
zmq::context_t context(1);
// Main thread acts as the listener proxy
zmq::socket_t proxy(context, ZMQ_PAIR);
proxy.bind("inproc://listener");
zmq::socket_t xsub(context, ZMQ_XSUB);
zmq::socket_t xpub(context, ZMQ_XPUB);
xpub.bind("tcp://*:6001");
sleep(1);
// Start publisher and subscriber threads
std::thread pub_thread(publisher_thread, std::ref(context));
std::thread sub_thread(subscriber_thread, std::ref(context));
// Set up listener thread
std::thread lis_thread(listener_thread, std::ref(context));
sleep(1);
xsub.connect("tcp://:6000");
// Proxy messages between SUB and PUB sockets
zmq_proxy(xsub, xpub, proxy);
// Wait for threads to finish
pub_thread.join();
sub_thread.join();
lis_thread.join();
return 0;
}
espresso: C# 中的 Espresso 模式
espresso: CL 中的 Espresso 模式
espresso: Delphi 中的 Espresso 模式
espresso: Erlang 中的 Espresso 模式
espresso: Elixir 中的 Espresso 模式
espresso: F# 中的 Espresso 模式
espresso: Felix 中的 Espresso 模式
espresso: Go 中的 Espresso 模式
espresso: Haskell 中的 Espresso 模式
espresso: Haxe 中的 Espresso 模式
espresso: Java 中的 Espresso 模式
package guide;
import java.util.Random;
import org.zeromq.*;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZThread.IAttachedRunnable;
// Espresso Pattern
// This shows how to capture data using a pub-sub proxy
public class espresso
{
// The subscriber thread requests messages starting with
// A and B, then reads and counts incoming messages.
private static class Subscriber implements IAttachedRunnable
{
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
// Subscribe to "A" and "B"
Socket subscriber = ctx.createSocket(SocketType.SUB);
subscriber.connect("tcp://:6001");
subscriber.subscribe("A".getBytes(ZMQ.CHARSET));
subscriber.subscribe("B".getBytes(ZMQ.CHARSET));
int count = 0;
while (count < 5) {
String string = subscriber.recvStr();
if (string == null)
break; // Interrupted
count++;
}
ctx.destroySocket(subscriber);
}
}
// .split publisher thread
// The publisher sends random messages starting with A-J:
private static class Publisher implements IAttachedRunnable
{
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
Socket publisher = ctx.createSocket(SocketType.PUB);
publisher.bind("tcp://*:6000");
Random rand = new Random(System.currentTimeMillis());
while (!Thread.currentThread().isInterrupted()) {
String string = String.format("%c-%05d", 'A' + rand.nextInt(10), rand.nextInt(100000));
if (!publisher.send(string))
break; // Interrupted
try {
Thread.sleep(100); // Wait for 1/10th second
}
catch (InterruptedException e) {
}
}
ctx.destroySocket(publisher);
}
}
// .split listener thread
// The listener receives all messages flowing through the proxy, on its
// pipe. In CZMQ, the pipe is a pair of ZMQ_PAIR sockets that connect
// attached child threads. In other languages your mileage may vary:
private static class Listener implements IAttachedRunnable
{
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
// Print everything that arrives on pipe
while (true) {
ZFrame frame = ZFrame.recvFrame(pipe);
if (frame == null)
break; // Interrupted
frame.print(null);
frame.destroy();
}
}
}
// .split main thread
// The main task starts the subscriber and publisher, and then sets
// itself up as a listening proxy. The listener runs as a child thread:
public static void main(String[] argv)
{
try (ZContext ctx = new ZContext()) {
// Start child threads
ZThread.fork(ctx, new Publisher());
ZThread.fork(ctx, new Subscriber());
Socket subscriber = ctx.createSocket(SocketType.XSUB);
subscriber.connect("tcp://:6000");
Socket publisher = ctx.createSocket(SocketType.XPUB);
publisher.bind("tcp://*:6001");
Socket listener = ZThread.fork(ctx, new Listener());
ZMQ.proxy(subscriber, publisher, listener);
System.out.println(" interrupted");
// NB: child threads exit here when the context is closed
}
}
}
espresso: Julia 中的 Espresso 模式
espresso: Lua 中的 Espresso 模式
espresso: Node.js 中的 Espresso 模式
/**
* Pub-Sub Tracing (Espresso Pattern)
* explained in
* https://zguide.zeromq.cn/docs/chapter5
*/
"use strict";
Object.defineProperty(exports, "__esModule", { value: true });
exports.runListenerThread = exports.runPubThread = exports.runSubThread = void 0;
const zmq = require("zeromq"),
publisher = new zmq.Publisher,
pubKeypair = zmq.curveKeyPair(),
publicKey = pubKeypair.publicKey;
var interrupted = false;
function getRandomInt(max) {
return Math.floor(Math.random() * Math.floor(max));
}
async function runSubThread() {
const subscriber = new zmq.Subscriber;
const subKeypair = zmq.curveKeyPair();
// Setup encryption.
for (const s of [subscriber]) {
subscriber.curveServerKey = publicKey; // '03P+E+f4AU6bSTcuzvgX&oGnt&Or<rN)FYIPyjQW'
subscriber.curveSecretKey = subKeypair.secretKey;
subscriber.curvePublicKey = subKeypair.publicKey;
}
await subscriber.connect("tcp://127.0.0.1:6000");
console.log('subscriber connected! subscribing A,B,C and D..');
//subscribe all at once - simultaneous subscriptions needed
Promise.all([
subscriber.subscribe("A"),
subscriber.subscribe("B"),
subscriber.subscribe("C"),
subscriber.subscribe("D"),
subscriber.subscribe("E"),
]);
for await (const [msg] of subscriber) {
console.log(`Received at subscriber: ${msg}`);
if (interrupted) {
await subscriber.disconnect("tcp://127.0.0.1:6000");
await subscriber.close();
break;
}
}
}
//Run the Publisher Thread!
async function runPubThread() {
// Setup encryption.
for (const s of [publisher]) {
s.curveServer = true;
s.curvePublicKey = publicKey;
s.curveSecretKey = pubKeypair.secretKey;
}
await publisher.bind("tcp://127.0.0.1:6000");
console.log(`Started publisher at tcp://127.0.0.1:6000 ..`);
var subs = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789';
while (!interrupted) { //until ctl+c
var str = `${subs.charAt(getRandomInt(10))}-${getRandomInt(100000).toString().padStart(6, '0')}`; //"%c-%05d";
console.log(`Publishing ${str}`);
if (-1 == await publisher.send(str))
break; //Interrupted
await new Promise(resolve => setTimeout(resolve, 1000));
}
//if(! publisher.closed())
await publisher.close();
}
//Run the Pipe
async function runListenerThread() {
//a pipe using 'Pair' which receives and transmits data
const pipe = new zmq.Pair;
await pipe.connect("tcp://127.0.0.1:6000");
await pipe.bind("tcp://127.0.0.1:6001");
console.log('starting pipe (using Pair)..');
while (!interrupted) {
await pipe.send(await pipe.receive());
}
setTimeout(() => {
console.log('Terminating pipe..');
pipe.close();
}, 1000);
//a pipe using 'Proxy' <= not working, but give it a try.
// Still working with Proxy
/*
const pipe = new zmq.Proxy (new zmq.Router, new zmq.Dealer)
await pipe.backEnd.connect("tcp://127.0.0.1:6000")
await pipe.frontEnd.bind("tcp://127.0.0.1:6001")
await pipe.run()
setTimeout(() => {
console.log('Terminating pipe..');
await pipe.terminate()
}, 10000);
*/
}
exports.runSubThread = runSubThread;
exports.runPubThread = runPubThread;
exports.runListenerThread = runListenerThread;
process.on('SIGINT', function () {
interrupted = true;
});
process.setMaxListeners(30);
async function main() {
//execute all at once
Promise.all([
runPubThread(),
runListenerThread(),
runSubThread(),
]);
}
main().catch(err => {
console.error(err);
process.exit(1);
});
espresso: Objective-C 中的 Espresso 模式
espresso: ooc 中的 Espresso 模式
espresso: Perl 中的 Espresso 模式
espresso: PHP 中的 Espresso 模式
espresso: Python 中的 Espresso 模式
# Espresso Pattern
# This shows how to capture data using a pub-sub proxy
#
import time
from random import randint
from string import ascii_uppercase as uppercase
from threading import Thread
import zmq
from zmq.devices import monitored_queue
from zhelpers import zpipe
# The subscriber thread requests messages starting with
# A and B, then reads and counts incoming messages.
def subscriber_thread():
ctx = zmq.Context.instance()
# Subscribe to "A" and "B"
subscriber = ctx.socket(zmq.SUB)
subscriber.connect("tcp://:6001")
subscriber.setsockopt(zmq.SUBSCRIBE, b"A")
subscriber.setsockopt(zmq.SUBSCRIBE, b"B")
count = 0
while count < 5:
try:
msg = subscriber.recv_multipart()
except zmq.ZMQError as e:
if e.errno == zmq.ETERM:
break # Interrupted
else:
raise
count += 1
print ("Subscriber received %d messages" % count)
# publisher thread
# The publisher sends random messages starting with A-J:
def publisher_thread():
ctx = zmq.Context.instance()
publisher = ctx.socket(zmq.PUB)
publisher.bind("tcp://*:6000")
while True:
string = "%s-%05d" % (uppercase[randint(0,10)], randint(0,100000))
try:
publisher.send(string.encode('utf-8'))
except zmq.ZMQError as e:
if e.errno == zmq.ETERM:
break # Interrupted
else:
raise
time.sleep(0.1) # Wait for 1/10th second
# listener thread
# The listener receives all messages flowing through the proxy, on its
# pipe. Here, the pipe is a pair of ZMQ_PAIR sockets that connects
# attached child threads via inproc. In other languages your mileage may vary:
def listener_thread (pipe):
# Print everything that arrives on pipe
while True:
try:
print (pipe.recv_multipart())
except zmq.ZMQError as e:
if e.errno == zmq.ETERM:
break # Interrupted
# main thread
# The main task starts the subscriber and publisher, and then sets
# itself up as a listening proxy. The listener runs as a child thread:
def main ():
# Start child threads
ctx = zmq.Context.instance()
p_thread = Thread(target=publisher_thread)
s_thread = Thread(target=subscriber_thread)
p_thread.start()
s_thread.start()
pipe = zpipe(ctx)
subscriber = ctx.socket(zmq.XSUB)
subscriber.connect("tcp://:6000")
publisher = ctx.socket(zmq.XPUB)
publisher.bind("tcp://*:6001")
l_thread = Thread(target=listener_thread, args=(pipe[1],))
l_thread.start()
try:
monitored_queue(subscriber, publisher, pipe[0], b'pub', b'sub')
except KeyboardInterrupt:
print ("Interrupted")
del subscriber, publisher, pipe
ctx.term()
if __name__ == '__main__':
main()
espresso: Q 中的 Espresso 模式
espresso: Racket 中的 Espresso 模式
espresso: Ruby 中的 Espresso 模式
espresso: Rust 中的 Espresso 模式
espresso: Scala 中的 Espresso 模式
espresso: Tcl 中的 Espresso 模式
espresso: OCaml 中的 Espresso 模式
Espresso 的工作原理是创建一个监听线程,该线程读取一个 PAIR 套接字并打印其接收到的任何内容。该 PAIR 套接字是管道的一端;另一端(另一个 PAIR)是我们传递给 zmq_proxy()的方法。在实际应用中,您会过滤感兴趣的消息以获取您想要跟踪的核心内容(因此得名该模式)。
订阅者线程订阅“A”和“B”,接收五条消息,然后销毁其套接字。当您运行示例时,监听器打印两条订阅消息、五条数据消息、两条取消订阅消息,然后归于平静。
[002] 0141
[002] 0142
[007] B-91164
[007] B-12979
[007] A-52599
[007] A-06417
[007] A-45770
[002] 0041
[002] 0042
这清楚地展示了当没有订阅者订阅时,发布者套接字如何停止发送数据。发布者线程仍在发送消息。套接字只是默默地丢弃它们。
最新值缓存 #
如果您使用过商业发布/订阅系统,您可能习惯于 ZeroMQ 快速活泼的发布/订阅模式中缺少的一些功能。其中之一是最新值缓存 (LVC)。这解决了新订阅者加入网络时如何追赶数据的问题。理论上,发布者会在新订阅者加入并订阅特定主题时收到通知。然后,发布者可以重新广播这些主题的最新消息。
我已经解释了为什么在有新订阅者时发布者不会收到通知,因为在大型发布/订阅系统中,数据量使得这几乎不可能。要构建真正大规模的发布/订阅网络,您需要像 PGM 这样的协议,它利用高端以太网交换机将数据多播给数千个订阅者的能力。尝试通过 TCP 单播从发布者向数千个订阅者中的每一个发送数据根本无法扩展。你会遇到奇怪的峰值、不公平的分发(一些订阅者比其他人先收到消息)、网络拥塞以及普遍的不愉快。
PGM 是一种单向协议:发布者将消息发送到交换机上的一个多播地址,然后交换机将其重新广播给所有感兴趣的订阅者。发布者永远看不到订阅者何时加入或离开:这一切都发生在交换机中,而我们并不真正想开始重新编程交换机。
然而,在只有几十个订阅者和有限主题的低流量网络中,我们可以使用 TCP,这样 XSUB 和 XPUB 套接字确实会像我们在 Espresso 模式中看到的那样相互通信。
我们能否使用 ZeroMQ 构建一个 LVC?答案是肯定的,如果我们构建一个位于发布者和订阅者之间的代理;它类似于 PGM 交换机,但我们可以自己编程。
我将首先创建一个发布者和订阅者来突出最坏的情况。这个发布者是病态的。它一开始就立即向一千个主题中的每一个发送消息,然后每秒向一个随机主题发送一条更新。一个订阅者连接并订阅一个主题。如果没有 LVC,订阅者平均需要等待 500 秒才能获得任何数据。为了增加一些戏剧性,假设有一个名叫 Gregor 的越狱犯威胁说,如果我们不能解决那 8.3 分钟的延迟,他就要扯掉玩具兔子 Roger 的脑袋。
这是发布者代码。请注意,它有命令行选项可以连接到某个地址,但通常会绑定到一个端点。我们稍后会用它连接到我们的最新值缓存。
pathopub: Ada 中的病态发布者
pathopub: Basic 中的病态发布者
pathopub: C 中的病态发布者
// Pathological publisher
// Sends out 1,000 topics and then one random update per second
#include "czmq.h"
int main (int argc, char *argv [])
{
zctx_t *context = zctx_new ();
void *publisher = zsocket_new (context, ZMQ_PUB);
if (argc == 2)
zsocket_bind (publisher, argv [1]);
else
zsocket_bind (publisher, "tcp://*:5556");
// Ensure subscriber connection has time to complete
sleep (1);
// Send out all 1,000 topic messages
int topic_nbr;
for (topic_nbr = 0; topic_nbr < 1000; topic_nbr++) {
zstr_sendfm (publisher, "%03d", topic_nbr);
zstr_send (publisher, "Save Roger");
}
// Send one random update per second
srandom ((unsigned) time (NULL));
while (!zctx_interrupted) {
sleep (1);
zstr_sendfm (publisher, "%03d", randof (1000));
zstr_send (publisher, "Off with his head!");
}
zctx_destroy (&context);
return 0;
}
pathopub: C++ 中的病态发布者
// Pathological publisher
// Sends out 1,000 topics and then one random update per second
#include <thread>
#include <chrono>
#include "zhelpers.hpp"
int main (int argc, char *argv [])
{
zmq::context_t context(1);
zmq::socket_t publisher(context, ZMQ_PUB);
// Initialize random number generator
srandom ((unsigned) time (NULL));
if (argc == 2)
publisher.bind(argv [1]);
else
publisher.bind("tcp://*:5556");
// Ensure subscriber connection has time to complete
std::this_thread::sleep_for(std::chrono::seconds(1));
// Send out all 1,000 topic messages
int topic_nbr;
for (topic_nbr = 0; topic_nbr < 1000; topic_nbr++) {
std::stringstream ss;
ss << std::dec << std::setw(3) << std::setfill('0') << topic_nbr;
s_sendmore (publisher, ss.str());
s_send (publisher, std::string("Save Roger"));
}
// Send one random update per second
while (1) {
std::this_thread::sleep_for(std::chrono::seconds(1));
std::stringstream ss;
ss << std::dec << std::setw(3) << std::setfill('0') << within(1000);
s_sendmore (publisher, ss.str());
s_send (publisher, std::string("Off with his head!"));
}
return 0;
}
pathopub: C# 中的病态发布者
pathopub: CL 中的病态发布者
pathopub: Delphi 中的病态发布者
pathopub: Erlang 中的病态发布者
pathopub: Elixir 中的病态发布者
pathopub: F# 中的病态发布者
pathopub: Felix 中的病态发布者
pathopub: Go 中的病态发布者
pathopub: Haskell 中的病态发布者
pathopub: Haxe 中的病态发布者
pathopub: Java 中的病态发布者
package guide;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
// Pathological publisher
// Sends out 1,000 topics and then one random update per second
public class pathopub
{
public static void main(String[] args) throws Exception
{
try (ZContext context = new ZContext()) {
Socket publisher = context.createSocket(SocketType.PUB);
if (args.length == 1)
publisher.connect(args[0]);
else publisher.bind("tcp://*:5556");
// Ensure subscriber connection has time to complete
Thread.sleep(1000);
// Send out all 1,000 topic messages
int topicNbr;
for (topicNbr = 0; topicNbr < 1000; topicNbr++) {
publisher.send(String.format("%03d", topicNbr), ZMQ.SNDMORE);
publisher.send("Save Roger");
}
// Send one random update per second
Random rand = new Random(System.currentTimeMillis());
while (!Thread.currentThread().isInterrupted()) {
Thread.sleep(1000);
publisher.send(
String.format("%03d", rand.nextInt(1000)), ZMQ.SNDMORE
);
publisher.send("Off with his head!");
}
}
}
}
pathopub: Julia 中的病态发布者
pathopub: Lua 中的病态发布者
pathopub: Node.js 中的病态发布者
pathopub: Objective-C 中的病态发布者
pathopub: ooc 中的病态发布者
pathopub: Perl 中的病态发布者
pathopub: PHP 中的病态发布者
pathopub: Python 中的病态发布者
#
# Pathological publisher
# Sends out 1,000 topics and then one random update per second
#
import sys
import time
from random import randint
import zmq
def main(url=None):
ctx = zmq.Context.instance()
publisher = ctx.socket(zmq.PUB)
if url:
publisher.bind(url)
else:
publisher.bind("tcp://*:5556")
# Ensure subscriber connection has time to complete
time.sleep(1)
# Send out all 1,000 topic messages
for topic_nbr in range(1000):
publisher.send_multipart([
b"%03d" % topic_nbr,
b"Save Roger",
])
while True:
# Send one random update per second
try:
time.sleep(1)
publisher.send_multipart([
b"%03d" % randint(0,999),
b"Off with his head!",
])
except KeyboardInterrupt:
print "interrupted"
break
if __name__ == '__main__':
main(sys.argv[1] if len(sys.argv) > 1 else None)
pathopub: Q 中的病态发布者
pathopub: Racket 中的病态发布者
pathopub: Ruby 中的病态发布者
#!/usr/bin/env ruby
#
# Pathological publisher
# Sends out 1,000 topics and then one random update per second
#
require 'ffi-rzmq'
context = ZMQ::Context.new
TOPIC_COUNT = 1_000
publisher = context.socket(ZMQ::PUB)
if ARGV[0]
publisher.bind(ARGV[0])
else
publisher.bind("tcp://*:5556")
end
# Ensure subscriber connection has time to complete
sleep 1
TOPIC_COUNT.times do |n|
topic = "%03d" % [n]
publisher.send_strings([topic, "Save Roger"])
end
loop do
sleep 1
topic = "%03d" % [rand(1000)]
publisher.send_strings([topic, "Off with his head!"])
end
pathopub: Rust 中的病态发布者
pathopub: Scala 中的病态发布者
pathopub: Tcl 中的病态发布者
pathopub: OCaml 中的病态发布者
这是订阅者代码
pathosub: Ada 中的病态订阅者
pathosub: Basic 中的病态订阅者
pathosub: C 中的病态订阅者
// Pathological subscriber
// Subscribes to one random topic and prints received messages
#include "czmq.h"
int main (int argc, char *argv [])
{
zctx_t *context = zctx_new ();
void *subscriber = zsocket_new (context, ZMQ_SUB);
if (argc == 2)
zsocket_connect (subscriber, argv [1]);
else
zsocket_connect (subscriber, "tcp://:5556");
srandom ((unsigned) time (NULL));
char subscription [5];
sprintf (subscription, "%03d", randof (1000));
zsocket_set_subscribe (subscriber, subscription);
while (true) {
char *topic = zstr_recv (subscriber);
if (!topic)
break;
char *data = zstr_recv (subscriber);
assert (streq (topic, subscription));
puts (data);
free (topic);
free (data);
}
zctx_destroy (&context);
return 0;
}
pathosub: C++ 中的病态订阅者
// Pathological subscriber
// Subscribes to one random topic and prints received messages
#include "zhelpers.hpp"
int main (int argc, char *argv [])
{
zmq::context_t context(1);
zmq::socket_t subscriber (context, ZMQ_SUB);
// Initialize random number generator
srandom ((unsigned) time (NULL));
if (argc == 2)
subscriber.connect(argv [1]);
else
subscriber.connect("tcp://:5556");
std::stringstream ss;
ss << std::dec << std::setw(3) << std::setfill('0') << within(1000);
std::cout << "topic:" << ss.str() << std::endl;
subscriber.set( zmq::sockopt::subscribe, ss.str().c_str());
while (1) {
std::string topic = s_recv (subscriber);
std::string data = s_recv (subscriber);
if (topic != ss.str())
break;
std::cout << data << std::endl;
}
return 0;
}
pathosub: C# 中的病态订阅者
pathosub: CL 中的病态订阅者
pathosub: Delphi 中的病态订阅者
pathosub: Erlang 中的病态订阅者
pathosub: Elixir 中的病态订阅者
pathosub: F# 中的病态订阅者
pathosub: Felix 中的病态订阅者
pathosub: Go 中的病态订阅者
pathosub: Haskell 中的病态订阅者
pathosub: Haxe 中的病态订阅者
pathosub: Java 中的病态订阅者
package guide;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
// Pathological subscriber
// Subscribes to one random topic and prints received messages
public class pathosub
{
public static void main(String[] args)
{
try (ZContext context = new ZContext()) {
Socket subscriber = context.createSocket(SocketType.SUB);
if (args.length == 1)
subscriber.connect(args[0]);
else subscriber.connect("tcp://:5556");
Random rand = new Random(System.currentTimeMillis());
String subscription = String.format("%03d", rand.nextInt(1000));
subscriber.subscribe(subscription.getBytes(ZMQ.CHARSET));
while (true) {
String topic = subscriber.recvStr();
if (topic == null)
break;
String data = subscriber.recvStr();
assert (topic.equals(subscription));
System.out.println(data);
}
}
}
}
pathosub: Julia 中的病态订阅者
pathosub: Lua 中的病态订阅者
pathosub: Node.js 中的病态订阅者
pathosub: Objective-C 中的病态订阅者
pathosub: ooc 中的病态订阅者
pathosub: Perl 中的病态订阅者
pathosub: PHP 中的病态订阅者
pathosub: Python 中的病态订阅者
#
# Pathological subscriber
# Subscribes to one random topic and prints received messages
#
import sys
import time
from random import randint
import zmq
def main(url=None):
ctx = zmq.Context.instance()
subscriber = ctx.socket(zmq.SUB)
if url is None:
url = "tcp://:5556"
subscriber.connect(url)
subscription = b"%03d" % randint(0,999)
subscriber.setsockopt(zmq.SUBSCRIBE, subscription)
while True:
topic, data = subscriber.recv_multipart()
assert topic == subscription
print data
if __name__ == '__main__':
main(sys.argv[1] if len(sys.argv) > 1 else None)
pathosub: Q 中的病态订阅者
pathosub: Racket 中的病态订阅者
pathosub: Ruby 中的病态订阅者
#!/usr/bin/env ruby
#
# Pathological subscriber
# Subscribes to one random topic and prints received messages
#
require 'ffi-rzmq'
context = ZMQ::Context.new
subscriber = context.socket(ZMQ::SUB)
subscriber.connect(ARGV[0] || "tcp://:5556")
topic = "%03d" % [rand(1000)]
subscriber.setsockopt(ZMQ::SUBSCRIBE, topic)
loop do
subscriber.recv_strings(parts = [])
topic, data = parts
puts "#{topic}: #{data}"
end
pathosub: Rust 中的病态订阅者
pathosub: Scala 中的病态订阅者
pathosub: Tcl 中的病态订阅者
pathosub: OCaml 中的病态订阅者
尝试构建并运行这些代码:先运行订阅者,再运行发布者。你会看到订阅者按预期报告收到“Save Roger”
./pathosub &
./pathopub
当你运行第二个订阅者时,你就会明白 Roger 的困境。你需要等待相当长的时间,它才会报告收到任何数据。所以,这就是我们的最新值缓存。正如我承诺的,它是一个代理,绑定到两个套接字,然后处理这两个套接字上的消息。
lvcache: Ada 中的最新值缓存代理
lvcache: Basic 中的最新值缓存代理
lvcache: C 中的最新值缓存代理
// Last value cache
// Uses XPUB subscription messages to re-send data
#include "czmq.h"
int main (void)
{
zctx_t *context = zctx_new ();
void *frontend = zsocket_new (context, ZMQ_SUB);
zsocket_connect (frontend, "tcp://*:5557");
void *backend = zsocket_new (context, ZMQ_XPUB);
zsocket_bind (backend, "tcp://*:5558");
// Subscribe to every single topic from publisher
zsocket_set_subscribe (frontend, "");
// Store last instance of each topic in a cache
zhash_t *cache = zhash_new ();
// .split main poll loop
// We route topic updates from frontend to backend, and
// we handle subscriptions by sending whatever we cached,
// if anything:
while (true) {
zmq_pollitem_t items [] = {
{ frontend, 0, ZMQ_POLLIN, 0 },
{ backend, 0, ZMQ_POLLIN, 0 }
};
if (zmq_poll (items, 2, 1000 * ZMQ_POLL_MSEC) == -1)
break; // Interrupted
// Any new topic data we cache and then forward
if (items [0].revents & ZMQ_POLLIN) {
char *topic = zstr_recv (frontend);
char *current = zstr_recv (frontend);
if (!topic)
break;
char *previous = zhash_lookup (cache, topic);
if (previous) {
zhash_delete (cache, topic);
free (previous);
}
zhash_insert (cache, topic, current);
zstr_sendm (backend, topic);
zstr_send (backend, current);
free (topic);
}
// .split handle subscriptions
// When we get a new subscription, we pull data from the cache:
if (items [1].revents & ZMQ_POLLIN) {
zframe_t *frame = zframe_recv (backend);
if (!frame)
break;
// Event is one byte 0=unsub or 1=sub, followed by topic
byte *event = zframe_data (frame);
if (event [0] == 1) {
char *topic = zmalloc (zframe_size (frame));
memcpy (topic, event + 1, zframe_size (frame) - 1);
printf ("Sending cached topic %s\n", topic);
char *previous = zhash_lookup (cache, topic);
if (previous) {
zstr_sendm (backend, topic);
zstr_send (backend, previous);
}
free (topic);
}
zframe_destroy (&frame);
}
}
zctx_destroy (&context);
zhash_destroy (&cache);
return 0;
}
lvcache: C++ 中的最新值缓存代理
// Last value cache
// Uses XPUB subscription messages to re-send data
#include <unordered_map>
#include "zhelpers.hpp"
int main ()
{
zmq::context_t context(1);
zmq::socket_t frontend(context, ZMQ_SUB);
zmq::socket_t backend(context, ZMQ_XPUB);
frontend.connect("tcp://:5557");
backend.bind("tcp://*:5558");
// Subscribe to every single topic from publisher
frontend.set(zmq::sockopt::subscribe, "");
// Store last instance of each topic in a cache
std::unordered_map<std::string, std::string> cache_map;
zmq::pollitem_t items[2] = {
{ static_cast<void*>(frontend), 0, ZMQ_POLLIN, 0 },
{ static_cast<void*>(backend), 0, ZMQ_POLLIN, 0 }
};
// .split main poll loop
// We route topic updates from frontend to backend, and we handle
// subscriptions by sending whatever we cached, if anything:
while (1)
{
if (zmq::poll(items, 2, 1000) == -1)
break; // Interrupted
// Any new topic data we cache and then forward
if (items[0].revents & ZMQ_POLLIN)
{
std::string topic = s_recv(frontend);
std::string data = s_recv(frontend);
if (topic.empty())
break;
cache_map[topic] = data;
s_sendmore(backend, topic);
s_send(backend, data);
}
// .split handle subscriptions
// When we get a new subscription, we pull data from the cache:
if (items[1].revents & ZMQ_POLLIN) {
zmq::message_t msg;
backend.recv(&msg);
if (msg.size() == 0)
break;
// Event is one byte 0=unsub or 1=sub, followed by topic
uint8_t *event = (uint8_t *)msg.data();
if (event[0] == 1) {
std::string topic((char *)(event+1), msg.size()-1);
auto i = cache_map.find(topic);
if (i != cache_map.end())
{
s_sendmore(backend, topic);
s_send(backend, i->second);
}
}
}
}
return 0;
}
lvcache: C# 中的最新值缓存代理
lvcache: CL 中的最新值缓存代理
lvcache: Delphi 中的最新值缓存代理
lvcache: Erlang 中的最新值缓存代理
lvcache: Elixir 中的最新值缓存代理
lvcache: F# 中的最新值缓存代理
lvcache: Felix 中的最新值缓存代理
lvcache: Go 中的最新值缓存代理
lvcache: Haskell 中的最新值缓存代理
lvcache: Haxe 中的最新值缓存代理
lvcache: Java 中的最新值缓存代理
package guide;
import java.util.HashMap;
import java.util.Map;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZFrame;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
// Last value cache
// Uses XPUB subscription messages to re-send data
public class lvcache
{
public static void main(String[] args)
{
try (ZContext context = new ZContext()) {
Socket frontend = context.createSocket(SocketType.SUB);
frontend.bind("tcp://*:5557");
Socket backend = context.createSocket(SocketType.XPUB);
backend.bind("tcp://*:5558");
// Subscribe to every single topic from publisher
frontend.subscribe(ZMQ.SUBSCRIPTION_ALL);
// Store last instance of each topic in a cache
Map<String, String> cache = new HashMap<String, String>();
Poller poller = context.createPoller(2);
poller.register(frontend, Poller.POLLIN);
poller.register(backend, Poller.POLLIN);
// .split main poll loop
// We route topic updates from frontend to backend, and we handle
// subscriptions by sending whatever we cached, if anything:
while (true) {
if (poller.poll(1000) == -1)
break; // Interrupted
// Any new topic data we cache and then forward
if (poller.pollin(0)) {
String topic = frontend.recvStr();
String current = frontend.recvStr();
if (topic == null)
break;
cache.put(topic, current);
backend.sendMore(topic);
backend.send(current);
}
// .split handle subscriptions
// When we get a new subscription, we pull data from the cache:
if (poller.pollin(1)) {
ZFrame frame = ZFrame.recvFrame(backend);
if (frame == null)
break;
// Event is one byte 0=unsub or 1=sub, followed by topic
byte[] event = frame.getData();
if (event[0] == 1) {
String topic = new String(event, 1, event.length - 1, ZMQ.CHARSET);
System.out.printf("Sending cached topic %s\n", topic);
String previous = cache.get(topic);
if (previous != null) {
backend.sendMore(topic);
backend.send(previous);
}
}
frame.destroy();
}
}
}
}
}
lvcache: Julia 中的最新值缓存代理
lvcache: Lua 中的最新值缓存代理
lvcache: Node.js 中的最新值缓存代理
// Last value cache
// Uses XPUB subscription messages to re-send data
var zmq = require('zeromq');
var frontEnd = zmq.socket('sub');
var backend = zmq.socket('xpub');
var cache = {};
frontEnd.connect('tcp://127.0.0.1:5557');
frontEnd.subscribe('');
backend.bindSync('tcp://*:5558');
frontEnd.on('message', function(topic, message) {
cache[topic] = message;
backend.send([topic, message]);
});
backend.on('message', function(frame) {
// frame is one byte 0=unsub or 1=sub, followed by topic
if (frame[0] === 1) {
var topic = frame.slice(1);
var previous = cache[topic];
console.log('Sending cached topic ' + topic);
if (typeof previous !== 'undefined') {
backend.send([topic, previous]);
}
}
});
process.on('SIGINT', function() {
frontEnd.close();
backend.close();
console.log('\nClosed')
});
lvcache: Objective-C 中的最新值缓存代理
lvcache: ooc 中的最新值缓存代理
lvcache: Perl 中的最新值缓存代理
lvcache: PHP 中的最新值缓存代理
lvcache: Python 中的最新值缓存代理
#
# Last value cache
# Uses XPUB subscription messages to re-send data
#
import zmq
def main():
ctx = zmq.Context.instance()
frontend = ctx.socket(zmq.SUB)
frontend.connect("tcp://*:5557")
backend = ctx.socket(zmq.XPUB)
backend.bind("tcp://*:5558")
# Subscribe to every single topic from publisher
frontend.setsockopt(zmq.SUBSCRIBE, b"")
# Store last instance of each topic in a cache
cache = {}
# main poll loop
# We route topic updates from frontend to backend, and
# we handle subscriptions by sending whatever we cached,
# if anything:
poller = zmq.Poller()
poller.register(frontend, zmq.POLLIN)
poller.register(backend, zmq.POLLIN)
while True:
try:
events = dict(poller.poll(1000))
except KeyboardInterrupt:
print("interrupted")
break
# Any new topic data we cache and then forward
if frontend in events:
msg = frontend.recv_multipart()
topic, current = msg
cache[topic] = current
backend.send_multipart(msg)
# handle subscriptions
# When we get a new subscription we pull data from the cache:
if backend in events:
event = backend.recv()
# Event is one byte 0=unsub or 1=sub, followed by topic
if event[0] == 1:
topic = event[1:]
if topic in cache:
print ("Sending cached topic %s" % topic)
backend.send_multipart([ topic, cache[topic] ])
if __name__ == '__main__':
main()
lvcache: Q 中的最新值缓存代理
lvcache: Racket 中的最新值缓存代理
lvcache: Ruby 中的最新值缓存代理
#!/usr/bin/env ruby
#
# Last value cache
# Uses XPUB subscription messages to re-send data
#
require 'ffi-rzmq'
context = ZMQ::Context.new
frontend = context.socket(ZMQ::SUB)
frontend.connect("tcp://*:5557")
backend = context.socket(ZMQ::XPUB)
backend.bind("tcp://*:5558")
# Subscribe to every single topic from publisher
frontend.setsockopt(ZMQ::SUBSCRIBE, "")
# Store last instance of each topic in a cache
cache = {}
# We route topic updates from frontend to backend, and we handle subscriptions
# by sending whatever we cached, if anything:
poller = ZMQ::Poller.new
[frontend, backend].each { |sock| poller.register_readable sock }
loop do
poller.poll(1000)
poller.readables.each do |sock|
if sock == frontend
# Any new topic data we cache and then forward
frontend.recv_strings(parts = [])
topic, data = parts
cache[topic] = data
backend.send_strings(parts)
elsif sock == backend
# When we get a new subscription we pull data from the cache:
backend.recv_strings(parts = [])
event, _ = parts
# Event is one byte 0=unsub or 1=sub, followed by topic
if event[0].ord == 1
topic = event[1..-1]
puts "Sending cached topic #{topic}"
previous = cache[topic]
backend.send_strings([topic, previous]) if previous
end
end
end
end
lvcache: Rust 中的最新值缓存代理
lvcache: Scala 中的最新值缓存代理
lvcache: Tcl 中的最新值缓存代理
lvcache: OCaml 中的最新值缓存代理
现在,运行代理,然后再运行发布者
./lvcache &
./pathopub tcp://:5557
现在,运行任意数量的订阅者实例,每次都连接到端口 5558 上的代理
./pathosub tcp://:5558
每个订阅者都开心地报告收到“Save Roger”,而越狱犯 Gregor 则溜回座位享用晚餐和一杯热牛奶,这才是他真正想要的。
注意一点:默认情况下,XPUB 套接字不会报告重复订阅,这是您天真地将 XPUB 连接到 XSUB 时所期望的行为。我们的示例巧妙地绕过了这个问题,通过使用随机主题,这样它不工作的几率只有百万分之一。在真正的 LVC 代理中,您会希望使用ZMQ_XPUB_VERBOSE选项,我们在第 6 章 - ZeroMQ 社区中将其作为一个练习来实现。
慢速订阅者检测 (Suicidal Snail 模式) #
在实际应用中使用发布/订阅模式时,您会遇到的一个常见问题是慢速订阅者。在理想世界中,我们以全速将数据从发布者传输到订阅者。在现实中,订阅者应用程序通常是用解释型语言编写的,或者只是做了大量工作,或者写得很糟糕,以至于它们无法跟上发布者的速度。
我们如何处理慢速订阅者?理想的解决方案是让订阅者更快,但这可能需要工作和时间。一些处理慢速订阅者的经典策略包括:
-
在发布者端排队消息。当我不读邮件几个小时时,Gmail 就是这样做的。但在高流量消息传递中,将队列推向上游会导致发布者内存不足并崩溃,结果既惊心动魄又不划算——特别是当订阅者数量很多且出于性能原因无法刷新到磁盘时。
-
在订阅者端排队消息。这要好得多,如果网络能够跟上,ZeroMQ 默认就是这样做的。如果有人会内存不足并崩溃,那将是订阅者而不是发布者,这是公平的。这对于“峰值”流非常适用,在这种情况下,订阅者可能暂时无法跟上,但在流速变慢时可以赶上。然而,这对于总体上速度过慢的订阅者来说并非解决方案。
-
一段时间后停止新消息排队。当我的邮箱溢出其宝贵的几 GB 空间时,Gmail 就是这样做的。新消息会被拒绝或丢弃。从发布者的角度来看,这是一个很好的策略,也是 ZeroMQ 在发布者设置 HWM 时所做的事情。然而,这仍然无法帮助我们解决慢速订阅者的问题。现在我们的消息流中只会出现空白。
-
通过断开连接惩罚慢速订阅者。这是 Hotmail(还记得吗?)在我两周没有登录时做的事情,这也是当我意识到可能有更好的方法时,我已经在使用我的第十五个 Hotmail 账户的原因。这是一种很好的残酷策略,它迫使订阅者振作精神并集中注意力,这会很理想,但 ZeroMQ 不会这样做,并且没有办法在其之上实现这一层,因为订阅者对于发布者应用程序来说是不可见的。
这些经典策略都不适用,所以我们需要创新。与其断开发布者,不如说服订阅者自杀。这就是 Suicidal Snail 模式。当订阅者检测到自己运行速度过慢(其中“过慢”大概是一个配置选项,实际意思是“慢到如果你到达这里,就大声呼救,因为我需要知道,这样我才能修复它!”)时,它就会“呱”一声然后死去。
订阅者如何检测到这一点?一种方法是给消息编号(按顺序编号),并在发布者端使用 HWM。现在,如果订阅者检测到缺口(即编号不连续),它就知道有问题了。然后我们将 HWM 调整到“如果达到此水平就‘呱’一声死去”的程度。
这个解决方案有两个问题。第一,如果我们有多个发布者,如何给消息编号?解决方案是给每个发布者一个唯一的 ID 并添加到编号中。第二,如果订阅者使用ZMQ_SUBSCRIBE过滤器,他们从定义上就会获得缺口。我们宝贵的编号将毫无用处。
有些用例不使用过滤器,编号对它们有效。但更通用的解决方案是发布者为每条消息加上时间戳。当订阅者收到消息时,它检查时间,如果差值超过(比如)一秒,它就会执行“呱”一声死去的动作,可能会先向操作员控制台发送一声尖叫。
自杀蜗牛模式特别适用于订阅者拥有自己的客户端和服务水平协议,并且需要保证一定的最大延迟的情况。中止一个订阅者可能看起来不是一种建设性的方式来保证最大延迟,但这是一种断言模型。今天就中止,问题就会得到解决。允许延迟的数据向下游流动,问题可能会造成更广泛的损害,并且需要更长时间才能被发现。
这里是一个自杀蜗牛的最小示例
suisnail: 自杀蜗牛 使用 Ada
suisnail: 自杀蜗牛 使用 Basic
suisnail: 自杀蜗牛 使用 C
// Suicidal Snail
#include "czmq.h"
// This is our subscriber. It connects to the publisher and subscribes
// to everything. It sleeps for a short time between messages to
// simulate doing too much work. If a message is more than one second
// late, it croaks.
#define MAX_ALLOWED_DELAY 1000 // msecs
static void
subscriber (void *args, zctx_t *ctx, void *pipe)
{
// Subscribe to everything
void *subscriber = zsocket_new (ctx, ZMQ_SUB);
zsocket_set_subscribe (subscriber, "");
zsocket_connect (subscriber, "tcp://:5556");
// Get and process messages
while (true) {
char *string = zstr_recv (subscriber);
printf("%s\n", string);
int64_t clock;
int terms = sscanf (string, "%" PRId64, &clock);
assert (terms == 1);
free (string);
// Suicide snail logic
if (zclock_time () - clock > MAX_ALLOWED_DELAY) {
fprintf (stderr, "E: subscriber cannot keep up, aborting\n");
break;
}
// Work for 1 msec plus some random additional time
zclock_sleep (1 + randof (2));
}
zstr_send (pipe, "gone and died");
}
// .split publisher task
// This is our publisher task. It publishes a time-stamped message to its
// PUB socket every millisecond:
static void
publisher (void *args, zctx_t *ctx, void *pipe)
{
// Prepare publisher
void *publisher = zsocket_new (ctx, ZMQ_PUB);
zsocket_bind (publisher, "tcp://*:5556");
while (true) {
// Send current clock (msecs) to subscribers
char string [20];
sprintf (string, "%" PRId64, zclock_time ());
zstr_send (publisher, string);
char *signal = zstr_recv_nowait (pipe);
if (signal) {
free (signal);
break;
}
zclock_sleep (1); // 1msec wait
}
}
// .split main task
// The main task simply starts a client and a server, and then
// waits for the client to signal that it has died:
int main (void)
{
zctx_t *ctx = zctx_new ();
void *pubpipe = zthread_fork (ctx, publisher, NULL);
void *subpipe = zthread_fork (ctx, subscriber, NULL);
free (zstr_recv (subpipe));
zstr_send (pubpipe, "break");
zclock_sleep (100);
zctx_destroy (&ctx);
return 0;
}
suisnail: 自杀蜗牛 使用 C++
//
// Suicidal Snail
//
// Andreas Hoelzlwimmer <andreas.hoelzlwimmer@fh-hagenberg.at>
#include "zhelpers.hpp"
#include <thread>
// ---------------------------------------------------------------------
// This is our subscriber
// It connects to the publisher and subscribes to everything. It
// sleeps for a short time between messages to simulate doing too
// much work. If a message is more than 1 second late, it croaks.
#define MAX_ALLOWED_DELAY 1000 // msecs
namespace {
bool Exit = false;
};
static void *
subscriber () {
zmq::context_t context(1);
// Subscribe to everything
zmq::socket_t subscriber(context, ZMQ_SUB);
subscriber.connect("tcp://:5556");
subscriber.set(zmq::sockopt::subscribe, "");
std::stringstream ss;
// Get and process messages
while (1) {
ss.clear();
ss.str(s_recv (subscriber));
int64_t clock;
assert ((ss >> clock));
const auto delay = s_clock () - clock;
// Suicide snail logic
if (delay> MAX_ALLOWED_DELAY) {
std::cerr << "E: subscriber cannot keep up, aborting. Delay=" <<delay<< std::endl;
break;
}
// Work for 1 msec plus some random additional time
s_sleep(1000*(1+within(2)));
}
Exit = true;
return (NULL);
}
// ---------------------------------------------------------------------
// This is our server task
// It publishes a time-stamped message to its pub socket every 1ms.
static void *
publisher () {
zmq::context_t context (1);
// Prepare publisher
zmq::socket_t publisher(context, ZMQ_PUB);
publisher.bind("tcp://*:5556");
std::stringstream ss;
while (!Exit) {
// Send current clock (msecs) to subscribers
ss.str("");
ss << s_clock();
s_send (publisher, ss.str());
s_sleep(1);
}
return 0;
}
// This main thread simply starts a client, and a server, and then
// waits for the client to croak.
