第 8 章 - 分布式计算框架 #
我们已经深入了解了 ZeroMQ 的方方面面。现在你可能已经开始使用我解释过的技术以及你自己琢磨出来的方法来构建自己的产品了。你会开始面对如何在现实世界中让这些产品正常工作的问题。
但那个“现实世界”是什么呢?我会说它正成为一个拥有越来越多“运动部件”(moving pieces)的世界。有些人用“物联网”(Internet of Things)这个词,认为我们将看到一类新的设备,它们数量更多,但比我们现在的智能手机、平板电脑、笔记本电脑和服务器更“愚蠢”。然而,我根本不认为数据指向这个方向。是的,设备越来越多,但它们一点也不愚蠢。它们很智能,功能强大,并且一直在变得越来越强大。
其中的机制我称之为“成本引力”(Cost Gravity),它使得技术的成本每 18-24 个月减半。换句话说,我们全球的计算能力每两年翻一番,周而复始。未来充满了数万亿个设备,它们都是功能强大的多核计算机:它们运行的不是精简的“物联网操作系统”,而是完整的操作系统和完整的应用程序。
而这正是 ZeroMQ 的目标世界。当我们谈论“规模”时,我们指的不是几百台计算机,甚至不是几千台。想想围绕每个人、充满每个空间、覆盖每面墙壁、填满裂缝,最终成为我们如此一部分的微小、智能、甚至可能自我复制的机器云,我们出生前就拥有它们,它们伴随我们直到死亡。
这些微小的机器云通过短距离无线链路,使用 Internet 协议,时刻相互通信。它们创建 Mesh 网络,像神经信号一样传递信息和任务。它们增强我们的记忆、视觉、通信的各个方面以及身体功能。正是 ZeroMQ 为它们的对话、事件、工作和信息交换提供了动力。
现在,即使是为了让这一切在今天实现一个微薄的模仿,我们也需要解决一系列技术问题。其中包括:对等体如何发现彼此?它们如何与现有的网络(如 Web)通信?它们如何保护所携带的信息?我们如何跟踪和监控它们,以便了解它们在做什么?然后,我们需要做大多数工程师忘记的事情:将这个解决方案打包成一个框架,让普通开发者能够轻松使用。
这就是我们在本章中要尝试的:构建一个分布式应用的框架,包括 API、协议和实现。这不是一个小的挑战,但我经常声称 ZeroMQ 使这类问题变得简单,所以让我们看看这是否仍然是真的。
我们将涵盖
- 分布式计算的需求
- WiFi 在近距离网络中的优缺点
- 使用 UDP 和 TCP 进行发现
- 一个基于消息的 API
- 创建一个新的开源项目
- 对等连接(和谐模式)
- 跟踪对等体的存在和消失
- 无需中心协调的组消息
- 大规模测试和模拟
- 处理高水位标记和阻塞的对等体
- 分布式日志和监控
为现实世界设计 #
无论是通过 WiFi 连接房间里的移动设备,还是通过模拟以太网连接虚拟机集群,我们都会遇到同样的问题。这些问题是:
-
发现:我们如何了解网络上的其他节点?我们使用发现服务、集中中介,还是某种广播信标?
-
存在:我们如何跟踪其他节点何时出现和消失?我们使用某种中央注册服务,还是心跳或信标?
-
连接:我们如何实际连接一个节点到另一个节点?我们使用本地网络、广域网络,还是使用中央消息代理进行转发?
-
点对点消息:我们如何从一个节点向另一个节点发送消息?我们发送到节点的网络地址,还是通过集中式消息代理进行间接寻址?
-
组消息:我们如何从一个节点向一组其他节点发送消息?我们通过集中式消息代理工作,还是使用 ZeroMQ 这样的发布-订阅模型?
-
测试和模拟:我们如何模拟大量节点以便正确测试性能?我们必须购买二三十台 Android 平板电脑,还是可以使用纯软件模拟?
-
分布式日志:我们如何跟踪这朵节点云正在做什么,以便检测性能问题和故障?我们创建一个主日志服务,还是允许每个设备记录周围的世界?
-
内容分发:我们如何从一个节点向另一个节点发送内容?我们使用 FTP 或 HTTP 等服务器中心协议,还是使用 FileMQ 等去中心化协议?
如果我们能合理地解决这些问题,以及将来会出现的更多问题(如安全和广域桥接),我们就能得到一个框架,我称之为“非常酷的分布式应用”,或者我的孙子们称之为“我们世界运行的软件”。
你应该从我的反问句中猜到,我们有两个大的方向可以走。一个是将一切集中化。另一个是将一切去中心化。我将押注于去中心化。如果你想要集中化,你并不真的需要 ZeroMQ;你可以使用其他选择。
所以大致来说,故事是这样的。第一,运动部件的数量随时间呈指数级增长(每 24 个月翻一番)。第二,这些部件停止使用电线,因为到处拖拽电缆变得非常无聊。第三,未来的应用程序通过这些部件的集群运行,使用第 6 章 - ZeroMQ 社区中的“仁慈暴君”模式。第四,今天构建这样的应用程序确实非常困难,甚至可以说仍然相当不可能。第五,让我们利用我们已经构建的所有技术和工具,使其变得便宜且容易。第六,狂欢吧!
WiFi 的秘密生活 #
未来显然是无线的,尽管许多大企业通过将其数据集中在云中来生存,但未来看起来并不那么中心化。我们网络边缘的设备每年都在变得越来越智能,而不是越来越愚蠢。它们渴望工作和信息来消化和从中获利。它们不拖拽电缆,除了晚上充电一次。一切都是无线的,而且越来越多地是不同字母口味的 802.11 品牌 WiFi。
为什么 Mesh 网络尚未普及 #
作为我们未来如此重要的一部分,WiFi 有一个不常被讨论,但任何押注于它的人都需要意识到的巨大问题。世界上各地的电话公司几乎在每个功能正常的政府国家都建立起了盈利丰厚的移动电话卡特尔,它们说服政府,如果没有对电波和思想的垄断权,世界就会崩溃。从技术上讲,我们称之为“监管俘虏”和“专利”,但实际上这只是一种勒索和腐败。如果你,国家,给我,一个企业,过度收费、征税市场、禁止所有真正竞争对手的权利,我给你 5%。不够?10% 怎么样?好吧,15% 加零食。如果你拒绝,我们就撤销服务。
但是 WiFi 绕过了这一点,借用了未授权的空域,并搭载在开放、无专利且非常创新的 Internet 协议栈上。所以今天,我们面临一个奇怪的局面:如果我使用我们几十年补贴的国家支持的基础设施,从首尔打到布鲁塞尔每分钟要花几欧元,但如果我能找到一个不受监管的 WiFi 接入点,就完全免费。哦,而且我可以进行视频通话、发送文件和照片、下载完整的家庭电影,所有这些都以惊人的价格零点零零(任何货币都可以)实现。天啊,如果我尝试使用我实际付费的服务发送一张照片回家。那费用会比我拍照用的相机还贵。
这是我们长期容忍“相信我们,我们是专家”的专利系统所付出的代价。但这不仅仅如此,对于科技行业的某些部分——特别是拥有反互联网 GSM、GPRS、3G 和 LTE 协议栈专利的芯片制造商,他们将电信公司视为主要客户——这是一个巨大的经济激励,促使他们积极地限制 WiFi 的发展。当然,正是这些公司充斥着定义 WiFi 的 IEEE 委员会。
我之所以对律师驱动的“创新”进行抨击,是为了引导你的思维朝着“如果 WiFi 真的免费会怎样?”这个方向思考。这总有一天会发生,而且不会太远,值得押注。我们会看到几件事情发生。首先,对空域进行更积极的使用,特别是对于没有干扰风险的近距离通信。其次,随着我们学会并行使用更多空域,容量将大大提升。第三,标准化进程将加速。最后,设备将更广泛地支持真正有趣的连接。
现在,将电影从手机流式传输到电视被认为是“前沿”技术。这很荒谬。让我们变得真正有雄心。比如在一个体育场里,人们一边观看比赛,一边实时分享照片和高清视频,创建一个临时活动,字面上用数字狂热填满整个空域。我应该能在一个小时内从周围的人那里收集到数 TB 的图像。为什么这必须通过 Twitter 或 Facebook,通过那微小昂贵的移动数据连接?一个家里有几百个设备,它们都能通过 Mesh 网络相互通信,这样当有人按门铃时,门廊灯可以把视频流式传输到你的手机或电视上?一辆车可以和你的手机通信,播放你的 dubstep 播放列表,而且无需你插线。
更严肃地说,为什么我们的数字社会掌握在中央机构手中,它们被监控、审查、记录、用来追踪我们和谁说话、收集不利于我们的证据,然后当当局决定我们有太多言论自由时就被关闭?我们正在经历的隐私丧失只有在单向时才成为问题,但那样问题就变得灾难性。一个真正的无线世界将绕过所有中央审查。这正是互联网最初的设计方式,而且技术上是完全可行的(这是最棒的可行性)。
一些物理学 #
分布式软件的幼稚开发者把网络视为无限快且完全可靠。虽然这对于简单的以太网应用来说大致是正确的,但 WiFi 很快就证明了魔法思维与科学之间的区别。也就是说,WiFi 在压力下如此容易和剧烈地崩溃,有时我会怀疑为什么会有人敢用它来处理真正的工作。随着 WiFi 的改进,上限会提高,但速度永远不够快,无法阻止我们触及它。
要理解 WiFi 的技术性能,你需要理解一个基本的物理定律:连接两点所需的功率随着距离的平方而增加。像我在达拉斯学到的那样,住在更大房子里的人声音会指数级增大。对于 WiFi 网络来说,这意味着当两个无线电距离越远,它们要么使用更多的功率,要么降低信号速率。
一块电池能提供的功率是有限的,超出这个限度用户就会认为设备完全坏了。因此,即使 WiFi 网络额定速度为某个数值,接入点(AP)和客户端之间的实际比特率取决于它们之间的距离。当你把支持 WiFi 的手机从 AP 移开时,试图相互通信的两个无线电会先增加功率,然后降低比特率。
这种影响产生了一些后果,如果我们想构建健壮的分布式应用程序,而不是像木偶一样拖着电线,我们就应该意识到这些后果:
-
如果你有一组设备与 AP 通信,当 AP 与最慢的设备通信时,整个网络都必须等待。这就像在聚会上不得不向那个没有幽默感、仍然完全清醒且对语言掌握不好的指定司机重复一个笑话一样。
-
如果你使用单播 TCP 并向多个设备发送消息,AP 必须单独向每个设备发送数据包。是的,你知道这一点,以太网也是这样工作的。但现在要理解的是,一个遥远(或低功耗)的设备意味着一切都在等待那个最慢的设备跟上。
-
如果你使用组播或广播(在大多数情况下,它们的工作方式相同),AP 会一次性向整个网络发送单个数据包,这很棒,但它会以可能的最低比特率(通常是 1Mbps)发送。你可以在某些 AP 中手动调整这个速率。那只会减小你 AP 的覆盖范围。你也可以购买更昂贵的 AP,它们更智能一些,会找出可以安全使用的最高比特率。你还可以使用支持 IGMP(Internet Group Management Protocol)的企业级 AP 和 ZeroMQ 的 PGM 传输,只发送给订阅的客户端。然而,我不会押注于这类 AP 能广泛普及,永远不会。
当您尝试向 AP 添加更多设备时,性能会迅速恶化,以至于再添加一个设备可能会破坏整个网络。许多 AP 通过在达到某个限制时(例如移动热点为四到八个设备,消费级 AP 为 30-50 个设备,企业级 AP 可能为 100 个设备)随机断开客户端连接来解决这个问题。
现状如何? #
尽管 WiFi 在企业技术中扮演着不舒服的角色,然后以某种方式逃逸到民间,但它早已不仅仅用于免费的 Skype 通话。它并不理想,但足以让我们解决一些有趣的问题。让我给你一个快速的现状报告。
首先,点对点与接入点对客户端。传统的 WiFi 全部是 AP-客户端模式。每个数据包都必须从客户端 A 到 AP,然后再到客户端 B。你损失了 50% 的带宽,但这只是一半的问题。我解释过反平方律。如果 A 和 B 非常接近,但都远离 AP,它们都会使用较低的比特率。想象一下你的 AP 在车库里,你在客厅里试图将视频从手机流式传输到电视上。祝你好运!
