第 7 章 - 使用 ZeroMQ 的高级架构 #
大规模使用 ZeroMQ 的一个影响是,由于我们可以比以前更快地构建分布式架构,我们的软件工程流程的局限性变得更加明显。慢动作下的错误往往更难察觉(或者说,更容易被合理化掉)。
我在向工程师团队教授 ZeroMQ 时的经验是,仅仅解释 ZeroMQ 如何工作,然后期望他们开始构建成功的产品,这通常是不够的。就像任何消除摩擦的技术一样,ZeroMQ 为巨大的错误敞开了大门。如果 ZeroMQ 是分布式软件开发中的 ACME 火箭鞋,那么我们很多人就像威利狼一样,全速撞向那片众所周知的沙漠悬崖。
我们在第 6 章 - ZeroMQ 社区中看到,ZeroMQ 本身使用了一个正式的变更流程。我们花费数年时间构建这个流程的原因之一,就是为了阻止库本身内部重复发生的撞悬崖事件。
部分原因在于放慢速度,部分原因在于确保你在快速前进时,是朝着——亲爱的读者,这一点至关重要——正确的方向前进。这是我的标准面试谜题:任何软件系统中最罕见的属性是什么?绝对最难做到的事情是什么?它的缺失会导致绝大多数项目缓慢或快速死亡?答案不是代码质量、资金、性能,甚至也不是(尽管接近)流行度。答案是准确性。
准确性是挑战的一半,适用于任何工程工作。另一半是分布式计算本身,它带来了一系列我们需要解决的问题,以便创建架构。我们需要编码和解码数据;我们需要定义协议来连接客户端和服务器;我们需要保护这些协议免受攻击者的侵害;并且我们需要构建健壮的堆栈。异步消息传递很难做到正确。
本章将应对这些挑战,首先对如何设计和构建软件进行基本重新评估,最后提供一个用于大规模文件分发的分布式应用程序的完整示例。
我们将涵盖以下精彩主题
- 如何安全地从想法到工作原型(MOPED 模式)
- 将数据序列化为 ZeroMQ 消息的不同方式
- 如何代码生成二进制序列化编解码器
- 如何使用 GSL 工具构建自定义代码生成器
- 如何编写和许可协议规范
- 如何在 ZeroMQ 上构建快速可重启文件传输
- 如何使用基于信用的流量控制进行非阻塞传输
- 如何将协议服务器和客户端构建为状态机
- 如何在 ZeroMQ 上构建安全协议
- 大规模文件发布系统(FileMQ)
弹性设计的面向消息模式 #
我将介绍弹性设计的面向消息模式(MOPED),这是一种用于 ZeroMQ 架构的软件工程模式。它可以是“MOPED”或“BIKE”,即反向首字母缩略词诱发的动力效应。后者是“BICICLE”的缩写,即反向首字母缩略词膨胀看我是否在乎更少效应。人生在世,要学会选择最不令人尴尬的那个。
如果你仔细阅读了本书,你会发现 MOPED 已经在行动了。第 4 章 - 可靠请求-回复模式中 Majordomo 的开发就是一个近乎完美的例子。但可爱的名字胜过千言万语。
MOPED 的目标是定义一个流程,通过该流程,我们可以为一个新的分布式应用程序的粗略用例,在一周内用任何语言从“Hello World”过渡到功能齐全的原型。
使用 MOPED,你不是建造,而是成长出一个可用的 ZeroMQ 架构,从头开始,失败风险最小。通过关注契约而非实现,你避免了过早优化的风险。通过超短的、基于测试的周期驱动设计流程,你可以在添加更多内容之前更确定你的东西是工作的。
我们可以将其转化为五个实际步骤
- 步骤 1: 理解 ZeroMQ 语义。
- 步骤 2: 绘制粗略架构。
- 步骤 3: 决定契约。
- 步骤 4: 制作最小端到端解决方案。
- 步骤 5: 解决一个问题并重复。
步骤 1: 理解语义 #
你必须学习并消化 ZeroMQ 的“语言”,也就是 socket 模式及其工作原理。学习一门语言的唯一方法就是使用它。无法避免这项投入,没有睡觉时可以播放的磁带,也没有插上就能神奇变聪明的芯片。从头开始阅读本书,用你喜欢的任何语言练习代码示例,理解正在发生的事情,并且(最重要的是)自己写一些示例,然后扔掉它们。
在某个时刻,你会感觉到大脑里发出咔嗒声。也许你会做个奇怪的辣椒引起的梦,梦里小小的 ZeroMQ 任务跑来跑去想把你活吞了。也许你只是想,“啊哈,原来那是这个意思!” 如果我们做得对,这应该需要两到三天。不管花多久,在你开始用 ZeroMQ socket 和模式思考之前,你还没有为步骤 2 做好准备。
步骤 2: 绘制粗略架构 #
根据我的经验,能够绘制架构的核心至关重要。它有助于他人理解你的想法,也有助于你自己理清思路。设计一个好的架构,最好的方法莫过于使用白板向同事解释你的想法。
你不需要一次就做对,也不需要把它做得完整。你需要做的是把你的架构分解成有意义的部分。与建造桥梁相比,软件架构的好处在于,如果你将它们隔离起来,你真的可以廉价地替换整个层。
首先选择你要解决的核心问题。忽略与该问题不相关的任何东西:你稍后再添加。问题应该是一个端到端的问题:跨越峡谷的绳索。
例如,一个客户要求我们使用 ZeroMQ 构建一个超级计算集群。客户端创建工作包,发送给一个代理,代理将它们分发给工作节点(运行在快速图形处理器上),收集结果并返回给客户端。
跨越峡谷的绳索是一个客户端与一个代理通信,代理再与一个工作节点通信。我们画三个框:客户端、代理、工作节点。我们从一个框到另一个框画箭头,表示请求单向流动,响应流回。这就像我们在前面章节中看到的许多图表一样。
保持极简主义。你的目标不是定义一个真正的架构,而是跨越峡谷抛出一条绳索来启动你的流程。随着时间的推移,我们成功地使架构变得更完整和现实:例如,添加多个工作节点,添加客户端和工作节点的 API,处理故障等等。
步骤 3: 决定契约 #
好的软件架构依赖于契约,契约越明确,事情就越能更好地扩展。你不在乎事情是如何发生的;你只在乎结果。如果我发送一封电子邮件,我不在乎它是如何到达目的地的,只要契约得到遵守就行。电子邮件的契约是:它在几分钟内到达,没有人修改它,并且它不会丢失。
要构建一个运行良好的大型系统,你必须在实现之前专注于契约。这听起来可能很明显,但人们却常常忘记或忽略这一点,或者只是太害羞不敢坚持。我希望我能说 ZeroMQ 做到了这一点,但多年来,我们的公共契约一直只是次要的补充思考,而不是首要的、引人注目的工作。
那么,分布式系统中的契约是什么?根据我的经验,契约有两种类型
-
客户端应用程序的 API。记住心理要素。API 需要绝对地简单、一致和熟悉。是的,你可以从代码生成 API 文档,但你必须先设计它,而设计 API 通常很困难。
-
连接各部分的协议。这听起来像是高深的技术,但实际上只是一个简单的技巧,而且 ZeroMQ 让它变得特别容易。事实上,它们非常容易编写,并且几乎不需要官僚程序,所以我称它们为非协议。
你编写的最小契约大多只是占位符。大多数消息和大多数 API 方法都会缺失或为空。你还需要写下任何已知的技术要求,如吞吐量、延迟、可靠性等。这些是你接受或拒绝任何特定工作片的标准。
步骤 4: 编写最小端到端解决方案 #
目标是尽快测试整体架构。创建调用 API 的骨架应用程序,以及实现协议双方的骨架堆栈。你希望尽快获得一个可工作的端到端“Hello World”。你希望能够在编写代码时进行测试,以便剔除错误的假设和不可避免的错误。不要花六个月时间去编写测试套件!相反,构建一个使用我们仍在假设中的 API 的最精简应用程序。
如果你戴着实现者的帽子来设计 API,你会开始考虑性能、特性、选项等等。你会让它比应有的更复杂、更不规范、更令人惊讶。但是,诀窍来了(这是一个便宜的招数,在日本很流行):如果你戴着实际编写使用该 API 的应用程序的人的帽子来设计 API,你就可以利用所有的懒惰和恐惧来为自己服务。
在 wiki 或共享文档中写下协议,以便你可以在没有太多细节的情况下清楚地解释每个命令。剥离任何实际功能,因为它只会产生惯性,使事情难以移动。你总是可以增加重量。不要花费精力定义正式的消息结构:使用 ZeroMQ 的多部分帧以最简单的方式传递最少的数据。
我们的目标是让最简单的测试用例工作起来,而没有任何可避免的功能。所有你可以从待办事项列表中砍掉的东西,就砍掉。忽略同事和老板的抱怨。我再重复一遍:你总是可以添加功能,那相对容易。但目标是保持整体重量最小化。
步骤 5: 解决一个问题并重复 #
你现在处于问题驱动开发的快乐循环中,可以开始解决实际问题而不是添加功能。写下每个问题,提出解决方案。在设计 API 时,记住你的命名、一致性和行为标准。用散文形式写下这些通常有助于保持它们的合理性。
从这里开始,你对架构和代码所做的每一个改动都可以通过运行测试用例来证明:观察它不工作,进行修改,然后观察它工作。
现在你可以重复整个周期(根据需要扩展测试用例、修复 API、更新协议和扩展代码),一次解决一个问题,并单独测试解决方案。每个周期应该需要大约 10-30 分钟,偶尔因随机困惑而出现峰值。
非协议 (Unprotocols) #
没有山羊的协议 #
当这个人想到协议时,他想到的是委员会多年来编写的大量文档。他想到的是 IETF、W3C、ISO、Oasis、监管俘获、FRAND 专利许可纠纷,然后很快,这个人就想到退隐到玻利维亚北部山区一个舒适的小农场,在那里唯一其他不必要的固执生物就是嚼着咖啡植物的山羊。
现在,我个人对委员会没有意见。无用的人需要一个地方来度过一生,并尽量减少繁殖的风险;毕竟,这看起来很公平。但大多数委员会协议往往趋于复杂(那些能工作的),或者垃圾(那些我们不谈论的)。这有几个原因。一个是在其中的利益金额。钱越多,就越多人想把他们特定的偏见和假设写进文字中。但第二个原因是缺乏良好的抽象来构建基础。人们尝试构建可重用的协议抽象,比如 BEEP。大多数都没有坚持下来,而那些坚持下来的,比如 SOAP 和 XMPP,都偏于复杂。
几十年前,当互联网还是一个年轻而谦逊的事物时,协议是简短而美好的。它们甚至不是“标准”,而是“征求意见稿”,这已经够谦逊了。自 1995 年我们创立 iMatix 以来,我的目标之一就是找到一种方法,让像我这样的普通人也能在没有委员会的额外开销下编写小型、准确的协议。
现在,ZeroMQ 确实似乎提供了一个活生生、成功的协议抽象层,其工作方式是“我们将在随机传输层上传输多部分消息”。由于 ZeroMQ 静默处理帧、连接和路由,所以在 ZeroMQ 之上编写完整的协议规范出人意料地容易,我在第 4 章 - 可靠请求-回复模式和第 5 章 - 高级发布-订阅模式中展示了如何做到这一点。
2007 年年中左右,我启动了数字标准组织,旨在定义更简单的方式来制定小型标准、协议和规范。为自己辩护一下,那是一个宁静的夏天。当时,我写道,一个新的规范应该需要 [几分钟解释,几小时设计,几天编写,几周验证,几个月成熟,几年才能被取代。]
2010 年,我们开始将这些小型规范称为非协议(unprotocols),有些人可能会误认为这是某个神秘国际组织实施世界统治的邪恶计划,但它实际上只是意味着“没有山羊的协议”。
契约很难 #
编写契约可能是大规模架构中最困难的部分。使用非协议,我们去除了尽可能多的不必要的摩擦。剩下的仍然是一系列难以解决的问题。一个好的契约(无论是 API、协议还是租赁协议)必须简单、明确、技术上合理且易于执行。
像任何技术技能一样,这是你需要学习和实践的东西。ZeroMQ RFC 网站上有一系列规范,当你需要时,值得阅读并将其作为自己规范的基础。
我将尝试总结一下作为协议编写者的经验
-
从简单开始,逐步开发你的规范。不要解决眼前不存在的问题。
-
使用非常清晰和一致的语言。一个协议通常可以分解为命令和字段;为这些实体使用清晰的短名称。
-
尽量避免创造概念。尽可能重用现有规范中的任何内容。使用对你的受众来说显而易见和清晰的术语。
-
不要创造任何你无法证明其立即需求的东西。你的规范解决问题;它不提供功能。为你识别出的每个问题提供最简单的可行解决方案。
-
在构建协议的同时实现它,这样你就能意识到每个选择的技术后果。使用一种让事情变得困难的语言(比如 C),而不是一种让事情变得容易的语言(比如 Python)。
-
在构建规范的同时让其他人测试它。对规范最好的反馈是当其他人尝试在没有你脑海中假设和知识的情况下实现它时。
-
快速且持续地进行交叉测试,用其他人的客户端针对你的服务器,反之亦然。
-
准备好随时抛弃并重新开始。为此做好计划,通过对架构进行分层,以便例如你可以保留一个 API 但更改底层协议。
-
只使用与编程语言和操作系统无关的构造。
-
分层解决一个大问题,使每一层成为一个独立的规范。警惕创建单体协议。思考每一层的可重用性。思考不同的团队如何在每一层构建竞争性规范。
最重要的是,写下来。代码不是规范。书面规范的意义在于,无论它多么薄弱,都可以系统地改进。通过写下规范,你还会发现代码中不可能看到的矛盾和灰色区域。
如果这听起来很难,也不要太担心。使用 ZeroMQ 的一个不太明显的优势是,它可以将编写协议规范所需的工作量减少至少 90%,因为它已经处理了帧、路由、队列等。这意味着你可以快速实验,廉价犯错,从而快速学习。
如何编写非协议 #
当你开始编写非协议规范文档时,请遵循一致的结构,以便你的读者知道会看到什么。这是我使用的结构
- 封面部分:包括一行摘要、规范 URL、正式名称、版本、责任人。
- 文本许可:公共规范绝对需要。
- 变更流程:即,作为读者,我如何修复规范中的问题?