//
int main (void)
{
std::thread server_thread(&publisher);
std::thread client_thread(&subscriber);
client_thread.join();
server_thread.join();
return 0;
}
suisnail: 自杀蜗牛 使用 C#
suisnail: 自杀蜗牛 使用 CL
suisnail: 自杀蜗牛 使用 Delphi
suisnail: 自杀蜗牛 使用 Erlang
suisnail: 自杀蜗牛 使用 Elixir
suisnail: 自杀蜗牛 使用 F#
suisnail: 自杀蜗牛 使用 Felix
suisnail: 自杀蜗牛 使用 Go
suisnail: 自杀蜗牛 使用 Haskell
suisnail: 自杀蜗牛 使用 Haxe
suisnail: 自杀蜗牛 使用 Java
package guide;
import java.util.Random;
// Suicidal Snail
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZThread;
import org.zeromq.ZThread.IAttachedRunnable;
public class suisnail
{
private static final long MAX_ALLOWED_DELAY = 1000; // msecs
private static Random rand = new Random(System.currentTimeMillis());
// This is our subscriber. It connects to the publisher and subscribes to
// everything. It sleeps for a short time between messages to simulate
// doing too much work. If a message is more than one second late, it
// croaks.
private static class Subscriber implements IAttachedRunnable
{
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
// Subscribe to everything
Socket subscriber = ctx.createSocket(SocketType.SUB);
subscriber.subscribe(ZMQ.SUBSCRIPTION_ALL);
subscriber.connect("tcp://:5556");
// Get and process messages
while (true) {
String string = subscriber.recvStr();
System.out.printf("%s\n", string);
long clock = Long.parseLong(string);
// Suicide snail logic
if (System.currentTimeMillis() - clock > MAX_ALLOWED_DELAY) {
System.err.println(
"E: subscriber cannot keep up, aborting"
);
break;
}
// Work for 1 msec plus some random additional time
try {
Thread.sleep(1000 + rand.nextInt(2000));
}
catch (InterruptedException e) {
break;
}
}
pipe.send("gone and died");
}
}
// .split publisher task
// This is our publisher task. It publishes a time-stamped message to its
// PUB socket every millisecond:
private static class Publisher implements IAttachedRunnable
{
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
// Prepare publisher
Socket publisher = ctx.createSocket(SocketType.PUB);
publisher.bind("tcp://*:5556");
while (true) {
// Send current clock (msecs) to subscribers
String string = String.format("%d", System.currentTimeMillis());
publisher.send(string);
String signal = pipe.recvStr(ZMQ.DONTWAIT);
if (signal != null) {
break;
}
try {
Thread.sleep(1);
}
catch (InterruptedException e) {
}
}
}
}
// .split main task
// The main task simply starts a client and a server, and then waits for
// the client to signal that it has died:
public static void main(String[] args) throws Exception
{
try (ZContext ctx = new ZContext()) {
Socket pubpipe = ZThread.fork(ctx, new Publisher());
Socket subpipe = ZThread.fork(ctx, new Subscriber());
subpipe.recvStr();
pubpipe.send("break");
Thread.sleep(100);
}
}
}
suisnail: 自杀蜗牛 使用 Julia
suisnail: 自杀蜗牛 使用 Lua
--
-- Suicidal Snail
--
-- Author: Robert G. Jakabosky <bobby@sharedrealm.com>
--
require"zmq"
require"zmq.threads"
require"zhelpers"
-- ---------------------------------------------------------------------
-- This is our subscriber
-- It connects to the publisher and subscribes to everything. It
-- sleeps for a short time between messages to simulate doing too
-- much work. If a message is more than 1 second late, it croaks.
local subscriber = [[
require"zmq"
require"zhelpers"
local MAX_ALLOWED_DELAY = 1000 -- msecs
local context = zmq.init(1)
-- Subscribe to everything
local subscriber = context:socket(zmq.SUB)
subscriber:connect("tcp://:5556")
subscriber:setopt(zmq.SUBSCRIBE, "", 0)
-- Get and process messages
while true do
local msg = subscriber:recv()
local clock = tonumber(msg)
-- Suicide snail logic
if (s_clock () - clock > MAX_ALLOWED_DELAY) then
fprintf (io.stderr, "E: subscriber cannot keep up, aborting\n")
break
end
-- Work for 1 msec plus some random additional time
s_sleep (1 + randof (2))
end
subscriber:close()
context:term()
]]
-- ---------------------------------------------------------------------
-- This is our server task
-- It publishes a time-stamped message to its pub socket every 1ms.
local publisher = [[
require"zmq"
require"zhelpers"
local context = zmq.init(1)
-- Prepare publisher
local publisher = context:socket(zmq.PUB)
publisher:bind("tcp://*:5556")
while true do
-- Send current clock (msecs) to subscribers
publisher:send(tostring(s_clock()))
s_sleep (1); -- 1msec wait
end
publisher:close()
context:term()
]]
-- This main thread simply starts a client, and a server, and then
-- waits for the client to croak.
--
local server_thread = zmq.threads.runstring(nil, publisher)
server_thread:start(true)
local client_thread = zmq.threads.runstring(nil, subscriber)
client_thread:start()
client_thread:join()
suisnail: 自杀蜗牛 使用 Node.js
suisnail: 自杀蜗牛 使用 Objective-C
suisnail: 自杀蜗牛 使用 ooc
suisnail: 自杀蜗牛 使用 Perl
suisnail: 自杀蜗牛 使用 PHP
<?php
/* Suicidal Snail
*
* @author Ian Barber <ian(dot)barber(at)gmail(dot)com>
*/
/* ---------------------------------------------------------------------
* This is our subscriber
* It connects to the publisher and subscribes to everything. It
* sleeps for a short time between messages to simulate doing too
* much work. If a message is more than 1 second late, it croaks.
*/
define("MAX_ALLOWED_DELAY", 100); // msecs
function subscriber()
{
$context = new ZMQContext();
// Subscribe to everything
$subscriber = new ZMQSocket($context, ZMQ::SOCKET_SUB);
$subscriber->connect("tcp://:5556");
$subscriber->setSockOpt(ZMQ::SOCKOPT_SUBSCRIBE, "");
// Get and process messages
while (true) {
$clock = $subscriber->recv();
// Suicide snail logic
if (microtime(true)*100 - $clock*100 > MAX_ALLOWED_DELAY) {
echo "E: subscriber cannot keep up, aborting", PHP_EOL;
break;
}
// Work for 1 msec plus some random additional time
usleep(1000 + rand(0, 1000));
}
}
/* ---------------------------------------------------------------------
* This is our server task
* It publishes a time-stamped message to its pub socket every 1ms.
*/
function publisher()
{
$context = new ZMQContext();
// Prepare publisher
$publisher = new ZMQSocket($context, ZMQ::SOCKET_PUB);
$publisher->bind("tcp://*:5556");
while (true) {
// Send current clock (msecs) to subscribers
$publisher->send(microtime(true));
usleep(1000); // 1msec wait
}
}
/*
* This main thread simply starts a client, and a server, and then
* waits for the client to croak.
*/
$pid = pcntl_fork();
if ($pid == 0) {
publisher();
exit();
}
$pid = pcntl_fork();
if ($pid == 0) {
subscriber();
exit();
}
suisnail: 自杀蜗牛 使用 Python
"""
Suicidal Snail
Author: Min RK <benjaminrk@gmail.com>
"""
from __future__ import print_function
import sys
import threading
import time
from pickle import dumps, loads
import random
import zmq
from zhelpers import zpipe
# ---------------------------------------------------------------------
# This is our subscriber
# It connects to the publisher and subscribes to everything. It
# sleeps for a short time between messages to simulate doing too
# much work. If a message is more than 1 second late, it croaks.
MAX_ALLOWED_DELAY = 1.0 # secs
def subscriber(pipe):
# Subscribe to everything
ctx = zmq.Context.instance()
sub = ctx.socket(zmq.SUB)
sub.setsockopt(zmq.SUBSCRIBE, b'')
sub.connect("tcp://:5556")
# Get and process messages
while True:
clock = loads(sub.recv())
# Suicide snail logic
if (time.time() - clock > MAX_ALLOWED_DELAY):
print("E: subscriber cannot keep up, aborting", file=sys.stderr)
break
# Work for 1 msec plus some random additional time
time.sleep(1e-3 * (1+2*random.random()))
pipe.send(b"gone and died")
# ---------------------------------------------------------------------
# This is our server task
# It publishes a time-stamped message to its pub socket every 1ms.
def publisher(pipe):
# Prepare publisher
ctx = zmq.Context.instance()
pub = ctx.socket(zmq.PUB)
pub.bind("tcp://*:5556")
while True:
# Send current clock (secs) to subscribers
pub.send(dumps(time.time()))
try:
signal = pipe.recv(zmq.DONTWAIT)
except zmq.ZMQError as e:
if e.errno == zmq.EAGAIN:
# nothing to recv
pass
else:
raise
else:
# received break message
break
time.sleep(1e-3) # 1msec wait
# This main thread simply starts a client, and a server, and then
# waits for the client to signal it's died.
def main():
ctx = zmq.Context.instance()
pub_pipe, pub_peer = zpipe(ctx)
sub_pipe, sub_peer = zpipe(ctx)
pub_thread = threading.Thread(target=publisher, args=(pub_peer,))
pub_thread.daemon=True
pub_thread.start()
sub_thread = threading.Thread(target=subscriber, args=(sub_peer,))
sub_thread.daemon=True
sub_thread.start()
# wait for sub to finish
sub_pipe.recv()
# tell pub to halt
pub_pipe.send(b"break")
time.sleep(0.1)
if __name__ == '__main__':
main()
suisnail: 自杀蜗牛 使用 Q
suisnail: 自杀蜗牛 使用 Racket
suisnail: 自杀蜗牛 使用 Ruby
suisnail: 自杀蜗牛 使用 Rust
suisnail: 自杀蜗牛 使用 Scala
suisnail: 自杀蜗牛 使用 Tcl
#
# Suicidal Snail
#
package require zmq
if {[llength $argv] == 0} {
set argv [list driver]
} elseif {[llength $argv] != 1} {
puts "Usage: suisnail.tcl <driver|sub|pub>"
exit 1
}
lassign $argv what
set MAX_ALLOWED_DELAY 1000 ;# msecs
set tclsh [info nameofexecutable]
expr {srand([pid])}
switch -exact -- $what {
sub {
# This is our subscriber
# It connects to the publisher and subscribes to everything. It
# sleeps for a short time between messages to simulate doing too
# much work. If a message is more than 1 second late, it croaks.
zmq context context
zmq socket subpipe context PAIR
subpipe connect "ipc://subpipe.ipc"
# Subscribe to everything
zmq socket subscriber context SUB
subscriber setsockopt SUBSCRIBE ""
subscriber connect "tcp://:5556"
# Get and process messages
while {1} {
set string [subscriber recv]
puts "$string (delay = [expr {[clock milliseconds] - $string}])"
if {[clock milliseconds] - $string > $::MAX_ALLOWED_DELAY} {
puts stderr "E: subscriber cannot keep up, aborting"
break
}
after [expr {1+int(rand()*2)}]
}
subpipe send "gone and died"
subscriber close
subpipe close
context term
}
pub {
# This is our server task
# It publishes a time-stamped message to its pub socket every 1ms.
zmq context context
zmq socket pubpipe context PAIR
pubpipe connect "ipc://pubpipe.ipc"
# Prepare publisher
zmq socket publisher context PUB
publisher bind "tcp://*:5556"
while {1} {
# Send current clock (msecs) to subscribers
publisher send [clock milliseconds]
if {"POLLIN" in [pubpipe getsockopt EVENTS]} {
break
}
after 1 ;# 1msec wait
}
publisher close
pubpipe close
context term
}
driver {
zmq context context
zmq socket pubpipe context PAIR
pubpipe bind "ipc://pubpipe.ipc"
zmq socket subpipe context PAIR
subpipe bind "ipc://subpipe.ipc"
puts "Start publisher, output redirected to publisher.log"
exec $tclsh suisnail.tcl pub > publisher.log 2>@1 &
puts "Start subscriber, output redirected to subscriber.log"
exec $tclsh suisnail.tcl sub > subscriber.log 2>@1 &
subpipe recv
pubpipe send "break"
after 100
pubpipe close
subpipe close
context term
}
}
suisnail: 自杀蜗牛 使用 OCaml
关于自杀蜗牛示例的一些注意事项如下:
-
此处的消息仅包含当前系统时钟(表示为毫秒数)。在实际应用中,消息至少应包含带时间戳的消息头和带数据的消息体。
-
示例将订阅者和发布者作为两个线程放在同一个进程中。实际上,它们应该是独立的进程。使用线程只是为了方便演示。
高速订阅者(黑盒模式) #
现在我们来看一种方法来加快订阅者的速度。发布-订阅的一种常见用例是分发大型数据流,例如来自证券交易所的市场数据。典型的设置是发布者连接到证券交易所,获取报价,然后将其发送给许多订阅者。如果只有少数订阅者,我们可以使用 TCP。如果订阅者数量较多,我们可能会使用可靠的多播,例如 PGM。
假设我们的数据源平均每秒有 100,000 条 100 字节的消息。这是过滤掉不需要发送给订阅者的市场数据后的典型速率。现在我们决定记录一整天的数据(8 小时大约 250 GB),然后将其回放到一个模拟网络,即一小组订阅者。虽然每秒 10 万条消息对于 ZeroMQ 应用来说很容易,但我们想以快得多的速度回放它。
因此,我们建立了一个包含许多盒子的架构——一个用于发布者,每个订阅者一个。这些是配置良好的盒子——八核,发布者为十二核。
当我们将数据泵入订阅者时,我们注意到两件事
-
当我们对消息进行哪怕最少量的工作时,都会让我们的订阅者慢下来,以至于无法再次赶上发布者。
-
我们达到了一个上限,无论是在发布者还是订阅者端,大约是每秒 600 万条消息,即使经过仔细优化和 TCP 调优之后也是如此。
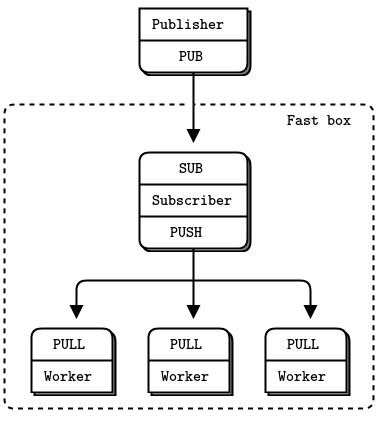
我们首先要做的是将订阅者拆分成多线程设计,这样我们就可以在一组线程中处理消息,同时在另一组线程中读取消息。通常,我们不想以相同的方式处理每条消息。相反,订阅者会过滤一些消息,可能通过前缀键进行过滤。当消息匹配某些条件时,订阅者将调用一个 worker 来处理它。用 ZeroMQ 的术语来说,这意味着将消息发送到 worker 线程。
因此,订阅者看起来像是一个队列设备。我们可以使用各种套接字来连接订阅者和 worker。如果我们假定是单向流量且所有 worker 都相同,我们可以使用 PUSH 和 PULL 并将所有路由工作委托给 ZeroMQ。这是最简单快捷的方法。
订阅者通过 TCP 或 PGM 与发布者通信。订阅者通过与位于同一进程中的 worker 通信,通过inproc:@<//>@.

现在来打破这个上限。订阅者线程会占用 100% 的 CPU,而且由于它是一个线程,所以无法使用超过一个核心。单个线程总是会达到上限,无论是在每秒 200 万、600 万还是更多消息时。我们希望将工作分配到多个可以并行运行的线程中。
许多高性能产品使用的方法(在此处也适用)是分片(sharding)。使用分片,我们将工作分解为并行且独立的流,例如将一半的主题键分到一个流中,另一半分到另一个流中。我们可以使用许多流,但除非有空闲核心,否则性能不会扩展。那么让我们看看如何分片成两个流。
使用两个流,以全速工作时,我们将按如下方式配置 ZeroMQ
- 两个 I/O 线程,而不是一个。
- 两个网络接口(NIC),每个订阅者一个。
- 每个 I/O 线程绑定到一个特定的 NIC。
- 两个订阅者线程,绑定到特定的核心。
- 两个 SUB 套接字,每个订阅者线程一个。
- 剩余的核心分配给 worker 线程。
- Worker 线程连接到两个订阅者 PUSH 套接字。
理想情况下,我们希望架构中满载线程的数量与核心数量相匹配。当线程开始争夺核心和 CPU 周期时,增加更多线程的成本将大于收益。例如,创建更多的 I/O 线程不会带来任何好处。
可靠的发布-订阅(克隆模式) #
作为一个更详细的示例,我们将探讨如何构建一个可靠的发布-订阅架构的问题。我们将分阶段开发它。目标是允许一组应用程序共享一些共同的状态。以下是我们的技术挑战
- 我们有大量的客户端应用程序,例如数千或数万个。
- 它们将随意加入和离开网络。
- 这些应用程序必须共享一个最终一致的状态。
- 任何应用程序都可以在任何时候更新状态。
假设更新量相对较低。我们没有实时性要求。整个状态可以放入内存。一些可能的用例包括
- 一组云服务器共享的配置。
- 一组玩家共享的游戏状态。
- 实时更新并可供应用程序使用的汇率数据。
中心化 vs 去中心化 #
我们首先需要决定的问题是是否使用中心服务器。这对最终的设计会产生很大影响。权衡如下
-
从概念上讲,中心服务器更容易理解,因为网络并非天然对称。使用中心服务器,我们可以避免所有关于服务发现、绑定(bind)与连接(connect)等问题。
-
通常,完全分布式的架构在技术上更具挑战性,但最终得到的协议更简单。也就是说,每个节点必须以正确的方式扮演服务器和客户端的角色,这很精妙。如果处理得当,结果会比使用中心服务器更简单。我们在第 4 章 - 可靠的请求-回复模式中的 Freelance 模式中看到了这一点。
-
中心服务器在高容量用例中会成为瓶颈。如果需要处理每秒数百万条消息的规模,我们应该立即考虑去中心化。
-
具有讽刺意味的是,中心化架构更容易扩展到更多节点,而去中心化架构则不然。也就是说,将 10,000 个节点连接到一个服务器比将它们相互连接更容易。
因此,对于克隆模式,我们将使用一个发布状态更新的服务器和一组代表应用程序的客户端。
将状态表示为键值对 #
我们将分阶段开发克隆模式,一次解决一个问题。首先,让我们看看如何在一组客户端之间更新共享状态。我们需要决定如何表示我们的状态以及更新。最简单的可行格式是键值存储,其中一个键值对代表共享状态中的一个原子变化单元。
我们在第 1 章 - 基础知识中有一个简单的发布-订阅示例,即天气服务器和客户端。让我们修改服务器来发送键值对,并让客户端将其存储在哈希表中。这使我们可以使用经典的发布-订阅模型从一个服务器向一组客户端发送更新。
更新可以是新的键值对、现有键的修改值或已删除的键。现在我们可以假设整个存储适合内存,并且应用程序通过键访问它,例如使用哈希表或字典。对于更大的存储和某种持久化需求,我们可能会将状态存储在数据库中,但这与此处无关。
这是服务器端
clonesrv1: 克隆服务器,模型一 使用 Ada
clonesrv1: 克隆服务器,模型一 使用 Basic
clonesrv1: 克隆服务器,模型一 使用 C
// Clone server Model One
#include "kvsimple.c"
int main (void)
{
// Prepare our context and publisher socket
zctx_t *ctx = zctx_new ();
void *publisher = zsocket_new (ctx, ZMQ_PUB);
zsocket_bind (publisher, "tcp://*:5556");
zclock_sleep (200);
zhash_t *kvmap = zhash_new ();
int64_t sequence = 0;
srandom ((unsigned) time (NULL));
while (!zctx_interrupted) {
// Distribute as key-value message
kvmsg_t *kvmsg = kvmsg_new (++sequence);
kvmsg_fmt_key (kvmsg, "%d", randof (10000));
kvmsg_fmt_body (kvmsg, "%d", randof (1000000));
kvmsg_send (kvmsg, publisher);
kvmsg_store (&kvmsg, kvmap);
}
printf (" Interrupted\n%d messages out\n", (int) sequence);
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
return 0;
}
clonesrv1: 克隆服务器,模型一 使用 C++
#include <iostream>
#include <unordered_map>
#include "kvsimple.hpp"
using namespace std;
int main() {
// Prepare our context and publisher socket
zmq::context_t ctx(1);
zmq::socket_t publisher(ctx, ZMQ_PUB);
publisher.bind("tcp://*:5555");
s_sleep(5000); // Sleep for a short while to allow connections to be established
// Initialize key-value map and sequence
unordered_map<string,string> kvmap;
int64_t sequence = 0;
srand(time(NULL));
s_catch_signals();
while (!s_interrupted) {
// Distribute as key-value message
string key = to_string(within(10000));
string body = to_string(within(1000000));
kvmsg kv(key, sequence, (unsigned char *)body.c_str());
kv.send(publisher); // Send key-value message
// Store key-value pair in map
kvmap[key] = body;
sequence++;
// Sleep for a short while before sending the next message
s_sleep(1000);
}
cout << "Interrupted" << endl;
cout << sequence << " messages out" << endl;
return 0;
}
clonesrv1: 克隆服务器,模型一 使用 C#
clonesrv1: 克隆服务器,模型一 使用 CL
clonesrv1: 克隆服务器,模型一 使用 Delphi
clonesrv1: 克隆服务器,模型一 使用 Erlang
clonesrv1: 克隆服务器,模型一 使用 Elixir
clonesrv1: 克隆服务器,模型一 使用 F#
clonesrv1: 克隆服务器,模型一 使用 Felix
clonesrv1: 克隆服务器,模型一 使用 Go
clonesrv1: 克隆服务器,模型一 使用 Haskell
clonesrv1: 克隆服务器,模型一 使用 Haxe
clonesrv1: 克隆服务器,模型一 使用 Java
package guide;
import java.nio.ByteBuffer;
import java.util.Random;
import java.util.concurrent.atomic.AtomicLong;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZContext;
/**
*
* Clone server model 1
* @author Danish Shrestha <dshrestha06@gmail.com>
*
*/
public class clonesrv1
{
private static AtomicLong sequence = new AtomicLong();
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket publisher = ctx.createSocket(SocketType.PUB);
publisher.bind("tcp://*:5556");
try {
Thread.sleep(200);
}
catch (InterruptedException e) {
e.printStackTrace();
}
Random random = new Random();
while (true) {
long currentSequenceNumber = sequence.incrementAndGet();
int key = random.nextInt(10000);
int body = random.nextInt(1000000);
ByteBuffer b = ByteBuffer.allocate(4);
b.asIntBuffer().put(body);
kvsimple kvMsg = new kvsimple(
key + "", currentSequenceNumber, b.array()
);
kvMsg.send(publisher);
System.out.println("sending " + kvMsg);
}
}
}
public static void main(String[] args)
{
new clonesrv1().run();
}
}
clonesrv1: 克隆服务器,模型一 使用 Julia
clonesrv1: 克隆服务器,模型一 使用 Lua
clonesrv1: 克隆服务器,模型一 使用 Node.js
clonesrv1: 克隆服务器,模型一 使用 Objective-C
clonesrv1: 克隆服务器,模型一 使用 ooc
clonesrv1: 克隆服务器,模型一 使用 Perl
clonesrv1: 克隆服务器,模型一 使用 PHP
clonesrv1: 克隆服务器,模型一 使用 Python
"""
Clone server Model One
"""
import random
import time
import zmq
from kvsimple import KVMsg
def main():
# Prepare our context and publisher socket
ctx = zmq.Context()
publisher = ctx.socket(zmq.PUB)
publisher.bind("tcp://*:5556")
time.sleep(0.2)
sequence = 0
random.seed(time.time())
kvmap = {}
try:
while True:
# Distribute as key-value message
sequence += 1
kvmsg = KVMsg(sequence)
kvmsg.key = "%d" % random.randint(1,10000)
kvmsg.body = "%d" % random.randint(1,1000000)
kvmsg.send(publisher)
kvmsg.store(kvmap)
except KeyboardInterrupt:
print " Interrupted\n%d messages out" % sequence
if __name__ == '__main__':
main()
clonesrv1: 克隆服务器,模型一 使用 Q
clonesrv1: 克隆服务器,模型一 使用 Racket
clonesrv1: 克隆服务器,模型一 使用 Ruby
clonesrv1: 克隆服务器,模型一 使用 Rust
clonesrv1: 克隆服务器,模型一 使用 Scala
clonesrv1: 克隆服务器,模型一 使用 Tcl
#
# Clone server Model One
#
lappend auto_path .
package require KVSimple
# Prepare our context and publisher socket
zmq context context
set pub [zmq socket publisher context PUB]
$pub bind "tcp://*:5556"
after 200
set sequence 0
expr srand([pid])
while {1} {
# Distribute as key-value message
set kvmsg [KVSimple new [incr sequence]]
$kvmsg set_key [expr {int(rand()*10000)}]
$kvmsg set_body [expr {int(rand()*1000000)}]
$kvmsg send $pub
$kvmsg store kvmap
puts [$kvmsg dump]
after 500
}
$pub close
context term
clonesrv1: 克隆服务器,模型一 使用 OCaml
这是客户端
clonecli1: 克隆客户端,模型一 使用 Ada
clonecli1: 克隆客户端,模型一 使用 Basic
clonecli1: 克隆客户端,模型一 使用 C
// Clone client Model One
#include "kvsimple.c"
int main (void)
{
// Prepare our context and updates socket
zctx_t *ctx = zctx_new ();
void *updates = zsocket_new (ctx, ZMQ_SUB);
zsocket_set_subscribe (updates, "");
zsocket_connect (updates, "tcp://:5556");
zhash_t *kvmap = zhash_new ();
int64_t sequence = 0;
while (true) {
kvmsg_t *kvmsg = kvmsg_recv (updates);
if (!kvmsg)
break; // Interrupted
kvmsg_store (&kvmsg, kvmap);
sequence++;
}
printf (" Interrupted\n%d messages in\n", (int) sequence);
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
return 0;
}
clonecli1: 克隆客户端,模型一 使用 C++
#include <iostream>
#include <unordered_map>
#include "kvsimple.hpp"
using namespace std;
int main() {
// Prepare our context and updates socket
zmq::context_t ctx(1);
zmq::socket_t updates(ctx, ZMQ_SUB);
updates.set(zmq::sockopt::subscribe, ""); // Subscribe to all messages
updates.connect("tcp://:5555");
// Initialize key-value map and sequence
unordered_map<string, string> kvmap;
int64_t sequence = 0;
while (true) {
// Receive key-value message
auto update_kv_msg = kvmsg::recv(updates);
if (!update_kv_msg) {
cout << "Interrupted" << endl;
return 0;
}
// Convert message to string and extract key-value pair
string key = update_kv_msg->key();
string value = (char *)update_kv_msg->body().c_str();
cout << key << " --- " << value << endl;
// Store key-value pair in map
kvmap[key] = value;
sequence++;
}
return 0;
}
clonecli1: 克隆客户端,模型一 使用 C#
clonecli1: 克隆客户端,模型一 使用 CL
clonecli1: 克隆客户端,模型一 使用 Delphi
clonecli1: 克隆客户端,模型一 使用 Erlang
clonecli1: 克隆客户端,模型一 使用 Elixir
clonecli1: 克隆客户端,模型一 使用 F#
clonecli1: 克隆客户端,模型一 使用 Felix
clonecli1: 克隆客户端,模型一 使用 Go
clonecli1: 克隆客户端,模型一 使用 Haskell
clonecli1: 克隆客户端,模型一 使用 Haxe
clonecli1: 克隆客户端,模型一 使用 Java
package guide;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.atomic.AtomicLong;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
/**
* Clone client model 1
* @author Danish Shrestha <dshrestha06@gmail.com>
*
*/
public class clonecli1
{
private static Map<String, kvsimple> kvMap = new HashMap<String, kvsimple>();
private static AtomicLong sequence = new AtomicLong();
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket subscriber = ctx.createSocket(SocketType.SUB);
subscriber.connect("tcp://:5556");
subscriber.subscribe(ZMQ.SUBSCRIPTION_ALL);
while (true) {
kvsimple kvMsg = kvsimple.recv(subscriber);
if (kvMsg == null)
break;
clonecli1.kvMap.put(kvMsg.getKey(), kvMsg);
System.out.println("receiving " + kvMsg);
sequence.incrementAndGet();
}
}
}
public static void main(String[] args)
{
new clonecli1().run();
}
}
clonecli1: 克隆客户端,模型一 使用 Julia
clonecli1: 克隆客户端,模型一 使用 Lua
clonecli1: 克隆客户端,模型一 使用 Node.js
clonecli1: 克隆客户端,模型一 使用 Objective-C
clonecli1: 克隆客户端,模型一 使用 ooc
clonecli1: 克隆客户端,模型一 使用 Perl
clonecli1: 克隆客户端,模型一 使用 PHP
clonecli1: 克隆客户端,模型一 使用 Python
"""
Clone Client Model One
Author: Min RK <benjaminrk@gmail.com>
"""
import random
import time
import zmq
from kvsimple import KVMsg
def main():
# Prepare our context and publisher socket
ctx = zmq.Context()
updates = ctx.socket(zmq.SUB)
updates.linger = 0
updates.setsockopt(zmq.SUBSCRIBE, '')
updates.connect("tcp://:5556")
kvmap = {}
sequence = 0
while True:
try:
kvmsg = KVMsg.recv(updates)
except:
break # Interrupted
kvmsg.store(kvmap)
sequence += 1
print "Interrupted\n%d messages in" % sequence
if __name__ == '__main__':
main()
clonecli1: 克隆客户端,模型一 使用 Q
clonecli1: 克隆客户端,模型一 使用 Racket
clonecli1: 克隆客户端,模型一 使用 Ruby
clonecli1: 克隆客户端,模型一 使用 Rust
clonecli1: 克隆客户端,模型一 使用 Scala
clonecli1: 克隆客户端,模型一 使用 Tcl
#
# Clone client Model One
#
lappend auto_path .
package require KVSimple
zmq context context
set upd [zmq socket updates context SUB]
$upd setsockopt SUBSCRIBE ""
$upd connect "tcp://:5556"
after 200
while {1} {
set kvmsg [KVSimple new]
$kvmsg recv $upd
$kvmsg store kvmap
puts [$kvmsg dump]
}
$upd close
context term
clonecli1: 克隆客户端,模型一 使用 OCaml
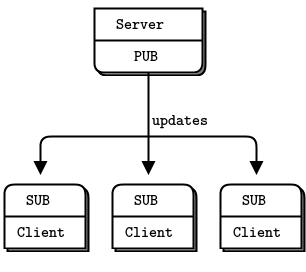
关于这个第一个模型的一些注意事项如下:
-
所有繁重的工作都在一个kvmsg类中完成。这个类处理键值消息对象,它们是多部分 ZeroMQ 消息,其结构包含三个帧:一个键(ZeroMQ 字符串)、一个序列号(64 位值,网络字节序)以及一个二进制消息体(包含其他所有内容)。
-
服务器生成带有随机 4 位数字键的消息,这使我们可以模拟一个大型但不巨大的哈希表(10K 条目)。
-
此版本中未实现删除功能:所有消息都是插入或更新。
-
服务器在绑定其套接字后暂停 200 毫秒。这是为了防止慢连接综合征(slow joiner syndrome),指订阅者在连接到服务器套接字时丢失消息的情况。我们会在后续版本的克隆代码中移除此暂停。
-
我们将在代码中使用术语发布者和订阅者来指代套接字。这将在稍后处理多个执行不同任务的套接字时有所帮助。
这是kvmsg类,这是目前可用的最简单形式
kvsimple: 键值消息类 使用 Ada
kvsimple: 键值消息类 使用 Basic
kvsimple: 键值消息类 使用 C
// kvsimple class - key-value message class for example applications
#include "kvsimple.h"
#include "zlist.h"
// Keys are short strings
#define KVMSG_KEY_MAX 255
// Message is formatted on wire as 3 frames:
// frame 0: key (0MQ string)
// frame 1: sequence (8 bytes, network order)
// frame 2: body (blob)
#define FRAME_KEY 0
#define FRAME_SEQ 1
#define FRAME_BODY 2
#define KVMSG_FRAMES 3
// The kvmsg class holds a single key-value message consisting of a
// list of 0 or more frames:
struct _kvmsg {
// Presence indicators for each frame
int present [KVMSG_FRAMES];
// Corresponding 0MQ message frames, if any
zmq_msg_t frame [KVMSG_FRAMES];
// Key, copied into safe C string
char key [KVMSG_KEY_MAX + 1];
};
// .split constructor and destructor
// Here are the constructor and destructor for the class:
// Constructor, takes a sequence number for the new kvmsg instance:
kvmsg_t *
kvmsg_new (int64_t sequence)
{
kvmsg_t
*self;
self = (kvmsg_t *) zmalloc (sizeof (kvmsg_t));
kvmsg_set_sequence (self, sequence);
return self;
}
// zhash_free_fn callback helper that does the low level destruction:
void
kvmsg_free (void *ptr)
{
if (ptr) {
kvmsg_t *self = (kvmsg_t *) ptr;
// Destroy message frames if any
int frame_nbr;
for (frame_nbr = 0; frame_nbr < KVMSG_FRAMES; frame_nbr++)
if (self->present [frame_nbr])
zmq_msg_close (&self->frame [frame_nbr]);
// Free object itself
free (self);
}
}
// Destructor
void
kvmsg_destroy (kvmsg_t **self_p)
{
assert (self_p);
if (*self_p) {
kvmsg_free (*self_p);
*self_p = NULL;
}
}
// .split recv method
// This method reads a key-value message from socket, and returns a new
// {{kvmsg}} instance:
kvmsg_t *
kvmsg_recv (void *socket)
{
assert (socket);
kvmsg_t *self = kvmsg_new (0);
// Read all frames off the wire, reject if bogus
int frame_nbr;
for (frame_nbr = 0; frame_nbr < KVMSG_FRAMES; frame_nbr++) {
if (self->present [frame_nbr])
zmq_msg_close (&self->frame [frame_nbr]);
zmq_msg_init (&self->frame [frame_nbr]);
self->present [frame_nbr] = 1;
if (zmq_msg_recv (&self->frame [frame_nbr], socket, 0) == -1) {
kvmsg_destroy (&self);
break;
}
// Verify multipart framing
int rcvmore = (frame_nbr < KVMSG_FRAMES - 1)? 1: 0;
if (zsocket_rcvmore (socket) != rcvmore) {
kvmsg_destroy (&self);
break;
}
}
return self;
}
// .split send method
// This method sends a multiframe key-value message to a socket:
void
kvmsg_send (kvmsg_t *self, void *socket)
{
assert (self);
assert (socket);
int frame_nbr;
for (frame_nbr = 0; frame_nbr < KVMSG_FRAMES; frame_nbr++) {
zmq_msg_t copy;
zmq_msg_init (©);
if (self->present [frame_nbr])
zmq_msg_copy (©, &self->frame [frame_nbr]);
zmq_msg_send (©, socket,
(frame_nbr < KVMSG_FRAMES - 1)? ZMQ_SNDMORE: 0);
zmq_msg_close (©);
}
}
// .split key methods
// These methods let the caller get and set the message key, as a
// fixed string and as a printf formatted string:
char *
kvmsg_key (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_KEY]) {
if (!*self->key) {
size_t size = zmq_msg_size (&self->frame [FRAME_KEY]);
if (size > KVMSG_KEY_MAX)
size = KVMSG_KEY_MAX;
memcpy (self->key,
zmq_msg_data (&self->frame [FRAME_KEY]), size);
self->key [size] = 0;
}
return self->key;
}
else
return NULL;
}
void
kvmsg_set_key (kvmsg_t *self, char *key)
{
assert (self);
zmq_msg_t *msg = &self->frame [FRAME_KEY];
if (self->present [FRAME_KEY])
zmq_msg_close (msg);
zmq_msg_init_size (msg, strlen (key));
memcpy (zmq_msg_data (msg), key, strlen (key));
self->present [FRAME_KEY] = 1;
}
void
kvmsg_fmt_key (kvmsg_t *self, char *format, ...)
{
char value [KVMSG_KEY_MAX + 1];
va_list args;
assert (self);
va_start (args, format);
vsnprintf (value, KVMSG_KEY_MAX, format, args);
va_end (args);
kvmsg_set_key (self, value);
}
// .split sequence methods
// These two methods let the caller get and set the message sequence number:
int64_t
kvmsg_sequence (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_SEQ]) {
assert (zmq_msg_size (&self->frame [FRAME_SEQ]) == 8);
byte *source = zmq_msg_data (&self->frame [FRAME_SEQ]);
int64_t sequence = ((int64_t) (source [0]) << 56)
+ ((int64_t) (source [1]) << 48)
+ ((int64_t) (source [2]) << 40)
+ ((int64_t) (source [3]) << 32)
+ ((int64_t) (source [4]) << 24)
+ ((int64_t) (source [5]) << 16)
+ ((int64_t) (source [6]) << 8)
+ (int64_t) (source [7]);
return sequence;
}
else
return 0;
}
void
kvmsg_set_sequence (kvmsg_t *self, int64_t sequence)
{
assert (self);
zmq_msg_t *msg = &self->frame [FRAME_SEQ];
if (self->present [FRAME_SEQ])
zmq_msg_close (msg);
zmq_msg_init_size (msg, 8);
byte *source = zmq_msg_data (msg);
source [0] = (byte) ((sequence >> 56) & 255);
source [1] = (byte) ((sequence >> 48) & 255);
source [2] = (byte) ((sequence >> 40) & 255);
source [3] = (byte) ((sequence >> 32) & 255);
source [4] = (byte) ((sequence >> 24) & 255);
source [5] = (byte) ((sequence >> 16) & 255);
source [6] = (byte) ((sequence >> 8) & 255);
source [7] = (byte) ((sequence) & 255);
self->present [FRAME_SEQ] = 1;
}
// .split message body methods
// These methods let the caller get and set the message body as a
// fixed string and as a printf formatted string:
byte *
kvmsg_body (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_BODY])
return (byte *) zmq_msg_data (&self->frame [FRAME_BODY]);
else
return NULL;
}
void
kvmsg_set_body (kvmsg_t *self, byte *body, size_t size)
{
assert (self);
zmq_msg_t *msg = &self->frame [FRAME_BODY];
if (self->present [FRAME_BODY])
zmq_msg_close (msg);
self->present [FRAME_BODY] = 1;
zmq_msg_init_size (msg, size);
memcpy (zmq_msg_data (msg), body, size);
}
void
kvmsg_fmt_body (kvmsg_t *self, char *format, ...)