有一种老旧的“ad-hoc”模式,可以让 A 和 B 直接通信,但它太慢了,无法进行任何有趣的活动,而且当然,它在所有移动芯片组上都被禁用了。实际上,它被禁用于芯片制造商善意提供给硬件制造商的绝密驱动程序中。有一种新的 Tunneled Direct Link Setup (TDLS) 协议,允许两个设备创建直接链接,使用 AP 进行发现但不进行流量传输。还有一种“5G”WiFi 标准(这是一个营销术语,所以用引号括起来)将链接速度提升到千兆位。TDLS 和 5G 一起使从手机流式传输高清电影到电视成为一个可能实现的现实。我猜想 TDLS 会受到各种限制,以安抚电信公司。
最后,我们看到 802.11s 网状协议在 2012 年标准化,经过了大约十年的惊人快速工作。网状网络完全去除了接入点,至少在它存在并被广泛使用的想象中的未来是如此。设备直接相互通信,并维护包含邻居的小型路由表,以便转发数据包。想象一下 AP 软件嵌入到每个设备中,而且足够智能(听起来不像听上去那么厉害)可以进行多跳。
任何从移动数据勒索中赚钱的人都不希望看到 802.11s 普及,因为城市范围的网状网络对利润来说简直是噩梦,所以它正在尽可能慢地发展。唯一拥有足够强大力量(并且,我猜想拥有地对地导弹)能将网状技术广泛推广的组织是美国陆军。但网状网络终将出现,我敢打赌 802.11s 在 2020 年左右将在消费电子产品中广泛可用。
其次,如果我们没有点对点连接,我们今天能在多大程度上信任 AP?嗯,如果你去美国的星巴克,尝试使用通过免费 WiFi 连接的两台笔记本电脑运行 ZeroMQ 的“Hello World”示例,你会发现它们无法连接。为什么?答案就在名称中:“attwifi”。AT&T 是一个老牌电信巨头,它痛恨 WiFi,大概为了阻止独立公司进入市场,它廉价地向星巴克等提供服务。但是你购买的任何接入点都支持客户端到 AP 再到客户端的访问,在美国以外,我从未发现有公共 AP 像 AT&T 那样被锁定。
第三,性能。AP 显然是一个瓶颈;即使你将 A 和 B 字面上放在 AP 旁边,你也无法获得比其宣传速度快一半以上的速度。更糟糕的是,如果同一空域中还有其他 AP,它们会互相干扰。在我家,WiFi 几乎完全无法工作,因为两家之外的邻居有一个他们增强了信号的 AP。即使在不同的频道上,它也会干扰我们家的 WiFi。我现在坐着的咖啡馆里有十几个网络。现实地说,只要我们依赖基于 AP 的 WiFi,我们就必然受到随机干扰和不可预测的性能影响。
第四,电池续航。WiFi 在空闲时比蓝牙等更耗电并没有内在原因。它们使用相同的无线电和低层帧。主要区别在于调整和协议。为了无线省电工作得好,设备必须大部分时间处于休眠状态,每隔一段时间才向其他设备发出信标。为了实现这一点,它们需要同步时钟。手机部分可以正常实现,这就是为什么我的老式翻盖手机充电一次可以用五天。当 WiFi 工作时,它会消耗更多电量。目前的功率放大器技术效率低下,这意味着你从电池中消耗的能量远多于你向空中泵入的能量(浪费的能量变成了发热的手机)。随着人们越来越关注移动 WiFi,功率放大器正在改进。
最后,移动接入点。如果我们无法信任集中式 AP,如果我们的设备足够智能可以运行完整的操作系统,难道我们就不能让它们充当 AP 吗?我非常高兴你问了这个问题。是的,我们可以,而且效果相当不错。特别是因为你可以在现代操作系统(如 Android)上通过软件开启和关闭此功能。再一次,破坏和平的罪魁祸首是美国电信公司,它们大多憎恶这项功能,并在其控制的手机上杀死或阉割它。更聪明的电信公司意识到这是一种放大其“最后一英里”并为更多用户带来更高价值产品的方式,但流氓不会在智能上竞争。
结论 #
WiFi 不是以太网,尽管我相信未来的 ZeroMQ 应用将在去中心化无线领域发挥非常重要的作用,但这不会是一条坦途。以太网中预期的基本可靠性和容量大部分都不存在。当你在 WiFi 上运行分布式应用程序时,你必须考虑到频繁的超时、随机的延迟、任意的断开连接、整个接口的上下线等等。
无线网络的技术演进最好描述为“缓慢且乏味”。试图利用去中心化无线的应用和框架大多缺席或表现不佳。唯一的现有开源近距离网络框架是高通的 AllJoyn。但通过 ZeroMQ,我们证明了现有参与者的惯性和衰朽无能并非我们停滞不前的理由。当我们准确理解问题时,我们就能解决它们。我们所想象的,我们就能变为现实。
发现 #
发现是网络编程的关键部分,也是 ZeroMQ 开发者面临的首要问题。zmq_connect ()每次调用都提供一个端点字符串,而这个字符串必须来自某个地方。我们目前看到的示例没有进行发现:它们连接的端点在代码中被硬编码为字符串。这对于示例代码来说没问题,但对于实际应用来说并不理想。网络并非总是如此友好。事情会发生变化,而我们如何处理变化决定了我们的长期成功。
服务发现 #
我们先从定义开始。网络发现是找出网络上有哪些其他对等体。服务发现是了解这些对等体能为我们做什么。维基百科将“网络服务”定义为“托管在计算机网络上的服务”,将“服务”定义为“一组相关的软件功能,可以重复用于不同目的,以及控制其使用的策略”。这不是很能说明问题。Facebook 是一个网络服务吗?
事实上,“网络服务”的概念随着时间发生了变化。运动部件的数量每 18-24 个月翻一番,打破了旧的概念模型,并推动着更简单、更具可伸缩性的模型出现。对我来说,服务是系统级应用程序,其他程序可以与其通信。网络服务是可以远程访问的服务(与命令行服务(如“grep”命令)相比)。
在经典的 BSD 套接字模型中,一个服务与一个网络端口一一对应。计算机系统提供多种服务,例如“FTP”和“HTTP”,每个服务都有指定的端口。BSD API 中有诸如getservbyname之类的函数,用于将服务名映射到端口号。因此,经典的服务映射到一个网络端点:如果你知道服务器的 IP 地址,然后你就可以找到其 FTP 服务(如果正在运行的话)。
然而,在现代消息传递中,服务与端点并非一一对应。一个端点可以导向许多服务,并且服务会随着时间在端口之间甚至系统之间移动。我的云存储今天在哪里?因此,在一个现实的大型分布式应用程序中,我们需要某种服务发现机制。
有很多方法可以做到这一点,我不会试图提供一个详尽的列表。然而,有一些经典的模式:
-
我们可以强制执行旧的端点到服务的一对一映射,并简单地预先声明某个 TCP 端口号代表某个服务。然后我们的协议应该允许我们检查这一点(“请求的前 4 个字节是‘HTTP’吗?”)。
-
我们可以通过另一个服务引导一个服务;连接到一个已知端点和服务,请求“真正”的服务,并获得一个端点作为回报。这为我们提供了一个服务查找服务。如果查找服务允许,服务就可以随处移动,只要它们更新位置即可。
-
我们可以通过另一个服务代理一个服务,这样已知端点和服务将间接提供其他服务(即通过将消息转发给它们)。例如,我们的 Majordomo 面向服务代理就是这样工作的。
-
我们可以使用流言(gossip)方法或集中式方法(如 Clone 模式)交换随时间变化的已知服务和端点列表,以便分布式网络中的每个节点都可以构建一个最终一致的整个网络地图。
-
我们可以在网络端点和服务之间创建进一步的抽象层,例如为每个节点分配一个唯一标识符,这样我们就可以得到一个“节点网络”,其中每个节点可能提供一些服务,并可能出现在随机的网络端点上。
-
我们可以机会性地发现服务,例如通过连接到端点,然后询问它们提供哪些服务。“你好,你提供共享打印机吗?如果提供,是什么制造商和型号?”
没有“正确答案”。选项范围很广,并且随着我们网络规模的增长而变化。在某些网络中,关于哪些服务运行在哪里的知识字面上可以变成政治权力。ZeroMQ 不强制采用特定的模型,但它使得设计和构建最适合我们的模型变得容易。然而,要构建服务发现,我们必须首先解决网络发现。
网络发现 #
以下是我所知的网络发现解决方案列表:
-
使用硬编码的端点字符串,即固定的 IP 地址和约定的端口。这在十年前的内部网络中奏效,当时只有几个“大型服务器”,它们非常重要,所以拥有静态 IP 地址。然而现在,除了示例或进程内工作(线程是新的大型机)之外,这没有什么用处。你可以通过使用 DNS 来减轻一点痛苦,但这对于不兼职做系统管理的人来说仍然很痛苦。
-
从配置文件获取端点字符串。这把名称解析推到用户空间,痛苦比 DNS 少,但这就像说脸上挨一拳比腹股沟挨一脚痛苦少一样。你现在面临着一个非平凡的管理问题。谁来更新配置文件,何时更新?它们放在哪里?我们需要安装像 Salt Stack 这样的分布式管理工具吗?
-
使用消息代理。你仍然需要硬编码或配置的端点字符串来连接代理,但这种方法将网络中不同端点的数量减少到一个。这会产生真正的影响,并且基于代理的网络扩展得很好。然而,代理是单点故障,并且带来了它们自己的管理和性能问题。
-
使用寻址代理。换句话说,使用中央服务来协调地址信息(就像动态 DNS 设置一样),但允许节点之间直接发送消息。这是一个不错的模型,但仍然会产生故障点和管理成本。
-
使用辅助库,如 ZeroConf,它在没有任何集中式基础设施的情况下提供 DNS 服务。对于某些应用程序来说,这是一个不错的答案,但效果会因情况而异。辅助库不是零成本的:它们使软件构建更复杂,它们有自己的限制,而且它们不一定可移植。
-
构建系统级发现,通过发送 ARP 或 ICMP ECHO 数据包,然后查询所有响应的节点。例如,你可以通过 TCP 连接查询,或者发送 UDP 消息。一些产品就是这样做的,比如 Eye-Fi 无线网卡。
-
进行用户级暴力发现,尝试连接网络段中的每一个地址。在 ZeroMQ 中,你可以轻而易举地做到这一点,因为它在后台处理连接。你甚至不需要多线程。这很残暴,但很有趣,在演示和研讨会上效果非常好。然而,它不具备可伸缩性,并且会惹恼有思想的工程师。
-
自行编写基于 UDP 的发现协议。很多人都这样做(我在 StackOverflow 上统计了大约 80 个关于这个主题的问题)。UDP 在这方面效果很好,而且技术上很清晰。但技术上要把它弄对很棘手,以至于任何第一次尝试这样做的开发者都会犯下严重的错误。
-
Gossip发现协议。对于少量节点(例如,最多100或200个),完全互联的网络非常有效。对于大量节点,我们需要某种Gossip协议。也就是说,我们可以合理发现的节点(例如,与我们在同一网段上的节点),会告诉我们关于更远节点的的信息。Gossip协议超出了目前ZeroMQ所需,但在未来可能会更常见。广域Gossip模型的一个例子是网状网络。
用例 #
让我们更明确地定义我们的用例。毕竟,所有这些不同的方法在某种程度上都曾经奏效,并且至今仍然奏效。作为一名架构师,我感兴趣的是未来,以及寻找能够持续运行多年而不仅仅是几年的设计。这意味着要识别长期趋势。我们的用例不是此时此刻,而是今天算起的十年或二十年后。
以下是我在分布式应用中看到的长期趋势
-
活动部件的总数持续增加。我估计它每24个月翻一番,但增长速度不如我们不断向网络添加更多节点这一事实重要。它们不仅仅是物理设备,还包括进程和线程。这里的驱动力是成本,它持续下降。十年后,普通青少年将随时携带30-50台设备。
-
控制权从中心转移。数据也可能如此,尽管我们离理解如何构建简单的去中心化信息存储还有很长的路要走。无论如何,星型拓扑正在慢慢消亡,被“云中之云”所取代。未来,本地环境(家庭、办公室、学校、酒吧)内的流量将远大于远程节点与中心之间的流量。这里的计算很简单:远程通信成本更高、运行更慢,并且不如近距离通信自然。无论是从技术上还是社交上,通过本地WiFi与朋友分享度假视频都比通过Facebook更合适。
-
网络日益协作化,中心控制减弱。这意味着人们携带自己的设备,并期望它们能无缝工作。Web展示了一种实现方式,但随着我们开始超过人均一台设备的平均水平,Web的能力正在达到极限。
-
连接新节点的成本必须按比例下降,如果网络要进行扩展的话。这意味着减少节点所需的配置量:更少预共享状态,更少上下文。同样,Web解决了这个问题,但代价是中心化。我们想要同样的即插即用体验,但没有中心机构。
在一个拥有数万亿节点的世界里,你与之交谈最多的节点是你最接近的节点。这是现实世界的运作方式,也是扩展大规模架构最明智的方法。节点组,逻辑上或物理上接近,通过桥连接到其他节点组。一个本地组可以是少至六七个节点,多至几千个节点。
因此,我们有两种基本用例
-
近距离网络发现,即一组发现彼此靠近的节点。我们可以将“彼此靠近”定义为“在同一网络段”。这并非在所有情况下都成立,但足以成为一个有用的起点。
-
广域网络发现,即将近距离网络桥接在一起。我们有时称之为“联邦化”。联邦化有很多种方式,但这很复杂,需要在其他地方讨论。目前,我们假设使用中心化的代理或服务进行联邦化。
因此,我们剩下近距离网络的问题。我只想将设备插入网络,让它们能彼此通信。无论它们是学校里的平板电脑还是一堆云服务器,前期的协议和协调越少,扩展成本就越低。所以配置文件、代理以及任何类型的中心化服务都被排除在外。
我还希望在一台设备上允许多个应用程序运行,这既是因为现实世界就是这样运作的(人们下载应用),也因为这样我可以在笔记本电脑上模拟大型网络。预先模拟是我所知的唯一确保系统在实际负载下能正常工作的方法。你会惊讶地发现工程师们只是希望事情能顺利进行。“哦,我肯定那个桥在我们开放交通时会保持畅通”。如果你没有模拟并修复最可能出现的三个故障,它们在开放日仍然存在。
在同一台机器上运行服务的多个实例——无需前期协调——意味着我们必须使用临时端口,即为服务随机分配的端口。临时端口排除了蛮力TCP发现以及包括ZeroConf在内的任何DNS解决方案。
最后,发现必须发生在用户空间,因为我们正在构建的应用将运行在我们不一定拥有和控制的随机设备上。例如,其他人的移动设备。因此,任何需要root权限的发现都被排除在外。这排除了ARP和ICMP,以及再次排除了ZeroConf,因为它也需要root权限来提供服务部分。
技术要求 #
让我们回顾一下需求
-
最简单的可行解决方案。自组织网络中存在如此多的边缘情况,以至于每一个额外的特性或功能都成为一种风险。
-
支持临时端口,以便我们可以运行真实的模拟。如果唯一的测试方法是使用真实设备,那么运行测试将变得极其昂贵和缓慢。
-
不需要root权限,它必须完全在用户空间运行。我们希望将完全打包的应用部署到我们不拥有且无法获取root权限的设备上,例如手机。
-
对系统管理员不可见,这样我们不需要他们的帮助来运行我们的应用程序。我们使用的任何技术都应该对网络友好,并且默认可用。
-
零配置,除了安装应用程序本身。要求用户进行任何配置都是给他们一个不使用应用程序的借口。
-
完全可移植到所有现代操作系统。我们不能假设将在任何特定的操作系统上运行。除了标准的用户空间网络功能,我们不能假设操作系统的任何支持。我们可以假设ZeroMQ和CZMQ是可用的。
-
对参与者最多100-150个的WiFi网络友好。这意味着保持消息体积小,并了解WiFi网络如何扩展以及在压力下如何崩溃。
-
协议中立,即我们的信标不应强制使用任何特定的发现协议。稍后我将解释这意味着什么。
-
易于在任何给定语言中重新实现。当然,我们有一个很好的C语言实现,但如果用另一种语言重新实现需要太长时间,那就会排除ZeroMQ社区的大部分成员。所以,再次强调,简单。
-
快速响应时间。我的意思是新节点应该在很短的时间内对其对等节点可见,最多一两秒。网络形态变化很快。花更长时间(即使30秒)来意识到对等节点已经消失是可以接受的。
从我收集的可行解决方案列表中,唯一没有因一个或多个原因被否决的选择是构建我们自己的基于UDP的发现栈。在经过了几十年的网络发现研究后,结果竟然如此,这多少有些令人失望。但计算的历史似乎确实是从复杂走向简单,所以也许这是正常的。
30秒内构建一个自愈的P2P网络 #
我提到了蛮力发现。让我们看看它是如何工作的。软件的一个好处是可以通过蛮力来获取学习经验。只要我们乐于放弃工作,我们就可以通过尝试那些在安逸环境中可能看起来疯狂的事情来快速学习。
我将解释一种在2012年一次研讨会上提出的ZeroMQ蛮力发现方法。它非常简单甚至可以说愚蠢:连接到房间里的每一个IP地址。例如,如果你的网络段是192.168.55.x,你就会这样做
connect to tcp://192.168.55.1:9000
connect to tcp://192.168.55.2:9000
connect to tcp://192.168.55.3:9000
...