- 语言使用:MUST、MAY、SHOULD 等,并参考 RFC 2119。
- 成熟度指标:这是实验性的、草稿、稳定、遗留还是已退役的?
- 协议目标:它试图解决什么问题?
- 形式化语法:防止因文本解释不同而引起的争论。
- 技术解释:每条消息的语义、错误处理等等。
- 安全讨论:明确说明协议的安全性。
- 参考文献:其他文档、协议等等。
编写清晰、富有表现力的文本很难。务必避免尝试描述协议的实现。记住你正在编写一个契约。你用清晰的语言描述各方的义务和期望、义务的程度以及违反规则的惩罚。你不要试图定义各方如何履行其交易部分。
以下是非协议的一些要点
-
只要你的流程是开放的,你就不需要委员会:只需做出清晰简洁的设计,并确保任何人都可以自由改进它们。
-
如果使用现有许可,那么之后你就没有法律上的担忧。我为我的公共规范使用 GPLv3,并建议你也这样做。对于内部工作,标准版权是完美的。
-
形式化是有价值的。也就是说,学习编写形式化语法,例如 ABNF(增强巴科斯-瑙尔范式),并使用它来完整记录你的消息。
-
使用诸如Digistan 的 COSS 这样的市场驱动的生命周期流程,以便人们在你的规范成熟时(或没有成熟时)给予正确的重视。
为什么公共规范使用 GPLv3? #
你选择的许可对于公共规范尤其重要。传统上,协议是根据自定义许可发布的,作者拥有文本版权,并禁止派生作品。这听起来很棒(毕竟,谁想看到协议被分叉?),但实际上风险很高。协议委员会容易被俘获,如果协议重要且有价值,被俘获的诱因就会增加。
一旦被俘获,就像一些野生动物一样,一个重要的协议往往会消亡。真正的问题在于,无法解放一个在传统许可下发布的被俘获协议。“自由”这个词不仅仅是用来形容言论或空气的形容词,它也是一个动词,而违背所有者意愿分叉作品的权利对于避免俘获至关重要。
让我用更简单的话解释一下。想象一下,iMatix 今天编写了一个非常出色且受欢迎的协议。我们发布了规范,很多人实现了它。这些实现快速且优秀,而且是免费的(像啤酒一样)。它们开始威胁现有的业务。他们的昂贵商业产品更慢,无法竞争。所以有一天,他们来到我们在韩国 Maetang-Dong 的 iMatix 办公室,提出收购我们的公司。因为我们在寿司和啤酒上花费巨大,我们欣然接受。新的协议所有者带着邪恶的笑声,停止改进公共版本,关闭规范,并添加专利扩展。他们的新产品支持这个新协议版本,但开源版本在法律上被阻止这样做。该公司接管了整个市场,竞争结束了。
当你为一个开源项目做出贡献时,你真的希望知道你的辛勤工作不会被闭源竞争对手用来对付你。这就是为什么对于大多数贡献者来说,GPL 胜过“更宽松的”BSD/MIT/X11 许可。这些许可允许作弊。这对于协议和源代码来说都同样适用。
当你实现一个 GPLv3 规范时,你的应用程序当然是你自己的,并且可以按你喜欢的任何方式许可。但你可以确定两件事。第一,该规范永远不会被接纳并扩展为专有形式。该规范的任何派生形式也必须是 GPLv3。第二,任何实现或使用该协议的人都不会对其涵盖的任何内容发起专利攻击,也无法在不授予全世界免费许可的情况下将他们的专利技术添加到其中。
使用 ABNF #
我写协议规范时的建议是学习和使用形式化语法。这比让别人解释你的意思,然后从不可避免的错误假设中恢复过来要省事得多。你的语法的目标是其他人、工程师,而不是编译器。
我最喜欢的语法是 ABNF,由RFC 2234定义,因为它可能是定义双向通信协议的最简单、最广泛使用的形式化语言。大多数 IETF(互联网工程任务组)规范都使用 ABNF,这是很好的借鉴对象。
我将给你一个 30 秒速成 ABNF 编写课程。它可能让你想起正则表达式。你将语法写成规则。每个规则的形式是“名称 = 元素”。一个元素可以是另一个规则(你在下面定义为另一个规则),也可以是预定义的终结符,例如CRLF, OCTET,或数字。该 RFC 列出了所有终结符。要定义备选元素,用斜杠分隔。要定义重复,使用星号。要分组元素,使用括号。阅读 RFC,因为它不直观。
我不确定这种扩展是否合适,但我会在元素前加上“C:”和“S:”前缀,以表示它们是来自客户端还是服务器。
这里是一段用于一个名为 NOM 的非协议的 ABNF 片段,我们将在本章后面回到它
nom-protocol = open-peering *use-peering
open-peering = C:OHAI ( S:OHAI-OK / S:WTF )
use-peering = C:ICANHAZ
/ S:CHEEZBURGER
/ C:HUGZ S:HUGZ-OK
/ S:HUGZ C:HUGZ-OK
我实际上在商业项目中使用过这些关键字(OHAI, WTF)。它们让开发者乐呵呵的。它们让管理层感到困惑。它们很适合用在以后想要扔掉的初稿中。
廉价或糟糕模式 #
在几十年的大大小小的协议编写过程中,我学到了一个通用教训。我称之为廉价或糟糕模式:你通常可以将你的工作分成两个方面或层,然后分别解决它们——一个使用“廉价”方法,另一个使用“糟糕”方法。
使廉价或糟糕模式奏效的关键洞察是,许多协议混合了一个用于控制的低流量聊天部分,和一个用于数据的高流量异步部分。例如,HTTP 有一个用于认证和获取页面的聊天对话,以及一个用于流式传输数据的异步对话。FTP 实际上将这部分拆分到两个端口;一个端口用于控制,一个端口用于数据。
不将控制与数据分离的协议设计者往往会设计出糟糕的协议,因为这两种情况下的权衡几乎完全相反。对控制完美的东西对数据来说很糟糕,而对数据理想的东西对控制来说根本行不通。当我们想要高性能的同时又要兼顾可扩展性和良好的错误检查时,这一点尤其正确。
让我们用一个经典的客户端/服务器用例来分解它。客户端连接到服务器并进行认证。然后它请求某个资源。服务器回复,然后开始向客户端发送数据。最终,客户端断开连接或服务器完成,会话结束。
现在,在开始设计这些消息之前,停下来思考一下,让我们比较一下控制对话和数据流
-
控制对话持续时间短,涉及的消息非常少。数据流可能持续数小时或数天,涉及数十亿条消息。
-
控制对话是所有“正常”错误发生的地方,例如,未认证、未找到、需要付费、被审查等等。相比之下,数据流期间发生的任何错误都是异常的(磁盘满、服务器崩溃)。
-
控制对话是随着时间推移,随着我们添加更多选项、参数等而发生变化的地方。数据流随着时间推移应该几乎不会变化,因为资源的语义在时间上是相当恒定的。
-
控制对话本质上是一个同步的请求/回复对话。数据流本质上是一个单向的异步流。
这些差异至关重要。当我们谈论性能时,它只适用于数据流。将一次性控制对话设计得很快是病态的。因此,当我们谈论序列化成本时,这只适用于数据流。控制流的编码/解码成本可能很高,但在许多情况下,这不会改变任何事情。因此,我们使用廉价方式编码控制,使用糟糕方式编码数据流。
廉价方式本质上是同步的、详细的、描述性的和灵活的。廉价消息包含了可以随每个应用程序变化的丰富信息。作为设计者,你的目标是使这些信息易于编码和解析,易于扩展以进行实验或增长,并且对前向和后向更改都高度健壮。协议的廉价部分如下所示
-
它使用简单、自描述的结构化数据编码,无论是 XML、JSON、HTTP 风格的头,还是其他。只要你的目标语言中有标准的简单解析器,任何编码都可以。
-
它使用简单的请求-回复模型,其中每个请求都有一个成功/失败回复。这使得为廉价对话编写正确的客户端和服务器变得轻而易举。
-
它根本不追求速度。当你每次会话只做一次或几次时,性能无关紧要。
廉价解析器是你拿来就可以用的东西,直接往里面扔数据。它不应该崩溃,不应该内存泄漏,应该高度容错,并且应该相对简单易用。就是这样。
然而,糟糕方式本质上是异步的、简洁的、静默的和不灵活的。糟糕消息携带几乎永不改变的最小信息。作为设计者,你的目标是使这些信息解析速度极快,甚至可能无法扩展和实验。理想的糟糕模式如下所示
-
它对数据使用手写优化的二进制布局,每个位都经过精确设计。
-
它使用纯异步模型,其中一个或两个对等方在没有确认的情况下发送数据(或者如果发送,它们使用巧妙的异步技术,如基于信用的流量控制)。
-
它根本不追求友好。当你每秒执行几百万次时,性能才是最重要的。
糟糕解析器是你手写的东西,它单独精确地写入或读取位、字节、字和整数。它拒绝任何它不喜欢的东西,完全不做内存分配,也从不崩溃。
廉价或糟糕模式并非通用模式;并非所有协议都有这种二分法。此外,你如何使用廉价或糟糕模式取决于具体情况。在某些情况下,它可以是一个协议的两个部分。在其他情况下,它可以是两个协议,一个叠加在另一个之上。
错误处理 #
使用 Cheap 或 Nasty 会使错误处理相当简单。你有两种命令和两种错误信号方式
- 同步控制命令:错误是正常的:每个请求都有一个响应,要么是 OK,要么是错误响应。
- 异步数据命令:错误是异常的:无效命令要么被静默丢弃,要么导致整个连接关闭。
通常最好区分几种错误,但一如既往,保持最小化,只添加你需要的东西。
序列化你的数据 #
当我们开始设计一个协议时,我们面临的第一个问题是如何在链路上编码数据。没有通用的答案。有六七种不同的数据序列化方法,每种都有优点和缺点。我们将探讨其中一些。
抽象级别 #
在探讨如何将数据放到链路上之前,值得问问我们实际上想在应用之间交换什么数据。如果我们不使用任何抽象,我们实际上会序列化和反序列化我们的内部状态。也就是说,我们用来实现功能的那些对象和结构。
然而,将内部状态放到链路上是一个非常糟糕的主意。这就像在 API 中暴露内部状态。当你这样做时,你是在将你的实现决策硬编码到你的协议中。你也会产生比实际需要复杂得多的协议。
这或许是许多旧协议和 API 如此复杂的主要原因:它们的设计者没有考虑如何将它们抽象成更简单的概念。当然,不能保证抽象会 更简单;这正是需要努力的地方。
一个好的协议或 API 抽象封装了自然的使用模式,并赋予它们可预测且有规律的名称和属性。它选择合理的默认值,以便可以最小化地指定主要用例。它旨在简单的情况下保持简单,在罕见的复杂情况下保持表达力。它不对内部实现做任何声明或假设,除非为了互操作性绝对需要。
ZeroMQ 帧格式 #
对于 ZeroMQ 应用来说,最简单、最广泛使用的序列化格式是 ZeroMQ 自己的多部分帧格式。例如,Majordomo Protocol 定义请求的方式如下
Frame 0: Empty frame
Frame 1: "MDPW01" (six bytes, representing MDP/Worker v0.1)
Frame 2: 0x02 (one byte, representing REQUEST)
Frame 3: Client address (envelope stack)
Frame 4: Empty (zero bytes, envelope delimiter)
Frames 5+: Request body (opaque binary)
在代码中读写这个很容易,但这是控制流的一个典型例子(整个 MDP 其实就是如此,因为它是一个冗长的请求-回复协议)。当我们改进 MDP 的第二个版本时,我们不得不改变这个帧格式。太棒了,我们破坏了所有现有的实现!