{
char value [255 + 1];
va_list args;
assert (self);
va_start (args, format);
vsnprintf (value, 255, format, args);
va_end (args);
kvmsg_set_body (self, (byte *) value, strlen (value));
}
// .split size method
// This method returns the body size of the most recently read message,
// if any exists:
size_t
kvmsg_size (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_BODY])
return zmq_msg_size (&self->frame [FRAME_BODY]);
else
return 0;
}
// .split store method
// This method stores the key-value message into a hash map, unless
// the key and value are both null. It nullifies the {{kvmsg}} reference
// so that the object is owned by the hash map, not the caller:
void
kvmsg_store (kvmsg_t **self_p, zhash_t *hash)
{
assert (self_p);
if (*self_p) {
kvmsg_t *self = *self_p;
assert (self);
if (self->present [FRAME_KEY]
&& self->present [FRAME_BODY]) {
zhash_update (hash, kvmsg_key (self), self);
zhash_freefn (hash, kvmsg_key (self), kvmsg_free);
}
*self_p = NULL;
}
}
// .split dump method
// This method prints the key-value message to stderr for
// debugging and tracing:
void
kvmsg_dump (kvmsg_t *self)
{
if (self) {
if (!self) {
fprintf (stderr, "NULL");
return;
}
size_t size = kvmsg_size (self);
byte *body = kvmsg_body (self);
fprintf (stderr, "[seq:%" PRId64 "]", kvmsg_sequence (self));
fprintf (stderr, "[key:%s]", kvmsg_key (self));
fprintf (stderr, "[size:%zd] ", size);
int char_nbr;
for (char_nbr = 0; char_nbr < size; char_nbr++)
fprintf (stderr, "%02X", body [char_nbr]);
fprintf (stderr, "\n");
}
else
fprintf (stderr, "NULL message\n");
}
// .split test method
// It's good practice to have a self-test method that tests the class; this
// also shows how it's used in applications:
int
kvmsg_test (int verbose)
{
kvmsg_t
*kvmsg;
printf (" * kvmsg: ");
// Prepare our context and sockets
zctx_t *ctx = zctx_new ();
void *output = zsocket_new (ctx, ZMQ_DEALER);
int rc = zmq_bind (output, "ipc://kvmsg_selftest.ipc");
assert (rc == 0);
void *input = zsocket_new (ctx, ZMQ_DEALER);
rc = zmq_connect (input, "ipc://kvmsg_selftest.ipc");
assert (rc == 0);
zhash_t *kvmap = zhash_new ();
// Test send and receive of simple message
kvmsg = kvmsg_new (1);
kvmsg_set_key (kvmsg, "key");
kvmsg_set_body (kvmsg, (byte *) "body", 4);
if (verbose)
kvmsg_dump (kvmsg);
kvmsg_send (kvmsg, output);
kvmsg_store (&kvmsg, kvmap);
kvmsg = kvmsg_recv (input);
if (verbose)
kvmsg_dump (kvmsg);
assert (streq (kvmsg_key (kvmsg), "key"));
kvmsg_store (&kvmsg, kvmap);
// Shutdown and destroy all objects
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
printf ("OK\n");
return 0;
}
kvsimple: 键值消息类 使用 C++
/* =====================================================================
* kvsimple - simple key-value message class for example applications
* ===================================================================== */
#ifndef __KVSIMPLE_HPP_INCLUDED__
#define __KVSIMPLE_HPP_INCLUDED__
#include "zhelpers.hpp"
#include "zmq.hpp"
#include <cstdint>
#include <iostream>
#include <optional>
#include <sstream>
#include <string>
#include <unordered_map>
using ustring = std::basic_string<unsigned char>;
struct kvmsg {
kvmsg(std::string key, int64_t sequence, ustring body);
kvmsg() = default;
// Reads key-value message from socket, returns new kvmsg instance.
static std::optional<kvmsg> recv(zmq::socket_t &socket);
// Send key-value message to socket; any empty frames are sent as such.
void send(zmq::socket_t &socket);
// Return key from last read message, if any, else NULL
std::string key() const;
// Return sequence nbr from last read message, if any
int64_t sequence() const;
// Return body from last read message, if any, else NULL
ustring body() const;
// Return body size from last read message, if any, else zero
size_t size() const;
// Set message key as provided
void set_key(std::string key);
// Set message sequence number
void set_sequence(int64_t sequence);
// Set message body
void set_body(ustring body);
// Dump message to stderr, for debugging and tracing
std::string to_string();
// Runs self test of class
static bool test(int verbose);
private:
static constexpr uint32_t kvmsg_key_max = 255;
static constexpr uint32_t frame_key = 0;
static constexpr uint32_t frame_seq = 1;
static constexpr uint32_t frame_body = 2;
static constexpr uint32_t kvmsg_frames = 3;
std::string key_;
ustring body_;
int64_t sequence_{};
};
namespace {
std::optional<zmq::message_t> receive_message(zmq::socket_t &socket) {
zmq::message_t message(0);
message.rebuild(0);
try {
if (!socket.recv(message, zmq::recv_flags::none)) {
return {};
}
} catch (zmq::error_t &error) {
std::cerr << "E: " << error.what() << std::endl;
return {};
}
return message;
}
} // namespace
kvmsg::kvmsg(std::string key, int64_t sequence, ustring body)
: key_(key), body_(body), sequence_(sequence) {}
// Reads key-value message from socket, returns new kvmsg instance.
std::optional<kvmsg> kvmsg::recv(zmq::socket_t &socket) {
auto key_message = receive_message(socket);
if (!key_message)
return {};
kvmsg msg;
msg.set_key(
std::string((char *)(*key_message).data(), (*key_message).size()));
auto sequence_message = receive_message(socket);
msg.set_sequence(*(int64_t *)(*sequence_message).data());
if (!sequence_message)
return {};
auto body_message = receive_message(socket);
if (!body_message)
return {};
msg.set_body(
ustring((unsigned char *)(*body_message).data(), (*body_message).size()));
return msg;
}
// Send key-value message to socket; any empty frames are sent as such.
void kvmsg::send(zmq::socket_t &socket) {
{
zmq::message_t message;
message.rebuild(key_.size());
std::memcpy(message.data(), key_.c_str(), key_.size());
socket.send(message, zmq::send_flags::sndmore);
}
{
zmq::message_t message;
message.rebuild(sizeof(sequence_));
std::memcpy(message.data(), (void *)&sequence_, sizeof(sequence_));
socket.send(message, zmq::send_flags::sndmore);
}
{
zmq::message_t message;
message.rebuild(body_.size());
std::memcpy(message.data(), body_.c_str(), body_.size());
socket.send(message, zmq::send_flags::none);
}
}
// Return key from last read message, if any, else NULL
std::string kvmsg::key() const { return key_; }
// Return sequence nbr from last read message, if any
int64_t kvmsg::sequence() const { return sequence_; }
// Return body from last read message, if any, else NULL
ustring kvmsg::body() const { return body_; }
// Return body size from last read message, if any, else zero
size_t kvmsg::size() const { return body_.size(); }
// Set message key as provided
void kvmsg::set_key(std::string key) { key_ = key; }
// Set message sequence number
void kvmsg::set_sequence(int64_t sequence) { sequence_ = sequence; }
// Set message body
void kvmsg::set_body(ustring body) { body_ = body; }
std::string kvmsg::to_string() {
std::stringstream ss;
ss << "key=" << key_ << ",sequence=" << sequence_ << ",body=";
s_dump_message(ss, body_);
return ss.str();
}
// Dump message to stderr, for debugging and tracing
// Runs self test of class
bool kvmsg::test(int verbose) {
zmq::context_t context;
zmq::socket_t output(context, ZMQ_DEALER);
output.bind("ipc://kvmsg_selftest.ipc");
zmq::socket_t input(context, ZMQ_DEALER);
input.connect("ipc://kvmsg_selftest.ipc");
kvmsg message("key", 1, (unsigned char *)"body");
if (verbose) {
std::cout << message.to_string()<<std::endl;
}
message.send(output);
std::unordered_map<std::string, kvmsg> kvmap;
kvmap["key"] = message;
auto input_message_opt = kvmsg::recv(input);
if (!input_message_opt)
return false;
assert((*input_message_opt).key() == "key");
assert((*input_message_opt).sequence() == 1);
assert((*input_message_opt).body() == (unsigned char *)"body");
if (verbose) {
std::cout << (*input_message_opt).to_string()<<std::endl;
}
return true;
}
// Main routine for running the basic test
//int main() {
// std::cout << (kvmsg::test(1) ? "SUCCESS" : "FAILURE") << std::endl;
// return 0;
//}
#endif // Included
kvsimple: 键值消息类 使用 C#
kvsimple: 键值消息类 使用 CL
kvsimple: 键值消息类 使用 Delphi
kvsimple: 键值消息类 使用 Erlang
kvsimple: 键值消息类 使用 Elixir
kvsimple: 键值消息类 使用 F#
kvsimple: 键值消息类 使用 Felix
kvsimple: 键值消息类 使用 Go
kvsimple: 键值消息类 使用 Haskell
kvsimple: 键值消息类 使用 Haxe
kvsimple: 键值消息类 使用 Java
package guide;
import java.nio.ByteBuffer;
import java.util.Arrays;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
/**
*
* A simple getKey value message class
* @author Danish Shrestha <dshrestha06@gmail.com>
*
*/
public class kvsimple
{
private final String key;
private long sequence;
private final byte[] body;
public kvsimple(String key, long sequence, byte[] body)
{
this.key = key;
this.sequence = sequence;
this.body = body; // clone if needed
}
public String getKey()
{
return key;
}
public long getSequence()
{
return sequence;
}
public void setSequence(long sequence)
{
this.sequence = sequence;
}
public byte[] getBody()
{
return body;
}
public void send(Socket publisher)
{
publisher.send(key.getBytes(ZMQ.CHARSET), ZMQ.SNDMORE);
ByteBuffer bb = ByteBuffer.allocate(8);
bb.asLongBuffer().put(sequence);
publisher.send(bb.array(), ZMQ.SNDMORE);
publisher.send(body, 0);
}
public static kvsimple recv(Socket updates)
{
byte[] data = updates.recv(0);
if (data == null || !updates.hasReceiveMore())
return null;
String key = new String(data, ZMQ.CHARSET);
data = updates.recv(0);
if (data == null || !updates.hasReceiveMore())
return null;
Long sequence = ByteBuffer.wrap(data).getLong();
byte[] body = updates.recv(0);
if (body == null || updates.hasReceiveMore())
return null;
return new kvsimple(key, sequence, body);
}
@Override
public String toString()
{
return "kvsimple [getKey=" + key + ", getSequence=" + sequence + ", body=" + Arrays.toString(body) + "]";
}
@Override
public int hashCode()
{
final int prime = 31;
int result = 1;
result = prime * result + Arrays.hashCode(body);
result = prime * result + ((key == null) ? 0 : key.hashCode());
result = prime * result + (int) (sequence ^ (sequence >>> 32));
return result;
}
@Override
public boolean equals(Object obj)
{
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
kvsimple other = (kvsimple) obj;
if (!Arrays.equals(body, other.body))
return false;
if (key == null) {
if (other.key != null)
return false;
}
else if (!key.equals(other.key))
return false;
if (sequence != other.sequence)
return false;
return true;
}
}
kvsimple: 键值消息类 使用 Julia
kvsimple: 键值消息类 使用 Lua
kvsimple: 键值消息类 使用 Node.js
kvsimple: 键值消息类 使用 Objective-C
kvsimple: 键值消息类 使用 ooc
kvsimple: 键值消息类 使用 Perl
kvsimple: 键值消息类 使用 PHP
kvsimple: 键值消息类 使用 Python
"""
=====================================================================
kvsimple - simple key-value message class for example applications
Author: Min RK <benjaminrk@gmail.com>
"""
import struct # for packing integers
import sys
import zmq
class KVMsg(object):
"""
Message is formatted on wire as 3 frames:
frame 0: key (0MQ string)
frame 1: sequence (8 bytes, network order)
frame 2: body (blob)
"""
key = None # key (string)
sequence = 0 # int
body = None # blob
def __init__(self, sequence, key=None, body=None):
assert isinstance(sequence, int)
self.sequence = sequence
self.key = key
self.body = body
def store(self, dikt):
"""Store me in a dict if I have anything to store"""
# this seems weird to check, but it's what the C example does
if self.key is not None and self.body is not None:
dikt[self.key] = self
def send(self, socket):
"""Send key-value message to socket; any empty frames are sent as such."""
key = '' if self.key is None else self.key
seq_s = struct.pack('!l', self.sequence)
body = '' if self.body is None else self.body
socket.send_multipart([ key, seq_s, body ])
@classmethod
def recv(cls, socket):
"""Reads key-value message from socket, returns new kvmsg instance."""
key, seq_s, body = socket.recv_multipart()
key = key if key else None
seq = struct.unpack('!l',seq_s)[0]
body = body if body else None
return cls(seq, key=key, body=body)
def dump(self):
if self.body is None:
size = 0
data='NULL'
else:
size = len(self.body)
data=repr(self.body)
print >> sys.stderr, "[seq:{seq}][key:{key}][size:{size}] {data}".format(
seq=self.sequence,
key=self.key,
size=size,
data=data,
)
# ---------------------------------------------------------------------
# Runs self test of class
def test_kvmsg (verbose):
print " * kvmsg: ",
# Prepare our context and sockets
ctx = zmq.Context()
output = ctx.socket(zmq.DEALER)
output.bind("ipc://kvmsg_selftest.ipc")
input = ctx.socket(zmq.DEALER)
input.connect("ipc://kvmsg_selftest.ipc")
kvmap = {}
# Test send and receive of simple message
kvmsg = KVMsg(1)
kvmsg.key = "key"
kvmsg.body = "body"
if verbose:
kvmsg.dump()
kvmsg.send(output)
kvmsg.store(kvmap)
kvmsg2 = KVMsg.recv(input)
if verbose:
kvmsg2.dump()
assert kvmsg2.key == "key"
kvmsg2.store(kvmap)
assert len(kvmap) == 1 # shouldn't be different
print "OK"
if __name__ == '__main__':
test_kvmsg('-v' in sys.argv)
kvsimple: 键值消息类 使用 Q
kvsimple: 键值消息类 使用 Racket
kvsimple: 键值消息类 使用 Ruby
kvsimple: 键值消息类 使用 Rust
kvsimple: 键值消息类 使用 Scala
kvsimple: 键值消息类 使用 Tcl
# =====================================================================
# kvsimple - simple key-value message class for example applications
# =====================================================================
lappend auto_path .
package require TclOO
package require zmq
package require mdp
package provide KVSimple 1.0
# Keys are short strings
set KVMSG_KEY_MAX 255
# Message is formatted on wire as 3 frames:
# frame 0: key (0MQ string)
# frame 1: sequence (8 bytes, network order)
# frame 2: body (blob)
set FRAME_KEY 0
set FRAME_SEQ 1
set FRAME_BODY 2
set KVMSG_FRAMES 3
oo::class create KVSimple {
variable frame key
# Constructor, sets sequence as provided
constructor {{isequence 0}} {
set frame [list]
my set_sequence $isequence
}
destructor {
}
# Reads key-value message from socket
method recv {socket} {
set frame [list]
# Read all frames off the wire
for {set frame_nbr 0} {$frame_nbr < $::KVMSG_FRAMES} {incr frame_nbr} {
lappend frame [$socket recv]
# Verify multipart framing
if {![$socket getsockopt RCVMORE]} {
break
}
}
}
# Send key-value message to socket; any empty frames are sent as such.
method send {socket} {
for {set frame_nbr 0} {$frame_nbr < $::KVMSG_FRAMES} {incr frame_nbr} {
if {$frame_nbr == ($::KVMSG_FRAMES - 1)} {
$socket send [lindex $frame $frame_nbr]
} else {
$socket sendmore [lindex $frame $frame_nbr]
}
}
}
# Return key from last read message, if any, else NULL
method key {} {
if {[llength $frame] > $::FRAME_KEY} {
if {![info exists key]} {
set size [string length [lindex $frame $::FRAME_KEY]]
if {$size > $::KVMSG_KEY_MAX} {
set size $::KVMSG_KEY_MAX
}
set key [string range [lindex $frame $::FRAME_KEY] 0 [expr {$size - 1}]]
}
return $key
} else {
return {}
}
}
# Return sequence nbr from last read message, if any
method sequence {} {
if {[llength $frame] > $::FRAME_SEQ} {
set s [lindex $frame $::FRAME_SEQ]
if {[string length $s] != 8} {
error "sequence frame must have length 8"
}
binary scan [lindex $frame $::FRAME_SEQ] W r
return $r
} else {
return 0
}
}
# Return body from last read message, if any, else NULL
method body {} {
if {[llength $frame] > $::FRAME_BODY} {
return [lindex $frame $::FRAME_BODY]
} else {
return {}
}
}
# Return body size from last read message, if any, else zero
method size {} {
if {[llength $frame] > $::FRAME_BODY} {
return [string length [lindex $frame $::FRAME_BODY]]
} else {
return {}
}
}
# Set message key as provided
method set_key {ikey} {
while {[llength $frame] <= $::FRAME_KEY} {
lappend frame {}
}
lset frame $::FRAME_KEY $ikey
}
# Set message sequence number
method set_sequence {isequence} {
while {[llength $frame] <= $::FRAME_SEQ} {
lappend frame {}
}
set sequence [binary format W $isequence]
lset frame $::FRAME_SEQ $sequence
}
# Set message body
method set_body {ibody} {
while {[llength $frame] <= $::FRAME_KEY} {
lappend frame {}
}
lset frame $::FRAME_BODY $ibody
}
# Set message key using printf format
method fmt_key {format args} {
my set_key [format $format {*}$args]
}
# Set message body using printf format
method fmt_body {format args} {
my set_body [format $format {*}$args]
}
# Store entire kvmsg into hash map, if key/value are set
# Nullifies kvmsg reference, and destroys automatically when no longer
# needed.
method store {hashnm} {
upvar $hashnm hash
if {[info exists hash([my key])]} {
$hash([my key]) destroy
}
set hash([my key]) [self]
}
# Dump message to stderr, for debugging and tracing
method dump {} {
set rt ""
append rt [format {[seq:%lld]} [my sequence]]
append rt [format {[key:%s]} [my key]]
append rt [format {[size:%d] } [my size]]
set size [my size]
set body [my body]
for {set i 0} {$i < $size} {incr i} {
set c [lindex $body $i]
if {[string is ascii $c]} {
append rt $c
} else {
append rt [binary scan H2 $c]
}
}
return $rt
}
}
namespace eval ::KVSimpleTest {
proc test {verbose} {
puts -nonewline " * kvmsg: "
# Prepare our context and sockets
zmq context context
set os [zmq socket output context DEALER]
output bind "ipc://kvmsg_selftest.ipc"
set is [zmq socket input context DEALER]
input connect "ipc://kvmsg_selftest.ipc"
# Test send and receive of simple message
set kvmsg [KVSimple new 1]
$kvmsg set_key "key"
$kvmsg set_body "body"
if {$verbose} {
puts [$kvmsg dump]
}
$kvmsg send $os
$kvmsg store kvmap
$kvmsg recv $is
if {$verbose} {
puts [$kvmsg dump]
}
if {[$kvmsg key] ne "key"} {
error "Unexpected key: [$kvmsg key]"
}
$kvmsg store kvmap
# Shutdown and destroy all objects
input close
output close
context term
puts "OK"
}
}
#::KVSimpleTest::test 1
kvsimple: 键值消息类 使用 OCaml
稍后,我们将创建一个更精密的kvmsg类,它将在实际应用中工作。
服务器和客户端都维护哈希表,但只有在我们先启动所有客户端,然后启动服务器,并且客户端从不崩溃的情况下,这个第一个模型才能正常工作。这非常不切实际。
获取带外快照 #
因此,现在我们面临第二个问题:如何处理延迟加入的客户端或崩溃后重启的客户端。
为了让延迟(或恢复)的客户端追赶上服务器,它必须获取服务器状态的快照。正如我们将“消息”简化为“一个带序列号的键值对”,我们也可以将“状态”简化为“一个哈希表”。要获取服务器状态,客户端打开一个 DEALER 套接字并明确请求。
为了实现这一点,我们必须解决一个时序问题。获取状态快照需要一定时间,如果快照很大,时间可能会相当长。我们需要将更新正确地应用到快照上。但是服务器不知道何时开始向我们发送更新。一种方法是先订阅,获取第一个更新,然后请求“更新 N 的状态”。这将要求服务器为每次更新存储一个快照,这不切实际。
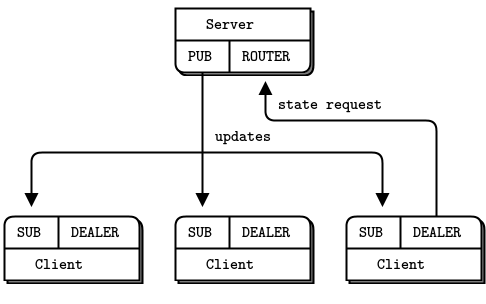
因此,我们将在客户端进行同步,步骤如下
-
客户端首先订阅更新,然后发出状态请求。这保证了状态将比它收到的最旧的更新要新。
-
客户端等待服务器返回状态,同时将所有更新排队。它通过不读取这些消息来做到这一点:ZeroMQ 将它们保存在套接字队列中。
-
当客户端收到其状态更新时,它再次开始读取更新。但是,它会丢弃任何比状态更新更旧的更新。因此,如果状态更新包含截至 200 的更新,客户端将丢弃截至 201 的更新。
-
然后,客户端将更新应用到自己的状态快照上。
这是一个利用 ZeroMQ 自身内部队列的简单模型。这是服务器端
clonesrv2: 克隆服务器,模型二 使用 Ada
clonesrv2: 克隆服务器,模型二 使用 Basic
clonesrv2: 克隆服务器,模型二 使用 C
// Clone server - Model Two
// Lets us build this source without creating a library
#include "kvsimple.c"
static int s_send_single (const char *key, void *data, void *args);
static void state_manager (void *args, zctx_t *ctx, void *pipe);
int main (void)
{
// Prepare our context and sockets
zctx_t *ctx = zctx_new ();
void *publisher = zsocket_new (ctx, ZMQ_PUB);
zsocket_bind (publisher, "tcp://*:5557");
int64_t sequence = 0;
srandom ((unsigned) time (NULL));
// Start state manager and wait for synchronization signal
void *updates = zthread_fork (ctx, state_manager, NULL);
free (zstr_recv (updates));
while (!zctx_interrupted) {
// Distribute as key-value message
kvmsg_t *kvmsg = kvmsg_new (++sequence);
kvmsg_fmt_key (kvmsg, "%d", randof (10000));
kvmsg_fmt_body (kvmsg, "%d", randof (1000000));
kvmsg_send (kvmsg, publisher);
kvmsg_send (kvmsg, updates);
kvmsg_destroy (&kvmsg);
}
printf (" Interrupted\n%d messages out\n", (int) sequence);
zctx_destroy (&ctx);
return 0;
}
// Routing information for a key-value snapshot
typedef struct {
void *socket; // ROUTER socket to send to
zframe_t *identity; // Identity of peer who requested state
} kvroute_t;
// Send one state snapshot key-value pair to a socket
// Hash item data is our kvmsg object, ready to send
static int
s_send_single (const char *key, void *data, void *args)
{
kvroute_t *kvroute = (kvroute_t *) args;
// Send identity of recipient first
zframe_send (&kvroute->identity,
kvroute->socket, ZFRAME_MORE + ZFRAME_REUSE);
kvmsg_t *kvmsg = (kvmsg_t *) data;
kvmsg_send (kvmsg, kvroute->socket);
return 0;
}
// .split state manager
// The state manager task maintains the state and handles requests from
// clients for snapshots:
static void
state_manager (void *args, zctx_t *ctx, void *pipe)
{
zhash_t *kvmap = zhash_new ();
zstr_send (pipe, "READY");
void *snapshot = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_bind (snapshot, "tcp://*:5556");
zmq_pollitem_t items [] = {
{ pipe, 0, ZMQ_POLLIN, 0 },
{ snapshot, 0, ZMQ_POLLIN, 0 }
};
int64_t sequence = 0; // Current snapshot version number
while (!zctx_interrupted) {
int rc = zmq_poll (items, 2, -1);
if (rc == -1 && errno == ETERM)
break; // Context has been shut down
// Apply state update from main thread
if (items [0].revents & ZMQ_POLLIN) {
kvmsg_t *kvmsg = kvmsg_recv (pipe);
if (!kvmsg)
break; // Interrupted
sequence = kvmsg_sequence (kvmsg);
kvmsg_store (&kvmsg, kvmap);
}
// Execute state snapshot request
if (items [1].revents & ZMQ_POLLIN) {
zframe_t *identity = zframe_recv (snapshot);
if (!identity)
break; // Interrupted
// Request is in second frame of message
char *request = zstr_recv (snapshot);
if (streq (request, "ICANHAZ?"))
free (request);
else {
printf ("E: bad request, aborting\n");
break;
}
// Send state snapshot to client
kvroute_t routing = { snapshot, identity };
// For each entry in kvmap, send kvmsg to client
zhash_foreach (kvmap, s_send_single, &routing);
// Now send END message with sequence number
printf ("Sending state shapshot=%d\n", (int) sequence);
zframe_send (&identity, snapshot, ZFRAME_MORE);
kvmsg_t *kvmsg = kvmsg_new (sequence);
kvmsg_set_key (kvmsg, "KTHXBAI");
kvmsg_set_body (kvmsg, (byte *) "", 0);
kvmsg_send (kvmsg, snapshot);
kvmsg_destroy (&kvmsg);
}
}
zhash_destroy (&kvmap);
}
clonesrv2: 克隆服务器,模型二 使用 C++
#include "kvsimple.hpp"
#include <thread>
static int s_send_snapshot(std::unordered_map<std::string, kvmsg>& kvmap, zmq::socket_t* snapshot);
static void state_manager(zmq::context_t* ctx);
// simulate zthread_fork, create attached thread and return the pipe socket
std::pair<std::thread, zmq::socket_t> zthread_fork(zmq::context_t& ctx, void (*thread_func)(zmq::context_t*)) {
// create the pipe socket for the main thread to communicate with its child thread
zmq::socket_t pipe(ctx, ZMQ_PAIR);
pipe.connect("inproc://state_manager");
// start child thread
std::thread t(thread_func, &ctx);
return std::make_pair(std::move(t), std::move(pipe));
}
int main(void) {
// Prepare our context and socket
zmq::context_t ctx(1);
zmq::socket_t publisher(ctx, ZMQ_PUB);
publisher.bind("tcp://*:5557");
int64_t sequence = 0;
// Start state manager and wait for synchronization signal
auto [state_manager_thread, state_manager_pipe] = zthread_fork(ctx, state_manager);
zmq::message_t sync_msg;
state_manager_pipe.recv(sync_msg);
s_catch_signals();
while(!s_interrupted) {
kvmsg msg = kvmsg("key", ++sequence, (unsigned char *)"value");
msg.set_key(std::to_string(within(10000)));
msg.set_body((unsigned char *)std::to_string(within(1000000)).c_str());
msg.send(publisher);
msg.send(state_manager_pipe);
s_sleep(500);
}
std::cout << " Interrupted\n" << sequence << " messages out\n" << std::endl;
kvmsg msg("END", sequence, (unsigned char *)"");
msg.send(state_manager_pipe);
state_manager_thread.join();
return 0;
}
// Routing information for a key-value snapshot
typedef struct {
zmq::socket_t *socket; // ROUTER socket to send to
std::string identity; // Identity of peer who requested state
} kvroute_t;
// Send one state snapshot key-value pair to a socket
// Hash item data is our kvmsg object, ready to send
static int s_send_snapshot(std::unordered_map<std::string, kvmsg>& kvmap, kvroute_t& kvroute) {
for (auto& kv : kvmap) {
s_sendmore(*kvroute.socket, kvroute.identity);
kv.second.send(*kvroute.socket);
}
return 0;
}
// .split state manager
// The state manager task maintains the state and handles requests from
// clients for snapshots:
static void state_manager(zmq::context_t *ctx) {
std::unordered_map<std::string, kvmsg> kvmap;
zmq::socket_t pipe(*ctx, ZMQ_PAIR);
pipe.bind("inproc://state_manager");
s_send(pipe, std::string("READY"));
zmq::socket_t snapshot(*ctx, ZMQ_ROUTER);
snapshot.bind("tcp://*:5556");
zmq::pollitem_t items[] = {
{pipe, 0, ZMQ_POLLIN, 0},
{snapshot, 0, ZMQ_POLLIN, 0}
};
int64_t sequence = 0;
while(true) {
zmq::poll(&items[0], 2, -1);
if (items[0].revents & ZMQ_POLLIN) {
auto msg = kvmsg::recv(pipe);
if (!msg || msg->key() == "END") {
break;
}
sequence = msg->sequence();
kvmap[msg->key()] = *msg;
}
// Execute state snapshot request
if (items[1].revents & ZMQ_POLLIN) {
std::string identity = s_recv(snapshot);
std::string request = s_recv(snapshot);
if (request != "ICANHAZ?") {
std::cerr << "E: bad request, aborting\n";
break;
}
// Send state snapshot to client
kvroute_t kvroute = {&snapshot, identity};
// For each entry in kvmap, send kvmsg to client
s_send_snapshot(kvmap, kvroute);
// Now send END message with sequence number
std::cout << "sending state snapshot=" << sequence << std::endl;
s_sendmore(snapshot, identity);
kvmsg msg("KTHXBAI", sequence, (unsigned char *)"");
msg.send(snapshot);
}
}
}
clonesrv2: 克隆服务器,模型二 使用 C#
clonesrv2: 克隆服务器,模型二 使用 CL
clonesrv2: 克隆服务器,模型二 使用 Delphi
clonesrv2: 克隆服务器,模型二 使用 Erlang
clonesrv2: 克隆服务器,模型二 使用 Elixir
clonesrv2: 克隆服务器,模型二 使用 F#
clonesrv2: 克隆服务器,模型二 使用 Felix
clonesrv2: 克隆服务器,模型二 使用 Go
clonesrv2: 克隆服务器,模型二 使用 Haskell
clonesrv2: 克隆服务器,模型二 使用 Haxe
clonesrv2: 克隆服务器,模型二 使用 Java
package guide;
import java.nio.ByteBuffer;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZThread;
import org.zeromq.ZThread.IAttachedRunnable;
/**
* Clone server Model Two
*
* @author Danish Shrestha <dshrestha06@gmail.com>
*
*/
public class clonesrv2
{
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket publisher = ctx.createSocket(SocketType.PUB);
publisher.bind("tcp://*:5557");
Socket updates = ZThread.fork(ctx, new StateManager());
Random random = new Random();
long sequence = 0;
while (!Thread.currentThread().isInterrupted()) {
long currentSequenceNumber = ++sequence;
int key = random.nextInt(10000);
int body = random.nextInt(1000000);
ByteBuffer b = ByteBuffer.allocate(4);
b.asIntBuffer().put(body);
kvsimple kvMsg = new kvsimple(
key + "", currentSequenceNumber, b.array()
);
kvMsg.send(publisher);
kvMsg.send(updates); // send a message to State Manager thread.
try {
Thread.sleep(1000);
}
catch (InterruptedException e) {
}
}
System.out.printf(" Interrupted\n%d messages out\n", sequence);
}
}
public static class StateManager implements IAttachedRunnable
{
private static Map<String, kvsimple> kvMap = new LinkedHashMap<String, kvsimple>();
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
pipe.send("READY"); // optional
Socket snapshot = ctx.createSocket(SocketType.ROUTER);
snapshot.bind("tcp://*:5556");
Poller poller = ctx.createPoller(2);
poller.register(pipe, ZMQ.Poller.POLLIN);
poller.register(snapshot, ZMQ.Poller.POLLIN);
long stateSequence = 0;
while (!Thread.currentThread().isInterrupted()) {
if (poller.poll() < 0)
break; // Context has been shut down
// apply state updates from main thread
if (poller.pollin(0)) {
kvsimple kvMsg = kvsimple.recv(pipe);
if (kvMsg == null)
break;
StateManager.kvMap.put(kvMsg.getKey(), kvMsg);
stateSequence = kvMsg.getSequence();
}
// execute state snapshot request
if (poller.pollin(1)) {
byte[] identity = snapshot.recv(0);
if (identity == null)
break;
String request = new String(snapshot.recv(0), ZMQ.CHARSET);
if (!request.equals("ICANHAZ?")) {
System.out.println("E: bad request, aborting");
break;
}
Iterator<Entry<String, kvsimple>> iter = kvMap.entrySet().iterator();
while (iter.hasNext()) {
Entry<String, kvsimple> entry = iter.next();
kvsimple msg = entry.getValue();
System.out.println("Sending message " + entry.getValue().getSequence());
this.sendMessage(msg, identity, snapshot);
}
// now send end message with getSequence number
System.out.println("Sending state snapshot = " + stateSequence);
snapshot.send(identity, ZMQ.SNDMORE);
kvsimple message = new kvsimple("KTHXBAI", stateSequence, ZMQ.MESSAGE_SEPARATOR);
message.send(snapshot);
}
}
}
private void sendMessage(kvsimple msg, byte[] identity, Socket snapshot)
{
snapshot.send(identity, ZMQ.SNDMORE);
msg.send(snapshot);
}
}
public static void main(String[] args)
{
new clonesrv2().run();
}
}
clonesrv2: 克隆服务器,模型二 使用 Julia
clonesrv2: 克隆服务器,模型二 使用 Lua
clonesrv2:克隆服务器,Node.js 版模型二
clonesrv2:克隆服务器,Objective-C 版模型二
clonesrv2:克隆服务器,ooc 版模型二
clonesrv2:克隆服务器,Perl 版模型二
clonesrv2:克隆服务器,PHP 版模型二
clonesrv2:克隆服务器,Python 版模型二
"""
Clone server Model Two
Author: Min RK <benjaminrk@gmail.com>
"""
import random
import threading
import time
import zmq
from kvsimple import KVMsg
from zhelpers import zpipe
def main():
# Prepare our context and publisher socket
ctx = zmq.Context()
publisher = ctx.socket(zmq.PUB)
publisher.bind("tcp://*:5557")
updates, peer = zpipe(ctx)
manager_thread = threading.Thread(target=state_manager, args=(ctx,peer))
manager_thread.daemon=True
manager_thread.start()
sequence = 0
random.seed(time.time())
try:
while True:
# Distribute as key-value message
sequence += 1
kvmsg = KVMsg(sequence)
kvmsg.key = "%d" % random.randint(1,10000)
kvmsg.body = "%d" % random.randint(1,1000000)
kvmsg.send(publisher)
kvmsg.send(updates)
except KeyboardInterrupt:
print " Interrupted\n%d messages out" % sequence
# simple struct for routing information for a key-value snapshot
class Route:
def __init__(self, socket, identity):
self.socket = socket # ROUTER socket to send to
self.identity = identity # Identity of peer who requested state
def send_single(key, kvmsg, route):
"""Send one state snapshot key-value pair to a socket
Hash item data is our kvmsg object, ready to send
"""
# Send identity of recipient first
route.socket.send(route.identity, zmq.SNDMORE)
kvmsg.send(route.socket)
def state_manager(ctx, pipe):
"""This thread maintains the state and handles requests from clients for snapshots.
"""
kvmap = {}
pipe.send("READY")
snapshot = ctx.socket(zmq.ROUTER)
snapshot.bind("tcp://*:5556")
poller = zmq.Poller()
poller.register(pipe, zmq.POLLIN)
poller.register(snapshot, zmq.POLLIN)
sequence = 0 # Current snapshot version number
while True:
try:
items = dict(poller.poll())
except (zmq.ZMQError, KeyboardInterrupt):
break # interrupt/context shutdown
# Apply state update from main thread
if pipe in items:
kvmsg = KVMsg.recv(pipe)
sequence = kvmsg.sequence
kvmsg.store(kvmap)
# Execute state snapshot request
if snapshot in items:
msg = snapshot.recv_multipart()
identity = msg[0]
request = msg[1]
if request == "ICANHAZ?":
pass
else:
print "E: bad request, aborting\n",
break
# Send state snapshot to client
route = Route(snapshot, identity)
# For each entry in kvmap, send kvmsg to client
for k,v in kvmap.items():
send_single(k,v,route)
# Now send END message with sequence number
print "Sending state shapshot=%d\n" % sequence,
snapshot.send(identity, zmq.SNDMORE)
kvmsg = KVMsg(sequence)
kvmsg.key = "KTHXBAI"
kvmsg.body = ""
kvmsg.send(snapshot)
if __name__ == '__main__':
main()
clonesrv2:克隆服务器,Q 版模型二
clonesrv2:克隆服务器,Racket 版模型二
clonesrv2:克隆服务器,Ruby 版模型二
clonesrv2:克隆服务器,Rust 版模型二
clonesrv2:克隆服务器,Scala 版模型二
clonesrv2:克隆服务器,Tcl 版模型二
#
# Clone server Model Two
#
lappend auto_path .
package require KVSimple
if {[llength $argv] == 0} {
set argv "pub"
} elseif {[llength $argv] != 1} {
puts "Usage: clonesrv2.tcl <pub|upd>"
exit 1
}
lassign $argv what
set tclsh [info nameofexecutable]
expr srand([pid])
switch -exact -- $what {
pub {
# Prepare our context and publisher socket
zmq context context
set pub [zmq socket publisher context PUB]
$pub bind "tcp://*:5557"
set upd [zmq socket updates context PAIR]
$upd bind "ipc://updates.ipc"
set sequence 0
# Start state manager and wait for synchronization signal
exec $tclsh clonesrv2.tcl upd > upd.log 2>@1 &
$upd recv
while {1} {
# Distribute as key-value message
set kvmsg [KVSimple new [incr sequence]]
$kvmsg set_key [expr {int(rand()*10000)}]
$kvmsg set_body [expr {int(rand()*1000000)}]
$kvmsg send $pub
$kvmsg send $upd
puts [$kvmsg dump]
after 500
}
$pub close
$upd close
context term
}
upd {
zmq context context
set upd [zmq socket updates context PAIR]
$upd connect "ipc://updates.ipc"
$upd send "READY"
set snp [zmq socket snapshot context ROUTER]
$snp bind "tcp://*:5556"
set sequence 0 ;# Current snapshot version number
# Apply state update from main thread
proc apply_state_update {upd} {
global kvmap sequence
set kvmsg [KVSimple new]
$kvmsg recv $upd
set sequence [$kvmsg sequence]
$kvmsg store kvmap
}
# Execute state snapshot request
proc execute_state_snapshot_request {snp} {
global kvmap sequence
set identity [$snp recv]
# Request is in second frame of message
set request [$snp recv]
if {$request ne "ICANHAZ?"} {
puts "E: bad request, aborting"
exit 1
}
# Send state snapshot to client
# For each entry in kvmap, send kvmsg to client
foreach {key value} [array get kvmap] {
# Send one state snapshot key-value pair to a socket
# Hash item data is our kvmsg object, ready to send
$snp sendmore $identity
$value send $snp
}
# Now send END message with sequence number
puts "Sending state snapshot=$sequence"
$snp sendmore $identity
set kvmsg [KVSimple new $sequence]
$kvmsg set_key "KTHXBAI"
$kvmsg set_body ""
$kvmsg send $snp
$kvmsg destroy
}
$upd readable [list apply_state_update $upd]
$snp readable [list execute_state_snapshot_request $snp]
vwait forever
$upd close
$snp close
context term
}
}
clonesrv2:克隆服务器,OCaml 版模型二
这是客户端
clonecli2:克隆客户端,Ada 版模型二
clonecli2:克隆客户端,Basic 版模型二
clonecli2:克隆客户端,C 版模型二
// Clone client - Model Two
// Lets us build this source without creating a library
#include "kvsimple.c"
int main (void)
{
// Prepare our context and subscriber
zctx_t *ctx = zctx_new ();
void *snapshot = zsocket_new (ctx, ZMQ_DEALER);
zsocket_connect (snapshot, "tcp://:5556");
void *subscriber = zsocket_new (ctx, ZMQ_SUB);
zsocket_set_subscribe (subscriber, "");
zsocket_connect (subscriber, "tcp://:5557");
zhash_t *kvmap = zhash_new ();
// Get state snapshot
int64_t sequence = 0;
zstr_send (snapshot, "ICANHAZ?");
while (true) {
kvmsg_t *kvmsg = kvmsg_recv (snapshot);
if (!kvmsg)
break; // Interrupted
if (streq (kvmsg_key (kvmsg), "KTHXBAI")) {
sequence = kvmsg_sequence (kvmsg);
printf ("Received snapshot=%d\n", (int) sequence);
kvmsg_destroy (&kvmsg);
break; // Done
}
kvmsg_store (&kvmsg, kvmap);
}
// Now apply pending updates, discard out-of-sequence messages
while (!zctx_interrupted) {
kvmsg_t *kvmsg = kvmsg_recv (subscriber);
if (!kvmsg)
break; // Interrupted
if (kvmsg_sequence (kvmsg) > sequence) {
sequence = kvmsg_sequence (kvmsg);
kvmsg_store (&kvmsg, kvmap);
}
else
kvmsg_destroy (&kvmsg);
}
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
return 0;
}
clonecli2:克隆客户端,C++ 版模型二
#include "kvsimple.hpp"
int main(void) {
zmq::context_t ctx(1);
zmq::socket_t snapshot(ctx, ZMQ_DEALER);
snapshot.connect("tcp://:5556");
zmq::socket_t subscriber(ctx, ZMQ_SUB);
subscriber.set(zmq::sockopt::subscribe, "");
subscriber.connect("tcp://:5557");
std::unordered_map<std::string, kvmsg> kvmap;
// Get state snapshot
int64_t sequence = 0;
s_send(snapshot, std::string("ICANHAZ?"));
while (true) {
auto kv = kvmsg::recv(snapshot);
if (!kv) break;
if (kv->key() == "KTHXBAI") {
sequence = kv->sequence();
std::cout << "Received snapshot=" << sequence << std::endl;
break;
}
kvmap[kv->key()] = *kv;
}
// Now apply pending updates, discard out-of-sequence messages
while(true) {
auto kv = kvmsg::recv(subscriber);
if (!kv) break;
if (kv->sequence() > sequence) {
sequence = kv->sequence();
kvmap[kv->key()] = *kv;
std::cout << "Received update=" << sequence << std::endl;
}
}
return 0;
}
clonecli2:克隆客户端,C# 版模型二
clonecli2:克隆客户端,CL 版模型二
clonecli2:克隆客户端,Delphi 版模型二
clonecli2:克隆客户端,Erlang 版模型二
clonecli2:克隆客户端,Elixir 版模型二
clonecli2:克隆客户端,F# 版模型二
clonecli2:克隆客户端,Felix 版模型二
clonecli2:克隆客户端,Go 版模型二
clonecli2:克隆客户端,Haskell 版模型二
clonecli2:克隆客户端,Haxe 版模型二
clonecli2:克隆客户端,Java 版模型二
package guide;
import java.util.HashMap;
import java.util.Map;
import org.zeromq.SocketType;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZContext;
/**
* Clone client Model Two
*
* @author Danish Shrestha <dshrestha06@gmail.com>
*
*/
public class clonecli2
{
private static Map<String, kvsimple> kvMap = new HashMap<String, kvsimple>();
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket snapshot = ctx.createSocket(SocketType.DEALER);
snapshot.connect("tcp://:5556");
Socket subscriber = ctx.createSocket(SocketType.SUB);
subscriber.connect("tcp://:5557");
subscriber.subscribe(ZMQ.SUBSCRIPTION_ALL);
// get state snapshot
snapshot.send("ICANHAZ?".getBytes(ZMQ.CHARSET), 0);
long sequence = 0;
while (true) {
kvsimple kvMsg = kvsimple.recv(snapshot);
if (kvMsg == null)
break;
sequence = kvMsg.getSequence();
if ("KTHXBAI".equalsIgnoreCase(kvMsg.getKey())) {
System.out.println("Received snapshot = " + kvMsg.getSequence());
break; // done
}
System.out.println("receiving " + kvMsg.getSequence());
clonecli2.kvMap.put(kvMsg.getKey(), kvMsg);
}
// now apply pending updates, discard out-of-getSequence messages
while (true) {
kvsimple kvMsg = kvsimple.recv(subscriber);
if (kvMsg == null)
break;
if (kvMsg.getSequence() > sequence) {
sequence = kvMsg.getSequence();
System.out.println("receiving " + sequence);
clonecli2.kvMap.put(kvMsg.getKey(), kvMsg);
}
}
}
}
public static void main(String[] args)
{
new clonecli2().run();
}
}
clonecli2:克隆客户端,Julia 版模型二
clonecli2:克隆客户端,Lua 版模型二
clonecli2:克隆客户端,Node.js 版模型二
clonecli2:克隆客户端,Objective-C 版模型二
clonecli2:克隆客户端,ooc 版模型二
clonecli2:克隆客户端,Perl 版模型二
clonecli2:克隆客户端,PHP 版模型二
clonecli2:克隆客户端,Python 版模型二
"""
Clone client Model Two
Author: Min RK <benjaminrk@gmail.com>
"""
import time
import zmq
from kvsimple import KVMsg
def main():
# Prepare our context and subscriber
ctx = zmq.Context()
snapshot = ctx.socket(zmq.DEALER)
snapshot.linger = 0
snapshot.connect("tcp://:5556")
subscriber = ctx.socket(zmq.SUB)
subscriber.linger = 0
subscriber.setsockopt(zmq.SUBSCRIBE, '')
subscriber.connect("tcp://:5557")
kvmap = {}
# Get state snapshot
sequence = 0
snapshot.send("ICANHAZ?")
while True:
try:
kvmsg = KVMsg.recv(snapshot)
except:
break; # Interrupted
if kvmsg.key == "KTHXBAI":
sequence = kvmsg.sequence
print "Received snapshot=%d" % sequence
break # Done
kvmsg.store(kvmap)
# Now apply pending updates, discard out-of-sequence messages
while True:
try:
kvmsg = KVMsg.recv(subscriber)
except:
break # Interrupted
if kvmsg.sequence > sequence:
sequence = kvmsg.sequence
kvmsg.store(kvmap)
if __name__ == '__main__':
main()
clonecli2:克隆客户端,Q 版模型二
clonecli2:克隆客户端,Racket 版模型二
clonecli2:克隆客户端,Ruby 版模型二
clonecli2:克隆客户端,Rust 版模型二
clonecli2:克隆客户端,Scala 版模型二
clonecli2:克隆客户端,Tcl 版模型二
#
# Clone client Model Two
#
lappend auto_path .
package require KVSimple
# Prepare our context and subscriber
zmq context context
set snp [zmq socket snapshot context DEALER]
$snp connect "tcp://:5556"
set sub [zmq socket subscriber context SUB]
$sub setsockopt SUBSCRIBE ""
$sub connect "tcp://:5557"
# Get state snapshot
set sequence 0
$snp send "ICANHAZ?"
while {1} {
set kvmsg [KVSimple new]
$kvmsg recv $snp
if {[$kvmsg key] eq "KTHXBAI"} {
set sequence [$kvmsg sequence]
puts "Received snapshot=$sequence"
$kvmsg destroy
break
}
$kvmsg store kvmap
}
# Now apply pending updates, discard out-of-sequence messages
while {1} {
set kvmsg [KVSimple new]
$kvmsg recv $sub
puts [$kvmsg dump]
if {[$kvmsg sequence] > $sequence} {
puts " store"
$kvmsg store kvmap
} else {
puts " ignore"
$kvmsg destroy
}
}
$snp close
$sub close
context term
clonecli2:克隆客户端,OCaml 版模型二
关于这两个程序,有几点需要注意
-
服务器使用了两个任务。一个线程(随机地)生成更新并发送到主 PUB 套接字,而另一个线程则在 ROUTER 套接字上处理状态请求。这两个线程通过 PAIR 套接字 over aninproc:@<//>@连接进行通信。
-
客户端非常简单。在 C 语言中,它只有大约五十行代码。大部分繁重的工作是在kvmsg类中完成的。即便如此,基本的克隆模式实现起来比最初看起来要容易。
-
我们没有使用任何花哨的方法来序列化状态。哈希表保存了一组kvmsg对象,服务器将这些对象作为一批消息发送给请求状态的客户端。如果多个客户端同时请求状态,每个客户端将获得一个不同的快照。
-
我们假定客户端恰好有一个服务器进行通信。服务器必须正在运行;我们不尝试解决服务器崩溃时会发生什么的问题。
目前,这两个程序并没有做任何实际的事情,但它们能够正确同步状态。这是一个巧妙的示例,展示了如何混合不同的模式:PAIR-PAIR、PUB-SUB 和 ROUTER-DEALER。
从客户端重新发布更新 #
在我们的第二个模型中,键值存储的更改来自服务器本身。这是一个中心化模型,例如,当我们需要分发一个中心配置文件并在每个节点上进行本地缓存时,这个模型就很有用。一个更有趣的模型是接收来自客户端而不是服务器的更新。因此,服务器成为了一个无状态代理。这为我们带来了一些好处:
-
我们对服务器的可靠性担忧较少。如果它崩溃,我们可以启动一个新的实例并向其馈送新值。
-
我们可以使用键值存储在活跃对等方之间共享信息。
要将客户端的更新发送回服务器,我们可以使用多种套接字模式。最简单的可行方案是 PUSH-PULL 组合。
为什么我们不允许客户端之间直接发布更新?虽然这会降低延迟,但会失去一致性保证。如果允许更新的顺序根据接收者而改变,就无法获得一致的共享状态。假设我们有两个客户端,正在更改不同的键。这会工作良好。但如果两个客户端尝试大致同时更改同一个键,它们最终会对该键的值产生不同的看法。
当多个地方同时发生更改时,有几种实现一致性的策略。我们将采用中心化所有更改的方法。无论客户端进行更改的确切时机如何,所有更改都会通过服务器推送,服务器根据接收更新的顺序强制执行一个单一的序列。
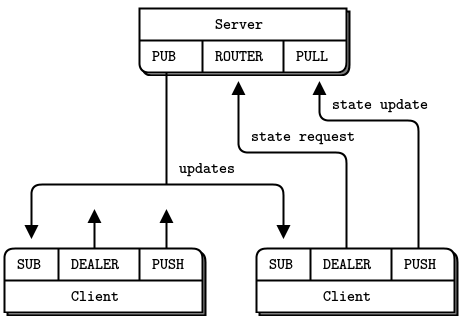
通过中介所有更改,服务器还可以为所有更新添加一个唯一的序列号。有了唯一的序列,客户端就可以检测到更严重的故障,包括网络拥塞和队列溢出。如果客户端发现其接收的消息流有缺失,它可以采取行动。客户端联系服务器并请求缺失的消息似乎是合理的,但在实践中这并没有用。如果存在缺失,它们是由网络压力引起的,给网络增加更多压力只会让情况变得更糟。客户端所能做的就是警告用户它“无法继续”,停止运行,并且在有人手动检查问题原因之前不再重启。
现在我们将在客户端生成状态更新。这是服务器
clonesrv3:克隆服务器,Ada 版模型三
clonesrv3:克隆服务器,Basic 版模型三
clonesrv3:克隆服务器,C 版模型三
// Clone server - Model Three
// Lets us build this source without creating a library
#include "kvsimple.c"
// Routing information for a key-value snapshot
typedef struct {
void *socket; // ROUTER socket to send to
zframe_t *identity; // Identity of peer who requested state
} kvroute_t;
// Send one state snapshot key-value pair to a socket
// Hash item data is our kvmsg object, ready to send
static int
s_send_single (const char *key, void *data, void *args)
{
kvroute_t *kvroute = (kvroute_t *) args;
// Send identity of recipient first
zframe_send (&kvroute->identity,
kvroute->socket, ZFRAME_MORE + ZFRAME_REUSE);
kvmsg_t *kvmsg = (kvmsg_t *) data;
kvmsg_send (kvmsg, kvroute->socket);
return 0;
}
int main (void)
{
// Prepare our context and sockets
zctx_t *ctx = zctx_new ();
void *snapshot = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_bind (snapshot, "tcp://*:5556");
void *publisher = zsocket_new (ctx, ZMQ_PUB);
zsocket_bind (publisher, "tcp://*:5557");
void *collector = zsocket_new (ctx, ZMQ_PULL);
zsocket_bind (collector, "tcp://*:5558");
// .split body of main task
// The body of the main task collects updates from clients and
// publishes them back out to clients:
int64_t sequence = 0;
zhash_t *kvmap = zhash_new ();
zmq_pollitem_t items [] = {
{ collector, 0, ZMQ_POLLIN, 0 },
{ snapshot, 0, ZMQ_POLLIN, 0 }
};
while (!zctx_interrupted) {
int rc = zmq_poll (items, 2, 1000 * ZMQ_POLL_MSEC);
// Apply state update sent from client
if (items [0].revents & ZMQ_POLLIN) {
kvmsg_t *kvmsg = kvmsg_recv (collector);
if (!kvmsg)
break; // Interrupted
kvmsg_set_sequence (kvmsg, ++sequence);
kvmsg_send (kvmsg, publisher);
kvmsg_store (&kvmsg, kvmap);
printf ("I: publishing update %5d\n", (int) sequence);
}
// Execute state snapshot request
if (items [1].revents & ZMQ_POLLIN) {
zframe_t *identity = zframe_recv (snapshot);
if (!identity)
break; // Interrupted
// Request is in second frame of message
char *request = zstr_recv (snapshot);
if (streq (request, "ICANHAZ?"))