connect to tcp://192.168.55.254:9000
用ZeroMQ的说法,看起来像这样
int address;
for (address = 1; address < 255; address++)
zsocket_connect (listener, "tcp://192.168.55.%d:9000", address);
愚蠢的部分在于我们假设连接到自己是没问题的,我们假设所有对等节点都在同一个网络段,以及我们浪费文件句柄,就像它们是免费的一样。幸运的是,这些假设通常完全准确。至少,经常足够准确,让我们能做些有趣的事情。
这个循环有效是因为ZeroMQ的连接调用是异步且机会主义的。它们像饥饿的猫一样潜伏在阴影中,耐心等待着扑向任何敢于在端口9000上启动服务的无辜老鼠。它简单、有效,并且第一次尝试就奏效了。
更妙的是:随着对等节点离开和加入网络,它们会自动重新连接。我们在30秒内用三行代码设计了一个自愈的对等网络。
然而,这在实际情况中是行不通的。性能较差的操作系统往往会耗尽文件句柄,而且网络通常比一个网段更复杂。如果一个节点占用几百个文件句柄,大规模模拟(在一台设备或一个进程中运行许多节点)就根本不可能了。
不过,在我们放弃这种方法之前,让我们看看能走多远。这里有一个小型的去中心化聊天程序,它可以让你与同一网络段上的任何人交谈。代码有两个线程:一个监听器和一个广播器。监听器创建一个SUB套接字,并对网络中的所有对等节点进行蛮力连接。广播器接受控制台输入,并通过一个PUB套接字发送出去
C | Java | Python | Ada | Basic | C++ | C# | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCaml
该dechat程序需要知道当前的IP地址、接口和一个别名。我们可以在代码中从操作系统获取这些信息,但这会产生笨拙且不可移植的代码。所以我们在命令行上提供这些信息
dechat 192.168.55.122 eth0 Joe
通过原始套接字的抢占式发现 #
短距离无线网络的一大优点是其近距离特性。WiFi与物理空间紧密对应,这与我们自然的组织方式也紧密对应。事实上,互联网相当抽象,这让许多人感到困惑,他们觉得“懂了”,但实际上并非如此。通过WiFi,我们获得的连接在技术上可能非常具体、可感知。所见即所得。可感知意味着易于理解,这应该意味着用户的喜爱,而不是典型的沮丧和怒火。
近距离是关键。房间里有一堆WiFi设备,正愉快地相互发送信标。对于许多应用来说,它们能够相互发现并开始聊天而无需用户输入,这是很有意义的。毕竟,大多数现实世界的数据并非隐私,只是高度本地化。
我正在首尔江南的一家酒店房间里,带着一个4G无线热点,一台Linux笔记本电脑和几部安卓手机。手机和笔记本电脑正在与热点通信。该ifconfig命令显示我的IP地址是192.168.1.2。让我尝试一些ping命令。DHCP服务器倾向于按顺序分配地址,所以从数字上看,我的手机可能就在附近
$ ping 192.168.1.1
PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
64 bytes from 192.168.1.1: icmp_req=1 ttl=64 time=376 ms
64 bytes from 192.168.1.1: icmp_req=2 ttl=64 time=358 ms
64 bytes from 192.168.1.1: icmp_req=4 ttl=64 time=167 ms
^C
--- 192.168.1.1 ping statistics ---
3 packets transmitted, 2 received, 33% packet loss, time 2001ms
rtt min/avg/max/mdev = 358.077/367.522/376.967/9.445 ms
找到一个了!150-300毫秒的往返延迟……这是一个惊人高的数字,后面需要记住。现在我ping我自己,只是为了再次检查一下
$ ping 192.168.1.2
PING 192.168.1.2 (192.168.1.2) 56(84) bytes of data.
64 bytes from 192.168.1.2: icmp_req=1 ttl=64 time=0.054 ms
64 bytes from 192.168.1.2: icmp_req=2 ttl=64 time=0.055 ms
64 bytes from 192.168.1.2: icmp_req=3 ttl=64 time=0.061 ms
^C
--- 192.168.1.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 1998ms
rtt min/avg/max/mdev = 0.054/0.056/0.061/0.009 ms
现在的响应时间稍微快了一些,这是我们预期的。让我们尝试接下来的几个地址
$ ping 192.168.1.3
PING 192.168.1.3 (192.168.1.3) 56(84) bytes of data.
64 bytes from 192.168.1.3: icmp_req=1 ttl=64 time=291 ms
64 bytes from 192.168.1.3: icmp_req=2 ttl=64 time=271 ms
64 bytes from 192.168.1.3: icmp_req=3 ttl=64 time=132 ms
^C
--- 192.168.1.3 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 132.781/231.914/291.851/70.609 ms
那是第二部手机,延迟与第一部相同。我们继续看看热点是否还连接了其他设备
$ ping 192.168.1.4
PING 192.168.1.4 (192.168.1.4) 56(84) bytes of data.
^C
--- 192.168.1.4 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 2016ms
就这样。现在,ping使用原始IP套接字发送ICMP_ECHO消息。有用的是,ICMP_ECHO可以从任何未特意关闭回显的IP栈获得响应。在企业网站上,这仍然是一种常见做法,他们担心老式的“死亡之ping”攻击,其中格式错误的消息可能导致机器崩溃。
我称之为抢占式发现,因为它不需要设备的任何配合。我们无需手机的任何配合就能看到它们在那里;只要它们不主动忽略我们,我们就能看到它们。
你可能会问这有什么用。我们不知道响应ICMP_ECHO的对等节点正在运行ZeroMQ,它们有兴趣与我们交流,它们提供我们可以使用的任何服务,甚至它们是什么类型的设备。然而,知道地址192.168.1.3上存在某个东西就已经很有用了。我们也相对地知道设备有多远,知道网络上有多少设备,以及网络的大致状态(例如,良好、较差或糟糕)。
创建ICMP_ECHO消息并发送它们并不难。只需要几十行代码,我们就可以使用ZeroMQ多线程并行处理我们自身IP地址上下延伸的地址范围。这可能会很有趣。
然而,遗憾的是,我使用ICMP_ECHO来发现设备的想法存在致命缺陷。打开原始IP套接字在POSIX系统上需要root权限。这可以阻止流氓程序获取 intended for others 的数据。在Linux上,我们可以通过给我们的命令(ping有所谓的粘滞位设置)赋予sudo权限来获得打开原始套接字的能力。在像安卓这样的移动操作系统上,这需要root访问权限,即对手机或平板电脑进行root。这对大多数人来说是不可能的,因此ICMP_ECHO对大多数设备来说是遥不可及的。
粗话已删除!让我们在用户空间尝试一些方法。大多数人接下来会采取的步骤是UDP组播或广播。让我们沿着这条路走下去。
使用UDP广播进行协作发现 #
组播(Multicast)往往被视为比广播(Broadcast)更现代、“更好”。在IPv6中,广播根本不起作用:你必须始终使用组播。尽管如此,所有IPv4本地网络发现协议最终还是使用UDP广播。原因如下:广播和组播最终的工作方式大同小异,只是广播更简单、风险更低。网络管理员认为组播有点危险,因为它可能跨越网络段。
如果你从未使用过UDP,你会发现它是一个相当不错的协议。在某些方面,它让我想起ZeroMQ,使用两种不同的模式向对等节点发送完整的消息:一对一和一对多。UDP的主要问题在于 (a) POSIX套接字API的设计目标是通用灵活性,而非简单性,(b) UDP消息在局域网(LAN)上的实际限制约为1,500字节,在互联网上约为512字节,以及 (c) 当你开始将UDP用于实际数据时,你会发现消息会丢失,特别是因为基础设施倾向于优先处理TCP而非UDP。
这是一个使用UDP而非ICMP_ECHO:
C | C++ | Java | Python | Ada | Basic | C# | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCaml这段代码使用一个套接字广播1字节消息,并接收其他节点广播的任何内容。当我运行它时,它只显示一个节点,就是它自己
Pinging peers...
Found peer 192.168.1.2:9999
Pinging peers...
Found peer 192.168.1.2:9999
如果我关闭所有网络并再次尝试,发送消息会失败,这和我预期的一样
Pinging peers...
sendto: Network is unreachable
本着解决眼前最紧迫问题的原则,让我们来修复这个第一个模型中最紧急的问题。这些问题是
-
使用广播地址255.255.255.255有些可疑。一方面,这个广播地址确实意味着“发送到本地网络上的所有节点,且不转发”。然而,如果你有多个接口(有线以太网、WiFi),广播只会通过你的默认路由,并且只通过一个接口发送出去。我们想做的是要么在每个接口的广播地址上发送广播,要么找到WiFi接口及其广播地址。
-
就像套接字编程的许多方面一样,获取网络接口信息是不可移植的。我们想在应用程序中编写不可移植的代码吗?不,这最好隐藏在一个库中。
-
除了“abort”(中止)之外,没有错误处理,这对于像“你的WiFi关闭了”这样的暂时性问题来说过于粗暴。代码应该区分软错误(忽略并重试)和硬错误(断言)。
-
代码需要知道它自己的IP地址,并忽略它自己发送出去的信标。就像找到广播地址一样,这需要检查可用的接口。
解决这些问题最简单的方法是将UDP代码封装到一个单独的库中,提供一个干净的API,就像这样
// Constructor
static udp_t *
udp_new (int port_nbr);
// Destructor
static void
udp_destroy (udp_t **self_p);
// Returns UDP socket handle
static int
udp_handle (udp_t *self);
// Send message using UDP broadcast
static void
udp_send (udp_t *self, byte *buffer, size_t length);
// Receive message from UDP broadcast
static ssize_t
udp_recv (udp_t *self, byte *buffer, size_t length);
这是重构后的UDP ping程序,它调用这个库,变得更干净、更好
C | Java | Python | Ada | Basic | C++ | C# | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCaml这个库,udplib,隐藏了许多令人不快的代码(随着我们在更多系统上实现它,代码会变得更丑陋)。我不打算在这里打印这些代码。你可以在仓库中阅读它。
现在,还有更多问题摆在我们面前,评估我们是否有弱点。首先是 IPv4 对比 IPv6 以及组播对比广播。在 IPv6 中,广播根本不存在;人们使用组播。根据我在 WiFi 方面的经验,IPv4 组播和广播工作方式基本相同,除了在某些广播工作正常的场景下组播会中断。一些接入点不转发组播数据包。当你有一个充当移动热点的设备(例如平板电脑)时,它可能收不到组播数据包。这意味着,它将无法看到网络上的其他对等方。
最简单的可行解决方案是现在暂时忽略 IPv6,使用广播。一个也许更聪明的解决方案是使用组播,并在出现不对称信标时进行处理。
现在我们坚持使用简单粗暴的方法。总是还有时间把它弄得更复杂。
单设备上的多个节点 #
所以我们只要按预期发送信标,就可以发现 WiFi 网络上的节点。于是我尝试用两个进程进行测试。但是当我两次运行 udpping2 时,第二个实例会报错“bind 时地址已被使用”然后退出。哦,对了。如果你尝试将两个不同的套接字绑定到同一个端口,UDP 和 TCP 都会返回错误。这是正确的。一个套接字上有两个读取器的语义至少可以说会很奇怪。奇数/偶数字节?你得到所有的 1,我得到所有的 0?