向后兼容性很难实现,但将 ZeroMQ 帧格式用于控制流 没有帮助。如果我遵循了自己的建议,我会这样设计这个协议(我会在下一个版本中修正这个问题)。它被分成了 Cheap 部分和 Nasty 部分,并使用 ZeroMQ 帧格式来分隔它们
Frame 0: "MDP/2.0" for protocol name and version
Frame 1: command header
Frame 2: command body
在各种中间件(客户端 API、代理和工作者 API)中,我们会解析命令头,并将命令体原封不动地从一个应用传递到另一个应用。
序列化语言 #
序列化语言各有其流行趋势。XML 曾经很流行,然后变得臃肿,然后落入了“企业信息架构师”手中,自那以后就再也没见过活的了。今天的 XML 是“在那一堆混乱中,有一个小巧优雅的语言正试图逃脱”的典型代表。
尽管如此,XML 比其前身好太多了,其中包括像标准通用标记语言(SGML)这样的怪物,与 EDIFACT 这种令人头痛的野兽相比,SGML 简直是小菜一碟。因此,序列化语言的历史似乎是理智逐渐浮现的历史,隐藏在企图保住工作的、令人反感的 EIA 掀起的波涛之下。
JSON 从 JavaScript 世界中涌现出来,作为一种快速粗糙的“我宁愿辞职也不愿在这里用 XML”的方式,用来将数据丢到链路上再取回来。JSON 只是以 JavaScript 源代码的形式偷偷表达的极简 XML。
这是在 Cheap 协议中使用 JSON 的一个简单示例
"protocol": {
"name": "MTL",
"version": 1
},
"virtual-host": "test-env"
相同的数据在 XML 中会是(XML 迫使我们必须发明一个单一的顶级实体)
<command>
<protocol name = "MTL" version = "1" />
<virtual-host>test-env</virtual-host>
</command>
使用普通的 HTTP 风格头部的形式如下
Protocol: MTL/1.0
Virtual-host: test-env
只要你不沉迷于验证解析器、Schema 以及其他“相信我们,这都是为了你好”之类的废话,这些都差不多。Cheap 序列化语言为你提供了免费的实验空间(“忽略任何你不认识的元素/属性/头部”),而且编写通用的解析器也很简单,例如,可以将命令转换(thunk)为一个哈希表,反之亦然。
然而,并非一切都一帆风顺。虽然现代脚本语言很容易支持 JSON 和 XML,但较旧的语言则不支持。如果你使用 XML 或 JSON,就会产生非平凡的依赖。在 C 语言这样的语言中处理树状结构的数据也有点麻烦。
因此,你可以根据你目标使用的语言来决定选择。如果你的世界是脚本语言,那就选择 JSON。如果你打算构建用于更广泛系统使用的协议,就让 C 开发者的事情简单点,坚持使用 HTTP 风格的头部。
序列化库 #
Themsgpack.org网站说:
它就像 JSON,但速度快且体积小。MessagePack 是一种高效的二进制序列化格式。它让你可以在多种语言之间交换数据,像 JSON 一样,但它更快更小。例如,小整数(如标志或错误码)被编码成一个字节,典型的短字符串除了自身内容外只需额外一个字节。
我想提出一个也许不受欢迎的观点:“快速和体积小”这些特性解决的不是实际问题。据我所知,序列化库唯一真正解决的问题是,需要记录消息契约以及实际将数据序列化到链路上或从链路上反序列化。
我们先来揭穿“快速和体积小”的说法。它基于一个两部分的论点。首先,让你的消息更小并降低编码和解码的 CPU 开销,会对你的应用性能产生显著影响。其次,这对于所有消息都普遍有效。
但大多数实际应用倾向于属于以下两类之一。要么是序列化速度和编码大小与其他开销(例如数据库访问或应用代码性能)相比微不足道。或者,网络性能确实是关键因素,此时所有显著开销都集中在少数特定消息类型上。
因此,全面追求“快速和体积小”是一种错误的优化。你既无法为不频繁的控制流获得 Cheap 的易用灵活性,也无法为高吞吐量数据流获得 Nasty 的极致效率。更糟的是,假设所有消息在某种程度上都是相等的,这可能会破坏你的协议设计。Cheap 或 Nasty 不仅仅关乎序列化策略,它还关乎同步与异步、错误处理以及变更成本。
我的经验是,基于消息的应用中的大多数性能问题可以通过以下方式解决:(a) 改进应用本身,以及 (b) 手动优化高吞吐量数据流。要手动优化最关键的数据流,你需要作弊;学习利用数据的特性,这是通用序列化器无法做到的。
现在我们来讨论文档以及需要明确且正式地编写契约,而不仅仅是在代码中。这是一个值得解决的问题,实际上,如果我们要构建持久的大规模消息驱动架构,这是主要问题之一。
这是使用 MessagePack 接口定义语言(IDL)描述典型消息的方式
message Person {
1: string surname
2: string firstname
3: optional string email
}
现在,使用 Google Protocol Buffers IDL 描述同一消息
message Person {
required string surname = 1;
required string firstname = 2;
optional string email = 3;
}
它确实有效,但在大多数实际情况下,与手动编写或自动生成的良好规范支持的序列化语言相比,优势不大(稍后我们会讨论这一点)。你付出的代价是增加一个额外的依赖,并且很可能,总体性能比你使用 Cheap 或 Nasty 更差。
手工编写的二进制序列化 #
正如你将从本书中了解到的,我首选的系统编程语言是 C(升级到 C99,带有构造函数/析构函数 API 模型和通用容器)。我喜欢这种现代化的 C 语言有两个原因。首先,我心智太弱,学不动像 C++ 这样的大语言。生活似乎充满了更多有趣的事情需要理解。其次,我发现这种特定程度的手动控制让我能够更快地产生更好的结果。
这里的重点不是 C 与 C++ 的对比,而是手动控制对于高端专业用户的价值。世界上最好的汽车、相机和意式咖啡机都有手动控制,这并非巧合。这种现场精细调整的能力通常决定了能否 achieve 世界一流的成功,抑或是屈居第二。
当你真正、非常关心序列化速度和/或结果大小(这两者常常互相矛盾)时,你就需要手工编写的二进制序列化。换句话说,让我们为 Nasty 先生鼓掌!
编写高效的 Nasty 编码器/解码器(codec)的基本流程是
- 构建有代表性的数据集和测试应用,以便对你的 codec 进行压力测试。
- 编写 codec 的第一个简单版本。
- 测试、测量、改进,并重复,直到你时间耗尽和/或没钱。
以下是我们用来改进 codec 的一些技术
-
使用性能分析器。在你分析代码的函数调用次数和每函数 CPU 开销之前,根本无法知道你的代码在做什么。当你找到热点时,修复它们。
-
消除内存分配。在现代 Linux 内核上,堆非常快,但在大多数简单的 codec 中仍然是瓶颈。在较旧的内核上,堆可能慢得令人绝望。在可能的情况下,使用局部变量(栈)代替堆。
-
在不同的平台以及使用不同的编译器和编译器选项进行测试。除了堆之外,还有许多其他差异。你需要了解主要的差异,并加以考虑。
-
使用状态来进行更好的压缩。如果你关心 codec 的性能,你几乎肯定会多次发送相同类型的数据。数据实例之间存在冗余。你可以检测到这些冗余并加以利用进行压缩(例如,一个短值表示“与上次相同”)。
-
了解你的数据。最好的压缩技术(就 CPU 开销和紧凑性而言)需要了解数据。例如,用于压缩单词列表、视频和股票市场数据流的技术都不同。
-
准备打破规则。你真的需要在网络字节序(大端)中编码整数吗?x86 和 ARM 几乎占了所有现代 CPU,但它们都使用小端序(ARM 实际上是双端序,但 Android,像 Windows 和 iOS 一样,是小端序)。
代码生成 #
阅读前两节后,你可能想知道,“我能不能写一个比通用 IDL 生成器更好的自定义生成器?” 如果这个念头掠过你的脑海,它可能很快就离开了,因为随之而来的是对实际工作量的黑暗估算。
如果我告诉你一种廉价快速构建自定义 IDL 生成器的方法呢?你可以获得完美文档化的契约,代码可以根据需要变得多么“邪恶”和领域特定,而你只需在这里签下你的灵魂(谁真的用到过这东西,我说对了吗?)…
在 iMatix,直到几年前,我们一直使用代码生成技术构建越来越大、越来越雄心勃勃的系统,直到我们认为这项技术(GSL)对于普通使用来说太危险了,于是我们将代码库封存,用沉重的锁链锁在深邃的地牢里。我们实际上把它发布在了 GitHub 上。如果你想尝试接下来的示例,克隆仓库,然后构建一个gsl命令。在 src 子目录中输入“make”就可以构建了(如果你是那个热爱 Windows 的家伙,我相信你会发送一个带有项目文件的补丁)。
本节并非完全关于 GSL,而是关于一个鲜为人知但非常有用的技巧,对于想要提升自身能力和工作产出的有抱负的架构师来说非常有用。一旦你学会了这个技巧,你可以在短时间内快速构建自己的代码生成器。大多数软件工程师了解的代码生成器都带有一个硬编码的模型。例如,Ragel“从正则表达式编译可执行的有限状态机”,也就是说,Ragel 的模型是正则表达式。这对于解决一系列问题当然是有效的,但远非通用。你如何在 Ragel 中描述一个 API?或者一个项目的 makefile?甚至是我们用来设计 第 4 章 - 可靠请求-回复模式 中 Binary Star 模式的有限状态机?
所有这些都会从代码生成中受益,但没有通用的模型。所以技巧在于根据需要设计你自己的模型,然后将代码生成器视为该模型的廉价编译器。你需要一些构建良好模型的经验,并且你需要一种能够廉价构建自定义代码生成器的技术。脚本语言,如 Perl 和 Python,是不错的选择。然而,我们实际上专门为此构建了 GSL,这也是我偏好的。
让我们来看一个与我们已知内容相关的简单例子。稍后我们会看到更广泛的例子,因为我确实相信代码生成对于大规模工作是至关重要的知识。在第 4 章 - 可靠请求-回复模式中,我们开发了Majordomo Protocol (MDP),并为其编写了客户端、代理和工作者。现在我们是否可以通过构建自己的接口描述语言和代码生成器来机械地生成这些部分?