free (request);
else {
printf ("E: bad request, aborting\n");
break;
}
// Send state snapshot to client
kvroute_t routing = { snapshot, identity };
// For each entry in kvmap, send kvmsg to client
zhash_foreach (kvmap, s_send_single, &routing);
// Now send END message with sequence number
printf ("I: sending shapshot=%d\n", (int) sequence);
zframe_send (&identity, snapshot, ZFRAME_MORE);
kvmsg_t *kvmsg = kvmsg_new (sequence);
kvmsg_set_key (kvmsg, "KTHXBAI");
kvmsg_set_body (kvmsg, (byte *) "", 0);
kvmsg_send (kvmsg, snapshot);
kvmsg_destroy (&kvmsg);
}
}
printf (" Interrupted\n%d messages handled\n", (int) sequence);
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
return 0;
}
clonesrv3:克隆服务器,C++ 版模型三
#include "kvsimple.hpp"
// Routing information for a key-value snapshot
typedef struct {
zmq::socket_t *socket; // ROUTER socket to send to
std::string identity; // Identity of peer who requested state
} kvroute_t;
// Send one state snapshot key-value pair to a socket
// Hash item data is our kvmsg object, ready to send
static int s_send_snapshot(std::unordered_map<std::string, kvmsg>& kvmap, kvroute_t& kvroute) {
for (auto& kv : kvmap) {
s_sendmore(*kvroute.socket, kvroute.identity);
kv.second.send(*kvroute.socket);
}
return 0;
}
int main(void) {
// Prepare our context and sockets
zmq::context_t ctx(1);
zmq::socket_t snapshot(ctx, ZMQ_ROUTER);
snapshot.bind("tcp://*:5556");
zmq::socket_t publisher(ctx, ZMQ_PUB);
publisher.bind("tcp://*:5557");
zmq::socket_t collector(ctx, ZMQ_PULL);
collector.bind("tcp://*:5558");
// .split body of main task
// The body of the main task collects updates from clients and
// publishes them back out to clients:
std::unordered_map<std::string, kvmsg> kvmap;
int64_t sequence = 0;
zmq::pollitem_t items[] = {
{collector, 0, ZMQ_POLLIN, 0},
{snapshot, 0, ZMQ_POLLIN, 0}
};
s_catch_signals();
while(!s_interrupted) {
try {
zmq::poll(items, 2, -1);
} catch (const zmq::error_t& e) {
break; // Interrupted
}
// Apply state update sent from client
if (items[0].revents & ZMQ_POLLIN) {
auto msg = kvmsg::recv(collector);
if (!msg) {
break; // Interrupted
}
msg->set_sequence(++sequence);
kvmap[msg->key()] = *msg;
msg->send(publisher);
std::cout << "I: publishing update " << sequence << std::endl;
}
// Execute state snapshot request
if (items[1].revents & ZMQ_POLLIN) {
std::string identity = s_recv(snapshot);
std::string request = s_recv(snapshot);
if (request != "ICANHAZ?") {
std::cerr << "E: bad request, aborting\n";
break;
}
// Send state snapshot to client
kvroute_t kvroute = {&snapshot, identity};
// For each entry in kvmap, send kvmsg to client
s_send_snapshot(kvmap, kvroute);
// Now send END message with sequence number
std::cout << "I: sending state snapshot=" << sequence << std::endl;
s_sendmore(snapshot, identity);
kvmsg msg("KTHXBAI", sequence, (unsigned char *)"");
msg.send(snapshot);
}
}
std::cout << "Interrupted\n" << sequence << " messages handled\n";
return 0;
}
clonesrv3:克隆服务器,C# 版模型三
clonesrv3:克隆服务器,CL 版模型三
clonesrv3:克隆服务器,Delphi 版模型三
clonesrv3:克隆服务器,Erlang 版模型三
clonesrv3:克隆服务器,Elixir 版模型三
clonesrv3:克隆服务器,F# 版模型三
clonesrv3:克隆服务器,Felix 版模型三
clonesrv3:克隆服务器,Go 版模型三
clonesrv3:克隆服务器,Haskell 版模型三
clonesrv3:克隆服务器,Haxe 版模型三
clonesrv3:克隆服务器,Java 版模型三
package guide;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Map.Entry;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
/**
* Clone server Model Three
* @author Danish Shrestha <dshrestha06@gmail.com>
*
*/
public class clonesrv3
{
private static Map<String, kvsimple> kvMap = new LinkedHashMap<String, kvsimple>();
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket snapshot = ctx.createSocket(SocketType.ROUTER);
snapshot.bind("tcp://*:5556");
Socket publisher = ctx.createSocket(SocketType.PUB);
publisher.bind("tcp://*:5557");
Socket collector = ctx.createSocket(SocketType.PULL);
collector.bind("tcp://*:5558");
Poller poller = ctx.createPoller(2);
poller.register(collector, Poller.POLLIN);
poller.register(snapshot, Poller.POLLIN);
long sequence = 0;
while (!Thread.currentThread().isInterrupted()) {
if (poller.poll(1000) < 0)
break; // Context has been shut down
// apply state updates from main thread
if (poller.pollin(0)) {
kvsimple kvMsg = kvsimple.recv(collector);
if (kvMsg == null) // Interrupted
break;
kvMsg.setSequence(++sequence);
kvMsg.send(publisher);
clonesrv3.kvMap.put(kvMsg.getKey(), kvMsg);
System.out.printf("I: publishing update %5d\n", sequence);
}
// execute state snapshot request
if (poller.pollin(1)) {
byte[] identity = snapshot.recv(0);
if (identity == null)
break; // Interrupted
String request = snapshot.recvStr();
if (!request.equals("ICANHAZ?")) {
System.out.println("E: bad request, aborting");
break;
}
Iterator<Entry<String, kvsimple>> iter = kvMap.entrySet()
.iterator();
while (iter.hasNext()) {
Entry<String, kvsimple> entry = iter.next();
kvsimple msg = entry.getValue();
System.out.println(
"Sending message " + entry.getValue().getSequence()
);
this.sendMessage(msg, identity, snapshot);
}
// now send end message with getSequence number
System.out.println("Sending state snapshot = " + sequence);
snapshot.send(identity, ZMQ.SNDMORE);
kvsimple message = new kvsimple(
"KTHXBAI", sequence, ZMQ.SUBSCRIPTION_ALL
);
message.send(snapshot);
}
}
System.out.printf(" Interrupted\n%d messages handled\n", sequence);
}
}
private void sendMessage(kvsimple msg, byte[] identity, Socket snapshot)
{
snapshot.send(identity, ZMQ.SNDMORE);
msg.send(snapshot);
}
public static void main(String[] args)
{
new clonesrv3().run();
}
}
clonesrv3:克隆服务器,Julia 版模型三
clonesrv3:克隆服务器,Lua 版模型三
clonesrv3:克隆服务器,Node.js 版模型三
clonesrv3:克隆服务器,Objective-C 版模型三
clonesrv3:克隆服务器,ooc 版模型三
clonesrv3:克隆服务器,Perl 版模型三
clonesrv3:克隆服务器,PHP 版模型三
clonesrv3:克隆服务器,Python 版模型三
"""
Clone server Model Three
Author: Min RK <benjaminrk@gmail.com
"""
import zmq
from kvsimple import KVMsg
# simple struct for routing information for a key-value snapshot
class Route:
def __init__(self, socket, identity):
self.socket = socket # ROUTER socket to send to
self.identity = identity # Identity of peer who requested state
def send_single(key, kvmsg, route):
"""Send one state snapshot key-value pair to a socket"""
# Send identity of recipient first
route.socket.send(route.identity, zmq.SNDMORE)
kvmsg.send(route.socket)
def main():
# context and sockets
ctx = zmq.Context()
snapshot = ctx.socket(zmq.ROUTER)
snapshot.bind("tcp://*:5556")
publisher = ctx.socket(zmq.PUB)
publisher.bind("tcp://*:5557")
collector = ctx.socket(zmq.PULL)
collector.bind("tcp://*:5558")
sequence = 0
kvmap = {}
poller = zmq.Poller()
poller.register(collector, zmq.POLLIN)
poller.register(snapshot, zmq.POLLIN)
while True:
try:
items = dict(poller.poll(1000))
except:
break # Interrupted
# Apply state update sent from client
if collector in items:
kvmsg = KVMsg.recv(collector)
sequence += 1
kvmsg.sequence = sequence
kvmsg.send(publisher)
kvmsg.store(kvmap)
print "I: publishing update %5d" % sequence
# Execute state snapshot request
if snapshot in items:
msg = snapshot.recv_multipart()
identity = msg[0]
request = msg[1]
if request == "ICANHAZ?":
pass
else:
print "E: bad request, aborting\n",
break
# Send state snapshot to client
route = Route(snapshot, identity)
# For each entry in kvmap, send kvmsg to client
for k,v in kvmap.items():
send_single(k,v,route)
# Now send END message with sequence number
print "Sending state shapshot=%d\n" % sequence,
snapshot.send(identity, zmq.SNDMORE)
kvmsg = KVMsg(sequence)
kvmsg.key = "KTHXBAI"
kvmsg.body = ""
kvmsg.send(snapshot)
print " Interrupted\n%d messages handled" % sequence
if __name__ == '__main__':
main()
clonesrv3:克隆服务器,Q 版模型三
clonesrv3:克隆服务器,Racket 版模型三
clonesrv3:克隆服务器,Ruby 版模型三
clonesrv3:克隆服务器,Rust 版模型三
clonesrv3:克隆服务器,Scala 版模型三
clonesrv3:克隆服务器,Tcl 版模型三
#
# Clone server Model Three
#
lappend auto_path .
package require KVSimple
# Prepare our context and sockets
zmq context context
set snp [zmq socket snapshot context ROUTER]
$snp bind "tcp://*:5556"
set pub [zmq socket publisher context PUB]
$pub bind "tcp://*:5557"
set col [zmq socket collector context PULL]
$col bind "tcp://*:5558"
set sequence 0
# Apply state update sent from client
proc apply_state_update {col pub} {
global sequence kvmap
set kvmsg [KVSimple new]
$kvmsg recv $col
$kvmsg set_sequence [incr sequence]
$kvmsg send $pub
$kvmsg store kvmap
puts "Publishing update $sequence"
}
# Execute state snapshot request
proc execute_state_snapshot_request {snp} {
global sequence
set identity [$snp recv]
# Request is in second frame of message
set request [$snp recv]
if {$request ne "ICANHAZ?"} {
puts "E: bad request, aborting"
exit 1
}
# Send state snapshot to client
# For each entry in kvmap, send kvmsg to client
foreach {key value} [array get kvmap] {
# Send one state snapshot key-value pair to a socket
# Hash item data is our kvmsg object, ready to send
$snp sendmore $identity
$value send $snp
}
# Now send END message with sequence number
puts "I: sending snapshot=$sequence"
$snp sendmore $identity
set kvmsg [KVSimple new $sequence]
$kvmsg set_key "KTHXBAI"
$kvmsg set_body ""
$kvmsg send $snp
$kvmsg destroy
}
$col readable [list apply_state_update $col $pub]
$snp readable [list execute_state_snapshot_request $snp]
vwait forever
$col close
$pub close
$snp close
context term
clonesrv3:克隆服务器,OCaml 版模型三
这是客户端
clonecli3:克隆客户端,Ada 版模型三
clonecli3:克隆客户端,Basic 版模型三
clonecli3:克隆客户端,C 版模型三
// Clone client - Model Three
// Lets us build this source without creating a library
#include "kvsimple.c"
int main (void)
{
// Prepare our context and subscriber
zctx_t *ctx = zctx_new ();
void *snapshot = zsocket_new (ctx, ZMQ_DEALER);
zsocket_connect (snapshot, "tcp://:5556");
void *subscriber = zsocket_new (ctx, ZMQ_SUB);
zsocket_set_subscribe (subscriber, "");
zsocket_connect (subscriber, "tcp://:5557");
void *publisher = zsocket_new (ctx, ZMQ_PUSH);
zsocket_connect (publisher, "tcp://:5558");
zhash_t *kvmap = zhash_new ();
srandom ((unsigned) time (NULL));
// .split getting a state snapshot
// We first request a state snapshot:
int64_t sequence = 0;
zstr_send (snapshot, "ICANHAZ?");
while (true) {
kvmsg_t *kvmsg = kvmsg_recv (snapshot);
if (!kvmsg)
break; // Interrupted
if (streq (kvmsg_key (kvmsg), "KTHXBAI")) {
sequence = kvmsg_sequence (kvmsg);
printf ("I: received snapshot=%d\n", (int) sequence);
kvmsg_destroy (&kvmsg);
break; // Done
}
kvmsg_store (&kvmsg, kvmap);
}
// .split processing state updates
// Now we wait for updates from the server and every so often, we
// send a random key-value update to the server:
int64_t alarm = zclock_time () + 1000;
while (!zctx_interrupted) {
zmq_pollitem_t items [] = { { subscriber, 0, ZMQ_POLLIN, 0 } };
int tickless = (int) ((alarm - zclock_time ()));
if (tickless < 0)
tickless = 0;
int rc = zmq_poll (items, 1, tickless * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Context has been shut down
if (items [0].revents & ZMQ_POLLIN) {
kvmsg_t *kvmsg = kvmsg_recv (subscriber);
if (!kvmsg)
break; // Interrupted
// Discard out-of-sequence kvmsgs, incl. heartbeats
if (kvmsg_sequence (kvmsg) > sequence) {
sequence = kvmsg_sequence (kvmsg);
kvmsg_store (&kvmsg, kvmap);
printf ("I: received update=%d\n", (int) sequence);
}
else
kvmsg_destroy (&kvmsg);
}
// If we timed out, generate a random kvmsg
if (zclock_time () >= alarm) {
kvmsg_t *kvmsg = kvmsg_new (0);
kvmsg_fmt_key (kvmsg, "%d", randof (10000));
kvmsg_fmt_body (kvmsg, "%d", randof (1000000));
kvmsg_send (kvmsg, publisher);
kvmsg_destroy (&kvmsg);
alarm = zclock_time () + 1000;
}
}
printf (" Interrupted\n%d messages in\n", (int) sequence);
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
return 0;
}
clonecli3:克隆客户端,C++ 版模型三
// Clone client - Model Three
#include "kvsimple.hpp"
int main(void) {
// Prepare our context and subscriber
zmq::context_t ctx(1);
zmq::socket_t snapshot(ctx, ZMQ_DEALER);
snapshot.connect("tcp://:5556");
zmq::socket_t subscriber(ctx, ZMQ_SUB);
subscriber.set(zmq::sockopt::subscribe, "");
subscriber.connect("tcp://:5557");
zmq::socket_t publisher(ctx, ZMQ_PUSH);
publisher.connect("tcp://:5558");
std::unordered_map<std::string, kvmsg> kvmap;
// .split getting a state snapshot
// We first request a state snapshot:
// Get state snapshot
int64_t sequence = 0;
s_send(snapshot, std::string("ICANHAZ?"));
while (true) {
auto kv = kvmsg::recv(snapshot);
if (!kv) break;
if (kv->key() == "KTHXBAI") {
sequence = kv->sequence();
std::cout << "I: received snapshot=" << sequence << std::endl;
break;
}
kvmap[kv->key()] = *kv;
}
// .split processing state updates
// Now we wait for updates from the server and every so often, we
// send a random key-value update to the server:
std::chrono::time_point<std::chrono::steady_clock> alarm = std::chrono::steady_clock::now() + std::chrono::seconds(1);
s_catch_signals();
while(!s_interrupted) {
zmq::pollitem_t items[] = {
{subscriber, 0, ZMQ_POLLIN, 0}
};
int tickless = std::chrono::duration_cast<std::chrono::milliseconds>(alarm - std::chrono::steady_clock::now()).count();
if (tickless < 0)
tickless = 0;
try {
zmq::poll(items, 1, tickless);
} catch (const zmq::error_t& e) {
break; // Interrupted
}
if (items[0].revents & ZMQ_POLLIN) {
auto kv = kvmsg::recv(subscriber);
if (!kv) break;
if (kv->sequence() > sequence) {
sequence = kv->sequence();
kvmap[kv->key()] = *kv;
std::cout << "I: received update=" << sequence << std::endl;
}
}
if (std::chrono::steady_clock::now() >= alarm) {
// Send random update to server
std::string key = std::to_string(within(10000));
kvmsg kv(key, 0, (unsigned char *)std::to_string(within(1000000)).c_str());
kv.send(publisher);
alarm = std::chrono::steady_clock::now() + std::chrono::seconds(1);
}
}
std::cout << " Interrupted\n" << sequence << " messages in\n" << std::endl;
return 0;
}
clonecli3:克隆客户端,C# 版模型三
clonecli3:克隆客户端,CL 版模型三
clonecli3:克隆客户端,Delphi 版模型三
clonecli3:克隆客户端,Erlang 版模型三
clonecli3:克隆客户端,Elixir 版模型三
clonecli3:克隆客户端,F# 版模型三
clonecli3:克隆客户端,Felix 版模型三
clonecli3:克隆客户端,Go 版模型三
clonecli3:克隆客户端,Haskell 版模型三
clonecli3:克隆客户端,Haxe 版模型三
clonecli3:克隆客户端,Java 版模型三
package guide;
import java.nio.ByteBuffer;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
/**
* Clone client Model Three
* @author Danish Shrestha <dshrestha06@gmail.com>
*
*/
public class clonecli3
{
private static Map<String, kvsimple> kvMap = new HashMap<String, kvsimple>();
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket snapshot = ctx.createSocket(SocketType.DEALER);
snapshot.connect("tcp://:5556");
Socket subscriber = ctx.createSocket(SocketType.SUB);
subscriber.connect("tcp://:5557");
subscriber.subscribe(ZMQ.SUBSCRIPTION_ALL);
Socket push = ctx.createSocket(SocketType.PUSH);
push.connect("tcp://:5558");
// get state snapshot
long sequence = 0;
snapshot.send("ICANHAZ?".getBytes(ZMQ.CHARSET), 0);
while (true) {
kvsimple kvMsg = kvsimple.recv(snapshot);
if (kvMsg == null)
break; // Interrupted
sequence = kvMsg.getSequence();
if ("KTHXBAI".equalsIgnoreCase(kvMsg.getKey())) {
System.out.println(
"Received snapshot = " + kvMsg.getSequence()
);
break; // done
}
System.out.println("receiving " + kvMsg.getSequence());
clonecli3.kvMap.put(kvMsg.getKey(), kvMsg);
}
Poller poller = ctx.createPoller(1);
poller.register(subscriber);
Random random = new Random();
// now apply pending updates, discard out-of-getSequence messages
long alarm = System.currentTimeMillis() + 5000;
while (true) {
int rc = poller.poll(
Math.max(0, alarm - System.currentTimeMillis())
);
if (rc == -1)
break; // Context has been shut down
if (poller.pollin(0)) {
kvsimple kvMsg = kvsimple.recv(subscriber);
if (kvMsg == null)
break; // Interrupted
if (kvMsg.getSequence() > sequence) {
sequence = kvMsg.getSequence();
System.out.println("receiving " + sequence);
clonecli3.kvMap.put(kvMsg.getKey(), kvMsg);
}
}
if (System.currentTimeMillis() >= alarm) {
int key = random.nextInt(10000);
int body = random.nextInt(1000000);
ByteBuffer b = ByteBuffer.allocate(4);
b.asIntBuffer().put(body);
kvsimple kvUpdateMsg = new kvsimple(key + "", 0, b.array());
kvUpdateMsg.send(push);
alarm = System.currentTimeMillis() + 1000;
}
}
}
}
public static void main(String[] args)
{
new clonecli3().run();
}
}
clonecli3:克隆客户端,Julia 版模型三
clonecli3:克隆客户端,Lua 版模型三
clonecli3:克隆客户端,Node.js 版模型三
clonecli3:克隆客户端,Objective-C 版模型三
clonecli3:克隆客户端,ooc 版模型三
clonecli3:克隆客户端,Perl 版模型三
clonecli3:克隆客户端,PHP 版模型三
clonecli3:克隆客户端,Python 版模型三
"""
Clone client Model Three
Author: Min RK <benjaminrk@gmail.com
"""
import random
import time
import zmq
from kvsimple import KVMsg
def main():
# Prepare our context and subscriber
ctx = zmq.Context()
snapshot = ctx.socket(zmq.DEALER)
snapshot.linger = 0
snapshot.connect("tcp://:5556")
subscriber = ctx.socket(zmq.SUB)
subscriber.linger = 0
subscriber.setsockopt(zmq.SUBSCRIBE, '')
subscriber.connect("tcp://:5557")
publisher = ctx.socket(zmq.PUSH)
publisher.linger = 0
publisher.connect("tcp://:5558")
random.seed(time.time())
kvmap = {}
# Get state snapshot
sequence = 0
snapshot.send("ICANHAZ?")
while True:
try:
kvmsg = KVMsg.recv(snapshot)
except:
return # Interrupted
if kvmsg.key == "KTHXBAI":
sequence = kvmsg.sequence
print "I: Received snapshot=%d" % sequence
break # Done
kvmsg.store(kvmap)
poller = zmq.Poller()
poller.register(subscriber, zmq.POLLIN)
alarm = time.time()+1.
while True:
tickless = 1000*max(0, alarm - time.time())
try:
items = dict(poller.poll(tickless))
except:
break # Interrupted
if subscriber in items:
kvmsg = KVMsg.recv(subscriber)
# Discard out-of-sequence kvmsgs, incl. heartbeats
if kvmsg.sequence > sequence:
sequence = kvmsg.sequence
kvmsg.store(kvmap)
print "I: received update=%d" % sequence
# If we timed-out, generate a random kvmsg
if time.time() >= alarm:
kvmsg = KVMsg(0)
kvmsg.key = "%d" % random.randint(1,10000)
kvmsg.body = "%d" % random.randint(1,1000000)
kvmsg.send(publisher)
kvmsg.store(kvmap)
alarm = time.time() + 1.
print " Interrupted\n%d messages in" % sequence
if __name__ == '__main__':
main()
clonecli3:克隆客户端,Q 版模型三
clonecli3:克隆客户端,Racket 版模型三
clonecli3:克隆客户端,Ruby 版模型三
clonecli3:克隆客户端,Rust 版模型三
clonecli3:克隆客户端,Scala 版模型三
clonecli3:克隆客户端,Tcl 版模型三
#
# Clone client Model Three
#
lappend auto_path .
package require KVSimple
# Prepare our context and subscriber
zmq context context
set snp [zmq socket snapshot context DEALER]
$snp connect "tcp://:5556"
set sub [zmq socket subscriber context SUB]
$sub setsockopt SUBSCRIBE ""
$sub connect "tcp://:5557"
set pub [zmq socket publisher context PUSH]
$pub connect "tcp://:5558"
expr srand([pid])
# Get state snapshot
set sequence 0
$snp send "ICANHAZ?"
while {1} {
set kvmsg [KVSimple new]
$kvmsg recv $snp
if {[$kvmsg key] eq "KTHXBAI"} {
set sequence [$kvmsg sequence]
puts "I: received snapshot=$sequence"
$kvmsg destroy
break
}
$kvmsg store kvmap
}
proc recv_kvmsg {pub sub} {
global after_id sequence kvmap alarm
after cancel $after_id
$sub readable {}
set kvmsg [KVSimple new]
$kvmsg recv $sub
if {[$kvmsg sequence] > $sequence} {
set sequence [$kvmsg sequence]
$kvmsg store kvmap
puts "I: received update=$sequence"
} else {
$kvmsg destroy
}
$sub readable [list recv_kvmsg $pub $sub]
set after_id [after [tickless] [list send_kvmsg $pub $sub]]
}
proc send_kvmsg {pub sub} {
global after_id sequence kvmap alarm
$sub readable {}
set kvmsg [KVSimple new 0]
$kvmsg set_key [expr {int(rand()*10000)}]
$kvmsg set_body [expr {int(rand()*1000000)}]
$kvmsg send $pub
$kvmsg destroy
set alarm [expr {[clock milliseconds] + 1000}]
$sub readable [list recv_kvmsg $pub $sub]
set after_id [after [tickless] [list send_kvmsg $pub $sub]]
}
proc tickless {} {
global alarm
set t [expr {[clock milliseconds] - $alarm}]
if {$t < 0} {
set t 0
}
return $t
}
set alarm [expr {[clock milliseconds] + 1000}]
$sub readable [list recv_kvmsg $pub $sub]
set after_id [after [tickless] [list send_kvmsg $pub $sub]]
vwait forever
$pub close
$sub close
$snp close
context term
clonecli3:克隆客户端,OCaml 版模型三
关于这第三个设计,有几点需要注意
-
服务器已精简为一个单独的任务。它管理一个用于接收传入更新的 PULL 套接字,一个用于状态请求的 ROUTER 套接字,以及一个用于发送传出更新的 PUB 套接字。
-
客户端使用一个简单的无时钟节拍计时器每秒向服务器发送一个随机更新。在实际实现中,我们将从应用代码驱动更新。
处理子树 #
随着客户端数量的增长,共享存储的大小也会增长。将所有内容发送给每个客户端变得不再合理。这是 pub-sub 的经典故事:当客户端数量很少时,可以将每条消息发送给所有客户端。随着架构的增长,这变得低效。客户端会在不同领域进行专业化。
因此,即使在使用共享存储时,一些客户端也只想使用存储的一部分,我们称之为子树。客户端在发出状态请求时必须请求该子树,并且在订阅更新时也必须指定相同的子树。
有几种常用的树结构语法。一种是路径层次结构,另一种是主题树。它们看起来像这样:
- 路径层次结构/一些/路径/列表
- 主题树一些.主题.列表
我们将使用路径层次结构,并扩展我们的客户端和服务器,以便客户端可以处理单个子树。一旦了解了如何处理单个子树,如果你的用例需要,你就可以自己扩展它来处理多个子树。
这是实现子树功能的服务器,是模型三的一个小变体
clonesrv4:克隆服务器,Ada 版模型四
clonesrv4:克隆服务器,Basic 版模型四
clonesrv4:克隆服务器,C 版模型四
// Clone server - Model Four
// Lets us build this source without creating a library
#include "kvsimple.c"
// Routing information for a key-value snapshot
typedef struct {
void *socket; // ROUTER socket to send to
zframe_t *identity; // Identity of peer who requested state
char *subtree; // Client subtree specification
} kvroute_t;
// Send one state snapshot key-value pair to a socket
// Hash item data is our kvmsg object, ready to send
static int
s_send_single (const char *key, void *data, void *args)
{
kvroute_t *kvroute = (kvroute_t *) args;
kvmsg_t *kvmsg = (kvmsg_t *) data;
if (strlen (kvroute->subtree) <= strlen (kvmsg_key (kvmsg))
&& memcmp (kvroute->subtree,
kvmsg_key (kvmsg), strlen (kvroute->subtree)) == 0) {
// Send identity of recipient first
zframe_send (&kvroute->identity,
kvroute->socket, ZFRAME_MORE + ZFRAME_REUSE);
kvmsg_send (kvmsg, kvroute->socket);
}
return 0;
}
// The main task is identical to clonesrv3 except for where it
// handles subtrees.
// .skip
int main (void)
{
// Prepare our context and sockets
zctx_t *ctx = zctx_new ();
void *snapshot = zsocket_new (ctx, ZMQ_ROUTER);
zsocket_bind (snapshot, "tcp://*:5556");
void *publisher = zsocket_new (ctx, ZMQ_PUB);
zsocket_bind (publisher, "tcp://*:5557");
void *collector = zsocket_new (ctx, ZMQ_PULL);
zsocket_bind (collector, "tcp://*:5558");
int64_t sequence = 0;
zhash_t *kvmap = zhash_new ();
zmq_pollitem_t items [] = {
{ collector, 0, ZMQ_POLLIN, 0 },
{ snapshot, 0, ZMQ_POLLIN, 0 }
};
while (!zctx_interrupted) {
int rc = zmq_poll (items, 2, 1000 * ZMQ_POLL_MSEC);
// Apply state update sent from client
if (items [0].revents & ZMQ_POLLIN) {
kvmsg_t *kvmsg = kvmsg_recv (collector);
if (!kvmsg)
break; // Interrupted
kvmsg_set_sequence (kvmsg, ++sequence);
kvmsg_send (kvmsg, publisher);
kvmsg_store (&kvmsg, kvmap);
printf ("I: publishing update %5d\n", (int) sequence);
}
// Execute state snapshot request
if (items [1].revents & ZMQ_POLLIN) {
zframe_t *identity = zframe_recv (snapshot);
if (!identity)
break; // Interrupted
// .until
// Request is in second frame of message
char *request = zstr_recv (snapshot);
char *subtree = NULL;
if (streq (request, "ICANHAZ?")) {
free (request);
subtree = zstr_recv (snapshot);
}
// .skip
else {
printf ("E: bad request, aborting\n");
break;
}
// .until
// Send state snapshot to client
kvroute_t routing = { snapshot, identity, subtree };
// .skip
// For each entry in kvmap, send kvmsg to client
zhash_foreach (kvmap, s_send_single, &routing);
// .until
// Now send END message with sequence number
printf ("I: sending shapshot=%d\n", (int) sequence);
zframe_send (&identity, snapshot, ZFRAME_MORE);
kvmsg_t *kvmsg = kvmsg_new (sequence);
kvmsg_set_key (kvmsg, "KTHXBAI");
kvmsg_set_body (kvmsg, (byte *) subtree, 0);
kvmsg_send (kvmsg, snapshot);
kvmsg_destroy (&kvmsg);
free (subtree);
}
}
// .skip
printf (" Interrupted\n%d messages handled\n", (int) sequence);
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
return 0;
}
clonesrv4:克隆服务器,C++ 版模型四
#include "kvsimple.hpp"
// Routing information for a key-value snapshot
typedef struct {
zmq::socket_t *socket; // ROUTER socket to send to
std::string identity; // Identity of peer who requested state
std::string subtree; // Client subtree specification
} kvroute_t;
// Send one state snapshot key-value pair to a socket
// Hash item data is our kvmsg object, ready to send
static int s_send_snapshot(std::unordered_map<std::string, kvmsg>& kvmap, kvroute_t& kvroute) {
for (auto& kv : kvmap) {
if (kvroute.subtree.size() <= kv.first.size() && kv.first.compare(0, kvroute.subtree.size(), kvroute.subtree) == 0) {
s_sendmore(*kvroute.socket, kvroute.identity);
kv.second.send(*kvroute.socket);
}
}
return 0;
}
int main(void) {
// Prepare our context and sockets
zmq::context_t ctx(1);
zmq::socket_t snapshot(ctx, ZMQ_ROUTER);
snapshot.bind("tcp://*:5556");
zmq::socket_t publisher(ctx, ZMQ_PUB);
publisher.bind("tcp://*:5557");
zmq::socket_t collector(ctx, ZMQ_PULL);
collector.bind("tcp://*:5558");
// .split body of main task
// The body of the main task collects updates from clients and
// publishes them back out to clients:
std::unordered_map<std::string, kvmsg> kvmap;
int64_t sequence = 0;
zmq::pollitem_t items[] = {
{collector, 0, ZMQ_POLLIN, 0},
{snapshot, 0, ZMQ_POLLIN, 0}
};
s_catch_signals();
while(!s_interrupted) {
try {
zmq::poll(items, 2, -1);
} catch (const zmq::error_t& e) {
break; // Interrupted
}
// Apply state update sent from client
if (items[0].revents & ZMQ_POLLIN) {
auto msg = kvmsg::recv(collector);
if (!msg) {
break; // Interrupted
}
msg->set_sequence(++sequence);
kvmap[msg->key()] = *msg;
msg->send(publisher);
std::cout << "I: publishing update " << sequence << std::endl;
}
// Execute state snapshot request
if (items[1].revents & ZMQ_POLLIN) {
std::string identity = s_recv(snapshot);
std::string request = s_recv(snapshot);
if (request != "ICANHAZ?") {
std::cerr << "E: bad request, aborting\n";
break;
}
// Client requests a subtree of the state
std::string subtree = s_recv(snapshot);
// Send state snapshot to client
kvroute_t kvroute = {&snapshot, identity, subtree};
// For each entry in kvmap, send kvmsg to client
s_send_snapshot(kvmap, kvroute);
// Now send END message with sequence number
std::cout << "I: sending state snapshot=" << sequence << std::endl;
s_sendmore(snapshot, identity);
kvmsg msg("KTHXBAI", sequence, (unsigned char *)subtree.c_str());
msg.send(snapshot);
}
}
std::cout << "Interrupted\n" << sequence << " messages handled\n";
return 0;
}
clonesrv4:克隆服务器,C# 版模型四
clonesrv4:克隆服务器,CL 版模型四
clonesrv4:克隆服务器,Delphi 版模型四
clonesrv4:克隆服务器,Erlang 版模型四
clonesrv4:克隆服务器,Elixir 版模型四
clonesrv4:克隆服务器,F# 版模型四
clonesrv4:克隆服务器,Felix 版模型四
clonesrv4:克隆服务器,Go 版模型四
clonesrv4:克隆服务器,Haskell 版模型四
clonesrv4:克隆服务器,Haxe 版模型四
clonesrv4:克隆服务器,Java 版模型四
package guide;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Map.Entry;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
/**
* Clone server Model Four
*/
public class clonesrv4
{
private static Map<String, kvsimple> kvMap = new LinkedHashMap<String, kvsimple>();
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket snapshot = ctx.createSocket(SocketType.ROUTER);
snapshot.bind("tcp://*:5556");
Socket publisher = ctx.createSocket(SocketType.PUB);
publisher.bind("tcp://*:5557");
Socket collector = ctx.createSocket(SocketType.PULL);
collector.bind("tcp://*:5558");
Poller poller = ctx.createPoller(2);
poller.register(collector, Poller.POLLIN);
poller.register(snapshot, Poller.POLLIN);
long sequence = 0;
while (!Thread.currentThread().isInterrupted()) {
if (poller.poll(1000) < 0)
break; // Context has been shut down
// apply state updates from main thread
if (poller.pollin(0)) {
kvsimple kvMsg = kvsimple.recv(collector);
if (kvMsg == null) // Interrupted
break;
kvMsg.setSequence(++sequence);
kvMsg.send(publisher);
clonesrv4.kvMap.put(kvMsg.getKey(), kvMsg);
System.out.printf("I: publishing update %5d\n", sequence);
}
// execute state snapshot request
if (poller.pollin(1)) {
byte[] identity = snapshot.recv(0);
if (identity == null)
break; // Interrupted
// .until
// Request is in second frame of message
String request = snapshot.recvStr();
if (!request.equals("ICANHAZ?")) {
System.out.println("E: bad request, aborting");
break;
}
String subtree = snapshot.recvStr();
Iterator<Entry<String, kvsimple>> iter = kvMap.entrySet()
.iterator();
while (iter.hasNext()) {
Entry<String, kvsimple> entry = iter.next();
kvsimple msg = entry.getValue();
System.out.println(
"Sending message " + entry.getValue().getSequence()
);
this.sendMessage(msg, identity, subtree, snapshot);
}
// now send end message with getSequence number
System.out.println("Sending state snapshot = " + sequence);
snapshot.send(identity, ZMQ.SNDMORE);
kvsimple message = new kvsimple(
"KTHXBAI", sequence, ZMQ.SUBSCRIPTION_ALL
);
message.send(snapshot);
}
}
System.out.printf(" Interrupted\n%d messages handled\n", sequence);
}
}
private void sendMessage(kvsimple msg, byte[] identity, String subtree, Socket snapshot)
{
snapshot.send(identity, ZMQ.SNDMORE);
snapshot.send(subtree, ZMQ.SNDMORE);
msg.send(snapshot);
}
public static void main(String[] args)
{
new clonesrv4().run();
}
}
clonesrv4:克隆服务器,Julia 版模型四
clonesrv4:克隆服务器,Lua 版模型四
clonesrv4:克隆服务器,Node.js 版模型四
clonesrv4:克隆服务器,Objective-C 版模型四
clonesrv4:克隆服务器,ooc 版模型四
clonesrv4:克隆服务器,Perl 版模型四
clonesrv4:克隆服务器,PHP 版模型四
clonesrv4:克隆服务器,Python 版模型四
"""
Clone server Model Four
Author: Min RK <benjaminrk@gmail.com
"""
import zmq
from kvsimple import KVMsg
# simple struct for routing information for a key-value snapshot
class Route:
def __init__(self, socket, identity, subtree):
self.socket = socket # ROUTER socket to send to
self.identity = identity # Identity of peer who requested state
self.subtree = subtree # Client subtree specification
def send_single(key, kvmsg, route):
"""Send one state snapshot key-value pair to a socket"""
# check front of key against subscription subtree:
if kvmsg.key.startswith(route.subtree):
# Send identity of recipient first
route.socket.send(route.identity, zmq.SNDMORE)
kvmsg.send(route.socket)
def main():
# context and sockets
ctx = zmq.Context()
snapshot = ctx.socket(zmq.ROUTER)
snapshot.bind("tcp://*:5556")
publisher = ctx.socket(zmq.PUB)
publisher.bind("tcp://*:5557")
collector = ctx.socket(zmq.PULL)
collector.bind("tcp://*:5558")
sequence = 0
kvmap = {}
poller = zmq.Poller()
poller.register(collector, zmq.POLLIN)
poller.register(snapshot, zmq.POLLIN)
while True:
try:
items = dict(poller.poll(1000))
except:
break # Interrupted
# Apply state update sent from client
if collector in items:
kvmsg = KVMsg.recv(collector)
sequence += 1
kvmsg.sequence = sequence
kvmsg.send(publisher)
kvmsg.store(kvmap)
print "I: publishing update %5d" % sequence
# Execute state snapshot request
if snapshot in items:
msg = snapshot.recv_multipart()
identity, request, subtree = msg
if request == "ICANHAZ?":
pass
else:
print "E: bad request, aborting\n",
break
# Send state snapshot to client
route = Route(snapshot, identity, subtree)
# For each entry in kvmap, send kvmsg to client
for k,v in kvmap.items():
send_single(k,v,route)
# Now send END message with sequence number
print "Sending state shapshot=%d\n" % sequence,
snapshot.send(identity, zmq.SNDMORE)
kvmsg = KVMsg(sequence)
kvmsg.key = "KTHXBAI"
kvmsg.body = subtree
kvmsg.send(snapshot)
print " Interrupted\n%d messages handled" % sequence
if __name__ == '__main__':
main()
clonesrv4:克隆服务器,Q 版模型四
clonesrv4:克隆服务器,Racket 版模型四
clonesrv4:克隆服务器,Ruby 版模型四
clonesrv4:克隆服务器,Rust 版模型四
clonesrv4:克隆服务器,Scala 版模型四
clonesrv4:克隆服务器,Tcl 版模型四
#
# Clone server Model Four
#
lappend auto_path .
package require KVSimple
# Prepare our context and sockets
zmq context context
set snp [zmq socket snapshot context ROUTER]
$snp bind "tcp://*:5556"
set pub [zmq socket publisher context PUB]
$pub bind "tcp://*:5557"
set col [zmq socket collector context PULL]
$col bind "tcp://*:5558"
set sequence 0
# Apply state update sent from client
proc apply_state_update {col pub} {
global sequence kvmap
set kvmsg [KVSimple new]
$kvmsg recv $col
$kvmsg set_sequence [incr sequence]
$kvmsg send $pub
$kvmsg store kvmap
puts "I: publishing update $sequence"
}
# Execute state snapshot request
proc execute_state_snapshot_request {snp} {
global sequence
set identity [$snp recv]
# Request is in second frame of message
set request [$snp recv]
if {$request ne "ICANHAZ?"} {
puts "E: bad request, aborting"
exit 1
}
set subtree [$snp recv]
# Send state snapshot to client
# For each entry in kvmap, send kvmsg to client
foreach {key value} [array get kvmap] {
# Send one state snapshot key-value pair to a socket
# Hash item data is our kvmsg object, ready to send
if {[string match $subtree* [$value key]]} {
$snp sendmore $identity
$value send $snp
}
}
# Now send END message with sequence number
puts "I: sending snapshot=$sequence"
$snp sendmore $identity
set kvmsg [KVSimple new $sequence]
$kvmsg set_key "KTHXBAI"
$kvmsg set_body $subtree
$kvmsg send $snp
$kvmsg destroy
}
$col readable [list apply_state_update $col $pub]
$snp readable [list execute_state_snapshot_request $snp]
vwait forever
$col close
$pub close
$snp close
context term
clonesrv4:克隆服务器,OCaml 版模型四
这是相应的客户端
clonecli4:克隆客户端,Ada 版模型四
clonecli4:克隆客户端,Basic 版模型四
clonecli4:克隆客户端,C 版模型四
// Clone client - Model Four
// Lets us build this source without creating a library
#include "kvsimple.c"
// This client is identical to clonecli3 except for where we
// handles subtrees.