然而,快速查阅 stackoverflow.com 并回忆起一个名为SO_REUSEADDR的套接字选项,找到了宝藏。如果我使用它,我可以将几个进程绑定到同一个 UDP 端口,并且它们都将接收到达该端口的任何消息。这几乎就像是设计它的人能读懂我的心!这比我可能正在重复发明轮子要靠谱得多。
快速测试表明,SO_REUSEADDR正如承诺的那样工作。这太好了,因为接下来我想做的是设计一个 API,然后启动几十个节点,看看它们是如何相互发现的。不得不在单独的设备上测试每个节点会非常麻烦。当我们测试真实流量在一个大型、不稳定的网络上如何表现时,两种选择是模拟或暂时的疯狂。
我是过来人:今年夏天,我们一次性在几十个设备上进行测试。设置一次完整的测试运行大约需要一个小时,如果你想获得任何形式的可重现性,你需要一个屏蔽 WiFi 干扰的空间(除非你的测试用例是“证明干扰杀死 WiFi 网络比 Orval 啤酒解渴更快”)。
如果我是一个空闲周末的 Android 开发高手,我会立刻(比如,两天内)把这段代码移植到我的手机上,让它向我的电脑发送信标。但有时懒惰更有益。我*喜欢*我的 Linux 笔记本电脑。我喜欢能够从一个进程启动十几个线程,并且让每个线程都像一个独立的节点一样运行。我喜欢不必在真实的法拉第笼中工作,而可以在我的笔记本电脑上模拟一个。
设计 API #
我将在一个设备上运行 N 个节点,它们必须相互发现,也要发现本地网络上的其他节点。我可以用 UDP 进行本地发现和远程发现。可以说,这不如使用例如 ZeroMQ 的 inproc:// 传输方式效率高,但它有一个巨大的优势:完全相同的代码可以在模拟环境和实际部署中工作。
如果一个设备上有多个节点,我们显然不能使用 IP 地址和端口号作为节点地址。我需要一个逻辑节点标识符。可以说,节点标识符可能只需要在设备的上下文中是唯一的。我脑子里充满了可以构建的复杂东西,比如驻留在真实 UDP 端口上并将消息转发给内部节点的超级节点。我把头撞在桌子上,直到这个*发明新概念*的想法消失。
经验告诉我们,在应用程序运行时,WiFi 会出现断开又重连的情况。用户点击操作,会发生有趣的事情,比如在会话进行到一半时改变 IP 地址。我们不能依赖 IP 地址,也不能依赖已建立的连接(TCP 方式)。我们需要一种持久的寻址机制,它能够在接口和连接被拆除然后重建后依然有效。
我能看到的最简单的解决方案:我们给每个节点一个 UUID,并指定节点(由其 UUID 表示)可以在特定的 IP 地址:端口端点出现或重新出现,然后再次消失。我们稍后会处理丢失消息的恢复问题。一个 UUID 是 16 字节。所以如果一个 WiFi 网络上有 100 个节点,那么(加上其他随机数据翻倍)每秒需要携带 3,200 字节的信标数据用于发现和存在性。似乎可以接受。
回到概念。我们确实需要为我们的 API 起一些名字。至少我们需要一种方法来区分代表“我们”的节点对象和代表我们对等方的节点对象。我们将做的事情包括创建一个“我们”,然后询问它知道多少个对等方以及它们是谁。“对等方”(peer)这个术语足够清晰。
从开发者的角度来看,一个节点(即应用程序)需要一种与外部世界交谈的方式。让我们借用网络中的一个术语,称之为“接口”(interface)。该接口将我们呈现给外部世界,并将外部世界作为一组其他对等方呈现给我们。它会自动执行所有必要的发现工作。当我们想与对等方交谈时,我们让接口为我们完成这件事。当一个对等方与我们交谈时,是接口将消息传递给我们。
这似乎是一个简洁的 API 设计。内部实现呢?
-
接口必须是多线程的,以便一个线程可以在后台执行 I/O,而前台 API 与应用程序交互。我们在 Clone 和 Freelance 客户端 API 中使用了这种设计。
-
接口后台线程负责发现事务;绑定到 UDP 端口,发送 UDP 信标,并接收信标。
-
我们至少需要在信标消息中发送 UUID,以便区分我们自己的信标和我们对等方的信标。
-
我们需要跟踪出现的和消失的对等方。为此,我将使用一个哈希表来存储所有已知对等方,并在一定超时后使对等方过期。
-
我们需要一种方式向调用者报告对等方和事件。这里我们遇到了一个棘手的问题。后台 I/O 线程如何告诉前台 API 线程有事情发生?回调怎么样?绝不。当然,我们将使用 ZeroMQ 消息。
UDP ping 程序的第三个迭代比第二个更加简单和优美。在 C 语言中,主程序体只有十行代码。
C | Java | Python | Ada | Basic | C++ | C# | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCaml如果你研究过我们如何构建多线程 API 类,那么接口代码应该看起来很熟悉
C | Java | Python | Ada | Basic | C++ | C# | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCaml当我在两个窗口中运行它时,它会报告一个对等方加入了网络。我终止那个对等方,几秒钟后,它告诉我该对等方离开了
--------------------------------------
[006] JOINED
[032] 418E98D4B7184844B7D5E0EE5691084C
--------------------------------------
[004] LEFT
[032] 418E98D4B7184844B7D5E0EE5691084C
基于 ZeroMQ 消息的 API 的优点在于我可以随意封装它。例如,如果我真的想要回调,我可以把它变成回调。我也可以非常轻松地跟踪 API 上的所有活动。
关于调优的一些注意事项。在以太网中,五秒(我在此代码中使用的过期时间)似乎很长。在一个负载很高的 WiFi 网络上,你可能会遇到 30 秒或更长的 ping 延迟。如果你使用过于激进的过期值,你就会断开仍然存在的节点。另一方面,终端用户应用程序期望有一定的活跃度。如果需要 30 秒才能报告一个节点已离开,用户会感到恼火。
一个不错的策略是快速检测和报告消失的节点,但只在更长时间间隔后才删除它们。在视觉上,一个节点活着时是绿色的,然后当它超出范围时会变灰一段时间,最后彻底消失。我们现在还没有这样做,但在我们正在构建的这个尚未命名的框架的实际实现中会这样做。
正如我们稍后会看到的,我们必须将来自节点的任何输入(而不仅仅是 UDP 信标)视为其存在的信号。当有很多 TCP 流量时,UDP 可能会被挤压。这也许是我们没有使用现有 UDP 发现库的主要原因:为了让它工作,有必要将其与我们的 ZeroMQ 消息机制紧密集成。
更多关于 UDP 的信息 #
所以我们已经通过 UDP IPv4 广播实现了发现和存在性检测。这不理想,但对于我们今天的本地网络来说可行。然而,我们不能将 UDP 用于实际工作,除非额外做工作使其可靠。有个关于 UDP 的笑话,但有时你会明白,有时不会。
所有一对一消息都坚持使用 TCP。发现之后 UDP 还有另一个用例,那就是组播文件分发。我将解释为什么以及如何,然后搁置到另一天再谈。原因很简单:我们所谓的“社交网络”只是增强型文化。我们通过分享创造文化,这意味着越来越多地分享我们制作或混编的作品。照片、文档、合同、推文。我们旨在构建的设备云将更多地做这件事,而不是更少。
现在,分享内容有两种主要模式。一种是发布-订阅模式,其中一个节点同时向一组其他节点发送内容。第二种是“迟到者”模式,其中一个节点稍后加入并想赶上对话。我们可以使用 TCP 单播处理迟到者。但同时向一组客户端进行 TCP 单播有一些缺点。首先,它可能比组播慢。其次,这不公平,因为有些人会比其他人先获得内容。
在你急着去设计一个 UDP 组播协议之前,要知道这并不是一个简单的计算。当你发送一个组播数据包时,WiFi 接入点会使用较低的比特率,以确保即使最远的设备也能安全接收到它。大多数普通 AP 不会进行明显的优化,即测量最远设备的距离并使用那个比特率。相反,它们只是使用一个固定值。所以如果你有一些设备靠近 AP,组播将慢得离谱。但如果房间里有很多设备都想获取教科书的下一章,组播可以非常有效。
根据网络情况,交叉点大约在 6-12 个设备处。理论上,你可以在实时测量这些曲线并创建一个自适应协议。这会很酷,但可能对我们中最聪明的人来说也太难了。
如果你真的坐下来草拟一个 UDP 组播协议,要知道你需要一个恢复通道来获取丢失的数据包。你可能想通过 TCP 来做这件事,使用 ZeroMQ。然而,目前我们先不考虑组播 UDP,并假设所有流量都通过 TCP 传输。
分离一个库项目 #
然而,到了这个阶段,代码已经比一个示例应有的规模要大,所以是时候创建一个正规的 GitHub 项目了。有个规则:在公共视野中构建你的项目,并随过程告诉人们,这样你的市场推广和社区建设从第一天就开始了。我将详细介绍这涉及什么。我在第 6 章 - ZeroMQ 社区中解释了如何围绕项目发展社区。我们需要一些东西
- 一个名字
- 一句口号
- 一个公开的 GitHub 仓库
- 一个链接到 C4 流程的 README
- 许可文件
- 一个问题跟踪器
- 两个维护者
- 第一个引导版本
名字和口号是第一步。21 世纪的商标是域名。所以当我分离一个项目时,我做的第一件事就是寻找一个可能可行的域名。碰巧的是,我们之前的一个消息项目叫做“Zyre”,并且我有它的域名。全称是一个反向首字母缩略词:ZeroMQ Realtime Exchange framework(零MQ实时交换框架)。
对于过于激进地将新项目推入 ZeroMQ 社区,我有些害羞,通常会在我的个人账户或 iMatix 组织下启动一个项目。但我们学到了一点,即项目流行后再迁移是事倍功半的。我对未来充满活动部件的预测要么是对的,要么是错的。如果这一章是有效的,我们不如从一开始就把它作为一个 ZeroMQ 项目启动。如果错了,我们以后可以删除仓库,或者让它沉到被遗忘的启动项目长列表的底部。
从基础开始。协议(UDP 和 ZeroMQ/TCP)将是 ZRE (ZeroMQ Realtime Exchange protocol),项目将是 Zyre。我需要第二个维护者,所以我邀请我的朋友董敏(JeroMQ 背后的韩国黑客,JeroMQ 是一个纯 Java 的 ZeroMQ 栈)加入。他一直在研究非常相似的想法,所以很热心。我们讨论后,有了在 JeroMQ 以及 CZMQ 和libzmq之上构建 Zyre 的想法。这将使 Zyre 更容易在 Android 上运行。它也会从一开始就给我们两个完全独立的实现,这对于协议来说总是好事。
我们将我在第 7 章 - 使用 ZeroMQ 的高级架构中构建的 FileMQ 项目作为一个新的 GitHub 项目模板。GNU autoconf 工具相当不错,但语法很痛苦。最简单的方法是复制现有项目文件并修改它们。FileMQ 项目构建了一个库,包含测试工具、许可文件、手册页等。它不太大,所以是一个好的起点。
我准备了一个 README 来总结项目的目标并指向 C4。在新的 GitHub 项目中,问题跟踪器默认是启用的,所以一旦我们将 UDP ping 代码作为第一个版本推送上去,我们就准备好了。然而,招募更多维护者总是好事,所以我创建一个名为“招募维护者”的问题,内容是
如果你想帮忙点击那个可爱的绿色“合并拉取请求”按钮并获得永恒的好 Karma,请添加一条评论确认你已阅读并理解位于https://rfc.zeromq.cn/spec:22的 C4 流程。
最后,我修改了问题跟踪器的标签。默认情况下,GitHub 提供了各种常见的问题类型,但使用 C4,我们不使用这些。相反,我们只需要两个标签(“Urgent”,红色;“Ready”,黑色)。
点对点消息传递 #
我将以上一个 UDP ping 程序为基础,在其之上构建一个点对点消息传递层。我们的目标是:我们能检测到对等方加入和离开网络,我们可以向它们发送消息,并且可以收到回复。这是一个不平凡的问题,我和董敏花了整整两天时间才让一个“Hello World”版本跑起来。
我们必须解决一些问题
- 在 UDP 信标中发送什么信息,以及如何格式化。
- 使用什么 ZeroMQ 套接字类型来互连节点。
- 发送什么 ZeroMQ 消息,以及如何格式化。
- 如何向特定节点发送消息。
- 如何知道任何消息的发送者,以便我们可以发送回复。
- 如何从丢失的 UDP 信标中恢复。
- 如何避免信标流量过载网络。
我将足够详细地解释这些问题,以便你理解我们为什么做出这些选择,并附带一些代码片段进行说明。我们将此代码标记为v0.1.0 版本,以便你可以查看代码:大部分艰苦工作是在zre_interface.c.