当我们编写 GSL 模型时,我们可以使用我们喜欢的 任何 语义,换句话说,我们可以即时发明领域特定语言。我会发明几个——看看你能不能猜出它们代表什么
slideshow
name = Cookery level 3
page
title = French Cuisine
item = Overview
item = The historical cuisine
item = The nouvelle cuisine
item = Why the French live longer
page
title = Overview
item = Soups and salads
item = Le plat principal
item = Béchamel and other sauces
item = Pastries, cakes, and quiches
item = Soufflé: cheese to strawberry
这个呢?
table
name = person
column
name = firstname
type = string
column
name = lastname
type = string
column
name = rating
type = integer
我们可以将第一个编译成一个演示文稿。第二个,我们可以编译成 SQL 来创建和操作数据库表。因此,在本练习中,我们的领域语言,即我们的 模型,由包含“消息”的“类”组成,“消息”又包含各种类型的“字段”。这是故意设计成熟悉的。这是 MDP 客户端协议
<class name = "mdp_client">
MDP/Client
<header>
<field name = "empty" type = "string" value = ""
>Empty frame</field>
<field name = "protocol" type = "string" value = "MDPC01"
>Protocol identifier</field>
</header>
<message name = "request">
Client request to broker
<field name = "service" type = "string">Service name</field>
<field name = "body" type = "frame">Request body</field>
</message>
<message name = "reply">
Response back to client
<field name = "service" type = "string">Service name</field>
<field name = "body" type = "frame">Response body</field>
</message>
</class>
这是 MDP 工作者协议
<class name = "mdp_worker">
MDP/Worker
<header>
<field name = "empty" type = "string" value = ""
>Empty frame</field>
<field name = "protocol" type = "string" value = "MDPW01"
>Protocol identifier</field>
<field name = "id" type = "octet">Message identifier</field>
</header>
<message name = "ready" id = "1">
Worker tells broker it is ready
<field name = "service" type = "string">Service name</field>
</message>
<message name = "request" id = "2">
Client request to broker
<field name = "client" type = "frame">Client address</field>
<field name = "body" type = "frame">Request body</field>
</message>
<message name = "reply" id = "3">
Worker returns reply to broker
<field name = "client" type = "frame">Client address</field>
<field name = "body" type = "frame">Request body</field>
</message>
<message name = "hearbeat" id = "4">
Either peer tells the other it's still alive
</message>
<message name = "disconnect" id = "5">
Either peer tells other the party is over
</message>
</class>
GSL 使用 XML 作为其建模语言。XML 的名声不太好,因为它被拖过太多企业级泥潭,不再“香甜可人”,但只要你保持简单,它还是有一些强项的。任何编写自描述的项目和属性层次结构的方式都可以。
现在,这里有一个用 GSL 编写的短 IDL 生成器,它可以将我们的协议模型转换为文档
.# Trivial IDL generator (specs.gsl)
.#
.output "$(class.name).md"
## The $(string.trim (class.?''):left) Protocol
.for message
. frames = count (class->header.field) + count (field)
A $(message.NAME) command consists of a multipart message of $(frames)
frames:
. for class->header.field
. if name = "id"
* Frame $(item ()): 0x$(message.id:%02x) (1 byte, $(message.NAME))
. else
* Frame $(item ()): "$(value:)" ($(string.length ("$(value)")) \
bytes, $(field.:))
. endif
. endfor
. index = count (class->header.field) + 1
. for field
* Frame $(index): $(field.?'') \
. if type = "string"
(printable string)
. elsif type = "frame"
(opaque binary)
. index += 1
. else
. echo "E: unknown field type: $(type)"
. endif
. index += 1
. endfor
.endfor
XML 模型和这个脚本在 examples/models 子目录中。要进行代码生成,我输入以下命令
gsl -script:specs mdp_client.xml mdp_worker.xml
这是我们为工作者协议生成的 Markdown 文本
## The MDP/Worker Protocol
A READY command consists of a multipart message of 4 frames:
* Frame 1: "" (0 bytes, Empty frame)
* Frame 2: "MDPW01" (6 bytes, Protocol identifier)
* Frame 3: 0x01 (1 byte, READY)
* Frame 4: Service name (printable string)
A REQUEST command consists of a multipart message of 5 frames:
* Frame 1: "" (0 bytes, Empty frame)
* Frame 2: "MDPW01" (6 bytes, Protocol identifier)
* Frame 3: 0x02 (1 byte, REQUEST)
* Frame 4: Client address (opaque binary)
* Frame 6: Request body (opaque binary)
A REPLY command consists of a multipart message of 5 frames:
* Frame 1: "" (0 bytes, Empty frame)
* Frame 2: "MDPW01" (6 bytes, Protocol identifier)
* Frame 3: 0x03 (1 byte, REPLY)
* Frame 4: Client address (opaque binary)
* Frame 6: Request body (opaque binary)
A HEARBEAT command consists of a multipart message of 3 frames:
* Frame 1: "" (0 bytes, Empty frame)
* Frame 2: "MDPW01" (6 bytes, Protocol identifier)
* Frame 3: 0x04 (1 byte, HEARBEAT)
A DISCONNECT command consists of a multipart message of 3 frames:
* Frame 1: "" (0 bytes, Empty frame)
* Frame 2: "MDPW01" (6 bytes, Protocol identifier)
* Frame 3: 0x05 (1 byte, DISCONNECT)
正如你所见,这与我在原始规范中手工编写的内容很接近。现在,如果你已经克隆了zguide仓库并且正在查看examples/models中的代码,你可以生成 MDP 客户端和工作者的 codec。我们将相同的两个模型传递给另一个代码生成器
gsl -script:codec_c mdp_client.xml mdp_worker.xml
这将生成mdp_client和mdp_worker类。实际上,MDP 如此简单,以至于编写代码生成器几乎不值得付出努力。收益体现在当我们想要修改协议时(我们在独立的 Majordomo 项目中就这么做了)。你修改协议,运行命令,然后就弹出了更完美的的代码。
Thecodec_c.gsl代码生成器并不短,但生成的 codec 比我最初为 Majordomo 手工编写的代码好得多。例如,手工编写的代码没有错误检查,如果你传入错误消息就会崩溃。
现在我将解释基于 GSL 的模型驱动代码生成的优缺点。力量不是免费的,我们行业中最大的陷阱之一就是凭空发明概念的能力。GSL 让这一点变得尤其容易,因此它可能成为同样危险的工具。
不要发明概念。设计师的工作是消除问题,而不是添加功能。
首先,我将列出模型驱动代码生成的优势
- 你可以创建与你的真实世界映射的近乎完美的抽象。因此,我们的协议模型 100% 映射到 Majordomo 的“真实世界”。如果没有随意调整和修改模型的自由,这是不可能的。
- 你可以快速且廉价地开发这些完美模型。
- 你可以生成 任何 文本输出。从单个模型中,你可以创建文档、任何语言的代码、测试工具——实际上是你能想到的任何输出。
- 你可以生成(我是认真的)完美 的输出,因为改进你的代码生成器到你想要的任何水平都很廉价。
- 你获得一个结合了规范和语义的单一来源。
- 你可以将一个小团队的产出扩大到巨大规模。在 iMatix,我们从大约 8.5 万行的输入模型(包括代码生成脚本本身)中生成了百万行的 OpenAMQ 消息产品。
现在我们来看看缺点
- 你会为你的项目增加工具依赖。
- 你可能会得意忘形,仅仅出于创造模型的乐趣而创建模型。
- 你可能会疏远新手,他们会觉得你的工作里有“奇怪的东西”。
- 你可能会给人们一个强烈的理由不去投资你的项目。
讽刺地说,模型驱动的滥用在某些环境中非常有效,这些环境是你想要生产大量完美代码的地方,这些代码你可以轻松维护,而且 谁也无法从你手中夺走。我个人喜欢过河拆桥。但如果长期饭票是你的目标,这几乎是完美的。
因此,如果你确实使用 GSL 并想围绕你的工作建立开放社区,这里是我的建议
- 只在你原本需要手工编写繁琐代码的地方使用它。
- 设计人们期望看到的自然模型。
- 先手工编写代码,这样你就知道要生成什么了。
- 不要过度使用。保持简单!不要太过元化!!
- 逐步引入项目中。
- 将生成的代码放入你的仓库中。
我们已经在 ZeroMQ 周围的一些项目中使用 GSL 了。例如,高级 C 绑定 CZMQ 使用 GSL 来生成套接字选项类(zsockopt)。一个 300 行的代码生成器可以将 78 行的 XML 模型转换为 1,500 行完美但非常无聊的代码。这是一笔不错的收获。
文件传输 #
让我们从讲课中休息一下,回到我们的初恋以及做这一切的原因:代码。
“如何发送文件?”是 ZeroMQ 邮件列表中常见的问题。这不足为奇,因为文件传输可能是最古老、最明显的消息传递类型。在网络中发送文件有很多用例,除了惹恼版权卡特尔之外。ZeroMQ 在发送事件和任务方面开箱即用就很好,但在发送文件方面则没那么好。
我承诺了一两年要写一个“proper”的解释。这里有一个无关紧要的信息来点亮你的早晨:“proper”这个词来自古法语 propre,意思是“干净”。中世纪的英国普通民众,不熟悉热水和肥皂,将这个词改成了“外国的”或“上层的”的意思,比如“那是 proper 的食物!”,但后来这个词又变回了仅仅表示“真实的”,比如“你给我们惹了 proper 的麻烦!”
那么,文件传输。你不能随便拿起一个随机文件,蒙上它的眼睛,然后一股脑塞进一个消息里,原因有好几个。最明显的原因是,尽管 RAM 大小几十年来一直在稳步增长(我们这些老家伙中,谁不怀念攒钱买那 1024 字节内存扩展卡的日子?!),磁盘大小仍然顽固地大得多。即使我们可以用一个指令发送一个文件(比如使用像 sendfile 这样的系统调用),我们也会遇到网络并非无限快或完全可靠的现实。在缓慢不稳定的网络上(WiFi,懂的都懂?)尝试上传大文件几次之后,你就会意识到,一个“proper”的文件传输协议需要一种从失败中恢复的方式。也就是说,它需要一种只发送文件中尚未接收部分的方式。
最后,经过这一切,如果你构建了一个“proper”的文件服务器,你会注意到,简单地向大量客户端发送海量数据会产生我们在技术术语中称之为“服务器因为设计糟糕的应用耗尽所有可用堆内存而崩溃”的情况。一个“proper”的文件传输协议需要关注内存使用。
我们将逐一“proper”地解决这些问题,这有望引导我们构建一个运行在 ZeroMQ 之上良好且“proper”的文件传输协议。首先,让我们生成一个包含随机数据的 1GB 测试文件(是真正的 2 的幂次方吉字节,符合冯·诺依曼的意图,而不是内存行业喜欢出售的虚假硅片容量)
dd if=/dev/urandom of=testdata bs=1M count=1024
当有大量客户端同时请求同一文件时,这个文件足够大,会带来麻烦,而且在许多机器上,1GB 无论如何都太大,无法在内存中一次性分配。作为基础参考,让我们测量将这个文件从磁盘复制到磁盘需要多久。这将告诉我们我们的文件传输协议在其上增加了多少开销(包括网络成本)。
$ time cp testdata testdata2
real 0m7.143s
user 0m0.012s
sys 0m1.188s
四位数的精度具有误导性;预计会有 25% 的上下波动。这只是一个“量级”的测量。
这是我们第一次尝试编写的代码,在这段代码中,客户端请求测试数据,服务器只是不停地将其作为一系列消息发送出去,每条消息包含一个 块
C | Java | Python | 贡献翻译:Ada | Basic | C++ | C# | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCaml
这相当简单,但我们已经遇到了一个问题:如果我们向 ROUTER 套接字发送太多数据,很容易导致其溢出。简单但愚蠢的解决方案是在套接字上设置无限高水位标记。这很愚蠢,因为我们现在没有任何保护措施来防止耗尽服务器内存。然而,如果没有无限 HWM,我们就有丢失大文件块的风险。
试试这个:将 HWM 设置为 1,000(在 ZeroMQ v3.x 中这是默认值),然后将块大小减小到 100K,这样我们一次性发送 10K 个块。运行测试,你会发现它永远不会完成。正如 zmq_socket()手册页愉快而残酷地说的那样,对于 ROUTER 套接字:“ZMQ_HWM 选项操作:丢弃”。
我们必须预先控制服务器发送的数据量。发送超过网络能处理的数据量是没有意义的。让我们尝试一次发送一个块。在这个版本的协议中,客户端会明确地说:“给我块 N”,服务器会从磁盘中获取该特定块并发送它。
这是改进后的第二个模型,客户端一次请求一个块,服务器每次收到客户端的请求时只发送一个块
C | Java | Python | 贡献翻译:Ada | Basic | C++ | C# | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCaml由于客户端和服务器之间的来回通信,现在的速度慢得多。在本地环回连接(客户端和服务器在同一台机器上)上,每次请求-回复往返大约需要300微秒。这听起来不多,但很快就会累积起来
$ time ./fileio1
4296 chunks received, 1073741824 bytes
real 0m0.669s
user 0m0.056s
sys 0m1.048s
$ time ./fileio2
4295 chunks received, 1073741824 bytes
real 0m2.389s
user 0m0.312s
sys 0m2.136s
这里有两点宝贵的经验。首先,虽然请求-回复方式简单,但对于高容量数据流来说太慢了。一次支付300微秒是可以接受的,但对每个块都支付这个延迟就无法接受了,特别是在实际网络中,延迟可能会高出1000倍。
第二点是我之前说过但要重申的:在ZeroMQ上实验、测量和改进协议是极其容易的。当某件事情的成本大幅下降时,你就可以承受更多。务必学会独立开发和验证你的协议:我见过一些团队浪费时间去改进那些设计糟糕且过于深入嵌入到应用程序中而难以测试或修复的协议。
我们的模型二文件传输协议除了性能问题外,并不算太差
- 它完全消除了内存耗尽的风险。为了证明这一点,我们在发送方和接收方都将高水位标记设置为1。
- 它允许客户端选择块大小,这非常有用,因为如果需要根据网络状况、文件类型或进一步减少内存消耗来调整块大小,这项工作应由客户端来完成。
- 它为我们提供了完全可重启的文件传输。
- 它允许客户端在任何时间点取消文件传输。
如果我们不需要为每个块发送一个请求,它就会是一个可用的协议。我们需要的是一种让服务器发送多个块而无需等待客户端请求或确认每一个块的方法。我们有哪些选择?