#define SUBTREE "/client/"
// .skip
int main (void)
{
// Prepare our context and subscriber
zctx_t *ctx = zctx_new ();
void *snapshot = zsocket_new (ctx, ZMQ_DEALER);
zsocket_connect (snapshot, "tcp://:5556");
void *subscriber = zsocket_new (ctx, ZMQ_SUB);
zsocket_set_subscribe (subscriber, "");
// .until
zsocket_connect (subscriber, "tcp://:5557");
zsocket_set_subscribe (subscriber, SUBTREE);
// .skip
void *publisher = zsocket_new (ctx, ZMQ_PUSH);
zsocket_connect (publisher, "tcp://:5558");
zhash_t *kvmap = zhash_new ();
srandom ((unsigned) time (NULL));
// .until
// We first request a state snapshot:
int64_t sequence = 0;
zstr_sendm (snapshot, "ICANHAZ?");
zstr_send (snapshot, SUBTREE);
// .skip
while (true) {
kvmsg_t *kvmsg = kvmsg_recv (snapshot);
if (!kvmsg)
break; // Interrupted
if (streq (kvmsg_key (kvmsg), "KTHXBAI")) {
sequence = kvmsg_sequence (kvmsg);
printf ("I: received snapshot=%d\n", (int) sequence);
kvmsg_destroy (&kvmsg);
break; // Done
}
kvmsg_store (&kvmsg, kvmap);
}
int64_t alarm = zclock_time () + 1000;
while (!zctx_interrupted) {
zmq_pollitem_t items [] = { { subscriber, 0, ZMQ_POLLIN, 0 } };
int tickless = (int) ((alarm - zclock_time ()));
if (tickless < 0)
tickless = 0;
int rc = zmq_poll (items, 1, tickless * ZMQ_POLL_MSEC);
if (rc == -1)
break; // Context has been shut down
if (items [0].revents & ZMQ_POLLIN) {
kvmsg_t *kvmsg = kvmsg_recv (subscriber);
if (!kvmsg)
break; // Interrupted
// Discard out-of-sequence kvmsgs, incl. heartbeats
if (kvmsg_sequence (kvmsg) > sequence) {
sequence = kvmsg_sequence (kvmsg);
kvmsg_store (&kvmsg, kvmap);
printf ("I: received update=%d\n", (int) sequence);
}
else
kvmsg_destroy (&kvmsg);
}
// .until
// If we timed out, generate a random kvmsg
if (zclock_time () >= alarm) {
kvmsg_t *kvmsg = kvmsg_new (0);
kvmsg_fmt_key (kvmsg, "%s%d", SUBTREE, randof (10000));
kvmsg_fmt_body (kvmsg, "%d", randof (1000000));
kvmsg_send (kvmsg, publisher);
kvmsg_destroy (&kvmsg);
alarm = zclock_time () + 1000;
}
// .skip
}
printf (" Interrupted\n%d messages in\n", (int) sequence);
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
return 0;
}
clonecli4:克隆客户端,C++ 版模型四
// Clone client - Model Four
#include "kvsimple.hpp"
// This client is identical to clonecli3 except for where we
// handles subtrees.
#define SUBTREE "/client/"
// .skip
int main (void)
{
// Prepare our context and subscriber
zmq::context_t ctx(1);
zmq::socket_t snapshot(ctx, ZMQ_DEALER);
snapshot.connect("tcp://:5556");
zmq::socket_t subscriber(ctx, ZMQ_SUB);
subscriber.set(zmq::sockopt::subscribe, SUBTREE);
subscriber.connect("tcp://:5557");
zmq::socket_t publisher(ctx, ZMQ_PUSH);
publisher.connect("tcp://:5558");
std::unordered_map<std::string, kvmsg> kvmap;
// .split getting a state snapshot
// We first request a state snapshot:
// Get state snapshot
int64_t sequence = 0;
s_sendmore(snapshot, std::string("ICANHAZ?"));
s_send(snapshot, std::string(SUBTREE));
while(true) {
auto kv = kvmsg::recv(snapshot);
if (!kv) break;
if (kv->key() == "KTHXBAI") {
sequence = kv->sequence();
std::cout << "I: received snapshot=" << sequence << std::endl;
break;
}
kvmap[kv->key()] = *kv;
}
// .split processing state updates
// Now we wait for updates from the server and every so often, we
// send a random key-value update to the server:
std::chrono::time_point<std::chrono::steady_clock> alarm = std::chrono::steady_clock::now() + std::chrono::seconds(1);
s_catch_signals();
while(!s_interrupted) {
zmq::pollitem_t items[] = {
{subscriber, 0, ZMQ_POLLIN, 0}
};
int tickless = std::chrono::duration_cast<std::chrono::milliseconds>(alarm - std::chrono::steady_clock::now()).count();
if (tickless < 0)
tickless = 0;
try {
zmq::poll(items, 1, tickless);
} catch (const zmq::error_t& e) {
break; // Interrupted
}
if (items[0].revents & ZMQ_POLLIN) {
auto kv = kvmsg::recv(subscriber);
if (!kv) break;
if (kv->sequence() > sequence) {
sequence = kv->sequence();
kvmap[kv->key()] = *kv;
std::cout << "I: received update=" << sequence << std::endl;
}
}
if (std::chrono::steady_clock::now() >= alarm) {
// Send random update to server
std::string key = std::string(SUBTREE) + std::to_string(within(10000));
kvmsg kv(key, 0, (unsigned char *)std::to_string(within(1000000)).c_str());
kv.send(publisher);
alarm = std::chrono::steady_clock::now() + std::chrono::seconds(1);
}
}
std::cout << " Interrupted\n" << sequence << " messages in\n" << std::endl;
return 0;
}
clonecli4:克隆客户端,C# 版模型四
clonecli4:克隆客户端,CL 版模型四
clonecli4:克隆客户端,Delphi 版模型四
clonecli4:克隆客户端,Erlang 版模型四
clonecli4:克隆客户端,Elixir 版模型四
clonecli4:克隆客户端,F# 版模型四
clonecli4:克隆客户端,Felix 版模型四
clonecli4:克隆客户端,Go 版模型四
clonecli4:克隆客户端,Haskell 版模型四
clonecli4:克隆客户端,Haxe 版模型四
clonecli4:克隆客户端,Java 版模型四
package guide;
import java.nio.ByteBuffer;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
/**
* Clone client Model Four
*
*/
public class clonecli4
{
// This client is identical to clonecli3 except for where we
// handles subtrees.
private final static String SUBTREE = "/client/";
private static Map<String, kvsimple> kvMap = new HashMap<String, kvsimple>();
public void run()
{
try (ZContext ctx = new ZContext()) {
Socket snapshot = ctx.createSocket(SocketType.DEALER);
snapshot.connect("tcp://:5556");
Socket subscriber = ctx.createSocket(SocketType.SUB);
subscriber.connect("tcp://:5557");
subscriber.subscribe(SUBTREE.getBytes(ZMQ.CHARSET));
Socket push = ctx.createSocket(SocketType.PUSH);
push.connect("tcp://:5558");
// get state snapshot
snapshot.sendMore("ICANHAZ?");
snapshot.send(SUBTREE);
long sequence = 0;
while (true) {
kvsimple kvMsg = kvsimple.recv(snapshot);
if (kvMsg == null)
break; // Interrupted
sequence = kvMsg.getSequence();
if ("KTHXBAI".equalsIgnoreCase(kvMsg.getKey())) {
System.out.println(
"Received snapshot = " + kvMsg.getSequence()
);
break; // done
}
System.out.println("receiving " + kvMsg.getSequence());
clonecli4.kvMap.put(kvMsg.getKey(), kvMsg);
}
Poller poller = ctx.createPoller(1);
poller.register(subscriber);
Random random = new Random();
// now apply pending updates, discard out-of-getSequence messages
long alarm = System.currentTimeMillis() + 5000;
while (true) {
int rc = poller.poll(
Math.max(0, alarm - System.currentTimeMillis())
);
if (rc == -1)
break; // Context has been shut down
if (poller.pollin(0)) {
kvsimple kvMsg = kvsimple.recv(subscriber);
if (kvMsg == null)
break; // Interrupted
if (kvMsg.getSequence() > sequence) {
sequence = kvMsg.getSequence();
System.out.println("receiving " + sequence);
clonecli4.kvMap.put(kvMsg.getKey(), kvMsg);
}
}
if (System.currentTimeMillis() >= alarm) {
String key = String.format(
"%s%d", SUBTREE, random.nextInt(10000)
);
int body = random.nextInt(1000000);
ByteBuffer b = ByteBuffer.allocate(4);
b.asIntBuffer().put(body);
kvsimple kvUpdateMsg = new kvsimple(key, 0, b.array());
kvUpdateMsg.send(push);
alarm = System.currentTimeMillis() + 1000;
}
}
}
}
public static void main(String[] args)
{
new clonecli4().run();
}
}
clonecli4:克隆客户端,Julia 版模型四
clonecli4:克隆客户端,Lua 版模型四
clonecli4:克隆客户端,Node.js 版模型四
clonecli4:克隆客户端,Objective-C 版模型四
clonecli4:克隆客户端,ooc 版模型四
clonecli4:克隆客户端,Perl 版模型四
clonecli4:克隆客户端,PHP 版模型四
clonecli4:克隆客户端,Python 版模型四
"""
Clone client Model Four
Author: Min RK <benjaminrk@gmail.com
"""
import random
import time
import zmq
from kvsimple import KVMsg
SUBTREE = "/client/"
def main():
# Prepare our context and subscriber
ctx = zmq.Context()
snapshot = ctx.socket(zmq.DEALER)
snapshot.linger = 0
snapshot.connect("tcp://:5556")
subscriber = ctx.socket(zmq.SUB)
subscriber.linger = 0
subscriber.setsockopt(zmq.SUBSCRIBE, SUBTREE)
subscriber.connect("tcp://:5557")
publisher = ctx.socket(zmq.PUSH)
publisher.linger = 0
publisher.connect("tcp://:5558")
random.seed(time.time())
kvmap = {}
# Get state snapshot
sequence = 0
snapshot.send_multipart(["ICANHAZ?", SUBTREE])
while True:
try:
kvmsg = KVMsg.recv(snapshot)
except:
raise
return # Interrupted
if kvmsg.key == "KTHXBAI":
sequence = kvmsg.sequence
print "I: Received snapshot=%d" % sequence
break # Done
kvmsg.store(kvmap)
poller = zmq.Poller()
poller.register(subscriber, zmq.POLLIN)
alarm = time.time()+1.
while True:
tickless = 1000*max(0, alarm - time.time())
try:
items = dict(poller.poll(tickless))
except:
break # Interrupted
if subscriber in items:
kvmsg = KVMsg.recv(subscriber)
# Discard out-of-sequence kvmsgs, incl. heartbeats
if kvmsg.sequence > sequence:
sequence = kvmsg.sequence
kvmsg.store(kvmap)
print "I: received update=%d" % sequence
# If we timed-out, generate a random kvmsg
if time.time() >= alarm:
kvmsg = KVMsg(0)
kvmsg.key = SUBTREE + "%d" % random.randint(1,10000)
kvmsg.body = "%d" % random.randint(1,1000000)
kvmsg.send(publisher)
kvmsg.store(kvmap)
alarm = time.time() + 1.
print " Interrupted\n%d messages in" % sequence
if __name__ == '__main__':
main()
clonecli4:克隆客户端,Q 版模型四
clonecli4:克隆客户端,Racket 版模型四
clonecli4:克隆客户端,Ruby 版模型四
clonecli4:克隆客户端,Rust 版模型四
clonecli4:克隆客户端,Scala 版模型四
clonecli4:克隆客户端,Tcl 版模型四
#
# Clone client Model Four
#
lappend auto_path .
package require KVSimple
set SUBTREE "/client/"
# Prepare our context and subscriber
zmq context context
set snp [zmq socket snapshot context DEALER]
$snp connect "tcp://:5556"
set sub [zmq socket subscriber context SUB]
$sub setsockopt SUBSCRIBE ""
$sub connect "tcp://:5557"
$sub setsockopt SUBSCRIBE $SUBTREE
set pub [zmq socket publisher context PUSH]
$pub connect "tcp://:5558"
expr srand([pid])
# Get state snapshot
set sequence 0
$snp sendmore "ICANHAZ?"
$snp send $SUBTREE
while {1} {
set kvmsg [KVSimple new]
$kvmsg recv $snp
if {[$kvmsg key] eq "KTHXBAI"} {
set sequence [$kvmsg sequence]
puts "I: received snapshot=$sequence"
$kvmsg destroy
break
}
$kvmsg store kvmap
}
proc recv_kvmsg {pub sub} {
global after_id sequence kvmap alarm
after cancel $after_id
$sub readable {}
set kvmsg [KVSimple new]
$kvmsg recv $sub
if {[$kvmsg sequence] > $sequence} {
set sequence [$kvmsg sequence]
$kvmsg store kvmap
puts "I: received update=$sequence"
} else {
$kvmsg destroy
}
$sub readable [list recv_kvmsg $pub $sub]
set after_id [after [tickless] [list send_kvmsg $pub $sub]]
}
proc send_kvmsg {pub sub} {
global after_id sequence kvmap alarm SUBTREE
$sub readable {}
set kvmsg [KVSimple new 0]
$kvmsg set_key $SUBTREE[expr {int(rand()*10000)}]
$kvmsg set_body [expr {int(rand()*1000000)}]
$kvmsg send $pub
$kvmsg destroy
set alarm [expr {[clock milliseconds] + 1000}]
$sub readable [list recv_kvmsg $pub $sub]
set after_id [after [tickless] [list send_kvmsg $pub $sub]]
}
proc tickless {} {
global alarm
set t [expr {[clock milliseconds] - $alarm}]
if {$t < 0} {
set t 0
}
return $t
}
set alarm [expr {[clock milliseconds] + 1000}]
$sub readable [list recv_kvmsg $pub $sub]
set after_id [after [tickless] [list send_kvmsg $pub $sub]]
vwait forever
$pub close
$sub close
$snp close
context term
clonecli4:克隆客户端,OCaml 版模型四
短暂值 #
短暂值是一种会自动过期除非定期刷新的值。如果你考虑将 Clone 用于注册服务,那么短暂值就可以实现动态值。一个节点加入网络,发布其地址,并定期刷新。如果该节点死亡,其地址最终会被移除。
短暂值的通常抽象是将其附加到会话,并在会话结束时删除。在 Clone 中,会话由客户端定义,并在客户端死亡时结束。一个更简单的替代方案是为短暂值附加一个生存时间 (TTL),服务器用它来使未及时刷新的值过期。
我在可能的情况下会遵循一个好的设计原则:不发明非绝对必要的概念。如果我们有大量短暂值,会话将提供更好的性能。如果我们使用少量短暂值,为每个值设置 TTL 就可以。如果我们使用海量短暂值,将它们附加到会话并批量过期会更高效。这并不是我们在当前阶段面临的问题,可能永远不会面临,所以我们将暂时放弃会话。
现在我们将实现瞬时值(ephemeral values)。首先,我们需要一种方法在键值消息中编码 TTL(存活时间)。我们可以添加一个帧。使用 ZeroMQ 帧来承载属性的问题在于,每当我们想添加一个新属性时,都必须改变消息结构。这会破坏兼容性。因此,让我们在消息中添加一个属性帧,并编写代码来获取和设置属性值。
接下来,我们需要一种方式来表示“删除这个值”。到目前为止,服务器和客户端总是盲目地将新值插入或更新到它们的哈希表中。我们将规定,如果值为空,则意味着“删除这个键”。
以下是kvmsg类的一个更完整版本,它实现了属性帧(并添加了一个我们稍后会需要的 UUID 帧)。它还通过在必要时从哈希表中删除键来处理空值。
kvmsg:键值消息类:Ada 完整版
kvmsg:键值消息类:Basic 完整版
kvmsg:键值消息类:C 完整版
// kvmsg class - key-value message class for example applications
#include "kvmsg.h"
#include <uuid/uuid.h>
#include "zlist.h"
// Keys are short strings
#define KVMSG_KEY_MAX 255
// Message is formatted on wire as 5 frames:
// frame 0: key (0MQ string)
// frame 1: sequence (8 bytes, network order)
// frame 2: uuid (blob, 16 bytes)
// frame 3: properties (0MQ string)
// frame 4: body (blob)
#define FRAME_KEY 0
#define FRAME_SEQ 1
#define FRAME_UUID 2
#define FRAME_PROPS 3
#define FRAME_BODY 4
#define KVMSG_FRAMES 5
// Structure of our class
struct _kvmsg {
// Presence indicators for each frame
int present [KVMSG_FRAMES];
// Corresponding 0MQ message frames, if any
zmq_msg_t frame [KVMSG_FRAMES];
// Key, copied into safe C string
char key [KVMSG_KEY_MAX + 1];
// List of properties, as name=value strings
zlist_t *props;
size_t props_size;
};
// .split property encoding
// These two helpers serialize a list of properties to and from a
// message frame:
static void
s_encode_props (kvmsg_t *self)
{
zmq_msg_t *msg = &self->frame [FRAME_PROPS];
if (self->present [FRAME_PROPS])
zmq_msg_close (msg);
zmq_msg_init_size (msg, self->props_size);
char *prop = zlist_first (self->props);
char *dest = (char *) zmq_msg_data (msg);
while (prop) {
strcpy (dest, prop);
dest += strlen (prop);
*dest++ = '\n';
prop = zlist_next (self->props);
}
self->present [FRAME_PROPS] = 1;
}
static void
s_decode_props (kvmsg_t *self)
{
zmq_msg_t *msg = &self->frame [FRAME_PROPS];
self->props_size = 0;
while (zlist_size (self->props))
free (zlist_pop (self->props));
size_t remainder = zmq_msg_size (msg);
char *prop = (char *) zmq_msg_data (msg);
char *eoln = memchr (prop, '\n', remainder);
while (eoln) {
*eoln = 0;
zlist_append (self->props, strdup (prop));
self->props_size += strlen (prop) + 1;
remainder -= strlen (prop) + 1;
prop = eoln + 1;
eoln = memchr (prop, '\n', remainder);
}
}
// .split constructor and destructor
// Here are the constructor and destructor for the class:
// Constructor, takes a sequence number for the new kvmsg instance:
kvmsg_t *
kvmsg_new (int64_t sequence)
{
kvmsg_t
*self;
self = (kvmsg_t *) zmalloc (sizeof (kvmsg_t));
self->props = zlist_new ();
kvmsg_set_sequence (self, sequence);
return self;
}
// zhash_free_fn callback helper that does the low level destruction:
void
kvmsg_free (void *ptr)
{
if (ptr) {
kvmsg_t *self = (kvmsg_t *) ptr;
// Destroy message frames if any
int frame_nbr;
for (frame_nbr = 0; frame_nbr < KVMSG_FRAMES; frame_nbr++)
if (self->present [frame_nbr])
zmq_msg_close (&self->frame [frame_nbr]);
// Destroy property list
while (zlist_size (self->props))
free (zlist_pop (self->props));
zlist_destroy (&self->props);
// Free object itself
free (self);
}
}
// Destructor
void
kvmsg_destroy (kvmsg_t **self_p)
{
assert (self_p);
if (*self_p) {
kvmsg_free (*self_p);
*self_p = NULL;
}
}
// .split recv method
// This method reads a key-value message from the socket and returns a
// new {{kvmsg}} instance:
kvmsg_t *
kvmsg_recv (void *socket)
{
// This method is almost unchanged from kvsimple
// .skip
assert (socket);
kvmsg_t *self = kvmsg_new (0);
// Read all frames off the wire, reject if bogus
int frame_nbr;
for (frame_nbr = 0; frame_nbr < KVMSG_FRAMES; frame_nbr++) {
if (self->present [frame_nbr])
zmq_msg_close (&self->frame [frame_nbr]);
zmq_msg_init (&self->frame [frame_nbr]);
self->present [frame_nbr] = 1;
if (zmq_msg_recv (&self->frame [frame_nbr], socket, 0) == -1) {
kvmsg_destroy (&self);
break;
}
// Verify multipart framing
int rcvmore = (frame_nbr < KVMSG_FRAMES - 1)? 1: 0;
if (zsocket_rcvmore (socket) != rcvmore) {
kvmsg_destroy (&self);
break;
}
}
// .until
if (self)
s_decode_props (self);
return self;
}
// Send key-value message to socket; any empty frames are sent as such.
void
kvmsg_send (kvmsg_t *self, void *socket)
{
assert (self);
assert (socket);
s_encode_props (self);
// The rest of the method is unchanged from kvsimple
// .skip
int frame_nbr;
for (frame_nbr = 0; frame_nbr < KVMSG_FRAMES; frame_nbr++) {
zmq_msg_t copy;
zmq_msg_init (©);
if (self->present [frame_nbr])
zmq_msg_copy (©, &self->frame [frame_nbr]);
zmq_msg_send (©, socket,
(frame_nbr < KVMSG_FRAMES - 1)? ZMQ_SNDMORE: 0);
zmq_msg_close (©);
}
}
// .until
// .split dup method
// This method duplicates a {{kvmsg}} instance, returns the new instance:
kvmsg_t *
kvmsg_dup (kvmsg_t *self)
{
kvmsg_t *kvmsg = kvmsg_new (0);
int frame_nbr;
for (frame_nbr = 0; frame_nbr < KVMSG_FRAMES; frame_nbr++) {
if (self->present [frame_nbr]) {
zmq_msg_t *src = &self->frame [frame_nbr];
zmq_msg_t *dst = &kvmsg->frame [frame_nbr];
zmq_msg_init_size (dst, zmq_msg_size (src));
memcpy (zmq_msg_data (dst),
zmq_msg_data (src), zmq_msg_size (src));
kvmsg->present [frame_nbr] = 1;
}
}
kvmsg->props_size = zlist_size (self->props);
char *prop = (char *) zlist_first (self->props);
while (prop) {
zlist_append (kvmsg->props, strdup (prop));
prop = (char *) zlist_next (self->props);
}
return kvmsg;
}
// The key, sequence, body, and size methods are the same as in kvsimple.
// .skip
// Return key from last read message, if any, else NULL
char *
kvmsg_key (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_KEY]) {
if (!*self->key) {
size_t size = zmq_msg_size (&self->frame [FRAME_KEY]);
if (size > KVMSG_KEY_MAX)
size = KVMSG_KEY_MAX;
memcpy (self->key,
zmq_msg_data (&self->frame [FRAME_KEY]), size);
self->key [size] = 0;
}
return self->key;
}
else
return NULL;
}
// Set message key as provided
void
kvmsg_set_key (kvmsg_t *self, char *key)
{
assert (self);
zmq_msg_t *msg = &self->frame [FRAME_KEY];
if (self->present [FRAME_KEY])
zmq_msg_close (msg);
zmq_msg_init_size (msg, strlen (key));
memcpy (zmq_msg_data (msg), key, strlen (key));
self->present [FRAME_KEY] = 1;
}
// Set message key using printf format
void
kvmsg_fmt_key (kvmsg_t *self, char *format, ...)
{
char value [KVMSG_KEY_MAX + 1];
va_list args;
assert (self);
va_start (args, format);
vsnprintf (value, KVMSG_KEY_MAX, format, args);
va_end (args);
kvmsg_set_key (self, value);
}
// Return sequence nbr from last read message, if any
int64_t
kvmsg_sequence (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_SEQ]) {
assert (zmq_msg_size (&self->frame [FRAME_SEQ]) == 8);
byte *source = zmq_msg_data (&self->frame [FRAME_SEQ]);
int64_t sequence = ((int64_t) (source [0]) << 56)
+ ((int64_t) (source [1]) << 48)
+ ((int64_t) (source [2]) << 40)
+ ((int64_t) (source [3]) << 32)
+ ((int64_t) (source [4]) << 24)
+ ((int64_t) (source [5]) << 16)
+ ((int64_t) (source [6]) << 8)
+ (int64_t) (source [7]);
return sequence;
}
else
return 0;
}
// Set message sequence number
void
kvmsg_set_sequence (kvmsg_t *self, int64_t sequence)
{
assert (self);
zmq_msg_t *msg = &self->frame [FRAME_SEQ];
if (self->present [FRAME_SEQ])
zmq_msg_close (msg);
zmq_msg_init_size (msg, 8);
byte *source = zmq_msg_data (msg);
source [0] = (byte) ((sequence >> 56) & 255);
source [1] = (byte) ((sequence >> 48) & 255);
source [2] = (byte) ((sequence >> 40) & 255);
source [3] = (byte) ((sequence >> 32) & 255);
source [4] = (byte) ((sequence >> 24) & 255);
source [5] = (byte) ((sequence >> 16) & 255);
source [6] = (byte) ((sequence >> 8) & 255);
source [7] = (byte) ((sequence) & 255);
self->present [FRAME_SEQ] = 1;
}
// Return body from last read message, if any, else NULL
byte *
kvmsg_body (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_BODY])
return (byte *) zmq_msg_data (&self->frame [FRAME_BODY]);
else
return NULL;
}
// Set message body
void
kvmsg_set_body (kvmsg_t *self, byte *body, size_t size)
{
assert (self);
zmq_msg_t *msg = &self->frame [FRAME_BODY];
if (self->present [FRAME_BODY])
zmq_msg_close (msg);
self->present [FRAME_BODY] = 1;
zmq_msg_init_size (msg, size);
memcpy (zmq_msg_data (msg), body, size);
}
// Set message body using printf format
void
kvmsg_fmt_body (kvmsg_t *self, char *format, ...)
{
char value [255 + 1];
va_list args;
assert (self);
va_start (args, format);
vsnprintf (value, 255, format, args);
va_end (args);
kvmsg_set_body (self, (byte *) value, strlen (value));
}
// Return body size from last read message, if any, else zero
size_t
kvmsg_size (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_BODY])
return zmq_msg_size (&self->frame [FRAME_BODY]);
else
return 0;
}
// .until
// .split UUID methods
// These methods get and set the UUID for the key-value message:
byte *
kvmsg_uuid (kvmsg_t *self)
{
assert (self);
if (self->present [FRAME_UUID]
&& zmq_msg_size (&self->frame [FRAME_UUID]) == sizeof (uuid_t))
return (byte *) zmq_msg_data (&self->frame [FRAME_UUID]);
else
return NULL;
}
// Sets the UUID to a randomly generated value
void
kvmsg_set_uuid (kvmsg_t *self)
{
assert (self);
zmq_msg_t *msg = &self->frame [FRAME_UUID];
uuid_t uuid;
uuid_generate (uuid);
if (self->present [FRAME_UUID])
zmq_msg_close (msg);
zmq_msg_init_size (msg, sizeof (uuid));
memcpy (zmq_msg_data (msg), uuid, sizeof (uuid));
self->present [FRAME_UUID] = 1;
}
// .split property methods
// These methods get and set a specified message property:
// Get message property, return "" if no such property is defined.
char *
kvmsg_get_prop (kvmsg_t *self, char *name)
{
assert (strchr (name, '=') == NULL);
char *prop = zlist_first (self->props);
size_t namelen = strlen (name);
while (prop) {
if (strlen (prop) > namelen
&& memcmp (prop, name, namelen) == 0
&& prop [namelen] == '=')
return prop + namelen + 1;
prop = zlist_next (self->props);
}
return "";
}
// Set message property. Property name cannot contain '='. Max length of
// value is 255 chars.
void
kvmsg_set_prop (kvmsg_t *self, char *name, char *format, ...)
{
assert (strchr (name, '=') == NULL);
char value [255 + 1];
va_list args;
assert (self);
va_start (args, format);
vsnprintf (value, 255, format, args);
va_end (args);
// Allocate name=value string
char *prop = malloc (strlen (name) + strlen (value) + 2);
// Remove existing property if any
sprintf (prop, "%s=", name);
char *existing = zlist_first (self->props);
while (existing) {
if (memcmp (prop, existing, strlen (prop)) == 0) {
self->props_size -= strlen (existing) + 1;
zlist_remove (self->props, existing);
free (existing);
break;
}
existing = zlist_next (self->props);
}
// Add new name=value property string
strcat (prop, value);
zlist_append (self->props, prop);
self->props_size += strlen (prop) + 1;
}
// .split store method
// This method stores the key-value message into a hash map, unless
// the key and value are both null. It nullifies the {{kvmsg}} reference
// so that the object is owned by the hash map, not the caller:
void
kvmsg_store (kvmsg_t **self_p, zhash_t *hash)
{
assert (self_p);
if (*self_p) {
kvmsg_t *self = *self_p;
assert (self);
if (kvmsg_size (self)) {
if (self->present [FRAME_KEY]
&& self->present [FRAME_BODY]) {
zhash_update (hash, kvmsg_key (self), self);
zhash_freefn (hash, kvmsg_key (self), kvmsg_free);
}
}
else
zhash_delete (hash, kvmsg_key (self));
*self_p = NULL;
}
}
// .split dump method
// This method extends the {{kvsimple}} implementation with support for
// message properties:
void
kvmsg_dump (kvmsg_t *self)
{
// .skip
if (self) {
if (!self) {
fprintf (stderr, "NULL");
return;
}
size_t size = kvmsg_size (self);
byte *body = kvmsg_body (self);
fprintf (stderr, "[seq:%" PRId64 "]", kvmsg_sequence (self));
fprintf (stderr, "[key:%s]", kvmsg_key (self));
// .until
fprintf (stderr, "[size:%zd] ", size);
if (zlist_size (self->props)) {
fprintf (stderr, "[");
char *prop = zlist_first (self->props);
while (prop) {
fprintf (stderr, "%s;", prop);
prop = zlist_next (self->props);
}
fprintf (stderr, "]");
}
// .skip
int char_nbr;
for (char_nbr = 0; char_nbr < size; char_nbr++)
fprintf (stderr, "%02X", body [char_nbr]);
fprintf (stderr, "\n");
}
else
fprintf (stderr, "NULL message\n");
}
// .until
// .split test method
// This method is the same as in {{kvsimple}} with added support
// for the uuid and property features of {{kvmsg}}:
int
kvmsg_test (int verbose)
{
// .skip
kvmsg_t
*kvmsg;
printf (" * kvmsg: ");
// Prepare our context and sockets
zctx_t *ctx = zctx_new ();
void *output = zsocket_new (ctx, ZMQ_DEALER);
int rc = zmq_bind (output, "ipc://kvmsg_selftest.ipc");
assert (rc == 0);
void *input = zsocket_new (ctx, ZMQ_DEALER);
rc = zmq_connect (input, "ipc://kvmsg_selftest.ipc");
assert (rc == 0);
zhash_t *kvmap = zhash_new ();
// .until
// Test send and receive of simple message
kvmsg = kvmsg_new (1);
kvmsg_set_key (kvmsg, "key");
kvmsg_set_uuid (kvmsg);
kvmsg_set_body (kvmsg, (byte *) "body", 4);
if (verbose)
kvmsg_dump (kvmsg);
kvmsg_send (kvmsg, output);
kvmsg_store (&kvmsg, kvmap);
kvmsg = kvmsg_recv (input);
if (verbose)
kvmsg_dump (kvmsg);
assert (streq (kvmsg_key (kvmsg), "key"));
kvmsg_store (&kvmsg, kvmap);
// Test send and receive of message with properties
kvmsg = kvmsg_new (2);
kvmsg_set_prop (kvmsg, "prop1", "value1");
kvmsg_set_prop (kvmsg, "prop2", "value1");
kvmsg_set_prop (kvmsg, "prop2", "value2");
kvmsg_set_key (kvmsg, "key");
kvmsg_set_uuid (kvmsg);
kvmsg_set_body (kvmsg, (byte *) "body", 4);
assert (streq (kvmsg_get_prop (kvmsg, "prop2"), "value2"));
if (verbose)
kvmsg_dump (kvmsg);
kvmsg_send (kvmsg, output);
kvmsg_destroy (&kvmsg);
kvmsg = kvmsg_recv (input);
if (verbose)
kvmsg_dump (kvmsg);
assert (streq (kvmsg_key (kvmsg), "key"));
assert (streq (kvmsg_get_prop (kvmsg, "prop2"), "value2"));
kvmsg_destroy (&kvmsg);
// .skip
// Shutdown and destroy all objects
zhash_destroy (&kvmap);
zctx_destroy (&ctx);
printf ("OK\n");
return 0;
}
// .until
kvmsg:键值消息类:C++ 完整版
/* =====================================================================
* kvmsg - key-value message class for example applications
* ===================================================================== */
#ifndef __KVMSG_HPP_INCLUDED__
#define __KVMSG_HPP_INCLUDED__
#include <random>
#include <string>
#include <unordered_map>
#include <csignal>
#include <atomic>
#include <cstdlib> // for rand
#include <zmqpp/zmqpp.hpp>
using ustring = std::basic_string<unsigned char>;
class KVMsg {
public:
KVMsg() = default;
// Constructor, sets sequence as provided
KVMsg(int64_t sequence);
// Destructor
~KVMsg();
// Create duplicate of kvmsg
KVMsg(const KVMsg &other);
// Create copy
KVMsg& operator=(const KVMsg &other);
// Reads key-value message from socket, returns new kvmsg instance.
static KVMsg* recv(zmqpp::socket_t &socket);
// Send key-value message to socket; any empty frames are sent as such.
void send(zmqpp::socket_t &socket);
// Return key from last read message, if any, else NULL
std::string key() const;
// Return sequence nbr from last read message, if any
int64_t sequence() const;
// Return body from last read message, if any, else NULL
ustring body() const;
// Return body size from last read message, if any, else zero
size_t size() const;
// Return UUID from last read message, if any, else NULL
std::string uuid() const;
// Set message key as provided
void set_key(std::string key);
// Set message sequence number
void set_sequence(int64_t sequence);
// Set message body
void set_body(ustring body);
// Set message UUID to generated value
void set_uuid();
// Set message key using printf format
void fmt_key(const char *format, ...);
// Set message body using printf format
void fmt_body(const char *format, ...);
// Get message property, if set, else ""
std::string property(const std::string &name) const;
// Set message property
// Names cannot contain '='. Max length of value is 255 chars.
void set_property(const std::string &name, const char *format, ...);
// Store entire kvmsg into hash map, if key/value are set
// Nullifies kvmsg reference, and destroys automatically when no longer
// needed.
void store(std::unordered_map<std::string, KVMsg*> &hash);
// clear the hash map, free elements
static void clear_kvmap(std::unordered_map<std::string, KVMsg*> &hash);
// Dump message to stderr, for debugging and tracing
std::string to_string();
void encode_frames(zmqpp::message &frames);
void decode_frames(zmqpp::message &frames);
// Runs self test of class
static bool test(int verbose);
private:
// Message is formatted on wire as 5 frames:
// frame 0: key (0MQ string)
// frame 1: sequence (8 bytes, network order)
// frame 2: uuid (blob, 16 bytes)
// frame 3: properties (0MQ string)
// frame 4: body (blob)
static constexpr uint32_t FRAME_KEY = 0;
static constexpr uint32_t FRAME_SEQ = 1;
static constexpr uint32_t FRAME_UUID = 2;
static constexpr uint32_t FRAME_PROPS = 3;
static constexpr uint32_t FRAME_BODY = 4;
static constexpr uint32_t KVMSG_FRAMES = 5;
std::string key_;
int64_t sequence_{};
std::string uuid_;
ustring body_;
std::unordered_map<std::string, std::string> properties_;
bool presents_[KVMSG_FRAMES];
};
namespace {
std::string generateUUID() {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(0, 15);
std::uniform_int_distribution<> dis2(8, 11);
std::stringstream ss;
ss << std::hex;
for (int i = 0; i < 8; ++i) ss << dis(gen);
// ss << "-";
for (int i = 0; i < 4; ++i) ss << dis(gen);
ss << "4"; // UUID version 4
for (int i = 0; i < 3; ++i) ss << dis(gen);
// ss << "-";
ss << dis2(gen); // UUID variant
for (int i = 0; i < 3; ++i) ss << dis(gen);
// ss << "-";
for (int i = 0; i < 12; ++i) ss << dis(gen);
return ss.str();
}
}
KVMsg::KVMsg(int64_t sequence) {
sequence_ = sequence;
presents_[FRAME_SEQ] = true;
}
KVMsg::~KVMsg() {
std::cout << "DEBUG: freeing key=" << key_ << std::endl;
}
KVMsg::KVMsg(const KVMsg &other) {
std::cout << "copy construct\n";
key_ = other.key_;
sequence_ = other.sequence_;
uuid_ = other.uuid_;
body_ = other.body_;
properties_ = other.properties_;
for (int i = 0; i < KVMSG_FRAMES; i++) {
presents_[i] = other.presents_[i];
}
}
KVMsg& KVMsg::operator=(const KVMsg &other) {
std::cout << "copy assign\n";
key_ = other.key_;
sequence_ = other.sequence_;
uuid_ = other.uuid_;
body_ = other.body_;
properties_ = other.properties_;
for (int i = 0; i < KVMSG_FRAMES; i++) {
presents_[i] = other.presents_[i];
}
return *this;
}
// implement the static method recv
KVMsg* KVMsg::recv(zmqpp::socket_t &socket) {
KVMsg* kvmsg = new KVMsg(-1);
zmqpp::message frames;
if (!socket.receive(frames)) {
return nullptr;
}
kvmsg->decode_frames(frames);
return kvmsg;
}
void KVMsg::send(zmqpp::socket_t &socket) {
zmqpp::message frames;
encode_frames(frames);
socket.send(frames);
}
std::string KVMsg::key() const {
return key_;
}
int64_t KVMsg::sequence() const {
return sequence_;
}
ustring KVMsg::body() const {
return body_;
}
size_t KVMsg::size() const {
return body_.size();
}
std::string KVMsg::uuid() const {
return uuid_;
}
void KVMsg::set_key(std::string key) {
key_ = key;
presents_[FRAME_KEY] = true;
}
void KVMsg::set_sequence(int64_t sequence) {
sequence_ = sequence;
presents_[FRAME_SEQ] = true;
}
void KVMsg::set_body(ustring body) {
body_ = body;
presents_[FRAME_BODY] = true;
}
void KVMsg::set_uuid() {
uuid_ = generateUUID();
presents_[FRAME_UUID] = true;
}
void KVMsg::fmt_key(const char *format, ...) {
char buffer[256];
va_list args;
va_start(args, format);
vsnprintf(buffer, 256, format, args);
va_end(args);
key_ = buffer;
presents_[FRAME_KEY] = true;
}
void KVMsg::fmt_body(const char *format, ...) {
char buffer[256];
va_list args;
va_start(args, format);
vsnprintf(buffer, 256, format, args);
va_end(args);
// body_ = ustring(buffer, buffer + strlen(buffer));
body_ = ustring((unsigned char *)buffer, strlen(buffer));
presents_[FRAME_BODY] = true;
}
std::string KVMsg::property(const std::string &name) const {
if (!presents_[FRAME_PROPS]) {
return "";
}
auto it = properties_.find(name);
if (it == properties_.end()) {
return "";
}
return it->second;
}
void KVMsg::set_property(const std::string &name, const char *format, ...) {
char buffer[256];
va_list args;
va_start(args, format);
vsnprintf(buffer, 256, format, args);
va_end(args);
properties_[name] = buffer;
presents_[FRAME_PROPS] = true;
}
void KVMsg::encode_frames(zmqpp::message &frames) {
// assert(frames.parts() == 0);
if (presents_[FRAME_KEY]) {
frames.add(key_);
} else {
frames.add("");
}
if (presents_[FRAME_SEQ]) {
frames.add(sequence_);
} else {
frames.add(-1);
}
if (presents_[FRAME_UUID]) {
frames.add(uuid_);
} else {
frames.add("");
}
if (presents_[FRAME_PROPS]) {
std::string props;
for (auto &prop : properties_) {
props += prop.first + "=" + prop.second + "\n";
}
frames.add(props);
} else {
frames.add("");
}
if (presents_[FRAME_BODY]) {
frames.add_raw(body_.data(), body_.size());
} else {
frames.add("");
}
}
void KVMsg::decode_frames(zmqpp::message &frames) {
assert(frames.parts() == KVMSG_FRAMES);
frames.get(key_, 0);
if (!key_.empty()) {
presents_[FRAME_KEY] = true;
}
frames.get(sequence_, 1);
if (sequence_ != -1) {
presents_[FRAME_SEQ] = true;
}
frames.get(uuid_, 2);
if (!uuid_.empty()) {
presents_[FRAME_UUID] = true;
}
std::string props = frames.get<std::string>(3);
properties_.clear();
if (!props.empty()) {
presents_[FRAME_PROPS] = true;
size_t pos = 0;
while (pos < props.size()) {
size_t end = props.find('=', pos);
std::string name = props.substr(pos, end - pos);
pos = end + 1;
end = props.find('\n', pos);
std::string value = props.substr(pos, end - pos);
pos = end + 1;
properties_[name] = value;
}
}
char const* raw_body = frames.get<char const*>(4);
size_t size = frames.size(4);
if (size > 0) {
presents_[FRAME_BODY] = true;
body_ = ustring((unsigned char const*)raw_body, size);
}
}
void KVMsg::store(std::unordered_map<std::string, KVMsg*> &hash) {
if (size() == 0) {
hash.erase(key_);
return;
}
if (presents_[FRAME_KEY] && presents_[FRAME_BODY]) {
hash[key_] = this;
}
}
void KVMsg::clear_kvmap(std::unordered_map<std::string, KVMsg*> &hash) {
for (auto &kv : hash) {
delete kv.second;
kv.second = nullptr;
}
hash.clear();
}
std::string KVMsg::to_string() {
std::stringstream ss;
ss << "key=" << key_ << ",sequence=" << sequence_ << ",uuid=" << uuid_ << std::endl;
ss << "propes={";
for (auto &prop : properties_) {
ss << prop.first << "=" << prop.second << ",";
}
ss << "},";
ss << "body=";
for (auto &byte : body_) {
ss << std::hex << byte;
}
return ss.str();
}
bool KVMsg::test(int verbose) {
zmqpp::context context;
zmqpp::socket output(context, zmqpp::socket_type::dealer);
output.bind("ipc://kvmsg_selftest.ipc");
zmqpp::socket input(context, zmqpp::socket_type::dealer);
input.connect("ipc://kvmsg_selftest.ipc");
KVMsg kvmsg(1);
kvmsg.set_key("key");
kvmsg.set_uuid();
kvmsg.set_body((unsigned char *)"body");
if (verbose) {
std::cout << kvmsg.to_string() << std::endl;
}
kvmsg.send(output);
std::unordered_map<std::string, KVMsg*> kvmap;
kvmsg.store(kvmap);
std::cout << "print from kvmap[key]" << std::endl;
std::cout << kvmap["key"]->to_string() << std::endl;
KVMsg *kvmsg_p = KVMsg::recv(input);
if (!kvmsg_p) {
return false;
}
assert(kvmsg_p->key() == "key");
delete kvmsg_p;
kvmsg_p = new KVMsg(2);
kvmsg_p->set_key("key2");
kvmsg_p->set_property("prop1", "value1");
kvmsg_p->set_property("prop2", "value2");
kvmsg_p->set_body((unsigned char *)"body2");
kvmsg_p->set_uuid();
assert(kvmsg_p->property("prop2") == "value2");
kvmsg_p->send(output);
delete kvmsg_p;
kvmsg_p = KVMsg::recv(input);
if (!kvmsg_p) {
return false;
}
assert(kvmsg_p->key() == "key2");
assert(kvmsg_p->property("prop2") == "value2");
if (verbose) {
std::cout << kvmsg_p->to_string() << std::endl;
}
delete kvmsg_p;
std::cout << "KVMsg self test passed" << std::endl;
return true;
}
// ---------------------------------------------------------------------
// Signal handling
//
// Call s_catch_signals() in your application at startup, and then exit
// your main loop if s_interrupted is ever 1. Works especially well with
// zmq_poll.
static std::atomic<int> s_interrupted(0);
void s_signal_handler(int signal_value) {
s_interrupted = 1;
}
// setting signal handler
void s_catch_signals() {
std::signal(SIGINT, s_signal_handler);
std::signal(SIGTERM, s_signal_handler);
}
// Provide random number from 0..(num-1)
static int within(int num) {
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<> dis(0, num - 1);
return dis(gen);
}
#endif // Included
kvmsg:键值消息类:C# 完整版
kvmsg:键值消息类:CL 完整版
kvmsg:键值消息类:Delphi 完整版
kvmsg:键值消息类:Erlang 完整版
kvmsg:键值消息类:Elixir 完整版
kvmsg:键值消息类:F# 完整版
kvmsg:键值消息类:Felix 完整版
kvmsg:键值消息类:Go 完整版
kvmsg:键值消息类:Haskell 完整版
kvmsg:键值消息类:Haxe 完整版
kvmsg:键值消息类:Java 完整版
package guide;
import java.nio.ByteBuffer;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Properties;
import java.util.UUID;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.Socket;
public class kvmsg
{
// Keys are short strings
private static final int KVMSG_KEY_MAX = 255;
// Message is formatted on wire as 4 frames:
// frame 0: getKey (0MQ string)
// frame 1: getSequence (8 bytes, network order)
// frame 2: uuid (blob, 16 bytes)
// frame 3: properties (0MQ string)
// frame 4: body (blob)
private static final int FRAME_KEY = 0;
private static final int FRAME_SEQ = 1;
private static final int FRAME_UUID = 2;
private static final int FRAME_PROPS = 3;
private static final int FRAME_BODY = 4;
private static final int KVMSG_FRAMES = 5;
// Presence indicators for each frame
private boolean[] present = new boolean[KVMSG_FRAMES];
// Corresponding 0MQ message frames, if any
private byte[][] frame = new byte[KVMSG_FRAMES][];
// Key, copied into safe string
private String key;
// List of properties, as name=value strings
private Properties props;
private int props_size;
// .split property encoding
// These two helpers serialize a list of properties to and from a
// message frame:
private void encodeProps()
{
ByteBuffer msg = ByteBuffer.allocate(props_size);
for (Entry<Object, Object> o : props.entrySet()) {
String prop = o.getKey().toString() + "=" + o.getValue().toString() + "\n";
msg.put(prop.getBytes(ZMQ.CHARSET));
}
present[FRAME_PROPS] = true;
frame[FRAME_PROPS] = msg.array();
}
private void decodeProps()
{
byte[] msg = frame[FRAME_PROPS];
props_size = msg.length;
props.clear();
if (msg.length == 0)
return;
System.out.println("" + msg.length + " :" + new String(msg, ZMQ.CHARSET));
for (String prop : new String(msg, ZMQ.CHARSET).split("\n")) {
String[] split = prop.split("=");
props.setProperty(split[0], split[1]);
}
}
// .split constructor and destructor
// Here are the constructor and destructor for the class:
// Constructor, takes a getSequence number for the new kvmsg instance:
public kvmsg(long sequence)
{
props = new Properties();
setSequence(sequence);
}
public void destroy()
{
}
// .split recv method
// This method reads a getKey-value message from the socket and returns a
// new {{kvmsg}} instance:
public static kvmsg recv(Socket socket)
{
// This method is almost unchanged from kvsimple
// .skip
assert (socket != null);
kvmsg self = new kvmsg(0);
// Read all frames off the wire, reject if bogus
int frameNbr;
for (frameNbr = 0; frameNbr < KVMSG_FRAMES; frameNbr++) {
//zmq_msg_init (&self->frame [frameNbr]);
self.present[frameNbr] = true;
if ((self.frame[frameNbr] = socket.recv(0)) == null) {
self.destroy();
break;
}
// Verify multipart framing
boolean rcvmore = (frameNbr < KVMSG_FRAMES - 1) ? true : false;
if (socket.hasReceiveMore() != rcvmore) {
self.destroy();
break;
}
}
// .until
self.decodeProps();
return self;
}
// Send getKey-value message to socket; any empty frames are sent as such.
public void send(Socket socket)
{
assert (socket != null);
encodeProps();
// The rest of the method is unchanged from kvsimple
// .skip
int frameNbr;
for (frameNbr = 0; frameNbr < KVMSG_FRAMES; frameNbr++) {
byte[] copy = ZMQ.MESSAGE_SEPARATOR;
if (present[frameNbr])
copy = frame[frameNbr];
socket.send(copy, (frameNbr < KVMSG_FRAMES - 1) ? ZMQ.SNDMORE : 0);
}
}
// .until
// .split dup method
// This method duplicates a {{kvmsg}} instance, returns the new instance:
public kvmsg dup()
{
kvmsg kvmsg = new kvmsg(0);
int frameNbr;
for (frameNbr = 0; frameNbr < KVMSG_FRAMES; frameNbr++) {
if (present[frameNbr]) {
kvmsg.frame[frameNbr] = new byte[frame[frameNbr].length];
System.arraycopy(frame[frameNbr], 0, kvmsg.frame[frameNbr], 0, frame[frameNbr].length);
kvmsg.present[frameNbr] = true;
}
}
kvmsg.props_size = props_size;
kvmsg.props.putAll(props);
return kvmsg;
}
// The getKey, getSequence, body, and size methods are the same as in kvsimple.