UDP 信标帧格式 #
在网络上传输 UUID 是逻辑寻址方案的最低要求。然而,在实际使用中能正常工作之前,还有一些其他方面需要实现
- 我们需要一些协议标识,以便我们可以检查并拒绝无效数据包。
- 我们需要一些版本信息,以便随着时间的推移我们可以更改此协议。
- 我们需要告诉其他节点如何通过 TCP 联系我们,即它们可以与我们通信的 ZeroMQ 端口。
让我们从信标消息格式开始。我们可能需要一个在未来版本中永不更改的固定协议头,以及一个取决于版本的主体。
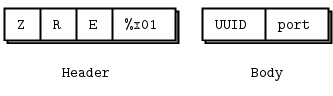
版本可以是从 1 开始的 1 字节计数器。UUID 是 16 字节,端口是一个 2 字节端口号,因为 UDP 很友好地告诉我们接收到的每条消息的发送者 IP 地址。这给了我们一个 22 字节的帧。
C 语言(以及 Erlang 等少数其他语言)使得读写二进制结构变得简单。我们定义信标帧结构
#define BEACON_PROTOCOL "ZRE"
#define BEACON_VERSION 0x01
typedef struct {
byte protocol [3];
byte version;
uuid_t uuid;
uint16_t port;
} beacon_t;
这使得发送和接收信标非常简单。以下是如何发送信标,使用zre_udp类执行不可移植的网络调用
// Beacon object
beacon_t beacon;
// Format beacon fields
beacon.protocol [0] = 'Z';
beacon.protocol [1] = 'R';
beacon.protocol [2] = 'E';
beacon.version = BEACON_VERSION;
memcpy (beacon.uuid, self->uuid, sizeof (uuid_t));
beacon.port = htons (self->port);
// Broadcast the beacon to anyone who is listening
zre_udp_send (self->udp, (byte *) &beacon, sizeof (beacon_t));
当我们接收到信标时,需要防范伪造数据。我们不会对例如拒绝服务攻击持偏执态度。我们只想确保当一个糟糕的 ZRE 实现发送错误帧时,我们不会崩溃。
要验证一个帧,我们检查其大小和头部。如果这些都没问题,我们假定主体是可用的。当我们收到一个不是我们自己的 UUID 时(记住,我们会收到我们自己的 UDP 广播),我们可以将其视为一个对等方
// Get beacon frame from network
beacon_t beacon;
ssize_t size = zre_udp_recv (self->udp,
(byte *) &beacon, sizeof (beacon_t));
// Basic validation on the frame
if (size != sizeof (beacon_t)
|| beacon.protocol [0] != 'Z'
|| beacon.protocol [1] != 'R'
|| beacon.protocol [2] != 'E'
|| beacon.version != BEACON_VERSION)
return 0; // Ignore invalid beacons
// If we got a UUID and it's not our own beacon, we have a peer
if (memcmp (beacon.uuid, self->uuid, sizeof (uuid_t))) {
char *identity = s_uuid_str (beacon.uuid);
s_require_peer (self, identity,
zre_udp_from (self->udp), ntohs (beacon.port));
free (identity);
}
真正的对等连接 (Harmony 模式) #
因为 ZeroMQ 旨在使分布式消息传递变得容易,人们经常问如何互连一组真正的对等方(与明显的客户端和服务器相比)。这是一个棘手的问题,ZeroMQ 并没有提供一个单一的明确答案。
TCP 是 ZeroMQ 中最常用的传输方式,它不是对称的;一方必须绑定,一方必须连接,尽管 ZeroMQ 试图对此保持中立,但事实并非如此。当你连接时,你创建一个出站消息管道。当你绑定时,你不会创建。当没有管道时,你无法写入消息(ZeroMQ 将返回EAGAIN).
)。
研究 ZeroMQ 然后尝试在相等对等方之间创建 N 对 N 连接的开发者通常会尝试 ROUTER-to-ROUTER 流程。原因很明显:每个对等方需要寻址一组对等方,这需要 ROUTER。这通常以一封发到邮件列表的哀怨邮件告终。经验告诉我们,ROUTER-to-ROUTER 特别难以成功使用。至少一个对等方必须绑定,一个必须连接,这意味着架构不是对称的。而且因为你根本无法确定何时可以安全地向对等方发送消息。这是个先有鸡还是先有蛋的问题:对等方跟你说过话后你才能跟它说话,但对等方必须等你跟它说过话后才能跟你说话。某一方将会丢失消息,因此必须重试,这意味着对等方无法做到平等。
我将解释 Harmony 模式,它解决了这个问题,并且我们在 Zyre 中使用了它。
我们希望保证当一个对等方在我们的网络上“出现”时,我们可以安全地与它交谈而不会丢失消息。为此,我们必须使用一个*连接到对等方*的 DEALER 或 PUSH 套接字,这样即使该连接需要非零时间,也会立即建立一个管道,ZeroMQ 将接受出站消息。
一个 DEALER 套接字不能单独寻址多个对等方。但如果每个对等方我们都有一个 DEALER,并且我们将该 DEALER 连接到对等方,那么一旦连接建立,我们就可以安全地向该对等方发送消息。
现在,下一个问题是如何知道谁向我们发送了特定消息。我们需要一个回复地址,即发送任何给定消息的节点的 UUID。DEALER 无法做到这一点,除非我们在每条消息前都加上那个 16 字节的 UUID,那样会很浪费。如果我们在连接到 ROUTER 之前正确设置了 identity,ROUTER 可以做到。
因此,Harmony 模式归结为这些组件
- 一个 ROUTER 套接字,我们将其绑定到一个临时端口,并在信标中广播该端口。
- 每个对等节点一个 DEALER 套接字,用于连接到对等节点的 ROUTER 套接字。
- 从我们的 ROUTER 套接字读取消息。
- 向对等节点的 DEALER 套接字写入消息。
下一个问题是发现过程不是整齐同步的。我们可能在开始接收来自对等节点的消息之后才收到其第一个信标。消息到达 ROUTER 套接字时带有很好用的 UUID,但没有物理 IP 地址和端口。我们必须强制通过 TCP 进行发现。为此,我们连接到任何新对等节点时发送的第一个命令是OHAI命令,其中包含我们的 IP 地址和端口。这确保接收方在我们尝试向其发送任何命令之前先连接回我们。
下面是按步骤细分的过程:
- 如果收到来自新对等节点的 UDP 信标,我们通过 DEALER 套接字连接到该对等节点。
- 我们从 ROUTER 套接字读取消息,每条消息都附带发送方的 UUID。
- 如果是OHAI消息,如果尚未连接,我们就连接回该对等节点。
- 如果是任何其他消息,我们必须已经连接到该对等节点(这里适合添加断言)。
- 我们使用每个对等节点的 DEALER 套接字向每个对等节点发送消息,该套接字必须已连接。
- 当我们连接到对等节点时,我们也会告知我们的应用程序该对等节点存在。
- 每次收到来自对等节点的消息时,我们都将其视为心跳(它还活着)。
如果我们不使用 UDP 而是使用其他发现机制,我仍然会使用 Harmony 模式来构建真正的对等网络:一个 ROUTER 用于接收所有对等节点的输入,以及每个对等节点一个 DEALER 用于输出。绑定 ROUTER,连接 DEALER,并以一个OHAI等效命令开始每次对话,该命令提供返回的 IP 地址和端口。您将需要一些外部机制来引导每个连接。
检测消失 #
心跳机制听起来很简单,但并非如此。当 TCP 流量很大时,UDP 数据包会丢失,所以如果我们依赖 UDP 信标,就会出现误判的断开连接。如果网络非常繁忙,TCP 流量可能会延迟 5 秒、10 秒,甚至 30 秒。所以如果我们在对等节点安静下来时将其杀死,就会出现误判的断开连接。
因为 UDP 信标不可靠,所以很容易想要添加 TCP 信标。毕竟,TCP 会可靠地传递它们。然而,这里有一个小问题。想象一下,网络中有 100 个节点,每个节点每秒发送一次 TCP 信标。每个信标是 22 字节,不包括 TCP 的帧开销。这意味着每秒发送 100 * 99 * 22 字节,或者说仅心跳流量就达到 217,000 字节/秒。这大约占典型 WiFi 网络理想容量的 1-2%,听起来还不错。但当网络承受压力或与其他网络争夺空中资源时,额外的 200K 每秒流量会雪上加霜。UDP 广播至少成本较低。
所以我们要做的是,只有当某个对等节点有一段时间没有向我们发送任何 UDP 信标时,才切换到 TCP 心跳。然后我们只向那一个对等节点发送 TCP 心跳。如果该对等节点继续保持沉默,我们就认为它已经消失了。如果该对等节点以不同的 IP 地址和/或端口返回,我们必须断开我们的 DEALER 套接字并重新连接到新的端口。
这为每个对等节点提供了一组状态,尽管在现阶段代码没有使用正式的状态机
- 通过 UDP 信标可见的对等节点(我们使用信标中的 IP 地址和端口连接)
- 通过OHAI命令可见的对等节点(我们使用命令中的 IP 地址和端口连接)
- 对等节点似乎还活着(我们最近收到了 UDP 信标或通过 TCP 收到了命令)
- 对等节点似乎安静(一段时间没有活动,所以我们发送一个HUGZ命令)
- 对等节点已消失(没有回复我们的HUGZ命令,所以我们销毁该对等节点)
在这个阶段的代码中,还有一个我们没有解决的场景。对等节点可能会更改 IP 地址和端口,而实际上并未触发消失事件。例如,如果用户关闭 WiFi 然后再打开,接入点可能会为该对等节点分配一个新的 IP 地址。我们需要处理我们节点上消失的 WiFi 接口,通过解绑 ROUTER 套接字并在可能时重新绑定。因为这现在不是设计的核心,所以我决定在 GitHub 问题跟踪器上记录一个问题,留待以后处理。
组消息 #
组消息是一种常见且非常有用的模式。概念很简单:不是与单个节点通信,而是与一组节点通信。组只是一个名称,一个您在应用程序中约定好的字符串。这就像在 PUB 和 SUB 套接字中使用发布-订阅前缀一样。实际上,我之所以说“组消息”而不是“发布-订阅”,只是为了避免混淆,因为我们不会为此使用 PUB-SUB 套接字。
PUB-SUB 套接字几乎可以工作。但我们刚刚做了大量工作来解决延迟加入者问题。应用程序不可避免地会在向组发送消息之前等待对等节点到达,因此我们必须在 Harmony 模式的基础上构建,而不是从头开始。
我们来看看我们想在组上执行的操作:
- 我们想加入和离开组。
- 我们想知道任何给定组中有哪些其他节点。
- 我们想向(组中的所有节点)发送消息。
这些对于使用过 Internet 中继聊天的人来说很熟悉,只是我们没有服务器。每个节点都需要跟踪每个组代表什么。这些信息在整个网络中不会总是完全一致,但会足够接近。
我们的接口将跟踪一组组(每个都是一个对象)。这些是所有已知拥有一个或多个成员节点的组,不包括我们自己。我们将跟踪节点何时离开和加入组。由于节点可以随时加入网络,我们必须告知新对等节点我们所在的组。当对等节点消失时,我们会将其从我们知道的所有组中移除。
这为我们提供了一些新的协议命令:
- JOIN- 当我们加入一个组时,将其发送给所有对等节点。
- LEAVE- 当我们离开一个组时,将其发送给所有对等节点。
此外,我们将一个groups字段添加到我们发送的第一个命令中(此时已从OHAIOHAI你好,因为我需要一个更大的命令动词词汇表)。
我将使用 UDP 信标来做这件事。我们想要的是一个滚动计数器,它简单地告诉一个节点有多少加入和离开操作(“转换”)发生过。它从 0 开始,并为我们加入或离开的每个组递增。我们可以使用最小的 1 字节值,因为这将捕获除了极少发生的“我们连续丢失了 256 条消息”故障之外的所有故障(这正是在第一次演示时出现的故障)。我们还会将转换计数器放入 UDP 信标、
OHAIJOIN, LEAVEJOIN你好和 LEAVE 命令中。为了尝试引发问题,我们将通过加入/离开几百个组进行测试,并将高水位标记设置为大约 10。
是时候为组消息选择动词了。我们需要一个表示“与单个对等节点通信”的命令和一个表示“与许多对等节点通信”的命令。经过一些尝试,我最好的选择是WHISPER和SHOUT,代码中使用的就是这些。这个SHOUTSHOUT 命令需要告诉用户组名以及发送方对等节点。
因为组类似于发布-订阅,您可能会倾向于使用它来广播JOIN和LEAVEOHAIJOIN命令,您如何加入全局组?第二,这会产生特殊的用例(保留名称),这很麻烦。
简单地向所有已连接的对等节点显式发送JOINHELLOLEAVE和 LEAVE 命令,就足够了。我现在不打算详细介绍组消息的实现细节,因为它相当冗长且不太令人兴奋。组和对等节点管理的数据结构并非最优,但可行。我们使用以下结构:
我将不再详细介绍组消息的实现,因为它相当乏味且不太令人兴奋。用于组和对等方管理的数据结构不是最优的,但它们是可行的。我们使用以下内容
- 我们接口的组列表,我们可以在你好HELLO
- 命令中发送给新对等节点;你好, JOINJOINLEAVE其他对等节点的组哈希表,我们使用
- 每个组的对等节点哈希表,我们使用相同的三个命令来更新它。
在这个阶段,我对二进制序列化(我们来自第 7 章 - 使用 ZeroMQ 的高级架构的编解码器生成器)感到非常满意,它可以处理列表和字典以及字符串和整数。
此版本在仓库中被标记为 v0.2.0,如果您想查看代码在此阶段的样子,可以下载 tarball。
测试与仿真 #