-
服务器可以一次发送10个块,然后等待一个确认。这就像是将块大小乘以10,因此毫无意义。是的,对于所有10的倍数来说,这同样毫无意义。
-
服务器可以在没有客户端任何通信的情况下发送块,但在每次发送之间稍作延迟,以便只以网络能够处理的速度发送块。这将要求服务器了解网络层发生的情况,这听起来很麻烦。这也会严重破坏分层结构。如果网络非常快,但客户端本身很慢怎么办?块会排队在哪里?
-
服务器可以尝试监视发送队列,即查看队列的满度,只有当队列不满时才发送。ZeroMQ不允许这样做,因为它不起作用,原因与限流不起作用一样。服务器和网络可能非常快,但客户端可能是一个缓慢的小设备。
-
我们可以修改libzmq以便在达到高水位标记(HWM)时采取其他操作。也许可以阻塞?那意味着一个慢客户端会阻塞整个服务器,所以不必了。也许可以向调用者返回一个错误?然后服务器可以做一些聪明的事情,比如……嗯,实际上它能做的任何事情都不比丢弃消息更好。
除了复杂和各种不愉快之外,这些选项中没有一个能奏效。我们需要的是一种让客户端异步地、在后台告诉服务器它已准备好接收更多数据的方法。我们需要某种异步流控制。如果我们做得对,数据应该从服务器不间断地流向客户端,但前提是客户端正在读取数据。我们来回顾一下我们的三个协议。这是第一个
C: fetch
S: chunk 1
S: chunk 2
S: chunk 3
....
第二个协议为每个块引入了一个请求
C: fetch chunk 1
S: send chunk 1
C: fetch chunk 2
S: send chunk 2
C: fetch chunk 3
S: send chunk 3
C: fetch chunk 4
....
现在——神秘地挥挥手——这里有一个改进后的协议,它解决了性能问题
C: fetch chunk 1
C: fetch chunk 2
C: fetch chunk 3
S: send chunk 1
C: fetch chunk 4
S: send chunk 2
S: send chunk 3
....
它看起来非常相似。事实上,除了我们发送多个请求而无需等待每个请求的回复之外,它是完全相同的。这是一种称为“流水线(pipelining)”的技术,之所以奏效,是因为我们的DEALER和ROUTER套接字是完全异步的。
这是我们的文件传输测试平台的第三个模型,使用了流水线技术。客户端预先发送一定数量的请求(“信用”),然后每处理一个接收到的块,就再发送一个信用。服务器发送的块永远不会超过客户端请求的数量
C | Java | Python | 贡献翻译:Ada | Basic | C++ | C# | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCaml这一微调使我们能够完全控制端到端流水线,包括发送方和接收方的所有网络缓冲区和ZeroMQ队列。我们确保流水线始终充满数据,同时永不超过预设的限制。更重要的是,客户端精确地决定何时向发送方发送“信用”。这可以在接收到块时发送,或者在完全处理完块时发送。这以异步方式发生,没有明显的性能开销。
在第三个模型中,我选择了10条消息的流水线大小(每条消息是一个块)。这将为每个客户端带来最多2.5MB的内存开销。因此,使用1GB内存,我们可以处理至少400个客户端。我们可以尝试计算理想的流水线大小。发送1GB文件大约需要0.7秒,每个块大约需要160微秒。一次往返需要300微秒,因此流水线需要至少3-5个块才能让服务器保持忙碌。实践中,当我使用5个块的流水线时仍然出现性能峰值,可能是因为信用消息有时会被传出的数据延迟。所以在10个块时,它能稳定工作。
$ time ./fileio3
4291 chunks received, 1072741824 bytes
real 0m0.777s
user 0m0.096s
sys 0m1.120s
务必严格测量。你的计算可能很准确,但现实世界往往有它自己的看法。
我们目前构建的显然还不是一个真正完善的文件传输协议,但它证明了这种模式,而且我认为这是最简单的可行设计。对于一个真正可用的协议,我们可能需要添加以下部分或全部内容
-
身份验证和访问控制,即使没有加密:重点不在于保护敏感数据,而在于捕获将测试数据发送到生产服务器等错误。
-
一种Cheap风格的请求,包括文件路径、可选压缩以及我们从HTTP中学到的其他有用内容(例如If-Modified-Since)。
-
一种Cheap风格的响应,至少对于第一个块,提供元数据,例如文件大小(这样客户端可以预分配空间,避免磁盘满的尴尬情况)。
-
一次性获取一组文件的能力,否则对于大量小文件来说,该协议效率低下。
-
客户端在完全接收文件后发送确认,以便在客户端意外断开连接时恢复可能丢失的块。
到目前为止,我们的语义是“获取”;也就是说,接收方(以某种方式)知道他们需要某个特定的文件,因此他们请求它。关于哪些文件存在以及它们在哪里这些信息是通过带外方式传递的(例如,在HTTP中,通过HTML页面中的链接)。
那“推送”语义呢?这有两种可能的用例。首先,如果我们采用中心化架构,文件存储在主“服务器”上(我并不提倡,但有些人确实喜欢这样做),那么允许客户端上传文件到服务器将非常有用。其次,它允许我们对文件进行一种发布-订阅,客户端请求某种类型的所有新文件;当服务器获取到这些文件时,就会将它们转发给客户端。
获取语义是同步的,而推送语义是异步的。异步更少通信,因此更快。此外,你还可以做一些巧妙的事情,比如“订阅此路径”,从而创建一个发布-订阅的文件传输架构。这显然非常棒,我应该不需要解释它解决了什么问题。
然而,获取语义的问题在于:那个带外通知客户端哪些文件存在的途径。无论你如何做,这都会变得复杂。客户端要么需要轮询,要么你需要一个单独的发布-订阅通道来保持客户端更新,或者你需要用户交互。
再深入思考一下,我们可以看到获取只是发布-订阅的一个特例。所以我们可以两全其美。这是通用的设计
- 获取此路径
- 这是信用(重复)
为了实现这一点(亲爱的读者们,我们会做到的),我们需要更明确地说明如何向服务器发送信用。将流水线化的“获取块”请求视为信用的巧妙技巧行不通,因为客户端不再知道实际存在哪些文件、它们有多大或其他任何信息。如果客户端说“我可以处理250,000字节的数据”,这应该对1个250K字节的文件或100个2,500字节的文件同样有效。
这为我们提供了“基于信用的流量控制”,它有效地消除了对高水位标记的需求,以及任何内存溢出的风险。
状态机 #
软件工程师倾向于将(有限)状态机视为一种中间解释器。也就是说,你获取一种正则语言,将其编译成状态机,然后执行状态机。状态机本身很少对开发者可见:它是一种内部表示——优化、压缩且怪异。
然而,事实证明,状态机作为协议处理程序(例如ZeroMQ客户端和服务器)的一流建模语言也非常有价值。ZeroMQ使得设计协议相当容易,但我们从未定义过一个编写这些客户端和服务器的良好模式。
一个协议至少有两个层次
- 我们如何在链路上表示单个消息。
- 消息如何在对等方之间流动,以及每条消息的意义。
在本章中,我们已经了解了如何生成处理序列化的编解码器。这是一个好的开始。但是,如果我们将第二项工作留给开发者,他们就会有很大的解释空间。随着我们构建更复杂的协议(文件传输+心跳+信用+身份验证),手动实现客户端和服务器变得越来越不理智。
是的,人们几乎总是这样做。但成本很高,而且这是可以避免的。我将解释如何使用状态机对协议进行建模,以及如何从这些模型生成整洁且可靠的代码。
我使用状态机作为软件构建工具的经验可以追溯到1985年,那是我第一份真正的工作,为应用程序开发者制作工具。1991年,我将这些知识转化为一个名为Libero的免费软件工具,它可以根据简单的文本模型生成可执行的状态机。
Libero模型的一个特点是它具有可读性。也就是说,你将程序逻辑描述为命名状态,每个状态接受一组事件,每个事件执行一些实际工作。生成的状态机连接到你的应用程序代码中,像老板一样驱动它。
Libero非常善于完成它的工作,精通多种语言,并且考虑到状态机的神秘性质,它适度地受到欢迎。我们在数十个大型分布式应用程序中大量使用了Libero,其中一个在运行20年后于2011年最终关闭。状态机驱动的代码构建效果如此之好,以至于令人印象深刻的是这种方法从未成为软件工程的主流。
因此,在本节中,我将解释Libero的模型,并演示如何使用它来生成ZeroMQ客户端和服务器。我们将再次使用GSL,但正如我所说,其原理是通用的,你可以使用任何脚本语言构建代码生成器。
作为一个具体的例子,让我们看看如何在ROUTER套接字上与对等方进行有状态的对话。我们将使用状态机开发服务器(客户端手动开发)。我们有一个简单的协议,我称之为“NOM”。我使用的是那个非常严肃的非协议关键词提案
nom-protocol = open-peering *use-peering
open-peering = C:OHAI ( S:OHAI-OK / S:WTF )
use-peering = C:ICANHAZ
/ S:CHEEZBURGER
/ C:HUGZ S:HUGZ-OK
/ S:HUGZ C:HUGZ-OK
我还没有找到一种快速方法来解释状态机编程的真正本质。根据我的经验,这总是需要几天的练习。接触这个概念三四天后,大脑中的某个地方会连接所有部分,发出几乎能听到的“咔嗒”声!我们将通过查看NOM服务器的状态机来使其具体化。
关于状态机的一个有用之处在于,你可以逐个状态地阅读它们。每个状态都有一个唯一的描述性名称和一个或多个 事件,我们按任意顺序列出这些事件。对于每个事件,我们执行零个或多个 动作,然后移动到 下一个状态(或停留在同一状态)。
在ZeroMQ协议服务器中,我们有 每个客户端 一个状态机实例。这听起来很复杂,但实际上并不是,稍后我们会看到。我们描述了第一个状态,Start,只有一个有效事件OHAI。我们检查用户的凭据,然后进入Authenticated状态。
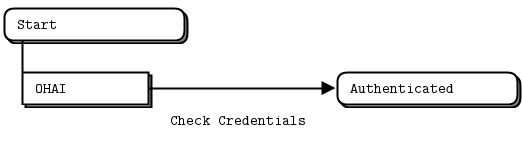
TheCheck Credentials动作产生一个ok或一个error事件。在Authenticated状态下,我们通过向客户端发送适当的回复来处理这两个可能的事件。如果身份验证失败,我们将返回到Start状态,客户端可以在此状态下再次尝试。
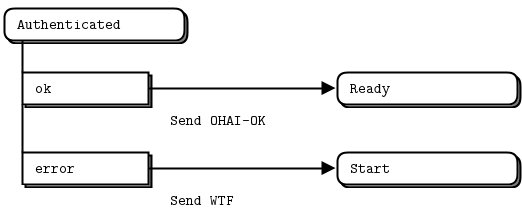
当身份验证成功时,我们进入Ready状态。这里有三种可能的事件:来自客户端的ICANHAZ或HUGZ消息,或者心跳计时器事件。

关于这个状态机模型,还有一些值得了解的事情
- 大写的事件(例如“HUGZ”)是作为消息从客户端传来的 外部事件。
- 小写的事件(例如“heartbeat”)是由服务器代码产生的 内部事件。
- “Send SOMETHING”动作是向客户端发送特定回复的简写。
- 在特定状态中未定义的事件将被静默忽略。
现在,这些漂亮图片的原始来源是一个XML模型
<class name = "nom_server" script = "server_c">
<state name = "start">
<event name = "OHAI" next = "authenticated">
<action name = "check credentials" />
</event>
</state>
<state name = "authenticated">
<event name = "ok" next = "ready">
<action name = "send" message ="OHAI-OK" />
</event>
<event name = "error" next = "start">
<action name = "send" message = "WTF" />
</event>
</state>
<state name = "ready">
<event name = "ICANHAZ">
<action name = "send" message = "CHEEZBURGER" />
</event>
<event name = "HUGZ">
<action name = "send" message = "HUGZ-OK" />
</event>
<event name = "heartbeat">
<action name = "send" message = "HUGZ" />
</event>
</state>
</class>
代码生成器在examples/models/server_c.gsl中。这是一个相当完整的工具,我以后会用于更重要的工作并加以扩展。它生成
- 一个C语言的服务器类(nom_server.c, nom_server.h)实现整个协议流程。
- 一个自测方法,运行XML文件中列出的自测步骤。
- 图形形式的文档(那些漂亮的图片)。
这是一个启动生成的NOM服务器的简单主程序
#include "czmq.h"
#include "nom_server.h"
int main (int argc, char *argv [])
{
printf ("Starting NOM protocol server on port 5670...\n");
nom_server_t *server = nom_server_new ();
nom_server_bind (server, "tcp://*:5670");
nom_server_wait (server);
nom_server_destroy (&server);
return 0;
}
生成的nom_server类是一个相当经典的模型。它在ROUTER套接字上接收客户端消息,因此每个请求的第一个帧是客户端的连接标识。服务器管理一组客户端,每个客户端都有状态。当消息到达时,它将这些消息作为 事件 馈送给状态机。这是状态机的核心部分,是GSL命令和我们打算生成的C代码的混合体
client_execute (client_t *self, int event)
{
self->next_event = event;
while (self->next_event) {
self->event = self->next_event;
self->next_event = 0;
switch (self->state) {
.for class.state
case $(name:c)_state:
. for event
. if index () > 1
else
. endif
if (self->event == $(name:c)_event) {
. for action
. if name = "send"
zmsg_addstr (self->reply, "$(message:)");
. else
$(name:c)_action (self);
. endif
. endfor