// .skip
// Return getKey from last read message, if any, else NULL
public String getKey()
{
if (present[FRAME_KEY]) {
if (key == null) {
int size = frame[FRAME_KEY].length;
if (size > KVMSG_KEY_MAX)
size = KVMSG_KEY_MAX;
byte[] buf = new byte[size];
System.arraycopy(frame[FRAME_KEY], 0, buf, 0, size);
key = new String(buf, ZMQ.CHARSET);
}
return key;
}
else return null;
}
// Set message getKey as provided
public void setKey(String key)
{
byte[] msg = new byte[key.length()];
System.arraycopy(key.getBytes(ZMQ.CHARSET), 0, msg, 0, key.length());
frame[FRAME_KEY] = msg;
present[FRAME_KEY] = true;
}
// Set message getKey using printf format
public void fmtKey(String fmt, Object... args)
{
setKey(String.format(fmt, args));
}
// Return getSequence nbr from last read message, if any
public long getSequence()
{
if (present[FRAME_SEQ]) {
assert (frame[FRAME_SEQ].length == 8);
ByteBuffer source = ByteBuffer.wrap(frame[FRAME_SEQ]);
return source.getLong();
}
else return 0;
}
// Set message getSequence number
public void setSequence(long sequence)
{
ByteBuffer msg = ByteBuffer.allocate(8);
msg.putLong(sequence);
present[FRAME_SEQ] = true;
frame[FRAME_SEQ] = msg.array();
}
// Return body from last read message, if any, else NULL
public byte[] body()
{
if (present[FRAME_BODY])
return frame[FRAME_BODY];
else return null;
}
// Set message body
public void setBody(byte[] body)
{
byte[] msg = new byte[body.length];
System.arraycopy(body, 0, msg, 0, body.length);
frame[FRAME_BODY] = msg;
present[FRAME_BODY] = true;
}
// Set message body using printf format
public void fmtBody(String fmt, Object... args)
{
setBody(String.format(fmt, args).getBytes(ZMQ.CHARSET));
}
// Return body size from last read message, if any, else zero
public int size()
{
if (present[FRAME_BODY])
return frame[FRAME_BODY].length;
else return 0;
}
// .until
// .split UUID methods
// These methods get and set the UUID for the getKey-value message:
public byte[] UUID()
{
if (present[FRAME_UUID])
return frame[FRAME_UUID];
else return null;
}
// Sets the UUID to a randomly generated value
public void setUUID()
{
byte[] msg = UUID.randomUUID().toString().getBytes(ZMQ.CHARSET);
present[FRAME_UUID] = true;
frame[FRAME_UUID] = msg;
}
// .split property methods
// These methods get and set a specified message property:
// Get message property, return "" if no such property is defined.
public String getProp(String name)
{
return props.getProperty(name, "");
}
// Set message property. Property name cannot contain '='. Max length of
// value is 255 chars.
public void setProp(String name, String fmt, Object... args)
{
String value = String.format(fmt, args);
Object old = props.setProperty(name, value);
if (old != null)
props_size -= old.toString().length();
else props_size += name.length() + 2;
props_size += value.length();
}
// .split store method
// This method stores the getKey-value message into a hash map, unless
// the getKey and value are both null. It nullifies the {{kvmsg}} reference
// so that the object is owned by the hash map, not the caller:
public void store(Map<String, kvmsg> hash)
{
if (size() > 0) {
if (present[FRAME_KEY] && present[FRAME_BODY]) {
hash.put(getKey(), this);
}
}
else hash.remove(getKey());
}
// .split dump method
// This method extends the {{kvsimple}} implementation with support for
// message properties:
public void dump()
{
int size = size();
byte[] body = body();
System.err.printf("[seq:%d]", getSequence());
System.err.printf("[getKey:%s]", getKey());
// .until
System.err.printf("[size:%d] ", size);
System.err.printf("[");
for (String key : props.stringPropertyNames()) {
System.err.printf("%s=%s;", key, props.getProperty(key));
}
System.err.printf("]");
// .skip
for (int charNbr = 0; charNbr < size; charNbr++)
System.err.printf("%02X", body[charNbr]);
System.err.printf("\n");
}
// .until
// .split test method
// This method is the same as in {{kvsimple}} with added support
// for the uuid and property features of {{kvmsg}}:
public void test(boolean verbose)
{
System.out.printf(" * kvmsg: ");
// Prepare our context and sockets
try (ZContext ctx = new ZContext()) {
Socket output = ctx.createSocket(SocketType.DEALER);
output.bind("ipc://kvmsg_selftest.ipc");
Socket input = ctx.createSocket(SocketType.DEALER);
input.connect("ipc://kvmsg_selftest.ipc");
Map<String, kvmsg> kvmap = new HashMap<String, kvmsg>();
// .until
// Test send and receive of simple message
kvmsg kvmsg = new kvmsg(1);
kvmsg.setKey("getKey");
kvmsg.setUUID();
kvmsg.setBody("body".getBytes(ZMQ.CHARSET));
if (verbose)
kvmsg.dump();
kvmsg.send(output);
kvmsg.store(kvmap);
kvmsg = guide.kvmsg.recv(input);
if (verbose)
kvmsg.dump();
assert (kvmsg.getKey().equals("getKey"));
kvmsg.store(kvmap);
// Test send and receive of message with properties
kvmsg = new kvmsg(2);
kvmsg.setProp("prop1", "value1");
kvmsg.setProp("prop2", "value1");
kvmsg.setProp("prop2", "value2");
kvmsg.setKey("getKey");
kvmsg.setUUID();
kvmsg.setBody("body".getBytes(ZMQ.CHARSET));
assert (kvmsg.getProp("prop2").equals("value2"));
if (verbose)
kvmsg.dump();
kvmsg.send(output);
kvmsg.destroy();
kvmsg = guide.kvmsg.recv(input);
if (verbose)
kvmsg.dump();
assert (kvmsg.key.equals("getKey"));
assert (kvmsg.getProp("prop2").equals("value2"));
kvmsg.destroy();
}
System.out.printf("OK\n");
}
// .until
}
kvmsg:键值消息类:Julia 完整版
kvmsg:键值消息类:Lua 完整版
kvmsg:键值消息类:Node.js 完整版
kvmsg:键值消息类:Objective-C 完整版
kvmsg:键值消息类:ooc 完整版
kvmsg:键值消息类:Perl 完整版
kvmsg:键值消息类:PHP 完整版
kvmsg:键值消息类:Python 完整版
"""
=====================================================================
kvmsg - key-value message class for example applications
Author: Min RK <benjaminrk@gmail.com>
"""
import struct # for packing integers
import sys
from uuid import uuid4
import zmq
# zmq.jsonapi ensures bytes, instead of unicode:
def encode_properties(properties_dict):
prop_s = b""
for key, value in properties_dict.items():
prop_s += b"%s=%s\n" % (key, value)
return prop_s
def decode_properties(prop_s):
prop = {}
line_array = prop_s.split(b"\n")
for line in line_array:
try:
key, value = line.split(b"=")
prop[key] = value
except ValueError as e:
#Catch empty line
pass
return prop
class KVMsg(object):
"""
Message is formatted on wire as 5 frames:
frame 0: key (0MQ string)
frame 1: sequence (8 bytes, network order)
frame 2: uuid (blob, 16 bytes)
frame 3: properties (0MQ string)
frame 4: body (blob)
"""
key = None
sequence = 0
uuid=None
properties = None
body = None
def __init__(self, sequence, uuid=None, key=None, properties=None, body=None):
assert isinstance(sequence, int)
self.sequence = sequence
if uuid is None:
uuid = uuid4().bytes
self.uuid = uuid
self.key = key
self.properties = {} if properties is None else properties
self.body = body
# dictionary access maps to properties:
def __getitem__(self, k):
return self.properties[k]
def __setitem__(self, k, v):
self.properties[k] = v
def get(self, k, default=None):
return self.properties.get(k, default)
def store(self, dikt):
"""Store me in a dict if I have anything to store
else delete me from the dict."""
if self.key is not None and self.body is not None:
dikt[self.key] = self
elif self.key in dikt:
del dikt[self.key]
def send(self, socket):
"""Send key-value message to socket; any empty frames are sent as such."""
key = b'' if self.key is None else self.key
seq_s = struct.pack('!q', self.sequence)
body = b'' if self.body is None else self.body
prop_s = encode_properties(self.properties)
socket.send_multipart([ key, seq_s, self.uuid, prop_s, body ])
@classmethod
def recv(cls, socket):
"""Reads key-value message from socket, returns new kvmsg instance."""
return cls.from_msg(socket.recv_multipart())
@classmethod
def from_msg(cls, msg):
"""Construct key-value message from a multipart message"""
key, seq_s, uuid, prop_s, body = msg
key = key if key else None
seq = struct.unpack('!q',seq_s)[0]
body = body if body else None
prop = decode_properties(prop_s)
return cls(seq, uuid=uuid, key=key, properties=prop, body=body)
def __repr__(self):
if self.body is None:
size = 0
data=b'NULL'
else:
size = len(self.body)
data = repr(self.body)
mstr = "[seq:{seq}][key:{key}][size:{size}][props:{props}][data:{data}]".format(
seq=self.sequence,
# uuid=hexlify(self.uuid),
key=self.key,
size=size,
props=encode_properties(self.properties),
data=data,
)
return mstr
def dump(self):
print("<<", str(self), ">>", file=sys.stderr)
# ---------------------------------------------------------------------
# Runs self test of class
def test_kvmsg (verbose):
print(" * kvmsg: ", end='')
# Prepare our context and sockets
ctx = zmq.Context()
output = ctx.socket(zmq.DEALER)
output.bind("ipc://kvmsg_selftest.ipc")
input = ctx.socket(zmq.DEALER)
input.connect("ipc://kvmsg_selftest.ipc")
kvmap = {}
# Test send and receive of simple message
kvmsg = KVMsg(1)
kvmsg.key = b"key"
kvmsg.body = b"body"
if verbose:
kvmsg.dump()
kvmsg.send(output)
kvmsg.store(kvmap)
kvmsg2 = KVMsg.recv(input)
if verbose:
kvmsg2.dump()
assert kvmsg2.key == b"key"
kvmsg2.store(kvmap)
assert len(kvmap) == 1 # shouldn't be different
# test send/recv with properties:
kvmsg = KVMsg(2, key=b"key", body=b"body")
kvmsg[b"prop1"] = b"value1"
kvmsg[b"prop2"] = b"value2"
kvmsg[b"prop3"] = b"value3"
assert kvmsg[b"prop1"] == b"value1"
if verbose:
kvmsg.dump()
kvmsg.send(output)
kvmsg2 = KVMsg.recv(input)
if verbose:
kvmsg2.dump()
# ensure properties were preserved
assert kvmsg2.key == kvmsg.key
assert kvmsg2.body == kvmsg.body
assert kvmsg2.properties == kvmsg.properties
assert kvmsg2[b"prop2"] == kvmsg[b"prop2"]
print("OK")
if __name__ == '__main__':
test_kvmsg('-v' in sys.argv)
kvmsg:键值消息类:Q 完整版
kvmsg:键值消息类:Racket 完整版
kvmsg:键值消息类:Ruby 完整版
kvmsg:键值消息类:Rust 完整版
kvmsg:键值消息类:Scala 完整版
kvmsg:键值消息类:Tcl 完整版
# =====================================================================
# kvmsg - key-value message class for example applications
lappend auto_path .
package require TclOO
package require uuid
package require zmq
package provide KVMsg 1.0
# Keys are short strings
set KVMSG_KEY_MAX 255
# Message is formatted on wire as 5 frames:
# frame 0: key (0MQ string)
# frame 1: sequence (8 bytes, network order)
# frame 2: uuid (blob, 16 bytes)
# frame 3: properties (0MQ string)
# frame 4: body (blob)
set FRAME_KEY 0
set FRAME_SEQ 1
set FRAME_UUID 2
set FRAME_PROPS 3
set FRAME_BODY 4
set KVMSG_FRAMES 5
oo::class create KVMsg {
variable frame key props
# Constructor, sets sequence as provided
constructor {{isequence 0}} {
set frame [list]
#props array
my set_sequence $isequence
}
destructor {
}
method set_frame {iframe} {
set frame $iframe
}
method set_props {ipropsnm} {
upvar $ipropsnm iprops
unset -nocomplain props
foreay {k v} [array get iprops] {
set props($k) $v
}
}
# Serialize list of properties to a message frame
method encode_props {} {
while {[llength $frame] < $::FRAME_PROPS} {
lappend frame {}
}
if {[array size props]} {
set s ""
foreach k [lsort -dictionary [array names props]] {
append s "$k=$props($k)\n"
}
lset frame $::FRAME_PROPS $s
}
}
# Rebuild properties list from message frame
method decode_props {} {
unset -nocomplain props
foreach s [split [string trimright [lindex $frame $::FRAME_PROPS] \n] \n] {
lassign [split $s =] k v
set props($k) $v
}
}
# Create duplicate of kvmsg
method dup {} {
set kvmsg [KVMsg new 0]
$kvmsg set_frame $frame
$kvmsg set_props props
return $kvmsg
}
# Reads key-value message from socket
method recv {socket} {
set frame [list]
# Read all frames off the wire
for {set frame_nbr 0} {$frame_nbr < $::KVMSG_FRAMES} {incr frame_nbr} {
lappend frame [$socket recv]
# Verify multipart framing
if {![$socket getsockopt RCVMORE]} {
break
}
}
my decode_props
}
# Send key-value message to socket; any empty frames are sent as such.
method send {socket} {
my encode_props
for {set frame_nbr 0} {$frame_nbr < $::KVMSG_FRAMES} {incr frame_nbr} {
if {$frame_nbr == ($::KVMSG_FRAMES - 1)} {
$socket send [lindex $frame $frame_nbr]
} else {
$socket sendmore [lindex $frame $frame_nbr]
}
}
}
# Return key from last read message, if any, else NULL
method key {} {
if {[llength $frame] > $::FRAME_KEY} {
if {![info exists key]} {
set size [string length [lindex $frame $::FRAME_KEY]]
if {$size > $::KVMSG_KEY_MAX} {
set size $::KVMSG_KEY_MAX
}
set key [string range [lindex $frame $::FRAME_KEY] 0 [expr {$size - 1}]]
}
return $key
} else {
return {}
}
}
# Return sequence nbr from last read message, if any
method sequence {} {
if {[llength $frame] > $::FRAME_SEQ} {
set s [lindex $frame $::FRAME_SEQ]
if {[string length $s] != 8} {
error "sequence frame must have length 8"
}
binary scan [lindex $frame $::FRAME_SEQ] W r
return $r
} else {
return 0
}
}
# Return UUID from last read message, if any, else NULL
method body {} {
if {[llength $frame] > $::FRAME_UUID} {
return [lindex $frame $::FRAME_UUID]
} else {
return {}
}
}
# Return body from last read message, if any, else NULL
method body {} {
if {[llength $frame] > $::FRAME_BODY} {
return [lindex $frame $::FRAME_BODY]
} else {
return {}
}
}
# Return body size from last read message, if any, else zero
method size {} {
if {[llength $frame] > $::FRAME_BODY} {
return [string length [lindex $frame $::FRAME_BODY]]
} else {
return {}
}
}
# Set message key as provided
method set_key {ikey} {
while {[llength $frame] <= $::FRAME_KEY} {
lappend frame {}
}
lset frame $::FRAME_KEY $ikey
}
# Set message sequence number
method set_sequence {isequence} {
while {[llength $frame] <= $::FRAME_SEQ} {
lappend frame {}
}
set sequence [binary format W $isequence]
lset frame $::FRAME_SEQ $sequence
}
# Set message UUID to generated value
method set_uuid {} {
while {[llength $frame] <= $::FRAME_UUID} {
lappend frame {}
}
lset frame $::FRAME_UUID [uuid::uuid generate]
}
# Set message body
method set_body {ibody} {
while {[llength $frame] <= $::FRAME_BODY} {
lappend frame {}
}
lset frame $::FRAME_BODY $ibody
}
# Set message key using printf format
method fmt_key {format args} {
my set_key [format $format {*}$args]
}
# Set message body using printf format
method fmt_body {format args} {
my set_body [format $format {*}$args]
}
# Get message property, if set, else ""
method get_prop {name} {
if {[info exists props($name)]} {
return $props($name)
}
return ""
}
# Set message property
# Names cannot contain '='.
method set_prop {name value} {
if {[string first "=" $name] >= 0} {
error "property name can not contain a '=' character"
}
set props($name) $value
}
# Store entire kvmsg into hash map, if key/value are set.
# Nullifies kvmsg reference, and destroys automatically when no longer
# needed. If value is empty, deletes any previous value from store.
method store {hashnm} {
upvar $hashnm hash
if {[my size]} {
if {[info exists hash([my key])]} {
$hash([my key]) destroy
}
set hash([my key]) [self]
} else {
if {[info exists hash([my key])]} {
$hash([my key]) destroy
unset -nocomplain hash([my key])
}
}
}
# Dump message to stderr, for debugging and tracing
method dump {} {
set rt ""
append rt [format {[seq:%lld]} [my sequence]]
append rt [format {[key:%s]} [my key]]
append rt [format {[size:%d] } [my size]]
if {[array size props]} {
append rt "\["
}
foreach k [lsort -dictionary [array names props]] {
append rt "$k=$props($k);"
}
if {[array size props]} {
append rt "\]"
}
set size [my size]
set body [my body]
for {set i 0} {$i < $size} {incr i} {
set c [lindex $body $i]
if {[string is ascii $c]} {
append rt $c
} else {
append rt [binary scan H2 $c]
}
}
return $rt
}
}
namespace eval ::KVMsgTest {
proc test {verbose} {
puts -nonewline " * kvmsg: "
# Prepare our context and sockets
zmq context context
set os [zmq socket output context DEALER]
output bind "ipc://kvmsg_selftest.ipc"
set is [zmq socket input context DEALER]
input connect "ipc://kvmsg_selftest.ipc"
# Test send and receive of simple message
set kvmsg [KVMsg new 1]
$kvmsg set_key "key"
$kvmsg set_uuid
$kvmsg set_body "body"
if {$verbose} {
puts [$kvmsg dump]
}
$kvmsg send $os
$kvmsg store kvmap
$kvmsg recv $is
if {$verbose} {
puts [$kvmsg dump]
}
if {[$kvmsg key] ne "key"} {
error "Unexpected key: [$kvmsg key]"
}
$kvmsg destroy
# Test send and receive of message with properties
set kvmsg [KVMsg new 2]
$kvmsg set_prop "prop1" "value1"
$kvmsg set_prop "prop2" "value2"
$kvmsg set_prop "prop3" "value3"
$kvmsg set_key "key"
$kvmsg set_uuid
$kvmsg set_body "body"
if {$verbose} {
puts [$kvmsg dump]
}
$kvmsg send $os
$kvmsg recv $is
if {$verbose} {
puts [$kvmsg dump]
}
if {[$kvmsg key] ne "key"} {
error "Unexpected key: [$kvmsg key]"
}
if {[$kvmsg get_prop "prop2"] ne "value2"} {
error "Unexpected property value: [$kvmsg get_prop "prop2"]"
}
$kvmsg destroy
# Shutdown and destroy all objects
input close
output close
context term
puts "OK"
}
}
#::KVMsgTest::test 1
kvmsg:键值消息类:OCaml 完整版
模型五客户端与模型四几乎相同。它使用了完整的kvmsg类,并为每条消息设置了一个随机的ttl属性(以秒为单位)
kvmsg_set_prop (kvmsg, "ttl", "%d", randof (30));
使用 Reactor #
到目前为止,我们在服务器中使用了 poll 循环。在服务器的下一个模型中,我们切换到使用 Reactor。在 C 语言中,我们使用 CZMQ 的zloop类。使用 Reactor 会使代码更冗长,但更容易理解和扩展,因为服务器的每个部分都由一个独立的 Reactor 处理器处理。
我们使用单线程并将服务器对象传递给 Reactor 处理器。我们可以将服务器组织成多个线程,每个线程处理一个 socket 或定时器,但这在线程不必共享数据时效果更好。在这种情况下,所有工作都围绕着服务器的哈希表,所以一个线程更简单。
有三个 Reactor 处理器:
- 一个处理来自 ROUTER socket 的快照请求;
- 一个处理来自客户端的更新,通过 PULL socket 接收;
- 一个处理已过 TTL 的瞬时值过期。
clonesrv5:克隆服务器,模型五 Ada 完整版
clonesrv5:克隆服务器,模型五 Basic 完整版
clonesrv5:克隆服务器,模型五 C 完整版
// Clone server - Model Five
// Lets us build this source without creating a library
#include "kvmsg.c"
// zloop reactor handlers
static int s_snapshots (zloop_t *loop, zmq_pollitem_t *poller, void *args);
static int s_collector (zloop_t *loop, zmq_pollitem_t *poller, void *args);
static int s_flush_ttl (zloop_t *loop, int timer_id, void *args);
// Our server is defined by these properties
typedef struct {
zctx_t *ctx; // Context wrapper
zhash_t *kvmap; // Key-value store
zloop_t *loop; // zloop reactor
int port; // Main port we're working on
int64_t sequence; // How many updates we're at
void *snapshot; // Handle snapshot requests
void *publisher; // Publish updates to clients
void *collector; // Collect updates from clients
} clonesrv_t;
int main (void)
{
clonesrv_t *self = (clonesrv_t *) zmalloc (sizeof (clonesrv_t));
self->port = 5556;
self->ctx = zctx_new ();
self->kvmap = zhash_new ();
self->loop = zloop_new ();
zloop_set_verbose (self->loop, false);
// Set up our clone server sockets
self->snapshot = zsocket_new (self->ctx, ZMQ_ROUTER);
zsocket_bind (self->snapshot, "tcp://*:%d", self->port);
self->publisher = zsocket_new (self->ctx, ZMQ_PUB);
zsocket_bind (self->publisher, "tcp://*:%d", self->port + 1);
self->collector = zsocket_new (self->ctx, ZMQ_PULL);
zsocket_bind (self->collector, "tcp://*:%d", self->port + 2);
// Register our handlers with reactor
zmq_pollitem_t poller = { 0, 0, ZMQ_POLLIN };
poller.socket = self->snapshot;
zloop_poller (self->loop, &poller, s_snapshots, self);
poller.socket = self->collector;
zloop_poller (self->loop, &poller, s_collector, self);
zloop_timer (self->loop, 1000, 0, s_flush_ttl, self);
// Run reactor until process interrupted
zloop_start (self->loop);
zloop_destroy (&self->loop);
zhash_destroy (&self->kvmap);
zctx_destroy (&self->ctx);
free (self);
return 0;
}
// .split send snapshots
// We handle ICANHAZ? requests by sending snapshot data to the
// client that requested it:
// Routing information for a key-value snapshot
typedef struct {
void *socket; // ROUTER socket to send to
zframe_t *identity; // Identity of peer who requested state
char *subtree; // Client subtree specification
} kvroute_t;
// We call this function for each key-value pair in our hash table
static int
s_send_single (const char *key, void *data, void *args)
{
kvroute_t *kvroute = (kvroute_t *) args;
kvmsg_t *kvmsg = (kvmsg_t *) data;
if (strlen (kvroute->subtree) <= strlen (kvmsg_key (kvmsg))
&& memcmp (kvroute->subtree,
kvmsg_key (kvmsg), strlen (kvroute->subtree)) == 0) {
zframe_send (&kvroute->identity, // Choose recipient
kvroute->socket, ZFRAME_MORE + ZFRAME_REUSE);
kvmsg_send (kvmsg, kvroute->socket);
}
return 0;
}
// .split snapshot handler
// This is the reactor handler for the snapshot socket; it accepts
// just the ICANHAZ? request and replies with a state snapshot ending
// with a KTHXBAI message:
static int
s_snapshots (zloop_t *loop, zmq_pollitem_t *poller, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
zframe_t *identity = zframe_recv (poller->socket);
if (identity) {
// Request is in second frame of message
char *request = zstr_recv (poller->socket);
char *subtree = NULL;
if (streq (request, "ICANHAZ?")) {
free (request);
subtree = zstr_recv (poller->socket);
}
else
printf ("E: bad request, aborting\n");
if (subtree) {
// Send state socket to client
kvroute_t routing = { poller->socket, identity, subtree };
zhash_foreach (self->kvmap, s_send_single, &routing);
// Now send END message with sequence number
zclock_log ("I: sending shapshot=%d", (int) self->sequence);
zframe_send (&identity, poller->socket, ZFRAME_MORE);
kvmsg_t *kvmsg = kvmsg_new (self->sequence);
kvmsg_set_key (kvmsg, "KTHXBAI");
kvmsg_set_body (kvmsg, (byte *) subtree, 0);
kvmsg_send (kvmsg, poller->socket);
kvmsg_destroy (&kvmsg);
free (subtree);
}
zframe_destroy(&identity);
}
return 0;
}
// .split collect updates
// We store each update with a new sequence number, and if necessary, a
// time-to-live. We publish updates immediately on our publisher socket:
static int
s_collector (zloop_t *loop, zmq_pollitem_t *poller, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
kvmsg_t *kvmsg = kvmsg_recv (poller->socket);
if (kvmsg) {
kvmsg_set_sequence (kvmsg, ++self->sequence);
kvmsg_send (kvmsg, self->publisher);
int ttl = atoi (kvmsg_get_prop (kvmsg, "ttl"));
if (ttl)
kvmsg_set_prop (kvmsg, "ttl",
"%" PRId64, zclock_time () + ttl * 1000);
kvmsg_store (&kvmsg, self->kvmap);
zclock_log ("I: publishing update=%d", (int) self->sequence);
}
return 0;
}
// .split flush ephemeral values
// At regular intervals, we flush ephemeral values that have expired. This
// could be slow on very large data sets:
// If key-value pair has expired, delete it and publish the
// fact to listening clients.
static int
s_flush_single (const char *key, void *data, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
kvmsg_t *kvmsg = (kvmsg_t *) data;
int64_t ttl;
sscanf (kvmsg_get_prop (kvmsg, "ttl"), "%" PRId64, &ttl);
if (ttl && zclock_time () >= ttl) {
kvmsg_set_sequence (kvmsg, ++self->sequence);
kvmsg_set_body (kvmsg, (byte *) "", 0);
kvmsg_send (kvmsg, self->publisher);
kvmsg_store (&kvmsg, self->kvmap);
zclock_log ("I: publishing delete=%d", (int) self->sequence);
}
return 0;
}
static int
s_flush_ttl (zloop_t *loop, int timer_id, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
if (self->kvmap)
zhash_foreach (self->kvmap, s_flush_single, args);
return 0;
}
clonesrv5:克隆服务器,模型五 C++ 完整版
// Clone server - Model Five
#include "kvmsg.hpp"
// Routing information for a key-value snapshot
typedef struct {
zmqpp::socket_t *socket; // ROUTER socket to send to
std::string identity; // Identity of peer who requested state
std::string subtree; // Client subtree specification
} kvroute_t;
typedef struct {
zmqpp::context_t *ctx; // Our context
std::unordered_map<std::string, KVMsg*> kvmap; // Key-value store
int64_t sequence; // How many updates we're at
int port; // Main port we're working on
zmqpp::socket_t* snapshot; // Handle snapshot requests
zmqpp::socket_t* publisher; // Publish updates to clients
zmqpp::socket_t* collector; // Collect updates from clients
} clonesrv_t;
// loop event handlers
static bool s_snapshots(clonesrv_t *self);
static bool s_collector(clonesrv_t *self);
static bool s_flush_ttl(clonesrv_t *self);
int main(void) {
zmqpp::loop loop; // Reactor loop
clonesrv_t *self = new clonesrv_t();
self->port = 5556;
self->ctx = new zmqpp::context_t();
// set up our clone server sockets
self->snapshot = new zmqpp::socket_t(*self->ctx, zmqpp::socket_type::router);
self->snapshot->bind("tcp://*:" + std::to_string(self->port));
self->publisher = new zmqpp::socket_t(*self->ctx, zmqpp::socket_type::pub);
self->publisher->bind("tcp://*:" + std::to_string(self->port + 1));
self->collector = new zmqpp::socket_t(*self->ctx, zmqpp::socket_type::pull);
self->collector->bind("tcp://*:" + std::to_string(self->port + 2));
loop.add(*self->snapshot, std::bind(s_snapshots, self));
loop.add(*self->collector, std::bind(s_collector, self));
loop.add(std::chrono::milliseconds(1000), 0, std::bind(s_flush_ttl, self));
s_catch_signals();
auto end_loop = []() -> bool {
return s_interrupted == 0;
};
loop.add(std::chrono::milliseconds(100), 0, end_loop);
try {
loop.start();
} catch (const std::exception &e) {
std::cerr << "Exception: " << e.what() << std::endl;
}
KVMsg::clear_kvmap(self->kvmap);
std::cout << "Interrupted\n";
return 0;
}
// .split snapshot handler
// This is the reactor handler for the snapshot socket; it accepts
// just the ICANHAZ? request and replies with a state snapshot ending
// with a KTHXBAI message:
static bool s_snapshots(clonesrv_t *self) {
zmqpp::message frames;
if (!self->snapshot->receive(frames)) {
return false;
}
std::string identity;
frames >> identity;
std::string request;
frames >> request;
std::string subtree;
if (request == "ICANHAZ?") {
assert(frames.parts() == 3);
frames >> subtree;
} else {
std::cerr << "E: bad request, aborting" << std::endl;
}
if (!subtree.empty()) {
kvroute_t routing = {self->snapshot, identity, subtree};
for (auto &kv : self->kvmap) {
if (subtree.size() <= kv.first.size() && kv.first.compare(0, subtree.size(), subtree) == 0) {
zmqpp::message_t frames;
frames << identity;
kv.second->encode_frames(frames);
routing.socket->send(frames);
}
}
std::cout << "I: sending snapshot=" << self->sequence << std::endl;
KVMsg *kvmsg = new KVMsg(self->sequence);
kvmsg->set_key("KTHXBAI");
kvmsg->set_body(ustring((unsigned char *)subtree.c_str(), subtree.size()));
// remember to send the identity frame
zmqpp::message_t frames;
frames << identity;
kvmsg->encode_frames(frames);
self->snapshot->send(frames);
delete kvmsg;
}
return true;
}
// .split collect updates
// We store each update with a new sequence number, and if necessary, a
// time-to-live. We publish updates immediately on our publisher socket:
static bool s_collector(clonesrv_t *self) {
KVMsg *kvmsg = KVMsg::recv(*self->collector);
if (!kvmsg) {
return false;
}
kvmsg->set_sequence(++self->sequence);
kvmsg->send(*self->publisher);
std::string ttl_second_str = kvmsg->property("ttl");
if (!ttl_second_str.empty()) {
int ttl_second = std::atoi(ttl_second_str.c_str());
auto now = std::chrono::high_resolution_clock::now();
auto expired_at = std::chrono::duration_cast<std::chrono::milliseconds>(now.time_since_epoch()).count() + ttl_second * 1000;
kvmsg->set_property("ttl", "%lld", expired_at);
}
kvmsg->store(self->kvmap);
return true;
}
// .split flush ephemeral values
// At regular intervals, we flush ephemeral values that have expired. This
// could be slow on very large data sets:
// If key-value pair has expired, delete it and publish the
// fact to listening clients.
static bool s_flush_ttl(clonesrv_t *self) {
auto now = std::chrono::high_resolution_clock::now();
for (auto it = self->kvmap.begin(); it != self->kvmap.end();) {
KVMsg *kvmsg = it->second;
std::string ttl_str = kvmsg->property("ttl");
if (!ttl_str.empty()) {
int64_t ttl = std::atoll(ttl_str.c_str());
if (ttl < std::chrono::duration_cast<std::chrono::milliseconds>(now.time_since_epoch()).count()) {
kvmsg->set_sequence(++self->sequence);
kvmsg->set_body(ustring());
kvmsg->send(*self->publisher);
it = self->kvmap.erase(it);
std::cout << "I: publishing delete=" << self->sequence << std::endl;
} else {
++it;
}
} else {
++it;
}
}
return true;
}
clonesrv5:克隆服务器,模型五 C# 完整版
clonesrv5:克隆服务器,模型五 CL 完整版
clonesrv5:克隆服务器,模型五 Delphi 完整版
clonesrv5:克隆服务器,模型五 Erlang 完整版
clonesrv5:克隆服务器,模型五 Elixir 完整版
clonesrv5:克隆服务器,模型五 F# 完整版
clonesrv5:克隆服务器,模型五 Felix 完整版
clonesrv5:克隆服务器,模型五 Go 完整版
clonesrv5:克隆服务器,模型五 Haskell 完整版
clonesrv5:克隆服务器,模型五 Haxe 完整版
clonesrv5:克隆服务器,模型五 Java 完整版
package guide;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZLoop;
import org.zeromq.ZLoop.IZLoopHandler;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.PollItem;
import org.zeromq.ZMQ.Socket;
// Clone server - Model Five
public class clonesrv5
{
private ZContext ctx; // Context wrapper
private Map<String, kvmsg> kvmap; // Key-value store
private ZLoop loop; // zloop reactor
private int port; // Main port we're working on
private long sequence; // How many updates we're at
private Socket snapshot; // Handle snapshot requests
private Socket publisher; // Publish updates to clients
private Socket collector; // Collect updates from clients
// .split snapshot handler
// This is the reactor handler for the snapshot socket; it accepts
// just the ICANHAZ? request and replies with a state snapshot ending
// with a KTHXBAI message:
private static class Snapshots implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv5 srv = (clonesrv5) arg;
Socket socket = item.getSocket();
byte[] identity = socket.recv();
if (identity != null) {
// Request is in second frame of message
String request = socket.recvStr();
String subtree = null;
if (request.equals("ICANHAZ?")) {
subtree = socket.recvStr();
}
else System.out.printf("E: bad request, aborting\n");
if (subtree != null) {
// Send state socket to client
for (Entry<String, kvmsg> entry : srv.kvmap.entrySet()) {
sendSingle(entry.getValue(), identity, subtree, socket);
}
// Now send END message with getSequence number
System.out.printf("I: sending shapshot=%d\n", srv.sequence);
socket.send(identity, ZMQ.SNDMORE);
kvmsg kvmsg = new kvmsg(srv.sequence);
kvmsg.setKey("KTHXBAI");
kvmsg.setBody(subtree.getBytes(ZMQ.CHARSET));
kvmsg.send(socket);
kvmsg.destroy();
}
}
return 0;
}
}
// .split collect updates
// We store each update with a new getSequence number, and if necessary, a
// time-to-live. We publish updates immediately on our publisher socket:
private static class Collector implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv5 srv = (clonesrv5) arg;
Socket socket = item.getSocket();
kvmsg msg = kvmsg.recv(socket);
if (msg != null) {
msg.setSequence(++srv.sequence);
msg.send(srv.publisher);
int ttl = Integer.parseInt(msg.getProp("ttl"));
if (ttl > 0)
msg.setProp("ttl", "%d", System.currentTimeMillis() + ttl * 1000);
msg.store(srv.kvmap);
System.out.printf("I: publishing update=%d\n", srv.sequence);
}
return 0;
}
}
private static class FlushTTL implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv5 srv = (clonesrv5) arg;
if (srv.kvmap != null) {
for (kvmsg msg : new ArrayList<kvmsg>(srv.kvmap.values())) {
srv.flushSingle(msg);
}
}
return 0;
}
}
public clonesrv5()
{
port = 5556;
ctx = new ZContext();
kvmap = new HashMap<String, kvmsg>();
loop = new ZLoop(ctx);
loop.verbose(false);
// Set up our clone server sockets
snapshot = ctx.createSocket(SocketType.ROUTER);
snapshot.bind(String.format("tcp://*:%d", port));
publisher = ctx.createSocket(SocketType.PUB);
publisher.bind(String.format("tcp://*:%d", port + 1));
collector = ctx.createSocket(SocketType.PULL);
collector.bind(String.format("tcp://*:%d", port + 2));
}
public void run()
{
// Register our handlers with reactor
PollItem poller = new PollItem(snapshot, ZMQ.Poller.POLLIN);
loop.addPoller(poller, new Snapshots(), this);
poller = new PollItem(collector, ZMQ.Poller.POLLIN);
loop.addPoller(poller, new Collector(), this);
loop.addTimer(1000, 0, new FlushTTL(), this);
loop.start();
loop.destroy();
ctx.destroy();
}
// We call this function for each getKey-value pair in our hash table
private static void sendSingle(kvmsg msg, byte[] identity, String subtree, Socket socket)
{
if (msg.getKey().startsWith(subtree)) {
socket.send(identity, // Choose recipient
ZMQ.SNDMORE);
msg.send(socket);
}
}
// .split flush ephemeral values
// At regular intervals, we flush ephemeral values that have expired. This
// could be slow on very large data sets:
// If getKey-value pair has expired, delete it and publish the
// fact to listening clients.
private void flushSingle(kvmsg msg)
{
long ttl = Long.parseLong(msg.getProp("ttl"));
if (ttl > 0 && System.currentTimeMillis() >= ttl) {
msg.setSequence(++sequence);
msg.setBody(ZMQ.MESSAGE_SEPARATOR);
msg.send(publisher);
msg.store(kvmap);
System.out.printf("I: publishing delete=%d\n", sequence);
}
}
public static void main(String[] args)
{
clonesrv5 srv = new clonesrv5();
srv.run();
}
}
clonesrv5:克隆服务器,模型五 Julia 完整版
clonesrv5:克隆服务器,模型五 Lua 完整版
clonesrv5:克隆服务器,模型五 Node.js 完整版
clonesrv5:克隆服务器,模型五 Objective-C 完整版
clonesrv5:克隆服务器,模型五 ooc 完整版
clonesrv5:克隆服务器,模型五 Perl 完整版
clonesrv5:克隆服务器,模型五 PHP 完整版
clonesrv5:克隆服务器,模型五 Python 完整版
"""
Clone server Model Five
Author: Min RK <benjaminrk@gmail.com
"""
import logging
import time
import zmq
from zmq.eventloop.ioloop import IOLoop, PeriodicCallback
from zmq.eventloop.zmqstream import ZMQStream
from kvmsg import KVMsg
from zhelpers import dump
# simple struct for routing information for a key-value snapshot
class Route:
def __init__(self, socket, identity, subtree):
self.socket = socket # ROUTER socket to send to
self.identity = identity # Identity of peer who requested state
self.subtree = subtree # Client subtree specification
def send_single(key, kvmsg, route):
"""Send one state snapshot key-value pair to a socket"""
# check front of key against subscription subtree:
if kvmsg.key.startswith(route.subtree):
# Send identity of recipient first
route.socket.send(route.identity, zmq.SNDMORE)
kvmsg.send(route.socket)
class CloneServer(object):
# Our server is defined by these properties
ctx = None # Context wrapper
kvmap = None # Key-value store
loop = None # IOLoop reactor
port = None # Main port we're working on
sequence = 0 # How many updates we're at
snapshot = None # Handle snapshot requests
publisher = None # Publish updates to clients
collector = None # Collect updates from clients
def __init__(self, port=5556):
self.port = port
self.ctx = zmq.Context()
self.kvmap = {}
self.loop = IOLoop.instance()
# Set up our clone server sockets
self.snapshot = self.ctx.socket(zmq.ROUTER)
self.publisher = self.ctx.socket(zmq.PUB)
self.collector = self.ctx.socket(zmq.PULL)
self.snapshot.bind("tcp://*:%d" % self.port)
self.publisher.bind("tcp://*:%d" % (self.port + 1))
self.collector.bind("tcp://*:%d" % (self.port + 2))
# Wrap sockets in ZMQStreams for IOLoop handlers
self.snapshot = ZMQStream(self.snapshot)
self.publisher = ZMQStream(self.publisher)
self.collector = ZMQStream(self.collector)
# Register our handlers with reactor
self.snapshot.on_recv(self.handle_snapshot)
self.collector.on_recv(self.handle_collect)
self.flush_callback = PeriodicCallback(self.flush_ttl, 1000)
# basic log formatting:
logging.basicConfig(format="%(asctime)s %(message)s", datefmt="%Y-%m-%d %H:%M:%S",
level=logging.INFO)
def start(self):
# Run reactor until process interrupted
self.flush_callback.start()
try:
self.loop.start()
except KeyboardInterrupt:
pass
def handle_snapshot(self, msg):
"""snapshot requests"""
if len(msg) != 3 or msg[1] != b"ICANHAZ?":
print("E: bad request, aborting")
dump(msg)
self.loop.stop()
return
identity, request, subtree = msg
if subtree:
# Send state snapshot to client
route = Route(self.snapshot, identity, subtree)
# For each entry in kvmap, send kvmsg to client
for k,v in self.kvmap.items():
send_single(k,v,route)
# Now send END message with sequence number
logging.info("I: Sending state shapshot=%d" % self.sequence)
self.snapshot.send(identity, zmq.SNDMORE)
kvmsg = KVMsg(self.sequence)
kvmsg.key = b"KTHXBAI"
kvmsg.body = subtree
kvmsg.send(self.snapshot)
def handle_collect(self, msg):
"""Collect updates from clients"""
kvmsg = KVMsg.from_msg(msg)
self.sequence += 1
kvmsg.sequence = self.sequence
kvmsg.send(self.publisher)
ttl = float(kvmsg.get(b'ttl', 0))
if ttl:
kvmsg[b'ttl'] = b'%f' % (time.time() + ttl)
kvmsg.store(self.kvmap)
logging.info("I: publishing update=%d", self.sequence)
def flush_ttl(self):
"""Purge ephemeral values that have expired"""
for key,kvmsg in list(self.kvmap.items()):
# used list() to exhaust the iterator before deleting from the dict
self.flush_single(kvmsg)
def flush_single(self, kvmsg):
"""If key-value pair has expired, delete it and publish the fact
to listening clients."""