当您将产品由多个部件组装而成时,其中包括像 Zyre 这样的分布式框架,唯一能知道它在实际生活中是否能正常工作的方法就是对每个部件进行实际活动的仿真。
关于断言 #
正确使用断言是专业程序员的标志之一。
我们作为创作者的确认偏误使得正确测试我们的工作变得困难。我们倾向于编写测试来证明代码有效,而不是试图证明代码无效。这有很多原因。我们对自己和他人假装我们可以做到(或者曾经可以做到)完美,而实际上我们不断犯错。代码中的错误被视为“坏事”,而不是“不可避免”,所以在心理上我们希望看到更少的错误,而不是发现更多的错误。“他写出了完美的代码”是一种赞美,而不是“他从不冒险,所以他的代码像冷意大利面一样无聊且被大量使用”的委婉说法。
有些文化教育我们追求完美并在教育和工作中惩罚错误,这使得这种态度变得更糟。接受我们是会犯错的,然后学习如何将这种特性转化为收益而不是耻辱,是任何行业中最困难的智力练习之一。我们通过与他人合作以及更早而不是更晚地挑战自己的工作来利用我们的缺点。
一个让事情变得更容易的技巧是使用断言。断言不是一种错误处理形式。它们是可执行的事实理论。代码断言:“在这一点上,某某事实必须为真”,如果断言失败,代码就会自行终止。
越快证明代码错误,就能越快、越准确地修复它。相信代码有效并证明其行为符合预期,这更像是魔法思维而非科学。能够说出“libzmqZyre
拥有五百个断言,尽管我竭尽全力,但没有一个失败”,这才好得多。所以 Zyre 代码库中散布着断言,尤其是在处理对等节点状态的代码中有几个。这是最难做对的地方:对等节点需要彼此跟踪并准确地交换状态,否则就会停止工作。算法依赖于异步消息的传递,我相当肯定最初的设计存在缺陷。这总是会发生的。
当我手动启动和停止zre_ping实例来测试原始 Zyre 代码时,偶尔会遇到断言失败。手动运行不足以经常重现这些问题,所以我们来制作一个合适的测试工具。
关于前期测试 #
能够在实验室中全面测试单个组件的实际行为,可以将项目的成本降低 10 倍甚至 100 倍。工程师对其自身工作的确认偏误使得前期测试利润丰厚,而后期测试成本极高。
我给您讲一个关于我们上世纪 90 年代后期参与的项目的故事。我们为一家工厂自动化项目提供了软件,而其他团队提供了硬件。三四个团队带着他们的专家来到现场,那是一家偏远的工厂(污染严重的工厂总是在偏远的边境地区,这很有趣)。
其中一个团队,一家工业自动化专业公司,负责建造售票机:自助服务终端及其运行软件。没有什么特别的:刷卡,选择选项,取出票。他们现场组装了两台这样的售票机,每周都会带来更多的零配件。打印票据的打印机,显示器屏幕,以色列特制的键盘。这些东西必须能防尘,因为售票机放在外面。结果什么都工作不正常。屏幕在阳光下无法看清。打印机不停地卡纸和错印。售票机的内部元件就放在木制货架上。售票机软件经常崩溃。这一切看起来像喜剧,只是这个项目真的、真的必须成功,所以我们花了数周乃至数月时间在现场,帮助其他团队调试他们的零零碎碎,直到它们能正常工作。
一年后,有了第二家工厂,故事和之前一样。此时,客户已经很不耐烦了。所以在第三家也是最大的一家工厂建成一年后,我们跳出来说:“请让我们来做售票机和软件以及所有的一切”。
我们为软件和硬件制定了详细的设计,并找到了所有部件的供应商。我们花了三个月时间在互联网上搜索每个组件(那时,互联网要慢得多),又花了两个月时间将它们组装成重约二十公斤的不锈钢块。这些不锈钢块是两英尺见方、八英寸厚,后面有一个大型平板屏幕,外面是防碎玻璃,有两个接口:一个电源接口,一个以太网接口。您装足能用六个月的纸,然后将不锈钢块拧入外壳,它会自动启动,找到 DNS 服务器,加载 Linux 操作系统,然后加载应用程序软件。它连接到真实的服务器,并显示主菜单。通过刷一张特殊的徽章并输入代码,您就可以访问配置屏幕。
软件是可移植的,所以我们在编写时就可以测试它,并且在我们从供应商那里收集部件时,我们保留了每个部件一份,这样我们就有了一个拆开的售票机可以用来把玩。当我们拿到成品售票机时,它们立刻就全部正常工作了。我们将它们运送给客户,客户将它们插入外壳,打开电源,就开始营业了。我们在现场待了一周左右,在十年里,只有一台售票机坏了(屏幕坏了,然后被更换了)。
教训是,提前测试,这样当你插入设备时,你就清楚地知道它会如何表现。如果你没有提前测试,你将花费数周数月的时间在现场解决本不应该出现的问题。
Zyre 测试工具 #
在手动测试过程中,我偶尔会遇到断言失败。然后它就消失了。因为我不相信魔法,我知道这意味着代码的某个地方仍然是错的。所以,下一步是对 Zyre v0.2.0 代码进行重度测试,试图触发其断言失败,并对其在现场的表现有一个清晰的认识。
我们将发现和消息功能打包成一个接口对象,由主程序创建、使用,然后销毁。我们不使用任何全局变量。这使得启动大量接口并在一个进程内模拟实际活动变得容易。而且,如果我们从编写大量示例中学到了什么,那就是 ZeroMQ 在单个进程中协调多个线程的能力比多个进程容易得多。
测试工具的第一个版本包含一个主线程,该线程启动和停止一组子线程,每个子线程运行一个接口,每个接口都有一个 ROUTER、DEALER 和 UDP 套接字(图中标为 R、D 和 U)。
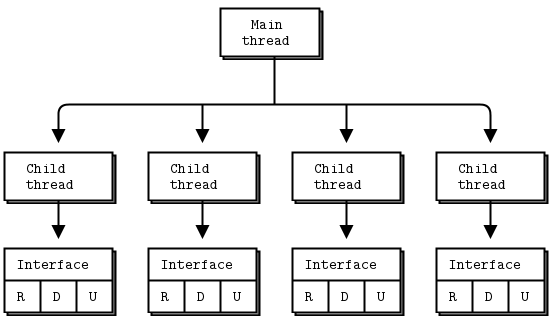
好处是,当我连接到 WiFi 接入点时,所有 Zyre 流量(甚至同一进程中两个接口之间的流量)都通过接入点传输。这意味着我只需在房间里运行几台 PC,就可以充分压力测试任何 WiFi 基础设施。这有多么宝贵是难以强调的:如果我们将 Zyre 构建成一个专门的 Android 服务,我们实际上需要几十台 Android 平板电脑或手机才能进行任何大规模测试。售货亭,以及所有这些。
现在的重点是打破当前的代码,尝试证明它是错误的。在现阶段,测试它的运行效果如何、速度多快、使用了多少内存或其他任何东西,都没有意义。我们将逐步尝试(并失败)打破每个独立的功能,但首先,我们尝试打破我放入代码中的一些核心断言。
这些是:
-
任何节点从对等节点收到的第一个命令必须是你好HELLO
-
。换句话说,在对等连接过程中不能丢失消息。每个节点计算出的对等节点状态与每个对等节点为自身计算出的状态相符。换句话说,同样地,网络中不会丢失消息。
-
当我的应用程序向对等节点发送消息时,我们已经与该对等节点建立了连接。换句话说,应用程序只有在我们与其建立 ZeroMQ 连接后才能“看到”该对等节点。
使用 ZeroMQ,在几种情况下可能会丢失消息。一是“延迟加入者”问题。二是关闭套接字时没有发送所有消息。三是 ROUTER 或 PUB 套接字上的高水位标记溢出。四是使用 ROUTER 套接字时使用了未知地址。
现在,我认为 Harmony 模式可以避开所有这些潜在情况。但我们也将 UDP 加入了混合。所以测试工具的第一个版本模拟了一个不稳定和动态的网络,节点随机出现和消失。正是在这里,事情将会出问题。
这是测试工具的主线程,它管理着一个由 100 个线程组成的池,随机启动和停止每个线程。每隔约 750 毫秒,它会随机启动或停止一个线程。我们随机化了计时,这样线程就不会完全同步。几分钟后,平均有 50 个线程像首尔江南地铁站里的韩国青少年一样愉快地互相聊天。
int main (int argc, char *argv [])
{
// Initialize context for talking to tasks
zctx_t *ctx = zctx_new ();
zctx_set_linger (ctx, 100);
// Get number of interfaces to simulate, default 100
int max_interface = 100;
int nbr_interfaces = 0;
if (argc > 1)
max_interface = atoi (argv [1]);
// We address interfaces as an array of pipes
void **pipes = zmalloc (sizeof (void *) * max_interface);
// We will randomly start and stop interface threads
while (!zctx_interrupted) {
uint index = randof (max_interface);
// Toggle interface thread
if (pipes [index]) {
zstr_send (pipes [index], "STOP");
zsocket_destroy (ctx, pipes [index]);
pipes [index] = NULL;
zclock_log ("I: Stopped interface (%d running)",
--nbr_interfaces);
}
else {
pipes [index] = zthread_fork (ctx, interface_task, NULL);
zclock_log ("I: Started interface (%d running)",
++nbr_interfaces);
}
// Sleep ~750 msecs randomly so we smooth out activity
zclock_sleep (randof (500) + 500);
}
zctx_destroy (&ctx);
return 0;
}
注意,我们维护了一个到每个子线程的管道(当我们使用zthread_fork方法时,CZMQ 会自动创建该管道)。正是通过这个管道,我们在子线程需要退出时通知它们停止。子线程执行以下操作(为了清晰起见,我切换到伪代码):
create an interface
while true:
poll on pipe to parent, and on interface
if parent sent us a message:
break
if interface sent us a message:
if message is ENTER:
send a WHISPER to the new peer
if message is EXIT:
send a WHISPER to the departed peer
if message is WHISPER:
send back a WHISPER 1/2 of the time
if message is SHOUT:
send back a WHISPER 1/3 of the time
send back a SHOUT 1/3 of the time
once per second:
join or leave one of 10 random groups
destroy interface
测试结果 #
是的,我们成功地使代码出错。实际上,是好几次。这令人满意。我将详细介绍我们发现的不同问题。
让节点们就一致的组状态达成一致是最困难的。正如我在“组消息”一节中已经解释的那样,每个节点都需要跟踪整个网络的组成员关系。组消息是一种发布-订阅模式。JOINHELLOLEAVE和 LEAVE 命令类似于订阅和取消订阅消息。这些消息绝不能丢失,否则我们会发现节点随机地从组中掉线。
所以每个节点计算它曾进行过的JOINHELLOLEAVEJOIN
操作总数,并在其 UDP 信标中广播此状态(作为一个 1 字节的滚动计数器)。其他节点接收到此状态,将其与自己的计算结果进行比较,如果存在差异,代码就会断言。JOIN和LEAVE第一个问题是 UDP 信标会被随机延迟,因此它们不适合携带状态。当信标延迟到达时,状态就不准确,我们就会得到一个假阴性。为了解决这个问题,我们将状态信息移到了你好JOIN
- 和 LEAVE 命令中。我们还将其添加到了你好HELLO
- 命令中。逻辑变为:JOIN从对等节点的LEAVEHELLO
- 命令中获取初始状态。当从对等节点接收到JOIN从对等节点的LEAVEJOIN
- 或
LEAVE你好命令时,递增状态计数器。检查新的状态计数器是否与你好HELLO命令中的值匹配。如果不匹配,则断言。, JOIN我们遇到的下一个问题是,在新连接上收到了意外的消息。Harmony 模式是先连接,然后发送
这 оказалось из-за логики временных портов CZMQ. Временный порт — это просто динамически назначаемый порт, который служба может получить, а не запрашивать фиксированный номер порта. Система POSIX обычно назначает временные порты в диапазоне от 0xC000 до 0xFFFF. Логика CZMQ заключается в поиске свободного порта в этом диапазоне, привязке к нему и возврате номера порта вызывающей стороне.
这似乎没问题,直到你遇到一个节点停止,另一个节点紧接着启动,而新节点获得了旧节点的端口号。记住 ZeroMQ 会尝试重新建立断开的连接。因此,当第一个节点停止时,其对等节点会尝试重新连接。当新节点出现在同一个端口上时,突然所有对等节点都连接到它,开始聊天,就像老朋友一样。
这是一个普遍问题,影响任何更大规模的动态 ZeroMQ 应用程序。有几种可能的解决方案。一种是不重用临时端口,这在同一系统上有多个进程时说起来容易做起来难。另一种解决方案是每次选择一个随机端口,这至少降低了命中刚释放的端口的风险。这可以将垃圾连接的风险降低到也许 1/1000,但风险仍然存在。也许最好的解决方案是接受这种情况可能发生,理解原因,并在应用程序层面处理它。
我们有一个有状态的协议,它总是以你好HELLO你好.
命令开始。我们知道对等节点有可能连接到我们,认为我们是一个已经离开又回来的现有节点,然后向我们发送其他命令。第一步是在发现一个新对等节点时,销毁连接到同一端点的任何现有对等节点。这不是一个完整的解决方案,但至少是礼貌的。第二步是忽略来自新对等节点的任何传入消息,直到该对等节点发送你好.