. if defined (event.next)
self->state = $(next:c)_state;
. endif
}
. endfor
break;
.endfor
}
if (zmsg_size (self->reply) > 1) {
zmsg_send (&self->reply, self->router);
self->reply = zmsg_new ();
zmsg_add (self->reply, zframe_dup (self->address));
}
}
}
每个客户端都作为一个对象持有,具有各种属性,包括表示状态机实例所需的变量
event_t next_event; // Next event
state_t state; // Current state
event_t event; // Current event
到目前为止,你会看到我们正在生成技术上完美的代码,它具有我们想要的精确设计和形状。唯一的线索表明nom_server类不是手写的,那就是代码 太好了。抱怨代码生成器生成代码质量差的人是习惯了差的代码生成器。根据需要扩展我们的模型是微不足道的。例如,我们是这样生成自测代码的。
首先,我们在状态机中添加一个“selftest”项并编写测试。我们没有使用任何XML语法或验证,所以这实际上只需要打开编辑器并添加六七行文本即可
<selftest>
<step send = "OHAI" body = "Sleepy" recv = "WTF" />
<step send = "OHAI" body = "Joe" recv = "OHAI-OK" />
<step send = "ICANHAZ" recv = "CHEEZBURGER" />
<step send = "HUGZ" recv = "HUGZ-OK" />
<step recv = "HUGZ" />
</selftest>
在构思时,我决定使用“send”和“recv”来表达“发送此请求,然后期望此回复”是个不错的选择。这是将此模型转换为实际代码的GSL代码
.for class->selftest.step
. if defined (send)
msg = zmsg_new ();
zmsg_addstr (msg, "$(send:)");
. if defined (body)
zmsg_addstr (msg, "$(body:)");
. endif
zmsg_send (&msg, dealer);
. endif
. if defined (recv)
msg = zmsg_recv (dealer);
assert (msg);
command = zmsg_popstr (msg);
assert (streq (command, "$(recv:)"));
free (command);
zmsg_destroy (&msg);
. endif
.endfor
最后,任何状态机生成器中一个更棘手但绝对必要的部分是 如何将其插入我自己的代码中? 作为本次练习的一个最小示例,我想实现“check credentials”动作,即接受我朋友Joe(你好Joe!)的所有OHAI,并拒绝其他人的OHAI。经过一番思考,我决定直接从状态机模型中获取代码,也就是说,将动作主体嵌入到XML文件中。因此,在nom_server.xml中,你会看到这个
<action name = "check credentials">
char *body = zmsg_popstr (self->request);
if (body && streq (body, "Joe"))
self->next_event = ok_event;
else
self->next_event = error_event;
free (body);
</action>
代码生成器抓取那段C代码并将其插入到生成的nom_server.cfile
.for class.action
static void
$(name:c)_action (client_t *self) {
$(string.trim (.):)
}
.endfor
文件中。并且现在我们得到了一个非常优雅的东西:一个源文件既描述了我的服务器状态机,又包含了我的动作的原生实现。这是高层和低层代码的良好结合,比C代码量减少了大约90%。
请注意,当你想到利用这种优势可以创造出所有令人惊叹的事物时,你的思绪可能会飞速旋转。虽然这种方法赋予你真正的力量,但它也会让你与同行疏远,如果你走得太远,你会发现自己孤军奋战。
顺便说一句,这个简单的状态机设计只向我们的自定义代码暴露了三个变量
- self->next_event
- self->request
- self->reply
在Libero状态机模型中,还有一些我们在这里没有使用过,但在编写更大的状态机时会需要的概念
- 异常(Exceptions),它使我们能够编写更简洁的状态机。当一个动作抛出异常时,对该事件的进一步处理就会停止。然后状态机可以定义如何处理异常事件。
- TheDefaults状态,我们可以在其中定义事件的默认处理方式(对异常事件尤其有用)。
使用SASL进行身份验证 #
当我们在 2007 年设计 AMQP 时,我们选择了简单认证和安全层(SASL)作为认证层,这是我们从BEEP 协议框架中借鉴的一个想法。SASL 初看起来很复杂,但它实际上很简单,并且非常适合基于 ZeroMQ 的协议。我特别喜欢 SASL 的地方在于它的可扩展性。你可以从匿名访问或纯文本认证和无安全性开始,随着时间的推移逐渐升级到更安全的机制,而无需更改你的协议。
我现在不会做深入解释,因为稍后我们将看到 SASL 的实际应用。但我会解释其原理,这样你就能有所准备了。
在 NOM 协议中,客户端以 OHAI 命令开始,服务器要么接受(“你好 Joe!”),要么拒绝。这很简单,但不具备可扩展性,因为服务器和客户端必须事先就认证类型达成一致。
SASL 引入的,这非常巧妙,是一个完全抽象且可协商的安全层,它在协议层面仍然易于实现。它的工作方式如下:
- 客户端连接。
- 服务器向客户端发起挑战,传递它所知的安全“机制”列表。
- 客户端选择它所知的安全机制,并用一块不透明数据回答服务器的挑战,这块数据(这里是巧妙之处)是由某个通用安全库计算并提供给客户端的。
- 服务器接收客户端选择的安全机制以及那块数据,并将其传递给自己的安全库。
- 该库要么接受客户端的回答,要么服务器再次发起挑战。
有许多免费的 SASL 库。当我们写实际代码时,我们将只实现两种机制:ANONYMOUS 和 PLAIN,它们不需要任何特殊库。
为了支持 SASL,我们必须在“开放对等”流程中添加一个可选的挑战/响应步骤。以下是修改 NOM 后所得协议语法:
secure-nom = open-peering *use-peering
open-peering = C:OHAI *( S:ORLY C:YARLY ) ( S:OHAI-OK / S:WTF )
ORLY = 1*mechanism challenge
mechanism = string
challenge = *OCTET
YARLY = mechanism response
response = *OCTET
其中 ORLY 和 YARLY 包含一个字符串(ORLY 中是机制列表,YARLY 中是单个机制)以及一块不透明数据。取决于机制,服务器的初始挑战可能是空的。我们不关心:我们只管将其传递给安全库处理。
SASL RFC 详细介绍了其他特性(我们不需要)、SASL 可能遭受的攻击类型等等。
大规模文件发布:FileMQ #
让我们将所有这些技术结合起来,构建一个文件分发系统,我称之为 FileMQ。这将是一个实际产品,位于 GitHub 上。我们在这里将构建 FileMQ 的第一个版本,作为培训工具。如果概念可行,这个实际产品最终可能会有自己的专属书籍。
为何构建 FileMQ? #
为什么要构建一个文件分发系统?我之前已经解释了如何通过 ZeroMQ 发送大文件,这确实非常简单。但是如果你想让消息传输触达比使用 ZeroMQ 的人多一百万倍的用户,你需要另一种 API。一种我五岁的儿子都能理解的 API。一种通用的、无需编程的、几乎与所有应用程序都能工作的 API。
是的,我指的是文件系统。这就是 DropBox 模式:把你的文件扔到某个地方,网络连接后它们就会神奇地复制到另一个地方。
然而,我追求的是一种更像 git 的完全去中心化架构,不需要任何云服务(尽管我们可以将 FileMQ 放在云上),并且支持多播,也就是说,可以将文件同时发送到多个地方。
FileMQ 必须是安全(可保证安全)的,易于接入各种脚本语言,并在我们的家庭和办公网络上尽可能快。
我想用它通过 WiFi 将手机里的照片备份到笔记本电脑上。在会议中向 50 台笔记本电脑实时共享演示文稿幻灯片。在会议中与同事共享文档。将地震数据从传感器发送到中心集群。在抗议或骚乱期间,边拍摄边将手机里的视频备份。同步 Linux 服务器云集群的配置文件。
这是个有远见的想法,不是吗?嗯,想法不值钱。难的是实现它,并且要把它做得简单。
初步设计方案:API #
这是我对第一个设计的看法。FileMQ 必须是分布式的,这意味着每个节点都可以同时是服务器和客户端。但我不想让协议是对称的,因为那样显得勉强。我们有一个文件从 A 点流向 B 点的自然流向,其中 A 是“服务器”,B 是“客户端”。如果文件反方向流动,那么我们就有了两个流。FileMQ 还不是一个目录同步协议,但我们会让它非常接近。
因此,我打算将 FileMQ 构建为两部分:客户端和服务器。然后,我将它们组合在一个主应用程序(即filemq工具)中,它可以同时充当客户端和服务器。这两部分看起来会非常类似于nom_server,具有相同的 API。
fmq_server_t *server = fmq_server_new ();
fmq_server_bind (server, "tcp://*:5670");
fmq_server_publish (server, "/home/ph/filemq/share", "/public");
fmq_server_publish (server, "/home/ph/photos/stream", "/photostream");
fmq_client_t *client = fmq_client_new ();
fmq_client_connect (client, "tcp://pieter.filemq.org:5670");
fmq_client_subscribe (server, "/public/", "/home/ph/filemq/share");
fmq_client_subscribe (server, "/photostream/", "/home/ph/photos/stream");
while (!zctx_interrupted)
sleep (1);
fmq_server_destroy (&server);
fmq_client_destroy (&client);
如果我们用其他语言封装这个 C API,我们可以轻松地编写 FileMQ 脚本,将其嵌入应用程序,移植到智能手机等等。
初步设计方案:协议 #
该协议的全称是“文件消息队列协议”(File Message Queuing Protocol),或大写的 FILEMQ,以便与软件区分。首先,我们用 ABNF 语法写下协议。我们的语法从客户端和服务器之间的命令流开始。你应该能认出这些是我们之前看过的各种技术的组合:
filemq-protocol = open-peering *use-peering [ close-peering ]
open-peering = C:OHAI *( S:ORLY C:YARLY ) ( S:OHAI-OK / error )
use-peering = C:ICANHAZ ( S:ICANHAZ-OK / error )
/ C:NOM
/ S:CHEEZBURGER
/ C:HUGZ S:HUGZ-OK
/ S:HUGZ C:HUGZ-OK
close-peering = C:KTHXBAI / S:KTHXBAI
error = S:SRSLY / S:RTFM
以下是发往服务器和来自服务器的命令:
; The client opens peering to the server
OHAI = signature %x01 protocol version
signature = %xAA %xA3
protocol = string ; Must be "FILEMQ"
string = size *VCHAR
size = OCTET
version = %x01
; The server challenges the client using the SASL model
ORLY = signature %x02 mechanisms challenge
mechanisms = size 1*mechanism
mechanism = string
challenge = *OCTET ; ZeroMQ frame
; The client responds with SASL authentication information
YARLY = %signature x03 mechanism response
response = *OCTET ; ZeroMQ frame
; The server grants the client access
OHAI-OK = signature %x04
; The client subscribes to a virtual path
ICANHAZ = signature %x05 path options cache
path = string ; Full path or path prefix
options = dictionary
dictionary = size *key-value
key-value = string ; Formatted as name=value
cache = dictionary ; File SHA-1 signatures
; The server confirms the subscription
ICANHAZ-OK = signature %x06
; The client sends credit to the server
NOM = signature %x07 credit
credit = 8OCTET ; 64-bit integer, network order
sequence = 8OCTET ; 64-bit integer, network order
; The server sends a chunk of file data