ttl = float(kvmsg.get(b'ttl', 0))
if ttl and ttl <= time.time():
kvmsg.body = b""
self.sequence += 1
kvmsg.sequence = self.sequence
kvmsg.send(self.publisher)
del self.kvmap[kvmsg.key]
logging.info("I: publishing delete=%d", self.sequence)
def main():
clone = CloneServer()
clone.start()
if __name__ == '__main__':
main()
clonesrv5:克隆服务器,模型五 Q 完整版
clonesrv5:克隆服务器,模型五 Racket 完整版
clonesrv5:克隆服务器,模型五 Ruby 完整版
clonesrv5:克隆服务器,模型五 Rust 完整版
clonesrv5:克隆服务器,模型五 Scala 完整版
clonesrv5:克隆服务器,模型五 Tcl 完整版
#
# Clone server Model Five
#
lappend auto_path .
package require TclOO
package require mdp
package require KVMsg
oo::class create CloneServer {
variable ctx kvmap sequence snapshot publisher collector afterid
constructor {port} {
# Set up our clone server sockets
set sequence 0
set ctx [zmq context cloneserver_context_[mdp::contextid]]
set snapshot [zmq socket clonserver_snapshot[mdp::socketid] $ctx ROUTER]
set publisher [zmq socket cloneserver_publisher_[mdp::socketid] $ctx PUB]
set collector [zmq socket cloneserver_collector_[mdp::socketid] $ctx PULL]
$snapshot bind "tcp://*:$port"
$publisher bind "tcp://*:[expr {$port+1}]"
$collector bind "tcp://*:[expr {$port+2}]"
# Register our handlers with reactor
my register
}
destructor {
$snapshot close
$publisher close
$collector close
$ctx term
}
method register {} {
$snapshot readable [list [self] s_snapshot]
$collector readable [list [self] s_collector]
set afterid [after 1000 [list [self] s_flush_ttl]]
}
method unregister {} {
$snapshot readable {}
$collector readable {}
catch {after cancel $afterid}
}
# Send snapshots to clients who ask for them
method s_snapshot {} {
set identity [$snapshot recv]
if {[string length $identity]} {
set request [$snapshot recv]
if {$request eq "ICANHAZ?"} {
set subtree [$snapshot recv]
} else {
puts "E: bad request, aborting"
}
if {[info exists subtree]} {
# Send state to client
foreach {key value} [array get kvmap] {
# Send one state snapshot key-value pair to a socket
# Hash item data is our kvmsg object, ready to send
if {[string match $subtree* [$value key]]} {
$snapshot sendmore $identity
$value send $snapshot
}
}
# Now send END message with sequence number
puts "I: sending snapshot=$sequence"
$snapshot sendmore $identity
set kvmsg [KVMsg new $sequence]
$kvmsg set_key "KTHXBAI"
$kvmsg set_body $subtree
$kvmsg send $snapshot
$kvmsg destroy
}
}
}
# Collect updates from clients
method s_collector {} {
set kvmsg [KVMsg new]
$kvmsg recv $collector
$kvmsg set_sequence [incr sequence]
$kvmsg send $publisher
set ttl [$kvmsg get_prop "ttl"]
if {$ttl} {
$kvmsg set_prop "ttl" [expr {[clock milliseconds] + $ttl * 1000}]
$kvmsg store kvmap
puts "I: publishing update=$sequence"
}
}
# Purge ephemeral values that have expired
method s_flush_ttl {} {
foreach {key value} [array names kvmap] {
# If key-value pair has expired, delete it and publish the
# fact to listening clients.
if {[clock milliseconds] >= [$value get_prop "ttl"]} {
$value set_sequence [incr sequence]
$value set_body ""
$value send $publisher
$value stor kvmap
puts "I: publishing delete=$sequence"
}
}
}
}
set server [CloneServer new 5556]
# Run reactor until process interrupted
vwait forever
$server destroy
clonesrv5:克隆服务器,模型五 OCaml 完整版
添加二进制星模式以提高可靠性 #
到目前为止,我们探讨的克隆模型相对简单。现在我们将进入令人不快的复杂领域,这让我需要再来一杯浓缩咖啡。你应该认识到,“可靠”消息传递的实现非常复杂,因此在着手之前,你总需要问一句:“我们真的需要这个吗?”如果你能接受不可靠或“足够好”的可靠性,那么在成本和复杂性方面将是一个巨大的胜利。当然,你可能会不时丢失一些数据。这通常是一个很好的权衡。话虽如此,并且……呷了一口……因为这杯浓缩咖啡确实很棒,让我们开始吧。
当你使用最后一个模型时,你会停止并重启服务器。它可能看起来像恢复了,但实际上它是在一个空状态而不是正确的当前状态上应用更新。任何加入网络的新客户端都只会收到最新的更新,而不是完整的历史记录。
我们想要的是一种服务器从被终止或崩溃中恢复的方法。我们还需要提供备份,以防服务器在任何时间长度内停止运行。当有人要求“可靠性”时,请他们列出他们希望处理的故障。在我们的例子中,这些故障包括:
-
服务器进程崩溃并自动或手动重启。进程丢失其状态,必须从某个地方获取回来。
-
服务器机器宕机并在较长时间内离线。客户端必须切换到某个备用服务器。
-
服务器进程或机器与网络断开连接,例如,交换机损坏或数据中心瘫痪。它可能在某个时候恢复,但在此期间客户端需要一个备用服务器。
我们的第一步是添加第二个服务器。我们可以使用第四章 - 可靠的请求-回复模式中的二进制星(Binary Star)模式将它们组织成主服务器和备份服务器。二进制星是一个 Reactor,所以我们已经将最后一个服务器模型重构为 Reactor 风格是很方便的。
我们需要确保主服务器崩溃时更新不会丢失。最简单的技术是将更新发送给两个服务器。备份服务器可以像客户端一样运行,通过接收所有客户端接收的更新来保持其状态同步。它也会接收来自客户端的新更新。它尚不能将这些更新存储到其哈希表中,但可以暂时保留它们。
因此,模型六在模型五的基础上引入了以下变化:
-
我们使用发布-订阅(pub-sub)流而不是推-拉(push-pull)流来处理发送给服务器的客户端更新。这负责将更新扇出到两个服务器。否则我们将不得不使用两个 DEALER socket。
-
我们在服务器更新(发送给客户端)中添加了心跳,以便客户端能够检测到主服务器何时宕机。然后它可以切换到备份服务器。
-
我们使用二进制星bstarReactor 类连接两个服务器。二进制星依赖于客户端通过向它们认为活动状态的服务器发出明确请求来进行投票。我们将使用快照请求作为投票机制。
-
我们通过添加一个 UUID 字段使所有更新消息具有唯一标识。客户端生成此 UUID,服务器在重新发布的更新中将其传回。
-
被动服务器维护一个“待处理列表”,包含它从客户端接收但尚未从活动服务器接收的更新;或者它从活动服务器接收但尚未从客户端接收的更新。该列表按从旧到新的顺序排列,以便轻松地从头部移除更新。
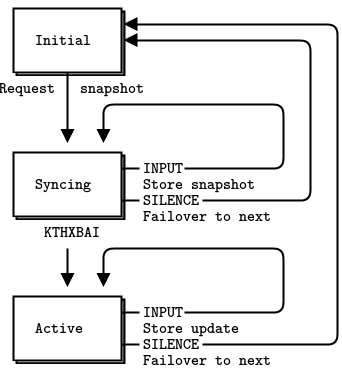
将客户端逻辑设计为有限状态机是很有用的。客户端会经历以下三种状态循环:
-
客户端打开并连接其 socket,然后向第一个服务器请求快照。为了避免请求风暴,它只会向任何给定的服务器请求两次。丢失一个请求可能是运气不好。丢失两个请求则属于疏忽大意。
-
客户端等待当前服务器的回复(快照数据),如果收到,则存储它。如果在一定时间内没有收到回复,则故障转移到下一个服务器。
-
当客户端获得快照后,它会等待并处理更新。同样,如果在一定时间内没有收到服务器的任何消息,它就会故障转移到下一个服务器。
客户端永远循环。在启动或故障转移期间,很可能有些客户端试图与主服务器通信,而另一些客户端试图与备份服务器通信。二进制星状态机会处理这种情况,希望是准确的。证明软件是正确的很难;相反,我们会不断测试它直到无法证明它是错误的。
故障转移过程如下:
-
客户端检测到主服务器不再发送心跳,并断定它已宕机。客户端连接到备份服务器并请求新的状态快照。
-
备份服务器开始接收来自客户端的快照请求,并检测到主服务器已失效,因此接管成为主服务器。
-
备份服务器将其待处理列表应用到其自身的哈希表中,然后开始处理状态快照请求。
当主服务器恢复在线时,它将:
-
作为被动服务器启动,并像克隆客户端一样连接到备份服务器。
-
通过其 SUB socket 开始接收来自客户端的更新。
我们做了一些假设:
-
至少有一个服务器将保持运行。如果两个服务器都崩溃,我们将丢失所有服务器状态,并且无法恢复。
-
多个客户端不会同时更新相同的哈希键。客户端更新将以不同的顺序到达两个服务器。因此,备份服务器可能会以与主服务器不同(或曾经)的顺序应用其待处理列表中的更新。来自单个客户端的更新总是以相同的顺序到达两个服务器,因此这是安全的。
因此,使用二进制星模式的高可用性服务器对的架构包含两个服务器和一组与两个服务器通信的客户端。
以下是克隆服务器的第六个也是最后一个模型:
clonesrv6:克隆服务器,模型六 Ada 完整版
clonesrv6:克隆服务器,模型六 Basic 完整版
clonesrv6:克隆服务器,模型六 C 完整版
// Clone server Model Six
// Lets us build this source without creating a library
#include "bstar.c"
#include "kvmsg.c"
// .split definitions
// We define a set of reactor handlers and our server object structure:
// Bstar reactor handlers
static int
s_snapshots (zloop_t *loop, zmq_pollitem_t *poller, void *args);
static int
s_collector (zloop_t *loop, zmq_pollitem_t *poller, void *args);
static int
s_flush_ttl (zloop_t *loop, int timer_id, void *args);
static int
s_send_hugz (zloop_t *loop, int timer_id, void *args);
static int
s_new_active (zloop_t *loop, zmq_pollitem_t *poller, void *args);
static int
s_new_passive (zloop_t *loop, zmq_pollitem_t *poller, void *args);
static int
s_subscriber (zloop_t *loop, zmq_pollitem_t *poller, void *args);
// Our server is defined by these properties
typedef struct {
zctx_t *ctx; // Context wrapper
zhash_t *kvmap; // Key-value store
bstar_t *bstar; // Bstar reactor core
int64_t sequence; // How many updates we're at
int port; // Main port we're working on
int peer; // Main port of our peer
void *publisher; // Publish updates and hugz
void *collector; // Collect updates from clients
void *subscriber; // Get updates from peer
zlist_t *pending; // Pending updates from clients
bool primary; // true if we're primary
bool active; // true if we're active
bool passive; // true if we're passive
} clonesrv_t;
// .split main task setup
// The main task parses the command line to decide whether to start
// as a primary or backup server. We're using the Binary Star pattern
// for reliability. This interconnects the two servers so they can
// agree on which one is primary and which one is backup. To allow the
// two servers to run on the same box, we use different ports for
// primary and backup. Ports 5003/5004 are used to interconnect the
// servers. Ports 5556/5566 are used to receive voting events (snapshot
// requests in the clone pattern). Ports 5557/5567 are used by the
// publisher, and ports 5558/5568 are used by the collector:
int main (int argc, char *argv [])
{
clonesrv_t *self = (clonesrv_t *) zmalloc (sizeof (clonesrv_t));
if (argc == 2 && streq (argv [1], "-p")) {
zclock_log ("I: primary active, waiting for backup (passive)");
self->bstar = bstar_new (BSTAR_PRIMARY, "tcp://*:5003",
"tcp://:5004");
bstar_voter (self->bstar, "tcp://*:5556",
ZMQ_ROUTER, s_snapshots, self);
self->port = 5556;
self->peer = 5566;
self->primary = true;
}
else
if (argc == 2 && streq (argv [1], "-b")) {
zclock_log ("I: backup passive, waiting for primary (active)");
self->bstar = bstar_new (BSTAR_BACKUP, "tcp://*:5004",
"tcp://:5003");
bstar_voter (self->bstar, "tcp://*:5566",
ZMQ_ROUTER, s_snapshots, self);
self->port = 5566;
self->peer = 5556;
self->primary = false;
}
else {
printf ("Usage: clonesrv6 { -p | -b }\n");
free (self);
exit (0);
}
// Primary server will become first active
if (self->primary)
self->kvmap = zhash_new ();
self->ctx = zctx_new ();
self->pending = zlist_new ();
bstar_set_verbose (self->bstar, true);
// Set up our clone server sockets
self->publisher = zsocket_new (self->ctx, ZMQ_PUB);
self->collector = zsocket_new (self->ctx, ZMQ_SUB);
zsocket_set_subscribe (self->collector, "");
zsocket_bind (self->publisher, "tcp://*:%d", self->port + 1);
zsocket_bind (self->collector, "tcp://*:%d", self->port + 2);
// Set up our own clone client interface to peer
self->subscriber = zsocket_new (self->ctx, ZMQ_SUB);
zsocket_set_subscribe (self->subscriber, "");
zsocket_connect (self->subscriber,
"tcp://:%d", self->peer + 1);
// .split main task body
// After we've setup our sockets, we register our binary star
// event handlers, and then start the bstar reactor. This finishes
// when the user presses Ctrl-C or when the process receives a SIGINT
// interrupt:
// Register state change handlers
bstar_new_active (self->bstar, s_new_active, self);
bstar_new_passive (self->bstar, s_new_passive, self);
// Register our other handlers with the bstar reactor
zmq_pollitem_t poller = { self->collector, 0, ZMQ_POLLIN };
zloop_poller (bstar_zloop (self->bstar), &poller, s_collector, self);
zloop_timer (bstar_zloop (self->bstar), 1000, 0, s_flush_ttl, self);
zloop_timer (bstar_zloop (self->bstar), 1000, 0, s_send_hugz, self);
// Start the bstar reactor
bstar_start (self->bstar);
// Interrupted, so shut down
while (zlist_size (self->pending)) {
kvmsg_t *kvmsg = (kvmsg_t *) zlist_pop (self->pending);
kvmsg_destroy (&kvmsg);
}
zlist_destroy (&self->pending);
bstar_destroy (&self->bstar);
zhash_destroy (&self->kvmap);
zctx_destroy (&self->ctx);
free (self);
return 0;
}
// We handle ICANHAZ? requests exactly as in the clonesrv5 example.
// .skip
// Routing information for a key-value snapshot
typedef struct {
void *socket; // ROUTER socket to send to
zframe_t *identity; // Identity of peer who requested state
char *subtree; // Client subtree specification
} kvroute_t;
// Send one state snapshot key-value pair to a socket
// Hash item data is our kvmsg object, ready to send
static int
s_send_single (const char *key, void *data, void *args)
{
kvroute_t *kvroute = (kvroute_t *) args;
kvmsg_t *kvmsg = (kvmsg_t *) data;
if (strlen (kvroute->subtree) <= strlen (kvmsg_key (kvmsg))
&& memcmp (kvroute->subtree,
kvmsg_key (kvmsg), strlen (kvroute->subtree)) == 0) {
zframe_send (&kvroute->identity, // Choose recipient
kvroute->socket, ZFRAME_MORE + ZFRAME_REUSE);
kvmsg_send (kvmsg, kvroute->socket);
}
return 0;
}
static int
s_snapshots (zloop_t *loop, zmq_pollitem_t *poller, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
zframe_t *identity = zframe_recv (poller->socket);
if (identity) {
// Request is in second frame of message
char *request = zstr_recv (poller->socket);
char *subtree = NULL;
if (streq (request, "ICANHAZ?")) {
free (request);
subtree = zstr_recv (poller->socket);
}
else
printf ("E: bad request, aborting\n");
if (subtree) {
// Send state socket to client
kvroute_t routing = { poller->socket, identity, subtree };
zhash_foreach (self->kvmap, s_send_single, &routing);
// Now send END message with sequence number
zclock_log ("I: sending shapshot=%d", (int) self->sequence);
zframe_send (&identity, poller->socket, ZFRAME_MORE);
kvmsg_t *kvmsg = kvmsg_new (self->sequence);
kvmsg_set_key (kvmsg, "KTHXBAI");
kvmsg_set_body (kvmsg, (byte *) subtree, 0);
kvmsg_send (kvmsg, poller->socket);
kvmsg_destroy (&kvmsg);
free (subtree);
}
zframe_destroy(&identity);
}
return 0;
}
// .until
// .split collect updates
// The collector is more complex than in the clonesrv5 example because the
// way it processes updates depends on whether we're active or passive.
// The active applies them immediately to its kvmap, whereas the passive
// queues them as pending:
// If message was already on pending list, remove it and return true,
// else return false.
static int
s_was_pending (clonesrv_t *self, kvmsg_t *kvmsg)
{
kvmsg_t *held = (kvmsg_t *) zlist_first (self->pending);
while (held) {
if (memcmp (kvmsg_uuid (kvmsg),
kvmsg_uuid (held), sizeof (uuid_t)) == 0) {
zlist_remove (self->pending, held);
return true;
}
held = (kvmsg_t *) zlist_next (self->pending);
}
return false;
}
static int
s_collector (zloop_t *loop, zmq_pollitem_t *poller, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
kvmsg_t *kvmsg = kvmsg_recv (poller->socket);
if (kvmsg) {
if (self->active) {
kvmsg_set_sequence (kvmsg, ++self->sequence);
kvmsg_send (kvmsg, self->publisher);
int ttl = atoi (kvmsg_get_prop (kvmsg, "ttl"));
if (ttl)
kvmsg_set_prop (kvmsg, "ttl",
"%" PRId64, zclock_time () + ttl * 1000);
kvmsg_store (&kvmsg, self->kvmap);
zclock_log ("I: publishing update=%d", (int) self->sequence);
}
else {
// If we already got message from active, drop it, else
// hold on pending list
if (s_was_pending (self, kvmsg))
kvmsg_destroy (&kvmsg);
else
zlist_append (self->pending, kvmsg);
}
}
return 0;
}
// We purge ephemeral values using exactly the same code as in
// the previous clonesrv5 example.
// .skip
// If key-value pair has expired, delete it and publish the
// fact to listening clients.
static int
s_flush_single (const char *key, void *data, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
kvmsg_t *kvmsg = (kvmsg_t *) data;
int64_t ttl;
sscanf (kvmsg_get_prop (kvmsg, "ttl"), "%" PRId64, &ttl);
if (ttl && zclock_time () >= ttl) {
kvmsg_set_sequence (kvmsg, ++self->sequence);
kvmsg_set_body (kvmsg, (byte *) "", 0);
kvmsg_send (kvmsg, self->publisher);
kvmsg_store (&kvmsg, self->kvmap);
zclock_log ("I: publishing delete=%d", (int) self->sequence);
}
return 0;
}
static int
s_flush_ttl (zloop_t *loop, int timer_id, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
if (self->kvmap)
zhash_foreach (self->kvmap, s_flush_single, args);
return 0;
}
// .until
// .split heartbeating
// We send a HUGZ message once a second to all subscribers so that they
// can detect if our server dies. They'll then switch over to the backup
// server, which will become active:
static int
s_send_hugz (zloop_t *loop, int timer_id, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
kvmsg_t *kvmsg = kvmsg_new (self->sequence);
kvmsg_set_key (kvmsg, "HUGZ");
kvmsg_set_body (kvmsg, (byte *) "", 0);
kvmsg_send (kvmsg, self->publisher);
kvmsg_destroy (&kvmsg);
return 0;
}
// .split handling state changes
// When we switch from passive to active, we apply our pending list so that
// our kvmap is up-to-date. When we switch to passive, we wipe our kvmap
// and grab a new snapshot from the active server:
static int
s_new_active (zloop_t *loop, zmq_pollitem_t *unused, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
self->active = true;
self->passive = false;
// Stop subscribing to updates
zmq_pollitem_t poller = { self->subscriber, 0, ZMQ_POLLIN };
zloop_poller_end (bstar_zloop (self->bstar), &poller);
// Apply pending list to own hash table
while (zlist_size (self->pending)) {
kvmsg_t *kvmsg = (kvmsg_t *) zlist_pop (self->pending);
kvmsg_set_sequence (kvmsg, ++self->sequence);
kvmsg_send (kvmsg, self->publisher);
kvmsg_store (&kvmsg, self->kvmap);
zclock_log ("I: publishing pending=%d", (int) self->sequence);
}
return 0;
}
static int
s_new_passive (zloop_t *loop, zmq_pollitem_t *unused, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
zhash_destroy (&self->kvmap);
self->active = false;
self->passive = true;
// Start subscribing to updates
zmq_pollitem_t poller = { self->subscriber, 0, ZMQ_POLLIN };
zloop_poller (bstar_zloop (self->bstar), &poller, s_subscriber, self);
return 0;
}
// .split subscriber handler
// When we get an update, we create a new kvmap if necessary, and then
// add our update to our kvmap. We're always passive in this case:
static int
s_subscriber (zloop_t *loop, zmq_pollitem_t *poller, void *args)
{
clonesrv_t *self = (clonesrv_t *) args;
// Get state snapshot if necessary
if (self->kvmap == NULL) {
self->kvmap = zhash_new ();
void *snapshot = zsocket_new (self->ctx, ZMQ_DEALER);
zsocket_connect (snapshot, "tcp://:%d", self->peer);
zclock_log ("I: asking for snapshot from: tcp://:%d",
self->peer);
zstr_sendm (snapshot, "ICANHAZ?");
zstr_send (snapshot, ""); // blank subtree to get all
while (true) {
kvmsg_t *kvmsg = kvmsg_recv (snapshot);
if (!kvmsg)
break; // Interrupted
if (streq (kvmsg_key (kvmsg), "KTHXBAI")) {
self->sequence = kvmsg_sequence (kvmsg);
kvmsg_destroy (&kvmsg);
break; // Done
}
kvmsg_store (&kvmsg, self->kvmap);
}
zclock_log ("I: received snapshot=%d", (int) self->sequence);
zsocket_destroy (self->ctx, snapshot);
}
// Find and remove update off pending list
kvmsg_t *kvmsg = kvmsg_recv (poller->socket);
if (!kvmsg)
return 0;
if (strneq (kvmsg_key (kvmsg), "HUGZ")) {
if (!s_was_pending (self, kvmsg)) {
// If active update came before client update, flip it
// around, store active update (with sequence) on pending
// list and use to clear client update when it comes later
zlist_append (self->pending, kvmsg_dup (kvmsg));
}
// If update is more recent than our kvmap, apply it
if (kvmsg_sequence (kvmsg) > self->sequence) {
self->sequence = kvmsg_sequence (kvmsg);
kvmsg_store (&kvmsg, self->kvmap);
zclock_log ("I: received update=%d", (int) self->sequence);
}
else
kvmsg_destroy (&kvmsg);
}
else
kvmsg_destroy (&kvmsg);
return 0;
}
clonesrv6:克隆服务器,模型六 C++ 完整版
clonesrv6:克隆服务器,模型六 C# 完整版
clonesrv6:克隆服务器,模型六 CL 完整版
clonesrv6:克隆服务器,模型六 Delphi 完整版
clonesrv6:克隆服务器,模型六 Erlang 完整版
clonesrv6:克隆服务器,模型六 Elixir 完整版
clonesrv6:克隆服务器,模型六 F# 完整版
clonesrv6:克隆服务器,模型六 Felix 完整版
clonesrv6:克隆服务器,模型六 Go 完整版
clonesrv6:克隆服务器,模型六 Haskell 完整版
clonesrv6:克隆服务器,模型六 Haxe 完整版
clonesrv6:克隆服务器,模型六 Java 完整版
package guide;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import org.zeromq.SocketType;
import org.zeromq.ZContext;
import org.zeromq.ZLoop;
import org.zeromq.ZLoop.IZLoopHandler;
import org.zeromq.ZMQ;
import org.zeromq.ZMQ.PollItem;
import org.zeromq.ZMQ.Socket;
// Clone server - Model Six
public class clonesrv6
{
private ZContext ctx; // Context wrapper
private Map<String, kvmsg> kvmap; // Key-value store
private bstar bStar; // Bstar reactor core
private long sequence; // How many updates we're at
private int port; // Main port we're working on
private int peer; // Main port of our peer
private Socket publisher; // Publish updates and hugz
private Socket collector; // Collect updates from clients
private Socket subscriber; // Get updates from peer
private List<kvmsg> pending; // Pending updates from clients
private boolean primary; // TRUE if we're primary
private boolean active; // TRUE if we're active
private boolean passive; // TRUE if we're passive
private static class Snapshots implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv6 srv = (clonesrv6) arg;
Socket socket = item.getSocket();
byte[] identity = socket.recv();
if (identity != null) {
// Request is in second frame of message
String request = socket.recvStr();
String subtree = null;
if (request.equals("ICANHAZ?")) {
subtree = socket.recvStr();
}
else System.out.printf("E: bad request, aborting\n");
if (subtree != null) {
// Send state socket to client
for (Entry<String, kvmsg> entry : srv.kvmap.entrySet()) {
sendSingle(entry.getValue(), identity, subtree, socket);
}
// Now send END message with getSequence number
System.out.printf("I: sending shapshot=%d\n", srv.sequence);
socket.send(identity, ZMQ.SNDMORE);
kvmsg kvmsg = new kvmsg(srv.sequence);
kvmsg.setKey("KTHXBAI");
kvmsg.setBody(subtree.getBytes(ZMQ.CHARSET));
kvmsg.send(socket);
kvmsg.destroy();
}
}
return 0;
}
}
private static class Collector implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv6 srv = (clonesrv6) arg;
Socket socket = item.getSocket();
kvmsg msg = kvmsg.recv(socket);
if (msg != null) {
if (srv.active) {
msg.setSequence(++srv.sequence);
msg.send(srv.publisher);
int ttl = Integer.parseInt(msg.getProp("ttl"));
if (ttl > 0)
msg.setProp("ttl", "%d", System.currentTimeMillis() + ttl * 1000);
msg.store(srv.kvmap);
System.out.printf("I: publishing update=%d\n", srv.sequence);
}
else {
// If we already got message from active, drop it, else
// hold on pending list
if (srv.wasPending(msg))
msg.destroy();
else srv.pending.add(msg);
}
}
return 0;
}
}
// .split heartbeating
// We send a HUGZ message once a second to all subscribers so that they
// can detect if our server dies. They'll then switch over to the backup
// server, which will become active:
private static class SendHugz implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv6 srv = (clonesrv6) arg;
kvmsg msg = new kvmsg(srv.sequence);
msg.setKey("HUGZ");
msg.setBody(ZMQ.MESSAGE_SEPARATOR);
msg.send(srv.publisher);
msg.destroy();
return 0;
}
}
private static class FlushTTL implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv6 srv = (clonesrv6) arg;
if (srv.kvmap != null) {
for (kvmsg msg : new ArrayList<kvmsg>(srv.kvmap.values())) {
srv.flushSingle(msg);
}
}
return 0;
}
}
// .split handling state changes
// When we switch from passive to active, we apply our pending list so that
// our kvmap is up-to-date. When we switch to passive, we wipe our kvmap
// and grab a new snapshot from the active server:
private static class NewActive implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv6 srv = (clonesrv6) arg;
srv.active = true;
srv.passive = false;
// Stop subscribing to updates
PollItem poller = new PollItem(srv.subscriber, ZMQ.Poller.POLLIN);
srv.bStar.zloop().removePoller(poller);
// Apply pending list to own hash table
for (kvmsg msg : srv.pending) {
msg.setSequence(++srv.sequence);
msg.send(srv.publisher);
msg.store(srv.kvmap);
System.out.printf("I: publishing pending=%d\n", srv.sequence);
}
return 0;
}
}
private static class NewPassive implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv6 srv = (clonesrv6) arg;
if (srv.kvmap != null) {
for (kvmsg msg : srv.kvmap.values())
msg.destroy();
}
srv.active = false;
srv.passive = true;
// Start subscribing to updates
PollItem poller = new PollItem(srv.subscriber, ZMQ.Poller.POLLIN);
srv.bStar.zloop().addPoller(poller, new Subscriber(), srv);
return 0;
}
}
// .split subscriber handler
// When we get an update, we create a new kvmap if necessary, and then
// add our update to our kvmap. We're always passive in this case:
private static class Subscriber implements IZLoopHandler
{
@Override
public int handle(ZLoop loop, PollItem item, Object arg)
{
clonesrv6 srv = (clonesrv6) arg;
Socket socket = item.getSocket();
// Get state snapshot if necessary
if (srv.kvmap == null) {
srv.kvmap = new HashMap<String, kvmsg>();
Socket snapshot = srv.ctx.createSocket(SocketType.DEALER);
snapshot.connect(String.format("tcp://:%d", srv.peer));
System.out.printf("I: asking for snapshot from: tcp://:%d\n", srv.peer);
snapshot.sendMore("ICANHAZ?");
snapshot.send(""); // blank subtree to get all
while (true) {
kvmsg msg = kvmsg.recv(snapshot);
if (msg == null)
break; // Interrupted
if (msg.getKey().equals("KTHXBAI")) {
srv.sequence = msg.getSequence();
msg.destroy();
break; // Done
}
msg.store(srv.kvmap);
}
System.out.printf("I: received snapshot=%d\n", srv.sequence);
srv.ctx.destroySocket(snapshot);
}
// Find and remove update off pending list
kvmsg msg = kvmsg.recv(item.getSocket());
if (msg == null)
return 0;
if (!msg.getKey().equals("HUGZ")) {
if (!srv.wasPending(msg)) {
// If active update came before client update, flip it
// around, store active update (with sequence) on pending
// list and use to clear client update when it comes later
srv.pending.add(msg.dup());
}
// If update is more recent than our kvmap, apply it
if (msg.getSequence() > srv.sequence) {
srv.sequence = msg.getSequence();
msg.store(srv.kvmap);
System.out.printf("I: received update=%d\n", srv.sequence);
}
}
msg.destroy();
return 0;
}
}
public clonesrv6(boolean primary)
{
if (primary) {
bStar = new bstar(true, "tcp://*:5003", "tcp://:5004");
bStar.voter("tcp://*:5556", SocketType.ROUTER, new Snapshots(), this);
port = 5556;
peer = 5566;
this.primary = true;
}
else {
bStar = new bstar(false, "tcp://*:5004", "tcp://:5003");
bStar.voter("tcp://*:5566", SocketType.ROUTER, new Snapshots(), this);
port = 5566;
peer = 5556;
this.primary = false;
}
// Primary server will become first active
if (primary)
kvmap = new HashMap<String, kvmsg>();
ctx = new ZContext();
pending = new ArrayList<kvmsg>();
bStar.setVerbose(true);
// Set up our clone server sockets
publisher = ctx.createSocket(SocketType.PUB);
collector = ctx.createSocket(SocketType.SUB);
collector.subscribe(ZMQ.SUBSCRIPTION_ALL);
publisher.bind(String.format("tcp://*:%d", port + 1));
collector.bind(String.format("tcp://*:%d", port + 2));
// Set up our own clone client interface to peer
subscriber = ctx.createSocket(SocketType.SUB);
subscriber.subscribe(ZMQ.SUBSCRIPTION_ALL);
subscriber.connect(String.format("tcp://:%d", peer + 1));
}
// .split main task body
// After we've setup our sockets, we register our binary star
// event handlers, and then start the bstar reactor. This finishes
// when the user presses Ctrl-C or when the process receives a SIGINT
// interrupt:
public void run()
{
// Register state change handlers
bStar.newActive(new NewActive(), this);
bStar.newPassive(new NewPassive(), this);
// Register our other handlers with the bstar reactor
PollItem poller = new PollItem(collector, ZMQ.Poller.POLLIN);
bStar.zloop().addPoller(poller, new Collector(), this);
bStar.zloop().addTimer(1000, 0, new FlushTTL(), this);
bStar.zloop().addTimer(1000, 0, new SendHugz(), this);
// Start the bstar reactor
bStar.start();
// Interrupted, so shut down
for (kvmsg value : pending)
value.destroy();
bStar.destroy();
for (kvmsg value : kvmap.values())
value.destroy();
ctx.destroy();
}
// Send one state snapshot key-value pair to a socket
// Hash item data is our kvmsg object, ready to send
private static void sendSingle(kvmsg msg, byte[] identity, String subtree, Socket socket)
{
if (msg.getKey().startsWith(subtree)) {
socket.send(identity, // Choose recipient
ZMQ.SNDMORE);
msg.send(socket);
}
}
// The collector is more complex than in the clonesrv5 example because the
// way it processes updates depends on whether we're active or passive.
// The active applies them immediately to its kvmap, whereas the passive
// queues them as pending:
// If message was already on pending list, remove it and return TRUE,
// else return FALSE.
boolean wasPending(kvmsg msg)
{
Iterator<kvmsg> it = pending.iterator();
while (it.hasNext()) {
if (java.util.Arrays.equals(msg.UUID(), it.next().UUID())) {
it.remove();
return true;
}
}
return false;
}
// We purge ephemeral values using exactly the same code as in
// the previous clonesrv5 example.
// .skip
// If key-value pair has expired, delete it and publish the
// fact to listening clients.
private void flushSingle(kvmsg msg)
{
long ttl = Long.parseLong(msg.getProp("ttl"));
if (ttl > 0 && System.currentTimeMillis() >= ttl) {
msg.setSequence(++sequence);
msg.setBody(ZMQ.MESSAGE_SEPARATOR);
msg.send(publisher);
msg.store(kvmap);
System.out.printf("I: publishing delete=%d\n", sequence);
}
}
// .split main task setup
// The main task parses the command line to decide whether to start
// as a primary or backup server. We're using the Binary Star pattern
// for reliability. This interconnects the two servers so they can
// agree on which one is primary and which one is backup. To allow the
// two servers to run on the same box, we use different ports for
// primary and backup. Ports 5003/5004 are used to interconnect the
// servers. Ports 5556/5566 are used to receive voting events (snapshot
// requests in the clone pattern). Ports 5557/5567 are used by the
// publisher, and ports 5558/5568 are used by the collector:
public static void main(String[] args)
{
clonesrv6 srv = null;
if (args.length == 1 && "-p".equals(args[0])) {
srv = new clonesrv6(true);
}
else if (args.length == 1 && "-b".equals(args[0])) {
srv = new clonesrv6(false);
}
else {
System.out.printf("Usage: clonesrv4 { -p | -b }\n");
System.exit(0);
}
srv.run();
}
}
clonesrv6:克隆服务器,模型六 Julia 完整版
clonesrv6:克隆服务器,模型六 Lua 完整版
clonesrv6:克隆服务器,模型六 Node.js 完整版
clonesrv6:克隆服务器,模型六 Objective-C 完整版
clonesrv6:克隆服务器,模型六 ooc 完整版
clonesrv6:克隆服务器,模型六 Perl 完整版
clonesrv6:克隆服务器,模型六 PHP 完整版
clonesrv6:克隆服务器,模型六 Python 完整版
"""
Clone server Model Six
Author: Min RK <benjaminrk@gmail.com
"""
import logging
import time
import zmq
from zmq.eventloop.ioloop import PeriodicCallback
from zmq.eventloop.zmqstream import ZMQStream
from bstar import BinaryStar
from kvmsg import KVMsg
from zhelpers import dump
# simple struct for routing information for a key-value snapshot
class Route:
def __init__(self, socket, identity, subtree):
self.socket = socket # ROUTER socket to send to
self.identity = identity # Identity of peer who requested state
self.subtree = subtree # Client subtree specification
def send_single(key, kvmsg, route):
"""Send one state snapshot key-value pair to a socket"""
# check front of key against subscription subtree:
if kvmsg.key.startswith(route.subtree):
# Send identity of recipient first
route.socket.send(route.identity, zmq.SNDMORE)
kvmsg.send(route.socket)
class CloneServer(object):
# Our server is defined by these properties
ctx = None # Context wrapper
kvmap = None # Key-value store
bstar = None # Binary Star
sequence = 0 # How many updates so far
port = None # Main port we're working on
peer = None # Main port of our peer
publisher = None # Publish updates and hugz
collector = None # Collect updates from clients
subscriber = None # Get updates from peer
pending = None # Pending updates from client
primary = False # True if we're primary
master = False # True if we're master
slave = False # True if we're slave
def __init__(self, primary=True, ports=(5556,5566)):
self.primary = primary
if primary:
self.port, self.peer = ports
frontend = "tcp://*:5003"
backend = "tcp://:5004"
self.kvmap = {}
else:
self.peer, self.port = ports
frontend = "tcp://*:5004"
backend = "tcp://:5003"
self.ctx = zmq.Context.instance()
self.pending = []
self.bstar = BinaryStar(primary, frontend, backend)
self.bstar.register_voter("tcp://*:%i" % self.port, zmq.ROUTER, self.handle_snapshot)
# Set up our clone server sockets
self.publisher = self.ctx.socket(zmq.PUB)
self.collector = self.ctx.socket(zmq.SUB)
self.collector.setsockopt(zmq.SUBSCRIBE, b'')
self.publisher.bind("tcp://*:%d" % (self.port + 1))
self.collector.bind("tcp://*:%d" % (self.port + 2))
# Set up our own clone client interface to peer
self.subscriber = self.ctx.socket(zmq.SUB)
self.subscriber.setsockopt(zmq.SUBSCRIBE, b'')
self.subscriber.connect("tcp://:%d" % (self.peer + 1))
# Register state change handlers
self.bstar.master_callback = self.become_master
self.bstar.slave_callback = self.become_slave
# Wrap sockets in ZMQStreams for IOLoop handlers
self.publisher = ZMQStream(self.publisher)
self.subscriber = ZMQStream(self.subscriber)
self.collector = ZMQStream(self.collector)
# Register our handlers with reactor
self.collector.on_recv(self.handle_collect)
self.flush_callback = PeriodicCallback(self.flush_ttl, 1000)
self.hugz_callback = PeriodicCallback(self.send_hugz, 1000)
# basic log formatting:
logging.basicConfig(format="%(asctime)s %(message)s", datefmt="%Y-%m-%d %H:%M:%S",
level=logging.INFO)
def start(self):
# start periodic callbacks
self.flush_callback.start()
self.hugz_callback.start()
# Run bstar reactor until process interrupted
try:
self.bstar.start()
except KeyboardInterrupt:
pass
def handle_snapshot(self, socket, msg):
"""snapshot requests"""
if msg[1] != b"ICANHAZ?" or len(msg) != 3:
logging.error("E: bad request, aborting")
dump(msg)
self.bstar.loop.stop()
return
identity, request = msg[:2]
if len(msg) >= 3:
subtree = msg[2]
# Send state snapshot to client
route = Route(socket, identity, subtree)
# For each entry in kvmap, send kvmsg to client
for k,v in self.kvmap.items():
send_single(k,v,route)
# Now send END message with sequence number
logging.info("I: Sending state shapshot=%d" % self.sequence)
socket.send(identity, zmq.SNDMORE)
kvmsg = KVMsg(self.sequence)
kvmsg.key = b"KTHXBAI"
kvmsg.body = subtree
kvmsg.send(socket)
def handle_collect(self, msg):
"""Collect updates from clients
If we're master, we apply these to the kvmap
If we're slave, or unsure, we queue them on our pending list
"""
kvmsg = KVMsg.from_msg(msg)
if self.master:
self.sequence += 1
kvmsg.sequence = self.sequence
kvmsg.send(self.publisher)
ttl = float(kvmsg.get(b'ttl', 0))
if ttl:
kvmsg[b'ttl'] = b'%f' % (time.time() + ttl)
kvmsg.store(self.kvmap)
logging.info("I: publishing update=%d", self.sequence)
else:
# If we already got message from master, drop it, else
# hold on pending list
if not self.was_pending(kvmsg):
self.pending.append(kvmsg)
def was_pending(self, kvmsg):
"""If message was already on pending list, remove and return True.
Else return False.
"""
found = False
for idx, held in enumerate(self.pending):
if held.uuid == kvmsg.uuid:
found = True
break
if found:
self.pending.pop(idx)
return found
def flush_ttl(self):
"""Purge ephemeral values that have expired"""
if self.kvmap:
for key,kvmsg in list(self.kvmap.items()):
self.flush_single(kvmsg)
def flush_single(self, kvmsg):
"""If key-value pair has expired, delete it and publish the fact
to listening clients."""
ttl = float(kvmsg.get(b'ttl', 0))
if ttl and ttl <= time.time():
kvmsg.body = b""
self.sequence += 1
kvmsg.sequence = self.sequence
logging.info("I: preparing to publish delete=%s", kvmsg.properties)
kvmsg.send(self.publisher)
del self.kvmap[kvmsg.key]
logging.info("I: publishing delete=%d", self.sequence)
def send_hugz(self):
"""Send hugz to anyone listening on the publisher socket"""
kvmsg = KVMsg(self.sequence)
kvmsg.key = b"HUGZ"
kvmsg.body = b""
kvmsg.send(self.publisher)
# ---------------------------------------------------------------------
# State change handlers
def become_master(self):
"""We're becoming master
The backup server applies its pending list to its own hash table,
and then starts to process state snapshot requests.
"""
self.master = True
self.slave = False
# stop receiving subscriber updates while we are master
self.subscriber.stop_on_recv()
# Apply pending list to own kvmap
while self.pending:
kvmsg = self.pending.pop(0)
self.sequence += 1
kvmsg.sequence = self.sequence
kvmsg.store(self.kvmap)
logging.info ("I: publishing pending=%d", self.sequence)
def become_slave(self):
"""We're becoming slave"""
# clear kvmap
self.kvmap = None
self.master = False
self.slave = True
self.subscriber.on_recv(self.handle_subscriber)
def handle_subscriber(self, msg):
"""Collect updates from peer (master)
We're always slave when we get these updates
"""
if self.master:
logging.warn("received subscriber message, but we are master %s", msg)
return
# Get state snapshot if necessary
if self.kvmap is None:
self.kvmap = {}
snapshot = self.ctx.socket(zmq.DEALER)
snapshot.linger = 0
snapshot.connect("tcp://:%i" % self.peer)
logging.info ("I: asking for snapshot from: tcp://:%d",
self.peer)
snapshot.send_multipart([b"ICANHAZ?", b''])
while True:
try:
kvmsg = KVMsg.recv(snapshot)
except KeyboardInterrupt:
# Interrupted
self.bstar.loop.stop()
return
if kvmsg.key == b"KTHXBAI":
self.sequence = kvmsg.sequence
break # Done
kvmsg.store(self.kvmap)
logging.info ("I: received snapshot=%d", self.sequence)
# Find and remove update off pending list
kvmsg = KVMsg.from_msg(msg)
# update float ttl -> timestamp
ttl = float(kvmsg.get(b'ttl', 0))
if ttl:
kvmsg[b'ttl'] = b'%f' % (time.time() + ttl)
if kvmsg.key != b"HUGZ":
if not self.was_pending(kvmsg):
# If master update came before client update, flip it
# around, store master update (with sequence) on pending
# list and use to clear client update when it comes later
self.pending.append(kvmsg)
# If update is more recent than our kvmap, apply it
if (kvmsg.sequence > self.sequence):
self.sequence = kvmsg.sequence
kvmsg.store(self.kvmap)
logging.info ("I: received update=%d", self.sequence)
def main():
import sys
if '-p' in sys.argv:
primary = True
elif '-b' in sys.argv:
primary = False
else:
print("Usage: clonesrv6.py { -p | -b }")
sys.exit(1)
clone = CloneServer(primary)
clone.start()
if __name__ == '__main__':
main()
clonesrv6:克隆服务器,模型六 Q 完整版
clonesrv6:克隆服务器,模型六 Racket 完整版
clonesrv6:克隆服务器,模型六 Ruby 完整版
clonesrv6:克隆服务器,模型六 Rust 完整版
clonesrv6:克隆服务器,模型六 Scala 完整版
clonesrv6:克隆服务器,模型六 Tcl 完整版
clonesrv6:克隆服务器,模型六 OCaml 完整版
这个模型只有几百行代码,但花了不少时间才让它正常工作。准确地说,构建模型六花了我整整一周的时间,期间不断冒出“天哪,这对于一个例子来说太复杂了”的想法。我们几乎将所有东西都塞进了这个小程序中,包括故障转移、瞬时值、子树等等。令我惊讶的是,前期的设计相当准确。尽管如此,编写和调试如此多 socket 流的细节仍然颇具挑战性。
基于 Reactor 的设计消除了代码中的大量繁重工作,剩下的部分更简单易懂。我们复用了第四章 - 可靠的请求-回复模式中的 bstar Reactor。整个服务器作为单个线程运行,因此没有线程间的奇怪问题——只有一个结构体指针(self)传递给所有处理器,它们可以愉快地完成自己的工作。使用 Reactor 的一个很好的副作用是,代码与 poll 循环的集成度较低,因此更容易重用。模型六的很大一部分代码来自模型五。
我一块一块地构建它,并在进入下一块之前确保每一块都 正常 工作。因为有四五个主要的 socket 流,这意味着大量的调试和测试。我只是通过将消息转储到控制台来进行调试。不要使用传统的调试器来单步调试 ZeroMQ 应用程序;你需要查看消息流才能理解正在发生的事情。
对于测试,我总是尝试使用 Valgrind,它可以捕获内存泄漏和无效的内存访问。在 C 语言中,这是一个主要问题,因为你不能依赖垃圾回收器。使用 kvmsg 和 CZMQ 等恰当且一致的抽象大大有所帮助。
集群哈希表协议 #
虽然服务器基本上是前一个模型加上二进制星模式的混合体,但客户端要复杂得多。但在讨论客户端之前,让我们先看看最终的协议。我已将其作为规范发布在 ZeroMQ RFC 网站上,名称为集群哈希表协议。
大致来说,设计像这样的复杂协议有两种方法。一种是将每个流分离到自己的一组 socket 中。这是我们在这里使用的方法。优点是每个流都很简单清晰。缺点是同时管理多个 socket 流会相当复杂。使用 Reactor 使其更简单,但仍然有很多移动的部分必须正确地协同工作。
设计这种协议的第二种方法是使用一对 socket 来处理所有事情。在这种情况下,我会在服务器端使用 ROUTER,客户端使用 DEALER,然后通过该连接完成所有操作。这会使协议更复杂,但至少复杂性集中在一处。在第七章 - 使用 ZeroMQ 的高级架构中,我们将看到一个通过 ROUTER-DEALER 组合实现的协议示例。
让我们来看看 CHP 规范。请注意,“SHOULD”、“MUST”和“MAY”是我们用于协议规范中表示要求级别的关键词。
目标
CHP 旨在为通过 ZeroMQ 网络连接的客户端集群提供可靠的发布-订阅基础。它定义了一个由键值对组成的“哈希表”抽象。任何客户端可以在任何时间修改任何键值对,并且更改会传播到所有客户端。客户端可以在任何时间加入网络。
架构
CHP 连接了一组客户端应用程序和一组服务器。客户端连接到服务器。客户端彼此不互相见。客户端可以随意加入和离开。
端口和连接
服务器 MUST(必须)打开以下三个端口:
- 快照端口(ZeroMQ ROUTER socket),端口号 P。
- 发布者端口(ZeroMQ PUB socket),端口号 P + 1。
- 收集者端口(ZeroMQ SUB socket),端口号 P + 2。
客户端 SHOULD(应该)打开至少两个连接:
- 快照连接(ZeroMQ DEALER socket),连接到端口 P。
- 订阅者连接(ZeroMQ SUB socket),连接到端口 P + 1。
如果客户端想要更新哈希表,MAY(可以)打开第三个连接:
- 发布者连接(ZeroMQ PUB socket),连接到端口 P + 2。
这个额外的帧未在下面解释的命令中显示。
状态同步
客户端 MUST(必须)首先向其快照连接发送一个 ICANHAZ 命令。该命令包含以下两个帧:
ICANHAZ command
-----------------------------------
Frame 0: "ICANHAZ?"