HELLO你好命令。这不需要更改协议,但必须在协议中指定:由于 ZeroMQ 连接的工作方式,可能从一个行为良好的对等节点接收到意外命令,并且没有办法返回错误代码或以其他方式告诉该对等节点重置其连接。因此,对等节点必须丢弃来自对等节点的任何命令,直到收到命令中的值匹配。如果不匹配,则断言。HELLOJOINHELLOLEAVEHELLO
命令。事实上,如果您把它画在纸上并仔细思考,您会发现永远不会从这样的连接中收到一个
HELLO
命令。该对等节点将发送libzmqPING
ulimit -n 30000
跟踪活动 #
为了调试我们在这里看到的问题,我们需要详细的日志记录。虽然有许多活动并行发生,但每个问题都可以追溯到两个节点之间的特定交互,包括一系列严格按顺序发生的事件。我们知道如何制作非常复杂的日志记录,但像往常一样,更明智的做法是只做我们需要做的,不多也不少。我们需要捕获:
- 每个事件的时间和日期。
- 事件发生在哪个节点上。
- 对等节点(如果存在)。
- 事件是什么(例如,收到了哪个命令)。
- 事件数据(如果存在)。
最简单的技术是将必要的信息打印到控制台,并带上时间戳。这就是我使用的方法。然后就可以很容易地找到受故障影响的节点,过滤日志文件只包含与它们相关的消息,并准确地查看发生了什么。
处理被阻塞的对等节点 #
在任何对性能敏感的 ZeroMQ 架构中,您都需要解决流量控制问题。您不能简单地向套接字无限发送消息并期望一切顺利。在一个极端情况下,可能会耗尽内存。这是消息代理的经典故障模式:一个慢速客户端停止接收消息;代理开始将消息排队,最终耗尽内存,整个进程死亡。在另一个极端情况下,当达到高水位标记时,套接字会丢弃消息或阻塞。
使用 Zyre,我们希望将消息公平地分发给一组对等节点。使用单个 ROUTER 套接字进行输出会存在问题,因为任何一个被阻塞的对等节点都会阻塞到所有对等节点的传出流量。TCP 确实有很好的算法来在连接集上分配网络容量。我们使用一个单独的 DEALER 套接字与每个对等节点通信,因此理论上每个 DEALER 套接字会在后台相当公平地发送其排队的消息。
DEALER 套接字达到高水位标记时的正常行为是阻塞。这通常是理想的,但对我们来说是一个问题。我们当前的接口设计使用一个线程来分发消息给所有对等节点。如果其中一个发送调用阻塞了,所有输出都会阻塞。
有几种选项可以避免阻塞。一种是对整个 DEALER 套接字集使用 zmq_poll(),并且只写入准备好的套接字。我不喜欢这个选项有几个原因。首先,DEALER 套接字隐藏在对等节点类内部,让每个类不透明地处理这个问题更清晰。其次,对于那些还不能发送给 DEALER 套接字的消息,我们该怎么办?在哪里排队?第三,这似乎是在回避问题。如果一个对等节点真的忙到无法读取其消息,那说明有问题。最有可能的是,它已经死了。
所以不对输出进行轮询。第二种选项是每个对等节点使用一个线程。我非常喜欢这个想法,因为它符合 ZeroMQ 设计模式“在一个线程中做一件事”。但这会在模拟中创建大量线程(启动的节点数的平方),而我们已经快耗尽文件句柄了。
第三个选项是使用非阻塞发送。这更好,也是我选择的解决方案。然后我们可以为每个对等节点提供一个合理的传出队列(HWM),如果队列满了,则将其视为该对等节点的致命错误。这适用于较小的消息。如果发送大块数据(例如,用于内容分发),我们将需要在其上增加一个基于信用的流量控制。
因此,第一步是向我们自己证明,我们可以将普通的阻塞 DEALER 套接字转换为非阻塞套接字。这个例子创建了一个普通的 DEALER 套接字,将其连接到某个端点(以便有传出管道并且套接字将接受消息),将高水位标记设置为四,然后将发送超时设置为零。
C | Java | Python | Ada | Basic | C++ | C# | CL | Delphi | Erlang | Elixir | F# | Felix | Go | Haskell | Haxe | Julia | Lua | Node.js | Objective-C | ooc | Perl | PHP | Q | Racket | Ruby | Rust | Scala | Tcl | OCaml当我们运行这个时,我们成功发送了四条消息(它们没有到达任何地方,套接字只是将它们排队),然后我们得到了一个不错的EAGAIN错误
Sending message 0
Sending message 1
Sending message 2
Sending message 3
Sending message 4
Resource temporarily unavailable
下一步是确定对等方合理的“高水位线”(high-water mark)是多少。Zyre 面向人机交互,即低频聊天的应用,例如两个游戏或一个共享绘图程序。我预计每秒一百条消息已经相当多了。我们的“对等方确实已死亡”超时时间是 10 秒。所以 1,000 的高水位线看起来是公平的。
我们不是设置固定的 HWM 或使用默认值(碰巧也是 1,000),而是将其计算为 100 * 超时时间。下面是我们如何为一个对等方配置新的 DEALER 套接字
// Create new outgoing socket (drop any messages in transit)
self->mailbox = zsocket_new (self->ctx, ZMQ_DEALER);
// Set our caller "From" identity so that receiving node knows
// who each message came from.
zsocket_set_identity (self->mailbox, reply_to);
// Set a high-water mark that allows for reasonable activity
zsocket_set_sndhwm (self->mailbox, PEER_EXPIRED * 100);
// Send messages immediately or return EAGAIN
zsocket_set_sndtimeo (self->mailbox, 0);
// Connect through to peer node
zsocket_connect (self->mailbox, "tcp://%s", endpoint);
最后,当我们在一个对等方上收到一个EAGAIN错误时该怎么办?我们无需费力销毁对等方,因为如果在过期超时时间内没有收到来自对等方的任何消息,接口会自动执行此操作。仅仅丢弃最后一条消息看起来非常弱;这会导致接收对等方出现空白。
我倾向于采取更“残酷”的响应。残酷是好的,因为它迫使设计做出“好”或“坏”的决定,而不是模糊的“应该能用,但说实话有很多边界情况,所以以后再担心”。销毁套接字,断开对等方连接,并停止向其发送任何内容。对等方最终将不得不重新连接并重新初始化任何状态。这有点像断言每秒 100 条消息对任何人来说都足够了。因此,在zre_peer_send方法
int
zre_peer_send (zre_peer_t *self, zre_msg_t **msg_p)
{
assert (self);
if (self->connected) {
if (zre_msg_send (msg_p, self->mailbox) && errno == EAGAIN) {
zre_peer_disconnect (self);
return -1;
}
}
return 0;
}
断开连接方法看起来像这样
void
zre_peer_disconnect (zre_peer_t *self)
{
// If connected, destroy socket and drop all pending messages
assert (self);
if (self->connected) {
zsocket_destroy (self->ctx, self->mailbox);
free (self->endpoint);
self->endpoint = NULL;
self->connected = false;
}
}
分布式日志记录和监控 #
让我们看看日志记录和监控。如果你曾管理过真正的服务器(例如 Web 服务器),你就知道捕获正在发生的事情有多么重要。原因有很多,尤其包括:
- 随时间测量系统的性能。
- 查看哪些工作完成得最多,以优化性能。
- 跟踪错误及其发生频率。
- 对故障进行事后分析。
- 在发生争议时提供审计跟踪。
让我们从我们认为必须解决的问题角度来界定范围
- 我们想要跟踪关键事件(例如节点离开和重新加入网络)。
- 对于每个事件,我们想要跟踪一组一致的数据:日期/时间、观察到事件的节点、创建事件的对等方、事件本身的类型以及其他事件数据。
- 我们想要能够在任何时候开启或关闭日志记录。
- 我们想要能够机械地处理日志数据,因为它会相当大。
- 我们想要能够监控正在运行的系统;也就是说,实时收集和分析日志。
- 我们想要日志流量对网络的影响最小化。
- 我们想要能够在网络中的单个点收集日志数据。
与任何设计一样,其中一些需求是相互冲突的。例如,实时收集日志数据意味着通过网络发送,这会在一定程度上影响网络流量。然而,与任何设计一样,这些需求在有运行代码之前也是假设性的,所以我们不能过于认真对待它们。我们将以合理够用为目标,并随着时间改进。
一个合理的最小实现 #
可以说,仅仅将日志数据转储到磁盘是一种解决方案,这也是大多数移动应用所做的(使用“调试日志”)。但大多数故障需要关联来自两个节点的事件。这意味着手动搜索大量调试日志以找到重要的日志。这不是一个非常聪明的方法。
我们想要将日志数据发送到某个中心位置,可以是立即发送,也可以是机会性发送(即存储转发)。目前,让我们专注于立即日志记录。我发送数据的第一个想法是为此使用 Zyre。只需将日志数据发送到一个名为“LOG”的组,然后希望有人收集它。
但使用 Zyre 来记录 Zyre 本身是一个 Catch-22(两难困境)。谁来记录记录器?如果我们想要记录发送的每条消息的详细日志怎么办?我们将日志消息包含在其中还是不包含?这很快变得混乱。我们想要一个独立于 Zyre 主要 ZRE 协议的日志协议。最简单的方法是一个发布/订阅协议,所有节点通过 PUB 套接字发布日志数据,而收集器通过 SUB 套接字接收这些数据。
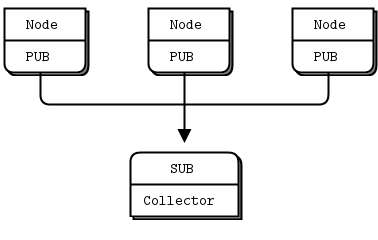
收集器当然可以在任何节点上运行。这为我们提供了一系列不错的用例
-
一个被动日志收集器,将日志数据存储在磁盘上用于最终的统计分析;这会是一台拥有足够硬盘空间存储数周或数月日志数据的 PC。
-
一个将日志数据存储到数据库中,以便其他应用程序可以实时使用它的收集器。这对于一个小型工作组来说可能大材小用,但对于跟踪大型组的性能会非常有用。收集器可以通过 WiFi 收集日志数据,然后通过以太网将其转发到某个数据库。
-
一个实时仪表应用程序,加入 Zyre 网络,然后从节点收集日志数据,实时显示事件和统计信息。
下一个问题是如何连接节点和收集器。哪一侧绑定,哪一侧连接?两种方式在这里都可行,但如果 PUB 套接字连接到 SUB 套接字会稍微好一些。如果你还记得,ZeroMQ 的内部缓冲区只有在存在连接时才会出现。这意味着节点一旦连接到收集器,就可以开始发送日志数据而不会丢失。
如何告知节点连接哪个端点?网络上可能有很多收集器,它们将使用任意的网络地址和端口。我们需要某种服务公告机制,在这里我们可以使用 Zyre 来为我们完成这项工作。我们可以使用组消息传递,但将服务发现构建到 ZRE 协议本身似乎更简洁。这并不复杂:如果一个节点提供服务 X,它可以在发送你好HELLO
命令时通过一个包含一组 name=value 对的 headers 字段将此信息告知其他节点。我们定义你好头部X-ZRELOG指定收集器端点(SUB 套接字)。充当收集器的节点可以添加这样的头部(例如)
X-ZRELOG=tcp://192.168.1.122:9992
当另一个节点看到此头部时,它只需将其 PUB 套接字连接到该端点。日志数据现在会分发到网络上的所有收集器(零个或多个)。
构建第一个版本相当简单,只花了半天时间。以下是我们必须创建或更改的部分
- 我们创建了一个新类zre_log该类接受日志数据,并(如果存在)管理与收集器的连接。
- 我们添加了一些基本的对等方头部管理,取自你好HELLO
- 当对等方包含X-ZRELOG头部时,我们会连接到它指定的端点。
- 我们以前记录到 stdout(标准输出),现在切换到通过zre_log类进行日志记录。
- 我们扩展了接口 API,添加了一个允许应用程序设置头部的方法。
- 我们编写了一个简单的日志记录应用程序,它管理 SUB 套接字并设置X-ZRELOG头部。
- 我们在发送你好HELLO
此版本在 Zyre 仓库中标记为 v0.4.0,如果您想查看此阶段的代码,可以下载 tar 包。
在此阶段,日志消息只是一个字符串。稍后我们将创建更专业的结构化日志数据。
首先,关于动态端口的一个说明。在zre_tester用于测试的应用程序中,我们积极地创建和销毁接口。一个后果是新接口很容易重用刚被另一个应用程序释放的端口。如果某个地方有一个 ZeroMQ 套接字试图连接这个端口,结果可能会很滑稽。
这是我遇到的一个场景,导致了几分钟的困惑。日志记录器正在一个动态端口上运行
- 启动日志记录应用程序
- 启动测试应用程序
- 停止日志记录器
- 测试程序收到无效消息(并按设计断言)
当测试程序创建了一个新的接口时,它重用了刚停止的日志记录器释放的动态端口,接口突然开始在其信箱中接收来自节点的日志数据。我们之前也见过类似的情况,新的接口会重用旧接口释放的端口并开始接收旧数据。
教训是,如果您使用动态端口,请做好准备接收来自尝试重新连接到您的、不知情的应用程序的随机数据。切换到静态端口阻止了连接的异常行为。但这并不是一个完整的解决方案。还有两个弱点
-
在我写这篇文章时,libzmq连接时不检查套接字类型。 ZMTP/2.0 协议确实会宣告每个对等方的套接字类型,因此此检查是可行的。
-
ZRE 协议没有快速失败(断言)机制;我们需要读取和解析整个消息后才能意识到它是无效的。
让我们解决第二个问题。套接字对验证无论如何也无法完全解决此问题。
协议断言 #
正如维基百科所述,“快速失败系统通常设计为停止正常运行,而不是尝试继续可能存在缺陷的过程。” 像 HTTP 这样的协议有一个快速失败机制,即客户端发送给 HTTP 服务器的前四个字节必须是“HTTP”。如果不是,服务器可以不读取更多内容就关闭连接。
我们的 ROUTER 套接字不是面向连接的,因此当我们收到不良的入站消息时,无法“关闭连接”。但是,如果消息无效,我们可以丢弃整个消息。当我们使用临时端口时,问题会更严重,但它广泛适用于所有协议。
因此,我们将协议断言定义为放置在每条消息开头的唯一签名,用于标识预期的协议。当我们读取消息时,我们会检查签名,如果不是我们期望的签名,就悄悄地丢弃该消息。好的签名应该很难与常规数据混淆,并为多种协议提供足够的空间。
我将使用一个 16 位签名,它由一个 12 位模式和一个 4 位协议 ID 组成。模式 %xAAA 旨在避开我们在消息开头可能期望看到的其他值:%x00、%xFF 和可打印字符。

由于我们的协议编解码器是生成的,添加此断言相对容易。逻辑如下:
- 获取消息的第一个帧。
- 检查前两个字节是否是 %xAAA 加上预期的 4 位签名。
- 如果是,则继续解析消息的其余部分。
- 如果不是,则跳过所有“更多”帧,获取第一个帧,然后重复。
为了测试这一点,我将日志记录器切换回使用临时端口。现在接口能够正确检测并丢弃任何没有有效签名的消息。如果消息具有有效签名但仍然是错误的,那就是一个真正的错误。
二进制日志记录协议 #
现在我们已经有了正常工作的日志记录框架,让我们看看协议本身。在网络中发送字符串很简单,但在 WiFi 环境下,我们真的不能浪费带宽。我们有工具来处理高效的二进制协议,所以让我们设计一个用于日志记录的协议。
这将是一个发布/订阅协议,在 ZeroMQ v3.x 中,我们进行发布者端过滤。这意味着如果我们将日志级别放在消息的开头,我们可以实现多级日志记录(错误、警告、信息)。因此,我们的消息以协议签名(两个字节)、日志级别(一个字节)和事件类型(一个字节)开头。
在第一个版本中,我们发送 UUID 字符串来标识每个节点。作为文本,它们每个都有 32 个字符。我们可以发送二进制 UUID,但这仍然冗长且浪费。我们不关心日志文件中的节点标识符。我们只需要一种方法来关联事件。那么,我们可以使用什么最短的标识符,它对于日志记录来说足够唯一呢?我说“足够唯一”是因为虽然我们在运行代码中确实希望 UUID 零重复,但日志文件并没有那么关键。
最简单的可行方法是将 IP 地址和端口哈希成一个 2 字节的值。我们会得到一些碰撞,但会很少见。有多罕见?为了快速进行健全性检查,我编写了一个小程序,它生成了一堆地址,并将它们哈希成 16 位值,寻找碰撞。为了确保,我在少量 IP 地址(匹配模拟设置)上生成了 10,000 个地址,然后在大量地址(匹配实际设置)上生成。哈希算法是一个修改后的 Bernstein。
uint16_t hash = 0;
while (*endpoint)
hash = 33 * hash ^ *endpoint++;
我在多次运行中没有得到任何碰撞,因此这将作为日志数据的标识符。这增加了四个字节(两个字节用于记录事件的节点,两个字节用于来自对等方的事件中其对等方)。
接下来,我们想要存储事件的日期和时间。POSIXtime_t类型以前是 32 位,但由于它会在 2038 年溢出,现在是 64 位值。我们将使用它;日志文件中不需要毫秒级分辨率:事件是顺序的,时钟不太可能如此紧密同步,网络延迟意味着精确的时间并没有那么大的意义。
我们现在总共有 16 个字节,这已经不错了。最后,我们想要允许一些额外的数据,格式化为文本,具体取决于事件的类型。将所有这些组合起来,得到以下消息规范
<class
name = "zre_log_msg"
script = "codec_c.gsl"
signature = "2"
>
This is the ZRE logging protocol - raw version.