CHEEZBURGER = signature %x08 sequence operation filename
offset headers chunk
sequence = 8OCTET ; 64-bit integer, network order
operation = OCTET
filename = string
offset = 8OCTET ; 64-bit integer, network order
headers = dictionary
chunk = FRAME
; Client or server sends a heartbeat
HUGZ = signature %x09
; Client or server responds to a heartbeat
HUGZ-OK = signature %x0A
; Client closes the peering
KTHXBAI = signature %x0B
以下是服务器告知客户端出现问题的方式:
; Server error reply - refused due to access rights
S:SRSLY = signature %x80 reason
; Server error reply - client sent an invalid command
S:RTFM = signature %x81 reason
FILEMQ 位于 ZeroMQ 非协议网站上,并在 IANA(互联网号码分配局)注册了一个 TCP 端口,即端口 5670。
构建和尝试 FileMQ #
FileMQ 栈位于 GitHub 上。它像一个经典的 C/C++ 项目一样工作:
git clone git://github.com/zeromq/filemq.git
cd filemq
./autogen.sh
./configure
make check
你应该使用最新的 CZMQ master 分支。现在尝试运行track命令,它是一个简单的工具,使用 FileMQ 来跟踪一个目录到另一个目录的变化:
cd src
./track ./fmqroot/send ./fmqroot/recv
并打开两个文件浏览器窗口,一个进入src/fmqroot/send另一个进入src/fmqroot/recv。将文件拖放到 send 文件夹中,你就会看到它们出现在 recv 文件夹中。服务器每秒检查一次新文件。删除 send 文件夹中的文件,它们也会在 recv 文件夹中被相应删除。
我使用 track 来做一些事情,比如更新挂载为 USB 驱动器的 MP3 播放器。当我在笔记本电脑的 Music 文件夹中添加或删除文件时,MP3 播放器上也会发生相同的变化。FILEMQ 还没成为一个完整的复制协议,但我们稍后会解决这个问题。
内部架构 #
为了构建 FileMQ,我使用了大量的代码生成,对于教程来说可能有点多。然而,这些代码生成器都可以在其他栈中重用,并且对于我们在第八章《分布式计算框架》中的最终项目来说非常重要。它们是我们之前看到的那组生成器的演进:
- codec_c.gslcodec_c.gsl:为给定协议生成消息编解码器。
- server_c.gslserver_c.gsl:为协议和状态机生成服务器类。
- client_c.gslclient_c.gsl:为协议和状态机生成客户端类。
学习使用 GSL 代码生成的最好方法是将这些翻译成你选择的语言,并创建自己的演示协议和栈。你会发现这相当容易。FileMQ 本身不试图支持多种语言。它可以,但这会使其变得不必要的复杂。
FileMQ 的架构实际上分为两层。有一组通用类用于处理块、目录、文件、补丁、SASL 安全和配置文件。然后是生成的栈:消息、客户端和服务器。如果我要创建一个新项目,我会 fork 整个 FileMQ 项目,然后去修改这三个模型:
- fmq_msg.xmlfmq_msg.xml:定义消息格式
- fmq_client.xmlfmq_client.xml:定义客户端状态机、API 和实现。
- fmq_server.xmlfmq_server.xml:对服务器做同样的事情。
你会想重命名一些东西以避免混淆。我为什么没有把这些可重用类做成一个单独的库?答案有两个方面。第一,目前(还没)没有人真正需要这个。第二,当你构建和使用 FileMQ 时,这会让你更复杂。为了解决理论问题而增加复杂性永远不值得。
虽然我是用 C 语言写的 FileMQ,但它很容易映射到其他语言。当你加入 CZMQ 通用的 zlist 和 zhash 容器以及类风格时,C 语言会变得多么美妙,这真是令人惊叹。让我快速介绍一下这些类:
-
fmq_saslfmq_sasl:编码和解码 SASL 挑战。我只实现了 PLAIN 机制,这足以证明概念。
-
fmq_chunkfmq_chunk:处理变长的数据块。不如 ZeroMQ 的消息高效,但它们带来的怪异行为较少,因此更容易理解。chunk 类有从磁盘读写数据块的方法。
-
fmq_filefmq_file:处理文件,这些文件可能存在也可能不存在于磁盘上。提供文件的信息(如大小),允许读写、删除文件,检查文件是否存在,以及检查文件是否“稳定”(稍后详细介绍)。
-
fmq_dirfmq_dir:处理目录,从磁盘读取并比较两个目录以查看哪些发生了变化。当有变化时,返回一个“补丁”列表。
-
fmq_patchfmq_patch:处理一个补丁,它实际上只是说“创建这个文件”或“删除这个文件”(每次都引用一个 fmq_file 项)。
-
fmq_configfmq_config:处理配置数据。稍后我会回过头来介绍客户端和服务器配置。
每个类都有一个测试方法,主要开发周期是“编辑、测试”。这些大多是简单的自测,但它们区分了我可以信任的代码和我知道仍然会出错的代码。可以肯定地说,任何没有测试用例覆盖的代码都会存在未被发现的错误。我不太喜欢外部测试工具。但是你在编写功能时编写的内部测试代码……那就像刀柄一样。
你应该能够真正地阅读源代码并快速理解这些类在做什么。如果你阅读代码时感到不顺畅,请告诉我。如果你想将 FileMQ 实现移植到其他语言,请先 fork 整个仓库,稍后我们将看看是否可以在一个总的仓库中完成这项工作。
公共 API #
公共 API 由两个类组成(如我们之前概述的):
-
fmq_clientfmq_client:提供客户端 API,包含连接服务器、配置客户端和订阅路径的方法。
-
fmq_serverfmq_server:提供服务器 API,包含绑定端口、配置服务器和发布路径的方法。
这些类提供了一个多线程 API,这是我们现在已经使用过几次的模型。当你创建一个 API 实例时(即,fmq_server_new()或fmq_client_new()),此方法启动一个后台线程来执行实际工作,即运行服务器或客户端。其他 API 方法随后通过 ZeroMQ 套接字(一个由两个基于 inproc:// 的 PAIR 套接字组成的 pipe)与此线程通信。
如果我是一个热衷于在其他语言中使用 FileMQ 的年轻开发者,我可能会愉快地花一个周末为此公共 API 编写一个绑定,然后将其放在 filemq 项目的一个子目录中,比如叫作bindings/,并提交一个 pull request。
实际的 API 方法来自状态机描述,就像这样(针对服务器):
<method name = "publish">
<argument name = "location" type = "string" />
<argument name = "alias" type = "string" />
mount_t *mount = mount_new (location, alias);
zlist_append (self->mounts, mount);
</method>
它被转化为以下代码:
void
fmq_server_publish (fmq_server_t *self, char *location, char *alias)
{
assert (self);
assert (location);
assert (alias);
zstr_sendm (self->pipe, "PUBLISH");
zstr_sendfm (self->pipe, "%s", location);
zstr_sendf (self->pipe, "%s", alias);
}
设计说明 #
构建 FileMQ 最困难的部分不是实现协议,而是在内部维护准确的状态。FTP 或 HTTP 服务器本质上是无状态的。但发布/订阅服务器至少必须维护订阅。
因此我将介绍一些设计方面的内容:
-
客户端通过服务器没有发送心跳(HUGZ)来检测服务器是否已死。然后它通过发送一个OHAI来重新开始对话。在OHAIOHAIOHAI上没有超时,因为 ZeroMQ DEALER 套接字会无限期地将传出消息排队。
-
如果客户端停止回复服务器发送的心跳(HUGZ-OK),服务器就会认为客户端已死,并删除客户端的所有状态,包括其订阅。HUGZ-OKHUGZ-OK
-
客户端 API 将订阅保存在内存中,并在成功连接后重新发送。这意味着调用者可以随时订阅(并且不关心连接和认证何时真正发生)。
-
服务器和客户端使用虚拟路径,很像 HTTP 或 FTP 服务器。你发布一个或多个挂载点,每个挂载点对应服务器上的一个目录。每个挂载点映射到一个虚拟路径,例如如果你只有一个挂载点,可以映射到“/”。然后客户端订阅虚拟路径,文件将到达一个收件箱目录。我们不在网络上传输物理文件名。
-
存在一些时序问题:如果服务器在客户端连接和订阅时创建挂载点,订阅将不会附加到正确的挂载点上。所以,我们最后绑定服务器端口。
-
客户端可以随时重新连接;如果客户端发送 OHAI,这标志着之前所有对话的结束和新对话的开始。也许有一天我会让服务器上的订阅持久化,这样它们就能在断开连接后继续存在。客户端栈在重新连接后,会重新发送调用应用程序已做的所有订阅。OHAIOHAI
配置 #
我构建过几个大型服务器产品,比如 90 年代后期流行的 Xitami Web 服务器,以及 OpenAMQ 消息服务器。让配置变得简单明了是让这些服务器用起来有趣的重要部分。
我们通常旨在解决以下一些问题:
- 随产品附带默认配置文件。
- 允许用户添加永不被覆盖的自定义配置文件。
- 允许用户从命令行配置。
然后将它们层叠起来,命令行设置会覆盖自定义设置,自定义设置会覆盖默认设置。要做好这件事可能需要很多工作。对于 FileMQ,我采用了稍微简单一点的方法:所有配置都通过 API 完成。
例如,我们这样启动和配置服务器:
server = fmq_server_new ();
fmq_server_configure (server, "server_test.cfg");
fmq_server_publish (server, "./fmqroot/send", "/");
fmq_server_publish (server, "./fmqroot/logs", "/logs");
fmq_server_bind (server, "tcp://*:5670");
我们确实使用了特定格式的配置文件,即 ZPL,这是一种极简语法,几年前我们开始用于 ZeroMQ 的“设备”,但它对任何服务器都适用:
# Configure server for plain access
#
server
monitor = 1 # Check mount points
heartbeat = 1 # Heartbeat to clients
publish
location = ./fmqroot/logs
virtual = /logs
security
echo = I: use guest/guest to login to server
# These are SASL mechanisms we accept
anonymous = 0
plain = 1
account
login = guest
password = guest
group = guest
account
login = super
password = secret
group = admin
生成的服务端代码做的一件巧妙的事情(看起来很有用)是解析这个 ZPL 配置文件(当你使用fmq_server_configure()方法时)并执行与 API 方法匹配的任何节。因此,publish节会像一个fmq_server_publish()方法一样工作。
文件稳定性 #
轮询目录以检测变化,然后对新文件做一些“有趣”的事情,这很常见。但是当一个进程正在写入文件时,其他进程不知道文件何时完全写入。一个解决方案是添加第二个“指示”文件,我们在创建第一个文件后创建它。然而,这具有侵入性。
有一个更巧妙的方法,就是检测文件何时“稳定”,即不再有人写入它。FileMQ 通过检查文件的修改时间来做到这一点。如果文件的修改时间超过一秒,那么该文件就被认为是稳定的,至少稳定到足以发送给客户端。如果一个进程在五分钟后进来并向文件追加内容,它将再次被发送出去。
为了使这工作,这也是任何希望成功使用 FileMQ 的应用程序的要求,在写入之前不要在内存中缓冲超过一秒的数据量。如果你使用非常大的块大小,文件可能在不稳定时看起来是稳定的。
送达通知 #
我们正在使用的多线程 API 模型的一个好处是,它本质上是基于消息的。这使得它非常适合将事件返回给调用者。更传统的 API 方法是使用回调。但是跨越线程边界的回调有些微妙。以下是客户端在接收到完整文件时发送消息回来的方式:
zstr_sendm (self->pipe, "DELIVER");
zstr_sendm (self->pipe, filename);
zstr_sendf (self->pipe, "%s/%s", inbox, filename);
我们现在可以在 API 中添加一个 _recv() 方法,该方法等待从客户端返回的事件。这为调用者提供了一个干净的风格:创建客户端对象,配置它,然后接收和处理它返回的任何事件。
符号链接 #
虽然使用暂存区域是一种很好的、简单的 API,但它也为发送者带来了成本。如果我的相机上已经有一个 2GB 的视频文件,并且想通过 FileMQ 发送它,当前的实现要求我在发送给订阅者之前将其复制到暂存区域。
一种选择是挂载整个内容目录(例如,/home/me/Movies),但这很脆弱,因为它意味着应用程序不能决定发送单个文件。要么全部,要么没有。
一个简单的答案是实现可移植的符号链接。正如维基百科解释的那样:“符号链接包含一个文本字符串,操作系统会自动将其解释并作为指向另一个文件或目录的路径进行跟随。这个其他文件或目录称为目标。符号链接是独立于其目标而存在的第二个文件。如果删除符号链接,其目标不受影响。”
这不会以任何方式影响协议;这是服务器实现中的一项优化。让我们做一个简单的可移植实现:
- 符号链接由一个带有扩展名.ln.