Frame 1: subtree specification
两个帧都是 ZeroMQ 字符串。子树规范 MAY(可以)为空。如果不为空,它由一个斜杠后跟一个或多个路径段组成,并以斜杠结尾。
服务器 MUST(必须)通过向其快照端口发送零个或多个 KVSYNC 命令来响应 ICANHAZ 命令,其后跟一个 KTHXBAI 命令。服务器 MUST(必须)在每个命令前加上客户端的身份,该身份由 ZeroMQ 在 ICANHAZ 命令中提供。KVSYNC 命令按如下方式指定一个键值对:
KVSYNC command
-----------------------------------
Frame 0: key, as ZeroMQ string
Frame 1: sequence number, 8 bytes in network order
Frame 2: <empty>
Frame 3: <empty>
Frame 4: value, as blob
序列号没有意义,可以为零。
KTHXBAI 命令形式如下:
KTHXBAI command
-----------------------------------
Frame 0: "KTHXBAI"
Frame 1: sequence number, 8 bytes in network order
Frame 2: <empty>
Frame 3: <empty>
Frame 4: subtree specification
序列号 MUST(必须)是先前发送的 KVSYNC 命令中的最高序列号。
当客户端收到 KTHXBAI 命令后,它 SHOULD(应该)开始从其订阅者连接接收消息并应用它们。
服务器到客户端的更新
当服务器对其哈希表有更新时,它 MUST(必须)在其发布者 socket 上以 KVPUB 命令广播此更新。KVPUB 命令形式如下:
KVPUB command
-----------------------------------
Frame 0: key, as ZeroMQ string
Frame 1: sequence number, 8 bytes in network order
Frame 2: UUID, 16 bytes
Frame 3: properties, as ZeroMQ string
Frame 4: value, as blob
序列号必须严格递增。客户端必须丢弃任何序列号不严格大于接收到的最后一个 KTHXBAI 或 KVPUB 命令的 KVPUB 命令。
UUID 是可选的,帧 2 可能为空(大小为零)。属性字段格式化为零个或多个“name=value”实例,后跟一个换行符。如果键值对没有属性,则属性字段为空。
如果值为零,客户端应删除具有指定键的键值条目。
在没有其他更新的情况下,服务器应按固定间隔发送 HUGZ 命令,例如每秒一次。HUGZ 命令的格式如下
HUGZ command
-----------------------------------
Frame 0: "HUGZ"
Frame 1: 00000000
Frame 2: <empty>
Frame 3: <empty>
Frame 4: <empty>
客户端可以将没有 HUGZ 命令视为服务器崩溃的指示(参见下面的可靠性)。
客户端到服务器的更新
当客户端对其散列映射有更新时,它可以通过其发布者连接作为 KVSET 命令发送给服务器。KVSET 命令的形式如下
KVSET command
-----------------------------------
Frame 0: key, as ZeroMQ string
Frame 1: sequence number, 8 bytes in network order
Frame 2: UUID, 16 bytes
Frame 3: properties, as ZeroMQ string
Frame 4: value, as blob
序列号没有意义,可以为零。如果使用可靠的服务器架构,UUID 应是一个通用唯一标识符。
如果值为空,服务器必须删除具有指定键的键值条目。
服务器应接受以下属性
- ttl: 指定生存时间(秒)。如果 KVSET 命令包含一个ttl属性,服务器应删除键值对并广播一个值为空的 KVPUB 命令,以便在 TTL 过期时从所有客户端中删除此条目。
可靠性
CHP 可用于双服务器配置,其中主服务器发生故障时由备用服务器接管。CHP 没有指定用于此故障转移的机制,但二进制星模式可能有所帮助。
为了提高服务器可靠性,客户端可以
- 在每个 KVSET 命令中设置一个 UUID。
- 检测一段时间内没有收到 HUGZ 命令,并将其用作当前服务器已发生故障的指示。
- 连接到备用服务器并重新请求状态同步。
可伸缩性和性能
CHP 设计用于扩展到大量(数千个)客户端,仅受限于代理上的系统资源。由于所有更新都通过单个服务器传递,因此峰值时的总吞吐量将限制在每秒数百万次更新,可能更少。
安全性
CHP 未实现任何身份验证、访问控制或加密机制,不应在需要这些功能的部署中使用。
构建多线程栈和 API #
我们目前使用的客户端栈不够智能,无法正确处理这个协议。一旦我们开始发送心跳,我们就需要一个可以在后台线程中运行的客户端栈。在第 4 章 - 可靠请求-回复模式末尾的 Freelance 模式中,我们使用了多线程 API,但没有详细解释。事实证明,当你开始构建像 CHP 这样更复杂的 ZeroMQ 协议时,多线程 API 非常有用。
如果你构建了一个非简单的协议,并期望应用程序能正确实现它,大多数开发者大部分时候都会搞错。你会遇到很多不高兴的人抱怨你的协议过于复杂、过于脆弱且难以使用。而如果你提供一个简单的 API 供调用,他们接受的可能性就会大得多。
我们的多线程 API 由一个前端对象和一个后台代理组成,它们通过两个 PAIR 套接字连接。像这样连接两个 PAIR 套接字非常有用,以至于你的高级绑定可能应该像 CZMQ 那样做,即封装一个“创建一个新线程,带有一个可用于向其发送消息的管道”的方法。
本书中我们看到的多线程 API 都采用相同的形式
-
对象的构造函数(clone_new)创建一个上下文并启动一个通过管道连接的后台线程。它持有管道的一端,以便可以向后台线程发送命令。
-
后台线程启动一个*代理*,它本质上是一个zmq_poll循环,从管道套接字和任何其他套接字(这里是 DEALER 和 SUB 套接字)读取。
-
主应用程序线程和后台线程现在只通过 ZeroMQ 消息通信。按照约定,前端发送字符串命令,以便类上的每个方法都变成发送到后端代理的消息,如下所示
void
clone_connect (clone_t *self, char *address, char *service)
{
assert (self);
zmsg_t *msg = zmsg_new ();
zmsg_addstr (msg, "CONNECT");
zmsg_addstr (msg, address);
zmsg_addstr (msg, service);
zmsg_send (&msg, self->pipe);
}
-
如果方法需要返回码,它可以等待代理的回复消息。
-
如果代理需要将异步事件发送回前端,我们添加一个recv方法到类中,该方法在前端管道上等待消息。
-
我们可能希望暴露前端管道套接字句柄,以便将类集成到进一步的轮询循环中。否则,任何recv方法都会阻塞应用程序。
clone 类与flcliapi第 4 章 - 可靠请求-回复模式中的类具有相同的结构,并添加了 Clone 客户端最后一个模型的逻辑。如果没有 ZeroMQ,这种多线程 API 设计将需要数周的艰苦工作。有了 ZeroMQ,只需一两天的工作。
clone 类的实际 API 方法非常简单
// Create a new clone class instance
clone_t *
clone_new (void);
// Destroy a clone class instance
void
clone_destroy (clone_t **self_p);
// Define the subtree, if any, for this clone class
void
clone_subtree (clone_t *self, char *subtree);
// Connect the clone class to one server
void
clone_connect (clone_t *self, char *address, char *service);
// Set a value in the shared hashmap
void
clone_set (clone_t *self, char *key, char *value, int ttl);
// Get a value from the shared hashmap
char *
clone_get (clone_t *self, char *key);
因此,这是 Clone 客户端的第六个模型,它现在只是一个使用 clone 类的薄层
clonecli6: Clone 客户端,Ada 语言的第六个模型
clonecli6: Clone 客户端,Basic 语言的第六个模型
clonecli6: Clone 客户端,C 语言的第六个模型
// Clone client Model Six
// Lets us build this source without creating a library
#include "clone.c"
#define SUBTREE "/client/"
int main (void)
{
// Create distributed hash instance
clone_t *clone = clone_new ();
// Specify configuration
clone_subtree (clone, SUBTREE);
clone_connect (clone, "tcp://", "5556");
clone_connect (clone, "tcp://", "5566");
// Set random tuples into the distributed hash
while (!zctx_interrupted) {
// Set random value, check it was stored
char key [255];
char value [10];
sprintf (key, "%s%d", SUBTREE, randof (10000));
sprintf (value, "%d", randof (1000000));
clone_set (clone, key, value, randof (30));
sleep (1);
}
clone_destroy (&clone);
return 0;
}
clonecli6: Clone 客户端,C++ 语言的第六个模型
clonecli6: Clone 客户端,C# 语言的第六个模型
clonecli6: Clone 客户端,CL 语言的第六个模型
clonecli6: Clone 客户端,Delphi 语言的第六个模型
clonecli6: Clone 客户端,Erlang 语言的第六个模型
clonecli6: Clone 客户端,Elixir 语言的第六个模型
clonecli6: Clone 客户端,F# 语言的第六个模型
clonecli6: Clone 客户端,Felix 语言的第六个模型
clonecli6: Clone 客户端,Go 语言的第六个模型
clonecli6: Clone 客户端,Haskell 语言的第六个模型
clonecli6: Clone 客户端,Haxe 语言的第六个模型
clonecli6: Clone 客户端,Java 语言的第六个模型
package guide;
import java.util.Random;
/**
* Clone client model 6
*/
public class clonecli6
{
private final static String SUBTREE = "/client/";
public void run()
{
// Create distributed hash instance
clone clone = new clone();
Random rand = new Random(System.nanoTime());
// Specify configuration
clone.subtree(SUBTREE);
clone.connect("tcp://", "5556");
clone.connect("tcp://", "5566");
// Set random tuples into the distributed hash
while (!Thread.currentThread().isInterrupted()) {
// Set random value, check it was stored
String key = String.format("%s%d", SUBTREE, rand.nextInt(10000));
String value = String.format("%d", rand.nextInt(1000000));
clone.set(key, value, rand.nextInt(30));
try {
Thread.sleep(1000);
}
catch (InterruptedException e) {
}
}
clone.destroy();
}
public static void main(String[] args)
{
new clonecli6().run();
}
}
clonecli6: Clone 客户端,Julia 语言的第六个模型
clonecli6: Clone 客户端,Lua 语言的第六个模型
clonecli6: Clone 客户端,Node.js 语言的第六个模型
clonecli6: Clone 客户端,Objective-C 语言的第六个模型
clonecli6: Clone 客户端,ooc 语言的第六个模型
clonecli6: Clone 客户端,Perl 语言的第六个模型
clonecli6: Clone 客户端,PHP 语言的第六个模型
clonecli6: Clone 客户端,Python 语言的第六个模型
"""
Clone server Model Six
"""
import random
import time
import zmq
from clone import Clone
SUBTREE = "/client/"
def main():
# Create and connect clone
clone = Clone()
clone.subtree = SUBTREE.encode()
clone.connect("tcp://", 5556)
clone.connect("tcp://", 5566)
try:
while True:
# Distribute as key-value message
key = b"%d" % random.randint(1,10000)
value = b"%d" % random.randint(1,1000000)
clone.set(key, value, random.randint(0,30))
time.sleep(1)
except KeyboardInterrupt:
pass
if __name__ == '__main__':
main()
clonecli6: Clone 客户端,Q 语言的第六个模型
clonecli6: Clone 客户端,Racket 语言的第六个模型
clonecli6: Clone 客户端,Ruby 语言的第六个模型
clonecli6: Clone 客户端,Rust 语言的第六个模型
clonecli6: Clone 客户端,Scala 语言的第六个模型
clonecli6: Clone 客户端,Tcl 语言的第六个模型
clonecli6: Clone 客户端,OCaml 语言的第六个模型
注意 connect 方法,它指定了一个服务器端点。实际上,我们在后台与三个端口通信。然而,正如 CHP 协议所说,这三个端口是连续的端口号
- 服务器状态路由器 (ROUTER) 在端口 P。
- 服务器更新发布者 (PUB) 在端口 P + 1。
- 服务器更新订阅者 (SUB) 在端口 P + 2。
因此,我们可以将这三个连接合并为一个逻辑操作(我们将其实现为三个单独的 ZeroMQ 连接调用)。
最后来看看 clone 栈的源代码。这是一段复杂的代码,但将其分解为前端对象类和后端代理会更容易理解。前端向代理发送字符串命令(“SUBTREE”、“CONNECT”、“SET”、“GET”),代理处理这些命令并与服务器通信。以下是代理的逻辑
- 启动时从第一个服务器获取快照
- 获得快照后,切换到从订阅者套接字读取。
- 如果没有获得快照,则故障转移到第二个服务器。
- 在管道和订阅者套接字上进行轮询。
- 如果从管道接收到输入,则处理来自前端对象的控制消息。
- 如果从订阅者接收到输入,则存储或应用更新。
- 如果在一定时间内没有从服务器收到任何消息,则进行故障转移。
- 重复此过程直到被 Ctrl-C 中断。
以下是实际的 clone 类实现
clone: Ada 语言的 Clone 类
clone: Basic 语言的 Clone 类
clone: C 语言的 Clone 类
// clone class - Clone client API stack (multithreaded)
#include "clone.h"
// If no server replies within this time, abandon request
#define GLOBAL_TIMEOUT 4000 // msecs
// =====================================================================
// Synchronous part, works in our application thread
// Structure of our class
struct _clone_t {
zctx_t *ctx; // Our context wrapper
void *pipe; // Pipe through to clone agent
};
// This is the thread that handles our real clone class
static void clone_agent (void *args, zctx_t *ctx, void *pipe);
// .split constructor and destructor
// Here are the constructor and destructor for the clone class. Note that
// we create a context specifically for the pipe that connects our
// frontend to the backend agent:
clone_t *
clone_new (void)
{
clone_t
*self;
self = (clone_t *) zmalloc (sizeof (clone_t));
self->ctx = zctx_new ();
self->pipe = zthread_fork (self->ctx, clone_agent, NULL);
return self;
}
void
clone_destroy (clone_t **self_p)
{
assert (self_p);
if (*self_p) {
clone_t *self = *self_p;
zctx_destroy (&self->ctx);
free (self);
*self_p = NULL;
}
}
// .split subtree method
// Specify subtree for snapshot and updates, which we must do before
// connecting to a server as the subtree specification is sent as the
// first command to the server. Sends a [SUBTREE][subtree] command to
// the agent:
void clone_subtree (clone_t *self, char *subtree)
{
assert (self);
zmsg_t *msg = zmsg_new ();
zmsg_addstr (msg, "SUBTREE");
zmsg_addstr (msg, subtree);
zmsg_send (&msg, self->pipe);
}
// .split connect method
// Connect to a new server endpoint. We can connect to at most two
// servers. Sends [CONNECT][endpoint][service] to the agent:
void
clone_connect (clone_t *self, char *address, char *service)
{
assert (self);
zmsg_t *msg = zmsg_new ();
zmsg_addstr (msg, "CONNECT");
zmsg_addstr (msg, address);
zmsg_addstr (msg, service);
zmsg_send (&msg, self->pipe);
}
// .split set method
// Set a new value in the shared hashmap. Sends a [SET][key][value][ttl]
// command through to the agent which does the actual work:
void
clone_set (clone_t *self, char *key, char *value, int ttl)
{
char ttlstr [10];
sprintf (ttlstr, "%d", ttl);
assert (self);
zmsg_t *msg = zmsg_new ();
zmsg_addstr (msg, "SET");
zmsg_addstr (msg, key);
zmsg_addstr (msg, value);
zmsg_addstr (msg, ttlstr);
zmsg_send (&msg, self->pipe);
}
// .split get method
// Look up value in distributed hash table. Sends [GET][key] to the agent and
// waits for a value response. If there is no value available, will eventually
// return NULL:
char *
clone_get (clone_t *self, char *key)
{
assert (self);
assert (key);
zmsg_t *msg = zmsg_new ();
zmsg_addstr (msg, "GET");
zmsg_addstr (msg, key);
zmsg_send (&msg, self->pipe);
zmsg_t *reply = zmsg_recv (self->pipe);
if (reply) {
char *value = zmsg_popstr (reply);
zmsg_destroy (&reply);
return value;
}
return NULL;
}
// .split working with servers
// The backend agent manages a set of servers, which we implement using
// our simple class model:
typedef struct {
char *address; // Server address
int port; // Server port
void *snapshot; // Snapshot socket
void *subscriber; // Incoming updates
uint64_t expiry; // When server expires
uint requests; // How many snapshot requests made?
} server_t;
static server_t *
server_new (zctx_t *ctx, char *address, int port, char *subtree)
{
server_t *self = (server_t *) zmalloc (sizeof (server_t));
zclock_log ("I: adding server %s:%d...", address, port);
self->address = strdup (address);
self->port = port;
self->snapshot = zsocket_new (ctx, ZMQ_DEALER);
zsocket_connect (self->snapshot, "%s:%d", address, port);
self->subscriber = zsocket_new (ctx, ZMQ_SUB);
zsocket_connect (self->subscriber, "%s:%d", address, port + 1);
zsocket_set_subscribe (self->subscriber, subtree);
zsocket_set_subscribe (self->subscriber, "HUGZ");
return self;
}
static void
server_destroy (server_t **self_p)
{
assert (self_p);
if (*self_p) {
server_t *self = *self_p;
free (self->address);
free (self);
*self_p = NULL;
}
}
// .split backend agent class
// Here is the implementation of the backend agent itself:
// Number of servers to which we will talk to
#define SERVER_MAX 2
// Server considered dead if silent for this long
#define SERVER_TTL 5000 // msecs
// States we can be in
#define STATE_INITIAL 0 // Before asking server for state
#define STATE_SYNCING 1 // Getting state from server
#define STATE_ACTIVE 2 // Getting new updates from server
typedef struct {
zctx_t *ctx; // Context wrapper
void *pipe; // Pipe back to application
zhash_t *kvmap; // Actual key/value table
char *subtree; // Subtree specification, if any
server_t *server [SERVER_MAX];
uint nbr_servers; // 0 to SERVER_MAX
uint state; // Current state
uint cur_server; // If active, server 0 or 1
int64_t sequence; // Last kvmsg processed
void *publisher; // Outgoing updates
} agent_t;
static agent_t *
agent_new (zctx_t *ctx, void *pipe)
{
agent_t *self = (agent_t *) zmalloc (sizeof (agent_t));
self->ctx = ctx;
self->pipe = pipe;
self->kvmap = zhash_new ();
self->subtree = strdup ("");
self->state = STATE_INITIAL;
self->publisher = zsocket_new (self->ctx, ZMQ_PUB);
return self;
}
static void
agent_destroy (agent_t **self_p)
{
assert (self_p);
if (*self_p) {
agent_t *self = *self_p;
int server_nbr;
for (server_nbr = 0; server_nbr < self->nbr_servers; server_nbr++)
server_destroy (&self->server [server_nbr]);
zhash_destroy (&self->kvmap);
free (self->subtree);
free (self);
*self_p = NULL;
}
}
// .split handling a control message
// Here we handle the different control messages from the frontend;
// SUBTREE, CONNECT, SET, and GET:
static int
agent_control_message (agent_t *self)
{
zmsg_t *msg = zmsg_recv (self->pipe);
char *command = zmsg_popstr (msg);
if (command == NULL)
return -1; // Interrupted
if (streq (command, "SUBTREE")) {
free (self->subtree);
self->subtree = zmsg_popstr (msg);
}
else
if (streq (command, "CONNECT")) {
char *address = zmsg_popstr (msg);
char *service = zmsg_popstr (msg);
if (self->nbr_servers < SERVER_MAX) {
self->server [self->nbr_servers++] = server_new (
self->ctx, address, atoi (service), self->subtree);
// We broadcast updates to all known servers
zsocket_connect (self->publisher, "%s:%d",
address, atoi (service) + 2);
}
else
zclock_log ("E: too many servers (max. %d)", SERVER_MAX);
free (address);
free (service);
}
else
// .split set and get commands
// When we set a property, we push the new key-value pair onto
// all our connected servers:
if (streq (command, "SET")) {
char *key = zmsg_popstr (msg);
char *value = zmsg_popstr (msg);
char *ttl = zmsg_popstr (msg);
// Send key-value pair on to server
kvmsg_t *kvmsg = kvmsg_new (0);
kvmsg_set_key (kvmsg, key);
kvmsg_set_uuid (kvmsg);
kvmsg_fmt_body (kvmsg, "%s", value);
kvmsg_set_prop (kvmsg, "ttl", ttl);
kvmsg_send (kvmsg, self->publisher);
kvmsg_store (&kvmsg, self->kvmap);
free (key);
free (value);
free (ttl);
}
else
if (streq (command, "GET")) {
char *key = zmsg_popstr (msg);
kvmsg_t *kvmsg = (kvmsg_t *) zhash_lookup (self->kvmap, key);
byte *value = kvmsg? kvmsg_body (kvmsg): NULL;
if (value)
zmq_send (self->pipe, value, kvmsg_size (kvmsg), 0);
else
zstr_send (self->pipe, "");
free (key);
}
free (command);
zmsg_destroy (&msg);
return 0;
}
// .split backend agent
// The asynchronous agent manages a server pool and handles the
// request-reply dialog when the application asks for it:
static void
clone_agent (void *args, zctx_t *ctx, void *pipe)
{
agent_t *self = agent_new (ctx, pipe);
while (true) {
zmq_pollitem_t poll_set [] = {
{ pipe, 0, ZMQ_POLLIN, 0 },
{ 0, 0, ZMQ_POLLIN, 0 }
};
int poll_timer = -1;
int poll_size = 2;
server_t *server = self->server [self->cur_server];
switch (self->state) {
case STATE_INITIAL:
// In this state we ask the server for a snapshot,
// if we have a server to talk to...
if (self->nbr_servers > 0) {
zclock_log ("I: waiting for server at %s:%d...",
server->address, server->port);
if (server->requests < 2) {
zstr_sendm (server->snapshot, "ICANHAZ?");
zstr_send (server->snapshot, self->subtree);
server->requests++;
}
server->expiry = zclock_time () + SERVER_TTL;
self->state = STATE_SYNCING;
poll_set [1].socket = server->snapshot;
}
else
poll_size = 1;
break;
case STATE_SYNCING:
// In this state we read from snapshot and we expect
// the server to respond, else we fail over.
poll_set [1].socket = server->snapshot;
break;
case STATE_ACTIVE:
// In this state we read from subscriber and we expect
// the server to give HUGZ, else we fail over.
poll_set [1].socket = server->subscriber;
break;
}
if (server) {
poll_timer = (server->expiry - zclock_time ())
* ZMQ_POLL_MSEC;
if (poll_timer < 0)
poll_timer = 0;
}
// .split client poll loop
// We're ready to process incoming messages; if nothing at all
// comes from our server within the timeout, that means the
// server is dead:
int rc = zmq_poll (poll_set, poll_size, poll_timer);
if (rc == -1)
break; // Context has been shut down
if (poll_set [0].revents & ZMQ_POLLIN) {
if (agent_control_message (self))
break; // Interrupted
}
else
if (poll_set [1].revents & ZMQ_POLLIN) {
kvmsg_t *kvmsg = kvmsg_recv (poll_set [1].socket);
if (!kvmsg)
break; // Interrupted
// Anything from server resets its expiry time
server->expiry = zclock_time () + SERVER_TTL;
if (self->state == STATE_SYNCING) {
// Store in snapshot until we're finished
server->requests = 0;
if (streq (kvmsg_key (kvmsg), "KTHXBAI")) {
self->sequence = kvmsg_sequence (kvmsg);
self->state = STATE_ACTIVE;
zclock_log ("I: received from %s:%d snapshot=%d",
server->address, server->port,
(int) self->sequence);
kvmsg_destroy (&kvmsg);
}
else
kvmsg_store (&kvmsg, self->kvmap);
}
else
if (self->state == STATE_ACTIVE) {
// Discard out-of-sequence updates, incl. HUGZ
if (kvmsg_sequence (kvmsg) > self->sequence) {
self->sequence = kvmsg_sequence (kvmsg);
kvmsg_store (&kvmsg, self->kvmap);
zclock_log ("I: received from %s:%d update=%d",
server->address, server->port,
(int) self->sequence);
}
else
kvmsg_destroy (&kvmsg);
}
}
else {
// Server has died, failover to next
zclock_log ("I: server at %s:%d didn't give HUGZ",
server->address, server->port);
self->cur_server = (self->cur_server + 1) % self->nbr_servers;
self->state = STATE_INITIAL;
}
}
agent_destroy (&self);
}
clone: C++ 语言的 Clone 类
clone: C# 语言的 Clone 类
clone: CL 语言的 Clone 类
clone: Delphi 语言的 Clone 类
clone: Erlang 语言的 Clone 类
clone: Elixir 语言的 Clone 类
clone: F# 语言的 Clone 类
clone: Felix 语言的 Clone 类
clone: Go 语言的 Clone 类
clone: Haskell 语言的 Clone 类
clone: Haxe 语言的 Clone 类
clone: Java 语言的 Clone 类
package guide;
import java.util.HashMap;
import java.util.Map;
import org.zeromq.*;
import org.zeromq.ZMQ.Poller;
import org.zeromq.ZMQ.Socket;
import org.zeromq.ZThread.IAttachedRunnable;
public class clone
{
private ZContext ctx; // Our context wrapper
private Socket pipe; // Pipe through to clone agent
// .split constructor and destructor
// Here are the constructor and destructor for the clone class. Note that
// we create a context specifically for the pipe that connects our
// frontend to the backend agent:
public clone()
{
ctx = new ZContext();
pipe = ZThread.fork(ctx, new CloneAgent());
}
public void destroy()
{
ctx.destroy();
}
// .split subtree method
// Specify subtree for snapshot and updates, which we must do before
// connecting to a server as the subtree specification is sent as the
// first command to the server. Sends a [SUBTREE][subtree] command to
// the agent:
public void subtree(String subtree)
{
ZMsg msg = new ZMsg();
msg.add("SUBTREE");
msg.add(subtree);
msg.send(pipe);
}
// .split connect method
// Connect to a new server endpoint. We can connect to at most two
// servers. Sends [CONNECT][endpoint][service] to the agent:
public void connect(String address, String service)
{
ZMsg msg = new ZMsg();
msg.add("CONNECT");
msg.add(address);
msg.add(service);
msg.send(pipe);
}
// .split set method
// Set a new value in the shared hashmap. Sends a [SET][key][value][ttl]
// command through to the agent which does the actual work:
public void set(String key, String value, int ttl)
{
ZMsg msg = new ZMsg();
msg.add("SET");
msg.add(key);
msg.add(value);
msg.add(String.format("%d", ttl));
msg.send(pipe);
}
// .split get method
// Look up value in distributed hash table. Sends [GET][key] to the agent and
// waits for a value response. If there is no value available, will eventually
// return NULL:
public String get(String key)
{
ZMsg msg = new ZMsg();
msg.add("GET");
msg.add(key);
msg.send(pipe);
ZMsg reply = ZMsg.recvMsg(pipe);
if (reply != null) {
String value = reply.popString();
reply.destroy();
return value;
}
return null;
}
// .split working with servers
// The backend agent manages a set of servers, which we implement using
// our simple class model:
private static class Server
{
private String address; // Server address
private int port; // Server port
private Socket snapshot; // Snapshot socket
private Socket subscriber; // Incoming updates
private long expiry; // When server expires
private int requests; // How many snapshot requests made?
protected Server(ZContext ctx, String address, int port, String subtree)
{
System.out.printf("I: adding server %s:%d...\n", address, port);
this.address = address;
this.port = port;
snapshot = ctx.createSocket(SocketType.DEALER);
snapshot.connect(String.format("%s:%d", address, port));
subscriber = ctx.createSocket(SocketType.SUB);
subscriber.connect(String.format("%s:%d", address, port + 1));
subscriber.subscribe(subtree.getBytes(ZMQ.CHARSET));
}
protected void destroy()
{
}
}
// .split backend agent class
// Here is the implementation of the backend agent itself:
// Number of servers to which we will talk to
private final static int SERVER_MAX = 2;
// Server considered dead if silent for this long
private final static int SERVER_TTL = 5000; // msecs
// States we can be in
private final static int STATE_INITIAL = 0; // Before asking server for state
private final static int STATE_SYNCING = 1; // Getting state from server
private final static int STATE_ACTIVE = 2; // Getting new updates from server
private static class Agent
{
private ZContext ctx; // Context wrapper
private Socket pipe; // Pipe back to application
private Map<String, String> kvmap; // Actual key/value table
private String subtree; // Subtree specification, if any
private Server[] server;
private int nbrServers; // 0 to SERVER_MAX
private int state; // Current state
private int curServer; // If active, server 0 or 1
private long sequence; // Last kvmsg processed
private Socket publisher; // Outgoing updates
protected Agent(ZContext ctx, Socket pipe)
{
this.ctx = ctx;
this.pipe = pipe;
kvmap = new HashMap<String, String>();
subtree = "";
state = STATE_INITIAL;
publisher = ctx.createSocket(SocketType.PUB);
server = new Server[SERVER_MAX];
}
protected void destroy()
{
for (int serverNbr = 0; serverNbr < nbrServers; serverNbr++)
server[serverNbr].destroy();
}
// .split handling a control message
// Here we handle the different control messages from the frontend;
// SUBTREE, CONNECT, SET, and GET:
private boolean controlMessage()
{
ZMsg msg = ZMsg.recvMsg(pipe);
String command = msg.popString();
if (command == null)
return false; // Interrupted
if (command.equals("SUBTREE")) {
subtree = msg.popString();
}
else if (command.equals("CONNECT")) {
String address = msg.popString();
String service = msg.popString();
if (nbrServers < SERVER_MAX) {
server[nbrServers++] = new Server(ctx, address, Integer.parseInt(service), subtree);
// We broadcast updates to all known servers
publisher.connect(String.format("%s:%d", address, Integer.parseInt(service) + 2));
}
else System.out.printf("E: too many servers (max. %d)\n", SERVER_MAX);
}
else
// .split set and get commands
// When we set a property, we push the new key-value pair onto
// all our connected servers:
if (command.equals("SET")) {
String key = msg.popString();
String value = msg.popString();
String ttl = msg.popString();
kvmap.put(key, value);
// Send key-value pair on to server
kvmsg kvmsg = new kvmsg(0);
kvmsg.setKey(key);
kvmsg.setUUID();
kvmsg.fmtBody("%s", value);
kvmsg.setProp("ttl", ttl);
kvmsg.send(publisher);
kvmsg.destroy();
}
else if (command.equals("GET")) {
String key = msg.popString();
String value = kvmap.get(key);
if (value != null)
pipe.send(value);
else pipe.send("");
}
msg.destroy();
return true;
}
}
private static class CloneAgent implements IAttachedRunnable
{
@Override
public void run(Object[] args, ZContext ctx, Socket pipe)
{
Agent self = new Agent(ctx, pipe);
Poller poller = ctx.createPoller(1);
poller.register(pipe, Poller.POLLIN);
while (!Thread.currentThread().isInterrupted()) {
long pollTimer = -1;
int pollSize = 2;
Server server = self.server[self.curServer];
switch (self.state) {
case STATE_INITIAL:
// In this state we ask the server for a snapshot,
// if we have a server to talk to...
if (self.nbrServers > 0) {
System.out.printf("I: waiting for server at %s:%d...\n", server.address, server.port);
if (server.requests < 2) {
server.snapshot.sendMore("ICANHAZ?");
server.snapshot.send(self.subtree);
server.requests++;
}
server.expiry = System.currentTimeMillis() + SERVER_TTL;
self.state = STATE_SYNCING;
poller.close();
poller = ctx.createPoller(2);
poller.register(pipe, Poller.POLLIN);
poller.register(server.snapshot, Poller.POLLIN);
}
else pollSize = 1;
break;
case STATE_SYNCING:
// In this state we read from snapshot and we expect
// the server to respond, else we fail over.
poller.close();
poller = ctx.createPoller(2);
poller.register(pipe, Poller.POLLIN);
poller.register(server.snapshot, Poller.POLLIN);
break;
case STATE_ACTIVE:
// In this state we read from subscriber and we expect
// the server to give hugz, else we fail over.
poller.close();
poller = ctx.createPoller(2);
poller.register(pipe, Poller.POLLIN);
poller.register(server.subscriber, Poller.POLLIN);
break;
}
if (server != null) {
pollTimer = server.expiry - System.currentTimeMillis();
if (pollTimer < 0)
pollTimer = 0;
}
// .split client poll loop
// We're ready to process incoming messages; if nothing at all
// comes from our server within the timeout, that means the
// server is dead:
int rc = poller.poll(pollTimer);
if (rc == -1)
break; // Context has been shut down
if (poller.pollin(0)) {
if (!self.controlMessage())
break; // Interrupted
}
else if (pollSize == 2 && poller.pollin(1)) {
kvmsg msg = kvmsg.recv(poller.getSocket(1));
if (msg == null)
break; // Interrupted
// Anything from server resets its expiry time
server.expiry = System.currentTimeMillis() + SERVER_TTL;
if (self.state == STATE_SYNCING) {
// Store in snapshot until we're finished
server.requests = 0;
if (msg.getKey().equals("KTHXBAI")) {
self.sequence = msg.getSequence();
self.state = STATE_ACTIVE;
System.out.printf("I: received from %s:%d snapshot=%d\n", server.address, server.port,
self.sequence);
msg.destroy();
}
}
else if (self.state == STATE_ACTIVE) {
// Discard out-of-sequence updates, incl. hugz
if (msg.getSequence() > self.sequence) {
self.sequence = msg.getSequence();
System.out.printf("I: received from %s:%d update=%d\n", server.address, server.port,
self.sequence);
}
else msg.destroy();
}
}
else {
// Server has died, failover to next
System.out.printf("I: server at %s:%d didn't give hugz\n", server.address, server.port);
self.curServer = (self.curServer + 1) % self.nbrServers;
self.state = STATE_INITIAL;
}
}
self.destroy();
}
}
}
clone: Julia 语言的 Clone 类
clone: Lua 语言的 Clone 类
clone: Node.js 语言的 Clone 类
clone: Objective-C 语言的 Clone 类
clone: ooc 语言的 Clone 类
clone: Perl 语言的 Clone 类
clone: PHP 语言的 Clone 类
clone: Python 语言的 Clone 类
"""
clone - client-side Clone Pattern class
Author: Min RK <benjaminrk@gmail.com>
"""
import logging
import threading
import time
import zmq
from zhelpers import zpipe
from kvmsg import KVMsg
# If no server replies within this time, abandon request
GLOBAL_TIMEOUT = 4000 # msecs
# Server considered dead if silent for this long
SERVER_TTL = 5.0 # secs
# Number of servers we will talk to
SERVER_MAX = 2
# basic log formatting:
logging.basicConfig(format="%(asctime)s %(message)s", datefmt="%Y-%m-%d %H:%M:%S",
level=logging.INFO)
# =====================================================================
# Synchronous part, works in our application thread
class Clone(object):
ctx = None # Our Context
pipe = None # Pipe through to clone agent
agent = None # agent in a thread
_subtree = None # cache of our subtree value
def __init__(self):
self.ctx = zmq.Context()
self.pipe, peer = zpipe(self.ctx)
self.agent = threading.Thread(target=clone_agent, args=(self.ctx,peer))
self.agent.daemon = True
self.agent.start()
# ---------------------------------------------------------------------
# Clone.subtree is a property, which sets the subtree for snapshot
# and updates
@property
def subtree(self):
return self._subtree
@subtree.setter
def subtree(self, subtree):
"""Sends [SUBTREE][subtree] to the agent"""
self._subtree = subtree
self.pipe.send_multipart([b"SUBTREE", subtree])
def connect(self, address, port):
"""Connect to new server endpoint
Sends [CONNECT][address][port] to the agent
"""
self.pipe.send_multipart([b"CONNECT", (address.encode() if isinstance(address, str) else address), b'%d' % port])
def set(self, key, value, ttl=0):
"""Set new value in distributed hash table
Sends [SET][key][value][ttl] to the agent
"""
self.pipe.send_multipart([b"SET", key, value, b'%i' % ttl])
def get(self, key):
"""Lookup value in distributed hash table
Sends [GET][key] to the agent and waits for a value response
If there is no clone available, will eventually return None.
"""
self.pipe.send_multipart([b"GET", key])
try:
reply = self.pipe.recv_multipart()
except KeyboardInterrupt:
return
else:
return reply[0]
# =====================================================================
# Asynchronous part, works in the background
# ---------------------------------------------------------------------
# Simple class for one server we talk to
class CloneServer(object):
address = None # Server address
port = None # Server port
snapshot = None # Snapshot socket
subscriber = None # Incoming updates
expiry = 0 # Expires at this time
requests = 0 # How many snapshot requests made?
def __init__(self, ctx, address, port, subtree):
self.address = address
self.port = port
self.snapshot = ctx.socket(zmq.DEALER)
self.snapshot.linger = 0
self.snapshot.connect("%s:%i" % (address.decode(),port))
self.subscriber = ctx.socket(zmq.SUB)
self.subscriber.setsockopt(zmq.SUBSCRIBE, subtree)
self.subscriber.setsockopt(zmq.SUBSCRIBE, b'HUGZ')
self.subscriber.connect("%s:%i" % (address.decode(),port+1))
self.subscriber.linger = 0
# ---------------------------------------------------------------------
# Simple class for one background agent
# States we can be in
STATE_INITIAL = 0 # Before asking server for state
STATE_SYNCING = 1 # Getting state from server
STATE_ACTIVE = 2 # Getting new updates from server
class CloneAgent(object):
ctx = None # Own context
pipe = None # Socket to talk back to application
kvmap = None # Actual key/value dict
subtree = '' # Subtree specification, if any
servers = None # list of connected Servers
state = 0 # Current state
cur_server = 0 # If active, index of server in list
sequence = 0 # last kvmsg procesed
publisher = None # Outgoing updates
def __init__(self, ctx, pipe):
self.ctx = ctx
self.pipe = pipe
self.kvmap = {}
self.subtree = ''
self.state = STATE_INITIAL
self.publisher = ctx.socket(zmq.PUB)
self.router = ctx.socket(zmq.ROUTER)
self.servers = []
def control_message (self):
msg = self.pipe.recv_multipart()
command = msg.pop(0)
if command == b"CONNECT":
address = msg.pop(0)
port = int(msg.pop(0))
if len(self.servers) < SERVER_MAX:
self.servers.append(CloneServer(self.ctx, address, port, self.subtree))
self.publisher.connect("%s:%i" % (address.decode(),port+2))
else:
logging.error("E: too many servers (max. %i)", SERVER_MAX)
elif command == b"SET":
key,value,sttl = msg
ttl = int(sttl)
# Send key-value pair on to server
kvmsg = KVMsg(0, key=key, body=value)
kvmsg.store(self.kvmap)
if ttl:
kvmsg[b"ttl"] = sttl
kvmsg.send(self.publisher)
elif command == b"GET":
key = msg[0]
value = self.kvmap.get(key)
self.pipe.send(value.body if value else '')
elif command == b"SUBTREE":
self.subtree = msg[0]
# ---------------------------------------------------------------------
# Asynchronous agent manages server pool and handles request/reply
# dialog when the application asks for it.
def clone_agent(ctx, pipe):
agent = CloneAgent(ctx, pipe)
server = None
while True:
poller = zmq.Poller()
poller.register(agent.pipe, zmq.POLLIN)
poll_timer = None
server_socket = None
if agent.state == STATE_INITIAL:
# In this state we ask the server for a snapshot,
# if we have a server to talk to...
if agent.servers:
server = agent.servers[agent.cur_server]
logging.info ("I: waiting for server at %s:%d...",
server.address, server.port)
if (server.requests < 2):
server.snapshot.send_multipart([b"ICANHAZ?", agent.subtree])
server.requests += 1
server.expiry = time.time() + SERVER_TTL
agent.state = STATE_SYNCING
server_socket = server.snapshot
elif agent.state == STATE_SYNCING:
# In this state we read from snapshot and we expect
# the server to respond, else we fail over.
server_socket = server.snapshot
elif agent.state == STATE_ACTIVE:
# In this state we read from subscriber and we expect
# the server to give hugz, else we fail over.
server_socket = server.subscriber
if server_socket:
# we have a second socket to poll:
poller.register(server_socket, zmq.POLLIN)
if server is not None:
poll_timer = 1e3 * max(0,server.expiry - time.time())
# ------------------------------------------------------------
# Poll loop
try:
items = dict(poller.poll(poll_timer))
except:
raise # DEBUG
break # Context has been shut down
if agent.pipe in items:
agent.control_message()
elif server_socket in items:
kvmsg = KVMsg.recv(server_socket)
# Anything from server resets its expiry time
server.expiry = time.time() + SERVER_TTL
if (agent.state == STATE_SYNCING):
# Store in snapshot until we're finished
server.requests = 0
if kvmsg.key == b"KTHXBAI":
agent.sequence = kvmsg.sequence
agent.state = STATE_ACTIVE
logging.info ("I: received from %s:%d snapshot=%d",
server.address, server.port, agent.sequence)
else:
kvmsg.store(agent.kvmap)
elif (agent.state == STATE_ACTIVE):
# Discard out-of-sequence updates, incl. hugz
if (kvmsg.sequence > agent.sequence):
agent.sequence = kvmsg.sequence
kvmsg.store(agent.kvmap)
action = "update" if kvmsg.body else "delete"
logging.info ("I: received from %s:%d %s=%d",
server.address, server.port, action, agent.sequence)
else:
# Server has died, failover to next
logging.info ("I: server at %s:%d didn't give hugz",
server.address, server.port)
agent.cur_server = (agent.cur_server + 1) % len(agent.servers)
agent.state = STATE_INITIAL