<include filename = "license.xml" />
<!-- Protocol constants -->
<define name = "VERSION" value = "1" />
<define name = "LEVEL_ERROR" value = "1" />
<define name = "LEVEL_WARNING" value = "2" />
<define name = "LEVEL_INFO" value = "3" />
<define name = "EVENT_JOIN" value = "1" />
<define name = "EVENT_LEAVE" value = "2" />
<define name = "EVENT_ENTER" value = "3" />
<define name = "EVENT_EXIT" value = "4" />
<message name = "LOG" id = "1">
<field name = "level" type = "number" size = "1" />
<field name = "event" type = "number" size = "1" />
<field name = "node" type = "number" size = "2" />
<field name = "peer" type = "number" size = "2" />
<field name = "time" type = "number" size = "8" />
<field name = "data" type = "string" />
Log an event
</message>
</class>
这生成了 800 行完美的二进制编解码器(即zre_log_msg类)。该编解码器像主要的 ZRE 协议一样进行协议断言。代码生成有一个相当陡峭的学习曲线,但这使得将你的设计从“业余”推向“专业”变得容易得多。
内容分发 #
我们现在有了一个强大的框架,用于创建节点组、让他们互相聊天以及监控所产生的网络。下一步是允许他们将内容作为文件进行分发。
像往常一样,我们将致力于最简单的可行解决方案,然后逐步改进。至少我们希望实现以下几点
- 应用程序可以告诉 Zyre API“发布此文件”,并提供文件系统中某个文件的路径。
- Zyre 会将该文件分发给所有对等方,包括当时在线的对等方和稍后到达的对等方。
- 每次接口接收到文件时,都会告诉其应用程序“这是文件”。
我们最终可能想要更多的区分度,例如发布到特定组。如果需要,我们可以稍后添加。在第七章 - 使用 ZeroMQ 的高级架构中,我们开发了一个文件分发系统(FileMQ),旨在插入到 ZeroMQ 应用程序中。所以让我们使用它。
每个节点都将是一个文件发布者和一个文件订阅者。我们将发布者绑定到一个临时端口(如果我们使用标准的 FileMQ 端口 5670,我们将无法在同一台机器上运行多个接口),并且我们在你好消息中广播发布者的端点,就像我们对日志收集器所做的那样。这使我们能够互连所有节点,从而使所有订阅者都能与所有发布者通信。
我们需要确保每个节点都有自己的文件发送和接收目录(发件箱和收件箱)。同样,这是为了我们可以在同一台机器上运行多个节点。因为每个节点已经有了唯一的 ID,我们只需将其用于目录名称。
下面是我们创建新接口时设置 FileMQ API 的方式
sprintf (self->fmq_outbox, ".outbox/%s", self->identity);
mkdir (self->fmq_outbox, 0775);
sprintf (self->fmq_inbox, ".inbox/%s", self->identity);
mkdir (self->fmq_inbox, 0775);
self->fmq_server = fmq_server_new ();
self->fmq_service = fmq_server_bind (self->fmq_server, "tcp://*:*");
fmq_server_publish (self->fmq_server, self->fmq_outbox, "/");
fmq_server_set_anonymous (self->fmq_server, true);
char publisher [32];
sprintf (publisher, "tcp://%s:%d", self->host, self->fmq_service);
zhash_update (self->headers, "X-FILEMQ", strdup (publisher));
// Client will connect as it discovers new nodes
self->fmq_client = fmq_client_new ();
fmq_client_set_inbox (self->fmq_client, self->fmq_inbox);
fmq_client_set_resync (self->fmq_client, true);
fmq_client_subscribe (self->fmq_client, "/");
当我们处理一个你好命令时,我们检查X-FILEMQ头部字段
// If peer is a FileMQ publisher, connect to it
char *publisher = zre_msg_headers_string (msg, "X-FILEMQ", NULL);
if (publisher)
fmq_client_connect (self->fmq_client, publisher);
最后一件事情是在 Zyre API 中公开内容分发。我们需要两件事
- 一种让应用程序说“发布此文件”的方式
- 一种让接口告诉应用程序“我们收到了这个文件”的方式。
理论上,应用程序只需在发件箱目录中创建一个符号链接就可以发布文件,但由于我们使用的是隐藏的发件箱,这有点困难。所以我们添加一个 API 方法publish:
// Publish file into virtual space
void
zre_interface_publish (zre_interface_t *self,
char *filename, char *external)
{
zstr_sendm (self->pipe, "PUBLISH");
zstr_sendm (self->pipe, filename); // Real file name
zstr_send (self->pipe, external); // Location in virtual space
}
API 将此请求传递给接口线程,接口线程在发件箱目录中创建文件,以便 FileMQ 服务器能够拾取并广播它。我们可以直接将文件数据复制到此目录中,但因为 FileMQ 支持符号链接,所以我们转而使用符号链接。该文件具有“.ln”扩展名,包含一行内容,即实际的路径名。
最后,我们如何通知接收方文件已到达?FileMQ 的fmq_clientAPI 有一条消息“DELIVER”用于此目的,因此我们在zre_interface中要做的就是从fmq_clientAPI 获取此消息并将其传递到我们自己的 API。
zmsg_t *msg = fmq_client_recv (fmq_client_handle (self->fmq_client));
zmsg_send (&msg, self->pipe);
这段代码很复杂,一次做了很多事情。但 FileMQ 和 Zyre 加起来,代码行数仅约 1 万行。最复杂的 Zyre 类,zre_interface,有 800 行代码。这很紧凑。如果组织得当,基于消息的应用程序确实能保持其结构。
编写协议规范 #
我们已经有了正式协议规范所需的所有要素,是时候将协议写在纸上(形成文档)了。这有两个原因。首先,确保任何其他实现都能正确地相互通信。其次,因为我想为 UDP 发现协议获得一个官方端口,这意味着要处理文书工作。
就像我们在本书中开发的所有其他协议规范一样,该协议位于ZeroMQ RFC 网站上。协议规范的核心是命令和字段的 ABNF 语法。
zre-protocol = greeting *traffic
greeting = S:HELLO
traffic = S:WHISPER
/ S:SHOUT
/ S:JOIN
/ S:LEAVE
/ S:PING R:PING-OK
; Greet a peer so it can connect back to us
S:HELLO = header %x01 ipaddress mailbox groups status headers
header = signature sequence
signature = %xAA %xA1
sequence = 2OCTET ; Incremental sequence number
ipaddress = string ; Sender IP address
string = size *VCHAR
size = OCTET
mailbox = 2OCTET ; Sender mailbox port number
groups = strings ; List of groups sender is in
strings = size *string
status = OCTET ; Sender group status sequence
headers = dictionary ; Sender header properties
dictionary = size *key-value
key-value = string ; Formatted as name=value
; Send a message to a peer
S:WHISPER = header %x02 content
content = FRAME ; Message content as ZeroMQ frame
; Send a message to a group
S:SHOUT = header %x03 group content
group = string ; Name of group
content = FRAME ; Message content as ZeroMQ frame
; Join a group
S:JOIN = header %x04 group status
status = OCTET ; Sender group status sequence
; Leave a group
S:LEAVE = header %x05 group status
; Ping a peer that has gone silent
S:PING = header %06
; Reply to a peer's ping
R:PING-OK = header %07
Zyre 应用程序示例 #
现在让我们创建一个最小示例,使用 Zyre 在分布式网络中广播文件。该示例包含两个程序
- 一个监听器,它加入 Zyre 网络并在收到文件时进行报告。
- 一个发送器,它加入 Zyre 网络并精确广播一个文件。
监听器代码很短
#include <zre.h>
int main (int argc, char *argv [])
{
zre_interface_t *interface = zre_interface_new ();
while (true) {
zmsg_t *incoming = zre_interface_recv (interface);
if (!incoming)
break;
zmsg_dump (incoming);
zmsg_destroy (&incoming);
}
zre_interface_destroy (&interface);
return 0;
}
发送器代码也不长
#include <zre.h>
int main (int argc, char *argv [])
{
if (argc < 2) {
puts ("Syntax: sender filename virtualname");
return 0;
}
printf ("Publishing %s as %s\n", argv [argv [2](1],));
zre_interface_t *interface = zre_interface_new ();
zre_interface_publish (interface, argv [argv [2](1],));
while (true) {
zmsg_t *incoming = zre_interface_recv (interface);
if (!incoming)
break;
zmsg_dump (incoming);
zmsg_destroy (&incoming);
}
zre_interface_destroy (&interface);
return 0;
}
结论 #
为不稳定的去中心化网络构建应用程序是 ZeroMQ 的最终目标之一。随着计算成本每年下降,这类网络变得越来越普遍,无论是消费电子产品还是云端的虚拟机。在本章中,我们结合了书中的许多技术来构建 Zyre,一个用于本地网络上的邻近计算框架。Zyre 并非独一无二;过去和现在都有许多尝试为应用程序开放这一领域:ZeroConf、SLP、SSDP、UPnP、DDS。但所有这些似乎都过于复杂或对应用程序开发者来说难以构建。
Zyre 尚未完成。像本书中的许多项目一样,它是一个为他人“破冰”的项目。还有一些主要的未完成领域,我们可能会在本书的后续版本或软件版本中解决。
-
高级 API:Zyre 现在提供的基于消息的 API 可用,但对于普通开发者来说仍然比我期望的要复杂得多。如果说我们绝对不能错过的一个目标是什么,那就是纯粹的简洁性。这意味着我们应该用多种语言构建高级 API,这些 API 隐藏所有消息传递细节,并简化为 start、join/leave group、get message、publish file、stop 等简单方法。
-
安全性:我们如何构建一个完全去中心化的安全系统?我们或许可以利用公钥基础设施来完成一些工作,但这要求节点有自己的互联网访问,而这是无法保证的。据我们所知,解决方案是使用任何现有的安全对等链接(TLS、蓝牙、也许是 NFC)来交换会话密钥并使用对称加密。对称加密有其优点和缺点。
-
游牧式内容:作为用户,我如何在多个设备之间管理我的内容?Zyre + FileMQ 的组合可能有助于本地网络的使用,但我也希望能够在互联网上做到这一点。是否有我可以使用的云服务?我可以使用 ZeroMQ 构建一些东西吗?
-
联邦:我们如何将本地分布式应用程序扩展到全球?一个合理的答案是联邦(federation),这意味着创建集群的集群。如果 100 个节点可以组合成一个本地集群,那么也许 100 个集群可以组合成一个广域集群。挑战则非常相似:发现、在线状态和组消息传递。