- 的文件组成。不带.ln.ln
- 的文件名是发布的文件名。
链接文件包含一行文本,即文件的真实路径。因为我们将所有文件操作都收集在一个类中(fmq_filefmq_file
),这是一个干净利落的改变。当我们创建一个新的文件对象时,我们会检查它是否是符号链接,然后所有只读操作(获取文件大小、读取文件)都作用于目标文件,而不是链接。
恢复和迟加入者 #
就目前而言,FileMQ 还有一个主要问题:它没有提供客户端从故障中恢复的方法。场景是一个连接到服务器的客户端开始接收文件,然后由于某种原因断开连接。网络可能太慢,或者中断。客户端可能在一台被关闭后又恢复的笔记本电脑上。WiFi 可能断开连接。随着我们进入更移动的世界(参见第八章《分布式计算框架》),这种用例变得越来越常见。在某些方面,它正在成为主要的用例。
在经典的 ZeroMQ 发布/订阅模式中,有两个强有力的潜在假设,这两者在 FileMQ 的实际世界中通常是错误的。第一,数据过期非常快,因此没有兴趣请求旧数据。第二,网络稳定且很少中断(因此最好多投资改善基础设施,少投入处理恢复)。
看看 FileMQ 的任何用例,你会发现如果客户端断开连接然后重新连接,它应该获取所有错过的东西。进一步的改进是能从部分故障中恢复,就像 HTTP 和 FTP 那样。但一次只做一件事。
恢复的一个答案是“持久订阅”,FILEMQ 协议的初稿旨在支持这一点,服务器可以保留和存储客户端标识符。这样如果客户端在故障后重新出现,服务器就会知道它没有收到哪些文件。
然而,有状态的服务器很难构建,也很难扩展。例如,我们如何进行故障转移到备用服务器?它从哪里获取订阅?如果每个客户端连接独立工作并携带所有必要状态,那会好得多。
持久订阅的另一个致命弱点是它需要预先协调。预先协调总是一个危险信号,无论是在一个团队协作中,还是一群进程相互通信时。迟加入者怎么办?在现实世界中,客户端不会整齐地排队然后同时说“准备好了!”。在现实世界中,它们随意来来去去,如果我们能够像对待一个离开又回来的客户端一样对待一个全新客户端,那将非常有价值。为了解决这个问题,我将在协议中增加两个概念:一个 resynchronization 选项和一个cache为了解决这个问题,我将在协议中增加两个概念:一个 resynchronization 选项和一个字段(一个字典)。如果客户端需要恢复,它会设置 resynchronization 选项,并通过 cache 字段告诉服务器它已经有哪些文件。我们需要这两个字段,因为协议中无法区分空字段和 null 字段。FILEMQ RFC 对这些字段的描述如下:
Theoptionsoptions 字段为服务器提供附加信息。服务器 SHOULD 实现这些选项:RESYNC=1 - 如果客户端设置此项,服务器 SHALL 将虚拟路径的全部内容发送给客户端,但排除客户端已有的文件,这些文件由其在 cache 字段中的 SHA-1 摘要标识。cache为了解决这个问题,我将在协议中增加两个概念:一个 resynchronization 选项和一个cache
以及
当客户端指定RESYNC选项时,为了解决这个问题,我将在协议中增加两个概念:一个 resynchronization 选项和一个cache为了解决这个问题,我将在协议中增加两个概念:一个 resynchronization 选项和一个字典字段告诉服务器客户端已经有哪些文件。cache 字典中的每个条目都是一个“文件名=摘要”的键/值对,其中摘要 SHALL 是可打印十六进制格式的 SHA-1 摘要。如果文件名以“/”开头,则 SHOULD 以路径开头,否则服务器 MUST 忽略它。如果文件名不以“/”开头,则服务器 SHALL 将其视为相对于路径的。
知道自己处于经典发布/订阅用例中的客户端不会提供任何缓存数据,而需要恢复的客户端则会提供其缓存数据。它不需要服务器端的任何状态,无需预先协调,并且对于全新客户端(它们可能通过某些带外方式接收了文件)以及接收了部分文件后断开连接一段时间的客户端都同样有效。
我决定使用 SHA-1 摘要有几个原因。首先,它足够快:在我的笔记本电脑上,处理一个 25MB 的 core dump 需要 150 毫秒。其次,它可靠:对于同一文件的不同版本,获得相同哈希的概率非常接近于零。第三,它是支持最广泛的摘要算法。循环冗余校验(例如 CRC-32)更快但不稳定。更新的 SHA 版本(SHA-256, SHA-512)更安全,但需要多 50% 的 CPU 周期,对于我们的需求来说是性能过剩。
以下是一个典型的 ICANHAZ 消息在使用缓存和重同步时的样子(这是生成的编解码器类的 dump 方法的输出):dumpcodec class
ICANHAZ:
path='/photos'
options={
RESYNC=1
}
cache={
DSCF0001.jpg=1FABCD4259140ACA99E991E7ADD2034AC57D341D
DSCF0006.jpg=01267C7641C5A22F2F4B0174FFB0C94DC59866F6
DSCF0005.jpg=698E88C05B5C280E75C055444227FEA6FB60E564
DSCF0004.jpg=F0149101DD6FEC13238E6FD9CA2F2AC62829CBD0
DSCF0003.jpg=4A49F25E2030B60134F109ABD0AD9642C8577441
DSCF0002.jpg=F84E4D69D854D4BF94B5873132F9892C8B5FA94E
}
虽然我们没有在 FileMQ 中实现这一点,但服务器可以使用缓存信息来帮助客户端追赶它错过的删除操作。要做到这一点,它必须记录删除操作,然后在客户端订阅时将此日志与客户端缓存进行比较。
测试用例:Track 工具 #
为了正确测试 FileMQ 这样的东西,我们需要一个能处理实时数据的测试用例。我的一个系统管理任务是管理我的音乐播放器上的 MP3 曲目,顺便说一下,它是一个刷了 Rock Box 固件的 Sansa Clip,我强烈推荐。当我将曲目下载到我的 Music 文件夹时,我想将它们复制到我的播放器,当找到让我烦恼的曲目时,我在 Music 文件夹中删除它们,并希望它们也从我的播放器中消失。
对于一个强大的文件分发协议来说,这有点大材小用。我可以用 bash 或 Perl 脚本来写这个,但老实说,FileMQ 中最难的工作是目录比较代码,我想从中获益。所以我写了一个简单的工具,叫作tracktrack
./track /home/ph/Music /media/3230-6364/MUSIC
,它调用 FileMQ API。从命令行运行它需要两个参数:发送目录和接收目录:
#include "czmq.h"
#include "../include/fmq.h"
int main (int argc, char *argv [])
{
fmq_server_t *server = fmq_server_new ();
fmq_server_configure (server, "anonymous.cfg");
fmq_server_publish (server, argv [1], "/");
fmq_server_set_anonymous (server, true);
fmq_server_bind (server, "tcp://*:5670");
fmq_client_t *client = fmq_client_new ();
fmq_client_connect (client, "tcp://:5670");
fmq_client_set_inbox (client, argv [2]);
fmq_client_set_resync (client, true);
fmq_client_subscribe (client, "/");
while (true) {
// Get message from fmq_client API
zmsg_t *msg = fmq_client_recv (client);
if (!msg)
break; // Interrupted
char *command = zmsg_popstr (msg);
if (streq (command, "DELIVER")) {
char *filename = zmsg_popstr (msg);
char *fullname = zmsg_popstr (msg);
printf ("I: received %s (%s)\n", filename, fullname);
free (filename);
free (fullname);
}
free (command);
zmsg_destroy (&msg);
}
fmq_server_destroy (&server);
fmq_client_destroy (&client);
return 0;
}
这段代码是如何使用 FileMQ API 进行本地文件分发的绝佳示例。以下是完整的程序,不含许可证文本(它是 MIT/X11 许可的):请注意我们在这个 track 工具中如何使用物理路径。服务器发布物理路径/home/ph/Music/并将其映射到虚拟路径//。客户端订阅/并接收所有文件到/media/3230-6364/MUSIC
。我可以使用服务器目录中的任何结构,它都会忠实地复制到客户端的收件箱。注意 API 方法
fmq_client_set_resync()
,它会触发服务器到客户端的同步。
获取官方端口号 #
-
我们在 FILEMQ 的示例中一直使用端口 5670。与本书之前所有示例不同,这个端口并非任意指定,而是由互联网号码分配局(IANA)分配的,该机构“负责 DNS 根、IP 地址和其他互联网协议资源的全球协调”。
-
我将非常简要地解释何时以及如何为你的应用协议请求注册端口号。主要原因是确保你的应用程序可以在实际环境中运行而不会与其他协议冲突。技术上,如果你发布的任何软件使用了 1024 到 49151 之间的端口号,你应该只使用 IANA 注册的端口号。然而,许多产品并不在意这一点,而是倾向于将 IANA 列表作为“要避免使用的端口”。
-
如果你打算创建一个有一定重要性的公共协议,例如 FILEMQ,你会希望获得一个 IANA 注册的端口。我将简要解释如何做到这一点:
-
清晰地记录你的协议,因为 IANA 需要一份说明你打算如何使用该端口的规范。它不必是完全成形的协议规范,但必须足够扎实以通过专家评审。
决定你想要的传输协议:UDP、TCP、SCTP 等等。使用 ZeroMQ,你通常只需要 TCP。